Noticia
El Instituto Canario de Estadística (ISTAC) ha añadido a su catálogo más de 500 activos semánticos y más de 2100 cubos estadísticos. Esta inmensa cantidad de información representa lustros de trabajo del ISTAC en materia de normalización y adaptación a estándares internacionales punteros, que habilitan una mejor compartición de datos y metadatos entre productores y consumidores de información nacionales e internacionales.
El incremento de conjuntos de datos mejora no solo cuantitativamente el directorio de datos.canarias.es y datos.gob.es, sino que amplía los usos que éste ofrece gracias al tipo de información añadida.
Nuevos activos semánticos
Los recursos semánticos, a diferencia de los estadísticos, no presentan datos numéricos cuantificables, como pueden ser datos de desempleo o el PIB, sino que proporcionan homogeneidad y reproducibilidad.
Estos activos suponen un paso adelante en materia de interoperabilidad, según lo dispuesto tanto a escala nacional con el Esquema Nacional de Interoperabilidad (artículo 10, activos semánticos), como a escala europea con el Marco Europeo de Interoperabilidad (artículo 3.4, interoperabilidad semántica). En ambos documentos se expone la necesidad y el valor de utilizar recursos comunes para el intercambio de información, máxima que se está implantando de manera transversal en el Gobierno de Canarias. Estos activos semánticos ya se están usando en los formularios de la sede electrónica y se espera que en el futuro sean los activos semánticos que use todo el Gobierno de Canarias.
Concretamente en esta carga de datos hay 4 tipos de activos semánticos:
- Clasificaciones (404 cargadas): Listados de códigos que se utilizan para representar los conceptos asociados a las variables o categorías que forman parte de los conjuntos de datos normalizados, como por ejemplo la Clasificación Nacional de Actividades Económicas (CNAE), clasificaciones de países como la M49, o clasificaciones de sexo y edad.
- Esquemas de conceptos (100 cargados): Los conceptos son las definiciones de las variables en las que se desagregan los datos y que finalmente se representan con una o varias clasificaciones. Pueden ser transversales como “Edad”, “Lugar de nacimiento” y “Actividad de la empresa” o específicos para cada operación estadística como “Tipo de tareas del hogar” o “Índice de confianza del consumidor”.
- Esquemas de temas (2 cargados): Incorporan listas de temas que pueden corresponder a la clasificación temática de las operaciones estadísticas o al registro de temas INSPIRE.
- Esquemas de organizaciones (4 cargados): Se incluyen esquemas de entidades como unidades organizativas, universidades, agencias mantenedoras o proveedores de datos.
Todos estos tipos de recursos forman parte del estándar internacional SDMX (Statistical Data and Metadata Exchange), que se utiliza para el intercambio de datos y metadatos estadísticos. El estándar SDMX proporciona un formato y estructura común para facilitar la interoperabilidad entre diferentes organizaciones que producen, publican y utilizan datos estadísticos.

Este estándar es promovido por organizaciones como el Banco Central Europeo (BCE), Naciones Unidas, la Oficina Estadística de la Unión Europea (Eurostat), el Fondo Monetario Internacional (FMI) o la Organización para la Cooperación y el Desarrollo Económico (OCDE).
Con la inclusión de estos conjuntos de datos, datos.canarias.es y datos.gob.es entrarían a formar parte de un selecto grupo de organizaciones que también ponen a disposición de la sociedad diversos recursos estructurales para fines estadísticos en los siguientes registros públicos:
- SDMX Global Registry
- Euro SDMX Registry
- United Nations Statistical Division
- UNICEF Indicator Data Warehouse
- IMF SDMX Central
Nuevos recursos estadísticos
Dada la creciente necesidad de compartir, procesar y comparar datos, se hace indispensable la aplicación de estándares internacionales para la publicación e intercambio de datos y metadatos. El ISTAC se encuentra inmerso en un proceso de revisión y actualización de sus publicaciones para adaptarlas al estándar internacional SDMX, empezando por el análisis de la información publicada, pasando por la definición de activos semánticos y recursos estructurales en general, hasta llegar a la publicación de recursos estadísticos como los cubos o tablas de datos.
Como parte de este objetivo y tras años de trabajo armonizando y estandarizando datos, el ISTAC ha cargado en su catálogo 2196 cubos estadísticos que hacen uso de los activos semánticos antes descritos y que se basan en el estándar SDMX.
