Word Embeddings - Ejercicio práctico de tratamiento de etiquetas


Fecha del documento: 14-11-2024

Los portales de datos abiertos juegan un papel fundamental en el acceso y reutilización de la información pública. Un aspecto clave en estos entornos es el etiquetado de los conjuntos de datos, que facilita su organización y recuperación.
Los word embeddings representan una tecnología transformadora en el campo del procesamiento del lenguaje natural, permitiendo representar palabras como vectores en un espacio multidimensional donde las relaciones semánticas se preservan matemáticamente. En este ejercicio se explora su aplicación práctica en un sistema de recomendación de etiquetas, utilizando como caso de estudio el portal de datos abiertos datos.gob.es.
El ejercicio se desarrolla en un notebook que integra la configuración del entorno, la adquisición de datos y el procesamiento del sistema de recomendación, todo ello implementado en Python. El proyecto completo se encuentra disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Entendiendo los word embeddings
Los word embeddings son representaciones numéricas de palabras que revolucionan el procesamiento del lenguaje natural al transformar el texto en un formato matemáticamente procesable. Esta técnica codifica cada palabra como un vector numérico en un espacio multidimensional, donde la posición relativa entre vectores refleja relaciones semánticas y sintácticas entre palabras. La verdadera potencia de los embeddings radica en tres aspectos fundamentales:
- Captura de contexto: a diferencia de técnicas tradicionales como one-hot encoding, los embeddings aprenden del contexto en el que aparecen las palabras, permitiendo capturar matices de significado.
- Algebra semántica: los vectores resultantes permiten operaciones matemáticas que preservan relaciones semánticas. Por ejemplo, vector('Madrid') - vector('España') + vector('Francia') ≈ vector('París'), demostrando la captura de relaciones capital-país.
- Similitud cuantificable: la similitud entre palabras se puede medir mediante métricas, permitiendo identificar no solo sinónimos exactos sino también términos relacionados en diferentes grados y generalizar estas relaciones a nuevas combinaciones de palabras.
En este ejercicio se han utilizado embeddings pre-entrenados GloVe (Global Vectors for Word Representation), un modelo desarrollado por Stanford que destaca por su capacidad de capturar relaciones semánticas globales en el texto. En nuestro caso, empleamos vectores de 50 dimensiones, un equilibrio entre complejidad computacional y riqueza semántica. Para evaluar exhaustivamente su capacidad de representar el lenguaje castellano, se han realizado múltiples pruebas:
- Se ha analizado la similitud entre palabras mediante la similitud coseno, una métrica que evalúa el ángulo entre los vectores de dos palabras. Esta medida resulta en valores entre -1 y 1, donde valores cercanos a 1 indican alta similitud semántica, mientras que valores cercanos a 0 indican poca o ninguna relación. Se evaluaron términos como "amor", "trabajo" y "familia" para verificar que el modelo identificara correctamente palabras semánticamente relacionadas.
- Se ha probado la capacidad del modelo para resolver analogías lingüísticas, por ejemplo, "hombre es a mujer lo que rey es a reina", confirmando su habilidad para capturar relaciones semánticas complejas.
- Se han realizado operaciones vectoriales (como "rey - hombre + mujer") para comprobar si los resultados mantenían coherencia semántica.
