Noticia
The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.

The Canary Islands Statistics Institute (ISTAC) has added more than 500 semantic assets and more than 2100 statistical cubes to its catalogue.
This vast amount of information represents decades of work by the ISTAC in standardisation and adaptation to leading international standards, enabling better sharing of data and metadata between national and international information producers and consumers.
The increase in datasets not only quantitatively improves the directory at datos.canarias.es and datos.gob.es, but also broadens the uses it offers due to the type of information added.
New semantic assets
Semantic resources, unlike statistical resources, do not present measurable numerical data , such as unemployment data or GDP, but provide homogeneity and reproducibility.
These assets represent a step forward in interoperability, as provided for both at national level with the National Interoperability Scheme ( Article 10, semantic assets) and at European level with the European Interoperability Framework (Article 3.4, semantic interoperability). Both documents outline the need and value of using common resources for information exchange, a maxim that is being pursued at implementing in a transversal way in the Canary Islands Government. These semantic assets are already being used in the forms of the electronic headquarters and it is expected that in the future they will be the semantic assets used by the entire Canary Islands Government.
Specifically in this data load there are 4 types of semantic assets:
- Classifications (408 loaded): Lists of codes that are used to represent the concepts associated with variables or categories that are part of standardised datasets, such as the National Classification of Economic Activities (CNAE), country classifications such as M49, or gender and age classifications.
- Concept outlines (115 uploaded): Concepts are the definitions of the variables into which the data are disaggregated and which are finally represented by one or more classifications. They can be cross-sectional such as "Age", "Place of birth" and "Business activity" or specific to each statistical operation such as "Type of household chores" or "Consumer confidence index".
- Topic outlines (2 uploaded): They incorporate lists of topics that may correspond to the thematic classification of statistical operations or to the INSPIRE topic register.
- Schemes of organisations (6 uploaded): This includes outlines of entities such as organisational units, universities, maintaining agencies or data providers.
All these types of resources are part of the international SDMX (Statistical Data and Metadata Exchange) standard, which is used for the exchange of statistical data and metadata. The SDMX provides a common format and structure to facilitate interoperability between different organisations producing, publishing and using statistical data.
Blog
The Hercules initiative was launched in November 2017, through an agreement between the University of Murcia and the Ministry of Economy, Industry and Competitiveness, with the aim of developing a Research Management System (RMS) based on semantic open data that offers a global view of the research data of the Spanish University System (SUE), to improve management, analysis and possible synergies between universities and the general public.
This initiative is complementary to UniversiDATA, where several Spanish universities collaborate to promote open data in the higher education sector by publishing datasets through standardised and common criteria. Specifically, a Common Core is defined with 42 dataset specifications, of which 12 have been published for version 1.0. Hercules, on the other hand, is a research-specific initiative, structured around three pillars:
- Innovative SGI prototype
- Unified knowledge graph (ASIO) 1],
- Data Enrichment and Semantic Analysis (EDMA)
The ultimate goal is the publication of a unified knowledge graph integrating all research data that participating universities wish to make public. Hercules foresees the integration of universities at different levels, depending on their willingness to replace their RMS with the Hercules RMS. In the case of external RMSs, the degree of accessibility they offer will also have an impact on the volume of data they can share through the unified network.
