Documentación
1. Introducción
En la era de la información, la inteligencia artificial ha demostrado ser una herramienta invaluable para una variedad de aplicaciones. Una de las manifestaciones más increíbles de esta tecnología es GPT (Generative Pre-trained Transformer), desarrollado por OpenAI. GPT es un modelo de lenguaje natural que puede entender y generar texto, ofreciendo respuestas coherentes y contextualmente relevantes. Con la reciente introducción de Chat GPT-4, las capacidades de este modelo se han ampliado aún más, permitiendo una mayor personalización y adaptabilidad a diferentes temáticas.
En este post, te mostraremos cómo configurar y personalizar un asistente especializado en minerales críticos utilizando GPT-4 y fuentes de datos abiertas. Como ya mostramos en previas publicaciones, los minerales críticos son fundamentales para numerosas industrias, incluyendo la tecnología, la energía y la defensa, debido a sus propiedades únicas y su importancia estratégica. Sin embargo, la información sobre estos materiales puede ser compleja y dispersa, lo que hace que un asistente especializado sea particularmente útil.
El objetivo de este post es guiarte paso a paso desde la configuración inicial hasta la implementación de un asistente GPT que pueda ayudarte a resolver dudas y proporcionar información valiosa sobre minerales críticos en tu día a día. Además, exploraremos cómo personalizar aspectos del asistente, como el tono y el estilo de las respuestas, para que se adapte perfectamente a tus necesidades. Al final de este recorrido, tendrás una herramienta potente y personalizada que transformará la manera en que accedes y utilizas la información en abierto sobre minerales críticos.
Accede al repositorio del laboratorio de datos en Github.
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
La transición hacia un futuro sostenible no solo implica cambios en las fuentes de energía, sino también en los recursos materiales que utilizamos. El éxito de sectores como baterías de almacenamiento de energía, aerogeneradores, paneles solares, electrolizadores, drones, robots, redes de transmisión de datos, dispositivos electrónicos o satélites espaciales, depende enormemente del acceso a las materias primas críticas para su desarrollo. Entendemos que un mineral es crítico cuando se cumplen los siguientes factores:
- Sus reservas mundiales son escasas
- No existen materiales alternativos que puedan ejercer su función (sus propiedades son únicas o muy singulares)
- Son materiales indispensables para sectores económicos clave de futuro, y/o su cadena de suministro es de elevado riesgo
Puedes aprender más sobre los minerales críticos en el post mencionado anteriormente.
3. Objetivo
Este ejercicio se centra en mostrar al lector cómo personalizar un modelo GPT especializado para un caso de uso concreto. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender cómo configurar y ajustar el modelo para resolver un problema real y relevante, como el asesoramiento experto en minerales críticos. Este enfoque práctico no solo mejora la comprensión de las técnicas de personalización de modelos de lenguaje, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
El asistente GPT especializado en minerales críticos estará diseñado para convertirse en una herramienta esencial para profesionales, investigadores y estudiantes. Su objetivo principal será facilitar el acceso a información precisa y actualizada sobre estos materiales, apoyar la toma de decisiones estratégicas y promover la educación en este campo. A continuación, se detallan los objetivos específicos que buscamos alcanzar con este asistente:
- Proporcionar información precisa y actualizada:
- El asistente debe ofrecer información detallada y precisa sobre diversos minerales críticos, incluyendo su composición, propiedades, usos industriales y disponibilidad.
- Mantenerse actualizado con las últimas investigaciones y tendencias del mercado en el ámbito de los minerales críticos.
- Asistir en la toma de decisiones:
- Proporcionar datos y análisis que puedan ayudar en la toma de decisiones estratégicas en la industria y la investigación sobre minerales críticos.
- Ofrecer comparativas y evaluaciones de diferentes minerales en función de su rendimiento, coste y disponibilidad.
- Promover la educación y la concienciación en torno a esta temática:
- Actuar como una herramienta educativa para estudiantes, investigadores y profesionales, ayudando a mejorar su conocimiento sobre los minerales críticos.
- Aumentar la conciencia sobre la importancia de estos materiales y los desafíos relacionados con su suministro y sostenibilidad.
4. Recursos
Para configurar y personalizar nuestro asistente GPT especializado en minerales críticos, es esencial disponer de una serie de recursos que faciliten la implementación y aseguren la precisión y relevancia de las respuestas del modelo. En este apartado, detallaremos los recursos necesarios que incluyen tanto las herramientas tecnológicas como las fuentes de información que serán integradas en la base de conocimiento del asistente.
Herramientas y Tecnologías
Las herramientas y tecnologías clave para desarrollar este ejercicio son:
- Cuenta de OpenAI: necesaria para acceder a la plataforma y utilizar el modelo GPT-4. En este post, utilizaremos la suscripción Plus de ChatGPT para mostrarte cómo crear y publicar un GPT personalizado. No obstante, puedes desarrollar este ejercicio de forma similar utilizando una cuenta gratuita de OpenAI y realizando el mismo conjunto de instrucciones a través de una conversación de ChatGPT estándar.
- Microsoft Excel: hemos diseñado este ejercicio de forma que cualquier persona sin conocimientos técnicos pueda desarrollarlo de principio a fin. Únicamente nos apoyaremos en herramientas ofimáticas como Microsoft Excel para realizar algunas adecuaciones de los datos descargados.
De forma complementaria, utilizaremos otro conjunto de herramientas que nos permitirán automatizar algunas acciones sin ser estrictamente necesaria su utilización:
- Google Colab: es un entorno de Python Notebooks que se ejecuta en la nube, permitiendo a los usuarios escribir y ejecutar código Python directamente en el navegador. Google Colab es especialmente útil para el aprendizaje automático, el análisis de datos y la experimentación con modelos de lenguaje, ofreciendo acceso gratuito a potentes recursos de computación y facilitando la colaboración y el intercambio de proyectos.
- Markmap: es una herramienta que visualiza mapas mentales de Markdown en tiempo real. Los usuarios escriben ideas en Markdown y la herramienta las renderiza como un mapa mental interactivo en el navegador. Markmap es útil para la planificación de proyectos, la toma de notas y la organización de información compleja visualmente. Facilita la comprensión y el intercambio de ideas en equipos y presentaciones.
Fuentes de Información
- Raw Materials Information System (RMIS): sistema de información sobre materias primas mantenido por el Joint Research Center de la Unión Europea. Proporciona datos detallados y actualizados sobre la disponibilidad, producción y consumo de materias primas en Europa.
- Catálogo de informes y datos de la Agencia Internacional de la Energía (IEA en sus siglas en inglés): ofrece un amplio catálogo de informes y datos relacionados con la energía, incluyendo estadísticas sobre producción, consumo y reservas de minerales energéticos y críticos.
- Base de datos de minerales del Instituto Geológico y Minero Español (BDMIN): contiene información detallada sobre los minerales y depósitos minerales en España, útil para obtener datos específicos sobre la producción y reservas de minerales críticos en el país.
Con estos recursos, estarás bien equipado para desarrollar un asistente GPT especializado que pueda proporcionar respuestas precisas y relevantes sobre minerales críticos, facilitando la toma de decisiones informadas en este campo.
5. Desarrollo del ejercicio
5.1. Construcción de la base de conocimiento
Para que nuestro asistente GPT especializado en minerales críticos sea verdaderamente útil y preciso, es esencial construir una base de conocimiento sólida y estructurada. Esta base de conocimiento será el conjunto de datos e información que el asistente utilizará para responder a las consultas. La calidad y relevancia de esta información determinarán la eficacia del asistente en proporcionar respuestas precisas y útiles.
Búsqueda de Fuentes de Datos
Comenzamos con la recopilación de fuentes de información que nutrirán nuestra base de conocimiento. No todas las fuentes de información son igualmente fiables. Es fundamental evaluar la calidad de las fuentes identificadas, asegurando que:
- La información esté actualizada: la relevancia de los datos puede cambiar con rapidez, especialmente en campos dinámicos como el de los minerales críticos.
- La fuente sea confiable y reconocida: es necesario utilizar fuentes de instituciones reconocidas y respetadas en el ámbito académico y profesional.
- Los datos sean completos y accesibles: es crucial que los datos sean detallados y que estén accesibles para su integración en nuestro asistente.
En nuestro caso, desarrollamos una búsqueda online en diferentes plataformas y repositorios de información tratando de seleccionar información perteneciente a diversas entidades reconocidas:
- Centros de investigación y universidades:
- Publican estudios y reportes detallados sobre la investigación y desarrollo de minerales críticos.
- Ejemplo: RMIS del Joint Research Center de la Unión Europea.
- Instituciones gubernamentales y organismos internacionales:
- Estas entidades suelen proporcionar datos exhaustivos y actualizados sobre la disponibilidad y el uso de minerales críticos.
- Ejemplo: Agencia Internacional de la Energía (IEA).
- Bases de datos especializadas:
- Contienen datos técnicos y específicos sobre depósitos y producción de minerales críticos.
- Ejemplo: Base de datos de Minerales del Instituto Geológico y Minero español (BDMIN).
Selección y preparación de la información
Nos centraremos ahora en la selección y preparación de la información existente en estas fuentes para asegurar que nuestro asistente GPT pueda acceder a datos precisos y útiles.
RMIS del Joint Research Center de la Unión Europea:
- Información seleccionada:
Seleccionamos el informe “Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU – A foresight study”. Se trata de un análisis de la cadena de suministro y la demanda de minerales en tecnologías y sectores estratégicos de la UE. Presenta un estudio detallado de las cadenas de suministro de materias primas críticas y pronostica la demanda de minerales hasta 2050.
- Preparación necesaria:
El formato del documento, PDF, permite la ingesta directa de la información por parte de nuestro asistente. No obstante, como se observa en la Figura 1, existe una tabla especialmente relevante en sus páginas 238-240 donde se analiza, para cada mineral, su riesgo de suministro, tipología (estratégico, crítico o no crítico) y las tecnologías clave que lo emplean. Decidimos, por ello, extraer esta tabla a un formato estructurado (CSV), de tal forma que dispongamos de dos piezas de información que pasarán a formar parte de nuestra base de conocimiento.

