Blog
Hoy en día, la calidad de los datos desempeña un papel fundamental en el mundo actual, donde la información es un activo valioso. Asegurar que los datos sean precisos, completos y confiables se ha vuelto esencial para el éxito de las organizaciones y garantiza el éxito de la toma de decisiones informadas.
La calidad de los datos tiene un impacto directo no solo en el intercambio y uso a nivel interno de cada organización, sino también en la compartición de datos entre diferentes entidades, siendo una variable clave en el éxito del nuevo paradigma de los espacios de datos. Cuando los datos son de alta calidad, se crea un entorno propicio para el intercambio de información precisa y consistente, lo cual permite a las organizaciones colaborar de manera más efectiva, fomentando la innovación y el desarrollo conjunto de soluciones.
Una buena calidad de datos facilita la reutilización de la información en diferentes contextos, generando valor más allá del sistema que los crea. Los datos de alta calidad son más fiables y accesibles, y pueden ser utilizados por múltiples sistemas y aplicaciones, lo que aumenta su valor y utilidad. Al reducir considerablemente la necesidad de realizar correcciones y ajustes constantes, se ahorra tiempo y recursos, permitiendo una mayor eficiencia en la implementación de proyectos y la creación de nuevos productos y servicios.
La calidad de los datos también juega un papel fundamental en el avance de la inteligencia artificial y el aprendizaje automático. Los modelos de IA se basan en grandes volúmenes de datos para obtener resultados precisos y confiables. Si los datos utilizados están contaminados o son de baja calidad, los resultados de los algoritmos de IA serán poco confiables o incluso erróneos. Por lo tanto, garantizar la calidad de los datos es esencial para lograr el máximo rendimiento de las aplicaciones de IA, reducir o eliminar sesgos y aprovechar su potencial al máximo.
Con el objetivo de ofrecer un proceso basado en estándares internacionales que pueda ayudar a las organizaciones a utilizar un modelo de calidad y a definir características y métricas de calidad adecuadas, la Oficina del Dato ha patrocinado, promovido y participado en la generación de la especificación UNE 0081 Evaluación de la calidad del dato que complementa la especificación ya existente UNE 0079 Gestión de la calidad del dato, centrada más en la definición de procesos de gestión de la calidad del dato que en la calidad del dato como tal.
Especificación UNE – Guía de Evaluación de la calidad del dato
La especificación UNE 0081, familia de estándares internacionales ISO/IEC 25000, permite conocer y evaluar la calidad de los datos de toda organización, permitiendo establecer un plan futuro para su mejora, y pudiéndose incluso llegar a certificar su calidad formalmente. Los destinatarios de está especificación, aplicable a cualquier tipo de organización independientemente de su tamaño o dedicación, serán los responsables de calidad de datos, así como los consultores y auditores que necesiten llevar a cabo una evaluación de los conjuntos de datos dentro de sus funciones.
La especificación primero expone el modelo de calidad del dato, en dónde se detallan las características de calidad que pueden tener los datos, así como algunas métricas aplicables, para una vez definido este marco de trabajo, pasar a definir el proceso que se debe seguir para evaluar la calidad de un conjunto de datos. Finalmente, la especificación acaba detallando como interpretar los resultados obtenidos de la evaluación mostrando algún ejemplo concreto de aplicación.
Modelo de calidad del dato
La guía propone una serie de características de calidad siguiendo las presentes en la norma ISO/IEC 25012, clasificándolas entre aquellas inherentes al dato, dependientes del sistema donde se aloja el dato o dependientes de ambas circunstancias. Se justifica la elección de estas características dado que abarcan las presentes en otros marcos de referencia tales como DAMA, FAIR, EHDS, IA Act y RGPD.
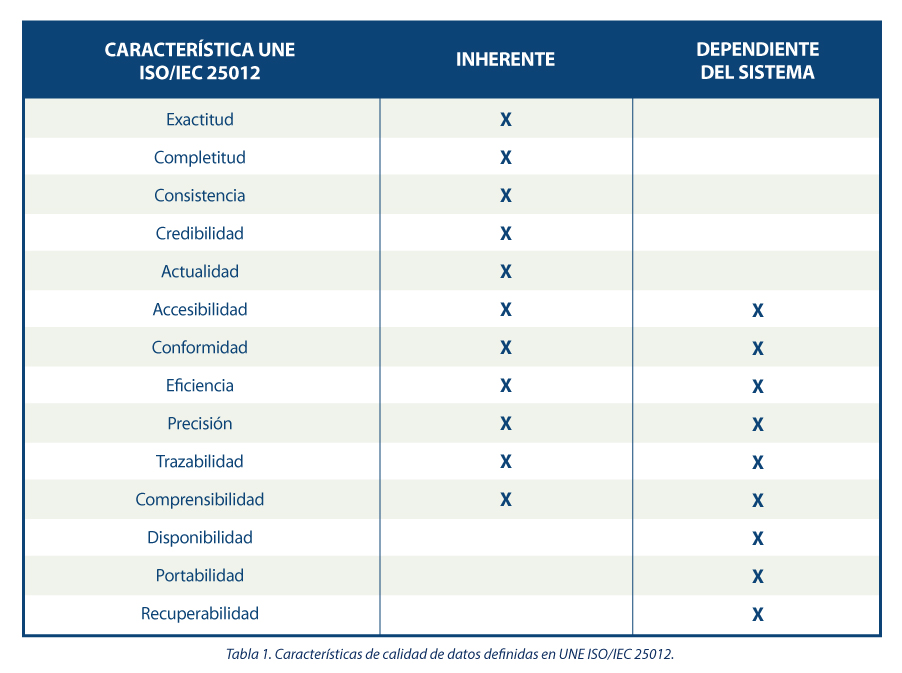
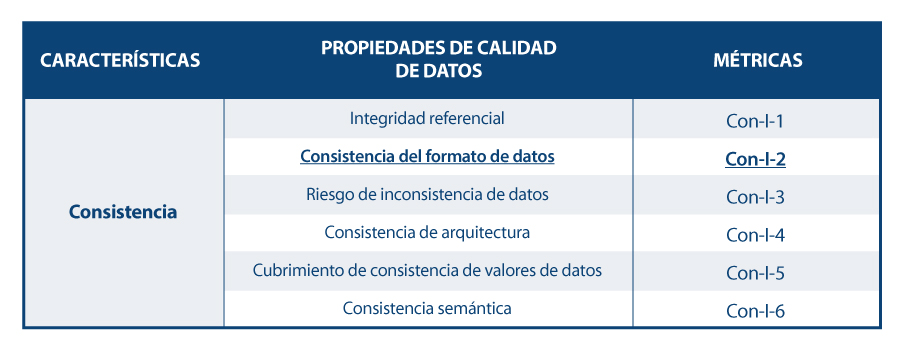
En base a las características definidas, la guía se apoya en la norma ISO/IEC 25024 para proponer un conjunto de métricas que sirvan para medir las propiedades de las características, entendiendo estas propiedades como “subcaracteristicas” de las características.

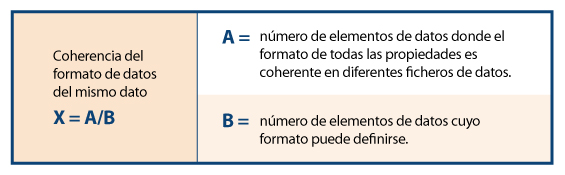
Así, a modo de ejemplo, siguiendo el esquema de dependencias, para la característica concreta de “consistencia del formato de datos” se muestran sus propiedades y métricas, detallándose una de ellas.
Proceso para evaluar la calidad de un conjunto de datos
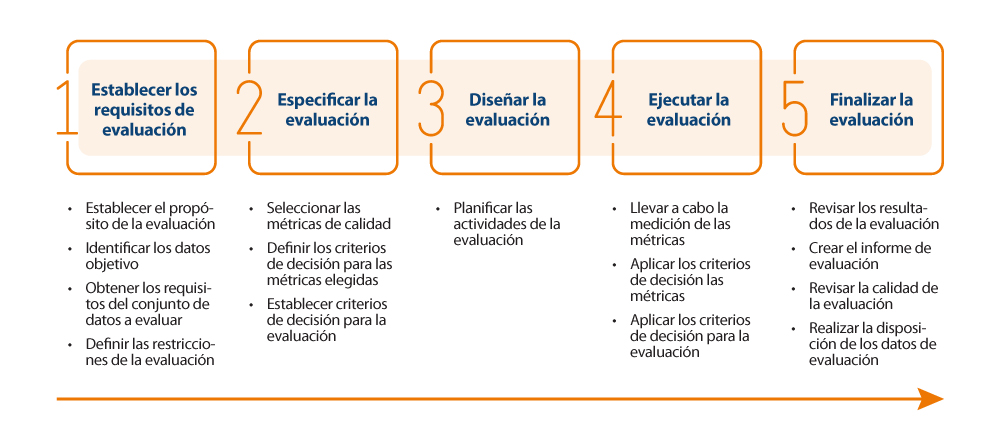
Para realizar la evaluación en sí de la calidad de los datos, la guía propone seguir la norma ISO/IEC 25040, que establece un modelo de evaluación que tiene en cuenta tanto los requisitos y restricciones definidas por la organización, como los recursos necesarios tanto materiales como personales. Con estos requisititos, se establece un plan de evaluación a través de unas métricas y criterios de decisión concretos en función de los requisitos de negocio, que permita realizar la correcta medición de las propiedades y características e interpretar sus resultados.
A continuación, se muestra un esquema con los pasos a realizar en el proceso, así como sus principales actividades:
Resultados de la evaluación de calidad
El resultado de la evaluación dependerá directamente de los requisitos marcados por la organización y los criterios de cumplimiento. Las propiedades de las características suelen evaluarse de 0 a 100 a partir de los valores obtenidos en las métricas definidas para cada uno de ellos, y las características a su vez se evalúan por agregación de las anteriores también de 0 a 100 o mediante la conversión a un valor discreto de 1 a 5 (1 calidad deficiente, 5 calidad excelente) en función de las reglas de cálculo y ponderación que se hayan establecido. Al igual que de la medición de las propiedades se obtiene la de sus características, lo mismo pasa con estas características, que mediante su suma ponderada en base a las reglas que se hayan definido (pudiendo establecer más peso a unas características que a otras), se pueda obtener un resultado final de la calidad de los datos. Por ejemplo, si queremos calcular la calidad de los datos en base a una suma ponderada de sus características intrínsecas, en donde por el tipo de negocio, interese darle mayor peso a la exactitud, entonces se podría definir una fórmula como la siguiente:
Calidad de datos = 0.4*Exactitud + 0.15*Completitud + 0.15*Consistencia + 0.15*Credibilidad + 0.15*Actualidad
Supongamos que de forma similar se han calculado cada una de las características de la calidad en base la suma ponderada de sus propiedades, resultando los siguientes valores: Exactitud=50%, Completitud=45%, Consistencia=35%, Credibilidad=100% y Actualidad=50%. De esta forma la calidad de datos resultaría:
Calidad de datos = 0.4*50% + 0.15*45% + 0.15*35% + 0.15*100% + 0.15*50% = 54.5%
Si suponemos que se han establecido en la organización unos requisitos como los que se muestran en la siguiente tabla:
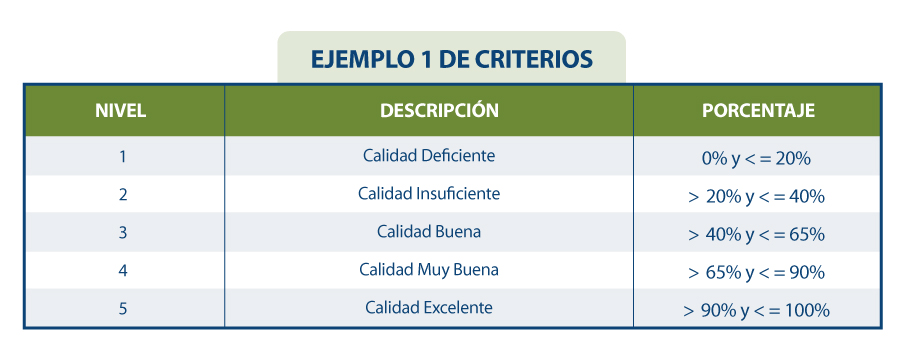
Se podría concluir que la organización en general cuenta con una calificación del dato de “3= Calidad Buena”.
