Documentación
In the field of data science, the ability to build robust predictive models is fundamental. However, a model is not just a set of algorithms; it is a tool that must be understood, validated, and ultimately useful for decision-making.
Thanks to the transparency and accessibility of open data, we have the unique opportunity to work in this exercise with real, updated, and institutional-quality information that reflects environmental issues. This democratization of access not only allows for the development of rigorous analyses with official data but also contributes to informed public debate on environmental policies, creating a direct bridge between scientific research and societal needs.
In this practical exercise, we will dive into the complete lifecycle of a modeling project, using a real case study: the analysis of air quality in Castile and León. Unlike approaches that focus solely on the implementation of algorithms, our methodology focuses on:
- Loading and initial data exploration: identifying patterns, anomalies, and underlying relationships that will guide our modeling.
- Exploratory analysis for modeling: building visualizations and performing feature engineering to optimize the model.
- Development and evaluation of regression models: building and comparing multiple iterative models to understand how complexity affects performance.
- Model application and conclusions: using the final model to simulate scenarios and quantify the impact of potential environmental policies.
Access the data laboratory repository on Github
Run the data pre-processing code on Google Colab
Analysis Architecture
The core of this exercise follows a structured flow in four key phases, as illustrated in Figure 1. Each phase builds on the previous one, from initial data exploration to the final application of the model.

Figure 1. Phases of the predictive modeling project.
Development Process
1. Loading and Initial Data Exploration
The first step is to understand the raw material of our analysis: the data. Using an air quality dataset from Castile and León, spanning 24 years of measurements, we face common real-world challenges:
- Missing Values: variables such as CO and PM2.5 have limited data coverage.
- Anomalous Data: negative and extreme values are detected, likely due to sensor errors.
Through a process of cleaning and transformation, we convert the raw data into a clean and structured dataset, ready for modeling.
2. Exploratory Analysis for Modeling
Once the data is clean, we look for patterns. Visual analysis reveals a strong seasonality in NO₂ levels, with peaks in winter and troughs in summer. This observation is crucial and leads us to create new variables (feature engineering), such as cyclical components for the months, which allow the model to "understand" the circular nature of the seasons.

Figure 2. Seasonal variation of NO₂ levels in Castile and León.
3. Development and Evaluation of Regression Models
With a solid understanding of the data, we proceed to build three linear regression models of increasing complexity:
- Base Model: uses only pollutants as predictors.
- Seasonal Model: adds time variables.
- Complete Model: includes interactions and geographical effects.
Comparing these models allows us to quantify the improvement in predictive capability. The Seasonal Model emerges as the optimal choice, explaining almost 63% of the variability in NO₂, a remarkable result for environmental data.
4. Model Application and Conclusions
Finally, we subject the model to a rigorous diagnosis and use it to simulate the impact of environmental policies. For example, our analysis estimates that a 20% reduction in NO emissions could translate into a 4.8% decrease in NO₂ levels.

Figure 3. Performance of the seasonal model. The predicted values align well with the actual values.
What can you learn?
This practical exercise allows you to learn:
- Data project lifecycle: from cleaning to application.
- Linear regression techniques: construction, interpretation, and diagnosis.
- Handling time-series data: capturing seasonality and trends.
- Model validation: techniques like cross-validation and temporal validation.
- Communicating results: how to translate findings into actionable insights.
Conclusions and Future
This exercise demonstrates the power of a structured and rigorous approach in data science. We have transformed a complex dataset into a predictive model that is not only accurate but also interpretable and useful.
For those interested in taking this analysis to the next level, the possibilities are numerous:
- Incorporation of meteorological data: variables such as temperature and wind could significantly improve accuracy.
- More advanced models: exploring techniques such as Generalized Additive Models (GAM) or other machine learning algorithms.
- Spatial analysis: investigating how pollution patterns vary between different locations.
In summary, this exercise not only illustrates the application of regression techniques but also underscores the importance of an integrated approach that combines statistical rigor with practical relevance.
Noticia
Today, 23 April, is World Book Day, an occasion to highlight the importance of reading, writing and the dissemination of knowledge. Active reading promotes the acquisition of skills and critical thinking by bringing us closer to specialised and detailed information on any subject that interests us, including the world of data.
Therefore, we would like to take this opportunity to showcase some examples of books and manuals regarding data and related technologies that can be found on the web for free.
1. Fundamentals of Data Science with R, edited by Gema Fernandez-Avilés and José María Montero (2024)
Access the book here.
- What is it about? The book guides the reader from the problem statement to the completion of the report containing the solution to the problem. It explains some thirty data science techniques in the fields of modelling, qualitative data analysis, discrimination, supervised and unsupervised machine learning, etc. It includes more than a dozen use cases in sectors as diverse as medicine, journalism, fashion and climate change, among others. All this, with a strong emphasis on ethics and the promotion of reproducibility of analyses.
- Who is it aimed at? It is aimed at users who want to get started in data science. It starts with basic questions, such as what is data science, and includes short sections with simple explanations of probability, statistical inference or sampling, for those readers unfamiliar with these issues. It also includes replicable examples for practice.
- Language: Spanish.
2. Telling stories with data, Rohan Alexander (2023).
Access the book here.
- What is it about? The book explains a wide range of topics related to statistical communication and data modelling and analysis. It covers the various operations from data collection, cleaning and preparation to the use of statistical models to analyse the data, with particular emphasis on the need to draw conclusions and write about the results obtained. Like the previous book, it also focuses on ethics and reproducibility of results.
- Who is it aimed at? It is ideal for students and entry-level users, equipping them with the skills to effectively conduct and communicate a data science exercise. It includes extensive code examples for replication and activities to be carried out as evaluation.
- Language: English.
3. The Big Book of Small Python Projects, Al Sweigart (2021)
Access the book here.
- What is it about? It is a collection of simple Python projects to learn how to create digital art, games, animations, numerical tools, etc. through a hands-on approach. Each of its 81 chapters independently explains a simple step-by-step project - limited to a maximum of 256 lines of code. It includes a sample run of the output of each programme, source code and customisation suggestions.
- Who is it aimed at? The book is written for two groups of people. On the one hand, those who have already learned the basics of Python, but are still not sure how to write programs on their own. On the other hand, those who are new to programming, but are adventurous, enthusiastic and want to learn as they go along. However, the same author has other resources for beginners to learn basic concepts.
- Language: English.
4. Mathematics for Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Access the book here.
- What is it about? Most books on machine learning focus on machine learning algorithms and methodologies, and assume that the reader is proficient in mathematics and statistics. This book foregrounds the mathematical foundations of the basic concepts behind machine learning
- Who is it aimed at? The author assumes that the reader has mathematical knowledge commonly learned in high school mathematics and physics subjects, such as derivatives and integrals or geometric vectors. Thereafter, the remaining concepts are explained in detail, but in an academic style, in order to be precise.
- Language: English.
5. Dive into Deep Learning, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, continually updated)
Access the book here.
- What is it about? The authors are Amazon employees who use the mXNet library to teach Deep Learning. It aims to make deep learning accessible, teaching basic concepts, context and code in a practical way through examples and exercises. The book is divided into three parts: introductory concepts, deep learning techniques and advanced topics focusing on real systems and applications.
- Who is it aimed at? This book is aimed at students (undergraduate and postgraduate), engineers and researchers, who are looking for a solid grasp of the practical techniques of deep learning. Each concept is explained from scratch, so no prior knowledge of deep or machine learning is required. However, knowledge of basic mathematics and programming is necessary, including linear algebra, calculus, probability and Python programming.
- Language: English.
6. Artificial intelligence and the public sector: challenges, limits and means, Eduardo Gamero and Francisco L. Lopez (2024)
Access the book here.
- What is it about? This book focuses on analysing the challenges and opportunities presented by the use of artificial intelligence in the public sector, especially when used to support decision-making. It begins by explaining what artificial intelligence is and what its applications in the public sector are, and then moves on to its legal framework, the means available for its implementation and aspects linked to organisation and governance.
- Who is it aimed at? It is a useful book for all those interested in the subject, but especially for policy makers, public workers and legal practitioners involved in the application of AI in the public sector.
- Language: Spanish
7. A Business Analyst’s Introduction to Business Analytics, Adam Fleischhacker (2024)
Access the book here.
- What is it about? The book covers a complete business analytics workflow, including data manipulation, data visualisation, modelling business problems, translating graphical models into code and presenting results to stakeholders. The aim is to learn how to drive change within an organisation through data-driven knowledge, interpretable models and persuasive visualisations.
- Who is it aimed at? According to the author, the content is accessible to everyone, including beginners in analytical work. The book does not assume any knowledge of the programming language, but provides an introduction to R, RStudio and the "tidyverse", a series of open source packages for data science.
- Language: English.
We invite you to browse through this selection of books. We would also like to remind you that this is only a list of examples of the possibilities of materials that you can find on the web. Do you know of any other books you would like to recommend? let us know in the comments or email us at dinamizacion@datos.gob.es!
Documentación
1. Introduction
Visualizations are graphical representations of data that allow the information linked to them to be communicated in a simple and effective way. The visualization possibilities are very wide, from basic representations, such as a line chart, bars or sectors, to visualizations configured on dashboards or interactive dashboards.
In this "Step-by-Step Visualizations" section we are regularly presenting practical exercises of open data visualizations available on datos.gob.es or similar catalogs. They address and describe in a simple way the stages necessary to obtain the data, perform the transformations and analysis that are relevant to and finally, the creation of interactive visualizations; from which we can extract information summarized in final conclusions. In each of these practical exercises, simple and well-documented code developments are used, as well as free to use tools. All generated material is available for reuse in GitHub's Data Lab repository.
Run the data pre-processing code on top of Google Colab.
Below, you can access the material that we will use in the exercise and that we will explain and develop in the following sections of this post.
Access the data lab repository on Github.
Run the data pre-processing code on top of Google Colab.
2. Objective
The main objective of this exercise is to make an analysis of the meteorological data collected in several stations during the last years. To perform this analysis, we will use different visualizations generated by the "ggplot2" library of the programming language "R".
Of all the Spanish weather stations, we have decided to analyze two of them, one in the coldest province of the country (Burgos) and another in the warmest province of the country (Córdoba), according to data from the AEMET. Patterns and trends in the different records between 1990 and 2020 will be sought to understand the meteorological evolution suffered in this period of time.
Once the data has been analyzed, we can answer questions such as those shown below:
- What is the trend in the evolution of temperatures in recent years?
- What is the trend in the evolution of rainfall in recent years?
