Data publicación
16/06/2026
Comparte este contido

Descrición
Durante años la gestión del dato siguió una lógica centralizada: recoger información, transportarla, almacenarla y procesarla en el mismo lugar. La nube (cloud) concentró gran parte del procesamiento empresarial gracias a su capacidad de almacenamiento y cómputo. Sin embargo, la evolución de los sistemas conectados está modificando este modelo. Hoy, una parte creciente del valor asociado al dato se genera cerca de su punto de origen: fábricas, tiendas, vehículos, sensores o terminales de pago. Y en muchos casos, las decisiones deben tomarse allí mismo, sin depender de la conexión constante con un servidor remoto.
Qué es exactamente Edge AI
El edge (el borde) es cualquier punto de cómputo cercano al origen del dato: una cámara con procesador integrado, un PLC (por sus siglas en inglés, Programmable Logic Controller) en una línea de producción, una pasarela industrial, un smartphone, un sensor LiDAR en un vehículo, una antena de comunicaciones en una red móvil. Edge AI consiste en ejecutar modelos de inteligencia artificial directamente en esos dispositivos, en lugar de enviar el dato crudo a un servidor remoto para que decida.
La diferencia operativa se entiende mejor con cuatro ejes.
-
Latencia: un modelo local responde en milisegundos, frente a las decenas o cientos que añade un viaje a la nube. Esta diferencia resulta determinante en aplicaciones que requieren actuar en tiempo real, donde incluso pequeñas demoras pueden comprometer la utilidad o la seguridad del sistema.
-
Ancho de banda: no toda la información generada por los dispositivos tiene el mismo valor. Transferir datos sin filtrar a la nube implica un uso intensivo de la red y un coste asociado que crece con la escala. El procesamiento en el borde permite reducir drásticamente ese tráfico al enviar únicamente la información que aporta valor. Por ejemplo, enviar el flujo de vídeo en bruto de mil cámaras es caro e innecesario si lo que interesa es solo el evento puntual.
-
Autonomía: un sistema que decide en el dispositivo mismo sigue funcionando aunque la conectividad falle, algo que puede ser crítico en muchos sectores que operan las 24 horas de los 365 días del año.
-
Privacidad y soberanía del dato: hay información (como la sanitaria, biométrica, financiera o personal) que por sensibilidad o por exigencia regulatoria no puede salir del lugar donde se genera, ni cruzar fronteras geográficas, ni alojarse en la infraestructura de un tercero. Mantener el procesamiento en el borde no es solo una decisión técnica, en muchos sectores, es la única opción legalmente viable.
Estos cuatro factores han dejado de ser preferencias técnicas para convertirse en requisitos de muchos casos de uso.
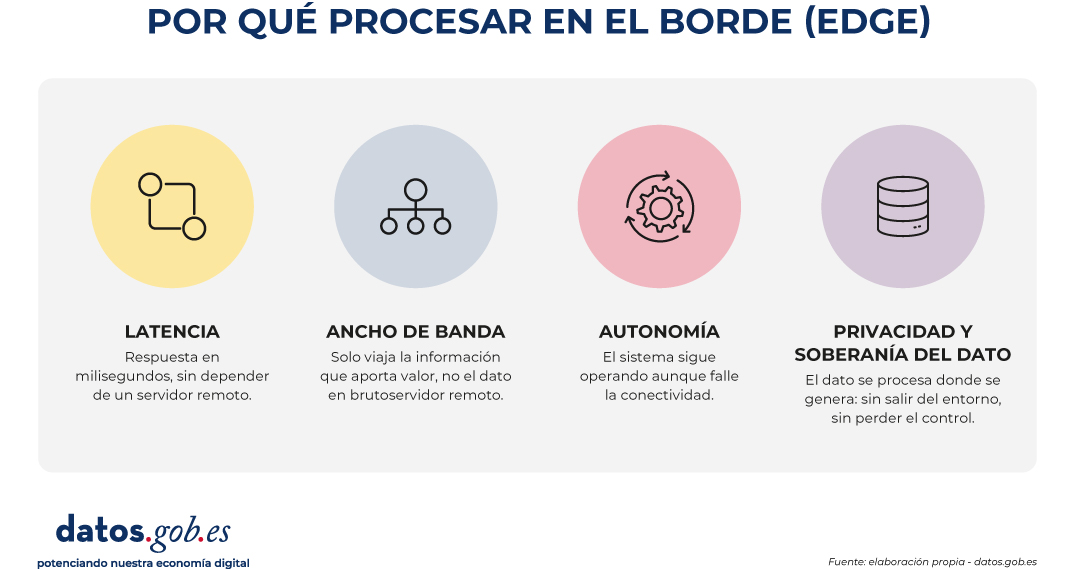
Figura 1. Visual explicativo sobre las ventajas de procesar en el borde. Fuente: elaboración propia - datos.gob.es
Algunos ejemplos de aplicación real
Una parte importante del Edge AI no necesita una fábrica, un banco, ni un supermercado: ya está en el bolsillo. El teclado predictivo del teléfono que aprende cómo escribe cada uno, el reconocimiento facial para desbloquear la pantalla, la organización automática de fotos por personas o lugares, la transcripción de notas de voz, los efectos de cámara en tiempo real. Todo eso son modelos de inteligencia artificial que se ejecutan directamente en el dispositivo. Funcionan sin conexión, no envían el dato sensible fuera del aparato y responden con una inmediatez que ningún servicio remoto puede igualar.
