Blog
In the medical sector, access to information can transform lives. This is one of the main reasons why data sharing and open data communities or open science linked to medical research have become such a valuable resource. Medical research groups that champion the use and reuse of data are leading this transformation, driving innovation, improving collaboration and accelerating the advancement of science.
As we saw in the case of FISABIO Fundation, the open data in the health sector foster collaboration between researchers, speed up the process of validating study results and, ultimately, help save lives. This trend not only facilitates faster discoveries, but also helps to create more effective solutions. In Spain, the Consejo Superior de Investigación Científica (CSIC) is committed to open data and some renowned hospitals also share their research results while protecting their patients' sensitive data.
In this post, we will explore how research groups and health communities are sharing and reusing data to drive groundbreaking research and showcase more inspiring use cases. From developing new treatments to identifying trends in public health, data is redefining the medical research landscape and opening up new opportunities to improve global health.
Medical research groups committed to working with shared data
In Spain, there are several research groups and communities that share their findings more freely through platforms and databases that facilitate global collaboration and data reuse in the field of health. Below, we highlight some of the most influential cases, demonstrating how access to information can accelerate scientific progress and improve health outcomes.
-
H2O - Health Outcomes Observatory clinical data repository
H2O is a strategic public-private partnership to create a robust data infrastructure and governance model to collect and incorporate patient outcomes at scale into health decision-making at the individual and population level. H2O's approach puts patients in ultimate control of their health and ensures that only they exercise that control and ensures that only they exercise that control. Hospitals from all over the world participate in this consortium, including the Spanish Hospital Universitario Fundación Jiménez Díaz and the Hospital Vall d'Hebron. The Spain Research Unit collects patient-reported health outcomes and other clinical data to build an observatory to improve patient care.
-
Carlos III Health Institute: IMPaCT open science research projects
Within the framework of the IMPaCT infrastructure, different projects are being developed and approved as part of the Action in Health's grants for Precision Personalised Medicine Research Projects:
- COHORTE Programme - Predictive Medicine
- DATA programme: Data science
- GENOMICS Programme - Genomic medicine
The information, data, metadata and scientific products generated in IMPaCT are open access, to make science more accessible, efficient, democratic and transparent. Hospitals and research institutes from all over Spain are participating in this project.
-
POP Health Data: medical research project of the Instituto de Salud Carlos III (ISCIII) and the Platform of Patients' Organisations (POP)
This is a data project developed collaboratively between ISCIII and POP to improve knowledge and evidence on the clinical, occupational and social reality of chronic patients, and social reality of chronic patients, which is crucial for us. This initiative involves 36 national patient organisations, 16 scientific societies and 3 public administrations, including the Ministry of Social Rights and Agenda 2030, the Carlos III Health Institute and the Spanish Agency for Medicines and Health Products.
-
European Cancer Imaging Initiative european project to provide cancer imaging and support cancer research.
One of the objectives of the European Cancer Plan is to maximise the potential of data and digital technologies such as artificial intelligence (AI) or high performance computing (HPC). The cornerstone of the initiative will be a federated European infrastructure for cancer imaging data, developed by the European Federation of Cancer Imaging (EUCAIM). The project starts with 21 clinical centres in 12 countries, including 4 Spanish centres located in Valencia, Barcelona, Seville and Madrid.
-
4CE: Research Consortium
It is an international consortium for the study of the COVID-19 pandemic using electronic health record (EHR) data. The aim of the project - led by the international international academic user group i2b2 - isto inform clinicians, epidemiologists and the general public about COVID-19 patients with data acquired through the healthcare process. The platform offers aggregated data that are available on the project's own website divided between adult and paediatric data. In both cases, the data must be used for academic and research purposes; the project does not allow the use of the data for medical guidance or clinical diagnosis.
In conclusion, the commitment to data sharing and reuse in medical research is proving to be a fundamental catalyst for scientific progress and the improvement of public health. Through initiatives such as H2O, IMPaCT, and the European Cancer Imaging Initiative, we see how accessibility in data management is redefining the way we approach disease research and treatment.
The integration of data analytics practices promises a future where innovation in healthcare is achieved faster, more equitably and efficiently, thus delivering better outcomes for patients globally.
Noticia
Navarra has been the chosen venue to bring together, for the first time, representatives of the Data Offices of the autonomous communities around the centrality of data in public management. The meeting, promoted by the Secretary of State for Digitalization and Artificial Intelligence (SEDIA) and the Government of Navarra, was aimed at sharing the advances in the world of data at the regional level, as well as the assumption of commitments to lay the foundations for a digital future linked to data and its transformative power.
Focus on the transformative power of data
The Councilor for University, Innovation and Digital Transformation of the Government of Navarra, Juan Cruz Cigudosa García, was in charge of opening the conference, emphasizing the need to strengthen the response to social challenges and stimulate innovation and economic development through data, highlighting the unavoidable commitment to innovation through the use of disruptive technologies such as Artificial Intelligence, always under an ethical prism and respect for European values and principles. In this last line of action, the launching of an Ethics Committee for the Navarra Data Office was announced. This committee, framed in the Digital Spain Strategy and the Navarra Digital Strategy 2030, is aligned with the active policies and the national and international leadership of SEDIA, reflected in its charter of digital rights.
Next, the Chief Data Officer of the Government of Spain, Alberto Palomo, highlighted the strategy that had been designed at European level in relation to data and its sovereign management. He also pointed out the transformative power of data, a key element in the digital transformation and in the entry of technologies such as artificial intelligence. He also reported on the recent statement published as a result of the current Spanish Presidency of the Council of the European Union, which was signed at the beginning of November during the Gaia-X Summit meeting under the name "The Trinity of Trusted Cloud, Data and AI as Gateway to EU's competitiveness". This document is a declaration that shows the commitment of the participants in this meeting to boost data spaces in Europe through strategic autonomy in the cloud, data and artificial intelligence. It agrees, among other points, to expand and improve coordination in the development of European cloud and data initiatives, advocating interoperability as a backbone element and advocating the development of Artificial Intelligence based on high quality data and with solid governance. It also highlights the need to homogenize data sources to better model relationships, optimize processes and innovate and create new business models.
The day continued as a communication forum, in which, as an example, direct experiences of the participants could be shared, thus creating a space for reflection and dialogue. The day was structured through three thematic blocks, about the who, the how and the what for, with each block being contextualized, before the specific presentations, by SEDIA's Data Office and grounded in practice by the Government of Navarra.
-
The first thematic block was "The data ecosystem: who". It addressed some of the strategies around data from the Generalitat de Catalunya and from the Basque Government.
-
This was followed by presentations in a second block entitled "Governance model, ethics and culture: how". The governments of Aragon, Andalusia, the Canary Islands, Valencia and the Spanish Federation of Municipalities and Provinces made presentations of their success stories in this area.
