Data publicació
29/05/2026
Data actualització
01/06/2026
Comparteix aquest contingut

Descripció
Imagina que tienes que cruzar datos de calidad del aire con padrón municipal, imágenes de satélite y un mapa de zonas inundables. Cada fuente llega en su propio sistema de referencia, su propia rejilla, su propio formato y su propia escala. Antes de poder analizar nada, dedicas horas —a veces semanas— a reproyectar, alinear, simplificar y reconciliar geometrías. Es un trabajo invisible que consume buena parte de los recursos de cualquier proyecto con dato espacial. Ahora imagina que todas esas fuentes hablan el mismo idioma desde el principio: el de un sistema de celdas globales, jerárquicas e interoperables que cubre toda la Tierra. Eso es, en esencia, lo que propone un DGGS.
DGGS son las siglas de Discrete Global Grid System (Sistema de Rejilla Global Discreta). En los últimos años han pasado de ser un concepto académico a convertirse en una infraestructura operativa, gracias al impulso de estándares como ISO 19170-1 (2021) y la reciente OGC API — DGGS, aprobada como estándar oficial en 2025. Para quienes nos dedicamos al gobierno del dato, esto no es una curiosidad técnica: es una nueva palanca para garantizar interoperabilidad, calidad y trazabilidad sobre la información geoespacial. En este artículo explicamos qué es exactamente un DGGS, por qué sus propiedades son relevantes para el dato, y cómo iniciativas como el piloto AI-DGGS de OGC están demostrando su valor.
Qué es exactamente un DGGS
La forma más sencilla de imaginar un DGGS es pensar en una pelota cubierta por un mosaico de celdas que encajan perfectamente entre sí, sin huecos ni solapes. La diferencia con la rejilla de latitud-longitud que conocemos está en cómo se construyen esas celdas: en lugar de simplemente cortar el globo en “cuadrículas” sobre el mapa, un DGGS parte de una figura geométrica regular —normalmente un icosaedro, un poliedro de 20 caras triangulares— que se ajusta sobre la esfera terrestre. Cada cara se subdivide después en celdas hexagonales, triangulares o cuadrangulares, y el resultado es una teselación homogénea que evita la deformación clásica de los mapas planos.
De este planteamiento se derivan las cuatro propiedades que caracterizan a cualquier DGGS conforme al estándar:
- Cobertura global y exhaustiva. Las celdas cubren toda la superficie terrestre. Cualquier punto del planeta cae en una y solo una celda.
- Área aproximadamente igual. Todas las celdas del mismo nivel tienen áreas equivalentes, sin la distorsión de las cuadrículas geográficas tradicionales (donde una celda cerca del ecuador puede ocupar varias veces más superficie que una celda en latitudes altas).
- Identificadores únicos. Cada celda lleva asociado un código único (Cell ID) que la identifica de forma inequívoca en todo el sistema. En lugar de decir “lat 40,4168, lon -3,7038” para localizar la Puerta del Sol, un DGGS diría algo como “celda 8a3969a05a07fff”.
- Jerarquía anidada. Cada celda se subdivide en un número fijo de celdas hijas (4, 7 o 9, dependiendo del DGGS) que cubren exactamente la celda original. Eso permite navegar entre niveles de resolución sin recalcular nada.
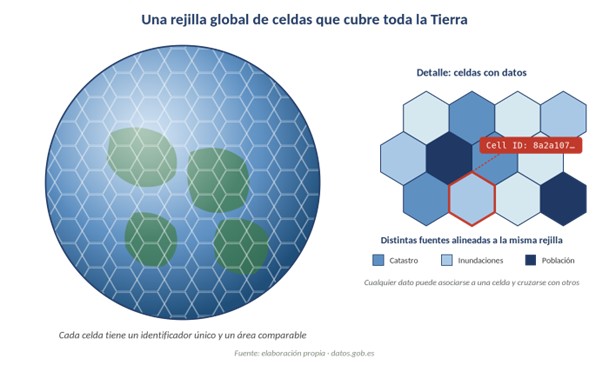
Figura 1. Una rejilla DGGS divide la Tierra en celdas comparables y con identificador propio. Cualquier dato —catastro, inundaciones, población— puede asociarse a una celda y cruzarse con el resto. Fuente: elaboración propia · datos.gob.es
La diferencia conceptual respecto a un sistema clásico de coordenadas es importante. Las coordenadas son continuas: existe un infinito de pares (lat, lon) entre dos puntos cualesquiera. Un DGGS, en cambio, es discreto: el conjunto de celdas a un nivel dado es finito y enumerable. Eso lo hace especialmente eficiente para almacenar, indexar y consultar grandes volúmenes de datos en bases de datos y procesos masivos. También simplifica muchas operaciones comunes que dejan de ser cálculos geométricos para convertirse en búsquedas sobre identificadores “¿qué hay alrededor de este punto?”, “¿qué zonas se solapan?” o “¿qué valor agregado tiene esta región?”, que pasan a ser búsquedas y operaciones sobre identificadores.
