Blog
The evolution of generative AI has been dizzying: from the first great language models that impressed us with their ability to reproduce human reading and writing, through the advanced RAG (Retrieval-Augmented Generation) techniques that quantitatively improved the quality of the responses provided and the emergence of intelligent agents, to an innovation that redefines our relationship with technology: Computer use.
At the end of April 2020, just one month after the start of an unprecedented period of worldwide home confinement due to the SAR-Covid19 global pandemic, we spread from datos.gob.es the large GPT-2 and GPT-3 language models. OpenAI, founded in 2015, had presented almost a year earlier (February 2019) a new language model that was able to generate written text virtually indistinguishable from that created by a human. GPT-2 had been trained on a corpus (set of texts prepared to train language models) of about 40 GB (Gigabytes) in size (about 8 million web pages), while the latest family of models based on GPT-4 is estimated to have been trained on TB (Terabyte) sized corpora; a thousand times more.
In this context, it is important to talk about two concepts:
- LLLMs (Large Language Models ): are large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks. Today, we have countless tools based on these LLMs that, by field of expertise, are able to generate programming code, ultra-realistic images and videos, and solve complex mathematical problems. All major companies and organisations in the digital-technology sector have embarked on integrating these tools into their different software and hardware products, developing use cases that solve or optimise specific tasks and activities that previously required a high degree of human intervention.
- Agents: The user experience with artificial intelligence models is becoming more and more complete, so that we can ask our interface not only to answer our questions, but also to perform complex tasks that require integration with other IT tools. For example, we not only ask a chatbot for information on the best restaurants in the area, but we also ask them to search for table availability for specific dates and make a reservation for us. This extended user experience is what artificial intelligence agentsprovide us with. Based on the large language models, these agents are able to interact with the outside world (to the model) and "talk" to other services via APIs and programming interfaces prepared for this purpose.
Computer use
However, the ability of agents to perform actions autonomously depends on two key elements: on the one hand, their concrete programming - the functionality that has been programmed or configured for them; on the other hand, the need for all other programmes to be ready to "talk" to these agents. That is, their programming interfaces must be ready to receive instructions from these agents. For example, the restaurant reservation application has to be prepared, not only to receive forms filled in by a human, but also requests made by an agent that has been previously invoked by a human using natural language. This fact imposes a limitation on the set of activities and/or tasks that we can automate from a conversational interface. In other words, the conversational interface can provide us with almost infinite answers to the questions we ask it, but it is severely limited in its ability to interact with the outside world due to the lack of preparation of the rest of computer applications.
This is where Computer use comes in. With the arrival of the Claude 3.5 Sonnet model, Anthropic has introduced Computer use, a beta capability that allows AI to interact directly with graphical user interfaces.
How does Computer use work?
Claude can move your computer cursor as if it were you, click buttons and type text, emulating the way humans operate a computer. The best way to understand how Computer use works in practice is to see it in action. Here is a link directly to the YouTube channel of the specific Computer use section.

Figure 1. Screenshot from Anthropic's YouTube channel, Computer use specific section.
Would you like to try it?
If you've made it this far, you can't miss out without trying it with your own hands.
Here is a simple guide to testing Computer use in an isolated environment. It is important to take into account the security recommendations that Antrophic proposes in its Computer use guidelines. This feature of the Claude Sonet model can perform actions on a computer and this can be potentially dangerous, so it is recommended to carefully review the security warning of Computer use.
All official developer documentation can be found in the antrophic's official Github repository. In this post, we have chosen to run Computer use in a Docker container environment. It is the easiest and safest way to test it. If you don't already have it, you can follow the simple official guidelines to pre-install it on your system.
To reproduce this test we propose to follow this script step by step:.
- Anthropic API Key. To interact with Claude Sonet you need an Anthropic account which you can create for free here. Once inside, you can go to the API Keys section and create a new one for your test
- Once you have your API Key, you must run this command in your terminal, substituting your key where it says "%your_api_key%":

3. If everything went well, you will see these messages in your terminal and now you just have to open your browser and type this url in the navigation bar: htttp://localhost:8080/.
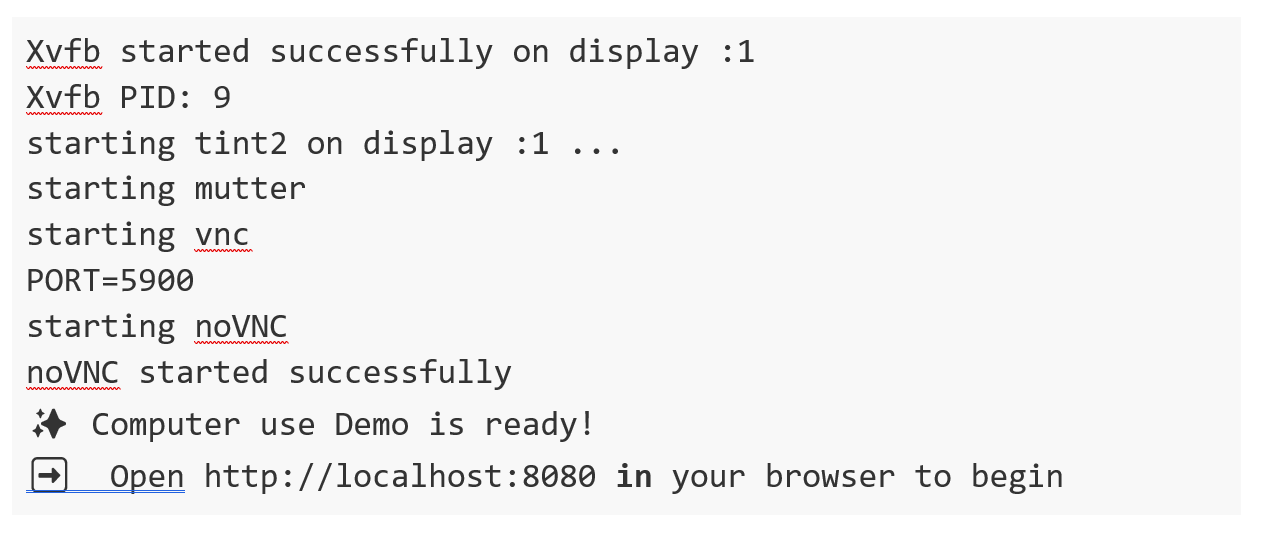
You will see your interface open:

Figure 2. Computer use interface.