Esto permite mejorar el uso y compartición de datos tanto para el usuario de a pie como de manera programática gracias al uso estandarizado de recursos semánticos. En definitiva, la incorporación al catálogo de esta relevante información, supone un paso muy importante en la interoperabilidad de los datos y, por tanto, en su reutilización.
Blog
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
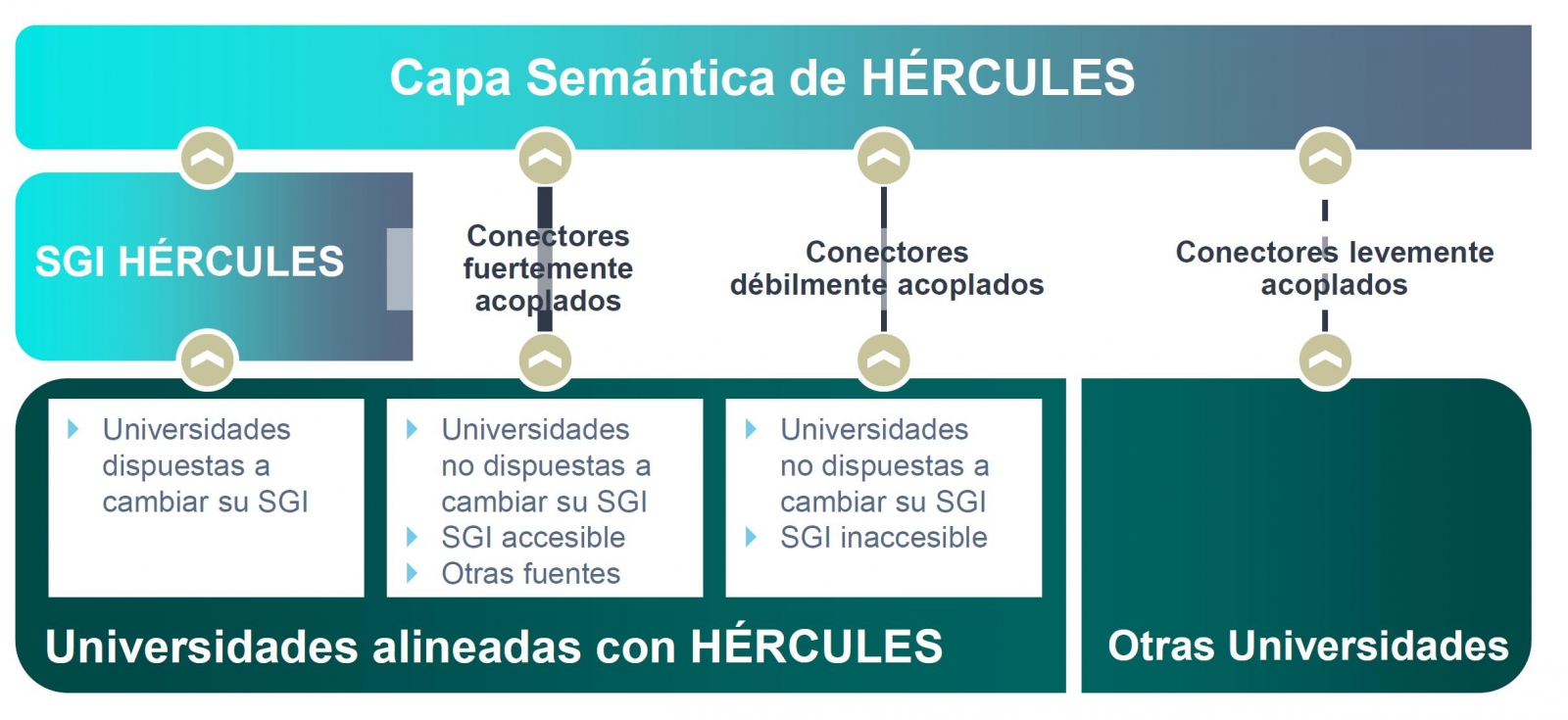
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
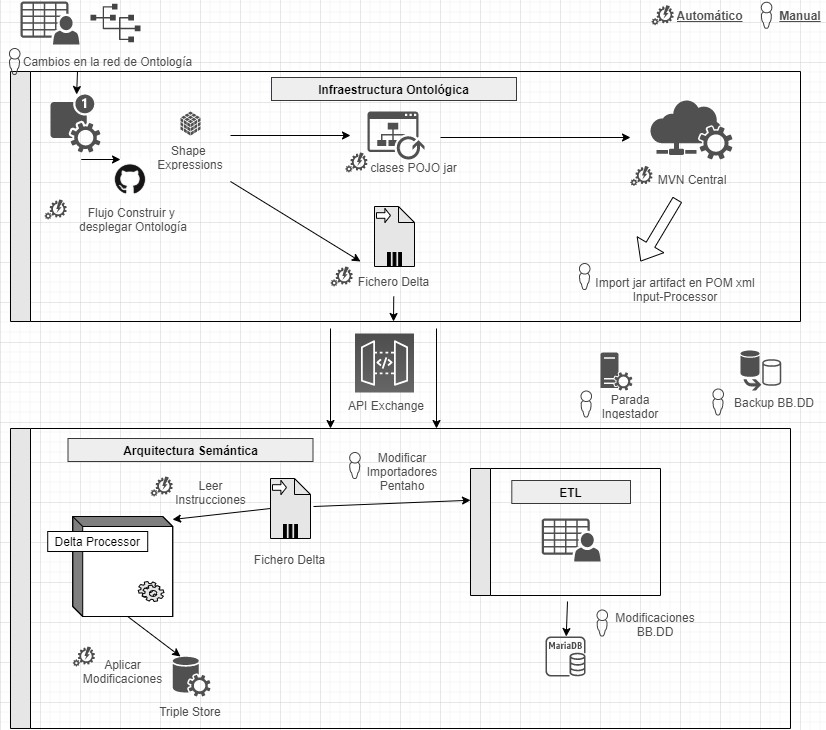
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
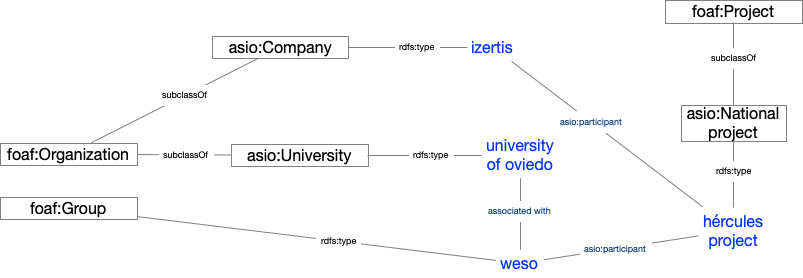
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
Resultados y conclusiones
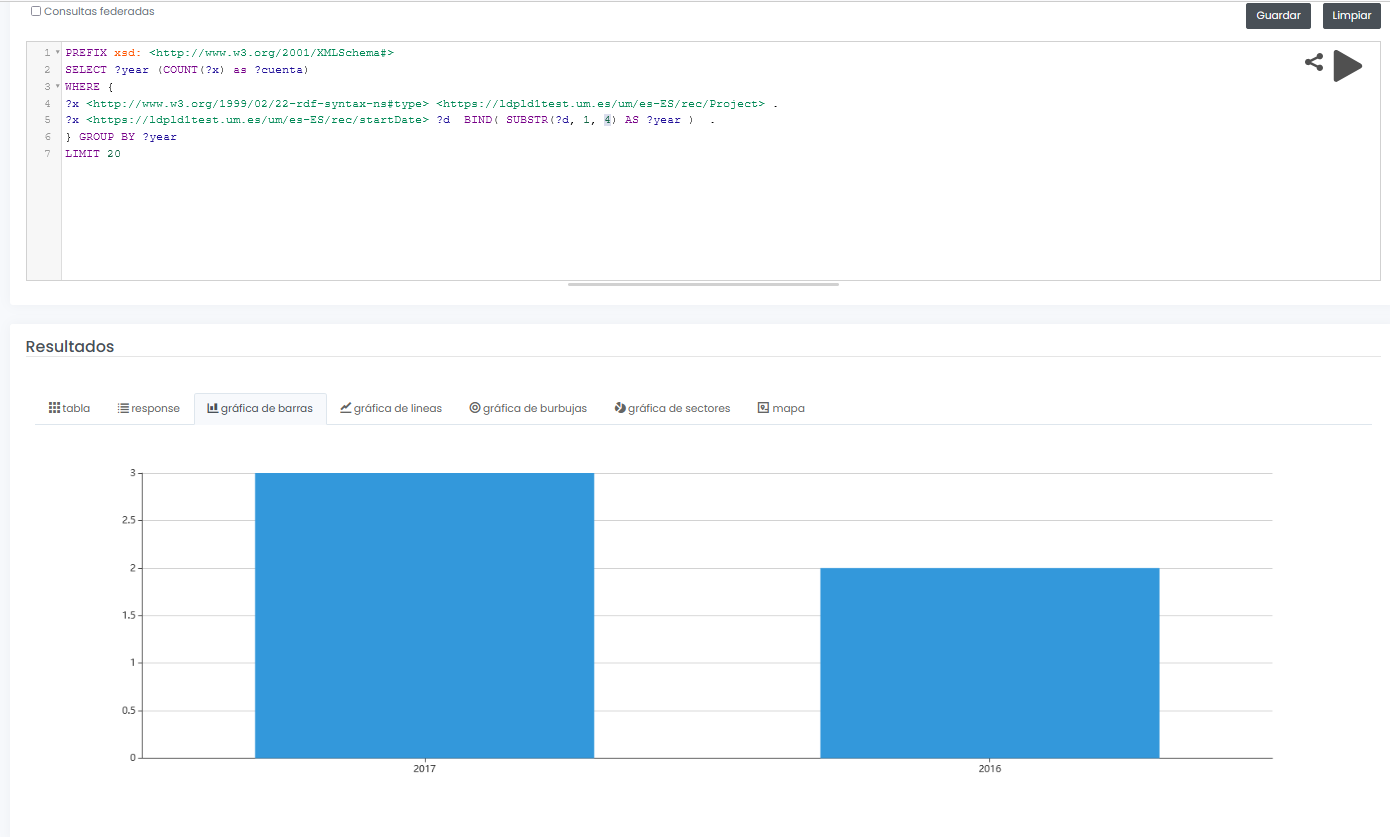
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Cada individuo, organización o colectivo usa en su comunicación diaria un número de palabras habituales, que serían sus vocabularios personales. Cuanto mayor sea el número de vocablos que utilicemos, mayor será nuestra capacidad para comunicarnos, pero también puede suponer una barrera, al aumentar la dificultad para entendernos con otras personas que no estén familiarizadas con los mismos términos que nosotros. Esto mismo sucede en el mundo de los datos.
