Entrevista
Publicar datos abiertos siguiendo las buenas prácticas del linked data (datos enlazados) permite impulsar su reutilización. Datos y metadatos se describen utilizando estándares RDF que permiten representar relaciones entre entidades, propiedades y valores. De esta forma los conjuntos de datos se interconectan entre sí, independientemente del repositorio digital donde se encuentren, lo que facilita su contextualización y explotación.
Si hay un campo donde este tipo de datos son especialmente valorados es el de la investigación. Por ello no es de extrañar que cada vez más universidades empiecen a utilizar esta tecnología. Es el caso de la Universidad de Extremadura (UEX), que cuenta con un portal de investigación que recopila de forma automática la producción científica ligada a la institución. Adolfo Lozano, Director de la Oficina de transparencia y datos abiertos de la Universidad de Extremadura y colaborador en la elaboración de la “Guía práctica para la publicación de datos enlazados en RDF", nos cuenta cómo han puesto en marcha este proyecto.
Entrevista completa:
1. El portal de investigación de la Universidad de Extremadura es una iniciativa pionera en nuestro país. ¿Cómo surgió el proyecto?
El portal de investigación de la Universidad de Extremadura se ha lanzado hace aproximadamente un año, y ha tenido una magnífica acogida entre los investigadores de la UEX y de entidades externas que buscan las líneas de trabajo de nuestros investigadores.
Pero la iniciativa del portal de datos abiertos de la UEX comenzó en 2015, aplicando el conocimiento de nuestro grupo de investigación Quercus de la Universidad de Extremadura sobre representación semántica, y con la experiencia que teníamos en el portal de datos abiertos del Ayuntamiento de Cáceres. El impulso mayor lo ha tenido hace unos 3 años cuando el Vicerrectorado de Transformación Digital creó la Oficina de Transparencia y Datos abiertos de la UEX.
Desde el principio, teníamos claro que queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. Aunque supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos como práctica habitual, podemos decir que a medio plazo los beneficios de organizar así la información nos da un gran potencial para poder extraer y manejar la información para múltiples propósitos.
Queríamos un portal con datos de calidad, con el máximo nivel de reutilización, y donde se aplicasen los estándares internacionales. [...] supuso un considerable esfuerzo publicar todos los datasets usando esquemas ontológicos, siempre representado los datos en RDF, y enlazando los recursos.
2. Uno de los primeros pasos en un proyecto de este tipo es seleccionar vocabularios que permitan conceptualizar y establecer relaciones semánticas entre los datos ¿existía un buen punto de partida o fue necesario crear un vocabulario ex-profeso para este contexto? ¿la disponibilidad de vocabularios de referencia constituye un freno para el desarrollo de la interoperabilidad de datos?
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets. Y además es una práctica que continúa conforme que se van incorporando nuevos conjuntos de datos.
En nuestro caso, hemos intentado reutilizar vocabularios lo más extendidos posible como foaf, schema, dublin core y también algunos específicos como vibo o bibo. Pero en muchos casos hemos tenido que definir términos propios en nuestra ontología porque no existían esos componentes. En nuestra opinión, cuando el proyecto Hércules de la CRUE-TIC esté operativo y se hayan definido los esquemas ontológicos genéricos para las universidades, va a mejorar mucho la intereoperabilidad entre nuestros datos, y sobre todo animará a otras universidades a crear sus portales de datos abiertos con estos modelos.
Uno de los primeros pasos para seguir esquemas ontológicos en un portal de datos abiertos es identificar los términos más adecuados para representar las clases, atributos y relaciones que van a configurar los datasets.
3. ¿Cómo se abordó el desarrollo de esta iniciativa, qué dificultades os encontrasteis y qué perfiles son necesarios para llevar a cabo un proyecto de este tipo?
En nuestra opinión, si se quiere hacer un portal que sea útil a medio plazo, está claro que se requiere un esfuerzo inicial para organizar la información. Quizás lo más complicado al principio es recopilar los datos que están dispersos en diferentes servicios de la Universidad en múltiples formatos, comprender en qué consisten, buscar la mejor forma de representación, y luego coordinar la forma de poder acceder a ellos de forma periódica para las actualizaciones.
En nuestro caso, hemos desarrollado scripts específicos para distintos formatos de fuentes datos, de diferentes Servicios de la UEX (como el Servicio de Informática, el Servicio de Transferencia, o desde servidores externos de publicaciones) y que los transforman en representación RDF. En este sentido, es imprescindible contar con Ingenieros Informáticos, especializados en representación semántica y con amplios conocimientos de RDF y SPARQL. Pero además, desde luego, se debe involucrar a diferentes servicios de la Universidad para coordinar este mantenimiento de la información.
4. ¿Cómo valora el impacto de la iniciativa? ¿Puede contarnos algunos casos de éxito de reutilización de los conjuntos de datos proporcionados?
Por los logs de consultas, sobre todo al portal de investigación, vemos que muchos investigadores utilizan el portal como punto de recogida de datos que usan para elaborar sus currículums. Además, sabemos que las empresas que necesitan algún desarrollo concreto, utilizan el portal para obtener el perfil de nuestros investigadores.
Pero, por otro lado es habitual que algunos usuarios (de dentro y fuera de la UEX) nos pidan consultas específicas a los datos del portal. Y curiosamente, en muchos casos, son los propios servicios de la Universidad que nos suministran los datos los que nos piden listados o gráficos específicos donde se enlacen y crucen con otros datasets del portal.
Al tener los datos enlazados, un profesor de la UEX está enlazado con la asignatura que imparte, el área de conocimiento, el departamento, el centro, pero también con su grupo de investigación, con cada una de sus publicaciones, los proyectos en los que participa, las patentes, etc. Las publicaciones están enlazadas con revistas y estas a su vez con sus índices de impacto.
Por otro lado, las asignaturas, están enlazadas con las titulaciones donde se imparten, los centros, y disponemos también de los números de matriculados por asignaturas, e índices de calidad y satisfacción de usuarios. De esta forma, se pueden realizar consultas e informes complejos manejando en conjunto toda esta información.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
Otro ejemplo, que hemos terminado este año, ha sido la memoria anual de investigación que se ha generado también automáticamente mediante consultas SPARQL. Estamos hablando de más de 1.500 páginas donde se expone toda la producción científica y de transferencia de la UEX, agrupada por institutos de investigación, grupos, centros y departamentos.
Como casos de uso, por ejemplo, podemos mencionar que los documentos Word de las 140 comisiones de calidad de los títulos, se generan automáticamente (incluidos gráficos de evolución anual y listados) mediante consultas al portal opendata. Esto ha permitido ahorrar decenas de horas de trabajo en conjunto a los miembros de estas comisiones.
5. ¿Cuáles son los planes de futuro de la Universidad de Extremadura en materia de datos abiertos?
Queda mucho por hacer. Por ahora estamos abordando en primer lugar aquellos temas que hemos considerado que eran más útiles para la comunidad universitaria, como son la producción científica y de transferencia, y la información académica de la UEX. Pero en el futuro cercano queremos desarrollar conjuntos de datos y aplicaciones relacionados con temas económicos (como contratos públicos, evolución del gastos, mesas de contratación) y administrativos (como el plan de organización docente, organigrama de Servicios, composiciones de órganos de gobierno, etc) para mejorar la transparencia de la institución.
Documentación
A la hora de publicar datos abiertos, es importante hacerlo siguiendo una serie de pautas que faciliten su reutilización, entre ellas, el uso de esquemas comunes, como formatos estándar, ontologías y vocabularios. De esta forma, los conjuntos de datos publicados por distintas organizaciones serán más homogéneos y los usuarios podrán extraer valor más fácilmente.
Una de las familias de formatos más recomendada para la publicación de datos abiertos es el RDF (Resource Description Framework). Se trata de un modelo estándar de intercambio de datos en la web recomendado por el World Wide Web Consortium, y destacado en los principios F.A.I.R. o el esquema de cinco estrellas en la publicación de datos abiertos.
