Blog
A medida que las organizaciones buscan aprovechar el potencial de los datos para tomar decisiones, innovar y mejorar sus servicios, surge un desafío fundamental: ¿cómo se puede equilibrar la recolección y el uso de datos con el respeto a la privacidad? Las tecnologías PET intentan dar solución a ese reto. En este post, exploraremos qué son y cómo funcionan.
¿Qué son las tecnologías PET?
Las tecnologías PET son un conjunto de medidas técnicas que utilizan diversos enfoques para la protección de la privacidad. El acrónimo PET viene de los términos en inglés “Privacy Enhancing Technologies” que se pueden traducir como “tecnologías de mejora de la privacidad”.
De acuerdo con la Agencia de la Unión Europea para la Ciberseguridad (ENISA) este tipo de sistemas protege la privacidad mediante:
- La eliminación o reducción de datos personales.
- Evitando el procesamiento innecesario y/o no deseado de datos personales.
Todo ello, sin perder la funcionalidad del sistema de información. Es decir, gracias a ellas se puede utilizar datos que de otra manera permanecerían sin explotar, ya que limita los riesgos de revelación de datos personales o protegidos, cumpliendo con la legislación vigente.
Relación entre utilidad y privacidad en datos protegidos
Para comprender la importancia de las tecnologías PET, es necesario abordar la relación que existe entre utilidad y privacidad del dato. La protección de datos de carácter personal siempre supone pérdida de utilidad, bien porque limita el uso de los datos o porque implica someterles a tantas transformaciones para evitar identificaciones que pervierte los resultados. La siguiente gráfica muestra cómo a mayor privacidad, menor es la utilidad de los datos.
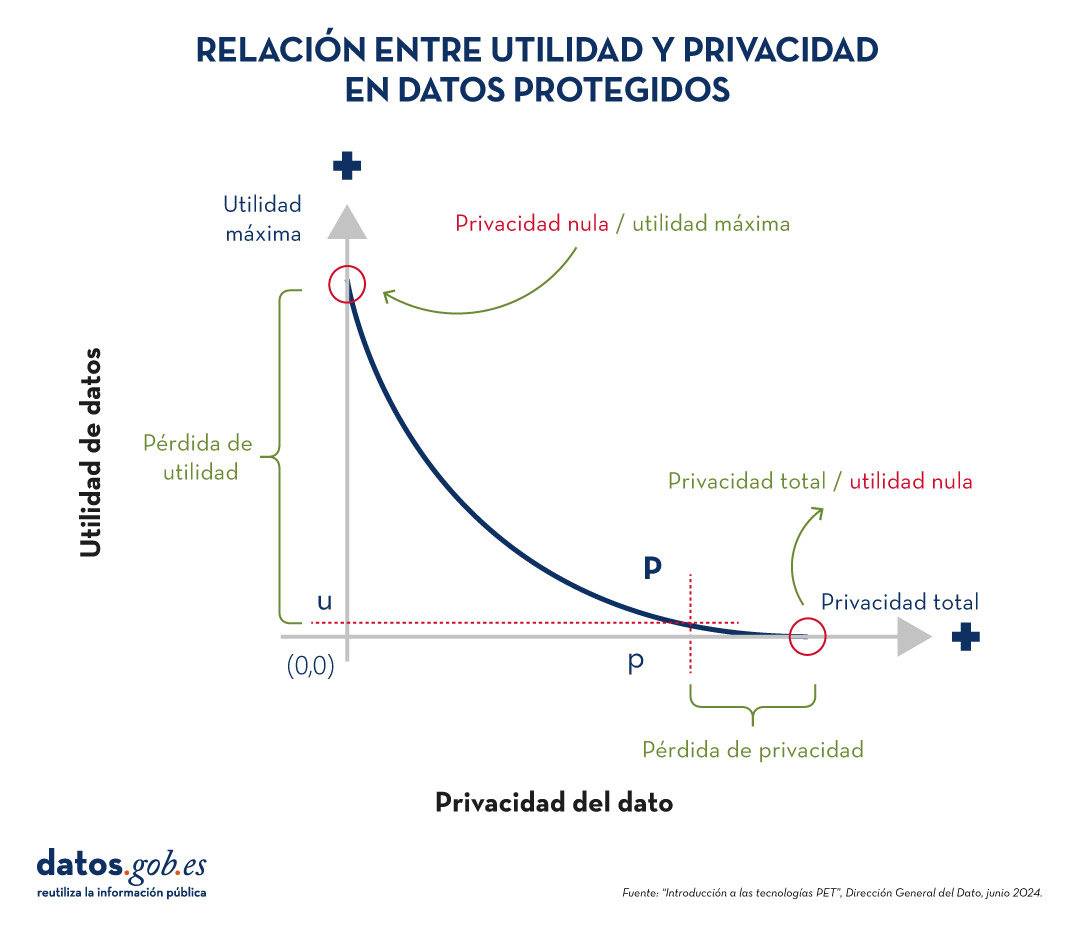
Figura 1. Relación entre utilidad y privacidad en datos protegido. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Las técnicas PET permiten alcanzar un compromiso entre privacidad y utilidad más favorable. No obstante, hay que tener en cuenta que siempre existirá cierta limitación de la utilidad cuando explotamos datos protegidos.
