Blog
Artificial intelligence (AI) has revolutionised various aspects of society and our environment. With ever faster technological advances, AI is transforming the way daily tasks are performed in different sectors of the economy.
As such, employment is one of the sectors where it is having the greatest impact. Among the main developments, this technology is introducing new professional profiles and modifying or transforming existing jobs. Against this backdrop, questions are being asked about the future of employment and how it will affect workers in the labour market.
What are the key figures for AI in employment?
The International Monetary Fund has recently pointed out: Artificial Intelligence will affect 40% of jobs worldwide, both replacing some and complementing and creating new ones.
The irruption of AI in the world of work has made it easier for some tasks that previously required human intervention to be carried out more automatically. Moreover, as the same international organisation warns, compared to other automation processes experienced in past decades, the AI era is also transforming highly skilled jobs.
The document also states that the impact of AI on the workplace will differ according to the country's level of development. It will be greater in the case of advanced economies, where up to 6 out of 10 jobs are expected to be conditioned by this technology. In the case of emerging economies, it will reach up to 40% and, in low-income countries, it will be reflected in 26% of jobs. For its part, the International Labour Organisation (ILO) also warns in its report ‘Generative AI and Jobs: A global analysis of potential effects on job quantity and quality’ that the effects of the arrival of AI in administrative positions will particularly affect women, due to the high rate of female employment in this labour sector.
In the Spanish case, according to figures from last year, not only is the influence of AI on jobs observed, but also the difficulty of finding people with specialised training. According to the report on talent in artificial intelligence prepared by Indesia, last year 20% of job offers related to data and Artificial Intelligence were not filled due to a lack of professionals with specialisation.
Future projections
Although there are no reliable figures yet to see what the next few years will look like, some organisations, such as the OECD, say that we are still at an early stage in the development of AI in the labour market, but on the verge of a large-scale breakthrough. According to its ‘Employment Outlook 2023’ report, ‘business adoption of AI remains relatively low’, although it warns that ‘rapid advances, including in generative AI (e.g. ChatGPT), falling costs and the growing availability of AI-skilled workers suggest that OECD countries may be on the verge of an AI revolution’. It is worth noting that generative AI is one of the fields where open data is having a major impact.
And what will happen in Spain? Perhaps it is still too early to point to very precise figures, but the report produced last year by Indesia already warned that Spanish industry will require more than 90,000 data and AI professionals by 2025. This same document also points out the challenges that Spanish companies will have to face, as globalisation and the intensification of remote work means that national companies are competing with international companies that also offer 100% remote employment, ‘with better salary conditions, more attractive and innovative projects and more challenging career plans’, says the report.
What jobs is AI changing?
Although one of the greatest fears of the arrival of this technology in the world of work is the destruction of jobs, the latest figures published by the International Labour Organisation (ILO) point to a much more promising scenario. Specifically, the ILO predicts that AI will complement jobs rather than destroy them.
There is not much unanimity on which sectors will be most affected. In its report ‘The impact of AI on the workplace: Main findings from the OECD AI surveys of employers and workers', the OECD points out that manufacturing and finance are two of the areas most affected by the irruption of Artificial Intelligence.
On the other hand, Randstad has recently published a report on the evolution of the last two years with a vision of the future until 2033. The document points out that the most affected sectors will be jobs linked to commerce, hospitality and transport. Among those jobs that will remain largely unaffected are agriculture, livestock and fishing, associative activities, extractive industries and construction. Finally, there is a third group, which includes employment sectors in which new profiles will be created. In this case, we find programming and consultancy companies, scientific and technical companies, telecommunications and the media and publications.
Beyond software developers, the new jobs that artificial intelligence is bringing will include everything from natural language processing experts or AI Prompt engineers (experts in asking the questions needed to get generative AI applications to deliver a specific result) to algorithm auditors or even artists.
Ultimately, while it is too early to say exactly which types of jobs are most affected, organisations point to one thing: the greater the likelihood of automation of job-related processes, the greater the impact of AI in transforming or modifying that job profile.
The challenges of AI in the labour market
One of the bodies that has done most research on the challenges and impacts of AI on employment is the ILO. At the level of needs, the ILO points to the need to design policies that support an orderly, just and consultative transition. To this end, it notes that workers' voice, training and adequate social protection will be key to managing the transition. ‘Otherwise, there is a risk that only a few countries and well-prepared market participants will benefit from the new technology,’ it warns.
For its part, the OECD outlines a series of recommendations for governments to accommodate this new employment reality, including the need to:
-
Establish concrete policies to ensure the implementation of key principles for the reliable use of AI. Through the implementation of these mechanisms, the OECD believes that the benefits that AI can bring to the workplace are harnessed, while at the same time addressing potential risks to fundamental rights and workers' well-being.
-
Create new skills, while others will change or become obsolete. To this end, he points to training, which is needed ‘both for the low-skilled and older workers, but also for the high-skilled’. Therefore, ‘governments should encourage business to provide more training, integrate AI skills into education and support diversity in the AI workforce’.
In summary, although the figures do not yet allow us to see the full picture, several international organisations do agree that the AI revolution is coming. They also point to the need to adapt to this new scenario through internal training in companies to be able to cope with the needs posed by the technology. Finally, in governmental matters, organisations such as the ILO point out that it is necessary to ensure that the transition in the technological revolution is fair and within the margins of reliable uses of Artificial Intelligence.
Application
It is a website that reuses open data to report on how green spaces and trees are distributed in the city of Valencia.
The information on the website is divided into three areas:
- Valencia city
- Municipal area of Valencia
- Data on trees in Valencia city
The data shown on Valencia Verde comes from open data catalogs on green spaces and trees available at Ajuntament de València - Dades Obertes, census data from the Oficina d'Estadística de València and information from the Institut Cartogràfric Valencià.
The last date for obtaining the aforementioned data, and for updating this website, is March 2024.
Thanks to this information, visualizations are created in which users can see, for example, the percentage of green area per neighborhood/district and the m2 of green area per inhabitant in each neighborhood/district. This application is a space that allows to know, in a clear and interactive way, the trees, green areas and their relationship with the population and neighborhoods of Valencia.
Blog
The European Union has placed the digital transformation of the public sector at the heart of its policy agenda. Through various initiatives under the Digital Decade policy programme, the EU aims to boost the efficiency of public services and provide a better experience for citizens. A goal for which the exchange of data and information in an agile manner between institutions and countries is essential.
This is where interoperability and the search for new solutions to promote it becomes important. Emerging technologies such as artificial intelligence (AI) offer great opportunities in this field, thanks to their ability to analyse and process huge amounts of data.
A report to analyse the state of play
Against this background, the European Commission has published an extensive and comprehensive report entitled "Artificial Intelligence for Interoperability in the European Public Sector", which provides an analysis of how AI is already improving interoperability in the European public sector. The report is divided into three parts:
- A literature and policy review on the synergies between IA and interoperability. It highlights the legislative work carried out by the EU. It highlights the Interoperable Europe Act which seeks to establish a governance structure and to foster an ecosystem of reusable and interoperable solutions for public administration. Mention is also made of the Artificial Intelligence Act, designed to ensure that AI systems used in the EU are safe, transparent, traceable, non-discriminatory and environmentally friendly.
- The report continues with a quantitative analysis of 189 use cases. These cases were selected on the basis of the inventory carried out in the report "AI Watch. European overview of the use of Artificial Intelligence by the public sector" which includes 686 examples, recently updated to 720.
- A qualitative study that elaborates on some of the above cases. Specifically, seven use cases have been characterised (two of them Spanish), with an exploratory objective. In other words, it seeks to extract knowledge about the challenges of interoperability and how AI-based solutions can help.
Conclusions of the study
AI is becoming an essential tool for structuring, preserving, standardising and processing public administration data, improving interoperability within and outside public administration. This is a task that many organisations are already doing.