Los RDFs son el fundamento de la web semántica, ya que permiten representar relaciones entre entidades, propiedades y valores, formando grafos. Así se interconectan datos y metadatos de manera automática, generando una red de datos enlazados que facilita su explotación por parte de los reutilizadores. Para ello también es necesario utilizar esquemas de datos consensuados (vocabularios u ontologías), con definiciones comunes que eviten malentendidos o ambigüedades.
Con el fin de promover el uso de este modelo, desde datos.gob.es ponemos a disposición de los usuarios la “Guía práctica para la publicación de datos enlazados”, elaborada con la colaboración del equipo del Ontology Engineering Group, del Departamento de Inteligencia Artificial de la ETSI Informáticos de la Universidad Politécnica de Madrid.
La guía destaca una serie de buenas prácticas, consejos y flujos de trabajo para la creación de conjuntos de datos en RDF a partir de datos tabulares, de una forma eficiente y sostenible en el tiempo.
¿A quién va dirigida la guía?
La guía está dirigida a los responsables de los portales de datos abiertos y a aquellos que preparan los datos para su publicación en dichos portales. No es necesario tener conocimientos previos sobre RDF, vocabularios u ontologías, aunque sí es recomendable una base técnica sobre XML, YAML, SQL y algún lenguaje de programación de scripting, como Python.
¿Qué incluye la guía?
Tras una pequeña introducción, se abordan algunos conceptos teóricos necesarios (tripletas, URIs, vocabularios controlados de dominio, etc.), a la vez que se explica cómo se organiza la información en un RDF o cómo funcionan las estrategias de nombrado.
A continuación, se describen detalladamente los pasos a seguir para transformar un fichero de datos CSV que es el más habitual en los portales de datos abiertos en un conjunto de datos RDF normalizados en base al uso de vocabularios controlados y enriquecido con datos externos que mejoran la información de contexto de los datos de partida. Estos pasos son los siguientes:
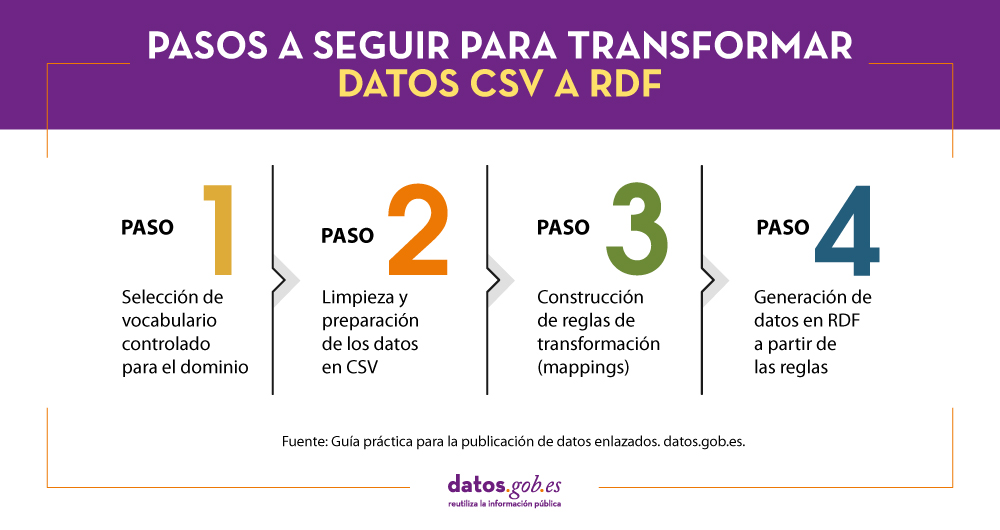
La guía finaliza con una sección orientada a perfiles más técnicos que implementa un ejemplo de uso de los datos en RDF generados utilizando algunas de las librerías de programación y bases de datos para almacenar tripletas más comunes para explotar datos en RDF.
Materiales adicionales
La guía práctica para la publicación de datos enlazados se complementa con una cheatsheet que resumen la información más importante de la guía y una serie de vídeos que ayudan a entender el conjunto de pasos llevados a cabo para la transformación de archivos CSV en RDF. Los vídeos se agrupan en dos series que se relacionan con los pasos explicados en la guía práctica:
1) Serie de vídeos explicativos para la preparación de datos en CSV utilizando OpenRefine. En esta serie se explican los pasos a realizar para preparar un archivo CSV para su posterior transformación en RDF:
- Vídeo 1: Pre-carga de los datos tabulares y creación de un proyecto OpenRefine.
- Vídeo 2: Modificación de valores en las columnas con funciones de transformación.
- Vídeo 3: Generación de valores para las listas controladas o SKOS.
- Vídeo 4: Enlazado de valores con fuentes externas (Wikidata) y descarga del archivo con las nuevas modificaciones.
2) Serie de vídeos explicativos para la construcción de reglas de transformación o mappings CSV a RDF. En esta serie se explican los pasos a realizar para transformar un archivo CSV en RDF mediante la aplicación de reglas de transformación.
- Vídeo 1: Descarga de la plantilla-básica para la creación de las reglas de transformación y creación del esqueleto del documento de reglas de transformación.
- Vídeo 2: Especificación de las referencias para cada propiedad y cómo añadir los valores reconciliados con Wikidata obtenidos a través de OpenRefine.
A continuación puedes descargarte la guía completa, así como la cheatsheet. Para ver los vídeos debes visitar nuestro canal de Youtube.
Noticia
El proyecto Cross-Forest combina dos campos de gran interés para Europa, recogidos en El Pacto Verde. Por un lado, el cuidado y protección del medio ambiente – en concreto de nuestros bosques-. Por otro, el impulso de un ecosistema digital europeo interoperable.
El proyecto empezó en 2018 y ha finalizado el pasado 23 de junio, dando como resultado distintas herramientas y recursos, como veremos a continuación.
¿En qué consiste Cross-Forest?
Cross-Forest es un proyecto cofinanciado por la Comisión Europea mediante el programa CEF (Connecting Europe Facility), que busca publicar y combinar conjuntos de datos abiertos y enlazados de inventarios forestales y mapas forestales, para impulsar modelos que faciliten la gestión y la protección de los bosques.
El proyecto ha sido llevado a cabo por un consorcio formado por el Grupo Público Tragsa, la Universidad de Valladolid y Scayle Supercomputacion de Castilla y León, con el apoyo institucional del Ministerio para la Transción Ecologica y el Reto Demográfico (MITECO). Por parte de Portugal ha participado la Direção-Geral do Território de Portugal.
En el marco del proyecto se ha desarrollado:
- Una Infraestructura de Servicios Digitales (DSI, en sus siglas en inglés) para datos forestales abiertos, orientada hacia la creación de modelos de evolución forestal a nivel de país, así como la predicción del comportamiento y la propagación de los incendios forestales. Se han utilizado datos sobre materiales combustibles, mapas forestales y modelos de propagación. Para su ejecución se han usado recursos de Computación de Alto Rendimiento (HPC), debido a la complejidad de los modelos y la necesidad de realizar numerosas simulaciones.
- Un modelo ontológico de datos forestales común a las administraciones públicas e instituciones académicas de Portugal y España, para la publicación de datos abiertos enlazados. En concreto, se ha creado un conjunto de once ontologías. Estas ontologías, que están alineadas con la Directiva Inspire, se interrelacionan entre sí y se enriquecen enlazando con ontologías externas. Aunque se han creado con el foco puesto en estos dos países, la idea es que cualquier otro territorio pueda utilizarlas para publicar sus datos forestales, en un formato abierto y estándar.
Los diferentes conjuntos de datos utilizados en el proyecto se han publican por separado, para que los usuarios puedan utilizar los que deseen. Se puede acceder a todos los datos, que se publican bajo licencia CC BY 4.0, a través del repositorio Github de Cross-Forest y del Catálogo de Datos del IEPNB.
4 proyectos emblemáticos en formato Linked Open Data
Gracias a Cross-Forest, se ha publicado en formato de datos abiertos enlazados gran parte de la información de 4 proyectos emblemáticos de la Dirección General de Biodiversidad Bosques y Desertificación del Ministerio para la Transción Ecologica y el Reto Demográfico:
- Inventario Forestal Nacional (IFN-3). Incluye más de 100 indicadores el estado y evolución de los montes. Estos indicadores abarcan desde su superficie o las especies arbóreas y arbustivas que habitan en ellos, hasta datos relacionados con la regeneración y biodiversidad. También incorpora el valor en términos monetarios de los aspectos ambientales, recreativos y productivos de los sistemas forestales, entre otros aspectos. Cuenta con más de 90.000 parcelas. Se han publicado en abierto dos bases de datos correspondientes a un subconjunto de los indicadores del IFN.
