Blog
A medida que las organizaciones buscan aprovechar el potencial de los datos para tomar decisiones, innovar y mejorar sus servicios, surge un desafío fundamental: ¿cómo se puede equilibrar la recolección y el uso de datos con el respeto a la privacidad? Las tecnologías PET intentan dar solución a ese reto. En este post, exploraremos qué son y cómo funcionan.
¿Qué son las tecnologías PET?
Las tecnologías PET son un conjunto de medidas técnicas que utilizan diversos enfoques para la protección de la privacidad. El acrónimo PET viene de los términos en inglés “Privacy Enhancing Technologies” que se pueden traducir como “tecnologías de mejora de la privacidad”.
De acuerdo con la Agencia de la Unión Europea para la Ciberseguridad (ENISA) este tipo de sistemas protege la privacidad mediante:
- La eliminación o reducción de datos personales.
- Evitando el procesamiento innecesario y/o no deseado de datos personales.
Todo ello, sin perder la funcionalidad del sistema de información. Es decir, gracias a ellas se puede utilizar datos que de otra manera permanecerían sin explotar, ya que limita los riesgos de revelación de datos personales o protegidos, cumpliendo con la legislación vigente.
Relación entre utilidad y privacidad en datos protegidos
Para comprender la importancia de las tecnologías PET, es necesario abordar la relación que existe entre utilidad y privacidad del dato. La protección de datos de carácter personal siempre supone pérdida de utilidad, bien porque limita el uso de los datos o porque implica someterles a tantas transformaciones para evitar identificaciones que pervierte los resultados. La siguiente gráfica muestra cómo a mayor privacidad, menor es la utilidad de los datos.
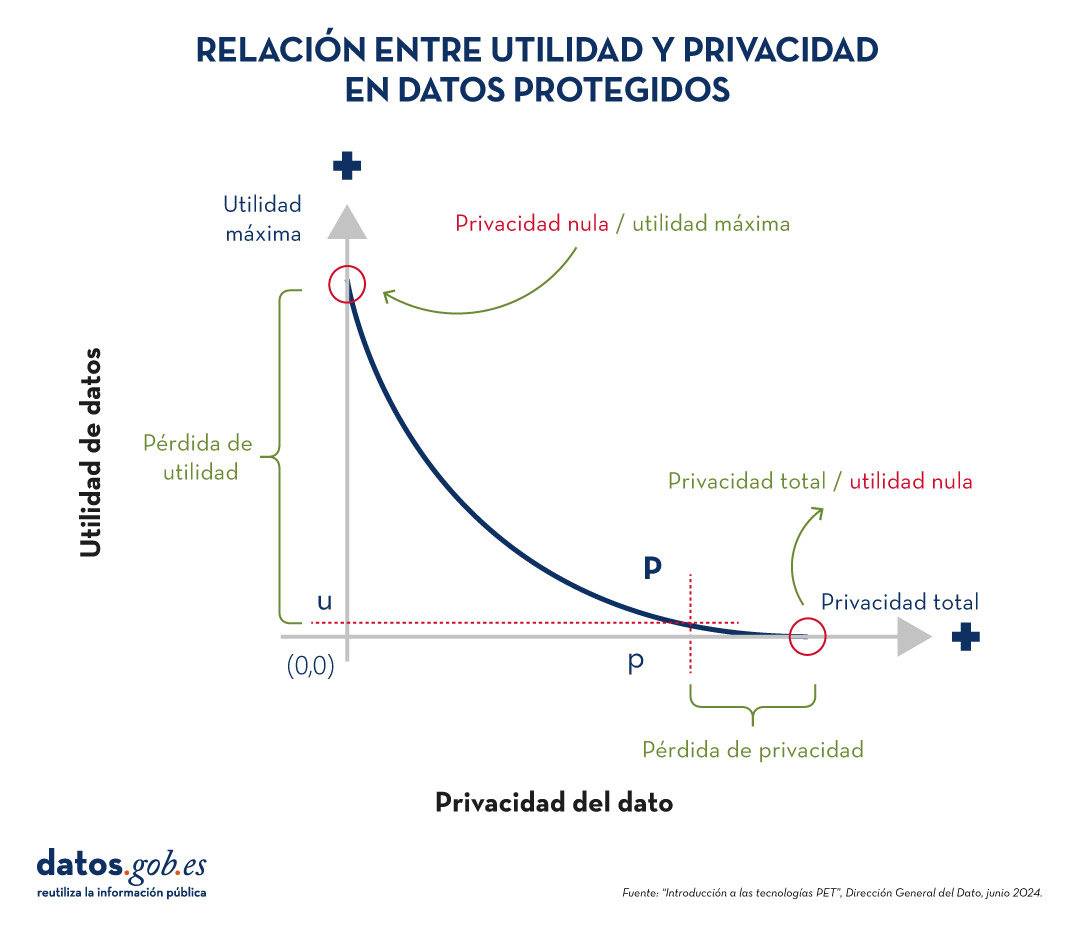
Figura 1. Relación entre utilidad y privacidad en datos protegido. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Las técnicas PET permiten alcanzar un compromiso entre privacidad y utilidad más favorable. No obstante, hay que tener en cuenta que siempre existirá cierta limitación de la utilidad cuando explotamos datos protegidos.
