Entrevista
In the last fifteen years we have seen how public administrations have gone from publishing their first open datasets to working with much more complex concepts. Interoperability, standards, data spaces or digital sovereignty are some of the trendy concepts. And, in parallel, the web has also changed. That open, decentralized, and interoperable space that inspired the first open data initiatives has evolved into a much more complex ecosystem, where technologies, new standards, and at the same time important challenges such as information silos to digital ethics and technological concentration coexist.
To talk about all this, today we are fortunate to have two voices that have not only observed this evolution, but have been direct protagonists of it at an international level:
- Josema Alonso, with more than twenty-five years of experience working on the open web, data and digital rights, has worked at the World Wide Web Foundation, the Open Government Partnership and the World Economic Forum, among others.
- Carlos Iglesias, an expert in web standards, open data and open government, has advised administrations around the world on more than twenty projects. He has been actively involved in communities such as W3C, the Web Foundation and the Open Knowledge Foundation.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. At what point do you think we are now and what has changed with respect to that first stage of open data?
Carlos Iglesias: Well, I think what has changed is that we understand that today that initial battle cry of "we want the data now" is not enough. It was a first phase that at the time was very useful and necessary because we had to break with that trend of having data locked up, not sharing data. Let's say that the urgency at that time was simply to change the paradigm and that is why the battle cry was what it was. I have been involved, like Josema, in studying and analyzing all those open data portals and initiatives that arose from this movement. And I have seen that many of them began to grow without any kind of strategy. In fact, several fell by the wayside or did not have a clear vision of what they wanted to do. Simple practice I believe came to the conclusion that the publication of data alone was not enough. And from there I think that they have been proposing, a little with the maturity of the movement, that more things have to be done, and today we talk more about data governance, about opening data with a specific purpose, about the importance of metadata, models. In other words, it is no longer simply having data for the sake of having it, but there is one more vision of data as one of the most valuable elements today, probably, and also as a necessary infrastructure for many things to work today. Just as infrastructures such as road or public transport networks or energy were key in their day. Right now we are at the moment of the great explosion of artificial intelligence. A series of issues converge that have made this explode and the change is immense, despite the fact that we are only talking about perhaps a little more than ten or fifteen years since that first movement of "we want the data now". I think that right now the panorama is completely different.
Josema Alonso: Yes, it is true that we had that idea of "you publish that someone will come and do something with it". And what that did is that people began to become aware. But I, personally, could not have imagined that a few years later we would have even had a directive at European level on the publication of open data. It was something, to be honest, that we received with great pleasure. And then it will begin to be implemented in all member states. That moved consciences a little and moved practices, especially within the administration. There was a lot of fear of "let's see if I put something in there that is problematic, that is of poor quality, that I will be criticized for it", etc. But it began to generate a culture of data and the usefulness of very important data. And as Carlos also commented in recent years, I think that no one doubts this anymore. The investments that are being made, for example, at European level and in Member States, including in our country, in Spain, in the promotion and development of data spaces, are hundreds of millions of euros. Nobody has that kind of doubt anymore and now the focus is more on how to do it well, on how to get everyone to interoperate. That is, when a European data space is created for a specific sector, such as agriculture or health, all countries and organisations can share data in the best possible way, so that they can be exchanged through common models and that they are done within trusted environments.
