
Description
For years, data management followed a centralized logic: collecting information, transporting it, storing it and processing it in the same place. The cloud concentrated a large part of the business processing thanks to its storage and computing capacity. However, the evolution of connected systems is modifying this model. Today, a growing part of the value associated with data is generated near its point of origin: factories, stores, vehicles, sensors or payment terminals. And in many cases, decisions need to be made right there, without relying on the constant connection to a remote server.
What exactly is Edge AI
The edge is any computing point close to the source of the data: a camera with an integrated processor, a PLC ( PortableLogic Controller) on a production line, an industrial gateway, a smartphone, a LiDAR sensor in a vehicle, a communications antenna in a mobile network. Edge AI consists of running AI models directly on those devices, rather than sending the raw data to a remote server to decide.
The operational difference is best understood with four axes.
-
Latency: An on-premises model responds in milliseconds, compared to the tens or hundreds that a trip to the cloud adds. This difference is decisive in applications that require real-time action, where even small delays can compromise the usefulness or security of the system.
-
Bandwidth: Not all information generated by devices has the same value. Transferring unfiltered data to the cloud is network-intensive and cost-intensive and increases with scale. Edge processing allows you to dramatically reduce that traffic by sending only the information that adds value. For example, sending the raw video stream of a thousand cameras is expensive and unnecessary if you are only interested in the one-off event.
-
Autonomy: a system that decides on the device itself continues to work even if connectivity fails, something that can be critical in many sectors that operate 24 hours a day, 365 days a year.
-
Data privacy and sovereignty: there is information (such as health, biometric, financial or personal information) that, due to sensitivity or regulatory requirements, cannot leave the place where it is generated, or cross geographical borders, or be housed in the infrastructure of a third party. Keeping processing at the edge isn't just a technical decision, in many sectors, it's the only legally viable option.
These four factors are no longer technical preferences but requirements for many use cases.
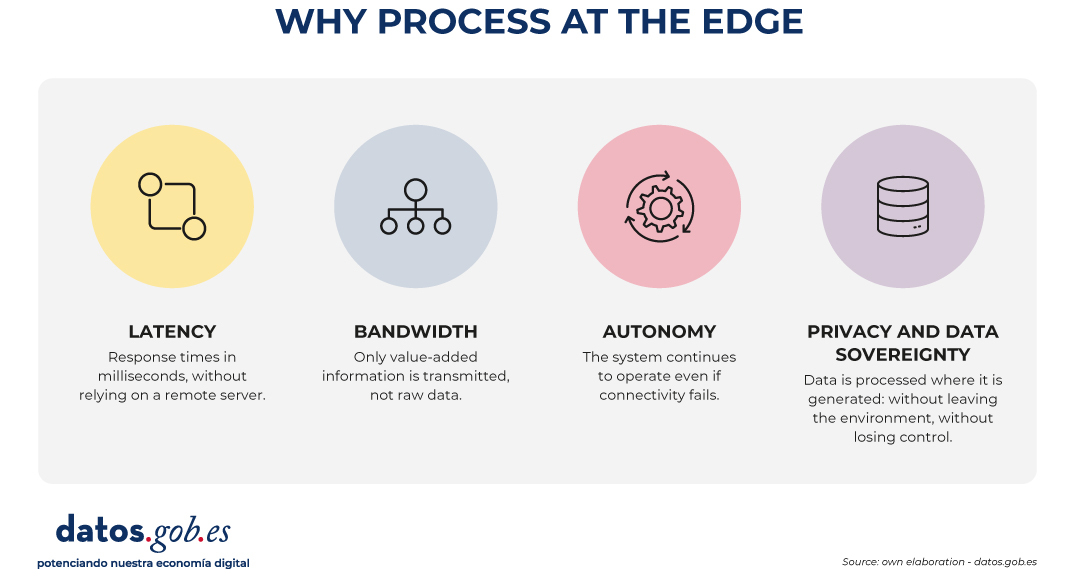
Figure 1. Illustration explaining the benefits of edge computing. Source: own creation – datos.gob.es
Some examples of real application
A significant part of Edge AI doesn't need a factory, a bank, or a supermarket – it's already in your pocket. The phone's predictive keyboard that learns how each one writes, facial recognition to unlock the screen, automatic organization of photos by people or places, voice note transcription, real-time camera effects. All of that is AI models running directly on the device. They work offline, do not send sensitive data outside the device, and respond with an immediacy that no remote service can match.
