Blog
The Spanish Data Protection Agency (AEPD), through its own Innovation and Technology section, carries out an essential didactic task by providing a documentary corpus that translates the legal obligations of the General Data Protection Regulation (GDPR) into specific technological realities. Its value lies in its ability to offer legal certainty and technical guidelines in areas where regulations are still finding their practical fit, such as artificial intelligence or biometrics.
These are reference guides, articles and other teaching materials aimed especially at SMEs and entrepreneurs. In this post we present some of the most recent, ordered by sector and subject.
The new trends in artificial intelligence and its secure deployment
The evolution of artificial intelligence towards increasingly autonomous systems poses new challenges in terms of data protection. For this reason, the Spanish Data Protection Agency has developed various guides and documents aimed at facilitating a secure and responsible deployment of this technology. In general, AI is one of the areas of greatest document activity of the AEPD due to its transversal impact. The Agency's resources range from internal management to state-of-the-art technologies.
- Guide to agentric artificial intelligence from the perspective of data protection: theso-called agentric AI is one capable of making decisions and acting with a certain degree of independence. Unlike purely reactive models, an agent AI can carry out multiple tasks autonomously and make intermediate decisions during complex processes. This guide discusses the risks of loss of human control and sets out criteria to ensure that decision traceability is not lost in automation.
- General policy for the use of generative AI in AEPD administrative processes: generative artificial intelligence (IAG or GenAI) is a type of AI capable of producing new content, such as text, images, audio or code from learned patterns. This document establishes an internal policy for its responsible use in administrative processes.
- Implementation annex of the AEPD's general IAG policy: this annex to the above document includes the permitted use cases, the type of systems recommended (external, internal or ad hoc), the level of risk associated with each application and the specific obligations of review, human control, security and data protection.
- Basic summary of obligations and recommendations for the management of generative AI: this is a synthesized outline on aspects of governance, design and development of use cases, processing of personal data and sensitive information, transparency and explainability, and responsible use of tools, among others.
- Federated Learning Report: Federated learning is an AI approach that allows models to be trained collaboratively without centralizing data, improving privacy, and aligning with GDPR. This guide explains what it consists of, where personal data can be processed and what are the benefits and challenges in data protection.
To complement this information, users can also visit the AEPD's blog, which serves as a trend observatory where the visible and invisible risks of consumer technologies are analyzed. Some of the topics covered are:
- Image and voice processing: Analyses have been published on AI voice transcription and the use of services that convert photos to other formats (such as animations). These articles warn about the processing of biometric data and the ownership of data in the cloud.
- Algorithmic literacy: resources such as "Addressing AI Misconceptions" seek to raise the level of critical judgment of users and managers in the face of the opacity of algorithms.
- Balance of rights: the analysis of the protection of minors in the digital environment and the design of public contracts that integrate privacy by design stands out.
European Digital Identity Wallet
The evolution towards an interconnected Europe requires robust identity standards and security measures accessible to all levels of business.
Building a secure, interoperable and trustworthy digital identity is one of the pillars of digital transformation in Europe. The future European Digital Identity Portfolio is a project that aims to allow citizens to identify themselves electronically and share personal attributes in a controlled way across multiple services, both public and private.
To analyse its implications from the point of view of privacy, the Spanish Data Protection Agency has published a series of four monographic articles throughout 2025. In them, the Agency breaks down the relationship between the new digital identity wallet and the GDPR.
These contents address key issues such as:
- Data minimisation and the principle of proportionality in information exchange: explains how the eIDAS2 Regulation boosts the European digital identity portfolio. This regulation establishes a framework for secure, interoperable and user-centric electronic identification, aligned with the GDPR to ensure the control and protection of personal data across the EU.
- The risks associated with interoperability between systems: delves into how to prevent the use of the European Digital Identity Wallet from tracking citizens when they present credentials in different public or private services, highlighting the need for advanced cryptographic solutions.
- The need to ensure user control over their credentials: examines identification threats in digital identity wallets under eIDAS2, highlighting that, without strong safeguards such as pseudonymization and non-bonding, even selective disclosure of data can allow for the improper identification and profiling of users.
- The security measures needed to prevent misuse or data breaches: Raises the threats of inaccuracy in digital identity wallets under eIDAS2, highlighting how outdated data or linkable cryptographic mechanisms can lead to erroneous decisions and compromise privacy. To solve this, it stresses the need for solutions that guarantee both reliability and plausible deniability (that there is no technical evidence to prove that a person has carried out a specific action with their wallet or digital credential).
This series provides a progressive overview that helps to understand both the potential of European digital identity and the challenges posed by its implementation from a data protection perspective.
Personal Data Protection Encryption in SMBs
For many small and medium-sized businesses, ensuring the security of personal data remains a challenge, especially due to a lack of technical resources or specialized knowledge. In this context, encryption is presented as a fundamental tool to protect the confidentiality and integrity of information.
With the aim of bringing this concept closer to a non-expert audience, the Spanish Data Protection Agency has published the Encryption Guide for the self-employed and SMEs, accompanied by an explanatory infographic.
These resources explain in a clear and practical way:
- What is encryption and why is it important in data protection?
- What types of encryption exist and in which cases they are applied.
- How to implement encryption measures in common situations, such as sending emails or storing information.
- Which tools can be used without the need for advanced knowledge.
Scientific research and the European legal framework
For profiles that require a more in-depth and academic analysis, the Agency has promoted the publication of scientific articles in various international media, which connect technology with ethics and law. Some examples are:
- Addictive patterns: analysis of how interface design affects human behavior.
- Neurotechnology: study on the risks of brain-computer interfaces.
- Algorithmic governance: A comprehensive analysis that aligns the GDPR with the European Artificial Intelligence Regulation (AI Act), the Digital Services Act (DSA), and the Cyber Resilience Act.
The didactic value of these materials lies in their ability to offer a 360-degree view of the data. From cutting-edge academic research to encryption infographics for a small business, the AEPD provides the building blocks for innovation that doesn't sacrifice privacy.
Together, these materials shared by the Spanish Data Protection Agency help to incorporate effective security measures and comply with the requirements of the General Data Protection Regulation in a proportionate and accessible way. All of them, and some others, are compiled and ordered by theme in its website, available here.
Blog
The importance of data in today's society and economy is no longer in doubt. Data is now present in virtually every aspect of our lives. This is why more and more countries have been incorporating specific data-related regulations into their policies: whether they relate to personal, business or government data, or to regulate a range of issues such as who can access it, where it can be stored, how it should be protected, and so on.