En resumen, la evaluación y mejora de la calidad del conjunto de datos podrá ser todo lo exhaustiva y rigurosa que sea necesaria, y se debe llevar a cabo de manera iterativa y constante de forma que los datos vayan incrementando su calidad de forma continua, de forma que se asegure una calidad del dato mínima o incluso se pueda certificar. Esta calidad mínima del dato puede referirse a mejorar los conjuntos de datos internos a una organización, es decir, los que la organización gestiona y explota para el funcionamiento de sus procesos de negocio; o bien puede utilizarse para favorecer la compartición de conjuntos de datos mediante el nuevo paradigma de los espacios de datos generando nuevas oportunidades de mercado. En este último caso, cuando una organización quiera integrar sus datos en un espacio de datos para su futura intermediación, es conveniente realizar una evaluación de calidad, etiquetando el conjunto de datos adecuadamente en referencia a su calidad (quizás mediante su metadatado). Un dato de calidad contrastada tiene una utilidad y un valor distinto de aquel que carece de ella, posicionando al primero en un lugar preferencial dentro del mercado competitivo.
El contenido de esta guía, así como del resto de especificaciones UNE mencionadas, puede visualizarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra y marcando “lectura” en el desplegable en el que aparece preseleccionado “pdf”. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la visualización requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
ESPECIFICACION UNE 0081:2023 | Normas AENOR
https://tienda.aenor.com/norma-une-especificacion-une-0080-2023-n0071383
https://tienda.aenor.com/norma-une-especificacion-une-0079-2023-n0071118
https://tienda.aenor.com/norma-une-especificacion-une-0078-2023-n0071117
https://tienda.aenor.com/norma-une-especificacion-une-0077-2023-n0071116
Blog
Continuamos en esta segunda entrega de la serie de artículos con la aplicación de las especificaciones UNE. Antes de nada, recordemos que las Especificaciones UNE 0077, UNE 0078 y UNE 0079 introducen las buenas prácticas en el gobierno del dato, gestión del dato y gestión de calidad del dato con una aproximación a procesos (véase Fig.1).

Fig. 1. Procesos contenidos en las especificaciones UNE 0077, UNE 0078 y UNE 0079
Anteriormente, hemos analizado la especificación UNE 0077:2023 sobre los procesos del gobierno del dato. En esta ocasión, nos centraremos en la UNE 0079 dedicada a la gestión de la calidad del dato para ilustrar su aplicación en el contexto de datos abiertos. En este sentido, es importante considerar que la calidad de los datos abiertos va más allá de las conocidas características FAIR. Los principios FAIR (por sus siglas en inglés: Findable, Accesible, Interoperable y Reusable) son aspectos específicos de diseño relacionados con la naturaleza de los datos abiertos que, aun cumpliéndose, no garantizan que los datos puedan ser usados para una tarea específica si no tienen el nivel de calidad adecuado.
Para evaluar la calidad de los datos se necesitan criterios objetivos expresados en términos de características o dimensiones de los mismos. Esto permite formular los requisitos de calidad de datos de los distintos usuarios. Se recogen clasificaciones de estos requisitos en publicaciones más genéricas como “Normas Técnicas para alcanzar la Calidad del Dato” (véase Fig.2. con una identificación de estas características de calidad del dato según ISO/IEC 25012) o bien en otras más específicas, como el caso que nos ocupa de los datos abiertos, tales como la Reunión de Sebastopol, o la Carta Internacional de Datos abiertos.
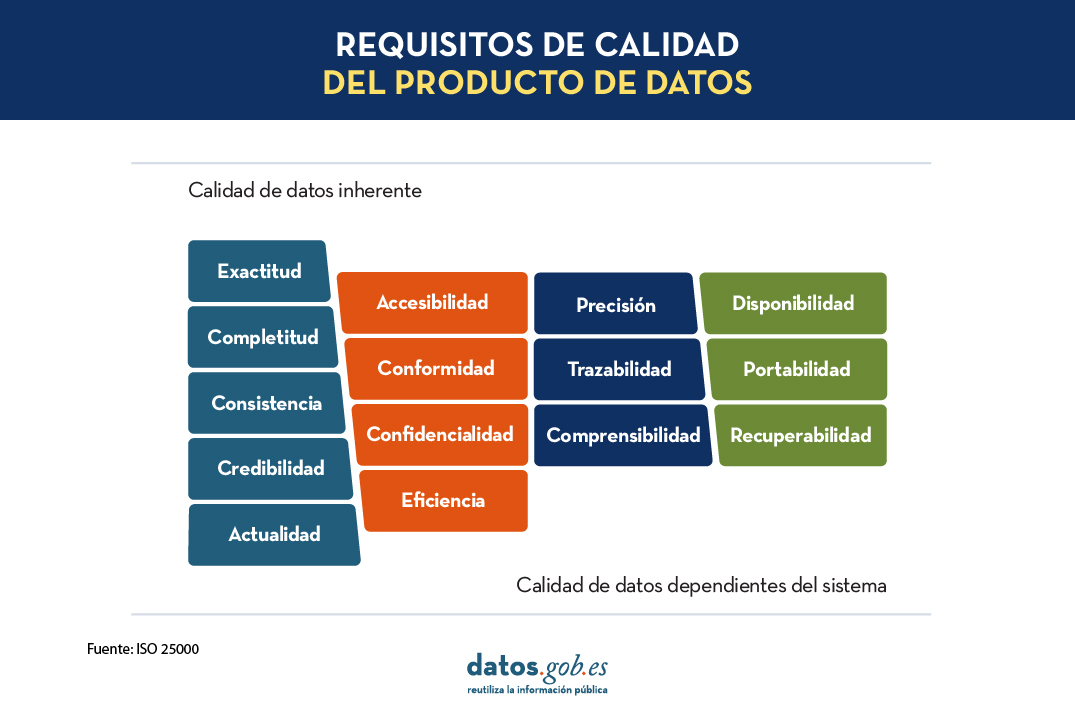
Fig. 2. Características de calidad de datos según ISO/IEC 25012 (de Normas Técnicas para alcanzar la Calidad del Dato)
Es posible que en diferentes foros se den nombre distintos o muy similares a las mismas características, lo que puede provocar malentendidos, o que lleguen a producirse debates entre los partidarios o detractores de un nombre en concreto. Al margen de los nombres, lo más importante es la interpretación de las definiciones de cada característica o dimensión, y sobre todo la definición de cómo medir esa dimensión o característica y entender el significado de las mediciones para poder actuar sobre los datos en caso de que se necesite.
En este segundo artículo se va a describir cómo el personal a cargo del proyecto de datos abiertos del Ayuntamiento de Vistabella ha abordado algunas de las recomendaciones que se especifican en el Manual práctico para mejorar la calidad de los datos abiertos como parte de su estrategia de potenciar la publicación de datos abiertos en los correspondientes portales del Ayuntamiento. Tal y como se señalaba en el artículo sobre la Aplicación de la especificación UNE 0077:2023, este ayuntamiento quiere potenciar la publicación de datos abiertos de transportes públicos urbanos y sobre la organización de eventos culturales del municipio.
En dicho artículo también se señalaba que, uno de los proyectos que forma parte del programa de gobierno de datos para implementar la estrategia, es el de “Planificación, control y mejora de la calidad de los datos abiertos”. Este proyecto vertebra el contenido de este artículo, una vez que los responsables de datos abiertos del Ayuntamiento han comprendido que la calidad de los datos publicados es casi tan importante como la cantidad.
La aplicación de la Especificación UNE 0079 se va a realizar en dos partes de este proyecto:
- Control de la calidad de los datos que se recogen desde las distintas concejalías y agentes asociadas, para lo que se aplicará el proceso de control y monitorización de calidad del dato.
- Producción y publicación de datos con niveles adecuados de calidad, para lo que se usará el proceso de planificación de calidad del dato.
Los otros dos procesos restantes de UNE 0079 (aseguramiento de calidad del dato y mejora de calidad del dato) se quedan fuera de este artículo por simplicidad.
Aplicación del proceso de Control y Monitorización de calidad del dato.
Como se comentó en el artículo anterior, la ejecución exitosa de los procesos de negocio se manifiesta porque se han conseguido los resultados de procesos específicos de cada uno de ellos (véase Figura 3 con los resultados de proceso para el proceso “control y monitorización de calidad del dato). Así, el primer resultado de proceso (RP.01) consiste en identificar los datos cuya calidad debe ser controlada y monitorizada: estos son aquellos datos en bruto que se reciben de las distintas concejalías y empresas públicas de transportes urbanos para crear los correspondientes conjuntos de datos que se pretenden publicar en el portal de datos abiertos.
|
Los resultados de la realización satisfactoria de este proceso son:
Nota: RP es el acrónimo de Resultado de Proceso |
Figura 3. Resultados de proceso del Proceso de Control y Monitorización de calidad del dato
Uno de los problemas más frecuentes con los que se encuentran los gestores de los proyectos de datos abiertos del Ayuntamiento de Vistabella con respecto a los datos de transporte es que para construir los conjuntos de datos que van a ser publicados, los datos en bruto recibidos están muy fragmentados, y no hay un plazo de entrega establecido, siendo éste además imprevisible. Esto provoca que la construcción de dichos conjuntos de datos esté amenazada por una serie de factores que hace que los resultados producidos sean en muchas ocasiones difícilmente aprovechables. Por ello, y como parte del segundo resultado de proceso (RP.02), se ha decidido estudiar el patrón de envíos de los datos en bruto por parte de los agentes colaboradores, así como los niveles de calidad mínimos necesarios para construir conjuntos de datos. Se llegó a la conclusión, consultando el Manual práctico para mejorar la calidad de los datos abiertos de datos.gob.es, de que las características de calidad afectadas eran la consistencia, la completitud, la credibilidad, la disponibilidad y la actualidad de esos datos. Conscientes de esta necesidad, y tomando como punto de partida los resultados de estas conclusiones, se desarrollaron como tercer resultado de proceso (RP.03) mecanismos de medición para esas características de calidad del dato sobre los datos en brutos recibidos desde cada uno de los agentes que se consideran que deben contribuir a elaborar los conjuntos de datos de transporte que el Ayuntamiento quiere publicar.
