Data publicación
06/10/2022
Comparte este contido

Descrición
16.500 millones de euros. Esos son los ingresos que se estima generarán la inteligencia artificial (IA) y los datos en la industria española para 2025, según se avanzó el pasado febrero en el foro de IndesIA, la asociación para la aplicación de la inteligencia artificial en la industria. La IA ya forma parte de nuestro día a día: ya sea haciendo más sencillo nuestro trabajo al realizar tareas rutinarias y repetitivas, o bien complementando las capacidades humanas en diversos ámbitos a través de modelos de aprendizaje automático que facilitan, por ejemplo, el reconocimiento de imágenes, la traducción automática o la predicción de diagnósticos médicos. Todas ellas, actividades que nos ayudan a mejorar la eficiencia de negocios y servicios, impulsando una toma de decisiones más certera.
Pero para que los modelos de aprendizaje automático (también conocidos por el término en inglés machine learning) funcionen correctamente, se necesitan datos de calidad y bien documentados. Todo modelo de aprendizaje automático se entrena y evalúa con datos. Las características de estos conjuntos de datos condicionan el comportamiento del modelo. Por ejemplo, si los datos de entrenamiento reflejan sesgos sociales no deseados es probable que estos también se incorporen en el modelo, lo cual puede tener graves consecuencias cuando se utiliza en ámbitos de gran importancia, como la justicia penal, la contratación de personas o el préstamo de créditos. Además, si no conocemos el contexto de los datos, puede que nuestro modelo no funcione correctamente, ya que en su proceso de construcción no se han tenido en cuenta las características intrínsecas de los datos sobre los cuales se sustenta.
Por estas y otras razones, el Foro Económico Mundial sugiere que todas las entidades deben documentar la procedencia, la creación y el uso de los conjuntos de datos de aprendizaje automático con el fin de evitar resultados erróneos o discriminatorios.
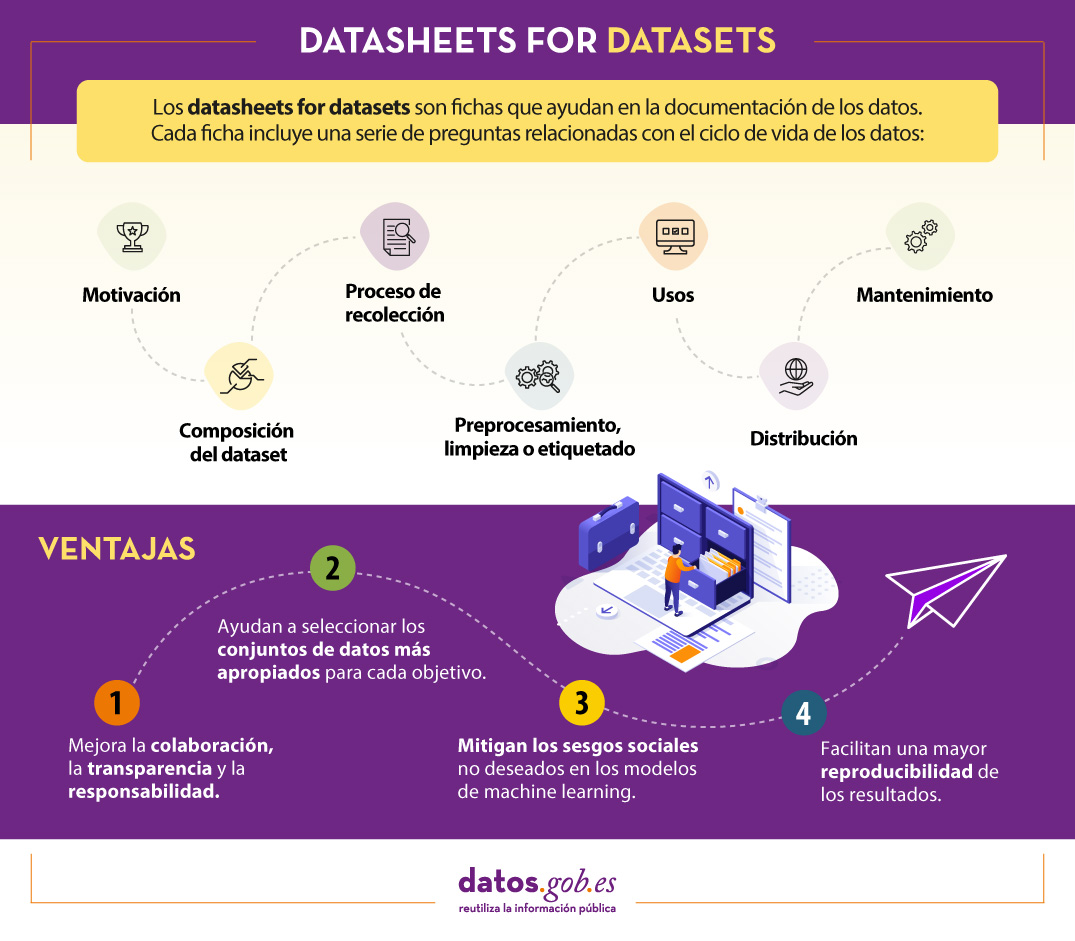
¿Qué son Datasheets for datasets?
