Blog
La inteligencia artificial (IA) ha revolucionado diversos aspectos de la sociedad y nuestro entorno. Con avances tecnológicos cada vez más rápidos, la IA está transformando la forma en que se realizan las tareas diarias en diferentes sectores de la economía.
Por ello, el empleo es uno de estos sectores en los que más impacto genera. Entre las principales novedades, esta tecnología está introduciendo nuevos perfiles profesionales y modificando o transformando puestos de trabajo ya existentes. Ante este panorama, se plantean interrogantes sobre el futuro del empleo y cómo afectará a los trabajadores en el mercado laboral.
¿Cuáles son las principales cifras de la IA en el empleo?
El Fondo Monetario Internacional lo ha señalado recientemente: la Inteligencia Artificial afectará a un 40% de los puestos de trabajo en todo el mundo, tanto remplazando unos como complementando y creando otros nuevos.
La irrupción de la IA en el mundo laboral ha facilitado que algunas tareas que antes requerían de la intervención humana, ahora se realicen de forma más automática. Además, como advierte este mismo organismo internacional, frente a otros procesos de automatización vividos en décadas pasadas, la era de la IA viene también a transformar puestos de trabajo de alta preparación o cualificación (high skilled job).
Asimismo, este documento expone que el impacto de la IA en el trabajo será diferente según el nivel de desarrollo del país. Así, será mayor en el caso de economías avanzadas, donde se prevé que hasta 6 de cada 10 empleos se vean condicionados por esta tecnología. En el caso de economías emergentes, llegará hasta un 40% y, en países de bajos ingresos, se reflejará en un 26% de los empleos. Por su parte, la Organización Internacional del Trabajo (OIT), también advierte en su informe ‘Generative AI and Jobs: A global analysis of potential effects on job quantity and quality’ que los efectos de la llegada de la IA a los puestos administrativos afectarán en particular a las mujeres, debido a la alta tasa de empleo femenino en este sector laboral.
En el caso español, según cifras del pasado año, no sólo se observa la influencia de la IA en los puestos de trabajo, sino que aflora la dificultad de conseguir personas con formación especializada. Según el informe sobre el talento en inteligencia artificial elaborado por Indesia, el pasado año un 20% de las ofertas de empleo relacionadas con datos e Inteligencia Artificial no se cubrió por falta de profesionales con especialización.
Proyecciones a futuro
Aunque aún no existen cifras fidedignas que permitan ver cómo serán los próximos años, algunos organismos, como la OCDE, afirman que aún estamos en un estadio inicial del desarrollo de la IA en el mercado laboral, pero a las puertas de un avance a gran escala. Según su informe ‘Employment Outlook 2023’, “la adopción de la IA por parte de las empresas sigue siendo relativamente baja”, aunque advierte de que “los rápidos avances, incluidos los de la IA generativa (por ejemplo, ChatGPT), la caída de los costes y la creciente disponibilidad de trabajadores con conocimientos de IA sugieren que los países de la OCDE pueden estar al borde de una revolución de la IA”. Cabe destacar que la IA generativa es uno de los campos donde tienen un gran impacto los datos abiertos.
¿Y qué ocurrirá en España? Quizá todavía es pronto para apuntar cifras muy precisas, pero el informe elaborado el pasado año por Indesia ya advirtió de que la industria española demandará más de 90.000 profesionales del área de data e IA hasta 2025. Este mismo documento apunta además los desafíos que deberán acometer las compañías españolas, ya que la globalización y la intensificación del trabajo en remoto lleva a que las empresas nacionales estén compitiendo con compañías internacionales que ofrecen también empleo 100% a distancia, “con mejores condiciones salariales, proyectos más atractivos e innovadores y planes de carrera más retadores”, señala el informe.
¿Qué empleos está modificando la IA?
A pesar de que uno de los mayores temores de la llegada de esta tecnología al mundo laboral es la destrucción del empleo, las últimas cifras publicadas por la Organización Internacional del Trabajo (OIT), apuntan a un escenario bastante más halagüeño. En concreto, este organismo prevé que la IA complementará puestos de trabajo en lugar de destruirlos.
No hay excesiva unanimidad con respecto a cuáles serán los sectores más afectados. En su informe ‘The impact of AI on the workplace: Main findings from the OECD AI surveys of employers and workers’, la OCDE señala que industria manufacturera y la financiera son dos de las áreas más afectadas por la irrupción de la Inteligencia Artificial.
Por otro lado, Randstad ha publicado recientemente un informe sobre la evolución de los últimos dos años con una visión a futuro hasta 2033. El documento apunta que los sectores más afectados serán los empleos ligados al comercio, la hostelería y el transporte. Entre aquellos empleos que permanecerán sin apenas afección, se encuentran la agricultura, ganadería y pesca, las actividades asociativas, las industrias extractivas o la construcción. Y, por último, un tercer grupo, en el que se encuentran los sectores laborales en los que habrá creación de perfiles nuevos. En este caso, se encuentran las empresas de programación y consultoría, las científicas y técnicas, las telecomunicaciones y los medios de comunicación y las publicaciones.
Más allá de los desarrolladores de software, entre los nuevos puestos de trabajo que está trayendo la inteligencia artificial, encontraremos alguno que van desde expertos en procesamiento del lenguaje natural o ingenieros de AI Prompt (expertos en hacer las preguntas necesarias para conseguir que aplicaciones de IA generativa ofrezcan un resultado específico) hasta auditores de algoritmos o incluso artistas.
En definitiva, aunque todavía es pronto para señalar qué tipo de empleos exactos son los más influenciados, las organizaciones apuntan un dato: a mayor probabilidad de automatización de los procesos ligados al puesto de trabajo, existe una mayor afección de la IA a la hora de transformar o modificar ese perfil laboral.
Los retos de la IA en el mercado laboral
Uno de los organismos que más ha estudiado cuáles son los retos y repercusiones de la IA en el empleo es la OIT. En el plano de las necesidades, la OIT señala la necesidad de diseñar políticas que apoyen una transición ordenada, justa y consultiva. Para ello, apunta que la voz de los trabajadores, la capacitación y una protección social adecuada serán claves para gestionar la transición. “De lo contrario, se corre el riesgo de que sólo unos pocos países y participantes en el mercado bien preparados se beneficien de la nueva tecnología”, advierte el organismo.
Por su parte, la OCDE señala una serie de recomendaciones para que los gobiernos puedan acomodar esta nueva realidad laboral, entre las que se encuentra la necesidad de:
-
Establecer políticas concretas que garanticen la aplicación de principios clave para un uso fiable de la IA. A través de la puesta en marcha de estos mecanismos, la OCDE considera que se aprovechan los beneficios que la IA puede aportar al lugar de trabajo y, al mismo tiempo, se hace frente a los posibles riesgos para los derechos fundamentales y en favor del bienestar de los trabajadores.
-
Crear nuevas cualificaciones, mientras que otras cambiarán o quedarán obsoletas. Para ello, apunta a la formación, necesaria “tanto para los trabajadores poco cualificados como para los de más edad, pero también para los más cualificados”. Por ello, “los gobiernos deberían animar al empresariado a ofrecer más formación, integrar las competencias en IA en la educación y apoyar la diversidad en la mano de obra de la IA”.
En resumen, aunque las cifras todavía no permiten observar el panorama al completo, varios organismos internacionales sí coinciden en que la revolución de la IA está por llegar. También, apuntan la necesidad de acomodarse a este nuevo escenario a través de la formación interna en las empresas para poder hacer frente a las necesidades que plantea la tecnología. Por último, en materia gubernamental, organismos como la OIT señalan que es necesario asegurar que la transición en la revolución tecnológica sea justa y dentro de unos márgenes de usos fiables de la Inteligencia Artificial.
Aplicación
Es una web que reutiliza datos abiertos para informar sobre cómo están distribuidos los espacios verdes y el arbolado de la ciudad de Valencia.
La información de la web se divide en tres zonas:
-
Valencia ciudad
-
Término municipal de Valencia
-
Datos sobre el arbolado de Valencia ciudad
Los datos que muestra Valencia Verde provienen de catálogos de datos abiertos sobre espacios verdes y arbolado disponibles en Ajuntament de València – Dades Obertes, datos del censo de la Oficina d'Estadística de València e información del Institut Cartogràfric Valencià.
Gracias a dicha información, se crean visualizaciones en las que los usuarios pueden ver, por ejemplo, el porcentaje de área verde por barrio/distrito y los m2 de zona verde por habitante en cada barrio/distrito. Esta aplicación es un espacio que permite conocer, de manera clara e interactiva, el arbolado, las zonas verdes y su relación con la población y los barrios de Valencia.
Blog
La Unión Europea ha situado la transformación digital del sector público en el centro de su agenda política. A través de diversas iniciativas, encuadradas dentro del programa político la Década Digital, la UE busca impulsar la eficiencia de los servicios públicos y ofrecer una mejor experiencia a los ciudadanos. Un objetivo para el que es fundamental el intercambio de datos e información de manera ágil entre instituciones y países.
Es aquí donde cobra importancia la interoperabilidad y la busca de nuevas soluciones para impulsarla. Las tecnologías emergentes como la inteligencia artificial (IA), suponen grandes oportunidades en este campo, gracias a su capacidad para analizar y procesar enormes cantidades de datos.
Un informe para analizar el estado de la cuestión
Ante este contexto, la Comisión Europea ha publicado un extenso y exhaustivo informe titulado “Artificial Intelligence for Interoperability in the European Public Sector”, donde ofrece un análisis sobre cómo la IA ya están mejorando la interoperabilidad en el sector público europeo. El informe se divide en tres partes:
- Una revisión bibliográfica y política sobre las sinergias entre AI y la interoperabilidad. En ella se destaca el trabajo legislativo llevado a cabo por la UE. Se resalta la Ley sobre la Europa Interoperable que busca establecer una estructura de gobernanza e impulsar un ecosistema de soluciones reutilizables e interoperables para la administración pública. También se menciona la Ley de Inteligencia Artificial, diseñada para garantizar que los sistemas de IA utilizados en la UE sean seguros, transparentes, trazables, no discriminatorios y respetuosos con el medio ambiente.
- El informe continúa con un análisis cuantitativo de 189 casos de uso. Para seleccionar estos casos, se ha tenido en cuenta el inventario realizado en el informe “AI Watch. Panorama europeo del uso de la Inteligencia Artificial por el sector público” que incluye 686 ejemplos, actualizado a 720 recientemente.