General organisation chart of the Hercule initiative
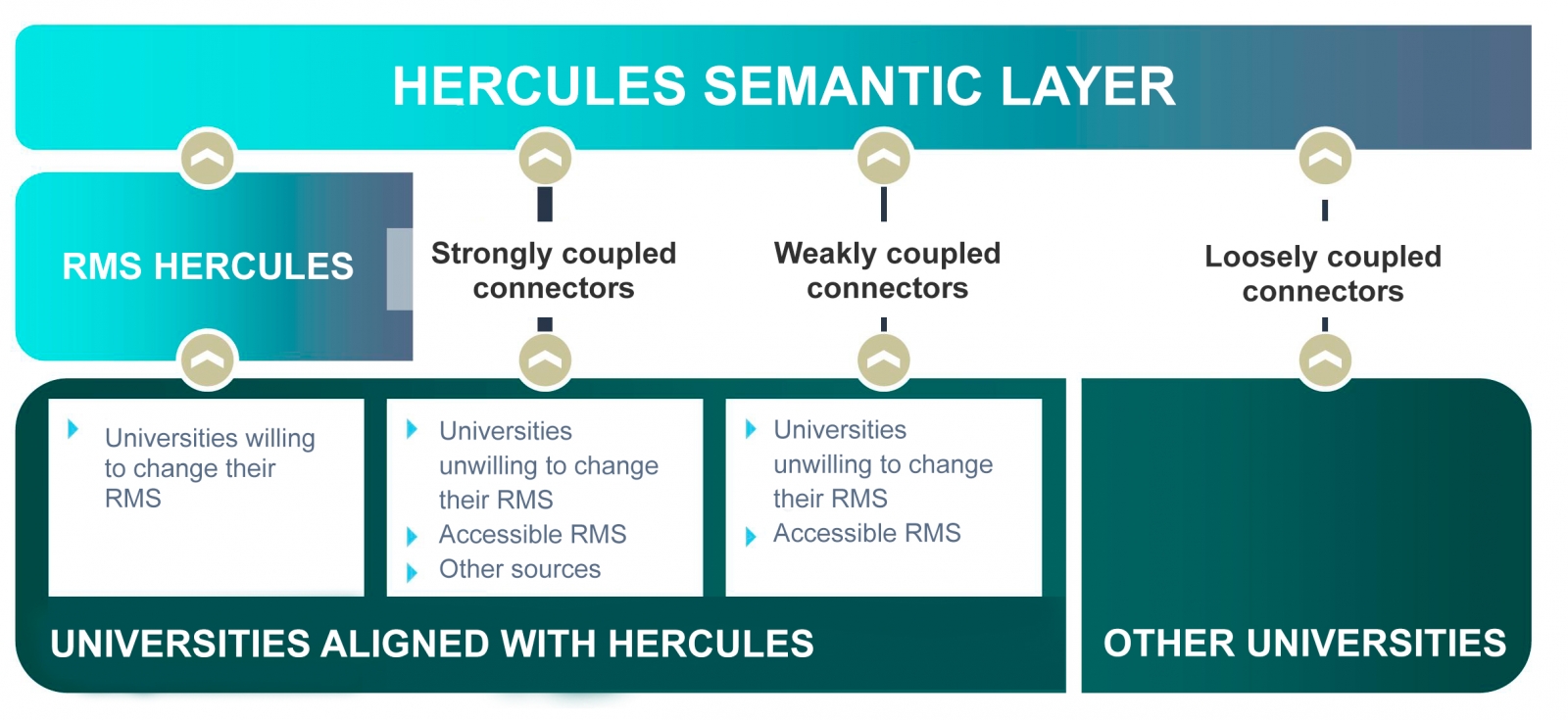
Within the Hercules initiative, the ASIO Project (Semantic Architecture and Ontology Infrastructure) is integrated. The purpose of this sub-project is to define an Ontology Network for Research Management (Ontology Infrastructure). An ontology is a formal definition that describes with fidelity and high granularity a particular domain of discussion. In this case, the research domain, which can be extrapolated to other Spanish and international universities (at the moment the pilot is being developed with the University of Murcia). In other words, the aim is to create a common data vocabulary.
Additionally, through the Semantic Data Architecture module, an efficient platform has been developed to store, manage and publish SUE research data, based on ontologies, with the capacity to synchronise instances installed in different universities, as well as the execution of distributed federated queries on key aspects of scientific production, lines of research, search for synergies, etc.
As a solution to this innovation challenge, two complementary lines have been proposed, one centralised (synchronisation in writing) and the other decentralised (synchronisation in consultation). The architecture of the decentralised solution is explained in detail in the following sections.
Domain Driven Design
The data model follows the Domain Driven Design approach, modelling common entities and vocabulary, which can be understood by both developers and domain experts. This model is independent of the database, the user interface and the development environment, resulting in a clean software architecture that can adapt to changes in the model.
This is achieved by using Shape Expressions (ShEx), a language for validating and describing RDF datasets, with human-readable syntax. From these expressions, the domain model is automatically generated and allows orchestrating a continuous integration (CI) process, as described in the following figure.
