Blog
As organisations seek to harness the potential of data to make decisions, innovate and improve their services, a fundamental challenge arises: how can data collection and use be balanced with respect for privacy? PET technologies attempt to address this challenge. In this post, we will explore what they are and how they work.
What are PET technologies?
PET technologies are a set of technical measures that use various approaches to privacy protection. The acronym PET stands for "Privacy Enhancing Technologies" which can be translated as "privacy enhancing technologies".
According to the European Union Agency for Cibersecurity this type of system protects privacy by:
- The deletion or reduction of personal data.
- Avoiding unnecessary and/or unwanted processing of personal data.
All this, without losing the functionality of the information system. In other words, they make it possible to use data that would otherwise remain unexploited, as they limit the risks of disclosure of personal or protected data, in compliance with current legislation.
Relationship between utility and privacy in protected data
To understand the importance of PET technologies, it is necessary to address the relationship between data utility and data privacy. The protection of personal data always entails a loss of usefulness, either because it limits the use of the data or because it involves subjecting them to so many transformations to avoid identification that it perverts the results. The following graph shows how the higher the privacy, the lower the usefulness of the data.

Figure 1. Relationship between utility and privacy in protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
PET techniques allow a more favourable privacy-utility trade-off to be achieved. However, it should be borne in mind that there will always be some limitation of usability when exploiting protected data.
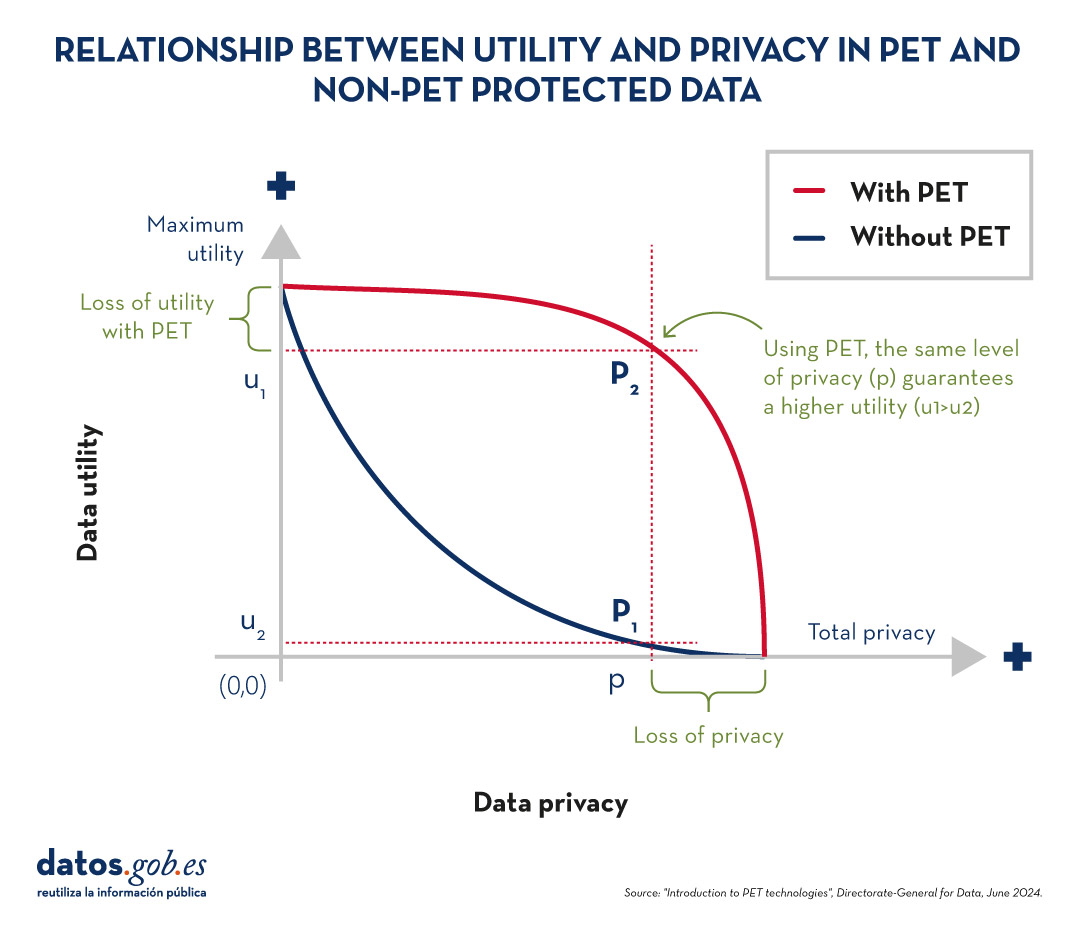
Figure 2. Relationship between utility and privacy in PET and non-PET protected data. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
Most popular PET techniques
In order to increase usability and to be able to exploit protected data while limiting risks, a number of PET techniques need to be applied. The following diagram shows some of the main ones:
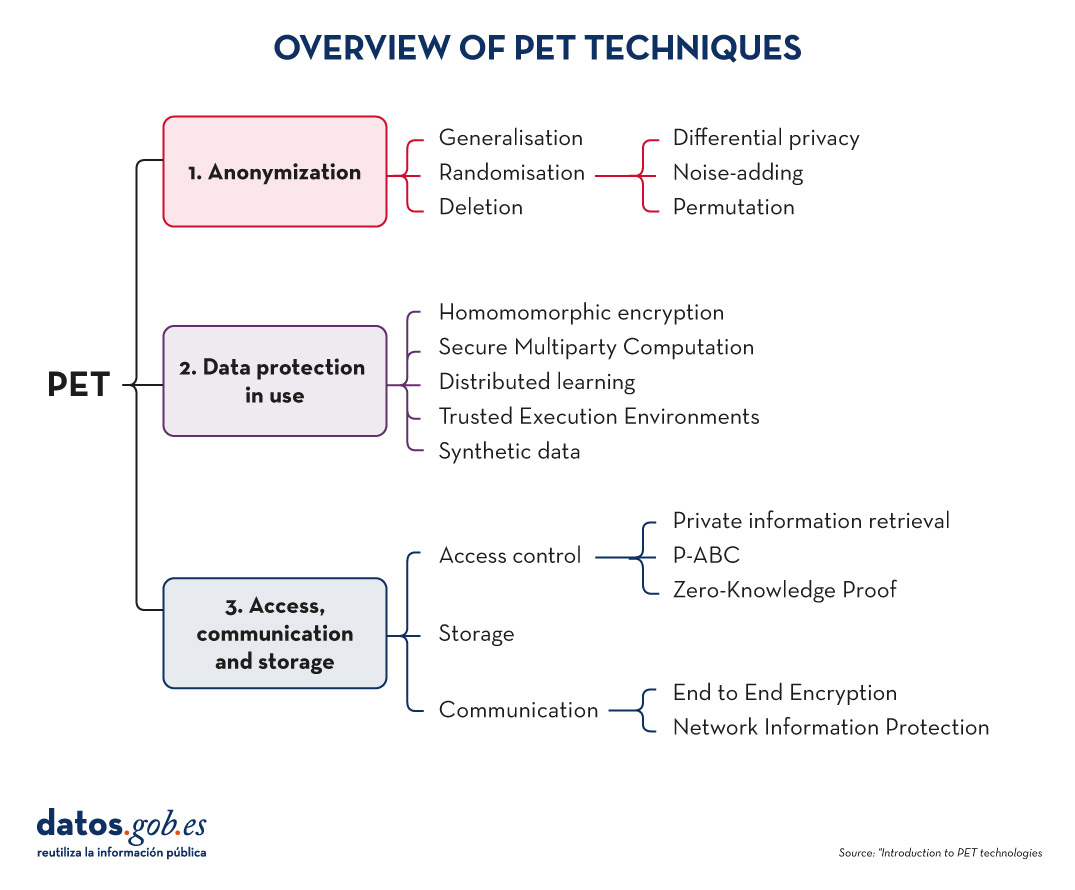
Figure 3. Overview of PET techniques. Source: "Introduction to PET technologies", Directorate-General for Data, June 2024.