- Un estudio cualitativo que profundiza en algunos de los casos anteriores. En concreto, se han caracterizado siete casos de uso (dos de e
sllos españoles), con un objetivo exploratorio. Es decir, se busca extraer conocimiento sobre los retos a afrontar de la interoperabilidad y cómo pueden ayudar las soluciones basadas en la IA a ello.
Conclusiones del estudio
La IA se está convirtiendo en una herramienta esencial para estructurar, conservar, normalizar y procesar los datos de la administración pública, mejorando la interoperabilidad dentro y fuera de la misma. Una tarea que ya realizan muchas organizaciones.
De entre todos los casos de uso de IA en el sector público analizados en el estudio, el 26% estaban relacionados con la interoperabilidad. Estas herramientas se utilizan para mejorar la interoperabilidad operando en diferentes niveles: técnico, semántico, jurídico y organizativo. Un mismo sistema de IA puede operar en distintas capas.
- La capa semántica de la interoperabilidad es la más relevante (91% de los casos). El uso de ontologías y taxonomías para crear un lenguaje común, combinado con la IA, puede ayudar a establecer la interoperabilidad semántica entre diferentes sistemas. Un ejemplo es el proyecto EPISA60, que se basa en procesamiento del lenguaje natural, utilizando reconocimiento de entidades y aprendizaje automático para explorar documentos digitales.
- En segundo lugar, se encuentra la capa organizativa, con un 35% de casos. Se destaca el uso de IA para la armonización de políticas, modelos de gobernanza y reconocimiento mutuo de datos, entre otros. En este sentido, el Ministerio de Justicia de Austria lanzó el proyecto JustizOnline que integra varios sistemas y procesos relacionados con la impartición de justicia.
- El 33% de los casos se centraba en la capa jurídica. En este caso se busca que el intercambio de datos se realice cumpliendo con los requisitos legales sobre protección de datos y privacidad. La Comisión Europea está elaborando un estudio para explorar cómo puede utilizarse la IA para verificar la transposición de la legislación de la UE por parte de los Estados miembros. Para ello se comparan distintos artículos de las leyes con ayuda de una IA.
- Por último, está la capa técnica, con un 21% de casos. En este campo, la IA puede ayudar al intercambio de datos de forma fluida y segura. Un ejemplo es el trabajo realizado en el centro de investigación belga VITO, basado en técnicas de codificación/decodificación y transporte de datos con IA.
En concreto, las tres acciones más comunes que los sistemas basados en IA realizan para impulsar la interoperabilidad de los datos son: detectar información (42%), estructurarla (22%) y clasificarla (16%). En la siguiente tabla, extraída del informe, se pueden ver todas las actividades detalladas:
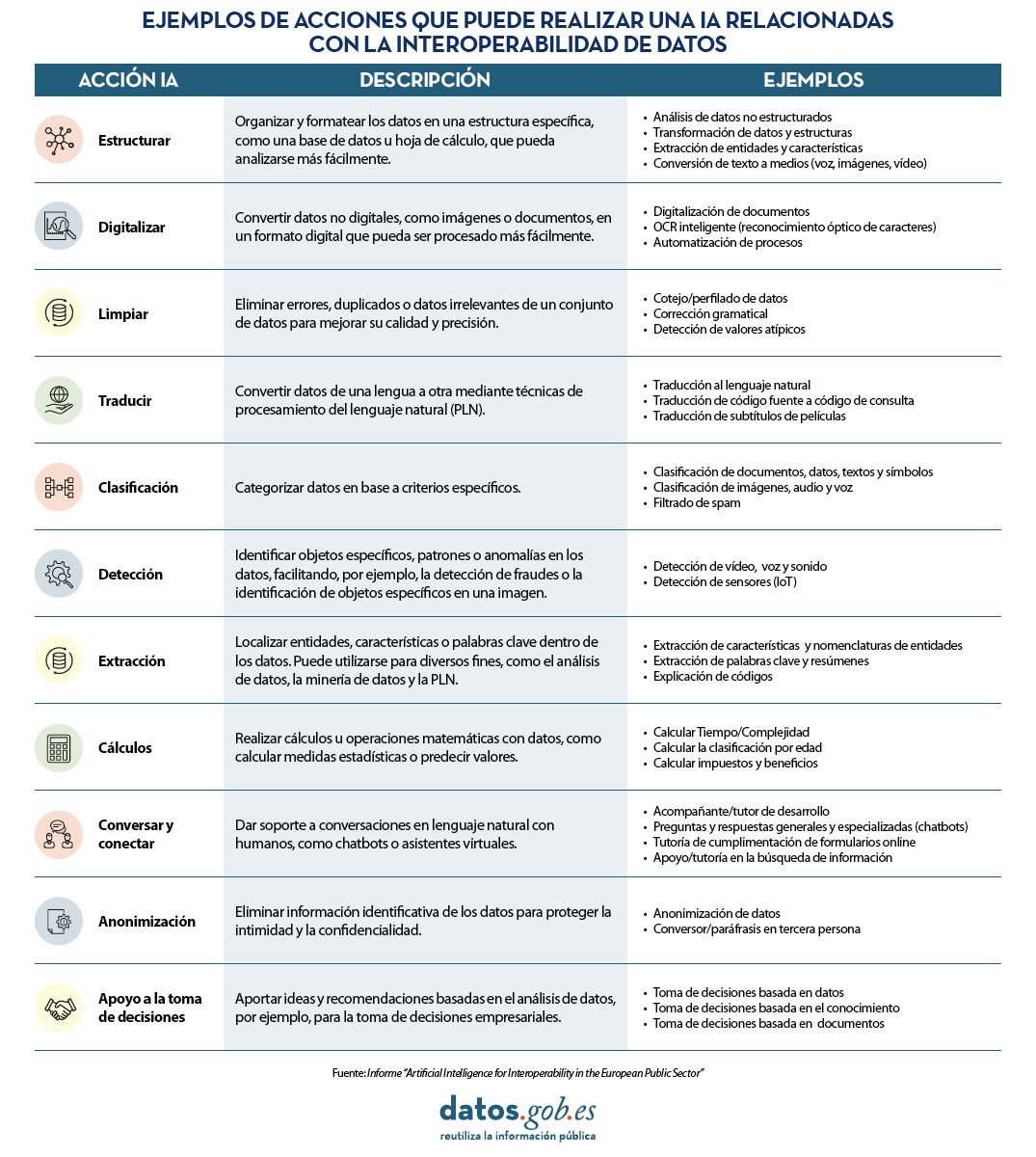
Descarga aquí la versión accesible de la tabla
El informe también analiza el uso de IA en áreas concretas. Destaca su uso en “servicios públicos generales” (41%), seguido de “orden público y seguridad” (17%) y “asuntos económicos” (16%). Con respecto a sus beneficios, destaca la simplificación administrativa (59%), seguido de la evaluación de la eficacia y la eficiencia (35%) y la preservación de la información (27%).
Casos de uso de IA en España
En la tercera parte del informe se analizan en detalle casos de uso concretos de soluciones basadas en IA que han ayudado a mejorar la interoperabilidad del sector público. De las siete soluciones caracterizadas, dos son de España:
- Vulnerabilidad energética - evaluación automatizada del informe sobre pobreza energética. Cuando las empresas proveedoras de servicios de energía detectan impagos, antes de cortar el servicio deben consultar con el ayuntamiento para determinar si el usuario se encuentra en situación de vulnerabilidad social, en cuyo caso no se le pueden cortar los suministros. Los ayuntamientos reciben mensualmente listados de las compañías en diferentes formatos y tienen que pasar por un costoso proceso burocrático manual para validar si un ciudadano está en riesgo social o económico. Para solucionar este reto, la Administració Oberta de Catalunya (AOC) ha desarrollado una herramienta que automatiza el proceso de verificación de datos mejorando la interoperabilidad entre las empresas, los municipios y otras administraciones.
- Transcripciones automatizadas para agilizar los procedimientos judiciales. En el País Vasco, las transcripciones de juicios por parte de la administración se realizan revisando manualmente los vídeos de todas las sesiones. Por lo tanto, no es posible buscar fácilmente palabras, frases, etc. Esta solución convierte los datos de voz en texto automáticamente, lo que permite realizar búsquedas y ahorrar tiempo.
Recomendaciones
El informe finaliza con una serie de recomendaciones sobre lo que deberían hacer las administraciones públicas:
- Aumentar la concienciación interna sobre las posibilidades de la IA para mejorar la interoperabilidad. A través de la experimentación, podrán descubrir los beneficios y el potencial de esta tecnología.
- Enfocar la adopción de una solución IA como un proyecto complejo con implicaciones no solo técnicas, sino también organizativas, legales, éticas, etc.
- Crear las condiciones óptimas para una colaboración efectiva entre agencias públicas. Para ello es necesaria una comprensión común de los retos a afrontar, con el fin de facilitar el intercambio de datos y la integración de los diferentes sistemas y servicios.
- Promover el uso de ontologías y taxonomías uniformes y estandarizadas para crear un lenguaje común y una comprensión compartida de los datos que ayuden a establecer la interoperabilidad semántica entre sistemas.
- Evaluar las legislaciones actuales, tanto en las primeras etapas de experimentación como durante la implementación de una solución de IA, de manera regular. También se debe considerar la posibilidad de colaborar con actores externos para evaluar la adecuación del marco jurídico. En este sentido, el informe también incluye recomendaciones para las próximas actualizaciones políticas de la UE.
- Apoyar la mejora de las competencias de los especialistas en IA e interoperabilidad dentro de la administración pública. Se busca que las tareas críticas de supervisión de los sistemas de IA queden dentro de la organización.
La interoperabilidad es uno de los motores clave del gobierno digital, ya que permite el intercambio fluido de datos y procesos, fomentando la colaboración eficaz. La IA puede ayudar a automatizar tareas y procesos, reducir costes y mejorar la eficiencia. Por eso es recomendable impulsar su adopción por los organismos públicos de todos los niveles.
Blog
Nadie duda ya de la importancia de los datos en la sociedad y la economía actuales. Los datos están presentes hoy en día en prácticamente todos los aspectos de nuestra vida. Es por ello que cada vez más países han ido incorporando a sus políticas normativas específicas referentes a los datos: ya sean sobre datos personales, empresariales o gubernamentales, o bien para regular una serie de cuestiones, como quién puede acceder a ellos, dónde pueden almacenarse, cómo deben protegerse, etc.