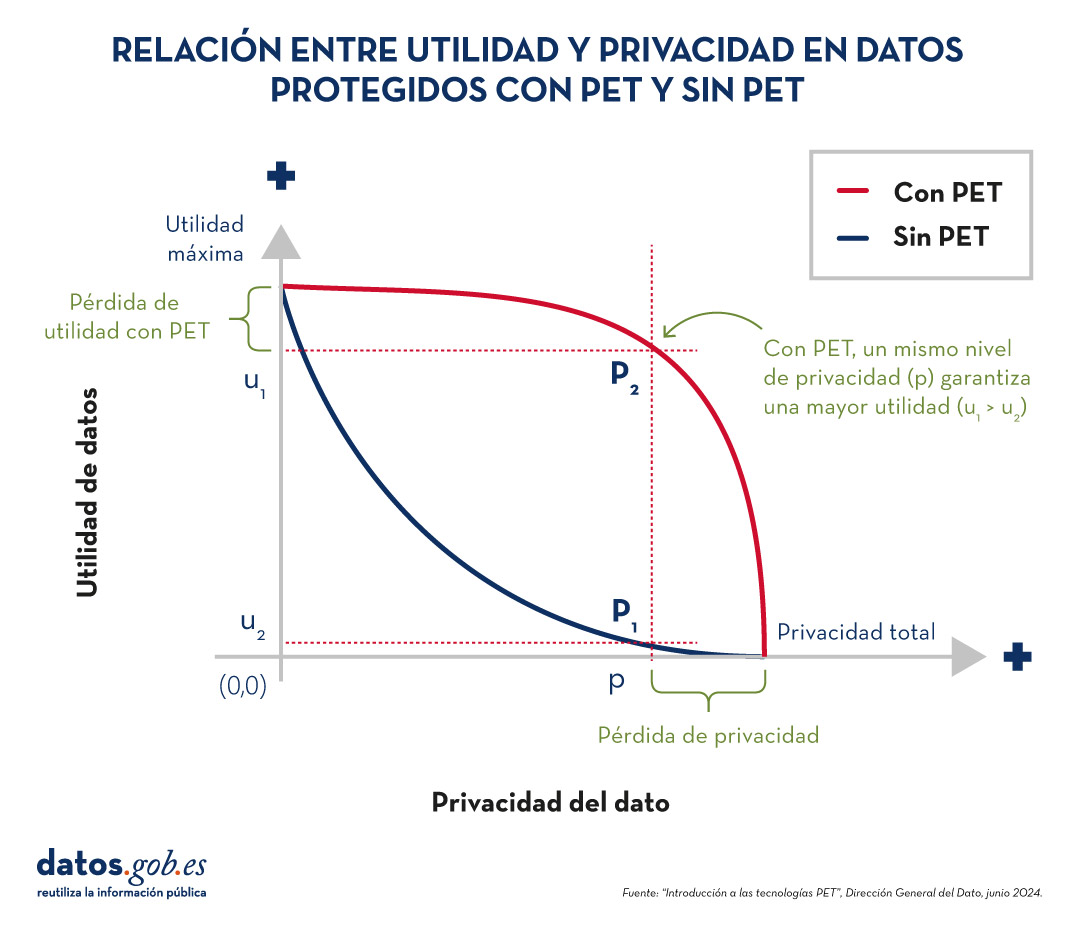
Figura 2. Relación entre utilidad y privacidad en datos protegidos con PET y sin PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Técnicas PET más populares
Para aumentar la utilidad y poder explotar datos protegidos limitando los riesgos, es necesario aplicar una serie de técnicas PET. El siguiente esquema, recoge algunas de las principales:
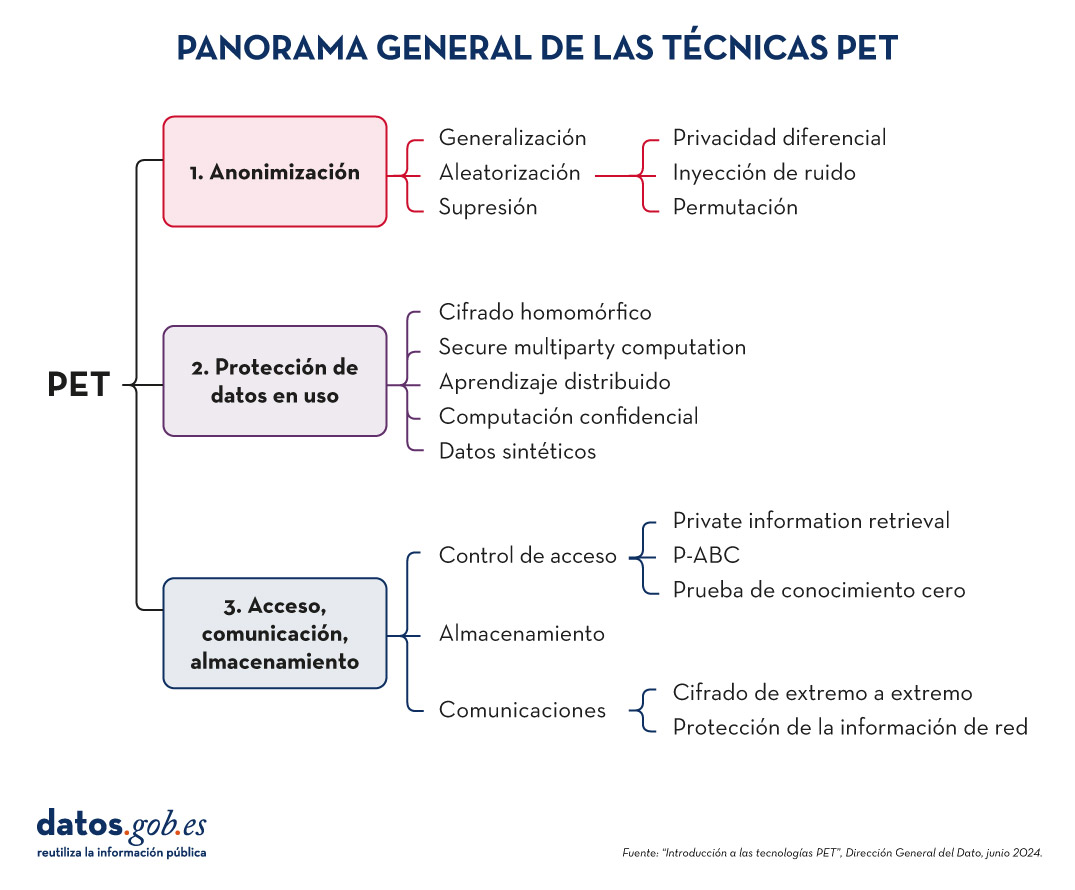
Figura 3. Panorama general de las técnicas PET. Fuente: “Introducción a las tecnologías PET”, Dirección General del Dato, junio 2024.