- Finalmente, se han aplicado técnicas de reducción de dimensionalidad sobre una muestra representativa de 40 palabras en español, permitiendo visualizar las relaciones semánticas en un espacio bidimensional. Los resultados revelaron patrones de agrupación natural entre términos semánticamente relacionados, como se observa en la figura:
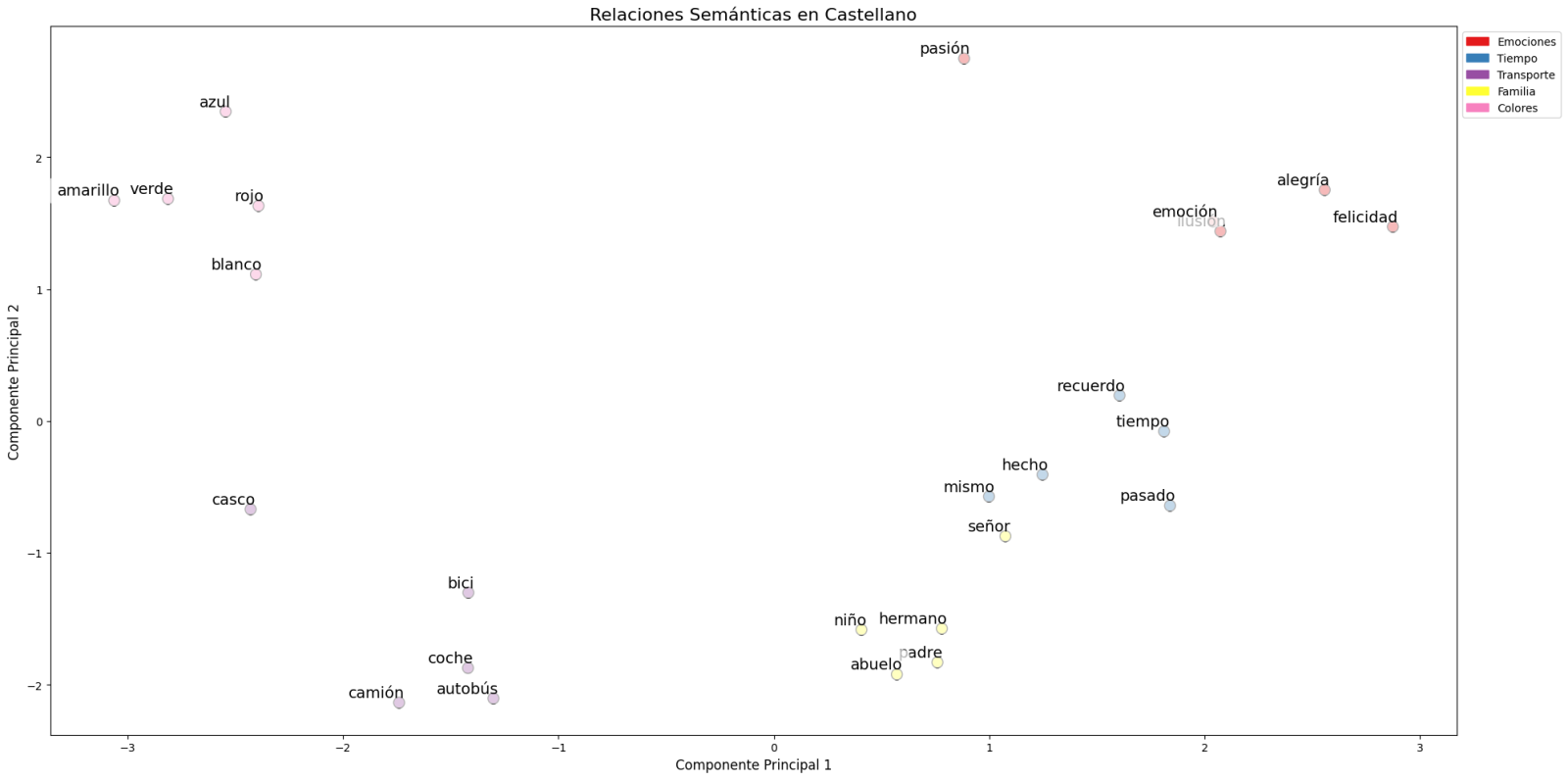
Figura 1. Análisis de Componentes principales sobre 50 dimensiones (embeddings) con un porcentaje de variabilidad explicada por los dos componentes de 0.46
- Los términos relacionados con familia (padre, hermano, abuelo) se concentran en la parte inferior.
- Los medios de transporte (coche, autobús, camión) forman un grupo distintivo.
- Los colores (azul, verde, rojo) aparecen próximos entre sí.