Además, como parte del cuarto resultado de proceso (RP.04), se establecen y aplican mecanismos para corregir aquellos valores de los datos que no satisfacen los umbrales mínimos de calidad necesarios para considerar que los datos en bruto pueden ser incorporados al proceso de creación de datos de transporte a ser publicados, dejando registros de los cambios proporcionados (como manifestación del quinto resultado de proceso RP.05).
El estudio de estos registros de cambios se utilizará para proponer cambios en la forma en la que los agentes colaboradores del ayuntamiento interactúan con el Ayuntamiento (como manifestación del sexto resultado de proceso RP.06).
Aplicación del proceso de planificación de calidad del dato
Al haberse invertido una cantidad importante de dinero público en la construcción del conjunto de datos, la principal preocupación de los responsables de datos abiertos del Ayuntamiento de Vistabella es asegurar que los conjuntos de datos publicados tengan niveles de calidad suficientes para asegurar que pueden ser usados y reusados. Tal y como se recoge en el proceso de construcción de los conjuntos de datos, es necesario planificar la calidad del conjunto de datos (en algunos entornos a esto lo llaman data quality by design). Conocedores de esta necesidad, desde el Ayuntamiento entienden las ventajas de ejecutar el proceso de planificación de calidad del dato, y de conseguir los correspondientes resultados de procesos (véase Figura 4, con los resultados de proceso del proceso “Planificación de calidad del dato”).
|
Los resultados de la realización satisfactoria de este proceso son:
Nota: RP es el acrónimo de Resultado de Proceso |
Figura 4. Resultados de proceso del Proceso de Planificación de calidad del dato
Para eso, los responsables de la oficina del dato combinan las actividades propias de este proceso con el proceso de producción y publicación de los conjuntos de datos. En este sentido, resulta de gran utilidad el Manual práctico para mejorar la calidad de los datos abiertos que identifica algunos problemas típicos en la publicación de datos abiertos (véase Fig.2) y proporciona recomendaciones para evitar que dichos problemas sucedan. Además, en el manual se identifican las características de calidad afectadas, lo que facilita su incorporación al diseño de los conjuntos de datos. Es muy importante tener en cuenta que algunas de estas recomendaciones afectan directamente a los propios datos (características inherentes de los datos en términos de ISO/IEC 25012), mientras que otras afectan al entorno de los datos (características dependientes del sistema en términos de ISO/IEC 25012). Para una mejor referencia de las características de calidad de datos, véase Fig.2.
Exploremos algunos ejemplos.
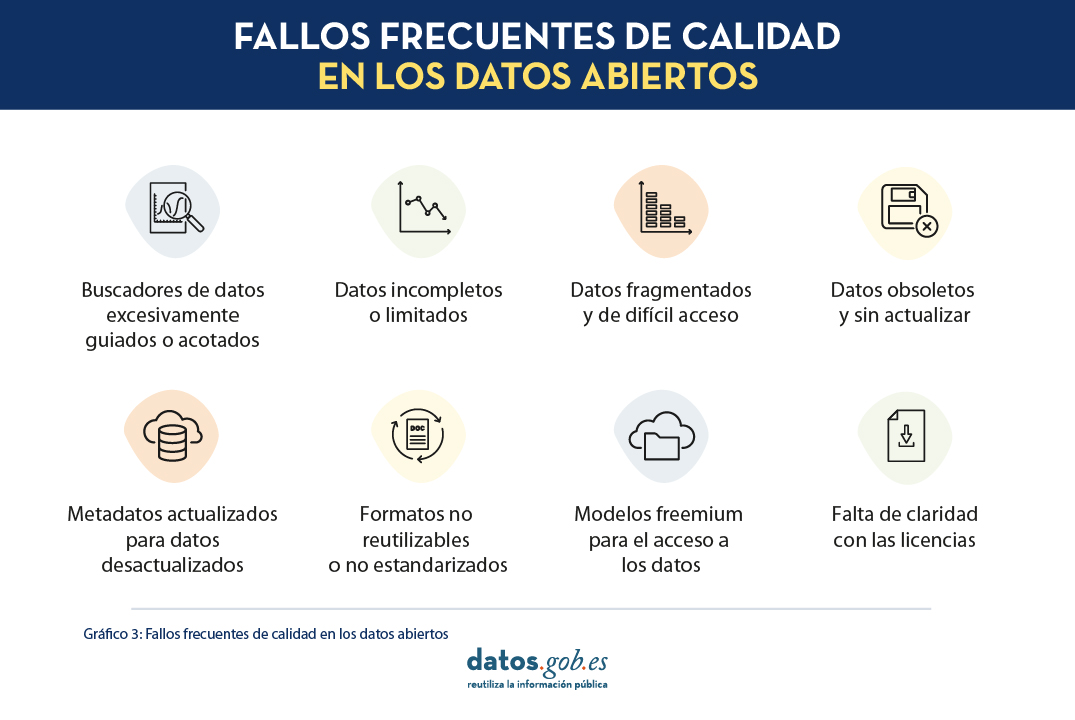
Fig. 5. Fallos frecuentes de calidad en los datos abiertos. Fuente: Manual práctico para mejorar la calidad de los datos abiertos
Uno de los problemas que los responsables de la Oficina del Dato del Ayuntamiento de Vistabella están más interesados en evitar es la publicación de datos incompletos o limitados (que afectan a las características de completitud, disponibilidad, actualidad, credibilidad y precisión) y la publicación de datos obsoletos y sin actualizar (que afecta a las características de disponibilidad, completitud y actualidad). El mismo manual nos está ayudando a completar el primer resultado de proceso (RP.01), ya que nos ha permitido identificar los requisitos de calidad del dato, expresado en esta ocasión en términos de las características de calidad mencionadas anteriormente. Además, teniendo en cuenta los problemas típicos relacionados con el uso de datos de transportes por distintos agentes consumidores de datos, las dos características que los responsables del servicio de publicación de datos abiertos del Ayuntamiento quieren priorizar son las de completitud y actualidad.
En este sentido, y como forma de abordar el segundo resultado de proceso RP.02, se pueden explorar las recomendaciones que hace el Manual práctico para mejorar la calidad de los datos abiertos. Este manual propone desarrollar un plan de publicación de datos en el que se incorporarán, por un lado, un inventario y catálogo de los datos que formarán parte del proceso de producción del conjunto de datos de transporte de los datos a publicar (para asegurar la completitud) y, por otro lado, se generará un plan de publicaciones que incluirá tanto los momentos de recogida de los datos desde los agentes colaboradores del ayuntamiento, como los momentos en que se deben publicar los datos de transportes resultantes de la integración de los diferentes conjuntos de datos (como forma de asegurar la actualidad).
Tanto los catálogos como los planes de publicación serán implementados y puestos en práctica como parte de los proyectos (se sustentarán en los procesos de gestión de datos que se abordarán en el tercer y último artículo de esta serie) y se establecerán mecanismos para monitorizar el desempeño de estas acciones (como parte del tercer resultado de proceso RP.03).
Por último, y como manifestación del RP.04, se abordarán qué problemas no se han cubierto adecuadamente con las acciones previstas, de modo que se puedan iterar nuevamente sobre el diseño del proceso de producción de los conjuntos de datos y desarrollar los mecanismos necesarios que eviten la aparición de problemas derivados de niveles inadecuados de calidad de datos que malogren su uso en diferentes aplicaciones.
Y con este pequeño extracto sobre cómo los responsables del Ayuntamiento de Vistabella aplican la especificación UNE 0079 en combinación con el Manual práctico para mejorar la calidad de los datos abiertos para abordar los problemas potenciales de calidad de datos llegamos al final de este segundo artículo.
En el tercer artículo de la serie se abordará cómo usar la especificación 0078, correspondiente a la gestión de los datos para implementar los proyectos derivados de la estrategia del dato.
El contenido de esta guía puede visualizarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra y marcando “lectura” en el desplegable en el que aparece preseleccionado “pdf”. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la visualización requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
Contenido elaborado por Dr. Ismael Caballero, Profesor titular en UCLM y Dr. Fernando Gualo PhD en Ciencia computacional y Chief Executive Officer and Data Quality and Data Governance Consultant
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de sus autores.
Blog
Los datos abiertos tienen un rol relevante en el desarrollo tecnológico por muchos motivos. A modo de ejemplo, son un componente fundamental en la toma de decisiones informadas, en la evaluación de procesos o incluso en el impulso de la innovación tecnológica. Siempre y cuando, cuenten con la calidad óptima, estén actualizados y respeten los aspectos éticos, los datos pueden ser el ingrediente clave para el alcanzar el éxito de un proyecto.
A fin de aprovechar plenamente las ventajas de los datos abiertos en la sociedad, la Unión Europea cuenta con diversas iniciativas para impulsar la economía del dato, un modelo digital único que fomenta el intercambio de datos, destacando la soberanía y el gobierno de los mismos, el marco ideal y necesario para los datos abiertos.
En la economía del dato, tal y como recoge la regulación vigente, se garantiza la privacidad de las personas y la interoperabilidad de los datos. El marco regulatorio se encarga de velar por el cumplimiento de esta premisa. Ejemplo de ello puede ser la modificación de la Ley 37/2007 para la reutilización de información del sector público en cumplimiento de la Directiva Europea 2019/1024. Esta regulación se alinea con la Estrategia de datos de la Unión Europea que define un horizonte con un mercado único de datos en el que se facilite un intercambio mutuo, libre y seguro entre el sector público y el privado.
Para lograr este objetivo, se deben abordar cuestiones clave, como preservar ciertas garantías jurídicas o acordar unas características comunes de descripción de metadatos que deben cumplir los dataset para facilitar el acceso y uso de los datos entre sectores, es decir, utilizar un lenguaje común que permita la interoperabilidad entre catálogos de conjuntos de datos.
¿Qué son los estándares de metadatos?
Un primer paso hacia la interoperabilidad y reutilización de los datos es desarrollar mecanismos que habiliten una descripción homogénea de los mismos y que, además, dicha descripción sea fácilmente interpretable y procesable tanto por humanos como por máquinas. En este sentido, se han ido creando diferentes vocabularios que, con el tiempo, se han ido consensuando hasta convertirse en estándares.
Los vocabularios estandarizados ofrecen una semántica que sirve como base para la publicación de conjuntos de datos que actúa como "leyenda" para facilitar la comprensión del contenido de los datos. Al fin y al cabo, se puede decir que estos vocabularios proporcionan una colección de metadatos para describir los datos que se publican; y como todos los usuarios de esos datos tienen acceso a los metadatos y entienden su significado, es más fácil interoperar y reutilizar los datos.
W3C: Estándares DCAT y DCAT-AP
A nivel internacional, se pueden destacar varias organizaciones que crean y mantienen estándares:
-
World Wide Web Consortium (W3C): desarrolla el Vocabulario de Catálogos de Datos (DCAT): un estándar de descripción diseñado con el objetivo de facilitar la interoperabilidad entre catálogos de conjuntos de datos publicados en la web.