As we will see below, these techniques address different phases of the data lifecycle.
Before data mining: anonymisation
Anonymisation is the transformation of private data sets so that no individual can be identified. Thus, the General Data Protection Regulation (GDPR) no longer applies to them.
It is important to ensure that anonymisation has been done effectively, avoiding risks that allow re-identification through techniques such as linkage (identification of an individual by cross-referencing data), inference (deduction of additional attributes in a dataset), singularisation (identification of individuals from the values of a record) or compounding (cumulative loss of privacy due to repeated application of treatments). For this purpose, it is advisable to combine several techniques, which can be grouped into three main families:
- Randomisation: involves modifying the original data by introducing an element of chance. This is achieved by adding noise or random variations to the data, so that general patterns and trends are preserved, but identification of individuals is made more difficult.
- Generalisation: is the replacement or hiding of specific values in a data set with broader or less precise values. For example, instead of recording the exact age of a person, a range of ages (such as 35-44 years) could be used.
- Deletion: implies the complete removal of certain data from the set, especially those that can identify a person directly. This is the case for names, addresses, identification numbers, etc.
You can learn more about these three general approaches and the various techniques involved in the practical guide "Introduction to data anonymisation: techniques and practical cases". We also recommend reading the article Common misunderstandings in data anonymisation.
Data protection in use
This section deals with techniques that safeguard data privacy during the implementation of operational processing.
-
Homomomorphic encryption: is a cryptographic technique which allows mathematical operations to be performed on encrypted data without first decrypting it. For example, a cipher will be homomorphic if it is true that, if two numbers are encrypted and a sum is performed in their encrypted form, the encrypted result, when decrypted, will be equal to the sum of the original numbers.
- Secure Multiparty Computation or SMPC: is an approach that allows multiple parties to collaborate to perform computations on private data without revealing their information to the other participants. In other words, it allows different entities to perform joint operations and obtain a common result, while maintaining the confidentiality of their individual data.
- Distributed learning: traditionally, machine learning models learn centrally, i.e., they require gathering all training data from multiple sources into a single dataset from which a central server builds the desired model. In el distributed learning, data is not concentrated in one place, but remains in different locations, devices or servers. Instead of moving large amounts of data to a central server for processing, distributed learning allows machine learning models to be trained at each of these locations, integrating and combining the partial results to obtain a final model.
- Trusted Execution Environments or TEE: trusted computing refers to a set of techniques and technologies that allow data to be processed securely within protected and certified hardware environments known as trusted computing environments.
- Synthetic data: is artificially generated data that mimics the characteristics and statistical patterns of real data without representing specific people or situations. They reproduce the relevant properties of real data, such as distribution, correlations and trends, but without information to identify specific individuals or cases. You can learn more about this type of data in the report Synthetic data:. What are they and what are they used for?
3. Access, communication and storage
PET techniques do not only cover data mining. These also include procedures aimed at ensuring access to resources, communication between entities and data storage, while guaranteeing the confidentiality of the participants. Some examples are:
Access control techniques
-
Private information retrieval or PIR: is a cryptographic technique that allows a user to query a database or server without the latter being able to know what information the user is looking for. That is, it ensures that the server does not know the content of the query, thus preserving the user's privacy.
-
Privacy-Attribute Based Credentials or P-ABC: is an authentication technology that allows users to demonstrate certain personal attributes or characteristics (such as age of majority or citizenship) without revealing their identity. Instead of displaying all his personal data, the user presents only those attributes necessary to meet the authentication or authorisation requirements, thus maintaining his privacy.
- Zero-Knowledge Proof or ZKP: is a cryptographic method that allows one party to prove to another that it possesses certain information or knowledge (such as a password) without revealing the content of that knowledge itself. This concept is fundamental in the field of cryptography and information security, as it allows the verification of information without the need to expose sensitive data.
