Documentación
1. Introduction
In the information age, artificial intelligence has proven to be an invaluable tool for a variety of applications. One of the most incredible manifestations of this technology is GPT (Generative Pre-trained Transformer), developed by OpenAI. GPT is a natural language model that can understand and generate text, providing coherent and contextually relevant responses. With the recent introduction of Chat GPT-4, the capabilities of this model have been further expanded, allowing for greater customisation and adaptability to different themes.
In this post, we will show you how to set up and customise a specialised critical minerals wizard using GPT-4 and open data sources. As we have shown in previous publications critical minerals are fundamental to numerous industries, including technology, energy and defence, due to their unique properties and strategic importance. However, information on these materials can be complex and scattered, making a specialised assistant particularly useful.
The aim of this post is to guide you step by step from the initial configuration to the implementation of a GPT wizard that can help you to solve doubts and provide valuable information about critical minerals in your day to day life. In addition, we will explore how to customise aspects of the assistant, such as the tone and style of responses, to perfectly suit your needs. At the end of this journey, you will have a powerful, customised tool that will transform the way you access and use critical open mineral information.
Access the data lab repository on Github.
2. Context
The transition to a sustainable future involves not only changes in energy sources, but also in the material resources we use. The success of sectors such as energy storage batteries, wind turbines, solar panels, electrolysers, drones, robots, data transmission networks, electronic devices or space satellites depends heavily on access to the raw materials critical to their development. We understand that a mineral is critical when the following factors are met:
- Its global reserves are scarce
- There are no alternative materials that can perform their function (their properties are unique or very unique)
- They are indispensable materials for key economic sectors of the future, and/or their supply chain is high risk
You can learn more about critical minerals in the post mentioned above.
3. Target
This exercise focuses on showing the reader how to customise a specialised GPT model for a specific use case. We will adopt a "learning-by-doing" approach, so that the reader can understand how to set up and adjust the model to solve a real and relevant problem, such as critical mineral expert advice. This hands-on approach not only improves understanding of language model customisation techniques, but also prepares readers to apply this knowledge to real-world problem solving, providing a rich learning experience directly applicable to their own projects.
The GPT assistant specialised in critical minerals will be designed to become an essential tool for professionals, researchers and students. Its main objective will be to facilitate access to accurate and up-to-date information on these materials, to support strategic decision-making and to promote education in this field. The following are the specific objectives we seek to achieve with this assistant:
- Provide accurate and up-to-date information:
- The assistant should provide detailed and accurate information on various critical minerals, including their composition, properties, industrial uses and availability.
- Keep up to date with the latest research and market trends in the field of critical minerals.
- Assist in decision-making:
- To provide data and analysis that can assist strategic decision making in industry and critical minerals research.
- Provide comparisons and evaluations of different minerals in terms of performance, cost and availability.
- Promote education and awareness of the issue:
- Act as an educational tool for students, researchers and practitioners, helping to improve their knowledge of critical minerals.
- Raise awareness of the importance of these materials and the challenges related to their supply and sustainability.
4. Resources
To configure and customise our GPT wizard specialising in critical minerals, it is essential to have a number of resources to facilitate implementation and ensure the accuracy and relevance of the model''s responses. In this section, we will detail the necessary resources that include both the technological tools and the sources of information that will be integrated into the assistant''s knowledge base.
Tools and Technologies
The key tools and technologies to develop this exercise are:
- OpenAI account: required to access the platform and use the GPT-4 model. In this post, we will use ChatGPT''s Plus subscription to show you how to create and publish a custom GPT. However, you can develop this exercise in a similar way by using a free OpenAI account and performing the same set of instructions through a standard ChatGPT conversation.
- Microsoft Excel: we have designed this exercise so that anyone without technical knowledge can work through it from start to finish. We will only use office tools such as Microsoft Excel to make some adjustments to the downloaded data.
In a complementary way, we will use another set of tools that will allow us to automate some actions without their use being strictly necessary:
- Google Colab: is a Python Notebooks environment that runs in the cloud, allowing users to write and run Python code directly in the browser. Google Colab is particularly useful for machine learning, data analysis and experimentation with language models, offering free access to powerful computational resources and facilitating collaboration and project sharing.
- Markmap: is a tool that visualises Markdown mind maps in real time. Users write ideas in Markdown and the tool renders them as an interactive mind map in the browser. Markmap is useful for project planning, note taking and organising complex information visually. It facilitates understanding and the exchange of ideas in teams and presentations.
Sources of information
- Raw Materials Information System (RMIS): raw materials information system maintained by the Joint Research Center of the European Union. It provides detailed and up-to-date data on the availability, production and consumption of raw materials in Europe.
- International Energy Agency (IEA) Catalogue of Reports and Data: the International Energy Agency (IEA) offers a comprehensive catalogue of energy-related reports and data, including statistics on production, consumption and reserves of energy and critical minerals.
- Mineral Database of the Spanish Geological and Mining Institute (BDMIN in its acronym in Spanish): contains detailed information on minerals and mineral deposits in Spain, useful to obtain specific data on the production and reserves of critical minerals in the country.
With these resources, you will be well equipped to develop a specialised GPT assistant that can provide accurate and relevant answers on critical minerals, facilitating informed decision-making in the field.
5. Development of the exercise
5.1. Building the knowledge base
For our specialised critical minerals GPT assistant to be truly useful and accurate, it is essential to build a solid and structured knowledge base. This knowledge base will be the set of data and information that the assistant will use to answer queries. The quality and relevance of this information will determine the effectiveness of the assistant in providing accurate and useful answers.
Search for Data Sources
We start with the collection of information sources that will feed our knowledge base. Not all sources of information are equally reliable. It is essential to assess the quality of the sources identified, ensuring that:
- Information is up to date: the relevance of data can change rapidly, especially in dynamic fields such as critical minerals.
- The source is reliable and recognised: it is necessary to use sources from recognised and respected academic and professional institutions.
- Data is complete and accessible: it is crucial that data is detailed and accessible for integration into our wizard.
In our case, we developed an online search in different platforms and information repositories trying to select information belonging to different recognised entities:
- Research centres and universities:
- They publish detailed studies and reports on the research and development of critical minerals.
- Example: RMIS of the Joint Research Center of the European Union.
- Governmental institutions and international organisations:
- These entities usually provide comprehensive and up-to-date data on the availability and use of critical minerals.
- Example: International Energy Agency (IEA).
- Specialised databases:
- They contain technical and specific data on deposits and production of critical minerals.
- Example: Minerals Database of the Spanish Geological and Mining Institute (BDMIN).
Selection and preparation of information
We will now focus on the selection and preparation of existing information from these sources to ensure that our GPT assistant can access accurate and useful data.
RMIS of the Joint Research Center of the European Union:
- Selected information:
We selected the report "Supply chain analysis and material demand forecast in strategic technologies and sectors in the EU - A foresight study". This is an analysis of the supply chain and demand for minerals in strategic technologies and sectors in the EU. It presents a detailed study of the supply chains of critical raw materials and forecasts the demand for minerals up to 2050.
- Necessary preparation:
The format of the document, PDF, allows the direct ingestion of the information by our assistant. However, as can be seen in Figure 1, there is a particularly relevant table on pages 238-240 which analyses, for each mineral, its supply risk, typology (strategic, critical or non-critical) and the key technologies that employ it. We therefore decided to extract this table into a structured format (CSV), so that we have two pieces of information that will become part of our knowledge base.