Para evitar equívocos, debemos utilizar un vocabulario controlado, que no es más que una lista definida de términos para organizar, categorizar o etiquetar sistemáticamente la información.
¿Qué es un vocabulario de datos?
Para una correcta implementación de una iniciativa de gobierno de datos, ya sean privados o públicos, debemos dotar al proceso de un business Glosary o vocabulario de referencia. Un vocabulario de referencia es un medio para poder compartir información y desarrollar y documentar definiciones de datos estándar, para reducir la ambigüedad y mejorar la comunicación. Estas definiciones deben ser claras, rigurosas en su redacción y explicar cualquier excepción, sinónimo o variante. Un ejemplo claro es EuroVoc, que cubre las actividades de la Unión Europea y, en particular, del Parlamento Europeo. Otro ejemplo es CIE10 que es el Manual de codificación de diagnósticos y procedimientos en el ámbito sanitario.
Los objetivos que persigue un vocabulario controlado son los siguientes:
- Permitir la comprensión común de los conceptos claves y de terminología, de forma precisa.
- Reducir el riesgo de que los datos sean mal utilizados debido a una comprensión inconsistente de los conceptos.
- Maximizar la capacidad de búsqueda, facilitando el acceso al conocimiento documentado.
- Impulsa la interoperabilidad y la reutilización de los datos, algo fundamental en el mundo del open data.
Los vocabularios varían en la complejidad de su desarrollo, desde listas simples o listas de selección, hasta anillos de sinónimos, taxonomías o los más complejos, tesauros y ontologías.
¿Cómo se crea un vocabulario?
A la hora de crear un vocabulario no se suele partir de cero, sino que se basa en ontologías y vocabularios preexistentes, lo que favorece la comunicación entre personas, agentes inteligentes y sistemas. Por ejemplo, Aragón Open Data ha desarrollado una ontologia llamada Estructura de Información Interoperable de Aragón EI2A que homogeniza estructuras, vocabularios y características, a través de la representación de entidades, propiedades y relaciones, para luchar contra la diversidad y heterogeneidad de datos existentes en la Administración aragonesa (datos de entidades locales que no siempre significan lo mismo). Para ello, se basa en propuestas como RDF Schema (un vocabulario general para el modelado de esquemas en RDF que se utiliza en la creación de otros Vocabularios), ISA Programme Person Core Vocabulary (destinado a describir personas) o OWL-Time (que describe conceptos temporales).