Sin embargo, cuando se examinan esas políticas con más detenimiento, se pueden observar diferencias significativas entre ellas, dependiendo de los objetivos principales que establece cada país a la hora de aplicar sus políticas de datos. Así pues, todos los países reconocen el valor social y económico de los datos, pero las políticas que implementan para maximizar ese valor pueden variar ampliamente. Para algunos, los datos son principalmente un activo económico, para otros puede ser un medio de innovación y modernización, y para otros una herramienta para el desarrollo.
Un informe reciente del Centro para la Innovación a través de los Datos compara las políticas generales aplicables en varios países que han sido precisamente seleccionados por las diferencias respecto a su visión de cómo se deben gestionar los datos: China, India, Singapur, el Reino Unido y la Unión Europea. A continuación, haremos un repaso de las características principales de sus políticas de datos, centrándonos principalmente en aquellos aspectos relacionados con el fomento de la innovación a través del uso de los datos.
CHINA
Sus esfuerzos se centran en construir una economía interna de datos sólida para fortalecer la competitividad nacional y mantener el control del gobierno a través de la recopilación y uso de datos. Cuenta con dos agencias desde las que se dirigen las políticas de datos: la administración del ciberespacio (CAC) y la administración nacional de datos (NDA).
Las principales políticas que gobiernan los datos en el país son:
- El plan quinquenal nacional de informatización, publicado a finales de 2021 para incrementar la recopilación de datos en la industria nacional.
- La ley de seguridad de los datos (DSL), efectiva desde septiembre de 2021 y donde se otorga especial protección a todos los datos que se considera puedan tener un impacto en la seguridad nacional.
- La ley de ciberseguridad (CSL), efectiva desde junio de 2017 y a través de la cual se prohíbe el anonimato online y se concede también acceso a los datos por parte del gobierno cuando sea requerido por cuestiones de seguridad.
- La ley de protección de la información personal (PIPL), efectiva desde noviembre de 2021 y que establece la obligatoriedad de mantener los datos en el territorio nacional.
INDIA
Su objetivo principal es utilizar la política de datos para desbloquear un nuevo recurso económico e impulsar la modernización y el desarrollo del país. El Ministerio de Electrónica y Tecnología de la Información (MEIT por sus siglas en inglés) rige y supervisa las políticas de datos en el país, que resumimos a continuación:
- La ley de protección de datos digitales personales del 2023, cuyo objetivo es habilitar el procesamiento de datos personales de forma que se reconozca, tanto el derecho de las personas a proteger sus datos, como la necesidad de procesarlos para fines legítimos.
- La arquitectura de empoderamiento y protección de los datos (DEPA), que se puso en marcha en el 2020 y otorga a los ciudadanos un mayor control sobre sus datos personales al establecer intermediarios entre los usuarios de la información y los proveedores, además de proporcionar consentimiento a las empresas en función de un conjunto de permisos establecido por el usuario.
- El marco de gobernanza de los datos no personales, también aprobado en el 2020 y a través del cual se establece que los beneficios obtenidos a través de los datos deben repercutir también en la comunidad, y no solo en las empresas que recopilan esos datos. También indica que deben compartirse datos de gran valor y aquellos relacionados con el interés público (como por ejemplo los datos de energía, transporte, geoespaciales o sanidad).
SINGAPUR
Pretende utilizar los datos como vehículo para atraer nuevas empresas a operar dentro del país. La Autoridad de Desarrollo de Medios Infocomm (IMDA) es la entidad encargada de gestionar las políticas de datos en este caso, lo que incluye el control de la Comisión de Protección de Datos Personales (PDPC).
Entre la normativa más relevante en este caso podemos encontrar:
- La ley de Protección de Datos Personales (PDPA), actualizada por última vez en el 2021 y que se basa en el consentimiento, pero también establece algunas excepciones por interés legítimo público.
- El marco de confianza para la compartición de datos, publicado en el 2019 y donde se establecen estándares para el intercambio de datos entre empresas (incluyendo plantillas para establecer acuerdos legales de intercambio), aunque con ciertas protecciones para el secreto comercial.
- La obligatoriedad de portabilidad de datos (DPO), que será próximamente incorporada a la PDPA para establecer el derecho a la transmisión de datos personales a otro servicio (siempre que cuente con sede en el país) en un formato estándar que facilite el intercambio.
REINO UNIDO
Quiere impulsar la competitividad económica del país, al mismo tiempo que protege la privacidad de los datos de sus ciudadanos. La Oficina del Comisionado de la Información (ICO) es el organismo encargado de la protección de datos y las pautas para poder compartirlos.
En el caso del Reino Unido el marco legislativo es muy amplio:
- El núcleo de los principios de privacidad, como la portabilidad de datos o las condiciones de acceso a los datos personales, está cubierto por el Reglamento General de Protección de Datos (GDPR) del 2016, la ley de Protección de Datos (DPA) del 2018, la regulación para la Privacidad de las Comunicaciones Electrónicas del 2013 y la propuesta de ley de Protección de Datos e Información Digital todavía bajo debate.
- La ley de Economía Digital, establecida en el 2017 y donde se definen las normas para compartir datos entre administraciones públicas para el desarrollo de los servicios públicos.
- El Código para Compartir Datos, que entró en vigor en Octubre de 2021 y determina buenas prácticas que sirven de guía a las empresas a la hora de compartir datos.
- La Directiva de Servicios de Pago (PSD2), que entró en vigor inicialmente en el 2018 requiriendo a los bancos compartir sus datos en formatos estandarizados para fomentar el desarrollo de nuevos servicios.
UNIÓN EUROPEA
Utiliza un enfoque basado en los derechos humanos para la protección de datos. El objetivo es dar prioridad a la creación de un mercado único que facilite el flujo libre de datos entre los estados miembro. Los Consejos Europeos de Protección de Datos (EDPB) y de Innovación a través de los Datos son los principales organismos responsables de supervisar la protección de datos en la Unión.
Nuevamente, la normativa aplicable es muy amplia y ha continuado extendiéndose recientemente:
- El Reglamento General de Protección de Datos (GDPR), que se ha convertido en la regulación más completa y descriptiva en el mundo, y que está basada en los principios de legalidad, equidad, transparencia, contención, minimización, exactitud, almacenamiento, integridad, confidencialidad y responsabilidad.
- El programa para la Década Digital, para el fomento de un mercado digital único, interoperable, interconectado y seguro.
- La Declaración de Principios y Derechos Digitales, que amplía los derechos digitales y sobre los datos ya existentes en la norma de protección.
- La Ley de Datos y el Reglamento de Gobernanza de Datos, que facilitan la accesibilidad a los datos de forma horizontal, es decir entre sectores y dentro de los mismos, siguiendo los principios de la UE. La Ley de Datos Impulsa reglas armonizadas relativas al acceso y uso equitativo de los datos, aclarando quién puede crear valor a partir de ellos y bajo qué condiciones. Por su parte, el Reglamento de Gobernanza de datos regula el intercambio seguro de conjuntos de datos que están bajo el poder de organismos públicos sobre los que concurren derechos de terceros, así como los servicios de intermediación de datos y su cesión altruista para el beneficio de la sociedad.
Las claves para el fomento de la innovación
En general, podríamos concluir que aquellas políticas de datos que adoptan un enfoque más orientado en favor de la innovación se caracterizan por:
- Protección de datos basada en distintos niveles de riesgo, priorizando la protección de los datos personales más sensibles, como la información médica o financiera, mientras se reduce los costes regulatorios para aquellos menos sensibles.
- Marcos de compartición para datos personales y no personales, fomentando la compartición de datos por defecto tanto en el sector público como privado y eliminando barreras a la compartición voluntaria de datos.
- Facilitar el flujo de datos, respaldando una economía digital abierta y competitiva.
- Políticas de producción de datos proactivas, fomentando el uso de los datos como factor de producción mediante la recopilación de datos en varios sectores y evitando lagunas en la información.
Como hemos visto, las políticas de datos se han convertido en un aspecto estratégico para muchos países, ya que no sólo contribuyen a reforzar sus objetivos y prioridades como nación, sino que además envían señales sobre cuáles son sus prioridades e intereses en el escenario internacional. Lograr un equilibrio adecuado entre la protección de datos y el fomento de la innovación es uno de los desafíos clave. Antes de abordar sus propias políticas, se recomienda a los países invertir tiempo en analizar y comprender los distintos enfoques existentes, incluyendo sus fortalezas y debilidades, para después tomar las medidas específicas más adecuadas a la hora de diseñar sus propias estrategias.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Vivimos un momento histórico en el que los datos son un activo clave, del que dependen cada día multitud de pequeñas y grandes decisiones de empresas, organismos públicos, entidades sociales y ciudadanos. Por ello, es importante conocer de donde proviene cada dato, para garantizar que las cuestiones que afectan a nuestra vida están basadas en información veraz.
¿Qué es la citación de datos?
Cuando hablamos de “citar” nos referimos al proceso de indicar qué fuentes externas se han utilizado para crear contenidos. Una cuestión ampliamente recomendable que afecta a todos los datos, incluidos los datos públicos como está recogido en nuestro ordenamiento jurídico. En el caso de los datos ofrecidos por las adminstraciones, el Real Decreto 1495/2011 incluye la necesidad del reutilizador de citar la fuente de origen de la información.
Para ayudar a los usuarios en esta tarea, la Oficina de Publicaciones de la Unión Europea editó Data Citation: A guide to best practice, donde se habla de la importancia de la citación de datos y se recogen recomendaciones de buenas prácticas, así como los retos a superar para citar conjuntos de datos de manera correcta.
¿Por qué es importante la citación de datos?
La guía menciona las razones más relevantes por las que es recomendable llevar a cabo esta práctica:
- El crédito. Crear conjuntos de datos conlleva trabajo. Citar al autor o autores les permite recibir feedback y saber que su trabajo es útil, lo que les anima a seguir trabajando en nuevos conjuntos de datos.
- La transparencia. Cuando los datos se citan, el lector puede acudir a ellos para revisarlos, comprender mejor su alcance y evaluar su idoneidad.
- La integridad. Los usuarios no deben de caer en el plagio. No deben atribuirse el mérito de la creación de conjuntos de datos que no son suyos..
- La reproducibilidad. La citación de los datos permite que una tercera persona pueda intentar reproducir los mismos resultados, utilizando la misma información.
- La reutilización. La citación de datos facilita que cada vez más conjuntos de datos se den a conocer y, por tanto, aumente su uso.