Como veremos a continuación, estas técnicas abordan distintas fases del ciclo de vida de los datos.
-
Antes de la explotación de los datos: anonimización
La anonimización consiste en transformar conjuntos de datos de carácter privado para que no se pueda identificar a ninguna persona. De esta forma, ya no les aplica el Reglamento General de Protección de Datos (RGPD).
Es importante garantizar que la anonimización se ha realizado de forma efectiva, evitando riesgos que permitan la reidentificación a través de técnicas como la vinculación (identificación de un individuo mediante el cruzado de datos), la inferencia (deducción de atributos adicionales en un dataset), la singularización (identificación de individuos a partir de los valores de un registro) o la composición (pérdida de privacidad acumulada debida a la aplicación reiterada de tratamientos). Para ello, es recomendable combinar varias técnicas, las cuales se pueden agrupar en tres grandes familias:
- Aleatorización: supone modificar los datos originales al introducir un elemento de azar. Esto se logra añadiendo ruido o variaciones aleatorias a los datos, de manera que se preserven patrones generales y tendencias, pero se haga más difícil la identificación de individuos.
- Generalización: consiste en reemplazar u ocultar valores específicos de un conjunto de datos por valores más amplios o menos precisos. Por ejemplo, en lugar de registrar la edad exacta de una persona, se podría utilizar un rango de edades (como 35-44 años).
- Supresión: implica eliminar completamente ciertos datos del conjunto, especialmente aquellos que pueden identificar a una persona de manera directa. Es el caso de los nombres, direcciones, números de identificación, etc.
Puedes profundizar sobre estos tres enfoques generales y las diversas técnicas que los integran en la guía práctica “Introducción a la anonimización de datos: técnicas y casos prácticos”. También recomendamos la lectura del artículo malentendidos comunes en la anonimización de datos.
2. Protección de datos en uso
En este apartado se abordan técnicas que salvaguardan la privacidad de los datos durante la aplicación de tratamientos de explotación.
-
Cifrado homomórfico: es una técnica de criptografía que permite realizar operaciones matemáticas sobre datos cifrados sin necesidad de descifrarlos primero. Por ejemplo, un cifrado será homomórfico si se cumple que, si se cifran dos números y se realiza una suma en su forma cifrada, el resultado cifrado, al ser descifrado, será igual a la suma de los números originales.
- Computación Segura Multipartita (Secure Multiparty Computation o SMPC): es un enfoque que permite que múltiples partes colaboren para realizar cálculos sobre datos privados sin revelar su información a los demás participantes. Es decir, permite que diferentes entidades realicen operaciones conjuntas y obtengan un resultado común, mientras mantienen la confidencialidad de sus datos individuales.
- Aprendizaje distribuido: tradicionalmente, los modelos de machine learning aprenden de forma centralizada, es decir, requieren reunir todos los datos de entrenamiento procedentes de múltiples fuentes en un único conjunto de datos a partir del cual un servidor central elabora el modelo que se desea. En el caso del aprendizaje distribuido, los datos no se concentran en un solo lugar, sino que permanecen en diferentes ubicaciones, dispositivos o servidores. En lugar de trasladar grandes cantidades de datos a un servidor central para su procesamiento, el aprendizaje distribuido permite que los modelos de machine learning se entrenen en cada una de estas ubicaciones, integrando y combinando los resultados parciales para obtener un modelo final.
- Computación confidencial y entornos de computación de confianza (Trusted Execution Environments o TEE): la computación confidencial se refiere a un conjunto de técnicas y tecnologías que permiten procesar datos de manera segura dentro de entornos de hardware protegidos y certificados, conocidos como entornos de computación de confianza.
- Datos sintéticos: son datos generados artificialmente que imitan las características y patrones estadísticos de datos reales sin representar a personas o situaciones específicas. Reproducen las propiedades relevantes de los datos reales, como distribución, correlaciones y tendencias, pero sin información que permita identificar a individuos o casos específicos. Puedes aprender más sobre este tipo de datos en el informe Datos sintéticos: ¿Qué son y para qué se usan?.
3. Acceso, comunicación y almacenamiento
Las técnicas PET no solo abarcan la explotación de los datos. Entre ellas también encontramos procedimientos dirigidos a asegurar el acceso a recursos, la comunicación entre entidades y el almacenamiento de datos, garantizando siempre la confidencialidad de los participantes. Algunos ejemplos son:
Técnicas de control de acceso
- Recuperación Privada de Información (Private information retrieval o PIR): es una técnica criptográfica que permite a un usuario consultar una base de datos o servidor sin que este último pueda saber qué información está buscando el usuario. Es decir, asegura que el servidor no conozca el contenido de la consulta, preservando así la privacidad del usuario.