Para sistematizar este proceso de evaluación, se ha desarrollado una función unificada que encapsula todas las pruebas descritas anteriormente. Esta arquitectura modular permite evaluar de manera automática y reproducible diferentes modelos de embeddings pre-entrenados, facilitando así la comparación objetiva de su rendimiento en el procesamiento del lenguaje castellano. La estandarización de estas pruebas no solo optimiza el proceso de evaluación, sino que también establece un marco consistente para futuras comparaciones y validaciones de nuevos modelos por parte del público.
La buena capacidad para capturar relaciones semánticas en el lenguaje castellano es la que aprovechamos en nuestro sistema de recomendación de etiquetas.
Sistema de recomendación basado en embeddings
Aprovechando las propiedades de los embeddings, desarrollamos un sistema de recomendación de etiquetas que sigue un proceso de tres fases:
- Generación de embeddings: para cada conjunto de datos del portal, generamos una representación vectorial combinando el título y la descripción. Esto nos permite comparar datasets por su similitud semántica.
- Identificación de datasets similares: utilizando la similitud coseno entre los vectores, identificamos los conjuntos de datos más similares semánticamente.
- Extracción y estandarización de etiquetas: a partir de los conjuntos similares, extraemos sus etiquetas asociadas y las mapeamos con términos del tesauro Eurovoc. Este tesauro, desarrollado por la Unión Europea, es un vocabulario controlado multilingüe que proporciona una terminología estandarizada para la catalogación de documentos y datos en el ámbito de las políticas europeas. Aprovechando nuevamente la potencia de los embeddings, identificamos los términos de Eurovoc semánticamente más cercanos a nuestras etiquetas, garantizando así una estandarización coherente y una mejor interoperabilidad entre sistemas de información europeos.
Los resultados muestran que el sistema es capaz de generar recomendaciones de etiquetas coherentes y estandarizadas. Para ilustrar el funcionamiento del sistema, tomemos el caso del conjunto de datos “Agenda de Actividades Ciudad de Tarragona”:
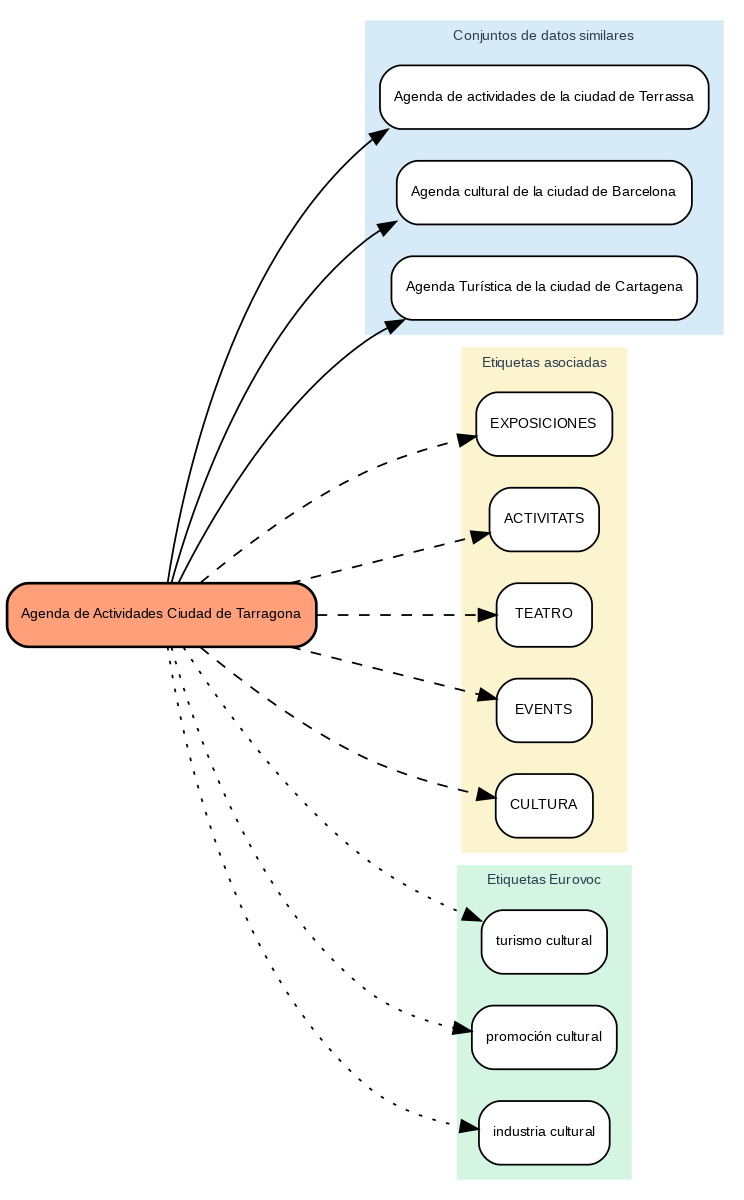
Figura 2. Agenda de Actividades Ciudad de Tarragona
El sistema:
- Encuentra conjuntos de datos similares como "Agenda de actividades de Terrassa" y "Agenda cultural de Barcelona".
- Identifica etiquetas comunes de estos conjuntos de datos, como "EXPOSICIONES", "TEATRO" y "CULTURA".
- Sugiere términos Eurovoc relacionados: "turismo cultural", "promoción cultural" e "industria cultural".
Ventajas del enfoque