- Minería de textos. Los datos no solo son consumidos por humanos, también pueden serlo por máquinas. Una correcta citación ayudará a las máquinas a comprender mejor el contexto de los conjuntos de datos, amplificando los beneficios de su reutilización.
Buenas prácticas generales
De entre todas las buenas prácticas generales incluidas en la guía, a continuación destacamos algunas de las más relevantes:
- Sé preciso. Es necesario que los datos citados estén definidos con exactitud. La citación de datos debe indicar qué datos concretos se han utilizado de cada conjunto de datos. También es importante señalar si han sido procesados y si provienen directamente del creador o de algún agregador (como un observatorio que ha tomado datos de diversas fuentes).
- Utiliza "identificadores persistentes" (persistent identifiers o PID). Al igual que cada libro que encontramos en una biblioteca tiene su identificador, los conjuntos de datos también pueden (y deben) tenerlo. Los identificadores persistentes son esquemas formales que proporcionan una nomenclatura común, que identifican de manera única los conjuntos de datos, evitando ambigüedades. A la hora de citar conjuntos de datos, es necesario localizarlos y escribirlos como un hipervínculo accionable, sobre el que se puede hacer clic para acceder al conjunto de datos citado y a sus metadatos. Existen diferentes familias de PID, pero la guía destaca dos de las más comunes: el sistema Handle y el identificador de objeto digital (DOI).
- Indica el momento en el que se ha accedido a los datos. Esta cuestión es de gran importancia cuando trabajamos con datos dinámicos (que se actualizan y cambian periódicamente) o continuos (sobre los que se añaden datos adicionales sin modificar los antiguos). En estos casos, es importante citar la fecha de acceso. Además, si es necesario, el usuario puede añadir “snapshots” o instantáneas del conjunto de datos, es decir, copias tomadas en momentos concretos.
- Consulta los metadatos del conjunto de datos utilizado y las funcionalidades del portal en que se ubica. En los metadatos se encuentra gran cantidad de la información necesaria para la cita.
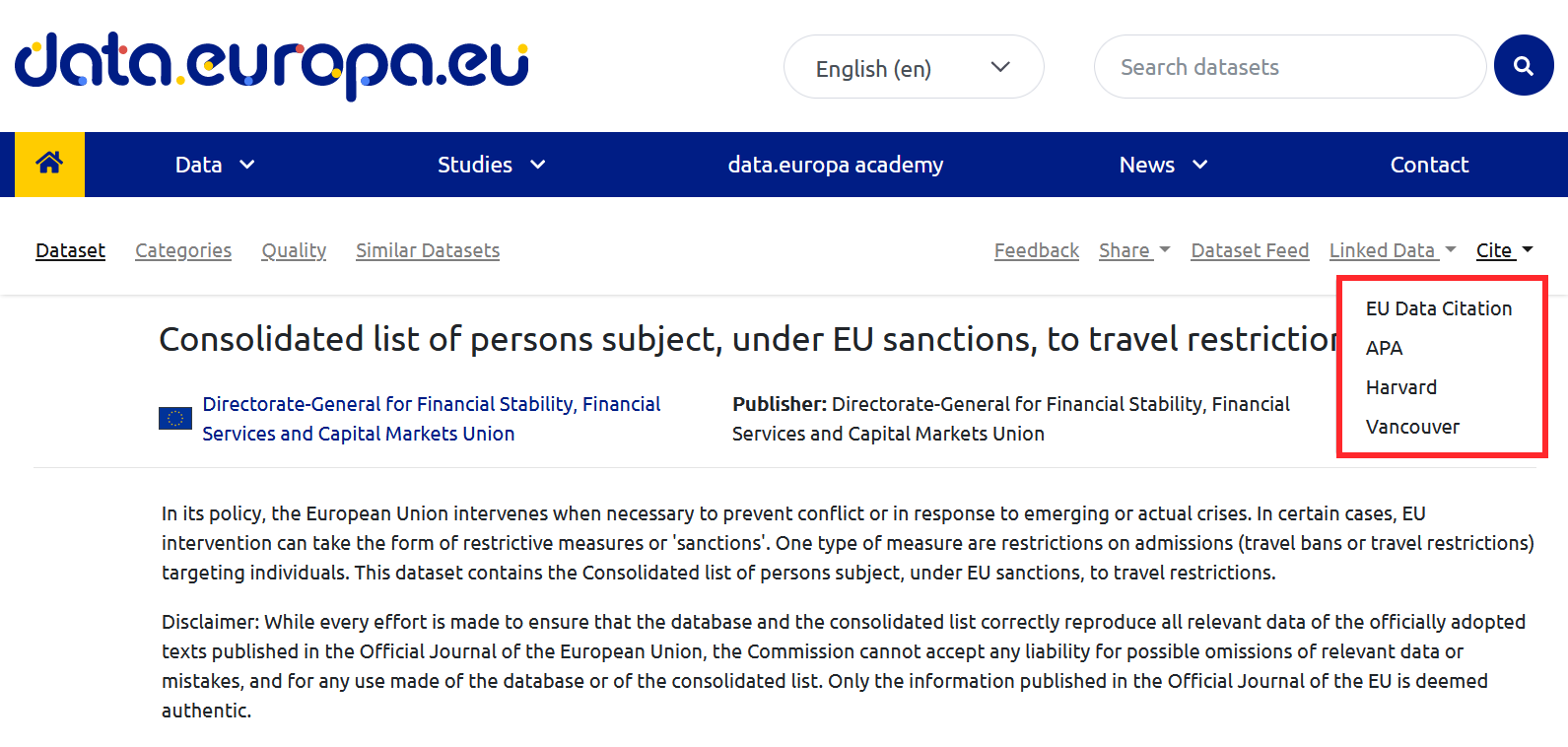
Además, los portales de datos pueden incluir herramientas que ayuden a la citación. Es el caso del Portal de datos abiertos de la Unión Europea en cuyo menú superior se puede encontrar el botón de citación.
- Apóyate en herramientas de software. La mayoría de los programas informáticos utilizados para crear documentos permiten crear y formatear citas automáticamente, asegurando su formato. Además, existen herramientas específicas de gestión de citas como BibTeX o Mendeley, que permiten crear bases de datos de citas teniendo en cuenta sus peculiaridades, una función de gran utilidad cuando es necesario citar numerosos conjuntos de datos en múltiples documentos.
Cómo citar correctamente
La segunda parte del informe contiene el material técnico de referencia para crear citas que cumplan las recomendaciones indicadas. Abarca los elementos que debe incluir una cita y cómo ordenarlos para distintos fines.
Entre los elementos que debe incluir una cita se encuentran:
- Autor, puede referir tanto al individuo que ha creado el conjunto de datos (autor personal) como a la organización responsable (autor corporativo).
- Título del dataset.
- Versión/edición.
- Publicador, que es la entidad que hace disponible el conjunto de datos y puede coincidir o no con el autor (en caso de que coincidan no es necesario repetirlo).
- Fecha de publicación, donde se indica el año en que se creó. Es importante incluir entre paréntesis el momento de la última actualización.
- Fecha de citación, que expresa la fecha en la que el creador de la cita accedió a los datos, incluyendo la hora si es necesario. Para los formatos de fechas y horas, la guía recomienda acudir a la especificación DCAT, ya que ofrece una precisión mayor en términos de interoperabilidad.
- Identificador persistente.
Respeto al orden de toda esa información, existen diferentes directrices en relación con la estructura general de las citas. La guía muestra las diferentes formas más adecuadas de citar según el tipo de documento en el que aparece la cita (documentos periodísticos, online, etc.), incluyendo ejemplos y recomendación. Entre otros, destaca el ejemplo del Libro de estilo interinstitucional (ISG), que edita la Oficina de Publicaciones de la UE. Este libro de estilo no contiene orientaciones específicas sobre cómo citar datos, pero sí una estructura general para citas que puede aplicarse a los conjuntos de datos, recogida en la siguiente imagen.

La guía finaliza con una serie de anexos con listas de control, diagramas y ejemplos.
Si quieres saber más sobre este documento, te recomendamos ver este seminario online donde se resumen los puntos más importantes.
En definitiva, citar correctamente los conjuntos de datos mejora la calidad y la transparencia del proceso de reutilización de los datos, estimulándolo al mismo tiempo. Por tanto, fomentar la citación correcta de los datos es una práctica no solo recomendable, sino cada vez más necesaria.
Blog
¿Qué retos afrontan los publicadores de datos?
En la era digital actual, la información es un activo estratégico que impulsa la innovación, la transparencia y la colaboración en todos los sectores de la sociedad. Es por ello por lo que las iniciativas de publicación de datos han experimentado un enorme desarrollo como mecanismo fundamental para desbloquear el potencial de estos datos, permitiendo que gobiernos, organizaciones y ciudadanos accedan, utilicen y compartan.
No obstante, existen aún muchos retos tanto para publicadores de datos como para consumidores de los mismos. Aspectos como el mantenimiento de las APIs (Application Programming Interfaces) que nos permiten acceder y consumir los conjuntos de datos publicados o la correcta replicación y sincronización de conjuntos de datos cambiantes siguen siendo desafíos muy relevantes para estos actores.
En este post, exploraremos cómo los Linked Data Event Streams (LDES), un nuevo mecanismo de publicación de datos, pueden ayudarnos a solventar estos retos. ¿Qué es exactamente LDES? ¿Cómo difiere de las prácticas tradicionales de publicación de datos? Y, lo más importante, ¿cómo puede ayudar a publicadores y consumidores de datos a facilitar el uso de los conjuntos de datos disponibles?
Destilando los aspectos claves de LDES
Cuando desde la Universidad de Gante se comenzó a trabajar en un nuevo mecanismo para la publicación de datos abiertos, la pregunta a la que pretendían dar respuesta era: ¿Cuál es la mejor API posible que podemos diseñar para exponer conjuntos de datos abiertos?
En la actualidad, los organismos publicadores de datos recurren a múltiples mecanismos para publicar sus diferentes conjuntos de datos. Por un lado, es fácil encontrarnos APIs. Destacan las de tipo SPARQL, estándar para consulta de datos enlazados (Link Data), pero también de tipo REST o de tipo WFS, para el acceso a conjuntos de datos con componente geoespacial. Por otro lado, es muy común que encontremos la posibilidad de acceder a volcados de datos en diferentes formatos (i.e. CSV, JSON, XLS, etc.) que podamos descargar para su utilización.
