¿Cuántos accidentes ocurren en la ciudad de Madrid?


Fecha del documento: 19-10-2021

1. Introducción
La visualización de datos es una tarea vinculada al análisis de datos que tiene como objetivo representar de manera gráfica información subyacente de los mismos. Las visualizaciones juegan un papel fundamental en la función de comunicación que poseen los datos, ya que permiten extraer conclusiones de manera visual y comprensible permitiendo, además, detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras funciones. Esto hace que su aplicación sea transversal a cualquier proceso en el que intervengan datos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones complejas configuradas desde dashboards interactivos.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando atención a la obtención de los mismos y validando su contenido, asegurando que no contienen errores y se encuentran en un formato adecuado y consistente para su procesamiento. Un tratamiento previo de los datos es esencial para abordar cualquier tarea de análisis de datos que tenga como resultado visualizaciones efectivas.
Se irán presentando periódicamente una serie de ejercicios prácticos de visualización de datos abiertos disponibles en el portal datos.gob.es u otros catálogos similares. En ellos se abordarán y describirán de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para la creación de visualizaciones interactivas, de las que podamos extraer la máxima información resumida en unas conclusiones finales. En cada uno de los ejercicios prácticos se utilizarán sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en Github.
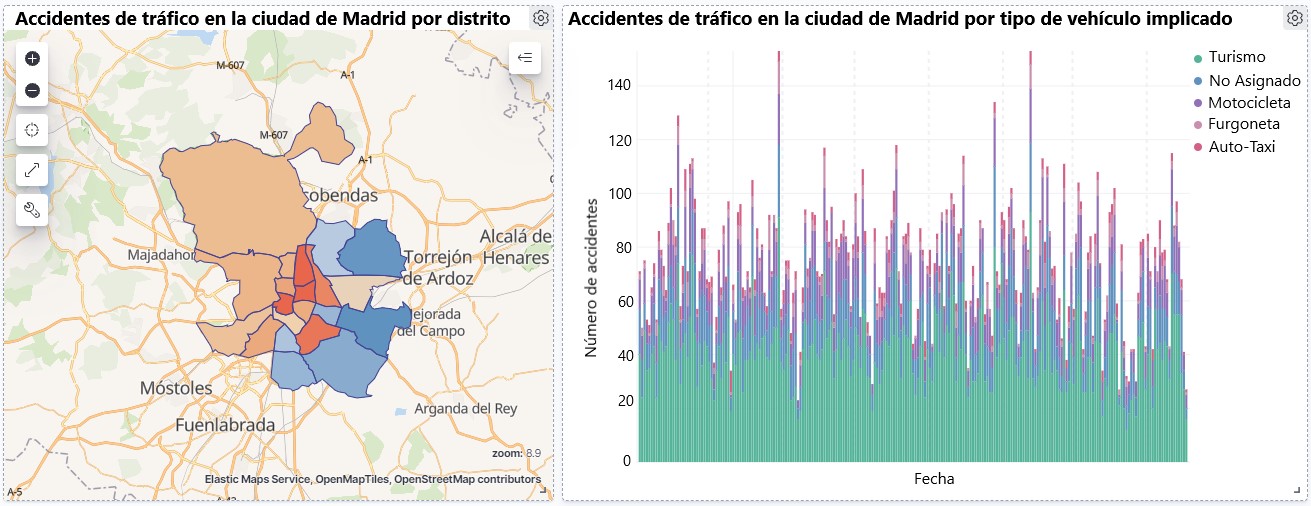
Visualización sobre la accidentalidad de tráfico ocurrida en la ciudad de Madrid, por distrito y tipo de vehículo
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos disponibles en este portal. Para este ejercicio práctico hemos escogido un conjunto de datos que abarca una amplio periodo temporal y que contiene información relevante sobre el registro de accidentes de tráfico que ocurren en la ciudad de Madrid. A partir de estos datos observaremos cuál es el tipo de accidentes más comunes en Madrid y la incidencia que en ellos tiene algunas variables como la edad, el tipo de vehículo o la lesividad que produce el accidente.
