Blog
In a world where immediacy is becoming increasingly important, predictive commerce has become a key tool for anticipating consumer behaviors, optimizing decisions, and offering personalized experiences. It's no longer just about reacting to the customer's needs, it's about predicting what they want before they even know it.
In this article we are going to explain what predictive commerce is and the importance of open data in it, including real examples.
What is predictive commerce?
Predictive commerce is a strategy based on data analysis to anticipate consumers' purchasing decisions. It uses artificial intelligence algorithms and statistical models to identify patterns of behavior, preferences, and key moments in the consumption cycle. Thanks to this, companies can know relevant information about which products will be most in demand, when and where a purchase will be made or which customers are most likely to purchase a certain brand.
This is of great importance in a market like the current one, where there is a saturation of products and competition. Predictive commerce allows companies to adjust inventories, prices, marketing campaigns or logistics in real time, becoming a great competitive advantage.
The role of open data in predictive commerce
These models are fed by large volumes of data: purchase history, web browsing, location or comments on social networks, among others. But the more accurate and diverse the data, the more fine-tuned the predictions will be. This is where open data plays a fundamental role, as it allows new variables to be taken into account when defining consumer behavior. Among other things, open data can help us:
- Enrich prediction models with external information such as demographic data, urban mobility or economic indicators.
- Detect regional patterns that influence consumption, such as the impact of climate on the sale of certain seasonal products.
- Design more inclusive strategies by incorporating public data on the habits and needs of different social groups.
The following table shows examples of datasets available in datos.gob.es that can be used for these tasks, at a national level, although many autonomous communities and city councils also publish this type of data along with others also of interest.
| Dataset | Example | Possible use |
|---|---|---|
| Municipal register by age and sex | National Institute of Statistics (INE) | Segment populations by territory, age, and gender. It is useful for customizing campaigns based on the majority population of each municipality or forecasting demand by demographic profile. |
| Household Budget Survey | National Institute of Statistics (INE) | It offers information on the average expenditure per household in different categories. It can help anticipate consumption patterns by socioeconomic level. |
| Consumer Price Index (CPI) | National Institute of Statistics (INE) | It disaggregates the CPI by territory, measuring how the prices of goods and services vary in each Spanish province. It is useful for adjusting prices and market penetration strategies. |
| Real-time weather warnings | Ministry for the Ecological Transition and Demographic Challenge | Alert of adverse weather phenomena. It allows correlating weather with product sales (clothing, beverages, heating, etc.). |
| Education and Digital Literacy Statistics | National Institute of Statistics (INE) | Provides information on internet usage in the last 3 months. It allows digital gaps to be identified and communication or training strategies to be adapted. |
| Facts about tourist stays | National Institute of Statistics (INE) | It reports on the average stay of tourists by autonomous community. It helps to anticipate demand in areas with high seasonal influx, such as local products or tourist services. |
| Number of prescriptions and pharmaceutical expenditure | General Mutual Society for Civil Servants of the State (MUFACE) | It offers information on the consumption of medicines by province and age subgroups. It facilitates the estimation of sales of other related medical and parapharmacy products by estimating how many users will go to the pharmacy. |
Real-world use cases
For years, we have already found companies that are using this type of data to optimize their business strategies. Let's look at some examples:
- Using weather data to optimize stock in large supermarkets
Walmart department stores use AI algorithms that incorporate weather data (such as heat waves, storms, or temperature changes) along with historical sales data, events, and digital trends, to forecast demand at a granular level and optimize inventories. This allows the replenishment of critical products to be automatically adjusted according to anticipated weather patterns. In addition, Walmart mentions that its system considers "future data" such as macroweather weather patterns, economic trends, and local demographics to anticipate demand and potential supply chain disruptions.
Tesco also uses public weather data in its predictive models. This allows you to anticipate buying patterns, such as that for every 10°C increase in temperature, barbecue sales increase by up to 300%. In addition, Tesco receives local weather forecasts up to three times a day, connecting them with data on 18 million products and the type of customers in each store. This information is shared with your suppliers to adjust shipments and improve logistics efficiency.
- Using demographic data to decide the location of premises
For years, Starbucks has turned to predictive analytics to plan its expansion. The company uses geospatial intelligence platforms, developed with GIS technology, to combine multiple sources of information – including open demographic and socioeconomic data such as population density, income level, mobility patterns, public transport or the type of nearby businesses – along with its own sales history. Thanks to this integration, you can predict which locations have the greatest potential for success, avoiding competition between stores and ensuring that each new store is located in the most suitable environment.
Domino's Pizza also used similar models to analyse whether opening a new location in one London neighbourhood would be successful and how it would affect other nearby locations, considering buying patterns and local demographics.
This approach makes it possible to predict customer flows and maximize profitability through more informed location decisions.
- Socioeconomic data for pricing based on demographics
An interesting example can be found in SDG Group, an international consulting firm specialising in advanced analytics for retail. The company has developed solutions that allow prices and promotions to be adjusted taking into account the demographic and socioeconomic characteristics of each area – such as the consumer base, location or the size of the point of sale. Thanks to these models, it is possible to estimate the elasticity of demand and design dynamic pricing strategies adapted to the real context of each area, optimizing both profitability and the shopping experience.
The future of predictive commerce
The rise of predictive commerce has been fueled by the advancement of artificial intelligence and the availability of data, both open and private. From choosing the ideal place to open a store to efficiently managing inventory, public data combined with advanced analytics allows you to anticipate consumer behaviors and needs with increasing accuracy.
However, there are still important challenges to be faced: the heterogeneity of data sources, which in many cases lack common standards; the need for robust technologies and infrastructures that allow open information to be integrated with companies' internal systems; and, finally, the challenge of ensuring ethical and transparent use, which respects people's privacy and avoids the generation of bias in models.
Overcoming these challenges will be key for predictive commerce to unfold its full potential and become a strategic tool for companies of all sizes. On this path, open data will play a fundamental role as a driver of innovation, transparency and competitiveness in the trade of the future..
Blog
Synthetic images are visual representations artificially generated by algorithms and computational techniques, rather than being captured directly from reality with cameras or sensors. They are produced from different methods, among which the antagonistic generative networks (Generative Adversarial NetworksGAN), the Dissemination models, and the 3D rendering techniques. All of them allow you to create images of realistic appearance that in many cases are indistinguishable from an authentic photograph.
When this concept is transferred to the field of Earth observation, we are talking about synthetic satellite images. These are not obtained from a space sensor that captures real electromagnetic radiation, but are generated digitally to simulate what a satellite would see from orbit. In other words, instead of directly reflecting the physical state of the terrain or atmosphere at a particular time, they are computational constructs capable of mimicking the appearance of a real satellite image.
The development of this type of image responds to practical needs. Artificial intelligence systems that process remote sensing data require very large and varied sets of images. Synthetic images allow, for example, to recreate areas of the Earth that are little observed, to simulate natural disasters – such as forest fires, floods or droughts – or to generate specific conditions that are difficult or expensive to capture in practice. In this way, they constitute a valuable resource for training detection and prediction algorithms in agriculture, emergency management, urban planning or environmental monitoring.
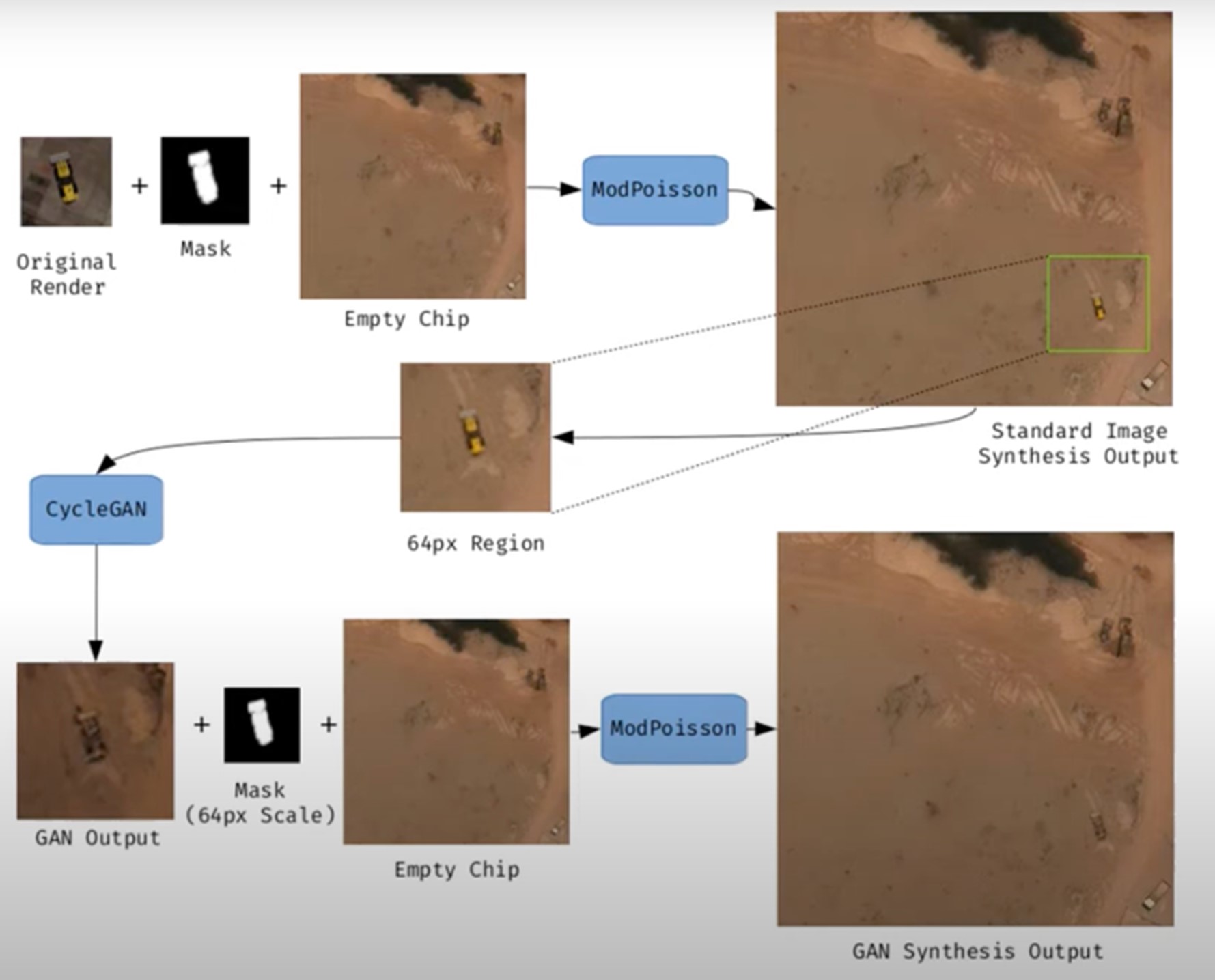
Figure 1. Example of synthetic satellite image generation.