Continuous integration process using Domain Driven Design (just available in Spanish)
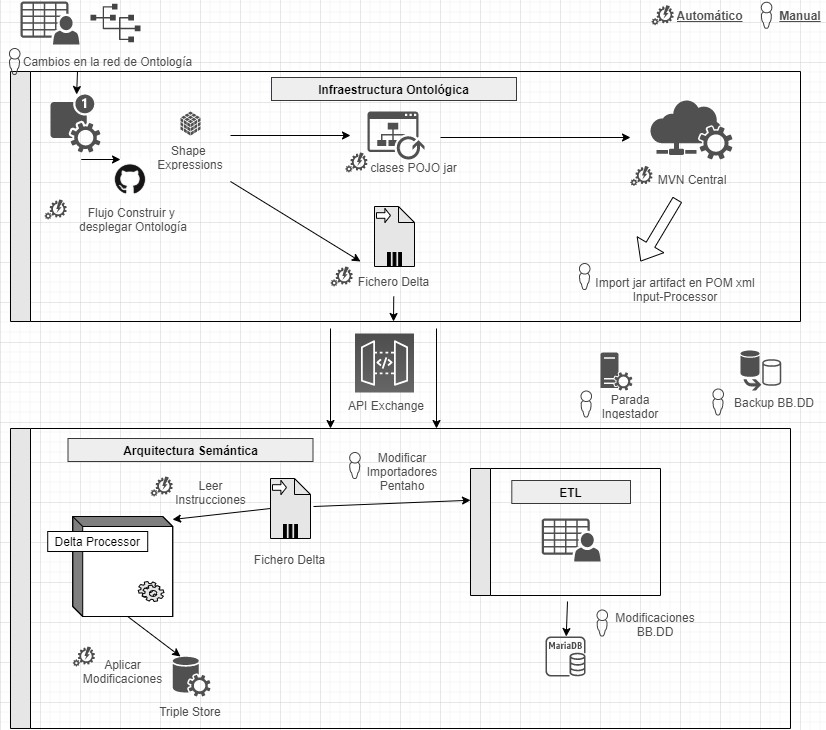
By means of a system based on version control as a central element, it offers the possibility for domain experts to build and visualise multilingual ontologies. These in turn rely on ontologies both from the research domain: VIVO, EuroCRIS/CERIF or Research Object, as well as general purpose ontologies for metadata tagging: Prov-O, DCAT, etc.
Linked Data Platform
The linked data server is the core of the architecture, in charge of rendering information about all entities. It does this by collecting HTTP requests from the outside and redirecting them to the corresponding services, applying content negotiation, which provides the best representation of a resource based on browser preferences for different media types, languages, characters and encoding.
All resources are published following a custom-designed persistent URI scheme. Each entity represented by a URI (researcher, project, university, etc.) has a series of actions to consult and update its data, following the patterns proposed by the Linked Data Platform (LDP) and the 5-star model.
This system also ensures compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) principles and automatically publishes the results of applying these metrics to the data repository.
Open data publication
The data processing system is responsible for the conversion, integration and validation of third-party data, as well as the detection of duplicates, equivalences and relationships between entities. The data comes from various sources, mainly the Hercules unified RMS, but also from alternative RMSs, or from other sources offering data in FECYT/CVN (Standardised Curriculum Vitae), EuroCRIS/CERIF and other possible formats.
The import system converts all these sources to RDF format and registers them in a specific purpose repository for linked data, called Triple Store, because of its capacity to store subject-predicate-object triples.
Once imported, they are organised into a knowledge graph, easily accessible, allowing advanced searches and inferences to be made, enhanced by the relationships between concepts.