-
In a final block entitled "Citizen service, innovation and data spaces: what for", presentations were given by Andalusia, the National Institute of Statistics, Castilla-la Mancha and the General Secretariat of Digital Administration, and Red.es, the latter presenting the services offered to the autonomous communities from the datos.gob.es platform.
Seven key principles to drive the data economy forward
The meeting culminated with the presentation of seven principles to advance the joint formulation of strategies and policies related to data management and the digital future. These are:
-
Establish effective data governance by setting policies, standards and procedures for the effective management, exploitation and sharing of data, while implementing controls and evaluations to ensure compliance.
-
Perform an ethical treatment of data, assessing the lawfulness and legitimacy of all data practices, seeking to minimize any adverse impact on individuals and society.
-
Prioritize reliable administrative processing centered on data, prioritizing the transition from document to data, capable of enabling and catalyzing the use of advanced technologies and tools for descriptive, predictive and prescriptive analytics (BI, big data, machine learning, deep learning), generative algorithms (LLM, GPT) and process automation (RPA).
-
Deployment of sovereign data sharing as a resource whose value increases with its dissemination, establishing who can access what data and under what conditions of use, security and trust.
-
Encourage the open dissemination of information, promoting its effective reuse and publication in accordance with FAIR principles, i.e., ensuring that data is findable, accessible, interoperable and reusable.
-
Designing and analyzing public policies based on evidence, in order to make informed decisions that lead to effective services and public innovation.
-
Fostering data culture, promoting the creation of new profiles, positions and responsibilities related to working with data, without neglecting the training and transmission of knowledge around data.
The success of the participation, the interventions and reflections raised show the consensus on advancing towards the achievement of a data-oriented Administration, capable of taking advantage, through the use of innovative technological means, of the potential of data, enabling the design, implementation and evaluation of public policies focused on the citizen, generating a data-oriented, sustainable, inclusive and social value-generating economy.
The Forum has thus become a meeting point and a place to generate synergies between the different public administrations. Interoperability between the various public sector agencies and between the different levels of government in the processing and exchange of information boosts territorial cohesion and enables the effective use of available technologies in the quest to satisfy the common good.
Noticia
Under the Spanish Presidency of the Council of the European Union, the Government of Spain has led the Gaia-X Summit 2023, held in Alicante on November 9 and 10. The event aimed to review the latest advances of Gaia-X in promoting data sovereignty in Europe. As presented on datos.gob.es, Gaia-X is a European private sector initiative for the creation of a federated, open, interoperable, and reversible data infrastructure, fostering digital sovereignty and data availability.
The summit has also served as a space for the exchange of ideas among the leading voices in the European data spaces community, culminating in the presentation of a statement to boost strategic autonomy in cloud computing, data, and artificial intelligence—considered crucial for EU competitiveness. The document, promoted by the State Secretariat for Digitization and Artificial Intelligence, constitutes a joint call for a "more coherent and coordinated" response in the development of programs and projects, both at the European and member state levels, related to data and sector technologies.
To achieve this, the statement advocates for interoperability supported by a robust cloud services infrastructure and the development of high-quality data-based artificial intelligence with a robust governance framework in compliance with European regulatory frameworks. Specifically, it highlights the possibilities offered by Deep Neural Networks, where success relies on three main factors: algorithms, computing capacity, and access to large amounts of data. In this regard, the document emphasizes the need to invest in the latter factor, promoting a neural network paradigm based on high-quality, well-parameterized data in shared infrastructures, not only saving valuable time for researchers but also mitigating environmental degradation by reducing computing needs beyond the brute force paradigm.
For this reason, another aspect addressed in the document is the stimulation of access to data sources from different complementary domains. This would enable a "flexible, dynamic, and highly scalable" data economy to optimize processes, innovate, and/or create new business models.
The call is optimistic about existing European initiatives and programs, starting with the Gaia-X project itself. Other projects highlighted include IPCEI-CIS or the Simpl European project. It also emphasizes the need for "broader and more effective coordination to drive industrial projects, advance the standardization of cloud and reliable data tags, ensuring high levels of cybersecurity, data protection, algorithmic transparency, and portability."
The statement underscores the importance of achieving a single data market that includes data exchange processes under a common governance framework. It values the innovative set of digital and data legislation, such as the Data Act, with the goal of promoting data availability across the Union. The statement is open to new members seeking to advance the promotion of a flexible, dynamic, and highly scalable data economy.
You can read the full document here: The Trinity of Trusted Cloud Data and AI as a Gateway to EU's Competitiveness
Blog
Aspects as relevant to our society as environmental sustainability, climate change mitigation or energy security have led to the energy transition taking on a very important role in the daily lives of nations, private and public organisations, and even in our daily lives as citizens of the world. The energy transition refers to the transformation of our energy production and consumption patterns towards less dependence on fossil fuels through low or zero carbon sources, such as renewable sources.
The measures needed to achieve a real transition are far-reaching and therefore complex. In this process, open data initiatives can contribute enormously by facilitating public awareness, improving the standardisation of metrics and mechanisms to measure the impact of measures taken to mitigate climate change globally, promoting the transparency of governments and companies in terms ofCO2emission reductions, or increasing the participation of citizens in the process citizen and scientific and scientific participation for the creation of new digital solutions, as well as the advancement of knowledge and innovation.
What initiatives are providing guidance?
The best way to understand how open data helps us to observe the effects of highCO2 emissions as well as the impact of different measures taken by all kinds of actors in favour of the energy transition is by looking at real examples.
The Energy Institute (IE), an organisation dedicated to accelerating the energy transition, publishes its annual World Energy Statistical Review, which in its latest version includes up to 80 datasets, some dating back as far as 1965, describing the behaviour of different energy sources as well as the use of key minerals in the transition to sustainability. Using its own online reporting tool to represent those variables we want to analyse, we can see how, despite the exponential growth of renewable energy generation in recent years (figure 1), there is still an increasing trend inCO2emissions (figure 2), although not as drastic as in the first decade of the 2000s.
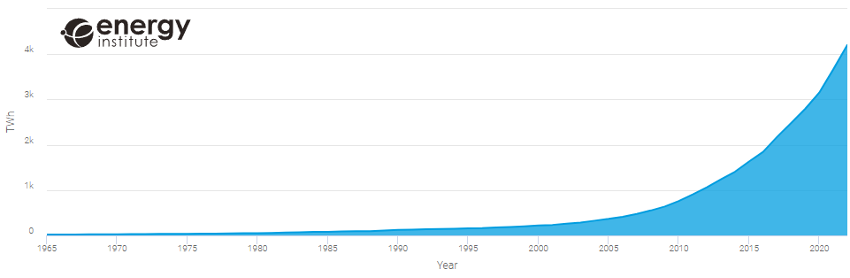
Figure 1: Evolution of global renewable generation in TWh.
