Evento
PRORROGADO: ¡Puedes enviar tu proyecto hasta el 20 de septiembre!
Ya está abierto el plazo para participar en la II edición del Datathon UniversiData. Esta competición reconoce el valor de proyectos que reutilicen datos abiertos universitarios publicados en el portal UniversiDATA, una iniciativa público-privada que nació a finales de 2020. Su objetivo era, y es, fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada.
Actualmente, UniversiDATA está integrada por la Universidad Rey Juan Carlos, la Universidad Complutense de Madrid, la Universidad Autónoma de Madrid, la Universidad Carlos III de Madrid, la Universidad de Valladolid y la Universidad de Huelva, en colaboración con la empresa DIMETRICAL, The Analytics Lab, S.L.
¿En qué consiste el Datathon UniversiDATA?
Como se indicaba previamente, los participantes deben presentar un proyecto de tratamiento de datos abiertos utilizando uno o varios de los conjuntos de datos publicados en UniversiDATA. Estos datos podrán ser combinados con otras fuentes de datos, pero siempre teniendo en cuenta que su uso no debe ser secundario o accesorio.
No hay limitaciones en la naturaleza del proyecto, las tecnologías implicadas o los formatos de presentación de los resultados. Se puede concursar con una App móvil, una aplicación web, un análisis de datos en Jupyter o R-Markdown, etc. También son válidos los trabajos ya presentados a otras competiciones, así como prácticas, trabajos fin de máster o grado o artículos de investigación.
Si quieres inspiración, puedes visitar la sección "UniversiDATA-Lab" donde se muestran ejemplos de aplicaciones y análisis de datos. También puedes revisar los proyectos ganadores de la primera edición.
¿Cómo se desarrolla la competición?
El concurso se divide en dos fases:
-
Fase eliminatoria
Aquellas personas interesadas en participar pueden presentar su candidatura desde el pasado día 6 de marzo hasta el 20 de septiembre, a través de este formulario. En dicha solicitud, además de los datos personales, es necesario detallar la siguiente información:
-
Integrantes del proyecto
-
Título del proyecto
-
Problemática a resolver
-
Solución propuesta
-
Identificación de destinatarios
-
Utilidad del proyecto
-
Conjuntos de datos a utilizar
Todos los proyectos presentados serán valorados por un jurado que seleccionará a 10 finalistas, los cuales pasarán a la fase final. La lista de proyectos seleccionados se hará pública el 27 de septiembre de 2024.
-
Fase Final
Una vez seleccionados, los finalistas empezarán a preparar sus proyectos para la presentación al jurado, que tendrá lugar durante una jornada online el 16 de diciembre. En dicha jornada los proyectos se presentarán por videoconferencia.
El 23 de diciembre se harán públicos los ganadores.
¿Quién puede participar?
La competición está abierta a cualquier persona física con residencia fiscal en la Unión Europea, tanto estudiantes como profesionales ya en activo o aficionados.
Se puede participar en grupo o de manera individual.
¿Cuáles son los premios?
Este año se ha incrementado la dotación económica hasta alcanzar un total de 9.000 €, divididos de la siguiente manera:
-
Primer premio: 4.000 €
-
Segundo premio: 3.000 €
-
Tercer premio: 1.500 €
Además de estos premios generales, también se quiere reconocer al mejor proyecto de estudiantes universitarios que haya sido finalista pero no premiado. Para ello se ha creado un accésit específico de 500 €.
En caso de participar en grupo, el premio se dividirá entre todos los integrantes del mismo.
¿Tienes alguna duda?
Antes de participar, es necesario descargar y leer las bases concretas del concurso. Para cualquier duda, se puede contactar con los organizadores a través de este formulario. También se irá informando de cualquier novedad en el perfil de Twitter de UniversiDATA.
Además, durante toda la competición se establecerá un canal de comunicación directo con los participantes, para plantear cualquier pregunta que surja, incluidas las relativas a los conjuntos de datos a utilizar.
El II Datathon UniversiDATA surge a raíz del éxito alcanzado en su primera edición, una experiencia muy positiva que ofrece a los participantes, un año más, la oportunidad no solo de alzarse con un reconocimiento económico, sino también de ganar visibilidad mostrando su talento a la hora de realizar tratamientos de datos que puedan dar respuesta a diversas cuestiones de interés social y económico.
Evento
¿Estás interesado en el análisis de datos? Si la respuesta es sí, te interesará saber que UniversiDATA ha puesto en marcha un datathon para reconocer proyectos de tratamiento de datos abiertos basados en los datasets disponibles en su portal.
Con esta iniciativa se busca no solo premiar el talento, sino también promocionar los contenidos que ofertan y fomentar su uso, inspirando nuevos proyectos gracias a la difusión de casos de referencia. Además, se trata de una oportunidad para conocer a sus reutilizadores y entender mejor sus objetivos, retos y necesidades. Una información de valor que se utilizará para impulsar mejoras en la plataforma.
¿Quién puede participar?
La convocatoria está abierta a cualquier persona física mayor de edad con residencia fiscal en la Unión Europea. Pueden participar estudiantes, desarrolladores, investigadores o cualquier ciudadano interesado en el análisis de datos.
¿Cómo se desarrolla la competición?
La competición se estructura en dos fases:
Fase eliminatoria
Un jurado de expertos evaluará todas las solicitudes recibidas atendiendo a las descripciones de los proyectos realizadas por los participantes en el formulario de inscripción. Para ello se tendrán en cuenta 4 criterios detallados en las bases de la competición: impacto, calidad de la propuesta, usabilidad/presentación y reusabilidad.
Tras la evaluación, un máximo de 10 finalistas pasará a la siguiente fase.
Fase final
Los finalistas tendrán que presentar sus proyectos por videoconferencia ante los miembros del jurado.
Tras la presentación se darán a conocer a los tres ganadores.
¿Cuáles son los requisitos de los proyectos presentados?
Los trabajos presentados deberán cumplir tres obligaciones:
- Es necesario utilizar al menos un conjunto de datos publicado en el portal de datos abiertos UniversiDATA. Estos datasets podrá combinarse con datos secundarios de otras fuentes.
- El uso que se haga de los conjuntos de datos de UniversiDATA debe ser esencial para obtener los resultados del análisis.
- El análisis de los datos debe tener un objetivo o utilidad claro. No se admitirán tratamientos de datos genéricos.
Cabe destacar que se pueden presentar trabajos ya existentes, previamente presentado en otros contextos. Además, no existen limitaciones con respecto a la tecnología a utilizar para el análisis -cada usuario puede usar las herramientas que considere adecuadas- ni relativas al formato del resultado final del análisis. Es decir, se puede concursar con una App móvil, una aplicación web, un análisis de datos en Jupyter o R-Markdown, etc...