You can now go to explore how Computer use works. We suggest the following prompt to get you started:
We suggest you start small. For example, ask them to open a browser and search for something. You can also ask him to give you information about your computer or operating system. Gradually, you can ask for more complex tasks. We have tested this prompt and after several trials we have managed to get Computer use to perform the complete task.
Open a browser, navigate to the datos.gob.es catalogue, use the search engine to locate a dataset on: Public security. Traffic accidents. 2014; Locate the file in csv format; download and open it with free Office.
Potential uses in data platforms such as datos.gob.es
In view of this first experimental version of Computer use, it seems that the potential of the tool is very high. We can imagine how many more things we can do thanks to this tool. Here are some ideas:
- We could ask the system to perform a complete search of datasets related to a specific topic and summarise the main results in a document. In this way, if for example we write an article on traffic data in Spain, we could unattended obtain a list of the main open datasets of traffic data in Spain in the datos.gob.es catalogue.
- In the same way, we could request a summary in the same way, but in this case, not of dataset, but of platform items.
- A slightly more sophisticated example would be to ask Claude, through the conversational interface of Computer use, to make a series of calls to the data API.gob.es to obtain information from certain datasets programmatically. To do this, we open a browser and log into an application such as Postman (remember at this point that Computer use is in experimental mode and does not allow us to enter sensitive data such as user credentials on web pages). We can then ask you to search for information about the datos.gob.es API and execute an http call, taking advantage of the fact that this API does not require authentication.
Through these simple examples, we hope that we have introduced you to a new application of generative AI and that you have understood the paradigm shift that this new capability represents. If the machine is able to emulate the use of a computer as we humans do, unimaginable new opportunities will open up in the coming months.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
The increasing adoption of artificial intelligence (AI) systems in critical areas such as public administration, financial services or healthcare has brought the need for algorithmic transparency to the forefront. The complexity of AI models used to make decisions such as granting credit or making a medical diagnosis, especially when it comes to deep learning algorithms, often gives rise to what is commonly referred to as the "black box" problem, i.e. the difficulty of interpreting and understanding how and why an AI model arrives at a certain conclusion. The LLLMs or SLMs that we use so much lately are a clear example of a black box system where not even the developers themselves are able to foresee their behaviour.
In regulated sectors, such as finance or healthcare, AI-based decisions can significantly affect people's lives and therefore it is not acceptable to raise doubts about possible bias or attribution of responsibility. As a result, governments have begun to develop regulatory frameworks such as the Artificial Intelligence Regulation that require greater explainability and oversight in the use of these systems with the additional aim of generating confidence in the advances of the digital economy.
Explainable artificial intelligence (XAI) is the discipline that has emerged in response to this challenge, proposing methods to make the decisions of AI models understandable. As in other areas related to artificial intelligence, such as LLLM training, open data is an important ally of explainable artificial intelligence to build audit and verification mechanisms for algorithms and their decisions.
What is explainable AI (XAI)?
Explainable AI refers to methods and tools that allow humans to understand and trust the results of machine learning models. According to the U.S. National Institute of Standards and Technology (NIST), the NIST is the only organisation in the U.S. that has a national standards body. The four key principles of Explainable Artificial Intelligence in the US are to ensure that AI systems are transparent, understandable and trusted by users:
- Explainability (Explainability): the AI must provide clear and understandable explanations of how it arrives at its decisions and recommendations.
- Meaningful (Meaningful): explanations must be meaningful and understandable to users.
- Accuracy (Accuracy): AI must generate accurate and reliable results, and the explanation of these results must accurately reflect its performance.
- Knowledge Limits (Knowledge Limits): AI must recognise when it does not have sufficient information or confidence in a decision and refrain from issuing responses in such cases.
Unlike traditional "black box" AI systems, which generate results without revealing their internal logic, XAI works on the traceability, interpretability and accountability of these decisions. For example, if a neural network rejects a loan application, XAI techniques can highlight the specific factors that influenced the decision. Thus, while a traditional model would simply return a numerical rating of the credit file, an XAI system could also tell us something like "Payment history (23%), job stability (38%) and current level of indebtedness (32%) were the determining factors in the loan denial". This transparency is vital not only for regulatory compliance, but also for building user confidence and improving AI systems themselves.
Key techniques in XAI
The Catalogue of trusted AI tools and metrics from the OECD's Artificial Intelligence Policy Observatory (OECD.AI) collects and shares tools and metrics designed to help AI actors develop trusted systems that respect human rights and are fair, transparent, explainable, robust, safe and reliable. For example, two widely adopted methodologies in XAI are Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP).
- LIME approximates complex models with simpler, interpretable versions to explain individual predictions. It is a generally useful technique for quick interpretations, but not very stable in assigning the importance of variables from one example to another.
- SHAP quantifies the exact contribution of each input to a prediction using game theory principles. This is a more precise and mathematically sound technique, but much more computationally expensive.
For example, in a medical diagnostic system, both LIME and SHAP could help us interpret that a patient's age and blood pressure were the main factors that led to a diagnosis of high risk of infarction, although SHAP would give us the exact contribution of each variable to the decision.
One of the most important challenges in XAI is to find the balance between the predictive ability of a model and its explainability. Hybrid approaches are therefore often used, integrating a posteriori explanatory methods of decision making with complex models. For example, a bank could implement a deep learning system for fraud detection, but use SHAP values to audit its decisions and ensure that no discriminatory decisions are made.
Open data in the XAI
There are at least two scenarios in which value can be generated by combining open data with explainable artificial intelligence techniques:
- The first of these is the enrichment and validation of the explanations obtained with XAI techniques. Open data makes it possible to add layers of context to many technical explanations, which is also true for the explainability of AI models. For example, if an XAI system indicates that air pollution influenced an asthma diagnosis, linking this result to open air quality datasets from patients' areas of residence would allow validation of the correctness of the result.
- Improving the performance of AI models themselves is another area where open data brings value. For example, if an XAI system identifies that the density of urban green space significantly affects cardiovascular risk diagnoses, open urban planning data could be used to improve the accuracy of the algorithm.