En el caso de los volcados de datos, es muy fácil encontrarnos con problemas de sincronización. Esto ocurre cuando, tras un primer volcado, se produce un cambio que requiere la modificación del conjunto de datos original como, por ejemplo, el cambio del nombre de una calle en un callejero previamente descargado. Ante este cambio, si el tercero opta por modificar el nombre de la calle sobre el volcado inicial en lugar de esperar a que el publicador actualice sus datos en el repositorio maestro para realizar un nuevo volcado, los datos manejados por el tercero quedarán desincronizados frente a los manejados por el publicador. De igual forma, si es el publicador el que actualiza su repositorio maestro pero estos cambios no son descargados por el tercero, ambos manejarán diferentes versiones del conjunto de datos.
Por otra parte, si el publicador ofrece el acceso a los datos a través de APIs de consulta, en lugar de mediante volcados de los datos a los terceros, se solucionan los problemas de sincronización, pero la construcción y mantenimiento de un alto y variado volumen de las mismas supone un elevado esfuerzo a los publicadores de datos.
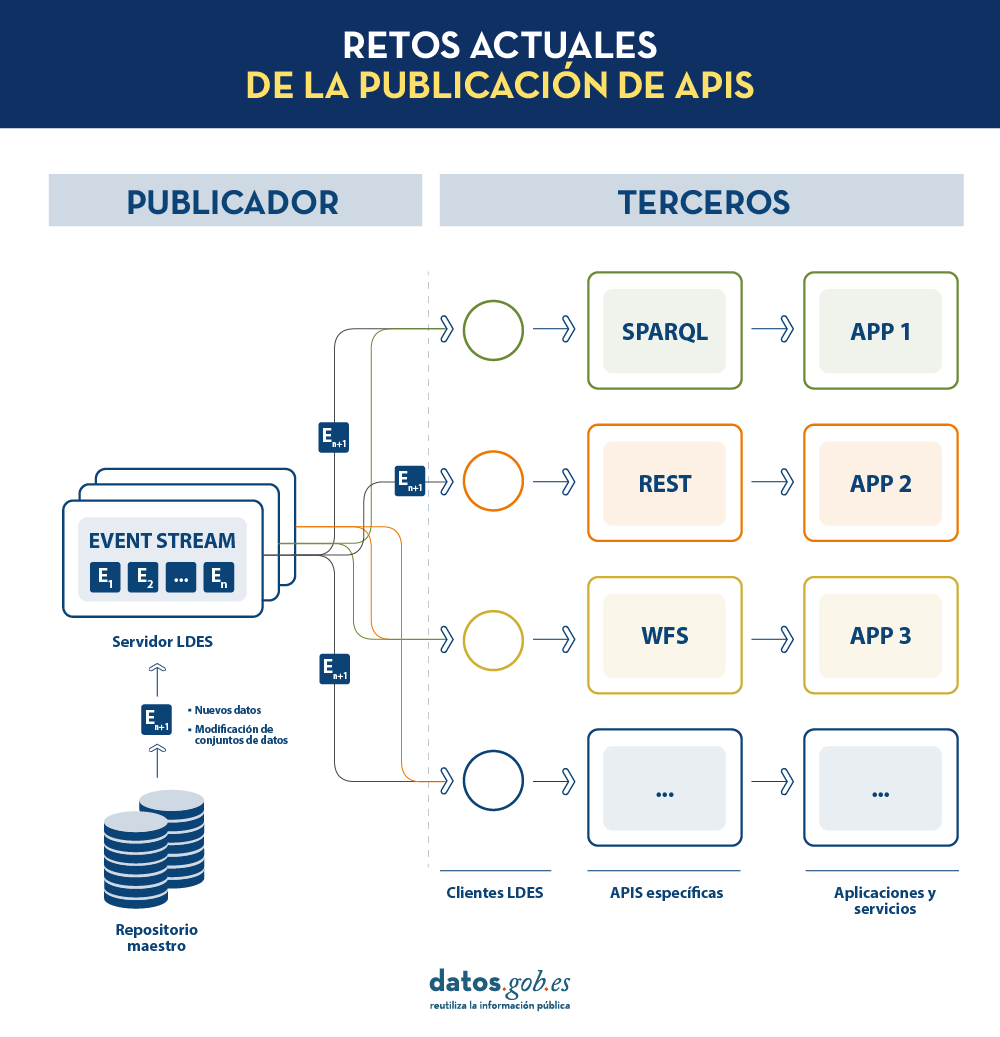
LDES busca solventar estas diferentes problemáticas aplicando el concepto de Linked Data a un event stream o flujo de datos. Según la definición que aparece en su propia especificación, un Linked Data Event Stream (LDES) es una colección de objetos inmutables donde cada objeto está descrito en ternas RDF.
En primer lugar, el hecho de que los LDES apuesten por Linked Data aporta principios de diseño que permiten combinar datos diversos y/o pertenecientes a diferentes fuentes, así como su consulta a través de mecanismos semánticos que permiten legibilidad tanto por humanos como por máquinas. En resumen, aporta interoperabilidad y consistencia entre conjuntos de datos, y facilita por tanto su búsqueda y descubrimiento.
Por otro lado, los event streams o flujos de datos, permiten a los consumidores replicar la historia de los conjuntos de datos, así como sincronizar los cambios recientes. Cualquier nuevo registro añadido a un conjunto de datos o cualquier modificación de los registros existentes (en definitiva, cualquier cambio), se registra como un nuevo evento incremental en el LDES que no alterará los eventos anteriores. Por tanto, pueden publicarse y consumirse datos como una secuencia de eventos, lo cual es útil para datos que cambian con frecuencia, como información en tiempo real o información que sufre actualizaciones constantes, ya que permite la sincronización de las últimas actualizaciones sin necesidad de hacer una nueva descarga completa de todo el repositorio maestro tras cada modificación.
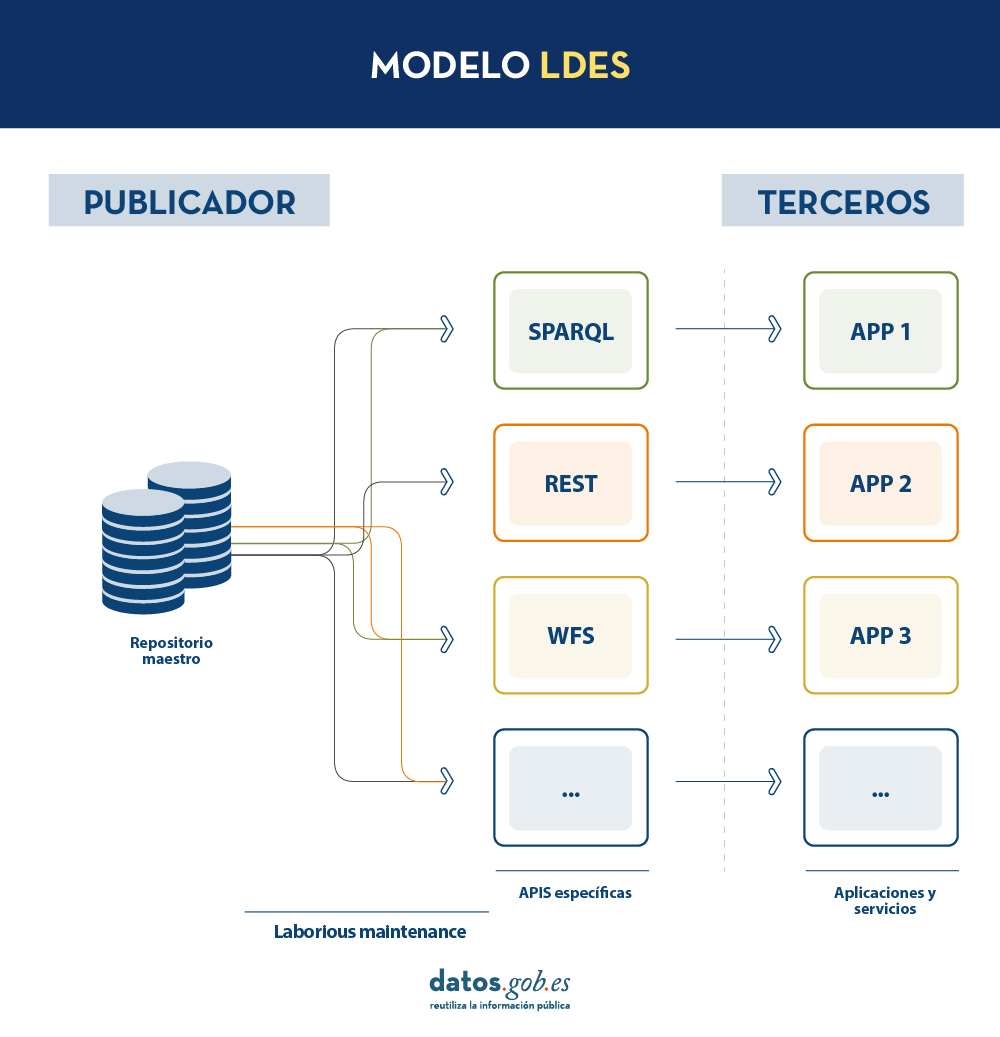
En un modelo de este tipo, el editor solo necesitará desarrollar y mantener una API, el LDES, en lugar de múltiples APIs como WFS, REST o SPARQL. Los diferentes terceros que deseen utilizar los datos publicados se conectarán (cada tercero implementará su cliente LDES) y recibirán los eventos de los streams a los que se hayan suscrito. Cada tercero creará a partir de la información recabada las APIs específicas que considere oportunas en base al tipo de aplicaciones que quieran desarrollar o fomentar. En definitiva, el publicador no tendrá que resolver todas las potenciales necesidades que tenga cada tercero en la publicación de datos, sino que dando un interfaz LDES (API base mínima) cada tercero se centrará en su problemática.
Además, para facilitar el acceso en grandes volúmenes de datos o a datos que pueden estar distribuidos en diferentes fuentes, como un inventario de puntos de recarga eléctrica en Europa, LDES aporta la capacidad de fragmentación de los conjuntos de datos. A través de la especificación TREE (en inglés, árbol), LDES permite establecer diferentes tipos de relaciones entre fragmentos de datos. Esta especificación permite publicar colecciones de entidades, llamados miembros, y ofrece la capacidad de generar una o más representaciones de estas colecciones. Estas representaciones se organizan como vistas, distribuyendo los miembros a través de páginas o nodos interconectados mediante relaciones. Así, si deseamos que los datos se puedan consultar a través de índices temporales, se podrá establecer una fragmentación temporal y acceder solo a las páginas de un intervalo temporal. De igual forma, se podrán plantear índices alfabéticos o geoespaciales y así un consumidor podrá acceder sólo a aquellos datos necesarios sin la necesidad de realizar el “volcado” del conjunto de datos completo.