¿Cuáles son los premios?
Los tres ganadores recibirán un total de 3.500€, distribuidos de la siguiente manera:
- Primer premio: 2.000 €
- Segundo premio: 1.000 €
- Tercer premio: 500 €
El resto de finalistas recibirán un diploma de reconocimiento
¿Cómo puedo participar?
El plazo de inscripción ya está abierto. La manera más sencilla de participar es rellenar el formulario disponible al final del espacio web de la competición antes del 14 de octubre de 2022.
Antes de inscribirte te recomendamos revisar toda la información completa en las bases del concurso. Si tienes cualquier duda, puedes ponerte en contacto con los organizadores. Próximamente se habilitarán diversos canales para que los participantes puedan plantear dudas relativas no solo a los procedimientos de la competición, sino también a los conjuntos de datos de la plataforma.
Calendario de la competición
- Recepción de candidaturas: hasta el 14 de octubre de 2022
- Publicación de los 10 finalistas: 14 de noviembre de 2022
- Comunicación de los tres ganadores: 16 de diciembre de 2022
Descubre más sobre UniversiDATA
UniversiDATA nació a finales de 2020 con el objetivo de fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada. Se trata de una iniciativa público-privada que actualmente engloba a la Universidad Rey Juan Carlos, la Universidad Complutense de Madrid, la Universidad Autónoma de Madrid, la Universidad Carlos III de Madrid, la Universidad de Valladolid, la Universidad de Huelva y Dimetrical, The Analytics Lab, S.L.
En 2021 UniversiDATA se hizo con el Primer Premio del III Desafío Aporta por su proyecto UniversiDATA-Lab, un portal público para el análisis avanzado y automático de los datasets publicados por las universidades. Puedes conocer más sobre el proyecto en esta entrevista.
Entrevista
El primer premio de nuestro III Desafío Aporta ha sido para UniversiData-Lab, un portal público para el análisis avanzado y automático de los datasets publicados por las universidades. Se trata de un proyecto complementario a UniversiData: mientras que el objetivo de UniversiDATA es facilitar el acceso a conjuntos de datos universitarios de alta calidad y con formatos y criterios estándar, el objetivo de UniversiDATA-Lab es poner en valor esos datasets, llevando a cabo análisis avanzados y automáticos de los mismos, aprovechando la homogeneidad del contenido.
Hablamos con dos de sus creadores: Manuel Gertrudix y Juan Jesús Alcolea.
Entrevista completa:
1 ¿En qué consiste su proyecto?
UniversiDATA-Lab es una iniciativa público-privada, en la que participan, además de la empresa Dimetrical, seis universidades públicas, en este momento, la Universidad Rey Juan Carlos, la Universidad Complutense de Madrid, la Universidad Autónoma de Madrid y también se han incorporado la Universidad Carlos III, la Universidad de Valladolid y muy recientemente, este próximo viernes, tenemos la oportunidad de se que incorpore la Universidad de Huelva.
Es una iniciativa que, sobre todo, lo que trata es de valorizar el enorme potencial que tienen los datos que se publican en UniversiDATA, una iniciativa que provee multitud de dataset sobre la actividad de las universidades en sus múltiples ámbitos de trabajo y que va a permitir de una forma absolutamente novedosa presentar de una manera dinámica informes, consultar los datos que publicamos a través de esta iniciativa, ofreciendo una posibilidad tanto a la ciudadanía y a la propia comunidad universitaria, de comprobar cómo esa información es comparable entre universidades y, sobre todo, contribuir decisivamente a la rendición de cuentas ya a la publicación de información fácil y accesible para la ciudadanía.
2 ¿Qué mejoras aporta su proyecto, basado en datos abiertos, al sector educativo?
Yo creo que UniversiDATA-Lab aporta en dos ámbitos fundamentalmente. El primero es que yo creo que contribuye a completar la cadena de valor del dato que han iniciado las universidades abriendo esta ingente cantidad de datos. UniversiDATA-Lab procesa toda esa información, procesa todos esos datos, los convierte en información. Esa información es presentada al usuario correspondiente, que idealmente se convierte en conocimiento y ese conocimiento idealmente en una acción que modifica la realidad para bien. Esa es la cadena de valor del dato y esa es la idea que tenemos en UniversiDATA-Lab, poder facilitar toda esa cadena de valor del dato a los usuarios. ¿Quién está interesado en este tipo de resultados? Cualquier persona que pertenezca a la comunidad universitaria, desde la capa de gestión hasta los propios estudiantes o cualquier persona, cualquier ciudadano que esté remotamente relacionado con la universidad superior. Yo creo que encontrará algo de interés en UniversiDATA-Lab.
Por otra parte, creemos y queremos hacer también una labor didáctica en este tipo de análisis, porque no solo mostramos qué se puede hacer sino cómo se está haciendo, ya que, evidentemente, las fuentes de datos son públicas pero también, el código de los propios análisis los vamos a hacer públicos, de tal forma que todo el mundo pueda ver cómo están implementados y esperamos también tener un efecto facilitador para que otros colectivos, otras personas, puedan hacer análisis similares a los que presentamos.
¿Quién está interesado en este tipo de resultados? Cualquier persona que pertenezca a la comunidad universitaria, desde la capa de gestión hasta los propios estudiantes o cualquier persona, cualquier ciudadano que esté remotamente relacionado con la universidad superior. Yo creo que encontrará algo de interés en UniversiDATA-Lab.
3. ¿Cómo ha sido su experiencia en el Desafío Aporta?
Creo que el Desafío Aporta, sin duda alguna, es un ejemplo de iniciativas que estimulan la acción, en este caso, del conjunto de las administraciones públicas para incentivar algo que creo que es fundamental, que es cómo contribuir a la apertura de datos, a la gestión de información pública, a hacernos comparables y medibles, en este caso, entre universidades… Y sin duda alguna, este tipo de iniciativas, promovidas y que son un claro ejemplo del impulso que, durante muchos años, viene desarrollando tanto la iniciativa Aporta, a través de Red.es, como desde el propio ministerio, supone para nosotros, para el conjunto de las universidades públicas que participamos en UniversiDATA-Lab, pero también, como no puede ser de otra forma, para el conjunto de nuestra comunidad universitaria, un estímulo para seguir trabajando en lo que es importante, que es ofrecer información abierta, contribuir a ese ecosistema de datos abiertos y, sobre todo, hacer que esa información sea reutilizable, y que genere valor añadido, para que no solamente las instituciones, sino en general el sector infomediario y la propia comunidad de reutilización, puedan ayudarnos a descubrir nuevas potencialidades de estos datos.