3. Recursos
3.1. Conjuntos de datos
Para este análisis se ha seleccionado un conjuntos de datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid publicados por el Ayuntamiento de Madrid y que se encuentra disponible en datos.gob.es. Este conjunto de datos contiene una serie temporal que abarca el periodo 2010 hasta 2021 con diferentes desagregaciones que facilitan el análisis de las características que presentan los accidentes de tráfico ocurridos, entre otras, las condiciones ambientales en las que se produjo cada siniestro o el tipo de accidente. La información de la estructura de cada archivo de datos está disponible en documentos que abarcan el periodo 2010-2018 y 2019 en adelante. Cabe destacar que existen inconsistencias en los datos antes y después del año 2019, ya que la estructura de datos varía. Esta es una situación bastante habitual a la que deben enfrentarse los analistas de datos a la hora de abordar las tareas de preprocesamiento de los datos con los que se trabajará posteriormente, derivada de la carencia de una estructura homogénea de los datos a lo largo del tiempo. Por ejemplo, alteración del número de variables, modificación del tipo de variables o cambios a diferentes unidades de medida. Esta es una razón de peso que justifica la necesidad de acompañar cada conjunto de datos abiertos de un completo documento que explique su estructura.
3.2. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo) se ha utilizado R (versión 4.0.3) y RStudio con el complemento de RMarkdown.
R es un lenguaje de programación open source orientado a objetos e interpretado, creado inicialmente para la computación estadística y la creación de representaciones gráficas. En la actualidad, es una herramienta muy poderosa para todo tipo de procesamiento y manipulación de datos que está permanentemente actualizada. Además dispone de un entorno de programación, RStudio, también open source.
Para la creación de la visualización interactiva se ha utilizado la herramienta Kibana.
Kibana es una herramienta open source que forma parte del paquete de productos Elastic Stack (Elasticsearch, Beats, Logstash y Kibana) que permite la creación de visualización y la exploración de datos indexados sobre el motor de analítica Elasticsearch.
Si quieres saber más sobre estas herramientas u otras que puedan ayudarte en el procesado de datos y la creación de visualizaciones interactivas, puedes consultar el informe "Herramientas de procesado y visualización de datos".
4. Tratamiento de datos
Para la realización de los análisis y visualizaciones posteriores, es necesario preparar los datos de una forma adecuada, para que los resultados obtenidos sean consistentes y efectivos. Debemos realizar un análisis exploratorio de los datos (EDA, por sus siglas en inglés), con el fin de conocer y comprender los datos con los cuales queremos trabajar. El objetivo principal de este pre-procesamiento de los datos es detectar posibles anomalías o errores que pudieran afectar a la calidad de los resultados posteriores e identificar patrones de información contenidos en los datos.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en R que se incluye a continuación, al que puedes acceder haciendo click en el botón de "Código" de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren forma alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de Github de datos.gob.es. La forma de proporcionar el código es a través de un documento de texto plano, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
4.1. Instalación y carga de librerías
Para el desarrollo de este análisis necesitamos instalar una serie de paquetes de R adicionales a la distribución base, incorporando al entorno de trabajo las funciones y objetos definidos por ellas. Hay muchos paquetes disponibles en R pero las más adecuadas para trabajar con este conjunto de datos son: tidyverse, lubridate y data.table. tidyverse es una colección de paquetes de R (contiene a su vez otros paquetes como dplyr, ggplot2, readr, etc) diseñados específicamente para trabajar en Data Science, que facilitar la carga y tratamiento de datos, y las representaciones gráficas, entre otras funcionalidades esenciales para el análisis de datos, pero que requiere un conocimiento progresivo para obtener el máximo partido de los paquetes que integra. Por otro lado, el paquete lubridate lo usaremos para el manejo de variables tipo fecha y por último el paquete data.table permite realizar una gestión más eficiente de conjuntos de datos grandes. Estos paquetes será preciso descargarlos e instalarlos en el entorno de desarrollo.