¿Qué conclusiones podemos extraer de LDES?
En este post hemos observado el potencial de LDES como mecanismo para la publicación de datos. Algunos de los aprendizajes más relevantes son:
- LDES persigue facilitar la publicación de datos a través de APIs base mínimas que sirvan como punto de conexión para cualquier tercero que desee consultar o construir aplicaciones y servicios sobre conjuntos de datos.
- La construcción de un servidor LDES, no obstante, tiene cierto nivel de complejidad técnica a la hora de establecer la arquitectura necesaria para el manejo de los flujos de datos publicados y su adecuada consulta por parte de consumidores de datos.
- El diseño de LDES permite la gestión tanto de datos con una elevada tasa de cambios (i.e. datos provenientes de sensores), como datos con una baja tasa de cambios (i.e. datos provenientes de un callejero). Ambos escenarios pueden manejar cualquier modificación del conjunto de datos como un flujo de datos.
- LDES soluciona de forma eficiente la gestión de registros históricos, versiones y fragmentos de conjuntos de datos. Para ello se apoya en la especificación TREE pudiendo establecer diferentes tipos de fragmentación sobre el mismo conjunto de datos.
¿Te gustaría saber más?
Dejamos a continuación algunas referencias que han servido para redactar este post y pueden servir al lector que desee profundizar en el mundo de LDES:
- Linked Data Event Streams: the core API for publishing base registries and sensor data, Pieter Colpaert. ENDORSE, 2021. https://youtu.be/89UVTahjCvo?si=Yk_Lfs5zt2dxe6Ve&t=1085
- Webinar on LDES and Base registries. Interoperable Europe, 17 January 2023. https://www.youtube.com/watch?v=wOeISYms4F0&ab_channel=InteroperableEurope
- SEMIC Webinar on the LDES specification. Interoperable Europe, 21 April 2023. https://www.youtube.com/watch?v=jjIq63ZdDAI&ab_channel=InteroperableEurope
- Linked Data Event Streams (LDES). SEMIC Support Centre. https://joinup.ec.europa.eu/collection/semic-support-centre/linked-data-event-streams-ldes
- Publishing data with Linked Data Event Streams: why and how. EU Academy. https://academy.europa.eu/courses/publishing-data-with-linked-data-event-streams-why-and-how
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Como dicta la tradición, el fin de año es un buen momento para reflexionar sobre nuestras metas y objetivos de cara a la nueva etapa que comienza tras las campanadas. En materia de datos, el inicio de un nuevo año también brinda oportunidades para trazar un futuro interoperable y digital que habilite el desarrollo de una economía del dato robusta, un escenario que beneficie tanto a investigadores como administraciones públicas o empresas privadas, así como que repercuta positivamente en el ciudadano como cliente final de muchas operaciones realizadas con datos, optimizando y reduciendo los tiempos de tramitación. Para lograr este fin, existe la Estrategia europea de datos que persigue desbloquear el potencial de los datos a través de, entre otras, la Ley de Datos (Data Act, en inglés) que recoge un conjunto de medidas relacionadas con el acceso y uso equitativo de los datos asegurando así mismo que el dato manejado sea de calidad, esté debidamente securizado, etc.
Como solución a esta necesidad, este último año se han publicado las especificaciones UNE de datos que son recursos normativos e informativos para implantar procesos comunes de gobierno, gestión y calidad del dato. Estas especificaciones, respaldadas por la Oficina del Dato, establecen estándares para disponer de datos bien gobernados (UNE 0077), gestionados (UNE 0078) y con niveles adecuados de calidad (UNE0079), permitiendo así mismo un crecimiento sostenible en la organización durante la implantación de los distintos procesos. Además de estas tres especificaciones, la especificación UNE 0080 define una guía y proceso de evaluación de madurez para medir el grado de implantación de los procesos de gobierno, gestión, y calidad del dato. Por su parte, la UNE 0081 también establece un proceso de evaluación del activo de datos en sí, es decir, de los conjuntos de datos, independientemente de su naturaleza o tipología; en resumen, su contenido está estrechamente relacionado con la UNE 0079 porque recoge unas características de calidad de los datos. La adopción de todas ellas puede proporcionar múltiples beneficios. En este post, analizamos cuáles son y cómo sería el proceso para cada especificación.
Así, con la mirada puesta en el futuro, planteamos un propósito de año nuevo: la aplicación de las especificaciones UNE del dato a una organización.
¿Qué ventajas tiene su aplicación y cómo puedo acceder a ellas?
En la era actual, donde el gobierno y la gestión eficiente de los datos se han convertido en un pilar fundamental para el éxito organizacional, la implementación de las especificaciones UNE sobre datos emerge como un faro guía hacia la excelencia marcando el camino a seguir. Estas especificaciones describen rigurosos procesos estandarizados que ofrecen a las organizaciones la posibilidad de construir una estructura robusta y confiable para el manejo de sus datos e información a lo largo de todo su ciclo de vida.
Al adoptar las especificaciones UNE, no solo se garantiza la calidad y seguridad de los datos, sino que también se constituye una base sólida y adecuada para la toma de decisiones informadas enriqueciendo los procesos organizacionales con buenas prácticas de datos. Por lo tanto, toda organización que decida abrazar estas normativas de cara al nuevo año estará acercándose a la innovación, la eficiencia y la confianza en el gobierno y la gestión de datos; así como preparándose para afrontar los desafíos y oportunidades que depara el futuro digital. La aplicación de especificaciones UNE no solo es un compromiso con la calidad, sino una inversión estratégica que pavimenta el camino hacia el éxito sostenible en un entorno empresarial cada vez más competitivo y dinámico porque:
- Maximiza la aportación de valor a la estrategia de negocio
- Minimiza riesgos en el tratamiento del dato
- Optimiza las tareas evitando trabajos innecesarios
- Establece marcos homogéneos de referencia y certificación
- Facilita la compartición de información con confianza y soberanía
El contenido de las guías puede visualizarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra y marcando “lectura” en el desplegable en el que aparece preseleccionado “pdf”. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la visualización requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
- ESPECIFICACION UNE 0077:2023
- ESPECIFICACION UNE 0078:2023
- ESPECIFICACION UNE 0079:2023
- ESPECIFICACIÓN UNE 0080:2023
- ESPECIFICACIÓN UNE 0081:2023
Desde datos.gob.es nos hemos hecho eco del contenido de las mismas y hemos preparado diferentes recursos didácticos como esta infografía o este vídeo explicativo.
¿Cómo se aplican a una organización?
Una vez tomada la decisión de abordar la implantación de estas especificaciones, surge un interrogante crucial: ¿Cuál es la manera más efectiva de hacerlo? La respuesta a esta cuestión dependerá de la situación inicial (marcada por una evaluación inicial de madurez), el tipo de organización y los recursos disponibles en el momento de establecer el plan director o plan de implantación. No obstante, en datos.gob.es, hemos publicado una serie de contenidos elaborados por expertos en tecnologías ligadas a la economía del dato datos.gob.es, hemos publicado una serie de contenidos elaborados por expertos en tecnologías ligadas a la economía del dato que te acompañarán en el proceso.
Antes de empezar, es importante conocer los diferentes procesos que constituyen cada una de las especificaciones UNE sobre datos. En esta imagen se exponen cuáles son.

Una vez entendido lo básico, la serie de contenidos ‘Aplicación de las especificaciones UNE sobre datos’ abordan un ejercicio práctico, desglosado en tres posts, sobre un caso de uso especifico: la aplicación de estas especificaciones a los datos abiertos. Como ejemplo, se define una necesidad que tiene el Ayuntamiento ficticio de Vistabella: avanzar en la publicación en abierto de información de transporte público y eventos culturales.
- En el primer post de la serie, se destaca la importancia de utilizar la especificación UNE 0077 de gobierno del dato para establecer mecanismos aprobados que respalden la apertura y publicación de los datos abiertos. A través de este primer contenido, se realiza un repaso de los procesos necesarios para alinear la estrategia organizacional de tal manera que se logre conseguir la máxima transparencia y calidad de los servicios públicos mediante la reutilización de información.
- El segundo artículo de la serie se sumerge en la norma UNE 0079 de gestión de calidad de los datos y su aplicación en el contexto de los datos abiertos. Este contenido subraya que la calidad de los datos abiertos va más allá de los principios FAIR y destaca la importancia de evaluar la calidad mediante criterios objetivos. A través del ejercicio práctico, se explora cómo el Ayuntamiento de Vistabella aborda los procesos de la UNE para mejorar la calidad de los datos abiertos como parte de su estrategia para potenciar la publicación de datos sobre transporte público y eventos culturales.
- Por último, la norma UNE 0078 sobre gestión de datos se explica en un tercer artículo en el que se presenta el proceso de Compartición, Intermediación e Integración de Datos (CIIDat) para la publicación de datos abiertos, combinado con plantillas específicas.
En conjunto, estos tres artículos ofrecen una guía para que cualquier organización avance con éxito hacia la publicación en abierto de información clave, asegurando la coherencia y calidad de los datos. Al seguir estos pasos, las organizaciones estarán preparadas para cumplir con los estándares normativos con todas las ventajas que supone.
Para finalizar, abrazar el propósito de año nuevo de aplicar las especificaciones UNE sobre datos representa un compromiso estratégico y visionario para cualquier organización que, además, estará alineado con la Estrategia europea de datos y la hoja de ruta europea que persigue configurar un futuro digital líder a nivel mundial.
Blog
En la primera parte de este artículo, se introducía el concepto de estrategia del dato como el esfuerzo que hacía la organización para poner los datos necesarios al servicio de su estrategia de negocio. En esta segunda parte, exploraremos algunos aspectos relacionados con la materialización de dicha estrategia como parte del diseño o mantenimiento – en caso de que ya exista- de un sistema de gobierno del dato.
Para la materialización de la estrategia del dato se deberá abordar un entorno de desarrollo recogido y descrito en un acta fundacional que recoge algunos aspectos como la identificación de los principales responsables de la implementación, los resultados esperados, los recursos disponibles y el plazo establecidos para conseguir los objetivos. Además, contendrá un portfolio de programas de gobierno del dato que incluya proyectos individuales o proyectos relacionados específicos para abordar la consecución de los objetivos estratégicos del dato.