Communication techniques
-
End to End Encryption or E2EE: This technique protects data while it is being transmitted between two or more devices, so that only authorised participants in the communication can access the information. Data is encrypted at the origin and remains encrypted all the way to the recipient. This means that, during the process, no intermediary individual or organisation (such as internet providers, application servers or cloud service providers) can access or decrypt the information. Once they reach their destination, the addressee is able to decrypt them again.
- Network Information Protection (Proxy & Onion Routing): a proxy is an intermediary server between a user's device and the connection destination on the Internet. When someone uses a proxy, their traffic is first directed to the proxy server, which then forwards the requests to the final destination, allowing content filtering or IP address change. The Onion Routing method protects internet traffic over a distributed network of nodes. When a user sends information using Onion Routing, their traffic is encrypted multiple times and sent through multiple nodes, or "layers" (hence the name "onion", meaning "onion").
Storage techniques
- Privacy Preserving Storage (PPS): its objective is to protect the confidentiality of data at rest and to inform data custodians of a possible security breach, using encryption techniques, controlled access, auditing and monitoring, etc.
These are just a few examples of PET technologies, but there are more families and subfamilies. Thanks to them, we have tools that allow us to extract value from data in a secure way, guaranteeing users' privacy. Data that can be of great use in many sectors, such as health, environmental care or the economy.
Blog
Data anonymisation is a complex process and often prone to misunderstandings. In the worst case, these misconceptions lead to data leakage, directly affecting the guarantees that should be offered to users regarding their privacy.
Anonymisation aims at rendering data anonymous, avoiding the re-identification of individuals. However, the mere application of anonymisation techniques does not guarantee the anonymisation of data. The main risk is measured precisely by the probability of re-identification, i.e. the probability that an individual is identified within a dataset.
Most attacks on anonymised datasets try to exploit common weaknesses in the process, usually through the use of complementary data. A well-known example is the case of the dataset released by Netflix in 2007, where, using data obtained from the Internet Movie Database (IMDb), two researchers from the University of Texas were able to identify users and link them to their possible political preferences and other sensitive data.
But these flaws do not only affect private companies; in the mid-1990s, Dr Sweeney was able to re-identify medical records of the Governor of Massachusetts, who had assured that the published dataset was secure. Later, in 2000, the same researcher demonstrated that he could re-identify 87% of the inhabitants of the United States just knowing their postcode, date of birth and gender.
Here are some common examples of misunderstandings that we should avoid if we want to approach an anonymisation process properly.
Anonymising a dataset is not always possible
Data anonymisation is a tailor-made process, designed for each data source and for each study or use case to be developed. Sometimes, the risk of re-identification may be unaffordable or the resulting dataset may not be sufficiently useful. Depending on the specific context and requirements, anonymisation may not be feasible.
However, a common misconception is that it is always feasible to anonymise a dataset, when it really depends on the level of assurance required or the utility needed for the case study.
Automation and reuse of anonymisation processes is Limited
Although it is possible to automate some parts of the process, other steps require manual intervention by an expert. In particular, there are no tools to reliably assess the usefulness of the resulting dataset for a given scenario, or the detection of possible indirect identifiers from external data sources.
Similarly, it is not advisable to reuse anonymisation processes applied on different data sources. The constraints vary from case to case, and it is critical to assess the volume of data available, the existence of complementary data sources and the target audience.
Anonymisation is neither permanent nor absolute.
Due to the possible emergence of new data or the development of new techniques, the risk of re-identification increases over time. The level of anonymisation must be measured on a scale, it is not a binary concept, where anonymisation cannot normally be considered absolute, because it is not possible to assume zero level of risk.
Pseudonymisation is not the same as anonymisation
Specifically, this technique consists of modifying the values of key attributes (such as identifiers) by other values that are not linked to the original record.
The main problem is that there is still a possibility to link the natural person indirectly from additional data, making it a reversible process. In fact, the data controller normally preserves the ability to undo such a process.
Encryption is not an anonymisation technique, but a pseudonymisation technique.
Data encryption is framed within the framework of pseudonymisation, in this case replacing key attributes with encrypted versions. The additional information would be the encryption key, held by the data controller.