It would be ideal if AI model training datasets could be shared as open data, so that it would be possible to verify model training and replicate the results. What is possible, however, is the open sharing of detailed metadata on such trainings as promoted by Google's Model Cards initiative, thus facilitating post-hoc explanations of the models' decisions. In this case it is a tool more oriented towards developers than towards the end-users of the algorithms.
In Spain, in a more citizen-driven initiative, but equally aimed at fostering transparency in the use of artificial intelligence algorithms, the Open Administration of Catalonia has started to publish comprehensible factsheets for each AI algorithm applied to digital administration services. Some are already available, such as the AOC Conversational Chatbots or the Video ID for Mobile idCat.
Real examples of open data and XAI
A recent paper published in Applied Sciences by Portuguese researchers exemplifies the synergy between XAI and open data in the field of real estate price prediction in smart cities. The research highlights how the integration of open datasets covering property characteristics, urban infrastructure and transport networks, with explainable artificial intelligence techniques such as SHAP analysis, unravels the key factors influencing property values. This approach aims to support the generation of urban planning policies that respond to the evolving needs and trends of the real estate market, promoting sustainable and equitable growth of cities.
Another study by researchers at INRIA (French Institute for Research in Digital Sciences and Technologies), also on real estate data, delves into the methods and challenges associated with interpretability in machine learning based on linked open data. The article discusses both intrinsic techniques, which integrate explainability into model design, and post hoc methods that examine and explain complex systems decisions to encourage the adoption of transparent, ethical and trustworthy AI systems.
As AI continues to evolve, ethical considerations and regulatory measures play an increasingly important role in creating a more transparent and trustworthy AI ecosystem. Explainable artificial intelligence and open data are interconnected in their aim to foster transparency, trust and accountability in AI-based decision-making. While XAI provides the tools to dissect AI decision-making, open data provides the raw material not only for training, but also for testing some XAI explanations and improving model performance. As AI continues to permeate every facet of our lives, fostering this synergy will contribute to building systems that are not only smarter, but also fairer.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
Since last week, the Artificial Intelligence (AI) language models trained in Spanish, Catalan, Galician, Valencian and Basque, which have been developed within ALIA, the public infrastructure of AI resources, are now available. Through the ALIA Kit users can access the entire family of models and learn about the methodology used, related documentation and training and evaluation datasets. In this article we tell you about its key features.
What is ALIA?
ALIA is a project coordinated by the Barcelona Supercomputing Center-Centro Nacional de Supercomputación (BSC-CNS). It aims to provide a public infrastructure of open and transparent artificial intelligence resources, capable of generating value in both the public and private sectors.
Specifically, ALIA is a family of text, speech and machine translation models. The training of artificial intelligence systems is computationally intensive, as huge volumes of data need to be processed and analysed. These models have been trained in Spanish, a language spoken by more than 600 million people worldwide, but also in the four co-official languages. The Real Academia Española (RAE) and the Asociación de Academias de la Lengua Española, which brings together the Spanish language institutions around the world, have collaborated in this project.
The MareNostrum 5, one of the most powerful supercomputers in the world, which is located at the Barcelona Supercomputing Center, has been used for the training. It has taken thousands of hours of work to process several billion words at a speed of 314,000 trillion calculations per second.
A family of open and transparent models
The development of these models provides an alternative that incorporates local data. One of ALIA's priorities is to be an open and transparent network, which means that users, in addition to being able to access the models, have the possibility of knowing and downloading the datasets used and all related documentation. This documentation makes it easier to understand how the models work and also to detect more easily where they fail, which is essential to avoid biases and erroneous results. Openness of models and transparency of data is essential, as it creates more inclusive and socially just models, which benefit society as a whole.
Having open and transparent models encourages innovation, research and democratises access to artificial intelligence, while ensuring that it is based on quality training data.
What can I find in ALIA Kit?
Through ALIA Kit, it is currently possible to access five massive language models (LLM) of general purpose, of which two have been trained with instructions from various open corpora. Also available are nine multilingual machine translation models, some of them trained from scratch, such as one for machine translation between Galician and Catalan, or between Basque and Catalan. In addition, translation models have been trained in Aranese, Aragonese and Asturian.
We also find the data and tools used to build and evaluate the text models, such as the massive CATalog textual corpus, consisting of 17.45 billion words (about 23 billion tokens), distributed over 34.8 million documents from a wide variety of sources, which have been largely manually reviewed.
To train the speech models, different speech corpora with transcription have been used, such as, for example, a dataset of the Valencian Parliament with more than 270 hours of recordings of its sessions. It is also possible to know the corpora used to train the machine translation models.
A freeAPI (from Python, Javascript or Curl) is also available through the ALIA Kit, with which tests can be carried out.
What can these models be used for?
The models developed by ALIA are designed to be adaptable to a wide range of natural language processing tasks. However, for specific needs it is preferable to use specialised models, which are more accurate and less resource-intensive.
As we have seen, the models are available to all interested users, such as independent developers, researchers, companies, universities or institutions. Among the main beneficiaries of these tools are developers and small and medium-sized enterprises, for whom it is not feasible to develop their own models from scratch, both for economic and technical reasons. Thanks to ALIA they can adapt existing models to their specific needs.
Developers will find resources to create applications that reflect the linguistic richness of Spanish and the co-official languages. For their part, companies will be able to develop new applications, products or services aimed at the broad international market offered by the Spanish language, opening up new business and expansion opportunities.
An innovative project financed with public funds
The ALIA project is fully publicly funded with the aim of fostering innovation and the adoption of value-generating technologies in both the public and private sectors. Having a public AI infrastructure democratises access to advanced technologies, allowing small businesses, institutions and governments to harness their full potential to innovate and improve their services. It also facilitates ethical oversight of AI development and encourages innovation.
ALIA is part of the Spain's Artificial Intelligence Strategy 2024, which aims to provide the country with the necessary capabilities to meet the growing demand for AI products and services and to boost the adoption of this technology, especially in the public sector and SMEs. Within Axis 1 of this strategy is the so-called Lever 3, which focuses on the generation of models and corpora for a public infrastructure of language models. With the publication of this family of models, advances in the development of artificial intelligence resources in Spain.