Figure 1: Table of minerals contained in the JRC PDF
To programmatically extract the data contained in this table and transform it into a more easily processable format, such as CSV(comma separated values), we will use a Python script that we can use through the platform Google Colab platform (Figure 2).

Figure 2: Script Python para la extracción de datos del PDF de JRC desarrollado en plataforma Google Colab.
To summarise, this script:
- It is based on the open source library PyPDF2capable of interpreting information contained in PDF files.
- First, it extracts in text format (string) the content of the pages of the PDF where the mineral table is located, removing all the content that does not correspond to the table itself.
- It then goes through the string line by line, converting the values into columns of a data table. We will know that a mineral is used in a key technology if in the corresponding column of that mineral we find a number 1 (otherwise it will contain a 0).
- Finally, it exports the table to a CSV file for further use.
International Energy Agency (IEA):
- Selected information:
We selected the report "Global Critical Minerals Outlook 2024". It provides an overview of industrial developments in 2023 and early 2024, and offers medium- and long-term prospects for the demand and supply of key minerals for the energy transition. It also assesses risks to the reliability, sustainability and diversity of critical mineral supply chains.
- Necessary preparation:
The format of the document, PDF, allows us to ingest the information directly by our virtual assistant. In this case, we will not make any adjustments to the selected information.
Spanish Geological and Mining Institute''s Minerals Database (BDMIN)
- Selected information:
In this case, we use the form to select the existing data in this database for indications and deposits in the field of metallogeny, in particular those with lithium content.

Figure 3: Dataset selection in BDMIN.
- Necessary preparation:
We note how the web tool allows online visualisation and also the export of this data in various formats. Select all the data to be exported and click on this option to download an Excel file with the desired information.

Figure 4: Visualization and download tool in BDMIN

Figure 5: BDMIN Downloaded Data.
All the files that make up our knowledge base can be found at GitHub, so that the reader can skip the downloading and preparation phase of the information.
5.2. GPT configuration and customisation for critical minerals
When we talk about "creating a GPT," we are actually referring to the configuration and customisation of a GPT (Generative Pre-trained Transformer) based language model to suit a specific use case. In this context, we are not creating the model from scratch, but adjusting how the pre-existing model (such as OpenAI''s GPT-4) interacts and responds within a specific domain, in this case, on critical minerals.
First of all, we access the application through our browser and, if we do not have an account, we follow the registration and login process on the ChatGPT platform. As mentioned above, in order to create a GPT step-by-step, you will need to have a Plus account. However, readers who do not have such an account can work with a free account by interacting with ChatGPT through a standard conversation.
Figure 6: ChatGPT login and registration page.
Once logged in, select the "Explore GPT" option, and then click on "Create" to begin the process of creating your GPT.

Figure 7: Creation of new GPT.
The screen will display the split screen for creating a new GPT: on the left, we will be able to talk to the system to indicate the characteristics that our GPT should have, while on the left we will be able to interact with our GPT to validate that its behaviour is adequate as we go through the configuration process.

Figure 8: Screen of creating new GPT.
In the GitHub of this project, we can find all the prompts or instructions that we will use to configure and customise our GPT and that we will have to introduce sequentially in the "Create" tab, located on the left tab of our screens, to complete the steps detailed below.
The steps we will follow for the creation of the GPT are as follows:
- First, we will outline the purpose and basic considerations for our GPT so that you can understand how to use it.
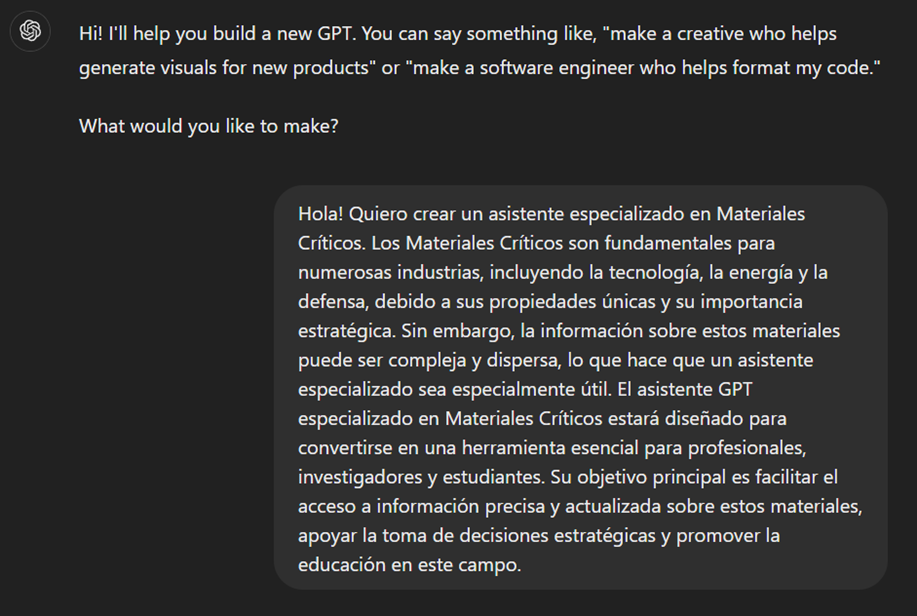
Figure 9: Basic instructions for new GPT.
2. We will then create a name and an image to represent our GPT and make it easily identifiable. In our case, we will call it MateriaGuru.

Figure 10: Name selection for new GPT.

Figure 11: Image creation for GPT.
3.We will then build the knowledge base from the information previously selected and prepared to feed the knowledge of our GPT.


Figure 12: Uploading of information to the new GPT knowledge base.
4. Now, we can customise conversational aspects such as their tone, the level of technical complexity of their response or whether we expect brief or elaborate answers.
5. Lastly, from the "Configure" tab, we can indicate the conversation starters desired so that users interacting with our GPT have some ideas to start the conversation in a predefined way.

