Caracterización del alumnado de la Universidad española y titulaciones más demandadas



Fecha del documento: 05-04-2022

1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos "Matriculaciones_NivelAcademico"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
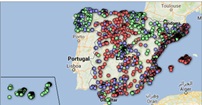
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción "Spain>>Provinces(2018)". Seguidamente procedemos a incorporar el conjunto de datos "Universidades", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos "Titulaciones_totales" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos "Matriculaciones_Rama_Grado" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos "Matriculaciones_Grado_nacionalidad" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos "Matriculaciones_Grado_edad". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!