Blog
Language models are at the epicentre of the technological paradigm shift that has been taking place in generative artificial intelligence (AI) over the last two years. From the tools with which we interact in natural language to generate text, images or videos and which we use to create creative content, design prototypes or produce educational material, to more complex applications in research and development that have even been instrumental in winning the 2024 Nobel Prize in Chemistry, language models are proving their usefulness in a wide variety of applicationsthat we are still exploring.
Since Google's influential 2017 paper "Attention is all you need" describing the architecture of the Transformers, the technology underpinning the new capabilities that OpenAI popularised in late 2022 with the launch of ChatGPT, the evolution of language models has been more than dizzying. In just two years, we have moved from models focused solely on text generation to multimodal versions that integrate interaction and generation of text, images and audio.
This rapid evolution has given rise to two categories of language models: SLMs (Small Language Models), which are lighter and more efficient, and LLLMs (Large Language Models), which are heavier and more powerful. Far from considering them as competitors, we should analyse SLM and LLM as complementary technologies. While LLLMs offer general processing and content generation capabilities, SLMs can provide support for more agile and specialised solutions for specific needs. However, both share one essential element: they rely on large volumes of data for training and at the heart of their capabilities is open data, which is part of the fuel used to train these language models on which generative AI applications are based.
LLLM: power driven by massive data
The LLLMs are large-scale language models with billions, even trillions, of parameters. These parameters are the mathematical units that allow the model to identify and learn patterns in the training data, giving them an extraordinary ability to generate text (or other formats) that is consistent and adapted to the users' context. These models, such as the GPT family from OpenAI, Gemini from Google or Llama from Meta, are trained on immense volumes of data and are capable of performing complex tasks, some even for which they were not explicitly trained.
Thus, LLMs are able to perform tasks such as generating original content, answering questions with relevant and well-structured information or generating software code, all with a level of competence equal to or higher than humans specialised in these tasks and always maintaining complex and fluent conversations.
The LLLMs rely on massive amounts of data to achieve their current level of performance: from repositories such as Common Crawl, which collects data from millions of web pages, to structured sources such as Wikipedia or specialised sets such as PubMed Open Access in the biomedical field. Without access to these massive bodies of open data, the ability of these models to generalise and adapt to multiple tasks would be much more limited.
However, as LLMs continue to evolve, the need for open data increases to achieve specific advances such as:
- Increased linguistic and cultural diversity: although today's LLMs are multilingual, they are generally dominated by data in English and other major languages. The lack of open data in other languages limits the ability of these models to be truly inclusive and diverse. More open data in diverse languages would ensure that LLMs can be useful to all communities, while preserving the world's cultural and linguistic richness.
- Reducción de sesgos: los LLM, como cualquier modelo de IA, son propensos a reflejar los sesgos presentes en los datos con los que se entrenan. This sometimes leads to responses that perpetuate stereotypes or inequalities. Incorporating more carefully selected open data, especially from sources that promote diversity and equality, is fundamental to building models that fairly and equitably represent different social groups.
- Constant updating: Data on the web and other open resources is constantly changing. Without access to up-to-date data, the LLMs generate outdated responses very quickly. Therefore, increasing the availability of fresh and relevant open data would allow LLMs to keep in line with current events[9].
- Entrenamiento más accesible: a medida que los LLM crecen en tamaño y capacidad, también lo hace el coste de entrenarlos y afinarlos. Open data allows independent developers, universities and small businesses to train and refine their own models without the need for costly data acquisitions. This democratises access to artificial intelligence and fosters global innovation.
To address some of these challenges, the new Artificial Intelligence Strategy 2024 includes measures aimed at generating models and corpora in Spanish and co-official languages, including the development of evaluation datasets that consider ethical evaluation.
SLM: optimised efficiency with specific data
On the other hand, SLMs have emerged as an efficient and specialised alternative that uses a smaller number of parameters (usually in the millions) and are designed to be lightweight and fast. Aunque no alcanzan la versatilidad y competencia de los LLM en tareas complejas, los SLM destacan por su eficiencia computacional, rapidez de implementación y capacidad para especializarse en dominios concretos.
For this, SLMs also rely on open data, but in this case, the quality and relevance of the datasets are more important than their volume, so the challenges they face are more related to data cleaning and specialisation. These models require sets that are carefully selected and tailored to the specific domain for which they are to be used, as any errors, biases or unrepresentativeness in the data can have a much greater impact on their performance. Moreover, due to their focus on specialised tasks, the SLMs face additional challenges related to the accessibility of open data in specific fields. For example, in sectors such as medicine, engineering or law, relevant open data is often protected by legal and/or ethical restrictions, making it difficult to use it to train language models.
The SLMs are trained with carefully selected data aligned to the domain in which they will be used, allowing them to outperform LLMs in accuracy and specificity on specific tasks, such as for example:
- Text autocompletion: a SLM for Spanish autocompletion can be trained with a selection of books, educational texts or corpora such as those to be promoted in the aforementioned AI Strategy, being much more efficient than a general-purpose LLM for this task.
- Legal consultations: a SLM trained with open legal datasets can provide accurate and contextualised answers to legal questions or process contractual documents more efficiently than a LLM.
- Customised education: ein the education sector, SLM trained with open data teaching resources can generate specific explanations, personalised exercises or even automatic assessments, adapted to the level and needs of the student.
- Medical diagnosis: An SLM trained with medical datasets, such as clinical summaries or open publications, can assist physicians in tasks such as identifying preliminary diagnoses, interpreting medical images through textual descriptions or analysing clinical studies.
Ethical Challenges and Considerations
We should not forget that, despite the benefits, the use of open data in language modelling presents significant challenges. One of the main challenges is, as we have already mentioned, to ensure the quality and neutrality of the data so that they are free of biases, as these can be amplified in the models, perpetuating inequalities or prejudices.
Even if a dataset is technically open, its use in artificial intelligence models always raises some ethical implications. For example, it is necessary to avoid that personal or sensitive information is leaked or can be deduced from the results generated by the models, as this could cause damage to the privacy of individuals.
The issue of data attribution and intellectual property must also be taken into account. The use of open data in business models must address how the original creators of the data are recognised and adequately compensated so that incentives for creators continue to exist.