Un vocabulario debe ir acompañado de un diccionario de datos, que es donde se describen los datos en términos de negocio e incluye otras informaciones necesarias para usar los datos, como por ejemplo, detalles de su estructura o las restricciones de seguridad. Debido a que los vocabularios evolucionan con el tiempo, requieren un mantenimiento evolutivo. Como ejemplo, ANSI/NIZO Z39.19-2005 es un estándar que proporciona pautas para la construcción, formato y gestión de vocabularios controlados. También encontramos SKOS, una iniciativa de W3C que proporciona un modelo para representar la estructura básica y el contenido de esquemas conceptuales en cualquier tipo de vocabulario controlado.
Ejemplos de Vocabularios en ámbitos concretos creados en España
En el contexto español, con una estructura administrativa fragmentada, donde cada organismo comparte su información en abierto de manera individual, es necesario contar con reglas comunes que nos permitan homogeneizar los datos, facilitando su interoperabilidad y reutilización. Por suerte, encontramos distintas propuestas que nos ayudan en estas tareas.
A continuación, se recogen ejemplo de vocabularios creados en nuestro país para 2 sectores fundamentales para el futuro de la sociedad, como son la educación y las ciudades inteligentes.
Smart cities
Un ejemplo sobre la construcción de vocabularios de un dominio específico lo podemos encontrar en ciudades-abiertas.es, que es una iniciativa de varios ayuntamientos de España (A Coruña, Madrid, Santiago de Compostela y Zaragoza) y Red.es.
Entre otras acciones, dentro del marco del proyecto, se está trabajando en el desarrollo de un catálogo de vocabularios bien definidos y documentados, con ejemplos de utilización y disponibles en varios lenguajes de representación. En concreto, se están desarrollando 11 vocabularios correspondientes a una serie de conjuntos de datos seleccionados por los Ayuntamientos que no cuentan con un estándar definido. Un ejemplo de estos vocabularios es la Agenda municipal.
Estos vocabularios son generados utilizando el lenguaje estándar OWL, que es el acrónimo del inglés Web Ontology Language, un lenguaje de marcado para publicar y compartir datos usando ontologías en la Web. También se dispone de los correspondientes contextos para JSON-LD, N-triples, TTL y RDF/XML. En este video explicativo podemos ver como se definen estos vocabularios. Los vocabularios generados están disponibles en el repositorio de Github.
Educación
En el ámbito de las universidades, por su parte, encontramos la propuesta de contenidos de datos abiertos para universidades desarrollada por la comunidad UniversiDATA: Núcleo Común. En la versión 1.0 se ha identificado 42 datasets que toda Universidad debería publicar, como es el caso de la información relativa a Titulaciones, Matriculas o Licitaciones y contratos. De momento hay 11 disponibles, mientras que el resto se encuentran en proceso de elaboración.
Por ejemplo la UAM (Autónoma de Madrid), la URJC (Rey Juan Carlos) y la UCM (Complutense de Madrid), han publicado sus titulaciones siguiendo un mismo vocabulario.
Aunque se ha avanzado mucho en la creación y aplicación de vocabularios de datos en general, todavía queda terreno para avanzar en el campo de la investigación sobre vocabularios controlados para la publicación y consulta de datos en la Web, por ejemplo, en la construcción de Business Glosaries vinculados a los diccionarios de datos técnicos. La aplicación de buenas prácticas y la creación de vocabularios para la representación de metadatos que describan el contenido, la estructura, procedencia, calidad y uso de conjuntos de datos permitirá definir con mayor precisión las características que deben incorporar las plataformas de publicación de datos en la Web.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Empresa reutilizadora
SIRIS Academic es una empresa de consultoría e investigación que diseña e implementa estrategias y policy solutions en el ámbito de la educación superior, la investigación y la innovación. Trabajan con agentes responsables en la toma de decisiones políticas, facilitando herramientas, procesos y reflexiones que ayuden a establecer y abordar cuestiones clave para su misión.
SIRIS Academic está orientada a organizaciones con vocación pública o social. Esta perspectiva sitúa el éxito en la generación de valor añadido para la sociedad, lo que se alinea con sus valores, cultura y enfoque.
Noticia
Roma fue la ciudad europea elegida para celebrar la última edición de la Conferencia de Interoperabilidad Semántica (SEMIC 2016), que tuvo lugar el pasado 12 de mayo bajo el lema “Estándares de datos para Administraciones Públicas interconectadas”. Los estándares de datos, especificaciones que describen, definen y estructuran la información, son imprescindibles para que sea posible la interoperabilidad, trazabilidad y reutilización de los mismos. Así, en esta última reunión, los asistentes tuvieron la oportunidad de debatir acerca de las políticas y prácticas de desarrollo y utilización de los estándares de datos al mismo tiempo que pudieron conocer la experiencia tanto de organizaciones especializadas en estandarización, como de gobiernos e instituciones europeas.