Figura 1: Tabla de minerales contenida en el PDF de JRC
Para extraer de forma programática los datos contenidos en esta tabla y transformarlos en un formato más fácilmente procesable, como CSV (comma separated values o valores separados por comas), utilizaremos un script de Python que podemos utilizar a través de la plataforma Google Colab (Figura 2).

Figura 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
A modo de resumen, este script:
- Se apoya en la librería de código abierto PyPDF2, capaz de interpretar información contenida en ficheros PDF.
- Primero, extrae en formato texto (cadena de caracteres) el contenido de las páginas del PDF donde se encuentra la tabla de minerales eliminando todo el contenido que no se corresponde con la propia tabla.
- Posteriormente, recorre, línea a línea, la cadena de caracteres convirtiendo los valores en columnas de una tabla de datos. Sabremos que un mineral es utilizado en una tecnología clave si en la columna correspondiente de dicho mineral encontramos un número 1 (en caso contrario contendrá un 0).
- Por último, exporta dicha tabla a un fichero CSV para su posterior utilización.
Agencia Internacional de la Energía (IEA):
- Información seleccionada:
Seleccionamos el informe “Global Critical Minerals Outlook 2024”. Este proporciona una visión general de los desarrollos industriales en 2023 y principios de 2024, y ofrece perspectivas a medio y largo plazo para la demanda y oferta de minerales clave para la transición energética. También evalúa los riesgos para la fiabilidad, sostenibilidad y diversidad de las cadenas de suministro de minerales críticos.
- Preparación necesaria:
El formato del documento, PDF, nos permite la ingesta directa de la información por parte de nuestro asistente virtual. No realizaremos en este caso ninguna adecuación de la información seleccionada.
Base de Datos de Minerales del Instituto Geológico y Minero Español (BDMIN)
- Información seleccionada:
En este caso, utilizamos el formulario para seleccionar los datos existentes en esta base de datos en cuanto a indicios y yacimientos del ámbito de la metalogenia, en particular seleccionamos aquellos con contenido de Litio.

Figura 3: Selección de conjunto de datos en BDMIN.
- Preparación necesaria:
Observamos cómo la herramienta web nos permite la visualización online y también la exportación de estos datos en varios formatos. Seleccionamos, por tanto, todos los datos a exportar y haciendo clic en esta opción, descargamos un fichero Excel con la información deseada.

Figura 4: Herramienta de visualización y descarga en BDMIN

Figura 5: Datos descargados BDMIN.
Todos los archivos que componen nuestra base de conocimiento se encuentran GitHub del proyecto, de tal forma que aquel lector que lo desee pueda saltarse la fase de descarga y preparación de la información.
5.2. Configuración y personalización del GPT para minerales críticos
Cuando hablamos de "crear un GPT," en realidad nos estamos refiriendo a la configuración y personalización de un modelo de lenguaje basado en GPT (Generative Pre-trained Transformer) para adaptarlo a un caso de uso específico. En este contexto, no estamos creando el modelo desde cero, sino ajustando cómo el modelo preexistente (como GPT-4 de OpenAI) interactúa y responde dentro de un dominio específico, en este caso, sobre minerales críticos.
En primer lugar, accedemos a la aplicación a través de nuestro navegador y, en caso de no tener una cuenta, seguimos el proceso de registro y login en la plataforma ChatGPT. Como indicamos con anterioridad, para realizar la creación de un GPT paso a paso será necesario disponer de una cuenta Plus. No obstante, aquellos lectores que no dispongan de dicha cuenta, podrán trabajar con una cuenta gratuita interactuando con ChatGPT a través de una conversación estándar.
Figura 6: Página de inicio de sesión y registro de ChatGPT.
Una vez iniciada la sesión, seleccionamos la opción "Explorar GPT", y posteriormente hacemos clic en "Crear" para comenzar el proceso de creación de nuestro GPT.

Figura 7: Creación de nuevo GPT.
En pantalla se nos mostrará la pantalla dividida de creación de un nuevo GPT: a la izquierda podremos conversar con el sistema para indicarle las características que debe tener nuestro GPT, mientras que a la izquierda podremos interactuar con nuestro GPT para validar que su comportamiento es el adecuado según vayamos avanzando en el proceso de configuración.

Figura 8: Pantalla de creación de nuevo GPT.
En el GitHub de este proyecto, podemos encontrar todos los prompts o instrucciones que utilizaremos para configurar y personalizar nuestro GPT y que deberemos introducir de forma secuencial en la pestaña "Crear", situada en la pestaña izquierda de nuestras pantallas, para completar los pasos que se detallan a continuación.
Los pasos que vamos a seguir para la creación del GPT son:
- En primer lugar, le indicaremos el objetivo y las consideraciones básicas a nuestro GPT para que pueda entender su modo de empleo.
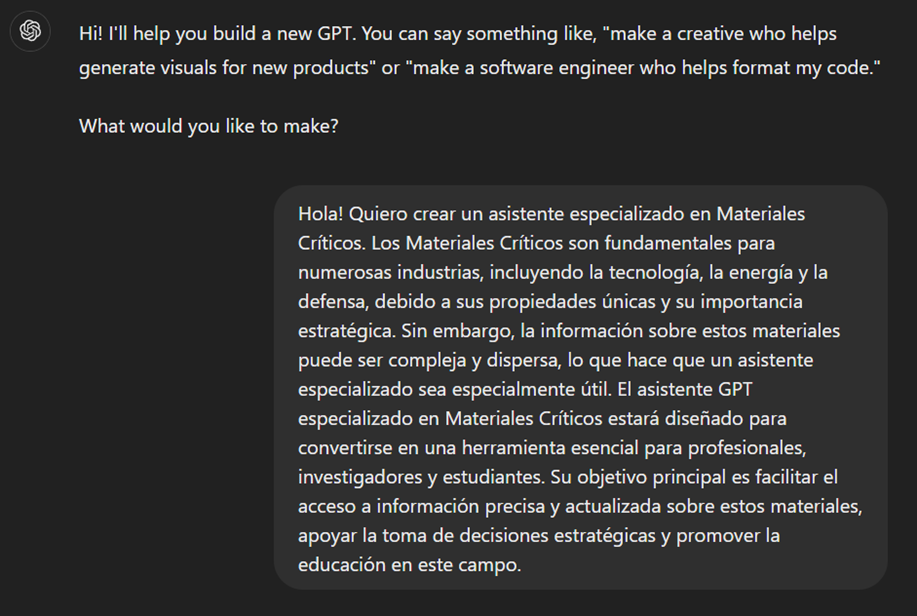
Figura 9: Instrucciones básicas de nuevo GPT.
2. Posteriormente crearemos un nombre y una imagen que representen a nuestro GPT y lo hagan fácilmente identificable. En nuestro caso, lo denominaremos MateriaGuru.

Figura 10: Selección de nombre para nuevo GPT.

Figura 11: Creación de imagen para GPT.
3. A continuación, construiremos la base de conocimiento a partir de la información anteriormente seleccionada y preparada para nutrir los conocimientos de nuestro GPT.


Figura 12: Carga de información a la base de conocimiento de nuevo GPT.
4. Ahora, podemos personalizar aspectos conversacionales como su tono, el nivel de complejidad técnica de sus repuesta o si esperamos respuestas escuetas o elaboradas.
5. Por último, desde la pestaña "Configurar", podemos indicar los iniciadores de conversación deseados para que los usuarios que interactúen con nuestro GPT tengan algunas ideas para empezar la conversación de forma predefinida.

