Blog
Enseñar a los ordenadores a entender cómo hablan y escriben los humanos es un viejo desafío en el campo de la inteligencia artificial, conocido como procesamiento de lenguaje natural (PLN). Sin embargo, desde hace poco más de dos años, estamos asistiendo a la caída de este antiguo bastión con la llegada de los modelos grandes del lenguaje (LLM) y los interfaces conversacionales. En este post, vamos a tratar de explicar una de las técnicas clave que hace posible que estos sistemas nos respondan con relativa precisión a las preguntas que les hacemos.
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog, varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del RAG. En este post vamos a tratar de explicarlo de la forma más sencilla posible.
Los modelos grandes del lenguaje o Large Language Models (hay cosas que es mejor no traducir…) son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los LLM por sí solos no proporcionarán respuestas específicas o habrá una alta probabilidad de que alucinen y se inventen completamente la respuesta. Que los LLM alucinen significa que generan texto inexacto, sin sentido o desconectado. Este efecto plantea riesgos y desafíos potenciales para las organizaciones que utilizan estos modelos fuera del entorno doméstico o cotidiano del uso personal de los LLM. La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para ChatGPT, puede tener implicaciones profundas para la reputación de las empresas y la fiabilidad de los sistemas de IA.
¿Qué es un RAG?
Precisamente, las técnicas RAG se han desarrollado para mejorar la calidad de las respuestas en contextos específicos, como por ejemplo, en una disciplina concreta o en base a repositorios de conocimiento privados como bases de datos de empresas.
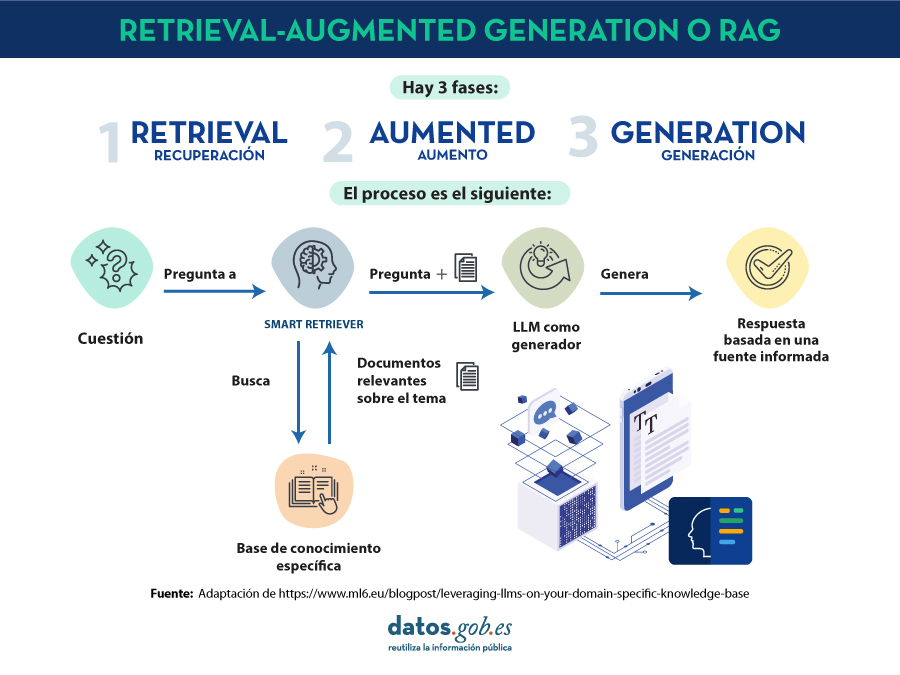
RAG es una técnica extra dentro de los marcos de trabajo de la inteligencia artificial, cuyo objetivo es recuperar hechos de una base de conocimientos externa para garantizar que los modelos de lenguaje devuelven información precisa y actualizada. Un sistema RAG típico (ver imágen) incluye un LLM, una base de datos vectorial (para almacenar convenientemente los datos externos) y una serie de comandos o preguntas. Es decir, de forma simplificada, cuándo hacemos una pregunta en lenguaje natural a un asistente cómo ChatGPT, lo que ocurre entre la pregunta y la respuesta es algo como:
- El usuario realiza la consulta, también denominada técnicamente prompt.
- El RAG se encarga de enriquecer ese prompt o pregunta con datos y hechos que ha obtenido de una base de datos externa que contiene información relevante relativa a la pregunta que ha realizado el usuario. A esta etapa se le denomina retrieval.
- El RAG se encarga de enviar el prompt del usuario enriquecido o aumentado al LLM que se encarga de generar una respuesta en lenguaje natural aprovechando toda la potencia del lenguaje humano que ha aprendido con sus datos de entrenamiento genéricos, pero también con los datos específicos proporcionados en la etapa de retrieval.
Entendiendo RAG con ejemplos
Pongamos un ejemplo concreto. Imagina que estás intentando responder una pregunta sobre dinosaurios. Un LLM generalista puede inventarse una respuesta perfectamente plausible, de forma que una persona no experta en la materia no la diferencia de una respuesta con base científica. Por el contrario, con el uso de RAG, el LLM buscaría en una base de datos de información sobre dinosaurios y recuperaría los hechos más relevantes para generar una respuesta completa.
Lo mismo ocurría si buscamos una información concreta en una base de datos privada. Por ejemplo, pensemos en un responsable de recursos humanos de una empresa. Éste desea recuperar información resumida y agregada sobre uno o varios empleados cuyos registros se encuentran en diferentes bases de datos de la empresa. Pensemos que podemos estar tratando de obtener información a partir de tablas salariales, encuestas de satisfacción, registros laborales, etc. Un LLM es de gran utilidad para generar una respuesta con un patrón humano. Sin embargo, es imposible que ofrezca datos coherentes y precisos puesto que nunca ha sido entrenado con esa información debido a su carácter privado. En este caso, RAG asiste al LLM para proporcionarle datos y contexto específico con el que poder devolver la respuesta adecuada.
De la misma forma, un LLM complementado con RAG sobre registros médicos podría ser un gran asistente en el ámbito clínico. También los analistas financieros se beneficiarían de un asistente vinculado a datos actualizados del mercado de valores. Prácticamente, cualquier caso de uso se beneficia de las técnicas RAG para enriquecer las capacidades de los LLM con datos de contexto específicos.
Recursos adicionales para entender mejor RAG
Cómo os podéis imaginar, tan pronto como nos asomamos por un momento a la parte más técnica de entender los LLM o RAG, las cosas se complican enormemente. En este post hemos tratado de explicar con palabras sencillas y ejemplos cotidianos cómo funciona la técnica de RAG para obtener respuestas más precisas y contextualizadas a las preguntas que le hacemos a un asistente conversacional como ChatGPT, Bard o cualquier otro. Sin embargo, para todos aquellos que tengáis ganas y fuerzas para profundizar en el tema, os dejamos una serie de recursos web disponibles para tratar de entender un poco más cómo se combinan los LLM con RAG y otras técnicas como la ingeniería de prompts para ofrecer las mejores apps de IA generativa posibles.
Videos introductorios:
Artículos de contenido de LLMs y RAG para principiantes:
- DEV - LLM for dummies
-
Digital Native - LLMs for Dummies
-
Hopsworks.ai - Retrieval Augmented Generation (RAG) for LLMs
-
Datalytyx - RAG For Dummies
¿Quieres pasar al siguiente nivel? Algunas herramientas para probar:
- LangChain. LangChain es un marco (framework) de desarrollo que facilita la construcción de aplicaciones usando LLMs, como GPT-3 y GPT-4. LangChain es para desarrolladores de software y permite integrar y gestionar varios LLMs, creando aplicaciones como chatbots y agentes virtuales. Su principal ventaja es simplificar la interacción y orquestación de LLMs para una amplia gama de aplicaciones, desde análisis de texto hasta asistencia virtual.
-
Hugging Face. Hugging Face es una plataforma con más de 350 mil modelos, 75 mil conjuntos de datos y 150 mil aplicaciones de demostración, todos ellos de código abierto y disponibles públicamente online donde la gente puede colaborar fácilmente y construir modelos de inteligencia artificial.
-
OpenAI. OpenAI es la plataforma más conocida en lo que a modelos de LLM e interfaces conversacionales se refiere. Los creadores de ChatGTP ponen a disposición de la comunidad de desarrolladores un conjunto de librerías para utilizar el API de OpenAI y poder crear sus propias aplicaciones utilizando los modelos GPT-3.5 y GPT- 4. Como ejemplo, os proponemos visitar la documentación de la librería de Python para entender cómo, con muy pocas líneas de código, podemos estar usando un LLM en nuestra propia aplicación. Aunque las interfaces conversacionales de OpenAI como ChatGPT, utilizan su propio sistema RAG, también podemos combinar los modelos GPT con nuestra propia RAG, como por ejemplo, lo que proponen en este artículo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Tras varios meses de pruebas y entrenamientos de distinto tipo, el primer sistema masivo de Inteligencia Artificial de la lengua española es capaz de generar sus propios textos y resumir otros ya existentes. MarIA es un proyecto que ha sido impulsado por la Secretaría de Estado de Digitalización e Inteligencia Artificial y desarrollado por el Centro Nacional de Supercomputación, a partir de los archivos web de la Biblioteca Nacional de España (BNE).