2. In this context, why have standards become so essential?
Josema Alonso: I think it's because of everything we've learned over the years. We have learned that it is necessary for people to be able to have a certain freedom when it comes to developing their own systems. The architecture of the website itself, for example, is how it works, it does not have a central control or anything, but each participant within the website manages things in their own way. But there are clear rules of how those things then have to interact with each other, otherwise it wouldn't work, otherwise we wouldn't be able to load a web page in different browsers or on different mobile phones. So, what we are seeing lately is that there is an increasing attempt to figure out how to reach that type of consensus in a mutual benefit. For example, part of my current work for the European Commission is in the Semantic Interoperability Community, where we manage the creation of uniform models that are used across Europe, definitions of basic standard vocabularies that are used in all systems. In recent years it has also been instrumentalized in a way that supports, let's say, that consensus through regulations that have been issued, for example, at the European level. In recent years we have seen the regulation of data, the regulation of data governance and the regulation of artificial intelligence, things that also try to put a certain order and barriers. It's not that everyone goes through the middle of the mountain, because if not, in the end we won't get anywhere, but we're all going to try to do it by consensus, but we're all going to try to drive within the same road to reach the same destination together. And I think that, from the part of the public administrations, apart from regulating, it is very interesting that they are very transparent in the way it is done. It is the way in which we can all come to see that what is built is built in a certain way, the data models that are transparent, everyone can see them participate in their development. And this is where we are seeing some shortcomings in algorithmic and artificial intelligence systems, where we do not know very well the data they use or where it is hosted. And this is where perhaps we should have a little more influence in the future. But I think that as long as this duality is achieved, of generating consensus and providing a context in which people feel safe developing it, we will continue to move in the right direction.
Carlos Iglesias: If we look at the principles that made the website work in its day, there is also a lot of focus on the community part and leaving an open platform that is developed in the open, with open standards in which everyone could join. The participation of everyone was sought to enrich that ecosystem. And I think that with the data we should think that this is the way to go. In fact, it's kind of also a bit like the concept that I think is behind data spaces. In the end, it is not easy to do something like that. It's very ambitious and we don't see an invention like the web every day.
3. From your perspective, what are the real risks of data getting trapped in opaque infrastructures or models? More importantly, what can we do to prevent it?
Carlos Iglesias: Years ago we saw that there was an attempt to quantify the amount of data that was generated daily. I think that now no one even tries it, because it is on a completely different scale, and on that scale there is only one way to work, which is by automating things. And when we talk about automation, in the end what you need are standards, interoperability, trust mechanisms, etc. If we look ten or fifteen years ago, which were the companies that had the highest share price worldwide, they were companies such as Ford or General Electric. If you look at the top ten worldwide, today there are companies that we all know and use every day, such as Meta, which is the parent company of Facebook, Instagram, WhatsApp and others, or Alphabet, which is the parent company of Google. In other words, in fact, I think I'm a little hesitant right now, but probably of the ten largest listed companies in the world, all are dedicated to data. We are talking about a gigantic ecosystem and, in order for this to really work and remain an open ecosystem from which everyone can benefit, the key is standardization.
Josema Alonso: I agree with everything Carlos said and we have to focus on not getting trapped. And above all, from the public administrations there is an essential role to play. I mentioned before about regulation, which sometimes people don't like very much because the regulatory map is starting to be extremely complicated. The European Commission, through an omnibus decree, is trying to alleviate this regulatory complexity and, as an example, in the data regulation itself, which obliges companies that have data to facilitate data portability to their users. It seems to me that it is something essential. We're going to see a lot of changes in that. There are three things that always come to mind; permanent training is needed. This changes every day at an astonishing speed. The volumes of data that are now managed are huge. As Carlos said before, a few days ago I was talking to a person who manages the infrastructure of one of the largest streaming platforms globally and he told me that they are receiving requests for data generated by artificial intelligence in such a large volume in just one week as the entire catalog they have available. So the administration needs to have permanent training on these issues of all kinds, both at the forefront of technology as we have just mentioned, and what we talked about before, how to improve interoperability, how to create better data models, etc. Another is the common infrastructure in Europe, such as the future European digital wallet, which would be the equivalent of the national citizen folder. A super simple example we are dealing with is the birth certificate. It is very complicated to try to integrate the systems of twenty-seven different countries, which in turn have regional governments and which in turn have local governments. So, the more we invest in common infrastructure, both at the semantic level and at the level of the infrastructure itself, the cloud, etc., I think the better we will do. And then the last one, which is the need for distributed but coordinated governance. Each one is governed by certain laws at local, national or European level. It is good that we begin to have more and more coordination in the higher layers and that those higher layers permeate to the lower layers and the systems are increasingly easier to integrate and understand each other. Data spaces are one of the major investments at the European level, where I believe this is beginning to be achieved. So, to summarize three things that are very practical to do: permanent training, investing in common infrastructure and that governance continues to be distributed, but increasingly coordinated.
