
Description
We are in a historical moment, where data has become a key asset for almost any process in our daily lives. There are more and more ways to collect data and more capacity to process and share it, where new technologies such as IoT, Blockchain, Artificial Intelligence, Big Data and Linked Data play a crucial role.
Both when we talk about open data, and data in general, it is critical to be able to guarantee the privacy of users and the protection of their personal data, understood as Fundamental rights. An aspect that sometimes does not receive special attention despite the rigorous existing regulations, such as the GDPR.
What is anonymization and what techniques are there?
The anonymization of data defines the methodology and the set of good practices and techniques that reduce the risk of identifying persons, the irreversibility of the anonymization process and the audit of the exploitation of the anonymized data, monitoring who, when and what they are used for. In other words, it covers both the objective of anonymization and that of mitigating the risk of re-identification, the latter being a key aspect.
To understand it well, it is necessary to speak of the confidentiality chain, a term that includes the analysis of specific risks for the purpose of the treatment to be carried out. The breaking of this chain implies the possibility of re-identification, that is, of identifying the specific people to whom it belongsns
Anonymization techniques are focused on identifying and obfuscating microdata, indirect identifiers and other sensitive data. When we talk about obfuscating, we refer to changing or altering sensitive data or data that identifies a person (personally identifiable information or PII, in English), in order to protect confidential information. In this case, lMicrodata are unique data for each individual, which can allow direct identification (ID, medical record code, full name, etc.). Indirect identification data can be crossed with the same or different sources to identify an individual (sociodemographic, browser configuration, etc.). It should be noted that sensitive data are those referred to in article 9 of the RGPD (especially financial and medical data).
In general, they can be considered various anonymization techniques, without European legislation contains any prescriptive rules, there are 4 general approaches:
- Randomization: alteration of the data, eliminating the correlation with the individual, by adding noise, permutation, or differential privacy (that is, collecting data from global users without knowing who each data corresponds to).
- Generalization: alteration of scales or orders of magnitude through techniques such as Aggregation / Anonymity-K or Diversity-l/Proximity-t.
- Encryption: obfuscation via HASH algorithms, with key erasure, or direct processing of encrypted data through homomorphic techniques. Both techniques can be complemented with time stamps or electronic signature.
- Pseudonymisation: replacement of attributes by encrypted versions or tokens that prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys. prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys.
Basic principles of anonymization
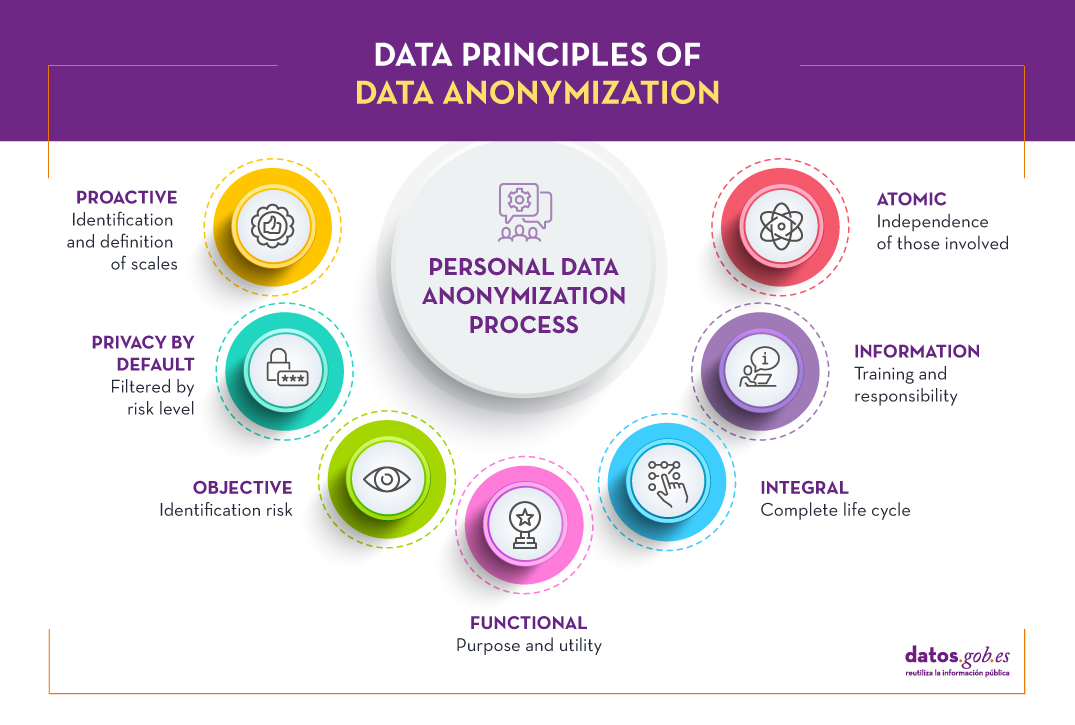
Like other data protection processes, anonymization must be governed by the concept of privacy by design and by default (Art. 25 of the RGPD), taking into account 7 principles:
- Proactive: the design must be considered from the initial stages of conceptualization, identifying microdata, indirect identification data and sensitive data, establishing sensitivity scales that are informed to all those involved in the anonymization process.