Figure 13: Configure GPT tab.
In Figure 13 we can also see the final result of our training, where key elements such as their image, name, instructions, conversation starters or documents that are part of their knowledge base appear.
5.3. Validation and publication of GPT
Before we sign off our new GPT-based assistant, we will proceed with a brief validation of its correct configuration and learning with respect to the subject matter around which we have trained it. For this purpose, we prepared a battery of questions that we will ask MateriaGuru to check that it responds appropriately to a real scenario of use.
| # | Question | Answer |
|---|---|---|
| 1 | Which critical minerals have experienced a significant drop in prices in 2023? | Battery mineral prices saw particularly large drops with lithium prices falling by 75% and cobalt, nickel and graphite prices falling by between 30% and 45%. |
| 2 | What percentage of global solar photovoltaic (PV) capacity was added by China in 2023? | China accounted for 62% of the increase in global solar PV capacity in 2023. |
| 3 | What is the scenario that projects electric car (EV) sales to reach 65% by 2030? | The Net Zero Emissions (NZE) scenario for 2050 projects that electric car sales will reach 65% by 2030. |
| 4 | What was the growth in lithium demand in 2023? | Lithium demand increased by 30% in 2023. |
| 5 | Which country was the largest electric car market in 2023? | China was the largest electric car market in 2023 with 8.1 million electric car sales representing 60% of the global total. |
| 6 | What is the main risk associated with market concentration in the battery graphite supply chain? | More than 90% of battery-grade graphite and 77% of refined rare earths in 2030 originate in China, posing a significant risk to market concentration. |
| 7 | What proportion of global battery cell production capacity was in China in 2023? | China owned 85% of battery cell production capacity in 2023. |
| 8 | How much did investment in critical minerals mining increase in 2023? | Investment in critical minerals mining grew by 10% in 2023. |
| 9 | What percentage of battery storage capacity in 2023 was composed of lithium iron phosphate (LFP) batteries? | By 2023, LFP batteries would constitute approximately 80% of the total battery storage market. |
| 10 | What is the forecast for copper demand in a net zero emissions (NZE) scenario for 2040? | In the net zero emissions (NZE) scenario for 2040, copper demand is expected to have the largest increase in terms of production volume. |
Figure 14: Table with battery of questions for the validation of our GPT.
Using the preview section on the right-hand side of our screens, we launch the battery of questions and validate that the answers correspond to those expected.

Figure 15: Validation of GPT responses.
Finally, click on the "Create" button to finalise the process. We will be able to select between different alternatives to restrict its use by other users.

Figure 16: Publication of our GPT.
6. Scenarios of use
In this section we show several scenarios in which we can take advantage of MateriaGuru in our daily life. On the GitHub of the project you can find the prompts used to replicate each of them.
6.1. Consultation of critical minerals information
The most typical scenario for the use of this type of GPTs is assistance in resolving doubts related to the topic in question, in this case, critical minerals. As an example, we have prepared a set of questions that the reader can pose to the GPT created to understand in more detail the relevance and current status of a critical material such as graphite from the reports provided to our GPT.

Figure 17: Resolution of critical mineral queries.
We can also ask you specific questions about the tabulated information provided on existing sites and evidence on Spanish territory.
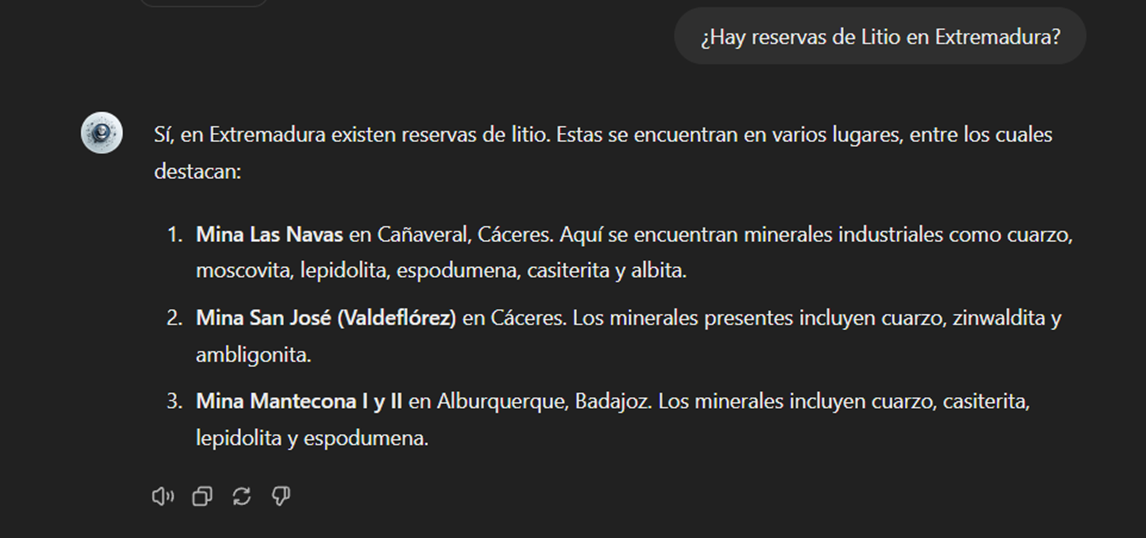
Figure 18: Lithium reserves in Extremadura.
6.2. Representation of quantitative data visualisations
Another common scenario is the need to consult quantitative information and make visual representations for better understanding. In this scenario, we can see how MateriaGuru is able to generate an interactive visualisation of graphite production in tonnes for the main producing countries.

Figure 19: Interactive visualisation generation with our GPT.
6.3. Generating mind maps to facilitate understanding
Finally, in line with the search for alternatives for a better access and understanding of the existing knowledge in our GPT, we will propose to MateriaGuru the construction of a mind map that allows us to understand in a visual way key concepts of critical minerals. For this purpose, we use the open Markmap notation (Markdown Mindmap), which allows us to define mind maps using markdown notation.

Figure 20: Generation of mind maps from our GPT
We will need to copy the generated code and enter it in a markmapviewer in order to generate the desired mind map. We facilitate here a version of this code generated by MateriaGuru.