Source: Energy Institute Statistical Review 2023
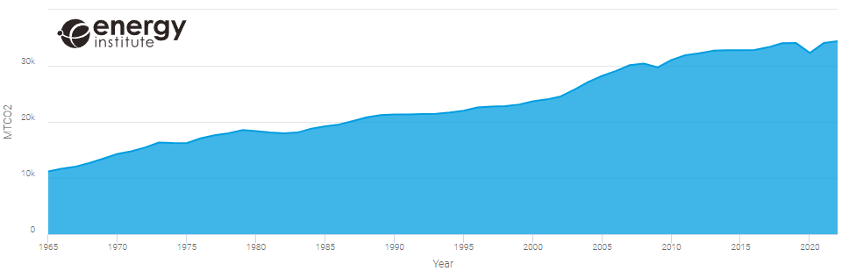
Figure 2: Evolution of global CO2 emissions in MTCO2
Source: Energy Institute Statistical Review 2023
Another international energy transition driver that offers an interesting catalogue of data is the International Energy Agency (IEA). In this case we can find more than 70 data sets, not all of them open without subscription, which include both historical energy data and future projections in order to reach the Net Zero 2050targets. The following is an example of this data taken from their library of graphical displays, in particular the expected evolution of energy generation to reach the Net Zero targets in 2050. In Figure 3 we can examine how, in order to achieve these targets, two main simultaneous processes must occur: reducing the total annual energy demand and progressively moving to lowerCO2emitting generation sources.
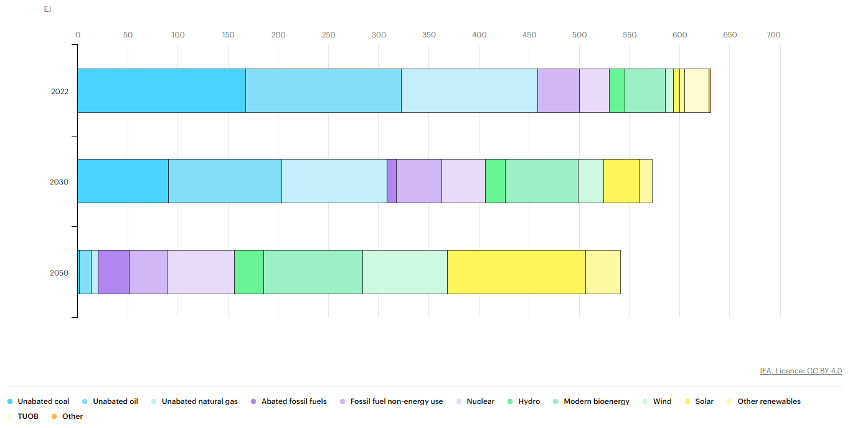
Figure 3: Energy generation 2020-2050 to achieve Net Zero emissions targets in Exajulios.
Source: IEA, Total energy supply by source in the Net Zero Scenario, 2022-2050, IEA, Paris, IEA. Licence: CC BY 4.0
To analyse in more detail how these two processes must happen in order to achieve the Net Zero objectives, IEA offers another very relevant visualisation (figure 4). In it, we can see how, in order to achieve the reduction of the total annual energy demand, it is necessary to make accelerated progress in the decade 2025-2035, thanks to measures such as electrification, technical improvements in the efficiency of energy systems or demand reduction. In this way, a reduction of close to 100EJs per year should be achieved by 2035, which should then be maintained throughout the rest of the period analysed. To try to understand the significance of these measures and taking as a reference the average electricity consumption of Spanish households, some 3,500kWh/year, the desired annual reduction would be equivalent to avoiding the consumption of some 7,937,000,000 households or, in other words, to avoiding in one year the electricity consumption that all Spanish households would consume for 418 years.
ith respect to the transition to lower emission sources, we can see in this figure how the expectation is that solar energy will be the leader in growth, ahead of wind energy, while unabated coal (energy from burning coal without usingCO2capture systems) is the source whose use is expected to be reduced the most.
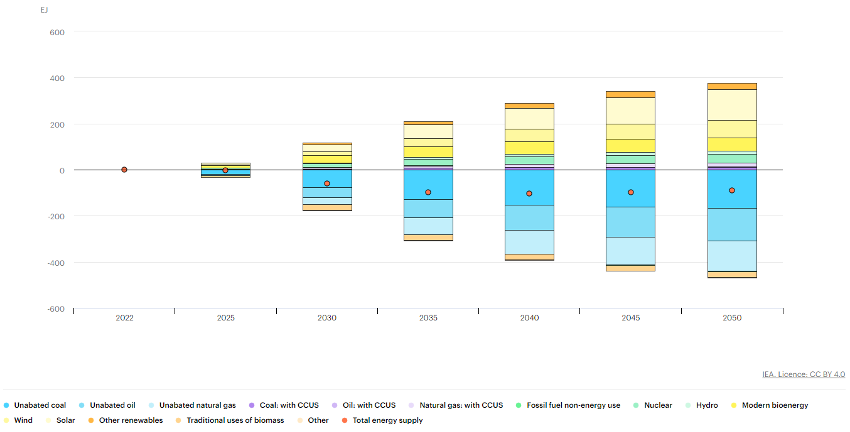
Figure 4: Changes in energy generation 2020-2050 to achieve Net Zero emissions targets in Exajulios.
Source: IEA, Changes in total energy supply by source in the Net Zero Scenario, 2022-2050, IEA, Paris, IEA. Licence: CC BY 4.0
Other interesting open data initiatives from an energy transition perspective are the catalogues of the European Commission (more than 1.5 million datasets) and of the Spanish Government through datos.gob.es (more than 70 thousand datasets). Both provide open datasets on topics such as environment, energy or transport.
In both portals, we can find a wide variety of information, such as energy consumption of cities and companies, authorised projects for the construction of renewable generation facilities or the evolution of hydrocarbon prices.
Finally, the REDatainitiative of Red Eléctrica Española (REE)offers a data area with a wide range of information related to the Spanish electricity system. Among others, information related to electricity generation, markets or the daily behaviour of the system.
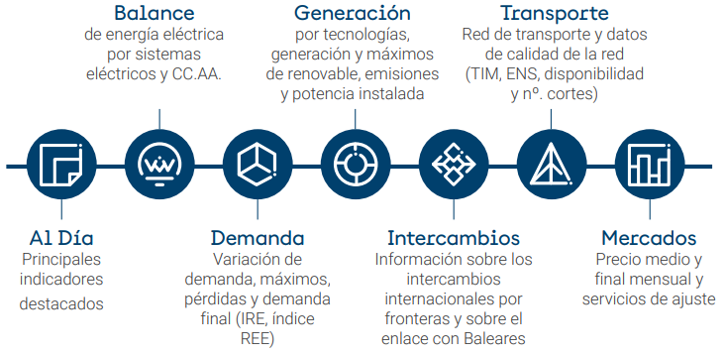
Figure 5: Sections of information provided from REData
Source: El sistema eléctrico: Guía de uso de REData, November 2022. Red Eléctrica Española.