The best known example is the dataset released in 2013 by the New York City Taxi and Limousine Commission. Among other data, it contained pick-up and drop-off locations, schedules and especially the encrypted licence number. It was later discovered that it was relatively easy to undo the encryption and identify the drivers.
Conclusions
There are other common misunderstandings about anonymisation, such as the widespread misunderstanding that an anonymised dataset is completely useless, or the lack of interest in re-identification of personal data.
Anonymisation is a technically complex process, requiring the involvement of specialised profesionals and advanced data analysis techniques. A robust anonymisation process assesses the risk of re-identification and defines guidelines for managing it over time.
In return, anonymisation allows more data sources to be shared, more securely and preserving their usefulness in a multitude of scenarios, with particular emphasis on health data analysis and research studies that enable the science advancement to new levels.
If you want to learn more about this subject, we invite you to read the guide Introduction to Data Anonymisation: Techniques and Case Studies, which includes a set of practical examples. The code and data used in the exercise are available on Github.
Content prepared by José Barranquero, expert in Data Science and Quantum Computing.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Documentación
Data anonymization defines the methodology and set of best practices and techniques that reduce the risk of identifying individuals, the irreversibility of the anonymization process, and the auditing of the exploitation of anonymized data by monitoring who, when, and for what purpose they are used.
This process is essential, both when we talk about open data and general data, to protect people's privacy, guarantee regulatory compliance, and fundamental rights.
The report "Introduction to Data Anonymization: Techniques and Practical Cases," prepared by Jose Barranquero, defines the key concepts of an anonymization process, including terms, methodological principles, types of risks, and existing techniques.
The objective of the report is to provide a sufficient and concise introduction, mainly aimed at data publishers who need to ensure the privacy of their data. It is not intended to be a comprehensive guide but rather a first approach to understand the risks and available techniques, as well as the inherent complexity of any data anonymization process.
What techniques are included in the report?
After an introduction where the most relevant terms and basic anonymization principles are defined, the report focuses on discussing three general approaches to data anonymization, each of which is further integrated by various techniques:
- Randomization: data treatment, eliminating correlation with the individual, through the addition of noise, permutation, or Differential Privacy.
- Generalization: alteration of scales or orders of magnitude through aggregation-based techniques such as K-Anonymity, L-Diversity, or T-Closeness.
- Pseudonymization: replacement of values with encrypted versions or tokens, usually through HASH algorithms, which prevent direct identification of the individual unless combined with additional data, which must be adequately safeguarded.
The document describes each of these techniques, as well as the risks they entail, providing recommendations to avoid them. However, the final decision on which technique or set of techniques is most suitable depends on each particular case.
The report concludes with a set of simple practical examples that demonstrate the application of K-Anonymity and pseudonymization techniques through encryption with key erasure. To simplify the execution of the case, users are provided with the code and data used in the exercise, available on GitHub. To follow the exercise, it is recommended to have minimal knowledge of the Python language.
You can now download the complete report, as well as the executive summary and a summary presentation.
Blog
We are in a historical moment, where data has become a key asset for almost any process in our daily lives. There are more and more ways to collect data and more capacity to process and share it, where new technologies such as IoT, Blockchain, Artificial Intelligence, Big Data and Linked Data play a crucial role.
Both when we talk about open data, and data in general, it is critical to be able to guarantee the privacy of users and the protection of their personal data, understood as Fundamental rights. An aspect that sometimes does not receive special attention despite the rigorous existing regulations, such as the GDPR.
What is anonymization and what techniques are there?
The anonymization of data defines the methodology and the set of good practices and techniques that reduce the risk of identifying persons, the irreversibility of the anonymization process and the audit of the exploitation of the anonymized data, monitoring who, when and what they are used for. In other words, it covers both the objective of anonymization and that of mitigating the risk of re-identification, the latter being a key aspect.