- Credenciales Basadas en Atributos con Privacidad (Privacy-Attribute Based Credentials o P-ABC): es una tecnología de autenticación que permite a los usuarios demostrar ciertos atributos o características personales (como la mayoría de edad o la ciudadanía) sin revelar su identidad. En lugar de mostrar todos sus datos personales, el usuario presenta solo aquellos atributos necesarios para cumplir con los requisitos de la autenticación o autorización, manteniendo así su privacidad.
- Prueba de conocimiento cero (Zero-Knowledge Proof o ZKP): es un método criptográfico que permite a una parte demostrar a otra que posee cierta información o conocimiento (como una contraseña) sin revelar el propio contenido de ese conocimiento. Este concepto es fundamental en el ámbito de la criptografía y la seguridad de la información, ya que permite la verificación de información sin la necesidad de exponer datos sensibles.
Técnicas de comunicaciones
- Cifrado extremo a extremo (End to End Encryption o E2EE): esta técnica protege los datos mientras se transmiten entre dos o más dispositivos, de forma que solo los participantes autorizados en la comunicación pueden acceder a la información. Los datos se cifran en el origen y permanecen cifrados durante todo el trayecto hasta que llegan al destinatario. Esto significa que, durante el proceso, ningún individuo u organización intermediaria (como proveedores de internet, servidores de aplicaciones o proveedores de servicios en la nube) puede acceder o descifrar la información. Una vez que llegan a destino, el destinatario es capaz de descifrarlos de nuevo.
- Protección de información de Red (Proxy & Onion Routing): un proxy es un servidor intermediario entre el dispositivo de un usuario y el destino de la conexión en internet. Cuando alguien utiliza un proxy, su tráfico se dirige primero al servidor proxy, que luego reenvía las solicitudes al destino final, permitiendo el filtrado de contenidos o el cambio de direcciones IP. Por su parte, el método Onion Routing protege el tráfico en internet a través de una red distribuida de nodos. Cuando un usuario envía información usando Onion Routing, su tráfico se cifra varias veces y se envía a través de múltiples nodos, o "capas" (de ahí el nombre "onion", que significa "cebolla" en inglés).
Técnicas de almacenamiento
- Almacenamiento garante de la confidencialidad (Privacy Preserving Storage o PPS): su objetivo es proteger la confidencialidad de los datos en reposo e informar a los custodios de los datos de una posible brecha de seguridad, utilizando técnicas de cifrado, acceso controlado, auditoría y monitoreo, etc.
Estos son solo algunos ejemplos de tecnologías PET, pero hay más familias y subfamilias. Gracias a ellas, contamos con herramientas que nos permiten extraer valor de los datos de forma segura, garantizando la privacidad de los usuarios. Datos que pueden ser de gran utilidad en múltiples sectores, como la salud, el cuidado del medio ambiente o la economía.
Blog
La anonimización de datos es un proceso complejo y habitualmente propenso a malentendidos. En el peor de los casos, estos errores de concepto conllevan la fuga de datos personales (data leakage), afectando directamente a las garantías que deberían ofrecerse a los usuarios con respecto a su privacidad.
La anonimización tiene por objetivo convertir los datos en anónimos, evitando la reidentificación de los individuos. Sin embargo, la mera aplicación de técnicas de anonimización no garantiza el anonimato de los datos. El riesgo principal se mide precisamente por la probabilidad de reidentificación, es decir, la probabilidad de que se identifique a un individuo dentro de un conjunto de datos.
La mayoría de los ataques realizados sobre conjuntos de datos anonimizados tratan de explotar debilidades comunes en el proceso, normalmente mediante el uso de datos complementarios. Un ejemplo muy conocido es el caso del conjunto de datos publicado por Netflix en 2007, donde a partir de los datos obtenidos de Internet Movie Database (IMDb), dos investigadores de la Universidad de Texas fueron capaces de identificar a los usuarios y vincularlos con sus posibles preferencias políticas y otros datos sensibles.
Pero estos fallos no sólo afectan a empresas privadas, a mediados de los 90, el Dr. Sweeney fue capaz de re-identificar registros médicos del Gobernador de Massachusetts, quién había asegurado que el conjunto de datos publicados era seguro. Más adelante, en el año 2000, el mismo investigador demostró que era posible re-identificar al 87% de los habitantes de Estados unidos con sólo conocer su código postal, fecha de nacimiento el sexo.
A continuación, veremos algunos ejemplos habituales de malentendidos que es importante evitar si queremos abordar un proceso de anonimización de forma adecuada.
No siempre es posible anonimizar un conjunto de datos
La anonimización de datos es un proceso diseñado a medida, para cada fuente de datos y para cada estudio o caso de uso a desarrollar. En ocasiones, el riesgo de reidentificación puede ser inasumible o el conjunto de datos resultante podría no tener la utilidad suficiente. Dependiendo del contexto concreto y los requisitos establecidos, la anonimización podría no ser viable.
Sin embargo, un error común es pensar que siempre es factible anonimizar un conjunto de datos, cuando realmente depende del nivel de garantías requerido o la utilidad necesaria para el caso de estudio.
