Evento
EXTENDED: You can submit your project until September 20th!
The deadline to participate in the II edition of the Datathon UniversiData is now open. This competition recognises the value of projects that reuse open university data published on the portal UniversiDATA,a public-private initiative that was born at the end of 2020. Its aim was, and is, to promote open data in the Spanish higher education sector in a harmonised way.
UniversiDATA is currently made up of the Universidad Rey Juan Carlos, the Universidad Complutense de Madrid, the Universidad Autónoma de Madrid, the Universidad Carlos III de Madrid, the Universidad de Valladolid and the Universidad de Huelva, in collaboration with the company DIMETRICAL, The Analytics Lab, S.L.
What is the UniversiDATA Datathon about?
As previously indicated, participants must submit an open data processing project using one or more of the datasets published in UniversiDATA. These data may be combined with other data sources, but always bearing in mind that their use should not be secondary or ancillary.
There are no limitations on the nature of the project, the technologies involved or the formats of presentatiing the results. You can compete with a mobile app, a web application, a data analysis in Jupyter or R-Markdown, etc. Works already submitted to other competitions, as well as internships, master's or bachelor's degree theses or research articles are also valid .
For inspiration, you can visit the "UniversiDATA-Lab" where examples of applications and data analysis are shown. You can also check out the winning projects of the first edition.
How does the competition unfold?
The competition is divided into two phases:
- Knockout stage
Those interested in participating can submit their candidature from 6 March until September 20, using this form. In addition to the personal data, the following information must be provided in the application:
- Members of the project
- Project title
- Problem to be solved
- Proposed solution
- Identification of addressees
- Usefulness of the project
- Data sets to be used
All the projects submitted will be evaluated by a jury. The jury will select 10 finalists, who will go on to the final phase. The list of selected projects will be made public on September 27, 2024.
- Final Phase
Once selected, the finalists will start preparing their projects for the presentation to the jury, which will take place during an online event on December 16. The projects will be presented by videoconference.
The winners will be announced on December 23.
Who can participate?
The competition is open to any natural person with tax residence in the European Union, whether they are students, working professionals or amateurs.
You can participate as a group or as an individual.
what are the prizes?
This year, the financial endowment has been increased to a total of €9,000, divided as follows:
- First prize: € 4,000
- Second prize: € 3,000
- Third prize: € 1,500
In addition to these general prizes, the aim is also to recognise the best university student project that has been a finalist but has not won a prize. A special prize of €500 has been created for this purpose.
In case of group participation, the prize will be divided among all members of the group.
Do you have any queries?
Before participating, it is necessary to download and read the specific rules of the competition. If you have any questions, you can contact the organisers through this form. You will also be informed of any new developments on the the UniversiDATA Twitter profile.
In addition, throughout the competition, a direct communication channel will be established with the participants for any questions that may arise, including those concerning the datasets to be used.
The II Datathon UniversiDATA arises as a result of the success achieved in its first edition. it is a very positive experience that offers participants, once again this year, the opportunity not only to win financial recognition, but also to gain visibility by showing their talent when it comes to processing data that can provide answers to various questions of social and economic interest.
Evento
UniversiDATA organizes its first Datathon.
Are you interested in data analysis? If the answer is yes, you will be interested to know that UniversiDATA has launched a datathon to recognize open data processing projects based on the datasets available on its portal.
This initiative seeks not only to reward talent, but also to promote the content offered and encourage its use, inspiring new projects through the dissemination of reference cases. It is also an opportunity to get to know their reusers and better understand their objectives, challenges and needs. This valuable information will be used to drive improvements to the platform.
Who can participate?
The call is open to any natural person of legal age with tax residence in the European Union. Students, developers, researchers or any citizen interested in data analysis can participate.
How does the competition take place?
The competition is structured in two phases:
Elimination phase
A jury of experts will evaluate all the applications received on the basis of the project descriptions provided by the participants in the registration form. Four criteria detailed in the competition rules will be taken into account: impact, quality of the proposal, usability/presentation and reusability.
After the evaluation, a maximum of 10 finalists will pass to the next phase.
Final phase
The finalists will have to present their projects via videoconference to the members of the jury.
After the presentation, the three winners will be announced.
What are the requirements for the projects submitted?
The submitted projects must fulfill three obligations:
- At least one dataset published on the open data portal UniversiDATA must be used. These datasets may be combined with secondary data from other sources.
- The use made of the UniversiDATA datasets must be essential to obtain the results of the analysis.
- The analysis of the data must have a clear purpose or utility. Generic data treatments will not be accepted.