Durante la primera parte de la conferencia, se explicó, a través de un caso práctico, la importancia de los estándares internacionales en las cadenas de suministro del sector sanitario. La implementación de dichos estándares no solo mejoraría la seguridad del paciente, incluso podrían salvar hasta 43.000 vidas al año. Tras esta charla fue el turno del el director ejecutivo del IJIS Institute, en EE.UU y de Kenji Hiramoto, procedente de Japón, quien explicó el proyecto IMI dirigido a mejorar la interoperabilidad semántica de los datos a través de un diccionario de términos que sirve como infraestructura de cooperación entre los sistemas y los datos abiertos.
Posteriormente tuvo lugar un debate formado por seis expertos procedentes de diferentes organismos internacionales, entre los que se encontraba Patrocinio Nieto, jefa de servicio del MINHAP y los cuales compartieron sus experiencias en la implementación práctica de estándares de datos a nivel nacional e internacional.
El resto de la jornada transcurrió con varias sesiones donde se abordaron diferentes temáticas como el potencial de los datos económicos, datos legales, el uso de estándares internacionales en el sector financiero o la presentación del programa europeo CEF cuya segunda convocatoria se ha lanzado este año, y a través del cual se destinará fondos para mejorar las infraestructuras de servicios digitales en la UE. Finalmente, la conferencia se clausuró con una mesa redonda donde los integrantes debatieron acerca de la necesidad de crear un ecosistema robusto de datos abiertos en Europa y presentaron casos reales de implementación de DCAT-AP.
A este respecto, al día siguiente se celebró una sesión sobre el perfil de aplicación de DCAT v1.1 para portales de datos abiertos en Europa. Enmarcado dentro del programa ISA², esta sesión invitó a los responsables europeos de la implementación de DCAT-AP con el fin de:
● Debatir acerca de los retos y buenas prácticas de su ejecución.
● Aprender sobre las directrices DCAT-AP que el Plan de Acción 2.1 del programa ISA2 está desarrollando en colaboración con otros agentes.
● Avanzar en el estado de las extensiones de DCAT-AP para datos geoespaciales y estadísticos.
● Debatir sobre las herramientas y software de soporte.
Actualmente, el programa ISA² promueve estándares de datos horizontales y reutilizables, los cuales ya se están implementando en sistemas operativos con el fin de facilitar la interoperabilidad de los datos a nivel regional, nacional y europeo. Esta iniciativa, que dio comienzo este año y se prolongará hasta el 2020, cuenta con una financiación aproximada de 131 millones de euros para desarrollar soluciones digitales interoperables que se pondrán a disposición de todas las administraciones públicas europeas, eliminando las barreras entre los diferentes organismos, compañías y ciudadanos de la UE.
La Conferencia SEMIC se ha consolidado como la gran cita de la interoperabilidad semántica a nivel internacional, y en esta edición, el encuentro reunió a más de doscientos profesionales, no sólo del sector público sino a investigadores, consultores y representantes de proyectos paneuropeos y de otros países del mundo interesados en aprender y seguir avanzado en materia de datos abiertos enlazados, tecnologías semánticas, administración electrónica y gestión de metadatos.
Entrevista
Asunción Gómez-Pérez es ingeniera informática, máster en Ingeniería del Conocimiento, doctorado en Informática y máster en Dirección y Administración de Empresas.
Ha publicado más de 150 artículos y es autora y coautora de varios libros sobre Ingeniería Ontológica e Ingeniería del Conocimiento. Ha sido directora del comité de programa de ASWC'09, ESWC'05 y EKAW'02 y coorganizadora de numerosos talleres en ontologías.
En la actualidad, dirige el Departamento de Inteligencia Artificial y el Ontology Engineer Group (Grupo de Ingeniería Ontológica) de la Universidad Politécnica de Madrid (UPM).
Participa, también, en iniciativas de Datos enlazados (Linked Data) de instituciones como la Biblioteca Nacional de España.
--
Oscar Corcho, por su parte, es Profesor Titular de Universidad en el citado Departamento de Inteligencia Artificial y miembro, también, del Grupo de Ingeniería Ontológica.
Ha trabajado como investigador Marie Curie en la Universidad de Manchester y como gestor de investigación en la empresa iSOCO. Es licenciado en informática, Máster en Ingeniería del Software y Doctor en Ciencias de la Computación e Inteligencia Artificial por la UPM.