Its value is not limited to model training. Where high-resolution images do not exist – due to technical limitations, access restrictions or economic reasons – synthesis makes it possible to fill information gaps and facilitate preliminary studies. For example, researchers can work with approximate synthetic images to design risk models or simulations before actual data are available.
However, synthetic satellite imagery also poses significant risks. The possibility of generating very realistic scenes opens the door to manipulation and misinformation. In a geopolitical context, an image showing non-existent troops or destroyed infrastructure could influence strategic decisions or international public opinion. In the environmental field, manipulated images could be disseminated to exaggerate or minimize the impacts of phenomena such as deforestation or melting ice, with direct effects on policies and markets.
Therefore, it is convenient to differentiate between two very different uses. The first is use as a support, when synthetic images complement real images to train models or perform simulations. The second is use as a fake, when they are deliberately presented as authentic images in order to deceive. While the former uses drive innovation, the latter threatens trust in satellite data and poses an urgent challenge of authenticity and governance.
Risks of satellite imagery applied to Earth observation
Synthetic satellite imagery poses significant risks when used in place of images captured by real sensors. Below are examples that demonstrate this.
A new front of disinformation: "deepfake geography"
The term deepfake geography has already been consolidated in the academic and popular literature to describe fictitious satellite images, manipulated with AI, that appear authentic, but do not reflect any existing reality. Research from the University of Washington, led by Bo Zhao, used algorithms such as CycleGAN to modify images of real cities—for example, altering the appearance of Seattle with non-existent buildings or transforming Beijing into green areas—highlighting the potential to generate convincing false landscapes.
One OnGeo Intelligence (OGC) platform article stresses that these images are not purely theoretical, but real threats affecting national security, journalism and humanitarian work. For its part, the OGC warns that fabricated satellite imagery, AI-generated urban models, and synthetic road networks have already been observed, and that they pose real challenges to public and operational trust.
Strategic and policy implications
Satellite images are considered "impartial eyes" on the planet, used by governments, media and organizations. When these images are faked, their consequences can be severe:
- National security and defense: if false infrastructures are presented or real ones are hidden, strategic analyses can be diverted or mistaken military decisions can be induced.
- Disinformation in conflicts or humanitarian crises: An altered image showing fake fires, floods, or troop movements can alter the international response, aid flows, or citizens' perceptions, especially if it is spread through social media or media without verification.
- Manipulation of realistic images of places: not only the general images are at stake. Nguyen et al. (2024) showed that it is possible to generate highly realistic synthetic satellite images of very specific facilities such as nuclear plants.
Crisis of trust and erosion of truth
For decades, satellite imagery has been perceived as one of the most objective and reliable sources of information about our planet. They were the graphic evidence that made it possible to confirm environmental phenomena, follow armed conflicts or evaluate the impact of natural disasters. In many cases, these images were used as "unbiased evidence," difficult to manipulate, and easy to validate. However, the emergence of synthetic images generated by artificial intelligence has begun to call into question that almost unshakable trust.
Today, when a satellite image can be falsified with great realism, a profound risk arises: the erosion of truth and the emergence of a crisis of confidence in spatial data.
The breakdown of public trust
When citizens can no longer distinguish between a real image and a fabricated one, trust in information sources is broken. The consequence is twofold:
- Distrust of institutions: if false images of a fire, a catastrophe or a military deployment circulate and then turn out to be synthetic, citizens may also begin to doubt the authentic images published by space agencies or the media. This "wolf is coming" effect generates skepticism even in the face of legitimate evidence.
- Effect on journalism: traditional media, which have historically used satellite imagery as an unquestionable visual source, risk losing credibility if they publish doctored images without verification. At the same time, the abundance of fake images on social media erodes the ability to distinguish what is real and what is not.
- Deliberate confusion: in contexts of disinformation, the mere suspicion that an image may be false can already be enough to generate doubt and sow confusion, even if the original image is completely authentic.
The following is a summary of the possible cases of manipulation and risk in satellite images:
|
Ambit |
Type of handling |
Main risk |
Documented example |
|---|---|---|---|
| Armed conflicts | Insertion or elimination of military infrastructures. | Strategic disinformation; erroneous military decisions; loss of credibility in international observation. | Alterations demonstrated in deepfake geography studies where dummy roads, bridges or buildings were added to satellite images. |
| Climate change and the environment | Alteration of glaciers, deforestation or emissions. | Manipulation of environmental policies; delay in measures against climate change; denialism. | Studies have shown the ability to generate modified landscapes (forests in urban areas, changes in ice) by means of GANs. |
| Gestión de emergencias | Creation of non-existent disasters (fires, floods). | Misuse of resources in emergencies; chaos in evacuations; loss of trust in agencies. | Research has shown the ease of inserting smoke, fire or water into satellite images. |
| Mercados y seguros | Falsification of damage to infrastructure or crops. | Financial impact; massive fraud; complex legal litigation. | Potential use of fake images to exaggerate damage after disasters and claim compensation or insurance. |
| Derechos humanos y justicia internacional | Alteration of visual evidence of war crimes. | Delegitimization of international tribunals; manipulation of public opinion. | Risk identified in intelligence reports: Doctored images could be used to accuse or exonerate actors in conflicts. |
| Geopolítica y diplomacia | Creation of fictitious cities or border changes. | Diplomatic tensions; treaty questioning; State propaganda | Examples of deepfake maps that transform geographical features of cities such as Seattle or Tacoma. |
Figure 2. Table showing possible cases of manipulation and risk in satellite images
Impact on decision-making and public policies
The consequences of relying on doctored images go far beyond the media arena:
- Urbanism and planning: decisions about where to build infrastructure or how to plan urban areas could be made on manipulated images, generating costly errors that are difficult to reverse.
- Emergency management: If a flood or fire is depicted in fake images, emergency teams can allocate resources to the wrong places, while neglecting areas that are actually affected.
- Climate change and the environment: Doctored images of glaciers, deforestation or polluting emissions could manipulate political debates and delay the implementation of urgent measures.
- Markets and insurance: Insurers and financial companies that rely on satellite imagery to assess damage could be misled, with significant economic consequences.
In all these cases, what is at stake is not only the quality of the information, but also the effectiveness and legitimacy of public policies based on that data.
The technological cat and mouse game
The dynamics of counterfeit generation and detection are already known in other areas, such as video or audio deepfakes: every time a more realistic generation method emerges, a more advanced detection algorithm is developed, and vice versa. In the field of satellite images, this technological career has particularities:
- Increasingly sophisticated generators: today's broadcast models can create highly realistic scenes, integrating ground textures, shadows, and urban geometries that fool even human experts.
- Detection limitations: Although algorithms are developed to identify fakes (analyzing pixel patterns, inconsistencies in shadows, or metadata), these methods are not always reliable when faced with state-of-the-art generators.
- Cost of verification: independently verifying a satellite image requires access to alternative sources or different sensors, something that is not always available to journalists, NGOs or citizens.
- Double-edged swords: The same techniques used to detect fakes can be exploited by those who generate them, further refining synthetic images and making them more difficult to differentiate.
From visual evidence to questioned evidence
The deeper impact is cultural and epistemological: what was previously assumed to be objective evidence now becomes an element subject to doubt. If satellite imagery is no longer perceived as reliable evidence, it weakens fundamental narratives around scientific truth, international justice, and political accountability.
- In armed conflicts, a satellite image showing possible war crimes can be dismissed under the accusation of being a deepfake.
- In international courts, evidence based on satellite observation could lose weight in the face of suspicion of manipulation.
- In public debate, the relativism of "everything can be false" can be used as a rhetorical weapon to delegitimize even the strongest evidence.
Strategies to ensure authenticity
The crisis of confidence in satellite imagery is not an isolated problem in the geospatial sector, but is part of a broader phenomenon: digital disinformation in the age of artificial intelligence. Just as video deepfakes have called into question the validity of audiovisual evidence, the proliferation of synthetic satellite imagery threatens to weaken the last frontier of perceived objective data: the unbiased view from space.
Ensuring the authenticity of these images requires a combination of technical solutions and governance mechanisms, capable of strengthening traceability, transparency and accountability across the spatial data value chain. The main strategies under development are described below.
Robust metadata: Record origin and chain of custody
Metadata is the first line of defense against manipulation. In satellite imagery, they should include detailed information about:
- The sensor used (type, resolution, orbit).
- The exact time of acquisition (date and time, with time precision).
- The precise geographical location (official reference systems).
- The applied processing chain (atmospheric corrections, calibrations, reprojections).
Recording this metadata in secure repositories allows the chain of custody to be reconstructed, i.e. the history of who, how and when an image has been manipulated. Without this traceability, it is impossible to distinguish between authentic and counterfeit images.