To understand it well, it is necessary to speak of the confidentiality chain, a term that includes the analysis of specific risks for the purpose of the treatment to be carried out. The breaking of this chain implies the possibility of re-identification, that is, of identifying the specific people to whom it belongsns
Anonymization techniques are focused on identifying and obfuscating microdata, indirect identifiers and other sensitive data. When we talk about obfuscating, we refer to changing or altering sensitive data or data that identifies a person (personally identifiable information or PII, in English), in order to protect confidential information. In this case, lMicrodata are unique data for each individual, which can allow direct identification (ID, medical record code, full name, etc.). Indirect identification data can be crossed with the same or different sources to identify an individual (sociodemographic, browser configuration, etc.). It should be noted that sensitive data are those referred to in article 9 of the RGPD (especially financial and medical data).
In general, they can be considered various anonymization techniques, without European legislation contains any prescriptive rules, there are 4 general approaches:
- Randomization: alteration of the data, eliminating the correlation with the individual, by adding noise, permutation, or differential privacy (that is, collecting data from global users without knowing who each data corresponds to).
- Generalization: alteration of scales or orders of magnitude through techniques such as Aggregation / Anonymity-K or Diversity-l/Proximity-t.
- Encryption: obfuscation via HASH algorithms, with key erasure, or direct processing of encrypted data through homomorphic techniques. Both techniques can be complemented with time stamps or electronic signature.
- Pseudonymisation: replacement of attributes by encrypted versions or tokens that prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys. prevents direct identification of the individual. The set continues to be considered as personal data, because re-identification is possible through guarded keys.
Basic principles of anonymization
Like other data protection processes, anonymization must be governed by the concept of privacy by design and by default (Art. 25 of the RGPD), taking into account 7 principles:
- Proactive: the design must be considered from the initial stages of conceptualization, identifying microdata, indirect identification data and sensitive data, establishing sensitivity scales that are informed to all those involved in the anonymization process.
- Privacy by default: it is necessary to establish the degree of detail or granularity of the anonymized data in order to preserve confidentiality, eliminating non-essential variables for the study to be carried out, taking into account risk and benefit factors.
- Objective: Given the impossibility of absolute anonymization, it is critical to assess the level of risk of re-identification assumed and to establish adequate contingency policies.
- Functional: To guarantee the usefulness of the anonymized data set, it is necessary to clearly define the purpose of the study and inform users of the distortion processes used so that they are taken into account during their exploitation.
- Integral: the anonymization process goes beyond the generation of the data set, being applicable also during the study of these, through confidentiality and limited use contracts, validated through the relevant audits throughout the life cycle.
- Informative: this is a key principle, being necessary that all the participants in the life cycle are properly trained and informed regarding their responsibility and the associated risks.
- Atomic It is recommended, as far as possible, that the work team be defined with independent people for each function within the process.
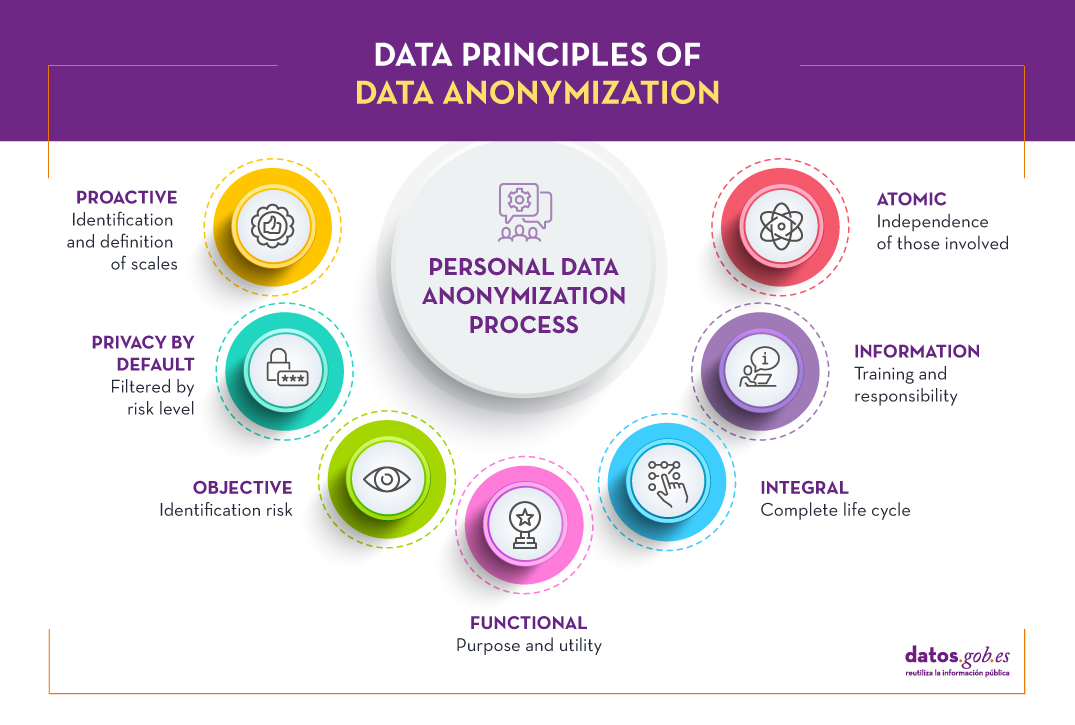
In an anonymization process, an essential task is to define a scheme based on the three levels of identification of people: microdata, indirect identifiers and sensitive data (principle of proactivity), where a quantitative value is assigned to each of the variables. This scale must be known to all the personnel involved (information principle) and is critical for the Impact Assessment on the Protection of Personal Data (EIPD).