Hablamos de un avance muy importante en este ámbito, ya que se trata del primer sistema de inteligencia artificial experto en comprender y escribir en lengua española. Enmarcada dentro del Plan de Tecnologías del Lenguaje, esta herramienta pretende contribuir al desarrollo de una economía digital en español, gracias al potencial que los desarrolladores pueden encontrar en ella.
El reto de crear los asistentes del lenguaje del futuro
Los modelos de lenguaje al estilo de MarIA son la piedra angular sobre la que se sustenta el desarrollo del procesamiento del lenguaje natural, la traducción automática o los sistemas conversacionales, tan necesarios para comprender y replicar de forma automática una lengua. MarIA es un sistema de inteligencia artificial formado por redes neuronales profundas que han sido entrenadas para adquirir una comprensión de la lengua, de su léxico y de sus mecanismos para expresar el significado y escribir a nivel experto.
Gracias a este trabajo previo, los desarrolladores pueden crear herramientas relacionadas con el lenguaje y capaces de clasificar documentos, realizar correcciones o elaborar herramientas de traducción.
La primera versión de MarIA fue elaborada con RoBERTa, una tecnología que crea modelos del lenguaje del tipo “codificadores”, capaces de generar una interpretación que puede servir para categorizar documentos, encontrar similitudes semánticas en diferentes textos o detectar los sentimientos que se expresan en ellos.
Así, la última versión de MarIA ha sido desarrollada con GPT-2, una tecnología más avanzada que crea modelos generativos decodificadores y añade prestaciones al sistema. Gracias a estos modelos decodificadores, la última versión de MarIA es capaz de generar textos nuevos a partir de un ejemplo previo, lo que resulta muy útil a la hora de elaborar resúmenes, simplificar grandes cantidades de información, generar preguntas y respuestas e, incluso, mantener un diálogo.
Avances como los anteriores convierten a MarIA en una herramienta que, con entrenamientos adaptados a tareas específicas, puede ser de gran utilidad para desarrolladores, empresas y administraciones públicas. En esta línea, modelos similares que se han desarrollado en inglés son utilizados para generar sugerencias de texto en aplicaciones de escritura, resumir contratos o buscar informaciones concretas dentro de grandes bases de datos de texto para relacionarlas posteriormente con otras informaciones relevantes.
En otras palabras, además de redactar textos a partir de titulares o palabras, MarIA puede comprender no solo conceptos abstractos, sino también el contexto de los mismos.
Más de 135 mil millones de palabras al servicio de la inteligencia artificial
Para ser exactos, MarIA se ha entrenado con 135.733.450.668 de palabras procedentes de millones de páginas web que recolecta la Biblioteca Nacional y que ocupan un total de 570 Gigabytes de información. Para estos mismos entrenamientos, se ha utilizado el superordenador MareNostrum del Centro Nacional de Supercomputación de Barcelona y ha sido necesaria una potencia de cálculo de 9,7 trillones de operaciones (969 exaflops).
Teniendo en cuenta que uno de los primeros pasos para diseñar un modelo del lenguaje pasa por construir un corpus de palabras y frases que sirva como base de datos para entrenar al propio sistema, en el caso de MarIA, fue necesario realizar un cribado para eliminar todos los fragmentos de texto que no fuesen “lenguaje bien formado” (elementos numéricos, gráficos, oraciones que no terminan, codificaciones erróneas, etc.) y así entrenar correctamente a la IA.
Debido al volumen de información que maneja, MarIA se sitúa ya como el tercer sistema de inteligencia artificial experto en comprender y escribir con mayor número de modelos masivos de acceso abierto. Por delante solo están los modelos del lenguaje elaborados para el inglés y el mandarín. Esto ha sido posible principalmente por dos razones. Por un lado, debido al elevado nivel de digitalización en el que se encuentra el patrimonio de la Biblioteca Nacional y, por el otro, gracias a la existencia de un Centro de Supercomputación Nacional que cuenta con superordenadores como el MareNostrum 4.
El papel de los conjuntos de datos de la BNE
Desde que en 2014 lanzase su propio portal de datos abiertos (datos.bne.es), la BNE ha apostado por acercar los datos que están a su disposición y bajo su custodia: datos de las obras que conserva, pero también de autores, vocabularios controlados de materias y términos geográficos, entre otros.
En los últimos años, se ha desarrollado también la plataforma educativa BNEscolar, que busca ofrecer contenidos digitales del fondo documental de la Biblioteca Digital Hispánica y que pueden resultar de interés para la comunidad educativa.
Así mismo y para cumplir con los estándares internacionales de descripción e interoperabilidad, los datos de la BNE están identificados mediante URIs y modelos conceptuales enlazados, a través de tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables. Además, cuentan con un alto nivel de normalización.
Próximos pasos
Así y con el objetivo de perfeccionar y ampliar las posibilidades de uso de MarIA, se pretende que la versión actual dé lugar a otras especializadas en áreas de conocimiento más concretas. Teniendo en cuenta que se trata de un sistema de inteligencia artificial dedicado a comprender y generar texto, se torna fundamental que este sea capaz de desenvolverse con soltura ante léxicos y conjuntos de información especializada.
Para ello, el PlanTL continuará expandiendo MarIA para adaptarse a los nuevos desarrollos tecnológicos en procesamiento del lenguaje natural (modelos más complejos que el GPT-2 ahora implementado, entrenados con mayor cantidad de datos) y se buscará la forma de crear espacios de trabajo para facilitar el uso de MarIA por compañías y grupos de investigación.
Contenido elaborado por el equipo de datos.gob.es.
Blog
El avance de la supercomputación y la analítica de datos en campos tan dispares como las redes sociales o la atención al cliente está fomentando que una parte de la inteligencia artificial (IA) se enfoque en desarrollar algoritmos capaces de procesar y generar un lenguaje natural.
Para poder llevar a cabo esta tarea en un contexto como el actual, tener acceso a un heterogéneo listado de bibliotecas de procesamiento de lenguaje natural es clave para diseñar soluciones IA eficaces y funcionales de forma ágil. Estos archivos de código fuente, que se utilizan para desarrollar software, facilitan la programación al proporcionar funcionalidades comunes, resueltas previamente por otros desarrolladores, evitando duplicidades y minimizando los errores.
Así y con el objetivo de fomentar la compartición y reutilización para diseñar aplicaciones y servicios que aporten valor económico y social, desglosamos cuatro conjuntos de bibliotecas de procesamiento de lenguaje natural, divididas en base al lenguaje de programación utilizado.
Librerías para Python
Idóneas para codificar utilizando el lenguaje de programación Python. Al igual que sucede con los ejemplos disponibles para otros lenguajes, estas librerías cuentan con gran variedad de implementaciones que permiten al desarrollador crear una nueva interfaz por su propia cuenta.
Algunos ejemplos son:
NLTK: Natural Language Toolkit
- Descripción: NLTK ofrece interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de textos. Permite realizar tareas de preprocesado de texto, entre las que encontramos, la clasificación, tokenización, lematización o la exclusión de stop words, el análisis sintáctico y el razonamiento semántico.
- Materiales de apoyo: Una de las secciones más interesantes para consultar información y resolver dudas es el apartado dedicado a las preguntas frecuentes. Puedes encontrarlo en este enlace. También tiene disponible ejemplos de uso y una wiki.
Gensim
- Descripción: Gensim es una biblioteca Python de código abierto para representar documentos como vectores semánticos. La diferencia principal respecto al resto de librerías de lenguaje natural para Python reside en que Gensim es capaz de identificar automáticamente la temática del conjunto de documentos a tratar. También permite analizar la similitud entre ficheros, algo realmente útil cuando utilizamos la librería para realizar búsquedas.
- Materiales de apoyo: En la sección de Documentación de su página web, es posible encontrar materiales didácticos enfocados a tres áreas muy concretas. Por un lado, hay una serie de tutoriales dirigidos a aquellos programadores que nunca antes han utilizado este tipo de bibliotecas. Existen lecciones formativas orientadas a cuestiones específicas del lenguaje de programación, una serie de guías cuyo objetivo es resolver las dudas que surgen ante determinados problemas y también una sección dedicada únicamente a las preguntas frecuentes
Librerías para JavaScript
Las librerías de JavaScript sirven para diversificar el abanico de recursos que pueden utilizar los programadores y desarrolladores web que hacen uso de este lenguaje. Puedes elegir entre los siguientes ejemplos propuestos a continuación:
Apache OpenNLP
- Descripción: La biblioteca Apache OpenNLP es un conjunto de herramientas basadas en el aprendizaje automático para el procesamiento de textos en lenguaje natural. Es compatible con las tareas básicas de programación de lenguaje natural, tokenización, segmentación de frases, el etiquetado de las partes de un discurso, la extracción de entidades con nombre o la detección de idiomas, entre otras muchas.