The website also offers an interactive viewer for consulting and downloading data, as shown below for electricity generation, as well as a programmatic interface (API - Application Programming Interface) for consulting the data repository provided by this entity.

Figure 6: REE REData Platform
Source: https://www.ree.es/es/datos/aldia
What conclusions can we draw from this movement?
As we have been able to observe, the enormous concern about the energy transition has motivated multiple organisations of different types to make data openly available for analysis and use by other organisations and the general public. Entities as varied as the Energy Institute, the International Energy Agency, the European Commission, the Spanish Government and Red Eléctrica Española publish valuable information through their data portals in search of greater transparency and awareness.
In this short article we have been able to examine how these data have been of great help to better understand the historical evolution ofCO2emissions, the installed wind power capacity or the expectations of energy demand to reach the Net Zero targets. Open data is a very good tool to improve the understanding of the need and depth of the energy transition, as well as the progress of the measures that are progressively being taken by multiple entities around the world, and we expect to see an increasing number of initiatives along these lines.
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
As more of our daily lives take place online, and as the importance and value of personal data increases in our society, standards protecting the universal and fundamental right to privacy, security and privacy - backed by frameworks such as the Universal Declaration of Human Rights or the European Declaration on Digital Rights - become increasingly important.
Today, we are also facing a number of new challenges in relation to our privacy and personal data. According to the latest Lloyd's Register Foundation report, at least three out of four internet users are concerned that their personal information could be stolen or otherwise used without their permission. It is therefore becoming increasingly urgent to ensure that people are in a position to know and control their personal data at all times.
Today, the balance is clearly tilted towards the large platforms that have the resources to collect, trade and make decisions based on our personal data - while individuals can only aspire to gain some control over what happens to their data, usually with a great deal of effort.
This is why initiatives such as MyData Global, a non-profit organisation that has been promoting a human-centred approach to personal data management for several years now and advocating for securing the right of individuals to actively participate in the data economy, are emerging. The aim is to redress the balance and move towards a people-centred view of data to build a more just, sustainable and prosperous digital society, the pillars of which would be:
- Establish relationships of trust and security between individuals and organisations.
- Achieve data empowerment, not only through legal protection, but also through measures to share and distribute the power of data.
- Maximising the collective benefits of personal data, sharing it equitably between organisations, individuals and society.
And in order to bring about the changes necessary to bring about this new, more humane approach to personal data, the following principles have been developed:
1 - People-centred control of data.
It is individuals who must have the power of decision in the management of everything that concerns their personal lives. They must have the practical means to understand and effectively control who has access to their data and how it is used and shared.
Privacy, security and minimal use of data should be standard practice in the design of applications, and the conditions of use of personal data should be fairly negotiated between individuals and organisations.
2 - People as the focal point of integration
The value of personal data grows exponentially with its diversity, while the potential threat to privacy grows at the same time. This apparent contradiction could be resolved if we place people at the centre of any data exchange, always focusing on their own needs above all other motivations.
Any use of personal data must revolve around the individual through deep personalisation of tools and services.
3 - Individual autonomy
In a data-driven society, individuals should not be seen solely as customers or users of services and applications. They should be seen as free and autonomous agents, able to set and pursue their own goals.
Individuals should be able to securely manage their personal data in the way they choose, with the necessary tools, skills and support.
4 - Portability, access and re-use
Enabling individuals to obtain and reuse their personal data for their own purposes and in different services is the key to moving from silos of isolated data to data as reusable resources.
Data portability should not merely be a legal right, but should be combined with practical means for individuals to effectively move data to other services or on their personal devices in a secure and simple way.
5 - Transparency and accountability
Organisations using an individual's data must be transparent about how they use it and for what purpose. At the same time, they must be accountable for their handling of that data, including any security incidents.
User-friendly and secure channels must be created so that individuals can know and control what happens to their data at all times, and thus also be able to challenge decisions based solely on algorithms.
6 - Interoperability
There is a need to minimise friction in the flow of data from the originating sources to the services that use it. This requires incorporating the positive effects of open and interoperable ecosystems, including protocols, applications and infrastructure. This will be achieved through the implementation of common norms and practices and technical standards.
The MyData community has been applying these principles for years in its work to spread a more human-centred vision of data management, processing and use, as it is currently doing for example through its role in the Data Spaces Support Centre, a reference project that is set to define the future responsible use and governance of data in the European Union.
And for those who want to delve deeper into people-centric data use, we will soon have a new edition of the MyData Conference, which this year will focus on showcasing case studies where the collection, processing and analysis of personal data primarily serves the needs and experiences of human beings.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Books are an inexhaustible source of knowledge and experiences lived by others before us, which we can reuse to move forward in our lives. Libraries, therefore, are places where readers looking for books, borrow them, and once they have used them and extracted from them what they need, return them. It is curious to imagine the reasons why a reader needs to find a particular book on a particular subject.
In case there are several books that meet the required characteristics, what might be the criteria that weigh most heavily in choosing the book that the reader feels best contributes to his or her task. And once the loan period of the book is over, the work of the librarians to bring everything back to an initial state is almost magical.
The process of putting books back on the shelves can be repeated indefinitely. Both on those huge shelves that are publicly available to all readers in the halls, and on those smaller shelves, out of sight, where books that for some reason cannot be made publicly available rest in custody. This process has been going on for centuries since man began to write and to share his knowledge among contemporaries and between generations.
In a sense, data are like books. And data repositories are like libraries: in our daily lives, both professionally and personally, we need data that are on the "shelves" of numerous "libraries". Some, which are open, very few still, can be used; others are restricted, and we need permissions to use them.
In any case, they contribute to the development of personal and professional projects; and so, we are understanding that data is the pillar of the new data economy, just as books have been the pillar of knowledge for thousands of years.
As with libraries, in order to choose and use the most appropriate data for our tasks, we need "data librarians to work their magic" to arrange everything in such a way that it is easy to find, access, interoperate and reuse data. That is the secret of the "data wizards": something they warily call FAIR principles so that the rest of us humans cannot discover them. However, it is always possible to give some clues, so that we can make better use of their magic:

- It must be easy to find the data. This is where the "F" in the FAIR principles comes from, from "findable". For this, it is important that the data is sufficiently described by an adequate collection of metadata, so that it can be easily searched. In the same way that libraries have a shingle to label books, data needs its own label. The "data wizards" have to find ways to write the tags so that the books are easy to locate, on the one hand, and provide tools (such as search engines) so that users can search for them, on the other. Users, for our part, have to know and know how to interpret what the different book tags mean, and know how the search tools work (it is impossible not to remember here the protagonists of Dan Brown's "Angels and Demons" searching in the Vatican Library).