However, when these policies are examined more closely, significant differences can be observed between them, depending on the main objectives that each country sets when implementing its data policies. Thus, all countries recognise the social and economic value of data, but the policies they implement to maximise that value can vary widely. For some, data is primarily an economic asset, for others it can be a means of innovation and modernisation, and for others a tool for development. In the following, we will review the main features of their data policies, focusing mainly on those aspects related to fostering innovation through the use of data.
A recent report by the Centre for Innovation through Data compares the general policies applicable in several countries that have been selected precisely because of differences in their vision of how data should be managed: China, India, Singapore, the United Kingdom and the European Union.
CHINA
Its efforts are focused on building a strong domestic data economy to strengthen national competitiveness and maintain government control through the collection and use of data. It has two agencies from which data policy is directed: the Cyberspace Administration (CAC) and the National Data Administration (NDA).
The main policies governing data in the country are:
- The five-year national informatisation plan, published by the end of 2021 to increase data collection in the national industry.
- The data Security Law (DSL), effective from September 2021, which gives special protection to all data considered to have an impact on national security.
- The cybersecurity law (CSL), effective since June 2017, prohibits online anonymisation and also grants government access to data when required for security purposes.
- The personal Information Protection Act (PIPL), effective from November 2021, which establishes the obligation to keep data on national territory.
INDIA
Its main objective is to use data policy to unlock a new economic resource and drive the modernisation and development of the country. The Ministry of Electronics and Information Technology (MEITy) governs and oversees data policies in the country, which we summarise below:
- The digital Personal Data Protection Act of 2023, which aims to enable the processing of personal data in a way that recognises both the right of individuals to protect their data and the need to process it for legitimate purposes.
- The data protection and empowerment architecture (DEPA), which was launched in 2020 and gives citizens greater control over their personal data by establishing intermediaries between information users and providers, as well as providing consent to companies based on a set of permissions established by the user.
- The non-personal data governance framework also adopted in 2020, which states that the benefits of data should also accrue to the community, not just to the companies that collect the data. It also indicates that high-value data and data related to the public interest (e.g. energy, transport, geospatial or health data) should be shared.
SINGAPORE
It aims to use data as a vehicle to attract new companies to operate within the country. The Infocomm Media Development Authority (IMDA) is the entity in charge of managing the data policies in this case, which includes the control of the Personal Data Protection Commission (PDPC).
Among the most relevant regulations in this case we can find:
- The personal Data Protection Act (PDPA), which was last updated in 2021 and is based on consent, but also provides for some exceptions for legitimate public interest.
- The trust Framework for Data Sharing published in 2019, which sets out standards for data sharing between companies (including templates for establishing legal sharing agreements), albeit with certain protections for trade secrecy.
- The data Portability Obligation (DPO), which will soon be incorporated into the PDPA to establish the right to transmit personal data to another service (provided it is based in the country) in a standard format that facilitates the exchange.
UNITED KINGDOM
It wants to boost the country's economic competitiveness while protecting the privacy of its citizens' data. The Office of the Information information Commissioner's Office (ICO) is the body in charge of data protection and data sharing guidelines.
In the case of the United Kingdom, the legislative framework is very broad:
- The core privacy principles, such as data portability or conditions of access to personal data, are covered by the General Data Protection Regulation (GDPR) of 2016, the law of Data Protection Act (DPA) of 2018, the Electronic Communications Privacy Regulation of 2013 and the proposed Digital Data and Information Protection Act still under discussion.
- The law on Digital Economy established in 2017, which defines the rules for sharing data between public administrations for the development of public services.
- The Data Sharing Code which came into force in October 2021 and sets out good practices to guide companies when sharing data.
- The Payment Services Directive (PSD2), which initially came into force in 2018 requiring banks to share their data in standardised formats to encourage the development of new services.
EUROPEAN UNION
It uses a human rights-based approach to data protection. The aim is to prioritise the creation of a single market that facilitates the free flow of data between member states. The European Data Protection Board (EDPB) and the European Data Protection and Innovation through Data Board are the main bodies responsible for supervising data protection in the Union.
Again, the applicable rules are very broad and have continued to expand recently:
- The General Data Protection Regulation (GDPR), which has become the most comprehensive and descriptive regulation in the world, and is based on the principles of legality, fairness, transparency, containment, minimisation, accuracy, storage, integrity, confidentiality and accountability.
- The programme for the Digital Decadeto promote a single, interoperable, interconnected and secure digital market.
- The Declaration on Digital Rights and Principleswhich expands on the digital and data rights already existing in the standard of protection.
- The Data Act and the Data Governance Regulation which facilitate accessibility to data horizontally accessibility to data horizontally, i.e. across and within sectors, following EU principles. The Data Law drives harmonised rules on fair access to and use of data, clarifying who can create value from data and under what conditions. The Data Governance Regulation regulates the secure exchange of data sets held by public bodies over which third party rights concur, as well as data brokering services and the altruistic transfer ofdata for the benefit of society for the benefit of society.
The keys to promoting innovation
In general, we could conclude that those data policies that adopt a more innovation-oriented approach are characterised by the following:
- Data protection based on different levels of risk, prioritising the protection of the most sensitive personal data, such as medical or financial information, while reducing regulatory costs for less sensitive data.
- Sharing frameworks for personal and non-personal data, encouraging data sharing by default in both the public and private sector and removing barriers to voluntary data sharing.
- Facilitating the flow of data, supporting an open and competitive digital economy.
- Proactive data production policies, encouraging the use of data as a factor of production by collecting data in various sectors and avoiding data gaps.
As we have seen, data policies have become a strategic issue for many countries, not only helping to reinforce their goals and priorities as a nation, but also sending signals about what their priorities and interests are on the international stage. Striking the right balance between data protection and fostering innovation is one of the key challenges. Before addressing their own policies, countries are advised to invest time in analysing and understanding the various existing approaches, including their strengths and weaknesses, and then take the most appropriate specific steps in designing their own strategies.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
Image segmentation is a method that divides a digital image into subgroups (segments) to reduce its complexity, thus facilitating its processing or analysis. The purpose of segmentation is to assign labels to pixels to identify objects, people, or other elements in the image.
Image segmentation is crucial for artificial vision technologies and algorithms, but it is also used in many applications today, such as medical image analysis, autonomous vehicle vision, face recognition and detection, and satellite image analysis, among others.
Segmenting an image is a slow and costly process. Therefore, instead of processing the entire image, a common practice is image segmentation using the mean-shift approach. This procedure employs a sliding window that progressively traverses the image, calculating the average pixel values within that region.