- Materiales de apoyo: Dentro de la categoría General de su web, encontramos un subapartado denominado Books, Tutorials and Talks donde se proporcionan una serie de charlas, tutoriales y publicaciones destinadas a resolver las dudas de los programadores. Igualmente, en la categoría Documentation disponen de distintos manuales de uso.
NLP.js
- Descripción: NLP.js está dirigida a node.js, un entorno de ejecución de JavaScript de código abierto. Admite 41 idiomas de forma nativa e, incluso, puede ampliarse hasta 104 idiomas con el uso de Bert embeddings. Se trata de una librería utilizada principalmente para la construcción de bots, el análisis de sentimiento o la identificación automática del lenguaje, entre otras funciones. Precisamente por esta razón, es una librería a tener en cuenta para la construcción de chatbots.
- Materiales de apoyo: Dentro de su perfil alojado en el portal de código Github ofrecen un apartado de preguntas frecuentes y otro de ejemplos de uso que pueden resultar útiles a la hora de hacer uso de la librería para desarrollar una app o servicio.
Natural
- Descripción: Al igual que NLP.js, Natural también facilita el procesamiento del lenguaje natural para node.js. Ofrece una variada gama de funcionalidades como la tokenización, coincidencia fonética, frecuencia de términos (TF-IDF) y la integración con la base de datos WordNet, entre otras.
- Materiales de apoyo: Al igual que la anterior biblioteca, esta librería tampoco tiene web propia. En su perfil de Github, dispone de contenidos de apoyo como ejemplos de casos de uso desarrollados anteriormente por otros programadores.
Wink
- Descripción: Wink es una familia de paquetes de código abierto para el análisis estadístico, el procesamiento del lenguaje natural y el aprendizaje automático en NodeJS. Ha sido optimizada para lograr un equilibrio entre rendimiento y precisión, lo que hace que el paquete pueda manejar grandes cantidades de texto en bruto a una alta velocidad.
- Materiales de apoyo: Acceder a los tutoriales desde su página web resulta muy intuitivo ya que una de las categorías que tiene el mismo nombre recoge precisamente este tipo de contenido divulgativo. En ella es posible encontrar guías de aprendizaje divididas según el nivel de experiencia del programador o de la parte del proceso en el que esté inmerso.
Librerías para R
En este último apartado aglutinamos las bibliotecas específicas para construir una web, aplicación o servicio utilizando el lenguaje de codificación R. Algunas de ellas son:
koRpus
- Descripción: Se trata de un paquete de análisis de textos capaz de detectar el idioma de manera automática y diversos índices de diversidad léxica o legibilidad, entre otras funciones. Además, incluye el plugin RKWard que proporciona cuadros de diálogo gráficos para sus funciones básicas.
- Materiales de apoyo: koRpus ofrece una serie de directrices enfocadas a su instalación y aglutinadas en el documento Read me que puedes encontrar en este enlace. Igualmente, en el aparado News están disponibles las actualizaciones y cambios que se han ido realizando en las sucesivas versiones de la librería.
Quanteda
- Descripción: Esta biblioteca ha sido diseñada para que los programadores que utilizan R apliquen técnicas de procesamiento de lenguaje natural a sus textos desde la versión original hasta la obtención de los resultados finales. Por ello, su API ha sido desarrollada para permitir un análisis potente y eficiente con un mínimo de pasos, reduciendo así las barreras de aprendizaje, al procesamiento del lenguaje natural y el análisis cuantitativo de textos.
- Materiales de apoyo: Ofrece como material de apoyo principal esta guía de inicio rápido. A través de ella, es posible seguir las instrucciones principales para no cometer ningún error. Incluye también varios ejemplos que pueden servir para comparar resultados.
Isa - Natural Language Processing
- Descripción: Esta librería se basa en el análisis semántico latente que consiste en crear datos estructurados a partir de una colección de textos no estructurados.
- Materiales de apoyo: En el apartado dedicado a la documentación, podemos encontrar información útil para el desarrollo.
Librerías para Python y R
Hablamos de librerías para Python y R para referirnos a aquellas que son compatibles para codificar utilizando ambos lenguajes de programación.
spaCy
- Descripción: Es una herramienta muy útil para preparar textos que, posteriormente, serán empleados en otras tareas de aprendizaje automático. Además, permite aplicar modelos lingüísticos estadísticos para resolver diferentes problemas de procesamiento del lenguaje natural.
- Materiales de apoyo: spaCy ofrece una serie de cursos online divididos en distintos capítulos y que podrás encontrar aquí. A través de los contenidos compartidos en NLP Advanced podrás seguir paso a paso las utilidades de esta biblioteca, ya que cada capítulo se centra en una parte del procesamiento del texto. Si aún quieres aprender más sobre esta librería, te recomendamos leer este artículo de Alejandro Alija sobre su experiencia probando esta biblioteca.
En este artículo hemos compartido una muestra de algunas de las librerías más populares para el procesamiento del lenguaje natural. Aun así, conviene subrayar que se trata de una mera selección.
Por todo ello, si conoces de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Pocas habilidades son tan características del ser humano como el lenguaje. Según la escuela Aristotélica, los humanos somos animales racionales que perseguimos el conocimiento por el mero hecho de saber. Sin entrar en profundas consideraciones filosóficas que exceden, con mucho, el propósito de este espacio de divulgación, podemos decir que esa búsqueda del saber y la acumulación de conocimiento no serían posibles sin la intervención del lenguaje humano. De ahí, que en este siglo XXI - el siglo de la explosión de la Inteligencia Artificial (IA)- buena parte de los esfuerzos se centren en soportar, complementar y aumentar las capacidades humanas relacionadas con el lenguaje.
Introducción
En este espacio, hemos hablado repetidamente de la disciplina del procesamiento del lenguaje natural (o NLP en inglés). La hemos abordado desde diferentes puntos de vista, todos ellos desde un enfoque práctico, técnico y relacionado con los datos - textos - que son el verdadero combustible de las tecnologías que sirven de apoyo a esta disciplina. Hemos realizado monográficos sobre el tema, introduciendo las bases de la tecnología e incluyendo ejemplos prácticos. También hemos comentado la actualidad y analizado las últimas tendencias tecnológicas, así como los últimos logros importantes en procesamiento del lenguaje natural. En casi todas las publicaciones sobre el tema, hemos mencionado herramientas, librerías y productos tecnológicos que, de una u otra manera, ayudan y soportan los diferentes procesos y aplicaciones del lenguaje natural. Desde la creación de resúmenes razonados de obras y textos largos, hasta la generación artificial de publicaciones o código para programadores, todas las aplicaciones utilizan librerías, paquetes o frameworks para el desarrollo de aplicaciones de inteligencia artificial aplicadas en el campo del procesamiento del lenguaje natural.
En anteriores ocasiones describimos el algoritmo GPT-3 de la compañía OpenAI o el Megatron-Turing NLG de Microsoft, como algunos de los exponentes actuales en cuanto a potencia de análisis y precisión en la generación de resultados de calidad. Sin embargo, en la mayoría de las ocasiones, tenemos que hablar de algoritmos o librerías que, dada su complejidad, quedan reservados a una pequeña comunidad técnica, de desarrolladores, académicos y profesionales, dentro de la disciplina del NLP. Es decir, si queremos emprender un nuevo proyecto relacionado con el procesamiento del lenguaje natural, debemos de partir de unas librerías de bajo nivel, para posteriormente ir añadiendo capas de funcionalidad a nuestro proyecto u aplicación hasta que esta esté lista para su uso. Normalmente, las librerías de NLP, se enfocan sobre una pequeña parte del recorrido de un proyecto de software (fundamentalmente la tarea de codificación), siendo los desarrolladores o equipos de software, los que deben de contemplar y añadir el resto de capas funcionales y técnicas (testing, empaquetado, publicación y puesta en producción, operaciones, etc.) para convertir los resultados de esa librería de NLP en un producto o aplicación tecnológica completa.
El reto de poner en marcha una aplicación
Pongamos un ejemplo. Supongamos que queremos construir una aplicación que, en base a un texto de partida, por ejemplo, nuestra factura de la luz, nos haga un resumen sencillo del contenido de nuestra factura. Todos sabemos que las facturas de la luz o las nóminas de los trabajadores no son documentos, precisamente, sencillos de entender para el común de la sociedad. La dificultad se encuentra, normalmente, en el empleo de una terminología muy técnica y, por qué no decirlo, en el bajo interés de algunas organizaciones en simplificar la vida de los ciudadanos facilitando el entendimiento de informaciones básicas como lo que pagamos por la electricidad o nuestras retribuciones como empleados por cuenta ajena. Volviendo al tema que nos ocupa. Si queremos construir una aplicación de software con este propósito, tendremos que utilizar un algoritmo que entienda nuestra factura. Para esto, los algoritmos de NLP, tienen que, primero de todo, realizar un análisis del texto y detectar las palabras clave y sus relaciones (lo que en terminología técnica se llama, detectar entidades y reconocerlas en el contexto). Es decir, el algoritmo tendrá que detectar las entidades clave, como el consumo de energía, sus unidades en kWh, los periodos temporales relevantes (consumo de este mes, del mes anterior, consumo diarios, histórico de consumo pasado, etc.). Una vez detectadas esas entidades relevantes (y descartadas las demás) y sus relaciones, todavía queda mucho por hacer. En términos de un proyecto de software en el campo del NLP, el reconocimiento de entidades (en inglés NER - Named-Entity-Recognition) es solo una pequeña parte de una aplicación lista para su uso por una persona o un sistema. Es aquí donde os presentamos la librería de software SpaCy.
