Fecha publicación
28/10/2021
Comparte este contenido

Descripción
Nos encontramos es un momento histórico, donde los datos se han convertido en un activo clave para casi cualquier proceso de nuestra vida cotidiana. Cada vez hay más formas de recoger datos y más capacidad para procesarlos y compartirlos, donde juegan un papel crucial nuevas tecnologías como IoT, Blockchain, Inteligencia Artificial, Big Data y Linked Data.
Tanto cuando hablamos de datos abiertos, como de datos en general, es crítico poder garantizar la privacidad de los usuarios y la protección de sus datos personales, entendidos como derechos fundamentales. Un aspecto que en ocasiones no recibe especial atención a pesar de las rigurosas normativas existentes, como el RGPD.
¿Qué es la anonimización y qué técnicas existen?
La anonimización de datos define la metodología y el conjunto de buenas prácticas y técnicas que reducen el riesgo de identificación de personas, la irreversibilidad del proceso de anonimización y la auditoría de la explotación de los datos anonimizados, monitorizando quién, cuándo y para qué se usan. Es decir, cubre tanto el objetivo de anonimización, como el de mitigación del riesgo de reidentificación, siendo este último un aspecto clave.
Para comprenderlo bien, es necesario hablar de cadena de confidencialidad, un término que incluye el análisis de riesgos específicos para la finalidad del tratamiento a realizar. La rotura de esta cadena implica la posibilidad de reidentificación, es decir de identificar a las personas específicas a las que pertenecen los datos a partir de ellos. Para evitarlo, existen múltiples técnicas de anonimización de datos, que buscan principalmente garantizar el avance de la sociedad de la información sin menoscabar el respeto a la protección de los datos.
Las técnicas de anonimización están enfocadas a identificar y ofuscar microdatos, identificadores indirectos y otros datos sensibles. Cuando hablamos de ofuscar, nos referimos a cambiar o alterar datos sensitivos o que identifican a una persona (personally identifiable information o PII, en inglés), con el objetivo de proteger la información confidencial. En este caso, los microdatos son datos únicos para cada individuo, que pueden permitir su identificación directa (DNI, código de historia clínica, nombre completo, etc). Los datos de identificación indirecta pueden ser cruzados con la misma o diferentes fuentes para identificar a un individuo (sociodemográficos, configuración del navegador, etc). Cabe destacar que son datos sensibles los referidos en el artículo 9 del RGPD (en especial, los datos financieros y médicos).
En general, pueden considerarse varias técnicas de anonimización, sin que la legislación europea contenga ninguna norma prescriptiva, existiendo 4 enfoques generales:
- Aleatorización: alteración de los datos, eliminando la correlación con el individuo, mediante la adición de ruido, la permutación, o la privacidad diferencial (es decir, recoger datos del global de usuarios sin saber a quién corresponde cada dato).
- Generalización: alteración de escalas u órdenes de magnitud a través de técnicas como Agregación/Anonimato-K o Diversidad-l/Proximidad-t.
- Cifrado: ofuscación a través de algoritmos de HASH, con borrado de clave, o procesado directo de datos cifrados a través de técnicas homomórficas. Ambas técnicas pueden ser complementadas con sellos de tiempo o firma electrónica.
- Seudonimización: reemplazo de atributos por versiones cifradas o tokens que impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas. impide la identificación directa del individuo. El conjunto sigue considerándose como datos de carácter personal, porque es factible la reidentificación a través de claves custodiadas.
Principios básicos de la anonimización
Al igual que otros procesos de protección de datos, la anonimización debe regirse por el concepto de privacidad desde el diseño y por defecto (Art. 25 del RGPD), teniendo en cuenta 7 principios:
- Proactivo: el diseño debe plantearse desde las etapas iniciales de conceptualización, identificando microdatos, datos de identificación indirecta y datos sensibles, estableciendo escalas de sensibilidad que sean informadas a todos los implicados en el proceso de anonimización.
- Privacidad por defecto: es necesario establecer el grado de detalle o granularidad de los datos anonimizados con el objetivo de preservar la confidencialidad, eliminando variables no esenciales para el estudio a realizar, teniendo en cuenta factores de riesgo y beneficio.
- Objetivo: dada la imposibilidad de una anonimización absoluta, es crítico evaluar el nivel de riesgo de re-identificación asumido y establecer las políticas adecuadas de contingencia.
- Funcional: para garantizar la utilidad del conjunto de datos anonimizado, es necesario definir claramente la finalidad del estudio e informar a los usuarios de los procesos de distorsión empleados para que sean tenidos en cuenta durante su explotación.
- Integral: el proceso de anonimización va más allá de la generación del conjunto de datos, siendo aplicable también durante el estudio de estos, a través de contratos de confidencialidad y uso limitado, validados mediante las auditorías pertinentes durante todo el ciclo de vida.
- Informativo: este es un principio clave, siendo necesario que todos los participantes en el ciclo de vida sean debidamente capacitados e informados respecto a su responsabilidad y los riegos asociados.
- Atómico es recomendable, en la medida de lo posible, que el equipo de trabajo se defina con personas independientes para cada función dentro del proceso.