Open data is the engine that drives the amazing capabilities of language models, both SLM and LLM. While the SLMs stand out for their efficiency and accessibility, the LLMs open doors to advanced applications that not long ago seemed impossible. However, the path towards developing more capable, but also more sustainable and representative models depends to a large extent on how we manage and exploit open data.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
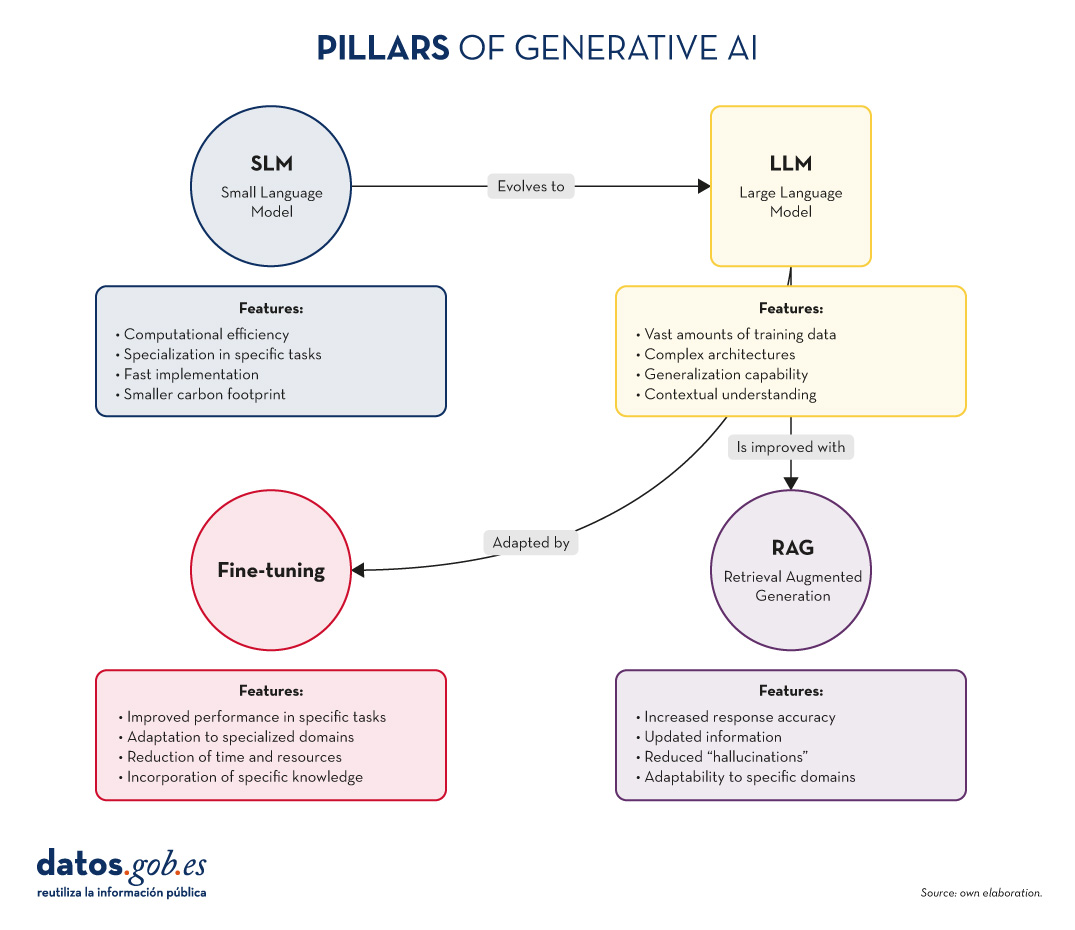
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
In recent months we have seen how the large language models (LLMs ) that enable Generative Artificial Intelligence (GenAI) applications have been improving in terms of accuracy and reliability. RAG (Retrieval Augmented Generation) techniques have allowed us to use the full power of natural language communication (NLP) with machines to explore our own knowledge bases and extract processed information in the form of answers to our questions. In this article we take a closer look at RAG techniques in order to learn more about how they work and all the possibilities they offer in the context of generative AI.
What are RAG techniques?
This is not the first time we have talked about RAG techniques. In this article we have already introduced the subject, explaining in a simple way what they are, what their main advantages are and what benefits they bring in the use of Generative AI.
Let us recall for a moment its main keys. RAG is translated as Retrieval Augmented Generation . In other words, RAG consists of the following: when a user asks a question -usually in a conversational interface-, the Artificial Intelligence (AI), before providing a direct answer -which it could give using the (fixed) knowledge base with which it has been trained-, carries out a process of searching and processing information in a specific database previously provided, complementary to that of the training. When we talk about a database, we refer to a knowledge base previously prepared from a set of documents that the system will use to provide more accurate answers. Thus, when using RAGtechniques, conversational interfaces produce more accurate and context-specific responses.
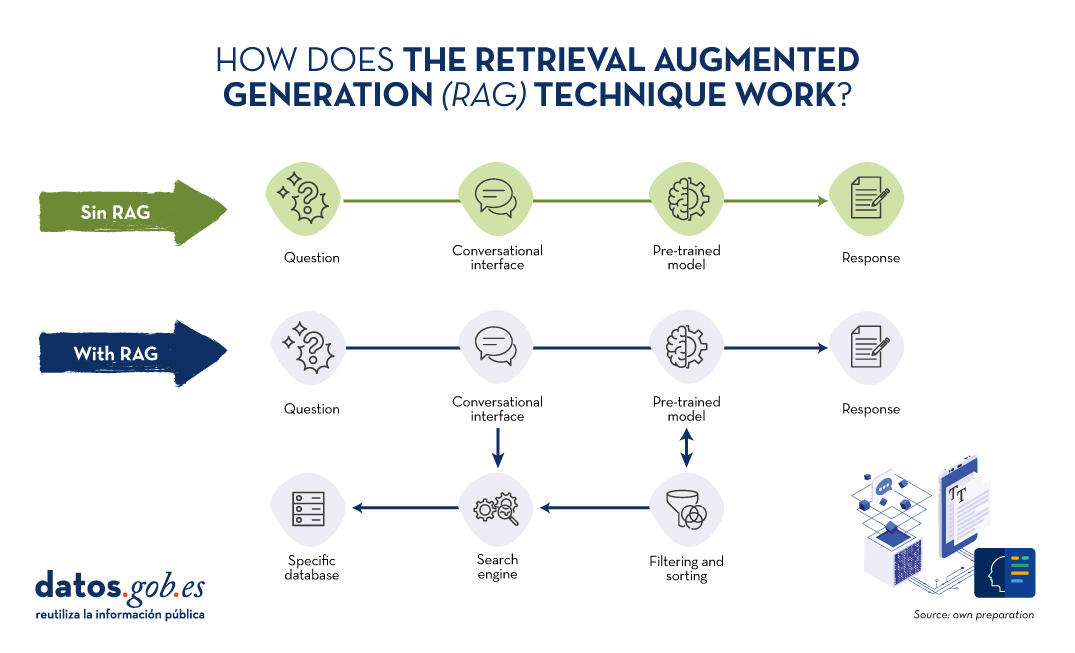
Source: Own preparation.