Of all the AI use cases in the public sector analysed in the study, 26% were related to interoperability. These tools are used to improve interoperability by operating at different levels: technical, semantic, legal and organisational. The same AI system can operate at different layers.
- The semantic layer of interoperability is the most relevant (91% of cases). The use of ontologies and taxonomies to create a common language, combined with AI, can help establish semantic interoperability between different systems. One example is the EPISA60 project, which is based on natural language processing, using entity recognition and machine learning to explore digital documents.
- In second place is the organisational layer, with 35% of cases. It highlights the use of AI for policy harmonisation, governance models and mutual data recognition, among others. In this regard, the Austrian Ministry of Justice launched the JustizOnline project which integrates various systems and processes related to the delivery of justice.
- The 33% of the cases focused on the legal layer. In this case, the aim is to ensure that the exchange of data takes place in compliance with legal requirements on data protection and privacy. The European Commission is preparing a study to explore how AI can be used to verify the transposition of EU legislation by Member States. For this purpose, different articles of the laws are compared with the help of an AI.
- Lastly, there is the technical layer, with 21% of cases. In this field, AI can help the exchange of data in a seamless and secure way. One example is the work carried out at the Belgian research centre VITO, based on AI data encoding/decoding and transport techniques.
Specifically, the three most common actions that AI-based systems take to drive data interoperability are: detecting information (42%), structuring it (22%) and classifying it (16%). The following table, extracted from the report, shows all the detailed activities:

Download here the accessible version of the table
The report also analyses the use of AI in specific areas. Its use in "general public services" stands out (41%), followed by "public order and security" (17%) and "economic affairs" (16%). In terms of benefits, administrative simplification stands out (59%), followed by the evaluation of effectiveness and efficiency (35%) and the preservation of information (27%).
AI use cases in Spain
The third part of the report looks in detail at concrete use cases of AI-based solutions that have helped to improve public sector interoperability. Of the seven solutions characterised, two are from Spain:
- Energy vulnerability - automated assessment of the fuel poverty report. When energy service providers detect non-payments, they must consult with the municipality to determine whether the user is in a situation of social vulnerability before cutting off the service, in which case supplies cannot be cut off. Municipalities receive monthly listings from companies in different formats and have to go through a costly manual bureaucratic process to validate whether a citizen is at social or economic risk. To solve this challenge, the Administració Oberta de Catalunya (AOC) has developed a tool that automates the data verification process, improving interoperability between companies, municipalities and other administrations.
- Automated transcripts to speed up court proceedings. In the Basque Country, trial transcripts by the administration are made by manually reviewing the videos of all sessions. Therefore, it is not possible to easily search for words, phrases, etc. This solution converts voice data into text automatically, which allows you to search and save time.
Recommendations
The report concludes with a series of recommendations on what public administrations should do:
- Raise internal awareness of the possibilities of AI to improve interoperability. Through experimentation, they will be able to discover the benefits and potential of this technology.
- Approach the adoption of an AI solution as a complex project with not only technical, but also organisational, legal, ethical, etc. implications.
- Create optimal conditions for effective collaboration between public agencies. This requires a common understanding of the challenges to be addressed in order to facilitate data exchange and the integration of different systems and services.
- Promote the use of uniform and standardised ontologies and taxonomies to create a common language and shared understanding of data to help establish semantic interoperability between systems.
- Evaluate current legislation, both in the early stages of experimentation and during the implementation of an AI solution, on a regular basis. Collaboration with external actors to assess the adequacy of the legal framework should also be considered. In this regard, the report also includes recommendations for the next EU policy updates.
- Support the upgrading of the skills of AI and interoperability specialists within the public administration. Critical tasks of monitoring AI systems are to be kept within the organisation.
Interoperability is one of the key drivers of digital government, as it enables the seamless exchange of data and processes, fostering effective collaboration. AI can help automate tasks and processes, reduce costs and improve efficiency. It is therefore advisable to encourage their adoption by public bodies at all levels.
Blog
The importance of data in today's society and economy is no longer in doubt. Data is now present in virtually every aspect of our lives. This is why more and more countries have been incorporating specific data-related regulations into their policies: whether they relate to personal, business or government data, or to regulate a range of issues such as who can access it, where it can be stored, how it should be protected, and so on.
However, when these policies are examined more closely, significant differences can be observed between them, depending on the main objectives that each country sets when implementing its data policies. Thus, all countries recognise the social and economic value of data, but the policies they implement to maximise that value can vary widely. For some, data is primarily an economic asset, for others it can be a means of innovation and modernisation, and for others a tool for development. In the following, we will review the main features of their data policies, focusing mainly on those aspects related to fostering innovation through the use of data.
A recent report by the Centre for Innovation through Data compares the general policies applicable in several countries that have been selected precisely because of differences in their vision of how data should be managed: China, India, Singapore, the United Kingdom and the European Union.
CHINA
Its efforts are focused on building a strong domestic data economy to strengthen national competitiveness and maintain government control through the collection and use of data. It has two agencies from which data policy is directed: the Cyberspace Administration (CAC) and the National Data Administration (NDA).
The main policies governing data in the country are:
- The five-year national informatisation plan, published by the end of 2021 to increase data collection in the national industry.
- The data Security Law (DSL), effective from September 2021, which gives special protection to all data considered to have an impact on national security.
- The cybersecurity law (CSL), effective since June 2017, prohibits online anonymisation and also grants government access to data when required for security purposes.
- The personal Information Protection Act (PIPL), effective from November 2021, which establishes the obligation to keep data on national territory.
INDIA
Its main objective is to use data policy to unlock a new economic resource and drive the modernisation and development of the country. The Ministry of Electronics and Information Technology (MEITy) governs and oversees data policies in the country, which we summarise below:
- The digital Personal Data Protection Act of 2023, which aims to enable the processing of personal data in a way that recognises both the right of individuals to protect their data and the need to process it for legitimate purposes.
- The data protection and empowerment architecture (DEPA), which was launched in 2020 and gives citizens greater control over their personal data by establishing intermediaries between information users and providers, as well as providing consent to companies based on a set of permissions established by the user.
- The non-personal data governance framework also adopted in 2020, which states that the benefits of data should also accrue to the community, not just to the companies that collect the data. It also indicates that high-value data and data related to the public interest (e.g. energy, transport, geospatial or health data) should be shared.
SINGAPORE
It aims to use data as a vehicle to attract new companies to operate within the country. The Infocomm Media Development Authority (IMDA) is the entity in charge of managing the data policies in this case, which includes the control of the Personal Data Protection Commission (PDPC).
Among the most relevant regulations in this case we can find:
- The personal Data Protection Act (PDPA), which was last updated in 2021 and is based on consent, but also provides for some exceptions for legitimate public interest.
- The trust Framework for Data Sharing published in 2019, which sets out standards for data sharing between companies (including templates for establishing legal sharing agreements), albeit with certain protections for trade secrecy.
- The data Portability Obligation (DPO), which will soon be incorporated into the PDPA to establish the right to transmit personal data to another service (provided it is based in the country) in a standard format that facilitates the exchange.
UNITED KINGDOM
It wants to boost the country's economic competitiveness while protecting the privacy of its citizens' data. The Office of the Information information Commissioner's Office (ICO) is the body in charge of data protection and data sharing guidelines.
In the case of the United Kingdom, the legislative framework is very broad:
- The core privacy principles, such as data portability or conditions of access to personal data, are covered by the General Data Protection Regulation (GDPR) of 2016, the law of Data Protection Act (DPA) of 2018, the Electronic Communications Privacy Regulation of 2013 and the proposed Digital Data and Information Protection Act still under discussion.
- The law on Digital Economy established in 2017, which defines the rules for sharing data between public administrations for the development of public services.
