Blog
Teaching computers to understand how humans speak and write is a long-standing challenge in the field of artificial intelligence, known as natural language processing (NLP). However, in the last two years or so, we have seen the fall of this old stronghold with the advent of large language models (LLMs) and conversational interfaces. In this post, we will try to explain one of the key techniques that makes it possible for these systems to respond relatively accurately to the questions we ask them.
Introduction
In 2020, Patrick Lewis, a young PhD in the field of language modelling who worked at the former Facebook AI Research (now Meta AI Research) publishes a paper with Ethan Perez of New York University entitled: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks in which they explained a technique to make current language models more precise and concrete. The article is complex for the general public, however, in their blog, several of the authors of the article explain in a more accessible way how the RAG technique works. In this post we will try to explain it as simply as possible.
Large Language Models are artificial intelligence models that are trained using Deep Learning algorithms on huge sets of human-generated information. In this way, once trained, they have learned the way we humans use the spoken and written word, so they are able to give us general and very humanly patterned answers to the questions we ask them. However, if we are looking for precise answers in a given context, LLMs alone will not provide specific answers or there is a high probability that they will hallucinate and completely make up the answer. For LLMs to hallucinate means that they generate inaccurate, meaningless or disconnected text. This effect poses potential risks and challenges for organisations using these models outside the domestic or everyday environment of personal LLM use. The prevalence of hallucination in LLMs, estimated at 15% to 20% for ChatGPT, may have profound implications for the reputation of companies and the reliability of AI systems.
What is a RAG?
Precisely, RAG techniques have been developed to improve the quality of responses in specific contexts, for example, in a particular discipline or based on private knowledge repositories such as company databases.
RAG is an extra technique within artificial intelligence frameworks, which aims to retrieve facts from an external knowledge base to ensure that language models return accurate and up-to-date information. A typical RAG system (see image) includes an LLM, a vector database (to conveniently store external data) and a series of commands or queries. In other words, in a simplified form, when we ask a natural language question to an assistant such as ChatGPT, what happens between the question and the answer is something like this:
- The user makes the query, also technically known as a prompt.
- The RAG enriches the prompt or question with data and facts obtained from an external database containing information relevant to the user's question. This stage is called retrieval
- The RAG is responsible for sending the user's prompt enriched or augmented to the LLM which is responsible for generate a natural language response taking advantage of the full power of the human language it has learned with its generic training data, but also with the specific data provided in the retrieval stage.

Understanding RAG with examples
Let us take a concrete example. Imagine you are trying to answer a question about dinosaurs. A generalist LLM can invent a perfectly plausible answer, so that a non-expert cannot distinguish it from a scientifically based answer. In contrast, using RAG, the LLM would search a database of dinosaur information and retrieve the most relevant facts to generate a complete answer.
The same was true if we searched for a particular piece of information in a private database. For example, think of a human resources manager in a company. It wants to retrieve summarised and aggregated information about one or more employees whose records are in different company databases. Consider that we may be trying to obtain information from salary scales, satisfaction surveys, employment records, etc. An LLM is very useful to generate a response with a human pattern. However, it is impossible for it to provide consistent and accurate data as it has never been trained with such information due to its private nature. In this case, RAG assists the LLM in providing specific data and context to return the appropriate response.
Similarly, an LLM complemented by RAG on medical records could be a great assistant in the clinical setting. Financial analysts would also benefit from an assistant linked to up-to-date stock market data. Virtually any use case benefits from RAG techniques to enrich LLM capabilities with context-specific data.
Additional resources to better understand RAG
As you can imagine, as soon as we look for a moment at the more technical side of understanding LLMs or RAGs, things get very complicated. In this post we have tried to explain in simple words and everyday examples how the RAG technique works to get more accurate and contextualised answers to the questions we ask to a conversational assistant such as ChatGPT, Bard or any other. However, for those of you who have the desire and strength to delve deeper into the subject, here are a number of web resources available to try to understand a little more about how LLMs combine with RAG and other techniques such as prompt engineering to deliver the best possible generative AI apps.
Introductory videos:
LLMs and RAG content articles for beginners
- DEV - LLM for dummies
- Digital Native - LLMs for Dummies
- Hopsworks.ai - Retrieval Augmented Augmented Generation (RAG) for LLMs
- Datalytyx - RAG For Dummies
Do you want to go to the next level? Some tools to try out:
- LangChain. LangChain is a development framework that facilitates the construction of applications using LLMs, such as GPT-3 and GPT-4. LangChain is for software developers and allows you to integrate and manage multiple LLMs, creating applications such as chatbots and virtual agents. Its main advantage is to simplify the interaction and orchestration of LLMs for a wide range of applications, from text analysis to virtual assistance.
- Hugging Face. Hugging Face is a platform with more than 350,000 models, 75,000 datasets and 150,000 demo applications, all open source and publicly available online where people can easily collaborate and build artificial intelligence models.
- OpenAI. OpenAI is the best known platform for LLM models and conversational interfaces. The creators of ChatGTP provide the developer community with a set of libraries to use the OpenAI API to create their own applications using the GPT-3.5 and GPT-4 models. As an example, we suggest you visit the Python library documentation to understand how, with very few lines of code, we can be using an LLM in our own application. Although OpenAI conversational interfaces, such as ChatGPT, use their own RAG system, we can also combine GPT models with our own RAG, for example, as proposed in this article.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
After several months of tests and different types of training, the first massive Artificial Intelligence system in the Spanish language is capable of generating its own texts and summarising existing ones. MarIA is a project that has been promoted by the Secretary of State for Digitalisation and Artificial Intelligence and developed by the National Supercomputing Centre, based on the web archives of the National Library of Spain (BNE).
This is a very important step forward in this field, as it is the first artificial intelligence system expert in understanding and writing in Spanish. As part of the Language Technology Plan, this tool aims to contribute to the development of a digital economy in Spanish, thanks to the potential that developers can find in it.
The challenge of creating the language assistants of the future
MarIA-style language models are the cornerstone of the development of the natural language processing, machine translation and conversational systems that are so necessary to understand and automatically replicate language. MarIA is an artificial intelligence system made up of deep neural networks that have been trained to acquire an understanding of the language, its lexicon and its mechanisms for expressing meaning and writing at an expert level.
Thanks to this groundwork, developers can create language-related tools capable of classifying documents, making corrections or developing translation tools.