Blog
While there is still no absolute consensus on the definition of Web3, the applications and concepts associated with the term have been increasingly widely explored in recent years and some of its propositions such as cryptocurrencies have already reached the general public. The term Web3 usually refers to the third generation of the World Wide Web, sometimes called the "decentralised web", which relies on the use of cryptography and decentralised technologies such as blockchain to create a more secure and transparent internet.
Although still in its infancy, we are already seeing the emergence of new concepts such as non-fungible tokens (NFTS), which are nothing more than encrypted digital assets, cryptocurrencies such as the well-known bitcoin, and decentralised applications (DApps), which are beginning to appear mainly in the financial world in the form of decentralised finance (DeFi).
However, the greatest promise of Web3 lies in the possibility of empowering users in a new form of decentralised internet that gives them back ownership and control of their data and identities, which are now held by large technology platforms. In fact, Web3 is true to the original concept of the internet and the World Wide Web, where no one's permission would be needed to publish data and information and where there was no provision for central control of interactions.
In the same way that Web 2.0 drove the explosion of content and data creation by all kinds of people, and a culture of participation through multiple forms of social networking that is influencing the way we live today, Web3 also has the potential to change our near future.
Open data on Web3
And among the major changes that will ideally unfold with the adoption of Web3 technologies and paradigms by an increasing number of users and organisations is a new revolution in open data.
On the one hand, one of the main advantages of open data in the Web3 environment is that it can contribute to creating a more transparent and trustworthy internet. With traditional centralised systems, it is very difficult to verify the accuracy and authenticity of data, and there needs to be trust in the organisation that collects and publishes it. In the case of data managed and opened by public administrations this is not a major problem because of the presumption of trust that public administrations enjoy. But it is very limiting when it comes to opening data with user-generated information or even to generating datasets with potentially sensitive information.
However, through a decentralised application, open data could ideally be stored on a blockchain, allowing for a transparent and immutable record of the data. This can help to increase trust in the data being used and help new open data sets to emerge that are not managed by public authorities, companies or other data management organisations.
Clearly, to realise the full potential of open data in the web3 environment, it is important that data is available in a machine-readable format and that there are clear guidelines on how it can be used and shared. This will help to ensure that the data is being used in a way that is ethical and respectful of the people or organisations that originally collected it. In this context the Semantic Web, as the "web of data" is expected to play an important role in the Web3 ecosystem, as decentralisation and transparency are key aspects of both. In Web3, ontologies and tags used in the Semantic Web have the potential to make data stored in the blockchain more easily accessible and understandable for machines.
In addition, the Semantic Web can also contribute to creating more intelligent and personalised applications on the Web3. For example, ontologies can be used to improve the accuracy of recommender systems and make chatbots and other virtual assistance systems more efficient and "smarter".
And in a context with a greater amount of open data that can also be enriched thanks to the semantic web, the application of artificial intelligence or automated learning will be able to generate more useful applications for users. It will probably even be possible to authorise artificial intelligence applications that are currently not allowed due to the limited capacity we have to control the use of data with security guarantees.
On the other hand, Web3 proposes greater transparency and security on the internet, but above all that users will once again be the owners of their own data, that they will have control over what others can and cannot do with this data and that they can be adequately compensated for these uses of data. In this way, a new explosion of open data is expected to be generated by the users themselves, who if they feel safe, secure and comfortable to share data, and even compensated for the use of their data, will be able to participate in the generation of many useful open data sets to enrich applications or create predictive models of all kinds.