- Once you have located the data you intend to use, it must be easy to access and use. This is the A in FAIR's "accessible". Just as you have to become a member and get a library card to borrow a book from a library, the same applies to data: you have to get a licence to access the data. In this sense, it would be ideal to be able to access any book without having any kind of prior lock-in, as is the case with open data licensed under CC BY 4.0 or equivalent. But being a member of the "data library" does not necessarily give you access to the entire library. Perhaps for certain data resting on those shelves guarded out of reach of all eyes, you may need certain permissions (it is impossible not to remember here Umberto Eco's "The Name of the Rose").
- It is not enough to be able to access the data, it has to be easy to interoperate with them, understanding their meaning and descriptions. This principle is represented by the "I" for "interoperable" in FAIR. Thus, the "data wizards" have to ensure, by means of the corresponding techniques, that the data are described and can be understood so that they can be used in the users' context of use; although, on many occasions, it will be the users who will have to adapt to be able to operate with the data (impossible not to remember the elvish runes in J.R.R. Tolkien's "The Lord of the Rings").
- Finally, data, like books, has to be reusable to help others again and again to meet their own needs. Hence the "R" for "reusable" in FAIR. To do this, the "data wizards" have to set up mechanisms to ensure that, after use, everything can be returned to that initial state, which will be the starting point from which others will begin their own journeys.
As our society moves into the digital economy, our data needs are changing. It is not that we need more data, but that we need to dispose differently of the data that is held, the data that is produced and the data that is made available to users. And we need to be more respectful of the data that is generated, and how we use that data so that we don't violate the rights and freedoms of citizens. So it can be said, we face new challenges, which require new solutions. This forces our "data wizards" to perfect their tricks, but always keeping the essence of their magic, i.e. the FAIR principles.
Recently, at the end of February 2023, an Assembly of these data wizards took place. And they were discussing about how to revise the FAIR principles to perfect these magic tricks for scenarios as relevant as European data spaces, geospatial data, or even how to measure how well the FAIR principles are applied to these new challenges. If you want to see what they talked about, you can watch the videos and watch the material at the following link: https://www.go-peg.eu/2023/03/07/go-peg-final-workshop-28-february-20203-1030-1300-cet/
Content prepared by Dr. Ismael Caballero, Lecturer at UCLM
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The rise of smart cities, the distribution of resources during pandemics or the fight against natural disasters has awakened interest in geographic data. In the same way that open data in the healthcare field helps to implement social improvements related to the diagnosis of diseases or the reduction of waiting lists, Geographic Information Systems help to streamline and simplify some of the challenges of the future, with the aim of making them more environmentally sustainable, more energy efficient and more livable for citizens.
As in other fields, professionals dedicated to optimizing Geographic Information Systems (GIS) also build their own working groups, associations and training communities. GIS communities are groups of volunteers interested in using geographic information to maximize the social benefits that this type of data can bring in collective terms.
Thus, by addressing the different approaches offered by the field of geographic information, data communities work on the development of applications, the analysis of geospatial information, the generation of cartographies and the creation of informative content, among others.
In the following lines, we will analyze step by step what is the commitment and objective of three examples of GIS communities that are currently active.
Gis and Beers
What is it and what is its objective?
Gis and Beers is an association focused on the dissemination, analysis and design of tools linked to geographic information and cartographic data. Specialized in sustainability and environment, they use open data to propose and disseminate solutions that seek to design a sustainable and nature-friendly environment.
What functions does it perform?
In addition to disseminating specialized content such as reports and data analysis, the members of Gis and Beers offer training resources dedicated to facilitating the understanding of geographic information systems from an environmental perspective. It is common to read articles on their website focused on new environmental data or watch tutorials on how to access open data platforms specialized in the environment or the tools available for their management. Likewise, every time they detect the publication of a new open data catalog, they share on their website the necessary instructions for downloading the data, managing it and representing it cartographically.
Next steps
In line with the environmental awareness that marks the project, Gis and Beers is devoting more and more effort to strengthening two key pillars for its content: raising awareness of the importance of citizen science (a collaborative movement that provides data observed by citizens) and promoting access to data that facilitate modeling without previously adapting them to cartographic analysis needs.
The role of open data
The origin of most of the open data they use comes from state sources such as the IIGN, Aemet or INE, although they also draw on other options such as those offered by Google Earth Engine and Google Public Data.
How to contact them?
If you are interested in learning more about the work of this community or need to contact Gis and Beers, you can visit their website or write directly to this email account.
Geovoluntarios
What is it and what is its objective?
It is a non-profit Organization formed by professionals experienced in the use and remote application of geospatial technology and whose objective is to cooperate with other organizations that provide support in emergency situations and in projects aligned with the Sustainable Development Goals.
The association's main objectives are:
- To provide help to organizations in any of the phases of an emergency, prioritizing help to non-profit, life-saving organizations or those supporting the third sector. Some of them are Red Cross, Civil Protection, humanitarian organizations, etc.
- Encourage digital volunteering among people with knowledge or interest in geospatial technologies and working with geolocated data.
- Find ways to support organizations working towards the Sustainable Development Goals (SDGs).
- Provide geospatial tools and geolocated data to non-profit projects that would otherwise not be technically or economically feasible.
What functions does it perform?
The professional experience accumulated by the members of geovolunteers allows them to offer support in tasks related to the analysis of geographic data, the design of models or the monitoring of special emergency situations. Thus, the most common functions carried out as an NGO can be summarized as follows:
- Training and providing means to volunteers and organizations in all the necessary aspects to provide aid with guarantees: geographic information systems, spatial analysis, RGPD, security, etc.
- Facilitate the creation of temporary work teams to respond to requests for assistance received and that are in line with the organization's goals.
- Create working groups that maintain data that serve a general purpose.
- Seek collaboration agreements with other entities, organize and participate in events and carry out campaigns to promote digital volunteering.
From a more specific point of view, among all the projects in which Geovolunteers has participated, two initiatives in which the members were particularly involved are worth mentioning. On the one hand, the Covid data project, where a community of digital volunteers committed to the search and analysis of reliable data was created to provide quality information on the situation being experienced in each of the different autonomous communities of Spain. Another initiative to highlight was Reactiva Madrid, an event organized by the Madrid City Council and Esri Spain, which was created to identify and develop work that, through citizen participation, would help to prevent and/or solve problems related to the pandemic caused by COVID-19 in the areas of the economy, mobility and society.
