Documentación
En el campo de la ciencia de datos, la capacidad de construir modelos predictivos robustos es fundamental. Sin embargo, un modelo no es solo un conjunto de algoritmos, es una herramienta que debe ser comprendida, validada y, en última instancia, útil para la toma de decisiones.
Gracias a la transparencia y accesibilidad de los datos abiertos, tenemos la oportunidad única de trabajar en este ejercicio con información real, actualizada y de calidad institucional que refleja problemáticas ambientales. Esta democratización del acceso permite no solo desarrollar análisis rigurosos con datos oficiales, sino también contribuir al debate público informado sobre políticas ambientales, creando un puente directo entre la investigación científica y las necesidades sociales.
En este ejercicio práctico, nos sumergiremos en el ciclo de vida completo de un proyecto de modelado, utilizando un caso de estudio real: el análisis de la calidad del aire en Castilla y León. A diferencia de los enfoques que se centran únicamente en la implementación de algoritmos, nuestra metodología se enfoca en:
- Carga y exploración inicial de los datos: identificar patrones, anomalías y relaciones subyacentes que guiarán nuestro modelado.
- Análisis exploratorio orientado al modelado: construir visualizaciones y realizar ingeniería de características para optimizar el modelado.
- Desarrollo y evaluación de modelos de regresión: construir y comparar múltiples modelos iterativos para entender cómo la complejidad afecta el rendimiento.
- Aplicación del modelo y conclusiones: utilizar el modelo final para simular escenarios y cuantificar el impacto de posibles políticas ambientales.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Arquitectura del Análisis
El núcleo de este ejercicio sigue un flujo estructurado en cuatro fases clave, como se ilustra en la Figura 1. Cada fase se construye sobre la anterior, desde la exploración inicial de los datos hasta la aplicación final del modelo.

Figura 1. Fases del proyecto de modelado predictivo.
Proceso de Desarrollo
1. Carga y exploración inicial de los datos
El primer paso es entender la materia prima de nuestro análisis: los datos. Utilizando un conjunto de datos de calidad del aire de Castilla y León, que abarca 24 años de mediciones, nos enfrentamos a desafíos comunes en el mundo real:
- Valores Faltantes: variables como el CO y el PM2.5 tienen una cobertura de datos limitada.
- Datos Anómalos: se detectan valores negativos y extremos, probablemente debidos a errores de los sensores.
A través de un proceso de limpieza y transformación, convertimos los datos brutos en un conjunto de datos limpio y estructurado, listo para el modelado.
2. Análisis exploratorio orientado al modelado
Una vez limpios los datos, buscamos patrones. El análisis visual revela una fuerte estacionalidad en los niveles de NO₂, con picos en invierno y valles en verano. Esta observación es crucial y nos lleva a la creación de nuevas variables (ingeniería de características), como componentes cíclicos para los meses, que permiten al modelo "entender" la naturaleza circular de las estaciones.

Figura 2. Variación estacional de los niveles de NO₂ en Castilla y León.
3. Desarrollo y evaluación de modelos de regresión
Con un conocimiento sólido de los datos, procedemos a construir tres modelos de regresión lineal de complejidad creciente:
- Modelo Base: utiliza solo los contaminantes como predictores.
- Modelo Estacional: añade las variables de tiempo.
- Modelo Completo: incluye interacciones y efectos geográficos.
La comparación de estos modelos nos permite cuantificar la mejora en la capacidad predictiva. El Modelo Estacional emerge como la opción óptima, explicando casi el 63% de la variabilidad del NO₂, un resultado notable para datos ambientales.
4. Aplicación del modelo y conclusiones
Finalmente, sometemos el modelo a un riguroso diagnóstico y lo utilizamos para simular el impacto de políticas ambientales. Por ejemplo, nuestro análisis estima que una reducción del 20% en las emisiones de NO podría traducirse en una disminución del 4.8% en los niveles de NO₂.

Figura 3. Rendimiento del modelo estacional. Los valores predichos se alinean bien con los valores reales.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Ciclo de vida de un proyecto de datos: desde la limpieza hasta la aplicación.
- Técnicas de regresión lineal: construcción, interpretación y diagnóstico.
- Manejo de datos temporales: captura de estacionalidad y tendencias.
- Validación de modelos: técnicas como la validación cruzada y temporal.
- Comunicación de resultados: cómo traducir hallazgos en insights accionables.
Conclusiones y Futuro
Este ejercicio demuestra el poder de un enfoque estructurado y riguroso en la ciencia de datos. Hemos transformado un conjunto de datos complejo en un modelo predictivo que no solo es preciso, sino también interpretable y útil.
Para aquellos interesados en llevar este análisis al siguiente nivel, las posibilidades son numerosas:
- Incorporación de datos meteorológicos: variables como la temperatura y el viento podrían mejorar significativamente la precisión.
- Modelos más avanzados: explorar técnicas como los Modelos Aditivos Generalizados (GAM) u otros algoritmos de machine learning.
- Análisis espacial: investigar cómo varían los patrones de contaminación entre diferentes ubicaciones.
En resumen, este ejercicio no solo ilustra la aplicación de técnicas de regresión, sino que también subraya la importancia de un enfoque integral que combine el rigor estadístico con la relevancia práctica.
Noticia
Hoy, 23 de abril, se celebra el Día del Libro, una ocasión para resaltar la importancia de la lectura, la escritura y la difusión del conocimiento. La lectura activa promueve la adquisición de habilidades y el pensamiento crítico, al acercarnos a información especializada y detallada sobre cualquier tema que nos interese, incluido el mundo de los datos.
Por ello, queremos aprovechar la ocasión para mostrar algunos ejemplos de libros y manuales relacionados con los datos y tecnologías relacionadas que se pueden encontrar en la red de manera gratuita.
1. Fundamentos de ciencia de datos con R, editado por Gema Fernandez-Avilés y José María Montero (2024)
Accede al libro aquí.
- ¿De qué trata? El libro guía al lector desde el planteamiento de un problema hasta la realización del informe que contiene su solución. Para ello, explica una treintena de técnicas de ciencia de datos en el ámbito de la modelización, análisis de datos cualitativos, discriminación, machine learning supervisado y no supervisado, etc. En él se incluyen más de una docena de casos de uso en sectores tan dispares como la medicina, el periodismo, la moda o el cambio climático, entre otros. Todo ello, con un gran énfasis en la ética y en el fomento de la reproductibilidad de los análisis.
-
¿A quién va dirigido? Está dirigido a usuarios que quieran iniciarse en la ciencia de datos. Parte de preguntas básicas, como qué es la ciencia de datos, e incluye breves secciones con explicaciones sencillas sobre la probabilidad, la inferencia estadística o el muestreo, para aquellos lectores no familiarizados con estas cuestiones. También incluye ejemplos replicables para practicar.
-
Idioma: Español
2. Contar historias con datos, Rohan Alexander (2023).
Accede al libro aquí.
-
¿De qué trata? El libro explica una amplia gama de temas relacionados con la comunicación estadística y el modelado y análisis de datos. Abarca las distintas operaciones desde la recopilación de datos, su limpieza y preparación, hasta el uso de modelos estadísticos para analizarlos, prestando especial importancia a la necesidad de extraer conclusiones y escribir sobre los resultados obtenidos. Al igual que el libro anterior, también pone el foco en la ética y la reproductibilidad de resultados.
-
¿A quién va dirigido? Es perfecto para estudiantes y usuarios con conocimientos básicos, a los que dota de capacidades para realizar y comunicar de manera efectiva un ejercicio de ciencia de datos. Incluye extensos ejemplos de código para replicar y actividades a realizar a modo de evaluación.
-
Idioma: Inglés.
3. El gran libro de los pequeños proyectos con Python, Al Sweigart (2021)
Accede al libro aquí.
- ¿De qué trata? Es una colección de sencillos proyectos en Python para aprender a crear arte digital, juegos, animaciones, herramientas numéricas, etc. a través de un enfoque práctico. Cada uno de sus 81 capítulos explica de manera independiente un proyecto sencillo paso a paso -limitados a máximo 256 líneas de código-. Incluye una ejecución de muestra del resultado de cada programa, el código fuente y sugerencias de personalización.
-
¿A quién va dirigido? El libro está escrito para dos grupos de personas. Por un lado, aquellos que ya han aprendido los conceptos básicos de Python, pero todavía no están seguros de cómo escribir programas por su cuenta. Por otro, aquellos que se inician en la programación, pero son aventureros, cuentan con grandes dosis de entusiasmo y quieren ir aprendiendo sobre la marcha. No obstante, el mismo autor tiene otros recursos para principiantes con los que aprender conceptos básicos.
-
Idioma: Inglés.
4. Matemáticas para Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Accede al libro aquí.
-
¿De qué trata? La mayoría de libros sobre machine learning se centran en algoritmos y metodologías de aprendizaje automático, y presuponen que el lector es competente en matemáticas y estadística. Este libro pone en primer plano los fundamentos matemáticos de los conceptos básicos detrás del aprendizaje automático
-
¿A quién va dirigido? El autor asume que el lector tiene conocimientos matemáticos comúnmente aprendidos en las materias de matemáticas y física de la escuela secundaria, como por ejemplo derivadas e integrales o vectores geométricos. A partir de ahí, el resto de conceptos se explican de manera detallada, pero con un estilo académico, con el fin de ser precisos.
-
Idioma: Inglés.
5. Profundizando en el aprendizaje profundo, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, se actualiza continuamente)
Accede al libro aquí.
-
¿De qué trata? Los autores son empleados de Amazon que utilizan la biblioteca MXNet para enseñar Deep Learning. Su objetivo es hacer accesible el aprendizaje profundo, enseñando los conceptos básicos, el contexto y el código de forma práctica a través de ejemplos y ejercicios. El libro se divide en tres partes: conceptos preliminares, técnicas de aprendizaje profundo y temas avanzados centrados en sistemas y aplicaciones reales.
-
¿A quién va dirigido? Este libro está dirigido a estudiantes (de grado o posgrado), ingenieros e investigadores, que buscan un dominio sólido de las técnicas prácticas del aprendizaje profundo. Cada concepto se explica desde cero, por lo que no es necesario tener conocimientos previos de aprendizaje profundo o automático. No obstante, sí son necesario conocimientos de matemáticas y programación básicas, incluyendo álgebra lineal, cálculo, probabilidad y programación en Python.
-
Idioma: Inglés.
6. Inteligencia artificial y sector público: retos límites y medios, Eduardo Gamero y Francisco L. Lopez (2024)
Accede al libro aquí.
-
¿De qué trata? Este libro se centra en analizar los retos y oportunidades que presenta el uso de la inteligencia artificial en el sector público, especialmente cuando se usa como soporte a la toma de decisiones. Comienza explicando qué es la inteligencia artificial y cuáles son sus aplicaciones en el sector público, para pasar a abordar su marco jurídico, los medios disponibles para su implementación y aspectos ligados a la organización y gobernanza.
-
¿A quién va dirigido? Es un libro útil para todos aquellos interesados en la temática, pero especialmente para responsables políticos, trabajadores públicos y operadores jurídicos relacionados con la aplicación de la IA en el sector público.
-
Idioma: español
7. Introducción del analista de negocio a la analítica empresarial, Adam Fleischhacker (2024)
Accede al libro aquí.
-
¿De qué trata? El libro aborda un flujo de trabajo de análisis empresarial completo, que incluye la manipulación de datos, su visualización, el modelado de problemas empresariales, la traducción de modelos gráficos a código y la presentación de resultados ante las partes interesadas. El objetivo es aprender a impulsar cambios dentro de una organización gracias al conocimiento basado en datos, modelos interpretables y visualizaciones persuasivas.
-
¿A quién va dirigido? Según su autor, se trata de un contenido accesible para todos, incluso para principiantes en la realización de trabajos de análisis. El libro no asume ningún conocimiento del lenguaje de programación, sino que proporciona una introducción a R, RStudio y al “tidyverse”, una serie de paquetes de código abierto para la ciencia de datos.
-
Idioma: Inglés.