Figura 13: Pestaña Configurar GPT.
En la Figura 13 podemos también observar el resultado definitivo de nuestro entrenamiento, donde aparecen elementos clave como su imagen, nombre, instrucciones, iniciadores de conversación o documentos que forma parte de su base de conocimiento.
5.3. Validación y publicación de GPT
Antes de dar por bueno a nuestro nuevo asistente basado en GPT, procederemos a realizar una breve validación de su correcta configuración y aprendizaje respecto a la temática en torno a la que le hemos entrenado. Para ello, preparamos una batería de preguntas que le realizaremos para comprobar que responde de forma adecuada ante un escenario real de utilización.
| # | Pregunta | Respuesta |
|---|---|---|
| 1 | ¿Qué minerales críticos han experimentado una caída significativa en los precios en 2023? | Los precios de los minerales para baterías vieron particularmente grandes caídas con los precios del litio cayendo un 75% y los precios del cobalto níquel y grafito cayendo entre un 30% y un 45%. |
| 2 | ¿Qué porcentaje de la capacidad solar fotovoltaica (PV) mundial fue añadido por China en 2023? | China representó el 62% del aumento en la capacidad solar fotovoltaica global en 2023. |
| 3 | ¿Cuál es el escenario que proyecta que las ventas de autos eléctricos (EV) alcanzarán el 65% en 2030? | El escenario de emisiones netas cero (NZE) para 2050 proyecta que las ventas de autos eléctricos alcanzarán el 65% en 2030. |
| 4 | ¿Cuál fue el crecimiento de la demanda de litio en 2023? | La demanda de litio aumentó en un 30% en 2023. |
| 5 | ¿Qué país fue el mayor mercado de autos eléctricos en 2023? | China fue el mayor mercado de autos eléctricos en 2023 con 8.1 millones de ventas de autos eléctricos representando el 60% del total global. |
| 6 | ¿Cuál es el principal riesgo asociado con la concentración de mercado en la cadena de suministro de grafito para baterías? | Más del 90% del grafito de grado batería y el 77% de las tierras raras refinadas en 2030 se originan en China lo que representa un riesgo significativo para la concentración del mercado. |
| 7 | ¿Qué proporción de la capacidad mundial de producción de celdas de batería estaba en China en 2023? | China poseía el 85% de la capacidad de producción de celdas de batería en 2023. |
| 8 | ¿Cuánto aumentó la inversión en minería de minerales críticos en 2023? | La inversión en minería de minerales críticos creció un 10% en 2023. |
| 9 | ¿Qué porcentaje de la capacidad de almacenamiento de baterías en 2023 estaba compuesto por baterías de fosfato de hierro y litio (LFP)? | En 2023, las baterías LFP constituían aproximadamente el 80% del mercado total de almacenamiento de baterías. |
| 10 | ¿Cuál es el pronóstico para la demanda de cobre en un escenario de emisiones netas cero (NZE) para 2040? | En el escenario de emisiones netas cero (NZE) para 2040 se espera que la demanda de cobre tenga el mayor aumento en términos de volumen de producción. |
Figura 14: Tabla con batería de preguntas para la validación de nuestro GPT.
Valiéndonos de la parte de previsualización, situada a la derecha de nuestras pantallas, lanzamos la batería de preguntas y validamos que las respuestas se corresponden con aquellas esperadas.

Figura 15: Validación de respuestas GPT.
Por último, hacemos clic en el botón "Crear" para finalizar el proceso. Podremos seleccionar entre diferentes alternativas para restringir su utilización por parte de otros usuarios.

Figura 16: Publicación de nuestro GPT.
6. Escenarios de uso
En este apartado mostramos varios escenarios en los que podremos sacar partido a MateriaGuru en nuestro día a día. En el GitHub del proyecto podremos encontrar los prompts utilizados para replicar cada uno de ellos.
6.1. Consulta de información de minerales críticos
El escenario más típico de utilización de este tipo de GPTs es la asistencia para resolución de dudas relacionadas con la temática en cuestión, en este caso, los minerales críticos. A modo de ejemplo, hemos preparado una batería de cuestiones que el lector podrá plantear al GPT creado para comprender en mayor detalle la relevancia y situación actual de un material crítico como es el grafito a partir de los informes provistos a nuestro GPT.

Figura 17: Resolución de dudas de minerales críticos.
También podemos plantearle preguntas concretas sobre la información tabulada provista respecto a los yacimientos e indicios existentes en el territorio español.
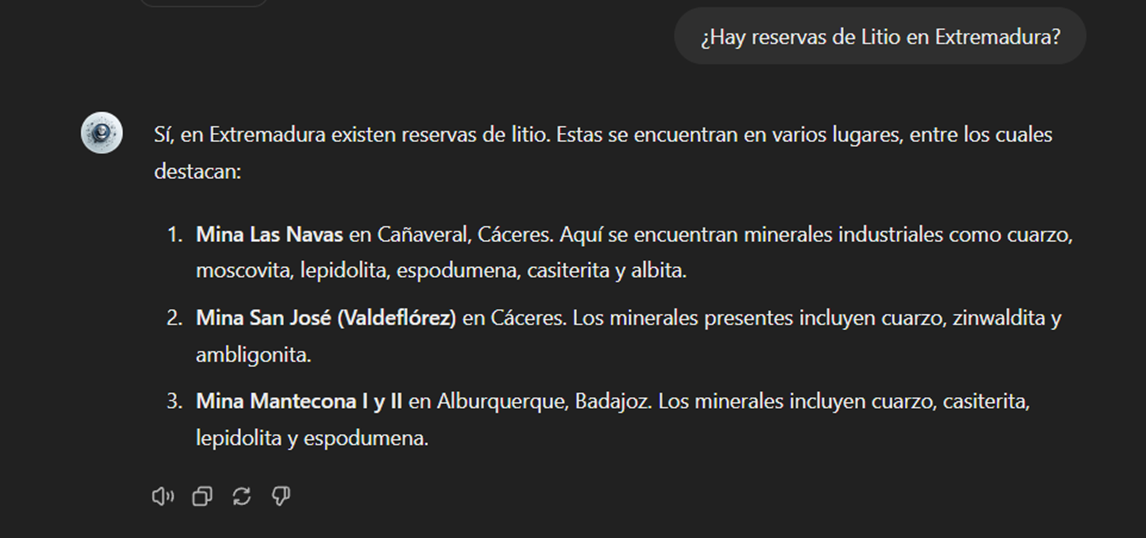
Figura 18: Reservas de litio en Extremadura.
6.2. Representación de visualizaciones de datos cuantitativos
Otro escenario común, es la necesidad de consultar información cuantitativa y realizar representaciones visuales para su mejor entendimiento. En este escenario, podemos observar cómo MateriaGuru es capaz de generar una visualización interactiva de la producción de grafito en toneladas de los principales países productores.

Figura 19: Generación de visualización interactiva con nuestro GPT.
6.3. Generación de mapas mentales para facilitar la comprensión
Por último, en línea con la búsqueda de alternativas para un mejor acceso y comprensión del conocimiento existente en nuestro GPT, plantearemos a MateriaGuru la construcción de un mapa mental que nos permita entender de una forma visual conceptos clave de los minerales críticos. Para ello, utilizamos la notación abierta Markmap (Markdown Mindmap), que nos permite definir mapas mentales utilizando notación markdown.

Figura 20: Generación de mapas mentales desde nuetro GPT.
Deberemos copiar el código generado e introducirlo en un visualizador de markmap para poder generar el mapa mental deseado. Facilitamos aquí una versión de este código generada por MateriaGuru.