Este enfoque ofrece ventajas significativas:
- Recomendaciones Contextuales: el sistema sugiere etiquetas basándose en el significado real del contenido, no solo en coincidencias textuales.
- Estandarización Automática: la integración con Eurovoc garantiza un vocabulario controlado y coherente.
- Mejora Continua: el sistema aprende y mejora sus recomendaciones a medida que se añaden nuevos datasets.
- Interoperabilidad: el uso de Eurovoc facilita la integración con otros sistemas europeos.
Conclusiones
Este ejercicio demuestra el gran potencial de los embeddings como herramienta para la asociación de textos en función de su naturaleza semántica. A través del caso práctico analizado, se ha podido observar cómo, mediante la identificación de títulos y descripciones similares entre datasets, es posible generar recomendaciones precisas de etiquetas o keywords. Estas etiquetas, a su vez, pueden vincularse con palabras clave de un tesauro estandarizado como Eurovoc, aplicando el mismo principio.
A pesar de los retos que pueden surgir, la implementación de este tipo de sistemas en entornos de producción presenta una valiosa oportunidad para mejorar la organización y recuperación de información. La precisión en la asignación de etiquetas puede verse influenciada por diversos factores interrelacionados del proceso:
- La especificidad de los títulos y descripciones de los datasets es fundamental, ya que de ella depende una correcta identificación de contenidos similares y, por tanto, una adecuada recomendación de etiquetas.
- La calidad y representatividad de las etiquetas existentes en los datasets similares determina directamente la relevancia de las recomendaciones generadas.
- La cobertura temática del tesauro Eurovoc, que, si bien es extensa, puede no abarcar términos específicos necesarios para describir ciertos datasets de manera precisa.
- La capacidad de los vectores para capturar fielmente las relaciones semánticas entre los contenidos, lo cual impacta directamente en la precisión de las etiquetas asignadas.
Para aquellos que deseen profundizar en el tema, existen otras aproximaciones interesantes al uso de embeddings que complementan lo visto en este ejercicio, tales como:
- Utilización de modelos de embeddings más complejos y computacionalmente costosos (como BERT, GPT, etc.).
- Entrenamiento de modelos en un corpus propio adaptado al dominio.
- Aplicación de técnicas más profundas de limpieza de datos.
En resumen, este ejercicio no solo demuestra la eficacia de los embeddings para la recomendación de etiquetas, sino que abre la puerta a que el lector explore todas las posibilidades que esta poderosa herramienta ofrece.