Conceptual diagram of the operation of a conversational interface or assistant without using RAG (top) and using RAG (bottom).
Drawing a comparison with the medical field, we could say that the use of RAG is as if a doctor, with extensive experience and therefore highly trained, in addition to the knowledge acquired during his academic training and years of experience, has quick and effortless access to the latest studies, analyses and medical databases instantly, before providing a diagnosis. Academic training and years of experience are equivalent to large language model (LLM) training and the "magic" access to the latest studies and specific databases can be assimilated to what RAG techniques provide.
Evidently, in the example we have just given, good medical practice makes both elements indispensable, and the human brain knows how to combine them naturally, although not without effort and time, even with today's digital tools, which make the search for information easier and more immediate.
RAG in detail
RAG Fundamentals
RAG combines two phases to achieve its objective: recovery and generation. In the first, relevant documents are searched for in a database containing information relevant to the question posed (e.g. a clinical database or a knowledge base of commonly asked questions and answers). In the second, an LLM is used to generate a response based on the retrieved documents. This approach ensures that responses are not only consistent but also accurate and supported by verifiable data.
Components of the RAG System
In the following, we will describe the components that a RAG algorithm uses to fulfil its function. For this purpose, for each component, we will explain what function it fulfils, which technologies are used to fulfil this function and an example of the part of the RAG process in which that component is involved.
- Recovery Model:
- Function: Identifies and retrieves relevant documents from a large database in response to a query.
- Technology: It generally uses Information Retrieval (IR) techniques such as BM25 or embedding-based retrieval models such as Dense Passage Retrieval (DPR).
- Process: Given a question, the retrieval model searches a database to find the most relevant documents and presents them as context for answer generation.
- Generation Model:
- Function: Generate coherent and contextually relevant answers using the retrieved documents.
- Technology: Based on some of the major Large Language Models (LLM) such as GPT-3.5, T5, or BERT, Llama.
- Process: The generation model takes the user's query and the retrieved documents and uses this combined information to produce an accurate response.
Detailed RAG Process
For a better understanding of this section, we recommend the reader to read this previous work in which we explain in a didactic way the basics of natural language processing and how we teach machines to read. In detail, a RAG algorithm performs the following steps:
- Reception of the question. The system receives a question from the user. This question is processed to extract keywords and understand the intention.
- Document retrieval. The question is sent to the recovery model.
- Example of Retrieval based on embeddings:
- The question is converted into a vector of embeddings using a pre-trained model.
- This vector is compared with the document vectors in the database.
- The documents with the highest similarity are selected.
- Example of BM25:
- The question is tokenised and the keywords are compared with the inverted indexes in the database.
- The most relevant documents are retrieved according to a relevance score.
- Example of Retrieval based on embeddings:
- Filtering and sorting. The retrieved documents are filtered to eliminate redundancies and to classify them according to their relevance. Additional techniques such as reranking can be applied using more sophisticated models.
- Response generation. The filtered documents are concatenated with the user's question and fed into the generation model. The LLM uses the combined information to generate an answer that is coherent and directly relevant to the question. For example, if we use GPT-3.5 as LLM, the input to the model includes both the user's question and fragments of the retrieved documents. Finally, the model generates text using its ability to understand the context of the information provided.
In the following section we will look at some applications where Artificial Intelligence and large language models play a differentiating role and, in particular, we will analyse how these use cases benefit from the application of RAGtechniques.
Examples of use cases that benefit substantially from using RAG vs. not using RAG
1. ECommerceCustomer Service
- No RAG:
- A basic chatbot can give generic and potentially incorrect answers about return policies.
- Example: Please review our returns policy on the website.
- With RAG:
- The chatbot accesses the database of updated policies and provides a specific and accurate response.
- Example: You may return products within 30 days of purchase, provided they are in their original packaging. See more details [here].
2. Medical Diagnosis
- No RAG:
- A virtual health assistant could offer recommendations based only on their previous training, without access to the latest medical information.
- Example: You may have the flu. Consult your doctor
- With RAG:
- The wizard can retrieve information from recent medical databases and provide a more accurate and up-to-date diagnosis.
- Example: Based on your symptoms and recent studies published in PubMed, you could be dealing with a viral infection. Consult your doctor for an accurate diagnosis.
3. Academic Research Assistance
- No RAG:
- A researcher receives answers limited to what the model already knows, which may not be sufficient for highly specialised topics.
- Example: Economic growth models are important for understanding the economy.
- With RAG:
- The wizard retrieves and analyses relevant academic articles, providing detailed and accurate information.
- Example: According to the 2023 study in the Journal of Economic Growth, the XYZ model has been shown to be 20% more accurate in predicting economic trends in emerging markets.
4. Journalism
- No RAG:
- A journalist receives generic information that may not be up to date or accurate.
- Example Artificial intelligence is changing many industries.
- With RAG:
- The wizard retrieves specific data from recent studies and articles, providing a solid basis for the article.
- Example: According to a 2024 report by 'TechCrunch', AI adoption in the financial sector has increased by 35% in the last year, improving operational efficiency and reducing costs.