La automatización y reutilización de procesos de anonimización es limitada
Aunque es posible automatizar algunas partes del proceso, otras fases requieren la intervención manual de un experto. Es especial, no existen herramientas que permitan evaluar de forma fiable la utilidad del conjunto de datos resultante para un escenario concreto, o la detección de posibles identificadores indirectos a partir de fuentes externas de datos.
De igual modo, no es recomendable reutilizar procesos de anonimización aplicados sobre fuentes de datos diferentes. Los condicionantes varían en cada caso concreto, siendo crítico evaluar el volumen de datos disponible, la existencia de fuentes de datos complementarias y el público objetivo.
La anonimización no es ni permanente ni absoluta
Debido a la posible aparición de nuevos datos o el desarrollo de nuevas técnicas, el riesgo de reidentificación aumenta con el paso del tiempo. El nivel de anonimización se debe medir en una escala, no es un concepto binario, donde normalmente la anonimización no puede considerarse absoluta, porque no es posible asumir un nivel de riesgo nulo.
La seudonimización no es lo mismo que la anonimización
En concreto, esta técnica consiste en modificar los valores de atributos clave (como identificadores) por otros valores que no estén vinculados al registro original.
El problema principal es que sigue existiendo la posibilidad de vincular a la persona física de manera indirecta a partir de datos adicionales, haciendo que sea un proceso reversible. De hecho, normalmente el responsable del tratamiento de datos preserva la capacidad de deshacer dicho proceso.
El cifrado no es una técnica de anonimización, sino de seudonimización
El cifrado de datos se enmarca en la seudonimización, en este caso reemplazando los atributos clave por versiones cifradas. La información adicional sería la clave de cifrado, custodiada por el responsable del tratamiento de los datos.
El ejemplo más conocido es el conjunto de datos publicado en 2013 por la Comisión de Taxis y Limusinas de la ciudad de Nueva York. Entre otros datos, contenía ubicaciones de recogida y destino, horarios y en especial el número de licencia cifrado. Posteriormente se descubrió que era relativamente sencillo deshacer el cifrado e identificar a los conductores.
Conclusiones
Existen otros lugares comunes que dan lugar a malentendidos respecto a la anonimización, como el equívoco generalizado sobre la pérdida total de la utilidad de un conjunto de datos anonimizado, o la falta de interés por la reidentificación de datos personales.
La anonimización es un proceso técnicamente complejo, que requiere de la participación de perfiles especializados y técnicas avanzadas de análisis de datos. Un proceso sólido de anonimización, evalúa el riesgo de reidentificación y define las pautas para gestionarlo a lo largo del tiempo.
A cambio, la anonimización permite compartir más fuentes de datos, de forma más segura y preservando su utilidad en multitud de escenarios, con especial hincapié en el análisis de datos de salud y estudios de investigación que habilitan el avance de la ciencia a nuevos niveles.
Si quieres profundizar en esta materia te invitamos a leer la guia de Introducción a la anonimización de datos: Técnicas y casos prácticos, la cual incluye un conjunto de ejemplos prácticos. El código y los datos utilizados en el ejercicio, están disponibles en Github.
Contenido elaborado por José Barranquero, experto en Ciencia de Datos y Computación Cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan.
Este proceso es fundamental, tanto cuando hablamos de datos abiertos como de datos en general, para proteger la privacidad de las personas, garantizando el cumplimiento normativo y de los derechos fundamentales.
El informe “Introducción a la anonimización de datos: Técnicas y casos prácticos”, elaborado por Jose Barranquero, define los conceptos clave de un proceso de anonimización, incluyendo términos, principios metodológicos, tipos de riesgos y técnicas existentes.
El objetivo del informe es ofrecer una introducción suficiente y concisa, principalmente orientada a publicadores de datos que necesitan garantizar la privacidad de estos. No se trata de una guía exhaustiva, sino una primera toma de contacto para entender los riesgos y técnicas disponibles, así como la complejidad inherente a cualquier proceso de anonimización de datos.
¿Qué técnicas se incluyen en el informe?
Tras una introducción donde se definen los términos más relevantes y los principios básicos de anonimización, el informe se centra en comentar tres enfoques generales para la anonimización de datos, cada uno de los cuales está integrado a su vez por diversas técnicas:
- Aleatorización: tratamiento de datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la Privacidad Diferencial.
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas basadas en agregación como Anonimato-K, Diversidad-L, o Proximidad-T.
- Seudonimización: reemplazo de valores por versiones cifradas o tokens, habitualmente a través de algoritmos de HASH, que impiden la identificación directa del individuo, a menos que se combine con otros datos adicionales, que deben estar custodiados de forma adecuada.
El documento describe cada una de estas técnicas, así como los riesgos que suponen, aportando recomendaciones para evitarlos. Si bien, la decisión final sobre qué técnica o conjunto de técnicas es más adecuada depende de cada caso particular.
El informe finaliza con un conjunto de ejemplos prácticos sencillos que muestran la aplicación de las técnicas Anonimato-K y seudonimización mediante cifrado con borrado de clave. Para simplificar la ejecución del caso, se pone a disposición de los usuarios el código y los datos utilizados en el ejercicio, disponibles en Github. Para seguir el ejercicio, es recomendable tener unos conocimientos mínimos del lenguaje pyhton.
A continuación, puedes descargar el informe completo, así como el resumen ejecutivo y una presentación-resumen.
Blog
Nos encontramos es un momento histórico, donde los datos se han convertido en un activo clave para casi cualquier proceso de nuestra vida cotidiana. Cada vez hay más formas de recoger datos y más capacidad para procesarlos y compartirlos, donde juegan un papel crucial nuevas tecnologías como IoT, Blockchain, Inteligencia Artificial, Big Data y Linked Data.