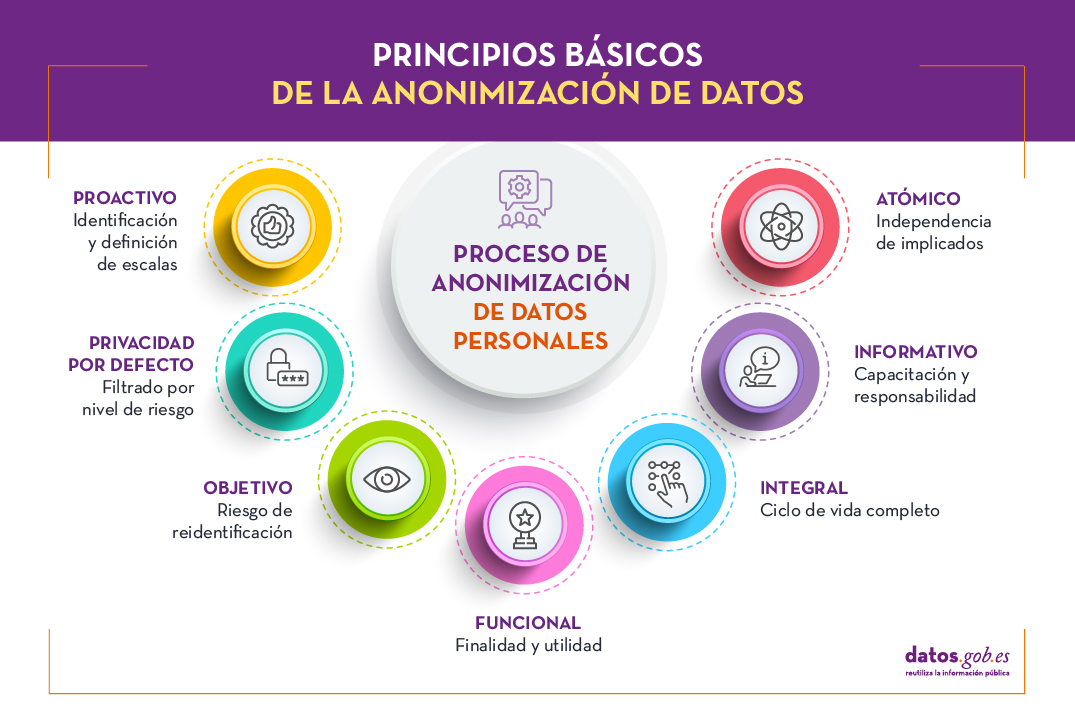
En un proceso de anonimización, una tarea esencial es definir un esquema basado en los tres niveles de identificación de personas: microdatos, identificadores indirectos y datos sensibles (principio de proactividad), donde se asigne un valor cuantitativo a cada una de las variables. Esta escala debe ser conocida por todo el personal implicado (principio de información) y es crítico para la Evaluación de Impacto en la Protección de los Datos Personales (EIPD).
¿Cuáles son los principales riesgos y retos asociados a la anonimización?
Dado el avance de la tecnología, es especialmente complejo poder garantizar la anonimización absoluta, por lo que el riesgo de reidentificación se aborda como un riesgo residual, asumido y gestionado, y no como un incumplimiento de la normativa. Es decir, se rige por el principio de objetividad, siendo necesario establecer políticas de contingencia. Estas políticas deben plantearse en términos de coste frente a beneficio, haciendo que el esfuerzo necesario para la reidentificación no sea asumible o sea razonablemente imposible.
Cabe señalar que el riesgo de reidentificación aumenta con el paso del tiempo, debido a la posible aparición de nuevos datos o el desarrollo de nuevas técnicas, como los futuros avances en computación cuántica, que podrían conllevar la ruptura de claves de cifrado.
En concreto se establecen tres vectores de riesgo concretos asociados a la reidentificación, definidos en el Dictamen 05/2014 sobre técnicas de anonimización:
- Singularización (singling out): riesgo de extraer atributos que permitan identificar a un individuo.
- Vinculabilidad (linkability): riesgo de vincular al menos dos atributos al mismo individuo o grupo, en uno o varios conjuntos de datos.
- Inferencia (inference): riesgo de deducir el valor de un atributo crítico a partir de otros atributos.
La siguiente tabla, propuesta en el mismo dictamen, muestra el nivel de garantías que podría ofrecer cada técnica:
| ¿Existe riesgo de singularización? | ¿Existe riesgo de vinculabilidad? | ¿Existe riesgo de inferencia? | |
|---|---|---|---|
| Seudonimización | Sí | Sí | Sí |
| Adición de ruido | Sí | Puede que no | Puede que no |
| Sustitución | Sí | Sí | Puede que no |
| Agregación y anonimato K | No | Sí | Sí |
| Diversidad l | No | Sí | Puede que no |
| Privacidad diferencial | Puede que no | Puede que no | Puede que no |
| Hash/Tokens | Sí | Sí | Puede que no |
Otro factor importante es la calidad de los datos resultantes para un fin determinado, también denominado utilidad, dado que en ocasiones es necesario sacrificar parte de la información (principio de privacidad por defecto). Esto conlleva un riesgo inherente para el que es necesario identificar y plantear medidas de mitigación para evitar la pérdida de potencial informativo del conjunto de datos anonimizado, enfocado a un caso de uso concreto (principio de funcionalidad).
En definitiva, el reto reside en conseguir que el análisis de los datos anonimizados no difiera significativamente con respecto al mismo análisis realizado sobre el conjunto de datos original, consiguiendo minimizar el riesgo de reidentificación mediante la combinación de varias técnicas de anonimización y la monitorización de todo el proceso; desde la anonimización a la explotación con una finalidad concreta.
Referencias y normativas
- REGLAMENTO (UE) 2016/679 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 27 de abril de 2016
- DIRECTIVA (UE) 2019/1024 DEL PARLAMENTO EUROPEO Y DEL CONSEJO de 20 de junio de 2019
- Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales
- Guidelines 03/2020 on the processing of data concerning health for the purpose of scientific research in the context of the COVID-19 outbreak – European Data Protection Board
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.



Comentarios