The first version of MarIA was developed with RoBERTa, a technology that creates language models of the "encoder" type, capable of generating an interpretation that can be used to categorise documents, find semantic similarities in different texts or detect the sentiments expressed in them.
Thus, the latest version of MarIA has been developed with GPT-2, a more advanced technology that creates generative decoder models and adds features to the system. Thanks to these decoder models, the latest version of MarIA is able to generate new text from a previous example, which is very useful for summarising, simplifying large amounts of information, generating questions and answers and even holding a dialogue.
Advances such as the above make MarIA a tool that, with training adapted to specific tasks, can be of great use to developers, companies and public administrations. Along these lines, similar models that have been developed in English are used to generate text suggestions in writing applications, summarise contracts or search for specific information in large text databases in order to subsequently relate it to other relevant information.
In other words, in addition to writing texts from headlines or words, MarIA can understand not only abstract concepts, but also their context.
More than 135 billion words at the service of artificial intelligence
To be precise, MarIA has been trained with 135,733,450,668 words from millions of web pages collected by the National Library, which occupy a total of 570 Gigabytes of information. The MareNostrum supercomputer at the National Supercomputing Centre in Barcelona was used for the training, and a computing power of 9.7 trillion operations (969 exaflops) was required.
Bearing in mind that one of the first steps in designing a language model is to build a corpus of words and phrases that serves as a database to train the system itself, in the case of MarIA, it was necessary to carry out a screening to eliminate all the fragments of text that were not "well-formed language" (numerical elements, graphics, sentences that do not end, erroneous encodings, etc.) and thus train the AI correctly.
Due to the volume of information it handles, MarIA is already the third largest artificial intelligence system for understanding and writing with the largest number of massive open-access models. Only the language models developed for English and Mandarin are ahead of it. This has been possible mainly for two reasons. On the one hand, due to the high level of digitisation of the National Library's heritage and, on the other hand, thanks to the existence of a National Supercomputing Centre with supercomputers such as the MareNostrum 4.
The role of BNE datasets
Since it launched its own open data portal (datos.bne.es) in 2014, the BNE has been committed to bringing the data available to it and in its custody closer: data on the works it preserves, but also on authors, controlled vocabularies of subjects and geographical terms, among others.
In recent years, the educational platform BNEscolar has also been developed, which seeks to offer digital content from the Hispánica Digital Library's documentary collection that may be of interest to the educational community.
Likewise, and in order to comply with international standards of description and interoperability, the BNE data are identified by means of URIs and linked conceptual models, through semantic technologies and offered in open and reusable formats. In addition, they have a high level of standardisation.
Next steps
Thus, and with the aim of perfecting and expanding the possibilities of use of MarIA, it is intended that the current version will give way to others specialised in more specific areas of knowledge. Given that it is an artificial intelligence system dedicated to understanding and generating text, it is essential for it to be able to cope with lexicons and specialised sets of information.
To this end, the PlanTL will continue to expand MarIA to adapt to new technological developments in natural language processing (more complex models than the GPT-2 now implemented, trained with larger amounts of data) and will seek ways to create workspaces to facilitate the use of MarIA by companies and research groups.
Content prepared by the datos.gob.es team.
Blog
The advance of supercomputing and data analytics in fields as diverse as social networks or customer service is encouraging a part of artificial intelligence (AI) to focus on developing algorithms capable of processing and generating natural language.
To be able to carry out this task in the current context, having access to a heterogeneous list of natural language processing libraries is key to designing effective and functional AI solutions in an agile way. These source code files, which are used to develop software, facilitate programming by providing common functionalities, previously solved by other developers, avoiding duplication and minimising errors.
Thus, with the aim of encouraging sharing and reuse to design applications and services that provide economic and social value, we break down four sets of natural language processing libraries, divided on the basis of the programming language used.
Python libraries
Ideal for coding using the Python programming language. As with the examples available for other languages, these libraries have a variety of implementations that allow the developer to create a new interface on their own.
Examples include:
NLTK: Natural Language Toolkit
- Description: NLTK provides easy-to-use interfaces to more than 50 corpora and lexical resources such as WordNet, together with a set of text processing libraries. It enables text pre-processing tasks, including classification, tokenisation, lemmatisation or exclusion of stop words, parsing and semantic reasoning.
- Supporting materials: One of the most interesting sections to consult information and resolve doubts is the section dedicated to frequently asked questions. You can find it at this link. It also has available examples of use and a wiki.
Gensim
- Description: Gensim is an open source Python library for representing documents as semantic vectors. The main difference with respect to other natural language libraries for Python is that Gensim is capable of automatically identifying the subject matter of the set of documents to be processed. It also allows us to analyse the similarity between files, which is really useful when we use the library to perform searches.
- Supporting materials: In the Documentation section of its website, it is possible to find didactic materials focused on three very specific areas. On the one hand, there is a series of tutorials aimed at programmers who have never used this type of library before. There are training lessons oriented towards specific programming language issues, a series of guides aimed at resolving doubts that arise when faced with certain problems, and also a section dedicated solely to frequently asked questions.
Libraries for JavaScript
JavaScript libraries serve to diversify the range of resources that can be used by programmers and web developers who make use of this language. You can choose from the following examples below:
Apache OpenNLP
- Description: The Apache OpenNLP library is a machine learning-based toolkit for natural language text processing. It supports the basic tasks of natural language programming, tokenisation, sentence segmentation, part-of-speech tagging, named entity extraction, language detection and much more.
- Supporting materials: Within the General category of its website, there is a sub-section called Books, Tutorials and Talks, which provides a series of talks, tutorials and publications aimed at resolving programmers' doubts. Likewise, in the Documentation category, they have different user manuals.
NLP.js
- Description: NLP.js targets node.js, an open source JavaScript runtime environment. It natively supports 41 languages and can even be extended to 104 languages with the use of Bert embeddings. It is a library mainly used for building bots, sentiment analysis or automatic language identification, among other functions. Precisely for this reason, it is a library to be taken into account for the construction of chatbots.
- Supporting materials: Within their profile hosted on the Github code portal, they offer a section of frequently asked questions and another of examples of use that may be useful when using the library to develop an app or service.
Natural
- Description: Like NLP.js, Natural also facilitates natural language processing for node.js. It offers a wide range of functionalities such as tokenisation, phonetic matching, term frequency (TF-IDF) and integration with the WordNet database, among others.