It should be noted that existing work, previously presented in other contexts, may be submitted. Furthermore, there are no limitations regarding the technology to be used for the analysis -each user may use the tools he/she considers appropriate- or regarding the format of the final result of the analysis. That is to say, you can compete with a mobile App, a web application, a data analysis in Jupyter or R-Markdown, etc...
What are the prizes?
The three winners will receive a total of €3,500, distributed as follows:
- First prize: €2,000
- Second prize: 1,000 €.
- Third prize: 500 €.
The other finalists will receive a diploma of recognition.
How can I participate?
The registration period is now open. The easiest way to participate is to fill out the form available at the end of the competition website before October 14, 2022.
Before registering, we recommend that you review all the complete information in the competition rules. If you have any questions, you can contact the organizers. Various channels will soon be available for participants to ask questions regarding not only the competition procedures, but also the platform's datasets.
Competition schedule
- Receipt of applications: until October 14, 2022
- Publication of the 10 finalists: November 14, 2022
- Communication of the three winners: December 16, 2022
Find out more about UniversiDATA
UniversiDATA was born at the end of 2020 with the aim of promoting open data in the higher education sector in Spain in a harmonized way. It is a public-private initiative that currently encompasses Universidad Rey Juan Carlos, Universidad Complutense de Madrid, Universidad Autónoma de Madrid, Universidad Carlos III de Madrid, Universidad de Valladolid, Universidad de Huelva and "Dimetrical, The Analytics Lab", S.L.
In 2021 UniversiDATA won the First Prize of the III Desafío Aporta for its project UniversiDATA-Lab, a public portal for the advanced and automatic analysis of datasets published by universities. You can learn more about the project in this interview.
Noticia
After months of work, the 3rd Aporta Challenge has come to an end. Under the slogan "the value of data in digital education", this year's competition sought solutions that used open data to drive improvements in the education sector.
The competition, organised by the Aporta Initiative, launched by Red.es together with the Secretary of State for Digitalisation and Artificial Intelligence, began in October 2020, with a first phase consisting of an ideas competition. After the jury's assessment, 10 finalists were chosen and have had three months to transform their ideas into a prototype. These prototypes were presented on 22 June in an online session.
10 proposals that stand out for their quality
The 10 papers presented are a great example of the power of open data to transform the education sector, improving its effectiveness and efficiency. The need for universal access to knowledge through inclusive and quality education has become even more evident in the current pandemic context. Open data can help to meet this challenge. Open data can be analysed and used to shape solutions that help to improve the student experience in the learning process, for example through personalisation of education, identification of behavioural problems or informed decision-making, among other issues.
All the entries were of a high quality, reflecting the efforts of all the finalist teams. The jury, made up of experts representing companies, public administrations and organisations linked to the digital economy and the academic world, had a difficult time choosing the three winners. In the end, the three winners were UniversiDATA-Lab, MIP Project and EducaWood, who received prizes of €4,000, €3,000 and €2,000 respectively.

First prize: UniversiDATA-Lab
-
Team: Rey Juan Carlos University, Complutense University of Madrid, Autonomous University of Madrid, Carlos III University of Madrid and DIMETRICAL The Analytics Lab S.L.
The first prize went to UniversiData-Lab, a public portal for the advanced and automatic analysis of datasets published by universities. It is a complementary project to UniversiData: while the objective of UniversiDATA is to facilitate access to high quality university datasets with standard formats and criteria, the objective of UniversiDATA-Lab is to enhance the value of these datasets, carrying out advanced and automatic analysis of them, taking advantage of the homogeneity of the content.