Las implementaciones más conocidas son H3 (de Uber, basada en hexágonos), S2 (de Google, basada en cuadrados sobre un cubo), rHEALPix (de origen astronómico) y la librería abierta DGGAL que utiliza el propio piloto AI-DGGS de OGC. Cada una toma decisiones distintas sobre forma de celda, factor de subdivisión y proyección, pero todas comparten la idea esencial de “tesela hierarquizada del planeta”.
Tres propiedades que cambian las reglas del juego
De las propiedades anteriores se derivan tres características que tienen consecuencias muy prácticas para quien trabaja con datos geoespaciales:
1. Jerarquía multiescala
Cada celda tiene un padre en el nivel superior, un número fijo de hijas en el nivel inferior y vecinos bien definidos en su mismo nivel. Esa estructura piramidal permite subir o bajar de resolución simplemente recorriendo la jerarquía, sin recalcular ninguna geometría. Agregar barrios para obtener una cifra municipal, o desagregar un indicador provincial al detalle de manzana, es seguir la jerarquía hacia arriba o hacia abajo.
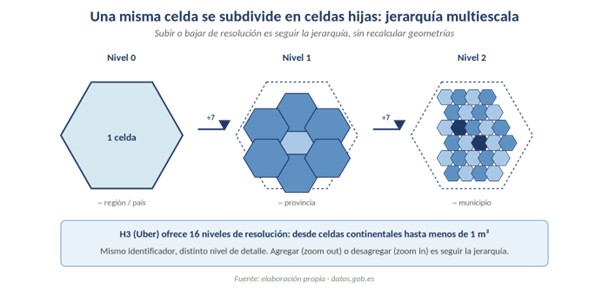
Figura 2. Una celda se subdivide en celdas hijas que, a su vez, vuelven a subdividirse. Mismo identificador estable, distinto nivel de detalle. Fuente: elaboración propia · datos.gob.es
La consecuencia práctica es directa: con un DGGS se puede pasar de celdas de varios kilómetros a celdas de menos de un metro cuadrado simplemente cambiando el nivel de resolución, manteniendo el mismo sistema de referencia. H3, por ejemplo, ofrece 16 niveles distintos. Y, más importante todavía, los datos no se duplican: el mismo dataset puede consumirse a la resolución adecuada para cada caso de uso —operativo, de gestión o estratégico— sin mantener réplicas separadas.
2. Área (aproximadamente) igual
Esta propiedad parece técnica, pero es decisiva. En las rejillas tradicionales en lat-long, una celda en el ecuador puede tener varias veces más superficie que una celda en Escandinavia. Cuando se calcula una densidad de población, una concentración de contaminantes o una intensidad de tráfico, esa diferencia de área distorsiona los resultados y obliga a aplicar correcciones. Con celdas de área equivalente, los cómputos son comparables entre regiones del planeta sin ajustes ad hoc.
3. Identificadores como sistema de referencia
Aquí está la idea más potente del estándar OGC, el identificador de cada celda funciona como una dirección. Pensemos en algo cotidiano: cuando enviamos un paquete, no escribimos las coordenadas GPS de la puerta del destinatario; escribimos un código postal y una calle. Todo el mundo —el remitente, la empresa de mensajería, el cartero— entiende esa dirección y la usa sin necesidad de hacer cálculos. Con un DGGS pasa algo parecido: en lugar de manejar coordenadas para localizar las cosas, usamos el código de la celda. Y, lo más importante, ese mismo código vale para localizar el dato, para preguntar por él y para combinarlo con datos de otras fuentes. Si dos organizaciones distintas dicen que algo está en la celda 8a3969a05a07fff, están hablando del mismo trozo de territorio sin posibilidad de confusión. Eso ahorra muchísimo trabajo previo de "poner los datos en la misma página" antes de poder analizarlos.
¿Por qué importa esto en el gobierno del dato?
El gobierno del dato persigue tres grandes objetivos: que los datos sean encontrables, fiables y reutilizables. Para conseguirlo, las organizaciones invierten en catálogos, en políticas de calidad, en marcos de linaje, en glosarios de negocio y en mecanismos de control de acceso. Cuando los datos llevan dimensión geoespacial, todo eso se complica: cada dataset puede haber sido capturado en una proyección distinta, con un detalle distinto y bajo un modelo de actualización distinto. Los DGGS no resuelven todos esos problemas, pero atacan varios de los más costosos.