- Mapa Forestal de España (Escala 1:50.000). Consiste en la cartografía de la situación de las masas forestales, siguiendo un modelo conceptual de usos del suelo jerarquizados.
- Inventario Nacional de Erosión de Suelos (INES). Se trata de un estudio que detecta, cuantifica y refleja cartográficamente los principales procesos de erosión que afectan al territorio español, tanto forestal como agrícola. Su objetivo es conocer su evolución en el tiempo gracias a la captación de datos continua. Cuenta con más de 20.000 parcelas
- Estadística General de Incendios Forestales. Incluye la información recogida en los Partes de Incendio que se cumplimentan por parte de las comunidades autónomas para cada uno de los incendios forestales que tienen lugar en España.
Estos conjuntos de datos, junto con otros de este Ministerio, se han federado con datos.gob.es, de tal forma que también están disponibles a través de nuestro catálogo de datos. Como cualquier otro conjunto de datos que se publica en datos.gob.es, automáticamente quedarán federados también con el portal europeo.
El antecedente de este proyecto fue CrossNature. Este proyecto dio como resultado la base de datos Eidos, que incluye datos enlazados de especies silvestres de fauna y flora de España y Portugal. También están disponible en datos.gob.es y se refleja en el portal europeo.
Ambos proyectos son un ejemplo de innovación y colaboración entre países, con el fin de conseguir unos datos más armonizados e interoperables, que permitan comparar indicadores y mejorar las actuaciones, en este caso, en materia de protección forestal.
Blog
La iniciativa Hércules se inicia en noviembre de 2017, mediante un convenio entre la Universidad de Murcia y el Ministerio de Economía, Industria y Competitividad, con el objetivo de desarrollar un Sistema de Gestión de Investigación (SGI) basado en datos abiertos semánticos que ofrezca una visión global de los datos de investigación del Sistema Universitario Español (SUE), para mejorar la gestión, el análisis y las posibles sinergias entre universidades y el gran público.
Esta iniciativa es complementaria a UniversiDATA, donde varias universidades españolas colaboran para fomentar los datos abiertos en el sector de la educación superior mediante la publicación de conjuntos de datos a través de criterios estandarizados y comunes. En concreto se define un Núcleo Común con 42 especificaciones de datasets, de los cuales se han publicado 12 para la versión 1.0. Hércules, en cambio es una iniciativa específica del ámbito de investigación, estructurada en torno a tres pilares:
- Prototipo innovador de SGI
- Grafo unificado de conocimiento (ASIO) 1],
- Enriquecimiento de datos y análisis semántico (EDMA)
El objetivo final es la publicación de un grafo unificado de conocimiento donde queden integrados todos los datos de investigación que deseen hacer públicos las universidades participantes. Hércules prevé la integración de universidades a diferentes niveles, dependiendo de su disposición a reemplazar su SGI por el SGI de Hércules. En el caso de SGIs externos, el grado de accesibilidad que ofrezcan también tendrá implicación en el volumen de datos que puedan compartir a través del grafo unificado.
Organigrama general de la iniciativa Hércules
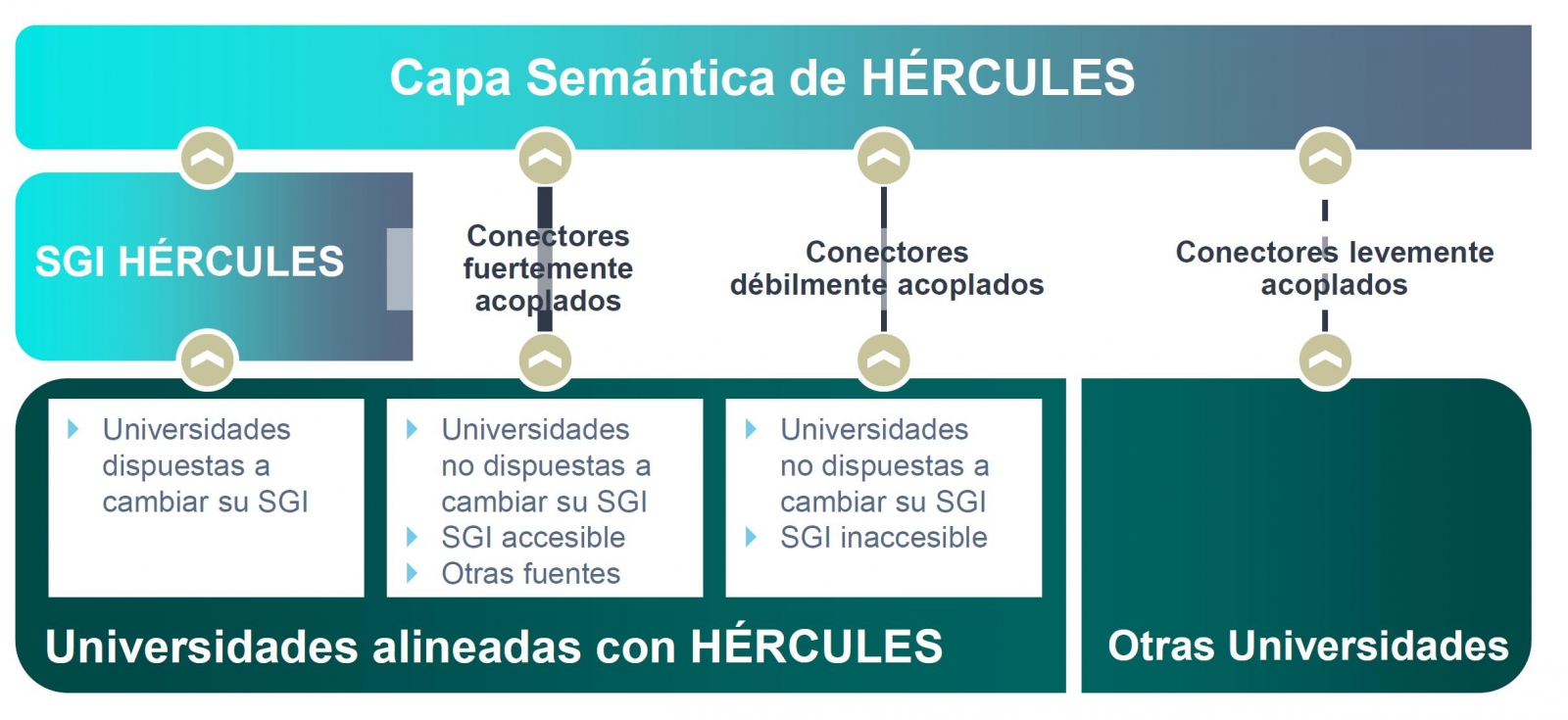
Dentro de la iniciativa Hércules, se integra el Proyecto ASIO (Arquitectura Semántica e Infraestructura Ontológica). El propósito de este sub-proyecto es definir una Red de Ontologías para la Gestión de la Investigación (Infraestructura Ontológica). Una ontología es una definición formal que describe con fidelidad y alta granularidad un dominio de discusión concreto. En este caso, el dominio de la investigación, que puede ser extrapolable a otras universidades españolas e internacionales (de momento el piloto se está desarrollando con la Universidad de Murcia). Es decir, se trata de crear un vocabulario de datos común.
Adicionalmente, a través del módulo de Arquitectura Semántica de Datos se ha desarrollado una plataforma eficiente para almacenar, gestionar y publicar datos de investigación del SUE, basándose en ontologías, con la capacidad de sincronizar instancias instaladas en diferentes universidades, así como la ejecución de consultas federadas distribuidas sobre aspectos clave de producción científica, líneas de investigación, búsqueda de sinergias, etc.