Quiero agradecer sinceramente también, no solamente a la organización del Desafío, sino al resto de compañeros de propuestas que hemos tenido la oportunidad de conocer en este Desafío Aporta relacionado con la educación porque, sinceramente creo que el nivel ha sido altísimo, creo que muestra el vigor y la vigencia de iniciativas como esta. Así que, para nosotros ha sido un verdadero placer poder contribuir a esta propuesta y a esta iniciativa este año.
4. ¿Qué retos ha encontrado a la hora de reutilizar información pública y cómo los ha solventado?
Yo clasificaría los retos en dos tipologías. Por un lado retos puramente técnicos y por otro lado retos más funcionales. Dentro de los retos técnicos, el primero que nos encontramos tenía que ver con el volumen de los datasets. Algunos de los datasets, puesto que se está publicando información al máximo nivel de detalle, son muy voluminosos, son millones de datos, y eso planteaba algún problema desde el punto de vista de las transferencias de datos y el retraso que eso podía implicar a la hora de un análisis ágil. Bueno, eso se solucionó aplicando unas políticas de caché bastante eficientes y quedó resuelto.
El otro reto, y este es muy importante, es que precisamente porque las universidades decidieron publicar la información al máximo nivel de detalle, tuvieron también que publicarla de manera anonimizada. Para proteger los derechos de los individuos que aparecen recogidos. Esto es fabuloso desde el punto de vista de la reutilización, es una demanda de los reutilizadores de largo tiempo, que la información se publique al máximo nivel de detalle, pero claro, hay que pagar un precio y el precio se paga en este caso en forma de complejidad. Analizar, procesar un dataset anonimizado no es tan sencillo como procesar un dataset agregado, contiene muchos más datos, mucha más información, pero también hay que conocer muy bien las implicaciones de los procesos de anonimización para que los análisis sean correctos. Por tanto el reto es ahí leer mucha documentación y enterarse muy bien de cómo están implementados esos procesos de anonimización de tal forma que conozcamos la implicaciones y el análisis que hagamos sea correcto y respetuoso con los procesos que están implícitos en esa publicación de datos.
Analizar, procesar un dataset anonimizado no es tan sencillo como procesar un dataset agregado, contiene muchos más datos, mucha más información, pero también hay que conocer muy bien las implicaciones de los procesos de anonimización para que los análisis sean correctos.
Desde el punto de vista funcional, yo creo que la principal fuente de complejidad está asociada a la propia complejidad del dominio en sí, es decir, la gestión universitaria es un dominio bastante complejo. A pesar de que los datos que se publican en UniversiDATA-Lab son datos perfectamente armonizados, con formatos compartidos y consensuados, con semánticas compartidas y consensuadas, nos hemos encontrado con pequeñas diferencias a la hora de representar determinadas realidades administrativas entre distintas universidades. Esas diferencias se detectan en el momento de preprocesamiento de datos, se habla con las universidades, se explican las realidades que hay detrás y lo que implica desde el punto de vista del análisis es que tenemos que hacer algunos ajustes previos en determinados casos y en determinadas universidades.
Por otro lado, y esto ya no es específico de los datos de universidad, sino de cualquier dataset, no siempre están todos los datos que uno querría tener o no están con la precisión que a uno le gustaría que estuvieran. El hecho de que un dataset recoja un determinado tipo de dato en concreto, no quiere decir que venga siempre informado, o no quiere decir que venga siempre informado con una precisión que a veces es necesaria. En este caso lo que hemos tenido que hacer es identificar esos casos e introducir en el análisis la incertidumbre que se deriva de la ausencia de determinados datos o de la imprecisión de determinados datos.
Noticia
Tras meses de trabajo, el III Desafío Aporta llega a su fin. Bajo el lema “el valor del dato en la educación digital”, este año se buscaban soluciones que utilizasen datos abiertos para impulsar mejoras en el sector educativo.
La competición, organizada por la Iniciativa Aporta, lanzada por Red.es junto con la Secretaría de Estado de Digitalización e Inteligencia Artificial, comenzó en octubre de 2020, con una primera fase que consistía en un concurso de ideas. Tras la valoración del jurado, se eligieron 10 finalistas que han contado con tres meses para transformar sus ideas en un prototipo. Estos prototipos fueron presentados el pasado 22 de junio en una sesión online.
10 propuestas que destacan por su calidad
Los 10 trabajos presentados son una gran muestra del poder de los datos abiertos para transformar el sector educativo, mejorando su eficacia y eficiencia. La necesidad de un acceso universal al conocimiento a través de una educación inclusiva y de calidad ha quedado aún más patente en el contexto actual de pandemia que vivimos. Los datos abiertos pueden ayudar a superar este reto. Pueden ser analizados y utilizados para dar forma a soluciones que ayuden a mejorar la experiencia del alumnado en el proceso de aprendizaje, por ejemplo, a través de la personalización de la educación, la identificación de problemas de comportamiento o la toma de decisiones informada, entre otros aspectos.
Todos los trabajos presentados mostraban una gran calidad, reflejo del esfuerzo demostrado por todos los equipos finalistas. El jurado, integrado por expertos representantes de empresas, administraciones públicas y organismos ligados a la economía digital y el mundo académico, lo ha tenido complicado a la hora de elegir a los tres ganadores. Finalmente, los tres ganadores son UniversiDATA-Lab, Proyecto MIP y EducaWood, que se llevan un premio de 4.000€, 3.000€ y 2.000€ respectivamente.

Primer premio: UniversiDATA-Lab
-
Equipo: Universidad Rey Juan Carlos, Universidad Complutense de Madrid, Universidad Autónoma de Madrid, Universidad Carlos III de Madrid y DIMETRICAL The Analytics Lab S.L.
El primer premio ha sido para UniversiDATA-Lab, un portal público para el análisis avanzado y automático de los datasets publicados por las universidades. Se trata de un proyecto complementario a UniversiDATA: mientras que el objetivo de UniversiDATA es facilitar el acceso a conjuntos de datos universitarios de alta calidad y con formatos y criterios estándar, el objetivo de UniversiDATA-Lab es poner en valor esos datasets, llevando a cabo análisis avanzados y automáticos de los mismos, aprovechando la homogeneidad del contenido.