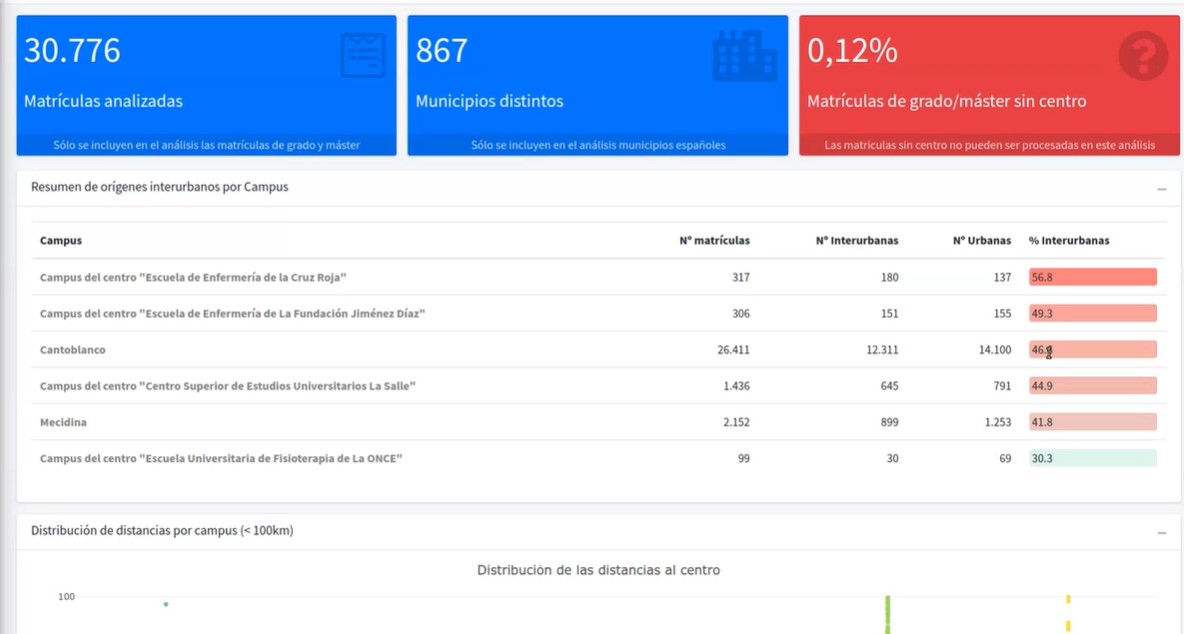
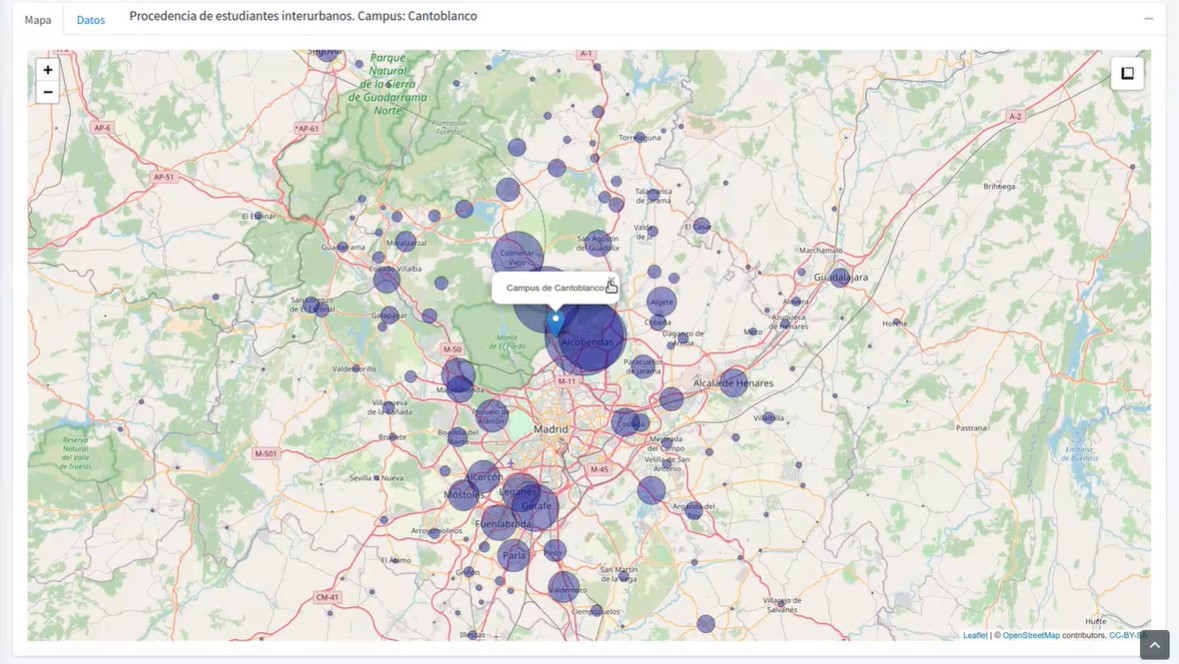
UniversiDATA-Lab offers a catalogue of applications created thanks to the application of advanced analysis and visualisation techniques, carried out in R language. In the online session they showed the analysis of interurban commuting, the analysis of CO2 generated by student commuting and the analysis of gender differences in the different university branches.
These analyses can be instrumental in helping universities to make decisions related to administration and management, with major benefits for the environment, the economy and society.
Screenshots of UniversiDATA-Lab
Second prize: MIP Project
- Team: Aday Melián Carrillo, Daydream Software.
