
Description
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
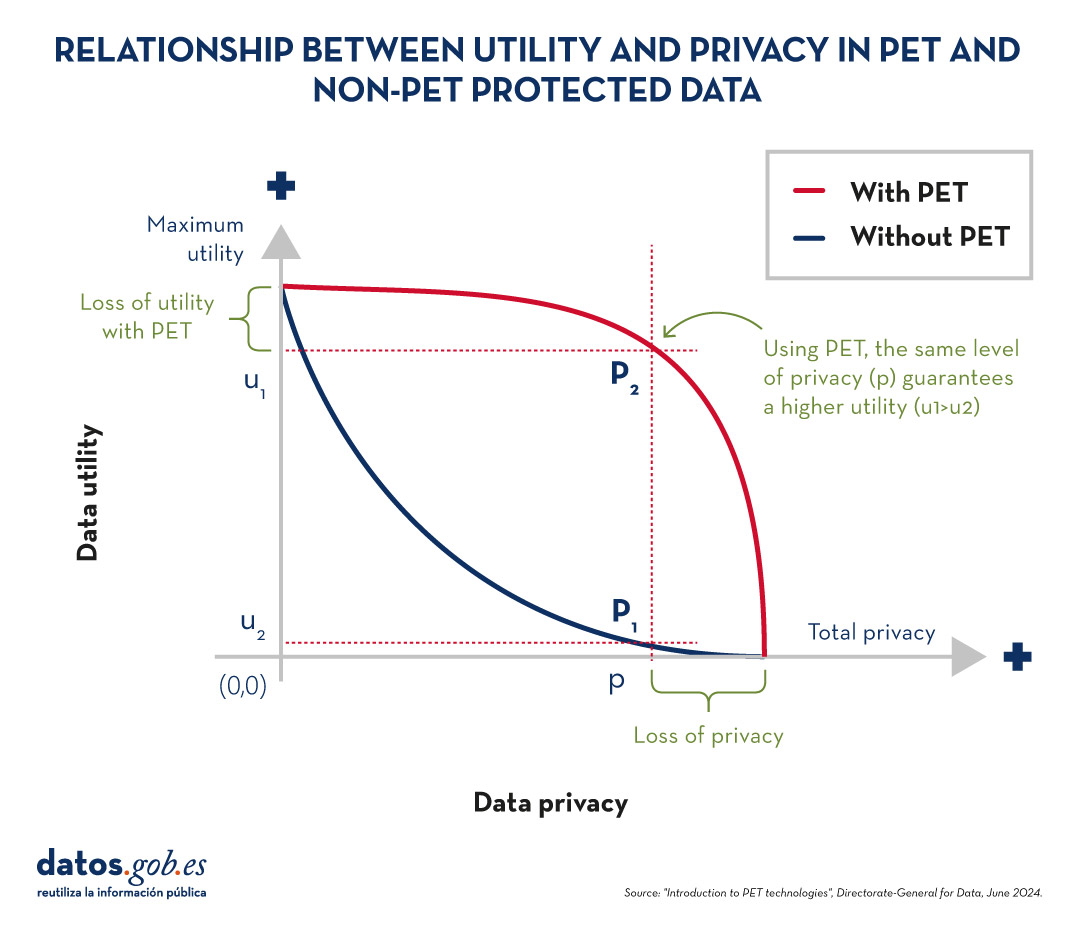
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
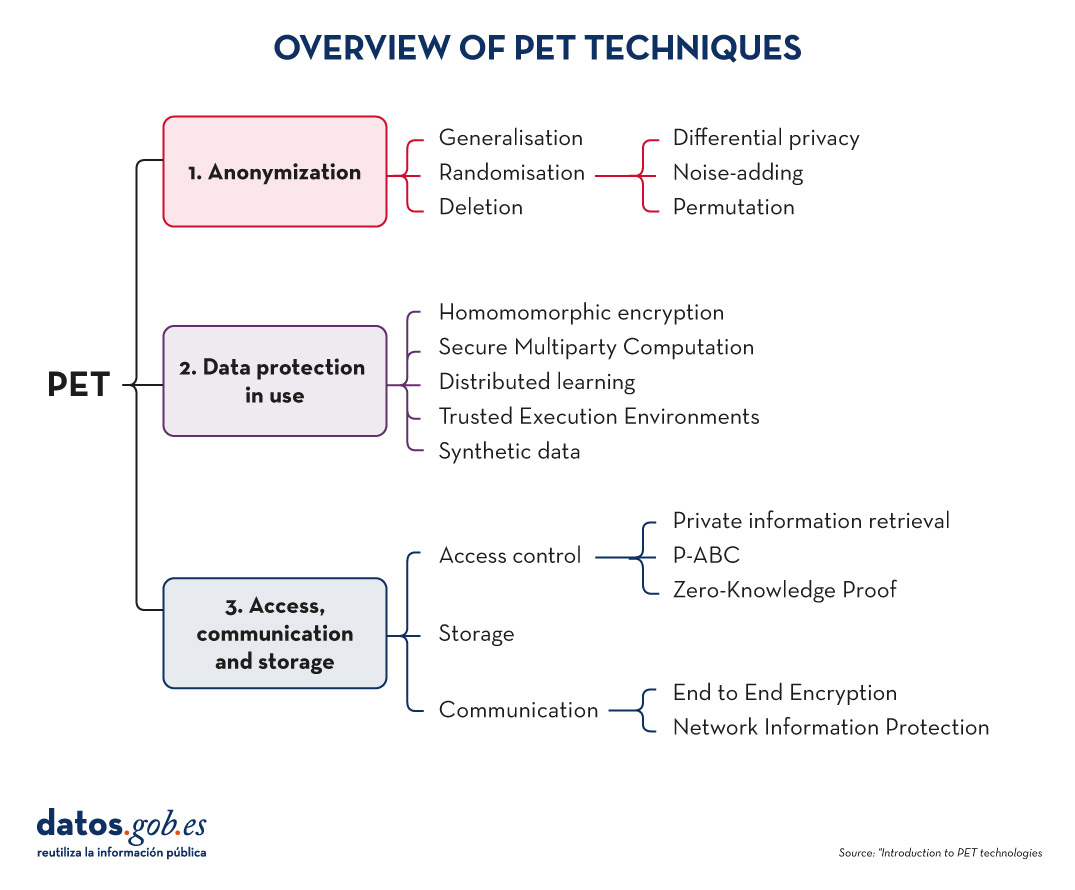
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.


Precisamente el manual que mencionáis (Introducción a la anonimización de datos: técnicas y casos prácticos) ha sido muy útil para un proyecto de recogida de datos personales con anonimización que hemos llevado a cabo en la D. G. de Seguros y Fondos de Pensiones. Altamente recomendable, tanto técnicamente como por el apoyo que supone su origen.