- Which weather station (Burgos or Córdoba) presents a greater variation of climatological data in recent years?
- What degree of correlation is there between the different climatological variables recorded?
These, and many other questions can be solved by using tools such as ggplot2 that facilitate the interpretation of data through interactive visualizations.
3. Resources
3.1. Datasets
The datasets contain different meteorological information of interest for the two stations in question broken down by year. Within the AEMET download center, we can download them, upon request of the API key, in the section "monthly / annual climatologies". From the existing weather stations, we have selected two of which we will obtain the data: Burgos airport (2331) and Córdoba airport (5402)
It should be noted that, along with the datasets, we can also download their metadata, which are of special importance when identifying the different variables registered in the datasets.
These datasets are also available in the Github repository.
3.2. Tools
To carry out the data preprocessing tasks, the R programming language written on a Jupyter Notebook hosted in the Google Colab cloud service has been used.
"Google Colab" or, also called Google Colaboratory, is a cloud service from Google Research that allows you to program, execute and share code written in Python or R on a Jupyter Notebook from your browser, so it does not require configuration. This service is free of charge.
For the creation of the visualizations, the ggplot2 library has been used.
"ggplot2" is a data visualization package for the R programming language. It focuses on the construction of graphics from layers of aesthetic, geometric and statistical elements. ggplot2 offers a wide range of high-quality statistical charts, including bar charts, line charts, scatter plots, box and whisker charts, and many others.
If you want to know more about tools that can help you in the treatment and visualization of data, you can use the report "Data processing and visualization tools".
4. Data processing or preparation
The processes that we describe below you will find them commented in the Notebook that you can also run from Google Colab.
Before embarking on building an effective visualization, we must carry out a prior treatment of the data, paying special attention to obtaining them and validating their content, ensuring that they are in the appropriate and consistent format for processing and that they do not contain errors.
As a first step of the process, once the necessary libraries have been imported and the datasets loaded, it is necessary to perform an exploratory analysis of the data (EDA) in order to properly interpret the starting data, detect anomalies, missing data or errors that could affect the quality of the subsequent processes and results. If you want to know more about this process, you can resort to the Practical Guide of Introduction to Exploratory Data Analysis.
The next step is to generate the preprocessed data tables that we will use in the visualizations. To do this, we will filter the initial data sets and calculate the values that are necessary and of interest for the analysis carried out in this exercise.
Once the preprocessing is finished, we will obtain the data tables "datos_graficas_C" and "datos_graficas_B" which we will use in the next section of the Notebook to generate the visualizations.
The structure of the Notebook in which the steps previously described are carried out together with explanatory comments of each of them, is as follows:
- Installation and loading of libraries.
- Loading datasets
- Exploratory Data Analysis (EDA)
- Preparing the data tables
- Views
- Saving graphics
You will be able to reproduce this analysis, as the source code is available in our GitHub account. The way to provide the code is through a document made on a Jupyter Notebook that once loaded into the development environment you can run or modify easily. Due to the informative nature of this post and in order to favor the understanding of non-specialized readers, the code is not intended to be the most efficient but to facilitate its understanding so you will possibly come up with many ways to optimize the proposed code to achieve similar purposes. We encourage you to do so!
5. Visualizations
Various types of visualizations and graphs have been made to extract information on the tables of preprocessed data and answer the initial questions posed in this exercise. As mentioned previously, the R "ggplot2" package has been used to perform the visualizations.
The "ggplot2" package is a data visualization library in the R programming language. It was developed by Hadley Wickham and is part of the "tidyverse" package toolkit. The "ggplot2" package is built around the concept of "graph grammar", which is a theoretical framework for building graphs by combining basic elements of data visualization such as layers, scales, legends, annotations, and themes. This allows you to create complex, custom data visualizations with cleaner, more structured code.
If you want to have a summary view of the possibilities of visualizations with ggplot2, see the following "cheatsheet". You can also get more detailed information in the following "user manual".
5.1. Line charts
Line charts are a graphical representation of data that uses points connected by lines to show the evolution of a variable in a continuous dimension, such as time. The values of the variable are represented on the vertical axis and the continuous dimension on the horizontal axis. Line charts are useful for visualizing trends, comparing evolutions, and detecting patterns.
Next, we can visualize several line graphs with the temporal evolution of the values of average, minimum and maximum temperatures of the two meteorological stations analyzed (Córdoba and Burgos). On these graphs, we have introduced trend lines to be able to observe their evolution in a visual and simple way.






To compare the evolutions, not only visually through the graphed trend lines, but also numerically, we obtain the slope coefficients of the trend line, that is, the change in the response variable (tm_ month, tm_min, tm_max) for each unit of change in the predictor variable (year).
- Average temperature slope coefficient Córdoba: 0.036
- Average temperature slope coefficient Burgos: 0.025
- Coefficient of slope minimum temperature Córdoba: 0.020
- Coefficient of slope minimum temperature Burgos: 0.020
- Slope coefficient maximum temperature Córdoba: 0.051
- Slope coefficient maximum temperature Burgos: 0.030
We can interpret that the higher this value, the more abrupt the average temperature rise in each observed period.
Finally, we have created a line graph for each weather station, in which we jointly visualize the evolution of average, minimum and maximum temperatures over the years.


The main conclusions obtained from the visualizations of this section are:
- The average, minimum and maximum annual temperatures recorded in Córdoba and Burgos have an increasing trend.
- The most significant increase is observed in the evolution of the maximum temperatures of Córdoba (slope coefficient = 0.051)
- The slightest increase is observed in the evolution of the minimum temperatures, both in Córdoba and Burgos (slope coefficient = 0.020)
5.2. Bar charts
Bar charts are a graphical representation of data that uses rectangular bars to show the magnitude of a variable in different categories or groups. The height or length of the bars represents the amount or frequency of the variable, and the categories are represented on the horizontal axis. Bar charts are useful for comparing the magnitude of different categories and for visualizing differences between them.
We have generated two bar graphs with the data corresponding to the total accumulated precipitation per year for the different weather stations.


As in the previous section, we plot the trend line and calculate the slope coefficient.
- Slope coefficient for accumulated rainfall Córdoba: -2.97
- Slope coefficient for accumulated rainfall Burgos: -0.36
The main conclusions obtained from the visualizations of this section are:
- The annual accumulated rainfall has a decreasing trend for both Córdoba and Burgos.
- The downward trend is greater for Córdoba (coefficient = -2.97), being more moderate for Burgos (coefficient = -0.36)
5.3. Histograms
Histograms are a graphical representation of a frequency distribution of numeric data in a range of values. The horizontal axis represents the values of the data divided into intervals, called "bin", and the vertical axis represents the frequency or amount of data found in each "bin". Histograms are useful for identifying patterns in data, such as distribution, dispersion, symmetry, or bias.
We have generated two histograms with the distributions of the data corresponding to the total accumulated precipitation per year for the different meteorological stations, being the chosen intervals of 50 mm3.


The main conclusions obtained from the visualizations of this section are:
- The records of annual accumulated precipitation in Burgos present a distribution close to a normal and symmetrical distribution.
- The records of annual accumulated precipitation in Córdoba do not present a symmetrical distribution.
5.4. Box and whisker diagrams
Box and whisker diagrams are a graphical representation of the distribution of a set of numerical data. These graphs represent the median, interquartile range, and minimum and maximum values of the data. The chart box represents the interquartile range, that is, the range between the first and third quartiles of the data. Out-of-the-box points, called outliers, can indicate extreme values or anomalous data. Box plots are useful for comparing distributions and detecting extreme values in your data.
We have generated a graph with the box diagrams corresponding to the accumulated rainfall data from the weather stations.
To understand the graph, the following points should be highlighted:
- The boundaries of the box indicate the first and third quartiles (Q1 and Q3), which leave below each, 25% and 75% of the data respectively.
- The horizontal line inside the box is the median (equivalent to the second quartile Q2), which leaves half of the data below.
- The whisker limits are the extreme values, that is, the minimum value and the maximum value of the data series.
- The points outside the whiskers are the outliers.

The main conclusions obtained from the visualization of this section are:
- Both distributions present 3 extreme values, being significant those of Córdoba with values greater than 1000 mm3.
- The records of Córdoba have a greater variability than those of Burgos, which are more stable
5.5. Pie charts
A pie chart is a type of pie chart that represents proportions or percentages of a whole. It consists of several sections or sectors, where each sector represents a proportion of the whole set. The size of the sector is determined based on the proportion it represents, and is expressed in the form of an angle or percentage. It is a useful tool for visualizing the relative distribution of the different parts of a set and facilitates the visual comparison of the proportions between the different groups.
We have generated two graphs of (polar) sectors. The first of them with the number of days that the values exceed 30º in Córdoba and the second of them with the number of days that the values fall below 0º in Burgos.
For the realization of these graphs, we have grouped the sum of the number of days described above into six groups, corresponding to periods of 5 years from 1990 to 2020.


The main conclusions obtained from the visualizations of this section are:
- There is an increase of 31.9% in the total number of annual days with temperatures above 30º in Córdoba for the period between 2015-2020 compared to the period 1990-1995.
- There is an increase of 33.5% in the total number of annual days with temperatures above 30º in Burgos for the period between 2015-2020 compared to the period 1990-1995.
5.6. Scatter plots
Scatter plots are a data visualization tool that represent the relationship between two numerical variables by locating points on a Cartesian plane. Each dot represents a pair of values of the two variables and its position on the graph indicates how they relate to each other. Scatter plots are commonly used to identify patterns and trends in data, as well as to detect any possible correlation between variables. These charts can also help identify outliers or data that doesn't fit the overall trend.
We have generated two scattering plots in which the values of maximum average temperatures and minimum averages are compared, looking for correlation trends between them for the values of each weather station.


To analyze the correlations, not only visually through graphs, but also numerically, we obtain Pearson's correlation coefficients. This coefficient is a statistical measure that indicates the degree of linear association between two quantitative variables. It is used to assess whether there is a positive linear relationship (both variables increase or decrease simultaneously at a constant rate), negative (the values of both variables vary oppositely) or null (no relationship) between two variables and the strength of such a relationship, the closer to +1, the higher their association.
- Pearson coefficient (Average temperature max VS min) Córdoba: 0.15
- Pearson coefficient (Average temperature max VS min) Burgos: 0.61
In the image we observe that while in Córdoba a greater dispersion is appreciated, in Burgos a greater correlation is observed.