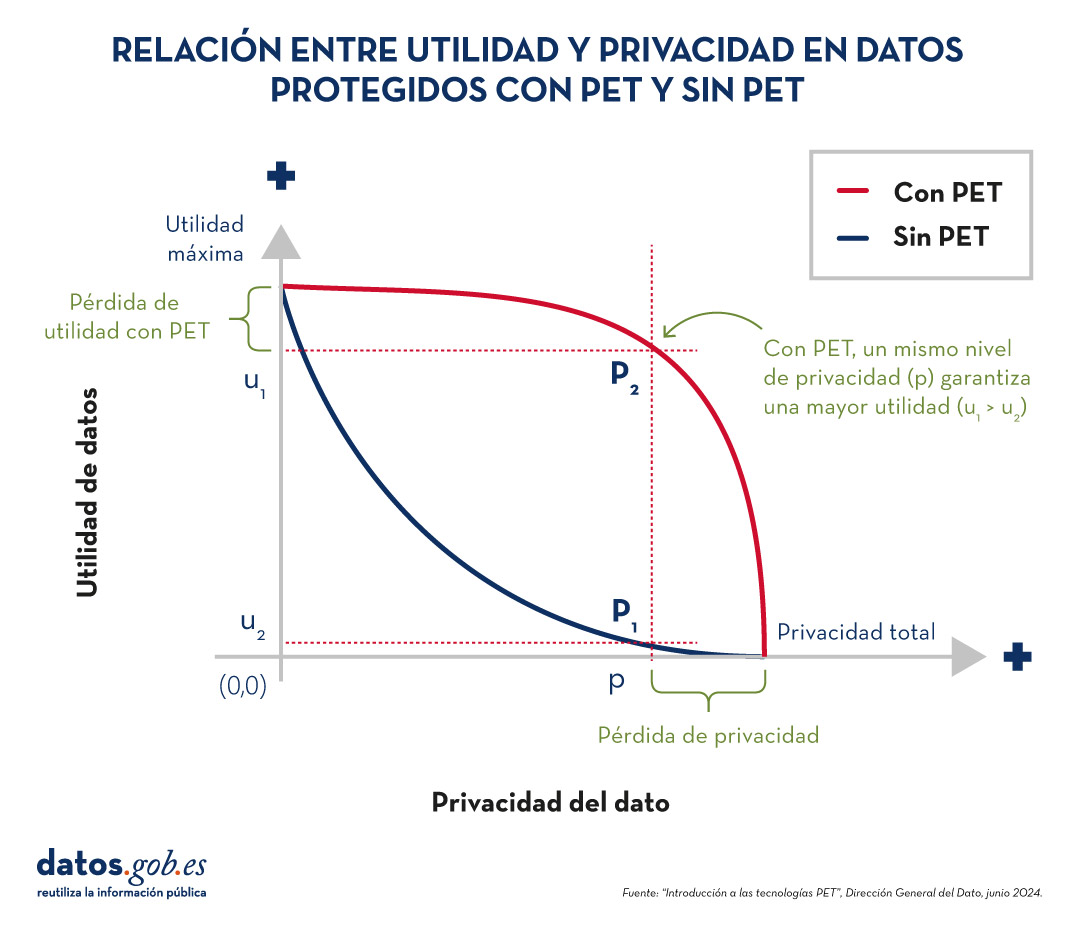
Figura 2. Relación entre utilidad y privacidad en datos protegidos con PET y sin PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Técnicas PET más populares
Para aumentar la utilidad y poder explotar datos protegidos limitando los riesgos, es necesario aplicar una serie de técnicas PET. El siguiente esquema, recoge algunas de las principales:
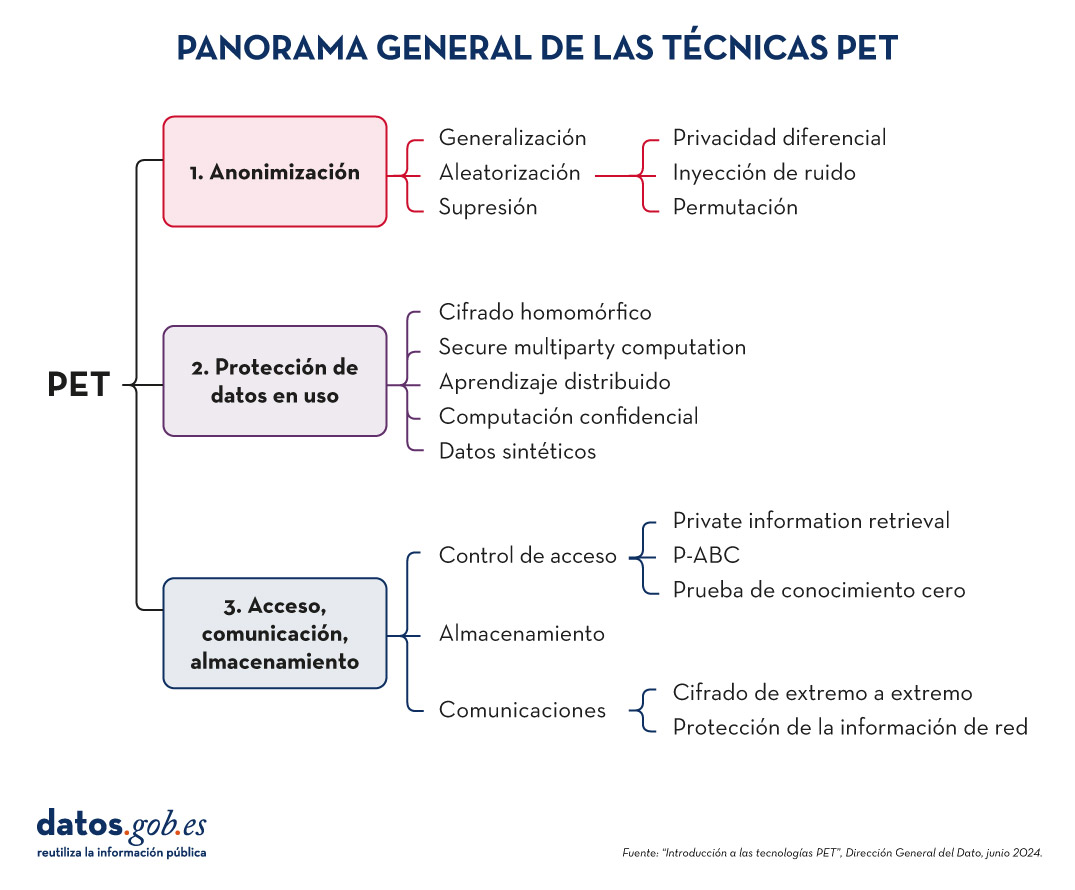
Figura 3. Panorama general de las técnicas PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Como veremos a continuación, estas técnicas abordan distintas fases del ciclo de vida de los datos.
-
Antes de la explotación de los datos: anonimización
La anonimización consiste en transformar conjuntos de datos de carácter privado para que no se pueda identificar a ninguna persona. De esta forma, ya no les aplica el Reglamento General de Protección de Datos (RGPD).
Es importante garantizar que la anonimización se ha realizado de forma efectiva, evitando riesgos que permitan la reidentificación a través de técnicas como la vinculación (identificación de un individuo mediante el cruzado de datos), la inferencia (deducción de atributos adicionales en un dataset), la singularización (identificación de individuos a partir de los valores de un registro) o la composición (pérdida de privacidad acumulada debida a la aplicación reiterada de tratamientos). Para ello, es recomendable combinar varias técnicas, las cuales se pueden agrupar en tres grandes familias:
- Aleatorización: supone modificar los datos originales al introducir un elemento de azar. Esto se logra añadiendo ruido o variaciones aleatorias a los datos, de manera que se preserven patrones generales y tendencias, pero se haga más difícil la identificación de individuos.