Figure 21: Visualisation of mind maps.
7. Results and conclusions
In the exercise of building an expert assistant using GPT-4, we have succeeded in creating a specialised model for critical minerals. This wizard provides detailed and up-to-date information on critical minerals, supporting strategic decision making and promoting education in this field. We first gathered information from reliable sources such as the RMIS, the International Energy Agency (IEA), and the Spanish Geological and Mining Institute (BDMIN). We then process and structure the data appropriately for integration into the model. Validations showed that the wizard accurately answers domain-relevant questions, facilitating access to your information.
In this way, the development of the specialised critical minerals assistant has proven to be an effective solution for centralising and facilitating access to complex and dispersed information.
The use of tools such as Google Colab and Markmap has enabled better organisation and visualisation of data, increasing efficiency in knowledge management. This approach not only improves the understanding and use of critical mineral information, but also prepares users to apply this knowledge in real-world contexts.
The practical experience gained in this exercise is directly applicable to other projects that require customisation of language models for specific use cases.
8. Do you want to do the exercise?
If you want to replicate this exercise, access this this repository where you will find more information (the prompts used, the code generated by MateriaGuru, etc.)
Also, remember that you have at your disposal more exercises in the section "Step-by-step visualisations".
Content elaborated by Juan Benavente, industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
We are currently in the midst of an unprecedented race to master innovations in Artificial Intelligence. Over the past year, the star of the show has been Generative Artificial Intelligence (GenAI), i.e., that which is capable of generating original and creative content such as images, text or music. But advances continue to come and go, and lately news is beginning to arrive suggesting that the utopia of Artificial General Intelligence (AGI) may not be as far away as we thought. We are talking about machines capable of understanding, learning and performing intellectual tasks with results similar to those of the human brain.
Whether this is true or simply a very optimistic prediction, a consequence of the amazing advances achieved in a very short space of time, what is certain is that Artificial Intelligence already seems capable of revolutionizing practically all facets of our society based on the ever-increasing amount of data used to train it.
And the fact is that if, as Andrew Ng argued back in 2017, artificial intelligence is the new electricity, open data would be the fuel that powers its engine, at least in a good number of applications whose main and most valuable source is public information that is accessible for reuse. In this article we will review a field in which we are likely to see great advances in the coming years thanks to the combination of artificial intelligence and open data: artistic creation.
Generative Creation Based on Open Cultural Data
The ability of artificial intelligence to generate new content could lead us to a new revolution in artistic creation, driven by access to open cultural data and a new generation of artists capable of harnessing these advances to create new forms of painting, music or literature, transcending cultural and temporal barriers.
Music
The world of music, with its diversity of styles and traditions, represents a field full of possibilities for the application of generative artificial intelligence. Open datasets in this field include recordings of folk, classical, modern and experimental music from all over the world and from all eras, digitized scores, and even information on documented music theories. From the arch-renowned MusicBrainz, the open music encyclopedia, to datasets opened by streaming industry dominators such as Spotify or projects such as Open Music Europe, these are some examples of resources that are at the basis of progress in this area. From the analysis of all this data, artificial intelligence models can identify unique patterns and styles from different cultures and eras, fusing them to create unpublished musical compositions with tools and models such as OpenAI's MuseNet or Google's Music LM.
Literature and painting
In the realm of literature, Artificial Intelligence also has the potential to make not only the creation of content on the Internet more productive, but to produce more elaborate and complex forms of storytelling. Access to digital libraries that house literary works from antiquity to the present day will make it possible to explore and experiment with literary styles, themes and storytelling archetypes from diverse cultures throughout history, in order to create new works in collaboration with human creativity itself. It will even be possible to generate literature of a more personalized nature to the tastes of more minority groups of readers. The availability of open data such as the Guttemberg Project with more than 70,000 books or the open digital catalogs of museums and institutions that have published manuscripts, newspapers and other written resources produced by mankind, are a valuable resource to feed the learning of artificial intelligence.
The resources of the Digital Public Library of America1 (DPLA) in the United States or Europeana in the European Union are just a few examples. These catalogs not only include written text, but also vast collections of visual works of art, digitized from the collections of museums and institutions, which in many cases cannot even be admired because the organizations that preserve them do not have enough space to exhibit them to the public. Artificial intelligence algorithms, by analyzing these works, discover patterns and learn about artistic techniques, styles and themes from different cultures and historical periods. This makes it possible for tools such as DALL-E2 or Midjourney to create visual works from simple text instructions with aesthetics of Renaissance painting, Impressionist painting or a mixture of both.
However, these fascinating possibilities are accompanied by a still unresolved controversy about copyright that is being debated in academic, legal and juridical circles and that poses new challenges to the definition of authorship and intellectual property. On the one hand, there is the question of the ownership of rights over creations produced by artificial intelligence. On the other hand, there is the use of datasets containing copyrighted works that have been used in the training of models without the consent of the authors. On both issues there are numerous legal disputes around the world and requests for explicit removal of content from the main training datasets.
In short, we are facing a field where the advance of artificial intelligence seems unstoppable, but we must be very aware not only of the opportunities, but also of the risks involved.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
We continue with the series of posts about Chat GPT-3. The expectation raised by the conversational system more than justifies the publication of several articles about its features and applications. In this post, we take a closer look at one of the latest news published by openAI related to Chat GPT-3. In this case, we introduce its API, that is, its programming interface with which we can integrate Chat GPT-3 into our own applications.
Introduction.
In our last post about Chat GPT-3 we carried out a co-programming or assisted programming exercise in which we asked the AI to write us a simple program, in R programming language, to visualise a set of data. As we saw in the post, we used Chat GTP-3's own available interface. The interface is very minimalistic and functional, we just have to ask the AI in the text box and it answers us in the subsequent text box. As we concluded in the post, the result of the exercise was more than satisfactory. However, we also detected some points for improvement. For example, the standard interface can be a bit slow. For a long exercise, with multiple conversational interactions with the AI (a long dialogue), the interface takes quite a long time to write the answers. Several users report the same feeling and so some, like this developer, have created their own interface with the conversational assistant to improve its response speed.
But how is this possible? The reason is simple, thanks to the GPT-3 Chat API. We have talked a lot about APIs in this space in the past. Not surprisingly, APIs are the standard mechanisms in the world of digital technologies for integrating services and applications. Any app on our smartphone makes use of APIs to show us results. When we consult the weather, sports results or the public transport timetable, apps make calls to the APIs of the services to consult the information and display the results.
The GPT-3 Chat API
Like any other current service, openAI provides its users with an API with which they can invoke (call) its different services based on the trained natural language model GPT-3. To use the API, we just have to log in with our account at https://platform.openai.com/ and locate the menu (top right) View API Keys. Click on create a new secret key and we have our new access key to the service.

What do we do now? Well, to illustrate what we can do with this brand new key, let's look at some examples:
As we said in the introduction, we may want to try alternative interfaces to Chat GPT-3 such as https://www.typingmind.com/. When we access this website, the first thing we have to do is enter our API Key.
Once inside, let's do an example and see how this new interface behaves. Let's ask Chat GPT-3 What is datos.gob.es?
| Note: It is important to note that most services will not work if we do not activate a means of payment on the OpenAI website. Normally, if we have not configured a credit card, the API calls will return an error message similar to \"You exceeded your current quota, please check your plan and billing details\". |

Let's now look at another application of the GPT-3 Chat API.
Programmatic access with R to access Chat GPT-3 programmatically (in other words, with a few lines of code in R we have access to the conversational power of the GPT-3 model). This demonstration is based on the recent post published in R Bloggers. Let's access Chat GPT-3 programmatically with the following example.
| Note: Note that the API Key has been hidden for security and privacy reasons. |

En este ejemplo, utilizamos código en R para hacer una llamada HTTPs de tipo POST y le preguntamos a Chat GPT-3 ¿Qué es datos.gob.es? Vemos que estamos utilizando el modelo gpt-3.5-turbo que, tal y como se especifica en la documentación está indicado para tareas de tipo conversacional. Toda la información sobre la API y los diferentes modelos está disponible aquí. Pero, veamos el resultado:

Not bad, right? As a curious fact we can see that a few GPT-3 Chat API calls have had the following API usage:

The use of the API is priced per token (something similar to words) and the public prices can be consulted here. Specifically, the model we are using has these prices:
For small tests and examples, we can afford it. In the case of enterprise applications for production environments, there is a premium model that allows you to control costs without being so dependent on usage.
Conclusion
Naturally, Chat GPT-3 enables an API to provide programmatic access to its conversational engine. This mechanism allows the integration of applications and systems (i.e. everything that is not human) opening the door to the definitive take-off of Chat GPT-3 as a business model. Thanks to this mechanism, the Bing search engine now integrates GPT-3 Chat for conversational search responses. Similarly, Microsoft Azure has just announced the availability of GPT-3 Chat as a new public cloud service. No doubt in the coming weeks we will see communications from all kinds of applications, apps and services, known and unknown, announcing their integration with GPT-3 Chat to improve conversational interfaces with their customers. See you in the next episode, maybe with GPT-4.
Blog
Talking about GPT-3 these days is not the most original topic in the world, we know it. The entire technology community is publishing examples, holding events and predicting the end of the world of language and content generation as we know it today. In this post, we ask ChatGPT to help us in programming an example of data visualisation with R from an open dataset available at datos.gob.es.
Introduction
Our previous post talked about Dall-e and GPT-3's ability to generate synthetic images from a description of what we want to generate in natural language. In this new post, we have done a completely practical exercise in which we ask artificial intelligence to help us make a simple program in R that loads an open dataset and generates some graphical representations.
We have chosen an open dataset from the platform datos.gob.es. Specifically, a simple dataset of usage data from madrid.es portals. The description of the repository explains that it includes information related to users, sessions and number of page views of the following portals of the Madrid City Council: Municipal Web Portal, Sede Electrónica, Transparency Portal, Open Data Portal, Libraries and Decide Madrid.
The file can be downloaded in .csv or .xslx format and if we preview it, it looks as follows:

OK, let's start co-programming with ChatGPT!
First we access the website and log in with our username and password. You need to be registered on the openai.com website to be able to access GPT-3 capabilities, including ChatGPT.
We start our conversation:

During this exercise we have tried to have a conversation in the same way as we would have with a programming partner. So the first step we do is to say ‘hello’ and mention the problem we have. When we ask the AI to help us create a small program in R that graphically represents some data, it gives us some examples and helps us with the explanation of the program:

Since we have no data, we cannot do anything practical at the moment, so we ask it to help us generate some synthetic data.
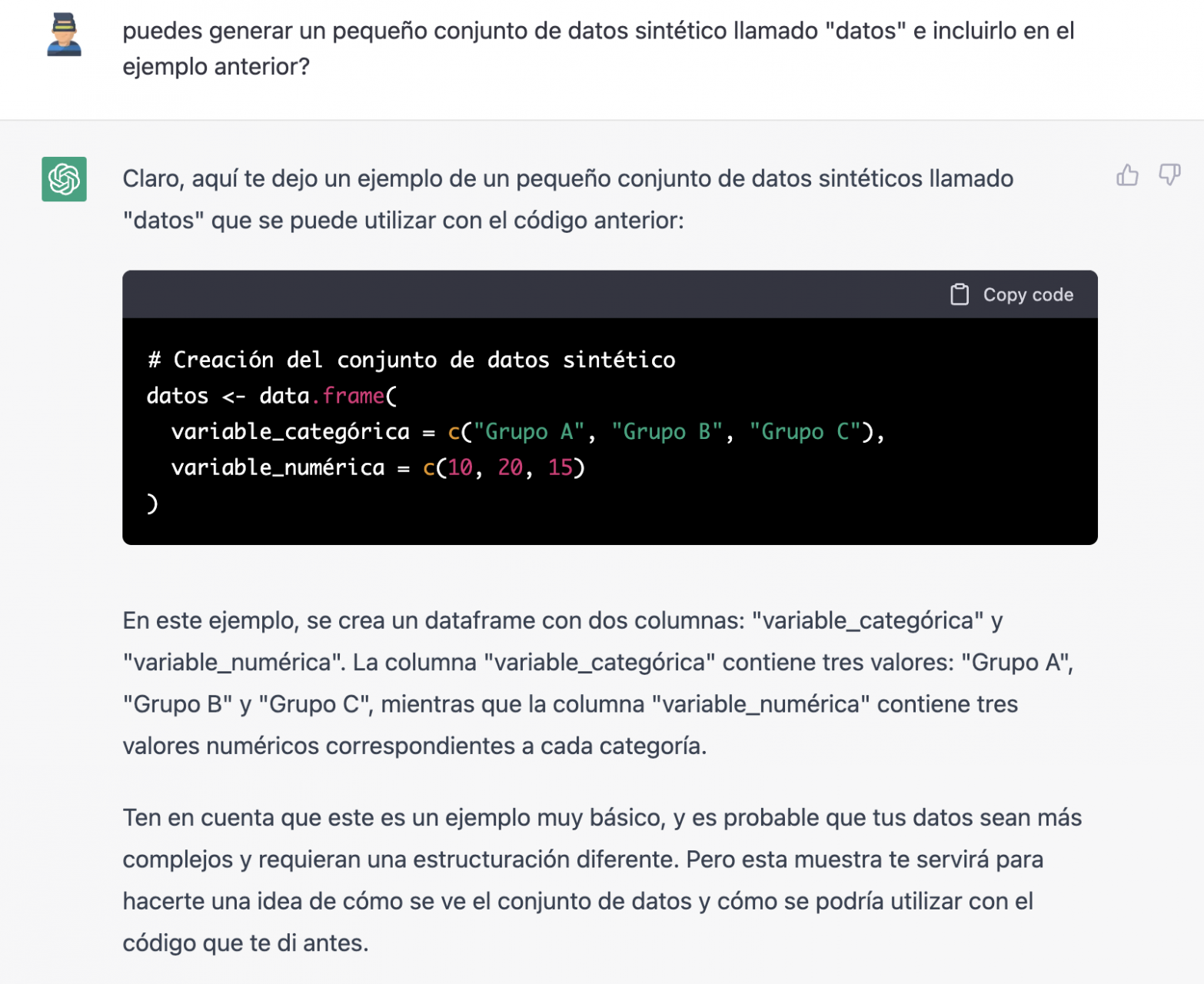
As we say, we behave with the AI as we would with a person (it looks good).

Once the AI seems to easily answer our questions, we go to the next step, we are going to give it the data. And here the magic begins... We have opened the data file that we have downloaded from datos.gob.es and we have copied and pasted a sample.
| Note: ChatGPT has no internet connection and therefore cannot access external data, so all we can do is give it an example of the actual data we want to work with. |


With the data copied and pasted as we have given it to it, the AI writes the code in R to load it manually into a dataframe called \"data\". It then gives us the code for ggplot2 (the most popular graphics library in R) to plot the data along with an explanation of how the code works.