- The Data Sharing Code which came into force in October 2021 and sets out good practices to guide companies when sharing data.
- The Payment Services Directive (PSD2), which initially came into force in 2018 requiring banks to share their data in standardised formats to encourage the development of new services.
EUROPEAN UNION
It uses a human rights-based approach to data protection. The aim is to prioritise the creation of a single market that facilitates the free flow of data between member states. The European Data Protection Board (EDPB) and the European Data Protection and Innovation through Data Board are the main bodies responsible for supervising data protection in the Union.
Again, the applicable rules are very broad and have continued to expand recently:
- The General Data Protection Regulation (GDPR), which has become the most comprehensive and descriptive regulation in the world, and is based on the principles of legality, fairness, transparency, containment, minimisation, accuracy, storage, integrity, confidentiality and accountability.
- The programme for the Digital Decadeto promote a single, interoperable, interconnected and secure digital market.
- The Declaration on Digital Rights and Principleswhich expands on the digital and data rights already existing in the standard of protection.
- The Data Act and the Data Governance Regulation which facilitate accessibility to data horizontally accessibility to data horizontally, i.e. across and within sectors, following EU principles. The Data Law drives harmonised rules on fair access to and use of data, clarifying who can create value from data and under what conditions. The Data Governance Regulation regulates the secure exchange of data sets held by public bodies over which third party rights concur, as well as data brokering services and the altruistic transfer ofdata for the benefit of society for the benefit of society.
The keys to promoting innovation
In general, we could conclude that those data policies that adopt a more innovation-oriented approach are characterised by the following:
- Data protection based on different levels of risk, prioritising the protection of the most sensitive personal data, such as medical or financial information, while reducing regulatory costs for less sensitive data.
- Sharing frameworks for personal and non-personal data, encouraging data sharing by default in both the public and private sector and removing barriers to voluntary data sharing.
- Facilitating the flow of data, supporting an open and competitive digital economy.
- Proactive data production policies, encouraging the use of data as a factor of production by collecting data in various sectors and avoiding data gaps.
As we have seen, data policies have become a strategic issue for many countries, not only helping to reinforce their goals and priorities as a nation, but also sending signals about what their priorities and interests are on the international stage. Striking the right balance between data protection and fostering innovation is one of the key challenges. Before addressing their own policies, countries are advised to invest time in analysing and understanding the various existing approaches, including their strengths and weaknesses, and then take the most appropriate specific steps in designing their own strategies.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
We are living in a historic moment in which data is a key asset, on which many small and large decisions of companies, public bodies, social entities and citizens depend every day. It is therefore important to know where each piece of information comes from, to ensure that the issues that affect our lives are based on accurate information.
What is data subpoena?
When we talk about "citing" we refer to the process of indicating which external sources have been used to create content. This is a highly commendable issue that affects all data, including public data as enshrined in our legal system. In the case of data provided by administrations, Royal Decree 1495/2011 includes the need for the reuser to cite the source of origin of the information.
To assist users in this task, the Publications Office of the European Union published Data Citation: A guide to best practice, which discusses the importance of data citation and provides recommendations for good practice, as well as the challenges to be overcome in order to cite datasets correctly.
Why is data citation important?
The guide mentions the most relevant reasons why it is advisable to carry out this practice:
- Credit. Creating datasets takes work. Citing the author(s) allows them to receive feedback and to know that their work is useful, which encourages them to continue working on new datasets.
- Transparency. When data is cited, the reader can refer to it to review it, better understand its scope and assess its appropriateness.
- Integrity. Users should not engage in plagiarism. They should not take credit for the creation of datasets that are not their own.
- Reproducibility. Citing the data allows a third party to attempt to reproduce the same results, using the same information.
- Re-use. Data citation makes it easier for more and more datasets to be made available and thus to increase their use.
- Text mining. Data is not only consumed by humans, it can also be consumed by machines. Proper citation will help machines better understand the context of datasets, amplifying the benefits of their reuse.
General good practice
Of all the general good practices included in the guide, some of the most relevant are highlighted below:
- Be precise. It is necessary that the data cited are precisely defined. The data citation should indicate which specific data have been used from each dataset. It is also important to note whether they have been processed and whether they come directly from the originator or from an aggregator (such as an observatory that has taken data from various sources).
- It uses "persistent identifiers" (PIDs). Just as every book in a library has an identifier, so too can (and should) have an identifier. Persistent identifiers are formal schemes that provide a common nomenclature, which uniquely identify data sets, avoiding ambiguities. When citing datasets, it is necessary to locate them and write them as an actionable hyperlink, which can be clicked on to access the cited dataset and its metadata. There are different families of PIDs, but the guide highlights two of the most common: the Handle system and the Digital Object Identifier (DOI).
- Indicates the time at which the data was accessed. This issue is of great importance when working with dynamic data (which are updated and changed periodically) or continuous data (on which additional data are added without modifying the old data). In such cases, it is important to cite the date of access. In addition, if necessary, the user can add "snapshots" of the dataset, i.e. copies taken at specific points in time.
- Consult the metadata of the dataset used and the functionalities of the portal in which it is located. Much of the information necessary for the citation is contained in the metadata.
In addition, data portals can include tools to assist with citation. This is the case of data.europa.ue, where you can find the citation button in the top menu.
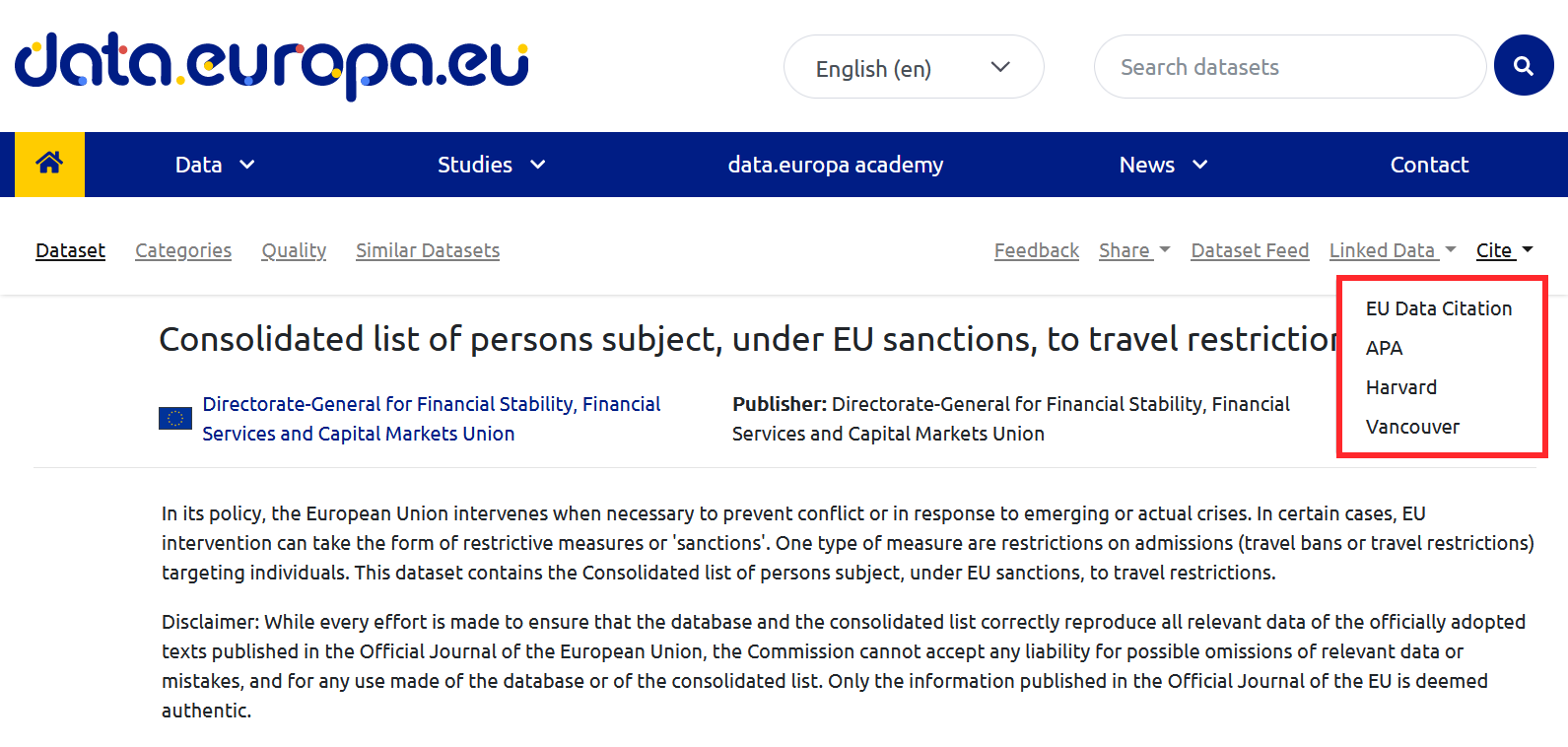
- Rely on software tools. Most of the software used to create documents allows for the automatic creation and formatting of citations, ensuring their formatting. In addition, there are specific citation management tools such as BibTeX or Mendeley, which allow the creation of citation databases taking into account their peculiarities, a very useful function when it is necessary to cite numerous datasets in multiple documents
With regard to the order of all this information, there are different guidelines for the general structure of citations. The guide shows the most appropriate forms of citation according to the type of document in which the citation appears (journalistic documents, online, etc.), including examples and recommendations. One example is the Interinstitutional Style Guide (ISG), which is published by the EU Publications Office. This style guide does not contain specific guidance on how to cite data, but it does contain a general citation structure that can be applied to datasets, shown in the image below.