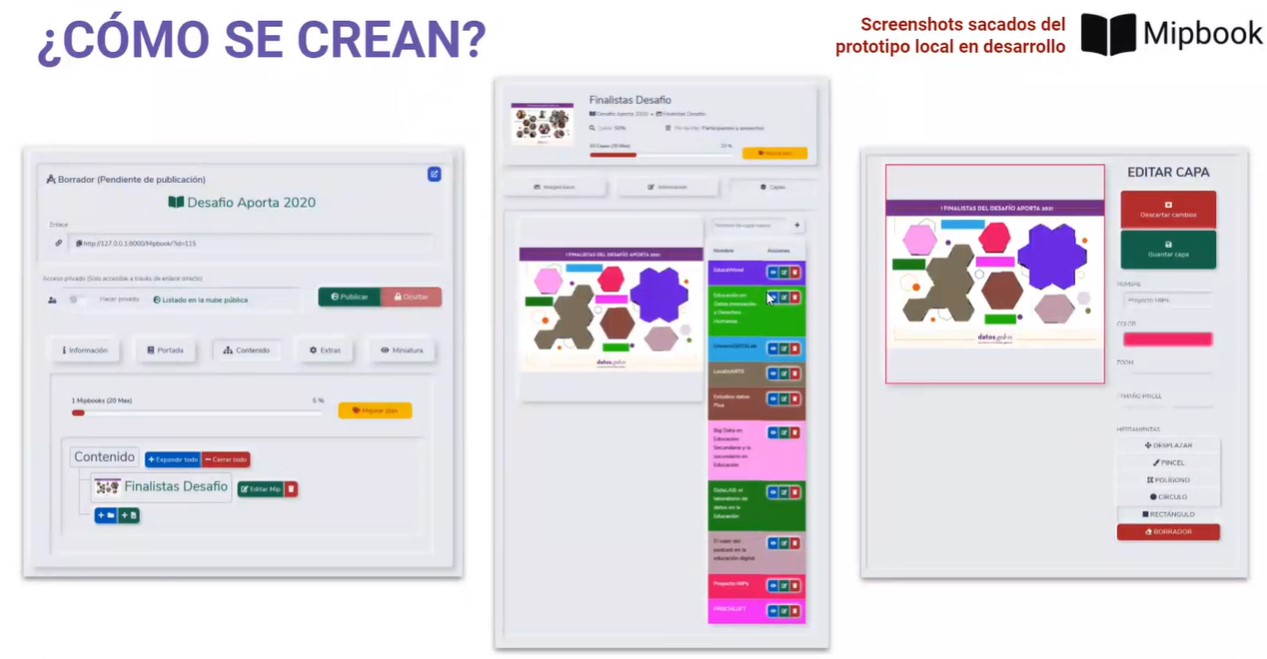
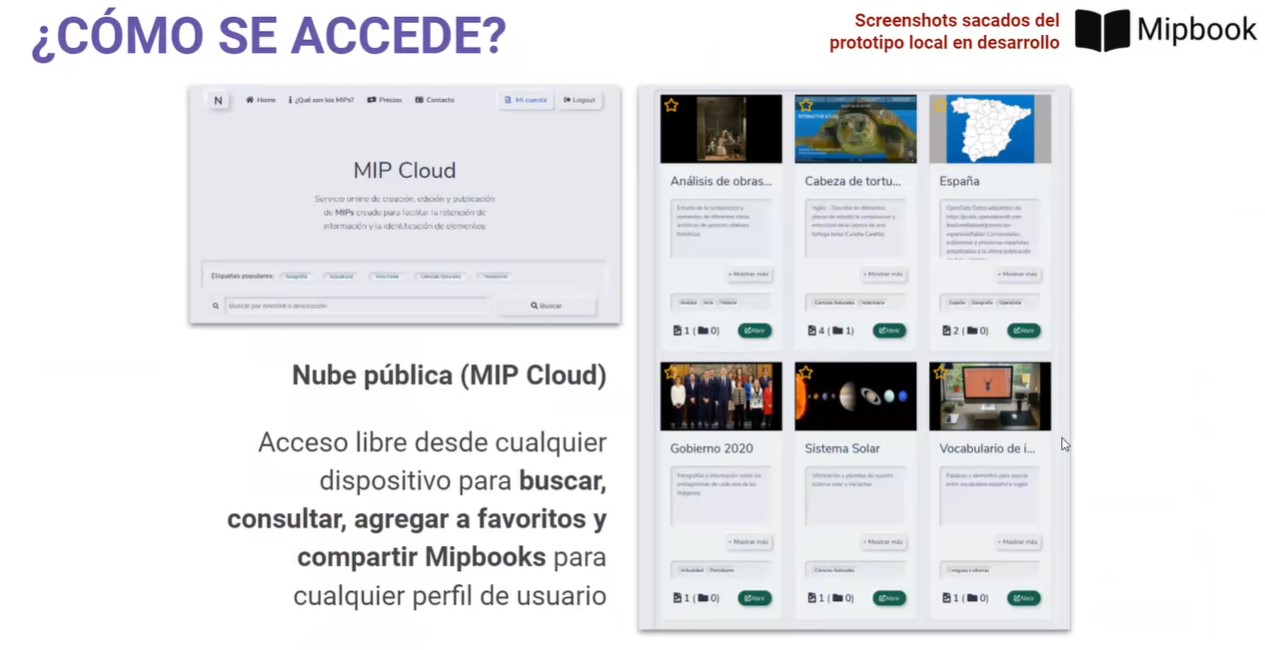
MIP Project, the second prize winner, is an online service where any user can register and start creating MIPs (Marked Information Pictures). A MIP is an information format consisting of a series of interactive layers over static images that facilitate the retention of information and the identification of elements.
