Blog
Data sandboxes are tools that provide us with environments to test new data-related practices and technologies, making them powerful instruments for managing and using data securely and effectively. These spaces are very useful in determining whether and under what conditions it is feasible to open the data. Some of the benefits they offer are:
- Controlled and secure environments: provide a workspace where information can be explored and its usefulness and quality assessed before committing to wider sharing. This is particularly important in sensitive sectors, where privacy and data security are paramount.
- Innovation: they provide a safe space for experimentation and rapid prototyping, allowing for rapid iteration, testing and refining new ideas and data-driven solutions as test bench before launching them to the public.
- Multi-sectoral collaboration: facilitate collaboration between diverse actors, including government entities, private companies, academia and civil society. This multi-sectoral approach helps to break down data silos and promotes the sharing of knowledge and good practices across sectors.
- Adaptive and scalable use: they can be adjusted to suit different data types, use cases and sectors, making them a versatile tool for a variety of data-driven initiatives.
- Cross-border data exchange: they provide a viable solution to manage the challenges of data exchange between different jurisdictions, especially with regard to international privacy regulations.
The report "Data Sandboxes: Managing the Open Data Spectrum" explores the concept of data sandboxes as a tool to strike the right balance between the benefits of open data and the need to protect sensitive information.
Value proposition for innovation
In addition to all the benefits outlined above, data sandboxes also offer a strong value proposition for organisations looking to innovate responsibly. These environments help us to improve data quality by making it easier for users to identify inconsistencies so that improvements can be made. They also contribute to reducing risks by providing secure environments to enable work with sensitive data. By fostering cross-disciplinary experimentation, collaboration and innovation, they contribute to increasing the usability of data and developing a data-driven culture within organisations. In addition, data sandboxes help reduce barriers to data access , improving transparency and accountability, which strengthens citizens' trust and leads to an expansion of data exchanges.
Types of data sandboxes and characteristics
Depending on the main objective when implementing a sandbox, there are three different types of sandboxes:
- Regulatory sandboxes, which allow companies and organisations to test innovative services under the close supervision of regulators in a specific sector or area.
- Innovation sandboxes, which are frequently used by developers to test new features and get quick feedback on their work.
- Research sandboxes, which make it easier for academia and industry to safely test new algorithms or models by focusing on the objective of their tests, without having to worry about breaching established regulations.
In any case, regardless of the type of sandbox we are working with, they are all characterised by the following common key aspects:

Figure 1. Characteristics of a data sandbox. Adaptation of a visual of The Govlab.
Each of these is described below:
- Controlled: these are restricted environments where sensitive and analysed data can be accessed securely, ensuring compliance with relevant regulations.
- Secure: they protect the privacy and security of data, often using anonymised or synthetic data.
- Collaborative: facilitating collaboration between different regions, sectors and roles, strengthening data ecosystems.
- High computational capacity: provide advanced computational resources capable of performing complex tasks on the data when needed.
- Temporal in nature: They are designed for temporary use and with a short life cycle, allowing for rapid and focused experimentation that either concludes once its objective is achieved or becomes a new long-term project.
- Adaptable: They are flexible enough to customise and scale according to needs and different data types, use cases and contexts.
Examples of data sandboxes
Data sandboxes have long been successfully implemented in multiple sectors across Europe and around the world, so we can easily find several examples of their implementation on our continent:
- Data science lab in Denmark: it provides access to sensitive administrative data useful for research, fostering innovation under strict data governance policies.
- TravelTech in Lithuania: an open access sandbox that provides tourism data to improve business and workforce development in the sector.
- INDIGO Open Data Sandbox: it promotes data sharing across sectors to improve social policies, with a focus on creating a secure environment for bilateral data sharing initiatives.
- Health data science sandbox in Denmark: a training platform for researchers to practice data analysis using synthetic biomedical data without having to worry about strict regulation.
Future direction and challenges
As we have seen, data sandboxes can be a powerful tool for fostering open data, innovation and collaboration, while ensuring data privacy and security. By providing a controlled environment for experimentation with data, they enable all interested parties to explore new applications and knowledge in a reliable and safe way. Sandboxes can therefore help overcome initial barriers to data access and contribute to fostering a more informed and purposeful use of data, thus promoting the use of data-driven solutions to public policy problems.