- Generalización: consiste en reemplazar u ocultar valores específicos de un conjunto de datos por valores más amplios o menos precisos. Por ejemplo, en lugar de registrar la edad exacta de una persona, se podría utilizar un rango de edades (como 35-44 años).
- Supresión: implica eliminar completamente ciertos datos del conjunto, especialmente aquellos que pueden identificar a una persona de manera directa. Es el caso de los nombres, direcciones, números de identificación, etc.
Puedes profundizar sobre estos tres enfoques generales y las diversas técnicas que los integran en la guía práctica “Introducción a la anonimización de datos: técnicas y casos prácticos”. También recomendamos la lectura del artículo malentendidos comunes en la anonimización de datos.
2. Protección de datos en uso
En este apartado se abordan técnicas que salvaguardan la privacidad de los datos durante la aplicación de tratamientos de explotación.
-
Cifrado homomórfico: es una técnica de criptografía que permite realizar operaciones matemáticas sobre datos cifrados sin necesidad de descifrarlos primero. Por ejemplo, un cifrado será homomórfico si se cumple que, si se cifran dos números y se realiza una suma en su forma cifrada, el resultado cifrado, al ser descifrado, será igual a la suma de los números originales.
- Computación Segura Multipartita (Secure Multiparty Computation o SMPC): es un enfoque que permite que múltiples partes colaboren para realizar cálculos sobre datos privados sin revelar su información a los demás participantes. Es decir, permite que diferentes entidades realicen operaciones conjuntas y obtengan un resultado común, mientras mantienen la confidencialidad de sus datos individuales.