Sus actividades de investigación se centran en la e-Ciencia Semántica, la Web Semántica y la Ingeniería Ontológica. Entre otros numerosos proyectos de relieve, ha participado en el International Classification for Patient Safety (ICPS), financiado por la Organización Mundial de la Salud.
Ha publicado más de 100 artículos en revistas, conferencias y workshops y es autor de varios libros, entre ellos el manual de referencia “Ontological Engineering".
¿Cómo definiríais el papel que desarrolla el Ontology Engineering Group respecto de la información del sector público?
Nuestro grupo de investigación ha sido pionero en España en la generación y publicación de Linked Data de calidad de varios conjuntos de datos del sector público estatal. Concretamente, somos responsables de la publicación de Linked Data de conjuntos de datos del Instituto Geográfico Nacional (a través de la Web), la Biblioteca Nacional y la Agencia Estatal de Meteorología.
En todos estos casos, hemos trabajado con miembros de estas organizaciones durante el proceso de generación de vocabularios, generación de datos en RDF y publicación de los datos como Linked Data.
También hemos participado en iniciativas trasnacionales, como la del observatorio Otalex con Portugal. En todas estas iniciativas se han utilizado vocabularios consensuados por las comunidades implicadas, tecnologías propuestas por el W3C, y un mismo enfoque metodológico.
Se destaca la inclusión de contenidos de “provenance” y licencias de uso en todas ellas.
Asimismo, somos miembros activos del grupo de trabajo del W3C sobre Linked Data gubernamental y hemos propuesto, entre otros, un documento de buenas prácticas sobre la generación de Linked Data en el sector público.
Igualmente, hemos participado en otros grupos de trabajo que de forma indirecta son de utilidad para el sector público. A modo de ejemplo, hemos participado en el Semantic Sensor Network Incubator Group que ha desarrollado una ontología de sensores que es de gran utilidad para representar datos dinámicos como pueden ser datos metereológicos, tráfico en ciudades, niveles de polución, etc. Además, ha participado en el Library Linked Data incubator group proporcionando soluciones para Bibliotecas.
Finalmente, el grupo lidera la Red temática española de Linked Data para la que uno de los objetivos primordiales es dar a conocer iniciativas de publicación de Linked Data de los sectores público y privado.
… hemos propuesto, entre otros, un documento de buenas prácticas sobre la generación de Linked data en el sector público…"
¿Qué valores encarna, en vuestra opinión y desde el punto de vista de la investigación, la actividad de apertura de datos?
En el contexto de la investigación, la apertura de datos nos permite en muchos casos poder llevar a cabo investigaciones o evaluaciones sobre nuestras investigaciones que no serían posibles o serían más costosas si no dispusiéramos de estos datos.
Por ejemplo, en nuestro grupo hemos utilizado datos públicos para estudiar el grado de reutilización de vocabularios en la nube, técnicas y métodos que permitan mejorar la calidad de los datos, para proponer técnicas para el acceso a datos dinámicos procedentes de redes sociales y sensores, mecanismos de consultas a datos distribuidos, desarrollar nuevos procesos en los que los especialistas de dominio participan en la apertura (como ocurrió en la transformación de los datos de la Biblioteca Nacional), etc.
… nos permite llevar a cabo investigaciones… que no serían posibles o serían más costosas si no dispusiéramos de estos datos".
¿Cómo surgió el interés por los datos públicos?
En primer lugar, nuestro interés surgió desde la perspectiva tecnológica y desde el punto de vista de los vocabularios que se pueden utilizar para representar y compartir mejor estos datos. Tratándose de un grupo de investigación que lleva trabajando en el área de los vocabularios (ontologías) desde el 1995, nos resulta muy interesante trabajar para conseguir que las distintas administraciones acuerden los vocabularios a utilizar para compartir sus datos. Asimismo, también podemos proporcionar los vocabularios en varios idiomas utilizando técnicas automáticas, evaluar y explotar nuestra experiencia en las tecnologías semánticas y de la Web de datos.
… nos resulta muy interesante trabajar para que las administraciones acuerden vocabularios para compartir sus datos…"
¿Cuáles son los actores, niveles o fases con los que identificaríais el sector?
Hay muchos tipos de actores involucrados en este sector. Desde las administraciones públicas, responsables de los datos en última instancia, hasta los usuarios finales, pasando por los agentes reutilizadores y los facilitadores tecnológicos. Nuestra experiencia nos dice que todos ellos son importantes.