EXAMPLE: The European Union's Copernicus program already implements standardized and open metadata for all its Sentinel images, facilitating subsequent audits and confidence in the origin.
Digital signatures and blockchain: ensuring integrity
Digital signatures allow you to verify that an image has not been altered since it was captured. They function as a cryptographic seal that is applied at the time of acquisition and validated at each subsequent use.
Blockchain technology offers an additional level of assurance: storing acquisition and modification records on an immutable chain of blocks. In this way, any changes in the image or its metadata would be recorded and easily detectable.
EXAMPLE: The ESA – Trusted Data Framework project explores the use of blockchain to protect the integrity of Earth observation data and bolster trust in critical applications such as climate change and food security.
Invisible watermarks: hidden signs in the image
Digital watermarking involves embedding imperceptible signals in the satellite image itself, so that any subsequent alterations can be detected automatically.
- It can be done at the pixel level, slightly modifying color patterns or luminance.
- It is combined with cryptographic techniques to reinforce its validity.
- It allows you to validate images even if they have been cropped, compressed, or reprocessed.
EXAMPLE: In the audiovisual sector, watermarks have been used for years in the protection of digital content. Its adaptation to satellite images is in the experimental phase, but it could become a standard verification tool.
Open Standards (OGC, ISO): Trust through Interoperability
Standardization is key to ensuring that technical solutions are applied in a coordinated and global manner.
- OGC (Open Geospatial Consortium) works on standards for metadata management, geospatial data traceability, and interoperability between systems. Their work on geospatial APIs and FAIR (Findable, Accessible, Interoperable, Reusable) metadata is essential to establishing common trust practices.
- ISO develops standards on information management and authenticity of digital records that can also be applied to satellite imagery.
EXAMPLE: OGC Testbed-19 included specific experiments on geospatial data authenticity, testing approaches such as digital signatures and certificates of provenance.
Cross-check: combining multiple sources
A basic principle for detecting counterfeits is to contrast sources. In the case of satellite imagery, this involves:
- Compare images from different satellites (e.g. Sentinel-2 vs. Landsat-9).
- Use different types of sensors (optical, radar SAR, hyperspectral).
- Analyze time series to verify consistency over time.
EXAMPLE: Damage verification in Ukraine following the start of the Russian invasion in 2022 was done by comparing images from several vendors (Maxar, Planet, Sentinel), ensuring that the findings were not based on a single source.
AI vs. AI: Automatic Counterfeit Detection
The same artificial intelligence that allows synthetic images to be created can be used to detect them. Techniques include:
- Pixel Forensics: Identify patterns generated by GANs or broadcast models.
- Neural networks trained to distinguish between real and synthetic images based on textures or spectral distributions.
- Geometric inconsistencies models: detect impossible shadows, topographic inconsistencies, or repetitive patterns.
EXAMPLE: Researchers at the University of Washington and other groups have shown that specific algorithms can detect satellite fakes with greater than 90% accuracy under controlled conditions.
Current Experiences: Global Initiatives
Several international projects are already working on mechanisms to reinforce authenticity:
- Coalition for Content Provenance and Authenticity (C2PA): A partnership between Adobe, Microsoft, BBC, Intel, and other organizations to develop an open standard for provenance and authenticity of digital content, including images. Its model can be applied directly to the satellite sector.
- OGC work: the organization promotes the debate on trust in geospatial data and has highlighted the importance of ensuring the traceability of synthetic and real satellite images (OGC Blog).
- NGA (National Geospatial-Intelligence Agency) in the US has publicly acknowledged the threat of synthetic imagery in defence and is driving collaborations with academia and industry to develop detection systems.
Towards an ecosystem of trust
The strategies described should not be understood as alternatives, but as complementary layers in a trusted ecosystem:
|
Id |
Layers |
Benefits |
|---|---|---|
| 1 | Robust metadata (source, sensor, chain of custody) |
Traceability guaranteed |
| 2 | Digital signatures and blockchain (data integrity) |
Ensuring integrity |
| 3 | Invisible watermarks (hidden signs) |
Add a hidden level of protection |
| 4 | Cross-check (multiple satellites and sensors) |
Validates independently |
| 5 | AI vs. AI (counterfeit detector) |
Respond to emerging threats |
| 6 | International governance (accountability, legal frameworks) |
Articulate clear rules of liability |
Figure 3. Layers to ensure confidence in synthetic satellite images
Success will depend on these mechanisms being integrated together, under open and collaborative frameworks, and with the active involvement of space agencies, governments, the private sector and the scientific community.
Conclusions
Synthetic images, far from being just a threat, represent a powerful tool that, when used well, can provide significant value in areas such as simulation, algorithm training or innovation in digital services. The problem arises when these images are presented as real without proper transparency, fueling misinformation or manipulating public perception.
The challenge, therefore, is twofold: to take advantage of the opportunities offered by the synthesis of visual data to advance science, technology and management, and to minimize the risks associated with the misuse of these capabilities, especially in the form of deepfakes or deliberate falsifications.
In the particular case of satellite imagery, trust takes on a strategic dimension. Critical decisions in national security, disaster response, environmental policy, and international justice depend on them. If the authenticity of these images is called into question, not only the reliability of the data is compromised, but also the legitimacy of decisions based on them.
The future of Earth observation will be shaped by our ability to ensure authenticity, transparency and traceability across the value chain: from data acquisition to dissemination and end use. Technical solutions (robust metadata, digital signatures, blockchain, watermarks, cross-verification, and AI for counterfeit detection), combined with governance frameworks and international cooperation, will be the key to building an ecosystem of trust.
In short, we must assume a simple but forceful guiding principle:
"If we can't trust what we see from space, we put our decisions on Earth at risk."
Content prepared by Mayte Toscano, Senior Consultant in Data Economy Technologies. The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
Data science has become a pillar of evidence-based decision-making in the public and private sectors. In this context, there is a need for a practical and universal guide that transcends technological fads and provides solid and applicable principles. This guide offers a decalogue of good practices that accompanies the data scientist throughout the entire life cycle of a project, from the conceptualization of the problem to the ethical evaluation of the impact.
- Understand the problem before looking at the data. The initial key is to clearly define the context, objectives, constraints, and indicators of success. A solid framing prevents later errors.
- Know the data in depth. Beyond the variables, it involves analyzing their origin, traceability and possible biases. Data auditing is essential to ensure representativeness and reliability.
- Ensure quality. Without clean data there is no science. EDA techniques, imputation, normalization and control of quality metrics allow to build solid and reproducible bases.
- Document and version. Reproducibility is a scientific condition. Notebooks, pipelines, version control, and MLOps practices ensure traceability and replicability of processes and models.
- Choose the right model. Sophistication does not always win: the decision must balance performance, interpretability, costs and operational constraints.
- Measure meaningfully. Metrics should align with goals. Cross-validation, data drift control and rigorous separation of training, validation and test data are essential to ensure generalization.
- Visualize to communicate. Visualization is not an ornament, but a language to understand and persuade. Data-driven storytelling and clear design are critical tools for connecting with diverse audiences.
- Work as a team. Data science is collaborative: it requires data engineers, domain experts, and business leaders. The data scientist must act as a facilitator and translator between the technical and the strategic.
- Stay up-to-date (and critical). The ecosystem is constantly evolving. It is necessary to combine continuous learning with selective criteria, prioritizing solid foundations over passing fads.
-
Be ethical. Models have a real impact. It is essential to assess bias, protect privacy, ensure explainability and anticipate misuse. Ethics is a compass and a condition of legitimacy.

Finally, the report includes a bonus-track on Python and R, highlighting that both languages are complementary allies: Python dominates in production and deployment, while R offers statistical rigor and advanced visualization. Knowing both multiplies the versatility of the data scientist.
The Data Scientist's Decalogue is a practical, timeless and cross-cutting guide that helps professionals and organizations turn data into informed, reliable and responsible decisions. Its objective is to strengthen technical quality, collaboration and ethics in a discipline in full expansion and with great social impact.
To explore the content of the report in greater depth, we have recorded a podcast and a video interview in which the author explains the key points of the Decalogue. In addition, an infographic and an executive summary have been produced.
Listen to the podcast with the author (only available in Spanish)
Watch the video-interview with the author
Download the infographic summary

Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
The open data sector is very active. To keep up to date with everything that happens, from datos.gob.es we publish a compilation of news such as the development of new technological applications, legislative advances or other related news.
Six months ago, we already made the last compilation of the year 2024. On this occasion, we are going to summarize some innovations, improvements and achievements of the first half of 2025.
Regulatory framework: new regulations that transform the landscape
One of the most significant developments is the publication of the Regulation on the European Health Data Space by the European Parliament and the Council. This regulation establishes a common framework for the secure exchange of health data between member states, facilitating both medical research and the provision of cross-border health services. In addition, this milestone represents a paradigmatic shift in the management of sensitive data, demonstrating that it is possible to reconcile privacy and data protection with the need to share information for the common good. The implications for the Spanish healthcare system are considerable, as it will allow greater interoperability with other European countries and facilitate the development of collaborative research projects.
On the other hand, the entry into force of the European AI Act establishes clear rules for the development of this technology, guaranteeing security, transparency and respect for human rights. These types of regulations are especially relevant in the context of open data, where algorithmic transparency and the explainability of AI models become essential requirements.
In Spain, the commitment to transparency is materialised in initiatives such as the new Digital Rights Observatory, which has the participation of more than 150 entities and 360 experts. This platform is configured as a space for dialogue and monitoring of digital policies, helping to ensure that the digital transformation respects fundamental rights.
Technological innovations in Spain and abroad
One of the most prominent milestones in the technological field is the launch of ALIA, the public infrastructure for artificial intelligence resources. This initiative seeks to develop open and transparent language models that promote the use of Spanish and Spanish co-official languages in the field of AI.