Figura 21: Visualización de mapas mentales.
7. Resultados y conclusiones
En el ejercicio de construcción de un asistente experto utilizando GPT-4, hemos logrado crear un modelo especializado en minerales críticos. Este asistente proporciona información detallada y actualizada sobre minerales críticos, apoyando la toma de decisiones estratégicas y promoviendo la educación en este campo. Primero recopilamos información de fuentes confiables como el RMIS, la Agencia Internacional de la Energía (IEA), y el Instituto Geológico y Minero Español (BDMIN). Posteriormente, procesamos y estructuramos los datos adecuadamente para su integración en el modelo. Las validaciones demostraron que el asistente responde de manera precisa a preguntas relevantes del dominio, facilitando el acceso a su información.
De esta forma, el desarrollo del asistente especializado en minerales críticos ha demostrado ser una solución efectiva para centralizar y facilitar el acceso a información compleja y dispersa.
La utilización de herramientas como Google Colab y Markmap ha permitido una mejor organización y visualización de los datos, aumentando la eficiencia en la gestión del conocimiento. Este enfoque no solo mejora la comprensión y el uso de la información sobre minerales críticos, sino que también prepara a los usuarios para aplicar estos conocimientos en contextos reales.
La experiencia práctica adquirida en este ejercicio es directamente aplicable a otros proyectos que requieran la personalización de modelos de lenguaje para casos de uso específicos.
8. ¿Quieres realizar el ejercicio?
Si quieres replicar este ejercicio, accede a este repositorio donde encontrarás más información (las prompt utilizadas, el código generado por MateriaGuru, etc.)
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En estos momentos nos encontramos en medio de una carrera sin precedentes por dominar las innovaciones en Inteligencia Artificial. Durante el último año, la estrella ha sido la Inteligencia Artificial Generativa (GenAI), es decir, aquella capaz de generar contenido original y creativo como imágenes, texto o música. Pero los avances no dejan de sucederse, y últimamente comienzan a llegar noticias en las que se sugiere que la utopía de la Inteligencia Artificial General (AGI) podría no estar tan lejos como pensábamos. Estamos hablando de máquinas capaces de comprender, aprender y realizar tareas intelectuales con resultados similares al cerebro humano.
Sea esto cierto o simplemente una predicción muy optimista, consecuencia de los asombrosos avances conseguido en un espacio muy corto de tiempo, lo cierto es que la Inteligencia Artificial parece ya capaz de revolucionar prácticamente todas las facetas de nuestra sociedad a partir de la cada vez mayor cantidad de datos que se utilizan para su entrenamiento.
Y es que si, como argumentaba Andrew Ng ya en 2017, la inteligencia artificial es la nueva electricidad, los datos abiertos serían el combustible que alimenta su motor, al menos en un buen número de aplicaciones cuya fuente principal y más valiosa es la información pública que se encuentra accesible para ser reutilizada. En este artículo vamos a repasar un campo en el que previsiblemente veremos grandes avances en los próximos años gracias a la combinación de inteligencia artificial y datos abiertos: la creación artística.
Creación Generativa basada en Datos Culturales Abiertos
La capacidad de la inteligencia artificial para generar nuevos contenidos podría llevarnos a una nueva revolución en la creación artística, impulsada por el acceso a datos culturales abiertos y a una nueva generación de artistas capaces de aprovechar estos avances para crear nuevas formas de pintura, música o literatura, trascendiendo barreras culturales y temporales.
Música
El mundo de la música, con su diversidad de estilos y tradiciones, representa un campo lleno de posibilidades para la aplicación de la inteligencia artificial generativa. Los conjuntos de datos abiertos en este ámbito incluyen grabaciones de música folclórica, clásica, moderna y experimental de todo el mundo y de todas las épocas, partituras digitalizadas, e incluso información sobre teorías musicales documentadas. Desde el archi-conocido MusicBrainz, la enciclopedia de la música abierta, hasta conjuntos de datos que abren los propios dominadores de la industria del streaming como Spotify o proyectos como Open Music Europe, son algunos ejemplos de recursos que están en la base del progreso en esta área. A partir del análisis de todos estos datos, los modelos de inteligencia artificial pueden identificar patrones y estilos únicos de diferentes culturas y épocas, fusionándolos para crear composiciones musicales inéditas con herramientas y modelos como MuseNet de OpenAI o Music LM de Google.
Literatura y pintura
En el ámbito de la literatura, la Inteligencia artificial también tiene potencial para hacer más productiva no solo la creación de contenidos en internet, sino para producir formas más elaboradas y complejas de contar historias. El acceso a bibliotecas digitales que albergan obras literarias desde la antigüedad hasta el momento actual hará posible explorar y experimentar con estilos literarios, temas y arquetipos de narración de diversas culturas a lo largo de la historia, con el fin de crear nuevas obras en colaboración con la propia creatividad humana. Incluso se podrá generar una literatura de carácter más personalizado a los gustos de grupos de lectores más minoritarios. La disponibilidad de datos abiertos como el Proyecto Guttemberg con más de 70.000 libros o los catálogos digitales abiertos de museos e instituciones que han publicado manuscritos, periódicos y otros recursos escritos producidos por la humanidad, son un recurso de gran valor para alimentar el aprendizaje de la inteligencia artificial.
Los recursos de la Digital Public Library of America (DPLA) en Estados Unidos o de Europeana en la Unión Europea son sólo algunos ejemplos. Estos catálogos no sólo incluyen texto escrito, sino que incluyen también vastas colecciones de obras de arte visuales, digitalizadas a partir de las colecciones de museos e instituciones, que en muchos casos ni tan siquiera pueden admirarse porque las organizaciones que las conservan no disponen de espacio suficiente para exponerlas al público. Los algoritmos de inteligencia artificial, al analizar estas obras, descubren patrones y aprenden sobre técnicas, estilos y temas artísticos de diferentes culturas y períodos históricos. Esto posibilita que herramientas como DALL-E2 o Midjourney puedan crear obras visuales a partir de unas sencillas instrucciones de texto con estética de pintura renacentista, impresionista o una mezcla de ambas.
Sin embargo, estas fascinantes posibilidades están acompañadas de una controversia aún no resuelta acerca de los derechos de autor que está siendo debatida en los ámbitos académicos, legales y jurídicos y que plantea nuevos desafíos en la definición de autoría y propiedad intelectual. Por una parte, está la cuestión sobre la propiedad de los derechos sobre las creaciones producidas por inteligencia artificial. Y por otra parte encontramos el uso de conjuntos de datos que contienen obras sujetas a derechos de propiedad intelectual y que se han utilizado en el entrenamiento de los modelos sin el consentimiento de los autores. En ambas cuestiones existen numerosas disputas judiciales en todo el mundo y solicitudes de retirada explícita de contenido de los principales conjuntos de datos de entrenamiento.
En definitiva, nos encontramos ante un campo donde el avance de la inteligencia artificial parece imparable, pero habrá que tener muy presente no solo las oportunidades, sino también los riesgos que supone.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Continuamos con la serie de posts sobre Chat GPT-3. La expectación levantada por el sistema conversacional justifica con creces la publicación de varios artículos sobre sus características y aplicaciones. En este post, profundizamos sobre una de las últimas novedades publicadas por openAI relacionadas con Chat GPT-3. En este caso introducimos su API, es decir, su interfaz de programación con la que podemos integrar Chat GPT-3 en nuestras propias aplicaciones.
Introducción.
En nuestro último post sobre Chat GPT-3 realizamos un ejercicio de co-programación o programación asistida en el que le solicitamos a la IA que nos escribiera un programa sencillo, en lenguaje de programación R, para visualizar un conjunto de datos. Como vimos en el post, utilizamos la propia interfaz disponible de Chat GTP-3. La interfaz es muy minimalista y funcional, tan solo tenemos que preguntar a la IA en el cuadro de texto y ella nos contesta en el cuadro de texto posterior. Tal y como concluimos en el post, el resultado del ejercicio fue más que satisfactorio. Sin embargo, también detectamos algunos puntos de mejora. Por ejemplo, la interfaz estándar puede resultar un poco lenta. Para un ejercicio largo, con múltiples interacciones conversacionales con la IA (un diálogo largo), la interfaz tarda bastante en escribir las respuestas. Varios usuarios reportan la misma sensación y por eso algunos, como este desarrollador, han creado su propia interfaz con el asistente conversacional para mejorar su velocidad de respuesta.
Pero, ¿cómo es posible esto? La razón es sencilla, gracias al API de Chat GPT-3. En este espacio de divulgación hemos hablado mucho sobre las APIs en el pasado. No en vano, las APIs son los mecanismos estándar en el mundo de las tecnologías digitales para integrar servicios y aplicaciones. Cualquier app en nuestro smartphone hace uso de las APIs para mostrarnos los resultados. Cuando consultamos el tiempo, los resultados deportivos o el horario del transporte público, las apps hacen llamadas a las APIs de los servicios para consultar la información y mostrar los resultados.
El API de Chat GPT-3
Como cualquier otro servicio actual, openAI pone a disposición de sus usuarios una API con la que poder invocar (llamar) a sus diferentes servicios basados en el modelo entrenado de lenguaje natural GPT-3. Para usar el API, tan solo tenemos que iniciar sesión con nuestra cuenta en https://platform.openai.com y localizar el menú (superior derecha) View API Keys. Hacemos click en create a new secret key y ya tenemos nuestra nueva clave de acceso al servicio.

¿Qué hacemos ahora? Bien, para ilustrar lo que podemos hacer con esta nueva y flamante clave veamos algunos ejemplos:
Como decíamos en la introducción, podemos querer probar interfaces alternativas a Chat GPT-3 como https://www.typingmind.com/. Cuando accedemos a esta web, lo primero que debemos hacer es ingresar nuestra API Key.
Una vez dentro, hagamos un ejemplo y veamos cómo se comporta esta nueva interfaz. Preguntemos a Chat GPT-3 ¿Qué es datos.gob.es?
| Nota: Es importante notar que la mayoría de servicios no funcionarán si no activamos algún medio de pago en la web de OpenAI. Lo normal es que, si no hemos configurado una tarjeta de crédito, las llamadas al API devuelvan un mensaje de error similar a \"You exceeded your current quota, please check your plan and billing details”. |

Veamos ahora otra aplicación del API de Chat GPT-3.
Acceso programático con R para acceder a Chat GPT-3 de modo programático (o lo que es lo mismo, con algunas líneas de código en R tenemos acceso a la potencia conversacional del modelo GPT-3). Esta demostración está basada en el reciente post publicado en R Bloggers. Vamos a acceder a Chat GPT-3 de modo programático con el siguiente ejemplo.
| Nota: Notar que el API Key se ha ocultado por motivos de seguridad y privacidad |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

¿Nada mal verdad? Como dato curioso podemos ver que unas pocas llamadas al API de Chat GPT-3 han tenido el siguiente uso del API:

El uso del API se cotiza por tokens (algo similar a las palabras) y los precios públicos pueden consultarse aquí. En concreto el modelo que estamos utilizando tiene estos precios:

Para pequeñas pruebas y ejemplos, nos lo podemos permitir. En caso de aplicaciones empresariales para entornos productivos existe un modelo premium que permite tener un control de los costes sin depender tanto del uso.
Conclusión
Como no podía ser de otra manera, Chat GPT-3 habilita un API para proporcionar acceso programático a su motor conversacional. Este mecanismo permite la integración de aplicaciones y sistemas (es decir, todo lo que no son humanos) abriendo la puerta al despegue definitivo del Chat GPT-3 como modelo de negocio. Gracias a este mecanismo, el buscador Bing ahora integra Chat GPT-3 para respuestas a las búsquedas en modo conversacional. De la misma forma, Microsoft Azure acaba de anunciar la disponibilidad de Chat GPT-3 como un nuevo servicio de la nube pública. Sin lugar a dudas, en las próximas semanas veremos comunicaciones de todo tipo de aplicaciones, apps y servicios, conocidos y desconocidos, anunciando su integración con Chat GPT-3 para mejorar las interfaces conversacionales con sus clientes. Nos vemos en el próximo episodio, quién sabe sin con GPT-4.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hablar estos días de GPT-3 no es lo más original del mundo, lo sabemos. Toda la comunidad tecnológica está publicando ejemplos, realizando eventos y pronosticando el final del mundo del lenguaje y la generación de contenidos tal y cómo la conocemos actualmente. En este post, le pedimos a ChatGPT que nos eche una mano para programar un ejemplo de visualización de datos con R partiendo de un conjunto de datos abiertos disponible en datos.gob.es.
Introducción
Nuestro anterior post hablaba sobre Dall-e y la capacidad de GPT-3 para generar imágenes sintéticas partiendo de una descripción de lo que pretendemos generar en lenguaje natural. En este nuevo post, hemos realizado un ejercicio completamente práctico en el que le pedimos a la inteligencia artificial que nos ayude a realizar un sencillo programa en R que cargue un conjunto de datos abierto y genere algunas representaciones gráficas.
Hemos escogido un conjunto de datos abiertos de la plataforma datos.gob.es. En concreto, un conjunto de datos sencillos de uso de portales madrid.es. La descripción del repositorio explica que se incluye la información relativa a usuarios, sesiones y número de visitas a páginas de los siguientes portales del Ayuntamiento de Madrid: Portal Web municipal, Sede Electrónica, Portal de Transparencia, Portal de Datos Abiertos, Bibliotecas y Decide Madrid.
El fichero se puede descargar en formato .csv o .xslx y si lo pre-visualizamos tiene el siguiente aspecto:

Vale, comencemos a co-programar con ChatGPT!
Primero accedemos a la web y nos identificamos con nuestro usuario y contraseña. Es necesario estar registrado en el sitio web de openai.com para poder acceder a las capacidades de GPT-3, entre otras ChatGPT.
Iniciamos nuestra conversación:

Durante este ejercicio hemos intentado mantener una conversación de la misma forma que la tendríamos con un compañero de programación. Así que lo primero que hacemos es saludar y enunciar el problema que tenemos. Cuándo le pedimos a la IA que nos ayude a crear un pequeño programa en R que represente gráficamente unos datos, nos ofrece algunos ejemplos y ayuda con la explicación del programa:

Puesto que no tenemos datos, no podemos hacer nada práctico por el momento, así que le pedimos si nos ayuda a generar unos datos sintéticos.
Como decimos, nos comportamos con la IA como lo haríamos con una persona (tiene buena pinta).

Una vez que parece que la IA responde con facilidad a nuestras preguntas, vamos con el siguiente paso, vamos a darle nosotros los datos. Y aquí empieza la magia… Hemos abierto el fichero de datos que nos hemos bajado de datos.gob.es y hemos copiado y pegado una muestra.
| Nota: ChatGPT no tiene conexión a Internet y por lo tanto no puede acceder a datos externos, así que lo único que podemos hacer es darle un ejemplo de los datos reales con los que queremos trabajar. |


Con los datos copiados y pegados tal cual se los hemos dado, nos escribe el código en R para cargarlos manualmente en un dataframe denominado “datos”. A continuación, nos proporciona el código de ggplot2 (la librería gráfica más conocida en R) para graficar los datos junto con una explicación del funcionamiento del código.

¡Genial! Es espectacular este resultado con un lenguaje totalmente natural y nada adaptado para hablar con una máquina. Veamos que pasa a continuación:
Pero resulta que al copiar y pegar el código en un entorno de RStudio comprobamos que este falla.

Así que le decimos lo que pasa y que nos ayude a solucionarlo.

Probamos de nuevo y ¡en este caso funciona!
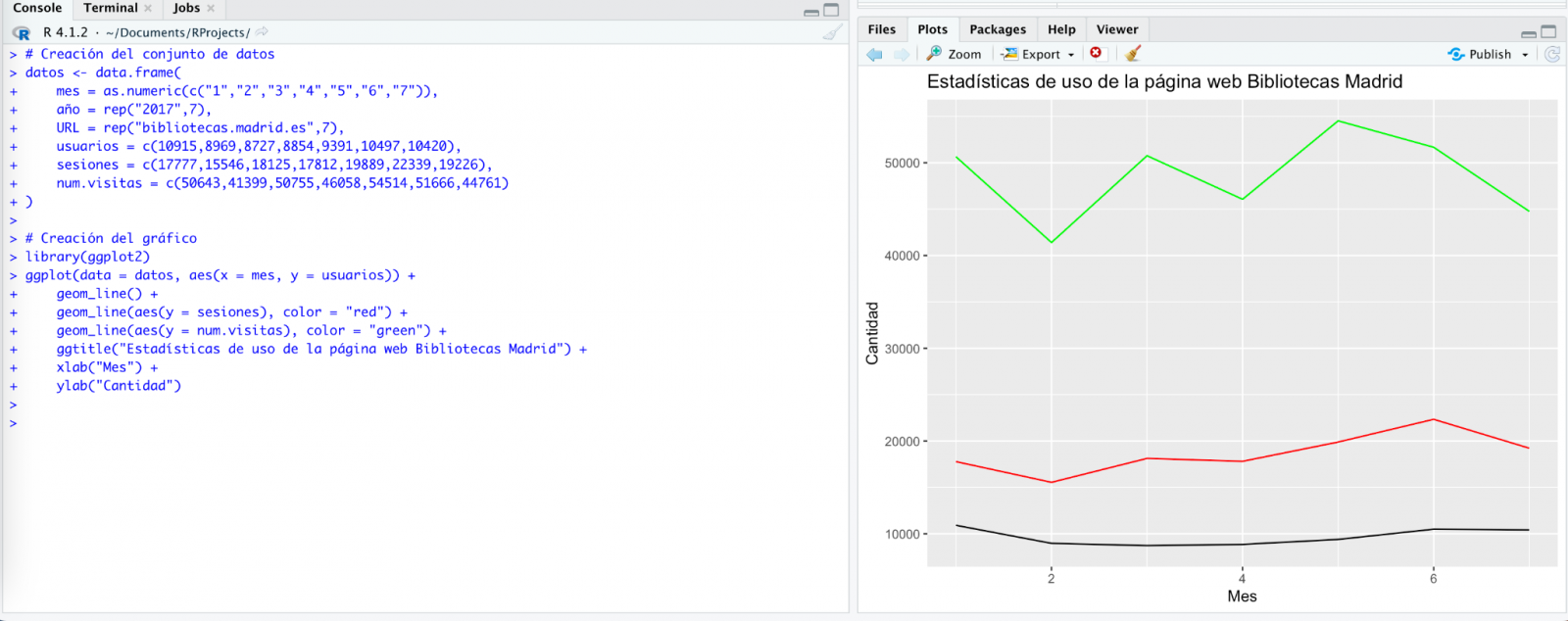
Sin embargo, el resultado es un poco tosco. Así que se lo decimos.

A partir de aquí (y tras varios intentos de copiar y pegar más y más filas de datos) la IA cambia ligeramente el enfoque y me proporciona instrucciones y código para cargar mi propio fichero de datos desde mi ordenador en lugar de introducir manualmente los datos en el código.

Le hacemos caso y copiamos un par de años de datos en un fichero de texto en nuestro ordenador. Fijaos, en lo que ocurre a continuación:

Probamos de nuevo:

Como veis, funciona, pero el resultado no es del todo acertado.
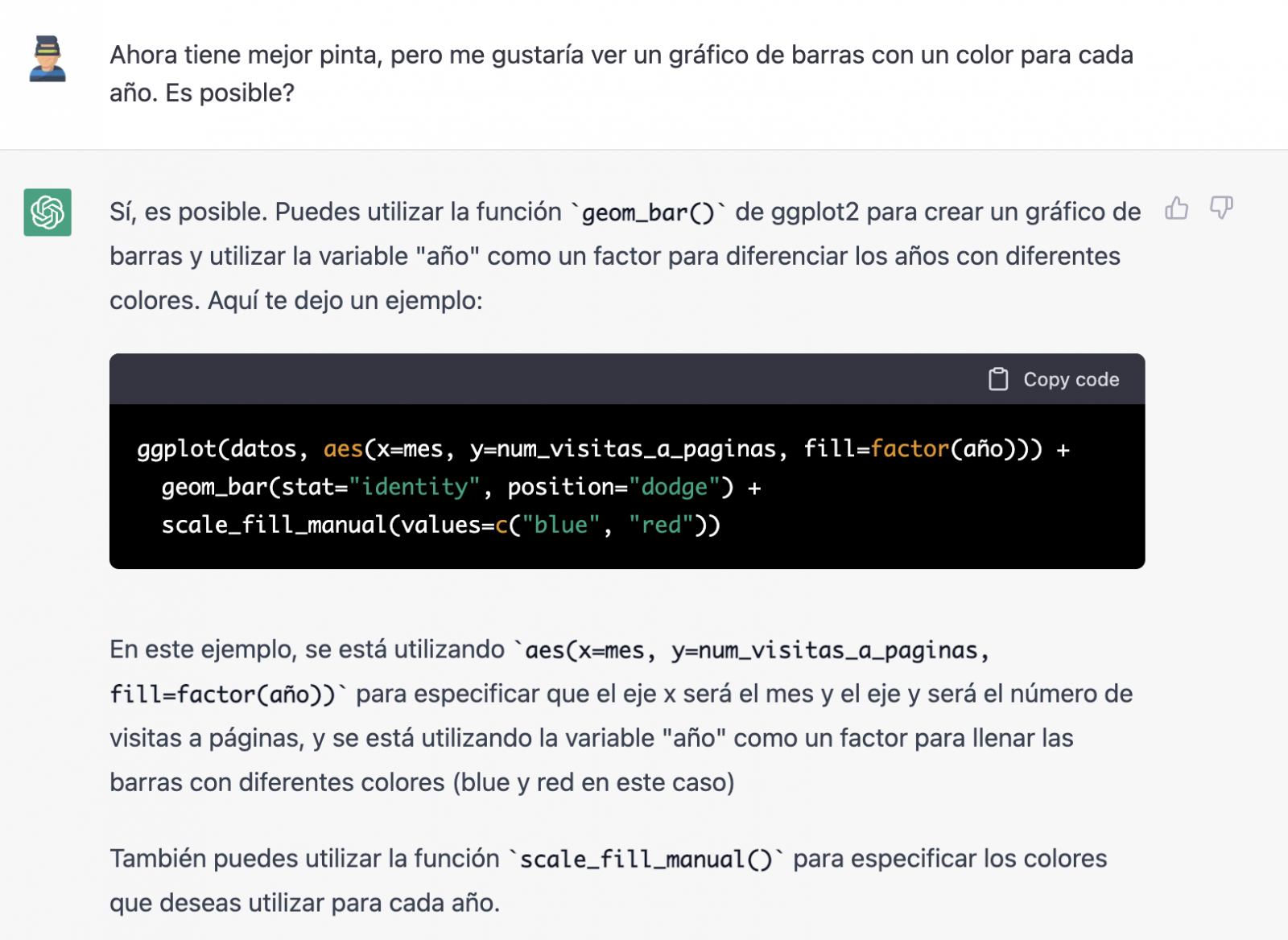
Y veamos lo que ocurre.