This calculation is done to determine which pixels should be incorporated into each of the delineated segments. As the window advances along the image, it iteratively recalibrates the calculation to ensure the suitability of each resulting segment.
When segmenting an image, the factors or characteristics primarily considered are:
-
Color: Graphic designers have the option to use a green-toned screen to ensure chromatic uniformity in the background of the image. This practice enables the automation of background detection and replacement during the post-processing stage.
-
Edges: Edge-based segmentation is a technique that identifies the edges of various objects in a given image. These edges are identified based on variations in contrast, texture, color, and saturation.
-
Contrast: The image is processed to distinguish between a dark figure and a light background based on high-contrast values.
These factors are applied in different segmentation techniques:
-
Thresholds: Divide the pixels based on their intensity relative to a specified threshold value. This method is most suitable for segmenting objects with higher intensity than other objects or backgrounds.
-
Regions: Divide an image into regions with similar characteristics by grouping pixels with similar features.
-
Clusters: Clustering algorithms are unsupervised classification algorithms that help identify hidden information in the images. The algorithm divides the images into groups of pixels with similar characteristics, separating elements into groups and grouping similar elements in these groups.
-
Watersheds: This process transforms grayscale images, treating them as topographic maps, where the brightness of pixels determines their height. This technique is used to detect lines forming ridges and watersheds, marking the areas between watershed boundaries.
Machine learning and deep learning have improved these techniques, such as cluster segmentation, and have also generated new segmentation approaches that use model training to enhance program capabilities in identifying important features. Deep neural network technology is especially effective for image segmentation tasks.
Currently, there are different types of image segmentation, with the main ones being:
- Semantic Segmentation: Semantic image segmentation is a process that creates regions within an image and assigns semantic meaning to each of them. These objects, also known as semantic classes, such as cars, buses, people, trees, etc., have been previously defined through model training, where these objects are classified and labeled. The result is an image where pixels are classified into each located object or class.
- Instance Segmentation: Instance segmentation combines the semantic segmentation method (interpreting the objects in an image) with object detection (locating them within the image). As a result of this segmentation, objects are located, and each of them is individualized through a bounding box and a binary mask, determining which pixels within that window belong to the located object.
- Panoptic Segmentation: This is the most recent type of segmentation. It combines semantic segmentation and instance segmentation. This method can determine the identity of each object because it locates and distinguishes different objects or instances and assigns two labels to each pixel in the image: a semantic label and an instance ID. This way, each object is unique.

In the image, you can observe the results of applying different segmentations to a satellite image. Semantic segmentation returns a category for each type of identified object. Instance segmentation provides individualized objects along with their bounding boxes, and in panoptic segmentation, we obtain individualized objects and also differentiate the context, allowing for the detection of the ground and street regions.
Meta's New Model: SAM
In April 2023, Meta's research department introduced a new Artificial Intelligence (AI) model called SAM (Segment Anything Model). With SAM, image segmentation can be performed in three ways:
-
By selecting a point in the image, SAM will search for and distinguish the object intersecting with that point and find all identical objects in the image.
-
Using a bounding box, a rectangle is drawn on the image, and all objects found in that area are identified.
-
By using keywords, users can type a word in a console, and SAM can identify objects that match that word or explicit command in both images and videos, even if that information was not included in its training.
SAM is a flexible model that was trained on the largest dataset to date, called SA-1B, which includes 11 million images and 1.1 billion segmentation masks. Thanks to this data, SAM can detect various objects without the need for additional training.
Currently, SAM and the SA-1B dataset are available for non-commercial use and research purposes only. Users who upload their images are required to commit to using it solely for academic purposes. To try it out, you can visit this GitHub link.
In August 2023, the Image and Video Analysis Group of the Chinese Academy of Sciences released an update to their model called FastSAM, significantly reducing processing time with a 50 times faster execution speed compared to the original SAM model. This makes the model more practical for real-world usage. FastSAM achieved this acceleration by training on only 2% of the data used to train SAM, resulting in lower computational requirements while maintaining high accuracy.
SAMGEO: The Version for Analyzing Geospatial Data
The segment-geospatial package developed by Qiusheng Wu aims to facilitate the use of the Segment Anything Model (SAM) for geospatial data. For this purpose, two Python packages, segment-anything-py and segment-geospatial, have been developed, and they are available on PyPI and conda-forge.
The goal is to simplify the process of leveraging SAM for geospatial data analysis, allowing users to achieve it with minimal coding effort. These libraries serve as the basis for the QGIS Geo-SAM plugin and the integration of the model in ArcGIS Pro.
En la imagen se pueden observar los resultados de aplicar las distintas segmentaciones a una imagen satelital. La segmentación semántica devuelve una categoría por cada tipo de objeto identificado. La segmentación por instancia devuelve los objetos individualizados y la caja delimitadora y, en la segmentación panóptica, obtenemos los objetos individualizados y el contexto también diferenciado, pudiendo detectar el suelo y la región de calles.

Conclusions
In summary, SAM represents a significant revolution not only for the possibilities it opens in terms of editing photos or extracting elements from images for collages or video editing but also for the opportunities it provides to enhance computer vision when using augmented reality glasses or virtual reality headsets.
SAM also marks a revolution in spatial information acquisition, improving object detection through satellite imagery and facilitating the rapid detection of changes in the territory.
Content created by Mayte Toscano, Senior Consultant in Data Economy Technologies.
The content and viewpoints reflected in this publication are the sole responsibility of the author.
Blog
The demand for professionals with skills related to data analytics continues to grow and it is already estimated that just the industry in Spain would need more than 90,000 data and artificial intelligence professionals to boost the economy. Training professionals who can fill this gap is a major challenge. Even large technology companies such as Google, Amazon or Microsoft are proposing specialised training programmes in parallel to those proposed by the formal education system. And in this context, open data plays a very relevant role in the practical training of these professionals, as open data is often the only possibility to carry out real exercises and not just simulated ones.
Moreover, although there is not yet a solid body of research on the subject, some studies already suggest positive effects derived from the use of open data as a tool in the teaching-learning process of any subject, not only those related to data analytics. Some European countries have already recognised this potential and have developed pilot projects to determine how best to introduce open data into the school curriculum.
In this sense, open data can be used as a tool for education and training in several ways. For example, open data can be used to develop new teaching and learning materials, to create real-world data-based projects for students or to support research on effective pedagogical approaches. In addition, open data can be used to create opportunities for collaboration between educators, students and researchers to share best practices and collaborate on solutions to common challenges.