-
Posteriormente, tomando como base DCAT, se desarrolló DCAT-AP, una especificación para el intercambio de descripciones de datos publicados en los portales de datos en Europa que cuenta con extensiones de DCAT-AP más específicas como:
- GeoDCAT-AP que extiende DCAT-AP para la publicación de datos espaciales.
- StatDCAT-AP que igualmente, extiende DCAT-AP para describir datasets de contenidos estadísticos.
-
ISO: Organización de Estandarización Internacional
Además de World Wide Web Consortium, existen otras organizaciones que se dedican a la estandarización, por ejemplo, la Organización de Estandarización Internacional (ISO, por sus siglas en inglés Internacional Standarization Organisation).
- Entre otros muchos tipos de estándares, ISO también ha definido normas de estandarización de metadatos de catálogos de datos:
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
- ISO 19115-2 para datos ráster e imágenes.
- ISO 19139 proporciona una implementación en XML del vocabulario.
- ISO 19115 para describir información geográfica. Como ocurre en DCAT, también se han desarrollado extensiones y especificaciones técnicas a partir de ISO 19115, por ejemplo:
El horizonte en los estándares de metadatos: retos y oportunidades
Tanto W3C como ISO trabajan en el desarrollo y mantenimiento de vocabularios estandarizados y adaptados a las necesidades de los usuarios. Su trabajo contribuye a lograr un ecosistema de datos abiertos interoperables que facilite la reutilización. Sin embargo, la interoperabilidad a menudo se encuentra con obstáculos derivados de debilidades de calidad, como pueden ser datos obsoletos, dificultades para acceder e interoperar con ellos o metadatos incompletos.
A pesar de ello, como se ha demostrado, la compartición de datos es un mecanismo fundamental en la economía del dato. Así que garantizar la interoperabilidad y reutilización de estos es una acción clave para abordar el desarrollo de la economía de los datos en línea con las expectativas de las organizaciones en lo que se refiere a innovación.
Entre las múltiples ventajas que ofrece la reutilización de conjuntos de datos y su interoperabilidad se puede destacar la creación de aplicaciones y servicios que aportan un valor a la sociedad o ayudan en la evaluación de políticas, por ejemplo.
Además, la reutilización e interoperabilidad de los conjuntos de datos favorece el desarrollo económico en general, y la economía del dato, en particular. Se estima que esta industria alcanzará un valor de 829.000 millones de euros en 2025, según previsiones de la Unión Europea. Para poder aprovechar los beneficios que ofrece compartir datos, primero, se deben acordar y respetar unas normas de descripción comunes: los estándares para describir metadatos de catálogos de conjuntos de datos.
Blog
Con el avance que la tecnología y la conectividad han venido experimentando durante los últimos años hemos entrado de lleno en una nueva era en la que los datos nunca duermen y la cantidad de datos circulando es mayor que nunca. En la actualidad, podríamos decir que vivimos encerrados en una esfera rodeados de datos y eso nos ha ido haciendo cada vez más dependientes de ellos. Por otro lado, nos hemos ido también transformando poco a poco en seres tanto productores como recolectores de datos.
El término datasfera se ha venido utilizado históricamente para definir el conjunto de toda la información existente en los espacios digitales, incluyendo también otros conceptos relacionados como los flujos de datos y las plataformas implicadas. Pero este concepto ha ido desarrollándose y cobrando cada vez más relevancia de forma paralela al creciente peso de los datos en nuestra sociedad actual, convirtiéndose en un concepto importante a la hora de definir el futuro de las relaciones entre tecnología y sociedad.
En los inicios de la era digital podíamos considerar que vivíamos en nuestras propias burbujas de datos que íbamos alimentando poco a poco a lo largo de nuestras vidas hasta acabar totalmente inmersos en los datos del mundo online, donde la distinción entre lo real y lo virtual es cada vez más irrelevante. Hoy en día vivimos en una sociedad interconectada a través de los datos y también mediante algoritmos que nos unen y establecen relaciones entre nosotros. Todos aquellos datos que compartimos de forma más o menos consciente ya no nos afectan únicamente a nosotros mismos como individuos, sino que pueden tener también su efecto en el resto de la sociedad, incluso de forma a veces totalmente imprevisible – como en una versión digital del efecto mariposa.
Por tanto, los modelos de gobernanza que se basen en trabajar con los datos y su relación con las personas, como si se tratasen simplemente de instancias aisladas con las que podemos trabajar individualmente, ya no nos serán de utilidad en este nuevo entorno.
La necesidad de una aproximación a los datos basada en sistemas
En la actualidad, ese concepto relativamente simple de la dataesfera ha ido evolucionando hasta convertirse en un ecosistema digital completo, altamente interconectado y complejo – compuesto por una amplia gama de datos y tecnologías – que nosotros habitamos y que afecta a la forma en la que vivimos nuestras vidas. Es un sistema en el que los datos tienen valor solo en el contexto de su relación con otros datos, con las personas y con las normas que regulan esas relaciones.
Por lo tanto, para una gestión eficaz de este nuevo ecosistema, será necesaria una mejor comprensión de cómo los diferentes componentes de la dataesfera se relacionan entre sí, de cómo los datos fluyen a través de estos componentes y de cuáles serán las normas adecuadas necesarias para que este sistema interconectado funcione.
Los datos como componente activo del sistema
En una aproximación basada en sistemas, los datos se consideran un componente activo dentro del ecosistema. Esto significa que los datos ya no son sólo información estática, sino que también tienen la capacidad de influir en el funcionamiento del propio ecosistema y, por tanto, serán un componente más a tener en cuenta para la gestión eficaz del mismo.
Por ejemplo, los datos pueden utilizarse para ajustar el funcionamiento de los algoritmos, mejorando la precisión y la eficiencia de los sistemas de inteligencia artificial y de aprendizaje automático. De forma similar, también podrían utilizarse para ajustar la forma en que se toman decisiones y se aplican políticas en diferentes sectores, como la atención médica, la educación y la seguridad.
La dataesfera y la evolución del gobierno de los datos
Por lo tanto, será necesario explorar nuevos marcos colectivos de gobernanza de datos que tengan en consideración a todos los elementos del ecosistema en su diseño, controlando la forma en que se accede, se utiliza y se protege la información en el conjunto de la dataesfera.
Así se podría garantizar que los datos sean utilizados de manera segura, ética y responsable para el conjunto del ecosistema y no sólo en casos individuales o aislados. Por ejemplo, algunas de las nuevas herramientas de gobernanza de datos que hace ya tiempo que se están experimentando y nos pueden servir a la hora de gestionar la dataesfera de forma colectiva son los data commons o bienes digitales de datos, los data trusts o fideicomisos de datos, las cooperativas de datos, o los data collaboratives o colaboraciones de datos, entre otros.
El futuro de la dataesfera
La dataesfera seguirá creciendo y evolucionando en los próximos años, impulsada una vez más por los nuevos avances tecnológicos y el aumento de la conectividad y la ubicuidad de los sistemas. Será importante que los gobiernos y las organizaciones se mantengan al día de estos cambios y adapten sus estrategias de gobierno y gestión de datos en consecuencia mediante marcos regulatorios sólidos, acompañados de pautas éticas y prácticas responsables que aseguren que los beneficios que nos prometen la explotación de los datos se puedan finalmente materializar al mismo tiempo que se minimizan los riesgos.
Para poder atender adecuadamente estos desafíos, y aprovechar así todo el potencial de la dataesfera para un cambio positivo y por el bien común, será esencial dejar de pensar en los datos como algo que podamos tratar de forma aislada y adoptar un enfoque basado en sistemas que reconozca la naturaleza interconectada de los datos y su impacto en el conjunto de la sociedad.
Hoy en día, podríamos considerar que los espacios comunes de datos (data spaces), que la Comisión Europea lleva ya algún tiempo desarrollando como parte clave de su nueva estrategia de datos, son precisamente una evolución lógica del concepto de la dataesfera adaptada a las necesidades particulares de nuestro tiempo y actuando sobre todos los componentes del ecosistema simultáneamente: técnico, funcional, operacional, legal y de negocio.
Contenido elaborado por Carlos Iglesias, Open data Researcher y consultor, World Wide Web Foundation.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el proceso de análisis de datos y entrenamiento de modelos de aprendizaje automático, es fundamental contar con un conjunto de datos adecuado. Por lo tanto, surgen las preguntas: ¿cómo se deben preparar los conjuntos de datos para el aprendizaje automático y el análisis? ¿Cómo se puede confiar en que los datos conducirán a conclusiones sólidas y predicciones precisas?
Lo primero que hay que tener en cuenta al preparar los datos es saber el tipo de problema que se intenta resolver. Por ejemplo, si tu intención es crear un modelo de aprendizaje automático capaz de reconocer el estado emocional de alguien a partir de sus expresiones faciales, necesitarás un conjunto de datos con imágenes o vídeos de caras de personas. O, tal vez, el objetivo es crear un modelo que identifique los correos electrónicos no deseados. Para ello, se necesitarán datos en formato texto de correos electrónicos.
Además, los datos que se precisan también dependen del tipo de algoritmo que quieras utilizar. Los algoritmos de aprendizaje supervisado, como la regresión lineal o los árboles de decisión, requieren un campo que contenga el valor verdadero de un resultado para que el modelo aprenda de él. Además de este valor verdadero, denominado objetivo, requieren campos que contengan información sobre las observaciones, algo que se conoce como características. En cambio, los algoritmos de aprendizaje no supervisado, como la agrupación k-means o los sistemas de recomendación basados en el filtrado colaborativo, por lo general sólo necesitan características.
Sin embargo, encontrar los datos es sólo la mitad del trabajo. Los conjuntos de datos del mundo real pueden contener todo tipo de errores que pueden hacer que todo el trabajo resulte inútil si no se detectan y corrigen antes de empezar. En este post, vamos a presentar algunos de los principales obstáculos que puede haber en los conjuntos de datos para el aprendizaje automático y el análisis, así como conocer algunas maneras en que la plataforma de ciencia de datos colaborativa, Datalore, puede ayudar a detectarlos rápidamente y ponerles remedio.
¿Los datos son representativos de aquello que se quiere medir?
La mayoría de los conjuntos de datos para proyectos o análisis de aprendizaje automático no están diseñados específicamente para ese fin. A falta de un diccionario de metadatos o de una explicación sobre lo qué significan los campos del conjunto de datos, es posible que el usuario tenga que resolver la incógnita basándose en la información de la que dispone.
Una forma de determinar lo que miden las características de un conjunto de datos es comprobar sus relaciones con otras características. Si se supone que dos campos miden cosas similares, es de esperar que estén muy relacionados. Por el contrario, si dos campos miden cosas muy diferentes, es de esperar que no estén relacionados. Estas ideas se conocen como validez convergente y discriminante, respectivamente.
Otra cosa importante que hay que comprobar es si alguno de los rasgos está demasiado relacionado con el público objetivo. Si esto ocurre, puede indicar que este rasgo está accediendo a la misma información que el objetivo a predecir. Este fenómeno se conoce como “feature leakage” (fuga de características). Si se emplean estos datos, existe el riesgo de inflar artificialmente el rendimiento del modelo.