However, despite their many benefits, data sandboxes also present a number of implementation challenges. The main problems we might encounter in implementing them include:
- Relevance: ensure that the sandbox contains high quality and relevant data, and that it is kept up to date.
- Governance: establish clear rules and protocols for data access, use and sharing, as well as monitoring and compliance mechanisms.
- Scalability: successfully export the solutions developed within the sandbox and be able to translate them into practical applications in the real world.
- Risk management: address comprehensively all risks associated with the re-use of data throughout its lifecycle and without compromising its integrity.
However, as technologies and policies continue to evolve, it is clear that data sandboxes are set to be a useful tool and play an important role in managing the spectrum of data openness, thereby driving the use of data to solve increasingly complex problems. Furthermore, the future of data sandboxes will be influenced by new regulatory frameworks (such as Data Regulations and Data Governance) that reinforce data security and promote data reuse, and by integration with privacy preservation and privacy enhancing technologies that allow us to use data without exposing any sensitive information. Together, these trends will drive more secure data innovation within the environments provided by data sandboxes.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views expressed in this publication are the sole responsibility of the author.
Blog
One of the key actions that we recently highlighted as necessary to build the future of open data in our country is the implementation of processes to improve data management and governance. It is no coincidence that proper data management in our organisations is becoming an increasingly complex and in-demand task. Data governance specialists, for example, are increasingly in demand - with more than 45,000 active job openings in the US for a role that was virtually non-existent not so long ago - and dozens of data management platforms now advertise themselves as data governance platforms.
But what's really behind these buzzwords - what is it that we really mean by data governance? In reality, what we are talking about is a series of quite complex transformation processes that affect the whole organisation.
This complexity is perfectly reflected in the framework proposed by the Open Data Policy Lab, where we can clearly see the different overlapping layers of the model and what their main characteristics are - leading to a journey through the elaboration of data, collaboration with data as the main tool, knowledge generation, the establishment of the necessary enabling conditions and the creation of added value.
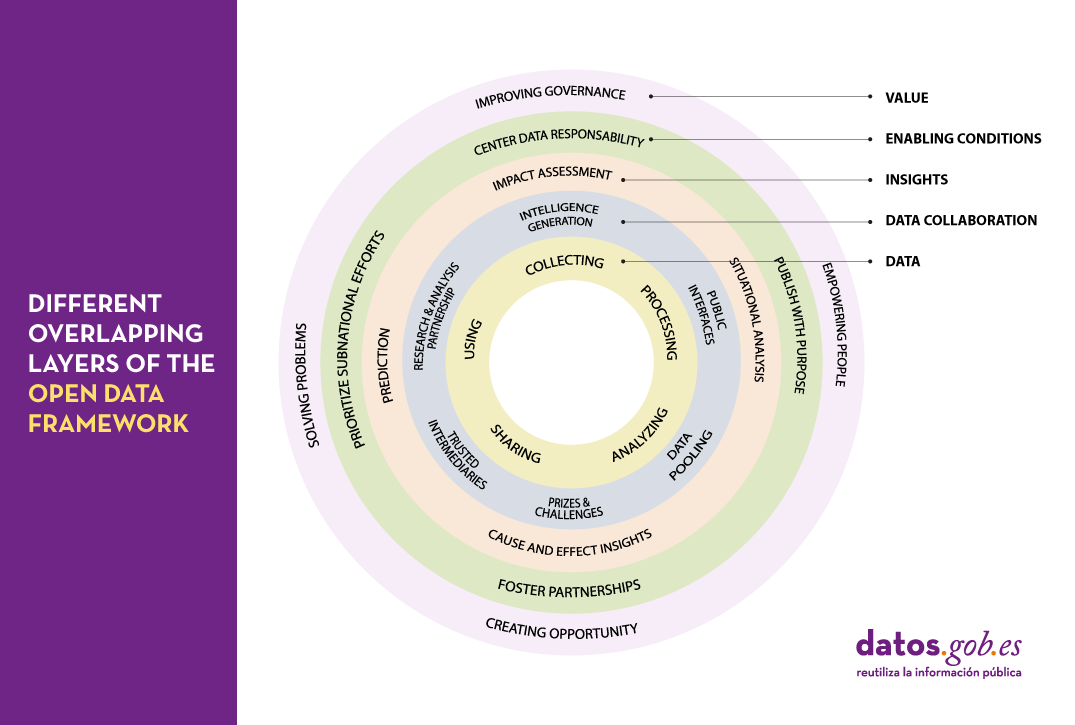
Let's now peel the onion and take a closer look at what we will find in each of these layers:
The data lifecycle
We should never consider data as isolated elements, but as part of a larger ecosystem, which is embedded in a continuous cycle with the following phases:
- Collection or collation of data from different sources.