Example of a knowledge network describing the ASIO project
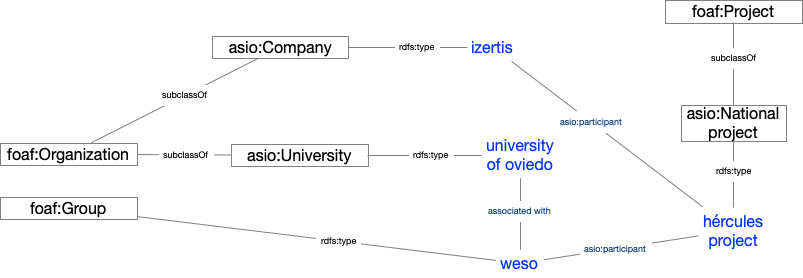
Results and conclusions
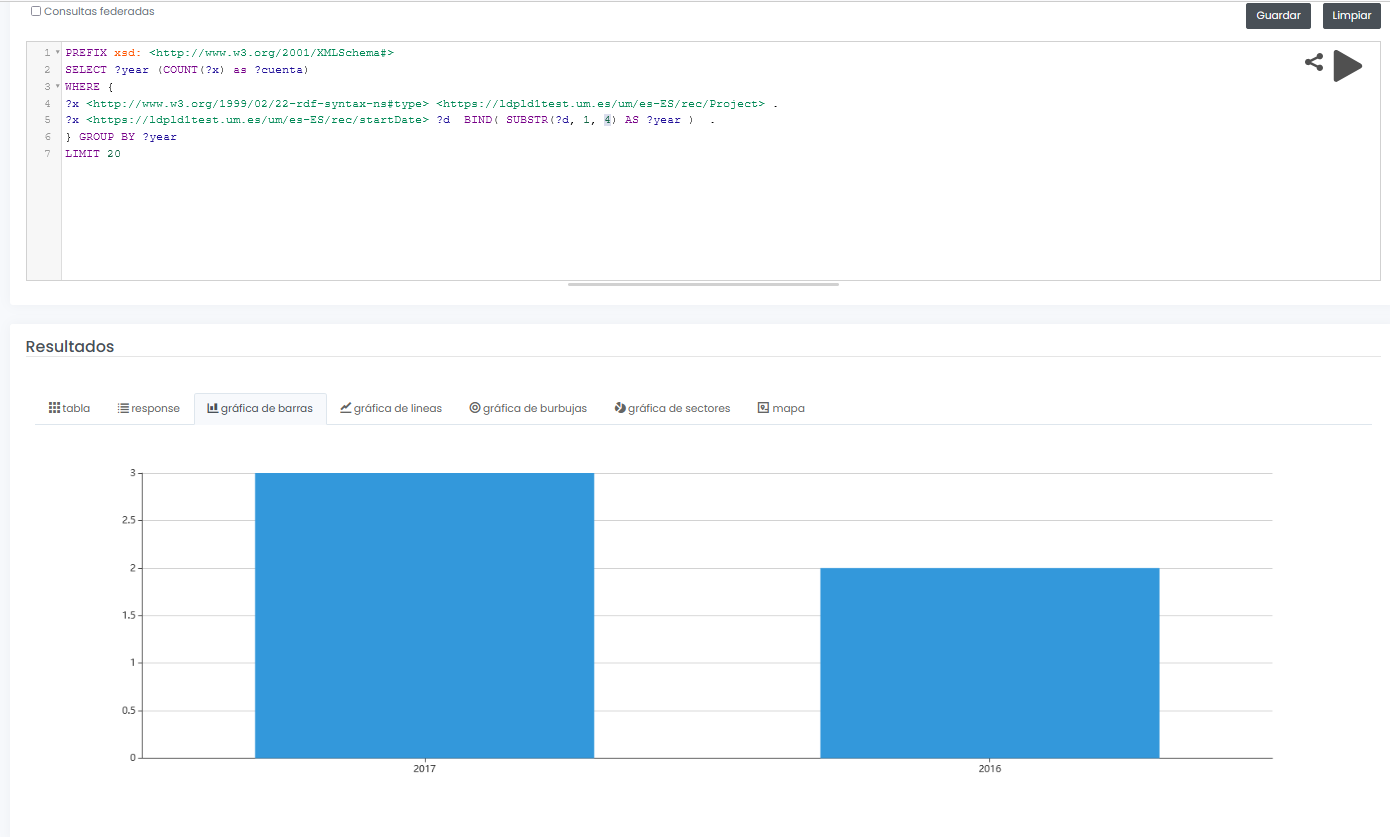
The final system not only allows to offer a graphical interface for interactive and visual querying of research data, but also to design SPARQL queries, such as the one shown below, even with the possibility to run the query in a federated way on all nodes of the Hercules network, and to display results dynamically in different types of graphs and maps.