Tanto cuando hablamos de datos abiertos, como de datos en general, es crítico poder garantizar la privacidad de los usuarios y la protección de sus datos personales, entendidos como derechos fundamentales. Un aspecto que en ocasiones no recibe especial atención a pesar de las rigurosas normativas existentes, como el RGPD.
¿Qué es la anonimización y qué técnicas existen?
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan. Es decir, cubre tanto el objetivo de anonimización, como el de mitigación del riesgo de reidentificación, siendo este último un aspecto clave.
Para comprenderlo bien, es necesario hablar de cadena de confidencialidad, un término que incluye el análisis de riesgos específicos para la finalidad del tratamiento a realizar. La rotura de esta cadena implica la posibilidad de reidentificación, es decir de identificar a las personas específicas a las que pertenecen los datos a partir de ellos. Para evitarlo, existen múltiples técnicas de anonimización de datos, que buscan principalmente garantizar el avance de la sociedad de la información sin menoscabar el respeto a la protección de los datos.
Las técnicas de anonimización están enfocadas a identificar y ofuscar microdatos, identificadores indirectos y otros datos sensibles. Cuando hablamos de ofuscar, nos referimos a cambiar o alterar datos sensitivos o que identifican a una persona (personally identifiable information o PII, en inglés), con el objetivo de proteger la información confidencial. En este caso, los microdatos son datos únicos para cada individuo, que pueden permitir su identificación directa (DNI, código de historia clínica, nombre completo, etc). Los datos de identificación indirecta pueden ser cruzados con la misma o diferentes fuentes para identificar a un individuo (sociodemográficos, configuración del navegador, etc). Cabe destacar que son datos sensibles los referidos en el artículo 9 del RGPD (en especial, los datos financieros y médicos).
En general, pueden considerarse varias técnicas de anonimización, sin que la legislación europea contenga ninguna norma prescriptiva, existiendo 4 enfoques generales:
- Aleatorización: alteración de los datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la privacidad diferencial (es decir, recoger datos del global de usuarios sin saber a quién corresponde cada dato).
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas como Agregación/Anonimato-K o Diversidad-l/Proximidad-t.
- Cifrado: ofuscación a través de algoritmos de HASH, con borrado de clave, o procesado directo de datos cifrados a través de técnicas homomórficas. Ambas técnicas pueden ser complementadas con sellos de tiempo o firma electrónica.
- Seudonimización: reemplazo de atributos por versiones cifradas o tokens que impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas. impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas.
Principios básicos de la anonimización
Al igual que otros procesos de protección de datos, la anonimización debe regirse por el concepto de privacidad desde el diseño y por defecto (Art. 25 del RGPD), teniendo en cuenta 7 principios:
- Proactivo: el diseño debe plantearse desde las etapas iniciales de conceptualización, identificando microdatos, datos de identificación indirecta y datos sensibles, estableciendo escalas de sensibilidad que sean informadas a todos los implicados en el proceso de anonimización.
- Privacidad por defecto: es necesario establecer el grado de detalle o granularidad de los datos anonimizados con el objetivo de preservar la confidencialidad, eliminando variables no esenciales para el estudio a realizar, teniendo en cuenta factores de riesgo y beneficio.
- Objetivo: dada la imposibilidad de una anonimización absoluta, es crítico evaluar el nivel de riesgo de re-identificación asumido y establecer las políticas adecuadas de contingencia.
- Funcional: para garantizar la utilidad del conjunto de datos anonimizado, es necesario definir claramente la finalidad del estudio e informar a los usuarios de los procesos de distorsión empleados para que sean tenidos en cuenta durante su explotación.
- Integral: el proceso de anonimización va más allá de la generación del conjunto de datos, siendo aplicable también durante el estudio de estos, a través de contratos de confidencialidad y uso limitado, validados mediante las auditorías pertinentes durante todo el ciclo de vida.
- Informativo: este es un principio clave, siendo necesario que todos los participantes en el ciclo de vida sean debidamente capacitados e informados respecto a su responsabilidad y los riegos asociados.
- Atómico es recomendable, en la medida de lo posible, que el equipo de trabajo se defina con personas independientes para cada función dentro del proceso.