- Processing and transformation of data to make it usable.
- Sharing and exchange of data between different members of the organisation.
- Analysis to extract the knowledge being sought.
- Using data according to the knowledge obtained.
Collaboration through data
It is not uncommon for the life cycle of data to take place solely within the organisation where it originates. However, we can increase the value of that data exponentially, simply by exposing it to collaboration with other organisations through a variety of mechanisms, thus adding a new layer of management:
- Public interfaces that provide selective access to data, enabling new uses and functions.
- Trusted intermediaries that function as independent data brokers. These brokers coordinate the use of data by third parties, ensuring its security and integrity at all times.
- Data pooling that provide a common, joint, complete and coherent view of data by aggregating portions from different sources.
- Research and analysis partnership, granting access to certain data for the purpose of generating specific knowledge.
- Prizes and challenges that give access to specific data for a limited period of time to promote new innovative uses of data.
- Intelligence generation, whereby the knowledge acquired by the organisation through the data is also shared and not just the raw material.
Insight generation
Thanks to the collaborations established in the previous layer, it will be possible to carry out new studies of the data that will allow us both to analyse the past and to try to extrapolate the future using various techniques such as:
- Situational analysis, knowing what is happening in the data environment.
- Cause and effect insigths, looking for an explanation of the origin of what is happening.
- Prediction, trying to infer what will happen next.
- Impact assessment, establishing what we expect should happen.
Enabling conditions
There are a number of procedures that when applied on top of an existing collaborative data ecosystem can lead to even more effective use of data through techniques such as:
- Publish with a purpose, with the aim of coordinating data supply and demand as efficiently as possible.
- Foster partnerships, including in our analysis those groups of people and organisations that can help us better understand real needs.
- Prioritize subnational efforts, strengthening of alternative data sources by providing the necessary resources to create new data sources in untapped areas.
- Center data responsability, establishing an accountability framework around data that takes into account the principles of fairness, engagement and transparency.
Value generation
Scaling up the ecosystem -and establishing the right conditions for that ecosystem to flourish- can lead to data economies of scale from which we can derive new benefits such as:
- Improving governance and operations of the organisation itself through the overall improvements in transparency and efficiency that accompany openness processes.
- Empowering people by providing them with the tools they need to perform their tasks in the most appropriate way and make the right decisions.
- Creating new opportunities for innovation, the creation of new business models and evidence-led policy making.
- Solving problems by optimising processes and services and interventions within the system in which we operate.
As we can see, the concept of data governance is actually much broader and more complex than one might initially expect and encompasses a number of key actions and tasks that in most organisations it will be practically impossible to try to centralise in a single role or through a single tool. Therefore, when establishing a data governance system in an organisation, we should face the challenge as an integral transformation process or a paradigm shift in which practically all members of the organisation should be involved to a greater or lesser extent. A good way to face this challenge with greater ease and better guarantees would be through the adoption and implementation of some of the frameworks and reference standards that have been created in this respect and that correspond to different parts of this model.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation.
The contents and views expressed in this publication are the sole responsibility of the author.
Documentación
"Information and data are more valuable when they are shared and the opening of government data could allow [...] to examine and use public information in a more transparent, collaborative, efficient and productive way". This was, in general terms, the idea that revolutionized more than ten years ago a society for which the opening of government data was a totally unknown action. It is from this moment that different trends began to emerge that will mark the evolution of the open data movement around the world.
This report, written by Carlos Iglesias, analyzes the main trends in the still incipient history of global open data, paying special attention to open data within public administrations. To this end, this analysis reflects the main problems and opportunities that have arisen over the years, as well as the trends that will help to continue driving the movement forward:
For the preparation of this report, we have used as a reference the report "“The Emergence of a Third Wave of Open Data”, which analyses the new stage that is opening up in the world of open data, published by the Open Data Policy Lab. This analysis serves as a reference to present both the current trends and the most important challenges associated with open data.