How to cite correctly
The second part of the report contains the technical reference material for creating citations that meet the above recommendations. It covers the elements that a citation should include and how to arrange them for different purposes.
Elements that should be included in a citation include:
- Author, can refer to either the individual who created the dataset (personal author) or the responsible organisation (corporate author).
- Title of the dataset.
- Version/edition.
- Publisher, which is the entity that makes the dataset available and may or may not coincide with the author (in case of coincidence it is not necessary to repeat it).
- Date of publication, indicating the year in which it was created. It is important to include the time of the last update in brackets.
- Date of citation, which expresses the date on which the creator of the citation accessed the data, including the time if necessary. For date and time formats, the guide recommends using the DCAT specification , as it offers greater accuracy in terms of interoperability.
- Persistent identifier.

The guide ends with a series of annexes containing checklists, diagrams and examples.
If you want to know more about this document, we recommend you to watch this webinar where the most important points are summarised.
Ultimately, correctly citing datasets improves the quality and transparency of the data re-use process, while at the same time stimulating it. Encouraging the correct citation of data is therefore not only recommended, but increasingly necessary.
Blog
What challenges do data publishers face?
In today's digital age, information is a strategic asset that drives innovation, transparency and collaboration in all sectors of society. This is why data publishing initiatives have developed enormously as a key mechanism for unlocking the potential of this data, allowing governments, organisations and citizens to access, use and share it.
However, there are still many challenges for both data publishers and data consumers. Aspects such as the maintenance of APIs(Application Programming Interfaces) that allow us to access and consume published datasets or the correct replication and synchronisation of changing datasets remain very relevant challenges for these actors.
In this post, we will explore how Linked Data Event Streams (LDES), a new data publishing mechanism, can help us solve these challenges. what exactly is LDES? how does it differ from traditional data publication practices? And, most importantly, how can you help publishers and consumers of data to facilitate the use of available datasets?
Distilling the key aspects of LDES
When Ghent University started working on a new mechanism for the publication of open data, the question they wanted to answer was: How can we make open data available to the public? What is the best possible API we can design to expose open datasets?
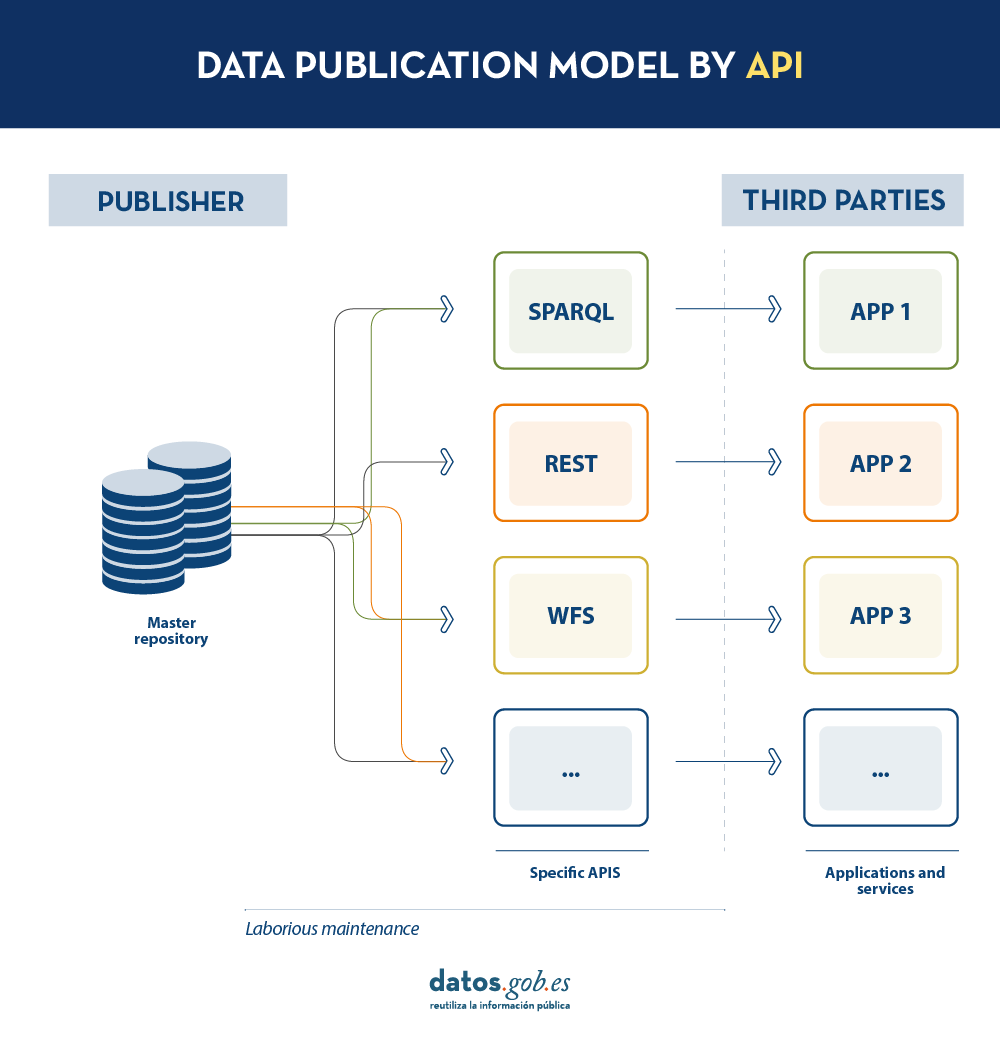
Today, data publishers use multiple mechanisms to publish their different datasets. On the one hand, it is easy to find APIs. These include SPARQL, a standard for querying linked data(Link Data), but also REST or WFS, for accessing datasets with a geospatial component. On the other hand, it is very common that we find the possibility to access data dumps in different formats (i.e. CSV, JSON, XLS, etc.) that we can download for use.