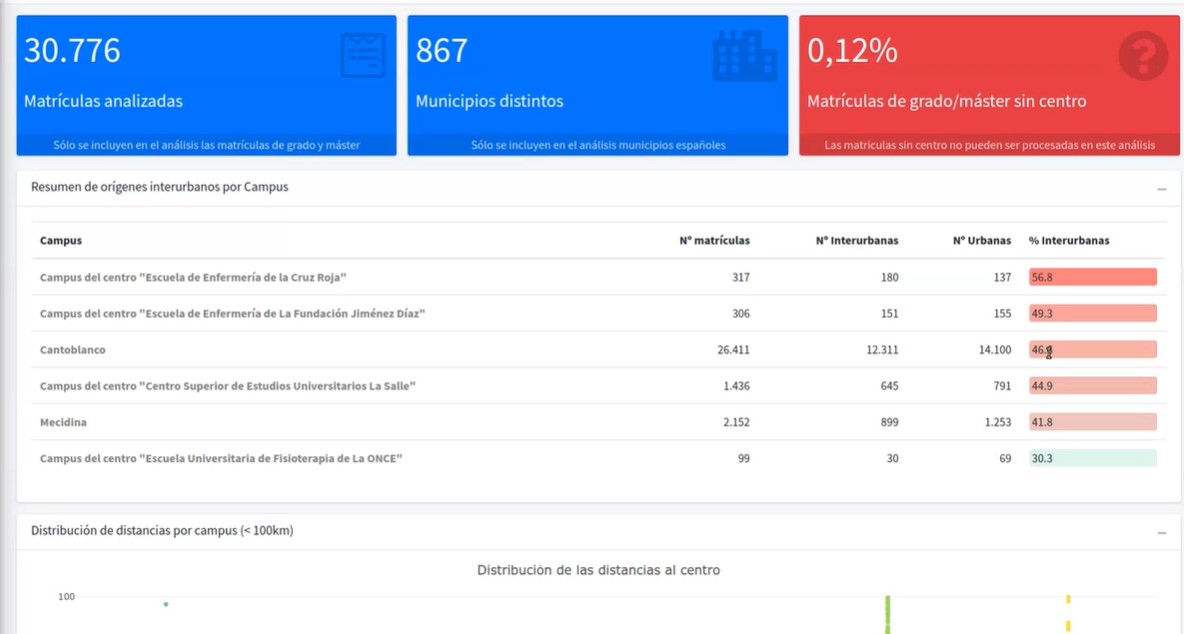
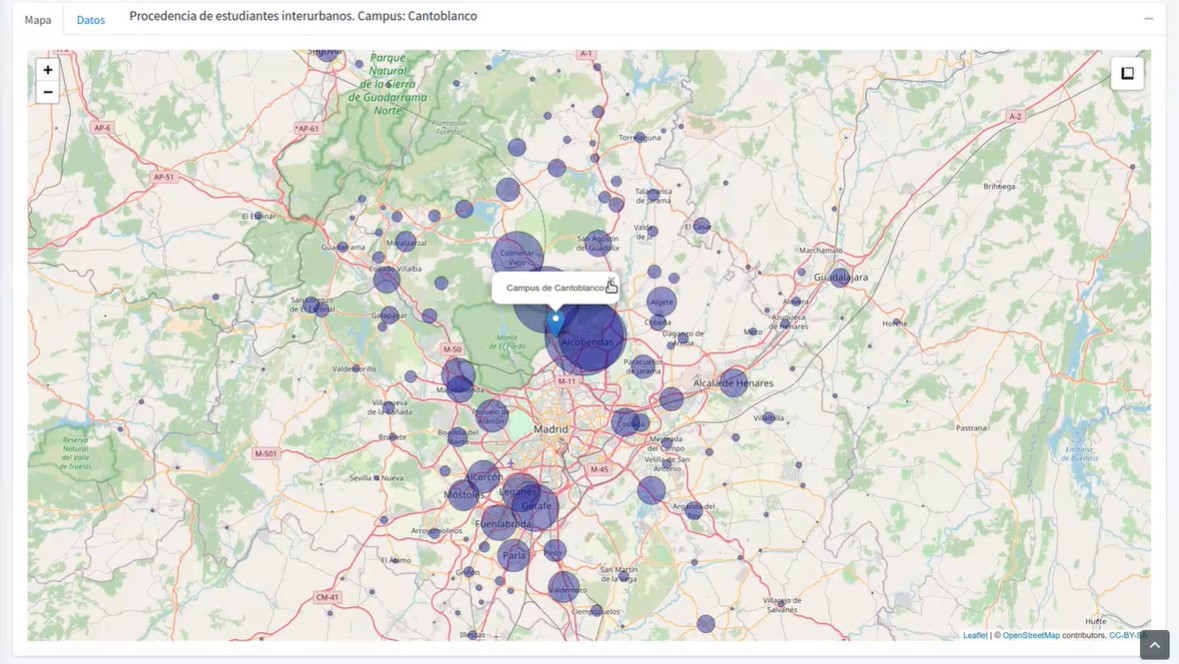
UniversiDATA-Lab ofrece un catálogo de aplicaciones creadas gracias a la aplicación de técnicas avanzadas de análisis y visualización, llevadas a cabo en lenguaje R. En la sesión online mostraron el análisis de desplazamientos interurbanos, el análisis del CO2 que generan los desplazamientos de los alumnos y el análisis de las diferencias de género en las distintas ramas universitarias.
Estos análisis pueden ser fundamentales a la hora de ayudar a las universidades a tomar decisiones relacionadas con la administración y la gestión, con grandes beneficios en el medio ambiente, la economía y la sociedad.
Capturas de UniversiDATA-Lab
Segundo premio: Proyecto MIP
- Equipo: Aday Melián Carrillo, Daydream Software.