Next, we will modify the previous scatter plots so that they provide us with more information visually. To do this, we divide the space by colored sectors (red with higher temperature values / blue lower temperature values) and show in the different bubbles the label with the corresponding year. It should be noted that the color change limits of the quadrants correspond to the average values of each of the variables.


The main conclusions obtained from the visualizations of this section are:
- There is a positive linear relationship between the average maximum and minimum temperature in both Córdoba and Burgos, this correlation being greater in the Burgos data.
- The years with the highest values of maximum and minimum temperatures in Burgos are (2003, 2006 and 2020)
- The years with the highest values of maximum and minimum temperatures in Córdoba are (1995, 2006 and 2020)
5.7. Correlation matrix
The correlation matrix is a table that shows the correlations between all variables in a dataset. It is a square matrix that shows the correlation between each pair of variables on a scale ranging from -1 to 1. A value of -1 indicates a perfect negative correlation, a value of 0 indicates no correlation, and a value of 1 indicates a perfect positive correlation. The correlation matrix is commonly used to identify patterns and relationships between variables in a dataset, which can help to better understand the factors that influence a phenomenon or outcome.
We have generated two heat maps with the correlation matrix data for both weather stations.


The main conclusions obtained from the visualizations of this section are:
- There is a strong negative correlation (-0.42) for Córdoba and (-0.45) for Burgos between the number of annual days with temperatures above 30º and accumulated rainfall. This means that as the number of days with temperatures above 30º increases, precipitation decreases significantly.
6. Conclusions of the exercise
Data visualization is one of the most powerful mechanisms for exploiting and analyzing the implicit meaning of data. As we have seen in this exercise, "ggplot2" is a powerful library capable of representing a wide variety of graphics with a high degree of customization that allows you to adjust numerous characteristics of each graph.
After analyzing the previous visualizations, we can conclude that both for the weather station of Burgos, as well as that of Córdoba, temperatures (minimum, average, maximum) have suffered a considerable increase, days with extreme heat (temperature > 30º) have also suffered and rainfall has decreased in the period of time analyzed, from 1990 to 2020.
We hope that this step-by-step visualization has been useful for learning some very common techniques in the treatment, representation and interpretation of open data. We will be back to show you new reuses. See you soon!
Blog
Python, R, SQL, JavaScript, C++, HTML... Nowadays we can find a multitude of programming languages that allow us to develop software programmes, applications, web pages, etc. Each one has unique characteristics that differentiate it from the rest and make it more appropriate for certain tasks. But how do we know when and where to use each language? In this article we give you some clues.
Types of programming languages
Programming languages are syntactic and semantic rules that allow us to execute a series of instructions. Depending on their level of complexity, we can speak of different levels:
- Low-level languages: they use basic instructions that are directly interpreted by the machine and are difficult for humans to understand. They are custom-designed for each hardware and cannot be migrated, but they are very efficient, as they make the most of the characteristics of each machine.
- High-level languages: they use clear instructions using natural language, which is more understandable by humans. These languages emulate our way of thinking and reasoning, but must then be translated into machine language through translators/interpreters or compilers. They can be migrated and are not hardware-dependent.
Medium-level languages are sometimes also described as languages that, although they function like a low-level language, allow some abstract machine-independent handling.
The most widely used programming languages
In this article we are going to focus on the most used high-level languages in data science. To do so, we look at this survey, conducted by Anaconda in 2021, and the article by KD Nuggets.
How often are the following programming languages used?
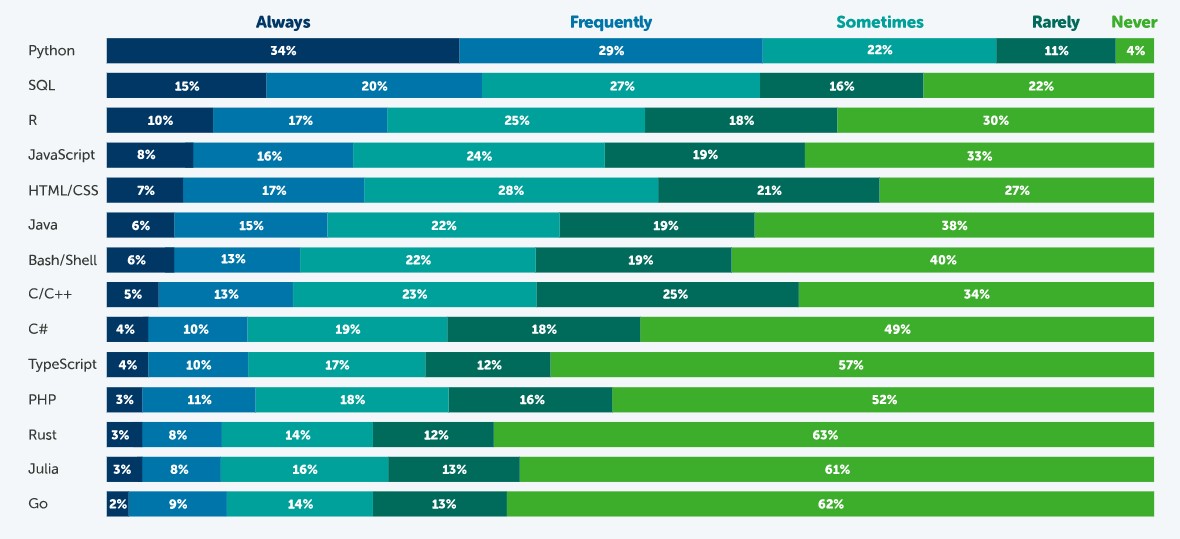
Source: State of Data Science in 2021, Anaconda.
According to this survey, the most popular language is Python. 63% of respondents - 3,104 data scientists, researchers, students and data professionals from around the world - indicated that they use Python always or frequently and only 4% indicated that they never use it. This is because it is a very versatile language, which can be used in the various tasks that exist throughout a data science project.
A data science project has different phases and tasks. Some languages can be used to perform different tasks, but with unequal performance. The following table, compiled by KD Nuggets, shows which language is most recommended for some of the most popular tasks:

Source: Data Science Programming Languages and When To Use Them, KD Nuggets, 2022.
As we can see, Python is the only language that is appropriate for all the areas analysed by KD Nuggets, although there are other options that are also very interesting, depending on the task to be carried out, as we will see below:
- Languages for data extraction and manipulation. These tasks are aimed at obtaining the data and debugging them in order to achieve a homogeneous structure, without incomplete data, free of errors and in the right format. For this purpose, it is recommended to perform an Exploratory Data Analysis. SQL is the programming language that excels the most with respect to data extraction, especially when working with relational databases. It is fast at retrieving data and has a standardised syntax, which makes it relatively simple. However, it is more limited when it comes to data manipulation. A task in which Python and R, two programs that have a large number of libraries for these tasks, give better results.
- Statistical analysis and data visualisation. This involves processing data to find patterns that are then converted into knowledge. There are different types of analysis depending on their purpose: to learn more about our environment, to make predictions or to obtain recommendations. The best language for this is R, an interpreted language that also has a programming environment, R-Studio, and a set of very flexible and versatile tools for statistical computing. Python, Java and Julia are other tools that perform well in this task, for which JavaScript can also be used. The above languages allow, in addition to performing analyses, the creation of graphical visualisations that facilitate the understanding of the information.
- Modelling/machine learning (ML). If we want to work with machine learning and build algorithms, Python, Java, Java/JavaScript, Julia and TypeScript are the best options. All of them simplify the task of writing code, although it is necessary to have extensive knowledge to be able to work with the different machine learning techniques. More experienced users can work with C/C++, a very machine-readable programming language, but with a lot of code, which can be difficult to learn. In contrast, R can be a good choice for less experienced users, although it is slower and not well suited for complex neural networks.
- Model deployment. Once a model has been created, it is necessary to deploy it, taking into account all the necessary requirements for its entry into production in a real environment. For this purpose, the most suitable languages are Python, Java, JavaScript and C#, followed by PHP, Rust, GoLang and, if we are working with basic applications, HTML/CSS.
- Automation. While not all parts of a data scientist's job can be automated, there are some tedious and repetitive tasks whose automation speeds up performance. Python, for example, has a large number of libraries for automating machine learning tasks. If we are working with mobile applications, then Java is our best option. Other options are C# (especially useful for automating model building), Bash/Shell (for data extraction and manipulation) and R (for statistical analysis and visualisations).
Ultimately, the programming language we use will depend entirely on the task at hand and our capabilities. Not all data science professionals need to know all languages, but should choose the one that is most appropriate for their daily work.
Some additional resources to learn more about these languages
At datos.gob.es we have prepared some guides and resources that may be useful for you to learn some of these languages:
- Data processing and visualization tools
- Courses to learn more about R
- Courses to learn more about Python
- Online courses to learn more about data visualization
- R and Python Communities for Developer
Content prepared by the datos.gob.es team.
Blog
The advance of supercomputing and data analytics in fields as diverse as social networks or customer service is encouraging a part of artificial intelligence (AI) to focus on developing algorithms capable of processing and generating natural language.
To be able to carry out this task in the current context, having access to a heterogeneous list of natural language processing libraries is key to designing effective and functional AI solutions in an agile way. These source code files, which are used to develop software, facilitate programming by providing common functionalities, previously solved by other developers, avoiding duplication and minimising errors.
Thus, with the aim of encouraging sharing and reuse to design applications and services that provide economic and social value, we break down four sets of natural language processing libraries, divided on the basis of the programming language used.
Python libraries
Ideal for coding using the Python programming language. As with the examples available for other languages, these libraries have a variety of implementations that allow the developer to create a new interface on their own.
Examples include:
NLTK: Natural Language Toolkit
- Description: NLTK provides easy-to-use interfaces to more than 50 corpora and lexical resources such as WordNet, together with a set of text processing libraries. It enables text pre-processing tasks, including classification, tokenisation, lemmatisation or exclusion of stop words, parsing and semantic reasoning.
- Supporting materials: One of the most interesting sections to consult information and resolve doubts is the section dedicated to frequently asked questions. You can find it at this link. It also has available examples of use and a wiki.
Gensim
- Description: Gensim is an open source Python library for representing documents as semantic vectors. The main difference with respect to other natural language libraries for Python is that Gensim is capable of automatically identifying the subject matter of the set of documents to be processed. It also allows us to analyse the similarity between files, which is really useful when we use the library to perform searches.