The prototype includes a Python converter from GeoJSON open data to the format needed to develop interactive atlases. It also offers a public cloud of freely accessible MIPs for consultation, study or independent learning.
Thanks to this tool, teachers can create MIPs quickly and easily by manually drawing regions of interest on any image imported through the web. A more enjoyable way to educate and to attract students' attention more easily.
Screenshots of MIP Project
Third prize EducaWood
-
Team: Jimena Andrade, Guillermo Vega, Miguel Bote, Juan Ignacio Asensio, Irene Ruano, Felipe Bravo and Cristóbal Ordóñez.
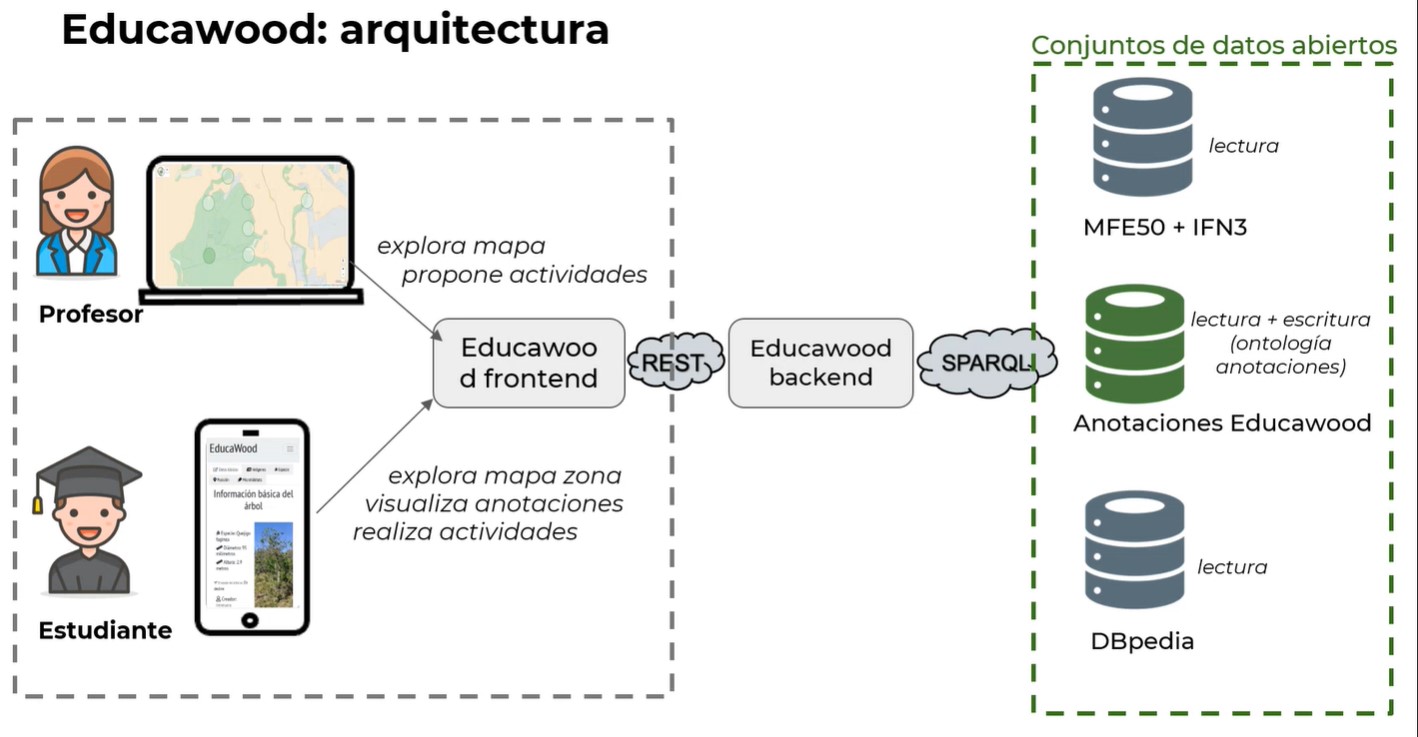
EducaWood is a socio-semantic web portal that allows you to explore the forest information of an area of Spanish territory and enrich it with tree annotations. Its aim is to promote environmental learning activities, one of the main aspects of UNESCO's "Education for Sustainable Development Goals", which is part of the Spanish Government's Agenda 2030.