Un mecanismo para documentar esta información son las conocidas como Datasheets for datasets. Este marco de trabajo propone que todo conjunto de datos debe ser acompañado de una “ficha de datos”, llamada datasheet, que consiste de un cuestionario que guía en la documentación de los datos y la reflexión a lo largo del ciclo de vida de los datos. Algunas de las ventajas que supone son:
- Mejora la colaboración, la transparencia y la responsabilidad dentro de la comunidad de aprendizaje automático.
- Mitiga los sesgos sociales no deseados en los modelos.
- Ayuda a los investigadores y desarrolladores a seleccionar los conjuntos de datos más apropiados para alcanzar sus objetivos específicos.
- Facilita una mayor reproducibilidad de los resultados.
Los datasheets variarán dependiendo de factores tales como el área de conocimiento, la infraestructura organizacional existente o los flujos de trabajo.
Para ayudar en la creación de las datasheet, se ha diseñado un cuestionario con una serie de preguntas, acordes a las etapas del ciclo de vida de los datos:
- Motivación. Recoge las razones que han llevado a la creación de los conjuntos de datos. También se pregunta sobre quién creó o financió dichos datasets.
- Composición. Ofrece a los usuarios la información necesaria sobre la adecuación del conjunto de datos a sus objetivos. Incluye, entre otras preguntas, qué unidades de observación representan el conjunto de datos (documentos, fotos, personas, países), qué tipo de información ofrece cada unidad o si hay errores, fuentes de ruido o redundancias en él. Reflexiona acerca de los datos que se refieren a personas para evitar posibles sesgos sociales o violaciones a la privacidad.
- Proceso de recolección. Su objetivo es ayudar a los investigadores y usuarios a pensar en cómo crear conjuntos de datos alternativos con similares características. Aquí se detalla, por ejemplo, cómo se adquirieron los datos, quién participó en el proceso de recopilación o cómo fue el proceso de revisión ética. Trata especialmente los aspectos éticos del procesamiento de datos protegidos por la RGPD.
- Preprocesamiento, limpieza o etiquetado. Gracias a estas preguntas, los usuarios de datos podrán determinar si estos han sido procesados de formas compatibles con los usos que les pretenden dar. Indaga sobre si se realizó algún preprocesamiento, limpieza o etiquetado de los datos, o si está disponible el software que se utilizó para preprocesarlos, limpiarlos y etiquetarlos.
- Usos. Esta sección proporciona información sobre aquellas tareas para las cuales los datos pueden o no pueden ser usados. Para ello, se debe responder a preguntas como: ¿El conjunto de datos ya ha sido usado para alguna tarea? ¿Para qué otras tareas pueden ser utilizados? ¿La composición del conjunto de datos o la forma en que se recopiló, preprocesó, limpió y etiquetó puede afectar a otros usos futuros?
- Distribución. Recoge cómo se difundirá el conjunto de datos. Las preguntas se centran en si los datos se distribuirán a terceros y, en caso afirmativo, cómo, cuándo, cuáles son las restricciones de uso y bajo qué licencias.
- Mantenimiento. El cuestionario finaliza con preguntas dirigidas a planificar el mantenimiento de los datos y comunicar el plan a los usuarios de los datos. Por ejemplo, se responde a si se actualizará el conjunto de datos o quién dará soporte.
Se recomienda que todas las preguntas sean tenidas en cuenta antes de la recolección de los datos, para que sus creadores puedan ser conscientes de los posibles problemas. Para ilustrar cómo se podría responder a cada una de ellas en la práctica, los creadores del modelo han elaborado un apéndice con un ejemplo para un conjunto de datos determinado.
¿Es efectivo Datasheets for datasets?
El marco para documentar los datos Datasheets for datasets ha recibido inicialmente buenas críticas, pero su implementación continúa acarreando diversos retos, sobre todo cuando se trabaja con datos dinámicos.