Como solución a este reto de innovación se han propuesto dos líneas complementarias, una centralizada (sincronización en escritura) y otra descentralizada (sincronización en consulta). En las próximas secciones se explica en detalle la arquitectura de la solución descentralizada.
Domain Driven Design
El modelo de datos sigue el enfoque Domain Driven Design, modelando entidades y vocabulario común, que pueda ser comprendido tanto por desarrolladores como expertos del dominio. Este modelo es independiente de la base de datos, del interfaz de usuario y del entorno de desarrollo, obteniendo una arquitectura de software limpia que permite adaptarse a los cambios del modelo.
Para ello se hace uso de Shape Expressions (ShEx), un lenguaje para validar y describir conjuntos de datos RDF, con sintaxis legible por humanos. A partir de estas expresiones se genera el modelo de dominio automáticamente y permite orquestar un proceso de integración continua (CI), tal y como se describe en la siguiente figura.
Proceso de integración continua mediante Domain Driven Design
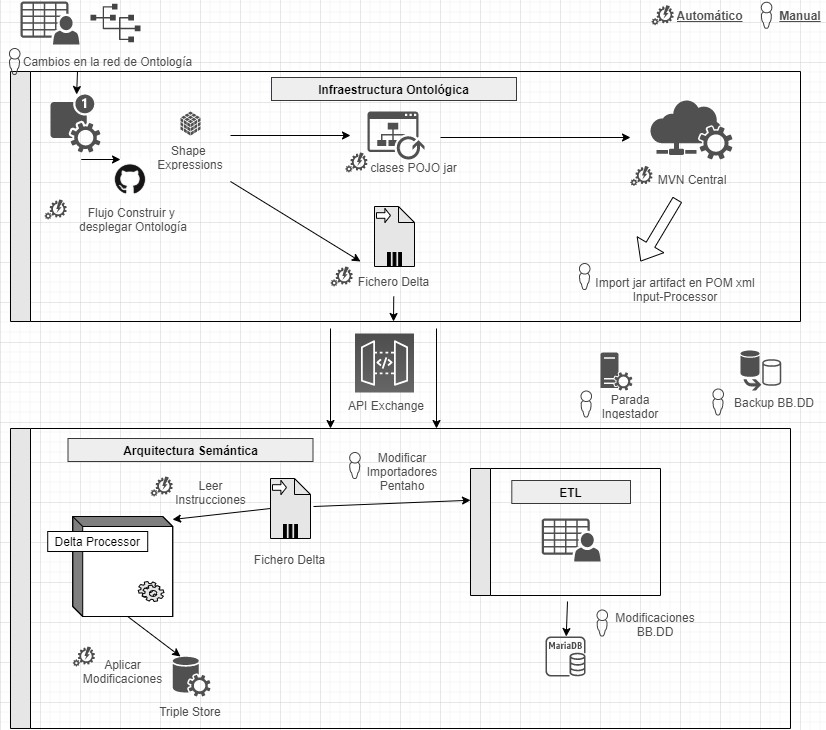
Mediante un sistema basado en de control de versiones como elemento central, se ofrece la posibilidad de que los expertos de dominio construyan y visualicen las ontologías multilingües. Estas a su vez se apoyan en ontologías tanto del ámbito de la investigación: VIVO, EuroCRIS/CERIF o Research Object, como ontologías de propósito general para la etiquetación de metadatos: Prov-O, DCAT, etc.
Linked Data Platform
El servidor de datos enlazados es el núcleo de la arquitectura, encargándose de renderizar la información sobre todas las entidades. Para ello recoge peticiones HTTP del exterior y las redirecciona a los servicios correspondientes, aplicando negociación de contenidos, la cual ofrece la mejor representación de un recurso basado en las preferencias del navegador para los distintos tipos de medios, idiomas, caracteres y codificación.
Todos los recursos se publican siguiendo un esquema de URIs persistentes diseñado a medida. Cada entidad representada mediante una URI (investigador, proyecto, universidad, etc) dispone de una serie de acciones para consultar y actualizar sus datos, siguiendo los patrones propuestos por Linked Data Platform (LDP) y el modelo de 5 estrellas.
Este sistema garantiza además el cumplimiento con los principios FAIR (Findable, Accesible, Interoperable, Reusable) y publica automáticamente los resultados de aplicar dichas métricas sobre el repositorio de datos.
Publicación de datos abiertos
El sistema de procesamiento de datos se encarga de la conversión, integración y validación de datos de terceras partes, así como la detección de duplicados, equivalencias y relaciones entre entidades. Los datos surgen de varias fuentes, principalmente el SGI unificado de Hércules, pero también de SGIs alternativos, o de otras fuentes que ofrecen datos en formato FECYT/CVN (Curriculum Vitae Normalizado), EuroCRIS/CERIF y otros posibles.
El sistema de importación convierte todas estas fuentes a formato RDF y los registra en un repositorio de propósito específico para datos enlazados, denominado Triple Store, por su capacidad para almacenar tripletas de tipo sujeto-predicado-objeto.
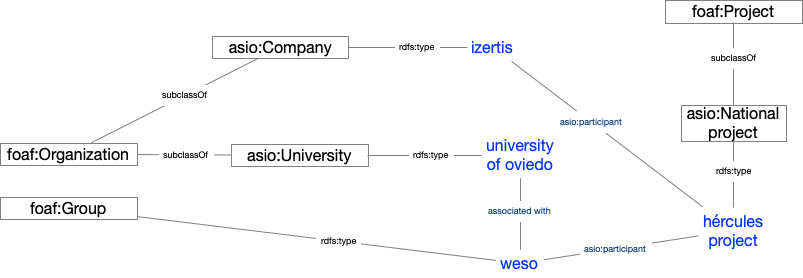
Una vez importados, se organizan formando un grafo de conocimiento, fácilmente accesible, permitiendo realizar inferencias y búsquedas avanzadas potenciadas por las relaciones entre conceptos.
Ejemplo de grafo de conocimiento describiendo el proyecto ASIO
Resultados y conclusiones
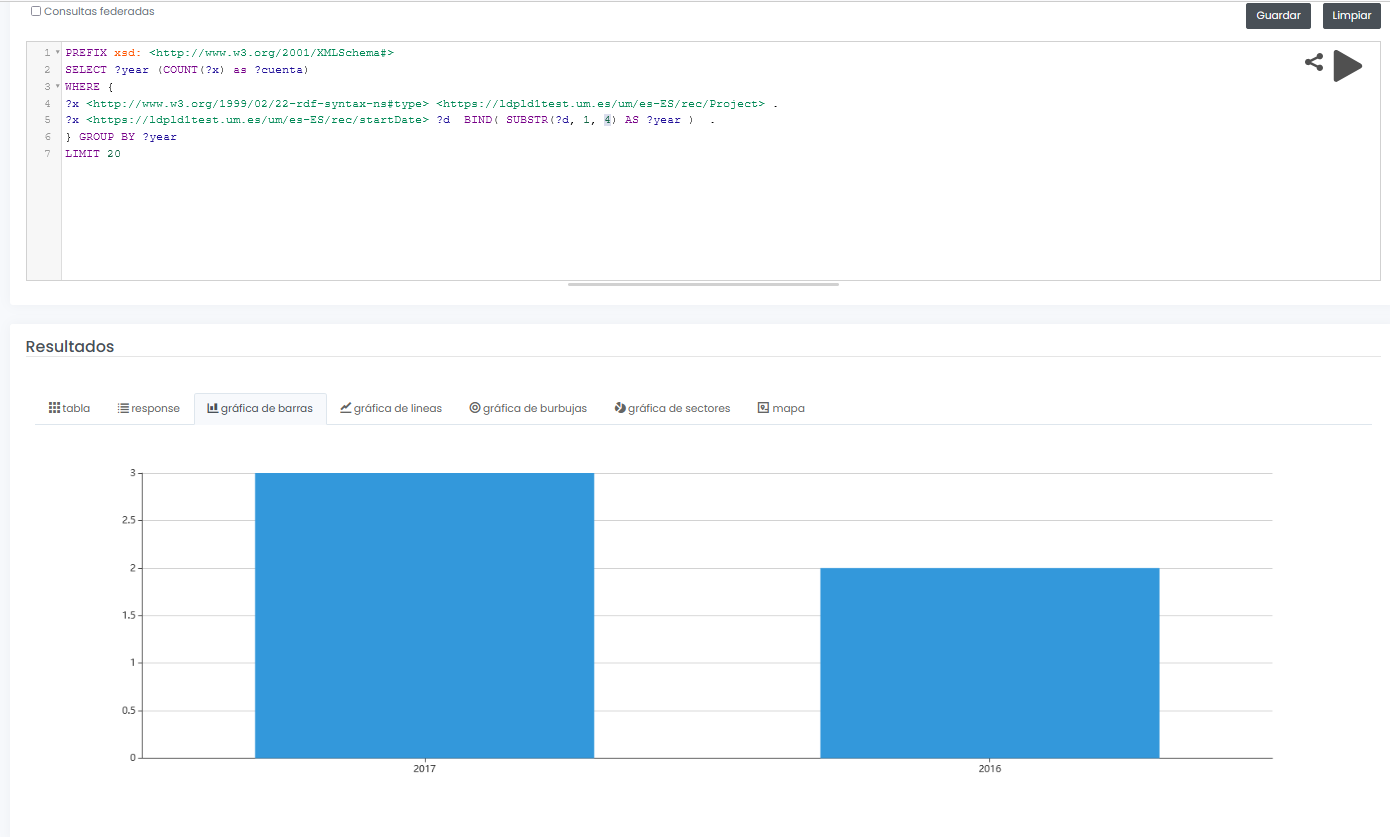
El sistema final no sólo permite ofrecer un interfaz gráfico para consulta interactiva y visual de datos de investigación, sino que además permite diseñar consultas SPARQL, como la que se muestra a continuación, incluso con la posibilidad de ejecutar la consulta de forma federada sobre todos los nodos de la red Hércules, y mostrar resultados de forma dinámica en diferentes tipos de gráficos y mapas.