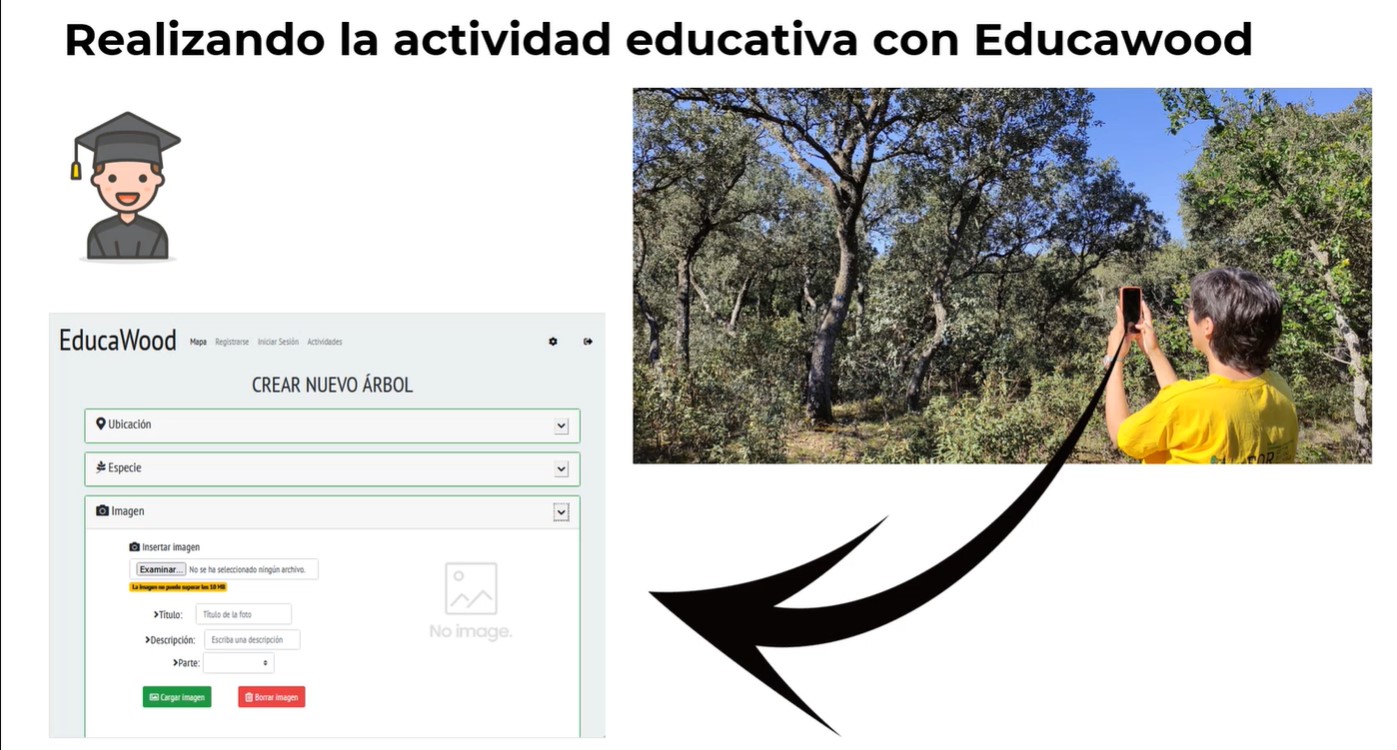
Thanks to the use of EducaWood, teachers can propose activities that students can carry out either face-to-face or online (through virtual field visits). In the face-to-face modality, students visit natural areas and make annotations of trees, such as location and identification of species, measurements, microhabitats, photos, etc. These annotations become available to the whole community as open data, thus enabling the application to be used remotely. These data are also enriched with other sources such as the Spanish Forest Map, the National Forest Inventory, GeoNames or DBPedia.
EducaWood helps students to learn more about their environment, while promoting ecological awareness.
Screenshots of Educawood
Alberto Martínez Lacambra, Director General of Red.es, presents the awards
The awards to the three winners were announced on 8 July at a ceremony held at Red.es headquarters.