While all this disruption sounds very promising, the transition from a data oligopoly to democratic and open data management will take time. The first steps towards decentralisation of internet applications are still being taken and the whole concept of Web3 is still a work in progress. Overall, Web3 is a desirable concept in terms of improved data security and privacy, and thus possibilities for opening up more data, but it still requires an advanced digital infrastructure and regulation that is not yet available for it to be fully deployed.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
An important part of the data which is published on the Semantic Web, where resources are identified by URIs, is stored within triple store databases. This data can only be accessed through SPARQL queries via a SPARQL endpoint.
Moreover, the URIs used, usually designed in a pattern, in most of the datasets which are stored in those databases are not dereferenced, meaning that requests made to that identifier are met with no response (an ‘error 404’ message).
Given the current situation, in which this data is only accessible by machines, and combined with the push of the Linked Data movement, various projects have emerged in which the main objective is to generate human views of the data through web interfaces (where the views of the resources are interlinked), as well as offering a service where the URIs are dereferenced.
Pubby is perhaps the best-known of the projects which have been created for this purpose. It is a Java developed web application, whose code is shared under the open source license Apache Version 2.0. It is designed to be deployed on a system that has SPARQL access to the database of triplets that you wish to apply.
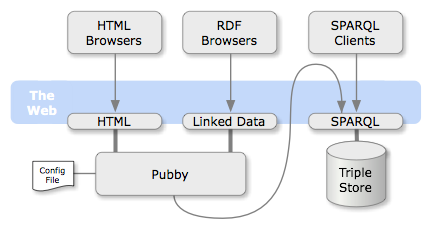
The non-dereferenced URIs and the dereferenced URIs are mapped through a configuration file which is managed by the Pubby server. The application uses this to process the requests to the mapped URIs, requesting the information of the original URI to the associated database (via a SPARQL ‘DESCRIBE’ query) and returning the results to the client in the requested format.
In addition, Pubby provides a simple HTML view of the stored data and manages content negotiation between the different representations. Users can navigate between the HTML views of the linked resources (Linked Data) via the web interface. These views show all the information of the resources, including their attributes and relationships with other resources.
Multiple parallel projects (forks) and inspired projects have emerged from the Pubby project. One of the most recent is the Linked Open Data Inspector (LODI) project, developed by the Quercus software engineering group at the University of Extremadura under Creative Commons 3.0. This project is developed in Node.js and features some positive differences with respect to Pubby:
● It provides a simple HTML view for a general audience, and a more detailed view for programmers.
● It provides resource information in N3 format (but not RDF/XML or Turtle).
● In the case of resources with geospatial information, it displays a map detailing the location.
● In the case of detected images (.jpg, .jpeg or .png), these images are shown automatically.
There are currently two open data portals which are using LODI: Open Data Cáceres and Open Data UEx.
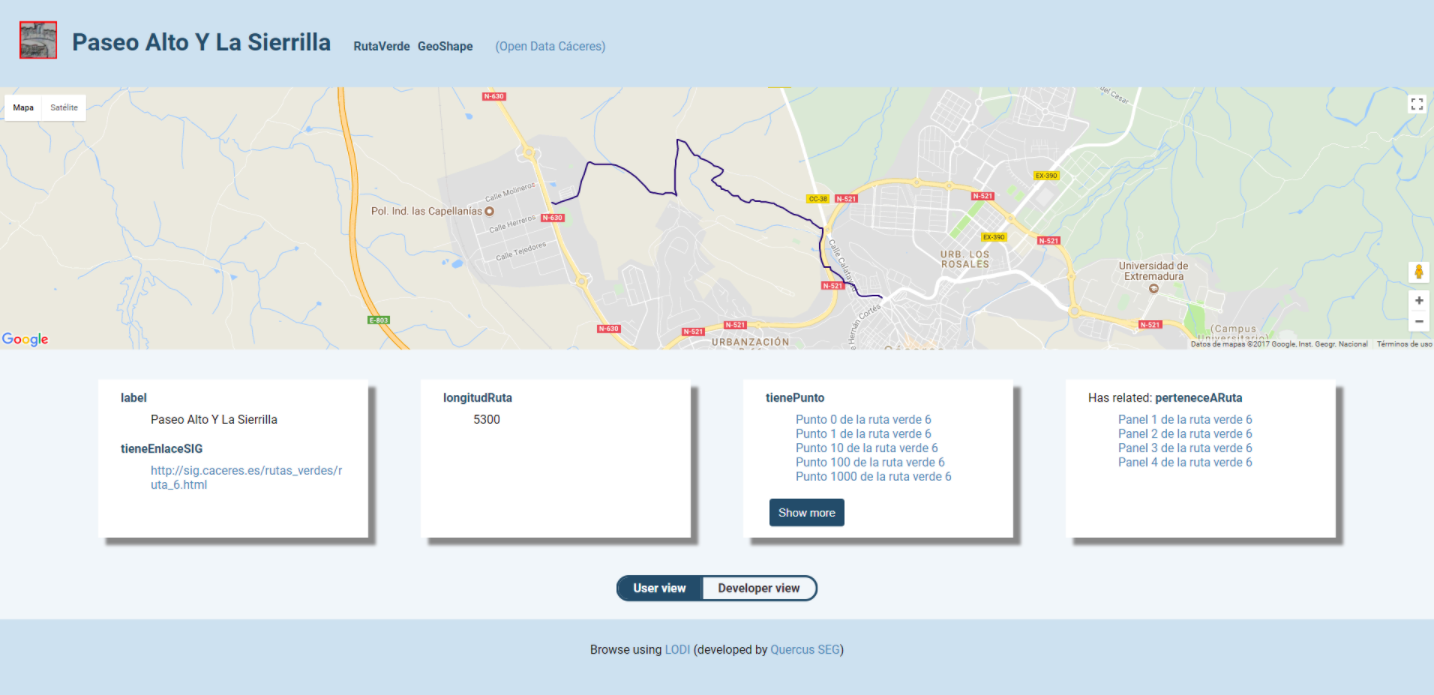
Pubby, LODI and other similar projects (such as LODDY), using the AGROVOC thesaurus, have managed to expose information that was retained within RDF databases which was not accessible to humans. Projects like these help the linked data web continue to grow, both in quantity and quality, putting human interaction at the centre of this progress.
Noticia
La red europea LAPSI ha seleccionado el portal datos.gob.es entre la terna de finalistas de su Tercer Premio al portal sobre información del sector público más amigable de la Unión Europea.
El jurado del concurso estima, así, que el sitio web que gestiona el Catálogo de Información Pública de la Administración General del Estado reúne las mejores valoraciones respecto a los criterios básicos de la convocatoria: diseño atractivo, usabilidad y difusión de la reutilización de los datos públicos.
Entre los proyectos elegidos para la fase final figura, además del portal sueco InfoTorg, la iniciativa española CartoCiudad, que está auspiciada por el Instituto Geográfico Nacional y que integra datos de otras fuentes como la Dirección General del Catastro.
La presencia de dos finalistas del sector público español en el premio LAPSI pone de manifiesto, tal y como recoge el Portal de Administración Electrónica, el esfuerzo de nuestro país para poner a disposición de empresas y ciudadanos la información del sector público y para promover su reutilización.
La Comisión Europea ha valorado en unos 2.000 millones de euros el potencial económico del sector infomediario en España, con una cuota ya alcanzada de entre 550 y 650 millones de euros, según el Estudio publicado el pasado mes de junio por el Observatorio Nacional de las Telecomunicaciones y para la Sociedad de la Información (ONTSI) y por Proyecto Aporta.
La reciente aprobación del Real Decreto 1495/2011 y la apertura de la versión beta del portal datos.gob.es en el mes de octubre de 2011 permitirán seguir avanzando en la potenciación de este sector de la economía digital y en la construcción de una administración más abierta y transparente.
El mantenimiento del portal datos.gob.es está encomendando por el Real Decreto 1495/2011 a la Secretaría de Estado de Administración Pública y a la Secretaría de Estado de Telecomunicaciones y Sociedad de la Información, en colaboración con el resto de organismos del sector público estatal.