- Supporting materials: Like the previous library, this library does not have its own website. In its Github profile, it has support content such as examples of use cases previously developed by other programmers.
Wink
- Description: Wink is a family of open source packages for statistical analysis, natural language processing and machine learning in NodeJS. It has been optimised to achieve a balance between performance and accuracy, making the package capable of handling large amounts of raw text at high speed.
- Supporting materials: Accessing the tutorials from its website is very intuitive, as one of the categories with the same name contains precisely this type of informative content. Here it is possible to find learning guides divided according to the level of experience of the programmer or the part of the process in which he/she is immersed.
Libraries for R
In this last section we bring together the specific libraries for building a website, application or service using the R coding language. Some of them are:
koRpus
- Description: This is a text analysis package capable of automatic language detection and various indexes of lexical diversity or readability, among other functions. It also includes the RKWard plugin which provides graphical dialogue boxes for its basic functions.
- Supporting materials: koRpus offers a series of guidelines focused on its installation and gathered in the Read me document that you can find in this link. Also, in the News section you can find the updates and changes that have been made in the successive versions of the library.
Quanteda
- Description: This library has been designed to allow programmers using R to apply natural language processing techniques to their texts from the original version to the final output. Therefore, its API has been developed to enable powerful and efficient analysis with a minimum of steps, thus reducing the learning barriers to natural language processing and quantitative text analysis.
- Supporting materials: It offers as main support material this quick start guide. Through it, it is possible to follow the main instructions in order not to make any mistakes. It also includes several examples that can be used to compare results.
Isa - Natural Language Processing
- Description: This library is based on latent semantic analysis, which consists of creating structured data from a collection of unstructured text.
- Supporting materials: In the documentation section, we can find useful information for development.
Libraries for Python and R
We talk about libraries for Python and R to refer to those that are compatible for coding using both programming languages.
spaCy
- Description: It is a very useful tool for preparing texts that will later be used in other machine learning tasks. It also allows statistical linguistic models to be applied to solve different natural language processing problems.
- Supporting materials: spaCy offers a series of online courses divided into different chapters that you can find here. Through the contents shared in NLP Advanced you will be able to follow step by step the utilities of this library, as each chapter focuses on a part of text processing. If you still want to learn more about this library, we recommend you to read this article by Alejandro Alija regarding his experience testing this library.
In this article we have shared a sample of some of the most popular libraries for natural language processing. However, it should be stressed that this is only a selection.
So, if you know of any other libraries of interest that you would like to recommend, please leave us a message in the comments or send us an email to dinamizacion@datos.gob.es.
Content prepared by the datos.gob.es team.
Blog
Few abilities are as characteristic of human beings as language. According to the Aristotelian school, humans are rational animals who pursue knowledge for the mere fact of knowing. Without going into deep philosophical considerations that far exceed the purpose of this space for dissemination, we can say that this search for knowledge and the accumulation of knowledge would not be possible without the intervention of human language. Hence, in this 21st century - the century of the explosion of Artificial Intelligence (AI) - a large part of the efforts are focused on supporting, complementing and increasing human capabilities related to language.
Introduction
In this space, we have repeatedly discussed the discipline of natural language processing (NLP). We have approached it from different points of view, all of them from a practical, technical and data-related approach - texts - which are the real fuel of the technologies that support this discipline. We have produced monographs on the subject, introducing the basics of the technology and including practical examples. We have also commented on current events and analysed the latest technological trends, as well as the latest major achievements in natural language processing. In almost all publications on the subject, we have mentioned tools, libraries and technological products that, in one way or another, help and support the different processes and applications of natural language. From the creation of reasoned summaries of works and long texts, to the artificial generation of publications or code for programmers, all applications use libraries, packages or frameworks for the development of artificial intelligence applications applied in the field of natural language processing.
On previous occasions we have described the GPT-3 algorithm of the OpenAI company or the Megatron-Turing NLG of Microsoft, as some of the current exponents in terms of analysis power and precision in the generation of quality results. However, on most occasions, we have to talk about algorithms or libraries that, given their complexity, are reserved for a small technical community of developers, academics and professionals within the NLP discipline. That is, if we want to undertake a new project related to natural language processing, we must start from low-level libraries, and then add layers of functionality to our project or application until it is ready for use. Normally, NLP libraries focus on a small part of the path of a software project (mainly the coding task), being the developers or software teams the ones who must contemplate and add the rest of the functional and technical layers (testing, packaging, publishing and putting into production, operations, etc.) to convert the results of that NLP library into a complete technological product or application.
The challenge of launching an application
Let's take an example. Let's suppose that we want to build an application that, based on a starting text, for example, our electricity bill, gives us a simple summary of the content of our bill. We all know that electricity bills or employee pay slips are not exactly simple documents for the general public to understand. The difficulty usually lies in the use of highly technical terminology and, why not say it, in the low interest of some organisations in simplifying the life of citizens by making it easier to understand basic information such as what we pay for electricity or our salaries as employees. Back to the topic at hand. If we want to build a software application for this purpose, we will have to use an algorithm that understands our bill. For this, NLP algorithms have to, first of all, perform an analysis of the text and detect the keywords and their relationships (what in technical terminology is called detecting entities and recognising them in context). That is, the algorithm will have to detect the key entities, such as energy consumption, its units in kWh, the relevant time periods (this month's consumption, last month's consumption, daily consumption, past consumption history, etc.). Once these relevant entities have been detected (and the others discarded), as well as their relationships, there is still a lot to do. In terms of a software project in the field of NLP, Named-Entity-Recognition (NER) is only a small part of an application ready to be used by a person or a system. This is where we introduce you to the SpaCy software library.