En este sentido, Datalore permite escanear rápidamente la relación entre variables continúas mediate el gráfico de correlación en la pestaña Visualizar para un DataFrame. Otra manera de comprobar estas relaciones es utilizando gráficos de barras o tabulaciones cruzadas, o medidas del tamaño del efecto como el coeficiente de determinación o la V de Cramér.
¿El conjunto de datos está correctamente filtrado y limpio?
Los conjuntos de datos pueden contener todo tipo de inconsistencias que pueden afectar negativamente a nuestros modelos o análisis. Algunos de los indicadores más importantes de datos sucios son:
- Valores inverosímiles: Esto incluye valores que están fuera de rango, como los negativos en una variable de recuento o frecuencias que son mucho más altas o más bajas de lo esperado para un campo en particular.
- Valores atípicos: Se trata de valores extremos, que pueden representar cualquier cosa, desde errores de codificación que se produjeron en el momento en que se escribieron los datos, hasta valores raros pero reales que se sitúan fuera del grueso de las demás observaciones.
- Valores perdidos: El patrón y la cantidad de datos que faltan determinan el impacto que tendrán, siendo los más graves los que están relacionados con el objetivo o las características.
Los datos sucios pueden mermar la calidad de sus análisis y modelos, en gran medida porque distorsionan las conclusiones o porque conducen a un rendimiento deficiente del modelo. La pestaña Estadísticas de Datalore permite comprobar fácilmente estos problemas, ya que muestra de un vistazo la distribución, el número de valores perdidos y la presencia de valores atípicos para cada campo. Datalore también facilita la exploración de los datos en bruto y permite realizar operaciones básicas de filtrado, ordenación y selección de columnas directamente en un DataFrame, exportando el código Python correspondiente a cada acción a una nueva celda.
¿Las variables están equilibradas?
Los datos desequilibrados se producen cuando los campos categóricos tienen una distribución desigual de observaciones entre todas las clases. Esta situación puede causar problemas importantes para los modelos y los análisis. Cuando se tiene un objetivo muy desequilibrado, se pueden crear modelos perezosos que aún pueden lograr un buen rendimiento simplemente prediciendo por defecto la clase mayoritaria. Pongamos un ejemplo extremo: tenemos un conjunto de datos en el que el 90% de las observaciones corresponden a una de las clases objetivo y el 10% a la otra. Si siempre predijéramos la clase mayoritaria para este conjunto de datos, seguiríamos obteniendo una precisión del 90%, lo que demuestra que, en estos casos, un modelo que no aprende nada de las características puede tener un rendimiento excelente.
Las características también se ven afectadas por el desequilibrio de clases. Los modelos funcionan aprendiendo patrones, y cuando las clases son demasiado pequeñas, es difícil para los modelos hacer predicciones para estos grupos. Estos efectos pueden agravarse cuando se tienen varias características desequilibradas, lo que lleva a situaciones en las que una combinación concreta de clases poco comunes sólo puede darse en un puñado de observaciones.
Los datos desequilibrados pueden rectificarse mediante diversas técnicas de muestreo. El submuestreo (undersampling, en inglés) consiste en reducir el número de observaciones en las clases más grandes para igualar la distribución de los datos, y el sobremuestreo (oversampling) consiste en crear más datos en las clases más pequeñas. Hay muchas formas de hacerlo. Algunos ejemplos incluyen el uso de paquetes Python como imbalanced-learn o servicios como Gretel. Las características desequilibradas también pueden corregirse mediante la ingeniería de características, cuyo objetivo es combinar clases dentro de un campo sin perder información.
En definitiva, ¿es representativo el conjunto de datos?
A la hora de crear un conjunto de datos, se tiene en mente un grupo objetivo o target para el cual deseas que tu modelo o análisis funcione. Por ejemplo, un modelo para predecir la probabilidad de que los hombres estadounidenses interesados en la moda compren una determinada marca. Este grupo objetivo es la población sobre la que se quiere poder hacer generalizaciones. Sin embargo, como no suele ser práctico recopilar información sobre todos los individuos que constituyen esta parte de la población, en su lugar se emplea un subconjunto denominado muestra.
A veces surgen problemas que hacen que los datos de la muestra para el modelo de aprendizaje automático y el análisis no representen correctamente el comportamiento de la población. Esto se denomina sesgo de los datos. Por ejemplo, es posible que la muestra no capte todos los subgrupos de la población, un tipo de sesgo denominado sesgo de selección.
Una forma de comprobar el sesgo es inspeccionar la distribución de los campos de sus datos y comprobar que tienen sentido basándose en lo que uno sabe sobre ese grupo de la población. El uso de la pestaña Estadísticas de Datalore permite escanear la distribución de las variables continuas y categóricas de un DataFrame.
¿Se está midiendo el rendimiento real de los modelos?
Una última cuestión que puede ponerle en un aprieto es la medición del rendimiento de sus modelos. Muchos modelos son propensos a un problema llamado sobreajuste que es cuando el modelo se ajusta tan bien a los datos de entrenamiento que no se generaliza bien a los nuevos datos. El signo revelador del sobreajuste es un modelo que funciona extremadamente bien con los datos de entrenamiento y su rendimiento es inferior con nuevos datos. La forma de tener esto en cuenta es dividir el conjunto de datos en varios conjuntos: un conjunto de entrenamiento para entrenar el modelo, un conjunto de validación para comparar el rendimiento de diferentes modelos y un conjunto de prueba final para comprobar cómo funcionará el modelo en el mundo real.
Sin embargo, crear una división limpia de entrenamiento-validación-prueba puede ser complicado. Un problema importante es la fuga de datos, por la que la información de los otros dos conjuntos de datos se filtra en el conjunto de entrenamiento. Esto puede dar lugar a problemas que van desde los obvios, como las observaciones duplicadas que terminan en los tres conjuntos de datos, a otros más sutiles, como el uso de información de todo el conjunto de datos para realizar el preprocesamiento de características antes de dividir los datos. Además, es importante que los tres conjuntos de datos tengan la misma distribución de objetivos y características, para que cada uno sea una muestra representativa de la población.
Para evitar cualquier problema, se debe dividir el conjunto de datos en conjuntos de entrenamiento, validación y prueba al principio de su trabajo, antes de realizar cualquier exploración o procesamiento. Para asegurarse de que cada conjunto de datos tiene la misma distribución de cada campo, se puede utilizar un método como train_test_split de scikit-learn, diseñado específicamente para crear divisiones representativas de los datos. Por último, es recomendable comparar las estadísticas descriptivas de cada conjunto de datos para comprobar si hay signos de fuga de datos o divisiones desiguales, lo que se hace fácilmente utilizando la pestaña Estadísticas de Datalore.
En definitiva, existen varios problemas que pueden ocurrir cuando se preparan los datos para el aprendizaje automático y el análisis y es importante saber cómo mitigarlos. Si bien esto puede ser una parte que consume mucho tiempo del proceso de trabajo, existen herramientas que pueden hacer que sea más rápido y fácil detectar problemas en una etapa temprana.
Contenido elaborado a partir del post de Jodie Burchell How to prepare your dataset for machine learning and analysis publicado en The JetBrains Datalore Blog
Blog
Motivación
De acuerdo con la Propuesta de Ley de datos europea los datos son un componente fundamental de la economía digital y un recurso esencial para garantizar las transiciones ecológica y digital. En los últimos años, el volumen de datos generados por seres humanos y máquinas ha experimentado un aumento exponencial. Es esencial desbloquear el potencial de estos datos mediante la creación de oportunidades para su reutilización, eliminando obstáculos al desarrollo de la economía del dato y respetando las normas y los valores europeos. En consonancia con la misión de reducir la brecha digital, se deben impulsar medidas que permitan que todos se beneficien de estas oportunidades de manera justa y equitativa.
Sin embargo, un inconveniente de la alta disponibilidad de datos es que a medida que se acumulan más datos, se genera un caos cuando éstos no se gestionan correctamente. El incremento del volumen de datos en velocidad, escala y variedad implica, a su vez, una mayor dificultad para asegurar su calidad. Y en situaciones de niveles inadecuados de calidad de datos, conforme las técnicas analíticas utilizadas para procesar los conjuntos de datos se vuelven más sofisticadas, los individuos y comunidades pueden resultar afectados de nuevas e inesperadas formas.
En este escenario cambiante, se hace necesario establecer procesos comunes aplicables a los activos de datos de toda organización a lo largo de su ciclo de vida maximizando su valor mediante iniciativas de gobierno de datos que aseguren un enfoque estructurado, gestionado, coherente y estandarizado a todas las actividades, operaciones y servicios relacionados con datos. En definitiva, se debe asegurar que la definición, creación, almacenamiento, mantenimiento, acceso y uso de los datos (gestión de los datos) se hace siguiendo una estrategia de datos alineada con las estrategias organizacionales (gobierno de los datos), y que los datos que se utilizan son adecuados para el uso que se pretende (calidad de los datos).
Especificaciones UNE de Gobierno, gestión y calidad del dato
La Oficina del Dato, unidad encargada de dinamizar la compartición, la gestión y el uso de los datos a lo largo de todos los sectores productivos de la Economía y Sociedad española, para dar respuesta a la necesidad de contar con un marco de referencia que dé soporte tanto a organismos públicos como privados en sus esfuerzos de realizar un adecuado Gobierno, gestión y calidad del dato, ha patrocinado, promovido y participado en la generación de especificaciones nacionales UNE al respecto.
Las especificaciones UNE 0077:2023 Gobierno del dato, UNE 0078:2023 Gestión del dato y UNE 0079:2023 Gestión de la calidad del dato están concebidas para ser aplicadas de forma conjunta, habilitando la concepción de un marco de referencia sólido y armonizado que fomente la adopción de prácticas sostenibles y efectivas alrededor del dato.
La coordinación es impulsada por el gobierno del dato que establece los mecanismos necesarios para asegurar el uso y explotación adecuado de los datos mediante la implantación y ejecución de los procesos de gestión del dato y procesos de gestión de calidad del dato, todo ello de acuerdo con las necesidades del oportuno proceso de negocio, y teniendo en cuenta las limitaciones y posibilidades de las organizaciones que utilizan los datos.

Cada especificación normativa se presenta con un enfoque orientado a procesos y cada uno de los procesos presentados se describe atendiendo a su contribución a los siete componentes de un sistema de gobierno y gestión del dato, tal como se introduce en COBIT 2019:
- Proceso, detallando su propósito, resultado, tareas y productos conforme a la Norma ISO 8000-61.
- Principios, políticas y marcos de referencia.
- Estructuras organizativas, que identifican los órganos de gobierno y toma de decisiones de los datos.
- Información
,que se requiere y se genera en cada uno de los procesos. - Cultura, ética y comportamiento, como conjunto de conductas individuales y colectivas de las personas y de la organización.
- Personas, habilidades y competencias necesarias para poder completar todas las actividades y la toma de decisiones y acciones correctivas.