Projects based on real-world data
A key contribution of open data is its authenticity, as it is a representation of the enormous complexity and even flaws of the real world as opposed to artificial constructs or textbook examples that are based on much simpler assumptions.
An interesting example in this regard is documented by Simon Fraser University in Canada in their Masters in Publishing where most of their students come from non-STEM university programmes and therefore had limited data handling skills. The project is available as an open educational resource on the OER Commons platform and aims to help students understand that metrics and measurement are important strategic tools for understanding the world around us.
By working with real-world data, students can develop story-building and research skills, and can apply analytical and collaborative skills in using data to solve real-world problems. The case study conducted with the first edition of this open data-based OER is documented in the book "Open Data as Open Educational Resources - Case studies of emerging practice". It shows that the opportunity to work with data pertaining to their field of study was essential to keep students engaged in the project. However, it was dealing with the messiness of 'real world' data that allowed them to gain valuable learning and new practical skills.
Development of new learning materials
Open datasets have a great potential to be used in the development of open educational resources (OER), which are free digital teaching, learning and research materials, as they are published under an open licence (Creative Commons) that allows their use, adaptation and redistribution for non-commercial uses according to UNESCO's definition.
In this context, although open data are not always OER, we can say that they become OER when are used in pedagogical contexts. Open data used as an educational resource facilitates students to learn and experiment by working with the same datasets used by researchers, governments and civil society. It is a key component for students to develop analytical, statistical, scientific and critical thinking skills.
It is difficult to estimate the current presence of open data as part of OER but it is not difficult to find interesting examples within the main open educational resource platforms. On the Procomún platform we can find interesting examples such as Learning Geography through the evolution of agrarian landscapes in Spain, which builds a Webmap for learning about agrarian landscapes in Spain on the ArcGIS Online platform of the Complutense University of Madrid. The educational resource uses specific examples from different autonomous communities using photographs or geolocated still images and its own data integrated with open data. In this way, students work on the concepts not through a mere text description but with interactive resources that also favour the improvement of their digital and spatial competences.
On the OER Commons platform, for example, we find the resource "From open data to civic engagement", which is aimed at audiences from secondary school upwards, with the objective of teaching them to interpret how public money is spent in a given regional, local area or neighbourhood. It is based on the well-known projects to analyse public budgets "Where do my taxes go?", available in many parts of the world as a result of the transparency policies of public authorities. This resource could be easily ported to Spain, as there are numerous "Where do my taxes go?" projects, such as the one maintained by Fundación Civio.
Data-related skills
When we refer to training and education in data-related skills, we are actually referring to a very broad area that is also very difficult to master in all its facets. In fact, it is common for data-related projects to be tackled in teams where each member has a specialised role in one of these areas. For example, it is common to distinguish at least data cleaning and preparation, data modelling and data visualisation as the main activities performed in a data science and artificial intelligence project.
In all cases, the use of open data is widely adopted as a central resource in the projects proposed for the acquisition of any of these skills. The well-known data science community Kaggle organises competitions based on open datasets contributed to the community and which are an essential resource for real project-based learning for those who want to acquire data-related skills. There are other subscription-based proposals such as Dataquest or ProjectPro but in all cases they use real datasets from multiple general open data repositories or knowledge area specific repositories.
Open data, as in other areas, has not yet developed its full potential as a tool for education and training. However, as can be seen in the programme of the latest edition of the OER Conference 2022, there are an increasing number of examples of open data playing a central role in teaching, new educational practices and the creation of new educational resources for all kinds of subjects, concepts and skills
Content written by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Blog
After several months of tests and different types of training, the first massive Artificial Intelligence system in the Spanish language is capable of generating its own texts and summarising existing ones. MarIA is a project that has been promoted by the Secretary of State for Digitalisation and Artificial Intelligence and developed by the National Supercomputing Centre, based on the web archives of the National Library of Spain (BNE).
This is a very important step forward in this field, as it is the first artificial intelligence system expert in understanding and writing in Spanish. As part of the Language Technology Plan, this tool aims to contribute to the development of a digital economy in Spanish, thanks to the potential that developers can find in it.
The challenge of creating the language assistants of the future
MarIA-style language models are the cornerstone of the development of the natural language processing, machine translation and conversational systems that are so necessary to understand and automatically replicate language. MarIA is an artificial intelligence system made up of deep neural networks that have been trained to acquire an understanding of the language, its lexicon and its mechanisms for expressing meaning and writing at an expert level.
Thanks to this groundwork, developers can create language-related tools capable of classifying documents, making corrections or developing translation tools.
The first version of MarIA was developed with RoBERTa, a technology that creates language models of the "encoder" type, capable of generating an interpretation that can be used to categorise documents, find semantic similarities in different texts or detect the sentiments expressed in them.
Thus, the latest version of MarIA has been developed with GPT-2, a more advanced technology that creates generative decoder models and adds features to the system. Thanks to these decoder models, the latest version of MarIA is able to generate new text from a previous example, which is very useful for summarising, simplifying large amounts of information, generating questions and answers and even holding a dialogue.
Advances such as the above make MarIA a tool that, with training adapted to specific tasks, can be of great use to developers, companies and public administrations. Along these lines, similar models that have been developed in English are used to generate text suggestions in writing applications, summarise contracts or search for specific information in large text databases in order to subsequently relate it to other relevant information.
In other words, in addition to writing texts from headlines or words, MarIA can understand not only abstract concepts, but also their context.
More than 135 billion words at the service of artificial intelligence
To be precise, MarIA has been trained with 135,733,450,668 words from millions of web pages collected by the National Library, which occupy a total of 570 Gigabytes of information. The MareNostrum supercomputer at the National Supercomputing Centre in Barcelona was used for the training, and a computing power of 9.7 trillion operations (969 exaflops) was required.
Bearing in mind that one of the first steps in designing a language model is to build a corpus of words and phrases that serves as a database to train the system itself, in the case of MarIA, it was necessary to carry out a screening to eliminate all the fragments of text that were not "well-formed language" (numerical elements, graphics, sentences that do not end, erroneous encodings, etc.) and thus train the AI correctly.
Due to the volume of information it handles, MarIA is already the third largest artificial intelligence system for understanding and writing with the largest number of massive open-access models. Only the language models developed for English and Mandarin are ahead of it. This has been possible mainly for two reasons. On the one hand, due to the high level of digitisation of the National Library's heritage and, on the other hand, thanks to the existence of a National Supercomputing Centre with supercomputers such as the MareNostrum 4.