¡Por fin parece que ya nos ha entendido! Es decir, tenemos un gráfico de barras con las visitas a la web por mes, para los años 2017 (azul) y 2018 (rojo). Sin embargo, no me convencen ni el formato del título del eje ni tampoco se distingue bien la numeración del mismo eje.

Veamos el resultado ahora.

Tiene mucha mejor pinta, ¿verdad? Pero ¿qué tal si todavía le damos una vuelta de tuerca más?
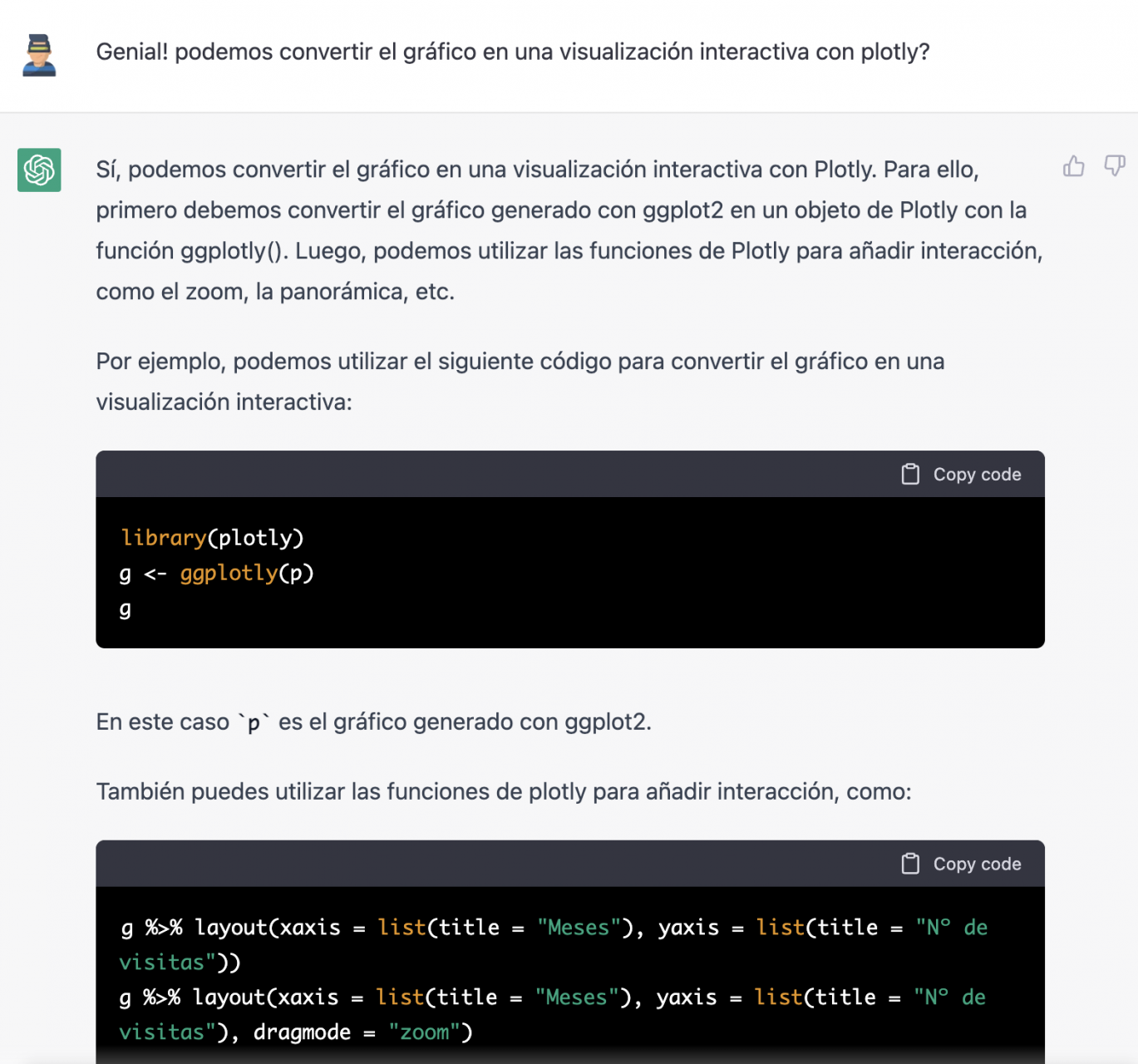
Sin embargo, se ha olvidado de decirnos que debemos instalar el paquete o librería plotly en R. Así que se lo recordamos.
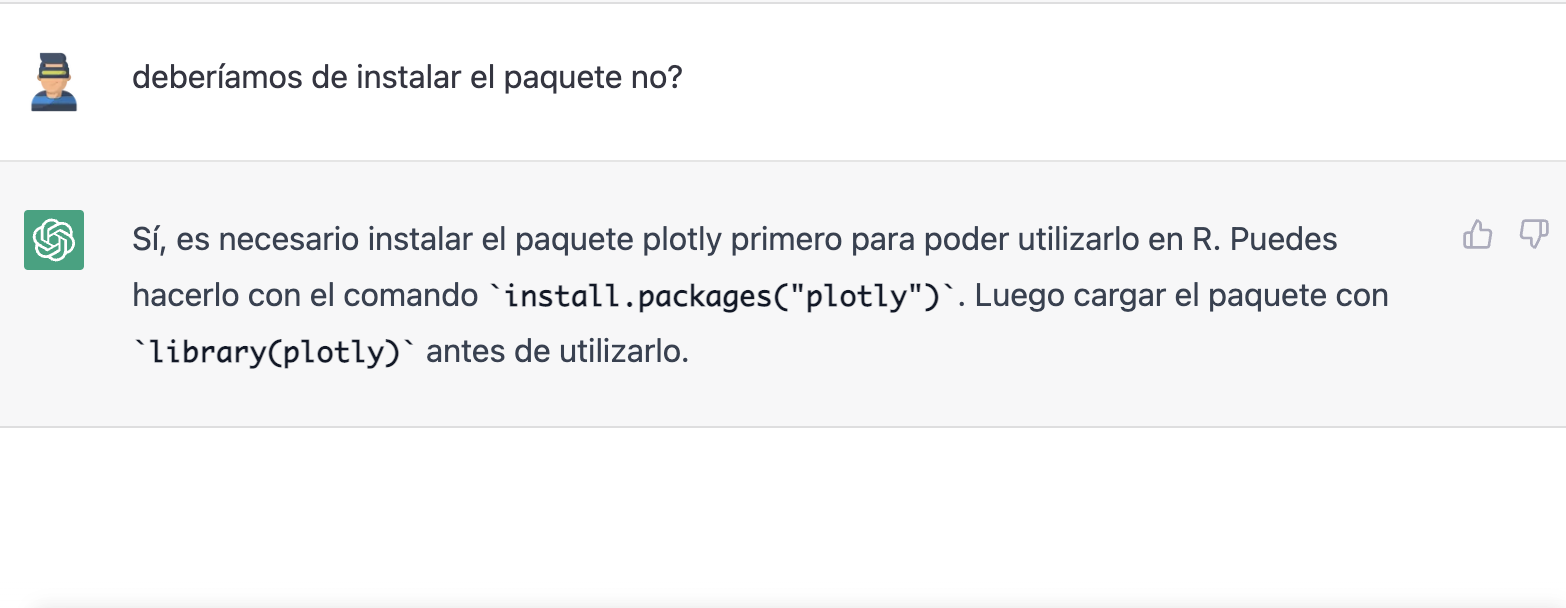
Veamos el resultado:

Como podéis ver, ahora tenemos los controles del gráfico interactivo, de tal modo que podemos seleccionar un año concreto de la leyenda, hacer zoom, etc.
Conclusión
Puede que seas de esos escépticos, conservadores o prudentes que piensan que las capacidades demostradas por GPT-3 hasta el momento (ChatGPT, Dall-E2, etc) son todavía muy infantiles y poco prácticas en la vida real. Todas las consideraciones a este respecto son legítimas y, muchas, probablemente bien fundamentadas.
Sin embargo, algunos hemos pasado buena parte de la vida escribiendo programas, buscando documentación y ejemplos de código que pudiéramos adaptar o en los que inspirarnos; depurando errores, etc. Para todos nosotros (programadores, analistas, científicos, etc.) poder experimentar este nivel de interlocución con una inteligencia artificial en modo beta, puesta a disposición del público de forma gratuita y siendo capaz de demostrar esta capacidad de asistencia en la co-programación, es, sin duda, un salto cualitativo y cuantitativo en la disciplina de la programación.
No sabemos qué va a pasar, pero probablemente estemos a las puertas de un gran cambio de paradigma en la ciencia de la computación, hasta el punto que, quizás, haya cambiado para siempre la forma de programar y aún no nos hayamos dado cuenta.
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial generativa se refiere a la capacidad de una máquina para generar contenido original y creativo, como imágenes, texto o música, a partir de un conjunto de datos de entrada. En lo que se refiere a la generación de texto, estos modelos son accesibles, en formato experimental, desde hace un tiempo, pero comenzaron a generar interés a mediados de 2020 cuando Open AI, una organización dedicada a la investigación en el campo de la inteligencia artificial general, publicó el acceso a su modelo de lenguaje GPT-3 a través de una API.
La arquitectura de GPT-3 está compuesta por 175 mil millones de parámetros, mientras que la de su antecesor GPT-2 era de 1.500 millones de parámetros, esto es, más de 100 veces más. GPT-3 representa por tanto un cambio de escala enorme ya que además fue entrenado con un corpus de datos mucho mayor y un tamaño de los tokens mucho más grande, lo que le permitió adquirir una comprensión más profunda y compleja del lenguaje humano.
A pesar de que fue de 2022 cuando OpenAI anunció la apertura de chatGPT, que permite dotar de una interfaz conversacional a un modelo de lenguaje basado en una versión mejorada de GPT-3, no ha sido hasta los últimos dos meses cuando la noticia ha llamado masivamente la atención del público, gracias a la amplia cobertura mediática que trata de dar respuesta al incipiente interés general.
Y es que, ChatGPT no sólo es capaz de generar texto a partir de un conjunto de caracteres (prompt) como GPT-3, sino que responde a preguntas en lenguaje natural en varios idiomas que incluyen inglés, español, francés, alemán, italiano o portugués. Es precisamente este cambio en la interfaz de acceso, pasando de ser una API a un chatbot, lo que lo ha convertido a la IA en accesible para cualquier tipo de usuario.
Tanto es así que más de un millón de personas se registraron para usarlo en tan solo cinco días, lo que ha motivado la multiplicación de ejemplos en los que chatGPT produce código de software, ensayos de nivel universitario, poemas e incluso chistes. Eso sin tener en cuenta que ha sido capaz de sacar adelante un examen de selectividad de Historia o de aprobar el examen final del MBA de la prestigiosa Wharton School.
Todo esto ha puesto a la IA generativa en el centro de una nueva ola de innovación tecnológica que promete revolucionar la forma en que nos relacionamos con internet y la web a través de búsquedas vitaminadas por IA o navegadores capaces de resumir el resultado de estas búsquedas.
Hace tan solo unos días, conocíamos la noticia de que Microsoft trabaja en la implementación de un sistema conversacional dentro de su propio buscador, el cual ha sido desarrollado a partir del conocido modelo de lenguaje de Open AI y cuya noticia ha puesto en jaque a Google.
Y es que, como consecuencia de esta nueva realidad en la que la IA ha llegado para quedarse, los gigantes tecnológicos han ido un paso más allá en la batalla por aprovechar al máximo los beneficios que esta reporta. En esta línea, Microsoft ha presentado una nueva estrategia dirigida a optimizar al máximo la manera en la que nos relacionamos con internet, introduciendo la IA para mejorar los resultados ofrecidos por los buscadores de navegadores, aplicaciones, redes sociales y, en definitiva, todo el ecosistema de la web.
Sin embargo, aunque el camino en el desarrollo de los nuevos y futuros servicios ofrecidos por la IA de Open AI aún están por ver, avances como los anteriores ofrecen una pequeña pista de la guerra de navegadores que se avecina y que, probablemente, cambie en el corto plazo la manera de crear y hallar contenido en la web.
Los datos abiertos
GPT-3, al igual que otros modelos que han sido generados con las técnicas descritas en la publicación científica original de GTP-3, es un modelo de lenguaje pre-entrenado, lo que significa que ha sido entrenado con un gran conjunto de datos, en total unos 45 terabytes de datos de texto. Según este paper, el conjunto de datos de entrenamiento estaba compuesto en un 60% por datos obtenidos directamente de internet en los que están contenidos millones de documentos de todo tipo, un 22% del corpus WebText2 construido a partir de Reddit, y el resto con una combinación de libros (16%) y Wikipedia (3%).
Sin embargo, no se sabe cuántos datos abiertos utiliza GPT-3 exactamente, ya que OpenAI no proporciona detalles más específicos sobre el conjunto de datos utilizado para entrenar el modelo. Lo que sí podemos hacer son algunas preguntas al propio chatGPT que nos ayuden a extraer interesantes conclusiones sobre el uso que hace de los datos abiertos.
Por ejemplo, si le preguntamos a chatGPT cuál era la población de España entre 2015 y 2020 (no podemos pedirle datos más recientes), obtenemos una respuesta de este tipo:

Tal como podemos ver en la imagen superior, aunque la pregunta sea la misma, la respuesta puede variar tanto en la redacción como en la información que contiene. Las variaciones pueden ser aún mayores si realizamos la pregunta en diferentes días o hilos de conversación:
Pequeñas variaciones en la redacción del texto, generar la pregunta en diferentes momentos del hilo de conversación (recordemos que guarda el contexto) o en hilos o días diferentes puede conducir a resultados ligeramente diferentes. Además, la respuesta no es completamente precisa, tal y como nos advierte la propia herramienta si las comparamos con las series de población residente en España del propio INE, donde nos recomienda consultar. Los datos que idealmente habríamos esperado en la respuesta podrían obtenerse en un conjunto de datos abiertos del INE:
Este tipo de respuestas sugieren que los datos abiertos no se han empleado como una fuente autoritativa para responder preguntas de tipo factual, o al menos que aún no está completamente refinado el modelo en este sentido. Haciendo algunas pruebas básicas con preguntas sobre otros países hemos observado errores parecidos, por lo que no parece que se trate de un problema sólo con preguntas referentes a España.
Si hacemos preguntas algo más específicas como pedir la lista de los municipios de la provincia de Burgos que comienzan por la letra “G” obtenemos respuestas que no son completamente correctas, como es propio de una tecnología que todavía está en fase incipiente.
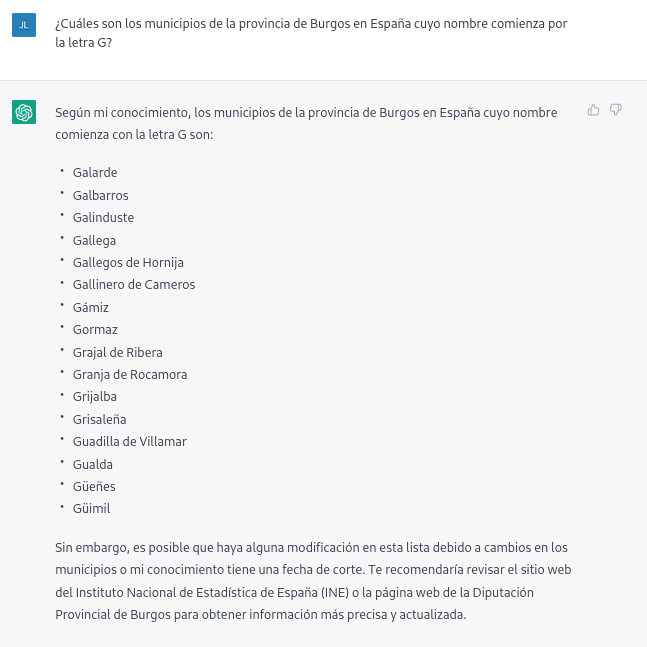
La respuesta correcta debería contener seis municipios: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán y Gumiel del Mercado. Sin embargo, la respuesta que hemos obtenido sólo contiene los cuatro primeros e incluye localidades de la provincia de Guadalajara (Gualda), municipios de la provincia de Valladolid (Gallegos de Hornija) o localidades de la provincia de Burgos que no son municipios (Galarde). En este caso, también podemos acudir a conjunto de datos abiertos para obtener la respuesta correcta.
A continuación, le preguntamos a ChatGPT por la lista de municipios que comienzan por la letra Z en la misma provincia. ChatGPT nos dice que nos hay ninguno, razonando la respuesta, cuando en realidad hay cuatro:
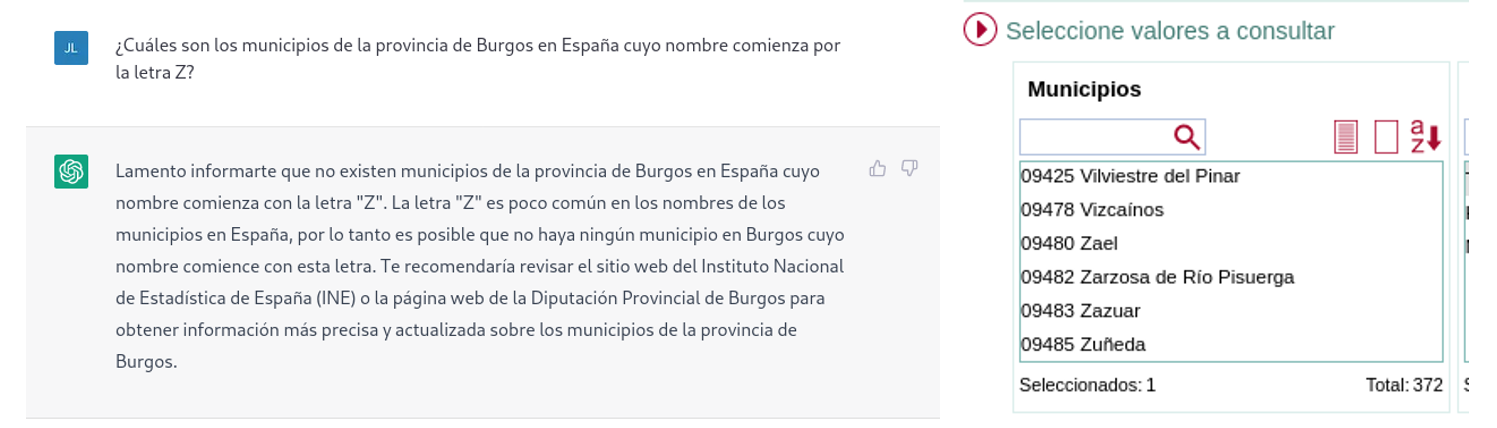
Como se deduce de los ejemplos anteriores, vemos cómo los datos abiertos sí pueden contribuir a la evolución tecnológica y, por ende, a mejorar el funcionamiento de la inteligencia artificial de Open AI. Sin embargo, dado el estado de madurez actual de la misma, aún es pronto para ver un empleo óptimo de estos, a la hora de dar respuesta a preguntas más complejas.
Por lo tanto, para que un modelo de inteligencia artificial generativa sea eficaz, es necesario que cuente con una gran cantidad de datos de alta calidad y diversidad, y los datos abiertos son una fuente de conocimiento valiosa para este fin.
Probablemente, en futuras versiones del modelo, podamos ver cómo los datos abiertos ya adquieren un peso mucho más importante en la composición del corpus de entrenamiento, logrando conseguir una mejora importante en la calidad de las respuestas de tipo factual.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Llevamos años anunciando que la Inteligencia Artificial está viviendo uno de sus periodos más prolíficos y excitantes. Un momento en el que comienzan a verse aplicaciones y casos de uso donde la inteligencia humana se funde con la artificial. Algunas profesiones están cambiando para siempre. Los periodistas y escritores disponen ahora de herramientas de software que pueden escribir por ellos. Los creadores de contenido - imágenes o video - pueden pedirle a la máquina que, mediante una frase, que cree por ellos. En este post profundizamos en este último ejemplo. Hemos podido probar Dall-e 2 y nos hemos quedado de piedra con los resultados.
Introducción
Estos días, en la comunidad tecnológica del mundo entero, hay un murmullo de fondo, una excitación colectiva de todos los amantes de las tecnologías digitales y en particular de la inteligencia artificial. En varias ocasiones hemos mencionado en este espacio de comunicación las innovaciones de la compañía OpenAI. Hemos escrito varios artículos donde hablamos del algoritmo GPT-3 y de lo que es capaz en el campo del procesamiento del lenguaje natural. Recientemente, OpenAI ha ido eliminando las listas de espera (en las que muchos llevábamos tiempo inscritos) para permitirnos probar de forma limitada las capacidades del algoritmo GPT-3 implementado en diferentes tipos de aplicación.
Ejemplo de las múltiples aplicaciones de GPT-3 en el ámbito del lenguaje natural.
Recomendamos a nuestros lectores experimentar con la herramienta para completar texto, en la que con tan solo proporcionar una corta frase, la IA nos completa el texto con varios párrafos indistinguibles de la redacción de un humano. Los últimos días, están siendo frenéticos con multitud de personas probando la herramienta de Chat GPT-3. El nivel de naturalidad de la IA para mantener una conversación es, sencillamente, alucinante. Los resultados están impactando en casos de uso muy variados, como por ejemplo, la asistencia para programadores de software. Chat GPT-3 está siendo capaz de programar sencillas rutinas de código o algoritmos con tan solo describir en lenguaje natural lo que se quiere programar. Pero, el resultado impresiona más aún si caemos en que la IA es capaz de corregir sus propios errores de programación.
DALL-E
Dejando a un lado, las capacidades de generar lenguaje natural indistinguible del escrito por un humano, vamos al tema central de este post. Una de las aplicaciones más sorprendentes de la IA de OpenAI es la solución conocida cómo DALL-E. Qué mejor manera de presentar DALL-E que preguntarle a Chat GPT-3 qué es DALL-E.
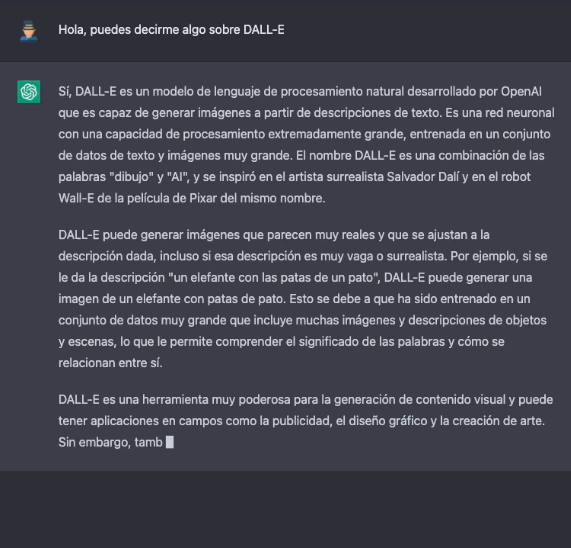
La descripción más formal de DALL-E, de acuerdo con su propia web es:
DALL·E es una versión de GPT-3 entrenado con 12 mil millones de parámetros para generar imágenes a partir de descripciones de texto. DALL-E tiene un conjunto diverso de capacidades, incluida la creación de versiones antropomórficas de animales y objetos, la combinación de conceptos no relacionados de manera plausible, la representación de texto y la aplicación de transformaciones a imágenes existentes.
Actualmente existe una segunda versión del algoritmo DALL-E 2 capaz de generar imágenes más realistas y precisas con una resolución 4 veces mayor. La herramienta para probar DALL-E está disponible aquí https://labs.openai.com/. Para usarla es necesario crear previamente una cuenta en OpenAI que nos permitirá jugar con todas las herramientas de la compañía. Cuándo accedemos a la web de prueba podemos escribir nuestro propio texto o pedirle a la herramienta que genere descripciones aleatorias de imágenes en lenguaje natural para crear imágenes. Por ejemplo, haciendo clic sobre el botón Surprise me:

La web nos genera esta descripción aleatoria: an astronaut lounging in a tropical resort in space, pixel art
Y este es el resultado:

Repetimos: an expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula

Podemos asegurar que el ejercicio resulta algo adictivo y damos fe de que algunos nos hemos pasado horas del fin de semana jugando con las descripciones y esperando, una y otra vez, el asombroso resultado.
Sobre el entrenamiento de DALL-E 2
DALL-E 2 (arXiv:2204.06125) es una versión refinada del sistema original DALL-E (arXiv:2102.12092). Para entrenar el modelo original de DALL-E, que contiene 12 mil millones de parámetros, se utilizó un conjunto de 250 millones de pares de texto-imagen (públicamente disponibles en Internet). Este conjunto de datos es una mezcla de varios datasets previos compuesto por: Conceptual Captions de Google; los pares de texto e imagen de Wikipedia y un subconjunto filtrado de YFCC100M.
Curiosidades de DALL-E 2
Algunas curiosidades más allá de las pruebas que podemos hacer para generar nuestras propias imágenes. OpenAI ha creado un repositorio específico de Github en el que describe los riesgos y limitaciones de DALL-E. En el sitio se informa, por ejemplo, de que, por el momento, el uso de DALL-E está limitado para propósitos no comerciales. Así que no es posible hacer ningún uso comercial de las imágenes generadas. Es decir, no pueden ser vendidas, ni licenciadas bajo ningún supuesto. En este sentido, todas las imágenes generadas por DALL-E incluyen una marca distintiva que permite saber que han sido generadas con la IA. En el sitio de Github podemos encontrar ingente cantidad de información sobre la generación de contenido explícito, los riesgos relacionados con el sesgo que la IA pueda introducir en la generación de imágenes y los usos inadecuados de DALL-E cómo por ejemplo, el acoso, el bullying o la explotación de individuos.

En clave nacional, MarIA
En clave nacional, tras meses de pruebas y ajustes, ha visto la luz MarIA: la primera inteligencia artificial supermasiva, entrenada con datos abiertos procedentes de los archivos web de la Biblioteca Nacional de España (BNE) y gracias a los recursos de computación del Centro Nacional de Supercomputación. En relación con este post, MarIA ha sido entrenada haciendo uso del algoritmo GPT-2, del que hemos hablado mucho meses atrás en este espacio. Para realizar el entrenamiento de MarIA, se han utilizado 135 mil millones de palabras precedentes del banco documental de la Biblioteca Nacional con un volumen total de 570 Gigabytes de información.
Conclusiones
A medida que transcurren los días y las semanas desde la apertura general de las APIs y las herramientas de OpenIA, se suceden torrencialmente las publicaciones en todo tipo de medios, redes sociales y blogs especializados sobre las capacidades y posibilidades de Chat GPT-3 y DALL-E. No creo que en estos momentos nadie sea capaz de avanzar las potenciales aplicaciones comerciales, científicas y sociales de esta tecnología. Lo que está claro, es que muchos pensamos que OpenAI ha enseñado solo una muestra de lo que es capaz y parece que podemos estar a las puertas de un hito histórico en el desarrollo de la IA tras muchos años de sobreexpectación y promesas a medio cumplir. Seguiremos informando sobre los avances de GTP-3, pero por el momento, no nos queda más que seguir disfrutando, jugando y aprendiendo con las sencillas herramientas que tenemos a disposición!
Contenido elaborado por Alejandro Alija, experto en Transformación Digital.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.