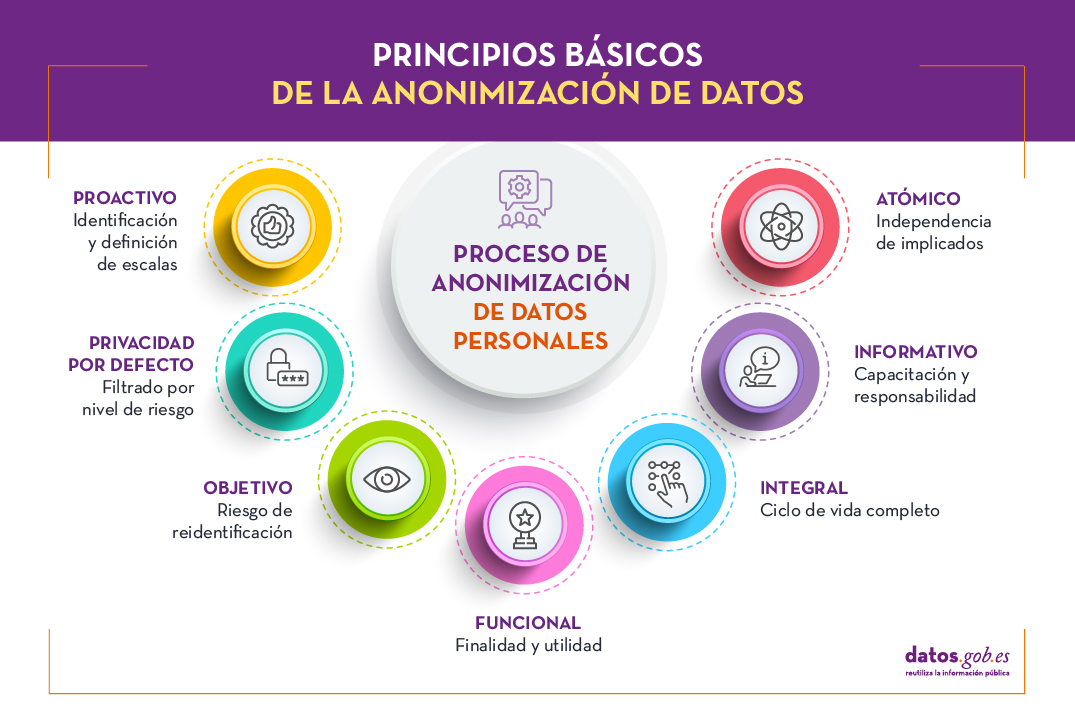
En un proceso de anonimización, una tarea esencial es definir un esquema basado en los tres niveles de identificación de personas: microdatos, identificadores indirectos y datos sensibles (principio de proactividad), donde se asigne un valor cuantitativo a cada una de las variables. Esta escala debe ser conocida por todo el personal implicado (principio de información) y es crítico para la Evaluación de Impacto en la Protección de los Datos Personales (EIPD).
¿Cuáles son los principales riesgos y retos asociados a la anonimización?
Dado el avance de la tecnología, es especialmente complejo poder garantizar la anonimización absoluta, por lo que el riesgo de reidentificación se aborda como un riesgo residual, asumido y gestionado, y no como un incumplimiento de la normativa. Es decir, se rige por el principio de objetividad, siendo necesario establecer políticas de contingencia. Estas políticas deben plantearse en términos de coste frente a beneficio, haciendo que el esfuerzo necesario para la reidentificación no sea asumible o sea razonablemente imposible.
Cabe señalar que el riesgo de reidentificación aumenta con el paso del tiempo, debido a la posible aparición de nuevos datos o el desarrollo de nuevas técnicas, como los futuros avances en computación cuántica, que podrían conllevar la ruptura de claves de cifrado.
En concreto se establecen tres vectores de riesgo concretos asociados a la reidentificación, definidos en el Dictamen 05/2014 sobre técnicas de anonimización:
- Singularización (singling out): riesgo de extraer atributos que permitan identificar a un individuo.
- Vinculabilidad (linkability): riesgo de vincular al menos dos atributos al mismo individuo o grupo, en uno o varios conjuntos de datos.
- Inferencia (inference): riesgo de deducir el valor de un atributo crítico a partir de otros atributos.
La siguiente tabla, propuesta en el mismo dictamen, muestra el nivel de garantías que podría ofrecer cada técnica:
| ¿Existe riesgo de singularización? | ¿Existe riesgo de vinculabilidad? | ¿Existe riesgo de inferencia? | |
|---|---|---|---|
| Seudonimización | Sí | Sí | Sí |
| Adición de ruido | Sí | Puede que no | Puede que no |
| Sustitución | Sí | Sí | Puede que no |
| Agregación y anonimato K | No | Sí | Sí |
| Diversidad l | No | Sí | Puede que no |
| Privacidad diferencial | Puede que no | Puede que no | Puede que no |
| Hash/Tokens | Sí | Sí | Puede que no |
Otro factor importante es la calidad de los datos resultantes para un fin determinado, también denominado utilidad, dado que en ocasiones es necesario sacrificar parte de la información (principio de privacidad por defecto). Esto conlleva un riesgo inherente para el que es necesario identificar y plantear medidas de mitigación para evitar la pérdida de potencial informativo del conjunto de datos anonimizado, enfocado a un caso de uso concreto (principio de funcionalidad).
En definitiva, el reto reside en conseguir que el análisis de los datos anonimizados no difiera significativamente con respecto al mismo análisis realizado sobre el conjunto de datos original, consiguiendo minimizar el riesgo de reidentificación mediante la combinación de varias técnicas de anonimización y la monitorización de todo el proceso; desde la anonimización a la explotación con una finalidad concreta.
Referencias y normativas
- REGLAMENTO (UE) 2016/679 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 27 de abril de 2016
- DIRECTIVA (UE) 2019/1024 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 20 de junio de 2019
- Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak – European Data Protection Board
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
La Agencia Española de Protección de Datos (AEPD) ha lanzado una guía de orientación para fomentar la reutilización de la información del sector público mientras se garantiza la privacidad de los ciudadanos. Con el fin de ofrecer unas directrices que acompañen en la implementación de estas técnicas, la AEPD ha publicado conjuntamente el documento Orientaciones y garantías en los procedimientos de anonimización de datos personales que explica pormenorizadamente cómo ocultar, enmascarar o disociar datos personales con el fin deeliminar o reducir al mínimo los riesgos de reidentificación de los datos anonimizados,permitiendo su divulgación y asegurando que no se vulneren los derechos a la protección de datos de las personas u organizaciones que no deseen ser identificadas, o que hayan puesto el anonimato como condición para ceder sus datos para su publicación. En resumen, una fórmula para compatibilizar el fomento de la reutilización y la normativa reguladora en materia de protección de datos, que asegure que el esfuerzo de reidentificación de los sujetos conlleva un coste suficientemente elevado para que no pueda ser abordado “en términos de relación esfuerzo-beneficio”.
