Argitalpen data
28/10/2025
Eguneratu data
26/12/2025
Partekatu eduki hau

Azalpena
La Inteligencia Artificial (IA) está convirtiéndose en uno de los principales motores del aumento de la productividad y la innovación tanto en el sector público como en el privado, siendo cada vez más relevante en tareas que van desde la creación de contenido en cualquier formato (texto, audio, video) hasta la optimización de procesos complejos a través de agentes de Inteligencia Artificial.
Sin embargo, los modelos avanzados de IA, y en particular los grandes modelos de lenguaje, exigen cantidades ingentes de datos para su entrenamiento, optimización y evaluación. Esta dependencia genera una paradoja: a la vez que la IA demanda más datos y de mayor calidad, la creciente preocupación por la privacidad y la confidencialidad (Reglamento General de Protección de Datos o RGPD), las nuevas reglas de acceso y uso de datos (Data Act), y los requisitos de calidad y gobernanza para sistemas de alto riesgo (Reglamento de IA), así como la inherente escasez de datos en dominios sensibles limitan el acceso a los datos reales.
En este contexto, los datos sintéticos pueden ser un mecanismo habilitador para conseguir nuevos avances, conciliando innovación y protección de la privacidad. Por una parte, permiten alimentar el progreso de la IA sin exponer información sensible, y cuando se combinan con datos abiertos de calidad amplían el acceso a dominios donde los datos reales son escasos o están fuertemente regulados.
¿Qué son los datos sintéticos y cómo se generan?
De forma sencilla, los datos sintéticos se pueden definir como información fabricada artificialmente que imita las características y distribuciones de los datos reales. La función principal de esta tecnología es reproducir las características estadísticas, la estructura y los patrones del dato real subyacente. En el dominio de las estadísticas oficiales existen casos como el del Censo de Estados Unidos que publica productos parcial o totalmente sintéticos como OnTheMap (movilidad de los trabajadores entre lugar de residencia y lugar trabajo) o el SIPP Synthetic Beta (microdatos socioeconómicos vinculados a impuestos y seguridad social).
La generación de datos sintéticos es actualmente un campo aún en desarrollo que se apoya en diversas metodologías. Los enfoques pueden ir desde métodos basados en reglas o modelado estadístico (simulaciones, bayesianos, redes causales), que imitan distribuciones y relaciones predefinidas, hasta técnicas avanzadas de aprendizaje profundo. Entre las arquitecturas más destacadas encontramos:
- Redes Generativas Adversarias (GAN): un modelo generativo, entrenado con datos reales, aprende a imitar sus características, mientras que un discriminador intenta distinguir entre datos reales y sintéticos. A través de este proceso iterativo, el generador mejora su capacidad para producir datos artificiales que son estadísticamente indistinguibles de los originales. Una vez entrenado, el algoritmo puede crear nuevos registros artificiales que son estadísticamente similares a la muestra original, pero completamente nuevos y seguros.
- Autoencoders Variacionales (VAE): Estos modelos se basan en redes neuronales que aprenden una distribución probabilística en un espacio latente de los datos de entrada. Una vez entrenado, el modelo utiliza esta distribución, para obtener nuevas observaciones sintéticas mediante el muestreo y decodificación de los vectores latentes. Los VAE son frecuentemente considerados una opción más estable y sencilla de entrenar en comparación con las GAN para la generación de datos tabulares.
- Modelos autorregresivos/jerárquicos y simuladores de dominio: utilizados, por ejemplo, en datos de historia clínica electrónica, que capturan dependencias temporales y jerárquicas. Los modelos jerárquicos estructuran el problema por niveles, primero muestrean variables de nivel superior y, después las de niveles inferiores condicionadas a las anteriores. Los simuladores de dominio codifican reglas del proceso y se calibran con datos reales, aportando control e interpretabilidad y garantizando el cumplimiento de reglas de negocio.