The role of BNE datasets
Since it launched its own open data portal (datos.bne.es) in 2014, the BNE has been committed to bringing the data available to it and in its custody closer: data on the works it preserves, but also on authors, controlled vocabularies of subjects and geographical terms, among others.
In recent years, the educational platform BNEscolar has also been developed, which seeks to offer digital content from the Hispánica Digital Library's documentary collection that may be of interest to the educational community.
Likewise, and in order to comply with international standards of description and interoperability, the BNE data are identified by means of URIs and linked conceptual models, through semantic technologies and offered in open and reusable formats. In addition, they have a high level of standardisation.
Next steps
Thus, and with the aim of perfecting and expanding the possibilities of use of MarIA, it is intended that the current version will give way to others specialised in more specific areas of knowledge. Given that it is an artificial intelligence system dedicated to understanding and generating text, it is essential for it to be able to cope with lexicons and specialised sets of information.
To this end, the PlanTL will continue to expand MarIA to adapt to new technological developments in natural language processing (more complex models than the GPT-2 now implemented, trained with larger amounts of data) and will seek ways to create workspaces to facilitate the use of MarIA by companies and research groups.
Content prepared by the datos.gob.es team.
Blog
Open data portals are experiencing a significant growth in the number of datasets being published in the transport and mobility category. For example, the EU's open data portal already has almost 48,000 datasets in the transport category or Spain's own portal datos.gob.es, which has around 2,000 datasets if we include those in the public sector category. One of the main reasons for the growth in the publication of transport-related data is the existence of three directives that aim to maximise the re-use of datasets in the area. The PSI directive on the re-use of public sector information in combination with the INSPIRE directive on spatial information infrastructure and the ITS directive on the implementation of intelligent transport systems, together with other legislative developments, make it increasingly difficult to justify keeping transport and mobility data closed.
In this sense, in Spain, Law 37/2007, as amended in November 2021, adds the obligation to publish open data to commercial companies belonging to the institutional public sector that act as airlines. This goes a step further than the more frequent obligations with regard to data on public passenger transport services by rail and road.
In addition, open data is at the heart of smart, connected and environmentally friendly mobility strategies, both in the case of the Spanish "es.movilidad" strategy and in the case of the sustainable mobility strategy proposed by the European Commission. In both cases, open data has been introduced as one of the key innovation vectors in the digital transformation of the sector to contribute to the achievement of the objectives of improving the quality of life of citizens and protecting the environment.
However, much less is said about the importance and necessity of open data during the research phase, which then leads to the innovations we all enjoy. And without this stage in which researchers work to acquire a better understanding of the functioning of the transport and mobility dynamics of which we are all a part, and in which open data plays a fundamental role, it would not be possible to obtain relevant innovations or well-informed public policies. In this sense, we are going to review two very relevant initiatives in which coordinated multi-national efforts are being made in the field of mobility and transport research.
The information and monitoring system for transport research and innovation
At the European level, the EU also strongly supports research and innovation in transport, aware that it needs to adapt to global realities such as climate change and digitalisation. The Strategic Transport Research and Innovation Agenda (STRIA) describes what the EU is doing to accelerate the research and innovation needed to radically change transport by supporting priorities such as electrification, connected and automated transport or smart mobility.
In this sense, the Transport Research and Innovation Monitoring and Information System (TRIMIS) is the tool maintained by the European Commission to provide open access information on research and innovation (R&I) in transport and was launched with the mission to support the formulation of public policies in the field of transport and mobility.
TRIMIS maintains an up-to-date dashboard to visualise data on transport research and innovation and provides an overview and detailed data on the funding and organisations involved in this research. The information can be filtered by the seven STRIA priorities and also includes data on the innovation capacity of the transport sector.
If we look at the geographical distribution of research funds provided by TRIMIS, we see that Spain appears in fifth place, far behind Germany and France. The transport systems in which the greatest effort is being made are road and air transport, beneficiaries of more than half of the total effort.
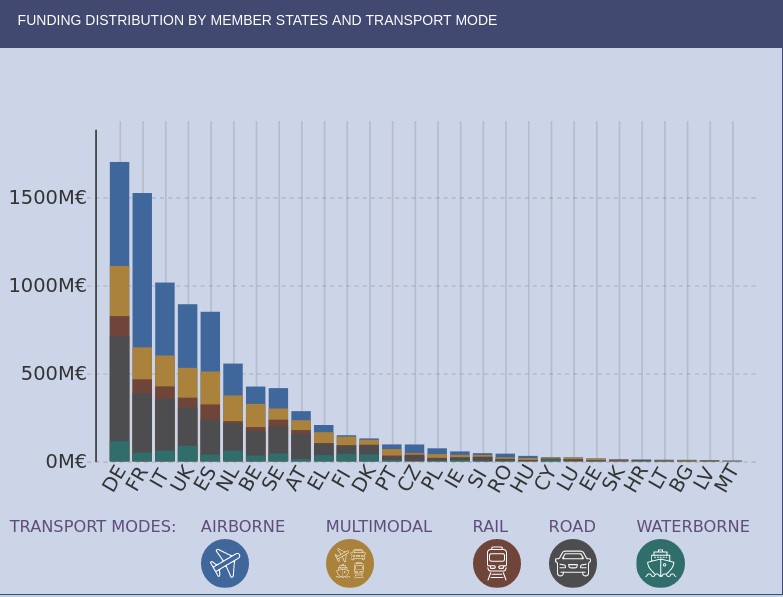
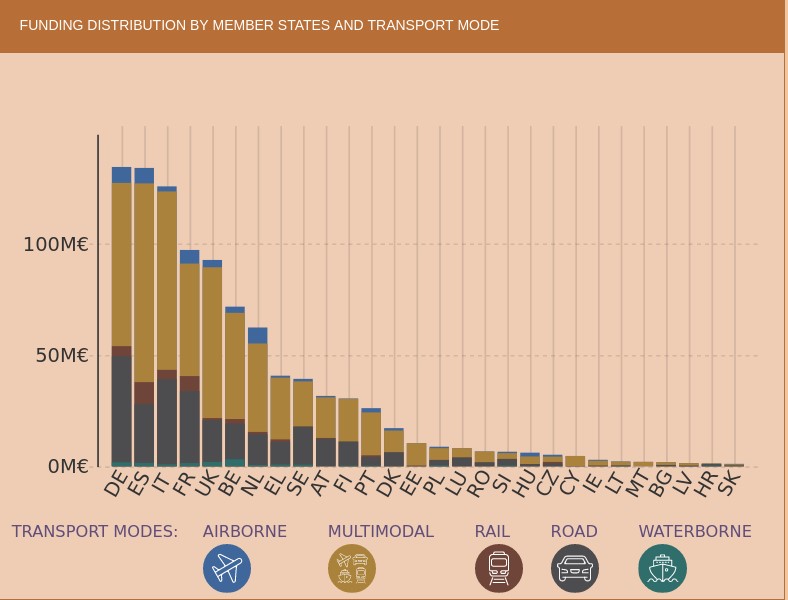
However, we find that in the strategic area of Smart Mobility and Services (SMO), which are evaluated in terms of their contribution to the overall sustainability of the energy and transport system, Spain is leading the research effort at the same level as Germany. It should also be noted that the effort being made in Spain in terms of multimodal transport is higher than in other countries.