Te invitamos a ojear esta selección de libros. Asimismo, recordamos que solo se trata de una lista con ejemplos de las posibilidades de materiales que puedes encontrar en la red. ¿Conoces algún otro libro que quieras recomendar? ¡Indícanoslo en los comentarios o manda un email a dinamizacion@datos.gob.es!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas, de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, puedes acceder al material que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es hacer un análisis de los datos meteorológicos recogidos en varias estaciones durante los últimos años. Para realizar este análisis utilizaremos distintas visualizaciones generadas mediante la librería “ggplot2” del lenguaje de programación “R”
De todas las estaciones meteorológicas españolas, hemos decidido analizar dos de ellas, una en la provincia más fría del país (Burgos) y otra en la provincia más cálida del país (Córdoba), según los datos de la AEMET. Se buscarán patrones y tendencias en los distintos registros entre los años 1990 y 2020 con el objetivo de entender la evolución meteorológica sufrida en este periodo de tiempo.
Una vez analizados los datos, podremos contestar a preguntas como las que se muestran a continuación:
-
¿Cuál es la tendencia en la evolución de las temperaturas en los últimos años?
-
¿Cuál es la tendencia en la evolución de las precipitaciones en los últimos años?
-
¿Qué estación meteorológica (Burgos o Córdoba) presenta una mayor variación de los datos climatológicos en estos últimos años?
-
¿Qué grado de correlación hay entre las distintas variables climatológicas registradas?
Estas, y muchas otras preguntas pueden ser resueltas mediante el uso de herramientas como ggplot2 que facilitan la interpretación de los datos mediante visualizaciones interactivas.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos contienen distinta información meteorológica de interés para las dos estaciones en cuestión desglosada por año. Dentro del centro de descargas de la AEMET, podremos descárgalos, previa solicitud de la clave API, en el apartado “climatologías mensuales/anuales”. De las estaciones meteorológicas existentes, hemos seleccionado dos de las que obtendremos los datos: Burgos aeropuerto (2331) y Córdoba aeropuerto (5402)
Cabe destacar, que, junto a los conjuntos de datos, también podremos descargar sus metadatos, los cuales son de especial importancia a la hora de identificar las distintas variables registradas en los conjuntos de datos.
Estos conjuntos de datos también se encuentran disponibles en el repositorio de Github
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación R escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones se ha usado la librería ggplot2.
"ggplot2" es un paquete de visualización de datos para el lenguaje de programación R. Se centra en la construcción de gráficos a partir de capas de elementos estéticos, geométricos y estadísticos. ggplot2 ofrece una amplia gama de gráficos estadísticos de alta calidad, incluyendo gráficos de barras, gráficos de líneas, diagramas de dispersión, gráficos de caja y bigotes, y muchos otros
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, una vez importadas las librerías necesarias y cargados los conjuntos de datos, es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso a dar es generar las tablas de datos preprocesadas que usaremos en las visualizaciones. Para ello, filtraremos los conjuntos de datos iniciales y calcularemos los valores que sean necesarios y de interés para el análisis realizado en este ejercicio.
Una vez terminado el preprocesamiento, obtendremos las tablas de datos “datos_graficas_C” y “datos_graficas_B” las cuales utilizaremos en el siguiente apartado del Notebook para generar las visualizaciones.
La estructura del Notebook en la que se realizan los pasos previamente descritos junto a comentarios explicativos de cada uno de ellos, es la siguiente:
- Instalación y carga de librerías
- Carga de los conjuntos de datos
- Análisis exploratorio de datos (EDA)
- Preparación de las tablas de datos
- Visualizaciones
- Guardado de gráficos
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y de cara a favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Visualizaciones
Diversos tipos de visualizaciones y gráficos se han realizado con la finalidad de extraer información sobre las tablas de datos preprocesadas y responder a las preguntas iniciales planteadas en este ejercicio. Como se ha mencionado previamente, se ha utilizado el paquete “ggplot2” de R para realizar las visualizaciones.
El paquete "ggplot2" es una biblioteca de visualización de datos en el lenguaje de programación R. Fue desarrollado por Hadley Wickham y es parte del conjunto de herramientas del paquete "tidyverse". El paquete "ggplot2" está construido en torno al concepto de "gramática de gráficos", que es un marco teórico para construir gráficos mediante la combinación de elementos básicos de la visualización de datos como capas, escalas, leyendas, anotaciones y temas. Esto permite crear visualizaciones de datos complejas y personalizadas, con un código más limpio y estructurado.
Si quieres tener una visión a modo resumen de las posibilidades de visualizaciones con ggplot2, consulta la siguiente “cheatsheet”. También puedes obtener información más en detalle en el siguiente "manual de uso".
5.1. Gráficos de líneas
Los gráficos de líneas son una representación gráfica de datos que utiliza puntos conectados por líneas para mostrar la evolución de una variable en una dimensión continua, como el tiempo. Los valores de la variable se representan en el eje vertical y la dimensión continua en el eje horizontal. Los gráficos de líneas son útiles para visualizar tendencias, comparar evoluciones y detectar patrones.
A continuación, podemos visualizar varios gráficos de líneas con la evolución temporal de los valores de temperaturas medias, mínimas y máximas de las dos estaciones meteorológicas analizadas (Córdoba y Burgos). Sobre estos gráficos, hemos introducido líneas de tendencia para poder observar de forma visual y sencilla su evolución.






Para poder comparar las evoluciones, no solamente de manera visual mediante las líneas de tendencia graficadas, sino también de manera numérica, obtenemos los coeficientes de pendiente de la recta de tendencia, es decir, el cambio en la variable respuesta (tm_ mes, tm_min, tm_max) por cada unidad de cambio en la variable predictora (año).
-
Coeficiente de pendiente temperatura media Córdoba: 0.036
-
Coeficiente de pendiente temperatura media Burgos: 0.025
-
Coeficiente de pendiente temperatura mínima Córdoba: 0.020
-
Coeficiente de pendiente temperatura mínima Burgos: 0.020
-
Coeficiente de pendiente temperatura máxima Córdoba: 0.051
-
Coeficiente de pendiente temperatura máxima Burgos: 0.030
Podemos interpretar que cuanto mayor es este valor, más abrupta es la subida de temperatura media en cada periodo observado.
Por últimos, hemos creado un gráfico de líneas para cada estación meteorológica, en el que visualizamos de forma conjunta la evolución de las temperaturas medias, mínimas y máximas a lo largo de los años.


Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Las temperaturas medias, mínimas y máximas anuales registradas en Córdoba y Burgos tienen una tendencia en aumento.
-
El aumento más significativo se observa en la evolución de las temperaturas máximas de Córdoba (coeficiente de pendiente = 0.051)
-
El aumento más tenue se observa en la evolución de las temperaturas mínimas, tanto de Córdoba cómo de Burgos (coeficiente de pendiente = 0.020)
5.2. Gráficos de barras
Los gráficos de barras son una representación gráfica de datos que utiliza barras rectangulares para mostrar la magnitud de una variable en diferentes categorías o grupos. La altura o longitud de las barras representa la cantidad o frecuencia de la variable y las categorías se representan en el eje horizontal. Los gráficos de barras son útiles para comparar la magnitud de diferentes categorías y para visualizar diferencias entre ellas.
Hemos generado dos gráficos de barras con los datos correspondientes a la precipitación total acumulada por año para las distintas estaciones meteorológicas.


Al igual que en el apartado anterior, graficamos la línea de tendencia y calculamos el coeficiente de pendiente.
-
Coeficiente de pendiente precipitaciones acumuladas Córdoba: -2.97
-
Coeficiente de pendiente precipitaciones acumuladas Burgos: -0.36
Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Las precipitaciones acumuladas anuales tienen una tendencia en descenso tanto para Córdoba como para Burgos.
-
La tendencia de descenso es mayor para Córdoba (coeficiente = -2.97), siendo más moderada para Burgos (coeficiente = -0.36)
5.3. Histogramas
Los histogramas son una representación gráfica de una distribución de frecuencia de datos numéricos en un intervalo de valores. El eje horizontal representa los valores de los datos divididos en intervalos, llamados "bin", y el eje vertical representa la frecuencia o la cantidad de datos que se encuentran en cada "bin". Los histogramas son útiles para identificar patrones en los datos, como su distribución, dispersión, simetría o sesgo.
Hemos generado dos histogramas con las distribuciones de los datos correspondientes a la precipitación total acumulada por año para las distintas estaciones meteorológicas, siendo los intervalos elegidos de 50 mm3.


Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Los registros de precipitación acumulada anual en Burgos presentan una distribución cercana a una distribución normal y simétrica.
-
Los registros de precipitación acumulada anual en Córdoba no presentan una distribución simétrica.
5.4. Diagramas de cajas y bigotes
Los diagramas de cajas y bigotes, son una representación gráfica de la distribución de un conjunto de datos numéricos. Estos gráficos representan la mediana, el rango intercuartílico y los valores mínimo y máximo de los datos. La caja del gráfico representa el rango intercuartílico, es decir, el rango entre el primer y tercer cuartil de los datos. Los puntos fuera de la caja, llamados valores atípicos, pueden indicar valores extremos o datos anómalos. Los diagramas de cajas son útiles para comparar distribuciones y detectar valores extremos en los datos.
Hemos generado un gráfico con los diagramas de cajas correspondientes a los datos de precipitaciones acumuladas de las estaciones meteorológicas.
De cara a entender el gráfico, hay que destacar los siguientes puntos:
-
Los límites de la caja indican el primer y el tercer cuartil (Q1 y Q3), que dejan por debajo de cada uno, el 25% y el 75% de los datos respectivamente.
-
La línea horizontal dentro de la caja es la mediana (equivalente al segundo cuartil Q2), que deja por debajo la mitad de los datos.
-
Los límites de los bigotes son los valores extremos, es decir, el valor mínimo y el valor máximo de la serie de datos.
-
Los puntos fuera de los bigotes son los valores atípicos (outliers)

Las principales conclusiones obtenidas de la visualización de este apartado son:
-
Ambas distribuciones presentan 3 valores extremos, siendo significativos los de Córdoba con valores superiores a 1000 mm3.
-
Los registros de Córdoba tienen una mayor variabilidad que los de Burgos, los cuales se presentan más estables.
5.5. Gráficos de sectores
Un gráfico de sectores es un tipo de gráfico circular que representa proporciones o porcentajes de un todo. Se compone de varias secciones o sectores, donde cada sector representa una proporción de la totalidad del conjunto. El tamaño del sector se determina en función de la proporción que representa, y se expresa en forma de ángulo o porcentaje. Es una herramienta útil para visualizar la distribución relativa de las diferentes partes de un conjunto y facilita la comparación visual de las proporciones entre los distintos grupos.
Hemos generamos dos gráficos de sectores (polares). El primero de ellos con el número de días que los valores superan los 30º en Córdoba y el segundo de ellos con el número de días que los valores bajan de los 0º en Burgos.
Para la realización de estos gráficos, hemos agrupado la suma del número de días anteriormente descrito en seis grupos, correspondientes a periodos de 5 años desde 1990 hasta el 2020.


Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Se da un aumento del 31,9% en el total de días anuales con temperaturas superiores a 30º en Córdoba para el periodo comprendido entre el 2015-2020 respecto al periodo 1990-1995.
-
Se da un aumento del 33,5% en el total de días anuales con temperaturas superiores a 30º en Burgos para el periodo comprendido entre el 2015-2020 respecto al periodo 1990-1995.
5.6. Gráficos de dispersión
Los gráficos de dispersión son una herramienta de visualización de datos que representan la relación entre dos variables numéricas mediante la ubicación de puntos en un plano cartesiano. Cada punto representa un par de valores de las dos variables y su posición en el gráfico indica cómo se relacionan entre sí. Los gráficos de dispersión se utilizan comúnmente para identificar patrones y tendencias en los datos, así como para detectar cualquier posible correlación entre las variables. Estos gráficos también pueden ayudar a identificar valores atípicos o datos que no encajan con la tendencia general.
Hemos generado dos gráficas de dispersión en las que se comparan los valores de temperaturas medias máximas y medias mínimas buscando tendencias de correlación entre ambas para los valores cada estación meteorológica.


Para poder analizar las correlaciones, no solamente de manera visual mediante las gráficas, sino también de manera numérica, obtenemos los coeficientes de correlación de Pearson. Este coeficiente es una medida estadística que indica el grado de asociación lineal entre dos variables cuantitativas. Se utiliza para evaluar si existe una relación lineal positiva (ambas variables aumentan o disminuyen simultáneamente a un ritmo constante), negativa (los valores de ambas variables varían de forma contraria) o nula (sin relación) entre dos variables y la fortaleza de dicha relación, cuanto más cerca de +1, más alta es su asociación.