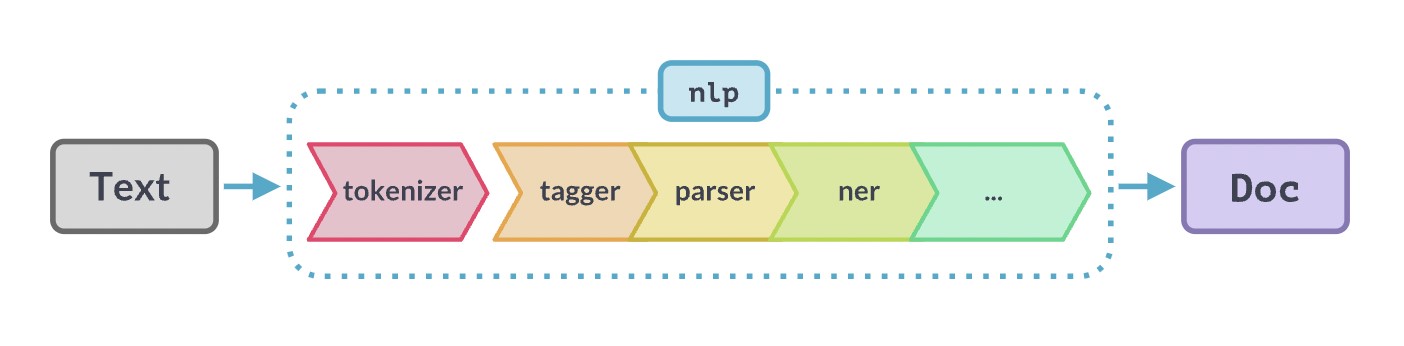
Ejemplo de flujo o pipeline de NLP desde que partimos del texto original que queremos analizar hasta que obtenemos el resultado final, bien sea un texto enriquecido o una página web con ayudas o explicaciones al usuario. Fuente original: https://SpaCy.io/
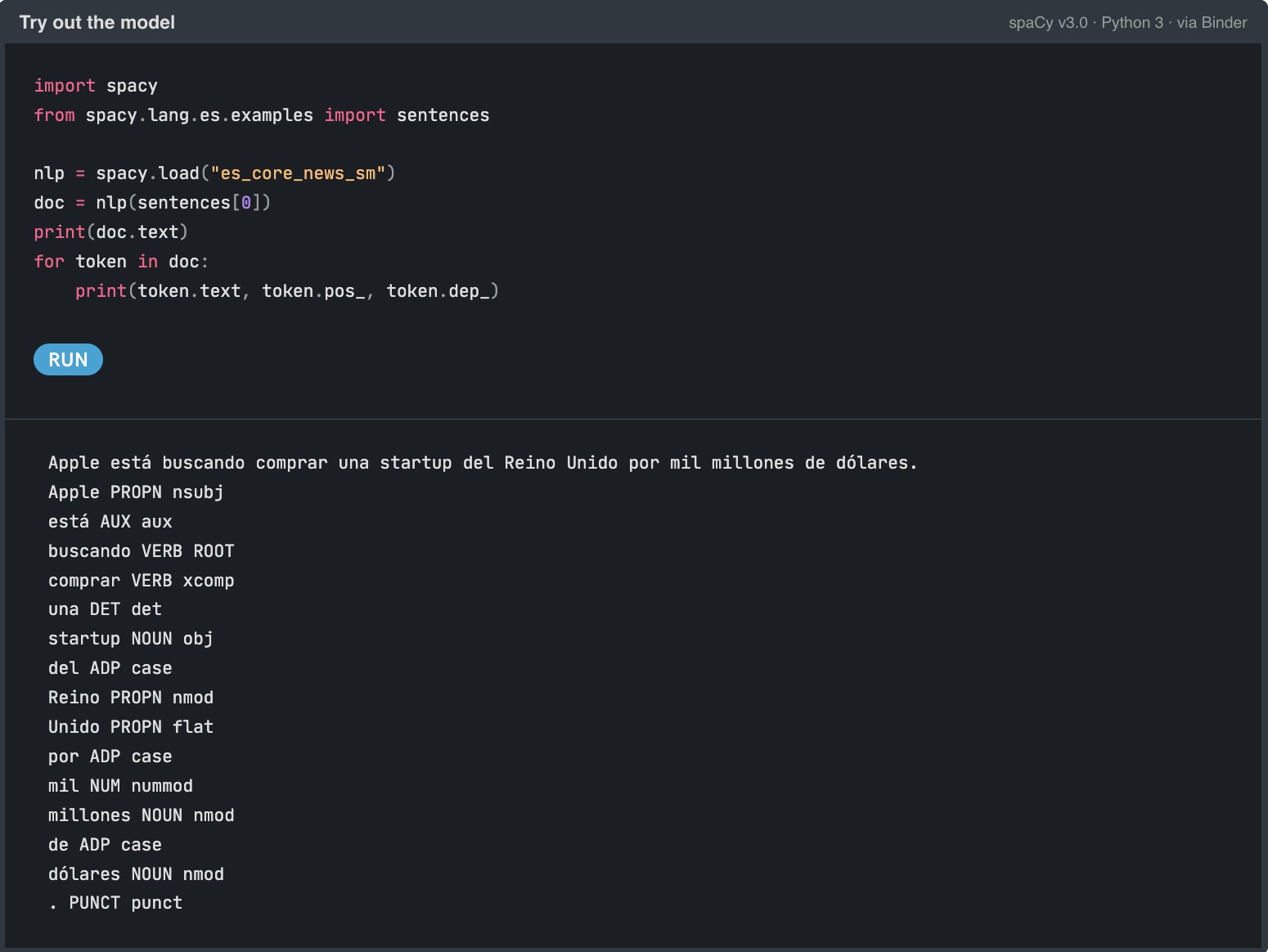
Ejemplo del uso de la pipeline (flujo) de Spacy es_core_news_sm para identificar entidades en una frase en español.
¿Qué es Spacy?
SpaCy tiene como objetivo facilitar la puesta en producción (hacer una aplicación lista para su uso por el consumidor final) de las aplicaciones de software en el ámbito del lenguaje natural. SpaCy es una librería de software de código abierto diseñada para facilitar tareas de procesamiento avanzado del lenguaje natural. SpaCy está escrita en Python y Cython (extensiones del lenguaje C para Python que permiten realizar una programación de bajo nivel muy eficiente). Es una librería open-source bajo la licencia MIT y todo el proyecto es accesible a través de su cuenta de Github.
Las ventajas de Spacy
Pero, ¿qué hace diferente a SpaCy? SpaCy se creó con el objetivo de facilitar la creación de productos reales. Es decir, la librería no es tan solo una librería con la que nos quedamos en el plano más técnico y de más bajo nivel dentro de las capas que componen una aplicación de software, desde los algoritmos más internos hasta las interfaces más visuales. La librería contempla los aspectos prácticos de un producto de software real, en el que es necesario tener en cuenta aspectos tan importantes como:
- Las grandes cargas de datos que se requieren procesar (imagina lo que implica, cargar los comentarios de productos completos de un gran e-commerce en Internet, por ejemplo).
- La velocidad de ejecución, puesto que cuando tenemos una aplicación real, necesitamos que la experiencia sea lo más fluida posible y no podemos soportar largos tiempos de espera entre ejecuciones de los algoritmos.
- El empaquetamiento de funcionalidades de NLP (como NER) listas para desplegar en uno o varios servidores de producción. SpaCy, no solo proporciona herramientas de código de bajo nivel, sino que soporta los procesos desde que creamos (compilamos y construimos una parte de una aplicación de software) hasta que integramos esta parte algorítmica con otras partes de la aplicación como las bases de datos o las interfaces de usuario final.
- La optimización de modelos de NLP para que puedan ejecutarse fácilmente en servidores estándar (basados en CPU) sin necesidad de usar procesadores gráficos (GPU)
- Las herramientas de visualización gráficas integradas para facilitar la depuración o el desarrollo de nuevas funcionalidades.
- Importante mencionar también, su fantástica documentación, desde su web más introductoria hasta su comunidad en Github. Esto facilita enormemente la rápida adopción entre la comunidad de desarrollo.