- Supporting materials: In the Documentation section of its website, it is possible to find didactic materials focused on three very specific areas. On the one hand, there is a series of tutorials aimed at programmers who have never used this type of library before. There are training lessons oriented towards specific programming language issues, a series of guides aimed at resolving doubts that arise when faced with certain problems, and also a section dedicated solely to frequently asked questions.
Libraries for JavaScript
JavaScript libraries serve to diversify the range of resources that can be used by programmers and web developers who make use of this language. You can choose from the following examples below:
Apache OpenNLP
- Description: The Apache OpenNLP library is a machine learning-based toolkit for natural language text processing. It supports the basic tasks of natural language programming, tokenisation, sentence segmentation, part-of-speech tagging, named entity extraction, language detection and much more.
- Supporting materials: Within the General category of its website, there is a sub-section called Books, Tutorials and Talks, which provides a series of talks, tutorials and publications aimed at resolving programmers' doubts. Likewise, in the Documentation category, they have different user manuals.
NLP.js
- Description: NLP.js targets node.js, an open source JavaScript runtime environment. It natively supports 41 languages and can even be extended to 104 languages with the use of Bert embeddings. It is a library mainly used for building bots, sentiment analysis or automatic language identification, among other functions. Precisely for this reason, it is a library to be taken into account for the construction of chatbots.
- Supporting materials: Within their profile hosted on the Github code portal, they offer a section of frequently asked questions and another of examples of use that may be useful when using the library to develop an app or service.
Natural
- Description: Like NLP.js, Natural also facilitates natural language processing for node.js. It offers a wide range of functionalities such as tokenisation, phonetic matching, term frequency (TF-IDF) and integration with the WordNet database, among others.
- Supporting materials: Like the previous library, this library does not have its own website. In its Github profile, it has support content such as examples of use cases previously developed by other programmers.
Wink
- Description: Wink is a family of open source packages for statistical analysis, natural language processing and machine learning in NodeJS. It has been optimised to achieve a balance between performance and accuracy, making the package capable of handling large amounts of raw text at high speed.
- Supporting materials: Accessing the tutorials from its website is very intuitive, as one of the categories with the same name contains precisely this type of informative content. Here it is possible to find learning guides divided according to the level of experience of the programmer or the part of the process in which he/she is immersed.
Libraries for R
In this last section we bring together the specific libraries for building a website, application or service using the R coding language. Some of them are:
koRpus
- Description: This is a text analysis package capable of automatic language detection and various indexes of lexical diversity or readability, among other functions. It also includes the RKWard plugin which provides graphical dialogue boxes for its basic functions.
- Supporting materials: koRpus offers a series of guidelines focused on its installation and gathered in the Read me document that you can find in this link. Also, in the News section you can find the updates and changes that have been made in the successive versions of the library.
Quanteda
- Description: This library has been designed to allow programmers using R to apply natural language processing techniques to their texts from the original version to the final output. Therefore, its API has been developed to enable powerful and efficient analysis with a minimum of steps, thus reducing the learning barriers to natural language processing and quantitative text analysis.
- Supporting materials: It offers as main support material this quick start guide. Through it, it is possible to follow the main instructions in order not to make any mistakes. It also includes several examples that can be used to compare results.
Isa - Natural Language Processing
- Description: This library is based on latent semantic analysis, which consists of creating structured data from a collection of unstructured text.
- Supporting materials: In the documentation section, we can find useful information for development.
Libraries for Python and R
We talk about libraries for Python and R to refer to those that are compatible for coding using both programming languages.
spaCy
- Description: It is a very useful tool for preparing texts that will later be used in other machine learning tasks. It also allows statistical linguistic models to be applied to solve different natural language processing problems.
- Supporting materials: spaCy offers a series of online courses divided into different chapters that you can find here. Through the contents shared in NLP Advanced you will be able to follow step by step the utilities of this library, as each chapter focuses on a part of text processing. If you still want to learn more about this library, we recommend you to read this article by Alejandro Alija regarding his experience testing this library.
In this article we have shared a sample of some of the most popular libraries for natural language processing. However, it should be stressed that this is only a selection.
So, if you know of any other libraries of interest that you would like to recommend, please leave us a message in the comments or send us an email to dinamizacion@datos.gob.es.
Content prepared by the datos.gob.es team.
Blog
Programming libraries refer to the sets of code files that have been created to develop software in a simple way . Thanks to them, developers can avoid code duplication and minimize errors with greater agility and lower cost. There are many bookstores, focused on different activities. A few weeks ago we saw some examples of libraries for creating visualizations , and this time we are going to focus on useful libraries for machine learning tasks .
These libraries are highly practical when implementing Machine Learning flows . This discipline, belonging to the field of Artificial Intelligence, uses algorithms that offer, for example, the ability to identify patterns in massive data or the ability to help develop predictive analysis.
Below, we show you some of the most popular data analysis and Machine Learning libraries that currently exist for the main programming languages, such as Python or R:
Libraries for Python
NumPy
- Description:
This Python library is specialized in mathematical computation and big data analysis . It allows working with arrays that allow representing collections of data of the same type in various dimensions, as well as very efficient functions for their manipulation.
- Support materials:
Here we find the Beginner's Guide , with basic concepts and tutorials, the User's Guide , with information on general features, or the Contributor's Guide , to help maintain and develop the code or write technical documentation. NumPy also has a Reference Guide that details functions, modules and objects included in this library, as well as a series of tutorials to learn how to use it easily.
Pandas
- Description :
It is one of the most used libraries for data processing in Python . This data analysis and manipulation tool is characterized, among other aspects, by defining new data functionalities based on the arrays of the NumPy library . It allows you to easily read and write files in CSV, Excel format and specify queries to SQL databases .
- Support materials:
Its website has different documents such as the User's Guide , with detailed basic information and useful explanations, the Developer's Guide , which details the steps to follow when identifying errors or suggestions for improvements in functionalities, as well as the Reference Guide , with a detailed description of its API. In addition, it offers a series of tutorials contributed by the community and references on equivalent operations in other software and languages such as SAS, SQL or R.
Scikit-learn
- Description:
Scikit-Learn is a library that implements a large number of Machine Learning algorithms for classification, regression, clustering , and dimensionality reduction tasks . In addition, it is compatible with other Python libraries such as NumPy, SciPy and Matplotlib (Matpotlib is a data visualization library and as such is included in the previous article ).
- Support materials:
This library has different help documents such as an Installation Manual , a User's Guide or a Glossary of common terms and elements of its API . In addition, it offers a section with different examples that illustrate the features of the library, as well as other sections of interest with tutorials , frequently asked questions or access to its GitHub .
Scipy
- Description:
This library features a collection of mathematical algorithms and functions built on top of the NumPy extension . It includes extension modules for Python on statistics, optimization, integration, linear algebra or image processing, among others.
- Support materials:
Like the previous examples, this library also has materials such as Installation Guides , User Guides , Developer Guides or a document with detailed descriptions of its API . It also provides information on act , a tool for running GitHub actions locally.
Libraries for R
mlr
- Description:
This library offers essential components to develop machine learning tasks, among others, preprocessing, pipelining , feature selection, visualization and implementation of supervised and unsupervised techniques using a wide range of algorithms.
- Support materials:
On its website, it has multiple resources for users and developers, among which a reference tutorial stands out that presents an extensive tour that covers the basic aspects of tasks, predictions or data preprocessing to the implementation of complex projects using advanced functions.
In addition, it has a section that redirects to GitHub in which it offers talks, videos and workshops of interest on the operation and uses of this library.
Tidyverse
- Description:
This library offers a collection of R packages designed for data science that provide very useful functionality to import, transform, visualize, model and communicate information from data. They all share the same design philosophy, grammar, and underlying data structures. The main packages that make it up are: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr and purrr.
- Support materials:
Tidyverse has a blog where you can find posts about programming, packages or tricks and techniques to work with this library. In addition, it has a section that recommends books and workshops to learn how to use this library in a simpler and more enjoyable way.
Caret
- Description:
This popular library contains an interface that unifies hundreds of functions for training classifiers and regressors under a single framework , greatly facilitating all stages of preprocessing, training, optimization and validation of predictive models.
- Support materials:
The project website contains exhaustive information that makes it easier for the user to tackle the aforementioned tasks. References can also be found on CRAN and the project is hosted on GitHub . Some resources of interest for managing this library can be found through books such as Applied Predictive Modeling , articles , seminars or tutorials , among others.
Libraries to tackle Big Data tasks
TensorFlow
- Description:
In addition to Python and R, this library is also compatible with other languages such as JavaScript, C++ or Julia. TensorFlow offers the ability to build and train ML models using APIs . The most prominent API is Keras , which allows building and training deep learning models (Deep Learning).
- Support materials:
On its website you can find resources such as previously established and developed models and data sets, tools , libraries and extensions , certification programs , knowledge about machine learning or resources and tools to integrate responsible AI practices . You can access their GitHub page here .
Dmlc XGBoost
- Description:
Scalable, portable and distributed "Gradient Boosting" (GBM, GBRT, GBDT) library supports C ++, Python, R, Java, Scala, Perl and Julia programming languages . This library allows you to solve many data science problems quickly and accurately and can be integrated with Flink, Spark and other cloud data flow systems to tackle Big Data tasks.
- Support materials:
On its website it has a blog with related topics such as algorithm updates or integrations, as well as a documentation section that has installation guides, tutorials, frequently asked questions, a user forum or packages for the different programming languages. You can access their GitHub page via this link .
H20
- Description:
This library combines the main algorithms of Machine Learning and statistical learning with Big Data , as well as being able to work with millions of records. H20 is written in Java , and follows the Key/Value paradigm to store data and Map/Reduce to implement algorithms. Thanks to its API , it can be accessed from R, Python or Scala.
- Support materials:
It has a series of videos in the form of a tutorial to teach and facilitate its use for users. On its GitHub page you can find additional resources such as blogs , projects, resources, research papers, courses or books about H20 .
In this article we have offered a sample of some of the most popular libraries that offer versatile functionality to tackle typical data science and machine learning tasks, although there are many others . This type of library is constantly evolving thanks to the possibility it offers its users to participate in its improvement through actions such as contributing to code writing, generating new documentation or reporting errors. All this allows you to continuously enrich and refine your results.
If you know of any other bookstore of interest that you want to recommend, you can leave us a message in comments or send us an email to dinamizacion@datos.gob.es
Content prepared by the datos.gob.es team.
Blog
Programming libraries are sets of code files that are used to develop software. Their purpose is to facilitate programming by providing common functionalities that have already been solved by other programmers.