Next steps
After two years focused on solving part of the problems generated by the Covid-19 crisis, Geovolunteers continues to focus on collaborating with organizations that are committed to assisting the most vulnerable people in emergency situations, without forgetting the commitment that links them to meeting the Sustainable Development Goals.
Thus, one of the projects in which the volunteers are most active is the implementation and improvement of GeoObs, an app to geolocate different observation projects on: dirty spots, fire danger, dangerous areas for bikers, improving a city, safe cycling, etc.
The role of open data
For an NGO like Geovolunteers, open data is essential both to develop the solidarity tasks they carry out together with other associations, as well as to design their own services and applications. Hence, these resources are part of the new functionalities on which the Association wants to focus.
So much so that data collection marks a starting point for the pilot projects that can currently be found under the Geovolunteers umbrella. Without going any further, the application mentioned above is an example that demonstrates how generating data by observation can contribute to enriching the available open data catalogs.
GIS Community
What is it and what is its objective?
GIS Community is a virtual collective that brings together professionals in the field of geographic data and information systems related to the same sector. Founded in 2009, they disseminate their work through social networks such as Facebook, Twitter or Instagram from where, in addition, they share news and relevant information on geotechnology, geoprocessing or land use planning among other topics.
Its objective is none other than to contribute to expand the informative and interesting knowledge for the geographic data community, a virtual space with little presence when this project began its work on the Internet.
What functions does it perform?
In line with the objectives mentioned above, the tasks developed by SIG are focused on the sharing and generation of content related to Geographic Information Systems. Given the diversity of fields and sectors of action within the same field, they try to balance the content of their publications to bring together both those who seek information and those who provide opportunities. For this reason it is possible to find news about events, training, research projects, news about entrepreneurs or literature among many others.
Next steps
Aware of the weight they have as a community within the field of geographic data, from SIG they plan to strengthen four axes that directly affect the work of the project: organize lectures and webinars, contact organizations and institutions capable of providing funding for projects in the GIS area, seek entities that provide open geospatial information and, finally, get part of the private sector to participate financially in the education and training of professionals in the field of GIS.
The role of open data
This is a community that is closely linked to the universe of open data, because it shares content that can be used, supplemented and redistributed freely by users. In fact, according to its own members, there is an increasing acceptance and preference for this trend, with community collaborators and their own projects driving the debate and interest in using open data in all active phases of their tasks or activities.
How to contact them?
As in the previous cases, if you are interested in contacting Comunidad SIG you can do so through their Facebook page, Twitter or Instagram or by sending an email to the following email.
Communities like Gis and Beers, SIG or Geovolunteers are just a small example of the work that the GIS collective is currently developing. If you are part of any data community in this or any other field or you know about the work of communities that may be of interest in datos.gob.es, do not hesitate to send us an email to dinamizacion@datos.gob.es.
Geo Developers
What is it and what is its purpose?
Geodevelopers is a community whose objective is to bring together developers and surveyors in the field of geographic data. The main function of this community is to share different professional experiences related to geographic data and, for this purpose, they organize talks where everyone can share their experience and knowledge with the rest.
Through their YouTube channel it is possible to access the trainings and talks held to date, as well as to be aware of the next ones that may be held.
The role of open data
Although this is not a community focused on the reuse of open data as such, they use it to develop some projects and extract new learnings that they then incorporate into their workflows.
Next steps and contact
The main objective for the future of Geodevelopers is to grow the community in order to continue sharing experiences and knowledge with the rest of the GIS stakeholders. If you want to get in touch and follow the evolution of this project you can do it through its Twitter profile.
Entrevista
R-Ladies is a software community that aims to give visibility to women who work or develop projects or software using R to do so. It is a local branch of R-Ladies Global, an open source community born in 2016.
Its organisers, Inés Huertas, Leticia Martín-Fuertes and Elen Irazabal, gave us a few minutes to talk about the activities carried out by this community and how to promote the presence of women in technological fields.
Full interview:
1. How does R-Ladies start?
R-Ladies Madrid was born from an international initiative, but it was also born from a local reality in Spain at that time, which was that few girls could be found at congresses or developing R packages, so nobody thought it was a problem until the first meetups, when many women who were attending a community for the first time started to appear and we didn't see them in those other spaces for different reasons. That motivated us to continue with the community, since in many occasions we were the gateway for them to be able to participate in these communities or conferences, etc.
2. What advantages and disadvantages does R have as a programming language compared to its competitors?
R is one of the first free software languages used in the world of data. It has been closely related to the university and research community, which initially fed a large part of the package that we have today. Today there are large companies that work to improve and maintain these repositories, because the spectrum of software that can be found in R is very broad and has a powerful community behind it. You can find developments ranging from niche research packages such as biogenetics, to less specific packages for general analysis.
3. The number of women in engineering is 25% (while the total number of women in the university system is 59%). In your opinion, what are the reasons behind this situation?
There are several reasons for this, but if we have to choose one, it is the lack of visibility of women in engineering. Great efforts are currently being made to give visibility to women who develop and work with data. At R-Ladies, for example, we have an international directory where you can find women to speak at conferences around the world, thus being able to create reference models for other women who are encouraged to participate. That's what we do at R-Ladies, we give visibility to women who are working with R.
In any case, and given the digital revolution we are living through, what we are seeing is the union between letters and sciences. For example, in the field of Artificial Intelligence, we are seeing how it is affecting areas that were previously literary, such as linguistics, law, marketing and so on. Given this intersection, mixed profiles are appearing that, without having studied an engineering degree, are dedicated to applying technical aspects to the non-technical world. For example, teaching natural language to machines.
The case of law is also paradigmatic; there are already regulations that require technical knowledge to apply them. In fact, even the technical world can also be interested in the world of letters, for example, how law and regulation affect how the internet works.
In short, the world of science and the world of literature should not be seen as separate careers, but as increasingly complementary.
We are seeing the union between the arts and the sciences. Mixed profiles are appearing that, without having studied an engineering degree, are dedicated to applying technical aspects to the non-technical world.
4. How do initiatives such as R-Ladies help to boost the presence of women in technology?
Precisely by helping to create Role Models. Supporting women so that they do not suffer from the so-called "imposter syndrome". Giving a talk in your free time about the things you work on or are interested in is much more than it seems, for many of these women it is a first step that can help them to present a project in their company or defend a proposal to a client.
5. What projects are you working on?
Currently with the pandemic we have had to adapt with a cycle of monthly online workshops/talks during 2020/2021 that does not limit us to be physically in Madrid, so we have speakers that otherwise would be more complicated to bring to Madrid. In addition, we have tried to do these monthly workshops in an incremental way, so that starting in September until now we have been increasing the level of the sessions starting from the first steps in R to finish with the realization of a data analysis with Neural Networks. We are also feeding with these sessions our YouTube channel, generating content in Spanish on how to use R that is having a great reception.