Something similar happens outside the mobile phone, in the devices that populate the home. Security cameras that distinguish a person from a pet or a parked car; monitors that detect a baby's crying and differentiate whether it is hunger, pain or sleep; thermostats that learn the routine of the house and adjust the temperature without instructions; robot vacuums that recognize and surround obstacles; headphones that cancel noise in real time. All of them run AI models inside the device itself, without sending the image, audio or sensor reading to the cloud.
The leap to the industrial world follows the same logic. A modern commercial aircraft has thousands of sensors spread across engines, fuselage, hydraulics, and avionics, generating continuous streams of vibration, temperature, pressure, and consumption information. Bringing all that wealth of real-time data to a remote server is unfeasible: the plane crosses oceans without reliable connectivity, the useful decision is measured in seconds, and the cost of transmitting each reading is prohibitive. The solution is to run the models on board. The Edge it processes the raw signal, detects the pattern that announces an anomaly and only sends back what really matters: the alert, the diagnosis, the context. When the device lands, the maintenance team already knows which part to check before the wheels touch the ground.
The same architecture is applied, with nuances, to multiple sectors that require anticipating failures and adjusting operations in real time. From oil rigs and wind farms to production lines, rail networks or transport fleets. In all cases the pattern is the same: many sensors generating data where there is no reliable connectivity, decisions that lose value if they arrive late, and AI models running inches away from the problem.
Cloud or Edge AI: when each alternative is right
It is worth dismantling a common misconception: Edge AI does not compete with the cloud. It complements it. The reasonable question is not which of the two, but which part of the problem lives better in each place.
The cloud is still the natural place for three things:
-
Train large-scale models, where thousands of GPUs and massive datasets are needed.
-
Consolidate information from multiple sites for aggregate analysis.
-
Operate loads where latency is secondary, such as long-term reporting, planning, or optimization.
Edge AI gains ground when the opposite conditions occur:
-
The decision must be immediate.
-
the data should not or cannot leave the place where it is generated.
-
and/or the cost of transporting it in raw form is prohibitive.
The pattern that is consolidating is clearly hybrid. Models are trained in the cloud, where there are massive datasets and abundant compute capacity, and deployed on the device to run. It is a logical division of labor: training is expensive, slower and consumes a lot of resources; inference, on the other hand, is continuous, in real time, and it is convenient to approximate it to the origin of the data.
The cloud acts as the brain that learns; Edge AI, like the nervous system that reacts.
There is also an increasingly relevant intermediate step: federated learning. Instead of uploading the user's data to the cloud to train the model, the model is partially trained on each device with the local data and only the learned parameters are returned to the central server to consolidate an enhanced global version. This is the technique used, for example, by predictive keyboards to learn from millions of users.
What Edge AI Makes Technically Possible
That intelligence runs outside the data center is not just an architectural decision, but the result of several advances that have matured in parallel. There are four particularly important ones.
Lightweight Inference Frameworks
These are the environments that allow you to bring trained models in the cloud to devices with limited resources. Tools such as LiteRT, ONNX Runtime or Core ML act as a bridge between two very different worlds: that of training (powerful and flexible) and that of deployment (restricted and specific). Without this layer, running models on Edge AI would be unfeasible.
Specialized Hardware
Nowadays, many devices incorporate chips designed for AI, such as NPUs or mobile GPUs , capable of running models with low consumption. This leap allows tasks that previously required servers to now be performed directly on a phone, camera, or sensor.
Model optimization
For a model to work at the edge, it needs to be adapted. Techniques such as reducing its size or simplifying its structure allow it to consume less memory and energy. Change is key here: it is no longer just the utmost precision that is sought, but the balance between precision, speed and efficiency.