Puedes conocer más sobre los datos sintéticos y cómo se crean en esta infografía:
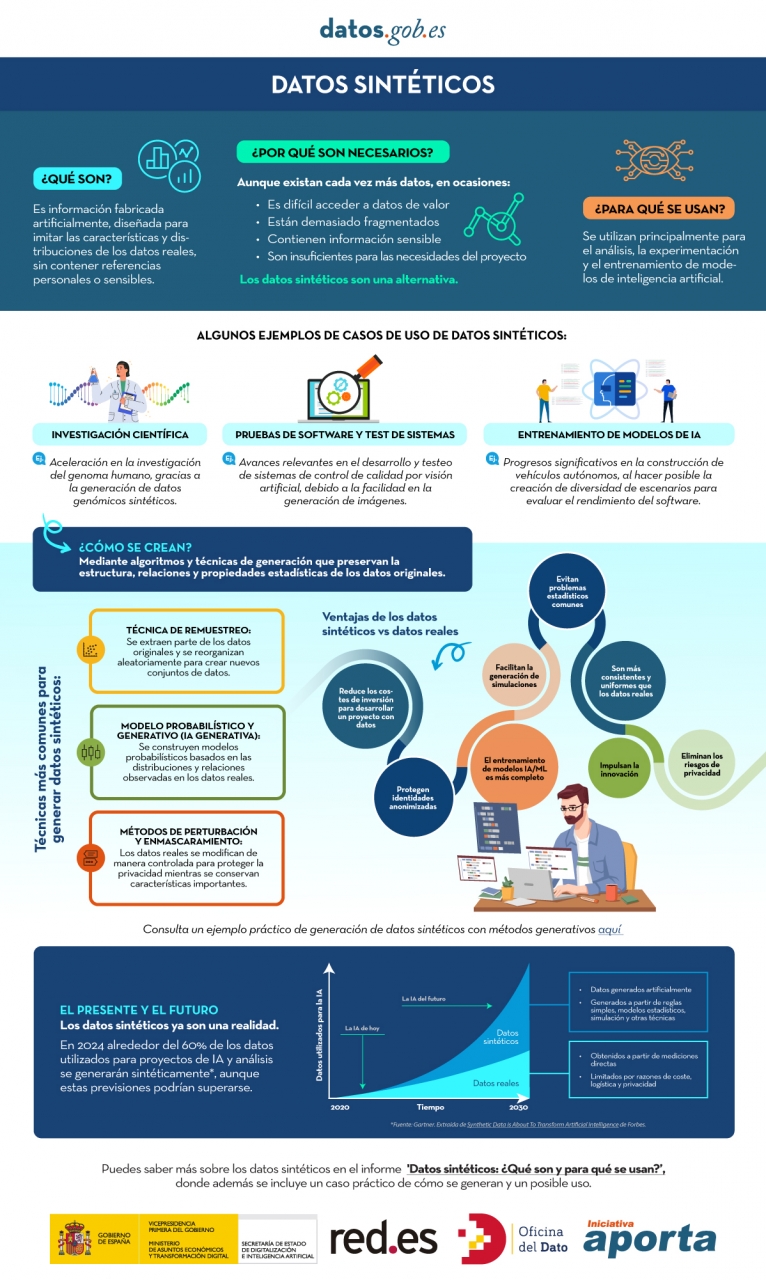
Figura 1. Infografía sobre datos sintéticos. Fuente: elaboración propia - datos.gob.es.
Si bien la generación sintética reduce inherentemente el riesgo de divulgación de datos personales, no lo elimina por completo. Sintético no significa automáticamente anónimo ya que, si los generadores se entrenan de forma inadecuada, pueden filtrarse trazas del conjunto real y ser vulnerables a ataques de inferencia de pertenencia (membership inference). De ahí que sea necesario utilizar Tecnologías de Mejora de la Privacidad (PET) como la privacidad diferencial y realizar evaluaciones de riesgo específicas. También el Supervisor Europeo de Protección de Datos (EDPS) ha subrayado la necesidad de realizar una evaluación de garantía de privacidad antes de que los datos sintéticos puedan ser compartidos, garantizando que el resultado no permita obtener datos personales reidentificables.
La Privacidad Diferencial (DP) es una de las tecnologías principales en este dominio. Su mecanismo consiste en añadir ruido controlado al proceso de entrenamiento o a los datos mismos, asegurando matemáticamente que la presencia o ausencia de cualquier individuo en el conjunto de datos original no altere significativamente el resultado final de la generación. El uso de métodos seguros, como el descenso de gradiente estocástico con privacidad diferencial (DP-SGD), garantiza que las muestras generadas no comprometan la privacidad de los usuarios que contribuyeron con sus datos al conjunto sensible.
¿Cuál es el papel de los datos abiertos?
Como es obvio, los datos sintéticos no aparecen de la nada, necesitan datos reales de alta calidad como semilla y, además, requieren buenas prácticas de validación. Por ello, los datos abiertos o los datos que no pueden abrirse por cuestiones relacionadas con la privacidad son, por una parte, una excelente materia prima para aprender patrones del mundo real y, por otra, una referencia independiente para verificar que lo sintético se parece a la realidad sin exponer a personas o empresas.