What are the main risks and challenges associated with anonymization?
Given the advancement of technology, it is especially complex to be able to guarantee absolute anonymization, so the risk of re-identification is approached as a residual risk, assumed and managed, and not as a breach of regulations. That is, it is governed by the principle of objectivity, being necessary to establish contingency policies. These policies must be considered in terms of cost versus benefit, making the effort required for re-identification unaffordable or reasonably impossible.
It should be noted that the risk of re-identification increases with the passage of time, due to the possible appearance of new data or the development of new techniques, such as future advances in quantum computing, which could lead to the encryption key break.
Specifically, three specific risk vectors associated with re-identification are established, defined in the Opinion 05/2014 on anonymization techniques:
- Singling out: risk of extracting attributes that allow an individual to be identified.
- Linkability: risk of linking at least two attributes to the same individual or group, in one or more data sets.
- Inference: risk of deducing the value of a critical attribute from other attributes.
The following table, proposed
| Is there a risk of singularization? | Is there a risk of linkability? | Is there a risk of inference? | |
|---|---|---|---|
| Pseudonymisation | Yes | Yes | Yes |
| Adding noise | Yes | Maybe not | Maybe not |
| Substitution | Yes | Yes | Maybe not |
| Aggregation and anonymity K | No | Yes | Yes |
| Diversity l | No | Yes | Maybe not |
| Differential privacy | Maybe not | Maybe not | Maybe not |
| Hash/Tokens | Yes | Yes | Maybe not |
Another important factor is the quality of the resulting data for a specific purpose, also called utility, since sometimes it is necessary to sacrifice part of the information (privacy principle by default). This entails an inherent risk for which it is necessary to identify and propose mitigation measures to avoid the loss of informative potential of the anonymized data set, focused on a specific use case (principle of functionality).
Ultimately, the challenge lies in ensuring that the analysis of the anonymized data does not differ significantly from the same analysis performed on the original data set, thus minimizing the risk of re-identification by combining various anonymization techniques and monitoring of everything. the process; from anonymization to exploitation for a specific purpose.
References and regulations
- REGULATION (EU) 2016/679 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of April 27, 2016
- DIRECTIVE (EU) 2019/1024 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL of 20 June 2019
- Organic Law 3/2018, of December 5, on Protection of Personal Data and guarantee of digital rights
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak - European Data Protection Board
Content written by Jose Barranquero, expert in data science and quantum computing.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Documentación
The Spanish Data Protection Agency (AEPD) has launched a guide to promote the re-use of public sector information whereas the privacy of citizens is guaranteed. In order to provide some guidelines that help the implementation of these techniques, the AEPD has also published the document entitled “Guidelines and guarantees in the process of personal data anonymisation” which explains in detail how to hide, mask or dissociate personal data in order to eliminate or minimize the risks of re-identification of anonymised data, enabling the release and guaranteeing the rights to data protection of individuals or organizations that do not wish to be identified, or have established the anonymity as a condition to transfer their data for publication. In other words, a formula to juggle the promotion of the re-use with the regulatory rules on data protection, which ensures that the effort in re-identification of individuals carries a cost high enough to not be addressed "in terms of relative effort -benefit".