Algo parecido ocurre fuera del móvil, en los dispositivos que pueblan el hogar. Cámaras de seguridad que distinguen una persona de una mascota o un coche aparcado; monitores que detectan el llanto de un bebé y diferencian si es de hambre, dolor o sueño; termostatos que aprenden la rutina de la casa y ajustan la temperatura sin instrucciones; robots aspiradores que reconocen y rodean obstáculos; auriculares que cancelan el ruido en tiempo real. Todos ellos ejecutan modelos de IA dentro del propio aparato, sin enviar a la nube la imagen, el audio o la lectura del sensor.
El salto al mundo industrial sigue la misma lógica . Un avión comercial moderno tiene miles de sensores repartidos por motores, fuselaje, sistemas hidráulicos y aviónica, que generan flujos continuos de información sobre vibración, temperatura, presión y consumo. Llevar todo ese caudal de datos en tiempo real a un servidor remoto es inviable: el avión cruza océanos sin conectividad fiable, la decisión útil se mide en segundos y el coste de transmitir cada lectura es prohibitivo. La solución es ejecutar los modelos a bordo. El edge procesa la señal en bruto, detecta el patrón que anuncia una anomalía y solo envía hacia atrás lo que de verdad importa: la alerta, el diagnóstico, el contexto. Cuando el aparato aterriza, el equipo de mantenimiento ya sabe qué pieza revisar antes de que las ruedas toquen el suelo.
La misma arquitectura se aplica, con matices, a múltiples sectores que requieren anticipar fallos y ajustar operaciones en tiempo real. Desde plataformas petrolíferas y parques eólicos hasta líneas de producción, redes ferroviarias o flotas de transporte. En todos los casos el patrón es el mismo: muchos sensores generando datos donde no hay conectividad fiable, decisiones que pierden valor si llegan tarde y modelos de IA ejecutándose a centímetros del problema.
Cloud o Edge AI: cuándo conviene cada alternativa
Conviene desmontar un equívoco frecuente: Edge AI no compite con el cloud. Lo complementa. La pregunta razonable no es cuál de los dos, sino qué parte del problema vive mejor en cada sitio.
El cloud sigue siendo el lugar natural para tres cosas:
-
Entrenar modelos a gran escala, donde se necesitan miles de GPU y conjuntos de datos masivos.
-
Consolidar información de múltiples emplazamientos para análisis agregado.
-
Operar cargas donde la latencia es secundaria, como reporting, planificación u optimización a largo plazo.
El edge AI gana terreno cuando concurren las condiciones contrarias:
-
la decisión debe ser inmediata.
-
el dato no debe o no puede salir del lugar donde se genera.
-
y/o el coste de transportarlo en bruto es prohibitivo.
El patrón que se está consolidando es claramente híbrido. Los modelos se entrenan en el cloud, donde hay datasets masivos y capacidad de cómputo abundante, y se despliegan en el dispositivo para ejecutarse. Es una división del trabajo lógica: el entrenamiento es caro, más lento y consume muchos recursos; la inferencia, en cambio, es continua, en tiempo real, y conviene aproximarla al origen del dato.
El cloud actúa como el cerebro que aprende; Edge AI, como el sistema nervioso que reacciona.
Existe, además, un paso intermedio cada vez más relevante: el aprendizaje federado o federated learning. En lugar de subir los datos del usuario al cloud para entrenar el modelo, este se entrena parcialmente en cada dispositivo con los datos locales y solo los parámetros aprendidos vuelven al servidor central para consolidar una versión global mejorada. Es la técnica que usan, por ejemplo, los teclados predictivos para aprender de millones de usuarios.
Qué hace técnicamente posible el Edge AI
Que la inteligencia se ejecute fuera del data center no es solo una decisión de arquitectura, sino el resultado de varios avances que han madurado en paralelo. Hay cuatro especialmente importantes.
Frameworks de inferencia ligera
Son los entornos que permiten llevar modelos entrenados en la nube a dispositivos con recursos limitados. Herramientas como LiteRT, ONNX Runtime o Core ML actúan como un puente entre dos mundos muy distintos: el del entrenamiento (potente y flexible) y el del despliegue (restringido y específico). Sin esta capa, ejecutar modelos en Edge AI sería inviable.