The three awards were announced by Alberto Martínez Lacambra, Director General of Red.es, who highlighted education as a key element in the evolution of a society marked by the pandemic, as well as the need to work to reduce the digital and social divide that still exists. He thanked all the participants for their participation, highlighting the quality of their work.
The event was attended by several members of the jury, who were able to talk to the three winning teams.
In the following video you can see how the event took place. Photos are also available on our Flickr account.
At datos.gob.es we are already working to shape the IV Aporta Challenge, which we hope to announce in the coming months.
Blog
Each individual, organization or group uses a number of common words in their daily communication, which would be their personal vocabularies. The greater the number of words we use, the greater our ability to communicate, but it can also be a barrier, increasing the difficulty of understanding other people who are not familiar with the same terms as we are. The same is true in the world of data.
To avoid misunderstandings, we must use a controlled vocabulary, which is nothing more than a defined list of terms to systematically organize, categorize or label information.
What is a data vocabulary?
For a successful implementation of a data governance initiative, whether private or public, we must provide the process with a business Glosary or reference vocabulary. A reference vocabulary is a means of sharing information and developing and documenting standard data definitions to reduce ambiguity and improve communication. These definitions should be clear, rigorous in their wording and explain any exceptions, synonyms or variants. A clear example is EuroVoc, which covers the activities of the European Union and, in particular, the European Parliament. Another example is ICD10, which is the Coding Manual for Diagnoses and Procedures in Health Care.
The objectives of a controlled vocabulary are as follows:
- To enable common understanding of key concepts and terminology, in a precise manner.
- To reduce the risk of data being misused due to inconsistent understanding of concepts.
- Maximize searchability, facilitating access to documented knowledge.
- Drive interoperability and data reuse, which is critical in the open data world.
Vocabularies vary in the complexity of their development, from simple lists or selection lists, to synonym rings, taxonomies or the most complex, thesauri and ontologies.
How is a vocabulary created?
When creating a vocabulary, it does not usually start from scratch, but is based on pre-existing ontologies and vocabularies, which favors communication between people, intelligent agents and systems. For example, Aragón Open Data has developed an ontology called Interoperable Information Structure of Aragón EI2A that homogenizes structures, vocabularies and characteristics, through the representation of entities, properties and relationships, to fight against the diversity and heterogeneity of existing data in the Aragonese Administration (data from local entities that do not always mean the same thing). For this purpose, it is based on proposals such as RDF Schema (a general vocabulary for modeling RDF schemas that is used in the creation of other Vocabularies), ISA Programme Person Core Vocabulary (aimed at describing persons) or OWL-Time (describing temporal concepts).
A vocabulary must be accompanied by a data dictionary, which is where the data is described in business terms and includes other information needed to use the data, such as details of its structure or security restrictions. Because vocabularies evolve over time, they require evolutionary maintenance. As an example, ANSI/NIZO Z39.19-2005 is a standard that provides guidelines for the construction, formatting and management of controlled vocabularies. We also find SKOS, a W3C initiative that provides a model for representing the basic structure and content of conceptual schemas in any type of controlled vocabulary.
Examples of Vocabularies in specific fields created in Spain
In the Spanish context, with a fragmented administrative structure, where each agency shares its open information individually, it is necessary to have common rules that allow us to homogenize the data, facilitating its interoperability and reuse. Fortunately, there are various proposals that help us in these tasks.
The following are examples of vocabularies created in our country for two fundamental sectors for the future of society, such as education and smart cities.
Smart cities
An example of the construction of domain-specific vocabularies can be found in ciudades-abiertas.es, which is an initiative of several city councils in Spain (A Coruña, Madrid, Santiago de Compostela and Zaragoza) and Red.es.
Among other actions, within the framework of the project, they are working on the development of a catalog of well-defined and documented vocabularies, with examples of use and available in several representation languages. Specifically, 11 vocabularies are being developed corresponding to a series of datasets selected by the municipalities that do not have a defined standard. An example of these vocabularies is the Municipal Agenda.
These vocabularies are generated using the OWL standard language, which is the acronym for Web Ontology Language, a markup language for publishing and sharing data using ontologies on the Web. The corresponding contexts for JSON-LD, N-triples, TTL and RDF/XML are also available. In this explanatory video we can see how these vocabularies are defined. The generated vocabularies are available in the Github repository.
Education
In the field of universities, on the other hand, we find the proposal for open data content for universities developed by the UniversiDATA community: Common Core. In version 1.0, 42 datasets have been identified that every university should publish, such as information related to Degrees, Enrolments or Tenders and contracts. At the moment there are 11 available, while the rest are in the process of elaboration.
For example, the UAM (Autónoma de Madrid), the URJC (Rey Juan Carlos) and the UCM (Complutense de Madrid) have published their degrees following the same vocabulary.