4.2. Carga y limpieza de datos
a. Carga de datasets
Los datos que vamos a utilizar en la visualización se encuentran divididos por anualidades en ficheros CSV. Como queremos realizar un análisis de varios años debemos descargar y cargar en nuestro entorno de desarrollo todos los conjuntos de datos que nos interesen.
Para ello, generamos el directorio de trabajo "datasets", donde descargaremos todos los conjuntos de datos. Usamos dos listas, una con todas las URLs donde se encuentran localizados los datasets y otra con los nombres que asignamos a cada fichero guardado en nuestra maquina, con ello facilitamos posteriores referencias a estos ficheros.
b. Creación de la tabla de trabajo
Una vez que tenemos todos los conjuntos de datos cargados en nuestro entorno de desarrollo, creamos una única tabla de trabajo que integra todos los años de la serie temporal.
Una vez generada la tabla de trabajo, debemos solucionar uno de los problemas más comunes en todo preprocesamiento de datos: la inconsistencia en el nombre de las variables en los diferentes ficheros que componen la serie temporal. Esta anomalía produce variables con nombres diferentes, pero sabemos que representan la misma información. En este caso porque está explicado en el diccionario de datos descrito en la documentación de los archivos, si no fuese así, es necesario recurrir a la observación y exploración descriptiva de los archivos. En este caso, la variable "RANGO EDAD" que presenta datos desde 2010 hasta 2018 y la variable "RANGO DE EDAD" que presenta los mismos datos pero desde el año 2019 hasta 2021 son diferentes. Para solucionar esta problemática debemos unificar las variables que presentan esta anomalía en una única variable.
Una vez que tenemos la tabla con la serie temporal completa, generamos una nueva tabla contiendo únicamente las variables que nos interesan para realizar la visualización interactiva que queremos desarrollar.
c. Transformación de variables
A continuación, examinamos el tipo de variables y valores para transformar los tipos que sea necesario para poder realizar futuras agregaciones, gráficos o diferentes análisis estadísticos.
d. Generación de nuevas variables
Vamos a dividir la variable "FECHA" en una jerarquía de variables de tipo fecha, "Año", "Mes" y "Día". Esta acción es muy común en la analítica de datos, ya que en muchas ocasiones interesa analizar otros rangos de tiempo, por ejemplo, años, meses, semanas y cualquier otra unidad de tiempo, o necesitamos generar agregaciones a partir del día de la semana.
e. Detección y tratamiento de datos perdidos
La detección y tratamiento de datos perdidos (NAs) es esencial para poder procesar de manera adecuada las variables que contiene la tabla, ya que la ausencia de datos puede ocasionar problemas a la hora de realizar agregaciones, gráficos o análisis estadísticos.
A continuación analizaremos la ausencia de datos (detección de NAs) en la tabla:
Una vez detectados los NAs que presenta el dataset, debemos tratarlos de alguna forma. En este caso, como todas las variables de interés, son categóricas, vamos a completar los valores ausentes por un valor de "No asignado", para no perder tamaño muestral e información relevante.
f. Asignaciones de niveles en las variables
Una vez que tenemos en la tabla las variables de interés, podemos realizar un examen más exhaustivo de los datos y categorías que presenta cada una de las variable. Si analizamos cada una de manera independiente, podemos observar que algunas de ellas presentan categorías repetidas, simplemente por uso de tildes, caracteres especiales o mayúsculas. Para que las futuras visualizaciones o análisis estadísticos se construyan de manera eficiente y sin errores, vamos a reasignar los niveles a las variables que lo requieran.
Por razones de espacio, en este post solo mostraremos un ejemplo con la variable "LESIVIDAD". Esta variable estaba tipificada hasta 2018 con una serie de categorías (IL, HL, HG, MT), mientras que a partir de 2019 se usaron otras categorías (valores del 0 al 14). Afortunadamente esta tarea resulta fácilmente abordable dado que está documentada en la información sobre la estructura que acompaña cada dataset, cuestión, como hemos comentado con anterioridad que no siempre ocurre, lo que dificulta enormemente este tipo de transformaciones de datos.