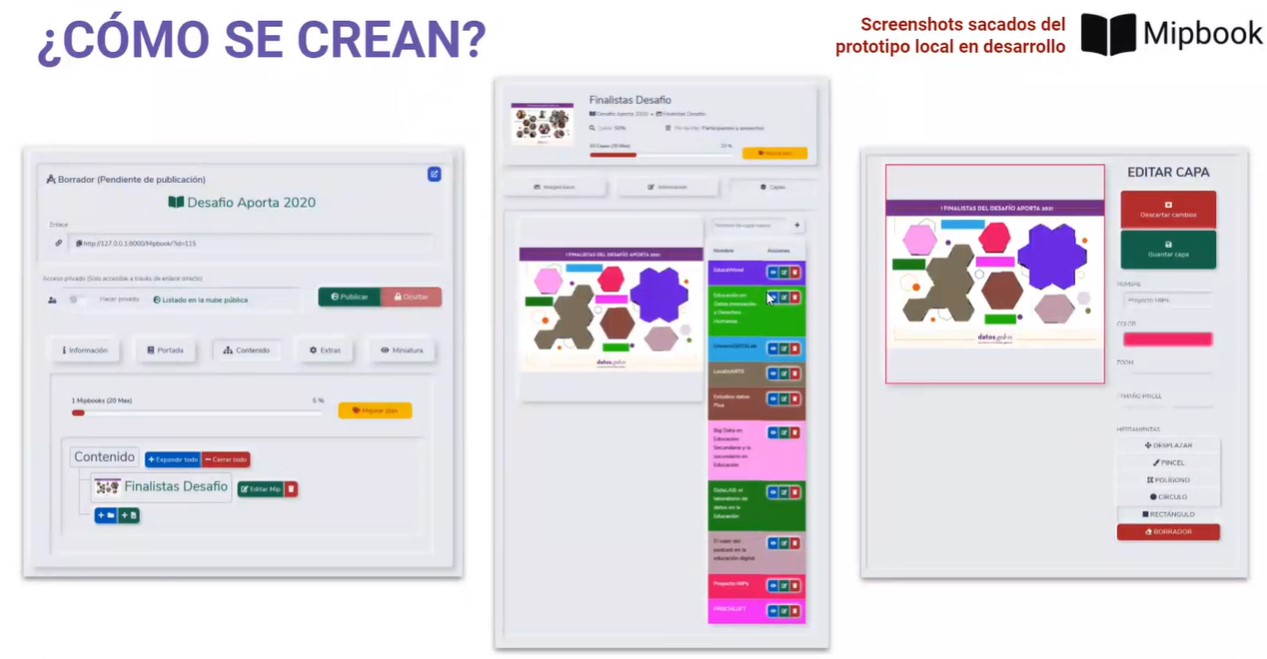
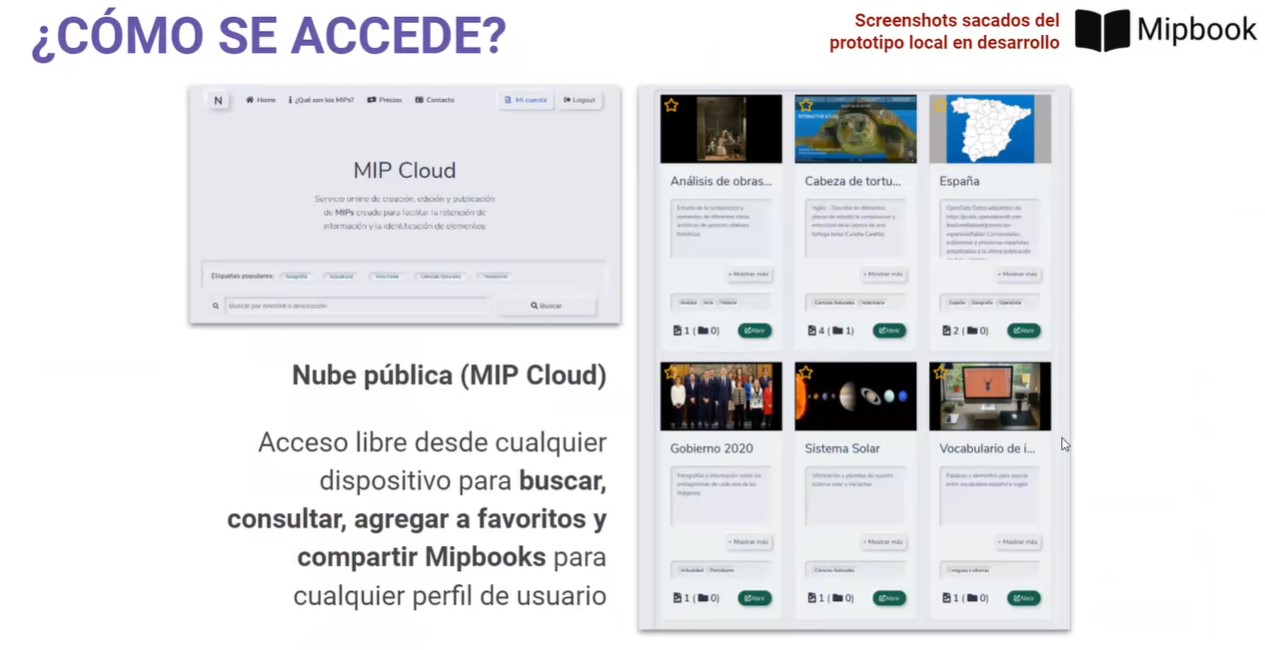
Proyecto MIP, el ganador del segundo premio, es un servicio online donde cualquier usuario puede registrarse y empezar a crear MIPs (Marked Information Picture). Un MIP es un soporte de información que consiste en una serie de capas interactivas sobre imágenes estáticas que facilitan la retención de información y la identificación de elementos.
El prototipo incluye un conversor en Python de datos abiertos GeoJSON al formato necesario para desarrollar atlas interactivos. A su vez, también ofrece una nube pública de MIPs accesibles libremente para consultas, estudios o aprendizaje independiente.
Gracias a esta herramienta los profesores pueden crear MIPs de forma rápida y sencilla, dibujando manualmente regiones de interés sobre cualquier imagen importada a través de la web. Una forma más amena de educar y con la que atraer más fácilmente la atención del alumnado.
Capturas de Proyecto MIP
Tercer premio EducaWood
-
Equipo: Jimena Andrade, Guillermo Vega, Miguel Bote, Juan Ignacio Asensio, Irene Ruano, Felipe Bravo y Cristóbal Ordóñez.