6. What types of open data have you used in your projects and what data would you like to work with?
On the use of open data, some of the working groups use data from the BOE or Open Data NASA for project development. We also helped to set up a working group that works with covid data.
We would like to be able to work with Spanish jurisprudence. It would be very interesting to see how in the history of democracy different sentences have been handed down and how they have evolved over the years.
We would also like to be able to work with the RAE's reference corpora, such as CREA, CORDE or CORPES XXI, which contain texts of various kinds, including oral transcriptions, with which we could carry out a great deal of linguistic analysis and serve as training data to improve the presence of Spanish in the field of AI.
On the use of open data, some of the working groups use data from the BOE or Open Data NASA for project development. We also helped set up a working group that works with covid data.
7. Finally, how can interested people follow R-Ladies and collaborate with you?
Super easy! You can write to us at madrid@rladies.org, sign up for our Meetup or simply tweet us at @RladiesMad. Everyone is welcome!
Entrevista
Hackathon Lovers is a community of hackathon lovers that holds regular events with a focus on solving technical problems in an innovative way.
In this interview they tell us about the advantages of this format and the challenge of going from face-to-face to online format.
Full interview:
1. Can you briefly explain what Hackathon Lovers is?
Hackathon Lovers is a technology company that organizes its own hackathons and helps other companies organize their own as long as they comply with non-abusive conditions for the participants that we have included in our ethical code (https://hackathonlovers.com/#principios).
2. What are the advantages of hackathons compared to other types of events?
Perhaps the biggest advantage is that with the solutions that are developed we can help solve real problems.
More bonds are created between the participants than in other events since you are working with them side by side for a couple of days without stopping and above all you learn a lot from your colleagues.
For the participants who are very juniors, they are a place where they can put into practice the knowledge they have, learn from those who already have more experience, make new contacts and, above all, who come out with projects that they can teach to find work.
3. One objective of this type of event is to address certain challenges that can be solved using public data. Would you like to highlight, by way of example, any of these and briefly comment on what kind of solutions the participants propose?
The use of public data in hackathons is quite common, since that public data can be used in conjunction with other APIs to develop better products than without that data.
For example, at #Hack4Good the map of the evolution of air pollution in Madrid was developed. At #DataFestMAD, a team developed an application that showed the optimal route between two points avoiding the pollution areas, and at #TWOC15 , the winning team developed an application that shows the reputation of places (neighborhoods) based on open data on crime, facilities and infrastructures.
The use of public data in hackathons is quite common, since that public data can be used in conjunction with other APIs to develop better products than without that data.
4. What kind of profiles come to your meetings?
This question depends on the challenge the hackathon is addressing. Normally the people who attend are from the technology sector and within this we can find profiles of web development, design, data analysis, blockchain ... Although we have also organized other types of hackathons in which people from the health sector (#Searchathon), legal (#JustiApps) and renewable energy (#Renovathon) have participated, among others because the challenge was more focused on these sectors .
5. What advice would you give to those who want to participate in a hackathon?
Let them sign up without fear. To participate in a hackathon you don't have to be a supercrack. The idea is to get together with other people with more / less level and work side by side to come up with a solution to the problem that arises, meet people from the sector or from other sectors, have a good time and learn.
6. The restrictions caused by the pandemic have been a challenge for you, how have you dealt with it?
A little because we have had to change and rethink the dynamics of a hackathon to adapt it to the online environment by using different platforms for communication during the hackathon. So we had to find which tools provided us with the functionalities we needed and at the same time that they were easy for the participants to use, and we even had to do some small development to facilitate our work.
7. What types of open data have you used in your projects and what data would you like to work with?
At the #OpenApiHackathon on Open Banking organized by Liberbank and atmira, Liberbank made available to the participants its catalog of Open Banking APIs developed following the technical guides of Directive 2015/2366 on payment services in the internal market, PSD2, standard community that obliges financial entities to share their data.
The API catalog dealt with Payments, Oauth Provider, Accounts, PSD2 Registration, and there were two work environments, a first using a Sandbox development environment and later a second step to Pro.
8. Finally, how can interested people follow Hackathon Lovers and collaborate with you?
You can follow us on twitter and join our meetup, where we have a mailing list in which we announce both the hackathons that we organize and those that we see that comply with our code of ethics.
Entrevista
R Hispano is a community of users and developers that was born in 2011, within the III Conference of R Users, with the aim of promoting the advancement of knowledge and the use of the programming language in R. From datos.gob.es we have spoken with them so that they can tell us more about the activities they carry out and the role of open data in them.
Full interview.
1. Can you briefly explain what the R-Hispano Community is?
It is an association created in Spain whose objective is to promote the use of R among a Hispanic audience. There are many R users worldwide and we try to serve as a meeting point for all those whose primary language is Spanish. By having a smaller group within such a large community as a reference, it is easier to build relationships and meet people to turn to when you want to learn more or share what you have learned.
2. R was born as a language linked to the statistical exploitation of data, however, it has become an essential tool of Data Science, why so much acceptance of this language by the community?
It's true that many data science and engineering professionals tend to use more generic languages like Python. However, there are several reasons why R is essential in the "Stack" of teams that work with data. First of all, R has its origin in the S language, which was designed in the 1970s specifically for data analysis, within the Bell Laboratories. This allows people with different computer backgrounds to participate in complex projects, focusing on analysis methods. Second, R has aged very well, and a broad community of users, developers, and businesses contribute to the project with packages and tools that quickly extend functionality to the most innovative methods with (relative) simplicity and rigor.
3. R Hispano works through numerous local initiatives, what advantages does this form of organization bring?
In day-to-day activities, especially when we had face-to-face meetings, more than a year ago, it is more comfortable to coordinate people as closely as possible. It makes no sense for a person in Madrid to organize monthly meetings in Malaga, Seville or the Canary Islands. The interesting thing about these events is to attend regularly, get to know the attendees, understand what the public demands and what can be offered. That, apart from pampering and dedication, requires being close because, otherwise, there is no way to establish that bond. That is why it seemed to us that it is from the cities themselves that this relationship has to be maintained from day to day. On the other hand, it is the way in which the Community of R has been organized around the world, with the success that we all know.
4. Do you consider open data initiatives a valuable source of information for the development of your projects? Any notable reuse examples? What aspects of the current initiatives do you consider could be improved?
The first thing to say is that R Hispano as such has no projects. However, many R Hispano partners work with open data in their professional field, be it academic or business. Of course, it is a very valuable source of information, with many examples, such as the analysis of data from the pandemic that we still suffer, data from sports competitions and athletes' performance, environmental, socio-economic data, ... We cannot highlight any of them because there are many very interesting that would deserve it equally. As for the improvements, there are still many public data repositories that do not publish it in a “treatable” format by analysts. A PDF report can be open data, but it certainly does not contribute to its dissemination, analysis, and exploitation for the good of society.