In the case of data dumps, it is very easy to encounter synchronisation problems. This occurs when, after a first dump, a change occurs that requires modification of the original dataset, such as changing the name of a street in a previously downloaded street map. Given this change, if the third party chooses to modify the street name on the initial dump instead of waiting for the publisher to update its data in the master repository to perform a new dump, the data handled by the third party will be out of sync with the data handled by the publisher. Similarly, if it is the publisher that updates its master repository but these changes are not downloaded by the third party, both will handle different versions of the dataset.
On the other hand, if the publisher provides access to data through query APIs, rather than through data dumps to third parties, synchronisation problems are solved, but building and maintaining a high and varied volume of query APIs is a major effort for data publishers.
LDES seeks to solve these different problems by applying the concept of Linked Data to an event stream . According to the definition in its own specification, a Linked Data Event Stream (LDES) is a collection of immutable objects where each object is described in RDF terns.
Firstly, the fact that the LDES are committed to Linked Data provides design principles that allow combining diverse data and/or data from different sources, as well as their consultation through semantic mechanisms that allow readability by both humans and machines. In short, it provides interoperability and consistency between datasets, thus facilitating search and discovery.
On the other hand, the event streams or data streams, allow consumers to replicate the history of datasets, as well as synchronise recent changes. Any new record added to a dataset, or any modification of existing records (in short, any change), is recorded as a new incremental event in the LDES that will not alter previous events. Therefore, data can be published and consumed as a sequence of events, which is useful for frequently changing data, such as real-time information or information that undergoes constant updates, as it allows synchronisation of the latest updates without the need for a complete re-download of the entire master repository after each modification.
In such a model, the publisher will only need to develop and maintain one API, the LDES, rather than multiple APIs such as WFS, REST or SPARQL. Different third parties wishing to use the published data will connect (each third party will implement its LDES client) and receive the events of the streams to which they have subscribed. Each third party will create from the information collected the specific APIs it deems appropriate based on the type of applications they want to develop or promote. In short, the publisher will not have to solve all the potential needs of each third party in the publication of data, but by providing an LDES interface (minimum base API), each third party will focus on its own problems.
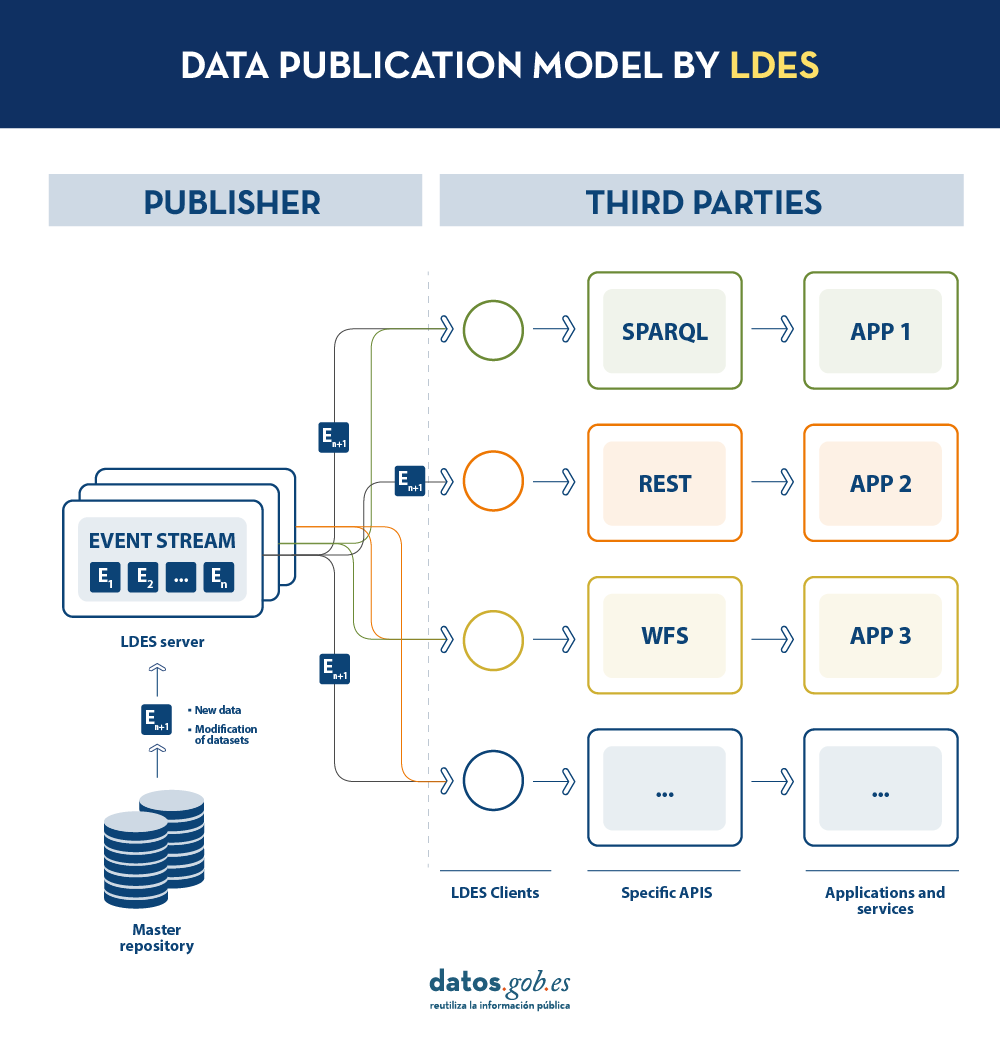
In addition, to facilitate access to large volumes of data or to data that may be distributed across different sources, such as an inventory of electric charging points in Europe, LDES provides the ability to fragment datasets. Through the TREE specification, LDES allows different types of relationships between data fragments to be established. This specification allows publishing collections of entities, called members, and provides the ability to generate one or more representations of these collections. These representations are organised as views, distributing the members through pages or nodes interconnected by relationships. Thus, if we want the data to be searchable through temporal indexes, it is possible to set a temporal fragmentation and access only the pages of a temporal interval. Similarly, alphabetical or geospatial indexes can be provided and a consumer can access only the data needed without the need to 'dump' the entire dataset.
What conclusions can we draw from LDES?
In this post we have looked at the potential of LDES as a mechanism for publishing data. Some of the most relevant learnings are:
- LDES aims to facilitate the publication of data through minimal base APIs that serve as a connection point for any third party wishing to query or build applications and services on top of datasets.
- The construction of an LDES server, however, has a certain level of technical complexity when it comes to establishing the necessary architecture for the handling of published data streams and their proper consultation by data consumers.
- The LDES design allows the management of both high rate of change data (i.e. data from sensors) and low rate of change data (i.e. data from a street map). Both scenarios can handle any modification of the dataset as a data stream.
- LDES efficiently solves the management of historical records, versions and fragments of datasets. This is based on the TREE specification, which allows different types of fragmentation to be established on the same dataset.
Would you like to know more?
Here are some references that have been used to write this post and may be useful to the reader who wishes to delve deeper into the world of LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
As tradition dictates, the end of the year is a good time to reflect on our goals and objectives for the new phase that begins after the chimes. In data, the start of a new year also provides opportunities to chart an interoperable and digital future that will enable the development of a robust data economy robust data economy, a scenario that benefits researchers, public administrations and private companies alike, as well as having a positive impact on the citizen as the end customer of many data-driven operations, optimising and reducing processing times. To this end, there is the European Data Strategy strategy, which aims to unlock the potential of data through, among others, the Data Act (Data Act), which contains a set of measures related to fair access to and use of data fair access to and use of data ensuring also that the data handled is of high quality, properly secured, etc.
