Partekatu eduki hau
Azalpena
En el ecosistema del sector público, las subvenciones representan uno de los mecanismos más importantes para impulsar proyectos, empresas y actividades de interés general. Sin embargo, entender cómo se distribuyen estos fondos, qué organismos convocan ayudas más voluminosas o cómo varía el presupuesto según la región o los beneficiarios no es trivial cuando se trabaja con cientos de miles de registros.
En esta línea, presentamos un nuevo ejercicio práctico de la serie “Ejercicios de datos paso a paso”, en el que aprenderemos a explorar y modelar datos abiertos utilizando Apache Spark, una de las plataformas más extendidas para el procesamiento distribuido y el machine learning a gran escala.
En este laboratorio trabajaremos con datos reales del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas (BDNS) y construiremos un modelo capaz de predecir el rango de presupuesto de nuevas convocatorias en función de sus características principales.
Todo el código utilizado está disponible en el correspondiente repositorio de GitHub para que puedas ejecutarlo, entenderlo y adaptarlo a tus propios proyectos.
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de Google Colab
Contexto: ¿por qué analizar las subvenciones públicas?
La BDNS recoge información detallada sobre cientos de miles de convocatorias publicadas por distintas administraciones españolas: desde ministerios y consejerías autonómicas hasta diputaciones y ayuntamientos. Este conjunto de datos es una fuente extraordinariamente valiosa para:
-
analizar la evolución del gasto público,
-
entender qué organismos son más activos en ciertas áreas,
-
identificar patrones en los tipos de beneficiarios,
-
y estudiar la distribución presupuestaria según sector o territorio.
En nuestro caso, utilizaremos el dataset para abordar una pregunta muy concreta, pero de gran interés práctico:
¿Podemos predecir el rango de presupuesto de una convocatoria a partir de sus características administrativas?
Esta capacidad facilitaría tareas de clasificación inicial, apoyo a la toma de decisiones o análisis comparativos dentro de una administración pública.
Objetivo del ejercicio
El objetivo del laboratorio es doble:
- Aprender a manejar Spark de forma práctica:
- Cargar un dataset real de gran volumen
- Realizar transformaciones y limpieza
- Manipular columnas categóricas y numéricas
- Estructurar un pipeline de machine learning
2. Construir un modelo predictivo
Entrenaremos un clasificador capaz de estimar si una convocatoria pertenece a uno de estos rangos de presupuesto bajo (hasta 20 k€), medio (entre 20 y 150k€) o alto (superior a 150k€), basándonos para ello en variables como:
- Organismo concedente
- Comunidad Autónoma
- Tipo de beneficiario
- Año de publicación
- Descripciones administrativas
Recursos utilizados
Para completar este ejercicio empleamos:
Herramientas analíticas
- Python, lenguaje principal del proyecto
- Google Colab, para ejecutar Spark y crear Notebooks de forma sencilla
- PySpark, para el procesamiento de datos en las etapas de limpieza y modelado
- Pandas, para pequeñas operaciones auxiliares
- Plotly, para algunas visualizaciones interactivas
Datos
Dataset oficial del Sistema Nacional de Publicidad de Subvenciones (BDNS), descargado desde el portal de subvenciones del Ministerio de Hacienda.
Los datos utilizados en este ejercicio fueron descargados el 28 de agosto de 2025. La reutilización de los datos del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas está sujeta a las condiciones legales recogidas en https://www.infosubvenciones.es/bdnstrans/GE/es/avisolegal.
Desarrollo del ejercicio
El proyecto se divide en varias fases, siguiendo el flujo natural de un caso real de data science.
5.1. Volcado y transformación de datos
En este primer apartado vamos a descargar automáticamente el dataset de subvenciones desde la API del portal del Sistema Nacional de Publicidad de Subvenciones (BDNS). Posteriormente transformaremos los datos a un formato optimizado como Parquet (formato de datos columnar) para facilitar su exploración y análisis.
En este proceso utilizaremos algunos conceptos complejos, como:
-
Funciones asíncronas: permite procesar en paralelo dos o más operaciones independientes, lo que facilita hacer más eficiente el proceso.
-
Escritor rotativo: cuando se supera un límite de cantidad de información el fichero que se está procesando se cierra y se abre uno nuevo con un índice autoincremental (a continuación del anterior). Esto evita procesar ficheros demasiado grandes y mejora la eficiencia.
Figura 1. Captura de la API del Sistema Nacional de Publicidad de Subvenciones y Ayudas Públicas
5.2. Análisis exploratorio
El objetivo de esta fase es obtener una primera idea de las características de los datos y de su calidad.
Analizaremos entre otros, aspectos como:
- Qué tipos de subvenciones tienen mayor número de convocatorias.
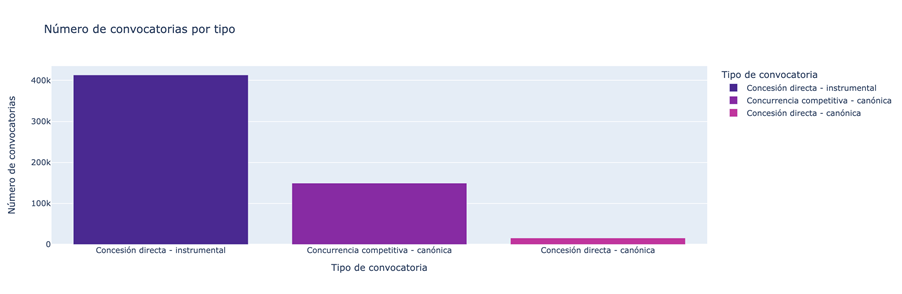
Figura 2. Tipos de subvenciones con mayor número de convocatorias.