- Servicios, infraestructuras y aplicaciones incluye lo relacionado con las tecnologías para dar soporte a los procesos de gestión de datos, gestión de calidad de datos y gobierno de datos.
Especificación UNE 0077:2023 Gobierno del dato
La especificación UNE 0077:2023 cubre aspectos relativos al gobierno del dato. Se describe la creación de un gobierno del dato con que evaluar, dirigir y monitorizar el uso de los datos de una organización, de forma que contribuyan al buen desempeño de la misma, obteniendo el mayor valor de los datos, a la vez que mitigando los riesgos derivados de su uso. El gobierno del dato tiene por tanto un carácter estratégico, mientras que la gestión del dato tiene un carácter más orientado a materializar los objetivos marcados en la estrategia.
La realización de un adecuado gobierno del dato implica el correcto desempeño siguientes procesos:
- Establecimiento de la estrategia del dato
- Establecimiento de políticas, buenas prácticas y procedimientos del dato
- Establecimiento de estructuras organizativas
- Optimización de los riesgos de los datos
- Optimización del valor de los datos
Especificación UNE 0078:2023 Gestión del dato
La especificación UNE 0078:2023 cubre los aspectos relativos a gestión del dato. La gestión del dato se define como el conjunto de actividades encaminadas a garantizar la entrega exitosa de datos relevantes y con niveles de calidad adecuados a los agentes involucrados a lo largo del ciclo de vida del dato, dando soporte a los procesos de negocio establecidos en la estrategia organizativa, siguiendo las directrices del gobierno del dato, y de acuerdo con los principios de la gestión de la calidad del dato.
La realización de una adecuada gestión del dato involucra el desarrollo de trece procesos:
- Procesamiento del dato
- Gestión de la infraestructura tecnológica
- Gestión de requisitos del dato
- Gestión de la configuración del dato
- Gestión de datos histórico
- Gestión de seguridad del dato
- Gestión del metadato
- Gestión de la arquitectura y diseño del dato
- Compartición, intermediación e integración del dato
- Gestión del dato maestro
- Gestión de recursos humanos
- Gestión del ciclo de vida del dato
- Análisis del dato
Especificación UNE 0079:2023 Gestión de la calidad del dato
La especificación UNE 0079:2023 cubre los procesos de gestión de la calidad del dato necesarios para establecer un marco de mejora de la calidad de los datos. La gestión de la calidad del dato se define como el conjunto de actividades encaminadas a asegurar que los datos tienen niveles de calidad adecuados para el uso que permita satisfacer la estrategia de una organización. Contar con datos de calidad permitirá obtener de los datos el máximo potencial a través de los procesos de negocio de una organización
De acuerdo con el circulo de mejora continua PDCA de Deming, la gestión de la calidad del dato involucra cuatro procesos:
- Planificación de calidad del dato,
- Control y monitorización de calidad del dato,
- Aseguramiento de calidad del dato, y
- Mejora de calidad del dato.
Los procesos de gestión de la calidad del dato están destinados a conseguir que los datos cumplan con los requisitos de calidad del dato expresados conforme al estándar ISO/IEC 25012.
Modelo de madurez
Como marco de aplicación conjunto de las diferentes especificaciones se esboza un modelo de madurez en datos, consistente con él, que integra los procesos de gobierno, gestión y gestión de la calidad del dato mostrando cómo se puede llevar a cabo la implantación progresiva de los procesos y sus capacidades, definiendo un camino de mejora y excelencia a lo largo de diferentes niveles para llegar a ser una organización madura en datos.

La Oficina del Dato promoverá la generación de la especificación UNE 0080 para proporcionar un modelo de evaluación de la madurez en datos que sea conforme con el contenido de las especificaciones de gobierno, gestión y gestión de la calidad del dato y el citado marco.
El contenido de esta guía puede descargarse de forma libre y gratuita desde el portal de AENOR a través del enlace que figura a continuación accediendo al apartado de compra. El acceso a esta familia de especificaciones UNE del dato está patrocinado por la Secretaría de Estado de Digitalización e Inteligencia Artificial, Dirección General del Dato. Aunque la descarga requiere registro previo, se aplica un descuento del 100% sobre el total del precio que se aplica en el momento de finalizar la compra. Tras finalizar la compra se podrá acceder a la norma o normas seleccionadas desde el área de cliente en el apartado mis productos.
Entrevista
La asociación AMETIC representa a empresas de todos los tamaños ligadas con la industria tecnológica digital española, un sector clave para el PIB nacional. Entre otras cuestiones, AMETIC busca impulsar un entorno favorable para el crecimiento de las empresas del sector, potenciando el talento digital y la creación y consolidación de nuevas empresas.
En datos.gob.es hemos hablado con Antonio Cimorra, Director de Transformación Digital y Tecnologías Habilitadoras de AMETIC, para reflexionar sobre el papel de los datos abiertos en la innovación y como base de nuevos productos, servicios e incluso modelos de negocio.
Entrevista completa:
1. ¿Cómo ayudan los datos abiertos a impulsar la transformación digital? ¿Qué tecnologías disruptivas son las más beneficiadas por la apertura de datos?
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad. Todas las industrias, administraciones publicas y la propia ciudadanía no hemos hecho más que comenzar a descubrir y utilizar el enorme potencial y utilidad que la utilización de los datos aporta a la mejora de la competitividad de las empresas, a la eficiencia y mejora de los servicios de las Administraciones Públicas y a las relaciones sociales y la calidad de vida de las personas.
2. Una de las áreas en las que trabajan desde AMETIC es la Inteligencia Artificial y el Big Data, entre cuyos objetivos está promover la creación de plataformas públicas de compartición de datos abiertos. ¿Podría explicarnos qué acciones llevan o han llevado a cabo para ello?
En AMETIC contamos con una Comisión de Inteligencia Artificial y Big Data en la que participan las principales empresas proveedoras de esta tecnología. Desde este ámbito, trabajamos en la definición de iniciativas y propuestas que contribuyen difundir su conocimiento entre los potenciales usuarios, con las consiguientes ventajas que supone su incorporación en los sectores público y privado. Son destacados ejemplos de las acciones en este ámbito la reciente presentación del Observatorio de Inteligencia Artificial de AMETIC, así como el AMETIC Artificial Intelligence Summit que en 2022 celebrará su quinta edición que pondrá foco en mostrar cómo la Inteligencia Artificial puede contribuir al cumplimiento de los Objetivos de Desarrollo Sostenible y a los Planes de Transformación a ejecutar con Fondos Europeos
3. Los datos abiertos pueden servir de base para desarrollar servicios y soluciones que den lugar a nuevas empresas. ¿Podría contarnos algún ejemplo de caso de uso llevado a cabo por sus asociados?
Los datos abiertos y muy particularmente la reutilización de la información del sector público son la base de desarrollo de un sinfín de aplicaciones e iniciativas emprendedoras tanto en empresas consolidadas de nuestro sector tecnológico como en otros muchos casos de pequeñas empresas o startups que encuentran en esta fuente de información el motor de desarrollo de nuevos negocios y acercamiento al mercado.
4. ¿Qué tipos de datos son los más demandados por las empresas a las que representan?
En la actualidad, todos los datos de actividad industrial y social cuentan con una importante demanda por las empresas, atendiendo a su gran valor en el desarrollo de proyectos y soluciones que vienen demostrando su interés y extensión en todos los ámbitos y tipología de organizaciones y usuarios en general.
5. También es fundamental contar con iniciativas de compartición de datos como GAIA-X, constituida sobre los valores de soberanía digital y disponibilidad de los datos. ¿Cómo han recibido las empresas la creación de un hub nacional?
El sector tecnológico ha recibido la creación del hub nacional de GAIA-X muy positivamente, entendiendo que nuestra aportación desde España a este proyecto europeo será de enorme valor para nuestras empresas de muy distintos ámbitos de actividad. Espacios de compartición de datos en sectores como el turismo, la sanidad, la movilidad, la industria, por poner algunos ejemplos, cuentan con empresas y experiencias españolas que son ejemplo y referencia a nivel europeo y mundial.
6. En este momento hay una gran demanda de profesionales relacionados con la captación, análisis y visualización de datos. Sin embargo, la oferta de profesionales, aunque va creciendo, continúa siendo limitada. ¿Qué habría que hacer para impulsar la capacitación en habilidades relacionadas con los datos y la digitalización?
La oferta de profesionales tecnológicos es uno de los mayores problemas para el desarrollo de nuestra industria local y para la transformación digital de la sociedad. Es una dificultad que podemos calificar como histórica, y que lejos de ir a menos, cada día es mayor en número de puestos y perfiles a cubrir. Es un problema a nivel mundial que evidencia que no existe una formula única o sencilla para solucionarlo, pero si podemos mencionar la importancia de que todos los agentes sociales y profesionales desarrollemos acciones conjuntas y en colaboración que permitan la capacitación digital de nuestra población desde edades tempranas y de ciclos y programas formativos y de grado especializados que se caractericen por su proximidad con lo que serán las carreras profesionales para lo que es necesario contar con la participación del sector empresarial
7. Durante los últimos años, has formado parte del jurado de las distintas ediciones del Desafío Aporta. ¿Cómo cree que contribuyen este tipo de acciones a impulsar negocios basados en datos?
El Desafío Aporta ha sido un ejemplo de apoyo y estímulo para la definición de muchos proyectos en torno a los datos abiertos y para el desarrollo de una industria propia que en estos últimos años ha venido creciendo de forma muy significativa con la puesta a disposición de datos de muy distintos colectivos, en muchos casos por parte de las Administraciones Públicas, y su posterior reutilización e incorporación a aplicaciones y soluciones de interés para muy distintos usuarios.
Los datos abiertos constituyen uno de los pilares de la economía del dato, que está llamada a ser la base de nuestro desarrollo presente y futuro y de la transformación digital de nuestra sociedad.
8. ¿Cuáles son las próximas acciones que van a llevar a cabo en AMETIC ligadas a la economía del dato?
Entre las acciones más destacadas de AMETIC en relación con la economía del dato cabría citar nuestra reciente incorporación al hub nacional de GAIA-X para el que hemos sido elegidos miembros de su junta directiva, y en donde representaremos e incorporaremos la visión y las aportaciones de la industria tecnológica digital en todos los espacios de datos que se constituyan, sirviendo de canal de participación de las empresas tecnológicas que desarrollan su actividad en nuestro país y que tienen que conformar la base de los proyectos y casos de uso que integrar en la red europea GAIA-X en colaboración con otros hubs nacionales.
Blog
La Comisión Europea estima que la economía del dato -aquella cuyo modelo de negocio se basa en la explotación de datos para generar productos y servicios- alcanzará un valor de 550.000 millones de euros en la UE27 en 2025. Esta cifra significa que pasará de ocupar el 2,8% del PIB a suponer el 4%. Solo en nuestro país, se apunta que generará más de 50.000 millones de euros y 750.000 puestos de trabajo.
En el mismo informe, la Comisión también indica que, para alcanzar un escenario de crecimiento alto, es necesario que disminuya la concentración de los datos en manos de unos pocos y se apueste por políticas de compartición de datos que fomenten la innovación y el avance de la sociedad. Por ello, entre otras acciones, la Comisión lanzó el Support Centre for Data Sharing (SCDS), enfocado en investigar e informar sobre las prácticas de compartir datos y aquellos elementos que influyen en su éxito.