4.3. Resumen del dataset
Veamos que variables y estructura presenta el nuevo conjunto de datos tras las transformaciones realizadas:
La salida de estos comandos la omitiremos para simplificar lectura. Las principales características que presenta el conjunto de datos son:
- Está compuesto por 14 variables: 1 variable tipo fecha y 13 variables de tipo categórico.
- El rango temporal abarca desde 01-01-2010 hasta el 31-06-2021 (la fecha final puede variar, ya que el dataset del año 2021 se esta actualizando periódicamente).
- Por cuestiones de espacio en este post, no todas las variables disponibles se han tenido en cuenta para el análisis y la visualización.
4.4. Guardar el dataset generado
Una vez que tenemos el conjunto de datos con la estructura y variables que nos interesan para realizar la visualización de los datos, lo guardaremos como archivo de datos en formato CSV para posteriormente realizar otros análisis estadísticos o utilizarlo en otras herramientas de procesado o visualización de datos como la que abordamos a continuación. Es importante guardarlo con una codificación UTF-8 (Formato de Transformación Unicode) para que los caracteres especiales sean identificados de manera correcta por cualquier software.
5. Creación de la visualización sobre los accidentes de tráfico que ocurren en la ciudad de Madrid usando Kibana
Para la realización de esta visualización interactiva se ha usado la herramienta Kibana en su versión gratuita sobre nuestro entorno local. Antes de poder realizar la visualización es necesario tener instalado el software y para ello hemos seguido los pasos del tutorial de descarga e instalación proporcionado por la compañía Elastic.
Una vez instalado el software de Kibana, procedemos a desarrollar la visualización interactiva. A continuación se incluyen dos vídeo tutoriales, en los cuales se muestra el proceso de realización de la visualización interactiva y la interacción con la misma.
En este primer vídeo tutorial, se muestra el proceso de desarrollo de la visualización realizando los pasos que se indican a continuación:
- Carga de datos en Elasticsearch, generación de un índice en Kibana que nos permita interactuar con los datos prácticamente en tiempo real e interacción con las variables que presenta el conjunto de datos.
- Generación de las siguientes representaciones gráficas:
- Gráfico de líneas para representar la serie temporal sobre los accidentes de tráfico ocurridos en la ciudad de Madrid.
- Gráfico de barras horizontales mostrando el tipo de accidente más común.
- Mapa temático, mostraremos el número de accidentes que ocurren en cada una de los distritos de la ciudad de Madrid. Para la creación de este visual es necesario la descarga del "conjunto de datos que contiene los distritos georreferenciados en formato GeoJSON".
- Construcción del dashboard integrando los visuales generados en el paso anterior.
En este segundo vídeo tutorial mostraremos la interacción con la visualización que acabamos de crear:
6. Conclusiones
Observando la visualización de los datos sobre los accidentes de tráfico ocurridos en la ciudad de Madrid desde 2010 hasta junio de 2021, se pueden obtener, entre otras, las siguientes conclusiones:
- El número de accidentes que ocurren en la ciudad de Madrid es estable a lo largo de los años, a excepción del año 2019 donde se observa un fuerte incremento y durante el segundo trimestre de 2020 donde se observa una significativa disminución, que coincide con el período del primer estado de alarma a causa de la pandemia del COVID-19.
- Todos los años se observa una disminución del número de accidentes durante el mes de agosto.
- Los hombres suelen tener un número significativamente mayor de accidentes que las mujeres.
- El tipo de accidente más común es la colisión doble, seguido del atropello a un animal y la colisión múltiple.
- Alrededor del 50% de los accidentes no ocasionan daños a las personas implicadas.
- Los distritos con mayor concentración de accidentes son: el distrito de Salamanca, el distrito de Chamartín y el distrito Centro.
La visualización de datos es una de los mecanismos más potentes para explotar y analizar de manera autónoma el significado implícito de los datos, independientemente del grado del conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Si quieres aprender cómo realizar una predicción sobre la siniestralidad futura de accidentes de tráfico utilizando técnicas de Inteligencia Artificial a partir de estos datos, consulta el post sobre "Tecnologías emergentes y datos abiertos: Analítica Predictiva".
Esperamos que os haya gustado este post y volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!