Blog
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
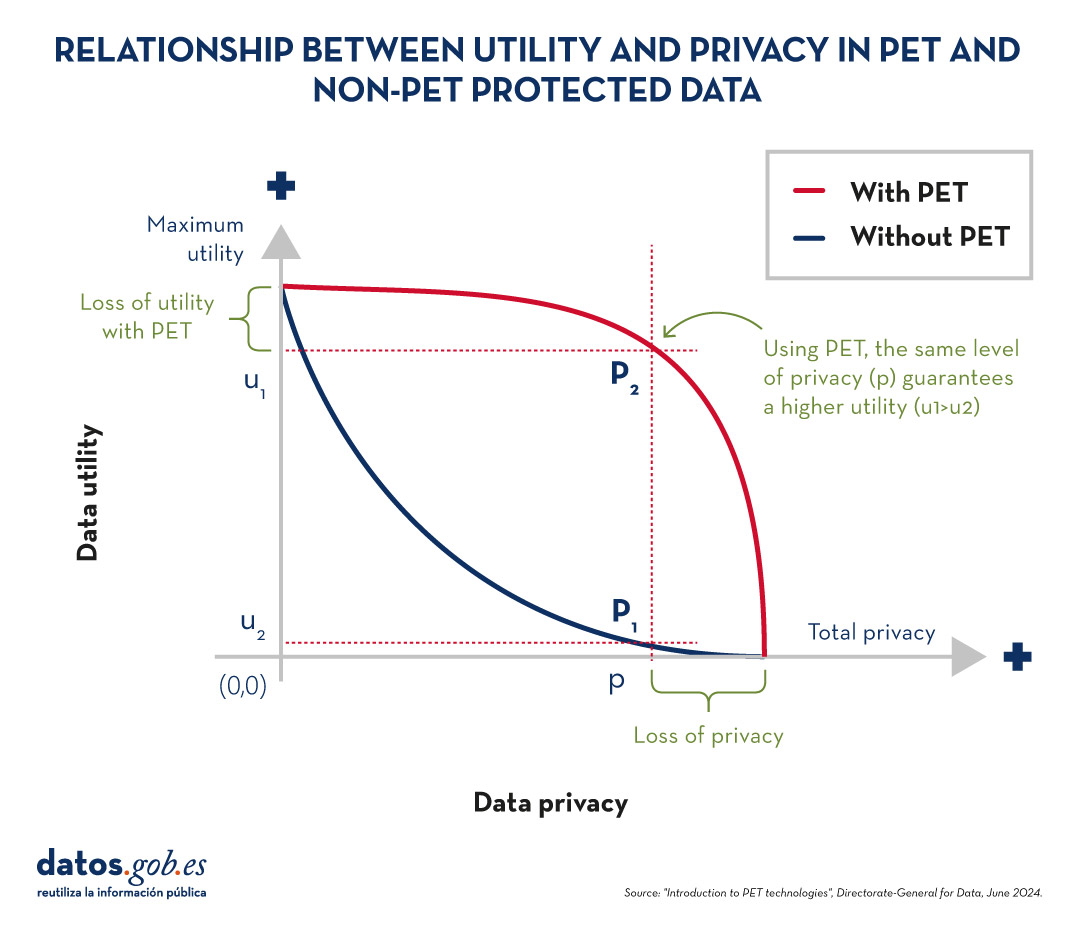
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
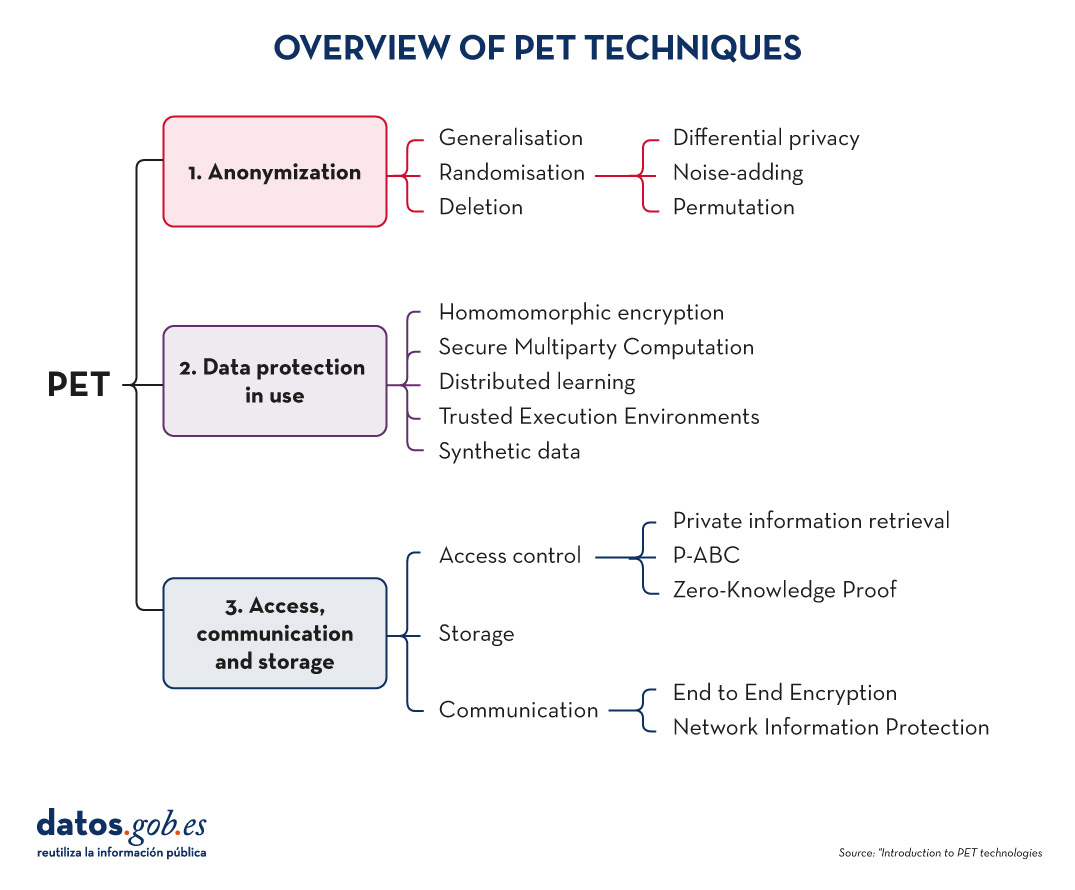
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.
Documentación
Data anonymization defines the methodology and set of best practices and techniques that reduce the risk of identifying individuals, the irreversibility of the anonymization process, and the auditing of the exploitation of anonymized data by monitoring who, when, and for what purpose they are used.
This process is essential, both when we talk about open data and general data, to protect people's privacy, guarantee regulatory compliance, and fundamental rights.
The report "Introduction to Data Anonymization: Techniques and Practical Cases," prepared by Jose Barranquero, defines the key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
The objective of the report is to provide a sufficient and concise introduction, mainly aimed at data publishers who need to ensure the privacy of their data. It is not intended to be a comprehensive guide but rather a first approach to understand the risks and available techniques, as well as the inherent complexity of any data anonymization process.
What techniques are included in the report?
After an introduction where the most relevant terms and basic anonymization principles are defined, the report focuses on discussing three general approaches to data anonymization, each of which is further integrated by various techniques:
- Randomization: data treatment, eliminating correlation with the individual, through the addition of noise, permutation, or Differential Privacy.
- Generalization: alteration of scales or orders of magnitude through aggregation-based techniques such as K-Anonymity, L-Diversity, or T-Closeness.
- Pseudonymization: replacement of values with encrypted versions or tokens, usually through HASH algorithms, which prevent direct identification of the individual unless combined with additional data, which must be adequately safeguarded.
The document describes each of these techniques, as well as the risks they entail, providing recommendations to avoid them. However, the final decision on which technique or set of techniques is most suitable depends on each particular case.
The report concludes with a set of simple practical examples that demonstrate the application of K-Anonymity and pseudonymization techniques through encryption with key erasure. To simplify the execution of the case, users are provided with the code and data used in the exercise, available on GitHub. To follow the exercise, it is recommended to have minimal knowledge of the Python language.