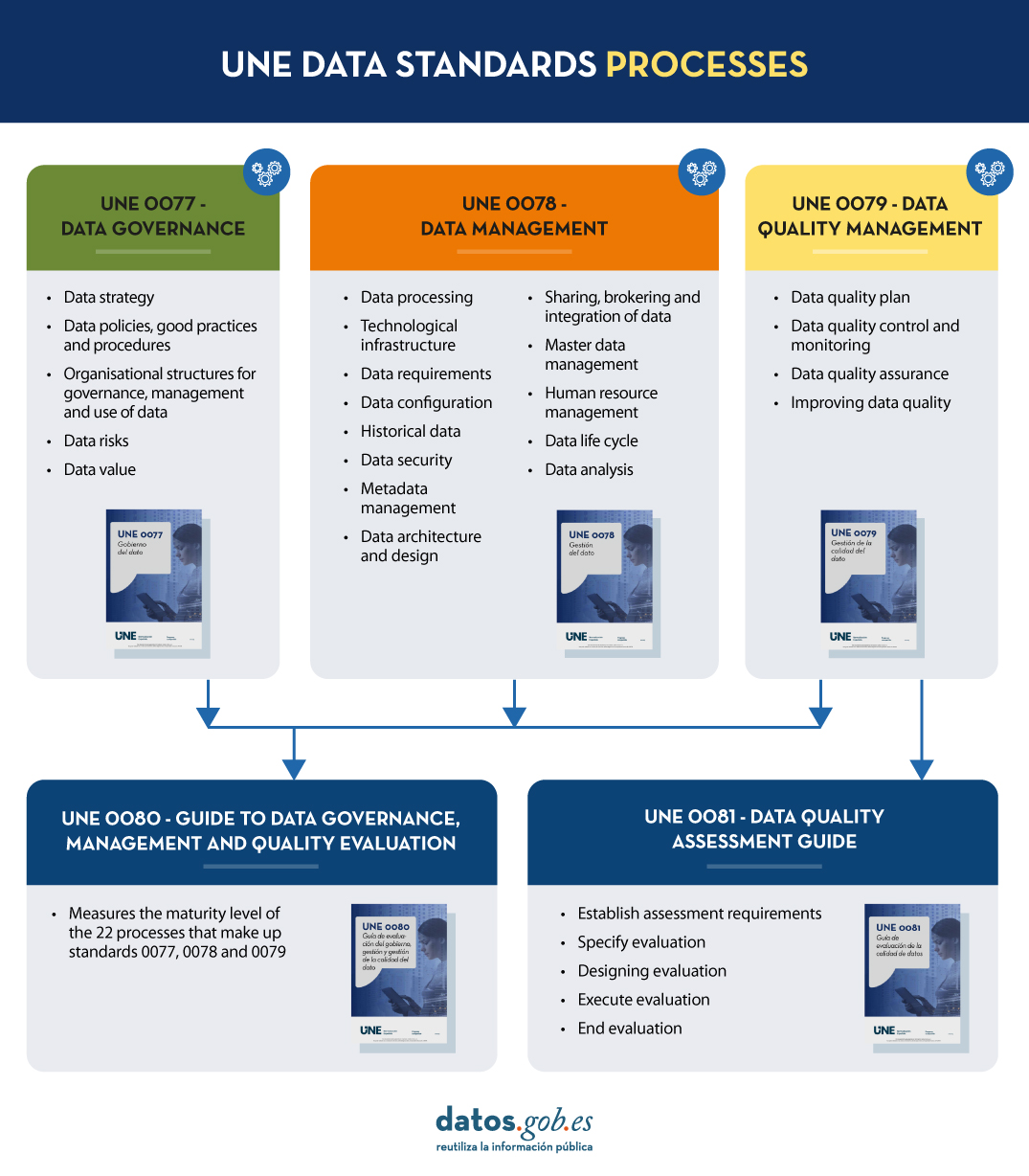
As a solution to this need, in the last year the uNE data specifications which are normative and informative resources for implementing common data governance, management and quality processes. These specifications, supported by the Data Officethese specifications, supported by the Data Office, establish standards for well-governed data (UNE 0077), managed (UNE 0078) and with adequate levels of quality (UNE 0079), thus allowing for sustainable growth in the organisation during the implementation of the different processes. In addition to these three specifications, the UNE 0080 specification defines a maturity assessment guide and process to measure the degree of implementation of data governance, management and quality processes. For its part, the UNE 0081 also establishes a process of evaluation of the data asset itself, i.e. of the data sets, regardless of their nature or typology; in short, its content is closely related to UNE 0079 because it sets out data quality characteristics. Adopting all of them can provide multiple benefits. In this post, we look at what they are and what the process would be like for each specification.
So, with an eye to the future, we set a New Year's resolution: the application of the UNE data specifications to an organisation.
What are the benefits of your application and how can I access them?
In today's era, where data governance and efficient data management have become a fundamental pillar of organisational success, the implementation of the uNE data specifications specifications emerge as a guiding light towards excellence, leading the way forward. These specifications describe rigorous standardised processes that offer organisations the possibility to build a robust and reliable structure for the management of their data and information throughout its lifecycle.
By adopting the UNE specifications, you not only ensure data quality and security, but also provide a solid and adequate basis for informed decision-making by enriching organisational processes with good data practices. Therefore, any organisation that chooses to embrace these regulations in the new year will be moving closer to innovation, efficiency and trust in data governance and management; as well as preparing to meet the challenges and opportunities that the digital future holds digital future. The application of UNE specifications is not only a commitment to quality, but a strategic investment that paves the way for sustainable success in an increasingly competitive and dynamic business environment because:
- Maximising value contribution to business strategy
- Minimises risks in data processing
- Optimise tasks by avoiding unnecessary work
- It establishes homogeneous frameworks for reference and certification
- Facilitates information sharing with trust and sovereignty
The content of the guides can be downloaded free of charge from the AENOR portal via the links below. Registration is required for downloading. The discount on the total price is applied at the time of checkout.
- SPECIFICATION UNE 0077:2023
- SPECIFICATION UNE 0078:2023
- SPECIFICATION UNE 0079:2023
- SPECIFICATION UNE 0080:2023
- SPECIFICATION UNE 0081:2023
From datos.gob.es we have echoed the content of the same and we have prepared different didactic resources such as this infographic or this explanatory video.
How do they apply to an organisation?
Once the decision has been taken to address the implementation of these specifications, a crucial question arises: what is the most effective way to do this? The answer to this question will depend on the initial situation (marked by an initial maturity assessment), the type of organisation and the resources available at the time of establishing the master plan or implementation plan. Nevertheless, at datos.gob.es, we have published a series of contents prepared by experts in technologies linked to the data economy datos.gob.es, we have published a series of contents elaborated by experts in technologies linked to the data economy that will accompany you in the process.
Before starting, it is important to know the different processes that make up each of the UNE data specifications. This image shows what they are.
Once the basics are understood, the series of contents 'Application of the UNE data specifications' deals with a practical exercise, broken down into three posts, on a specific use case: the application of these specifications to open data. As an example, a need is defined for the fictitious Vistabella Town Council: to make progress in the open publication of information on public transport and cultural events.
- In the first post of the series, the importance of using the UNE 0077 data using the UNE 0077 Data Governance Specification to establish approved mechanisms to support the openness and publication of open data. Through this first content, an overview of the processes necessary to align the organisational strategy in such a way as to achieve maximum transparency and quality of public services through the reuse of information is provided.
- The second article in the series takes a closer look at the uNE 0079 data quality management standard and its application in the context of open data and its application in the context of open data. This content underlines that the quality of open data goes beyond the FAIR principles fAIR principles principles and stresses the importance of assessing quality using objective criteria. Through the practical exercise, we explore how Vistabella Town Council approaches the UNE processes to improve the quality of open data as part of its strategy to enhance the publication of data on public transport and cultural events.