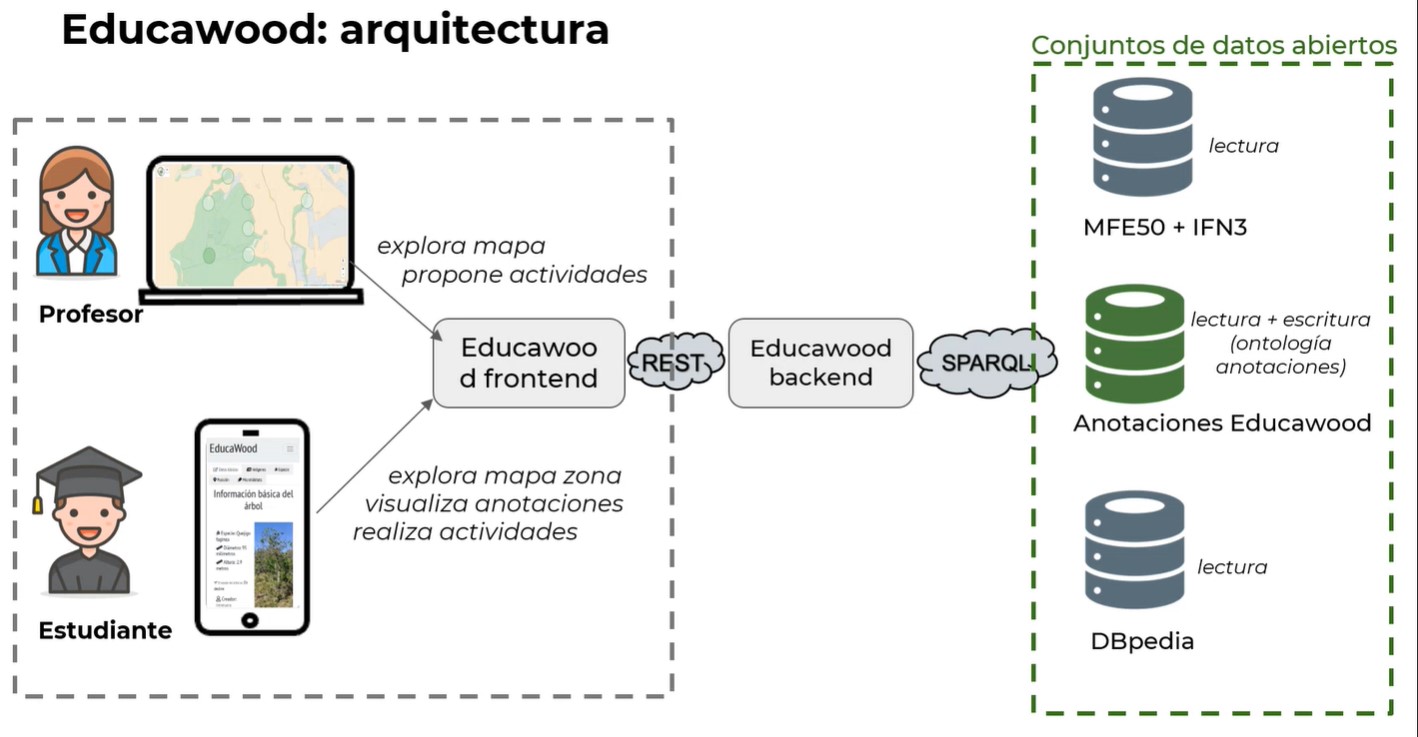
EducaWood es un portal web socio-semántico que permite explorar la información forestal de una zona del territorio español y enriquecerla con anotaciones de árboles. Su objetivo es impulsar las actividades de aprendizaje medioambiental, uno de los aspectos principales de la “Educación para los Objetivos de Desarrollo Sostenible” de la UNESCO, y que forma parte de la Agenda 2030 del Gobierno español.
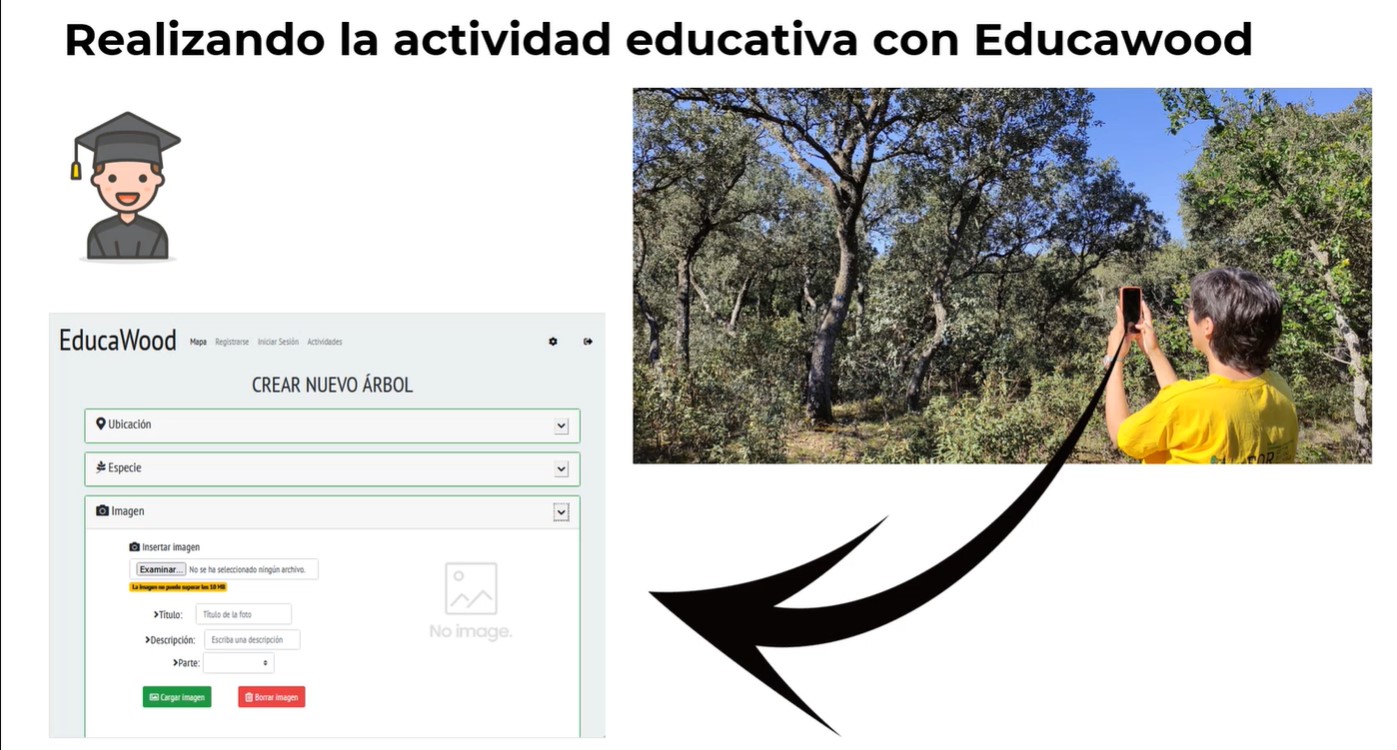
Gracias al uso de EducaWood, el profesorado puede proponer actividades que los estudiantes realizan de manera presencial u online (a través de visitas virtuales al campo). En la modalidad presencial, los estudiantes visitan zonas naturales y realizan anotaciones de árboles, como la localización e identificación de especies, medidas, microhábitats, fotos, etc. Estas anotaciones pasan a estar disponibles para toda la comunidad como datos abiertos, posibilitando así el uso de la aplicación en remoto. Estos datos son enriquecidos, además con otras fuentes como el Mapa Forestal Español, el Inventario Forestal Nacional, GeoNames o DBPedia.