-
Coeficiente de Pearson (Temperatura media max VS min) Córdoba: 0.15
-
Coeficiente de Pearson (Temperatura media max VS min) Burgos: 0.61
En la imagen observamos que mientras en Córdoba se aprecia una mayor dispersión, en Burgos se observa una mayor correlación.
A continuación, modificaremos las gráficas de dispersión anteriores para que nos aporten más información de forma visual. Para ello dividimos el espacio por sectores de colores (rojo con valores de temperatura más altos/ azul valores de temperatura más bajos) y mostramos en las distintas burbujas la etiqueta con el año correspondiente. Cabe destacar que los límites de cambio de color de los cuadrantes corresponden con los valores medios de cada una de las variables.


Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Existe una relación lineal positiva entre la temperatura media máxima y mínima tanto en Córdoba como en Burgos, siendo mayor esta correlación en los datos de Burgos.
-
Los años que presentan valores más elevados de temperaturas máximas y mínimas en Burgos son (2003, 2006 y 2020)
-
Los años que presentan valores más elevados de temperaturas máximas y mínimas en Córdoba son (1995, 2006 y 2020)
5.7. Matriz de correlación
La matriz de correlación es una tabla que muestra las correlaciones entre todas las variables en un conjunto de datos. Es una matriz cuadrada que muestra la correlación entre cada par de variables en una escala que va de -1 a 1. Un valor de -1 indica una correlación negativa perfecta, un valor de 0 indica que no hay correlación y un valor de 1 indica una correlación positiva perfecta. La matriz de correlación se utiliza comúnmente para identificar patrones y relaciones entre variables en un conjunto de datos, lo que puede ayudar a comprender mejor los factores que influyen en un fenómeno o resultado.
Hemos generado dos mapas de calor con los datos de las matrices de correlación para ambas estaciones meteorológicas.


Las principales conclusiones obtenidas de las visualizaciones de este apartado son:
-
Existe una fuerte correlación negativa (- 0.42) para Córdoba y (-0.45) para Burgos entre el número de días anuales con temperaturas superiores a 30º y las precipitaciones acumuladas. Esto quiere decir que conforme aumenta el número de días con temperaturas superiores a 30º disminuyen notablemente las precipitaciones.
6. Conclusiones del ejercicio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos. Como hemos observado en este ejercicio, "ggplot2" se trata de una potente librería capaz de representar una grán variedad de gráficos con un alto grado de personalización que permite ajustar numerosas caracteristicas propias de cada gráfico.
Una vez analizadas las visualizaciones anteriores, podemos concluir que tanto para la estación meteorológica de Burgos, como la de Córdoba, las temperaturas (mínimas, medias, máximas) han sufrido un aumento considerable, los días con calor extremo ( Tº > 30º) también lo han sufrido y las precipitaciones han disminuido en el periodo de tiempo analizado, desde 1990 hasta el 2020.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento, representación e interpretación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
Python, R, SQL, JavaScript, C++, HTML... Hoy en día podemos encontrar multitud de lenguajes de programación que nos permiten desarrollar programas de software, aplicaciones, páginas webs, etc. Cada uno tiene características únicas que lo diferencian del resto y que lo hacen más apropiado para determinadas tareas. Pero, ¿cómo sabemos cuándo y dónde utilizar cada lenguaje? En este artículo te damos algunas pistas.
Tipos de lenguajes de programación
Los lenguajes de programación son reglas sintácticas y semánticas que nos permiten ejecutar una serie de instrucciones. Según su nivel de complejidad, podemos hablar de distintos niveles:
- Lenguajes de bajo nivel: utilizan instrucciones básicas que la máquina interpreta directamente y que son difíciles de entender por las personas. Están diseñados a medida de cada hardware y no se pueden migrar, pero son muy eficaces, ya que aprovechan al máximo las características de cada máquina.
- Lenguajes de alto nivel: utilizan instrucciones claras usando un lenguaje natural, más entendible por los humanos. Estos lenguajes emulan nuestra forma de pensar y razonar, pero después deben ser traducidos a lenguaje máquina a través de traductores/intérpretes o compiladores. Se pueden migrar y no dependen del hardware.
En ocasiones también se habla de lenguajes de nivel medio para aquellos que, aunque funcionan como un lenguaje de bajo nivel, permiten cierto manejo abstracto independiente de la máquina.
Los lenguajes de programación más utilizados
En este artículo nos vamos a centrar en los lenguajes de alto nivel más utilizados en la ciencia de datos. Para ello nos vamos a fijar en esta encuesta, realizada por Anaconda en 2021, y en el artículo elaborado por KD Nuggets.
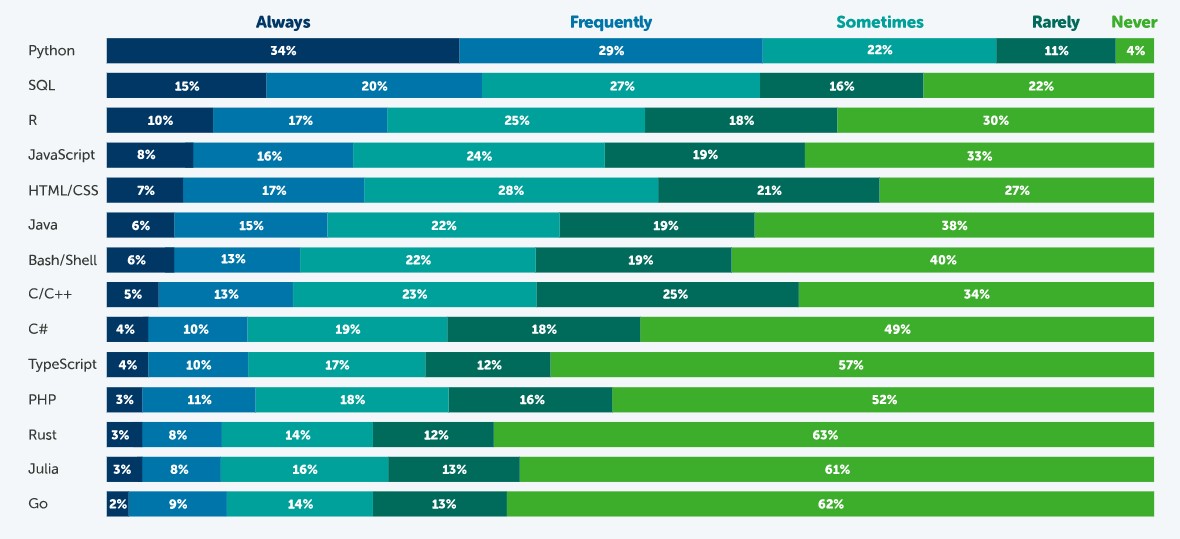
Fuente: Estado de la Ciencia de Datos en 2021, Anaconda.
Según esta encuesta, el lenguaje más popular es Python. El 63% de los encuestados – 3.104 científicos de datos, investigadores, estudiantes y profesionales del dato de todo el mundo- indicó que utiliza Python siempre o frecuentemente y solo un 4% indicó que nunca. Esto se debe a que es un lenguaje muy versátil, que se puede utilizar en las distintas tareas que existen a lo largo de un proyecto de ciencia de datos.
Un proyecto de ciencia de datos cuenta con distintas fases y tareas. Algunos lenguajes pueden ser utilizados para ejecutar distintas labores, pero con desigual rendimiento. La siguiente tabla, elaborada por KD Nuggets, muestra qué lenguaje es más recomendado para algunas de las tareas más populares:

Como vemos Python es el único lenguaje que resulta apropiado para todas las áreas analizadas por KD Nuggets, aunque existen otras opciones que también son muy interesantes, según la tarea a realizar, como veremos a continuación:
- Extracción y manipulación de datos. Estas tareas están dirigidas a obtener los datos y depurarlos con el fin de conseguir una estructura homogénea, sin datos incompletos, libre de errores y en el formato adecuado. Para ello se recomienda realizar un Análisis Exploratorio de Datos. SQL es el lenguaje de programación que más destaca con respecto a la extracción de datos, sobre todo cuando se trabaja con bases de datos relacionales. Es rápido en la recuperación de datos y cuenta con una sintaxis estandarizada, lo cual lo hace relativamente sencillo. Sin embargo, es más limitado a la hora de manipular datos. Una tarea en la que dan mejores resultados Python y R, dos programas que cuentan con una gran cantidad de librerías para estas tareas.
- Análisis estadístico y visualización de datos. Supone el tratamiento de los datos para encontrar patrones que luego se convierten en conocimiento. Existen distintos tipo de análisis según su propósito: conocer mejor nuestro entorno, realizar predicciones u obtener recomendaciones. El mejor lenguaje para ello es R, un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística. Python, Java y Julia son otras herramientas que dan un buen rendimiento en esta tarea, para la cual también se puede utilizar JavaScript. Los lenguajes anteriores permiten, además de realizar análisis, elaborar visualizaciones gráficas que facilitan la comprensión de la información.
- Modelización/aprendizaje automático (ML). Si queremos trabajar con machine learning y construir algoritmos, Python, Java, Java/JavaScript, Julia y TypeScript son las mejores opciones. Todas ellas simplifican la tarea de escribir código, aunque es necesario tener conocimientos amplios para poder trabajar con las diferentes técnicas de aprendizaje automático. Aquellos usuarios más expertos pueden trabajar con C/C++, un lenguaje de programación muy fácil de leer por máquinas, pero con mucho código, que puede ser difícil de aprender. Por el contrario, R puede ser una buena opción para aquellos menos expertos, aunque es más lento y poco apropiado para redes neuronales complejas.
- Despliegue de modelos. Una vez creado un modelo, es necesario su despliegue, teniendo en cuenta todos los requisitos necesarios para su entrada en producción en un entorno real. Para ello, los lenguajes más adecuados son Python, Java, JavaScript y C#, seguido de PHP, Rust, GoLang y, si trabajamos con aplicaciones básicas, HTML/CSS.
- Automatización. Aunque no todas las partes del trabajo de un científico de datos pueden automatizarse, hay algunas tareas tediosas y repetitivas cuya automatización agiliza el rendimiento. Python, por ejemplo, cuenta con una gran cantidad de librerías para la automatización de tareas de machine learning. Si trabajamos con aplicaciones móviles, entonces nuestra mejor opción será Java. Otras opciones son C# (especialmente útil para automatizar la construcción de modelos), Bash/Shell (para extracción y manipulación de datos) y R (para análisis estadísticos y visualizaciones).
En definitiva, el lenguaje de programación que utilicemos dependerá completamente de la tarea a realizar y de nuestras capacidades. No todos los profesionales de la ciencia de datos necesitan saber de todos los lenguajes, sino que deberán optar por profundizar en aquel más adecuado en base a su trabajo diario.
Algunos recursos adicionales para aprender más sobre estos lenguajes
En datos.gob.es hemos elaborado algunas guías y recursos que pueden ser de tu utilidad para aprender algunos de estos lenguajes:
- Informe sobre Herramientas de procesado y visualización de datos
- Cursos para aprender más sobre R
- Cursos para aprender más sobre Python
- Cursos online para aprender más sobre visualización de datos
- Comunidades de desarrolladores en R y Python
Contenido elaborado por el equipo de datos.gob.es.
Blog
El avance de la supercomputación y la analítica de datos en campos tan dispares como las redes sociales o la atención al cliente está fomentando que una parte de la inteligencia artificial (IA) se enfoque en desarrollar algoritmos capaces de procesar y generar un lenguaje natural.
Para poder llevar a cabo esta tarea en un contexto como el actual, tener acceso a un heterogéneo listado de bibliotecas de procesamiento de lenguaje natural es clave para diseñar soluciones IA eficaces y funcionales de forma ágil. Estos archivos de código fuente, que se utilizan para desarrollar software, facilitan la programación al proporcionar funcionalidades comunes, resueltas previamente por otros desarrolladores, evitando duplicidades y minimizando los errores.
Así y con el objetivo de fomentar la compartición y reutilización para diseñar aplicaciones y servicios que aporten valor económico y social, desglosamos cuatro conjuntos de bibliotecas de procesamiento de lenguaje natural, divididas en base al lenguaje de programación utilizado.
Librerías para Python
Idóneas para codificar utilizando el lenguaje de programación Python. Al igual que sucede con los ejemplos disponibles para otros lenguajes, estas librerías cuentan con gran variedad de implementaciones que permiten al desarrollador crear una nueva interfaz por su propia cuenta.