- El gran número de modelos y flujos pre-entrenados (73 flujos) en 22 idiomas diferentes. Además del soporte para más de 66 idiomas. En particular, en el caso del español, es complicado encontrar en otras librerías y herramientas, modelos optimizados para el idioma español.

Ejemplo de visualizador gráfico de entidades. Fuente original: https://SpaCy.io/
Como conclusión de este post. Si eres principiante y estás arrancando en el mundo del NLP, SpaCy te facilita el comienzo y viene con una amplia documentación, que incluye una guía 101 para principiantes, un curso interactivo gratuito en línea y una variedad de tutoriales en video. Si eres un desarrollador experimentado o formas parte de un equipo de desarrollo de software consolidado y quieres construir una aplicación de producción final, SpaCy está diseñado específicamente para uso en producción y te permite crear y entrenar flujos de datos (textos) potentes de NLP y empaquetarlas para una fácil implementación. Finalmente, si estás buscando alternativas a tu solución ya existente de NLP (buscas nuevos modelos de NLP, necesitas mayor flexibilidad y agilidad en tus despliegues a producción o buscas mejoras en rendimiento), SpaCy te permite personalizar probar diferentes arquitecturas y combinar, fácilmente, frameworks existentes y populares como PyTorch o TensorFlow.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Noticia
España ya cuenta con una nueva Estrategia Nacional de Inteligencia Artificial. El documento, que recoge 600 millones de euros para medidas relacionadas con la inteligencia artificial (IA), se presentó el pasado día 2 de diciembre en el Palacio de la Moncloa.
La Estrategia Nacional de Inteligencia Artificial (conocida como ENIA) es el componente 16 del Plan de Recuperación, Transformación y Resiliencia de la economía española, y una de las propuestas fundamentales de la Agenda España Digital 2025 en su línea 9 de acción, que destaca la IA como un elemento clave para impulsar el crecimiento de nuestra economía en los próximos años. Además, la nueva estrategia está alineada con los planes de acción europeos desarrollados en la materia, y en especial con Libro Blanco sobre Inteligencia Artificial.
Objetivos y ejes de actuación
La ENIA es un marco dinámico, flexible y abierto a la aportación de empresas, ciudadanos, agentes sociales y resto de Administraciones, que nace con 7 Objetivos: la excelencia científica y la innovación, la proyección de la lengua española, la creación de empleo cualificado, la transformación del tejido productivo español, la creación de un entorno de confianza en relación a la IA y el fomento de una IA inclusiva y sostenible que tenga en cuenta los valores humanistas.
Para alcanzar estos objetivos, se han creado 6 ejes de actuación que agrupan un total de 30 medidas a desarrollar en el período 2020-2025:

En definitiva, se trata de crear un ecosistema nacional de inteligencia artificial innovador, competitivo y ético. Y para ello, es fundamental contar con grandes volúmenes de datos y metadatos de calidad e interoperable, que sean accesibles, completos, seguros y respetuosos con la privacidad.
Los datos abiertos en la Estrategia Nacional de Inteligencia Artificial
La disponibilidad de datos abiertos es esencial para el correcto funcionamiento de la inteligencia artificial, ya que los algoritmos han de ser alimentados y entrenados por datos cuya calidad y disponibilidad permita una continua mejora. De ese modo podremos crear servicios de valor que repercutan en la mejora de la sociedad y la economía.
La Estrategia Nacional de Inteligencia Artificial resalta cómo gracias a las distintas iniciativas abordadas en los últimos años, España se sitúa como un referente europeo en materia de datos abiertos, destacando el papel de la Iniciativa Aporta en el impulso de la apertura y reutilización de información pública.
En el eje estratégico 3 del documento se resaltan varias áreas clave donde actuar ligadas a las plataformas de datos e infraestructuras tecnológicas de IA:
- Desarrollar el marco regulatorio del open data, para definir una estrategia de publicación y acceso a los datos públicos de las administraciones en formatos multilingües, y asegurar el uso correcto y seguro de los datos.
- Impulsar acciones en el ámbito de las plataformas de datos, modelos, algoritmos, motores de inferencia y ciberseguridad, con el foco puesto en impulsar la investigación y la innovación. Se hace referencia a la necesidad de impulsar Tecnología Habilitadoras Digitales como las infraestructuras de conectividad, los entornos masivos de datos (cloud) o la automatización y control de procesos, prestando especial atención a las Capacidades Estratégicas de Supercomputación (HPC).
- Impulsar el desarrollo específico de tecnologías IA en el ámbito del procesamiento del lenguaje natural, fomentando el uso del español en el mundo. En este sentido se impulsará el Plan Nacional de Tecnologías del Lenguaje y se apoyará el proyecto LEIA, desarrollado por la Real Academia Española para la defensa, proyección y buen uso de la lengua española en el universo digital.
En el caso concreto de los datos abiertos, una de las primeras medidas destacadas es la creación de la Oficina del Dato a nivel estatal que coordinará a todas las administraciones publicas con el fin de homogeneizar el almacenamiento, acceso y tratamiento de los datos. Para potenciar esta acción se nombrará un Chief Data Officer. Además, se articulará un grupo de trabajo multidisciplinar de datos abiertos en el sector público estatal para poner en valor el esfuerzo que se viene realizado en materia de datos en España y para seguir impulsando la apertura y reutilización de la información del sector público.
La estrategia también tiene en cuenta al sector privado, y resalta la necesidad de fomentar el desarrollo de repositorios accesibles y de orientar a las empresas en la definición de estrategias de datos abiertos o compartidos. En este sentido se crearán espacios compartidos de datos sectoriales e industriales, que faciliten la creación de aplicaciones de IA. Además, se hace mención a la necesidad de ofrecer los datos desagregados por sexo, edad, nacionalidad y territorio, de tal forma que se eliminen sesgos ligados a estos aspectos.
Con el fin de estimular el uso y la gobernanza de datos públicos y ciudadanos se establece como objetivo la creación del Proyecto Datos por el Bien Social donde los datos abiertos y generados por la ciudadanía tendrán un papel clave para impulsar la rendición de cuentas y participación pública en el gobierno.
El siguiente cuadro resume la medidas vistas en este apartado:

Otros aspectos destacados de la ENIA
Además de acciones relacionadas con los datos abiertos, la Estrategia Nacional de Inteligencia Artificial incluye acciones más transversales, por ejemplo:
- Se fomentará la incorporación de la IA en la administración pública, mejorando desde la transparencia y la toma de decisiones efectiva, hasta la productividad y calidad del servicio (haciendo más eficientes las gestiones y la relación con los ciudadanos). Aquí la Iniciativa Aporta viene jugando un rol clave con su apoyo a los organismos del sector público en la publicación de datos de calidad y el fomento de su reutilización. Se crearán repositorios de datos abiertos que permitan el acceso óptimo a la información necesaria para desarrollar nuevos servicios y aplicaciones para el sector público y privado. En este sentido, se creará un laboratorio de innovación (GobTechLab) y se llevarán a cabo programas de capacitación.
- Se busca impulsar la investigación científica a través de la creación de una Red española de excelencia en IA con programas de investigación y formación y la puesta en marcha de nuevos centros de desarrollo tecnológico. Se prestará especial atención a acabar con la brecha de género.
- Se pondrá en marcha un programa de ayudas a empresas para el desarrollo de soluciones de IA y datos, y se reforzará la red de Centros de Innovación Digital (Digital innovation Hubs). Se creará un Fondo NextTech de capital riesgo público-privado.
- Se impulsará el talento a través del Plan Nacional de Competencias Digitales. Se introducirán elementos relacionados con la IA en la escuela y se impulsará la oferta universitaria y de Formación Profesional en IA. Se desarrollará el programa SpAIn Talent Hub en coordinación con ICEX Invest para atraer inversión extranjera y talento.
- Una novedad de la estrategia es que tiene en cuenta la regulación ética y social para luchar contra la discriminación. Se crearán observatorios de evaluación ética y jurídica de los sistemas algorítmicos y se desarrollará la Carta de Derechos Digitales, que actualmente está en revisión.
En definitiva, estamos ante una estrategia necesaria para impulsar el crecimiento de la IA en España, impulsado nuestra sociedad y economía, y mejorando nuestra competitividad internacional.
Blog
¿Te imaginas una IA capaz de escribir canciones, novelas, comunicados de prensa, entrevistas, ensayos, manuales técnicos, código de programación, prescribir medicamentos y mucho más que aún no sabemos? Viendo a GPT-3 en acción no parece que estemos muy lejos.
En nuestro último informe sobre procesamiento del lenguaje natural (NLP) mencionamos el algoritmo GPT-2 desarrollado por OpenAI (la compañía fundada por nombres tan reconocidos cómo Elon Musk) como un exponente en cuanto a sus capacidades para la generación de texto sintético con una calidad indistinguible de cualquier otro texto creado por un humano. Los sorprendentes resultados de GPT-2 llevaron a la compañía a no publicar el código fuente del algoritmo por sus potenciales efectos negativos en la generación de deepfakes o noticias falsas.