- Aprendizaje distribuido: tradicionalmente, los modelos de machine learning aprenden de forma centralizada, es decir, requieren reunir todos los datos de entrenamiento procedentes de múltiples fuentes en un único conjunto de datos a partir del cual un servidor central elabora el modelo que se desea. En el caso del aprendizaje distribuido, los datos no se concentran en un solo lugar, sino que permanecen en diferentes ubicaciones, dispositivos o servidores. En lugar de trasladar grandes cantidades de datos a un servidor central para su procesamiento, el aprendizaje distribuido permite que los modelos de machine learning se entrenen en cada una de estas ubicaciones, integrando y combinando los resultados parciales para obtener un modelo final.
- Computación confidencial y entornos de computación de confianza (Trusted Execution Environments o TEE): la computación confidencial se refiere a un conjunto de técnicas y tecnologías que permiten procesar datos de manera segura dentro de entornos de hardware protegidos y certificados, conocidos como entornos de computación de confianza.
- Datos sintéticos: son datos generados artificialmente que imitan las características y patrones estadísticos de datos reales sin representar a personas o situaciones específicas. Reproducen las propiedades relevantes de los datos reales, como distribución, correlaciones y tendencias, pero sin información que permita identificar a individuos o casos específicos. Puedes aprender más sobre este tipo de datos en el informe Datos sintéticos: ¿Qué son y para qué se usan?.
3. Acceso, comunicación y almacenamiento
Las técnicas PET no solo abarcan la explotación de los datos. Entre ellas también encontramos procedimientos dirigidos a asegurar el acceso a recursos, la comunicación entre entidades y el almacenamiento de datos, garantizando siempre la confidencialidad de los participantes. Algunos ejemplos son:
Técnicas de control de acceso
- Recuperación Privada de Información (Private information retrieval o PIR): es una técnica criptográfica que permite a un usuario consultar una base de datos o servidor sin que este último pueda saber qué información está buscando el usuario. Es decir, asegura que el servidor no conozca el contenido de la consulta, preservando así la privacidad del usuario.
- Credenciales Basadas en Atributos con Privacidad (Privacy-Attribute Based Credentials o P-ABC): es una tecnología de autenticación que permite a los usuarios demostrar ciertos atributos o características personales (como la mayoría de edad o la ciudadanía) sin revelar su identidad. En lugar de mostrar todos sus datos personales, el usuario presenta solo aquellos atributos necesarios para cumplir con los requisitos de la autenticación o autorización, manteniendo así su privacidad.
- Prueba de conocimiento cero (Zero-Knowledge Proof o ZKP): es un método criptográfico que permite a una parte demostrar a otra que posee cierta información o conocimiento (como una contraseña) sin revelar el propio contenido de ese conocimiento. Este concepto es fundamental en el ámbito de la criptografía y la seguridad de la información, ya que permite la verificación de información sin la necesidad de exponer datos sensibles.
Técnicas de comunicaciones
- Cifrado extremo a extremo (End to End Encryption o E2EE): esta técnica protege los datos mientras se transmiten entre dos o más dispositivos, de forma que solo los participantes autorizados en la comunicación pueden acceder a la información. Los datos se cifran en el origen y permanecen cifrados durante todo el trayecto hasta que llegan al destinatario. Esto significa que, durante el proceso, ningún individuo u organización intermediaria (como proveedores de internet, servidores de aplicaciones o proveedores de servicios en la nube) puede acceder o descifrar la información. Una vez que llegan a destino, el destinatario es capaz de descifrarlos de nuevo.
- Protección de información de Red (Proxy & Onion Routing): un proxy es un servidor intermediario entre el dispositivo de un usuario y el destino de la conexión en internet. Cuando alguien utiliza un proxy, su tráfico se dirige primero al servidor proxy, que luego reenvía las solicitudes al destino final, permitiendo el filtrado de contenidos o el cambio de direcciones IP. Por su parte, el método Onion Routing protege el tráfico en internet a través de una red distribuida de nodos. Cuando un usuario envía información usando Onion Routing, su tráfico se cifra varias veces y se envía a través de múltiples nodos, o "capas" (de ahí el nombre "onion", que significa "cebolla" en inglés).
Técnicas de almacenamiento
- Almacenamiento garante de la confidencialidad (Privacy Preserving Storage o PPS): su objetivo es proteger la confidencialidad de los datos en reposo e informar a los custodios de los datos de una posible brecha de seguridad, utilizando técnicas de cifrado, acceso controlado, auditoría y monitoreo, etc.
Estos son solo algunos ejemplos de tecnologías PET, pero hay más familias y subfamilias. Gracias a ellas, contamos con herramientas que nos permiten extraer valor de los datos de forma segura, garantizando la privacidad de los usuarios. Datos que pueden ser de gran utilidad en múltiples sectores, como la salud, el cuidado del medio ambiente o la economía.
Documentación
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan.
Este proceso es fundamental, tanto cuando hablamos de datos abiertos como de datos en general, para proteger la privacidad de las personas, garantizando el cumplimiento normativo y de los derechos fundamentales.