Algunos ejemplos son:
NLTK: Natural Language Toolkit
- Descripción: NLTK ofrece interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de textos. Permite realizar tareas de preprocesado de texto, entre las que encontramos, la clasificación, tokenización, lematización o la exclusión de stop words, el análisis sintáctico y el razonamiento semántico.
- Materiales de apoyo: Una de las secciones más interesantes para consultar información y resolver dudas es el apartado dedicado a las preguntas frecuentes. Puedes encontrarlo en este enlace. También tiene disponible ejemplos de uso y una wiki.
Gensim
- Descripción: Gensim es una biblioteca Python de código abierto para representar documentos como vectores semánticos. La diferencia principal respecto al resto de librerías de lenguaje natural para Python reside en que Gensim es capaz de identificar automáticamente la temática del conjunto de documentos a tratar. También permite analizar la similitud entre ficheros, algo realmente útil cuando utilizamos la librería para realizar búsquedas.
- Materiales de apoyo: En la sección de Documentación de su página web, es posible encontrar materiales didácticos enfocados a tres áreas muy concretas. Por un lado, hay una serie de tutoriales dirigidos a aquellos programadores que nunca antes han utilizado este tipo de bibliotecas. Existen lecciones formativas orientadas a cuestiones específicas del lenguaje de programación, una serie de guías cuyo objetivo es resolver las dudas que surgen ante determinados problemas y también una sección dedicada únicamente a las preguntas frecuentes
Librerías para JavaScript
Las librerías de JavaScript sirven para diversificar el abanico de recursos que pueden utilizar los programadores y desarrolladores web que hacen uso de este lenguaje. Puedes elegir entre los siguientes ejemplos propuestos a continuación:
Apache OpenNLP
- Descripción: La biblioteca Apache OpenNLP es un conjunto de herramientas basadas en el aprendizaje automático para el procesamiento de textos en lenguaje natural. Es compatible con las tareas básicas de programación de lenguaje natural, tokenización, segmentación de frases, el etiquetado de las partes de un discurso, la extracción de entidades con nombre o la detección de idiomas, entre otras muchas.
- Materiales de apoyo: Dentro de la categoría General de su web, encontramos un subapartado denominado Books, Tutorials and Talks donde se proporcionan una serie de charlas, tutoriales y publicaciones destinadas a resolver las dudas de los programadores. Igualmente, en la categoría Documentation disponen de distintos manuales de uso.
NLP.js
- Descripción: NLP.js está dirigida a node.js, un entorno de ejecución de JavaScript de código abierto. Admite 41 idiomas de forma nativa e, incluso, puede ampliarse hasta 104 idiomas con el uso de Bert embeddings. Se trata de una librería utilizada principalmente para la construcción de bots, el análisis de sentimiento o la identificación automática del lenguaje, entre otras funciones. Precisamente por esta razón, es una librería a tener en cuenta para la construcción de chatbots.
- Materiales de apoyo: Dentro de su perfil alojado en el portal de código Github ofrecen un apartado de preguntas frecuentes y otro de ejemplos de uso que pueden resultar útiles a la hora de hacer uso de la librería para desarrollar una app o servicio.
Natural
- Descripción: Al igual que NLP.js, Natural también facilita el procesamiento del lenguaje natural para node.js. Ofrece una variada gama de funcionalidades como la tokenización, coincidencia fonética, frecuencia de términos (TF-IDF) y la integración con la base de datos WordNet, entre otras.
- Materiales de apoyo: Al igual que la anterior biblioteca, esta librería tampoco tiene web propia. En su perfil de Github, dispone de contenidos de apoyo como ejemplos de casos de uso desarrollados anteriormente por otros programadores.
Wink
- Descripción: Wink es una familia de paquetes de código abierto para el análisis estadístico, el procesamiento del lenguaje natural y el aprendizaje automático en NodeJS. Ha sido optimizada para lograr un equilibrio entre rendimiento y precisión, lo que hace que el paquete pueda manejar grandes cantidades de texto en bruto a una alta velocidad.
- Materiales de apoyo: Acceder a los tutoriales desde su página web resulta muy intuitivo ya que una de las categorías que tiene el mismo nombre recoge precisamente este tipo de contenido divulgativo. En ella es posible encontrar guías de aprendizaje divididas según el nivel de experiencia del programador o de la parte del proceso en el que esté inmerso.
Librerías para R
En este último apartado aglutinamos las bibliotecas específicas para construir una web, aplicación o servicio utilizando el lenguaje de codificación R. Algunas de ellas son:
koRpus
- Descripción: Se trata de un paquete de análisis de textos capaz de detectar el idioma de manera automática y diversos índices de diversidad léxica o legibilidad, entre otras funciones. Además, incluye el plugin RKWard que proporciona cuadros de diálogo gráficos para sus funciones básicas.
- Materiales de apoyo: koRpus ofrece una serie de directrices enfocadas a su instalación y aglutinadas en el documento Read me que puedes encontrar en este enlace. Igualmente, en el aparado News están disponibles las actualizaciones y cambios que se han ido realizando en las sucesivas versiones de la librería.
Quanteda
- Descripción: Esta biblioteca ha sido diseñada para que los programadores que utilizan R apliquen técnicas de procesamiento de lenguaje natural a sus textos desde la versión original hasta la obtención de los resultados finales. Por ello, su API ha sido desarrollada para permitir un análisis potente y eficiente con un mínimo de pasos, reduciendo así las barreras de aprendizaje, al procesamiento del lenguaje natural y el análisis cuantitativo de textos.
- Materiales de apoyo: Ofrece como material de apoyo principal esta guía de inicio rápido. A través de ella, es posible seguir las instrucciones principales para no cometer ningún error. Incluye también varios ejemplos que pueden servir para comparar resultados.
Isa - Natural Language Processing
- Descripción: Esta librería se basa en el análisis semántico latente que consiste en crear datos estructurados a partir de una colección de textos no estructurados.
- Materiales de apoyo: En el apartado dedicado a la documentación, podemos encontrar información útil para el desarrollo.
Librerías para Python y R
Hablamos de librerías para Python y R para referirnos a aquellas que son compatibles para codificar utilizando ambos lenguajes de programación.
spaCy
- Descripción: Es una herramienta muy útil para preparar textos que, posteriormente, serán empleados en otras tareas de aprendizaje automático. Además, permite aplicar modelos lingüísticos estadísticos para resolver diferentes problemas de procesamiento del lenguaje natural.
- Materiales de apoyo: spaCy ofrece una serie de cursos online divididos en distintos capítulos y que podrás encontrar aquí. A través de los contenidos compartidos en NLP Advanced podrás seguir paso a paso las utilidades de esta biblioteca, ya que cada capítulo se centra en una parte del procesamiento del texto. Si aún quieres aprender más sobre esta librería, te recomendamos leer este artículo de Alejandro Alija sobre su experiencia probando esta biblioteca.
En este artículo hemos compartido una muestra de algunas de las librerías más populares para el procesamiento del lenguaje natural. Aun así, conviene subrayar que se trata de una mera selección.
Por todo ello, si conoces de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación hacen referencia a los conjuntos de archivos de código que han sido creados para desarrollar software de manera sencilla. Gracias a ellas, los desarrolladores pueden evitar la duplicidad de código y minimizar errores con mayor agilidad y menor coste. Existen multitud de librerías, enfocadas en distintas actividades. Hace unas semanas vimos algunos ejemplos de librerías para la creación de visualizaciones, y en esta ocasión nos vamos a centrar en librerías de utilidad para tareas de aprendizaje automático (Machine Learning).
Estas librerías son altamente prácticas a la hora de implementar flujos de Machine Learning. Esta disciplina, perteneciente al campo de la Inteligencia Artificial, utiliza algoritmos que ofrecen, por ejemplo, la capacidad de identificar patrones de datos masivos o la capacidad de ayudar a elaborar análisis predictivos.
A continuación, te mostramos algunas de las librerías de análisis de datos y Machine Learning más populares que existen en la actualidad para los principales lenguajes de programación, como Python o R:
Librerías para Python
NumPy
- Descripción:
Esta librería de Python está especializada en el cálculo matemático y en el análisis de grandes volúmenes de datos. Permite trabajar con arrays que permiten representar colecciones de datos de un mismo tipo en varias dimensiones, además de funciones muy eficientes para su manipulación.
- Materiales de apoyo:
Aquí encontramos la Guía para principiantes, con conceptos básicos y tutoriales, la Guía del usuario, con información sobre las características generales, o la Guía del colaborador, para contribuir al mantenimiento y desarrollo del código o en la redacción de documentación técnica. NumPy también cuenta con una Guía de referencia que detalla funciones, módulos y objetos incluidos en esta librería, así como una serie de tutoriales para aprender a utilizarla de forma sencilla.
Pandas
- Descripción:
Se trata de una de las librerías más utilizadas para el tratamiento de datos en Python. Esta herramienta de análisis y manipulación de datos se caracteriza, entre otros aspectos, por definir nuevas funcionalidades de datos basadas en los arrays de la librería NumPy. Permite leer y escribir fácilmente ficheros en formato CSV, Excel y especificar consultas a bases de datos SQL.
- Materiales de apoyo:
Su web cuenta con diferentes documentos como la Guía del usuario, con información básica detallada y explicaciones útiles, la Guía del desarrollador, que detalla los pasos a seguir ante la identificación de errores o sugerencia de mejoras en las funcionalidades, así como la Guía de referencia, con descripción detallada de su API. Además, ofrece una serie de tutoriales aportados por la comunidad y referencias sobre operaciones equivalentes en otros softwares y lenguajes como SAS, SQL o R.
Scikit-learn
- Descripción:
Scikit-Learn es una librería que implementa una gran cantidad de algoritmos de Machine Learning para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Además, es compatible con otras librerías de Python como NumPy, SciPy y Matplotlib (Matpotlib es una librería de visualización de datos y como tal está incluida en el artículo anterior).
- Materiales de apoyo:
Esta librería cuenta con diferentes documentos de ayuda como un Manual de instalación, una Guía del Usuario o un Glosario de términos comunes y elementos de su API. Además, ofrece una sección con diferentes ejemplos que ilustran las características de la librería, así como otras secciones de interés con tutoriales, preguntas frecuentes o acceso a su GitHub.
Scipy
- Descripción:
Esta librería presenta una colección de algoritmos matemáticos y funciones construidas sobre la extensión de NumPy. Incluye módulos de extensión para Python sobre estadística, optimización, integración, álgebra lineal o procesamiento de imágenes, entre otros.
- Materiales de apoyo:
Al igual que los ejemplos anteriores, esta librería también cuenta con materiales como Guías de instalación, Guías para usuarios, para desarrolladores o un documento con descripciones detalladas sobre su API. Además, ofrece información sobre act, una herramienta para ejecutar acciones de GitHub de forma local.
Librerías para R
mlr
- Descripción:
Esta librería ofrece componentes fundamentales para desarrollar tareas de aprendizaje automático, entre otros, preprocesamiento, pipelining, selección de características, visualización e implementación de técnicas supervisadas y no supervisadas utilizando un amplio abanico de algoritmos.
- Materiales de apoyo:
En su web cuenta con múltiples recursos para usuarios y desarrolladores, entre los que destaca un tutorial de referencia que presenta un extenso recorrido que abarca los aspectos básicos sobre tareas, predicciones o preprocesamiento de datos hasta la implementación de proyectos complejos utilizando funciones avanzadas.
Además, cuenta con un apartado que redirige a GitHub en el que ofrece charlas, vídeos y talleres de interés sobre el funcionamiento y los usos de esta librería.
Tidyverse
- Descripción:
Esta librería ofrece una colección de paquetes de R diseñados para la ciencia de datos que aporta funcionalidades muy útiles para importar, transformar, visualizar, modelar y comunicar información a partir de datos. Todos ellos comparten una misma filosofía de diseño, gramática y estructuras de datos subyacentes. Los principales paquetes que lo componen son: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr y purrr.
- Materiales de apoyo:
Tidyverse cuenta con un blog en el que podrás encontrar posts sobre programación, paquetes o trucos y técnicas para trabajar con esta librería. Además, cuenta con una sección que recomienda libros y workshops para aprender a utilizar esta librería de una manera más sencilla y amena.