Recientemente (mayo de 2020) se ha liberado una nueva versión del algoritmo, ahora denominado GPT-3 que incluye novedades funcionales y mejoras de rendimiento y capacidad de analizar y generar textos en lenguaje natural.
En este post tratamos de resumir de forma sencilla y asequible las principales novedades de GPT-3. ¿Te atreves a descubrirlas?
Comenzamos de forma directa, yendo al grano. ¿Qué trae consigo GPT-3? (adaptación de el post original de Mayor Mundada).
- Es mucho más grande (complejo) que todo lo que teníamos antes. Los modelos de deep learning basados en redes neuronales se suelen clasificar por su número de parámetros. A mayor número de parámetros, mayor es la profundidad de la red y por lo tanto su complejidad. El entrenamiento de la versión completa de GPT-2 daba cómo resultado 1.500 millones de parámetros. GPT-3 da cómo resultado 175.000 millones de parámetros. GPT-3 ha sido entrenado sobre una base de 570 GB de texto comparados con los 40 GB de GPT-2.
- Por primera vez puede ser utilizado cómo un producto o servicio. Es decir, OpenAI, ha anunciado la puesta a disposición de los usuarios de un API público para poder experimentar con el algoritmo. En el momento de escribir este post, el acceso al API está restringido (es lo que denominamos un private preview) y hay que solicitar acceso.
- Lo más importante: sus resultados. A pesar de que la API se encuentra restringida por invitación, son numerosos los usuarios en Internet (con acceso a la API) que han publicado artículos sobre sus resultados en diferentes ámbitos.
¿Qué papel juegan los datos abiertos?
En pocas ocasiones se tiene la posibilidad de ver la potencia y los beneficios de los datos abiertos cómo en este tipo de proyectos. Cómo hemos comentado más arriba GPT-3 ha sido entrenado con 570 GB de datos en formato de texto. Pues bien, resulta que el 60% de los datos de entrenamiento del algoritmo vienen de la fuente https://commoncrawl.org. Common Crawl es un proyecto abierto y colaborativo que proporciona un corpus para la investigación, el análisis, la educación, etc. Cómo se especifica en la web de Common Crawl los datos proporcionados son abiertos y se hospedan bajo la iniciativa de datos abiertos de AWS. Buena parte del resto de datos de entrenamiento también son abiertos incluyendo fuentes cómo Wikipedia.
Casos de uso
A continuación mostramos algunos de los ejemplos y casos de uso impactantes.
Generación de texto sintético
En esta entrada (no spoilers ;) ) del blog de Manuel Araoz se muestra la potencia del algoritmo para generar un artículo 100% sintético sobre Inteligencia Artificial. Manuel realiza el siguiente experimento: proporciona a GPT-3 una mínima descripción de su biografía incluida en su blog y un pequeño fragmento de la última entrada en su blog. 117 palabras en total. Tras 10 ejecuciones de GPT-3 para generar texto artificial relacionado, Manuel es capaz de copiar y pegar el texto generado, colocar una imagen de portada y ya tiene listo un nuevo post para su blog. Honestamente, el texto del post sintético es indistinguible de un post original salvo por los posibles errores en nombres, fechas, etc. que pueda incluir el texto.
Productividad. Generación automática de tablas de datos.
En otro ámbito diferente, el algoritmo GPT-3 tiene aplicaciones en el ámbito de la productividad. En este ejemplo GPT-3 es capaz de crear una tabla de MS Excel sobre un determinado tema. Por ejemplo, si queremos obtener una tabla, a modo de lista, con las compañías tecnológicas más representativas y su año de fundación, simplemente proporcionamos a GPT-3 el patrón deseado y le pedimos que lo complete. El patrón de inicio puede ser algo similar a esta tabla de debajo (en un ejemplo real, los datos de entrada serán en inglés). GPT-3 completará la zona sombreada con datos reales. Sin embargo, si además del patrón de entrada, le proporcionamos al algoritmo una descripción verosímil de una compañía tecnológica ficticia y le volvemos a pedir que complete la tabla con la nueva información, el algoritmo incluirá los datos de esta nueva compañía ficticia.
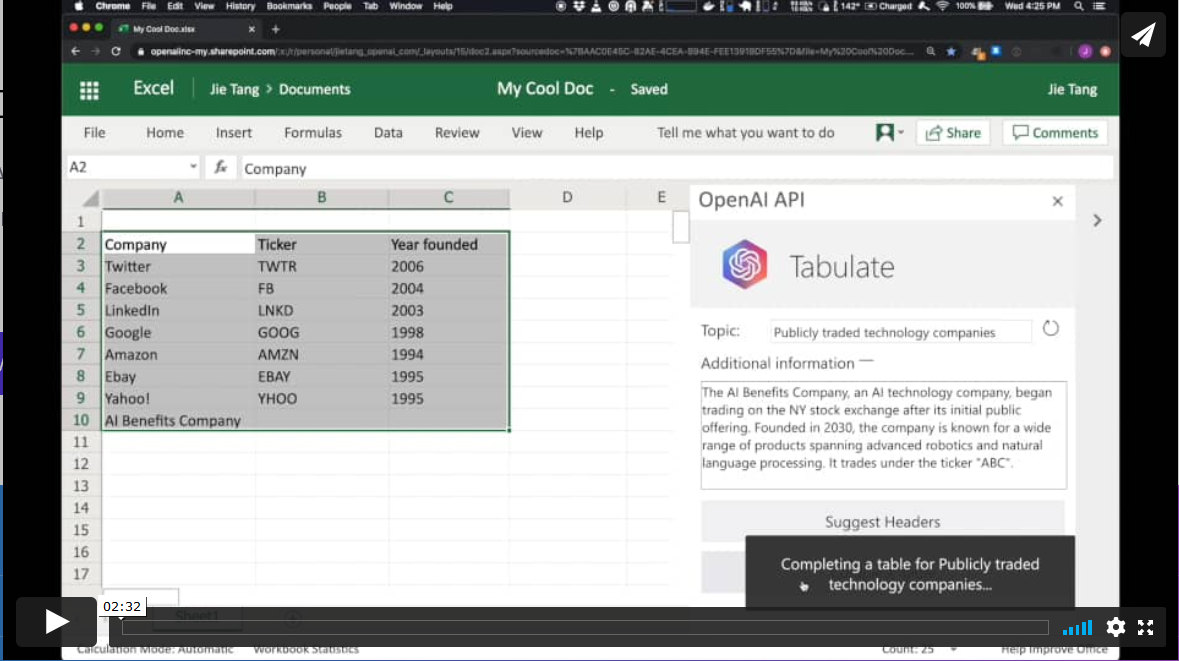
Estos ejemplos son solo una muestra de lo que GPT-3 es capaz de hacer. Entre sus funcionalidades o aplicaciones se encuentran:
- la búsqueda semántica (diferente de la búsqueda por palabras clave)
- los chatbots
- la revolución de los servicios de atención al cliente (call-center)
- la generación de texto multipropósito (creación de poemas, novelas, música, noticias falsas, artículos de opinión, etc.)
- las herramientas de productividad. Hemos visto un ejemplo sobre cómo crear tablas de datos, pero se está hablando (y mucho), sobre la posibilidad de crear programas informáticos sencillos cómo páginas web y pequeñas aplicaciones sencillas sin necesidad de codificar, tan solo preguntándole a GPT-3 y sus hermanos que están por llegar.
- las herramientas de traducción on-line
- la comprensión y resúmenes de textos.
y tantas otras cosas que aún no hemos descubierto... Seguiremos informándoles sobre las próximas novedades en NLP y en particular de GPT-3, un game-changer que ha venido para revolucionar todo lo que conocemos por el momento.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Nuestro lenguaje, tanto escrito como hablado, constituye un tipo muy particular de datos. El lenguaje es el medio de comunicación humana por excelencia y su principal característica es la ambigüedad y la complejidad. Su procesamiento, debido a que se trata de datos no estructurados, ha constituido tradicionalmente un desafío a las máquinas, dificultando su uso en los procesos de análisis de la información. Con la explosión de las redes sociales y el avance de la supercomputación y la analítica de datos en campos tan dispares como la medicina o los call-centers, no es extraño que buena parte de los subcampos de la inteligencia artificial se dediquen a desarrollar estrategias y algoritmos para procesar y generar lenguaje natural.
Introducción
En el dominio del análisis de datos aplicado al procesamiento del lenguaje natural se distinguen dos grandes metas: Comprender y Generar
- Comprender: existen un conjunto de técnicas, herramientas y algoritmos cuyo principal objetivo es el de procesar y comprender el lenguaje natural para, finalmente, convertir esta información en datos estructurados que puedan ser explotados/utilizados por una máquina. Existen diferentes niveles de complejidad, dependiendo de si el mensaje que se transmite en lenguaje natural se encuentra en forma escrita o hablada. Además, el idioma en el que se transmite el mensaje incrementa de forma notoria la complejidad de su procesamiento, pues los algoritmos de reconocimiento habrán de estar entrenados en ese idioma u otro similar.