Of course, for most of us who have experienced the more accessible conversational interfaces, such as ChatGPT, Gemini o Bing we can see that the answers are usually complete and quite precise when it comes to general questions. This is because these agents make use of AGN methods and other advanced techniques to provide the answers. However, it is not long before conversational assistants, such as Alexa, Siri u OK Google provided extremely simple answers and very similar to those explained in the previous examples when not making use of RAG.
Conclusions
Retrieval Augmented Generation (RAG) techniques improve the accuracy and relevance of language model answers by combining document retrieval and text generation. Using retrieval methods such as BM25 or DPR and advanced language models, RAG provides more contextualised, up-to-date and accurate responses.Today, RAG is the key to the exponential development of AI in the private data domain of companies and organisations. In the coming months, RAG is expected to see massive adoption in a variety of industries, optimising customer care, medical diagnostics, academic research and journalism, thanks to its ability to integrate relevant and current information in real time.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The era of digitalisation in which we find ourselves has filled our daily lives with data products or data-driven products. In this post we discover what they are and show you one of the key data technologies to design and build this kind of products: GraphQL.
Introduction
Let's start at the beginning, what is a data product? A data product is a digital container (a piece of software) that includes data, metadata and certain functional logics (what and how I handle the data). The aim of such products is to facilitate users' interaction with a set of data. Some examples are:
- Sales scorecard: Online businesses have tools to track their sales performance, with graphs showing trends and rankings, to assist in decision making.
- Apps for recommendations: Streaming TV services have functionalities that show content recommendations based on the user's historical tastes.
- Mobility apps. The mobile apps of new mobility services (such as Cabify, Uber, Bolt, etc.) combine user and driver data and metadata with predictive algorithms, such as dynamic fare calculation or optimal driver assignment, in order to offer a unique user experience.
- Health apps: These applications make massive use of data captured by technological gadgets (such as the device itself, smart watches, etc.) that can be integrated with other external data such as clinical records and diagnostic tests.
- Environmental monitoring: There are apps that capture and combine data from weather forecasting services, air quality systems, real-time traffic information, etc. to issue personalised recommendations to users (e.g. the best time to schedule a training session, enjoy the outdoors or travel by car).
As we can see, data products accompany us on a daily basis, without many users even realising it. But how do you capture this vast amount of heterogeneous information from different technological systems and combine it to provide interfaces and interaction paths to the end user? This is where GraphQL positions itself as a key technology to accelerate the creation of data products, while greatly improving their flexibility and adaptability to new functionalities desired by users.
What is GraphQL?
GraphQL saw the light of day on Facebook in 2012 and was released as Open Source in 2015. It can be defined as a language and an interpreter of that language, so that a developer of data products can invent a way to describe his product based on a model (a data structure) that makes use of the data available through APIs.
Before the advent of GraphQL, we had (and still have) the technology REST, which uses the HTTPs protocol to ask questions and get answers based on the data. In 2021, we introduced a post where we presented the technology and made a small demonstrative example of how it works. In it, we explain REST API as the standard technology that supports access to data by computer programs. We also highlight how REST is a technology fundamentally designed to integrate services (such as an authentication or login service).
In a simple way, we can use the following analogy. It is as if REST is the mechanism that gives us access to a complete dictionary. That is, if we need to look up any word, we have a method of accessing the dictionary, which is alphabetical search. It is a general mechanism for finding any available word in the dictionary. However, GraphQL allows us, beforehand, to create a dictionary model for our use case (known as a "data model"). So, for example, if our final application is a recipe book, what we do is select a subset of words from the dictionary that are related to recipes.
To use GraphQL, data must always be available via an API. GraphQL provides a complete and understandable description of the API data, giving clients (human or application) the possibility to request exactly what they need. As quoted in this post, GraphQL is like an API to which we add a SQL-style "Where" statement.
Below, we take a closer look at GraphQL's strengths when the focus is on the development of data products.
Benefits of using GraphQL in data products:
- With GraphQL, the amount of data and queries on the APIs is considerably optimised . APIs for accessing certain data are not intended for a specific product (or use case) but as a general access specification (see dictionary example above). This means that, on many occasions, in order to access a subset of the data available in an API, we have to perform several chained queries, discarding most of the information along the way. GraphQL optimises this process, as it defines a predefined (but adaptable in the future) consumption model over a technical API. Reducing the amount of data requested has a positive impact on the rationalisation of computing resources, such as bandwidth or caches, and improves the speed of response of systems.
- This has an immediate effect on the standardisation of data access. The model defined thanks to GraphQL creates a data consumption standard for a family of use cases. Again, in the context of a social network, if what we want is to identify connections between people, we are not interested in a general mechanism of access to all the people in the network, but a mechanism that allows us to indicate those people with whom I have some kind of connection. This kind of data access filter can be pre-configured thanks to GraphQL.
- Improved safety and performance: By precisely defining queries and limiting access to sensitive data, GraphQL can contribute to a more secure and better performing application.
Thanks to these advantages, the use of this language represents a significant evolution in the way of interacting with data in web and mobile applications, offering clear advantages over more traditional approaches such as REST.
Generative Artificial Intelligence. A new superhero in town.
If the use of GraphQL language to access data in a much more efficient and standard way is a significant evolution for data products, what will happen if we can interact with our product in natural language? This is now possible thanks to the explosive evolution in the last 24 months of LLMs (Large Language Models) and generative AI.
The following image shows the conceptual scheme of a data product, intLegrated with LLMS: a digital container that includes data, metadata and logical functions that are expressed as functionalities for the user, together with the latest technologies to expose information in a flexible way, such as GraphQL and conversational interfaces built on top of Large Language Models (LLMs).

How can data products benefit from the combination of GraphQL and the use of LLMs?
- Improved user experience. By integrating LLMs, people can ask questions to data products using natural language, . This represents a significant change in how we interact with data, making the process more accessible and less technical. In a practical way, we will replace the clicks with phrases when ordering a taxi.
- Security improvements along the interaction chain in the use of a data product. For this interaction to be possible, a mechanism is needed that effectively connects the backend (where the data resides) with the frontend (where the questions are asked). GraphQL is presented as the ideal solution due to its flexibility and ability to adapt to the changing needs of users,offering a direct and secure link between data and questions asked in natural language. That is, GraphQl can pre-select the data to be displayed in a query, thus preventing the general query from making some private or unnecessary data visible for a particular application.