- Interoperabilidad real entre dominios. Catastro, medio ambiente, movilidad, salud, energía y emergencias trabajan tradicionalmente con sus propios formatos, escalas y proyecciones. Cuando una organización tiene que cruzar, por ejemplo, datos de calidad del aire de una red de sensores con padrón municipal y con la red de transporte público, dedica una parte sustancial del esfuerzo a homogeneizar geometrías. Codificar la información sobre un mismo DGGS convierte ese cruce en un join sobre identificadores, que es la operación más básica y eficiente que existe en cualquier base de datos.
- Calidad y consistencia espacial. Los problemas clásicos de la información geográfica —solapes mínimos, huecos imperceptibles, geometrías inválidas, pequeñas diferencias entre versiones del mismo límite administrativo— desaparecen o se reducen mucho cuando la geometría se fija a celdas estables y conocidas. El identificador de celda actúa como una clave canónica: dos sistemas que asignen un dato a la misma celda están hablando, sin ambigüedad, del mismo trozo de territorio.
- Linaje y trazabilidad. Saber cómo se ha calculado un indicador es esencial en cualquier proceso de gobierno del dato. Con un DGGS, el linaje de un dato espacial se puede expresar de forma muy compacta: “este indicador se calculó al nivel 9 de H3, sobre estas celdas concretas, agregando estas fuentes”. Esa información cabe en metadatos estándar de un catálogo y es trivial de auditar a lo largo del tiempo.
- Análisis multiescala sin duplicar datos. Las administraciones suelen mantener la misma información a varias resoluciones —una versión para la web ciudadana, otra para gestión municipal, otra para el catálogo de datos abiertos— con el coste de mantenimiento que eso implica. Con DGGS, el mismo dataset puede consumirse al nivel adecuado en cada caso, agregando o desagregando sobre la marcha.
- Privacidad y agregación por diseño. Subir de resolución es un mecanismo natural de anonimización por agregación. En datos de salud, movilidad o consumo, agregar a una celda mayor reduce el riesgo de reidentificación manteniendo la utilidad analítica. Y, a diferencia de otros enfoques, esa agregación es reproducible: cualquier analista que parta del mismo nivel de celda obtendrá los mismos números.
- Mejor encaje con la analítica moderna y la IA. Las arquitecturas de datos actuales —data lakes, almacenes columnares, motores como BigQuery o Snowflake— funcionan especialmente bien con identificadores cortos como claves de partición. Y, como veremos más adelante, los modelos de IA también se benefician de poder razonar sobre celdas en lugar de sobre geometrías complejas.
DGGS en la práctica: quién los está usando
Aunque los DGGS pueden parecer un estándar reciente, varias organizaciones llevan años usando estos sistemas en producción con resultados muy concretos. Algunos ejemplos ilustrativos:
- Uber con H3. H3 nació dentro de Uber para resolver un problema muy concreto: calcular precios dinámicos y casar oferta y demanda en cada ciudad. La compañía agrupa los millones de eventos diarios (viajes, peticiones, posiciones de conductores) en celdas hexagonales y, sobre esa rejilla, calcula tarifas, predice demanda y optimiza despachos. La librería es de código abierto desde 2018 y se ha convertido en estándar de facto en muchos sectores.
- Foursquare y los “Hex Tiles”. El servicio de inteligencia de localización de Foursquare almacena y sirve sus datos sobre puntos de interés, visitas y movilidad usando Hex Tiles, un sistema de teselas basado en H3. Esto les permite ofrecer enriquecimiento de datos a sus clientes —cadenas de retail, plataformas de publicidad, urbanistas— con una sola clave de unión entre datasets que originalmente eran heterogéneos.
- Geoscience Australia y AusPIX. El gobierno australiano ha desarrollado AusPIX, una implementación de rHEALPix orientada a referenciar datos estadísticos, ambientales y de infraestructura sobre una misma rejilla. La iniciativa forma parte de su estrategia Loc-I (Location Index) y permite vincular información del censo, indicadores ambientales y datos sectoriales como capas alineadas sobre celdas comparables —un caso paradigmático de gobierno del dato espacial a escala nacional.
- Investigación en agricultura digital. Equipos de investigación españoles, como el Advanced Information Systems Laboratory de la Universidad de Zaragoza, están explorando DGGS como infraestructura de soporte a la transformación digital del sector agrario, donde conviven datos de muy distinta resolución: parcelas catastrales, imágenes Sentinel, mediciones de sensores y modelos climáticos.
- Inventarios de emisiones de metano. Trabajos recientes proponen rejillas DGGS como base para inventariar emisiones de metano del sector de petróleo y gas, donde la trazabilidad espacial y la comparabilidad entre regiones son críticas para la regulación internacional.