En este ejemplo, se muestra una consulta (con datos limitados de prueba) de todos proyectos de investigación disponibles agrupados gráficamente por año:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
En definitiva, ASIO ofrece un marco común de publicación de datos abiertos enlazados, ofrecido como código libre y fácilmente adaptable a otros dominios. Para dicha adaptación, bastaría con diseñar un modelo de dominio específico, incluyendo la ontología y los procesos de importación y validación comentados en este artículo.
Actualmente el proyecto, en sus dos variantes (centralizada y descentralizada), se encuentra en proceso de puesta en pre-producción dentro de la infraestructura de la Universidad de Murcia, y en breve será accesible públicamente.
[1 Los grafos son una forma de representación del conocimiento que permiten relacionar conceptos a través de la integración de conjuntos de datos, utilizando técnicas de web semántica. De esta forma se puede conocer mejor el contexto de los datos, lo que facilita el descubrimiento de nuevo conocimiento.
Contenido elaborado por Jose Barranquero, experto en Ciencia de datos y computación cuántica.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Una parte importante de los datos que están publicados bajo las premisas de la Web Semántica, donde los recursos están identificados por URIs, se almacenan dentro de bases de datos de tripletas (triplestore), y estos datos solo pueden ser accedidos mediante consultas SPARQL a través de un SPARQL endpoint.
Además, las URIs utilizadas, normalmente diseñadas bajo un patrón, en la mayoría de los conjuntos de datos (datasets) que se almacenan en esas bases de datos no son dereferenciables, esto es, que al realizar una petición a ese identificador no se recibe ninguna respuesta (error 404).
Ante esta situación, en el cual esos datos solo están accesibles para las máquinas, y aunado con el empuje del movimiento de los datos enlazados (Linked Data), son varios los proyectos que han surgido con el principal objetivo de generar vistas para humanos de esos datos mediante interfaces web (donde las vistas de los recursos estén enlazadas unas con otras), así como ofrecer un servicio donde las URIs sean dereferenciables.
Pubby es, posiblemente, el proyecto más conocido que se ha creado con este objetivo. Es una aplicación web desarrollada en java, cuyo código está compartido bajo la licencia de código abierto Apache License, Version 2.0., y que está diseñada para ser desplegada en sistema que posea acceso SPARQL a la base de datos de tripletas sobre la que se quiera aplicar.
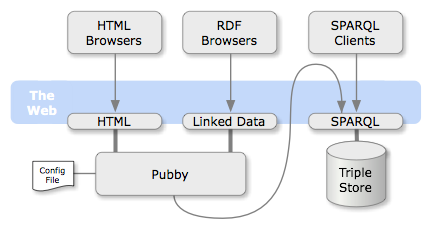
Mediante un fichero de configuración, se realiza un mapeo entre las URI no-dereferenciables y las URIs dereferenciables que son gestionadas por el servidor Pubby. Con ello, la aplicación tramita las peticiones a las URIs mapeadas, preguntando por la información de la URI original a la base datos asociada (mediante una consulta SPARQL DESCRIBE) y devuelve los resultados al cliente (en el formato de representación solicitado).
Además, Pubby proporciona una vista simple en HTML de los datos almacenados y gestiona la negociación de contenidos entre las diferentes representaciones. Mediante el interfaz web, el usuario puede navegar entre las vistas HTML de los recursos enlazados (Linked Data). En estas vistas se muestra toda la información de los recursos, incluyendo los atributos y relaciones con otros recursos.
Del proyecto Pubby han surgido múltiples proyectos paralelos (forks) y proyectos inspirados. Uno de los últimos ha sido el proyecto Linked Open Data Inspector (LODI), desarrollado desde el grupo de ingeniería software Quercus de la Universidad de Extremadura bajo licencia Creative Commons Atribución 3.0. Este proyecto está desarrollado en Node.js y posee algunas diferencias positivas respecto a Pubby:
-
Proporciona una vista simple en HTML para todos los públicos, y otra más detallada para programadores.
-
Proporciona información del recurso en el formato N3 (aunque no RDF/XML o Turtle).
-
En el caso de recursos con información geoespaciales, se muestra un mapa detallando la ubicación.
-
De igual manera, en el caso de detectar imágenes (.jpg, .jpeg o .png), estas son mostradas de forma automática.
Actualmente existen dos portales de datos abiertos que están utilizando LODI: Open Data Cáceres y Open Data UEx.
Pubby, LODI y otros proyectos similares (como LODDY), usando en el tesauro AGROVOC han conseguido exponer información que estaba retenida dentro de bases de datos RDF y que no era accesible para los humanos. Proyectos como estos hacen que la web de los datos enlazados siga creciendo en cantidad y en calidad, poniendo la interacción con las personas como el eje y centro de estos avances.
Noticia
La Biblioteca Nacional Española (BNE) continúa impulsando la difusión y reutilización de sus fondos documentales. Además de contribuir a la conservación del patrimonio cultural que custodia, a través de la digitalización y la preservación digital de sus colecciones, la BNE también busca facilitar el acceso de los ciudadanos a los datos culturales, enriquecerlos y fomentar su reutilización en todos los campos, más allá de la investigación, como el turismo, la moda o los videojuegos, entre otros.
Desde que lanzó la primera versión de su portal de datos enlazados datos.bne.es en 2014, la BNE ha apostado por ofrecer un nuevo acercamiento a la gran cantidad de datos que genera: datos de las obras que conserva pero también de autores, vocabularios controlados de materias, términos geográficos, etc. Dichos datos cuentan con un alto nivel de normalización y cumplen con estándares internacionales de descripción e interoperabilidad. También están identificados mediante URIs y modelos conceptuales nuevos, enlazados mediante tecnologías semánticas y ofrecidos en formatos abiertos y reutilizables.
Además, datos.bne.es es un claro ejemplo de cómo la aplicación de técnicas y estándares de Linked Open Data permite el enriquecimiento de datos con otras fuentes, convirtiéndose en herramienta y base para proyectos de investigación con big data o machine learning. Esto abre numerosas posibilidades de búsqueda y visualización de la información (mediante grafos, georreferenciación, etc.). En definitiva, datos.bne.es constituye el tránsito desde una herramienta para localizar ejemplares a una herramienta para localizar y utilizar datos, enriqueciéndolos e integrándolos en el universo Linked Open Data.