Educawood ayuda al alumnado a conocer mejor su entorno, a la vez que se promociona la toma de conciencia ecológica.
Capturas de Educawood
Alberto Martínez Lacambra, Director General de Red.es, hace entrega de los galardones
Los premios a los tres ganadores se han dado a conocer el 8 de julio en un acto organizado en la sede de Red.es.
Los 3 galardones han sido anunciados por Alberto Martínez Lacambra, Director General de Red.es, quien ha destacado la educación como elemento clave en la evolución de una sociedad marcada por la pandemia, así como la necesidad de trabajar para reducir la brecha digital y social que todavía existe. Ha agradecido la participación de todos los participantes, destacando la calidad de su trabajo.
El acto ha contado con la participación de varios miembros del jurado, que han podido conversar con los tres equipos ganadores.
En el siguiente video puedes ver cómo transcurrió el acto. También están disponibles las fotos en nuestra cuenta de Flickr.
En datos.gob.es ya estamos trabajando para dar forma al IV Desafío Aporta, que esperamos poder anunciar en los próximos meses.
Blog
Cada individuo, organización o colectivo usa en su comunicación diaria un número de palabras habituales, que serían sus vocabularios personales. Cuanto mayor sea el número de vocablos que utilicemos, mayor será nuestra capacidad para comunicarnos, pero también puede suponer una barrera, al aumentar la dificultad para entendernos con otras personas que no estén familiarizadas con los mismos términos que nosotros. Esto mismo sucede en el mundo de los datos.
Para evitar equívocos, debemos utilizar un vocabulario controlado, que no es más que una lista definida de términos para organizar, categorizar o etiquetar sistemáticamente la información.
¿Qué es un vocabulario de datos?
Para una correcta implementación de una iniciativa de gobierno de datos, ya sean privados o públicos, debemos dotar al proceso de un business Glosary o vocabulario de referencia. Un vocabulario de referencia es un medio para poder compartir información y desarrollar y documentar definiciones de datos estándar, para reducir la ambigüedad y mejorar la comunicación. Estas definiciones deben ser claras, rigurosas en su redacción y explicar cualquier excepción, sinónimo o variante. Un ejemplo claro es EuroVoc, que cubre las actividades de la Unión Europea y, en particular, del Parlamento Europeo. Otro ejemplo es CIE10 que es el Manual de codificación de diagnósticos y procedimientos en el ámbito sanitario.
Los objetivos que persigue un vocabulario controlado son los siguientes:
- Permitir la comprensión común de los conceptos claves y de terminología, de forma precisa.
- Reducir el riesgo de que los datos sean mal utilizados debido a una comprensión inconsistente de los conceptos.
- Maximizar la capacidad de búsqueda, facilitando el acceso al conocimiento documentado.
- Impulsa la interoperabilidad y la reutilización de los datos, algo fundamental en el mundo del open data.
Los vocabularios varían en la complejidad de su desarrollo, desde listas simples o listas de selección, hasta anillos de sinónimos, taxonomías o los más complejos, tesauros y ontologías.
¿Cómo se crea un vocabulario?
A la hora de crear un vocabulario no se suele partir de cero, sino que se basa en ontologías y vocabularios preexistentes, lo que favorece la comunicación entre personas, agentes inteligentes y sistemas. Por ejemplo, Aragón Open Data ha desarrollado una ontologia llamada Estructura de Información Interoperable de Aragón EI2A que homogeniza estructuras, vocabularios y características, a través de la representación de entidades, propiedades y relaciones, para luchar contra la diversidad y heterogeneidad de datos existentes en la Administración aragonesa (datos de entidades locales que no siempre significan lo mismo). Para ello, se basa en propuestas como RDF Schema (un vocabulario general para el modelado de esquemas en RDF que se utiliza en la creación de otros Vocabularios), ISA Programme Person Core Vocabulary (destinado a describir personas) o OWL-Time (que describe conceptos temporales).
Un vocabulario debe ir acompañado de un diccionario de datos, que es donde se describen los datos en términos de negocio e incluye otras informaciones necesarias para usar los datos, como por ejemplo, detalles de su estructura o las restricciones de seguridad. Debido a que los vocabularios evolucionan con el tiempo, requieren un mantenimiento evolutivo. Como ejemplo, ANSI/NIZO Z39.19-2005 es un estándar que proporciona pautas para la construcción, formato y gestión de vocabularios controlados. También encontramos SKOS, una iniciativa de W3C que proporciona un modelo para representar la estructura básica y el contenido de esquemas conceptuales en cualquier tipo de vocabulario controlado.
Ejemplos de Vocabularios en ámbitos concretos creados en España
En el contexto español, con una estructura administrativa fragmentada, donde cada organismo comparte su información en abierto de manera individual, es necesario contar con reglas comunes que nos permitan homogeneizar los datos, facilitando su interoperabilidad y reutilización. Por suerte, encontramos distintas propuestas que nos ayudan en estas tareas.
A continuación, se recogen ejemplo de vocabularios creados en nuestro país para 2 sectores fundamentales para el futuro de la sociedad, como son la educación y las ciudades inteligentes.
Smart cities
Un ejemplo sobre la construcción de vocabularios de un dominio específico lo podemos encontrar en ciudades-abiertas.es, que es una iniciativa de varios ayuntamientos de España (A Coruña, Madrid, Santiago de Compostela y Zaragoza) y Red.es.
Entre otras acciones, dentro del marco del proyecto, se está trabajando en el desarrollo de un catálogo de vocabularios bien definidos y documentados, con ejemplos de utilización y disponibles en varios lenguajes de representación. En concreto, se están desarrollando 11 vocabularios correspondientes a una serie de conjuntos de datos seleccionados por los Ayuntamientos que no cuentan con un estándar definido. Un ejemplo de estos vocabularios es la Agenda municipal.
Estos vocabularios son generados utilizando el lenguaje estándar OWL, que es el acrónimo del inglés Web Ontology Language, un lenguaje de marcado para publicar y compartir datos usando ontologías en la Web. También se dispone de los correspondientes contextos para JSON-LD, N-triples, TTL y RDF/XML. En este video explicativo podemos ver como se definen estos vocabularios. Los vocabularios generados están disponibles en el repositorio de Github.