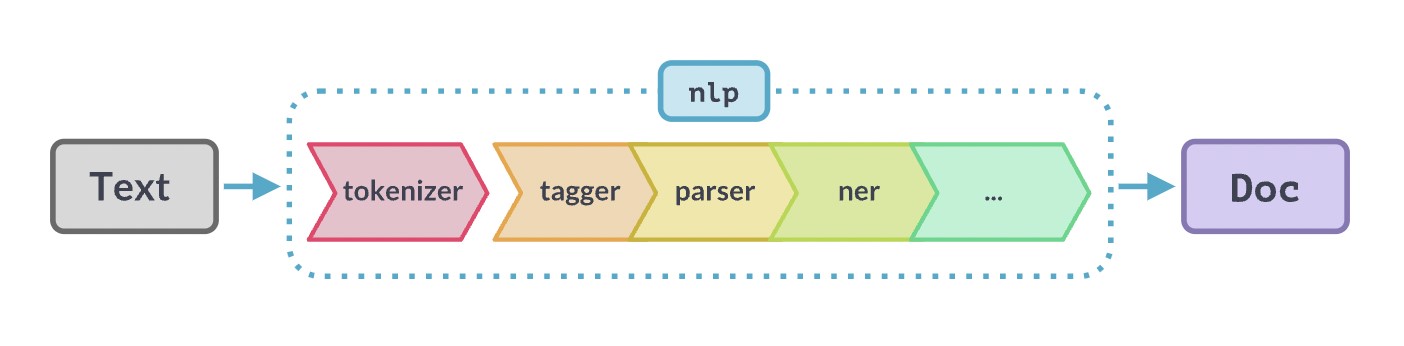
Example of NLP flow or pipeline from the moment we start from the original text we want to analyse until we obtain the final result, either a rich text or a web page with help or explanations to the user. Original source: https://SpaCy.io/
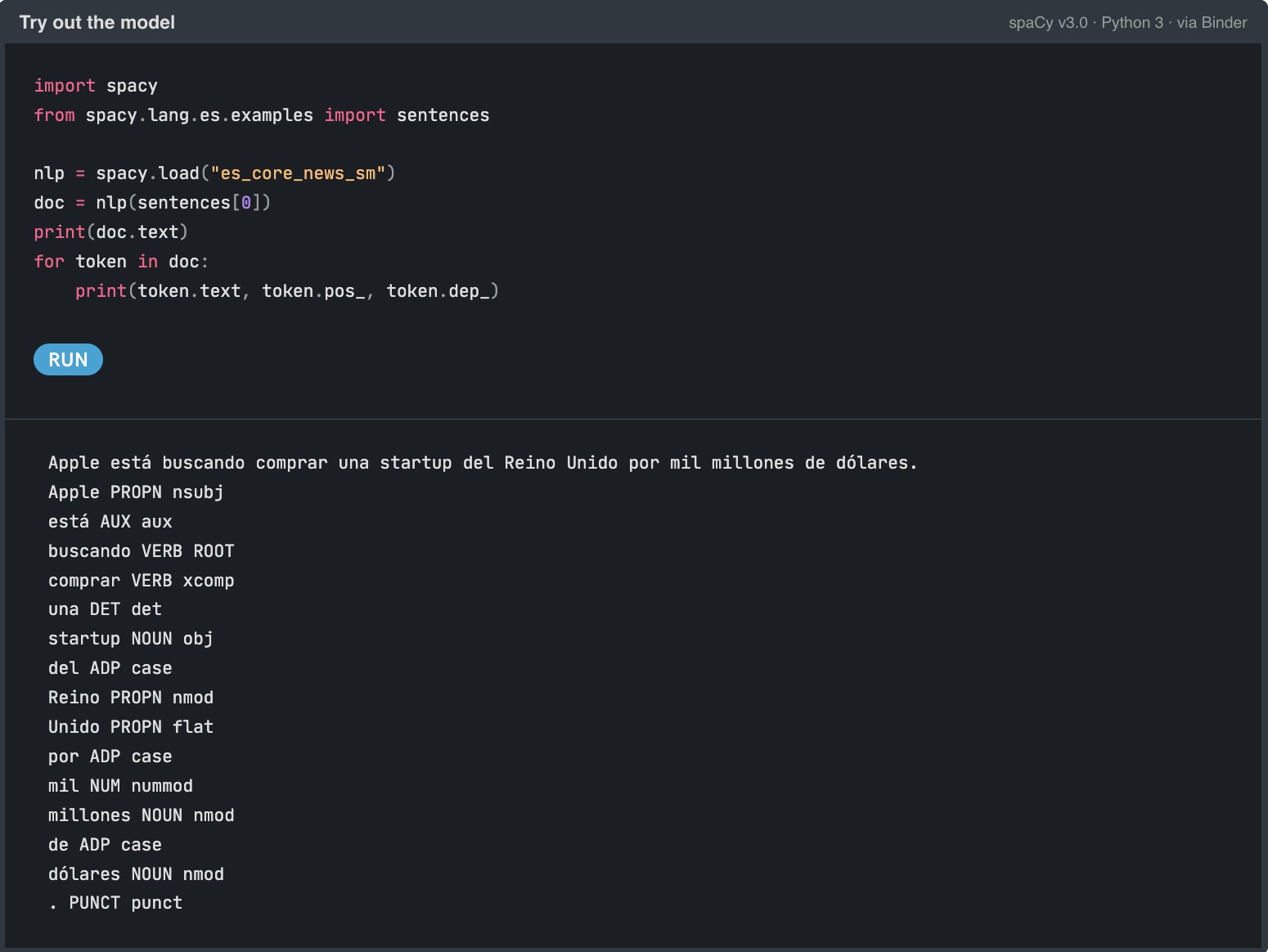
Example of the use of Spacy's es_core_news_sm pipeline to identify entities in a Spanish sentence.
What is Spacy?
SpaCy aims to facilitate the production release (making an application ready for use by the end consumer) of software applications in the natural language domain. SpaCy is an open source software library designed to facilitate advanced natural language processing tasks. SpaCy is written in Python and Cython (C language extensions for Python that allow very efficient low-level programming). It is an open-source library under the MIT license and the entire project is accessible through its Github account.
The advantages of Spacy
But what makes SpaCy different? SpaCy was created with the aim of facilitating the creation of real products. That is to say, the library is not just a library for the most technical and lowest levels within the layers that make up a software application, from the most internal algorithms to the most visual interfaces. The library contemplates the practical aspects of a real software product, in which it is necessary to take into account important aspects such as:
- The large data loads that are required to be processed (imagine what is involved, for example, loading the entire product reviews of a large e-commerce site).
- The speed of execution, since when we have a real application, we need the experience to be as smooth as possible and we can't put up with long waiting times between algorithm executions.
- The packaging of NLP functionality (such as NER) ready to deploy on one or more production servers. SpaCy, not only provides low-level code tools, but supports the processes from the time we create (compile and build a part of a software application) until we integrate this algorithmic part with other parts of the application such as databases or end-user interfaces.