Libraries are an essential component for developers to be able to program in a simple way, avoiding duplication of code and minimising errors. They also allow for greater agility by reducing development time and costs.
These advantages are reflected when using libraries to make visualisations using popular languages such as Python, R and JavaScript.
Python libraries
Python is one of the most widely used programming languages. It is an interpreted language (easy to read and write thanks to its similarity to the human language), multiplatform, free and open source. In this previous article you can find courses to learn more about it.
Given its popularity, it is not surprising that we can find many libraries on the web that make creating visualisations with this language easier, such as, for example:
Matplotlib
- Description:
Matplotlib is a complete library for generating static, animated and interactive visualisations from data contained in lists or arrays in the Python programming language and its mathematical extension NumPy.
- Supporting materials:
The website contains examples of visualisations with source code to inspire new users, and various guides for both beginners and more advanced users. An external resources section is also available on the website, with links to books, articles, videos and tutorials produced by third parties.
Seaborn
- Description:
Seaborn is a Python data visualisation library based on matplotlib. It provides a high-level interface to draw attractive and informative statistical graphs.
- Supporting materials:
Tutorials are available on their website, with information on the API and the different types of functions, as well as a gallery of examples. It is also advisable to take a look at this paper by The Journal of Open Source Software.
Bokeh
- Description:
Bokeh is a library for interactive data visualisation in a web browser. Its functions range from the creation of simple graphs to the creation of interactive dashboards.
- Supporting materials:
Users can find detailed descriptions and examples describing the most common tasks in the guide. The guide includes the definition of basic concepts, working with geographic data or how to generate interactions, among others.
The website also has a gallery with examples, tutorials and a community section, where doubts can be raised and resolved.
Geoplotlib
- Description:
Geoplotlib is an open source Python library for visualising geographic data. It is a simple API that produces visualisations on top of OpenStreetMap tiles. It allows the creation of point maps, data density estimators, spatial graphics and shapefiles, among many other spatial visualisations.
- Supporting materials:
In Github you have available this user guide, which explains how to load data, create colour maps or add interactivity to layers, among others. Code examples are also available.
Libraries for R
R is also an interpreted language for statistical computing and the creation of graphical representations (you can learn more about it by following one of these courses). It has its own programming environment, R-Studio, and a very flexible and versatile set of tools that can be easily extended by installing libraries or packages - using its own terminology - such as those detailed below:
ggplot 2
- Description:
Ggplot is one of the most popular and widely used libraries in R for the creation of interactive data visualisations. Its operation is based on the paradigm described in The Grammar of Graphics for the creation of visualisations with 3 layers of elements: data (data frame), the list of relationships between variables (aesthetics) and the geometric elements to be represented (geoms).
- Supporting materials:
On its website you can find various materials, such as this cheatsheet that summarises the main functionalities of ggplot2. This guide begins by explaining the general characteristics of the system, using scatter diagrams as an example, and then goes on to detail how to represent some of the most popular graphs. It also includes a number of FAQs that may be of help.
Lattice
- Description:
Lattice is a data visualisation system inspired by Trellis or raster graphs, with a focus on multivariate data. Lattice's user interface consists of several generic "high-level" functions, each designed to create a particular type of graph by default.
- Supporting materials:
In this manual you can find information about the different functionalities, although if you want to learn more about them, in this section of the web you can find several manuals such as R Graphics by Paul Murrell or Lattice by Deepayan Sarkar.
Esquisse
- Description:
Esquise allows you to interactively explore data and create detailed visualisations with the ggplot2 package through a drag-and-drop interface. It includes a multitude of elements: scatter plots, line plots, box plots, multi-axis plots, sparklines, dendograms, 3D plots, etc.
- Supporting materials:
Documentation is available via this link, including information on installation and the various functions. Information is also available on the R website.
Leaflet
- Description:
Leaflet allows the creation of highly detailed, interactive and customised maps. It is based on the JavaScript library of the same name.
- Supporting materials:
On this website you have documentation on the various functionalities: how the widget works, markers, how to work with GeoJSON & TopoJSON, how to integrate with Shiny, etc.
Librerías para JavaScript
JavaScript is also an interpreted programming language, responsible for making web pages more interactive and dynamic. It is an object-oriented, prototype-based and dynamic language.
Some of the main libraries for JavaScript are:
D3.js
- Description:
D3.js is aimed at creating data visualisations and animations using web standards, such as SVG, Canvas and HTML. It is a very powerful and complex library.
- Supporting materials:
On Github you can find a gallery with examples of the various graphics and visualisations that can be obtained with this library, as well as various tutorials and information on specific techniques.
Chart.js
- Description:
Chart.js is a JavaScript library that uses HTML5 canvas to create interactive charts. Specifically, it supports 9 chart types: bar, line, area, pie, bubble, radar, polar, scatter and mixed.
- Supporting materials:
On its own website you can find information on installation and configuration, and examples of the different types of graphics. There is also a section for developers with various documentation.
Other libraries
Plotly
- Description:
Plotly is a high-level graphics library, which allows the creation of more than 40 types of graphics, including 3D graphics, statistical graphics and SVG maps. It is an Open Source library, but has paid versions.
Plotly is not tied to a single programming language, but allows integration with R, Python and JavaScript.
- Supporting materials:
It has a complete website where users can find guides, use cases by application areas, practical examples, webinars and a community section where knowledge can be shared.
Any user can contribute to any of these libraries by writing code, generating new documentation or reporting bugs, among others. In this way they are enriched and perfected, improving their results continuously.
Do you know of any other library you would like to recommend? Leave us a message in the comments or send us an email to dinamizacion@datos.gob.es.
Content prepared by the datos.gob.es team.
Documentación
1. Introduction
Visualizations are graphical representations of data that allow to transmit in a simple and effective way the information linked to them. The visualization potential is very wide, from basic representations, such as a graph of lines, bars or sectors, to visualizations configured on control panels or interactive dashboards. Visualizations play a fundamental role in drawing conclusions from visual information, also allowing to detect patterns, trends, anomalous data, or project predictions, among many other functions.
Before proceeding to build an effective visualization, we need to perform a previous treatment of the data, paying special attention to obtaining them and validating their content, ensuring that they are in the appropriate and consistent format for processing and do not contain errors. A preliminary treatment of the data is essential to perform any task related to the analysis of data and of performing an effective visualization.
In the \"Visualizations step-by-step\" section, we are periodically presenting practical exercises on open data visualization that are available in the datos.gob.es catalog or other similar catalogs. There we approach and describe in a simple way the necessary steps to obtain the data, perform the transformations and analyzes that are pertinent to, finally, we create interactive visualizations, from which we can extract information that is finally summarized in final conclusions.
In this practical exercise, we have carried out a simple code development that is conveniently documented by relying on tools for free use. All generated material is available for reuse in the GitHub Data Lab repository.
Access the data lab repository on Github.
Run the data pre-processing code on Google Colab.
2. Objetives
The main objective of this post is to learn how to make an interactive visualization based on open data. For this practical exercise we have chosen datasets that contain relevant information about the students of the Spanish university over the last few years. From these data we will observe the characteristics presented by the students of the Spanish university and which are the most demanded studies.
3. Resources
3.1. Datasets
For this practical case, data sets published by the Ministry of Universities have been selected, which collects time series of data with different disaggregations that facilitate the analysis of the characteristics presented by the students of the Spanish university. These data are available in the datos.gob.es catalogue and in the Ministry of Universities' own data catalogue. The specific datasets we will use are:
- Enrolled by type of university modality, area of nationality and field of science, and enrolled by type and modality of university, gender, age group and field of science for PHD students by autonomous community from the academic year 2015-2016 to 2020-2021.
- Enrolled by type of university modality, area of nationality and field of science, and enrolled by type and modality of the university, gender, age group and field of science for master's students by autonomous community from the academic year 2015-2016 to 2020-2021.
- Enrolled by type of university modality, area of nationality and field of science and enrolled by type and modality of the university, gender, age group and field of study for bachelor´s students by autonomous community from the academic year 2015-2016 to 2020-2021.
- Enrolments for each of the degrees taught by Spanish universities that is published in the Statistics section of the official website of the Ministry of Universities. The content of this dataset covers from the academic year 2015-2016 to 2020-2021, although for the latter course the data with provisional.
3.2. Tools
To carry out the pre-processing of the data, the R programming language has been used from the Google Colab cloud service, which allows the execution of Notebooks de Jupyter.
Google Colaboratory also called Google Colab, is a free cloud service from Google Research that allows you to program, execute and share code written in Python or R from your browser, so it does not require the installation of any tool or configuration.
For the creation of the interactive visualization the Datawrapper tool has been used.
Datawrapper is an online tool that allows you to make graphs, maps or tables that can be embedded online or exported as PNG, PDF or SVG. This tool is very simple to use and allows multiple customization options.
If you want to know more about tools that can help you in the treatment and visualization of data, you can use the report \"Data processing and visualization tools\".
4. Data pre-processing
As the first step of the process, it is necessary to perform an exploratory data analysis (EDA) in order to properly interpret the initial data, detect anomalies, missing data or errors that could affect the quality of subsequent processes and results, in addition to performing the tasks of transformation and preparation of the necessary variables. Pre-processing of data is essential to ensure that analyses or visualizations subsequently created from it are reliable and consistent. If you want to know more about this process you can use the Practical Guide to Introduction to Exploratory Data Analysis.
The steps followed in this pre-processing phase are as follows:
- Installation and loading the libraries
- Loading source data files
- Creating work tables
- Renaming some variables
- Grouping several variables into a single one with different factors
- Variables transformation
- Detection and processing of missing data (NAs)
- Creating new calculated variables
- Summary of transformed tables
- Preparing data for visual representation
- Storing files with pre-processed data tables
You'll be able to reproduce this analysis, as the source code is available in this GitHub repository. The way to provide the code is through a document made on a Jupyter Notebook that once loaded into the development environment can be executed or modified easily. Due to the informative nature of this post and in order to facilitate learning of non-specialized readers, the code does not intend to be the most efficient, but rather make it easy to understand, therefore it is likely to come up with many ways to optimize the proposed code to achieve a similar purpose. We encourage you to do so!
You can follow the steps and run the source code on this notebook in Google Colab.
5. Data visualizations
Once the data is pre-processed, we proceed with the visualization. To create this interactive visualization we use the Datawrapper tool in its free version. It is a very simple tool with special application in data journalism that we encourage you to use. Being an online tool, it is not necessary to have software installed to interact or generate any visualization, but it is necessary that the data table that we provide is properly structured.