Great! This is a spectacular result with a totally natural language and not at all adapted to talk to a machine. Let's see what happens next:
But it turns out that when we copy and paste the code into an RStudio environment it is no running.

So, we tell to it what's going on and ask it to help us to solve it.

We tried again and, in this case, it works!
However, the result is a bit clumsy. So, we tell it.

From here (and after several attempts to copy and paste more and more rows of data) the AI changes the approach slightly and provides me with instructions and code to load my own data file from my computer instead of manually entering the data into the code.

We take its opinion into account and copy a couple of years of data into a text file on our computer. Watch what happens next:

We try again:
As you can see, it works, but the result is not quite right.
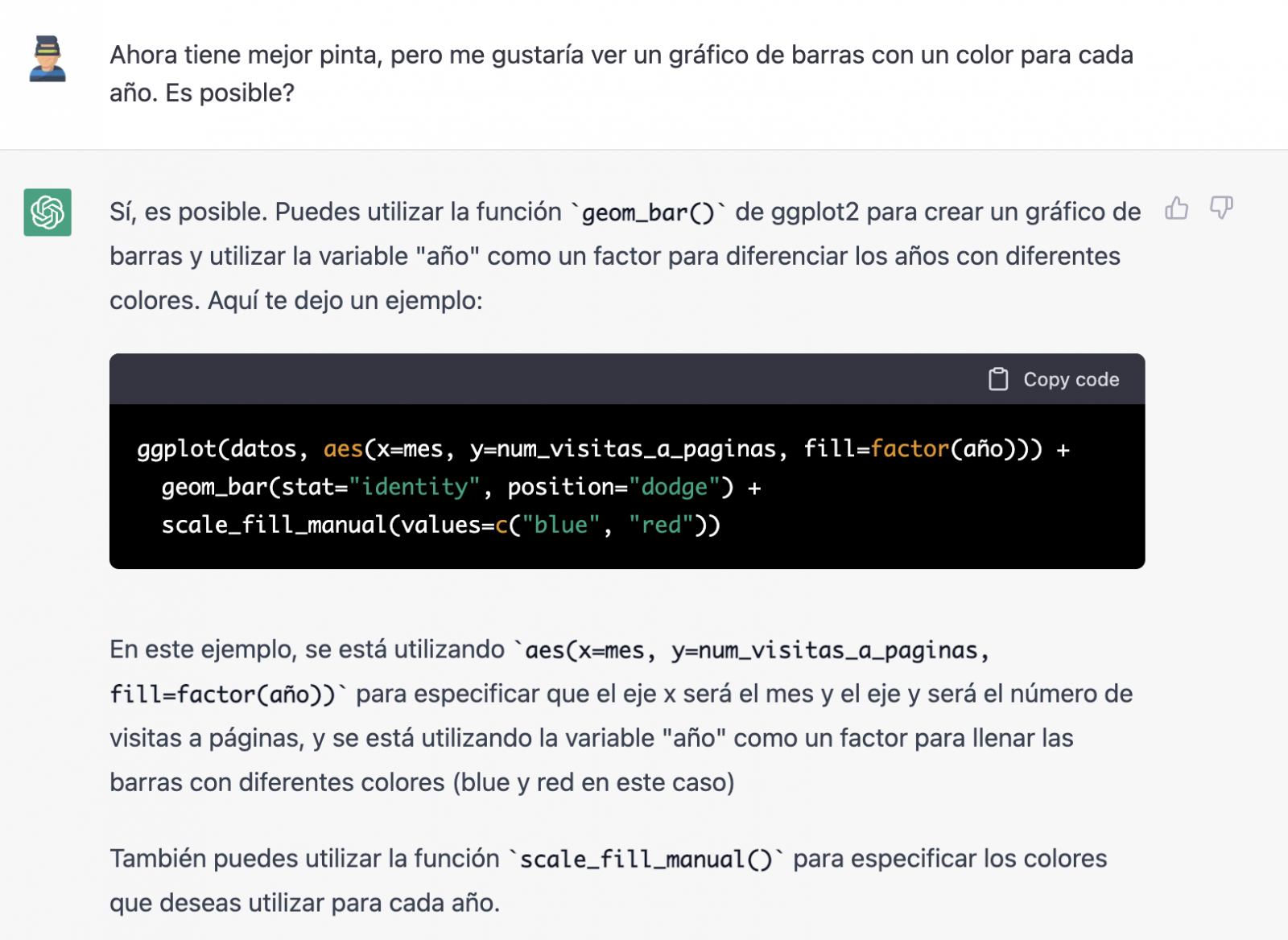
And let's see what happens.

Finally, it looks like it has understood us! That is, we have a bar chart with the visits to the website per month, for the years 2017 (blue) and 2018 (red). However, I am not convinced by the format of the axis title and the numbering of the axis itself.

Let's look at the result now.

It looks much better, doesn't it? But what if we give it one more twist?
However, it forgot to tell us that we must install the plotly package or library in R. So, we remind it.
Let's have a look at the result:

As you can see, we have now the interactive chart controls, so that we can select a particular year from the legend, zoom in and out, and so on.
Conclusion
You may be one of those sceptics, conservatives or cautious people who think that the capabilities demonstrated by GPT-3 so far (ChatGPT, Dall-E2, etc) are still very infantile and impractical in real life. All considerations in this respect are legitimate and, many of them, probably well-founded.
However, some of us have spent a good part of our lives writing programs, looking for documentation and code examples that we could adapt or take inspiration from; debugging bugs, etc. For all of us (programmers, analysts, scientists, etc.) to be able to experience this level of interlocution with an artificial intelligence in beta mode, made freely available to the public and being able to demonstrate this capacity for assistance in co-programming, is undoubtedly a qualitative and quantitative leap in the discipline of programming.
We don't know what is going to happen, but we are probably on the verge of a major paradigm shift in computer science, to the point that perhaps the way we program has changed forever and we haven't even realised it yet.
Content prepared by Alejandro Alija, Digital Transformation expert.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Generative artificial intelligence refers to machine’s ability to generate original and creative content, such as images, text or music, from a set of input data. As far as text generation is concerned, these models have been accessible, in an experimental format, for some time, but began to generate interest in mid-2020 when Open AI, an organisation dedicated to research in the field of artificial intelligence, published access to its GPT-3 language model via an API.
The GPT-3's architecture is composed of 175 billion parameters, comparing to its predecessor GPT-2 was 1.5 billion parameters, i.e. more than 100 times more. Therefore, GPT-3 represents a huge change in scale as it was also trained with a much larger corpus of data and a much larger token size, which allowed it to acquire a deeper and more complex understanding of the human language.
Although it was in 2022 when OpenAI announced the launch of chatGPT, which provides a conversational interface to a language model based on an improved version of GPT-3, it has only been in the last two months that the chat has attracted massive public attention, thanks to extensive media coverage that tries to respond to the emerging general interest.
In fact, ChatGPT is not only able to generate text from a set of characters (prompt) like GPT-3, but also it is able to respond to natural language questions in several languages including English, Spanish, French, German, Italian or Portuguese. This specific updated issue in the access interface from an API to a chatbot that has made the AI accessible to any type of user.
Maybe for this reason, more than a million people registered to use it in just five days, which has led to the multiplication of examples in which chatGPT produces software code, university-level essays, poems and even jokes. Not to mention the fact that it has been able to ace an history SAT or pass the final MBA exam at the prestigious Wharton School.
All of this has put generative AI at the centre of a new wave of technological innovation that promises to revolutionise the way we relate to the internet and the web through AI-powered searches or browsers capable of summarising the results of these searches.
Just a few days ago, we heard the news that Microsoft is working on the implementation of a conversational system within its own search engine, which has been developed based on the well-known Open AI language model and whose news has put Google in check.
As a result of this new reality in which AI is here to stay, the technological giants have gone a step further in the battle to make the most of the benefits it brings. Along these lines, Microsoft has presented a new strategy aimed at optimising the way in which we interact with the internet, introducing AI to improve the results offered by browser search engines, applications, social networks and, in short, the entire web ecosystem.
However, although the path in the development of new and future services offered by Open AI's remains to be seen, advances such as the mentioned above, offer a small hint of the browser war that is coming and that will probably change the way we create and find content on the web in the short term.
The open data
GPT-3, like other models that have been generated with the techniques described in the original GTP-3 scientific publication, is a pre-trained language model, which means that it has been trained with a large dataset, in total about 45 terabytes of text data. According to the paper, the training dataset was composed of 60% of data obtained directly from the internet containing millions of documents of all kinds, 22% from the WebText2 corpus built from Reddit, and the rest from a combination of books (16%) and Wikipedia (3%).
However, it is not known exactly how much open datasets GPT-3 uses, as OpenAI does not provide more specific details about the dataset used to train the model. What we can ask chatGPT itself are some questions that can help us draw interesting conclusions about its use of open data.
For example, if we ask chatGPT what was the population of Spain between 2015 and 2020 (we cannot ask for more recent data), we get an answer like this:

As we can see in the image above, although the question is the same, the answer may vary in both the wording and the information it contains. The variations can be even greater if we ask the question on different days or in different threads:
Small variations in the wording of the text, generating the question at different times in the conversation thread (remember that it saves the context) or in different threads or on different days may lead to slightly different results. Moreover, the answer is not completely accurate, as the tool itself warns us if we compare it with the INE's own series on the resident population in Spain, where it recommends us to consult. The data that we would ideally have expected in the response could be obtained in an open INE dataset:
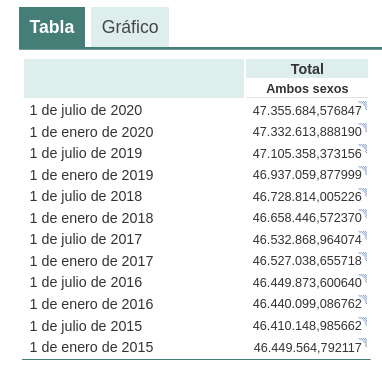
Such responses suggest that open data has not been used as an authoritative source for answering factual questions, or at least that the model is not yet fully refined on this matter. Doing some basic tests with questions about other countries we have observed similar errors, so this does not seem to be a problem only with questions referring to Spain.
If we ask more specific questions, such as asking for a list of the municipalities in the province of Burgos that begin with the letter "G", we get answers that are not completely correct, as is typical of a technology that is still in its infancy.
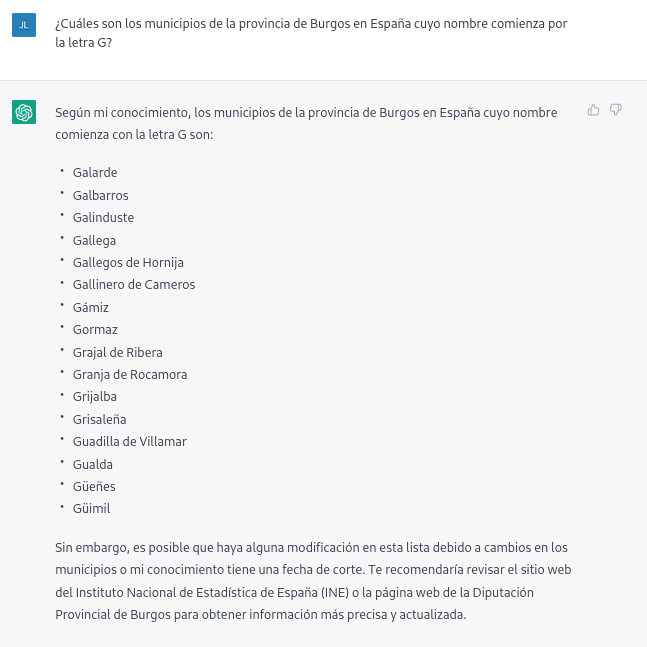
The correct answer should contain six municipalities: Galbarros, La Gallega, Grijalba, Grisaleña, Gumiel de Hizán and Gumiel del Mercado. However, the answer we have obtained only contains the first four and includes localities in the province of Guadalajara (Gualda), municipalities in the province of Valladolid (Gallegos de Hornija) or localities in the province of Burgos that are not municipalities (Galarde). In this case, we can also turn to the open dataset to get the correct answer.
Next, we ask ChatGPT for the list of municipalities beginning with the letter Z in the same province. ChatGPT tells us that there are none, reasoning the answer, when in fact there are four:
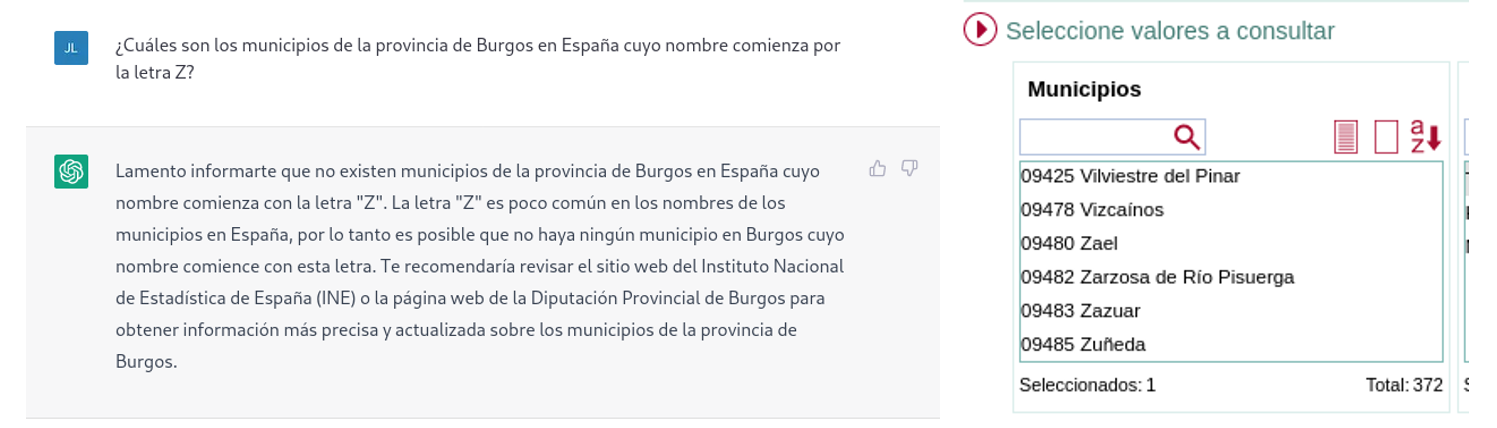
As can be seen from the examples above, we can see how open data can indeed contribute to technological evolution and thus improve the performance of Open AI's artificial intelligence. However, given its current state of maturity, it is still too early to see the optimal use of open data to answer more complex questions.
Therefore, for a generative AI model to be effective, it is necessary to have a large amount of high quality and diverse data, and open data is a valuable source of knowledge for this purpose.
In future versions of the model, we will probably be able to see how open data will acquire a much more important role in the composition of the training corpus, achieving a significant improvement in the quality of the factual answers.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
For years now we have been announcing that Artificial Intelligence is undergoing one of its most prolific, exciting periods. A time when applications and use cases begin to be seen in which human intelligence merges with artificial intelligence. Some occupations are changing forever. Journalists and writers now have software tools that can write for them. Content creators - images or video - can ask the machine to create for them just by saying a phrase. In this post we have taken a closer look at this last example. We have been able to test Dall-e 2 and the results have left us speechless.
Introduction
Nowadays, in the technological community worldwide, there is an underlying buzz, a collective excitement of all lovers of digital technologies and in particular of artificial intelligence. On several occasions we have mentioned the innovations of the company Open AI in this communication space. We have written several articles where we talk about the GPT-3 algorithm and what it is capable of in the field of natural language processing. Recently, OpenAI has been doing away with the waiting lists (on which many of us had been enrolled for a long time) to allow us to test in a limited way the capabilities of the GPT-3 algorithm implemented in different types of applications.
Example of the multiple applications of GPT-3 in the field of natural language.
We recommend our readers to try out the text completion tool with which, merely by providing a short sentence, the AI completes the text with several paragraphs indistinguishable from human writing. The last few days have been hectic with crowds of people testing the ChatGPT-3 tool. The degree of naturalness with which AI can have a conversation is simply amazing. The results are having an impact on a wide variety of use cases, such as support for software developers. ChatGPT-3 has been able to programme simple code routines or algorithms just from a description in natural language of what you want to programme. However, the result is even more impressive when we realise that AI is capable of correcting its own programming errors.
DALL-E
Leaving aside the capabilities of generating natural language indistinguishable from that written by a human, now let's take a look the main theme of this post. One of the most amazing applications of the AI of OpenAI is the solution known as DALL-E. What better way to introduce DALL-E than ask ChatGPT-3 what DALL-E is.
The more formal description of DALL-E, according to its own website, is as follows:
DALL·E is a 12-billion parameter version of GPT-3 trained to generate images from text descriptions. DALL-E has a diverse set of capabilities, including creating anthropomorphised versions of animals and objects, combining unrelated concepts in plausible ways, rendering text, and applying transformations to existing images..
There is currently a second version of the algorithm. DALL-E 2 capable of generating more realistic and precise images with a resolution 4 times higher. The tool for trying out DALL-E is available here https://labs.openai.com/. To use it, we first need to create an OpenAI account that will allow us to play with all the tools of the company. When we access the test website we can write our own text or ask the tool to generate random descriptions of images in natural language to create images. For example, by clicking the Surprise me button:

The web generates this random description for us: an astronaut lounging in a tropical resort in space, pixel art
And this is the result:

We repeat: An expressive oil painting of a basketball player dunking, depicted as an explosion of a nebula
We can assure you that the exercise is somewhat addictive and we admit that some of us have spent hours of our weekends playing with the descriptions and waiting, over and over again, for the amazing result.
About DALL-E 2 training
DALL-E 2 (arXiv:2204.06125) is a refined version of the original DALL-E system (arXiv:2102.12092). To train the original DALL-E model, which contains 12 billion parameters, a set of 250 million text-image pairs was used (publicly available online). This data set is a mixture of several prior datasets comprising: Conceptual Captions by Google; Wikipedia's text-image pairs and a filtered subset of YFCC100M.
DALL-E 2 trivia
Some interesting things besides the tests that we can do to generate our own images. OpenAI has created a specific Github repository which describes the risks and limitations of DALL-E. At the site it is reported, for example, that, for the time being, the use of DALL-E is limited to non-commercial purposes. So it is not possible to make any commercial use of the images generated. In other words, they cannot be sold or licensed under any circumstances. In this regard, all the images generated by DALL-E include a distinctive mark that lets you know that they have been generated by AI. At the Github site we can find loads of information about the generation of explicit content, the risks related with the bias that AI can introduce into the generation of images and the inappropriate uses of DALL-E such as the harassment, bullying or exploitation of individuals.

Along national lines, MarIA
Along national lines, after months of tests and adjustments, MarIA, the first supermassive artificial intelligence, has seen the light of day, trained with open data from the web archives of the National Library of Spain (BNE) and thanks to the computing resources of the National Supercomputing Centre. With regard to this post, MarIA has been trained using the GPT-2 algorithm which we have talked about many months ago in this space. To carry out the MarIA training, 135 billion previous words from the National Library's documentary bank have been used with a total volume of 570 Gigabytes of information.
Conclusions
As the days and weeks go by since the general opening of the APIs and the OpenIA tools, there has been a torrent of publications on all kinds of media, social media and specialised blogs about the capabilities and possibilities of Chat GPT-3 and DALL-E. I don't think that at this time anyone is capable of predicting the potential commercial, scientific and social applications of this technology. What is clear is that many of us think that OpenAI has shown only a sample of what it is capable of and it seems that we may be on the verge of a historic milestone in the development of AI after many years of overexpectations and unfulfilled promises. We will continue to report on the progress of GTP-3, but for the time being, all we can do is to keep enjoying, playing and learning with the simple tools that we have at our disposal!
Content prepared by Alejandro Alija, an expert in Digital Transformation.
The contents and points of view reflected in this publication are the sole responsibility of its author.