El patrón común en todos los casos es el mismo: cuando varias fuentes de datos heterogéneas tienen que combinarse a escala (continental, nacional o global) y el coste de mantener todo “en formato propio” se vuelve prohibitivo, los DGGS aparecen como la pieza que simplifica la integración.
El piloto AI-DGGS de OGC: cuando la IA necesita un “cerebro espacial”
Uno de los desarrollos más ilustrativos para entender el alcance práctico de los DGGS es el OGC AI-DGGS for Disaster Management Pilot, desarrollado entre 2025 y 2026 con el patrocinio de Natural Resources Canada y el USGS estadounidense, entre otros. El piloto se centró en la gestión de inundaciones en la cuenca del Río Rojo, en Manitoba (Canadá), un corredor de alto riesgo entre Winnipeg y la frontera con Estados Unidos.
La pregunta de partida no era trivial: en una emergencia, los responsables tienen demasiados datos, pero muy poca información accionable. Imágenes de satélite, modelos hidráulicos, capas de infraestructuras críticas y censos de población hablan formatos distintos. ¿Es posible que un usuario formule preguntas en lenguaje natural —del tipo “¿qué carreteras de Winnipeg pueden quedar cortadas?”— y obtenga respuestas trazables y precisas?
El planteamiento del piloto se apoya en dos piezas. La primera es un tejido digital (digital fabric) construido sobre DGGS: distintos servidores publican sus datos —hidrología, modelos de inundación, edificación, redes viarias— alineados sobre la misma rejilla global, accesible vía la OGC API — DGGS. La segunda es una capa de IA con arquitectura RAG (Retrieval-Augmented Generation): el modelo de lenguaje construye la respuesta recuperando contenidos autoritativos del propio DGGS.
La clave está en que la IA no calcula “dónde está el agua”: simplemente busca los Cell ID etiquetados como inundados y los cruza con los Cell ID de carreteras o de población. El razonamiento espacial se reduce a operaciones sobre identificadores, lo que hace las respuestas más rápidas, más explicables y, sobre todo, más auditables.
El resultado documentado por OGC fue una demostración con cuatro clientes de IA independientes y seis servidores DGGS funcionando como un único motor interoperable. Más allá del caso concreto de inundaciones, lo relevante para el gobierno del dato es el patrón: los DGGS proporcionan a los sistemas de IA una representación estable, multiescala y trazable del territorio, que es precisamente lo que evita las llamadas “alucinaciones espaciales” y permite explicar de dónde viene cada respuesta. Toda la documentación del piloto, los protocolos y los demostradores siguen disponibles en su página oficial.
A pesar de todo, los DGGS no sustituyen ni a las coordenadas ni a los SIG tradicionales. Conviven con ellos y, en muchos casos, se construyen encima. Lo que aportan es un eje común sobre el que apoyar la integración, especialmente cuando el volumen de datos crece y los casos de uso se diversifican.
Para una oficina de gobierno del dato, la conversación interesante no es “¿migramos todo a DGGS?”, sino más bien: ¿en qué dominios de nuestra organización tiene sentido empezar a usar identificadores DGGS como clave de integración? ¿Qué catálogos, indicadores o productos derivados ganarían en consistencia si se publicaran también referenciados sobre rejilla? ¿Qué políticas de calidad y de linaje queremos aplicar sobre esa rejilla común?
La buena noticia es que el ecosistema está madurando rápido: el estándar abstracto está consolidado, hay una API oficial, existen implementaciones abiertas —H3, S2, DGGAL, rHEALPix— y los pilotos como AI-DGGS demuestran que la pieza encaja con las arquitecturas modernas de datos e IA. La conversación, simplemente, ha empezado, y a las oficinas de gobierno del dato les corresponde liderarla en sus organizaciones.
Para saber más
Estándares y especificaciones
- OGC Abstract Specification Topic 21 — Discrete Global Grid Systems: https://docs.ogc.org/as/20-040r3/20-040r3.html
- ISO 19170-1:2021 — Geographic information — Discrete Global Grid Systems: https://www.iso.org/standard/82327.html
- OGC API — Discrete Global Grid Systems — Part 1: Core (2025): https://docs.ogc.org/is/21-038r1/21-038r1.html
Piloto AI-DGGS de OGC
- Página del piloto en OGC: https://www.ogc.org/initiatives/ai-dggs-pilot/
- Resultados técnicos y demostradores: https://aidggs-pilot.hartis.org/
Implementaciones de referencia
- H3 (Uber, hexagonal): https://h3geo.org/
- S2 (Google, cuadrangular): https://s2geometry.io/
- AusPIX (Geoscience Australia, rHEALPix): https://github.com/GeoscienceAustralia/AusPIX_DGGS
Contenido elaborado por Mayte Toscano, Senior Consultant en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autora



Comentaris