ALIA is not only a response to the hegemony of Anglo-Saxon models, but also a strategic commitment to technological sovereignty and linguistic diversity. The first models already available have been trained in Spanish, Catalan, Galician, Valencian and Basque, setting an important precedent in the development of inclusive and culturally sensitive technologies.
In relation to this innovation, the practical applications of artificial intelligence are multiplying in various sectors. For example, in the financial field, the Tax Agency has adopted an ethical commitment in the design and use of artificial intelligence. Within this framework, the community has even developed a virtual chatbot trained with its own data that offers legal guidance on fiscal and tax issues.
In the healthcare sector, a group of Spanish radiologists is working on a project for the early detection of oncological lesions using AI, demonstrating how the combination of open data and advanced algorithms can have a direct impact on public health.
Also combining AI with open data, projects related to environmental sustainability have been developed. This model developed in Spain combines AI and open weather data to predict solar energy production over the next 30 years, providing crucial information for national energy planning.
Another relevant sector in terms of technological innovation is that of smart cities. In recent months, Las Palmas de Gran Canaria has digitized its municipal markets by combining WiFi networks, IoT devices, a digital twin and open data platforms. This comprehensive initiative seeks to improve the user experience and optimize commercial management, demonstrating how technological convergence can transform traditional urban spaces.
Zaragoza, for its part, has developed a vulnerability map using artificial intelligence applied to open data, providing a valuable tool for urban planning and social policies.
Another relevant case is the project of the Open Data Barcelona Initiative, #iCuida, which stands out as an innovative example of reusing open data to improve the lives of caregivers and domestic workers. This application demonstrates how open data can target specific groups and generate direct social impact.
Last but not least, at a global level, this semester DeepSeek has launched DeepSeek-R1, a new family of generative models specialized in reasoning, publishing both the models and their complete training methodology in open source, contributing to the democratic advancement of AI.
New open data portals and improvement tools
In all this maelstrom of innovation and technology, the landscape of open data portals has been enriched with new sectoral initiatives. The Association of Commercial and Property Registrars of Spain has presented its open data platform, allowing immediate access to registry data without waiting for periodic reports. This initiative represents a significant change in the transparency of the registry sector.
In the field of health, the 'I+Health' portal of the Andalusian public health system collects and disseminates resources and data on research activities and results from a single site, facilitating access to relevant scientific information.
In addition to the availability of data, there is a treatment that makes them more accessible to the general public: data visualization. The University of Granada has developed 'UGR in figures', an open-access space with an open data section that facilitates the exploration of official statistics and stands as a fundamental piece in university transparency.
On the other hand, IDENA, the new tool of the Navarre Geoportal, incorporates advanced functionalities to search, navigate, incorporate maps, share data and download geographical information, being operational on any device.
Training for the future: events and conferences
The training ecosystem in this ecosystem is strengthened every year with events such as the Data Management Summit in Tenerife, which addresses interoperability in public administrations and artificial intelligence. Another benchmark event in open data that was also held in the Canary Islands was the National Open Data Meeting.
Beyond these events, collaborative innovation has also been promoted through specialized hackathons, such as the one dedicated to generative AI solutions for biodiversity or the Merkle Datathon in Gijón. These events not only generate innovative solutions, but also create communities of practice and foster emerging talent.
Once again, the open data competitions of Castilla y León and the Basque Country have awarded projects that demonstrate the transformative potential of the reuse of open data, inspiring new initiatives and applications.
International perspective and global trends: the fourth wave of open data
The Open Data Policy Lab spoke at the EU Open Data Days about what is known as the "fourth wave" of open data, closely linked to generative AI. This evolution represents a quantum leap in the way public data is processed, analyzed, and used, where natural language models allow for more intuitive interactions and more sophisticated analysis.
Overall, the open data landscape in 2025 reveals a profound transformation of the ecosystem, where the convergence between artificial intelligence, advanced regulatory frameworks, and specialized applications is redefining the possibilities of transparency and public innovation.
Evento
Data science is all the rage. Professions related to this field are among the most in-demand, according to the latest study ‘Posiciones y competencias más Demandadas 2024’, carried out by the Spanish Association of Human Resources Managers. In particular, there is a significant demand for roles related to data management and analysis, such as Data Analyst, Data Engineer and Data Scientist. The rise of artificial intelligence (AI) and the need to make data-driven decisions are driving the integration of this type of professionals in all sectors.
Universities are aware of this situation and therefore offer a large number of degrees, postgraduate courses and also summer courses, both for beginners and for those who want to broaden their knowledge and explore new technological trends. Here are just a few examples of some of them. These courses combine theory and practice, allowing you to discover the potential of data.
1. Data Analysis and Visualisation: Practical Statistics with R and Artificial Intelligence. National University of Distance Education (UNED).
This seminar offers comprehensive training in data analysis with a practical approach. Students will learn to use the R language and the RStudio environment, with a focus on visualisation, statistical inference and its use in artificial intelligence systems. It is aimed at students from related fields and professionals from various sectors (such as education, business, health, engineering or social sciences) who need to apply statistical and AI techniques, as well as researchers and academics who need to process and visualise data.
- Date and place: from 25 to 27 June 2025 in online and face-to-face mode (in Plasencia).
2. Big Data. Data analysis and automatic learning with Python. Complutense University.
Thanks to this training, students will be able to acquire a deep understanding of how data is obtained, managed and analysed to generate valuable knowledge for decision making. Among other issues, the life cycle of a Big Data project will be shown, including a specific module on open data. In this case, the language chosen for the training will be Python. No previous knowledge is required to attend: it is open to university students, teachers, researchers and professionals from any sector with an interest in the subject.
- Date and place: 30 June to 18 July 2025 in Madrid.
3. Challenges in Data Science: Big Data, Biostatistics, Artificial Intelligence and Communications. University of Valencia.
This programme is designed to help participants understand the scope of the data-driven revolution. Integrated within the Erasmus mobility programmes, it combines lectures, group work and an experimental lab session, all in English. Among other topics, open data, open source tools, Big Data databases, cloud computing, privacy and security of institutional data, text mining and visualisation will be discussed.
- Date and place: From 30 June to 4 July at two venues in Valencia. Note: Places are currently full, but the waiting list is open.
4. Digital twins: from simulation to intelligent reality. University of Castilla-La Mancha.
Digital twins are a fundamental tool for driving data-driven decision-making. With this course, students will be able to understand the applications and challenges of this technology in various industrial and technological sectors. Artificial intelligence applied to digital twins, high performance computing (HPC) and digital model validation and verification, among others, will be discussed. It is aimed at professionals, researchers, academics and students interested in the subject.
- Date and place: 3 and 4 July in Albacete.
5. Health Geography and Geographic Information Systems: practical applications. University of Zaragoza.
The differential aspect of this course is that it is designed for those students who are looking for a practical approach to data science in a specific sector such as health. It aims to provide theoretical and practical knowledge about the relationship between geography and health. Students will learn how to use Geographic Information Systems (GIS) to analyse and represent disease prevalence data. It is open to different audiences (from students or people working in public institutions and health centres, to neighbourhood associations or non-profit organisations linked to health issues) and does not require a university degree.
- Date and place: 7-9 July 2025 in Zaragoza.
6. Deep into data science. University of Cantabria.
Aimed at scientists, university students (from second year onwards) in engineering, mathematics, physics and computer science, this intensive course aims to provide a complete and practical vision of the current digital revolution. Students will learn about Python programming tools, machine learning, artificial intelligence, neural networks or cloud computing, among other topics. All topics are introduced theoretically and then experimented with in laboratory practice.
- Date and place: from 7 to 11 July 2025 in Camargo.
7. Advanced Programming. Autonomous University of Barcelona.
Taught entirely in English, the aim of this course is to improve students' programming skills and knowledge through practice. To do so, two games will be developed in two different languages, Java and Python. Students will be able to structure an application and program complex algorithms. It is aimed at students of any degree (mathematics, physics, engineering, chemistry, etc.) who have already started programming and want to improve their knowledge and skills.
- Date and place: 14 July to 1 August 2025, at a location to be defined.
8. Data visualisation and analysis with R. Universidade de Santiago de Compostela.
This course is aimed at beginners in the subject. It will cover the basic functionalities of R with the aim that students acquire the necessary skills to develop descriptive and inferential statistical analysis (estimation, contrasts and predictions). Search and help tools will also be introduced so that students can learn how to use them independently.
- Date and place: from 14 to 24 July 2025 in Santiago de Compostela.
9. Fundamentals of artificial intelligence: generative models and advanced applications. International University of Andalusia.
This course offers a practical introduction to artificial intelligence and its main applications. It covers concepts related to machine learning, neural networks, natural language processing, generative AI and intelligent agents. The language used will be Python, and although the course is introductory, it will be best used if the student has a basic knowledge of programming. It is therefore aimed primarily at undergraduate and postgraduate students in technical areas such as engineering, computer science or mathematics, professionals seeking to acquire AI skills to apply in their industries, and teachers and researchers interested in updating their knowledge of the state of the art in AI.
- Date and place: 19-22 August 2025, in Baeza.
10. IA Generative AI to innovate in the company: real cases and tools for its implementation. University of the Basque Country.
This course, open to the general public, aims to help understand the impact of generative AI in different sectors and its role in digital transformation through the exploration of real cases of application in companies and technology centres in the Basque Country. This will combine talks, panel discussions and a practical session focused on the use of generative models and techniques such as Retrieval-Augmented Generation (RAG) and Fine-Tuning.
- Date and place: 10 September in San Sebastian.