El informe “Introducción a la anonimización de datos: Técnicas y casos prácticos”, elaborado por Jose Barranquero, define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
El objetivo del informe es ofrecer una introducción suficiente y concisa, principalmente orientada a publicadores de datos que necesitan garantizar la privacidad de estos. No se trata de una guía exhaustiva, sino una primera toma de contacto para entender los riesgos y técnicas disponibles, así como la complejidad inherente a cualquier proceso de anonimización de datos.
¿Qué técnicas se incluyen en el informe?
Tras una introducción donde se definen los términos más relevantes y los principios básicos de anonimización, el informe se centra en comentar tres enfoques generales para la anonimización de datos, cada uno de los cuales está integrado a su vez por diversas técnicas:
- Aleatorización: tratamiento de datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la Privacidad Diferencial.
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas basadas en agregación como Anonimato-K, Diversidad-L, o Proximidad-T.
- Seudonimización: reemplazo de valores por versiones cifradas o tokens, habitualmente a través de algoritmos de HASH, que impiden la identificación directa del individuo, a menos que se combine con otros datos adicionales, que deben estar custodiados de forma adecuada.
El documento describe cada una de estas técnicas, así como los riesgos que suponen, aportando recomendaciones para evitarlos. Si bien, la decisión final sobre qué técnica o conjunto de técnicas es más adecuada depende de cada caso particular.
El informe finaliza con un conjunto de ejemplos prácticos sencillos que muestran la aplicación de las técnicas Anonimato-K y seudonimización mediante cifrado con borrado de clave. Para simplificar la ejecución del caso, se pone a disposición de los usuarios el código y los datos utilizados en el ejercicio, disponibles en Github. Para seguir el ejercicio, es recomendable tener unos conocimientos mínimos del lenguaje pyhton.
A continuación, puedes descargar el informe completo, así como el resumen ejecutivo y una presentación-resumen.
Blog
Desde la publicación inicial del borrador de Reglamento europeo sobre Gobernanza de los Datos se han ido sucediendo diversos trámites en el seno del procedimiento establecido para su aprobación, entre los cuales destacan algunos informes de singular relevancia. Por lo que se refiere a la incidencia de la propuesta sobre el derecho a la protección de datos de carácter personal podemos destacar los elaborados por algunos organismos europeos con la finalidad de ofrecer su opinión acerca de la normativa propuesta por la Comisión.
- Por una parte, el pasado mes de julio se hizo público el elaborado por el Consejo Económico y Social, donde se destaca la importancia de salvaguardar los derechos fundamentales, advirtiendo que “la protección adecuada de estos derechos se ve amenazada por el uso distorsionado de datos recabados libremente bajo un consentimiento que no siempre se obtiene siguiendo procedimientos sencillos”.
- Por otra parte, el Comité Europeo de Protección de Datos y el Supervisor Europeo de Protección de Datos han emitido un informe conjunto con el que pretenden ofrecer al legislador europeo orientaciones para que el futuro Reglamento sobre gobernanza de los datos “encaje plenamente con la legislación de la UE en materia de protección de datos personales, para así fomentar la confianza en la economía digital y dar el mismo amparo que garantiza el Derecho de la UE”. ¿Cuáles son las principales indicaciones que incluye el informe?
A través de sus correspondientes informes, varios organismos de la UE enfatizan la necesidad de garantizar la protección de datos personales en el futuro Reglamento sobre Gobernanza de los datos
Condiciones para la licitud del tratamiento
Una de las principales dificultades a la hora de reutilizar la información del sector público es su vinculación con personas físicas que se encuentren plenamente identificadas o, incluso, pudieran serlo. En estos casos nos encontraríamos ante datos de carácter personal y, en consecuencia, resultaría de aplicación la normativa que tiene por objeto la protección de este derecho fundamental en el ámbito de toda la Unión Europea: el Reglamento 2016/679, de 27 de abril, general sobre protección de datos (RGDP).
Con carácter general, tanto la difusión de los datos por parte de las entidades públicas como, asimismo, el tratamiento que lleven a cabo los reutilizadores han de respetar los principios que contempla el artículo 5 RGPD. En concreto, es necesario asegurar la minimización de los datos, respetar la limitación temporal del tratamiento o, entre otras obligaciones, garantizar su exactitud y su integridad, así como la confidencialidad. Especial importancia merece la prohibición de uso de los datos para fines incompatibles con respecto a los que inicialmente justificaron la recogida de la información, sobre todo si tenemos en cuenta que con frecuencia se habrán obtenido sin necesidad de contar con el consentimiento de la persona titular de los datos, al justificarse su tratamiento para la realización de actividades de interés público.