In this example, a query is shown (with limited test data) of all available research projects grouped graphically by year:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
In short, ASIO offers a common framework for publishing linked open data, offered as open source and easily adaptable to other domains. For such adaptation, it would be enough to design a specific domain model, including the ontology and the import and validation processes discussed in this article.
Currently the project, in its two variants (centralised and decentralised), is in the process of being put into pre-production within the infrastructure of the University of Murcia, and will soon be publicly accessible.
[1 Graphs are a form of knowledge representation that allow concepts to be related through the integration of data sets, using semantic web techniques. In this way, the context of the data can be better understood, which facilitates the discovery of new knowledge.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Each individual, organization or group uses a number of common words in their daily communication, which would be their personal vocabularies. The greater the number of words we use, the greater our ability to communicate, but it can also be a barrier, increasing the difficulty of understanding other people who are not familiar with the same terms as we are. The same is true in the world of data.
To avoid misunderstandings, we must use a controlled vocabulary, which is nothing more than a defined list of terms to systematically organize, categorize or label information.
What is a data vocabulary?
For a successful implementation of a data governance initiative, whether private or public, we must provide the process with a business Glosary or reference vocabulary. A reference vocabulary is a means of sharing information and developing and documenting standard data definitions to reduce ambiguity and improve communication. These definitions should be clear, rigorous in their wording and explain any exceptions, synonyms or variants. A clear example is EuroVoc, which covers the activities of the European Union and, in particular, the European Parliament. Another example is ICD10, which is the Coding Manual for Diagnoses and Procedures in Health Care.
The objectives of a controlled vocabulary are as follows:
- To enable common understanding of key concepts and terminology, in a precise manner.
- To reduce the risk of data being misused due to inconsistent understanding of concepts.
- Maximize searchability, facilitating access to documented knowledge.
- Drive interoperability and data reuse, which is critical in the open data world.
Vocabularies vary in the complexity of their development, from simple lists or selection lists, to synonym rings, taxonomies or the most complex, thesauri and ontologies.
How is a vocabulary created?
When creating a vocabulary, it does not usually start from scratch, but is based on pre-existing ontologies and vocabularies, which favors communication between people, intelligent agents and systems. For example, Aragón Open Data has developed an ontology called Interoperable Information Structure of Aragón EI2A that homogenizes structures, vocabularies and characteristics, through the representation of entities, properties and relationships, to fight against the diversity and heterogeneity of existing data in the Aragonese Administration (data from local entities that do not always mean the same thing). For this purpose, it is based on proposals such as RDF Schema (a general vocabulary for modeling RDF schemas that is used in the creation of other Vocabularies), ISA Programme Person Core Vocabulary (aimed at describing persons) or OWL-Time (describing temporal concepts).
A vocabulary must be accompanied by a data dictionary, which is where the data is described in business terms and includes other information needed to use the data, such as details of its structure or security restrictions. Because vocabularies evolve over time, they require evolutionary maintenance. As an example, ANSI/NIZO Z39.19-2005 is a standard that provides guidelines for the construction, formatting and management of controlled vocabularies. We also find SKOS, a W3C initiative that provides a model for representing the basic structure and content of conceptual schemas in any type of controlled vocabulary.
Examples of Vocabularies in specific fields created in Spain
In the Spanish context, with a fragmented administrative structure, where each agency shares its open information individually, it is necessary to have common rules that allow us to homogenize the data, facilitating its interoperability and reuse. Fortunately, there are various proposals that help us in these tasks.
The following are examples of vocabularies created in our country for two fundamental sectors for the future of society, such as education and smart cities.
Smart cities
An example of the construction of domain-specific vocabularies can be found in ciudades-abiertas.es, which is an initiative of several city councils in Spain (A Coruña, Madrid, Santiago de Compostela and Zaragoza) and Red.es.
Among other actions, within the framework of the project, they are working on the development of a catalog of well-defined and documented vocabularies, with examples of use and available in several representation languages. Specifically, 11 vocabularies are being developed corresponding to a series of datasets selected by the municipalities that do not have a defined standard. An example of these vocabularies is the Municipal Agenda.