You can now download the complete report, as well as the executive summary and a summary presentation.
Blog
Since the initial publication of the draft European Regulation on Data Governance, several steps have been taken during the procedure established for its approval, among which some reports of singular relevance stand out. With regard to the impact of the proposal on the right to the protection of personal data, we can highlight those prepared by some European organizations with the aim of offering their opinion on the regulation proposed by the Commission.
- On the one hand, last July the Economic and Social Council made public its opinion, which stresses the importance of safeguarding fundamental rights, warning that "the adequate protection of these rights is threatened by the distorted use of data freely collected under a consent that is not always obtained following simple procedures".
- On the other hand, the European Data Protection Committee and the European Data Protection Supervisor have issued a joint report aiming to provide the European legislator with guidance to ensure that the future Data Governance Regulation "fully dovetails with EU legislation on personal data protection, thus fostering trust in the digital economy and providing the same protection as guaranteed by EU law." What are the main indications included in the report?
Through their corresponding reports, several EU bodies emphasize the need to ensure the protection of personal data in the future Data Governance Regulation.
Conditions for lawfulness of processing
One of the main difficulties when reusing public sector information is its link to individuals who are fully identified or even could be identified. In these cases, we would be dealing with data of a personal nature and, consequently, the regulations aimed at protecting this fundamental right in the scope of the entire European Union would be applicable: the General Data Protection Regulation 2016/679 of 27 April (GDPR).
In general, both the dissemination of data by public entities and, likewise, the processing carried out by reusers must respect the principles provided for in Article 5 GDPR. Specifically, it is necessary to ensure the minimization of the data, respect the time limitation of the processing or, among other obligations, guarantee its accuracy and integrity, as well as confidentiality. Of particular importance is the prohibition on the use of data for purposes incompatible with those that initially justified the collection of the information, especially if we consider that the data will often have been obtained without the consent of the data subject, when processing is justified for the performance of activities in the public interest.
The dissemination and reuse of public sector information must comply with the requirements and obligations set forth in the General Data Protection Regulation (GDPR).
Pseudonymization and anonymization
The joint report of the Committee and the Supervisor emphasizes that the two techniques cannot be confused and, consequently, the applicable safeguards are different in each case. In particular, this distinction has to be considered by the respective public entity when assessing the feasibility of reuse from a data protection perspective.
- Anonymization means that, because there is no link to the natural persons, the data can be used without being subject to data protection regulations.
- In pseudonymization, on the other hand, it would be possible to re-identify the data subject, insofar as additional information is available to enable this. Therefore, in this case, the processing of the information would be subject to data protection regulations.
Consequently, when pseudonymized data are reused, it will be essential to base the processing on one of the conditions of lawfulness provided for in Articles 6 and 9 of the GDPR, to comply with the principles referred to above, to adopt appropriate security measures and also to respect the transparency obligations referred to in Articles 12 to 14 of the GDPR, the latter condition being particularly important to facilitate the exercise of their rights by the data subjects.
In any case, provided that it is compatible with the main purpose for which the data is used, pseudonymization is certainly a reasonable measure even when there is an adequate legal basis to proceed with the processing of personal data without the consent of the data subject, since it is a solution that strengthens his legal position against the use of the data by a third party. This is shown, for example, in the legal regulation that allows the reuse of health data for research purposes, where one of the essential conditions is precisely that the data must be pseudonymized under certain conditions. This makes it possible to guarantee re-identification when necessary for health care reasons and, at the same time, limits the impact of reuse on the legal sphere of the owner of the information.
In cases where pseudo-animation is used, it is also necessary to comply with data protection regulations
Data sharing providers and data donation
This is one of the main new features of the draft Regulation. As regards providers, the joint opinion of the Supervisor and the Committee emphasizes the need to strengthen controls prior to the start of their activity and, on the other hand, to ensure that they provide adequate information to data subjects, with particular attention being paid to the principles of data protection by design and by default, transparency and purpose limitation. It also stresses the importance of ensuring that such providers effectively assist individuals in exercising their rights under Articles 15 to 22 of the GDPR, as well as the desirability of encouraging their adherence to formalized codes of conduct.