Es importante mencionar que la implementación de una estrategia del dato repercute en el desarrollo y mantenimiento de los diferentes componentes de un sistema de gobierno del dato:
- Procesos
- Estructuras organizacionales
- Principios, políticas y marcos de referencia
- Información
- Cultura, ética y comportamiento
- Personas, habilidades y competencias
- Servicios, infraestructuras y aplicaciones.
En este sentido, puede decirse que cada uno de los proyectos incluidos en el programa del gobierno del dato, tiene como objetivo contribuir a desarrollar o mantener uno o varios de estos componentes.
Debe tenerse en cuenta que el diseño final de este sistema de gobierno de datos se consigue de manera iterativa e incremental en el tiempo, en función de las limitaciones y posibilidades de la organización y de su contexto actual de funcionamiento. Consecuentemente, la priorización, selección y secuenciación de los proyectos dentro del programa de gobierno del dato para implementar los objetivos estratégicos del dato tiene también una naturaleza iterativa e incremental[1].
Los tres mayores riesgos que se suelen encontrar en las organizaciones con respecto a los datos son:
- No saber quién tiene que responsabilizarse de implementar la estrategia del dato,
- No tener el conocimiento adecuado de los datos en cantidad y en calidad y
- No ejercer el control adecuado de los datos, por ejemplo, cumpliendo al menos la legislación vigente.
Por eso, en la medida de lo posible, los proyectos deberían abordarse de la siguiente forma:
- En primer lugar, abordar aquellos proyectos relacionados con la identificación, selección o mantenimiento de estructuras organizativas (objetivo del tipo “alineamiento estratégico”), conocido también como marco de gobierno.
- A continuación, acometer proyectos relacionados con el conocimiento de los procesos de negocio y de los datos que se usan (objetivo del tipo “alineamiento estratégico” orientado a la descripción de los datos mediante los metadatos correspondientes, incluyendo los referidos al ciclo de vida de los datos).
- Y finalmente, proceder a la definición de políticas y los controles derivados para distintas áreas de actuación (que pueden ser del tipo “alineamiento estratégico”, “optimización del riesgo” u “optimización de recursos”).
La aproximación por artefactos y la aproximación por procesos
A la hora de abordar la definición de estos programas de gobierno del dato, algunas organizaciones con un entendimiento de proyecto más orientado a la generación y despliegue de productos tecnológicos, siguen una aproximación por artefactos. Es decir, enfocan los proyectos que forman parte del programa de gobierno del dato como la consecución de determinados artefactos. Así, es posible encontrar organizaciones cuya primera preocupación a la hora de implantar el gobierno del dato es adquirir e instalar una herramienta específica que dé soporte, por ejemplo, a un glosario de términos, a un diccionario de datos, o a un data lake. Además, como por diversas circunstancias, algunas empresas no diferencian adecuadamente entre el gobierno del dato y la gestión del dato esta aproximación suele ser suficiente. Sin embargo, la aproximación por artefactos introduce el riesgo de “la herramienta sin el manual de instrucciones”: se adquiere la herramienta -probablemente tras una prueba de concepto del vendedor- y se despliega de acuerdo con las necesidades de la organización, pero se desconoce para qué se utiliza y cuándo hacerlo, quedándose el artefacto en numerosas ocasiones como un recurso aislado. Esto, a menos que la organización promueva un profundo cambio, puede acabar suponiendo a la larga un desperdicio de recursos al abandonarse el uso de los artefactos generados.
Una mejor alternativa, como se ha demostrado ampliamente en el sector del desarrollo del software, es la ejecución del programa de gobierno del dato con una aproximación por procesos. Esta aproximación por procesos permite, no solo desarrollar los artefactos necesarios, sino que, de partida modela la forma de trabajo de la organización con respecto a algún área de actuación, y contextualiza la razón de ser y el uso de los artefactos dentro del proceso, especificando quién debe usar el artefacto, para qué, cuándo, qué debe obtenerse al usar el artefacto, etc.
Esta aproximación por procesos es un instrumento idóneo para captar y modelar el conocimiento que la organización ya tiene con respecto a las tareas cubiertas por el proceso, y hacer que dicho conocimiento sea la referencia para nuevas operaciones que se realicen en el futuro. Además, la definición del proceso permite también particularizar las cadenas de responsabilidad y rendición de cuentas y el establecimiento de planes de comunicación, de modo que cada trabajador sabe qué tiene que hacer, qué artefactos debe usar, a quién tiene que pedir o de quién debe recibir recursos para realizar su trabajo, a quién tiene que comunicar sus resultados, o a quién debe escalar posibles problemas.
Esta forma de trabajar proporciona algunas ventajas, como por ejemplo, un comportamiento predecible de la organización con respecto al proceso; la posibilidad de utilizar esos procesos como componentes básicos para la ejecución de los proyectos de datos; la opción de reemplazar fácilmente un recurso humano; o la posibilidad de medir de forma eficiente el desempeño de un proceso. Pero sin duda, una de las mayores ventajas de esta aproximación por procesos, es que permite a las organizaciones adoptar las buenas prácticas contenidas en cualquiera de los modelos de referencia de procesos para el gobierno del dato, gestión del dato y gestión de calidad de los que existen en el panorama actual, como por ejemplo las especificaciones UNE 0077 (para el gobierno del dato), UNE 0078 (para la gestión del dato) y UNE 0079 (para la gestión de la calidad del dato).
Esta adopción habilita la posibilidad de utilizar marcos de trabajo para evaluación y la mejora de procesos, como el descrito en UNE 0080, que incluye el Modelo Alarcos de Madurez de Datos, en el que se introduce el concepto de madurez organizacional de gobierno del dato, gestión del dato y gestión de calidad del dato como un indicador del potencial de la organización para afrontar con determinadas garantías de éxito la consecución de los objetivos estratégicos. De hecho, suele ser frecuente que muchas organizaciones que adoptan la aproximación por procesos incluyan previamente objetivos específicos del dato (objetivos del tipo “alineamiento estratégico”) destinados a preparar la organización -mediante el incremento del nivel de madurez - para dar un mejor soporte a la ejecución del programa de gobierno del dato. Estos objetivos “preparatorios” se manifiestan fundamentalmente en la implantación de los procesos de gobierno del dato, gestión del dato y gestión de calidad del dato que permitan cerrar la brecha entre el estado de madurez inicial actual (AS_IS) y el estado de madurez final necesario de la organización (TO_BE).
En caso de que se elija la aproximación a procesos, los diferentes proyectos contenidos en el programa de datos generarán incrementos controlados y dirigidos en cada uno de los componentes del sistema de gobierno del dato, que permitirán afrontar la transformación de la organización para que se puedan llevar a cabo los objetivos estratégicos del negocio de la organización.
En definitiva, la implementación de una estrategia de datos se manifiesta en el desarrollo o mantenimiento de un sistema de gobierno del dato, que consigue que los datos de la organización se pongan al servicio de los objetivos estratégicos del negocio. El instrumento para conseguir este objetivo es el programa de gobierno del dato, que deseablemente debe ejecutarse mediante una aproximación por procesos para poder beneficiarse de todas las ventajas que esta aporta.
______________________________________________
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM y Dr. Fernando Gualo PhD en Tecnologías Informáticas Avanzadas – Consultor Gobierno y Calidad de datos
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de sus autores.
[1] Se recomienda la lectura del artículo https://hdl.handle.net/11705/JISBD/2019/083
[2] Véase el artículo https://dqteam.es/diferencias-entre-gobierno-gestion-y-calidad-de-datos/
Blog
Son cada vez más las organizaciones que deciden gobernar sus datos para asegurarse de que son relevantes, adecuados y suficientes para los usos previstos, esto es, que tienen un determinado valor organizacional.
Aunque los escenarios suelen ser muy variopintos, una observación detenida de las necesidades e intenciones permite descubrir que muchas de estas organizaciones ya habían comenzado a gobernar sus datos hace tiempo, pero no lo sabían. Quizás, lo único que estén haciendo a partir de esa decisión sea manifestarlo explícitamente. Esto suele ocurrir cuando empiezan a ser conscientes de la necesidad de contextualizar y justificar dichas iniciativas, por ejemplo, para hacer frente a un determinado cambio organizacional – como la ansiada transformación digital-, o para hacer frente a un determinado reto tecnológico como la implantación de un data lake para dar mejor soporte a los proyectos de analíticas del dato.
Una estrategia de negocio puede consistir en disminuir los costes necesarios para producir un determinado producto, definir nuevas líneas de negocio, conocer mejor los patrones de comportamiento de los clientes o elaborar políticas que aborden problemas específicos de la sociedad. Para implantar una estrategia de negocio se necesitan datos, pero no cualquier dato, sino datos que sean relevantes y útiles para los objetivos incluidos en la estrategia del negocio. Es decir, datos que se puedan usar como base para contribuir a la consecución de dichos objetivos. Por tanto, puede decirse, que cuando una organización reconoce que necesita gobernar sus datos, en realidad lo que está manifestando es su necesidad de poner determinados datos al servicio de la estrategia del negocio. Y esta es la verdadera misión del gobierno del dato.
Disponer de los datos adecuados para la estrategia de negocio requiere de una estrategia del dato. Es condición necesaria que la estrategia del dato se derive y se alinee con una estrategia de negocio. Por esta razón, es posible afirmar que los proyectos que se están desarrollando (sobre todo los que buscan desarrollar algún artefacto tecnológico), o los que deben desarrollarse en la organización, necesitan de una justificación determinada por una estrategia del dato[1] y, por tanto, formarán parte del gobierno del dato.