Investing in technology training during the summer is not only an excellent way to strengthen skills, but also to connect with experts, share ideas and discover opportunities for innovation. This selection is just a small sample of what's on offer. If you know of any other courses you would like to share with us, please leave a comment or write to dinamizacion@datos.gob.es
Entrevista
Did you know that data science skills are among the most in-demand skills in business? In this podcast, we are going to tell you how you can train yourself in this field, in a self-taught way. For this purpose, we will have two experts in data science:
- Juan Benavente, industrial and computer engineer with more than 12 years of experience in technological innovation and digital transformation. In addition, it has been training new professionals in technology schools, business schools and universities for years.
- Alejandro Alija, PhD in physics, data scientist and expert in digital transformation. In addition to his extensive professional experience focused on the Internet of Things (internet of things), Alejandro also works as a lecturer in different business schools and universities.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. What is data science? Why is it important and what can it do for us?
Alejandro Alija: Data science could be defined as a discipline whose main objective is to understand the world, the processes of business and life, by analysing and observing data.Data science is a discipline whose main objective is to understand the world, the processes of business and life, by analysing and observing the data.. In the last 20 years it has gained exceptional relevance due to the explosion in data generation, mainly due to the irruption of the internet and the connected world.
Juan Benavente: The term data science has evolved since its inception. Today, a data scientist is the person who is working at the highest level in data analysis, often associated with the building of machine learning or artificial intelligence algorithms for specific companies or sectors, such as predicting or optimising manufacturing in a plant.
The profession is evolving rapidly, and is likely to fragment in the coming years. We have seen the emergence of new roles such as data engineers or MLOps specialists. The important thing is that today any professional, regardless of their field, needs to work with data. There is no doubt that any position or company requires increasingly advanced data analysis. It doesn't matter if you are in marketing, sales, operations or at university. Anyone today is working with, manipulating and analysing data. If we also aspire to data science, which would be the highest level of expertise, we will be in a very beneficial position. But I would definitely recommend any professional to keep this on their radar.
2. How did you get started in data science and what do you do to keep up to date? What strategies would you recommend for both beginners and more experienced profiles?
Alejandro Alija: My basic background is in physics, and I did my PhD in basic science. In fact, it could be said that any scientist, by definition, is a data scientist, because science is based on formulating hypotheses and proving them with experiments and theories. My relationship with data started early in academia. A turning point in my career was when I started working in the private sector, specifically in an environmental management company that measures and monitors air pollution. The environment is a field that is traditionally a major generator of data, especially as it is a regulated sector where administrations and private companies are obliged, for example, to record air pollution levels under certain conditions. I found historical series up to 20 years old that were available for me to analyse. From there my curiosity began and I specialised in concrete tools to analyse and understand what is happening in the world.
Juan Benavente: I can identify with what Alejandro said because I am not a computer scientist either. I trained in industrial engineering and although computer science is one of my interests, it was not my base. In contrast, nowadays, I do see that more specialists are being trained at the university level. A data scientist today has manyskills on their back such as statistics, mathematics and the ability to understand everything that goes on in the industry. I have been acquiring this knowledge through practice. On how to keep up to date, I think that, in many cases, you can be in contact with companies that are innovating in this field. A lot can also be learned at industry or technology events. I started in the smart cities and have moved on to the industrial world to learn little by little.
Alejandro Alija:. To add another source to keep up to date. Apart from what Juan has said, I think it's important to identify what we call outsiders, the manufacturers of technologies, the market players. They are a very useful source of information to stay up to date: identify their futures strategies and what they are betting on.
3. If someone with little or no technical knowledge wants to learn data science, where do they start?
Juan Benavente: In training, I have come across very different profiless: from people who have just graduated from university to profiles that have been trained in very different fields and find in data science an opportunity to transform themselves and dedicate themselves to this. Thinking of someone who is just starting out, I think the best thing to do is put your knowledge into practice. In projects I have worked on, we defined the methodology in three phases: a first phase of more theoretical aspects, taking into account mathematics, programming and everything a data scientist needs to know; once you have those basics, the sooner you start working and practising those skills, the better. I believe that skill sharpens the wit and, both to keep up to date and to train yourself and acquire useful knowledge, the sooner you enter into a project, the better. And even more so in a world that is so frequently updated. In recent years, the emergence of the Generative AI has brought other opportunities. There are also opportunities for new profiles who want to be trained . Even if you are not an expert in programming, you have tools that can help you with programming, and the same can happen in mathematics or statistics.
Alejandro Alija:. To complement what Juan says from a different perspective. I think it is worth highlighting the evolution of the data science profession.. I remember when that paper about "the sexiest profession in the world" became famous and went viral, but then things adjusted. The first settlers in the world of data science did not come so much from computer science or informatics. There were more outsiders: physicists, mathematicians, with a strong background in mathematics and physics, and even some engineers whose work and professional development meant that they ended up using many tools from the computer science field. Gradually, it has become more and more balanced. It is now a discipline that continues to have those two strands: people who come from the world of physics and mathematics towards the more basic data, and people who come with programming skills. Everyone knows what they have to balance in their toolbox. Thinking about a junior profile who is just starting out, I think a very important thing - and we see this when we teach - is programming skills. I would say that having programming skills is not just a plus, but a basic requirement for advancement in this profession. It is true that some people can do well without a lot of programming skills, but I would argue that a beginner needs to have those first programming skills with a basic toolset . We're talking about languages such as Python and R, which are the headline languages. You don't need to be a great coder, but you do need to have some basic knowledge to get started. Then, of course, specific training in the mathematical foundations of data science is crucial. The fundamental statistics and more advanced statistics are complements that, if present, will move a person along the data science learning curve much faster. Thirdly, I would say that specialisation in particular tools is important. Some people are more oriented towards data engineering, others towards the modelling world. Ideally, specialise in a few frameworks and use them together, as optimally as possible.
4. In addition to teaching, you both work in technology companies. What technical certifications are most valued in the business sector and what open sources of knowledge do you recommend to prepare for them?
Juan Benavente: Personally, it's not what I look at most, but I think it can be relevant, especially for people who are starting out and need help in structuring their approach to the problem and understanding it. I recommend certifications of technologies that are in use in any company where you want to end up working. Especially from providers of cloud computing and widespread data analytics tools. These are certifications that I would recommend for someone who wants to approach this world and needs a structure to help them. When you don't have a knowledge base, it can be a bit confusing to understand where to start. Perhaps you should reinforce programming or mathematical knowledge first, but it can all seem a bit complicated. Where these certifications certainly help you is, in addition to reinforcing concepts, to ensure that you are moving well and know the typical ecosystem of tools you will be working with tomorrow. It is not just about theoretical concepts, but about knowing the ecosystems that you will encounter when you start working, whether you are starting your own company or working in an established company. It makes it much easier for you to get to know the typical ecosystem of tools. Call it Microsoft Computing, Amazon or other providers of such solutions. This will allow you to focus more quickly on the work itself, and less on all the tools that surround it. I believe that this type of certification is useful, especially for profiles that are approaching this world with enthusiasm. It will help them both to structure themselves and to land well in their professional destination. They are also likely to be valued in selection processes.
Alejandro Alija: If someone listens to us and wants more specific guidelines, it could be structured in blocks. There are a series of massive online courses that, for me, were a turning point. In my early days, I tried to enrol in several of these courses on platforms such as Coursera, edX, where even the technology manufacturers themselves design these courses. I believe that this kind of massive, self-service, online courses provide a good starting base. A second block would be the courses and certifications of the big technology providers, such as Microsoft, Amazon Web Services, Google and other platforms that are benchmarks in the world of data. These companies have the advantage that their learning paths are very well structured, which facilitates professional growth within their own ecosystems. Certifications from different suppliers can be combined. For a person who wants to go into this field, the path ranges from the simplest to the most advanced certifications, such as being a data solutions architect or a specialist in a specific data analytics service or product. These two learning blocks are available on the internet, most of them are open and free or close to free. Beyond knowledge, what is valued is certification, especially in companies looking for these professional profiles.
5. In addition to theoretical training, practice is key, and one of the most interesting methods of learning is to replicate exercises step by step. In this sense, from datos.gob.es we offer didactic resources, many of them developed by you as experts in the project, can you tell us what these exercises consist of?. How are they approached?
Alejandro Alija: The approach we always took was designed for a broad audience, without complex prerequisites. We wanted any user of the portal to be able to replicate the exercises, although it is clear that the more knowledge you have, the more you can use it to your advantage. Exercises have a well-defined structure: a documentary section, usually a content post or a report describing what the exercise consists of, what materials are needed, what the objectives are and what it is intended to achieve. In addition, we accompany each exercise with two additional resources. The first resource is a code repository where we upload the necessary materials, with a brief description and the code of the exercise. It can be a Python notebook , a Jupyter Notebook or a simple script, where the technical content is. And then another fundamental element that we believe is important and that is aimed at facilitating the execution of the exercises. In data science and programming, non-specialist users often find it difficult to set up a working environment. A Python exercise, for example, requires having a programming environment installed, knowing the necessary libraries and making configurations that are trivial for professionals, but can be very complex for beginners. To mitigate this barrier, we publish most of our exercises on Google Colab, a wonderful and open tool. Google Colab is a web programming environment where the user only needs a browser to access it. Basically, Google provides us with a virtual computer where we can run our programmes and exercises without the need for special configurations. The important thing is that the exercise is ready to use and we always check it in this environment, which makes it much easier to learn for beginners or less technically experienced users.
Juan Benavente: Yes, we always take a user-oriented approach, step by step, trying to make it open and accessible. The aim is for anyone to be able to run an exercise without the need for complex configurations, focusing on topics as close to reality as possible. We often take advantage of open data published by entities such as the DGT or other bodies to make realistic analyses. We have developed very interesting exercises, such as energy market predictions, analysis of critical materials for batteries and electronics, which allow learning not only about technology, but also about the specific subject matter.. You can get down to work right away, not only to learn, but also to find out about the subject.
6. In closing, we'd like you to offer a piece of advice that is more attitude-oriented than technical, what would you say to someone starting out in data science?