La difusión y reutilización de la información del sector público debe respetar los requisitos y las obligaciones que contempla el Reglamento General de protección de Datos (RGDP)
Seudonimización y anonimización
El informe conjunto del Comité y el Supervisor enfatiza que ambas técnicas no pueden confundirse y, en consecuencia, las garantías aplicables son distintas en cada caso. En concreto, esta distinción ha de tenerse en cuenta por la respectiva entidad pública a la hora de evaluar la viabilidad de la reutilización desde la perspectiva de la protección de datos.
- La anonimización supone que, al no existir vinculación con las personas físicas, los datos puedan utilizarse sin sujeción a la normativa sobre protección de datos.
- Por el contrario, en la seudonimización sí sería posible la reidentificación del titular, en la medida que se dispone de información adicional que así lo permite. Por tanto, en este supuesto el tratamiento de la información sí estaría sujeto a la normativa sobre protección de datos.
En consecuencia, cuando se reutilicen datos seudonimizados será imprescindible fundamentar el tratamiento en alguna de las condiciones de licitud que contemplan los artículos 6 y 9 del RGPD, cumplir con los principios antes referidos, adoptar las medidas de seguridad adecuadas y, asimismo, respetar las obligaciones de transparencia a que se refieren los artículos 12 a 14 RGPD, condición esta última de singular importancia para facilitar el ejercicio de sus derechos a los titulares de los datos.
En todo caso, siempre que sea compatible con la finalidad principal a la que se destina el uso de los datos, la seudonimización es sin duda una medida razonable incluso cuando se disponga de una base jurídica adecuada para proceder al tratamiento de los datos personales sin necesidad de consentimiento del titular, puesto que se trata de una solución que refuerza su posición jurídica frente al uso de los datos por un tercero. Así se muestra, por ejemplo, en la regulación legal que admite la reutilización de los datos de salud para fines de investigación, supuesto en el que una de las condiciones imprescindibles consiste precisamente en que los datos se encuentren seudonimizados en ciertas condiciones. De este modo se permite garantizar la reidentificación cuando sea precisa por razones asistenciales y, al mismo tiempo, se limita el impacto de la reutilización en la esfera jurídica del titular de la información.
En los casos en los que se recurra a la seudoanimización, también será necesario cumplir la normativa de protección de datos
Proveedores de intercambio de datos y donación de datos
Se trata de una de las principales novedades del borrador de Reglamento. Por lo que se refiere a los proveedores, el dictamen conjunto del Supervisor y el Comité enfatiza la necesidad de reforzar los controles previos al inicio de su actividad y, por otra parte, garantizar que proporcionan la información adecuada a los titulares de la información, debiendo además prestarse una especial atención a los principios de protección de datos desde el diseño y por defecto, transparencia y limitación de la finalidad. Destaca asimismo la importancia de asegurar que dichos proveedores asistan de manera eficaz a los particulares en el ejercicio de los derechos que reconocen los artículos 15 a 22 RGPD, así como la conveniencia de que se fomente su adhesión a códigos de conducta formalizados.
En cuanto a la donación de datos con fines altruistas, dado que la base jurídica aplicable para admitir la reutilización sería el consentimiento, el informe mantiene que es necesario mejorar la regulación propuesta de manera que se fijen con mayor precisión cuáles serían los fines de interés general a los que se podría destinar la reutilización de los datos. De lo contrario, considera el informe que se pondría en riesgo la seguridad jurídica y el nivel de protección de los datos personales que garantiza el RGPD, en particular por lo que se refiere al principio según el cual los datos se recogerán con fines determinados, explícitos y legítimos (artículo 5 RGPD)
Para poder reutilizar datos personales obtenidos de la donación con fines altruistas será necesario contar con el consentimiento del afectado para el fin concreto.
En definitiva, una de las principales razones que justifican el Reglamento sobre Gobernanza de los Datos consiste precisamente en la necesidad de establecer una nueva regulación para aquellos conjuntos de datos sobre los que concurren derechos de terceros que dificultan su reutilización, tal y como sucede singularmente con la protección de los datos de carácter personal. Por tanto, aun cuando resulte de gran importancia apostar decididamente por impulsar la economía basada en los datos, no por ello puede olvidarse que el modelo europeo se fundamenta precisamente en la protección y defensa de los derechos fundamentales y las libertades públicas, lo que necesariamente implica que las medidas que contempla el RGPD se encuentren en la base de dicho modelo como han recordado en su dictamen el Comité Europeo de Protección de Datos y el Supervisor Europeo de Protección de Datos.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Los datos abiertos tienen un gran potencial para mejorar la transparencia y la rendición de cuentas o para la mejora de los servicios públicos y la creación de nuevos servicios, pero al mismo tiempo muestran también una cara menos amigable al aumentar nuestra vulnerabilidad y exponer información cada vez más detallada que no siempre es utilizada en nuestro beneficio. Esta cada vez más abundante información personal convenientemente combinada puede a su vez llevar a la identificación personal final o incluso a sofisticadas herramientas de control masivo si no se toman las medidas necesarias para evitarlo. Prácticamente cada aspecto de nuestras vidas ofrece muestras ya de esa doble vertiente positiva y negativa:
-
Por un lado la medicina de precisión nos ofrece grandes avances en el diagnóstico y tratamiento de las enfermedades, pero para ello será necesario recopilar y analizar una gran cantidad de información sobre los pacientes.