La compartición de datos impulsa la colaboración entre los investigadores, desarrolladores y creadores de productos y servicios, lo que puede dar lugar a nuevos e importantes descubrimientos, además de repercutir en la reputación positiva de las compañías que ceden datos. Las empresas empiezan a ser conscientes de esta situación, lo que está llevando a que cada vez veamos más ejemplos de iniciativas privadas de intercambio y compartición de datos. Esto afecta a organizaciones de todo tipo, incluyendo grandes empresas que atesoaran, gestionan o tienen acceso a grandes volúmenes de datos. Veamos algunos ejemplos de compartición:
HealthData 29
La Fundación 29, junto a Microsoft, ha puesto en marcha Health29, una plataforma para compartir conjuntos de datos abiertos para fines de investigación. En el proyecto también han participado Garrigues y la Cátedra de Privacidad y Transformación Digital de la Universidad de Valencia.
Las organizaciones que lo deseen se pueden registrar como publicadores y empezar a compartir datos anonimizados, garantizando la privacidad y seguridad. Actualmente hay 3 organizaciones publicadoras. Todas ellas comparten datos relacionados con la COVID-19:
- HM Hospitales comparte datos clínicos relacionados con el tratamiento del COVID-19, incluyendo diagnósticos, tratamientos, ingresos, pasos por UCI, pruebas diagnósticas por imagen, resultados de laboratorio, alta o deceso, entre otros.
- LaLiga provee datos relativos a pruebas PCR y de antígenos realizadas a los jugadores y al personal de los clubes de LaLiga Santander y LaLiga SmartBank.
- Sanitas, como parte de su proyecto Data4good, proporciona a los investigadores datos demográficos e información clínica (medicamentos, constantes vitales, información de laboratorios y diagnóstico) de los pacientes con COVID-19 que han sido ingresados en sus centros médicos.
Estos datos pueden utilizarse para comprender mejor el comportamiento de esta enfermedad y su tratamiento, pero también para realizar modelos predictivos de la evolución de la enfermedad o modelos epidemiológicos. Los investigadores que quieran acceder a estos datos necesitan rellenar una solicitud, que el publicador deberá aprobar.
En el contexto del proyecto también se ha creado una guía con el marco técnico y legal para crear un repositorio público de datos procedentes de los sistemas de salud.
Cabe destacar que Microsoft engloba esta acción en su iniciativa de impulso de la compartición de datos, Open Data Campaign, como nos explicó Belén Gancedo, Directora de Educación en Microsoft Ibérica, en esta entrevista.
Data for Good
Data for Good es el nombre que lleva la iniciativa de compartición de datos de Meta, la compañía de Mark Zuckerberg, antes llamada Facebook, igual que la red social -la cual sí mantiene el nombre-. Facebook cuenta con tres mil millones de usuarios. Data for Good pretende utilizar información anonimizada sobre esta comunidad para “ayudar a las organizaciones a prestar mejores servicios”.
En la web se ofrecen diversos datos y herramientas, incluyendo mapas. También cuenta con una sección de impacto con ejemplos de uso de los datos. Mientras algunos productos requieren la firma de un acuerdo de intercambio de datos, otros son públicos y open source, como por ejemplo:
- High Resolution Settlement Layer: se trata de un mapa de densidad poblacional que utiliza datos censales, imágenes satelitales y algoritmos de machine learning para detectar estructuras. Ha sido utilizado, por ejemplo, para analizar el acceso a centros de salud en España.
- Movement Range Maps: consiste en un mapa con datos de movilidad actualizados diariamente (aquí hay un artículo sobre la metodología). Han sido utilizados por gobiernos y agencias alrededor del mundo para medir los efectos de las restricciones en movilidad durante la pandemia de COVID-19 o el nivel de actividad económica.
- Social Connectedness Index: mapa que mide los niveles de amistad en Facebook entre países y regiones en el mundo. Este índice ayuda a predecir patrones económicos, de migración o salud, entre otros. Ha sido utilizado por la Universidad de Nueva York, por ejemplo, para predecir intercambios comerciales entre unidades geográficas en Europa.
- Commuting Zones: mapea las áreas donde vive y trabaja la ciudadanía, en base a traslados, y utilizando algoritmos de machine learning. Esta información solo es accesible, de momento, para instituciones académicas, think-tank u ONGs.
Además, también ofrecen resultados de encuestas sobre el impacto económico en Pymes alrededor del mundo, el cambio climático, la igualdad en el hogar o las tendencias e impacto de la COVID-19 .
Estas herramientas están también disponibles a través del Humanitarian Data Exchange Portal de la Organización de las Naciones Unidas.
Google Health
Google Health tiene el objetivo organizar la información de salud del mundo y hacerla universalmente accesible y útil. Dentro del proyecto se ofrecen tanto servicios para todos los usuarios, como específicos para médicos.
En la parte de servicios generales, podemos encontrar:
- Repositorio de datos abiertos de COVID-19. Agrega datos de más de 20.000 fuentes para ayudar a conocer mejor el comportamiento del virus. Los usuarios pueden descargar los conjuntos de datos sin procesar o visualizarlos a través de mapas y tablas.
- Google Health Studies. Los usuarios pueden unirse a estudios y responder encuestas para ayudar a instituciones e investigadores a comprender mejor los problemas y las necesidades sanitarias específicas de una comunidad. Los datos particulares se encriptan para su posterior agregación y análisis de tal forma que ni Google ni los investigadores reciben ningún dato privado.
Google también desarrolla soluciones tecnológicas dirigidas a mejorar la atención médica. Uno de los campos donde están más enfocado es en los trabajos con Inteligencia Artificial con distintos fines como ayudar a diagnosticar el cáncer o prevenir la ceguera.
Uber Movement
La empresa de movilidad Uber también proporciona datos y herramientas, en este caso, para comprender cómo y por qué se mueven los ciudadanos. A través de la web Uber Movement se pueden visualizar, filtrar y descargar datos gratuitos, agregados y anonimizados de viajes realizados a través de su app. El servicio solo está disponible de momento para algunas ciudades, entre las que se encuentran Madrid y Barcelona.
En concreto cuenta con 3 servicios de datos:
- Travel Times. Proporciona el tiempo medio de viaje entre dos "zonas" de una ciudad para una hora y fecha determinadas.
- Speed. Ofrece datos sobre la velocidad media derivada de las lecturas de vehículos que proporcionan los servicios de Uber, agregadas por segmentos de calles y con una granularidad horaria.
- Mobility HeatMap. Se trata de un mapa de calor que muestra la densidad del tráfico en distintas zonas de cada ciudad.
Gracias a estos datos se pueden comparar los tiempos de traslado y comprender el impacto de diversos eventos en la ciudad. Son de gran utilidad para la toma de decisiones relacionadas con los retos del transporte urbano, desde reducir los embotellamientos y las emisiones hasta mejorar la seguridad vial. Todos los datos están disponible a través de una visualización interactiva, aunque también se puede descargar en formato CSV. Estos datos cuentan con una licencia Creative Commons, Attribution Non-Commercial.

En definitiva, estamos ante 4 ejemplos diferentes de compartición de datos, pero con un fin común: impulsar avances en la sociedad a través de la mejora del conocimiento. Todos estos datos son fundamentales para impulsar nuevas investigaciones, mejorar la toma de decisiones e incluso generar nuevos productos y servicios.
Contenido elaborado por el equipo de datos.gob.es.
Blog
Hace tan solo unos días se ha presentado oficialmente la Carta de Derechos Digitales. Se trata de una iniciativa que ha contado con una amplia representación de la sociedad civil ya que, de una parte, un amplio y diverso equipo de trabajo se ha encargado de su redacción y, de otra, durante el procedimiento de su elaboración se abrió un trámite de participación pública para que desde la sociedad civil se formularan las oportunas propuestas y observaciones.
¿Cuál es el valor de la Carta?
Durante los últimos años se han producido en España importantes avances en la regulación del uso de la tecnología en diversos ámbitos. Así ha sucedido, por ejemplo, con el uso de medios electrónicos por las Administraciones Públicas, la protección de datos personales, los servicios electrónicos de confianza, la transformación digital del sector financiero o, sin ánimo exhaustivo, las condiciones para el trabajo a distancia. También se han impulsado numerosas iniciativas normativas por parte de la Unión Europea en las que el uso de los datos ocupa un papel muy relevante. Entre ellas destacan la Directiva (UE) 2019/770 del Parlamento Europeo y del Consejo, de 20 de mayo de 2019, relativa a determinados aspectos de los contratos de suministro de contenidos y servicios digitales, y la Directiva 1024/2019, sobre datos abiertos y reutilización de la información del sector público. Incluso, en el futuro más inmediato, está prevista la aprobación de sendos reglamentos europeos sobre gobernanza de los datos e Inteligencia Artificial, proyectos directamente relacionados con la Estrategia Digital de la UE que se promueve por parte de la Comisión Europea.
Dado este panorama de intensa producción normativa, podría plantearse hasta qué punto es oportuna una nueva iniciativa como la que supone esta Carta. En primer lugar, debe enfatizarse que, a diferencia de las anteriormente citadas, la Carta no es una norma jurídica en sentido estricto, esto es, no añade nuevas obligaciones y, por tanto, sus previsiones carecen de valor normativo. De hecho, según se afirma expresamente en la misma, su objetivo no es “descubrir derechos digitales pretendiendo que sean algo distinto de los derechos fundamentales ya reconocidos o de que las nuevas tecnologías y el ecosistema digital se erijan por definición en fuente de nuevos derechos” sino, más bien, “perfilar los más relevantes en el entorno y los espacios digitales o describir derechos instrumentales o auxiliares de los primeros”.
Más allá del inexistente alcance jurídico de su contenido, la Carta pretende resaltar el impacto y las consecuencias que los escenarios digitales plantean para la efectividad de los derechos y libertades, sugiriendo de esta manera algunas pautas frente a los nuevos retos que dicho contexto tecnológico plantea para la interpretación y aplicación de los derechos en la actualidad, pero también en su futura evolución más inmediata, que ya puede incluso predecirse. Teniendo en cuenta estas pretensiones adquiere singular relevancia la llamada al cumplimiento normativo desde el diseño en los entornos digitales (apartado I.4), de manera que los requerimientos jurídicos de las iniciativas y proyectos digitales se integren en su concepción inicial desde una perspectiva sustantiva y no como un mero requisito formal que puede resolverse en cualquier momento posterior.
¿Cuál es el protagonismo que la Carta ha concedido a los datos?