Desde 2014, se han ido dando pasos en este sentido, buscando acercar los datos de la BNE a ciudadanos y reutilizadores. Para ello, la biblioteca acaba de lanzar una nueva versión de datos.bne.es. Esta nueva versión supone, por un lado, una actualización completa de los datos, y por otro, nuevas funcionalidades que facilitan el acceso a la información.
Entre estas novedades encontramos:
- Incorporación de un nuevo buscador especializado. A partir de ahora se podrán realizar búsquedas avanzadas sobre las ediciones de las obras, así como sobre las personas y las entidades que intervienen en ellas. De este modo, se podrán buscar autores en función de su fecha y lugar de nacimiento o fallecimiento, por su género o su profesión. Es importante señalar que estos datos aún no están disponibles para todas las personas y entidades del catálogo, por lo que los resultados deben ser considerados una muestra que se irá ampliando progresivamente.
- Posibilidad de realizar búsquedas multilingües. El buscador de Temas permite la búsqueda multilingüe de conceptos en inglés y francés. Por ejemplo, una búsqueda de “Droit à l'éducation” devolverá el concepto “Derecho a la educación”. Esta funcionalidad se ha podido conseguir explotando semánticamente la relación entre los vocabularios de BNE, Library of Congress y la Biblioteca Nacional de Francia. En posteriores actualizaciones se incrementará el número de idiomas.
- Mejora del acceso a recursos de la Biblioteca Digital Hispánica. A partir de ahora, las ediciones digitalizadas de recursos musicales y de prensa incluirán los accesos directos al recurso digitalizado.
Todas estas actualizaciones suponen un gran paso en el camino que la Biblioteca Nacional de España está llevando a cabo en favor de la promoción de los datos abiertos culturales, pero su esfuerzo no acaba aquí. Durante los próximos meses van a continuar trabajando para mejorar la usabilidad, apostando por un portal visual e intuitivo, con conjuntos de datos que sean fáciles de reutilizar (por ejemplo, incorporando nuevos formatos o enriqueciendo los datos a través de tecnologías semánticas). Además, se apostará por mejoras en la interoperabilidad y normalización. Todo ello son acciones necesarias para facilitar que los usuarios puedan reutilizar los datos disponibles y crear nuevos productos y servicios que aporten valor a la sociedad.
Para garantizar que todas las actuaciones que lleva a cabo están alineadas con las necesidades de los usuarios, la biblioteca Nacional de España también ha apostado por la creación de una Comunidad de datos abiertos. El objetivo es que, aquellos ciudadanos que lo deseen, puedan compartir un espacio de diálogo donde proponer nuevas mejoras, actualizaciones y usos de los datos abiertos culturales. Dicha comunidad estará formada por una conjunción de perfiles profesionales bibliotecarios y técnicos, lo cual ayudará a extraer todo el valor de los datos de la institución.
Noticia
La alta diplomacia desempeña tradicionalmente un papel en ayudar a culturas y naciones a dialogar entre sí. Pero cuando se trata de fortalecer el derecho a la tierra, son las propias comunidades locales quienes tienen que involucrarse.
Ésta es la visión de la Fundación Land Portal, y la razón principal por la cual ha creado el portal web landportal.org, un lugar donde los grupos interesados puedan recopilar y consultar información sobre la temática del derecho a la tierra y su gobernanza. Esta información proviene de diversas fuentes (fragmentadas y en ocasiones poco accesibles) y producida por gobiernos, la academia, organizaciones internacionales, pueblos indígenas y organizaciones no gubernamentales. Además de recopilar información, la plataforma promueve la generación de debates, el intercambio de información y la creación de redes de contactos.
En la base de la organización, y por ende de la plataforma, están las ideas del “movimiento abierto”, que se plasman en realidades concretas como establecer por defecto licencias de código abierto en todos sus desarrollos informáticos, el consumo de datos abiertos y la publicación de datos abiertos enlazados (Linked Open Data, LOD), o el uso de licencias abiertas a la hora de compartir información.
El portal recopila datos estadísticos, datos bibliográficos, o datos sobre diferentes recursos (organizaciones, eventos, noticias, proyectos) y los vuelve a publicar como LOD en un formato legible por máquinas (RDF), utilizando un modelo de datos basado en estándares y compartido bajo una licencia abierta. Con ello, la fundación pretende crear un ecosistema de información y de reutilización de la misma.
Para acceder a estos datos publicados bajo los criterios del Linked Open Data, se ha desplegado un SPARQL endpoint donde se pueden realizar consultas semánticas a los diferentes grafos en los que se agrupa el conocimiento.
Otro de los proyectos de la organización es LandVoc, un vocabulario controlado que recoge conceptos relacionados con la gobernanza de la tierra. Este vocabulario proviene del tesauro AGROVOC, y nace como un intento de estandarización de los conceptos relacionados con la gobernanza de la tierra. De esta manera las diferentes organizaciones del dominio pueden usar los conceptos para etiquetar contenido y así favorecer el intercambio de información y la integración de sistemas. Actualmente LandVoc consta de 270 conceptos, está disponible en 4 idiomas (inglés, francés, español y portugués), y se publica bajo la licencia abierta Creative Commons Reconocimiento-No comercial-CompartirIgual 3.0 IGO (CC BY-NC-SA 3.0 IGO).
La Fundación Land Portal realiza todo ello con el objetivo último de mejorar la gobernanza de la tierra y así beneficiar a los colectivos con mayor inseguridad en su derecho a la tierra. La teoría del cambio de la organización predice un aumento en la calidad de vida de los colectivos más vulnerables, si se consigue su derecho a vivir y cultivar sin temor a desalojos forzosos o ilegales; y con la seguridad de la tenencia de la tierra, también predice el progreso la seguridad alimentaria para las comunidades más vulnerables del mundo.
Noticia
Si lo analizamos con perspectiva, el concepto de datos abiertos no es realmente tan revolucionario o novedoso en sí mismo. Por un lado, la filosofía de apertura y/o reutilización en la que se basan los datos abiertos llevaba ya mucho tiempo establecida entre nosotros antes de su definición formal. Por otro lado, los objetivos del movimiento de los datos abiertos son también muy similares a aquellos que promueven otras comunidades con mayor recorrido y que podrían en cierto modo considerarse también afines, tales como el código abierto, el hardware abierto, el contenido abierto, el gobierno abierto o la ciencia abierta, entre muchos otros.
No obstante, tanto el término “open data” como la comunidad asociada a él pueden ambos considerarse relativamente recientes, empezando a ganar en popularidad hace ya unos diez años cuando un grupo de defensores del gobierno abierto establecieron los ocho principios de los datos abiertos gubernamentales durante la reunión que tuvo lugar en Sebastopol (California) en Diciembre de 2007. Acto seguido se lanzaron las iniciativas oficiales de datos abiertos de referencia por parte de los gobiernos de Estados Unidos (data.gov) y Reino Unido (data.gov.uk), dándole el empujón final que necesitaba esta nueva corriente para convertirse en un nuevo movimiento con identidad propia.
Desde entonces la comunidad global de los datos abiertos ha progresado enormemente, pero también se encuentra todavía muy lejos de sus objetivos iniciales. Al mismo tiempo, los datos en general se están consolidando como el activo más valioso con el que cuentan la mayoría de las organizaciones hoy en día. Es por ello que, en el décimo aniversario desde su formalización, la comunidad de los datos abiertos se plantea ahora una reflexión sobre su papel en el pasado - mirando hacia los logros obtenidos hasta el momento - y también sobre su rol en un futuro próximo dominado por los datos.