To address the process of designing the set of visual representations of the data, the first step is to consider the queries we intent to resolve. We propose the following:
- How is the number of men and women being distributed among bachelor´s, master's and PHD students over the last few years?
If we focus on the last academic year 2020-2021:
- What are the most demanded fields of science in Spanish universities? What about degrees?
- Which universities have the highest number of enrolments and where are they located?
- In what age ranges are bachelor´s university students?
- What is the nationality of bachelor´s students from Spanish universities?
Let's find out by looking at the data!
5.1. Distribution of enrolments in Spanish universities from the 2015-2016 academic year to 2020-2021, disaggregated by gender and academic level
We created this visual representation taking into account the bachelor, master and PHD enrolments. Once we have uploaded the data table to Datawrapper (dataset \"Matriculaciones_NivelAcademico\"), we have selected the type of graph to be made, in this case a stacked bar diagram to be able to reflect by each course and gender, the people enrolled in each academic level. In this way we can also see the total number of students enrolled per course. Next, we have selected the type of variable to represent (Enrolments) and the disaggregation variables (Gender and Course). Once the graph is obtained, we can modify the appearance in a very simple way, modifying the colors, the description and the information that each axis shows, among other characteristics.
To answer the following questions, we will focus on bachelor´s students and the 2020-2021 academic year, however, the following visual representations can be replicated for master's and PHD students, and for the different courses.
5.2. Map of georeferenced Spanish universities, showing the number of students enrolled in each of them
To create the map, we have used a list of georeferenced Spanish universities published by the Open Data Portal of Esri Spain. Once the data of the different geographical areas have been downloaded in GeoJSON format, we transform them into Excel, in order to combine the datasets of the georeferenced universities and the dataset that presents the number of enrolled by each university that we have previously pre-processed. For this we have used the Excel VLOOKUP() function that will allow us to locate certain elements in a range of cells in a table
Before uploading the dataset to Datawrapper, we need to select the layer that shows the map of Spain divided into provinces provided by the tool itself. Specifically, we have selected the option \"Spain>>Provinces(2018)\". Then we proceed to incorporate the dataset \"Universities\", previously generated, (this dataset is attached in the GitHub datasets folder for this step-by-step visualization), indicating which columns contain the values of the variables Latitude and Longitude.
From this point, Datawrapper has generated a map showing the locations of each of the universities. Now we can modify the map according to our preferences and settings. In this case, we will set the size and the color of the dots dependent from the number of registrations presented by each university. In addition, for this data to be displayed, in the \"Annotate\" tab, in the \"Tooltips\" section, we have to indicate the variables or text that we want to appear.
5.3. Ranking of enrolments by degree
For this graphic representation, we use the Datawrapper table visual object (Table) and the \"Titulaciones_totales\" dataset to show the number of registrations presented by each of the degrees available during the 2020-2021 academic year. Since the number of degrees is very extensive, the tool offers us the possibility of including a search engine that allows us to filter the results.
5.4. Distribution of enrolments by field of science
For this visual representation, we have used the \"Matriculaciones_Rama_Grado\" dataset and selected sector graphs (Pie Chart), where we have represented the number of enrolments according to sex in each of the field of science in which the degrees in the universities are divided (Social and Legal Sciences, Health Sciences, Arts and Humanities, Engineering and Architecture and Sciences). Just like in the rest of the graphics, we can modify the color of the graph, in this case depending on the branch of teaching.
5.5. Matriculaciones de Grado por edad y nacionalidad
For the realization of these two representations of visual data we use bar charts (Bar Chart), where we show the distribution of enrolments in the first, disaggregated by gender and nationality, we will use the data set \"Matriculaciones_Grado_nacionalidad\" and in the second, disaggregated by gender and age, using the data set \"Matriculaciones_Grado_edad \". Like the previous visuals, the tool easily facilitates the modification of the characteristics presented by the graphics.
6. Conclusions
Data visualization is one of the most powerful mechanisms for exploiting and analyzing the implicit meaning of data, regardless of the type of data and the degree of technological knowledge of the user. Visualizations allow us to extract meaning out of the data and create narratives based on graphical representation. In the set of graphical representations of data that we have just implemented, the following can be observed:
- The number of enrolments increases throughout the academic years regardless of the academic level (bachelor´s, master's or PHD).
- The number of women enrolled is higher than the men in bachelor's and master's degrees, however it is lower in the case of PHD enrollments, except in the 2019-2020 academic year.
- The highest concentration of universities is found in the Community of Madrid, followed by the autonomous community of Catalonia.
- The university that concentrates the highest number of enrollments during the 2020-2021 academic year is the UNED (National University of Distance Education) with 146,208 enrollments, followed by the Complutense University of Madrid with 57,308 registrations and the University of Seville with 52,156.
- The most demanded degree in the 2020-2021 academic year is the Degree in Law with 82,552 students nationwide, followed by the Degree in Psychology with 75,738 students and with hardly any difference, the Degree in Business Administration and Management with 74,284 students.
- The branch of education with the highest concentration of students is Social and Legal Sciences, while the least demanded is the branch of Sciences.
- The nationalities that have the most representation in the Spanish university are from the region of the European Union, followed by the countries of Latin America and the Caribbean, at the expense of the Spanish one.
- The age range between 18 and 21 years is the most represented in the student body of Spanish universities.
We hope that this step-by-step visualization has been useful for learning some very common techniques in the treatment and representation of open data. We will return to show you new reuses. See you soon!
Documentación
1. Introduction
Data visualization is a task linked to data analysis that aims to graphically represent underlying data information. Visualizations play a fundamental role in the communication function that data possess, since they allow to drawn conclusions in a visual and understandable way, allowing also to detect patterns, trends, anomalous data or to project predictions, alongside with other functions. This makes its application transversal to any process in which data intervenes. The visualization possibilities are very numerous, from basic representations, such as a line graphs, graph bars or sectors, to complex visualizations configured from interactive dashboards.
Before we start to build an effective visualization, we must carry out a pre-treatment of the data, paying attention to how to obtain them and validating the content, ensuring that they do not contain errors and are in an adequate and consistent format for processing. Pre-processing of data is essential to start any data analysis task that results in effective visualizations.
A series of practical data visualization exercises based on open data available on the datos.gob.es portal or other similar catalogues will be presented periodically. They will address and describe, in a simple way; the stages necessary to obtain the data, perform the transformations and analysis that are relevant for the creation of interactive visualizations, from which we will be able summarize on in its final conclusions the maximum mount of information. In each of the exercises, simple code developments will be used (that will be adequately documented) as well as free and open use tools. All generated material will be available for reuse in the Data Lab repository on Github.
Visualization of traffic accidents occurring in the city of Madrid, by district and type of vehicle
2. Objetives
The main objective of this post is to learn how to make an interactive visualization based on open data available on this portal. For this exercise, we have chosen a dataset that covers a wide period and contains relevant information on the registration of traffic accidents that occur in the city of Madrid. From these data we will observe what is the most common type of accidents in Madrid and the incidence that some variables such as age, type of vehicle or the harm produced by the accident have on them.
3. Resources
3.1. Datasets
For this analysis, a dataset available in datos.gob.es on traffic accidents in the city of Madrid published by the City Council has been selected. This dataset contains a time series covering the period 2010 to 2021 with different subcategories that facilitate the analysis of the characteristics of traffic accidents that occurred. For example, the environmental conditions in which each accident occurred or the type of accident. Information on the structure of each data file is available in documents covering the period 2010-2018 and 2019 onwards. It should be noted that there are inconsistencies in the data before and after the year 2019, due to data structure variations. This is a common situation that data analysts must face when approaching the preprocessing tasks of the data that will be used, this is derived from the lack of a homogeneous structure of the data over time. For example, alterations on the number of variables, modification of the type of variables or changes to different measurement units. This is a compelling reason that justifies the need to accompany each open data set with complete documentation explaining its structure.
3.2. Tools
R (versión 4.0.3) and RStudio with the RMarkdown complement have been used to carry out the pre-treatment of the data (work environment setup, programming and writing).
R is an object-oriented and interpreted open-source programming language, initially created for statistical computing and the creation of graphical representations. Nowadays, it is a very powerful tool for all types of data processing and manipulation permanently updated. It contains a programming environment, RStudio, also open source.
The Kibana tool has been used for the creation of the interactive visualization.
Kibana is an open source tool that belongs to the Elastic Stack product suite (Elasticsearch, Beats, Logstash and Kibana) that enables visualization creation and exploration of indexed data on top of the Elasticsearch analytics engine.
If you want to know more about these tools or anyother that can help you in data processing and creating interactive visualizations, you can consult the report \"Data processing and visualization tools\".
4. Data processing
For the realization of the subsequent analysis and visualizations, it is necessary to prepare the data adequately, so that the results obtained are consistent and effective. We must perform an exploratory data analysis (EDA), in order to know and understand the data with which we want to work. The main objective of this data pre-processing is to detect possible anomalies or errors that could affect the quality of subsequent results and identify patterns of information contained in the data.
To facilitate the understanding of readers not specialized in programming, the R code included below, which you can access by clicking on the \"Code\" button in each section, is not designed to maximize its efficiency, but to facilitate its understanding, so it is possible that more advanced readers in this language might consider alternatives more efficient to encode some functionalities. The reader will be able to reproduce this analysis if desired, as the source code is available on datos.gob.es's Github account. In order to provide the code a plain text document will be used, which once loaded into the development environment can be easily executed or modified if desired.
4.1. Installation and loading of libraries
For the development of this analysis, we need to install a series of additional R packages to the base distribution, incorporating the functions and objects defined by them into the work environment. There are many packages available in R but the most suitable to work with this dataset are: tidyverse, lubridate and data.table.Tidyverse is a collection of R packages (it contains other packages such as dplyr, ggplot2, readr, etc.) specifically designed to work in Data Science, facilitating the loading and processing of data, and graphical representations and other essential functionalities for data analysis. It requires a progressive knowledge to get the most out of the packages that integrates. On the other hand, the lubridate package will be used for the management of date variables. Finally the data.table package allows a more efficient management of large data sets. These packages will need to be downloaded and installed in the development environment.
#Lista de librerías que queremos instalar y cargar en nuestro entorno de desarrollo librerias <- c(\"tidyverse\", \"lubridate\", \"data.table\")#Descargamos e instalamos las librerías en nuestros entorno de desarrollo package.check <- lapplay (librerias, FUN = function(x) { if (!require (x, character.only = TRUE)) { install.packages(x, dependencies = TRUE) library (x, character.only = TRUE } }4.2. Uploading and cleaning data
a. Loading datasets
The data that we are going to use in the visualization are divided by annuities in CSV files. As we want to perform an analysis of several years we must download and upload in our development environment all the datasets that interest us.