As regards the donation of data for altruistic purposes, given that the applicable legal basis for admitting reuse would be consent, the report maintains that it is necessary to improve the proposed regulation so as to establish more precisely the purposes of general interest for which the reuse of data could be used. Otherwise, the report considers that legal certainty and the level of protection of personal data guaranteed by the GDPR would be jeopardized, in particular with regard to the principle that data shall be collected for specified, explicit and legitimate purposes (Article 5 GDPR).
In order to reuse personal data obtained from the donation for altruistic purposes, it will be necessary to have the consent of the person concerned for the specific purpose.
In short, one of the main reasons justifying the Data Governance Regulation is precisely the need to establish a new regulation for those sets of data over which there are third-party rights that hinder their reuse, as is particularly the case with the protection of personal data. Therefore, although it is of great importance to make a firm commitment to promoting the data-driven economy, it should not be forgotten that the European model is based precisely on the protection and defense of fundamental rights and public freedoms, which necessarily implies that the measures contemplated in the GDPR are at the basis of this model, as the European Data Protection Committee and the European Data Protection Supervisor have recalled in their opinions.
Content prepared by Julián Valero, Professor at the University of Murcia and Coordinator of the Research Group "Innovation, Law and Technology" (iDerTec).
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Open data has great potential to improve transparency and accountability or to enhance public services and the creation of new services, but at the same time they also show a less friendly face by increasing our vulnerability and exposing information increasingly more detailed that is not always used to our benefit. This increasingly abundant personal information conveniently combined can lead to final personal identification or even to sophisticated mass control tools if the necessary measures are not taken to avoid it. Practically every aspect of our lives offers examples of that double positive and negative slope:
-
On one hand, precision medicine offers great advances in the diagnosis and treatment of diseases, but it will be necessary to collect and analyze a large amount of information about patients.
-
The data has also revolutionized the way we travel through cities thanks to the multitude of applications available and these same data are also very useful in urban planning, but usually at the cost of sharing virtually all our movements.
- In the educational context, the data can offer learning experiences more adapted to the different profiles and needs, although it will again be necessary to expose sensitive data about the academic files.
Personal data is everywhere: every time we use social networks, when we shop online or offline, when we do an online search, every time we send an email or a message... Today we keep much more personal information on our phones than we used to keep in our personal journals. New challenges such as the large amount of data that digital cities manage about their citizens also require new practical approaches to guarantee the security and privacy of these data.
Moreover, as technology continues advancing so fast, it can become really difficult to guarantee that the future privacy of our data will be maintained unchanged, due to the multiple possibilities offered by the interconnection of all this data. Therefore, it seems that in this new world guided by data, it will also be necessary to begin to rethink the future of a new economy based on personal data, a new way of managing our identities and digital data and the new data markets associates.
The privacy problem in the management of personal data has only just begun and it is here to stay as part of our digital identities. Not only do we need a new legal framework and new standards that adapt to current times and protect our data, but we have to make an effort to raise awareness and educate a whole new generation about the importance of online privacy. Our data belongs to us and we should be able to retake and maintain full control over them and be able to guarantee that they will be used only with our explicit consent. Some pioneering initiatives are already working in key areas such as health, energy or social media to return control of the data to their real owners.
Evento
DataLab Madrid organizes a new edition of Visualizar'18, a data visualization workshop. Its objective is to create a spaces for collaborative work, knowledge exchange and theoretical and practical training to investigate the social, cultural and artistic implications of data culture, opening up avenues for participation and criticism.
The meeting will take place from September 21 to October 5 at Medialab Prado. On this occasion, the event will revolve around the power of personal data. Citizens’ concerns about this issue continue growing in a year marked by the entry into force of GDPR or scandals such as Cambridge Analytica. Therefore, it is a good opportunity to develop projects that enrich the debate on privacy and the use of our personal data.
The workshop will have 3 parts: an opening day, a workshop focused on the development of ideas and a final presentation. The opening day will take place on Friday, September 21 and Saturday, September 22. Those days, organizers will introduce the workshop, the selected projects and the teams’ members, and the exhibition The Glass Room will be inaugurated. The following days, it will be time for the workshop, where the different groups will work together for developing their projects. The results will be presented on Friday, October 5.