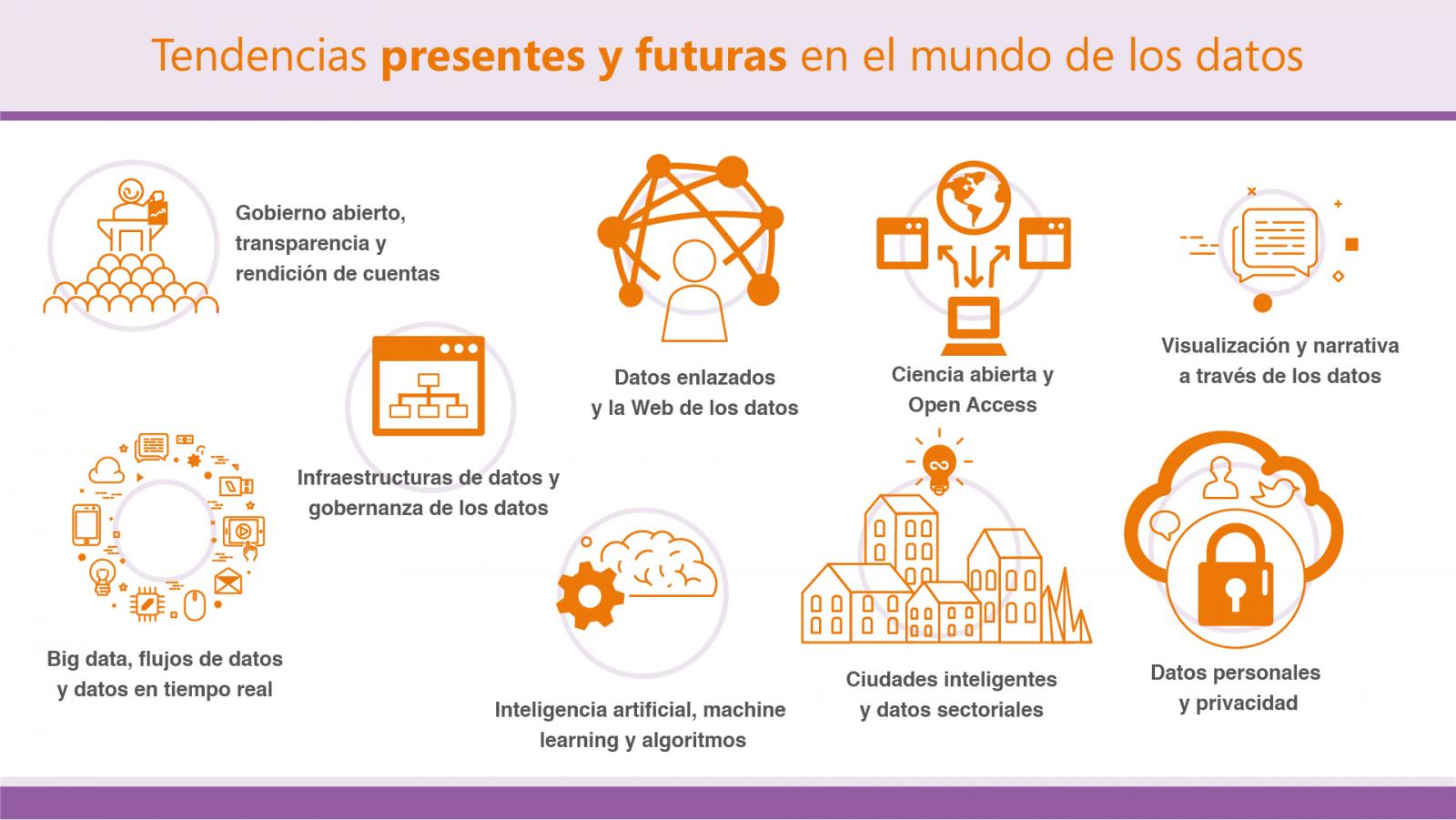
En este contexto tiene sentido hacer un breve repaso sobre algunas de las tendencias actuales en el mundo de los datos y cuál es el papel que podrían jugar los datos abiertos en cada una de ellas, empezando por las que sean quizás más afines:
Gobierno abierto, transparencia y rendición de cuentas
Aunque las comunidades de la libertad de información y datos abiertos a veces difieren en sus estrategias, ambas comparten el objetivo común de facilitar el acceso de los ciudadanos a la información necesaria para mejorar la transparencia y los servicios públicos. El potencial beneficio que se puede obtener de la colaboración entre ambos grupos es por tanto muy significativo, evolucionando del derecho a la información al derecho a los datos. Sin embargo después de varios esfuerzos no se ha conseguido todavía que la colaboración sea tan efectiva como sería deseable y existen también dudas acerca de si los datos abiertos se están utilizando realmente como una herramienta efectiva para la transparencia o precisamente como una excusa para no tener que hacer un ejercicio de transparencia más profundo.
Datos enlazados y la Web de los datos
El objetivo de la Web de los datos es poder crear conexiones explícitas entre aquellos datos que están relacionados entre sí y que ya están disponibles en la web, pero no convenientemente relacionados. No todos los datos enlazados necesitan forzosamente ser también abiertos, pero por el propio objetivo de los datos enlazados está claro que la combinación de ambos es lo que permitiría alcanzar su máximo potencial conjunto, como sucede ya por ejemplo con algunas grandes bases de datos globales de referencia como DBPedia, LexInfo, Freebase, NUTS o BabelNet.
Ciencia abierta y Open Access
Son muchas ya las ocasiones en las que se ha comentado la ironía de que en este mismo momento de la historia en el que contamos con las mejores herramientas y tecnologías para poder distribuir la ciencia y el conocimiento a lo largo del mundo, estamos precisamente muy ocupados poniendo nuevas barreras al uso de esos valiosos datos y ese conocimiento. El pujante movimiento del open access apuesta precisamente por aplicar nuevamente los criterios de los datos abiertos a la producción científica, de forma que pase a ser un bien intangible y acelerar así la nuestra capacidad de colaboración y descubrimiento conjunto para que genere nuevos logros para la humanidad.
Visualización y narrativa a través de los datos
A medida que más y más datos están disponibles para cualquier organización o individuo el siguiente paso indispensable será el de proporcionar también los medios para que se pueda extraer todo el valor de ellos. La capacidad de, partiendo de unos datos concretos, ser capaces de comprenderlos, procesarlos, extraer su valor y comunicarlo adecuadamente, va a ser una habilidad muy demandada en la próxima década. La elaboración de historias a partir de los datos no es más que una aproximación estructurada a la hora de comunicar el conocimiento que nos transmiten los datos a través de tres elementos clave combinados, capaces en conjunto de generar la influencia necesaria para dar lugar a cambios: datos, visualizaciones y narrativa.
Big data, flujos de datos y datos en tiempo real
En el presente las organizaciones tienen que lidiar con un volumen y variedad cada vez mayor de datos. Las técnicas de tratamiento de big data les permite analizar estos grandes volúmenes de información para aflorar distintos patrones y correlaciones que servirán para mejorar los procesos de toma de decisión. No obstante, el gran reto continua siendo cómo realizar este proceso de forma eficiente sobre flujos continuos de datos en tiempo real. Si bien el big data promete una capacidad de análisis sin precedentes, su combinación con la filosofía de los datos abiertos permitirá que ese poder pueda ser compartido por todos mejorando los servicios públicos.
{kind=link}
Inteligencia artificial, machine learning y algoritmos
Aunque la inteligencia artificial está cada vez más presente en varios aspectos de nuestras vidas cotidianas, podríamos considerar que todavía nos encontramos en una etapa muy temprana de lo que podría llegar a ser una revolución global. La inteligencia artificial cuenta ya con un éxito relativo en alguna tareas que tradicionalmente habían siempre requerido de lo que consideramos inteligencia humana para poder llevarse a cabo. Para que esto sea posible son también necesarios algoritmos alimentados por datos que sostengan estos sistemas automatizados. Una mayor disponibilidad y calidad de los datos abiertos servirá para alimentar esos algoritmos y a la vez poder también mejorarlos y auditar su correcto funcionamiento.
Ciudades inteligentes y datos sectoriales
El movimiento de los datos abiertos se encuentra también en un periodo de transición en el que se están empezando a focalizar los esfuerzos en publicar los datos necesarios para dar respuesta a problemas concretos en lugar de simplemente intentar publicar cualquier dato en general. Esta aproximación temática o sectorial resulta generalmente más eficiente porque no solo requiere de menos recursos para su ejecución, sino que también está más centrada en la necesidades de los usuarios y beneficiarios finales de los datos. En este sentido destaca el área concreta de las ciudades inteligentes o las open cities como ejemplo de integración de las distintas tecnologías y filosofías de datos para la mejora de los servicios que se ofrecen a los ciudadanos.