To do this, we generate the working directory \"datasets\", where we will download all the datasets. We use two lists, one with all the URLs where the datasets are located and another with the names that we assign to each file saved on our machine, with this we facilitate subsequent references to these files.
#Generamos una carpeta en nuestro directorio de trabajo para guardar los datasets descargadosif (dir.exists(\".datasets\") == FALSE)#Nos colocamos dentro de la carpetasetwd(\".datasets\")#Listado de los datasets que nos interese descargardatasets <- c(\"https://datos.madrid.es/egob/catalogo/300228-10-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-11-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-12-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-13-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-14-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-15-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-16-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-17-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-18-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-19-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-21-accidentes-trafico-detalle.csv\", \"https://datos.madrid.es/egob/catalogo/300228-22-accidentes-trafico-detalle.csv\")#Descargamos los datasets de interésdt <- list()for (i in 1: length (datasets)){ files <- c(\"Accidentalidad2010\", \"Accidentalidad2011\", \"Accidentalidad2012\", \"Accidentalidad2013\", \"Accidentalidad2014\", \"Accidentalidad2015\", \"Accidentalidad2016\", \"Accidentalidad2017\", \"Accidentalidad2018\", \"Accidentalidad2019\", \"Accidentalidad2020\", \"Accidentalidad2021\") download.file(datasets[i], files[i]) filelist <- list.files(\".\") print(i) dt[i] <- lapply (filelist[i], read_delim, sep = \";\", escape_double = FALSE, locale = locale(encoding = \"WINDOWS-1252\", trim_ws = \"TRUE\") }b. Creating the worktable
Once we have all the datasets loaded into our development environment, we create a single worktable that integrates all the years of the time series.
Accidentalidad <- rbindlist(dt, use.names = TRUE, fill = TRUE)Once the worktable is generated, we must solve one of the most common problems in all data preprocessing: the inconsistency in the naming of the variables in the different files that make up the time series. This anomaly produces variables with different names, but we know that they represent the same information. In this case it is explained in the data dictionary described in the documentation of the files, if this was not the case, it is necessary to resort to the observation and descriptive exploration of the files. In this case, the variable \"\"RANGO EDAD\"\" that presents data from 2010 to 2018 and the variable \"\"RANGO EDAD\"\" that presents the same data but from 2019 to 2021 are different. To solve this problem, we must unite/merge the variables that present this anomaly in a single variable.
#Con la función unite() unimos ambas variables. Debemos indicarle el nombre de la tabla, el nombre que queremos asignarle a la variable y la posición de las variables que queremos unificar. Accidentalidad <- unite(Accidentalidad, LESIVIDAD, c(25, 44), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, NUMERO_VICTIMAS, c(20, 27), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, RANGO_EDAD, c(26, 35, 42), remove = TRUE, na.rm = TRUE)Accidentalidad <- unite(Accidentalidad, TIPO_VEHICULO, c(20, 27), remove = TRUE, na.rm = TRUE)Once we have the table with the complete time series, we create a new table counting only the variables that are relevant to us to make the interactive visualization that we want to develop.
Accidentalidad <- Accidentalidad %>% select (c(\"FECHA\", \"DISTRITO\", \"LUGAR ACCIDENTE\", \"TIPO_VEHICULO\", \"TIPO_PERSONA\", \"TIPO ACCIDENTE\", \"SEXO\", \"LESIVIDAD\", \"RANGO_EDAD\", \"NUMERO_VICTIMAS\") c. Variable transformation
Next, we examine the type of variables and values to transform the necessary variables to be able to perform future aggregations, graphs or different statistical analyses.
#Re-ajustar la variable tipo fechaAccidentalidad$FECHA <- dmy (Accidentalidad$FECHA #Re-ajustar el resto de variables a tipo factor Accidentalidad$'TIPO ACCIDENTE' <- as.factor(Accidentalidad$'TIPO.ACCIDENTE')Accidentalidad$'Tipo Vehiculo' <- as.factor(Accidentalidad$'Tipo Vehiculo')Accidentalidad$'TIPO PERSONA' <- as.factor(Accidentalidad$'TIPO PERSONA')Accidentalidad$'Tramo Edad' <- as.factor(Accidentalidad$'Tramo Edad')Accidentalidad$SEXO <- as.factor(Accidentalidad$SEXO)Accidentalidad$LESIVIDAD <- as.factor(Accidentalidad$LESIVIDAD)Accidentalidad$DISTRITO <- as.factor (Accidentalidad$DISTRITO)d. Creation of new variables
Let's divide the variable \"\"FECHA\"\" into a hierarchy of variables of date types, \"\"Año\", \"\"Mes\"\" and \"\"Día\"\". This action is very common in data analytics, since it is interesting to analyze other time ranges, for example; years, months, weeks (and any other unit of time), or we need to generate aggregations from the day of the week.
#Generación de la variable AñoAccidentalidad$Año <- year(Accidentalidad$FECHA)Accidentalidad$Año <- as.factor(Accidentalidad$Año) #Generación de la variable MesAccidentalidad$Mes <- month(Accidentalidad$FECHA)Accidentalidad$Mes <- as.factor(Accidentalidad$Mes)levels (Accidentalidad$Mes) <- c(\"Enero\", \"Febrero\", \"Marzo\", \"Abril\", \"Mayo\", \"Junio\", \"Julio\", \"Agosto\", \"Septiembre\", \"Octubre\", \"Noviembre\", \"Diciembre\") #Generación de la variable DiaAccidentalidad$Dia <- month(Accidentalidad$FECHA)Accidentalidad$Dia <- as.factor(Accidentalidad$Dia)levels(Accidentalidad$Dia)<- c(\"Domingo\", \"Lunes\", \"Martes\", \"Miercoles\", \"Jueves\", \"Viernes\", \"Sabado\")e. Detection and processing of lost data
The detection and processing of lost data (NAs) is an essential task in order to be able to process the variables contained in the table, since the lack of data can cause problems when performing aggregations, graphs or statistical analysis.
Next, we will analyze the absence of data (detection of NAs) in the table:
#Suma de todos los NAs que presenta el datasetsum(is.na(Accidentalidad))#Porcentaje de NAs en cada una de las variablescolMeans(is.na(Accidentalidad))Once the NAs presented by the dataset have been detected, we must treat them somehow. In this case, as all the interesting variables are categorical, we will complete the missing values with the new value \"Unassigned\", this way we do not lose sample size and relevant information.
#Sustituimos los NAs de la tabla por el valor \"No asignado\"Accidentalidad [is.na(Accidentalidad)] <- \"No asignado\"f. Level assignments in variables
Once we have the variables of interest in the table, we can perform a more exhaustive analysis of the data and categories presented by each of the variables. If we analyze each one independently, we can see that some of them have repeated categories, simply by use of accents, special characters or capital letters. We will reassign the levels to the variables that require so that future visualizations or statistical analysis are built efficiently and without errors.
For space reasons, in this post we will only show an example with the variable \"HARMFULNESS\". This variable was typified until 2018 with a series of categories (IL, HL, HG, MT), while from 2019 other categories were used (values from 0 to 14). Fortunately, this task is easily approachable since it is documented in the information about the structure that accompanies each dataset. This issue (as we have said before), that does not always happen, greatly hinders this type of data transformations.
#Comprobamos las categorías que presenta la variable \"LESIVIDAD\"levels(Accidentalidad$LESIVIDAD)#Asignamos las nuevas categoríaslevels(Accidentalidad$LESIVIDAD)<- c(\"Sin asistencia sanitaria\", \"Herido leve\", \"Herido leve\", \"Herido grave\", \"Fallecido\", \"Herido leve\", \"Herido leve\", \"Herido leve\", \"Ileso\", \"Herido grave\", \"Herido leve\", \"Ileso\", \"Fallecido\", \"No asignado\")#Comprobamos de nuevo las catergorías que presenta la variablelevels(Accidentalidad$LESIVIDAD)4.3. Dataset Summary
Let's see what variables and structure the new dataset presents after the transformations made:
str(Accidentalidad)summary(Accidentalidad)The output of these commands will be omitted for reading simplicity. The main characteristics of the dataset are:
- It is composed of 14 variables: 1 date variable and 13 categorical variables.
- The time range covers from 01-01-2010 to 31-06-2021 (the end date may vary, since the dataset of the year 2021 is being updated periodically).
- For space reasons in this post, not all available variables have been considered for analysis and visualization.
4.4. Save the generated dataset
Once we have the dataset with the structure and variables ready for us to perform the visualization of the data, we will save it as a data file in CSV format to later perform other statistical analysis. Or use it in other data processing or visualization tools such as the one we address below. It is important to save it with a UTF-8 (Unicode Transformation Format) encoding so that special characters are correctly identified by any software.
write.csv(Accidentalidad, file = Accidentalidad.csv\", fileEncoding=\"UTF-8\")5. Creation of the visualization on traffic accidents that occur in the city of Madrid using Kibana
To create this interactive visualization the Kibana tool (in its free version) has been used on our local environment. Before being able to perform the visualization it is necessary to have the software installed since we have followed the steps of the download and installation tutorial provided by the company Elastic.
Once the Kibana software is installed, we proceed to develop the interactive visualization. Below there are two video tutorials, which show the process of creating the visualization and interacting with it.
This first video tutorial shows the visualization development process by performing the following steps:
- Loading data into Elasticsearch, generating an index in Kibana that allows us to interact with the data practically in real time and interaction with the variables presented by the dataset.
- Generation of the following graphical representations:
- Line graph to represent the time series on traffic accidents that occurred in the city of Madrid.
- Horizontal bar chart showing the most common accident type
- Thematic map, we will show the number of accidents that occur in each of the districts of the city of Madrid. For the creation of this visual it is necessary to download the \"dataset containing the georeferenced districts in GeoJSON format\".
- Construction of the dashboard integrating the visuals generated in the previous step.
In this second video tutorial we will show the interaction with the visualization that we have just created:
6. Conclusions
Observing the visualization of the data on traffic accidents that occurred in the city of Madrid from 2010 to June 2021, the following conclusions can be drawn:
- The number of accidents that occur in the city of Madrid is stable over the years, except for 2019 where a strong increase is observed and during the second quarter of 2020 where a significant decrease is observed, which coincides with the period of the first state of alarm due to the COVID-19 pandemic.