Alejandro Alija: As for an attitude tip for someone starting out in data science, I suggest be brave. There is no need to worry about being unprepared, because in this field everything is to be done and anyone can contribute value. Data science is multi-faceted: there are professionals closer to the business world who can provide valuable insights, and others who are more technical and need to understand the context of each area. My advice is to be content with the resources available without panicking, because, although the path may seem complex, the opportunities are very high. As a technical tip, it is important to be sensitive to the development and use of data. The more understanding one has of this world, the smoother the approach to projects will be.
Juan Benavente: I endorse the advice to be brave and add a reflection on programming: many people find the theoretical concept attractive, but when they get to practice and see the complexity of programming, some are discouraged by lack of prior knowledge or different expectations. It is important to add the concepts of patience and perseverance. When you start in this field, you are faced with multiple areas that you need to master: programming, statistics, mathematics, and specific knowledge of the sector you will be working in, be it marketing, logistics or another field. The expectation of becoming an expert quickly is unrealistic. It is a profession that, although it can be started without fear and by collaborating with professionals, requires a journey and a learning process. You have to be consistent and patient, managing expectations appropriately. Most people who have been in this world for a long time agree that they have no regrets about going into data science. It is a very attractive profession where you can add significant value, with an important technological component. However, the path is not always straightforward. There will be complex projects, moments of frustration when analyses do not yield the expected results or when working with data proves more challenging than expected. But looking back, few professionals regret having invested time and effort in training and developing in this field. In summary, the key tips are: courage to start, perseverance in learning and development of programming skills.
Interview clips
1. Is it worth studying data science?
2. How are the data science exercises on datos.gob.es approached?
3. What is data science? What skills are required?
Blog
There is no doubt that data has become the strategic asset for organisations. Today, it is essential to ensure that decisions are based on quality data, regardless of the alignment they follow: data analytics, artificial intelligence or reporting. However, ensuring data repositories with high levels of quality is not an easy task, given that in many cases data come from heterogeneous sources where data quality principles have not been taken into account and no context about the domain is available.
To alleviate as far as possible this casuistry, in this article, we will explore one of the most widely used libraries in data analysis: Pandas. Let's check how this Python library can be an effective tool to improve data quality. We will also review the relationship of some of its functions with the data quality dimensions and properties included in the UNE 0081 data quality specification, and some concrete examples of its application in data repositories with the aim of improving data quality.
Using Pandas for data profiling
Si bien el data profiling y la evaluación de calidad de datos están estrechamente relacionados, sus enfoques son diferentes:
- Data Profiling: is the process of exploratory analysis performed to understand the fundamental characteristics of the data, such as its structure, data types, distribution of values, and the presence of missing or duplicate values. The aim is to get a clear picture of what the data looks like, without necessarily making judgements about its quality.
- Data quality assessment: involves the application of predefined rules and standards to determine whether data meets certain quality requirements, such as accuracy, completeness, consistency, credibility or timeliness. In this process, errors are identified and actions to correct them are determined. A useful guide for data quality assessment is the UNE 0081 specification.
It consists of exploring and analysing a dataset to gain a basic understanding of its structure, content and characteristics, before conducting a more in-depth analysis or assessment of the quality of the data. The main objective is to obtain an overview of the data by analysing the distribution, types of data, missing values, relationships between columns and detection of possible anomalies. Pandas has several functions to perform this data profiling.
En resumen, el data profiling es un paso inicial exploratorio que ayuda a preparar el terreno para una evaluación más profunda de la calidad de los datos, proporcionando información esencial para identificar áreas problemáticas y definir las reglas de calidad adecuadas para la evaluación posterior.
What is Pandas and how does it help ensure data quality?
Pandas is one of the most popular Python libraries for data manipulation and analysis. Its ability to handle large volumes of structured information makes it a powerful tool in detecting and correcting errors in data repositories. With Pandas, complex operations can be performed efficiently, from data cleansing to data validation, all of which are essential to maintain quality standards. The following are some examples of how to improve data quality in repositories with Pandas:
1. Detection of missing or inconsistent values: One of the most common data errors is missing or inconsistent values. Pandas allows these values to be easily identified by functions such as isnull() or dropna(). This is key for the completeness property of the records and the data consistency dimension, as missing values in critical fields can distort the results of the analyses.
-
# Identify null values in a dataframe.
df.isnull().sum()
2. Data standardisation and normalisation: Errors in naming or coding consistency are common in large repositories. For example, in a dataset containing product codes, some may be misspelled or may not follow a standard convention. Pandas provides functions like merge() to perform a comparison with a reference database and correct these values. This option is key to maintaining the dimension and semantic consistency property of the data.
# Substitution of incorrect values using a reference table
df = df.merge(product_codes, left_on='product_code', right_on='ref_code', how= 'left')
3. Validation of data requirements: Pandas allows the creation of customised rules to validate the compliance of data with certain standards. For example, if an age field should only contain positive integer values, we can apply a function to identify and correct values that do not comply with this rule. In this way, any business rule of any of the data quality dimensions and properties can be validated.
# Identify records with invalid age values (negative or decimals)
age_errors = df[(df['age'] < 0) | (df['age'] % 1 != 0)])
4. Exploratory analysis to identify anomalous patterns: Functions such as describe() or groupby() in Pandas allow you to explore the general behaviour of your data. This type of analysis is essential for detecting anomalous or out-of-range patterns in any data set, such as unusually high or low values in columns that should follow certain ranges.
# Statistical summary of the data
df.describe()
#Sort by category or property
df.groupby()
5. Duplication removal: Duplicate data is a common problem in data repositories. Pandas provides methods such as drop_duplicates() to identify and remove these records, ensuring that there is no redundancy in the dataset. This capacity would be related to the dimension of completeness and consistency.
# Remove duplicate rows
df = df.drop_duplicates()
Practical example of the application of Pandas
Having presented the above functions that help us to improve the quality of data repositories, we now consider a case to put the process into practice. Suppose we are managing a repository of citizens' data and we want to ensure:
- Age data should not contain invalid values (such as negatives or decimals).
- That nationality codes are standardised.
- That the unique identifiers follow a correct format.
- The place of residence must be consistent.
With Pandas, we could perform the following actions:
1. Age validation without incorrect values:
# Identify records with ages outside the allowed ranges (e.g. less than 0 or non-integers)
age_errors = df[(df['age'] < 0) | (df['age'] % 1 != 0)])
2. Correction of nationality codes:
# Use of an official dataset of nationality codes to correct incorrect entries
df_corregida = df.merge(nacionalidades_ref, left_on='nacionalidad', right_on='codigo_ref', how='left')
3. Validation of unique identifiers:
# Check if the format of the identification number follows a correct pattern
df['valid_id'] = df['identificacion'].str.match(r'^[A-Z0-9]{8}$')
errores_id = df[df['valid_id'] == False]
4. Verification of consistency in place of residence:
# Detect possible inconsistencies in residency (e.g. the same citizen residing in two places at the same time).
duplicados_residencia = df.groupby(['id_ciudadano', 'fecha_residencia'])['lugar_residencia'].nunique()
inconsistencias_residencia = duplicados_residencia[duplicados_residencia > 1]
Integration with a variety of technologies
Pandas is an extremely flexible and versatile library that integrates easily with many technologies and tools in the data ecosystem. Some of the main technologies with which Pandas is integrated or can be used are:
- SQL databases:
Pandas integrates very well with relational databases such as MySQL, PostgreSQL, SQLite, and others that use SQL. The SQLAlchemy library or directly the database-specific libraries (such as psycopg2 for PostgreSQL or sqlite3) allow you to connect Pandas to these databases, perform queries and read/write data between the database and Pandas.
- Common function: pd.read_sql() to read a SQL query into a DataFrame, and to_sql() to export the data from Pandas to a SQL table.
- REST and HTTP-based APIs:
Pandas can be used to process data obtained from APIs using HTTP requests. Libraries such as requests allow you to get data from APIs and then transform that data into Pandas DataFrames for analysis.
- Big Data (Apache Spark):
Pandas can be used in combination with PySpark, an API for Apache Spark in Python. Although Pandas is primarily designed to work with in-memory data, Koalas, a library based on Pandas and Spark, allows you to work with Spark distributed structures using a Pandas-like interface. Tools like Koalas help Pandas users scale their scripts to distributed data environments without having to learn all the PySpark syntax.
- Hadoop and HDFS:
Pandas can be used in conjunction with Hadoop technologies, especially the HDFS distributed file system. Although Pandas is not designed to handle large volumes of distributed data, it can be used in conjunction with libraries such as pyarrow or dask to read or write data to and from HDFS on distributed systems. For example, pyarrow can be used to read or write Parquet files in HDFS.
- Popular file formats:
Pandas is commonly used to read and write data in different file formats, such as:
- CSV: pd.read_csv()
- Excel: pd.read_excel() and to_excel().
- JSON: pd.read_json()
- Parquet: pd.read_parquet() for working with space and time efficient files.
- Feather: a fast file format for interchange between languages such as Python and R (pd.read_feather()).
- Data visualisation tools:
Pandas can be easily integrated with visualisation tools such as Matplotlib, Seaborn, and Plotly.. These libraries allow you to generate graphs directly from Pandas DataFrames.
- Pandas includes its own lightweight integration with Matplotlib to generate fast plots using df.plot().
- For more sophisticated visualisations, it is common to use Pandas together with Seaborn or Plotly for interactive graphics.
- Machine learning libraries:
Pandas is widely used in pre-processing data before applying machine learning models. Some popular libraries with which Pandas integrates are:
- Scikit-learn: la mayoría de los pipelines de machine learning comienzan con la preparación de datos en Pandas antes de pasar los datos a modelos de Scikit-learn.