- The optimisation of NLP models so that they can easily run on standard (CPU-based) servers without the need for graphics processors (GPUs).
- Integrated graphical visualisation tools to facilitate debugging or development of new functionality.
- Also important to mention, its fantastic documentation, from its most introductory website to its community on Github. This greatly facilitates rapid adoption among the development community.
- The large number of pre-trained models and flows (73 flows) in 22 different languages. In addition to support for more than 66 languages. In particular, in the case of Spanish language, it is difficult to find models optimised for Spanish in other libraries and tools.

Example of a graphical entity viewer. Original source: https://SpaCy.io/
As a conclusion to this post. If you are a beginner and just starting out in the world of NLP, SpaCy makes it easy to get started and comes with extensive documentation, including a 101 guide for beginners, a free interactive online course and a variety of video tutorials. If you are an experienced developer or part of an established software development team and want to build a final production application, SpaCy is designed specifically for production use and allows you to create and train powerful NLP data streams (texts) and package them for easy deployment. Finally, if you are looking for alternatives to your existing NLP solution (looking for new NLP models, need more flexibility and agility in your production deployments or looking for performance improvements), SpaCy allows you to customise, test different architectures and easily combine existing and popular frameworks such as PyTorch or TensorFlow.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Noticia
Spain already has a new National Artificial Intelligence Strategy. The document, which includes 600 million euros for measures related to artificial intelligence (AI), was presented on December 2 at the Palacio de la Moncloa.
The National Strategy for Artificial Intelligence (known as ENIA) is component 16 of the Plan for the Recovery, Transformation and Resilience of the Spanish economy, and one of the fundamental proposals of the Digital Spain Agenda 2025 in its line 9 of action, which highlights AI as a key element for boosting the growth of our economy in the coming years. In addition, the new strategy is aligned with the European action plans developed in this area, and especially with the White Paper on Artificial Intelligence.
Objectives and lines of action
The ENIA is a dynamic and flexible framework, open to the contribution of companies, citizens, social agents and the rest of the administrations, which was created with 7 objectives: scientific excellence and innovation, the projection of the Spanish language, the creation of qualified employment, the transformation of the Spanish productive fabric, the creation of an environment of trust in relation to AI and the promotion of an inclusive and sustainable AI that takes into account humanist values.
To achieve these objectives, 6 lines of action have been created, which bring together a total of 30 measures to be developed in the period 2020-2025:

In short, the aim is to create a national ecosystem of innovative, competitive and ethical artificial intelligence. And to do this, it is essential to have large volumes of quality and interoperable data and metadata, which are accessible, complete, secure and respectful of privacy.
Open data in the National Strategy of Artificial Intelligence
The availability of open data is essential for the proper functioning of artificial intelligence, since the algorithms must be fed and trained by data whose quality and availability allows continuous improvement. In this way we can create value services that impact on the improvement of society and the economy.
The National Strategy for Artificial Intelligence highlights how, thanks to the various initiatives undertaken in recent years, Spain has become a European benchmark for open data, highlighting the role of the Aporta Initiative in promoting the openness and reuse of public information.
In strategic axis 3 of the document, several key areas are highlighted where to act linked to AI data platforms and technological infrastructures:
- Developing the regulatory framework for open data, to define a strategy for publication and access to public data from administrations in multilingual formats, and to ensure the correct and safe use of the data.
- Promote actions in the field of data platforms, models, algorithms, inference engines and cyber security, with the focus on boosting research and innovation. Reference is made to the need to promote Digital Enabling Technologies such as connectivity infrastructures, massive data environments (cloud) or process automation and control, paying special attention to Strategic Supercomputing Capabilities (HPC).
- Promote the specific development of AI technologies in the field of natural language processing, promoting the use of Spanish in the world. In this sense, the National Plan of Language Technologies will be promoted and the LEIA project, developed by the Royal Spanish Academy for the defense, projection and good use of the Spanish language in the digital universe, will be supported.
In the specific case of open data, one of the first measures highlighted is the creation of the Data Office at the state level that will coordinate all public administrations in order to homogenize the storage, access and processing of data. To strengthen this action, a Chief Data Officer will be appointed. In addition, a multidisciplinary working group on open data in the state public sector will be set up to highlight the efforts that have been made in the field of data in Spain and to continue promoting the openness and reuse of public sector information.
The strategy also considers the private sector, and highlights the need to promote the development of accessible repositories and to guide companies in the definition of open or shared data strategies. In this sense, shared spaces of sectorial and industrial data will be created, which will facilitate the creation of AI applications. Furthermore, mention is made of the need to offer data disaggregated by sex, age, nationality and territory, in such a way as to eliminate biases linked to these aspects.
In order to stimulate the use and governance of public and citizen data, the creation of the Data for Social Welfare Project is established as an objective, where open and citizen-generated data will play a key role in promoting accountability and public participation in government.

Other highlights of the ENIA
In addition to actions related to open data, the National Strategy of Artificial Intelligence includes more transversal actions, for example:
- The incorporation of AI in the public administration will be promoted, improving from transparency and effective decision-making to productivity and quality of service (making management and the relationship with citizens more efficient). Here the Aporta Initiative has been playing a key role with its support to public sector bodies in the publication of quality data and the promotion of its reuse. Open data repositories will be created to allow optimal access to the information needed to develop new services and applications for the public and private sectors. In this sense, an innovation laboratory (GobTechLab) will be created and training programs will be carried out.
- The aim is to promote scientific research through the creation of a Spanish Network of Excellence in AI with research and training programs and the setting up of new technological development centers. Special attention will be given to closing the gender gap.
- A program of aid to companies for the development of AI and data solutions will be launched, and the network of Digital innovation Hubs will be reinforced. A NextTech Fund for public-private venture capital will be created.
- Talent will be promoted through the National Digital Skills Plan. AI-related elements will be introduced in schools and the university and professional AI training offer will be boosted. The SpAIn Talent Hub program will be developed in coordination with ICEX Invest to attract foreign investment and talent.
- A novelty of the strategy is that it takes into account ethical and social regulation to fight discrimination. Observatories for ethical and legal evaluation of algorithmic systems will be created and the Digital Rights Charter, currently under revision, will be developed.