- Finally, the uNE 0078 standard on data management is explained in a third article presenting the Data Sharing, Intermediation and Integration (CIIDat) process for the publication of open data, combined with specific templates.
Together, these three articles provide a guide for any organisation to move successfully towards open publication of key information, ensuring consistency and quality of data. By following these steps, organisations will be prepared to comply with regulatory standards with all the benefits that this entails.
Finally, embracing the New Year's resolution to implement the UNE data specifications represents a strategic and visionary commitment for any organisation, which will also be aligned with the European Data Strategy and the European roadmap that aims to shape a world-leading digital future.
Blog
In the first part of this article, the concept of data strategy was introduced as the organisation's effort to put the necessary data at the service of its business strategy. In this second part, we will explore some aspects related to the materialisation of such a strategy as part of the design or maintenance - if it already exists - of a data governance system.
For the materialisation of the data strategy, a development environment will have to be addressed, as described in a founding act that includes some aspects such as the identification of the main people responsible for the implementation, the expected results, the available resources and the timeframe established to achieve the objectives. In addition, it will contain a portfolio of data governance programmes including individual projects or specific related projects to address the achievement of the strategic objectives of the data.
It is important to mention that the implementation of a data strategy has an impact on the development and maintenance of the different components of a data governance system:
- Manager
- Organisational structures
- Principles, policies and frameworks
- For Information
- Culture, ethics and behaviour
- People, skills and competences
- Services, infrastructures and applications.
In this sense, it can be said that each of the projects included in the data government's programme aims to contribute to developing or maintaining one or more of these components.
It should be noted that the final design of this data governance system is achieved in an iterative and incremental manner over time, depending on the constraints and possibilities of the organisation and its current operating context. Consequently, the prioritisation, selection and sequencing of projects within the data governance programme to implement the strategic objectives of data also has an iterative and incremental nature[1].
The three biggest data risks commonly encountered in organisations are:
- Not knowing who has to take responsibility for implementing the data strategy,
- Not having adequate knowledge of data in quantity and quality, and
- Failure to exercise adequate control over the data, e.g. by at least complying with current legislation.
Therefore, as far as possible, projects should be approached in the following way:
- Firstly, to address those projects related to the identification, selection or maintenance of organisational structures ("strategic alignment" type objective), also known as governance framework.
- Next, undertake projects related to the knowledge of the business processes and the data used (a "strategic alignment" type objective aimed at the description of data through the corresponding metadata, including data lifecycle metadata).
- And finally, proceed to the definition of policies and derived controls for different policy areas (which may be of the "strategic alignment", "risk optimisation" or "value for money" type).
The artefact-based approach and the process approach
In approaching the definition of these data governance programmes, some organisations with a project understanding more oriented to the generation and deployment of technological products follow an artefact-based approach. That is, they approach the projects that are part of the data governance programme as the achievement of certain artefacts. Thus, it is possible to find organisations whose first concern when implementing data governance is to acquire and install a specific tool that supports, for example, a glossary of terms, a data dictionary, or a data lake. Moreover, as for various reasons some companies do not adequately differentiate between data governance and data management, this approach is often sufficient. However, the artefact approach introduces the risk of "the tool without the instruction manual the artefact approach introduces the risk of "the tool without the instruction manual": the tool is purchased - probably after a proof of concept by the vendor - and deployed according to the needs of the organisation, but what it is used for and when it is used is unknown, leaving the artefact often as an isolated resource. This, unless the organisation promotes a profound change, may end up being a waste of resources in the long run as the use of the artefacts generated is abandoned.
A better alternative, as has been widely demonstrated in the software development sector, is the execution of the data governance programme with a process approach. This process approach allows not only to develop the necessary artefacts, but also to model the way the organisation works with respect to some area of performance, and contextualises the rationale and use of the artefacts within the process, specifying who should use the artefact, for what, when, what should be obtained by using the artefact, etc.
This process approach is an ideal instrument to capture and model the knowledge that the organisation already has regarding the tasks covered by the process, and to make this knowledge the reference for new operations to be carried out in the future. In addition, the definition of the process also allows for the particularisation of chains of responsibility and accountability and the establishment of communication plans, so that each worker knows what to do, what artefacts to use, who to ask for or receive resources from to carry out their work, who to communicate their results to, or who to escalate potential problems to.
This way of working provides some advantages, such as predictable behaviour of the organisation with respect to the process; the possibility to use these processes as building blocks for the execution of data projects; the option to easily replace a human resource; or the possibility to efficiently measure the performance of a process. But undoubtedly, one of the greatest advantages of this process approach is that it allows organisations to adopt the good practices contained in any of the process reference models for data governance, data management and quality management that exist in the current panorama, such as the UNE 0077 specifications (for data governance), UNE 0078 (for data management) and UNE 0079 (for data quality management).
This adoption enables the possibility of using frameworks for process assessment and improvement, such as the one described in UNE 0080, which includes the Alarcos Data Maturity Model, in which the concept of organisational maturity of data governance, data management and data quality management is introduced as an indicator of the organisation's potential to face the achievement of strategic objectives with certain guarantees of success. In fact, it is common for many organisations adopting the process approach to pre-include specific data objectives ("strategic alignment" type objectives) aimed at preparing the organisation - by increasing the level of maturity - to better support the execution of the data governance programme. These "preparatory" objectives are mainly manifested in the implementation of data governance, data management and data quality management processes to close the gap between the current initial state of maturity (AS_IS) and the required final state of maturity of the organisation (TO_BE).
If the process approach is chosen, the different projects contained in the data programme will generate controlled and targeted increments in each of the components of the data governance system, which will enable the transformation of the organisation to meet the organisation's strategic business objectives.
Ultimately, the implementation of a data strategy manifests itself in the development or maintenance of a data governance system, which ensures that the organisation's data is put at the service of strategic business objectives. The instrument to achieve this objective is the data governance programme, which should ideally be implemented through a process approach in order to benefit from all the advantages it brings.
______________________________________________
Content developed by Dr. Ismael Caballero, Associate Professor at UCLM, and Dr. Fernando Gualo, PhD in Computer Science, and Chief Executive Officer and Data Quality and Data Governance Consultant.
The content and viewpoints reflected in this publication are the sole responsibility of the authors.
[1] We recommend reading the article https://hdl.handle.net/11705/JISBD/2019/083
Blog
More and more organisations are deciding to govern their data to ensure that it is relevant, adequate and sufficient for its intended uses, i.e. that it has a certain organisational value.
Although the scenarios are often very diverse, a close look at needs and intentions reveals that many of these organisations had already started to govern their data some time ago but did not know it. Perhaps the only thing they are doing as a result of this decision is to state it explicitly. This is often the case when they become aware of the need to contextualise and justify such initiatives, for example, to address a particular organisational change - such as a long-awaited digital transformation - or to address a particular technological challenge such as the implementation of a data lake to better support data analytics projects.
A business strategy may be to reduce the costs required to produce a certain product, to define new lines of business, to better understand customer behaviour patterns, or to develop policies that address specific societal problems. To implement a business strategy you need data, but not just any data, but data that is relevant and useful for the objectives included in the business strategy. In other words, data that can be used as a basis for contributing to the achievement of these objectives. Therefore, it can be said that when an organisation recognises that it needs to govern its data, it is really expressing its need to put certain data at the service of the business strategy. And this is the real mission of data governance.
Having the right data for the business strategy requires a data strategy. It is a necessary condition that the data strategy is derived from and aligned with a business strategy. For this reason, it is possible to affirm that the projects that are being developed (especially those that seek to develop some technological artefact), or those that are to be developed in the organisation, need a justification determined by a data strategy[1] and, therefore, will be part of data governance.