Edge MLOps
The challenge does not end when the model is deployed. It must be kept up to date, its behavior monitored and managed on thousands of distributed devices. Unlike the traditional environment, here you don't manage a server, but an entire fleet, which completely changes the complexity of the problem.
The Recent Twist: LLM on the Device
Until recently, the edge was associated with small and highly specialized models such as object detection, signal classification or statistical anomalies. Language generation and complex reasoning were considered to be reserved for the cloud. That border is moving.
The so-called Small Language Models (i.e. Microsoft Phi, Google Gemma, Meta Llama in their variants of 1B and 3B parameters) achieve in limited tasks a performance comparable to that of models ten or a hundred times higher just a year and a half ago. And they do it with a consumption that fits in a phone.
The infrastructure has accompanied the movement. Apple runs its Apple Intelligence models directly on the device's Neural Engine, without sending the personal data to a server. Qualcomm has integrated NPUs (Neural Processing Units) of 45 TOPS (Trillion Operations per Second) into its Snapdragon laptops, capable of moving multi-billion parameter models locally. The industrial roadmap aims to cross the barrier of 100 TOPS in entry range before 2027.
What this changes, in practice, is the catalog of possible applications at the edge. An assistant that responds offline, a technical support system that operates on the plant without sending voice to the cloud, an industrial co-pilot that interprets local documentation and generates summaries without leaving the company's perimeter. Generative reasoning, which until recently was exclusive to the data center, is beginning to have a local version that makes sense.
An infrastructure that becomes distributed
The picture that emerges is not that of the displaced cloud, but that of a truly distributed architecture. Intelligence trained in the center, executed at the ends, coordinated by the medium. Data ceases to be a material that is always transported to be processed and becomes a signal that is interpreted in many cases where it is born.
For those who design systems, the implication is straightforward: the question is no longer just where I store the data but where the decision lives. And the answer, increasingly, is the same: where is the sensor, the camera, the ATM or the phone. The corporate brain has become polycentric, and that forces us to think about architecture, security, and the model lifecycle differently.
References
[1] EE Times. "Edge AI Is Forcing a Rethink of Predictive Maintenance Architecture." (2024). https://www.eetimes.com/edge-ai-is-forcing-a-rethink-of-predictive-maintenance-architecture/
[2] Oxmaint. "Predictive Maintenance in Aviation: Using IoT Sensors to Monitor Aircraft and Ground Assets." (2024). https://oxmaint.com/industries/aviation-management/predictive-maintenance-aviation-iot-sensors-aircraft-assets
[3] Google Research. "Federated Learning: Collaborative Machine Learning without Centralized Training Data." (2017). https://research.google/blog/federated-learning-collaborative-machine-learning-without-centralized-training-data/
[4] Local AI Master. "Best Small AI Models 2026: Phi-4, Gemma 3, Qwen 3 Picks." (2026). https://localaimaster.com/blog/small-language-models-guide-2026
[5] Apple Machine Learning Research. "Updates to Apple's On-Device and Server Foundation Language Models." (2025). https://machinelearning.apple.com/research/apple-foundation-models-2025-updates
[6] Heqingele. "Snapdragon X Plus: 64/100 Integrated AI Power for Your 2025 PC." (2025). https://heqingele.com/blog/snapdragon-x-plus-64-100-integrated-ai-power-2025-pcs/
[7] Google AI Edge. "LiteRT: lightweight runtime for on-device AI (antes TensorFlow Lite)." (2024). https://ai.google.dev/edge/litert
[8] ONNX Runtime. "High performance ML inferencing and training accelerator." (2025). https://onnxruntime.ai/
[9] tinyML Foundation. "Machine learning on ultra-low-power microcontrollers." (2025). https://www.tinyml.org/
[10] Intel. "OpenVINO toolkit documentation." (2025). https://docs.openvino.ai/
Content produced by Juan Benavente, a senior industrial engineer and expert in technologies related to the data economy. The content and views expressed in this publication are the sole responsibility of the author.


Comments