The document shows both the principles to be considered in a process of anonymization in the design stages of the information system (principle of privacy by default, objective privacy, of full functionality, etc.), as the phases of the performance protocol in the process of anonymisation, including the following:
- Defining the team detailing the functions of each profile, and ensuring, as far as possible, that each member performs the tasks independently of the rest. Thus, it prevents that an error in a level is reviewed and approved at a different level by the same agent.
- Risk analysis to manage risks arising from the principle that any anonymisation technique can guarantee absolutely the impossibility of re-identification.
- Defining goals and objectives of the anonymised information.
- Preanonymisation, elimination/reduction of variables and cryptographic anonymisation through techniques such as hashing algorithms, encryption algorithms, time stamp, and anonymisation layers, etc.
- Creating a map of information systems to ensure segregated environments for each processing of personal data involving the separation of personnel accessing such information.
Finally, the document highlights the importance of training and informing the personnel involved in the processes of anonymization who work with anonymised data, focussing on the need of establishing guarantees to protect the rights of stakeholders (confidentiality agreements, audits of the use of anonymised information by the recipient ...) and establishes as a fundamental conducting regular audits of anonymization policies, which must be documented.

The AEPD offers these guidelines even knowing that the same technological capabilities that are used to anonymise personal data can be used for re-identification of people. That is the reason to emphasize the importance of considering the risk as a latent contingency and sustain the strength of the anonymisation in impact assessment measures, organizational, technological, etc. .; all in order to combine the provision of public data and ensure the protection of personal data in the re-use of information with social, scientific and economic purposes.
Documentación
Law 18/2015, of 9 July, amending Law 37/2007, of 16 November, on re-use of public sector information, provides that the authorities and public bodies have a clear obligation to authorize the re-use of their information, including those institutions in the cultural field such as museums, archives and libraries.
In order that the provision of information for its re-use does not interfere with the privacy of personal data, the Spanish Data Protection Agency has published a Guidance document on data protection in the re-use of public sector information which gathers all aspects to be considered by the public sector to release data ensuring the fundamental right to data protection recognized in Article 18.4 of the Constitution, in the Article 4.6 of Law 15/1999 on Protection of Personal Data and in the Article 8 of the Charter of Fundamental Rights of the European Union.
As laid out in the document, the treatment and re-use of public sector information by the re-user may involve the combination of that information with other data sources, using technologies of big data or data mining that limit the monitoring and control over the use of public open data and, therefore, could cause uncertainty about the privacy of such information. Nevertheless, according to the AEPD, these associated risks should not lead to a restriction of re-use considering its advantages to the whole society. The guide attempts to answer this question, highlighting the importance of preventive methodologies such as the assessment of re-use impact in the protection of personal data -which analyzes the potential risks that the treatment of the personal data may involve- and proactive solutions such as the anonymization of data, as well as the legal guarantees and tools needed thereof.
The document shows how to evaluate the impact on data protection by the body that authorizes the re-use of the information, which can develop the analysis independently or with the help of the re-user, without providing, in such case, sensitive or personal data.
In addition, the text indicates how anonymization can be strengthened through legally binding commitments such as the express indication to prohibit the re-identification and use of personal data in decision-making. Finally, it also includes some example measurements to ensure the compliance with these legal guarantees: from periodic assessments of the re-identification risks; audits on the use of reused information or the inclusion of warnings on the re-identification of personal data on websites.
Thanks to this guidance, the Spanish Data Protection Agency opens the way to spread good practices in finding the answer to one of the main risks associated with the re-use of public sector information such as the re-identification of citizens, instructing managers of public institutions in how to facilitate open data in compliance with the legal guarantees of data protection.