- Privacy by default: it is necessary to establish the degree of detail or granularity of the anonymized data in order to preserve confidentiality, eliminating non-essential variables for the study to be carried out, taking into account risk and benefit factors.
- Objective: Given the impossibility of absolute anonymization, it is critical to assess the level of risk of re-identification assumed and to establish adequate contingency policies.
- Functional: To guarantee the usefulness of the anonymized data set, it is necessary to clearly define the purpose of the study and inform users of the distortion processes used so that they are taken into account during their exploitation.
- Integral: the anonymization process goes beyond the generation of the data set, being applicable also during the study of these, through confidentiality and limited use contracts, validated through the relevant audits throughout the life cycle.
- Informative: this is a key principle, being necessary that all the participants in the life cycle are properly trained and informed regarding their responsibility and the associated risks.
- Atomic It is recommended, as far as possible, that the work team be defined with independent people for each function within the process.
In an anonymization process, an essential task is to define a scheme based on the three levels of identification of people: microdata, indirect identifiers and sensitive data (principle of proactivity), where a quantitative value is assigned to each of the variables. This scale must be known to all the personnel involved (information principle) and is critical for the Impact Assessment on the Protection of Personal Data (EIPD).
What are the main risks and challenges associated with anonymization?
Given the advancement of technology, it is especially complex to be able to guarantee absolute anonymization, so the risk of re-identification is approached as a residual risk, assumed and managed, and not as a breach of regulations. That is, it is governed by the principle of objectivity, being necessary to establish contingency policies. These policies must be considered in terms of cost versus benefit, making the effort required for re-identification unaffordable or reasonably impossible.
It should be noted that the risk of re-identification increases with the passage of time, due to the possible appearance of new data or the development of new techniques, such as future advances in quantum computing, which could lead to the encryption key break.
Specifically, three specific risk vectors associated with re-identification are established, defined in the Opinion 05/2014 on anonymization techniques:
- Singling out: risk of extracting attributes that allow an individual to be identified.
- Linkability: risk of linking at least two attributes to the same individual or group, in one or more data sets.
- Inference: risk of deducing the value of a critical attribute from other attributes.
The following table, proposed
| Is there a risk of singularization? | Is there a risk of linkability? | Is there a risk of inference? | |
|---|---|---|---|
| Pseudonymisation | Yes | Yes | Yes |
| Adding noise | Yes | Maybe not | Maybe not |
| Substitution | Yes | Yes | Maybe not |
| Aggregation and anonymity K | No | Yes | Yes |
| Diversity l | No | Yes | Maybe not |
| Differential privacy | Maybe not | Maybe not | Maybe not |
| Hash/Tokens | Yes | Yes | Maybe not |
Another important factor is the quality of the resulting data for a specific purpose, also called utility, since sometimes it is necessary to sacrifice part of the information (privacy principle by default). This entails an inherent risk for which it is necessary to identify and propose mitigation measures to avoid the loss of informative potential of the anonymized data set, focused on a specific use case (principle of functionality).
Ultimately, the challenge lies in ensuring that the analysis of the anonymized data does not differ significantly from the same analysis performed on the original data set, thus minimizing the risk of re-identification by combining various anonymization techniques and monitoring of everything. the process; from anonymization to exploitation for a specific purpose.
References and regulations
- REGULATION (EU) 2016/679 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of April 27, 2016
- DIRECTIVE (EU) 2019/1024 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of 20 June 2019
- Organic Law 3/2018, of December 5, on Protection of Personal Data and guarantee of digital rights
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak - European Data Protection Board
Content written by Jose Barranquero, expert in data science and quantum computing.
The contents and points of view reflected in this publication are the sole responsibility of its author.



Comments