- Generar: encontramos algoritmos que tratan de generar mensajes en lenguaje natural. Es decir, algoritmos que consumen datos clásicos o estructurados para generar una comunicación en lenguaje natural, ya sea escrita o hablada.
En la Figura 1. Procesado de lenguaje natural y sus dos enfoques asociados, se muestra un diagrama para entender mejor estas tareas que forman parte del campo del procesado del lenguaje natural.
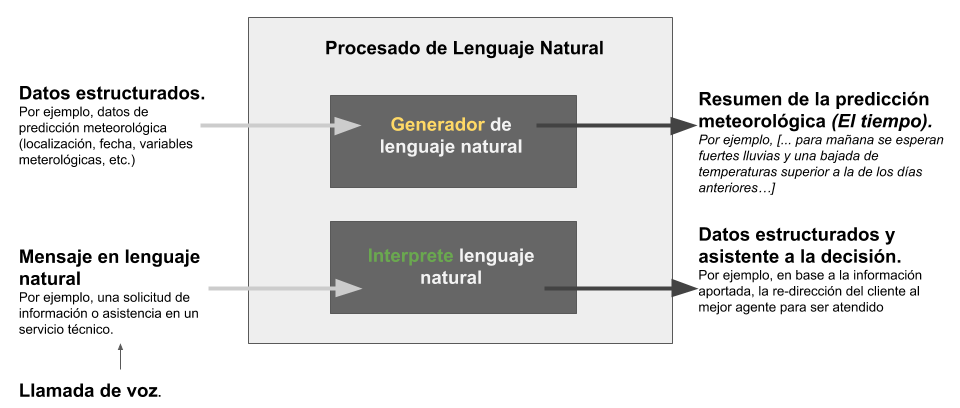
Para entender estas técnicas de forma práctica, pongamos algunos ejemplos:
Comprensión de lenguaje natural
En el primer grupo, se encuentran aquellas aplicaciones en las que un humano, solicita una determinada información o realiza una descripción de algo y una máquina es la encargada de recibir y procesar ese mensaje con el objetivo de resolver o atender dicha petición. Por ejemplo, cuando llamamos al teléfono de información de casi cualquier compañía de servicios, nos responde un contestador automático que, a través de un diálogo guiado o asistido, intenta dirigirnos al servicio o departamento más adecuado. En este ejemplo concreto, la dificultad es doble, ya que, por un lado, el sistema ha de convertir nuestro mensaje hablado en escrito y almacenarlo, para posteriormente pasarlo por una rutina o algoritmo de procesamiento del lenguaje natural que interprete la petición y tome la decisión correcta en base a un árbol de decisión pre-establecido.
Otro ejemplo de aplicación de este tipo de técnicas, son aquellas situaciones en las que se cuenta con mucha información escrita en texto libre procedente de informes rutinarios. Por ejemplo, un informe médico tras una consulta en atención primaria, o un informe policial que se genera al poner una denuncia en una comisaría. Este tipo de informes, suelen contener una cantidad de datos estructurados en campos en las respectivas aplicaciones software en las que se generan - por ejemplo, fecha, asunto, nombre del declarante o paciente, etc.- sin embargo, también suelen contener uno o varios campos para introducir texto libre donde se narran los hechos acontecidos.
En la actualidad, ese texto libre (introducido de forma digital) se almacena, pero no se procesa para interpretar su contenido. En el campo de la Sanidad, para cambiar esta situación se podría utilizar, por ejemplo, la herramienta Apache CTAKES, un framework de desarrollo software que permite la interpretación y extracción de términos clínicos en informes médicos para su posterior uso en forma de asistente al diagnóstico o la creación de diccionarios médicos (más información en este interesante video que explica el funcionamiento de CTAKES).
Generación de lenguaje natural
Por otro lado, las aplicaciones y ejemplos que demuestran el potencial de la generación de lenguaje natural, ya sea en forma de texto o habla, son múltiples y muy variadas. Uno de los ejemplos más conocidos en este sentido es el de la generación de resúmenes meteorológicos. La mayor parte de los resúmenes e informes meteorológicos que se encuentran en la Web han sido generados con un motor de generación de lenguaje natural a partir de los datos cuantitativos de predicción que ofrecen las agencias y organismos oficiales. De forma muy simplificada, un algoritmo de generación de lenguaje natural, generaría la expresión "El tiempo está empeorando" como descripción lingüística de la siguiente variable cuantitativa (∆P=Pt0-Pt1), que es un cálculo que muestra que la presión atmosférica está bajando. Los cambios en la presión atmosférica son un indicador bien conocido de la evolución del tiempo a corto plazo. La pregunta evidente ahora es cómo determina el algoritmo lo que ha de escribir. La respuesta es simple en primera aproximación. La mayoría de estas técnicas utilizan plantillas para generar el lenguaje natural. Plantillas que utilizan frases que se van combinando en función de las salidas que determine el algoritmo. Dicho así, esto podría parecer sencillo, sin embargo, el sistema puede alcanzar un alto grado de complejidad si se introduce lógica difusa para determinar (en el ejemplo) en qué grado el tiempo está empeorando.
Otros ejemplos típicos donde se encuentra comúnmente generación de lenguaje natural es en los resúmenes de encuentros deportivos o en informes periódicos de algunos mercados como el bursátil o el inmobiliario. Por ejemplo, haciendo uso de una herramienta sencilla para generar lenguaje natural a partir del siguiente conjunto de datos estructurados (en formato JSON):

Obtendremos el siguiente resumen en lenguaje natural (en el ejemplo, en inglés) junto con algunos detalles adicionales en cuanto a la legibilidad y métricas del texto devuelto:

Otro ejemplo es la traducción automática, una de las aplicaciones con más impacto en el ámbito del procesamiento del lenguaje natural. Abarca tanto la comprensión como la generación con la complejidad añadida de que la comprensión y el procesamiento es sobre la lengua de origen y la generación del mensaje es en la lengua destino.
Todos estos ejemplos demuestran que los beneficios del uso de herramientas para procesado de lenguaje natural son múltiples. Estas herramientas permiten un escalado que posibilita a algunas empresas generar del orden de 10.000 o 100.000 narrativas semanales que dan valor a sus clientes. Sin estas herramientas de generación y automatización sería imposible alcanzar esas cotas. Estas herramientas permiten democratizar determinados servicios para usuarios no expertos en el manejo de variables cuantitativas. Este es el caso de narrativas que resumen nuestro consumo de electricidad sin necesidad de ser un experto conocedor de variables como los kWh. Desde el punto de vista del procesamiento del lenguaje natural, estas tecnologías han cambiado radicalmente la forma de entender el servicio posventa al cliente. Combinadas con tecnologías como los chatbots o robots conversacionales, permiten mejorar la experiencia del cliente al ser atendido rápidamente y sin necesidad de horarios. Ejecutadas por máquinas, estas tecnologías de procesamiento del lenguaje natural, pueden además, consultar datos del cliente de forma eficiente mientras se le guía a través del diálogo (asistido) en su lenguaje natural.
Ante todas estas posibilidades de futuro, no es de extrañar que cada vez más empresas y organismos estén apostando por desarrollar el procesamiento del lenguaje natural, un campo que puede aportar grandes beneficios a nuestra sociedad. Cabe destacar la iniciativa de la Secretaría de Estado para el Avance Digital que ha diseñado un plan específico para el impulso de las tecnologías del lenguaje (www.PlanTL.es), entendiendo por tales, el procesamiento del lenguaje natural, la traducción automática y los sistemas conversacionales.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Entrevista
qMe-Aporta, tercer premiado en el Desafío Aporta 2017, es un prototipo para la construcción intuitiva de consultas, en lenguaje natural guiado, sobre la base de conocimiento de datos.gob.es. Se trata de un sistema que guía al usuario en la construcción de la pregunta, mostrando múltiples alternativas para iniciar y continuar la pregunta. No sólo utiliza términos del sistema (metadatos), también los datos y sus sinónimos. Estas preguntas se pueden hacer en varios idiomas.
Hablamos con Mariano Rico Almodóvar, investigador de la Universidad Politécnica de Madrid (UPM) y responsable de esta iniciativa, para que nos cuente cómo está llevando a cabo este proyecto.
¿En qué punto del desarrollo de qMe-Aporta te encuentras actualmente?
Estamos a la espera de financiación. Es una lástima que un sistema tan útil desde nuestro punto de vista para la reutilización de los datos de las administraciones públicas esté parado, pero así es. Hicimos el esfuerzo, a coste cero, de analizar la aplicación del sistema Dylan-Q (el núcleo de qMe-Aporta) a los datasets del Desafío Aporta (datos.gob.es) pero aún no hemos podido crear el sistema.