Sobre las fases para generar y publicar Linked Data de calidad, hemos propuesto guías de buenas prácticas que se pueden seguir para llevar a cabo este proceso de manera sistemática (https://dvcs.w3.org/hg/gld/raw-file/default/bp/index.html).
Hemos propuesto guías de buenas prácticas para llevar a cabo este proceso de manera sistematica..."
¿Qué escenario ideal imaginaríais a partir de la información del sector público?
El sector público debe proveer los datos en tiempo, forma y con la calidad adecuada. Un escenario en el que los datos que se publican son ampliamente reutilizados para fines que no se habían previsto inicialmente, y que redundan de nuevo en la mejora de la calidad de los datos originales, y por tanto son útiles también para la propia administración pública.
… datos reutilizados para fines no previstos inicialmente y que redundan en la mejora de los datos originales… y son útiles para la propia administración… "
¿Qué acciones inmediatas tomaríais para fomentar esta actividad?
La creación de un instituto como el Open Data Institute del Reino Unido podría ser una muy buena iniciativa a tener en cuenta para aglutinar y fomentar la sostenibilidad de este modelo de publicación de datos.
La creación de un Plan Estratégico que refleje cuál será la estrategia a seguir por la Administración en los próximos años. Dicho plan debería incluir:
- La creación de una metodología común para todas las administraciones públicas (nacional, autonómica y local). De la misma forma que se construyó Métrica para el desarrollo de software en la Administración, debiera crearse una metodología específica que sistematice los procesos a seguir en la apertura de datos y su exposición como datos enlazados.
- Acordar los modelos a utilizar por las administraciones públicas para representar: personas, organismos, estructuras organizativas, información estadística, geográfica, documental, licencias, `datos de “provenance”, etc.
- Analizar los vocabularios que otras iniciativas europeas están utilizando con el fin de preparar las bases para un futuro intercambio de datos entre administraciones e instituciones europeas y de otros países.
- Cursos de Capacitación en sus distintas modalidades de presencia para la Administración General del Estado, autonomías y ayuntamientos sobre: aspectos legales, estándares y de normativa del W3C, procesos de liberación de datos, tecnologías semánticas relacionadas con la Web de Datos, etc.
- Cursos de formación en apertura de datos y tecnologías semánticas dentro de los estudios de Informática.
- La creación de un Observatorio que monitorice el impacto de la apertura de datos en el mercado y su creación de valor, así como la calidad de las diferentes iniciativas.
Como profesionales pero, también, como usuarios, ¿qué responsabilidad tiene el conjunto de la sociedad en esta materia Open Data?
La sociedad tiene tanta responsabilidad como las administraciones públicas en este proceso. Los ciudadanos no son sólo los usuarios finales potenciales de esta actividad de generación y publicación de Linked Data, sino también responsables de mejorar su calidad en caso de que esto sea posible.
Los ciudadanos no son sólo los usuarios finales… sino también responsables…"
Si fuera una administración pública, ¿qué información entendéis que debería ser abierta?
En general, debería ser abierta toda la información que esté disponible en la administración y que no afecte a la Seguridad Nacional o a la Privacidad de las personas físicas o jurídicas.
La Administración pública debe proporcionar mecanismos para proporcionar datos en diferentes formatos estandarizados que fomenten la interoperabilidad, incluyendo en todos ellos el “provenance” del dato y las licencias de uso.
Y si fuera una empresa, ¿qué datos esperaríais y para qué aplicación concreta?
Estamos seguros de que cualquier fuente de datos puede ser reutilizada incluso aunque a priori la administración pública correspondiente no pensara que pudiera ser reutilizada.
En nuestra opinión, lo mejor es disponer de estos datos de manera abierta, para que las empresas puedan dedicarse a obtener el máximo valor añadido de los mismos. Incluso las propias administraciones pueden ser las primeras beneficiarias de estos datos abiertos.
¿Cómo veis ahora mismo el estado del Open Data en el ámbito estatal y en el conjunto de España?
A pesar de que existen iniciativas como datos.gob.es y también iniciativas puntuales autonómicas y locales bastante importantes, queda mucho camino por realizar en España para conseguir estar a la altura de los procesos de apertura de datos de otros países de nuestro entorno, como por ejemplo el Reino Unido.
Los pasos que se están dando son adecuados, aunque muy lentos e insuficientes. Se echa en falta directrices más detalladas que vayan más allá de reales decretos y normativas y una voluntad expresa de muchas instituciones de publicar datos de mayor utilidad.
Los pasos que se están dando son adecuados, aunque muy lentos e insuficientes…"