The 6 selected projects are:
- A-9. Black Eyes: The project consists of a video-installation whit a map that integrates roads from all over the world. The user can interact directly with the work by selecting any point on the map to view real-time imagen. The objective is to raise awareness about the power of information and its influence in a globalized world.
- Microblogs and micropolitics: Participants will be able to export, scrape, encode and visualize, in an original way, the personal data that they daily produce on their public Twitter timeline. If time permits, the process will be repeated with data from public institutions and elected politicians.
- My [inte] gration. This project seeks to change the perception of the migration crisis based on the data. Through big data and thick data technologies, the rights and needs of migrants, refugees, minorities and vulnerable communities will be analyzed, with the ultimate goal of creating spaces, cities and inclusive policies. Although the proposal focuses on the city of Madrid, it is intended to be scaled to other cities and regions.
- Bad Data Challenge. During this Project, the participants will investigate erroneous data problems (that is, data sets that contain lost data, incompatible data, corrupt data, outdated data, etc.), using various tools and methodologies.
- Personal Data Game. This project want to create a board game with modeled visualizations of personal data in order to raise awareness about this topic. Those data (physical characteristics, identification properties, social features, political ideas, etc.) will give rise to attractive objects that complement each other or not. The objective of the game is to cross the board keeping the greatest amount of personal data, protecting them from the enemy (who can steal or exchange them).
- The big G and his henchmen. Those people who participate in this project will be able to develop a web tool to know what personal information store the different applications. Once this information is gathered, the participants will develop a webcomic to show how the devices collect data from users through mobile devices.
In addition, during the event various lectures and workshops will take place, as well as a meeting of citizen initiatives for privacy and personal data security.
Those people who wish to participate in visualize'18, can still sign up as collaborators. Registration, which is free up to 30 participants, will be open until Wednesday 19 at 23:59 CEST.
Documentación
The Spanish Data Protection Agency (AEPD) has launched a guide to promote the re-use of public sector information whereas the privacy of citizens is guaranteed. In order to provide some guidelines that help the implementation of these techniques, the AEPD has also published the document entitled “Guidelines and guarantees in the process of personal data anonymisation” which explains in detail how to hide, mask or dissociate personal data in order to eliminate or minimize the risks of re-identification of anonymised data, enabling the release and guaranteeing the rights to data protection of individuals or organizations that do not wish to be identified, or have established the anonymity as a condition to transfer their data for publication. In other words, a formula to juggle the promotion of the re-use with the regulatory rules on data protection, which ensures that the effort in re-identification of individuals carries a cost high enough to not be addressed "in terms of relative effort -benefit".
The document shows both the principles to be considered in a process of anonymization in the design stages of the information system (principle of privacy by default, objective privacy, of full functionality, etc.), as the phases of the performance protocol in the process of anonymisation, including the following:
- Defining the team detailing the functions of each profile, and ensuring, as far as possible, that each member performs the tasks independently of the rest. Thus, it prevents that an error in a level is reviewed and approved at a different level by the same agent.
- Risk analysis to manage risks arising from the principle that any anonymisation technique can guarantee absolutely the impossibility of re-identification.
- Defining goals and objectives of the anonymised information.
- Preanonymisation, elimination/reduction of variables and cryptographic anonymisation through techniques such as hashing algorithms, encryption algorithms, time stamp, and anonymisation layers, etc.
- Creating a map of information systems to ensure segregated environments for each processing of personal data involving the separation of personnel accessing such information.
Finally, the document highlights the importance of training and informing the personnel involved in the processes of anonymization who work with anonymised data, focussing on the need of establishing guarantees to protect the rights of stakeholders (confidentiality agreements, audits of the use of anonymised information by the recipient ...) and establishes as a fundamental conducting regular audits of anonymization policies, which must be documented.

The AEPD offers these guidelines even knowing that the same technological capabilities that are used to anonymise personal data can be used for re-identification of people. That is the reason to emphasize the importance of considering the risk as a latent contingency and sustain the strength of the anonymisation in impact assessment measures, organizational, technological, etc. .; all in order to combine the provision of public data and ensure the protection of personal data in the re-use of information with social, scientific and economic purposes.