Estoy aplicando Dylan-Q a un proyecto europeo llamado SlideWiki, y por ahí esperamos lograr la visibilidad necesaria para lograr financiación privada. También confiamos en que el Catálogo de Tecnologías UPM, del que forma parte la tecnología Dylan-Q, nos dé suficiente visibilidad como para atraer clientes o inversores.
¿En qué fuentes de información, públicas o privadas, se basa su proyecto?
La tecnología Dylan-Q se aplica a datasets RDF, el formato estándar de datos semánticos. En el caso del Desafío Aporta nos centramos en los datasets RDF que hay en datos.gob.es, donde hay datos de todo tipo: comercio, demografía, educación, y un largo etcétera. De los 2018 datasets que había disponibles en la fecha del concurso, la mayoría no eran datasets RDF. Pero conviene destacar que disponemos de herramientas para convertir a RDF datasets (ficheros y bases de datos) en cualquier formato.
Las tecnologías semánticas nos permiten una integración de información mucho más sencilla que con las técnicas tradicionales. Si unimos a esto la lexicalización de las ontologías y un poco de magia (tenemos un informe positivo de patente de la tecnología Dylan-Q), logramos sistemas que permiten hacer consultas guiadas en lenguaje natural sobre cualquier conjunto de datos RDF.
¿Cree que iniciativas como el Desafío Aporta 2017 pueden ayudar a empresas y emprendedores a poner en marcha sus proyectos de reutilización de datos abiertos? ¿Qué otras iniciativas de este tipo cree que deberían ponerse en práctica?
La visibilidad que nos proporcionan estos premios es muy importante, pero son necesarios otros elementos para poder materializar estos proyectos. Es frecuente que las empresas se interesen por proyectos que conocen a través de premios como éste, pero suelen exigir el desarrollo a coste cero de un prototipo (lo que en la jerga se denomina, “prueba de concepto”). Además, aunque los resultados del prototipo sean buenos, no se garantiza la implementación completa del proyecto. También es habitual que los potenciales inversores exijan dedicación exclusiva y sin sueldo por un periodo de hasta dos años. Se tiende a concebir la innovación como una lotería en la que se sabe que una de cada diez start-ups tendrá éxito y permitirá multiplicar considerablemente su inversión, pero, por lo general, no se siguen criterios de inversión a largo plazo y solo se pretende rentabilizar la inversión en un plazo típico de dos años. En estas condiciones es muy difícil emprender.
En países como Alemania o Estados Unidos está más extendida entre las empresas la idea de inversión a fondo perdido. Entienden que para ganar hay que arriesgar, y están dispuestas a asumir el coste del riesgo. No hay miedo al “fracaso”, que se ve como algo natural en los procesos de innovación. Por el contrario, está muy extendido en las empresas de nuestro país que el riesgo lo debe asumir la Administración o, como es nuestro caso, los investigadores. Un siglo después de la frase de Unamuno “¡Qué inventen ellos!”, la situación parece no haber cambiado. Y no creo que sea una cuestión de mayor o menor economía, o de mayor o menor crisis económica, excusas tradicionales para condicionar la inversión en I+D+i, sino de una mayor cultura de inversión en innovación. De hecho, sabemos desde hace tiempo que es la inversión en I+D+i lo que hace que los países sean más o menos prósperos, y no al revés.
Pero no desfallecemos. Seguimos presentándonos a todas las reuniones que nos solicitan. Soñamos con una empresa que esté dispuesta a arriesgar una pequeña cantidad, digamos 30 mil euros, para que le hagamos un prototipo adaptado a su negocio y a una muestra de sus datos, durante 6 meses. Si ese prototipo le convence, haríamos un nuevo proyecto usando todos sus datos y todo su modelo de negocio. ¿Quién quiere ser el primero?.
Pero pese a todo lo dicho, debo insistir en que Iniciativas como Aporta, o como las que promueve el Centro de Apoyo a la Innovación Tecnológica (CAIT) de la UPM, son excelentes para acercar a tecnólogos y empresas. Debería haber encuentros de este tipo con más frecuencia.
Como usuario de datos abiertos, ¿qué retos se ha encontrado a la hora de reutilizar la información pública? ¿Cómo los ha solucionado?
El reto principal ha sido, y sigue siendo, encontrar el dataset más adecuado a nuestras necesidades. A veces es un único dataset, pero la mayoría de las veces queremos varios datasets inicialmente no relacionados entre sí. Creo que se ilustra con la frase “en un mar de datos, pescamos con una caña”. Necesitamos herramientas más potentes para poder pescar de forma más eficiente.
La búsqueda de información es un problema difícil cuando el volumen de datos aumenta, no tanto por el número de datos de un tipo dado como por el número de tipos de datos y las relaciones que hay entre ellos. Las tecnologías semánticas nos permiten relacionar los tipos de datos y dotarles de significado, por lo que podemos abordar este problema con más probabilidades de éxito.
¿Qué actuaciones considera que España debe priorizar en materia de disposición de datos?
Creo que hay que repartir claramente las tareas. Por una parte, las administraciones locales deben recopilar los datos. Por otra, la Administración general debe proporcionar las herramientas necesarias para que las administraciones locales incorporen de forma sencilla y eficiente los datos recopilados. La iniciativa datos.gob.es trabaja en esta línea, pero aún se puede ir más allá. Por ejemplo, es necesaria la integración de los datos recopilados por las administraciones locales, esto es, relacionar los tipos de datos con otros tipos de datos de otros datasets. Podría facilitarse mediante el uso de las tecnologías semánticas. Una vez integrada la información, la Administración podría ofrecer nuevos servicios a los usuarios, como el que proporcionaría qMe-Aporta, y muchos otros que todavía no imaginamos.
Para terminar, ¿cuáles son sus planes de futuro? ¿Están inmersos o tienen en mente algún otro proyecto de reutilización de datos abiertos?
En nuestro grupo de investigación tenemos varios proyectos que utilizan datos abiertos, en lo que se ha denominado “ciencia ciudadana”, como Farolapp (http://farolapp.linkeddata.es), o Stars4All (http://stars4all.eu), pero quizás nuestra principal contribución es la DBpedia del español (es.dbpedia.org). Tenemos un proyecto con la multinacional española TAIGER para aumentar la calidad de los datos de la DBpedia del español, y hemos desarrollado varias técnicas con muy buenos resultados. En junio (2018) hemos organizado el primer congreso internacional de grafos de conocimiento aplicados a turismo y viajes, donde hemos constatado la importancia que tiene este sector que representa el 14% del PIB español y el 10% mundial. Pensamos que la información almacenada en la DBpedia del español puede ser de mucha utilidad para este sector económico. Hay que saber que el 40% de los datos de la DBpedia del español sólo se encuentran en nuestra DBpedia.
La mayor parte de las técnicas que hemos aplicado sobre la DBpedia se pueden aplicar a otros conjuntos de datos, por lo que los datos abiertos se pueden beneficiar de estas técnicas.
Afortunadamente, seguimos investigando y desarrollando proyectos donde aplicar nuestros conocimientos sobre tecnologías semánticas, procesamiento de lenguaje natural y aprendizaje automático (machine learning). Querría aprovechar para agradecer a los responsables del grupo de investigación, Asunción Gómez Pérez y Oscar Corcho, la confianza que han depositado en nosotros, y el tiempo que nos han permitido dedicar a este concurso.
Evento
La Secretaría de Estado para la Sociedad de la Información y la Agenda Digital (SESIAD), junto con la Entidad Pública Empresarial Red.es, organizan el primer Hackathon de Tecnología de Lenguaje con el objetivo de fomentar el desarrollo de aplicaciones tecnológicas basadas en el procesamiento del lenguaje natural (PLN) y la traducción automática a través de la creación de prototipos de código abierto con funcionalidades concretas para este ámbito.
El concurso consta de dos fases: en primer lugar, los participantes deberán presentar ideas sobre la temática: “Cómo aplicar Tecnologías del Lenguaje a datos abiertos”, en concreto, una propuesta de prototipo de código abierto en un plazo de 15 días naturales desde la publicación del listado de admitidos.
Pasarán a la segunda fase las 10 mejores propuestas de prototipo seleccionadas por un jurado que elegirá las candidaturas de acuerdo a los criterios establecidos en el documento de condiciones del concurso y valorando:
- El grado de innovación, originalidad y creatividad en el ámbito de las tecnologías del lenguaje.
- La viabilidad del prototipo.
- La utilidad de la propuesta, teniendo en cuenta el nivel de dificultad del problema que resuelve , el número de potenciales destinatarios, etc.
Los participantes seleccionados participarán, el próximo 27 de febrero en Barcelona, en una competición presencial donde desarrollar y presentar, en el marco del evento 4YFN 2017, los prototipos de código abierto propuestos en los cuales se podrá utilizar cualquier lenguaje de programación.
La participación en este primer Hackathon de Tecnología de Lenguaje es gratuito y está abierto a cualquier persona física, jurídica o empresarial que cumpla las bases y condiciones, disponibles a través de la sede electrónica de Red.es, y que realice la inscripción que se mantendrá abierta hasta el 16 de enero.