Caret
- Descripción:
Esta popular librería contiene una interfaz que unifica bajo un único marco de trabajo cientos de funciones para entrenar clasificadores y regresores, facilitando en gran medida todas las etapas de preprocesado, entrenamiento, optimización y validación de modelos predictivos.
- Materiales de apoyo:
La web del proyecto contine exhaustiva información que facilita al usuario abordar tareas mencionadas. También se puede encontrar referencias en CRAN y el proyecto está alojado en GitHub. Algunos recursos de interés para el manejo de esta librería se pueden encontrar a través de libros como Applied Predictive Modeling, artículos, seminarios o tutoriales, entre otros.
Librerías para abordar tareas de Big Data
TensorFlow
- Descripción:
Además de Python y R, esta librería también es compatible con otros lenguajes como JavaScript, C++ o Julia. TensorFlow ofrece la posibilidad de compilar y entrenar modelos de ML utilizando APIs. La API más destacada es Keras, que permite construir y entrenar modelos de aprendizaje profundo (Deep Learning).
- Materiales de apoyo:
En su web se pueden encontrar recursos como modelos y conjuntos de datos previamente establecidos y desarrollados, herramientas, bibliotecas y extensiones, programas de certificación, conocimientos sobre aprendizaje automático o recursos y herramientas para integrar las prácticas de IA responsable. Puedes acceder a su página de GitHub aquí.
Dmlc XGBoost
- Descripción:
Librería de "Gradient Boosting" (GBM, GBRT, GBDT) escalable, portátil y distribuida es compatible con los lenguajes de programación C++, Python, R, Java, Scala, Perl y Julia. Esta librería permite resolver muchos problemas de ciencia de datos de una manera rápida y precisa y se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube para abordar tareas Big Data.
- Materiales de apoyo:
En su web cuenta con un blog con temáticas relacionadas como actualizaciones de algoritmos o integraciones, además de una sección de documentación que cuenta con guías de instalación, tutoriales, preguntas frecuentes, foro de usuarios o paquetes para los distintos lenguajes de programación. Puedes acceder a su página de GitHub a través de este enlace.
H20
- Descripción:
Esta librería combina los principales algoritmos de Machine Learning y aprendizaje estadístico con Big Data, además de ser capaz de trabajar con millones de registros. H20 está escrita en Java, y sigue el paradigma Key/Value para almacenar datos y Map/Reduce para implementar algoritmos. Gracias a su API, se puede acceder desde R, Python o Scala.
- Materiales de apoyo:
Cuenta con una serie de vídeos en forma de tutorial para enseñar y facilitar su uso a los usuarios. En su página de GitHub podrás encontrar recursos adicionales como blogs, proyectos, recursos, trabajos de investigación, cursos o libros sobre H20.
En este artículo hemos ofrecido una muestra de algunas de las librerías más populares que ofrecen funcionalidades versátiles para abordar tareas típicas de ciencia de datos y aprendizaje automático, aunque hay muchas otras. Este tipo de librerías está en constante evolución gracias a la posibilidad que ofrece a sus usuarios de participar en su mejora a través de acciones como la contribución a la escritura de código, la generación de nueva documentación o el reporte de errores. Todo ello permite enriquecer y perfeccionar sus resultados continuamente.
Si sabes de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación son conjuntos de archivos de código que se utilizan para desarrollar software. Su objetivo es facilitar la programación, al proporcionar funcionalidades comunes, que ya han sido resueltas previamente por otros programadores. Como curiosidad, el término proviene de una mala traducción de la palabra inglesa library, que en realidad significa biblioteca.
Las librerías (o bibliotecas) son un componente esencial para que los desarrolladores puedan programar de forma sencilla, evitando la duplicidad de código y minimizando errores. También permiten una mayor agilidad, al reducir el tiempo de desarrollo, así como los costes.
Estas ventajas se reflejan a la hora de usar librerías para realizar visualizaciones utilizando lenguajes tan populares como Python, R y JavaScript.
Librerías para Python
Python es uno de lenguajes de programación más utilizados. Se trata de un lenguaje interpretado (fácil de leer y escribir gracias a la semejanza que presenta con el lenguaje humano), multiplataforma, gratuito y de código abierto. En este artículo previo puedes encontrar cursos para aprender más sobre él.
Dada su popularidad, no es de extrañar que encontremos en la red múltiples librerías que nos facilitarán la creación de visualizaciones con este lenguaje, como por ejemplo:
Matplotlib
- Descripción:
Matplotlib es una biblioteca completa para la generación de visualizaciones estáticas, animadas e interactivas a partir de datos contenidos en listas o arrays en el lenguaje de programación Python y su extensión matemática NumPy.
- Materiales de apoyo:
En su web se recogen ejemplos de visualizaciones con el código fuente, para inspirar a nuevos usuarios, y diversas guías dirigidas tanto a usuarios principiantes como a aquellos más avanzados. En la web también hay disponible una sección de recursos externos que redirige a libros, artículos, vídeos y tutoriales elaborados por terceros.
Seaborn
- Descripción:
Seaborn es una biblioteca de visualización de datos en Python basada en matplotlib. Proporciona una interfaz de alto nivel que permite dibujar gráficos estadísticos atractivos e informativos.
- Materiales de apoyo:
En su web hay disponibles tutoriales, con información sobre la API y los distintos tipos de funciones, así como una galería de ejemplos. También es recomendable echar un vistazo a este paper elaborado por The Journal of Open Source Software.
Bokeh
- Descripción:
Bokeh es una librería para la visualización de datos de forma interactiva en un navegador web. Entre sus funciones está desde la creación de gráficos simples hasta la elaboración de cuadros de mando interactivos.
- Materiales de apoyo:
Los usuarios pueden encontrar en su guía descripciones detalladas y ejemplos que describen las tareas más comunes. La guía incluye la definición de conceptos básicos, el trabajo con datos geográficos o cómo generar interacciones, entre otros.
La web también cuenta con una galería con ejemplos, tutoriales y un apartado de comunidad, donde plantear y resolver dudas.
Geoplotlib
- Descripción:
Geoplotlib es una librería de código abierto en python para la visualización de datos geográficos. Se trata de una sencilla API que produce visualizaciones sobre mosaicos de OpenStreetMap. Permite la creación de mapas de puntos, estimadores de densidad de datos, gráficos espaciales y archivos ”shapes”, entre muchas otras visualizaciones espaciales.
- Materiales de apoyo:
En Github tienes disponible esta guía de usuarios, donde se explica cómo cargar datos, crear mapas de colores o añadir interactividad a las capas, entre otros. También hay disponibles ejemplos de código.
Librerías para R
R también es un lenguaje interpretado para la computación estadística y la creación de representaciones gráficas (puedes aprender más sobre ello siguiendo alguno de estos cursos). Cuenta con su propio entorno de programación, R-Studio, y con un conjunto de herramientas muy flexibles y versátiles que se pueden ampliar fácilmente mediante la instalación de librerías o paquetes –usando su propia terminología-, como las que se detallan a continuación:
ggplot 2
- Descripción:
Ggplot es una de las librerías más populares y utilizadas en R para la creación de visualizaciones interactivas de datos. Su funcionamiento se basa en el paradigma descrito en The Grammar of Graphics para la creación de visualizaciones con 3 capas de elementos: datos (data frame), la lista de relaciones entre las variables (aesthetics) y los elementos geométricos que se van a representar (geoms).
- Materiales de apoyo:
En su web puedes encontrar diversos materiales, como esta cheatsheet que recoge de manera resumida las principales funcionalidades de ggplot2. Por su parte, esta guía comienza explicando las características generales del sistema utilizando como ejemplo los diagramas de dispersión para detallar, a continuación, cómo representar algunos de los gráficos más conocidos. También se incluyen diversas FAQ que pueden ser de ayuda.
Lattice
- Descripción:
Lattice es un sistema de visualización de datos inspirado en los gráficos Trellis o de trama, prestando especial atención a los datos multivariantes. La interfaz de usuario de Lattice consiste en varias funciones genéricas de "alto nivel", cada una de ellas diseñada para crear un tipo particular de gráfico por defecto.
- Materiales de apoyo:
En este manual puedes encontrar información sobre las diversas funcionalidades, aunque si quieres profundizar en ellas, en esta sección de la web puedes encontrar diversos manuales como R Graphics de Paul Murrell o Lattice de Deepayan Sarkar.
Esquisse
- Descripción:
Esquise permite explorar interactivamente los datos y crear visualizaciones detalladas con el paquete ggplot2 a través de una interfaz de arrastrar y soltar. Incluye multitud de elementos: gráficos de dispersión, de líneas, de cajas, con ejes múltiples, sparklines, dendogramas, gráficos 3D, etc.
- Materiales de apoyo:
La documentación está disponible a través de este enlace, incluyendo información sobre la instalación y las diversas funciones. También tienes información en la web de R.
Leaflet
- Descripción:
Leaflet permite la creación de mapas altamente detallados, interactivos y personalizados. Está basado en la biblioteca de JavaScript del mismo nombre.
- Materiales de apoyo:
En esta web tienes documentación sobre las diversas funcionalidades: el funcionamiento del widget, marcadores, cómo trabajar con GeoJSON & TopoJSON, cómo integrarse con Shiny, etc.
Librerías para JavaScript
JavaScript también es un lenguaje de programación interpretado, responsable de dotar de mayor interactividad y dinamismo a las páginas web. Es un lenguaje orientado a objetos, basado en prototipos y dinámico.
Algunas de las principales librerías para JavaScript son:
D3.js
- Descripción:
D3.js está dirigida a la creación de visualizaciones de datos y animaciones utilizando estándares web, como SVG, Canvas y HTML. Es una librería muy potente y de cierta complejidad.
- Materiales de apoyo:
En Github puedes encontrar una galería con ejemplos de los diversos gráficos y visualizaciones que se pueden obtener con esta librería, así como diversos tutoriales e información sobre técnicas específicas.
Chart.js
- Descripción:
Chart.js es una librería de JavaScript que utiliza canvas de HTML5 para la creación de gráficos interactivos. En concreto, admite 9 tipos de gráficos: barra, línea, área, circular, burbuja, radar, polar, dispersión y mixtos.
- Materiales de apoyo:
En su propia web tienes información sobre la instalación y configuración, y ejemplos de los distintos tipos de gráficos. También hay un apartado para desarrolladores con diversa documentación.
Otras librerias
Plotly
- Descripción:
Plotly es una biblioteca de gráficos de alto nivel, que permite la creación de más de 40 tipos de gráficos, incluidos gráficos 3D, estadísticos y mapas SVG. Es una librería Open Source, pero tiene versiones de pago.
Plotly no está ligada a un único lenguaje de programación, si no que permite la integración con R, Python y JavaScript.
- Materiales de apoyo:
Cuenta con una completa página web donde los usuarios pueden encontrar guías, casos de uso por ámbitos de aplicación, ejemplos prácticos, webinars y una sección de comunidad donde compartir conocimiento.
Cualquier usuario que lo desee puede contribuir con cualquiera de estas librerías, escribiendo código, generando nueva documentación o reportando errores, entre otros. De esta forma se enriquecen y perfeccionan, mejorando sus resultados de manera continua.
¿Conoces alguna otra librería que quieras recomendar? Déjanos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información que finalmente se resume en unas conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre el alumnado de la universidad española a lo largo de los últimos años. A partir de estos datos observaremos las características que presenta el alumnado de la universidad española y cuáles son los estudios más demandados.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio de Universidades, que recoge series temporales de datos con diferentes desagregaciones que facilitan el análisis de las características que presenta el alumnado de la universidad española. Estos datos se encuentran disponibles en el catálogo de datos.gob.es y en el propio catálogo de datos del Ministerio de Universidades. Concretamente los datasets que usaremos son:
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de doctorado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio, y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de máster por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculados por tipo de modalidad de la universidad, zona de nacionalidad y ámbito de estudio y Matriculados por tipo y modalidad de la universidad, sexo, grupo de edad y ámbito de estudio para estudiantes de grado por comunidad autónoma desde el curso 2015-2016 hasta 2020-2021.
- Matriculaciones por cada una de las titulaciones impartidas por las universidades españolas que se encuentra publicado en la sección de Estadísticas de la página oficial del Ministerio de Universidades. El contenido de esta dataset abarca desde el curso 2015-2016 al 2020-2021, aunque para este último curso los datos con provisionales.
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación R desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Datawrapper.