El documento muestra, tanto los principios a tener en cuenta en un proceso de anonimización en las etapas de diseño del sistema de información(principio de privacidad por defecto, de privacidad objetiva, de plena funcionalidad, etc.), como las fases del protocolo de actuación en el proceso de anonimización, entre otras las siguientes:
- Definición del equipo de trabajo detallando las funciones de cada perfil, y garantizando, en la medida de lo posible, que cada miembro desempeñe sus tareas de forma independiente del resto. De esta manera, se evita que un error en un nivel sea revisado y aprobado en un nivel distinto por el mismo agente.
- Análisis de riesgos para gestionar los riesgos resultantes del principio de que ninguna técnica de anonimización puede garantizar en términos absolutos la imposibilidad de reidentificación.
- Definición de objetivos y finalidad de la información anonimizada.
- Preanonimización, eliminación/reducción de variables y anonimización criptográfica a través de técnicas tales como los algoritmos de Hash, algoritmos de cifrado, sello de tiempo, capas de anonimización, etc.
- Creación de un mapa de sistemas de información que asegure entornos segregados para cada tratamiento de datos personales que implique la separación del personal que accede a dicha información.
Por último el documento señala la importancia de formar e informar al personal implicado en los procesos de anonimización y al que trabaja con los datos anonimizados, destaca la necesidad de establecer garantías para proteger los derechos de los interesados (acuerdos de confidencialidad, auditorías del uso de la información anonimizada por parte de su destinatario…) y establece como fundamental la realización de auditorías periódicas de las políticas de anonimización, que deben estar documentadas.

La AEPD ofrece estas orientaciones aún a sabiendas que las mismas capacidades tecnológicas que se utilizan para anonimizar datos personales pueden ser utilizadas para la reidentificación de las personas. Es por ello por lo que insiste en la importancia de contemplar el riesgo como una contingencia latente y sustentar la fortaleza de la anonimización en medidas de evaluación del impacto, organizativas, tecnológicas, etc.; todo ello con el fin de conjugar la puesta a disposición de datos públicos y, a su vez, garantizar la protección de datos personales en la reutilización de la información con fines sociales, científicos y económicos.
Documentación
La Ley 18/2015, de 9 de julio, por la que se modifica la Ley 37/2007, de 16 de noviembre, sobre reutilización de la información del sector público, establece que las Administraciones y los organismos públicos tienen la obligación inequívoca de autorizar la reutilización de su información, incluyendo a aquellas instituciones del ámbito cultural como museos, archivos y bibliotecas.
Con el fin de que la puesta a disposición de la información para su reutilización no interfiera con la privacidad de los datos de carácter personal, la Agencia Española de Protección de Datos ha publicado un documento de Orientaciones sobre protección de datos en la reutilización de la información del sector público donde se reúnen aquellos aspectos a tener en cuenta por el sector público a la hora de abrir sus datos de forma compatible con la garantía del derecho fundamental a la protección de datos reconocido en el artículo 18.4 de la Constitución, en el artículo 4.6 de la Ley Orgánica 15/1999 de Protección de Datos de Carácter Personal y en el artículo 8 de la Carta de los Derechos Fundamentales de la Unión Europea.
Tal y como se refiere en el documento, el tratamiento y reutilización de la información del sector público por parte del reutilizador puede comportar la combinación de dicha información con otras fuentes de datos, la utilización de tecnologías de datos masivos (big data) o de minería de datos (data mining) que limitan el seguimiento y control sobre el uso de los datos abiertos públicos y, por ende, lo que podría producir incertidumbre respecto de la privacidad de dicha información. Sin embargo, según la AEPD, estos riesgos asociados no deberían suponer una restricción de la reutilizaciónteniendo en cuenta las ventajas que supone para el conjunto de la sociedad. La guía intenta dar respuesta a esta cuestión, resaltando la importancia de metodologías preventivas como la evaluación de impacto de la reutilización en la protección de datos personales (EIPD) -que analiza los posibles riesgos que puede implicar el tratamiento de los datos personales- y de soluciones proactivas como la anonimización de los datos, así como las garantías jurídicas e instrumentos jurídicos precisos para recoger estas garantías.
El documento muestra cómo realizar la evaluación de impacto en la protección de datos por parte del organismo que autoriza la reutilización, el cual puede elaborar el análisis de forma autónoma o con la ayuda del reutilizador, sin facilitar, en tal caso, datos sensibles o de carácter personal.
A su vez, el texto indica cómo la anonimización puede reforzarse por medio de compromisos jurídicamente vinculantes como la indicación expresa de prohibir la reidentificación y reutilización de los datos personales en la toma de decisiones. Por último, también incluye algunas medidas de ejemplo para asegurar el cumplimiento de dichas garantías jurídicas: desde las evaluaciones periódicas sobre el riesgo de reidentificación; la realización de auditorías sobre el uso de la información reutilizada o la inclusión de advertencias en los sitios web sobre la reidentificación de los datos personales.
Gracias a esta guía de orientación, la Agencia Española de Protección de Datos abre el camino para difundir buenas prácticas de cara a encontrar la respuesta a uno de los principales riesgos asociados a la reutilización de la información del sector público como es la reidentificación de los ciudadanos, instruyendo a los gestores de las instituciones públicas sobre cómo facilitar los datos abiertos cumpliendo las debidas garantías jurídicas de protección de datos.