- TensorFlow y PyTorch: aunque estos frameworks están más orientados al manejo de matrices numéricas (Numpy), Pandas se utiliza frecuentemente para la carga y limpieza de datos antes de entrenar modelos de deep learning.
- XGBoost, LightGBM, CatBoost: Pandas supports these high-performance machine learning libraries, where DataFrames are used as input to train models.
- Jupyter Notebooks:
Pandas is central to interactive data analysis within Jupyter Notebooks, which allow you to run Python code and visualise the results immediately, making it easy to explore data and visualise it in conjunction with other tools.
- Cloud Storage (AWS, GCP, Azure):
Pandas can be used to read and write data directly from cloud storage services such as Amazon S3, Google Cloud Storage and Azure Blob Storage. Additional libraries such as boto3 (for AWS S3) or google-cloud-storage facilitate integration with these services. Below is an example for reading data from Amazon S3.
import pandas as pd
import boto3
#Create an S3 client
s3 = boto3.client('s3')
#Obtain an object from the bucket
obj = s3.get_object(Bucket='mi-bucket', Key='datos.csv')
#Read CSV file from a DataFrame
df = pd.read_csv(obj['Body'])
10. Docker and containers:
Pandas can be used in container environments using Docker.. Containers are widely used to create isolated environments that ensure the replicability of data analysis pipelines .
In conclusion, the use of Pandas is an effective solution to improve data quality in complex and heterogeneous repositories. Through clean-up, normalisation, business rule validation, and exploratory analysis functions, Pandas facilitates the detection and correction of common errors, such as null, duplicate or inconsistent values. In addition, its integration with various technologies, databases, big dataenvironments, and cloud storage, makes Pandas an extremely versatile tool for ensuring data accuracy, consistency and completeness.
Content prepared by Dr. Fernando Gualo, Professor at UCLM and Data Governance and Quality Consultant. The content and point of view reflected in this publication is the sole responsibility of its author.
Blog
Natural language processing (NLP) is a branch of artificial intelligence that allows machines to understand and manipulate human language. At the core of many modern applications, such as virtual assistants, machine translation and chatbots, are word embeddings. But what exactly are they and why are they so important?
What are word embeddings?
Word embeddings are a technique that allows machines to represent the meaning of words in such a way that complex relationships between words can be captured. To understand this, let's think about how words are used in a given context: a word acquires meaning depending on the words surrounding it. For example, the word bank can refer to a financial institution or to a headquarters, depending on the context in which it is found.
The idea behind word embeddings is that each word is assigned a vector in a multi-dimensional space. The position of these vectors in space reflects the semantic closeness between the words. If two words have similar meanings, their vectors will be close. If their meanings are opposite or unrelated, they are distant in vector space.
To visualise this, imagine that words like lake, river and ocean would be close together in this space, while words like lake and building would be much further apart. This structure enables language processing algorithms to perform complex tasks, such as finding synonyms, making accurate translations or even answering context-based questions.
How are word embeddings created?
The main objective of word embeddings is to capture semantic relationships and contextual information of words, transforming them into numerical representations that can be understood by machine learning algorithms. Instead of working with raw text, machines require words to be converted into numbers in order to identify patterns and relationships effectively.
The process of creating word embeddings consists of training a model on a large corpus of text, such as Wikipedia articles or news items, to learn the structure of the language. The first step involves performing a series of pre-processing on the corpus, which includes tokenise the words, removing punctuation and irrelevant terms, and, in some cases, converting the entire text to lower case to maintain consistency.
The use of context to capture meaning
Once the text has been pre-processed, a technique known as "sliding context window" is used to extract information. This means that, for each target word, the surrounding words within a certain range are taken into account. For example, if the context window is 3 words, for the word airplane in the sentence "The plane takes off at six o'clock", the context words will be The, takes off, to.
The model is trained to learn to predict a target word using the words in its context (or conversely, to predict the context from the target word). To do this, the algorithm adjusts its parameters so that the vectors assigned to each word are closer in vector space if those words appear frequently in similar contexts.
How models learn language structure
The creation of word embeddings is based on the ability of these models to identify patterns and semantic relationships. During training, the model adjusts the values of the vectors so that words that often share contexts have similar representations. For example, if airplane and helicopter are frequently used in similar phrases (e.g. in the context of air transport), the vectors of airplane and helicopter will be close together in vector space.
As the model processes more and more examples of sentences, it refines the positions of the vectors in the continuous space. Thus, the vectors reflect not only semantic proximity, but also other relationships such as synonyms, categories (e.g., fruits, animals) and hierarchical relationships (e.g., dog and animal).
A simplified example
Imagine a small corpus of only six words: guitar, bass, drums, piano, car and bicycle. Suppose that each word is represented in a three-dimensional vector space as follows:
guitar [0.3, 0.8, -0.1]
bass [0.4, 0.7, -0.2]
drums [0.2, 0.9, -0.1]
piano [0.1, 0.6, -0.3]
car [0.8, -0.1, 0.6]
bicycle [0.7, -0.2, 0.5]
In this simplified example, the words guitar, bass, drums and piano represent musical instruments and are located close to each other in vector space, as they are used in similar contexts. In contrast, car and bicycle, which belong to the category of means of transport, are distant from musical instruments but close to each other. This other image shows how different terms related to sky, wings and engineering would look like in a vector space.

Figure 1. Examples of representation of a corpus in a vector space. Source: Adapted from “Word embeddings: the (very) basics”, by Guillaume Desagulier.
This example only uses three dimensions to illustrate the idea, but in practice, word embeddings usually have between 100 and 300 dimensions to capture more complex semantic relationships and linguistic nuances.
The result is a set of vectors that efficiently represent each word, allowing language processing models to identify patterns and semantic relationships more accurately. With these vectors, machines can perform advanced tasks such as semantic search, text classification and question answering, significantly improving natural language understanding.
Strategies for generating word embeddings
Over the years, multiple approaches and techniques have been developed to generate word embeddings. Each strategy has its own way of capturing the meaning and semantic relationships of words, resulting in different characteristics and uses. Some of the main strategies are presented below:
1. Word2Vec: local context capture
Developed by Google, Word2Vec is one of the most popular approaches and is based on the idea that the meaning of a word is defined by its context. It uses two main approaches:
- CBOW (Continuous Bag of Words): In this approach, the model predicts the target word using the words in its immediate environment. For example, given a context such as "The dog is ___ in the garden", the model attempts to predict the word playing, based on the words The, dog, is and garden.
- Skip-gram: Conversely, Skip-gram uses a target word to predict the surrounding words. Using the same example, if the target word is playing, the model would try to predict that the words in its environment are The, dog, is and garden.
The key idea is that Word2Vec trains the model to capture semantic proximity across many iterations on a large corpus of text. Words that tend to appear together have closer vectors, while unrelated words appear further apart.
2. GloVe: global statistics-based approach
GloVe, developed at Stanford University, differs from Word2Vec by using global co-occurrence statistics of words in a corpus. Instead of considering only the immediate context, GloVe is based on the frequency with which two words appear together in the whole corpus.
For example, if bread and butter appear together frequently, but bread and planet are rarely found in the same context, the model adjusts the vectors so that bread and butter are close together in vector space.
This allows GloVe to capture broader global relationships between words and to make the representations more robust at the semantic level. Models trained with GloVe tend to perform well on analogy and word similarity tasks.
3. FastText: subword capture
FastText, developed by Facebook, improves on Word2Vec by introducing the idea of breaking down words into sub-words. Instead of treating each word as an indivisible unit, FastText represents each word as a sum of n-grams. For example, the word playing could be broken down into play, ayi, ing, and so on.
This allows FastText to capture similarities even between words that did not appear explicitly in the training corpus, such as morphological variations (playing, play, player). This is particularly useful for languages with many grammatical variations.
4. Embeddings contextuales: dynamic sense-making
Models such as BERT and ELMo represent a significant advance in word embeddings. Unlike the previous strategies, which generate a single vector for each word regardless of the context, contextual embeddings generate different vectors for the same word depending on its use in the sentence.
For example, the word bank will have a different vector in the sentence "I sat on the park bench" than in "the bank approved my credit application". This variability is achieved by training the model on large text corpora in a bidirectional manner, i.e. considering not only the words preceding the target word, but also those following it.
Practical applications of word embeddings
ord embeddings are used in a variety of natural language processing applications, including:
- Named Entity Recognition (NER): allows you to identify and classify names of people, organisations and places in a text. For example, in the sentence "Apple announced its new headquarters in Cupertino", the word embeddings allow the model to understand that Apple is an organisation and Cupertino is a place.
- Automatic translation: helps to represent words in a language-independent way. By training a model with texts in different languages, representations can be generated that capture the underlying meaning of words, facilitating the translation of complete sentences with a higher level of semantic accuracy.
- Information retrieval systems: in search engines and recommender systems, word embeddings improve the match between user queries and relevant documents. By capturing semantic similarities, they allow even non-exact queries to be matched with useful results. For example, if a user searches for "medicine for headache", the system can suggest results related to analgesics thanks to the similarities captured in the vectors.
- Q&A systems: word embeddings are essential in systems such as chatbots and virtual assistants, where they help to understand the intent behind questions and find relevant answers. For example, for the question "What is the capital of Italy?", the word embeddings allow the system to understand the relationship between capital and Italy and find Rome as an answer.
- Sentiment analysis: word embeddings are used in models that determine whether the sentiment expressed in a text is positive, negative or neutral. By analysing the relationships between words in different contexts, the model can identify patterns of use that indicate certain feelings, such as joy, sadness or anger.
- Semantic clustering and similarity detection: word embeddings also allow you to measure the semantic similarity between documents, phrases or words. This is used for tasks such as grouping related items, recommending products based on text descriptions or even detecting duplicates and similar content in large databases.