Para conocer si el marco resuelve de forma efectiva las necesidades de documentación de los creadores y los usuarios de los datos, en junio del 2022, Microsoft USA y la Universidad de Michigan llevaron a cabo un estudio sobre su implementación. Para ello realizaron una serie de entrevistas y un seguimiento de la aplicación del cuestionario por parte de varios profesionales del aprendizaje automático.
En resumen, los participantes expresaron la necesidad de que los marcos de documentación sean adaptables a los diferentes contextos, se integren en las herramientas existentes y en los flujos de trabajo, y que sean tan automatizados como sea posible, debido en parte a la extensión de las preguntas. No obstante, también resaltaron sus ventajas, como, por ejemplo, que reduce el riesgo de pérdida de información, promueve la colaboración entre todos los que participan en el ciclo de vida de los datos, facilita el descubrimiento de los datos o impulsa el pensamiento crítico, entre otras.
En definitiva, nos encontramos ante un buen punto de partida, pero que deberá evolucionar, sobre todo para adaptarse a las necesidades de los datos dinámicos y a los flujos de documentación aplicados en diferentes contextos.
Contenido elaborado por el equipo de datos.gob.es.
Propuestas como Datasheets for datasets están dando es una paso más para crear aplicaciones de IA (inteligencia artificial) más seguras. Y uso el término "seguras", dado que estudios recientes (A. Paullada 2021) muestran como los datos pueden ser la fuente de problemas en estas aplicaciones (sesgos en reconocimiento facial, perdida de precisión al actuar sobre determinados grupos sociales, problemas entre estilos de lenguaje, etc.).
Esto provoca que una administración pública que pretenda desplegar una de estas aplicaciones, debería (y deberá viendo los borradores de la UE y EE. UU. en la materia) poder demostrar una serie de requisitos sobre los datos que ha empleado para entrenar sus apps de IA. Utilizando texto natural (como hace Datasheets), imagino que el proceso de demostración sería una serie de trabajadores públicos analizando Datasheets y sacando conclusiones.
Sin embargo, utilizando un formato estructurado (sobre el mismo Datasheets), puede facilitar la tarea, dado que sería fácilmente computables por ordenadores, "obligaría" a expresar conceptos de la misma forma, e incluso a partir de una descripción válida se podrían generar test que asegurarán que los datos cumplen, y siguen cumpliendo (caso de datasets incrementales) una serie de requisitos para ser usados para entrenar IA en la administración pública.
Desde el grupo de investigación de SOM Research, hemos propuesto una aproximación a este idea de formato estructurado (Domain-specific language) inspirada en Datasheets for datasets. Por si interesa: https://ingenieriadesoftware.es/describeml-describir-datasets-ml/
Muchas gracias por su comentario y por el enlace a su proyecto. ¡Muy interesante!
Un cordial saludo,
1) Sería ilustrativo ver un ejemplo de como son las datasheets
2) También sería ilustrativo hablar de cual es la conexión (o la posible conexión) entre estas datasheets y el estandar DCAT-AP
Estimado Alberto,
DCAT es una ontología orientada a describir conjuntos de datos de todo tipo dispuestos para su reutilización a través de catálogos de datos -generalistas mayoritariamente-. Para ello utiliza un conjunto de propiedades que toman valores en rangos definidos (taxonomías, listas de nombres o tesauros) mantenidos por organismos como la Oficina de Publicaciones Europea, entre otros, asegurando de esta forma interoperabilidad semántica y técnica entre ellos. Aunque estas propiedades permiten describir atributos correspondientes a determinadas etapas del ciclo de vida de los datos (procedencia, versionado, estructura, conformidad a estándares, formatos, etc.), Datasheets for datasets es un modelo descriptivo mucho más exhaustivo que, utilizando preguntas y respuestas abiertas (en lenguaje natural), detalla ampliamente características de cada etapa del ciclo de vida del dato. Algunas de estas preguntas/respuestas pueden ser compatibles con propiedades/rangos DCAT y ser ajustadas utilizando vocabularios controlados y esto es algo que probablemente ocurrirá. No obstante, el objetivo en Datasheets y DCAT es algo distinto: Datasheets persigue generar una documentación exhaustiva que permita a los reutilizadores descubrir detalles relevantes sobre los datos. Datasheets, en resumen, es un mecanismo de documentación de datasets muy completo y por tanto muy útil, sobre todo en determinados ámbitos de aplicación como la descripción de datos para la IA pero, de momento, conlleva un coste alto debido fundamentalmente a la falta de integración con herramientas de gestión de ciclo de vida de datos que automaticen su generación.
Con respecto al ejemplo, puedes encontrar el enlace en el texto: https://dl.acm.org/action/downloadSupplement?doi=10.1145%2F3458723&file…;
Un cordial saludo,