-
Los datos han revolucionado también la forma en la que nos desplazamos por las ciudades gracias a la multitud de aplicaciones disponibles y esos mismos datos son de gran utilidad también en la planificación urbana, pero por lo general al coste de compartir prácticamente todos nuestros movimientos a lo largo del día.
-
En el entorno educativo los datos pueden ofrecer experiencias de aprendizaje más adaptadas a los distintos perfiles y necesidades, aunque para ello será nuevamente necesario exponer datos sensibles sobre los expedientes académicos.
En definitiva, los datos personales están en todas partes: cada vez que usamos las redes sociales, cuando hacemos nuestras compras ya sea online o en una gran superficie, cuando hacemos una búsqueda online, cada vez que enviamos un correo electrónico o un mensaje o simplemente navegando por la red… Hoy en día guardamos mucha más información íntima en nuestros móviles que la que solíamos guardar en nuestros diarios personales. Nuevos retos como la gran cantidad de datos que las ciudades digitales gestionan sobre sus ciudadanos necesitan también de nuevos enfoques prácticos para garantizar la seguridad y privacidad de esos datos.
A todo lo anterior hay que sumar que, al ritmo al que sigue avanzado la tecnología hoy en día, puede llegar a ser realmente difícil el garantizar que la privacidad futura de nuestros datos se seguirá manteniendo inalterada, debido a las múltiples posibilidades que ofrece la interconexión de todos estos datos. Parece pues que en este nuevo mundo dirigido por los datos en el que nos adentramos será necesario también empezar a replantearnos el futuro de una nueva economía basada en los datos personales, una nueva forma de gestionar nuestras identidades y datos digitales y los nuevos mercados de datos asociados.
El problema de la privacidad en la gestión de los datos personales no ha hecho más que empezar y está aquí para quedarse como parte de nuestras identidades digitales. No sólo necesitamos un nuevo marco legal y nuevos estándares que se adapten a los tiempos actuales y protejan nuestros datos, sino que también debemos esforzarnos en concienciar y educar a toda una nueva generación sobre la importancia de la privacidad online. Nuestros datos nos pertenecen y debemos ser capaces de retomar y mantener el pleno control sobre ellos y poder así garantizar que se usarán únicamente bajo nuestro consentimiento explícito. Algunas iniciativas pioneras están trabajando ya en áreas clave como la sanidad, la energía o las redes sociales para devolver el control de los datos a sus verdaderos dueños.
Evento
DataLab Madrid organiza una nueva edición del taller de visualización de datos Visualizar´18. Su objetivo es crear un espacio de trabajo colaborativo, intercambio de conocimientos y formación teórico-práctica para investigar las implicaciones sociales, culturales y artísticas de la cultura de los datos, abriendo caminos para la participación y la crítica.
La cita tendrá lugar del 21 de septiembre al 5 de octubre en la sede de Medialab Prado. En esta ocasión, el evento girará en torno al poder de los datos personales. La preocupación de los ciudadanos por este asunto no ha dejado de crecer en un año marcado por la entrada en vigor del GDPR o por escándalos como el de Cambridge Analytica. Por ello, es una buena oportunidad para desarrollar proyectos que enriquezcan el debate sobre la privacidad y el uso de nuestros datos personales.
El taller se desarrollará en 3 partes: una jornada inaugural, un taller de desarrollo de ideas y una presentación final. La jornada inaugural tendrá lugar durante el viernes 21 y el sábado 22 de septiembre. En ella se presentará el propio taller, los proyectos seleccionados y los integrantes de los equipos, y se inaugurará la exposición The Glass Room. Los días siguientes tendrá lugar el taller de desarrollo de ideas, donde los distintos grupos trabajarán en común en el desarrollo de sus proyectos. Los resultados se presentarán el viernes 5 de octubre.
Los 6 proyectos seleccionados sobre los que trabajarán los distintos participantes son:
-
A-9. Black Eyes. El proyecto consiste en una video-instalación donde se mostrará un mapa que integra carreteras de todo el mundo. El usuario podrá interaccionar de manera directa con la obra seleccionando cualquier punto del mapa para visualizar imágenes en tiempo real del mismo. El objetivo es concienciar sobre el poder de la información y su influencia en un mundo globalizado.
-
Microblogs y micropolítica. Los participantes podrán exportar, scrapear, codificar y visualizar, de manera original, los datos personales que ellos mismos producen diariamente en su timeline público de Twitter. Si el tiempo lo permite, se repetirá el proceso con los datos de instituciones públicas y políticos electos.
-
My [inte] gration. Este proyecto busca cambiar la percepción de la crisis migratoria en base a los datos. A través de tecnologías big data y thick data se analizarán los derechos y necesidades de los migrantes, refugiados, minorías y comunidades vulnerables, con el objetivo final de crear espacios, ciudades y políticas inclusivas. Aunque la propuesta se centra en la ciudad de Madrid, está pensado para ser escalado a otras ciudades y regiones.