Como semilla de aprendizaje los datos abiertos de calidad, como los conjuntos de datos de alto valor, con metadatos completos, definiciones claras y esquemas estandarizados, aportan cobertura, granularidad y actualidad. Cuando ciertos conjuntos no pueden hacerse públicos por motivos de privacidad, pueden emplearse internamente con las adecuadas salvaguardas para producir datos sintéticos que sí podrían liberarse. En salud, por ejemplo, existen generadores abiertos como Synthea, que producen historias clínicas ficticias sin las restricciones de uso propias de los datos reales.
Por otra parte, frente a un conjunto sintético, los datos abiertos permiten actuar como patrón de verificación, para contrastar distribuciones, correlaciones y reglas de negocio, así como evaluar la utilidad en tareas reales (predicción, clasificación) sin recurrir a información sensible. En este sentido ya existen trabajos, como el del Gobierno de Gales con datos de salud, que han experimentado con distintos indicadores,. Entre ellos destacan la distancia de variación total (TVD), el índice de propensión (propensity score) y el desempeño en tareas de aprendizaje automático.
¿Cómo se evalúan los datos sintéticos?
La evaluación de los conjuntos de datos sintéticos se articula a través de tres dimensiones que, por su naturaleza, implican un compromiso:
- Fidelidad (Fidelity): mide lo cerca que está el dato sintético de replicar las propiedades estadísticas, correlaciones y la estructura de los datos originales.
- Utilidad (Utility): mide el rendimiento del conjunto de datos sintéticos en tareas posteriores de aprendizaje automático, como la predicción o la clasificación.
- Privacidad (Privacy): mide la efectividad con la que el dato sintético oculta la información sensible y el riesgo de que los sujetos de los datos originales puedan ser reidentificados.

Figura 2. Tres dimensiones para evaluar datos sintéticos. Fuente: elaboración propia - datos.gob.es.
El reto de gobernanza reside en que no es posible optimizar las tres dimensiones simultáneamente. Por ejemplo, aumentar el nivel de privacidad (inyectando más ruido mediante privacidad diferencial) inevitablemente puede reducir la fidelidad estadística y, en consecuencia, la utilidad para ciertas tareas. La elección de qué dimensión priorizar (máxima utilidad para investigación estadística o máxima privacidad) se convierte en una decisión estratégica que debe ser transparente y específica para cada caso de uso.
¿Datos abiertos sintéticos?
La combinación de datos abiertos y datos sintéticos ya puede considerarse algo más que una idea, ya que existen casos reales que demuestran su utilidad para acelerar la innovación y, al mismo tiempo, proteger la privacidad. Además de los ya citados OnTheMap o SIPP Synthetic Beta en Estados Unidos, también encontramos ejemplos en Europa y el resto del mundo. Por ejemplo, el Centro Común de Investigación (JRC) de la Comisión Europea ha analizado el papel de los datos sintéticos generados con IA en la formulación de políticas “AI Generated Synthetic Data in Policy Applications”, destacando su capacidad para acortar el ciclo de vida de las políticas públicas al reducir la carga de acceso a datos sensibles y habilitar fases de exploración y prueba más ágiles. También ha documentado aplicaciones de poblaciones sintéticas multipropósito para análisis de movilidad, energía o salud, reforzando la idea de que los datos sintéticos actúan como habilitador transversal.
En Reino Unido, el Office for National Statistics (ONS) llevó a cabo un Synthetic Data Pilot para entender la demanda de datos sintéticos. En el piloto se exploró la producción de herramientas de generación de microdatos sintéticos de alta calidad para requisitos específicos de los usuarios.
También en salud se observan avances que ilustran el valor de datos abiertos sintéticos para innovación responsable. El Departamento de Salud de la región de Australia Occidental ha impulsado un Synthetic Data Innovation Project y hackatones sectoriales donde se liberan conjuntos sintéticos realistas que permiten a equipos internos y externos probar algoritmos y servicios sin acceso a información clínica identificable, fomentando la colaboración y acelerando la transición de prototipos a casos de uso reales.
En definitiva, los datos sintéticos ofrecen una vía prometedora, aunque no suficientemente explorada, para el desarrollo de las aplicaciones de inteligencia artificial, ya que contribuyen al equilibrio entre el fomento de la innovación y la protección de la privacidad.
Los datos sintéticos no sustituyen a los datos abiertos, sino que se potencian mutuamente. En particular, representan una oportunidad para que las Administraciones públicas pueden ampliar su oferta de datos abiertos con versiones sintéticas de conjuntos sensibles para educación o investigación, y para facilitar que las empresas y desarrolladores independientes experimenten cumpliendo la regulación y puedan generar un mayor valor económico y social.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.



Iruzkinak