Datawrapper es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en línea o exportarse como PNG, PDF o SVG. Esta herramienta es muy sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Preprocesamiento de datos
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Creación de tablas de trabajo
- Ajuste del nombre de algunas variables
- Agrupación de varias variables en una única con diferentes factores
- Transformación de variables
- Detección y tratamiento de datos ausentes (NAs)
- Creación de nuevas variables calculadas
- Resumen de las tablas transformadas
- Preparación de datos para su representación visual
- Almacenamiento de archivos con las tablas de datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
5. Visualización de datos
Una vez realizado el preprocesamiento de los datos, vamos con la visualización. Para la realización de esta visualización interactiva usamos la herramienta Datawrapper en su versión gratuita. Se trata de una herramienta muy sencilla con especial aplicación en el periodismo de datos que te animamos a utilizar. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que la tabla de datos que le proporcionemos este estructurada adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos la siguientes:
- ¿Cómo se está distribuyendo el número de hombres y mujeres entre los alumnos matriculados de grado, máster y doctorado a lo largo de los últimos cursos?
Si nos centramos en el último curso 2020-2021:
- ¿Cuáles son las ramas de enseñanza más demandadas en las universidades españolas? ¿Y las titulaciones?
- ¿Cuáles son las universidades con mayor número de matriculaciones y dónde se ubican?
- ¿En qué rangos de edad se encuentra el alumnado universitario de grado?
- ¿Cuál es la nacionalidad de los estudiantes de grado de las universidades españolas?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Distribución de las matriculaciones en las universidades españolas desde el curso 2015-2016 hasta 2020-2021, desagregado por sexo y nivel académico
Esta representación visual la hemos realizado teniendo en cuenta las matriculaciones de grado, master y Doctorado. Una vez que hemos subido la tabla de datos a Datawrapper (conjunto de datos \"Matriculaciones_NivelAcademico\"), hemos seleccionado el tipo de gráfico a realizar, en este caso un diagrama de barras apiladas (stacked bars) para poder reflejar por cada curso y sexo, las personas matriculadas en cada nivel académico. De esta forma podemos ver, además, el global de estudiantes matriculados por curso. A continuación, hemos seleccionado el tipo de variable a representar (Matriculaciones) y las variables de desagregación (Sexo y Curso). Una vez obtenido el gráfico, podemos modificar de forma muy sencilla la apariencia, modificando los colores, la descripción y la información que muestra cada eje, entre otras características.
Para responder a las siguientes preguntas, nos centraremos en el alumnado de grado y en el curso 2020-2021, no obstante, las siguientes representaciones visuales pueden ser replicadas para el alumnado de máster y doctorado, y para los diferentes cursos.
5.2. Mapa de las universidades españolas georreferenciadas, donde se muestra el número de matriculados que presentan cada una de ellas
Para la realización del mapa hemos utilizado un listado de las universidades españolas georreferenciadas publicado por el Portal de Datos Abiertos de Esri España. Una vez descargados los datos de las distintas áreas geográficas en formato GeoJSON, los transformamos en Excel, para poder realizar una unión entre el datasets de las universidades georreferenciadas y el dataset que presenta el número de matriculados por cada universidad que previamente hemos preprocesado. Para ello hemos utilizado la función BUSCARV() de Excel que nos permitirá localizar determinados elementos en un rango de celdas de una tabla.
Antes de subir el conjunto de datos a Datawrapper, debemos seleccionar la capa que muestra el mapa de España dividido en provincias que nos proporciona la propia herramienta. Concretamente, hemos seleccionado la opción \"Spain>>Provinces(2018)\". Seguidamente procedemos a incorporar el conjunto de datos \"Universidades\", antes generado, (este conjunto de datos se adjunta en la carpeta de conjuntos de datos de GitHub para esta visualización paso a paso), indicando que columnas contienen los valores de las variables Latitud y Longitud.
A partir de este punto, Datawrapper ha generado un mapa en el que se muestran las ubicaciones de cada una de las universidades. Ahora podemos modificar el mapa según nuestras preferencias y ajustes. En este caso, haremos que el tamaño de los puntos y el color dependa del número de matriculaciones que presente cada universidad. Además, para que estos datos se muestren, en la pestaña “Annotate”, en la sección “Tooltips”, debemos indicarle las variables o el texto que deseemos que aparezca.
5.3. Ranking de matriculaciones por titulación
Para esta representación gráfica utilizamos el objeto visual de Datawrapper tabla (Table) y el conjunto de datos \"Titulaciones_totales\" para mostrar el número de matriculaciones que presenta cada una de las titulaciones impartidas durante el curso 2020-2021. Dado que el número de titulaciones es muy extenso, la herramienta nos ofrece la posibilidad de incluir un buscador que permite filtrar los resultados.
5.4. Distribución de matriculaciones por rama de enseñanza
Para esta representación visual, hemos utilizado el conjunto de datos \"Matriculaciones_Rama_Grado\" y seleccionado gráficos de sectores (Pie Chart), donde hemos representado el número de matriculaciones según sexo en cada una de las ramas de enseñanza en las cuales se dividen las titulaciones impartidas por las universidades (Ciencias Sociales y Jurídicas, Ciencias de la Salud, Artes y Humanidades, Ingeniería y Arquitectura y Ciencias). Al igual que en el resto de gráficos, podemos modificar el color del gráfico, en este caso en función de la rama de enseñanza.
5.5. Matriculaciones de Grado por edad y nacionalidad
Para la realización de estas dos representaciones de datos visuales utilizamos diagramas de barras (Bar Chart), donde mostramos la distribución de matriculaciones en el primero, desagregada por sexo y nacionalidad, utilizaremos el conjunto de datos \"Matriculaciones_Grado_nacionalidad\" y en el segundo, desagregada por sexo y edad, utilizando el conjunto de datos \"Matriculaciones_Grado_edad\". Al igual que los visuales anteriores, la herramienta facilita de forma sencilla la modificación de las características que presentan los gráficos.
6. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implamentar se puede observar lo siguiente:
- El número de matriculaciones aumenta a lo largo de los cursos académicos independientemente del nivel académico (grado, máster o doctorado).
- El número de mujeres matriculadas es mayor que el de hombres en grado y máster, sin embargo es menor en el caso de las matriculaciones de doctorado, excepto en el curso 2019-2020.
- La mayor concentración de universidades la encontramos en la Comunidad de Madrid, seguido de la comunidad autónoma de Cataluña.
- La universidad que concentra mayor número de matriculaciones durante el curso 2020-2021 es la UNED (Universidad Nacional de Educación a Distancia) con 146.208 matriculaciones, seguida de la Universidad Complutense de Madrid con 57.308 matriculaciones y la Universidad de Sevilla con 52.156.
- La titulación más demandada el curso 2020-2021 es el Grado en Derecho con 82.552 alumnos a nivel nacional, seguido del Grado de Psicología con 75.738 alumnos y sin apenas diferencia, el Grado en Administración y Dirección de Empresas con 74.284 alumnos.
- La rama de enseñanza con mayor concentración de alumnos es Ciencias Sociales y Jurídicas, mientras que la menos demandada es la rama de Ciencias.
- Las nacionalidades que más representación tienen en la universidad española son de la región de la unión europea, seguido de los países de América Latina y Caribe, a expensas de la española.
- El rango de edad entre los 18 y 21 años es el más representado en el alumnado de las universidades españolas.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
Visualización sobre la accidentalidad de tráfico ocurrida en la ciudad de Madrid, por distrito y tipo de vehículo
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos disponibles en este portal. Para este ejercicio práctico hemos escogido un conjunto de datos que abarca una amplio periodo temporal y que contiene información relevante sobre el registro de accidentes de tráfico que ocurren en la ciudad de Madrid. A partir de estos datos observaremos cuál es el tipo de accidentes más comunes en Madrid y la incidencia que en ellos tiene algunas variables como la edad, el tipo de vehículo o la lesividad que produce el accidente.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se ha seleccionado un conjuntos de datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid publicados por el Ayuntamiento de Madrid y que se encuentra disponible en datos.gob.es. Este conjunto de datos contiene una serie temporal que abarca el periodo 2010 hasta 2021 con diferentes desagregaciones que facilitan el análisis de las características que presentan los accidentes de tráfico ocurridos, entre otras, las condiciones ambientales en las que se produjo cada siniestro o el tipo de accidente. La información de la estructura de cada archivo de datos está disponible en documentos que abarcan el periodo 2010-2018 y 2019 en adelante. Cabe destacar que existen inconsistencias en los datos antes y después del año 2019, ya que la estructura de datos varía. Esta es una situación bastante habitual a la que deben enfrentarse los analistas de datos a la hora de abordar las tareas de preprocesamiento de los datos con los que se trabajará posteriormente, derivada de la carencia de una estructura homogénea de los datos a lo largo del tiempo. Por ejemplo, alteración del número de variables, modificación del tipo de variables o cambios a diferentes unidades de medida. Esta es una razón de peso que justifica la necesidad de acompañar cada conjunto de datos abiertos de un completo documento que explique su estructura.
3.2. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
R es un lenguaje de programación open source orientado a objetos e interpretado, creado inicialmente para la computación estadística y la creación de representaciones gráficas. En la actualidad, es una herramienta muy poderosa para todo tipo de procesamiento y manipulación de datos que está permanentemente actualizada. Además dispone de un entorno de programación, RStudio, también open source.
Para la creación de la visualización interactiva se ha utilizado la herramienta Kibana.
Kibana es una herramienta open source que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstash y Kibana) que permite la creación de visualización y la exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres saber más sobre estas herramientas u otras que puedan ayudarte en el procesado de datos y la creación de visualizaciones interactivas, puedes consultar el informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento de datos
Para la realización de los análisis y visualizaciones posteriores, es necesario preparar los datos de una forma adecuada, para que los resultados obtenidos sean consistentes y efectivos. Debemos realizar un análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer y comprender los datos con los cuales queremos trabajar. El objetivo principal de este pre-procesamiento de los datos es detectar posibles anomalías o errores que pudieran afectar a la calidad de los resultados posteriores e identificar patrones de información contenidos en los datos.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo click en el botón de \"Código\" de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren forma alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de texto plano, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
Para el desarrollo de este análisis necesitamos instalar una serie de paquetes de R adicionales a la distribución base, incorporando al entorno de trabajo las funciones y objetos definidos por ellas. Hay muchos paquetes disponibles en R pero las más adecuadas para trabajar con este conjunto de datos son: tidyverse, lubridate y data.table. tidyverse es una colección de paquetes de R (contiene a su vez otros paquetes como dplyr, ggplot2, readr, etc) diseñados específicamente para trabajar en Data Science, que facilitar la carga y tratamiento de datos, y las representaciones gráficas, entre otras funcionalidades esenciales para el análisis de datos, pero que requiere un conocimiento progresivo para obtener el máximo partido de los paquetes que integra. Por otro lado, el paquete lubridate lo usaremos para el manejo de variables tipo fecha y por último el paquete data.table permite realizar una gestión más eficiente de conjuntos de datos grandes. Estos paquetes será preciso descargarlos e instalarlos en el entorno de desarrollo.
#Lista de librerías que queremos instalar y cargar en nuestro entorno de desarrollo librerias <- c(\"tidyverse\", \"lubridate\", \"data.table\")#Descargamos e instalamos las librerías en nuestros entorno de desarrollo package.check <- lapplay (librerias, FUN = function(x) { if (!require (x, character.only = TRUE)) { install.packages(x, dependencies = TRUE) library (x, character.only = TRUE } }4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros CSV. Como queremos realizar un análisis de varios años debemos descargar y cargar en nuestro entorno de desarrollo todos los conjuntos de datos que nos interesen.
Para ello, generamos el directorio de trabajo \"datasets\", donde descargaremos todos los conjuntos de datos. Usamos dos listas, una con todas las URLs donde se encuentran localizados los datasets y otra con los nombres que asignamos a cada fichero guardado en nuestra maquina, con ello facilitamos posteriores referencias a estos ficheros.