- Cuál es la distribución de las subvenciones en función de su finalidad (i.e. Cultura, Educación, Fomento del empleo…).
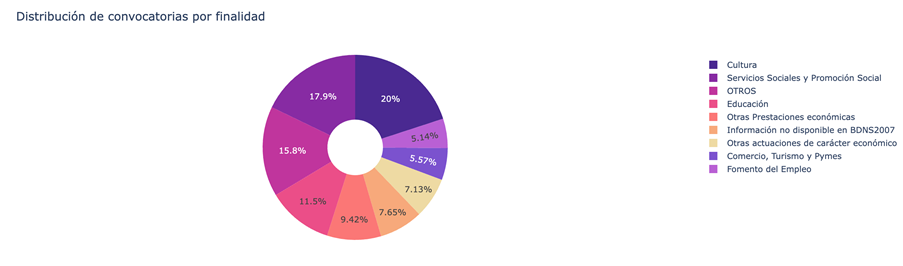
Figura 3. Distribución de las subvenciones en función de su finalidad.
- Qué finalidades agregan un mayor volumen presupuestario.
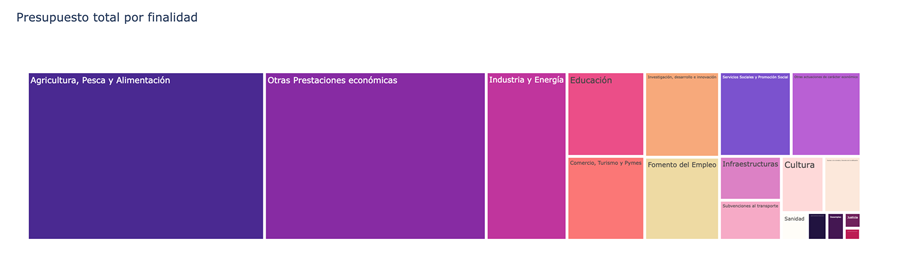
Figura 4. Finalidades con mayor volumen presupuestario.
5.3. Modelado: construcción del clasificador de presupuesto
Llegados a este punto, entramos en la parte más analítica del ejercicio: enseñar a una máquina a predecir si una nueva convocatoria tendrá un presupuesto bajo, medio o alto a partir de sus características administrativas. Para conseguirlo, diseñamos un pipeline completo de machine learning en Spark que nos permite transformar los datos, entrenar el modelo y evaluarlo de forma uniforme y reproducible.
Primero preparamos todas las variables —muchas de ellas categóricas, como el órgano convocante— para que el modelo pueda interpretarlas. Después combinamos toda esa información en un único vector que sirve como punto de partida para la fase de aprendizaje.
Con esa base construida, entrenamos un modelo de clasificación que aprende a distinguir patrones sutiles en los datos: qué organismos tienden a publicar convocatorias más voluminosas o cómo influyen elementos administrativos específicos en el tamaño de una ayuda.
Una vez entrenado, analizamos su rendimiento desde distintos ángulos. Evaluamos su capacidad para clasificar correctamente los tres rangos de presupuesto y analizamos su comportamiento mediante métricas como la accuracy o la matriz de confusión.
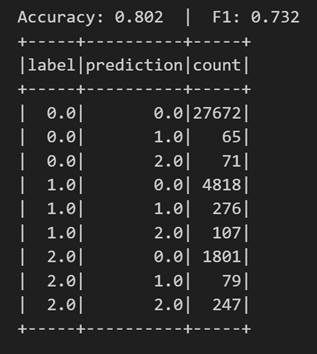
Figura 5. Métricas accuracy.
Pero no nos quedamos ahí: también estudiamos qué variables han tenido mayor peso en las decisiones del modelo, lo que nos permite entender qué factores parecen más determinantes a la hora de anticipar el presupuesto de una convocatoria.
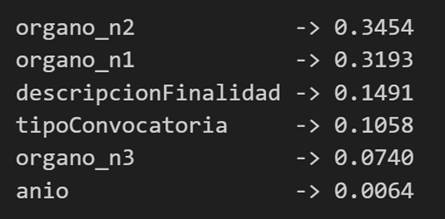
Figura 6. Variables que han tenido mayor peso en las decisiones del modelo.
Conclusiones del ejercicio
Este laboratorio nos permitirá comprobar cómo Spark simplifica el procesamiento y modelado de datos de gran volumen, especialmente útiles en entornos donde las administraciones generan miles de registros al año, y conocer mejor el sistema de subvenciones tras analizar algunos aspectos clave de la organización de estas convocatorias.
¿Quieres realizar el ejercicio?
Si te interesa profundizar en el uso de Spark y en el análisis avanzado de datos públicos, puedes acceder al repositorio y ejecutar el Notebook completo paso a paso.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.



Iruzkinak