- Empowering queries with Artificial Intelligence: The artificial intelligence not only plays a role in natural language interaction with the user. One can think of scenarios where the very model that is defined with GraphQL is assisted by artificial intelligence itself. This would enrich interactions with data products, allowing a deeper understanding and richer exploration of the information available. For example, we can ask a generative AI (such as ChatGPT) to take this catalogue data that is exposed as an API and create a GraphQL model and endpoint for us.
In short, the combination of GraphQL and LLMs represents a real evolution in the way we access data. GraphQL's integration with LLMs points to a future where access to data can be both accurate and intuitive, marking a move towards more integrated information systems that are accessible to all and highly reconfigurable for different use cases. This approach opens the door to a more human and natural interaction with information technologies, aligning artificial intelligence with our everyday experiences of communicating using data products in our day-to-day lives.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Teaching computers to understand how humans speak and write is a long-standing challenge in the field of artificial intelligence, known as natural language processing (NLP). However, in the last two years or so, we have seen the fall of this old stronghold with the advent of large language models (LLMs) and conversational interfaces. In this post, we will try to explain one of the key techniques that makes it possible for these systems to respond relatively accurately to the questions we ask them.
Introduction
In 2020, Patrick Lewis, a young PhD in the field of language modelling who worked at the former Facebook AI Research (now Meta AI Research) publishes a paper with Ethan Perez of New York University entitled: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks in which they explained a technique to make current language models more precise and concrete. The article is complex for the general public, however, in their blog, several of the authors of the article explain in a more accessible way how the RAG technique works. In this post we will try to explain it as simply as possible.
Large Language Models are artificial intelligence models that are trained using Deep Learning algorithms on huge sets of human-generated information. In this way, once trained, they have learned the way we humans use the spoken and written word, so they are able to give us general and very humanly patterned answers to the questions we ask them. However, if we are looking for precise answers in a given context, LLMs alone will not provide specific answers or there is a high probability that they will hallucinate and completely make up the answer. For LLMs to hallucinate means that they generate inaccurate, meaningless or disconnected text. This effect poses potential risks and challenges for organisations using these models outside the domestic or everyday environment of personal LLM use. The prevalence of hallucination in LLMs, estimated at 15% to 20% for ChatGPT, may have profound implications for the reputation of companies and the reliability of AI systems.
What is a RAG?
Precisely, RAG techniques have been developed to improve the quality of responses in specific contexts, for example, in a particular discipline or based on private knowledge repositories such as company databases.
RAG is an extra technique within artificial intelligence frameworks, which aims to retrieve facts from an external knowledge base to ensure that language models return accurate and up-to-date information. A typical RAG system (see image) includes an LLM, a vector database (to conveniently store external data) and a series of commands or queries. In other words, in a simplified form, when we ask a natural language question to an assistant such as ChatGPT, what happens between the question and the answer is something like this:
- The user makes the query, also technically known as a prompt.
- The RAG enriches the prompt or question with data and facts obtained from an external database containing information relevant to the user's question. This stage is called retrieval
- The RAG is responsible for sending the user's prompt enriched or augmented to the LLM which is responsible for generate a natural language response taking advantage of the full power of the human language it has learned with its generic training data, but also with the specific data provided in the retrieval stage.

Understanding RAG with examples
Let us take a concrete example. Imagine you are trying to answer a question about dinosaurs. A generalist LLM can invent a perfectly plausible answer, so that a non-expert cannot distinguish it from a scientifically based answer. In contrast, using RAG, the LLM would search a database of dinosaur information and retrieve the most relevant facts to generate a complete answer.
The same was true if we searched for a particular piece of information in a private database. For example, think of a human resources manager in a company. It wants to retrieve summarised and aggregated information about one or more employees whose records are in different company databases. Consider that we may be trying to obtain information from salary scales, satisfaction surveys, employment records, etc. An LLM is very useful to generate a response with a human pattern. However, it is impossible for it to provide consistent and accurate data as it has never been trained with such information due to its private nature. In this case, RAG assists the LLM in providing specific data and context to return the appropriate response.
Similarly, an LLM complemented by RAG on medical records could be a great assistant in the clinical setting. Financial analysts would also benefit from an assistant linked to up-to-date stock market data. Virtually any use case benefits from RAG techniques to enrich LLM capabilities with context-specific data.
Additional resources to better understand RAG
As you can imagine, as soon as we look for a moment at the more technical side of understanding LLMs or RAGs, things get very complicated. In this post we have tried to explain in simple words and everyday examples how the RAG technique works to get more accurate and contextualised answers to the questions we ask to a conversational assistant such as ChatGPT, Bard or any other. However, for those of you who have the desire and strength to delve deeper into the subject, here are a number of web resources available to try to understand a little more about how LLMs combine with RAG and other techniques such as prompt engineering to deliver the best possible generative AI apps.
Introductory videos:
LLMs and RAG content articles for beginners
- DEV - LLM for dummies
- Digital Native - LLMs for Dummies
- Hopsworks.ai - Retrieval Augmented Augmented Generation (RAG) for LLMs
- Datalytyx - RAG For Dummies
Do you want to go to the next level? Some tools to try out:
- LangChain. LangChain is a development framework that facilitates the construction of applications using LLMs, such as GPT-3 and GPT-4. LangChain is for software developers and allows you to integrate and manage multiple LLMs, creating applications such as chatbots and virtual agents. Its main advantage is to simplify the interaction and orchestration of LLMs for a wide range of applications, from text analysis to virtual assistance.
- Hugging Face. Hugging Face is a platform with more than 350,000 models, 75,000 datasets and 150,000 demo applications, all open source and publicly available online where people can easily collaborate and build artificial intelligence models.
- OpenAI. OpenAI is the best known platform for LLM models and conversational interfaces. The creators of ChatGTP provide the developer community with a set of libraries to use the OpenAI API to create their own applications using the GPT-3.5 and GPT-4 models. As an example, we suggest you visit the Python library documentation to understand how, with very few lines of code, we can be using an LLM in our own application. Although OpenAI conversational interfaces, such as ChatGPT, use their own RAG system, we can also combine GPT models with our own RAG, for example, as proposed in this article.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.