-
Bad Data Challenge. Durante este proyecto los participantes investigarán problemas de datos erróneos (es decir, conjuntos de datos que contengan datos perdidos, datos incompatibles, datos corruptos, datos desactualizados, etc.), utilizando diversas herramientas y metodologías.
-
Juego de Datos Personales. Este proyecto propone realizar un juego de mesa con visualizaciones modeladas de los datos personales para concienciar sobre su importancia. Los datos (características físicas, propiedades de identificación, rasgos sociales, ideas políticas, etc.) darán lugar a objetos atractivos al tacto que se complementen o no encajen. El objetivo del juego es atravesar el tablero conservando la mayor cantidad de datos personales, protegiendolos del enemigo (que los puede robar o intercambiar).
-
El gran G y sus secuaces. Aquellas personas que participen en este proyecto podrán desarrollar una herramienta web para conocer qué información personal almacenan las diferentes aplicaciones sobre ellos. Una vez recopilada esta información, los participantes desarrollarán un webcomic donde se cuente cómo los dispositivos recopilan datos de los usuarios a través de los dispositivos móviles.
Además, durante el transcurso del evento tendrán lugar diversas charlas y talleres prácticos, así como un encuentro de iniciativas ciudadanas por la privacidad y seguridad de los datos personales.
Aquellas personas que deseen participar en visualizar´18, todavía pueden apuntarse como colaboradores. La inscripción, que es gratuita hasta un máximo de 30 participantes, estará abierta hasta el miércoles 19 a las 23:59 CEST.
Documentación
La Agencia Española de Protección de Datos (AEPD) ha lanzado una guía de orientación para fomentar la reutilización de la información del sector público mientras se garantiza la privacidad de los ciudadanos. Con el fin de ofrecer unas directrices que acompañen en la implementación de estas técnicas, la AEPD ha publicado conjuntamente el documento Orientaciones y garantías en los procedimientos de anonimización de datos personales que explica pormenorizadamente cómo ocultar, enmascarar o disociar datos personales con el fin deeliminar o reducir al mínimo los riesgos de reidentificación de los datos anonimizados,permitiendo su divulgación y asegurando que no se vulneren los derechos a la protección de datos de las personas u organizaciones que no deseen ser identificadas, o que hayan puesto el anonimato como condición para ceder sus datos para su publicación. En resumen, una fórmula para compatibilizar el fomento de la reutilización y la normativa reguladora en materia de protección de datos, que asegure que el esfuerzo de reidentificación de los sujetos conlleva un coste suficientemente elevado para que no pueda ser abordado “en términos de relación esfuerzo-beneficio”.
El documento muestra, tanto los principios a tener en cuenta en un proceso de anonimización en las etapas de diseño del sistema de información(principio de privacidad por defecto, de privacidad objetiva, de plena funcionalidad, etc.), como las fases del protocolo de actuación en el proceso de anonimización, entre otras las siguientes:
- Definición del equipo de trabajo detallando las funciones de cada perfil, y garantizando, en la medida de lo posible, que cada miembro desempeñe sus tareas de forma independiente del resto. De esta manera, se evita que un error en un nivel sea revisado y aprobado en un nivel distinto por el mismo agente.
- Análisis de riesgos para gestionar los riesgos resultantes del principio de que ninguna técnica de anonimización puede garantizar en términos absolutos la imposibilidad de reidentificación.
- Definición de objetivos y finalidad de la información anonimizada.
- Preanonimización, eliminación/reducción de variables y anonimización criptográfica a través de técnicas tales como los algoritmos de Hash, algoritmos de cifrado, sello de tiempo, capas de anonimización, etc.
- Creación de un mapa de sistemas de información que asegure entornos segregados para cada tratamiento de datos personales que implique la separación del personal que accede a dicha información.
Por último el documento señala la importancia de formar e informar al personal implicado en los procesos de anonimización y al que trabaja con los datos anonimizados, destaca la necesidad de establecer garantías para proteger los derechos de los interesados (acuerdos de confidencialidad, auditorías del uso de la información anonimizada por parte de su destinatario…) y establece como fundamental la realización de auditorías periódicas de las políticas de anonimización, que deben estar documentadas.

La AEPD ofrece estas orientaciones aún a sabiendas que las mismas capacidades tecnológicas que se utilizan para anonimizar datos personales pueden ser utilizadas para la reidentificación de las personas. Es por ello por lo que insiste en la importancia de contemplar el riesgo como una contingencia latente y sustentar la fortaleza de la anonimización en medidas de evaluación del impacto, organizativas, tecnológicas, etc.; todo ello con el fin de conjugar la puesta a disposición de datos públicos y, a su vez, garantizar la protección de datos personales en la reutilización de la información con fines sociales, científicos y económicos.