In short, we are facing a necessary strategy to boost the growth of AI in Spain, promoting our society and economy, and improving our international competitiveness.
Blog
Can you imagine an AI capable of writing songs, novels, press releases, interviews, essays, technical manuals, programming code, prescribing medication and much more that we don't know yet? Watching GPT-3 in action doesn't seem like we're very far away.
In our latest report on natural language processing (NLP) we mentioned the GPT-2 algorithm developed by OpenAI (the company founded by such well-known names as Elon Musk) as an exponent of its capabilities for generating synthetic text with a quality indistinguishable from any other human-created text. The surprising results of GPT-2 led the company not to publish the source code of the algorithm because of its potential negative effects on the generation of deepfakes or false news
Recently (May 2020) a new version of the algorithm has been released, now called GPT-3, which includes functional innovations and improvements in performance and capacity to analyse and generate natural language texts.
In this post we try to summarize in a simple and affordable way the main new features of GPT-3. Do you dare to discover them?
We start directly, getting to the point. What does GPT-3 bring with it? (adaptation of the original post by Mayor Mundada).
- It is much bigger (complex) than everything we had before. Deep learning models based on neural networks are usually classified by their number of parameters. The greater the number of parameters, the greater the depth of the network and therefore its complexity. The training of the full version of GPT-2 resulted in 1.5 billion parameters. GPT-3 results in 175 billion parameters. GPT-3 has been trained on a basis of 570 GB of text compared to 40 GB of GPT-2.
- For the first time, it can be used as a product or service. For the first time it can be used as a product or service. That is, OpenAI has announced the availability of a public API for users to experiment with the algorithm. At the time of writing this post, access to the API is restricted (this is what we call a private preview) and access must be requested.
- The most important thing: the results. Despite the fact that the API is restricted by invitation, many Internet users (with access to the API) have published articles on its results in different fields.
What role do open data play?
It is rarely possible to see the power and benefits of open data as in this type of project. As mentioned above GPT-3 has been trained with 570 GB of data in text format. Well, it turns out that 60% of the training data of the algorithm comes from the source https://commoncrawl.org. Common Crawl is an open and collaborative project that provides a corpus for research, analysis, education, etc. As specified on the Common Crawl website the data provided are open and hosted under the AWS open data initiative. Much of the rest of the training data is also open including sources such as Wikipedia.
Use cases
Below are some of the examples and use cases that have had an impact.
Generation of synthetic text
This entry (no spoilers ;) ) from Manuel Araoz's blog shows the power of the algorithm to generate a 100% synthetic article on Artificial Intelligence. Manuel performs the following experiment: he provides GPT-3 with a minimal description of his biography included in his blog and a small fragment of the last entry in his blog. 117 words in total. After 10 runs of GPT-3 to generate related artificial text, Manuel is able to copy and paste the generated text, place a cover image and has a new post ready for his blog. Honestly, the text of the synthetic post is indistinguishable from an original post except for possible errors in names, dates, etc. that the text may include.
Productivity. Automatic generation of data tables.
In a different field, the GPT-3 algorithm has applications in the field of productivity. In this example GPT-3 is able to create a MS Excel table on a certain topic. For example, if we want to obtain a table, as a list, with the most representative technology companies and their year of foundation, we simply provide GPT-3 with the desired pattern and ask it to complete it. The starting pattern can be something similar to this table below (in a real example, the input data will be in English). GPT-3 will complete the shaded area with actual data. However, if in addition to the input pattern, we provide the algorithm with a plausible description of a fictitious technology company and ask you again to complete the table with the new information, the algorithm will include the data from this new fictitious company.
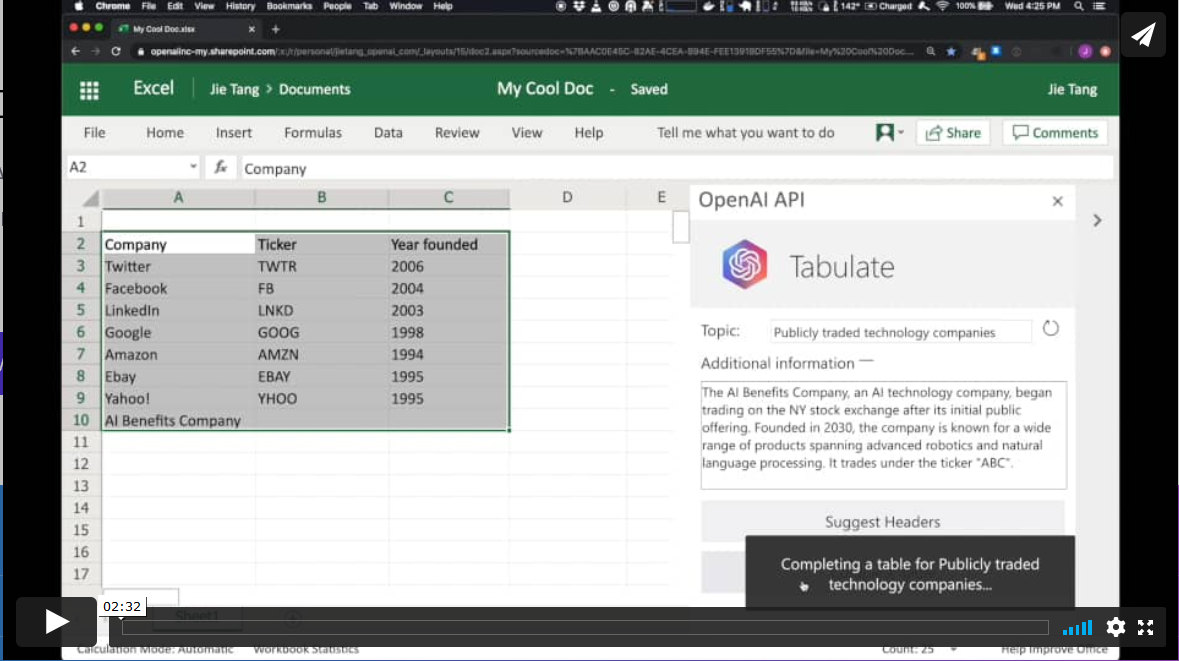
These examples are just a sample of what GPT-3 is capable of doing. Among its functionalities or applications are:
- semantic search (different from keyword search)
- the chatbots
- the revolution in customer services (call-center)
- the generation of multi-purpose text (creation of poems, novels, music, false news, opinion articles, etc.)