#Generamos una carpeta en nuestro directorio de trabajo para guardar los datasets descargadosif (dir.exists(\".datasets\") == FALSE)#Nos colocamos dentro de la carpetasetwd(\".datasets\")#Listado de los datasets que nos interese descargardatasets <- c(\"https://datos.madrid.es/egob/catalogo/300228-10-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-11-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-12-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-13-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-14-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-15-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-16-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-17-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-18-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-19-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-21-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-22-accidentes-trafico-detalle.csv\")#Descargamos los datasets de interésdt <- list()for (i in 1: length (datasets)){ files <- c(\"Accidentalidad2010\", \"Accidentalidad2011\", \"Accidentalidad2012\", \"Accidentalidad2013\", \"Accidentalidad2014\", \"Accidentalidad2015\", \"Accidentalidad2016\", \"Accidentalidad2017\", \"Accidentalidad2018\", \"Accidentalidad2019\", \"Accidentalidad2020\", \"Accidentalidad2021\") download.file(datasets[i], files[i]) filelist <- list.files(\".\") print(i) dt[i] <- lapply (filelist[i], read_delim, sep = \";\", escape_double = FALSE, locale = locale(encoding = \"WINDOWS-1252\", trim_ws = \"TRUE\") }b. Creación de la tabla de trabajo
Una vez que tenemos todos los conjuntos de datos cargados en nuestro entorno de desarrollo, creamos una única tabla de trabajo que integra todos los años de la serie temporal.
Accidentalidad <- rbindlist(dt, use.names = TRUE, fill = TRUE)Una vez generada la tabla de trabajo, debemos solucionar uno de los problemas más comunes en todo preprocesamiento de datos: la inconsistencia en el nombre de las variables en los diferentes ficheros que componen la serie temporal. Esta anomalía produce variables con nombres diferentes, pero sabemos que representan la misma información. En este caso porque está explicado en el diccionario de datos descrito en la documentación de los archivos, si no fuese así, es necesario recurrir a la observación y exploración descriptiva de los archivos. En este caso, la variable \"RANGO EDAD\" que presenta datos desde 2010 hasta 2018 y la variable \"RANGO DE EDAD\" que presenta los mismos datos pero desde el año 2019 hasta 2021 son diferentes. Para solucionar esta problemática debemos unificar las variables que presentan esta anomalía en una única variable.
#Con la función unite() unimos ambas variables. Debemos indicarle el nombre de la tabla, el nombre que queremos asignarle a la variable y la posición de las variables que queremos unificar. Accidentalidad <- unite(Accidentalidad, LESIVIDAD, c(25, 44), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, NUMERO_VICTIMAS, c(20, 27), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, RANGO_EDAD, c(26, 35, 42), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, TIPO_VEHICULO, c(20, 27), remove = TRUE, na.rm = TRUE)Una vez que tenemos la tabla con la serie temporal completa, generamos una nueva tabla contiendo únicamente las variables que nos interesan para realizar la visualización interactiva que queremos desarrollar.
Accidentalidad <- Accidentalidad %>% select (c(\"FECHA\", \"DISTRITO\", \"LUGAR ACCIDENTE\", \"TIPO_VEHICULO\", \"TIPO_PERSONA\", \"TIPO ACCIDENTE\", \"SEXO\", \"LESIVIDAD\", \"RANGO_EDAD\", \"NUMERO_VICTIMAS\") c. Transformación de variables
A continuación, examinamos el tipo de variables y valores para transformar los tipos que sea necesario para poder realizar futuras agregaciones, gráficos o diferentes análisis estadísticos.
#Re-ajustar la variable tipo fechaAccidentalidad$FECHA <- dmy (Accidentalidad$FECHA #Re-ajustar el resto de variables a tipo factor Accidentalidad$'TIPO ACCIDENTE' <- as.factor(Accidentalidad$'TIPO.ACCIDENTE')Accidentalidad$'Tipo Vehiculo' <- as.factor(Accidentalidad$'Tipo Vehiculo')Accidentalidad$'TIPO PERSONA' <- as.factor(Accidentalidad$'TIPO PERSONA')Accidentalidad$'Tramo Edad' <- as.factor(Accidentalidad$'Tramo Edad')Accidentalidad$SEXO <- as.factor(Accidentalidad$SEXO)Accidentalidad$LESIVIDAD <- as.factor(Accidentalidad$LESIVIDAD)Accidentalidad$DISTRITO <- as.factor (Accidentalidad$DISTRITO)d. Generación de nuevas variables
Vamos a dividir la variable \"FECHA\" en una jerarquía de variables de tipo fecha, \"Año\", \"Mes\" y \"Día\". Esta acción es muy común en la analítica de datos, ya que en muchas ocasiones interesa analizar otros rangos de tiempo, por ejemplo, años, meses, semanas y cualquier otra unidad de tiempo, o necesitamos generar agregaciones a partir del día de la semana.
#Generación de la variable AñoAccidentalidad$Año <- year(Accidentalidad$FECHA)Accidentalidad$Año <- as.factor(Accidentalidad$Año) #Generación de la variable MesAccidentalidad$Mes <- month(Accidentalidad$FECHA)Accidentalidad$Mes <- as.factor(Accidentalidad$Mes)levels (Accidentalidad$Mes) <- c(\"Enero\", \"Febrero\", \"Marzo\", \"Abril\", \"Mayo\", \"Junio\", \"Julio\", \"Agosto\", \"Septiembre\", \"Octubre\", \"Noviembre\", \"Diciembre\") #Generación de la variable DiaAccidentalidad$Dia <- month(Accidentalidad$FECHA)Accidentalidad$Dia <- as.factor(Accidentalidad$Dia)levels(Accidentalidad$Dia)<- c(\"Domingo\", \"Lunes\", \"Martes\", \"Miercoles\", \"Jueves\", \"Viernes\", \"Sabado\")e. Detección y tratamiento de datos perdidos
La detección y tratamiento de datos perdidos (NAs) es esencial para poder procesar de manera adecuada las variables que contiene la tabla, ya que la ausencia de datos puede ocasionar problemas a la hora de realizar agregaciones, gráficos o análisis estadísticos.
A continuación analizaremos la ausencia de datos (detección de NAs) en la tabla:
#Suma de todos los NAs que presenta el datasetsum(is.na(Accidentalidad))#Porcentaje de NAs en cada una de las variablescolMeans(is.na(Accidentalidad))Una vez detectados los NAs que presenta el dataset, debemos tratarlos de alguna forma. En este caso, como todas las variables de interés, son categóricas, vamos a completar los valores ausentes por un valor de \"No asignado\", para no perder tamaño muestral e información relevante.
#Sustituimos los NAs de la tabla por el valor \"No asignado\"Accidentalidad [is.na(Accidentalidad)] <- \"No asignado\"f. Asignaciones de niveles en las variables
Una vez que tenemos en la tabla las variables de interés, podemos realizar un examen más exhaustivo de los datos y categorías que presenta cada una de las variable. Si analizamos cada una de manera independiente, podemos observar que algunas de ellas presentan categorías repetidas, simplemente por uso de tildes, caracteres especiales o mayúsculas. Para que las futuras visualizaciones o análisis estadísticos se construyan de manera eficiente y sin errores, vamos a reasignar los niveles a las variables que lo requieran.
Por razones de espacio, en este post solo mostraremos un ejemplo con la variable \"LESIVIDAD\". Esta variable estaba tipificada hasta 2018 con una serie de categorías (IL, HL, HG, MT), mientras que a partir de 2019 se usaron otras categorías (valores del 0 al 14). Afortunadamente esta tarea resulta fácilmente abordable dado que está documentada en la información sobre la estructura que acompaña cada dataset, cuestión, como hemos comentado con anterioridad que no siempre ocurre, lo que dificulta enormemente este tipo de transformaciones de datos.
#Comprobamos las categorías que presenta la variable \"LESIVIDAD\"levels(Accidentalidad$LESIVIDAD)#Asignamos las nuevas categoríaslevels(Accidentalidad$LESIVIDAD)<- c(\"Sin asistencia sanitaria\", \"Herido leve\", \"Herido leve\", \"Herido grave\", \"Fallecido\", \"Herido leve\", \"Herido leve\", \"Herido leve\", \"Ileso\", \"Herido grave\", \"Herido leve\", \"Ileso\", \"Fallecido\", \"No asignado\")#Comprobamos de nuevo las catergorías que presenta la variablelevels(Accidentalidad$LESIVIDAD)4.3. Resumen del dataset
Veamos que variables y estructura presenta el nuevo conjunto de datos tras las transformaciones realizadas:
str(Accidentalidad)summary(Accidentalidad)La salida de estos comandos la omitiremos para simplificar lectura. Las principales características que presenta el conjunto de datos son:
- Está compuesto por 14 variables: 1 variable tipo fecha y 13 variables de tipo categórico.
- El rango temporal abarca desde 01-01-2010 hasta el 31-06-2021 (la fecha final puede variar, ya que el dataset del año 2021 se esta actualizando periódicamente).
- Por cuestiones de espacio en este post, no todas las variables disponibles se han tenido en cuenta para el análisis y la visualización.
4.4. Guardar el dataset generado
Una vez que tenemos el conjunto de datos con la estructura y variables que nos interesan para realizar la visualización de los datos, lo guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos como la que abordamos a continuación. Es importante guardarlo con una codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier software.
write.csv(Accidentalidad, file = Accidentalidad.csv\", fileEncoding=\"UTF-8\")5. Creación de la visualización sobre los accidentes de tráfico que ocurren en la ciudad de Madrid usando Kibana
Para la realización de esta visualización interactiva se ha usado la herramienta Kibana en su versión gratuita sobre nuestro entorno local. Antes de poder realizar la visualización es necesario tener instalado el software y para ello hemos seguido los pasos del tutorial de descarga e instalación proporcionado por la compañía Elastic.
Una vez instalado el software de Kibana, procedemos a desarrollar la visualización interactiva. A continuación se incluyen dos vídeo tutoriales, en los cuales se muestra el proceso de realización de la visualización interactiva y la interacción con la misma.
En este primer vídeo tutorial, se muestra el proceso de desarrollo de la visualización realizando los pasos que se indican a continuación:
- Carga de datos en Elasticsearch, generación de un índice en Kibana que nos permita interactuar con los datos prácticamente en tiempo real e interacción con las variables que presenta el conjunto de datos.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los accidentes de tráfico ocurridos en la ciudad de Madrid.
- Gráfico de barras horizontales mostrando el tipo de accidente más común.
- Mapa temático, mostraremos el número de accidentes que ocurren en cada una de los distritos de la ciudad de Madrid. Para la creación de este visual es necesario la descarga del \"conjunto de datos que contiene los distritos georreferenciados en formato GeoJSON\".
- Construcción del dashboard integrando los visuales generados en el paso anterior.
En este segundo vídeo tutorial mostraremos la interacción con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid desde 2010 hasta junio de 2021, se pueden obtener, entre otras, las siguientes conclusiones:
- El número de accidentes que ocurren en la ciudad de Madrid es estable a lo largo de los años, a excepción del año 2019 donde se observa un fuerte incremento y durante el segundo trimestre de 2020 donde se observa una significativa disminución, que coincide con el período del primer estado de alarma a causa de la pandemia del COVID-19.
- Todos los años se observa una disminución del número de accidentes durante el mes de agosto.
- Los hombres suelen tener un número significativamente mayor de accidentes que las mujeres.
- El tipo de accidente más común es la colisión doble, seguido del atropello a un animal y la colisión múltiple.
- Alrededor del 50% de los accidentes no ocasionan daños a las personas implicadas.
- Los distritos con mayor concentración de accidentes son: el distrito de Salamanca, el distrito de Chamartín y el distrito Centro.
La visualización de datos es una de los mecanismos más potentes para explotar y analizar de manera autónoma el significado implícito de los datos, independientemente del grado del conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Si quieres aprender cómo realizar una predicción sobre la siniestralidad futura de accidentes de tráfico utilizando técnicas de Inteligencia Artificial a partir de estos datos, consulta el post sobre \"Tecnologías emergentes y datos abiertos: Analítica Predictiva\".
Esperamos que os haya gustado este post y volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!
Noticia
R es uno de los lenguajes de programación más populares en el mundo de la ciencia de datos.
Es un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística y creación de representaciones gráficas.
Una de sus ventajas es que las funciones pueden ampliarse fácilmente, mediante la instalación de librerías -denominados paquetes en el entorno de R- o la definición de funciones personalizadas. Además, está permanentemente actualizado, ya que su amplia comunidad de usuarios desarrolla constantemente nuevos paquetes, funciones y actualizaciones disponibles gratuitamente.