As an example of the research effort being carried out in Spain, we have the pilot dataset to implement semantic capabilities on traffic incident information related to safety on the Spanish state road network, except for the Basque Country and Catalonia, which is published by the General Directorate of Traffic and which uses an ontology to represent traffic incidents developed by the University of Valencia.
The area of intelligent mobility systems and services aims to contribute to the decarbonisation of the European transport sector and its main priorities include the development of systems that connect urban and rural mobility services and promote modal shift, sustainable land use, travel demand sufficiency and active and light travel modes; the development of mobility data management solutions and public digital infrastructure with fair access or the implementation of intermodality, interoperability and sectoral coupling.
The 100 mobility questions initiative
The 100 Questions Initiative, launched by The Govlab in collaboration with Schmidt Futures, aims to identify the world's 100 most important questions in a number of domains critical to the future of humanity, such as gender, migration or air quality.
One of these domains is dedicated precisely to transport and urban mobility and aims to identify questions where data and data science have great potential to provide answers that will help drive major advances in knowledge and innovation on the most important public dilemmas and the most serious problems that need to be solved.
In accordance with the methodology used, the initiative completed the fourth stage on 28 July, in which the general public voted to decide on the final 10 questions to be addressed. The initial 48 questions were proposed by a group of mobility experts and data scientists and are designed to be data-driven and planned to have a transformative impact on urban mobility policies if they can be solved.
In the next stage, the GovLab working group will identify which datasets could provide answers to the selected questions, some as complex as "where do commuters want to go but really can't and what are the reasons why they can't reach their destination easily?" or "how can we incentivise people to make trips by sustainable modes, such as walking, cycling and/or public transport, rather than personal motor vehicles?"
Other questions relate to the difficulties encountered by reusers and have been frequently highlighted in research articles such as "Open Transport Data for maximising reuse in multimodal route": "How can transport/mobility data collected with devices such as smartphones be shared and made available to researchers, urban planners and policy makers?"
In some cases it is foreseeable that the datasets needed to answer the questions may not be available or may belong to private companies, so an attempt will also be made to define what new datasets should be generated to help fill the gaps identified. The ultimate goal is to provide a clear definition of the data requirements to answer the questions and to facilitate the formation of data collaborations that will contribute to progress towards these answers.
Ultimately, changes in the way we use transport and lifestyles, such as the use of smartphones, mobile web applications and social media, together with the trend towards renting rather than owning a particular mode of transport, have opened up new avenues towards sustainable mobility and enormous possibilities in the analysis and research of the data captured by these applications.
Global initiatives to coordinate research efforts are therefore essential as cities need solid knowledge bases to draw on for effective policy decisions on urban development, clean transport, equal access to economic opportunities and quality of life in urban centres. We must not forget that all this knowledge is also key to proper prioritisation so that we can make the best use of the scarce public resources that are usually available to meet the challenges.
Content written by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and views reflected in this publication are the sole responsibility of the author.
Noticia
The Data Spaces Business Alliance (DSBA) was born in September 2021, a collaboration of four major organisations with much to contribute to the data economy: the Big Data Value Association (BDVA), FIWARE, Gaia-X and the International Data Spaces Association (IDSA). Its goal: to drive the adoption of data spaces across Europe by leveraging synergies.
How does the DSBA work?
The DSBA brings together diverse actors to realise a data-driven future, where public and private organisations can share data and thus unlock its full value, ensuring sovereignty, interoperability, security and reliability. To achieve this goal, DSBA offers support to organisations, as well as tools, resources and expertise. For example, it is working on the development of a common framework of technology agnostic blocks that are reusable across different domains to ensure the interoperability of different data spaces.
The four founding organisations, BDVA, FIWARE, Gaia-X and IDSA, have a number of international networks of national or regional hubs, with more than 90 initiatives in 34 countries. These initiatives, although very heterogeneous in focus, legal form, level of maturity, etc., have commonalities and great potential to collaborate, complement each other and create impact. Moreover, by operating at local, regional and/or national level, these initiatives provide regular feedback to European associations on the different regional policies, cultures and entrepreneurial ecosystems within the EU.
In addition, DSBA's application has been successful in the European Commission's call for the creation of a Support Centre, which will promote and coordinate actions related to sectoral data spaces. This centre will make available technologies, processes, standards and tools to support the deployment of common data spaces, thus enabling the re-use of data across sectors.
The DSBA hubs
The DSBA hubs refer to the global network combining the existing BDVA, FIWARE, Gaia-X and IDSA initiatives, as shown in the figure below.