- productivity tools. We have seen an example on how to create data tables, but there is talk (and much) about the possibility of creating simple software such as web pages and small simple applications without the need for coding, just by asking GPT-3 and its brothers who are coming.
- online translation tools
- understanding and summarizing texts.
and so many other things we haven't discovered yet... We will continue to inform you about the next developments in NLP and in particular about GPT-3, a game-changer that has come to revolutionize everything we know at the moment.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
Our language, both written and spoken, constitutes a peculiar type of data. Language is the human means of communication par excellence and its main features are ambiguity and complexity. Due to language is unstructured data, its processing has traditionally been a challenge to the machines, making it difficult to use in the analysis processes of the information. With the explosion of social networks and the advancement of supercomputing and data analytics in fields as diverse as medicine or call-centers, it is not surprising that a large part of artificial intelligence subfields are dedicated to developing strategies and algorithms to process and generate natural language.
Introduction
In the domain of data analysis applied to natural language processing, there are two major goals: Understanding and Generating.
- Understand: there are a set of techniques, tools and algorithms whose main objective is to process and understand the natural language to finally transform this information into structured data that can be exploited / used by a machine. There are different levels of complexity, depending on whether the message that is transmitted in natural language have a written or spoken format. In addition, the language of the message greatly increases the processing complexity, since the recognition algorithms must be trained in that specific language or another similar one.
- Generate: we find algorithms that try to generate messages in natural language. That is, algorithms that consume classical or structured data to generate a communication in natural language, whether written or spoken.
Figure 1. Natural language processing and its two associated approaches show a diagram to better understand these tasks that are part of natural language processing.

To better understand these techniques, let's give some examples:
Natural Language Understanding
In the first group, we can find those applications using by a human to request a certain information or describe a problem and a machine is responsible for receiving and processing that message with the aim of resolving or addressing the request. For example, when we call the information services of almost any company, our call is answered by a machine that, through a guided or assisted dialogue, tries to direct us to the most appropriate service or department. In this concrete example, the difficulty is twofold: the system has to convert our spoken message into a written message and store it, and then treat it with a routine or natural language processing algorithm that interprets the request and makes the correct decision based on a pre-established decision tree.
Another example of application of this techniques is those situations whit lot of written information from routine reports. For example, a medical or a police report. This type of reports usually contain structured data, filling different boxes into a specific software applications - for example, date, subject, name of the declarant or patient, etc. - However, they also usually contain one or several free-format fields where the events are described.
Currently, that free-format text (written digitally) is stored, but is not processed to interpret its content. In Health field, for example, the Apache CTAKES tool could be used to change this situation. It is a software development framework that allows the interpretation and extraction of clinical terms included in medical reports for later use in the form of diagnostic assistant or the creation of medical dictionaries (you can find more information in this interesting video that explains how CTAKES works).
Natural Language Generation
On the other hand, the applications and examples that demonstrate the potential of natural language generation, whether text-form or speech-form, are multiple and very varied. One of the best known examples is the generation of weather summaries. Most of the summaries and meteorological reports found on the Web have been generated with a natural language generation engine based on the quantitative prediction data offered by official agencies. In a very simplified way, a natural language generation algorithm would generate the expression “Time is getting worse” as a linguistic description of the next quantitative variable (∆P=Pt0-Pt1), which is a calculation that shows that atmospheric pressure is going down. Changes in atmospheric pressure are a well-known indicator of the evolution of short-term weather. The obvious question now is how the algorithm determines what to write. The answer is simple. Most of these techniques use templates to generate natural language. Templates that use phrases that are combined depending on the outputs determined by the algorithm. That said, this might seem simple, however, the system can reach a high degree of complexity if fuzzy logic is introduced to determine (in the example) to what degree the time is getting worse.
Other typical examples where natural language generation is commonly found are the summaries of sporting events or the periodic reports of some markets such as stock market or real estate. For example, making use of a simple tool to generate natural language from the following set of structured data (in JSON format):

We will obtain the following summary in natural language, in addition to some details regarding the readability and metrics of the returned text:

Another example is machine translation, one of the applications with most impact in natural language processing. It covers both comprehension and generation with an added complexity: understanding and processing is based on the origin-language and the message-generation is written on the target language.
All these examples show that the benefits of using tools for processing natural language are multiple. These tools facilitate an escalation that allows some companies to generate 10,000 or 100,000 weekly narratives that give value to their clients. Without these generation and automation tools it would be impossible to reach these levels. These tools allow the democratization of certain services for non-expert users in the management of quantitative variables. This is the case of narratives that summarize our electricity consumption without having to be an expert aware of variables such as kWh.
From the point of view of natural language processing, these technologies have radically changed the way to understand after-sales service to the customer. Combined with technologies such as chatbots or conversational robots, they improve the customer experience, taking care of clients quickly and without schedules needs. Executed by machines, these natural language processing technologies can also consult customer data efficiently while being guided through (assisted) dialogue in their natural language.
Given all these possibilities for the future, it is not surprising that an increasing number of companies and organizations are developing natural language processing, a field that can bring great benefits to our society. Noteworthy is the initiative of the State Secretariat for Digital Progress, which has designed a specific plan for the promotion of language technologies (www.PlanTL.es), meaning natural language processing, machine translation and conversational systems.
Content prepared by Alejandro Alija, expert in Digital Transformation and innovation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Entrevista
qMe-Aporta, third prize winner at Desafío Aporta 2017, is a prototype for the intuitive construction of queries, in guided natural language, based on datos.gob.es knowledge. It is a system that guides the user in the construction of the question, showing multiple alternatives to start and continue the question. It not only uses the system terms (metadata), but also the data and its synonyms. These questions can be asked in several languages.
We have spoken with Mariano Rico Almodóvar, researcher at the Polytechnic University of Madrid (UPM) and responsible for this initiative, to tell us how he is carrying out this project.
Currently, at what of qMe-Aporta development are you?
We are waiting for funding. It is a pity that a system so useful, from our point of view, for the reuse of data from public administrations is stopped, but it is. We made the effort, at zero cost, to analyze the application of Dylan-Q system (the core of qMe-Aporta) to the datasets related to Desafío Aporta (datos.gob.es) but we have not yet been able to create the system.