5. Can you tell us about some of the activities carried out by these local Initiatives?
Several local R groups, both in Spain and Latam, recently collaborated with the technology training company, UTad, in the event “Encounters in the R phase”. Held online for two days. The R user days that we celebrate each year are usually organized by one of the local groups at the headquarters. The Córdoba group is organizing the next ones, postponed due to the pandemic and for which we hope to announce dates soon.
The Madrid R User Group began to function as a local group linked to the Hispanic R Community more than fifteen years ago. Since its origin, it has maintained a monthly periodicity of meetings announced on the social network Meetup (sponsored by RConsortium, entity, founded and subsidized by large companies to favor the use of R). The activity has been interrupted by the limitations of the Covid-19, but all the history of the presentations has been compiled in this portal.
From the Group of R Canarias they have been involved in the conference TabularConf, which took place on January 30, online, with an agenda of a dozen presentations on data science and artificial intelligence. In the past the Canarian group carried out a R user meeting with communications on various topics, including modeling, geographic data processing, as well as queries to public data APIs, such as datos.gob.es, with the library opendataes. Other bookstores presented at a meetup they held in 2020 areistacr or inebaseR, always betting on access to public data.
In the Local Group of Seville, during the hackathons held in recent years they have begun to develop several packages totally linked to open data.
- Air: To get air quality data in Andalusia (works, but needs some adjustments)
- Aemet: R package to interact with the AEMET API (climatic data). We took the first steps in a hackathon, then Manuel Pizarro made a fully functional package.
- Andaclima: Package to obtain climatic data from agroclimatic stations of the Junta de Andalucía
- Data.gob.es.r: Package embryo to interact with http://datos.gob.es. Really just an exploration of ideas, nothing functional for now.
Regarding COVID-19, it is worth highlighting the development by the UCLM, with the collaboration of a former member of the Board of Directors of the R Hispano Community, of this COVID-19 analysis panel, with the cases that the Board of Communities of Castilla-La Mancha presented by municipality. It consists of a interactive tool to consult the information on the incidence and rates per 100,000 inhabitants.
6. In addition, they also collaborate with other groups and initiatives.
Yes, we collaborate with other groups and initiatives focused on data, such as the UNED (Faculty of Sciences), which for a long period of time welcomed us as its permanent headquarters. I would also highlight our performances with:
- Data Journalism Group. Joint filings with the Data Journalism group, sharing the benefits of R for their analysis.
- A collaboration with the Group Machine Learning Spain that resulted in a common presentation in the Google Campus of Madrid.
- With groups of other data languages, such as Python.
- Collaborations with companies. At this point we highlight having participated in two Advanced Analytics events organized by Microsoft, as well as having received small financial aid from companies such as Kabel or Kernel Analytics (recently acquired by Boston Consulting Group).
These are some examples of presentations in the Madrid group based on open data:
-
Madrid Air Quality Analysis (First Y Second version)
- ENRON data analysis
In addition, different partners of R-Hispano also collaborate with academic institutions, in which they teach different courses related to Data analysis, especially promoting the use and analysis of open data, such as the Faculty of Economics of the UNED, the Faculties of Statistics and Tourism and Commerce of the UCM, the University of Castilla-La Mancha, the EOI (specific subject on open data), the Francisco de Vitoria University, the Higher School of Telecommunications Engineering, the ESIC and the K- School.
Finally, we would like to highlight the constant link that is maintained with different relevant entities of the R ecosystem: with R-Consortium (https://www.r-consortium.org/) and RStudio (https://rstudio.com/). It is through the R-Consortium where we have obtained the recognition of the Madrid Group as a stable group and from which we obtain the sponsorship for the payment of Meetup. Within RStudio we maintain different contacts that have also allowed us to obtain sponsorships that have helped in the R Conference, as well as speakers of the stature of Javier Luraschi (author of the package and book on “sparklyr”) or Max Kuhn (author of packages such as "Caret" and its evolution "tidymodels").
7. Through ROpenSpain, some RHispano partners have collaborated in the creation of packages in R that facilitate the use of open data.
ROpenSpain is a community of R, open data and reproducibility enthusiasts who come together and organize to create R packages of the highest quality for the exploitation of Spanish data of general interest. It was born, with the inspiration of ROpenSci, in February 2018 as an organization ofGitHub and has a collaboration channel in Slack. As of January 2021, ROpenSpain groups the following R packages:
- opendataes: Easily interact with the data.gob.es API, which provides data from public administrations throughout Spain.
- MicroData: Allows importing to R various types of INE microdata files: EPA, Census, etc.
- caRtocity: Consult the Cartociudad API, which provides geolocation services, routes, maps, etc.
- Siane: To represent statistical information on the maps of the National Geographic Institute.
- airquality: Air quality data in Spain from 2011 to 2018.
- mapSpain: To load maps of municipalities, provinces and Autonomous Communities. Includes a plugin for leaflet.
- MorbiditySpainR: Read and manipulate data from the Hospital Morbidity Survey
- spanish: For the processing of certain types of Spanish information: numbers, cadastral geocoding, etc.
- BOE: For the processing of the Official State Gazette and the Official Gazette of the Mercantile Registry.
- istacbaser: To consult the API of the Canary Institute of Statistics.
- Cadastre: Consult the Land Registry API.
Some of these packages have been featured at events organized by the R Hispano Community.
8. Finally, how can interested people follow R-Hispano and collaborate with you?
An important element as a link in the entire community of R users in Spanish is the R-Help-es help list:
- Search: https://r-help-es.r-project.narkive.com/;
- Subscription: https://stat.ethz.ch/mailman/listinfo/r-help-es ).
It is one of the few active R-Help lists independent of the main English R-Help that has generated more than 12,800 entries in its more than 12-year history.
In addition, a high level of activity is maintained in social networks that serve as a speaker, a lever through which future events or different news related to data of interest to the community are announced.
We can highlight the following initiatives in each of the platforms:
- Twitter: Presence of the R-Hispano association itself; https://twitter.com/R_Hisp and participation in the hashtag #rstatsES (R in Spanish) of different R collaborators at the national level.
- LinkedIn: In this professional network, "R" has a presence through the company page https://www.linkedin.com/company/comunidad-r-hispano/. In addition, many R-Hispano partners from both Spain and Latam are part of this network, sharing open resources.
- Telegram channel: (https://t.me/rhispano) There is a telegram channel where news of interest to the community is disseminated with certain periodicity
Finally, on the association's website, http://r-es.org, you can find information about the association, as well as how to become a member (the fee is, like R, free)