Por este motivo, R es uno de los lenguajes más demandados y existe un gran número de recursos para aprender más sobre ello. A continuación, te mostramos una selección basada en las recomendaciones de los expertos que colaboran con datos.gob.es y las comunidades de usuarios R-Hispano y R-Ladies, que reúnen a gran cantidad de usuarios de este lenguaje en nuestro país.
Cursos online
En la red podemos encontrar numerosos cursos online que introducen R a aquellos usuarios noveles.
Curso de R básico
- Impartido por: Universidad de Cádiz
- Duración: No disponible.
- Idioma: Español
- Gratuito.
Enfocado a estudiantes que están realizando un trabajo fin de grado o master, el curso busca proporcionar los elementos básicos para empezar a trabajar con el lenguaje de programación R en el ámbito de la estadística. Incluye conocimientos sobre estructura de datos (vectores, matrices, data frames…), gráficos, funciones y elementos de programación, entre otros.
Introducción a R
- Impartido por: Datacamp
- Duración: 4 horas.
- Idioma: Inglés.
- Gratuito
El curso comienza con conceptos básicos, empezando por cómo utilizar la consola como una calculadora y cómo asignar variables. A continuación, se aborda la creación de vectores en R, cómo trabajar con matrices, cómo comparar factores y el uso de data frames o listas.
Introducción a R
- Impartido por: Red de Universidades Anáhuac
- Duración: 4 semanas (5-8 horas por semana).
- Idioma: Español.
- Modalidad gratuita y de pago.
A través de un enfoque práctico, con este curso aprenderás a crear un ambiente de trabajo para R con R Studio, clasificar y manipular datos, así como realizar gráficas. También aporta nociones básicas de programación en R, abarcando condicionales, ciclos y funciones.
R Programming Fundamentals
- Impartido por: Stanford School of Engineering
- Duración: 6 semanas (2-3 horas por semana).
- Idioma: Inglés
- Gratuito, aunque el certificado tiene un coste de 79$.
Este curso cubre una introducción a R, desde la instalación hasta las funciones estadísticas básicas. Los estudiantes aprenden a trabajar con conjuntos de datos dinámicos y externos, así como a escribir funciones. En el curso podrás escuchar a uno de los co-creadores del lenguaje R, Robert Gentleman.
Programación R
- Impartido por: Johns Hopkins University
- Duración: 57 horas
- Idioma: Inglés, con subtítulos en español.
- De pago.
Este curso forma parte de los programas de Ciencia de Datos y Ciencia de los datos: bases utilizando R. Se puede cursar por separado o como parte de dichos programas. Con él aprenderás a comprender los conceptos fundamentales del lenguaje de programación, a utilizar las funciones de loop de R y las herramientas de depuración o a recoger información detallada con R profiler, entre otras cuestiones.
Data Visualization & Dashboarding with R
- Impartido por: Johns Hopkins University
- Duración: 4 meses (5 horas por semana)
- Idioma: Inglés.
- De pago.
La Universidad John Hopkins también ofrece este curso donde los alumnos generarán diferentes tipos de visualizaciones para explorar los datos, desde figuras sencillas como gráficos de barras y de dispersión hasta cuadros de mando interactivos. Los estudiantes integrarán estas figuras en productos de investigación reproducibles y los compartirán online.
Introducción al software estadístico R
- Impartido por: Asociación Española para la Calidad (AEC)
- Duración: Del 5 de octubre al 3 de diciembre de 2021 (50 horas)
- Idioma: Español
- De pago.
Se trata de una formación inicial práctica en el uso del software R para el tratamiento de datos y su análisis estadístico a través de las técnicas más sencillas y habituales: análisis exploratorio y relación entre variables. Entre otras cuestiones, los estudiantes adquirirán la capacidad de extraer información valiosa de los datos a través del análisis exploratorio, la regresión y el análisis de la varianza.
Introducción a la programación en R
- Impartido por: Abraham Requena
- Duración: 6 horas
- Idioma: Español
- De pago (por suscripción)
Diseñado para iniciarse en el mundo de R y aprender a programar con este lenguaje. Podrás aprender los diferentes tipos de datos y objetos que hay en R, a trabajar con ficheros y a utilizar condicionales, así como a crear funciones y gestionar errores y excepciones.
Programación y análisis de datos con R
- Impartido por: Universidad de Salamanca
- Duración: Del 25 de octubre de 2021 - 22 de abril de 2022 (80 horas lectivas)
- Idioma: Español
- De pago
Empieza desde un nivel básico, con información sobre los primeros comandos y la instalación de paquetes, para continuar con las estructuras de datos (variables, vectores, factores, etc.), funciones, estructuras de control, funciones gráficas y representaciones interactivas, ente otros temas. Incluye un trabajo de fin de curso.
- Impartido por: Harvard University
- Duración: 4 semanas (2-4 horas por semana).
- Idioma: Inglés
- De pago
Una introducción a los conceptos estadísticos básicos y a los conocimientos de programación en R necesarios para el análisis de datos en biociencia. A través de ejemplos de programación en R se establece la conexión entre los conceptos y la aplicación.
Para aquellos que quieran aprender más sobre álgebra matricial, la Universidad de Harvard también ofrece de forma online el curso Introduction to Linear Models and Matrix Algebra, donde se utiliza el lenguaje de programación R para llevar a cabo los análisis.
Curso de R gratuito
- Impartido por: Afi Escuela
- Duración: 7,5 horas
- Idioma: Español
- Gratuito
Este curso fue impartido por Rocío Parrilla, responsable de Data Science en Atresmedia, en formato presencial virtual. La sesión se grabó y está disponible a través de Youtube. Se estructura en tres clases donde se explican los elementos básicos de la programación en R, se hace una introducción al análisis de datos y se aborda la visualización con este lenguaje (visualización estática, visualización dinámica, mapas con R y materiales).
Programación R para principiantes
- Impartido por: Keepcoding
- Duración: 12 horas de contenido en video
- Idioma: Español
- Gratuito
Consta de 4 capítulos, cada uno de ellos integrado por varios vídeos de corta duración. El primero “Introducción”, aborda la instalación. El segundo, llamado “primeros pasos en R” explica ejecuciones básicas, así como vectores, matrices o data frames, entre otros. El tercero aborda el “Flujo Programa R” y el último los gráficos.
Curso online autónomo Introducción a R
- Impartido por: Universidad de Murcia
- Duración: 4 semanas (4-7 horas por semana)
- Idioma: Español
- Gratuito
Se trata de un curso práctico dirigido a jóvenes investigadores que necesitan realizar el análisis de los datos de su trabajo y buscan una metodología de que optimice su esfuerzo.
El curso forma parte de un conjunto de cursos relacionados con R que ofrece la Universidad de Murcia, sobre Métodos de análisis de datos multivariantes, Elaboración de documentos e informes técnico–científicos o Métodos de contraste de hipótesis y diseño de experimentos, entre otros.
Libros online relacionados con R
Si en vez de un curso, prefiere un manual o documentación que te pueda ayudar a mejorar tus conocimientos de una manera más amplia, también existen opciones, como las que te detallamos a continuación.
R para profesionales de Datos. Una Introducción
- Autor: Carlos Gil Bellosta
- Gratuito
El libro cubre 3 aspectos básicos muy demandados por los profesionales de los datos: la creación de visualizaciones de datos de alta calidad, la creación de dashboards para visualizar y analizar datos, y la creación de informes automáticos. Su objetivo es que el lector puede comenzar a aplicar métodos estadísticos (y de la llamada ciencia de datos) por su cuenta.
Aprendiendo R sin morir en el intento
- Autor: Javier Álvarez Liébana
- Gratuito
El objetivo de este tutorial es introducir en la programación y análisis estadístico en R a personas sin necesidad de conocimientos previos de programación. Su objetivo es entender los conceptos básicos de R y dotar al usuario de trucos sencillos y de autonomía básica para poder trabajar con datos.
Aprendizaje Estadístico
- Autor: Rubén F. Casal
- Gratuito
Se trata de un documento con los apuntes de la asignatura de Aprendizaje Estadístico del Máster en Técnicas Estadísticas. Ha sido escrito en R-Markdown empleando el paquete bookdown y está disponible en Github. El libro no trata directamente de R, si no que aborda desde una introducción al aprendizaje estadístico, hasta las redes neuronales, pasando por los arboles de decisión o los modelos lineales, entre otros.
Simulación Estadística
- Autor: Rubén F. Casal y Ricardo Cao
- Gratuito
Al igual que en el caso anterior, este libro es el manual de una asignatura, en este caso de Simulación Estadística del Máster en Técnicas Estadísticas. También ha sido escrito en R-Markdown empleando el paquete bookdown y está disponible en el repositorio Github. Tras una introducción a la simulación, el libro aborda la generación de números pseudoaleatorios en R, el análisis de resultados de simulación o la simulación de variables continuas y discretas, entre otros.
Estadística con R
- Autor: Joaquín Amat Rodrigo
- Gratuito
No es un libro directamente, sino una web donde podrás encontrar diversos recursos y trabajos que te pueden servir de ejemplo a la hora de practicar con R. Su autor es Joaquín Amat Rodrigo también responsable de Machine Learning con R.
la página oficial de R-Studio también disponen de recursos para aprender diferentes paquetes o funciones de R, utilizando diversas cheatsheet.
Masters
Además de cursos, cada vez es más habitual encontrar en universidades masters relacionados con esta materia, como por ejemplo:
Master en Estadística Aplicada con R / Máster en Machine Learning con R
- Impartido por: Máxima Formación
- Duración: 10 meses
- Idioma: Español
La Escuela Máxima Formación ofrece dos masters que comienzan en octubre de 2021 relacionados con R. El Máster en Estadística Aplicada para la Ciencia de Datos con R Software (13ª edición) está dirigido a profesionales que quieran desarrollar desarrolla competencias prácticas avanzadas para solucionar los problemas reales relacionados con el análisis, la manipulación y la representación gráfica de los datos. El Máster en Machine Learning con R Software (2ª edición) está enfocado en el trabajo con datos en tiempo real para crear modelos de análisis y algoritmos con aprendizaje supervisado, no supervisado y aprendizaje profundo.
Además, cada vez más centros de estudio ofrecen masters o programas relacionados con la ciencia de datos que recogen en su temario conocimientos sobre R, tanto generalistas como enfocados en sectores concretos. Algunos ejemplos son:
- Máster en Data Science, de la Universidad Rey Juan Carlos, que integra aspectos de ingeniería de datos (Spark, Hadoop, arquitecturas cloud, obtención y almacenamiento de datos) y analítica de datos (modelos estadísticos, minería de datos, simulación, análisis de grafos o visualización y comunicación).
- Master en Big Data, de la Universidad Nacional de Educación a Distancia (UNED), incluye un módulo de Introducción al Machine Learning con R y otro de paquetes avanzados con R.
- Máster en Big Data y Data Science Aplicado a la Economía, de la Universidad Nacional de Educación a Distancia (UNED), introduce conceptos de R como uno de los programas de software más utilizados.
- Máster Big Data - Business – Analytics, de la Universidad Complutense de Madrid, incluye un tema de Minería de datos y modelización predictiva con R.
- Master en Big Data y Data Science aplicado a la Economía y Comercio, también de la Universidad Complutense de Madrid, donde se estudia programación en R, por ejemplo, para el diseño de mapas, entre otros.
- Máster en Humanidades Digitales para un Mundo Sostenible, de la Universidad Autónoma de Madrid, donde los alumnos serán capaces de programar en Python y R para conseguir datos estadísticos a partir de textos (PLN).
- Máster en Data Science & Business Analytics, de la Universidad de Castilla-La Mancha, cuyo ojetivo es aprender y/o profundizar en la Ciencia de Datos, la Inteligencia Artificial y el Business Analytics, utilizando el software estadístico R.
- Experto en Modeling & Data Mining, de la Universidad de Castilla-La Mancha, donde al igual que en el caso anterior también se trabaja con R para transformar datos no estructurados en conocimiento.
- Máster de Big Data Finanzas, donde se habla de Programación para data science / big data o visualización de información con R.
- Programa en Big Data y Business Intelligence, de la universidad de Deusto, que capacita para realizar ciclos completos de análisis de datos (extracción, gestión, procesamiento (ETL) y visualización).
Esperamos que alguno de estos cursos responda a tus necesidades y puedas convertirte en un experto en R. Si conoces algún otro curso que quieras recomendar, déjanos un comentario o escríbenos a dinamizacion@datos.gob.es.