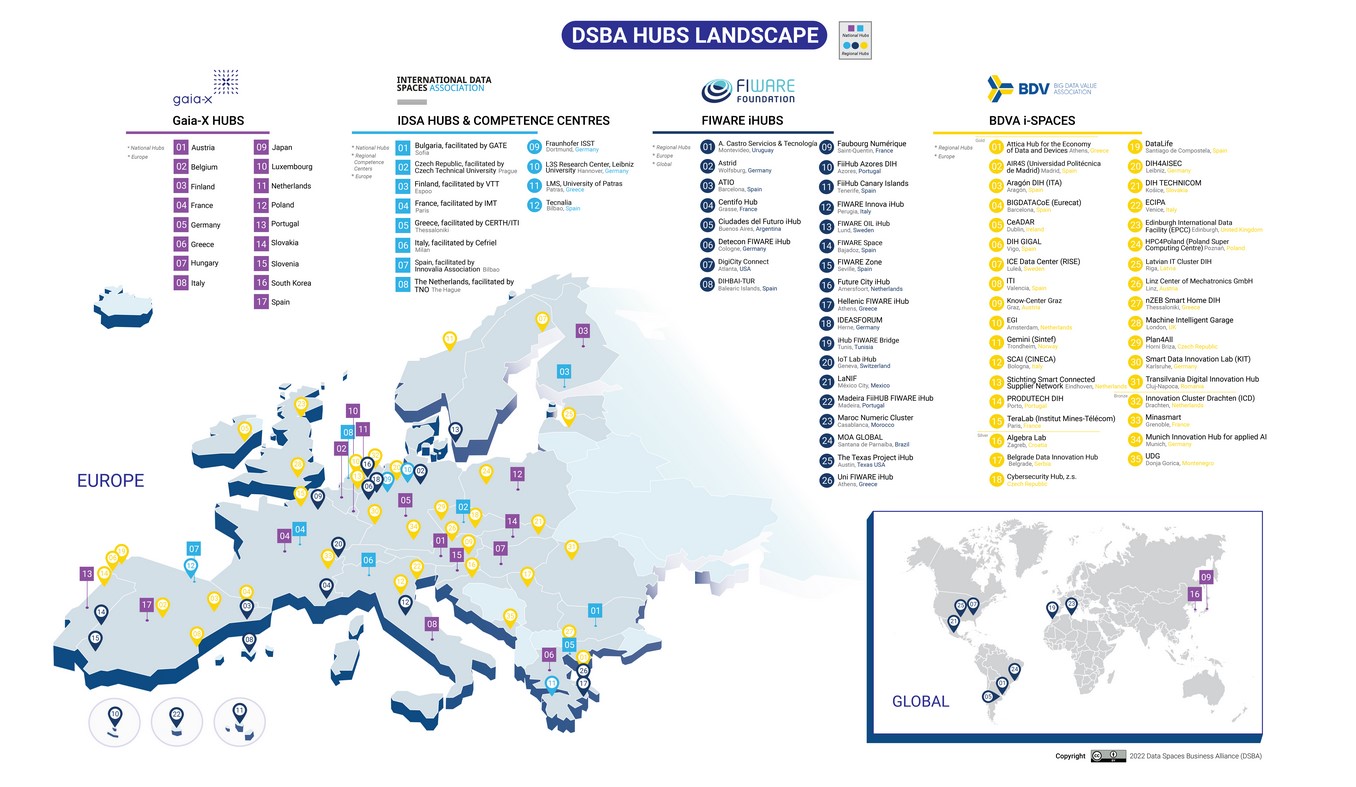
The main characteristics of each of these groups are as follows:
BDVA i-Spaces
BDVA i-Spaces are cross-sector and cross-organisational data incubators and innovation hubs, aimed at accelerating data-driven innovation and artificial intelligence in the public and private sectors. They provide secure experimentation environments, bringing together all the technical and non-technical aspects necessary for organisations, especially SMEs, to rapidly test, pilot and exploit their services, products and applications.
i-Spaces offer access to data sources, data management tools and artificial intelligence technologies, among others. They host closed and open data from corporate and public sources, such as language resources, geospatial data, health data, economic statistics, transport data, weather data, etc. The i-spaces have their own Big Data infrastructure with ad hoc processing power, online storage and state-of-the-art accelerators, all within European borders.
To become an i-Space, organisations must go through an assessment process, using a system of 5 categories, which are ranked according to gold, silver and bronze levels. These hubs must renew their labels every two years, and these certifications allow them to join a pan-European federation to foster cross-border data innovation, through the EUHubs4Data project.
FIWARE iHubs
FIWARE is an open software community promoted by the ICT industry, which - with the support of the European Commission - provides tools and an innovation ecosystem for entrepreneurs to create new Smart applications and services. FIWARE iHubs are innovation hubs focused on creating communities and collaborative environments that drive the advancement of digital businesses in this area. These centres provide private companies, public administrations, academic institutions and developers with access to knowledge and a worldwide network of suppliers and integrators of this technology, which has also been endorsed by international standardisation bodies.
There are 5 types of iHubs:
- iHub School: An environment focused on learning FIWARE, from a business and technical perspective, taking advantage of practical use cases.
- iHub Lab: Laboratory where you can run tests and pilots, as well as obtain FIWARE certifications.
- iHub Business Mentor: Space to learn how to build a viable business model.
- iHub Community Creator: Physical meeting point for the local community to bring together all stakeholders, acting as a gateway to the local and global FIWARE ecosystem.
Gaia-X Hubs
The Gaia-X Hubs are the national contact points for the Gaia-X initiative. It should be noted that they are not as such part of Gaia-X AISBL (the European non-profit association), but act as independent think tanks, which cooperate with the association in project deployment, communication tasks, and generation of business requirements for the definition of the architecture of the initiative (as the hubs are close to the industrial projects in each country).
Through them, specific data spaces are developed based on national needs, as well as the identification of funding opportunities to implement Gaia-X services and technology. They also seek to interact with other regions to build transnational data spaces, facilitating the exchange of information and the scaling up of national use cases internationally. To this end, the AISBL provides access to a collaborative platform, as well as support to the respective hubs in the distribution and communication of the use cases.
IDSA Hubs
The IDSA Hubs enable the exchange of knowledge around the reference architecture (known as the IDS-RAM) at country level. By bringing together research organisations, innovation promotion organisations, non-profit organisations, and companies that use IDS concepts and standards in the region, they seek to foster their adoption, and thus promote a sovereign data economy with greater capillarity.
These centres are driven in each country by a university, research organisation, or non-profit entity, working with IDSA to raise awareness of data sovereignty, transfer knowledge, recruit new members, and disseminate IDS-RAM-based use cases. To this end, they develop activities ranging from training sessions to meetings with decision-makers from different public administrations. They also promote and coordinate research and development projects with international organisations and companies, as well as with governments and other public entities.
Conclusion
As we said at the beginning, there is a great potential for synergies between these groups, which should be explored, discussed and articulated in concrete actions and projects. We are facing a promising opportunity to join forces and make further progress in the development and expansion of data spaces, in order to generate a significant impact on the Data Economy.
To stimulate the initial debate, the Data Spaces Business Alliance has prepared the document "Data Spaces Business Alliance Hubs: potential for synergies and impact", which explores the situation described above.
Blog
Data has become central to our increasingly digitised economies and societies. The five largest companies in the S&P500 index (Apple, Microsoft, Amazon, Facebook and Alphabet) all have data as the primary foundation underpinning their businesses. Together they account for approximately a quarter of the index's total capitalisation. This gives a clear picture of the weight of data in today's economy. The global volume of data is expected to grow from 33ZB (ZettaBytes - a 1 followed by 21 zeros) in 2018 to 175ZB in 2025. By then it is also expected that up to 75% of the world's population will be living with data on a daily basis, with an average of one data interaction per person every 18 seconds.