Conclusion
Word embeddings have transformed the field of natural language processing by providing dense and meaningful representations of words, capable of capturing their semantic and contextual relationships. With the emergence of contextual embeddings , the potential of these representations continues to grow, allowing machines to understand even the subtleties and ambiguities of human language. From applications in translation and search systems, to chatbots and sentiment analysis, word embeddings will continue to be a fundamental tool for the development of increasingly advanced and humanised natural language technologies.
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Noticia
For many people, summer means the arrival of the vacations, a time to rest or disconnect. But those days off are also an opportunity to train in various areas and improve our competitive skills.
For those who want to take advantage of the next few weeks and acquire new knowledge, Spanish universities have a wide range of courses on a variety of subjects. In this article, we have compiled some examples of courses related to data training.
Geographic Information Systems (GIS) with QGIS. University of Alcalá de Henares (link not available).
The course aims to train students in basic GIS skills so that they can perform common processes such as creating maps for reports, downloading data from a GPS, performing spatial analysis, etc. Each student will have the possibility to develop their own GIS project with the help of the faculty. The course is aimed at university students of any discipline, as well as professionals interested in learning basic concepts to create their own maps or use geographic information systems in their activities.
- Date and place: June 27-28 and July 1-2 in online mode.
Citizen science applied to biodiversity studies: from the idea to the results. Pablo de Olavide University (Seville).
This course addresses all the necessary steps to design, implement and analyze a citizen science project: from the acquisition of basic knowledge to its applications in research and conservation projects. Among other issues, there will be a workshop on citizen science data management, focusing on platforms such as Observation.org y GBIF. It will also teach how to use citizen science tools for the design of research projects. The course is aimed at a broad audience, especially researchers, conservation project managers and students.
- Date and place: From July 1 to 3, 2024 in online and on-site (Seville).
Big Data. Data analysis and machine learning with Python. Complutense University of Madrid.
This course aims to provide students with an overview of the broad Big Data ecosystem, its challenges and applications, focusing on new ways of obtaining, managing and analyzing data. During the course, the Python language is presented, and different machine learning techniques are shown for the design of models that allow obtaining valuable information from a set of data. It is aimed at any university student, teacher, researcher, etc. with an interest in the subject, as no previous knowledge is required.
- Date and place: July 1 to 19, 2024 in Madrid.
Introduction to Geographic Information Systems with R. University of Santiago de Compostela.
Organized by the Working Group on Climate Change and Natural Hazards of the Spanish Association of Geography together with the Spanish Association of Climatology, this course will introduce the student to two major areas of great interest: 1) the handling of the R environment, showing the different ways of managing, manipulating and visualizing data. 2) spatial analysis, visualization and work with raster and vector files, addressing the main geostatistical interpolation methods. No previous knowledge of Geographic Information Systems or the R environment is required to participate.
- Date and place: July 2-5, 2024 in Santiago de Compostela
Artificial Intelligence and Large Language Models: Operation, Key Components and Applications. University of Zaragoza.
Through this course, students will be able to understand the fundamentals and practical applications of artificial intelligence focused on Large Language Model (LLM). Students will be taught how to use specialized libraries and frameworks to work with LLM, and will be shown examples of use cases and applications through hands-on workshops. It is aimed at professionals and students in the information and communications technology sector.
- Date and place: July 3 to 5 in Zaragoza.
Deep into Data Science. University of Cantabria.
This course focuses on the study of big data using Python. The emphasis of the course is on Machine Learning, including sessions on artificial intelligence, neural networks or Cloud Computing. This is a technical course, which presupposes previous knowledge in science and programming with Python.
- Date and place: From July 15 to 19, 2024 in Torrelavega.
Data management for the use of artificial intelligence in tourist destinations. University of Alicante.
This course approaches the concept of Smart Tourism Destination (ITD) and addresses the need to have an adequate technological infrastructure to ensure its sustainable development, as well as to carry out an adequate data management that allows the application of artificial intelligence techniques. During the course, open data and data spaces and their application in tourism will be discussed. It is aimed at all audiences with an interest in the use of emerging technologies in the field of tourism.
- Date and place: From July 22 to 26, 2024 in Torrevieja.
The challenges of digital transformation of productive sectors from the perspective of artificial intelligence and data processing technologies. University of Extremadura.
Now that the summer is over, we find this course where the fundamentals of digital transformation and its impact on productive sectors are addressed through the exploration of key data processing technologies, such as the Internet of Things, Big Data, Artificial Intelligence, etc. During the sessions, case studies and implementation practices of these technologies in different industrial sectors will be analyzed. All this without leaving aside the ethical, legal and privacy challenges. It is aimed at anyone interested in the subject, without the need for prior knowledge.
- Date and place: From September 17 to 19, in Cáceres.
These courses are just examples that highlight the importance that data-related skills are acquiring in Spanish companies, and how this is reflected in university offerings. Do you know of any other courses offered by public universities? Let us know in comments.
Noticia
Today, 23 April, is World Book Day, an occasion to highlight the importance of reading, writing and the dissemination of knowledge. Active reading promotes the acquisition of skills and critical thinking by bringing us closer to specialised and detailed information on any subject that interests us, including the world of data.
Therefore, we would like to take this opportunity to showcase some examples of books and manuals regarding data and related technologies that can be found on the web for free.
1. Fundamentals of Data Science with R, edited by Gema Fernandez-Avilés and José María Montero (2024)
Access the book here.
- What is it about? The book guides the reader from the problem statement to the completion of the report containing the solution to the problem. It explains some thirty data science techniques in the fields of modelling, qualitative data analysis, discrimination, supervised and unsupervised machine learning, etc. It includes more than a dozen use cases in sectors as diverse as medicine, journalism, fashion and climate change, among others. All this, with a strong emphasis on ethics and the promotion of reproducibility of analyses.
- Who is it aimed at? It is aimed at users who want to get started in data science. It starts with basic questions, such as what is data science, and includes short sections with simple explanations of probability, statistical inference or sampling, for those readers unfamiliar with these issues. It also includes replicable examples for practice.
- Language: Spanish.
2. Telling stories with data, Rohan Alexander (2023).
Access the book here.
- What is it about? The book explains a wide range of topics related to statistical communication and data modelling and analysis. It covers the various operations from data collection, cleaning and preparation to the use of statistical models to analyse the data, with particular emphasis on the need to draw conclusions and write about the results obtained. Like the previous book, it also focuses on ethics and reproducibility of results.
- Who is it aimed at? It is ideal for students and entry-level users, equipping them with the skills to effectively conduct and communicate a data science exercise. It includes extensive code examples for replication and activities to be carried out as evaluation.
- Language: English.
3. The Big Book of Small Python Projects, Al Sweigart (2021)
Access the book here.
- What is it about? It is a collection of simple Python projects to learn how to create digital art, games, animations, numerical tools, etc. through a hands-on approach. Each of its 81 chapters independently explains a simple step-by-step project - limited to a maximum of 256 lines of code. It includes a sample run of the output of each programme, source code and customisation suggestions.
- Who is it aimed at? The book is written for two groups of people. On the one hand, those who have already learned the basics of Python, but are still not sure how to write programs on their own. On the other hand, those who are new to programming, but are adventurous, enthusiastic and want to learn as they go along. However, the same author has other resources for beginners to learn basic concepts.
- Language: English.
4. Mathematics for Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Access the book here.
- What is it about? Most books on machine learning focus on machine learning algorithms and methodologies, and assume that the reader is proficient in mathematics and statistics. This book foregrounds the mathematical foundations of the basic concepts behind machine learning
- Who is it aimed at? The author assumes that the reader has mathematical knowledge commonly learned in high school mathematics and physics subjects, such as derivatives and integrals or geometric vectors. Thereafter, the remaining concepts are explained in detail, but in an academic style, in order to be precise.
- Language: English.
5. Dive into Deep Learning, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, continually updated)
Access the book here.
- What is it about? The authors are Amazon employees who use the mXNet library to teach Deep Learning. It aims to make deep learning accessible, teaching basic concepts, context and code in a practical way through examples and exercises. The book is divided into three parts: introductory concepts, deep learning techniques and advanced topics focusing on real systems and applications.
- Who is it aimed at? This book is aimed at students (undergraduate and postgraduate), engineers and researchers, who are looking for a solid grasp of the practical techniques of deep learning. Each concept is explained from scratch, so no prior knowledge of deep or machine learning is required. However, knowledge of basic mathematics and programming is necessary, including linear algebra, calculus, probability and Python programming.
- Language: English.
6. Artificial intelligence and the public sector: challenges, limits and means, Eduardo Gamero and Francisco L. Lopez (2024)
Access the book here.
- What is it about? This book focuses on analysing the challenges and opportunities presented by the use of artificial intelligence in the public sector, especially when used to support decision-making. It begins by explaining what artificial intelligence is and what its applications in the public sector are, and then moves on to its legal framework, the means available for its implementation and aspects linked to organisation and governance.
- Who is it aimed at? It is a useful book for all those interested in the subject, but especially for policy makers, public workers and legal practitioners involved in the application of AI in the public sector.
- Language: Spanish
7. A Business Analyst’s Introduction to Business Analytics, Adam Fleischhacker (2024)
Access the book here.
- What is it about? The book covers a complete business analytics workflow, including data manipulation, data visualisation, modelling business problems, translating graphical models into code and presenting results to stakeholders. The aim is to learn how to drive change within an organisation through data-driven knowledge, interpretable models and persuasive visualisations.
- Who is it aimed at? According to the author, the content is accessible to everyone, including beginners in analytical work. The book does not assume any knowledge of the programming language, but provides an introduction to R, RStudio and the "tidyverse", a series of open source packages for data science.
- Language: English.
We invite you to browse through this selection of books. We would also like to remind you that this is only a list of examples of the possibilities of materials that you can find on the web. Do you know of any other books you would like to recommend? let us know in the comments or email us at dinamizacion@datos.gob.es!