Although much progress has been made in the creation and application of data vocabularies in general, there is still room for progress in the field of research on controlled vocabularies for publishing and querying data on the Web, for example, in the construction of Business Glosaries linked to technical data dictionaries. The application of best practices and the creation of vocabularies for the representation of metadata describing the content, structure, provenance, quality and use of datasets will help to define more precisely the characteristics that should be incorporated into Web data publishing platforms.
Content elaborated by David Puig, Graduate in Information and Documentation and responsible for the Master Data and Reference Group at DAMA ESPAÑA.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
UniversiDATA, the Open Data collaborative portal specialized in the Higher Education sector, is born
Noticia
During the last few years, we have seen more and more Spanish universities betting on the opening of their data. With goals such as improving transparency and promoting the reuse of the information they generated and guarded, open data portals linked to higher education centers have been emerging, many of which have federated with data.gob.es.
These initiatives were individual projects, promoted by pioneering centers that saw in open data a way to share their information with society and promote greater knowledge, as well as the creation of new products and services of value based on their data. During these years, there have been some attempts at harmonization. For example, the Sectoral Commission on Information and Communication Technologies of the Conference of Spanish University Rectors (CRUE-TIC) prepared a manual to guide university entities on the path to open their data, but there was a lack of a joint framework among the universities themselves that would help unify criteria.
With this objective UniversiData was born.
What is UniversiData?
Universidata is a collaborative project oriented and driven by public universities that seeks to promote open data in the higher education sector in Spain in a harmonized way.
The initiative arises from a public-private collaboration between 3 universities (the Universidad Autónoma de Madrid, the Universidad Complutense de Madrid and the Universidad Rey Juan Carlos), together with the company Dimetrical. The objective is twofold:
- On the one hand, to create a single access point where the different universities could share their data, facilitating the work of reusers and infomediaries.
- On the other hand, to facilitate the work of publishing data to the universities themselves. Through UniversiData they can publish their data without the need to create their own portal and share the processes of data generation and transformation, with the time and resource savings that this implies.
Universidata es un proyecto colaborativo orientado e impulsado por universidades públicas que busca fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada.
UniversiData as a single access point
Reusers can find in UniversiData homogeneous and documented contents, which follow the same specification, called "Common Core". Thanks to it, the datasets maintain a common structure, with homogenized metadata. The contents are offered following accepted standards, such as DCAT and DCMI (adopted by NTI RISP), and the most useful formats for reuse such as CSV, XLSX or JSON.
Users can access the data through a search engine. To facilitate their location, the datasets have been classified according to a series of topics. Each dataset can only belong to one category, even if it has different tags that limit the content. In addition, a free API has been made available to users without the need for registration.
The topics currently available are as follows:

Finally, it should be noted that UniversiDATA includes a laboratory section with examples of analyses carried out with the data it offers, such as the analysis of interurban travel in students or retirement forecasts.
UniversiDATA for data publishers
UniversiData offers a comprehensive and standardized solution for the management, processing, enrichment, automated anonymization and publication of data sets, making it easier for publishers to do their job. The platform is based on open source DKAN. The publication in UniversiDATA helps Universities to comply with the requirements of the Transparency Law 19/2013 and other regional regulations such as the Law of the Community of Madrid 10/2019.
Apart from standardizing the datasets in general formats, UniversiDATA adheres -if they exist- to specific internationally accepted thematic standards, such as Open Fiscal Data Package for public budgets, which allows their integration in portals such as OpenSpending (http://openspending.org/s/?q=universidad), or Open Contracting Data Standard for public procurement processes, datasets in the process of definition by the working group at the time of writing.
A growing project that wants to listen to reusers
UniversiDATA takes its first step with 11 defined and published datasets from a target set of more than 40, and 3 universities actively publishing, making nearly 200 data resources available already at launch.
In its eagerness to grow, more publishing universities and new datasets are expected to be incorporated soon.
In order to continue developing the project, UniversiData considers it essential to listen to the reusers. Therefore, they have enabled different communication channels:
- Users can write comments on each dataset and rate them by "star marker", without the need for registration.
- Periodically, surveys are conducted to find out users' opinions about datasets that should be offered in open access.
- The link to the official information request point is provided on each university's page.
- Users can subscribe through a form on the home page to receive automatic notifications every time new content is published.
Finally, if you have any suggestions, the UniversiDATA team will listen and assist you at universidata@dimetrical.es.
In short, we are before a project that seeks to unify criteria and facilitate the opening of data from universities, and therefore responds to one of the key objectives of the European Data Strategy: the construction of common and interoperable data spaces in a key sector such as data from the university.