The final part of this report presents some of the actions that will play a key role in strengthening and consolidating the future of open data over the next ten years. These actions have been adapted to the European Union environment, and specifically to Spain (including its regulatory framework).
Below, you can download the full report, as well as its executive summary and a summary presentation in power point format.
Blog
Current approaches to public policy-making that respond quickly to changing trends in technology are too often unsuccessful. Policy makers are often pressured to develop and adopt laws or guidelines without the evidence needed to do so safely and without the opportunity to consult affected experts and users - meaning that they will not be designed with the needs of those who will be directly affected by them later in life in mind.
This problem is particularly acute in the case of emerging technologies, where, in addition, some companies often actively resist regulation by using their own lobbying, or simply by occupying the regulatory vacuum by setting de facto standards through their own practices.
For all these reasons, policymakers are beginning to adopt some alternative approaches to public policymaking in the technological environment. Among these alternatives is the rise of laboratories of innovation on public policy, whose main objective is to offer a tool that facilitates the agile creation of such policies by ensuring that they are oriented towards the public interest while at the same time enabling innovation and the development of enterprises.
What is a public policy laboratory?
A Policy Lab is a space where different stakeholders are invited to work together, each contributing their particular skills to find solutions to common problems. This is done through an open and iterative process in which possible solutions are experimented with, while maintaining a permanent focus on the needs and expectations of the individuals concerned. The work of these laboratories is based on evidence to address issues that are of particular social relevance, often in very dynamic and growing areas such as technology, climate change or finance.
Policy labs are therefore becoming increasingly popular mechanisms for building bridges between experts, public administration and society in order to solve outstanding challenges while taking advantage of the opportunities offered by emerging areas of knowledge. Such laboratories have been flourishing profusely lately, both in Europe and in the United States. Technology policy labs in particular aim to advance technology policies through research, education and thought leadership, thereby restoring confidence in the design and decision-making mechanisms needed to make such policies successful. Some current examples are:
- The Tech Policy Lab at the University of Washington focuses on Artificial Intelligence and influences both state and federal legislation.
- The Digital Technologies Policy Laboratory at University College London (UCL), whose current projects address the Internet of Things and online privacy.
- The EU Policy Lab, of the European Commission, which experiments with the design of services in priority thematic areas for the EU - such as shared economy, blockchain technologies or health.
Open Data Policy Labs
Within the technology policy labs it is also common to find some specialised in more specific subjects, as is the case of the Open Data Policy Labs. The aim here is to support decision makers in their work to accelerate the responsible re-use and exchange of data for the benefit of society and the equitable dissemination of social and economic opportunities associated with such data.
A clear example is the Open Data Policy Lab, recently launched by Microsoft and the GovLab to help government agencies at all levels identify best practices to improve the availability, reuse and usefulness of the data they manage - from developing effective legislative models to addressing the challenge of identifying and publishing high-value datasets needed to help address critical societal challenges.
Its work is to facilitate collaboration between governments, the private sector and society to address a number of obstacles that currently stand in the way of accessing data responsibly - including the absence of an enabling governance model, lack of internal capacity, or limited access to external knowledge and resources. To this end, the Open Data Policy Lab focuses on four main activities:
- Analysis: through research to identify best practices in the field of open data and inform about the development of data initiatives that contribute to economic and social development.
- Guidance: by developing methodologies, guidelines, toolkits and other materials to facilitate more effective data sharing and promote evidence-based decision making when addressing public policy issues.
- Community networks: building a community of data managers and decision makers in the public and private sectors to share knowledge, conduct collaborative work and stimulate data exchange.
- Action: Identifying key societal challenges that can benefit from open data and implementing proof-of-concept initiatives that demonstrate how to harness the power of open data to solve those challenges.
In short, public policy laboratories are promising tools that can definitively contribute to taking the step towards the expected third wave in the movement of open data, since they have all the elements necessary to confront and provide solutions in an agile manner to the limitations in current data governance models through openness that is respectful of data, based on public interests and built on collaborative action.
Content prepared by Carlos Iglesias, Open data Researcher and consultan, World Wide Web Foundation.
Contents and points of view expressed in this publication are the exclusive responsibility of its author.