These vocabularies are generated using the OWL standard language, which is the acronym for Web Ontology Language, a markup language for publishing and sharing data using ontologies on the Web. The corresponding contexts for JSON-LD, N-triples, TTL and RDF/XML are also available. In this explanatory video we can see how these vocabularies are defined. The generated vocabularies are available in the Github repository.
Education
In the field of universities, on the other hand, we find the proposal for open data content for universities developed by the UniversiDATA community: Common Core. In version 1.0, 42 datasets have been identified that every university should publish, such as information related to Degrees, Enrolments or Tenders and contracts. At the moment there are 11 available, while the rest are in the process of elaboration.
For example, the UAM (Autónoma de Madrid), the URJC (Rey Juan Carlos) and the UCM (Complutense de Madrid) have published their degrees following the same vocabulary.
Although much progress has been made in the creation and application of data vocabularies in general, there is still room for progress in the field of research on controlled vocabularies for publishing and querying data on the Web, for example, in the construction of Business Glosaries linked to technical data dictionaries. The application of best practices and the creation of vocabularies for the representation of metadata describing the content, structure, provenance, quality and use of datasets will help to define more precisely the characteristics that should be incorporated into Web data publishing platforms.
Content elaborated by David Puig, Graduate in Information and Documentation and responsible for the Master Data and Reference Group at DAMA ESPAÑA.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Empresa reutilizadora
SIRIS Academic is a consulting and research company that designs and implements strategies and policy solutions in the field of higher education, research and innovation. They work with agents in charge of political decision-making, providing tools, processes and reflections that help to establish and address key issues for their mission.
SIRIS Academic is focused on organizations with public or social vocation. This perspective places success in the generation of added value for society, aligned with its values, culture and focus.
Noticia
Rome was the European city chosen to host the latest edition of the Semantic Interoperability Conference (SEMIC 2016), which took place on 12th May under the slogan "Data Standards for interconnected Public Administrations". A data standard is a specification that describes, defines and/or structures information to support interoperability, traceability and effective re-use. In this meeting, participants had the opportunity to follow discussions and panels on policies and practices for developing and using data standards and learn from the experience of standardisation organisations, governments and European institutions.
During the first part of the conference, the importance of international standards in the supply chains of the health sector was explained through a case study. The implementation of these standards would not only improve patient safety, but they could even save up to 43,000 lives a year. After this talk, it was the turn of the executive director of IJIS Institute (USA) and Kenji Hiramoto, from Japan, who explained the IMI project to enhance “semantic level” interoperability for data by creating a reference dictionary of terms that serves as an infrastructure to facilitate cooperation between systems and re-use of open data.
Afterwards, a discussion panel formed by six experts from different international organizations was held -including Patricinio Nieto, head of service at MINHAP- who shared their experiences in the practical implementation of data standards at national and international level.
The rest of the day was spent between several sessions where different topics such as the potential of economic data, legal data, the use of international standards in the financial sector or the presentation of the European CEF program, whose second call has been launched this year, were addressed. Finally, the conference ended with a roundtable where members discussed the need to create a sound open data ecosystem in Europe and presented current cases of DCAT-AP implementation.
In this regard, the next day the ISA² programme of the European Commission hosted a workshop on DCAT-AP. The workshop was organised in the context of the ISA Action 1.1 and invited implementers of DCAT-AP:
● to discuss implementation challenges and good practices;
●to learn more about the DCAT-AP implementation guidelines that Action 2.1 of the ISA2 programme is developing in collaboration with DCAT-AP implementers;
● to discover more about the status of the extensions of the DCAT-AP for geospatial and statistical data;
● to discuss about tool and software support.
Currently, ISA² program promotes horizontal and reusable data standards, which are already being implemented in operating systems in order to facilitate the data interoperability at regional, national and European level. This initiative, started this year 2016 and it will last until 2020, includes an EUR 131 million programme to support the development of interoperable digital solutions, which will be available to all interested public administrations in Europe, deleting barriers between public administrations, businesses and citizens.
The SEMIC Conference has turned into the great event of semantic interoperability at international level, and this year the meeting brought together more than two hundred professionals, not only from the public sector but researchers, consultants and representatives of international projects interested in learning and making further progress in the field of open linked data, semantic technologies, eGovernment and metadata management.