Educación
En el ámbito de las universidades, por su parte, encontramos la propuesta de contenidos de datos abiertos para universidades desarrollada por la comunidad UniversiDATA: Núcleo Común. En la versión 1.0 se ha identificado 42 datasets que toda Universidad debería publicar, como es el caso de la información relativa a Titulaciones, Matriculas o Licitaciones y contratos. De momento hay 11 disponibles, mientras que el resto se encuentran en proceso de elaboración.
Por ejemplo la UAM (Autónoma de Madrid), la URJC (Rey Juan Carlos) y la UCM (Complutense de Madrid), han publicado sus titulaciones siguiendo un mismo vocabulario.
Aunque se ha avanzado mucho en la creación y aplicación de vocabularios de datos en general, todavía queda terreno para avanzar en el campo de la investigación sobre vocabularios controlados para la publicación y consulta de datos en la Web, por ejemplo, en la construcción de Business Glosaries vinculados a los diccionarios de datos técnicos. La aplicación de buenas prácticas y la creación de vocabularios para la representación de metadatos que describan el contenido, la estructura, procedencia, calidad y uso de conjuntos de datos permitirá definir con mayor precisión las características que deben incorporar las plataformas de publicación de datos en la Web.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
Durante los últimos años, hemos visto cómo cada vez más universidades españolas apostaban por la apertura de sus datos. Con metas como la mejora de la transparencia y el impulso de la reutilización de la información que generaban y custodiaban, han ido surgiendo portales de datos abiertos ligados a centros de estudios superiores, muchos de las cuales han federado con datos.gob.es.
Estas iniciativas eran proyectos individuales, promovidos por centros pioneros que veían en los datos abiertos una forma de compartir su información con la sociedad y promover un mayor conocimiento, así como la creación de nuevos productos y servicios de valor basados en sus datos. Durante estos años, se han producido algunos intentos de armonización. Por ejemplo, la Comisión Sectorial de Tecnologías de la Información y las Comunicaciones de la Conferencia de Rectores de Universidades Españolas (CRUE-TIC) elaboró un manual para guiar a las entidades universitarias en el camino hacia la apertura de sus datos, pero faltaba un marco de trabajo conjunto entre las propias universidades que ayudará a unificar criterios.
Con este objetivo nace UniversiData.
¿Qué es UniversiData?
Universidata es un proyecto colaborativo orientado e impulsado por universidades públicas que busca fomentar los datos abiertos en el sector de la educación superior en España de una forma armonizada.
La iniciativa surge de una colaboración público-privada entre 3 universidades (la Universidad Autónoma de Madrid, la Universidad Complutense de Madrid y la Universidad Rey Juan Carlos), junto con la empresa Dimetrical. El objetivo es doble:
- Por un lado, crear un punto de acceso único donde las distintas universidades pudieran compartir sus datos, facilitando el trabajo de los reutilizadores y las empresas infomediarias.
- Por otro, facilitar el trabajo de publicación de datos a las propias universidades. A través de UniversiData pueden publicar sus datos sin la necesidad de crear un portal propio y compartiendo los procesos de generación y transformación de datos, con el ahorro de tiempo y recursos que ello supone.
UniversiData como punto de acceso único
Los reutilizadores pueden encontrar en UniversiData contenidos homogéneos y documentados, que siguen una misma especificación, llamada "Núcleo Común". Gracias a ella los conjuntos de datos mantienen una estructura común, con metadatos homogeneizados. Los contenidos se ofrecen siguiendo estándares aceptados, como DCAT y DCMI (adoptados por la NTI RISP), y los formatos más útiles para su reutilización como CSV, XLSX o JSON.
Los usuarios pueden acceder a los datos a través de un buscador. Para facilitar su localización, los datasets se han clasificado siguiendo una serie de topics. Cada datasets solo puede pertenecer a una categoría, aunque cuente con distintas etiquetas que acoten el contenido. Además, se ha puesto a disposición de los usuarios un API gratuito y de libre acceso sin necesidad de registro.
Las temáticas actualmente disponibles son los siguientes:

Por último, cabe destacar que UniversiDATA incluye una sección de laboratorio con ejemplos de análisis realizados con los datos que ofrece, como el análisis de desplazamientos interurbanos en estudiantes o la previsión de jubilaciones.
UniversiDATA para publicadores de datos
UniversiData ofrece una solución integral y estandarizada para la gestión, tratamiento, enriquecimiento, anonimización automatizada y publicación de los conjuntos de datos, facilitando a los publicadores su labor. La plataforma se basa en código abierto DKAN. La publicación en UniversiDATA ayuda a las Universidades a cumplir tanto con los requerimientos planteados en la Ley de Transparencia 19/2013 como con otras normativas autonómicas como la Ley de la Comunidad de Madrid 10/2019.
Aparte de estandarizar los datasets en formatos generalistas, UniversiDATA se adhiere - si existen - a estándares temáticos específicos internacionalmente aceptados, como Open Fiscal Data Package para los presupuestos públicos, lo que permite su integración en portales como OpenSpending (http://openspending.org/s/?q=universidad), u Open Contracting Data Standard para los procesos de contratación pública, dataset en proceso de definición por parte del grupo de trabajo en el momento de redactar esta noticia.
Un proyecto en crecimiento que quiere escuchar a los reutilizadores
UniversiDATA da su primer paso con 11 datasets definidos y publicados de un conjunto objetivo de más de 40, y 3 universidades publicando activamente, lo que supone cerca de 200 recursos de datos disponibles ya en su lanzamiento.
En su afán de crecimiento, se espera incorporar próximamente más universidades publicadoras y nuevos datasets.
A la hora de seguir desarrollando el proyecto, desde UniversiData consideran fundamental escuchar a los reutilizadores. Por ello han habilitado distintos canales de comunicación:
- Los usuarios pueden escribir comentarios en cada datasets y valorarlos mediante "marcador de estrellas", sin necesidad de registro.
- De manera periódica se realizan encuestas para conocer la opinión de los usuarios sobre datasets que se deberían ofrecer en abierto.
- En la página de cada Universidad se ofrece el enlace al punto oficial de solicitud de información.
- Los usuarios pueden suscribirse a través de un formulario en la home para recibir notificaciones automáticas cada vez que se publique nuevo contenido.
Por último, si tienes cualquier sugerencia el equipo UniversiDATA te escuchará y atenderá en la dirección de correo universidata@dimetrical.es.
En definitiva, estamos antes un proyecto que busca unificar criterios y facilitar la apertura de datos de universidades, y que por tanto da repuesta a uno de los objetivos clave de la Estrategia europea de datos: la construcción de espacios de datos comunes e interoperables en un sector clave como el de los datos procedentes del ámbito universitario.