- Every year there is a decrease in the number of accidents during the month of August.
- Men tend to have a significantly higher number of accidents than women.
- The most common type of accident is the double collision, followed by the collision of an animal and the multiple collision.
- About 50% of accidents do not cause harm to the people involved.
- The districts with the highest concentration of accidents are: the district of Salamanca, the district of Chamartín and the Centro district.
Data visualization is one of the most powerful mechanisms for autonomously exploiting and analyzing the implicit meaning of data, regardless of the degree of the user's technological knowledge. Visualizations allow us to build meaning on top of data and create narratives based on graphical representation.
If you want to learn how to make a prediction about the future accident rate of traffic accidents using Artificial Intelligence techniques from this data, consult the post on \"Emerging technologies and open data: Predictive Analytics\".
We hope you liked this post and we will return to show you new data reuses. See you soon!
Noticia
R is one of the programming languages most popular in the world of data science.
It has a programming environment, R-Studio and a set of very flexible and versatile tools for statistical computing and creation of graphical representations.
One of its advantages is that functions can be easily expanded, by installing libraries or defining custom functions. In addition, it is permanently updated, since its wide community of users constantly develops new functions, libraries and updates available for free.
For this reason, R is one of the most demanded languages and there are a large number of resources to learn more about it. Here is a selection based on the recommendations of the experts who collaborate with datos.gob.es and the user communities R-Hispanic and R-Ladies, which bring together a large number of users of this language in our country.
Online courses
On the web we can find numerous online courses that introduce R to new users.
Basic R course
- Taught by: University of Cádiz
- Duration: Not available.
- Language: Spanidh
- Free
Focused on students who are doing a final degree or master's project, the course seeks to provide the basic elements to start working with the R programming language in the field of statistics. It includes knowledge about data structure (vectors, matrices, data frames ...), graphics, functions and programming elements, among others.
Introduction to R
- Taught by: Datacamp
- Duration: 4 hours.
- Language: English
- Free
The course begins with the basics, starting with how to use the console as a calculator and how to assign variables. Next, we cover the creation of vectors in R, how to work with matrices, how to compare factors, and the use of data frames or lists.
Introduction to R
- Taught by: Anáhuac University Network
- Duration: 4 weeks (5-8 hours per week).
- Language: Spanish
- Free and paid mode
Through a practical approach, with this course you will learn to create a work environment for R with R Studio, classify and manipulate data, as well as make graphs. It also provides basic notions of R programming, covering conditionals, loops, and functions.
R Programming Fundamentals
- Taught by: Stanford School of Engineering
- Duration: 6 weeks (2-3 hours per week).
- Language: English
- Free, although the certificate costs.
This course covers an introduction to R, from installation to basic statistical functions. Students learn to work with variable and external data sets, as well as to write functions. In the course you will hear one of the co-creators of the R language, Robert Gentleman.
R programming
- Taught by: Johns Hopkins University
- Duration: 57 hours
- Language: English, with Spanish subtitles.
- Of payment
This course is part of the programs of Data science and Data Science: Basics Using R. It can be taken separately or as part of these programs. With it, you will learn to understand the fundamental concepts of the programming language, to use R's loop functions and debugging tools, or to collect detailed information with R profiler, among other things.
Data Visualization & Dashboarding with R
- Taught by: Johns Hopkins University
- Duration: 4 months (5 hours per week)
- Language: English
- Of payment
Johns Hopkins University also offers this course where students will generate different types of visualizations to explore the data, from simple figures like bar and scatter charts to interactive dashboards. Students will integrate these figures into reproducible research products and share them online.
Introduction to R statistical software
- Taught by: Spanish Association for Quality (AEC)
- Duration: From October 5 to December 3, 2021 (50 hours)
- Language: Spanish
- Of payment
This is an initial practical training in the use of R software for data processing and statistical analysis through the simplest and most common techniques: exploratory analysis and relationship between variables. Among other things, students will acquire the ability to extract valuable information from data through exploratory analysis, regression, and analysis of variance.
Introduction to R programming
- Taught by: Abraham Requena
- Duration: 6 hours
- Language: Spanish
- Paid (by subscription)
Designed to get started in the world of R and learn to program with this language. You will be able to learn the different types of data and objects that are in R, to work with files and to use conditionals, as well as to create functions and handle errors and exceptions.
Programming and data analysis with R
- Taught by: University of Salamanca
- Duration: From October 25, 2021 - April 22, 2022 (80 teaching hours)
- Language: Spanish
- Payment
It starts from a basic level, with information about the first commands and the installation of packages, to continue with the data structures (variables, vectors, factors, etc.), functions, control structures, graphical functions and interactive representations, among others topics. Includes an end-of-course project.
Statistics and R
- Taught by: Harvard University
- Duration: 4 weeks (2-4 hours per week).
- Language: English
- Payment
An introduction to basic statistical concepts and R programming skills required for data analysis in bioscience. Through programming examples in R, the connection between the concepts and the application is established.
For those who want to learn more about matrix algebra, Harvard University also offers online the Introduction to Linear Models and Matrix Algebra course, where the R programming language is used to carry out the analyzes.
Free R course
- Taught by: Afi Escuela
- Duration: 7.5 hours
- Language: Spanish
- Free
This course was taught by Rocío Parrilla, Head of Data Science at Atresmedia, in virtual face-to-face format. The session was recorded and is available through Yotube. It is structured in three classes where the basic elements of R programming are explained, an introduction to data analysis is made and visualization with this language is approached (static visualization, dynamic visualization, maps with R and materials).
R programming for beginners
- Taught by: Keepcoding
- Duration: 12 hours of video content
- Language: Spanish
- Free
It consists of 4 chapters, each of them made up of several short videos. The first "Introduction" deals with the installation. The second, called "first steps in R" explains basic executions, as well as vectors, matrices or data frames, among others. The third deals with the “Flow Program R” and the last one deals with the graphs.
Autonomous online course Introduction to R
- Taught by: University of Murcia
- Duration: 4 weeks (4-7 hours per week)
- Language: Spanish
- Free
It is a practical course aimed at young researchers who need to analyze their work data and seek a methodology that optimizes their effort.
The course is part of a set of R-related courses offered by the University of Murcia, onMultivariate data analysis methods, Preparation of technical-scientific documents and reports or Methods of hypothesis testing and design of experiments, among others.
Online books related to R
If instead of a course, you prefer a manual or documentation that can help you improve your knowledge in a broader way, there are also options, such as those detailed below.
R for Data Professionals. An introduction
- Author: Carlos Gil Bellosta
- Free
The book covers 3 basics in high demand by data professionals: creating high-quality data visualizations, creating dashboards to visualize and analyze data, and creating automated reports. Its aim is that the reader can begin to apply statistical methods (and so-called data science) on their own.
Learning R without dying trying
- Author: Javier Álvarez Liébana
- Free
The objective of this tutorial is to introduce people to programming and statistical analysis in R without the need for prior programming knowledge. Its objective is to understand the basic concepts of R and provide the user with simple tricks and basic autonomy to be able to work with data.
Statistical Learning
- Author: Rubén F. Casal
- Free
It is a document with the notes of the subject of Statistical Learning of the Master in Statistical Techniques. Has been written inR-Markdown using the package bookdown and is available in Github. The book does not deal directly with R, but deals with everything from an introduction to statistical learning, to neural networks, through decision trees or linear models, among others.
Statistical simulation
- Author: Rubén F. Casal and Ricardo Cao
- Free
As in the previous case, this book is the manual of a subject, in this case ofStatistical simulation of the Master in Statistical Techniques. It has also been written inR-Markdown using the package bookdown and is available in the repository Github. After an introduction to simulation, the book addresses the generation of pseudo-random numbers in R, the analysis of simulation results or the simulation of continuous and discrete variables, among others.
Statistics with R
- Author: Joaquín Amat Rodrigo
- Free
It is not a book directly, but a website where you can find various resources and works that can serve as an example when practicing with R. Its author is Joaquín Amat Rodrigo also responsible forMachine Learning with R.
Masters
In addition to courses, it is increasingly common to find master's degrees related to this subject in universities, such as:
Master in Applied Statistics with R / Master in Machine Learning with R
- Taught by: Esucela Máxima Formación
- Duration: 10 months
- Language: Spanish
The Esucela Máxima Formación offers two masters that begin in October 2021 related to R. The Master in Applied Statistics for Data Science with R Software (13th edition) is aimed at professionals who want to develop advanced practical skills to solve real problems related to the analysis, manipulation and graphical representation of data. The Master in Machine Learning with R Software (2nd edition) is focused on working with real-time data to create analytical models and algorithms with supervised, unsupervised and deep learning.
In addition, more and more study centers offer master's degrees or programs related to data science that collect knowledge on R, both general and focused on specific sectors, in their syllabus. Some examples are:
- Master in Data Science, from the Rey Juan Carlos University, which integrates aspects of data engineering (Spark, Hadoop, cloud architectures, data collection and storage) and data analytics (statistical models, data mining, simulation, graph analysis or visualization and communication) .
- Master in Big Data, from the National University of Distance Education (UNED), includes an Introduction to Machine Learning module with R and another of advanced packages with R.
- Master in Big Data and Data Science Applied to Economics, from the National University of Distance Education (UNED), introduces R concepts as one of the most widely used software programs.
- Master Big Data - Business - Analytics, from the Complutense University of Madrid, includes a topic on Data Mining and Predictive Modeling with R.
- Master in Big Data and Data Science applied to Economics and Commerce, also from the Complutense University of Madrid, where R programming is studied, for example, for the design of maps, among others.
- Master in Digital Humanities for a Sustainable World, from the Autonomous University of Madrid, where students will be able to program in Python and R to obtain statistical data from texts (PLN).
- Master in Data Science & Business Analytics, from the University of Castilla-La Mancha, whose objective is to learn and/or deepen in Data Science, Artificial Intelligence and Business Analytics, using R statistical software.
- Expert in Modeling & Data Mining, from the University of Castilla-La Mancha, where as in the previous case also works with R to transform unstructured data into knowledge.
- Master of Big Data Finance, where they talk about Programming for data science / big data or information visualization with R.
- Big Data and Business Intelligence Program, from the University of Deusto, which enables you to perform complete cycles of data analysis (extraction, management, processing (ETL) and visualization).
We hope that some of these courses respond to your needs and you can become an expert in R. If you know of any other course that you want to recommend, leave us a comment or write to us at dinamizacion@datos.gob.es.