Strategic objectives of the data
A data strategy is composed of a set of strategic data objectives, which may be one or a necessary combination of the following four generic types:
- Benefits realisation: ensuring that all data producers have the appropriate mechanisms in place to produce the data sources that support the business strategy, and that data consumers have the necessary data to be able to perform the tasks required to achieve the strategic objectives of the business. Examples of such objectives could be:
- the definition of the organisation's reporting processes;
- the identification of the most relevant data architecture to service all data needs in a timely manner;
- the creation of data service layers;
- the acquisition of data from third party sources to meet certain data demands; or
- the implementation of information technologies supporting data provisioning and consumption
- Strategic alignment: the objective is to align the data with basic principles or behavioural guidelines that the organisation has defined, should have defined, or will define as part of the strategy. This alignment seeks to homogenise the way of working with the organisation's data. Examples of this type of objective include:
- establish organisational structures to support chains of responsibility and accountability;
- homogenise, reconcile and unify the description of data in different types of metadata repositories;
- define and implement the organisation's best practices with respect to data governance, data management and data quality management[2];
- readapt or enrich (what in DAMA terminology is known as operationalising data governance) the organisation's data procedures in order to align them with the good practices implemented by the organisation in the different processes;
- or define data policies in any of the areas of data management[3] and ensure compliance with them, including security, master data management, historical data management, etc.
- Resource optimisation: this consists of establishing guidelines to ensure that the generation, use and exploitation of data makes the most appropriate and efficient use of the organisation's resources. Examples of such targets could include:
- the decrease of data storage and processing costs to much more efficient and effective storage systems, such as migrations of data storage and processing layers to the cloud[4];
- improving response times of certain applications by removing historical data; improving data quality;
- improving the skills and knowledge of the different actors involved in the exploitation and use of data;
- the redesign of business plans to make them more efficient; or
- the redefinition of roles to simplify the allocation and delegation of responsibilities.
- Risk optimisation: the fundamental objective is to analyse the possible risks related to data that may undermine the achievement of the different business objectives of the organisation, or even jeopardise its viability as an entity, and to develop the appropriate data processing mechanisms. Some examples of this type of target would be:
- the definition or implementation of security and data protection mechanisms;
- the establishment of the necessary ethical parameters; or
- securing sufficiently qualified human resources to cope with functional turnover.
A close reading of the proposed examples might lead one to think that some of these strategic data objectives could be understood as being of different types simultaneously. For example, ensuring the quality of data to be used in certain business processes may seek, in some way, to ensure that the data is not only used ('benefit realisation' and 'risk optimisation'), but also helps to ensure that the organisation has a serious and responsible brand image with data ('strategic alignment') that avoids having to perform frequent data cleansing actions, with the consequent waste of resources ('value for money' and 'risk optimisation').
Typically, the process of selecting one or more strategic data objectives should not only take into account the context of the organisation and the scope of these objectives in functional, geographic or dataterms, but also consider the dependency between the objectives and the way in which they should be sequenced. It may be common for the same strategic objective to cover data used in different departments or even to apply to different data. For example, the strategic objective of the types "benefit realisation" and "risk optimisation", called "ensuring the level of access to personal data repositories", would cover personal data that can be used in the commercial and operational departments.
Taking into account typical data governance responsibilities (evaluate, manage, monitor), the use of the SMART (specific, measurable, achievable, realistic, time-bound) technique is recommended for the selection of strategic objectives. Thus, these strategic objectives should:
- be specific,
- the level of achievement can be measured and monitored,
- that are achievable and realistic within the context of the strategy and the company, and finally,
- that their achievement is limited in time.
Once the strategic data objectives have been identified, and the backing and financial support of the organisation's management is in place, their implementation must be addressed, taking into account the dimensions discussed above (context, functional aspects and dependencies between objectives), by defining a specific data governance programme. It is interesting to note that behind the concept of "programme" is the idea of "a set of interrelated projects contributing to a specific objective".
In short, a data strategy is the way in which an organisation puts the necessary data at the service of the organisation's business strategy. This data strategy is composed of a series of strategic objectives that can be of one of the four types outlined above or a combination of them. Finally, the implementation of this data strategy will be done through the design and execution of a data governance programme, aspects that we will address in a future post.
______________________________________________
Content developed by Dr. Ismael Caballero, Associate Professor at UCLM, and Dr. Fernando Gualo, PhD in Computer Science, and Chief Executive Officer and Data Quality and Data Governance Consultant.
The content and viewpoints reflected in this publication are the sole responsibility of the authors.
______________________________________________
[1] It is easy to find digital transformation projects where the only thing that is changed is the core technology to a more modern sounding one, but still doing the same thing.
[2] In this example of a strategic objective for data it is essential to consider the UNE 0077, UNE 0078 and UNE 0079 specifications because they provide an adequate definition of the different processes of data governance, data management and data quality management respectively.
[3] Meaning security, quality, master data management, historical data management, metadata management, integration management…
[4] Examples of such initiatives are migrations of data storage and processing layers to the cloud.
Evento
Alicante will host the Gaia-X Summit 2023 on November 9 and 10, which will review the latest progress made by this initiative in promoting data sovereignty in Europe. Interoperability, transparency and regulatory compliance acquire a practical dimension through the exchange and exploitation of data articulated under a reliable cloud environment.
It will also address the relationships established with industry leaders, experts, companies, governments, academic institutions and various organisations, facilitating the exchange of ideas and experiences between the various stakeholders involved in the European digital transformation. The event will feature keynotes, interactive workshops and panel discussions, exploring the limitless possibilities of cooperative digital ecosystems, and a near future where data has become a high value-added asset.
This event is organised by the european association Gaia-X, in collaboration with the Spanish Gaia-X Hub. It also counts with the participation of the Data Office the project is being developed under the auspices of the Spanish Presidency of the Council of the European Union. The project is being developed under the auspices of the Spanish Presidency of the Council of the European Union.
The Gaia-X initiative aims to ensure that data is stored and processed in a secure and sovereign manner, respecting European regulations, and to foster collaboration between different and heterogeneous actors, such as companies, governments and organisations. Thus, Gaia-X promotes innovation promotes innovation and data-driven economic development in Europe. The open and collaborative relationship with the European Union is therefore essential for the achievement of its objectives.
Digital sovereignty: a Europe fit for the data age
As for Gaia-X, one of the major objectives of the European Union is to to promote digital sovereignty throughout the European Union. To this end, it promotes the development of key industries and technologies for its competitiveness and security, strengthens its trade relations and supply chains, and mitigates external dependencies, focusing on the reindustrialisation of its territory and on ensuring its strategic digital autonomy.
The concept of digital sovereignty encompasses different dimensions: technological, regulatory and socio-economic. The technology dimension refers to the hardware, software, cloud and network infrastructure used to access, process and store data. Meanwhile, the regulatory dimension refers to the rules that provide legal certainty to citizens, businesses and institutions operating in a digital environment. Finally, the socio-economic dimension focuses on entrepreneurship and individual rights in the new global digital environment. To make progress in all these dimensions, the EU relies on projects such as Gaia-X.
The initiative seeks to create federated, open, secure and transparent open, secure and transparent ecosystems, where data sets and services comply with a minimum set of common rules, thus allowing them to be reusable under environments of trust and transparency. In turn, this enables the creation of reliable, high-quality data ecosystems, with which European organisations will be able to drive their digitisation process, enhancing value chains across different industrial sectors. These value chains, digitally deployed on federated and trusted cloud environments ("Trusted Cloud"), are traceable and transparent, and thus serve to drive regulatory compliance and digital sovereignty efforts.
In short, this approach is based on building on and reinforcing values reflected in a developing regulatory framework that seeks to embed concepts such as trust and governance in data environments. This seeks to make the EU a leader in a society and economy where digitalisation is a vector for re-industrialisation and prosperity, but always within the framework of our defining values.
The full programme of the Summit is available on the official website of the European association: https://gaia-x.eu/summit-2023/agenda/.