I'm applying Dylan-Q to a European project called SlideWiki, and that's where we hope to achieve the visibility needed for private funding. We also trust that the UPM Technologies Catalog (Dylan-Q technology is part of it), will give us enough visibility to attract customers or investors.
What information sources, public or private, is your project based on?
Dylan-Q technology is applied to RDF datasets, the standard semantic data format. In the case of Desafío Aporta, we focus on RDF datasets from datos.gob.es, where there is all kinds of data: trade, demography, education, etcetera. Most of the 2018 datasets that were available on the date of the contest were not RDF datasets. But it should be noted that we have tools to convert RDF datasets (files and databases) in any format.
Semantic technologies allow us to integrate information much more easily than with traditional techniques. If we add to this the lexicalization of the ontologies and a bit of magic (we have a positive patent report of the Dylan-Q technology), we achieve systems that allow guided consultations in natural language related to any RDF data set.
Do you think that initiatives such as the Desafio Aporta 2017 can help companies and entrepreneurs launch their open data reuse projects? What other initiatives of this kind do you think should be put into practice?
The visibility that these awards give us is very important, but other elements are necessary to be able to materialize these projects. It is common for companies to be interested in projects they know through awards like this one, but they usually demand the development at zero cost of a prototype (what in the jargon is called "proof of concept"). In addition, although the results of the prototype are good, the full implementation of the project is not guaranteed. It is also common for potential investors to demand exclusive dedication without pay for a period of up to two years. There is a tendency to think of innovation as a lottery in which it is known that one in ten start-ups will be successful and will considerably multiply their investment, but, in general, long-term investment criteria are not followed and the objective is just to make the investment profitable within a typical period of two years. In these conditions it is very difficult to undertake.
In countries such as Germany or the United States, the idea of a non-repayable investment is more widespread among companies. They understand that you have to take risks to win, and are willing to assume the cost of risk. There is no fear of "failure", which is seen as something natural in innovation processes. On the contrary, it is very widespread in the companies of our country that the risk should be assumed by the Administration or, as our case, the researchers. A century after the sentence of Unamuno " Let them do the inventing", The situation seems not to have changed. And I do not believe that it is a matter of higher or lesser economy, or of major or minor economic crisis, traditional excuses to condition the investment in R & D, but of a higher culture of innovation investment. In fact, we have known for a long time that investment in R + D + I is what makes countries more or less prosperous, and not vice versa.
But do not lose heart. We continue attending all meetings that organizations request. We dream of a company that is willing to risk a small amount, say 30 thousand euros, for us to make a prototype adapted to their business and a sample of their data, for 6 months. If that prototype convinces them, we would make a new project using all data and the entire business model. Who wants to be the first?
But in spite of all that has been said, I must insist that initiatives as Aporta or those promoted by the Technological Innovation Support Center (CAIT) of the UPM are excellent for bringing together technologists and companies. There should be meetings of this type more frequently.
As a user of open data, what challenges have you found when reusing public information? How have you solved those challenges?
The main challenge has been, and still is, to find the dataset that best suits our needs. Sometimes it is a single dataset, but most of the time we want several datasets initially unrelated. I think it is illustrated with the phrase "in a sea of data, we fish with a rod". We need more powerful tools to be able to fish more efficiently.
The search for information is a difficult problem when the volume of data increases, not so much by the number of data of a given type, but by the number of data categories and the relationships between them. Semantic technologies allow us to relate categories of data and give them meaning, so we can address this problem with more chances of success.
What actions do you consider that Spain should prioritize in terms of data provision?
I think you have to clearly divide the tasks. On the one hand, local administrations must collect the data. On the other hand, the General Administration must provide the necessary tools so that the local administrations incorporate in a simple and efficient way the collected data. The initiative datos.gob.es works in this line, but you can still go further. For example, it is necessary to integrate the data collected by local administrations, that is, link data categories. It could be facilitated through the use of semantic technologies. Once the information is integrated, the Administration could offer new services to users, such as the one provided by QMe-Aporta, and many others that we still cannot imagine.
Finally, what are your future plans? Are you immersed or have any other open data reuse project in mind?
In our research group we have several projects that use open data, in what has been called "citizen science", such as Farolapp (http://farolapp.linkeddata.es), or Stars4All (http://stars4all.eu), but perhaps our main contribution is the Spanish DBpedia (es.dbpedia.org). We have a project with the Spanish multinational TAIGER to increase the quality of Spanish DBpedia data, and we have developed several techniques with very good results. In June (2018) we organized the first international congress of knowledge graphs applied to tourism and travel, where we have confirmed the importance of this sector, which represents 14% of Spanish GDP and 10% worldwide. We think that the information stored in the Spanish DBpedia can be very useful for this economic sector. You have to know that 40% of the DBpedia data in Spanish is only found in our DBpedia.
Most of the techniques we have applied to DBpedia can be applied to other data sets, so that open data can benefit from these techniques.
Fortunately, we continue to research and develop projects where we apply our knowledge on semantic technologies, natural language processing and machine learning. I would like to take this opportunity to thank those responsible for the research group, Asunción Gómez Pérez and Oscar Corcho, for the trust they have placed in us, and the time they have allowed us to spend in this contest.
Evento
The State Secretariat for the Information Society and the Digital Agenda (SESIAD), together with the Public Business Entity Red.es, organize the first Hackathon of Language Technology with the goal of promoting the development of technological applications based on the natural language processing and the automatic translation through the creation of open source prototypes with concrete functionalities related to this area.
The competition consists of two phases: first, the participants will have to present their ideas on the theme: "How to apply Open Language Technologies", in particular, a proposal of an open source within 15 calendar days once the list of admissions is published.
The 10 best prototype proposals will go to the second phase, selected by a jury that will choose the candidates according to the criteria established in the conditions of the hackathon and assessing:
- The degree of innovation, originality and creativity in the area of language technologies.
- The feasibility of the prototype.
- The utility of the proposal, taking into account the difficulty level of the problem it solves, the number of potential recipients, etc.
The selected participants will participate, next February 27 in Barcelona, in a competition where they will develop and present, at the 4YFN 2017 event, the proposed open-source prototypes in which any programming language can be used.
The participation in this first Hackathon of Technology of Language is free and open to any physical, legal or business person who meets the terms and conditions, available on the website of Red.es, and submits the form before January 16.