Objetivos estratégicos del dato
Una estrategia del dato está compuesta por una serie de objetivos estratégicos del dato, que pueden ser de uno o de una combinación necesaria de los siguientes cuatro tipos genéricos:
- Realización de beneficios: consiste en asegurar que, todos los productores de datos tienen los mecanismos adecuados para producir las fuentes que soporten a la estrategia del negocio, y que los consumidores de datos disponen de aquellos necesarios para poder realizar las tareas precisas para conseguir los objetivos estratégicos del negocio. Ejemplos de este tipo de objetivos puede ser:
- la definición de los procesos de generación de informes (reporting) de la organización;
- la identificación de la arquitectura de datos más relevante para dar servicio a todas las necesidades de datos en tiempo y forma;
- la creación de capas de servicios de datos;
- la adquisición de datos desde terceras fuentes para satisfacer determinadas demandas de datos; o
- la implantación de las tecnologías de información que dan soporte al aprovisionamiento y consumo de datos
- Alineamiento estratégico: el objetivo es conseguir que los datos se alineen con unos principios o directrices básicas de comportamiento que la organización ha definido, debería haber definido, o que va a definir como parte de la estrategia. Este alineamiento busca homogeneizar la forma de trabajar con los datos de la organización. Ejemplos de este tipo de objetivo pueden ser:
- establecer unas estructuras organizativas que den soporte a las cadenas de responsabilidad y de rendición de cuentas;
- homogeneizar, reconciliar y unificar la descripción de los datos en diferentes tipos de repositorios de metadatos;
- definir e implementar las buenas prácticas de la organización con respecto al gobierno del dato, la gestión del dato y la gestión de la calidad del dato[2];
- readaptar o enriquecer (lo que en terminología DAMA se conoce como operativizar el gobierno del dato) los procedimientos de datos de la organización para alinearlos a las buenas prácticas instauradas por la organización en los diferentes procesos;
- o definir políticas del dato en cualquiera de las áreas de actuación de la gestión del dato[3] y asegurar su cumplimiento, entendiendo esta como seguridad, gestión de datos maestros, gestión de datos históricos, etc.
- Optimización de recursos: consiste en establecer directrices para asegurar que la generación, uso y explotación de los datos utiliza los recursos de la organización de la forma más adecuada y eficiente posible. Algunos ejemplos de este tipo de objetivos podrían incluir:
- la disminución de costes de almacenamiento y procesamiento de datos a sistemas de almacenamiento mucho más eficientes y eficaces, como las migraciones de las capas de almacenamiento y procesamiento de los datos a la nube[4];
- la mejora de los tiempos de respuestas de determinadas aplicaciones mediante la retirada de datos históricos; la mejora de la calidad de los datos;
- la mejora de las habilidades y conocimientos de los diferentes participantes en la explotación y uso de los datos;
- el rediseño de planes de negocio para hacerlos más eficientes; o
- la redefinición de roles para simplificar la asignación y delegación de responsabilidades.
- Optimización de riesgos: el objetivo fundamental es analizar los posibles riesgos relacionados con los datos que pueden malograr la consecución de los diferentes objetivos de negocio de la organización, o incluso poner en peligro su viabilidad como entidad, y desarrollar los mecanismos adecuados de tratamiento del dato. Algunos ejemplos de este tipo de objetivo serían:
- la definición o la implantación de mecanismos de seguridad y protección de datos;
- el establecimiento de los parámetros éticos necesarios; o
- el aseguramiento de recursos humanos suficientemente cualificados para hacer frente a la rotación funcional.
Una lectura detenida de los ejemplos propuestos puede llegar a hacer pensar que algunos de estos objetivos estratégicos del dato podrían entenderse como si fueran de distintos tipos simultáneamente. Por ejemplo, asegurar la calidad de los datos que se van a usar en determinados procesos de negocio puede buscar, de alguna forma, garantizar que los datos no solo se usen (“realización de beneficios” y “optimización de riesgos”), sino que también contribuyan a garantizar que la organización tenga una imagen de marca seria y responsable con los datos (“alineamiento estratégico”) que evite tener que realizar frecuentemente acciones de limpieza de datos, con el consiguiente desperdicio de recursos (“optimización de recursos” y “optimización de riesgos”).
Habitualmente, el proceso de selección de uno o más objetivos estratégicos del dato debe realizarse no solo teniendo en cuenta el contexto de la organización y el alcance de dichos objetivos en términos funcionales, geográficos o de datos, sino que también se debe considerar la dependencia entre los objetivos planteados y la forma en la que éstos deban secuenciarse. Puede ser habitual que el mismo objetivo estratégico abarque datos que se usan en distintos departamentos o incluso que se aplique a diferentes datos. Por ejemplo, el objetivo estratégico de los tipos “realización de beneficio” y “optimización de riesgos”, llamado “garantizar el nivel de acceso a los repositorios de datos personales”, abarcaría los datos personales que se pueden usar en los departamentos comercial y de operaciones.
Teniendo en cuenta las responsabilidades típicas de gobierno del dato (evaluar, dirigir, monitorizar), se recomienda el uso de la técnica SMART (por sus siglas en inglés: specific, measurable, achievable, realistic, time-bound) para la selección de los objetivos estratégicos. Así, estos objetivos estratégicos deben:
- ser específicos,
- poder medirse y monitorizarse su nivel de consecución,
- que sean alcanzables y realistas dentro del contexto de la estrategia y de la empresa y, por último,
- que su consecución sea limitada en el tiempo.
Una vez que se han identificado los objetivos estratégicos del dato, y que se cuenta con el respaldo y apoyo económico de la directiva de la organización, debe afrontarse su implementación teniendo en cuenta las dimensiones comentadas anteriormente (contexto, aspectos funcionales y dependencias entre los objetivos), mediante la definición de un determinado programa de gobierno del dato. Es interesante resaltar el hecho de que, tras el concepto de “programa”, está la idea de “conjunto de proyectos interrelacionados entre sí que contribuyen a un objetivo específico”.
En definitiva, una estrategia del dato es la forma en la que una organización pone los datos necesarios al servicio de la estrategia del negocio de la organización. Esta estrategia del dato está compuesta por una serie de objetivos estratégicos que pueden ser de uno de los cuatro tipos expuestos o una combinación de los mismos. Finalmente, la implementación de esta estrategia del dato se realizará mediante el diseño y ejecución de un programa de gobierno de datos, aspectos que abordaremos en un próximo post.
______________________________________________
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM y Dr. Fernando Gualo PhD en Tecnologías Informáticas Avanzadas y – Consultor Gobierno y Calidad de datos
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de sus autores.
[1] Es fácil encontrar proyectos de transformación digital en donde lo único que se cambia es la tecnología de base hacia una que suena más moderna, pero seguir haciendo lo mismo.
[2] En este ejemplo de objetivo estratégico del dato es fundamental considerar las especificaciones UNE 0077, UNE 0078 y UNE 0079 porque proporcionan una definición adecuada de los diferentes procesos de gobierno del dato, gestión del dato y gestión de calidad del dato respectivamente.
[3] Entiéndase seguridad, calidad, gestión de datos maestros, gestión de datos históricos, gestión de metadatos, gestión de la integración …
[4] Ejemplos de estas iniciativas son las migraciones de las capas de almacenamiento y procesamiento de los datos a la nube.
Evento
Alicante acogerá los próximos días 9 y 10 de noviembre el Summit 2023 de Gaia-X, en el que se llevará a cabo un repaso sobre los últimos progresos realizados por esta iniciativa en la promoción de la soberanía de datos en Europa. La interoperabilidad, transparencia y el cumplimiento normativo adquieren una dimensión práctica a través del intercambio y explotación de datos articulados bajo un entorno de nube confiable.
También se abordarán las relaciones establecidas con líderes del sector, expertos, empresas, gobiernos, instituciones académicas y organizaciones varias, facilitando el intercambio de ideas y experiencias entre los diversos grupos de interés involucrados en la transformación digital europea. El evento contará con conferencias magistrales, talleres interactivos y mesas redondas, en las que se explorarán las posibilidades ilimitadas de los ecosistemas digitales cooperativos, y de un futuro próximo en el que los datos se hayan convertido en un activo de alto valor añadido.
Este evento está organizado por la asociación europea Gaia-X, en colaboración con el Hub español de Gaia-X. Cuenta también con la participación de la Oficina del Dato, dependiente de la Secretaría de Estado de Digitalización e Inteligencia Artificial, y se desarrolla bajo los auspicios de la presidencia española del Consejo de la Unión Europea.
La iniciativa Gaia-X busca garantizar que los datos sean almacenados y procesados de manera segura y soberana, respetando las regulaciones europeas, además de fomentar la colaboración entre diferentes y heterogéneos actores, como empresas, gobiernos y organizaciones. Así, Gaia-X promueve la innovación y el desarrollo económico basado en datos en Europa. Por tanto, la relación abierta en colaboración con la Unión Europea resulta fundamental para la consecución de sus objetivos.
La soberanía digital: una Europa adaptada a la era de los datos
Como para Gaia-X, uno de los grandes objetivos de la Unión Europea es el de fomentar la soberanía digital a lo largo de todo su territorio. Para ello, promueve el desarrollo de industrias y tecnologías clave para su competitividad y seguridad, fortalece sus relaciones comerciales y cadenas de suministro, y mitiga dependencias externas, concentrándose en la reindustrialización de su territorio y en asegurar su autonomía digital estratégica.
El concepto de soberanía digital abarca distintas dimensiones: tecnológica, regulatoria y socioeconómica. La dimensión tecnológica se refiere al hardware, software, nube e infraestructura de redes utilizados para acceder, procesar y almacenar datos. Mientras, la dimensión regulatoria se refiere a las normas que proporcionan seguridad jurídica a los ciudadanos, empresas e instituciones que operan en un ámbito digital. Finalmente, la dimensión socioeconómica se enfoca en las iniciativas empresariales y los derechos individuales en el nuevo entorno digital global. Para avanzar en todas estas dimensiones, la UE se apoya en proyectos como Gaia-X.
La iniciativa busca crear ecosistemas federados, abiertos, seguros y transparentes, donde los conjuntos y servicios de datos cumplen una serie mínima de reglas comunes que les permiten así ser reutilizables bajo entornos de confianza y transparencia. A su vez, esto habilita la creación de ecosistemas de datos confiables de alta calidad, con que las organizaciones europeas podrán impulsar su proceso de digitalización, mejorando las cadenas de valor a lo largo de diferentes sectores industriales. Estas cadenas de valor, desplegadas digitalmente sobre entornos de nube federada y confiable (“Trusted Cloud”), gozan de trazabilidad y transparencia, y sirven por tanto para impulsar los esfuerzos de cumplimiento normativo y soberanía digital.
En resumen, este enfoque se basa en aprovechar y reforzar unos valores reflejados en un marco regulatorio en desarrollo que busca incorporar conceptos como la confianza y la gobernanza en los entornos de datos. Esto busca convertir la UE en líder de una sociedad y economía donde la digitalización sea vector para reindustrializarnos y prosperar, pero siempre bajo el marco de unos valores que nos definen.
Se puede acceder al programa completo de este Summit desde la página oficial de la asociación europea: https://gaia-x.eu/summit-2023/agenda/.