On the other hand, and due to the spread of the COVID-19 pandemic that started last year, we have witnessed a prolonged transition in our most day-to-day activities from physical to digital interactions in education, business, government and family settings - which will surely lead to this expected growth in the data universe taking hold, but also to an increasing societal demand for services that make respectful and responsible use of data. In addition, the European Commission's recovery plan in response to the pandemic will provide the largest financial investment ever made by the European Union, with nearly 2 trillion of investment over the next few years. Within this plan, the largest package of investment foreseen will be aimed at fostering innovation and digitisation in Europe. This, together with the strategic and regulatory framework that is being put in place, will only consolidate and even accelerate these trends in our continent.
Already a few months ago, in this particular and decisive context in which we find ourselves, the World Economic Forum (WEF) invited us to reflect on the new paradigms of innovation and business that are emerging around the way we relate and interact with technology and data. The idea is to also take this opportunity to rethink the current business models around information in order to experiment and start using data more fairly and creatively.
New areas of innovation
These new emerging opportunities would still be based primarily on creating value through data, but would also be characterised by being more respectful of consumer data, enabling more trusting relationships between all actors involved and where all would benefit from the end result. The WEF classifies these opportunities into four main groups:
- New areas of value creation: using the knowledge gained through data and new technologies emerging in its environment to find new sources of revenue and to incorporate new products and services, as well as to provide richer information to a wider range of stakeholders, while ensuring privacy and security.
A good example of how these new value areas are emerging is how Airbus has been able to expand its market beyond its traditional customer base through the new geospatial product services it provides through its new subsidiary UP42, serving as an intermediary between its traditional geospatial data providers and new customers with their own geospatial data needs.
- New business models: reinventing and proposing collaboration models that enable new use cases, always focusing on the consumer in order to respond to their basic needs while generating trust.
A nearby example in this field is BBVA's data-driven banking strategy. This strategy is based on the concept that data belongs to the customer and it is the customer who decides how to manage it. To this end, they have created a platform through which other external collaborators can access this data in a secure and consensual manner and thus offer a range of additional services that the bank could not provide on its own.
- Enriched experiences: using data to better understand their own employees as well as their partners and customers, thus being able to offer more personalised products and services and a more complete and enriching experience.
This is the case of Digi.me, a platform where users can voluntarily collect their personal, financial and health data, and then share it according to their own interests. In this way, companies get a unique and reliable source of data and in return, users receive compensation in the form of products or services, while maintaining control over their own privacy at all times.
- Improved decision making: identifying which business process optimisations can lead to better streamlining of internal processes to achieve further reductions in operating costs.
For example, Aera Technology is a company that combines big data, machine learning and artificial intelligence to develop supply chain automation. It provides real-time data on demand, supply, production and inventory performance through a simple search interface that directly asks questions in natural language.
Collaborative, respectful and sustainable
In this environment of increasing dependence on data, the world is preparing for a paradigm shift in the use of data by business. The new approaches that emerge must be responsible with the use of data, as well as respecting the baseline regulations on data protection, pursuing not only economic benefit but also the creation of value for individuals and society as a whole. Companies now have the opportunity and the imperative to rethink their current models, to start using data more creatively and to experiment with new forms of monetisation, thus becoming trusted custodians of data. The key to success will be the creation of collaborative ecosystems that enable the participation of all stakeholders and pursue a change in current systems for the co-creation of value through data in a sustainable and respectful way.
The WEF has already taken a first step in collaboration with more than 50 companies from 20 countries through its recent pioneering Data for Common Purpose Initiative (DCPI), focused on designing a flexible data governance framework to exploit the societal benefit of data.
Content prepared by Carlos Iglesias, Open data Researcher and consultan, World Wide Web Foundation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.
Blog
On 12 September, the deadline ends for companies and entities that have developed projects with public data to submit their projects in the first Aporta Awards in 2017. These awards are focused on divulging and recognising professionals who have opted for reusing open data and innovation as a driving force for digital transformation and who are promoted by the Secretariat of State for the Information Society and the Digital Agenda, the Public Business Entity Red.es and the General Secretariat of Digital Administration.
With this initiative, the aim is to promote and make visible the value of the data generated by the Spanish public administrations, as well as to reuse them. Projects that may qualify for these awards must have been developed in the last two years, reusing public data and contributing to generate social value, new business and/or improvements for society.
Applications will be evaluated during the month of September by representatives from the Aporta Initiative. The originality, utility and impact of the initiative will be considered in terms of beneficiaries. The two best initiatives will receive recognition at the Aporta Conference which will take place at the end of October 2017.
We invite and encourage industry professionals and innovative companies to apply for the Aporta Awards, through the form available on the Red.es website. The deadline is 12 September. Come participate!
All the information is available at dagos.gob.es and in the Terms and Conditions of the 2017 Aporta Awards.
Evento
For the third consecutive year, Correos has launched the Lehnica challenge, an entrepreneurial contest that seeks to boost innovation as an essential value of business progress. Through this challenge, a maximum of 5 projects will be selected to become part of Correoslabs, the entrepreneurship and innovation space of Correos.
Who is it for?
The Lehnica Challenge is aimed at newly created companies with a maximum age of three years and having their registered office in Spain.
What does it consist of?
Interested companies have to sign up on the Correoslabs website. Once registered, they can download a template that must be filled in with all the requested information and submitted following the rules indicated in the contest rules.
The projects presented must be focused on the development of innovative products or services in one of the following categories:
- Emerging technologies: projects aimed at transforming traditional businesses or creating new services using artificial intelligence, Blockchain, Big Data or Internet of things, among other technologies.
- Logistics: projects that improve the logistics experience, in areas such as traceability, new delivery models, circular economy or energy efficiency.
- Social: projects that contribute to the promotion and revitalization of rural environments.
- Public services: projects focused on improving the provision of public services.
After an evaluation process, a maximum of 5 projects will be selected.
What benefits do the selected companies obtain?
The selected companies will receive up to 30,000 euros to develop their project. The program will be developed over a year, based on a personalized calendar proposed by Correos where the achievements will be included.
In addition, these companies will have at their disposal:
- Correoslabs facilities, a fully equipped coworking space where you can share opinions with other entrepreneurs.
- A personalized mentoring program, which includes individual tutoring with internal post experts who will accompany and work as a guide for the selected companies.
- A coaching program with professional experts in business development.
- The possibility of integrating into the entrepreneurial and accelerating community of the different collaborating partners of Correoslabs ecosystem.
How long the call is open?
Applications can be submitted until Friday, December 13 at 2:00 p.m.
The program will begin in February 2020.