Por lo que respecta a los derechos digitales de la ciudadanía en sus relaciones con las Administraciones Públicas, en la Sección 3 (Derechos de participación y conformación del espacio público) se han establecido algunas previsiones donde el protagonismo de los datos resulta incuestionable (Apartado XVIII):
- Así, se establece que el principio de transparencia y de reutilización de datos del sector público guiará la actuación de la Administración digital, si bien su alcance se condiciona a lo que establezca la normativa aplicable. En todo caso, dicho principio se refuerza con la promoción de la publicidad y la rendición de cuentas. Igualmente se velará por la portabilidad de los datos y la interoperabilidad de los formatos, sistemas y aplicaciones, en los términos que prevea el ordenamiento jurídico vigente. En concreto (Sección 5, Apartado XXI), se reconoce el uso para el bien común de los datos personales y no personales, ya provengan del sector público o del privado, incluyendo entre las finalidades el archivo en interés público, la investigación, la estadística, así como la innovación y el desarrollo. En este sentido, se insta a que se promuevan “condiciones que garanticen la reutilización de la información y el uso de los datos en formato de datos abiertos y reutilizables”, así como, en línea con la regulación europea que se está tramitando, modelos de gobernanza adecuados de los repositorios y programas de donación de datos.
- También se enfatiza la importancia de la transparencia sobre el uso de instrumentos de inteligencia artificial, en particular, acerca de los datos utilizados, su margen de error, su ámbito de aplicación y su carácter decisorio o no decisorio. Más allá de su incidencia en el sector público, la no discriminación por lo que se refiere al uso de los datos se proscribe con carácter general (Sección 5, Apartado XXV), debiendo establecerse condiciones adecuadas de transparencia, auditabilidad, explicabilidad, trazabilidad, supervisión humana y gobernanza.
- Igualmente se establece la necesidad de realizar una evaluación de impacto en los derechos digitales a la hora de diseñar los algoritmos en el caso de adopción de decisiones automatizadas o semiautomatizadas. Parece, por tanto, inexcusable que dicha evaluación preste especial atención a los sesgos que se puedan producir por lo que respecta a los datos utilizados y el tratamiento que de los mismos se pueda llevar a cabo en el proceso decisional. La evaluación de impacto desde la perspectiva de los principios éticos y los derechos relativos a la inteligencia artificial también se contempla específicamente para el ámbito laboral (Sección 4, Apartado XIX), con especial atención a eventuales discriminaciones y a los derechos de conciliación.
- Singular importancia se otorga a la necesidad de que las Administraciones ofrezcan una motivación comprensible en lenguaje natural de las decisiones que adopten utilizando medios digitales, debiendo justificarse especialmente qué criterios de aplicación de las normas se han utilizado y, por tanto, los datos que se hayan podido manejar a tal efecto.
- Por lo que se refiere específicamente al sistema de salud (Sección 5, Apartado XXIII), de una parte, se exige asegurar la interoperabilidad, el acceso y la portabilidad de la información del paciente y, con relación a los dispositivos tecnológicos desarrollados con fines terapéuticos o asistenciales, se intenta impedir que su uso gratuito no quede condicionado a la cesión de datos personales del paciente.
Así pues, aunque la Carta de los Derechos Digitales no incorpore por si misma obligaciones jurídicas, sin embargo, ofrece criterios interpretativos que pueden tener relevancia en el proceso de interpretación y aplicación del marco legislativo vigente, así como servir de orientación a la hora de impulsar futuros proyectos regulatorios.
Por otro lado, aun cuando no establezca derechos jurídicamente exigibles, su contenido establece relevantes medidas dirigidas a los poderes públicos, en particular por lo que se refiere a la Administración General del Estado y las entidades del sector público estatal ya que, en última instancia, se trata de una iniciativa impulsada y asumida formalmente por el Gobierno estatal.
En definitiva, sus previsiones presentan especial importancia por lo que se refiere a los datos abiertos y la reutilización de la información del sector público dado que en los próximos meses habrán de aprobarse importantes regulaciones tanto en el ámbito estatal como europeo, de manera que el contenido de la Carta puede adquirir un singular protagonismo en el desarrollo y aplicación de dichas normas.
Contenido elaborado por Julián Valero, catedrático de la Universidad de Murcia y Coordinador del Grupo de Investigación “Innovación, Derecho y Tecnología” (iDerTec).
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hace un par de semanas, comentamos a través de este artículo la importancia de las herramientas de análisis de datos para generar representaciones que permitan comprender mejor la información y tomar decisiones más acertadas. En dicho artículo dividimos estas herramientas en 2 categorías: herramientas de visualización de datos genéricas - como son Kibana, Tableau Public, SpagoBI (actual Knowage) y Grafana - y las librerías y APIs de visualización. Este nuevo post se lo vamos a dedicar a las segundas.
Las librerías y APIs de visualización son más versátiles que las herramientas de visualización genéricas, pero para poder trabajar con ellas es necesario que el usuario conozca del lenguaje de programación donde se implemente la librería.
Existe una amplia gama de librerías y APIs para diferentes lenguajes de programación o plataformas, que implementan funcionalidades relacionadas con la visualización de datos. A continuación, os mostraremos una selección tomando como criterio fundamental la popularidad que les otorga la Comunidad de usuarios.
Google Chart Tools
Funcionalidad:
Google Chart Tools es la API de Google para la creación de visualizaciones interactivas. Permite la creación de dashboards utilizando diferentes tipos de widgets, como selectores de categoría, rangos temporales o autocompletadores, entre otros.
Principales ventajas:
Se trata de una herramienta muy fácil de usar e intuitiva, que permite la interacción con datos en tiempo real. Además, las visualizaciones generadas pueden ser integradas en portales webs utilizando tecnología HTML5/SVG.
¿Quieres saber más?
-
Materiales de ayuda: En Youtube encontramos diversos tutoriales elaborados por usuarios de la API.
-
Repositorio: En Github podemos acceder a una biblioteca común para los paquetes de gráficos, así como conocer los tipos de gráficos compatibles y ejemplos de cómo personalizar los componentes de cada gráfico, entre otros.
-
Comunidad de usuarios: Los usuarios de Google Chart Tools pueden plantear sus dudas en la comunidad de Google, en el espacio habilitado para ello.
JavaScript InfoVis Toolkit
Funcionalidad:
JavaScript InfoVis Toolkit es la librería de JavaScript que proporciona funciones para la creación de múltiples visualizaciones interactivas como mapas, árboles jerárquicos o gráficos de líneas.
Principales ventajas:
Es eficiente en el manejo de estructuras de datos complejas y dispone de una gran diversidad de opciones de visualización, por lo que se adapta a cualquier necesidad del desarrollador.
¿Quieres saber más?
-
Materiales de ayuda: Este manual de usuario explica las principales opciones de visualización y cómo trabajar con la librería. También hay disponibles demos para la creación de diferentes tipos de gráficos.
-
Repositorio: Los usuarios deben descargar el proyecto de http://thejit.org, aunque también tienen disponible un repositorio en Github donde, entre otras cosas, pueden descargar extras.
-
Comunidad de usuarios: Tanto en la comunidad de usuarios de Google como en Stackoverflow encontramos espacios dedicados a JavaScript InfoVis Tookit para que los usuarios compartan dudas y experiencias.
Data-Driven Documents (D3.js)
Funcionalidad:
Data-Driven Documents (D3.js) es la librería de Javascript que permite la creación de gráficos interactivos y visualizaciones complejas. Gracias a ella se pueden manipular documentos basados en datos usando estándares abiertos de la web (HTML. SVG y CSS), de forma que los navegadores puedan interpretarlos para crear visualizaciones independientemente del software propietario.
Principales ventajas:
Esta librería permite la manipulación de un DOM (Modelo en Objetos para la Representación de Documentos) aplicando las transformaciones necesarias a la estructura en función de los datos vinculados a un documento HTML o XML. Esto proporciona una versatilidad prácticamente ilimitada.
¿Quieres saber más?
-
Materiales de ayuda: En Github puedes encontrar numerosos tutoriales, aunque principalmente dedicados a las versiones antiguas (actualmente están en proceso de actualizar esta sección de la wiki y escribir nuevos tutoriales sobre la versión 4.0 de D3).
-
Repositorio: También en Github encontramos hasta 53 repositorios, que abarcan distintos materiales para gestionar miles de animaciones simultáneas, agrupar puntos bidimensionales en bandejas hexagonales o trabajar con el módulo d3-color, entre otros. En esta galería puedes ver algunos de los trabajos realizados.
-
Comunidad de usuarios: Existen espacios de discusión sobre D3 en la Comunidad de Google, Stackoverflow, Gitter y Slack.
-
Redes sociales: En la cuenta de Twitter @d3js_org se comparten experiencias, novedades y casos de uso. También existe un grupo en LinkedIn.
Matplotlib
Funcionalidad:
Matplotlib es una de las librerías más populares en Python para la creación de visualizaciones y gráficos de alta calidad. Se caracteriza por presentar una organización jerárquica que va desde el nivel más general, como puede ser el contorno de una matriz 2D, hasta un nivel muy específico, como puede ser colorear un pixel determinado.
Principales ventajas:
Matplotlib soporta texto y etiquetas en formato LaTeX. Además, los usuarios pueden personalizar su funcionalidad a través de paquetes diseñados por terceros (Cartopy, Ridge Map, holoviews, entre otros).
¿Quieres saber más?
-
Materiales de ayuda: En su propia web encontramos una guía de usuario que incluye información sobre la instalación y el uso de las diversas funcionalidades. También hay disponibles tutoriales para usuarios tanto principiantes, como intermedios o avanzados.
-
Repositorio: En este repositorio Github están los materiales que necesitas para su instalación. En la web puedes ver una galería con ejemplos de trabajos para tu inspiración.
-
Comunidad de usuarios: La web oficial dispone de una sección de comunidad, aunque también puedes encontrar grupos de usuarios que te ayuden con tus dudas en Stackoverflow y Gitter.
-
Redes sociales: En el perfil de Twitter @matplotlib también se comparten ejemplos de visualizaciones y trabajos de usuarios, así como información sobre las últimas novedades de la herramienta.
Bokeh
Funcionalidad:
Bokeh es la librería de Python orientada a la creación de gráficas interactivas basadas en HTML/JS. Tiene la capacidad de generar visualizaciones interactivas con características como, texto flotante, zoom, filtros o selecciones, entre otros.
Principales ventajas:
Su principal ventaja es la simplicidad en la implementación: con pocas líneas de código se pueden crear visualizaciones interactivas complejas. Además, permite embeber código JavaScript para implementar funcionalidades específicas.
¿Quieres saber más?
-
Materiales de ayuda: Esta guía del usuario proporciona descripciones detalladas y ejemplos que describen muchas tareas comunes que se puede realizar con Bokeh. En la web de Bokeh también encontramos este tutorial y ejemplos de aplicaciones construidas con esta herramienta.
-
Repositorio: En este repositorio Github están los materiales e instrucciones para su instalación, así como ejemplos de uso. También hay ejemplos disponibles en esta galería.
-
Comunidad de usuarios: La comunidad oficial se encuentra en la propia web de Bokeh, aunque los usuarios de esta herramienta también se reúnen en Stackoverflow.
-
Redes sociales: Para estar al día de las novedades, puedes seguir la cuenta de Twitter @bokeh o su perfil en LinkedIn.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:
¿Estás de acuerdo con nuestra selección? Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, recientemente actualizado, así como los siguientes artículos monográficos:
- Las herramientas de análisis de datos más populares
- Las herramientas de depuración y conversión de datos más populares
- Las herramientas de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.