Hardware especializado
Hoy en día muchos dispositivos incorporan chips diseñados para IA, como NPU o GPU móviles, capaces de ejecutar modelos con bajo consumo. Este salto permite que tareas que antes requerían servidores ahora puedan realizarse directamente en un teléfono, una cámara o un sensor.
Optimización de modelos
Para que un modelo funcione en el edge, hay que adaptarlo. Técnicas como reducir su tamaño o simplificar su estructura permiten que consuma menos memoria y energía. Aquí el cambio es clave: ya no se busca solo la máxima precisión, sino el equilibrio entre precisión, velocidad y eficiencia.
Edge MLOps
El reto no termina al desplegar el modelo. Hay que mantenerlo actualizado, monitorizar su comportamiento y gestionarlo en miles de dispositivos distribuidos. A diferencia del entorno tradicional, aquí no se gestiona un servidor, sino una flota entera, lo que cambia completamente la complejidad del problema.
El giro reciente: LLM en el dispositivo
Hasta hace poco, el edge se asociaba a modelos pequeños y muy especializados como detección de objetos, clasificación de señales o anomalías estadísticas. La generación de lenguaje y el razonamiento complejo se daban por reservados a la nube. Esa frontera se está moviendo.
Los llamados Small Language Models (i.e. Microsoft Phi, Google Gemma, Meta Llama en sus variantes de 1B y 3B parámetros) alcanzan en tareas acotadas un rendimiento comparable al de modelos diez o cien veces mayores hace apenas año y medio. Y lo hacen con un consumo que cabe en un teléfono.
La infraestructura ha acompañado el movimiento. Apple ejecuta sus modelos de Apple Intelligence directamente en el Neural Engine del dispositivo, sin enviar el dato personal a un servidor. Qualcomm ha integrado NPU (Neural Processing Units) de 45 TOPS (Trillion Operations per Second) en sus Snapdragon para portátiles, capaces de mover modelos de varios miles de millones de parámetros en local. La hoja de ruta industrial apunta a cruzar la barrera de los 100 TOPS en gama de entrada antes de 2027.
Lo que esto cambia, en la práctica, es el catálogo de aplicaciones posibles en el borde. Un asistente que responde sin conexión, un sistema de soporte técnico que opera en planta sin enviar voz al cloud, un copiloto industrial que interpreta documentación local y genera resúmenes sin salir del perímetro de la empresa. El razonamiento generativo, que hasta hace nada exclusivo del data center, empieza a tener una versión local con sentido.
Una infraestructura que se vuelve distribuida
La fotografía que emerge no es la del cloud desplazado, sino la de una arquitectura verdaderamente distribuida. Inteligencia entrenada en el centro, ejecutada en los extremos, coordinada por el medio. El dato deja de ser un material que siempre se transporta para procesarse y pasa a ser una señal que se interpreta en muchos casos donde nace.
Para quien diseña sistemas, la implicación es directa: la pregunta ya no es solo dónde guardo los datos sino dónde vive la decisión. Y la respuesta, cada vez más, es la misma: donde está el sensor, la cámara, el cajero o el teléfono. El cerebro corporativo se ha vuelto policéntrico, y eso obliga a pensar la arquitectura, la seguridad y el ciclo de vida del modelo de otra manera.
Referencias
[1] EE Times. "Edge AI Is Forcing a Rethink of Predictive Maintenance Architecture." (2024). https://www.eetimes.com/edge-ai-is-forcing-a-rethink-of-predictive-maintenance-architecture/
[2] Oxmaint. "Predictive Maintenance in Aviation: Using IoT Sensors to Monitor Aircraft and Ground Assets." (2024). https://oxmaint.com/industries/aviation-management/predictive-maintenance-aviation-iot-sensors-aircraft-assets
[3] Google Research. "Federated Learning: Collaborative Machine Learning without Centralized Training Data." (2017). https://research.google/blog/federated-learning-collaborative-machine-learning-without-centralized-training-data/
[4] Local AI Master. "Best Small AI Models 2026: Phi-4, Gemma 3, Qwen 3 Picks." (2026). https://localaimaster.com/blog/small-language-models-guide-2026
[5] Apple Machine Learning Research. "Updates to Apple's On-Device and Server Foundation Language Models." (2025). https://machinelearning.apple.com/research/apple-foundation-models-2025-updates
[6] Heqingele. "Snapdragon X Plus: 64/100 Integrated AI Power for Your 2025 PC." (2025). https://heqingele.com/blog/snapdragon-x-plus-64-100-integrated-ai-power-2025-pcs/
[7] Google AI Edge. "LiteRT: lightweight runtime for on-device AI (antes TensorFlow Lite)." (2024). https://ai.google.dev/edge/litert
[8] ONNX Runtime. "High performance ML inferencing and training accelerator." (2025). https://onnxruntime.ai/
[9] tinyML Foundation. "Machine learning on ultra-low-power microcontrollers." (2025). https://www.tinyml.org/
[10] Intel. "OpenVINO toolkit documentation." (2025). https://docs.openvino.ai/
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.


Comentarios