Datos personales y privacidad
Hoy en día pasamos una buen parte de nuestras vidas online y eso está contribuyendo a generar una cantidad de información sobre nosotros que no tiene precedente. Gracias a estos datos podemos disfrutar de nuevos servicios de gran utilidad, pero también cuentan con una parte negativa importante. En caso de que exista por ejemplo algún fallo en la cadena de custodia de nuestros datos se podría revelar importante información personal sobre nuestra capacidad económica, posicionamiento político o hábitos de consumo entre otros. Por otra parte, existen también cada vez más usos poco éticos por parte de algunas empresas. Usando los mismos principios de los datos abiertos se está experimentando con nuevas formas de autogestión de nuestros datos personales para conseguir un balance entre retomar el control de nuestros propios datos y los beneficios que podemos obtener mediante su explotación, siempre con nuestro expreso conocimiento y consentimiento.
Infraestructuras de datos y gobernanza de los datos
La gestión del día a día de los datos comienza a ser una tarea tan valiosa como compleja para cualquier organización en general, pero particularmente complicada para la administración debido a su propio volumen y la necesidad de combinar distintos modelos de gestión que se corresponden también con los distintos niveles administrativos. Para afrontar esta tarea de gestión con garantías será necesario invertir en las infraestructuras de datos adecuadas, tanto a nivel físico como de gestión. Establecer los frameworks tecnológicos y los modelos de gobernanza de los datos necesarios para que puedan ser compartidos con agilidad será un requisito indispensable para conseguir un modelo de administración eficiente en el futuro.
Con todo lo anterior, es posible que en un futuro no muy lejano dejemos de tratar los datos abiertos como la única solución posible para los retos que se plantean a los gobiernos y empecemos a tratarlos como otra herramienta clave a nuestra disposición que utilizaremos de forma más diluida e integrada junto a las otras tendencias actuales en el mundo de los datos y la apertura que hemos repasado.
Noticia
Una de las grandes preocupaciones de los organismos internacionales es dispersión en la categorización e indexación del conocimiento creado en cada una de las partes que los componen (tales como agencias, unidades, departamentos, sedes o programas). Esto se debe a que, por ejemplo, cuando una persona de un departamento quiera buscar contenido sobre una temática concreta en todos los repositorios de conocimiento de cada una de las partes de la organización, normalmente tiene que realizar una búsqueda en cada repositorio. Para ello utiliza las palabras clave definidas para cada repositorio (que pueden ser diferentes), en vez utilizar las mismas, o incluso, realizar solo una única búsqueda (en caso de existir un sistema de búsqueda donde todos los repositorios estuvieran integrados). Para solventar esta preocupación y facilitar así el intercambio de información entre cada una de sus partes, es habitual la creación de vocabularios controlados para la clasificación de los contenidos generados.
La Organización de las Naciones Unidas para la Alimentación y la Agricultura (FAO) estaba en esta situación, y por ello a principios de los años 80 creó AGROVOC.
AGROVOC es un tesauro que organiza conceptos relacionados con los ámbitos de interés de la FAO, como son la agricultura (principalmente), la alimentación, la nutrición, la pesca, las ciencias forestales o el medio ambiente.
Este tesauro (y por ende, vocabulario controlado) que está compuesto actualmente (agosto 2017) por más de 33.000 conceptos, ha seguido un proceso evolutivo, pasando de estar en 3 idiomas a 23 (siendo el español uno de los tres primeros), de estar disponible solo en papel impreso a estar disponible como un esquema conceptual SKOS-XL.
Además, AGROVOC está disponible como un conjunto de datos enlazados (LOD) alineado con otros 16 sistemas multilingües de organización del conocimiento relacionados con la agricultura (como DBPedia, EUROVOC, el tesauro de la biblioteca nacional de agricultura (NAL) de los Estados Unidos de América, el tesauro del Centro Internacional para la agricultura y la biotecnología (CABI)).
De hecho, múltiples organizaciones están trabajando en proyectos, como Global Agricultural Concept Scheme (GACS), donde se explora la posibilidad de crear un tesauro conceptos y terminología en el área de la agricultura, reutilizando los tesauros de AGROVOC, CABI y NAL.
La gestión de AGROVOC se divide en varias partes, por un lado la FAO es la encargada de su publicación y revisión final, mientras que por otro lado, una comunidad de organizaciones y expertos externos de diferentes áreas de conocimiento se encargan de su edición (proponiendo nuevos conceptos, ampliando la terminología de los conceptos ya existentes en otros idiomas, revisando y conservando la terminología ya creada...). Para realizar este trabajo de edición, la comunidad utiliza VocBench, una herramienta de gestión de vocabularios de código abierto .
Sin duda, una de las características clave que ha facilitado la extensión del uso de AGROVOC en la comunidad es que su acceso y utilización es gratuita, distribuyendose bajo licencia Creative Commons 3.0 Atribución (CC-BY).
AGROVOC es comúnmente utilizado por personal investigador, bibliotecarios y gestores de conocimiento para para la indización, recuperación y organización de datos en sistemas de información sobre agricultura y los otros ámbitos de interés de la FAO anteriormente mencionados. Como ejemplos de dogfooding (cuando una organización utiliza su propio producto para probarlo y promocionarlo) está el uso de AGROVOC en AGRIS, la base de datos de información bibliográfica relativa a ciencia y tecnología agrícola, o FAOLEX, una base de datos de legislación y políticas nacionales sobre alimentación, agricultura y gestión de recursos naturales, ambas gestionadas por la FAO.
Las maneras de acceder, consultar y reutilizar AGROVOC son variadas
-
Se pueden consultar conceptos o navegar por la jerarquía
-
Se puede descargar como un conjunto de datos RDF en dos versiones: Agrovoc Core (incluye todos los conceptos en todos los idiomas, pero sin enlaces a vocabularios externos) y Agrovoc LOD (que sí incluye los enlaces a vocabularios externos)
-
Se pueden consumir los servicios web disponibles
-
Se puede indagar mediante consultas SPARQL, utilizando para ello un SPARQL endpoint público
Los datos relacionados con la agricultura que se están generando, están creciendo exponencialmente, ya sea por la captación de datos medioambientales a través de sensores, por los datos económicos sobre precios, por datos sobre producción de las cosechas, por datos sobre enfermedades y plagas, por la recopilación de normativas legales, etc... Todo este conocimiento, si es cuidadosamente catalogado, podrá ser fuente de futuros estudios y descubrimientos, tanto en el ámbito público como en el privado. En este marco, AGROVOC (y quizás en un futuro GACS) supone una valiosa herramienta para que los datos se clasifiquen homogéneamente, facilitando la interoperabilidad y reutilización de los mismos, tanto dentro de una misma organización como fuera de ella.
Noticia
El Consorcio W3C define los datos enlazados (linked data) como la forma de vincular los distintos datos distribuidos en Internet del mismo modo que se interconectan los enlaces de las páginas web. De esta manera, se permite a los usuarios y máquinas acceder, explorar, consultar y reutilizar dichos datos desde diferentes fuentes.
Actualmente, solo unas pocas universidades en Europa publican sus datos en formato linked data, usando tecnologías RDF y SPARQL y dando acceso directo a la información relativa a cursos, material educativo, investigación o publicaciones. Sumado a este primer obstáculo, además estas iniciativas no están conectadas entre ellas. Bajo este marco nace Linked Universities; un acuerdo entre diferentes universidades europeas que fomenta la publicación y reutilización de su conocimiento a partir de los datos enlazados.
Conscientes del potencial que ofrece el linked data para el sector académico y de investigación, los miembros de dicha alianza –formada por 11 entidades entre las que se encuentra la Universitat Pompeu Fabra- trabajan para desarrollar una plataforma de datos universitarios vinculados; un espacio colaborativo donde instituciones y ciudadanos puedan acceder, compartir y reutilizar la información. Entre los objetivos principales del proyecto se encuentran:
- Identificar, desarrollar y estandarizar vocabularios comunes de linked data para enlazar cursos, calificaciones, material educativo…
- Describir fórmulas de reutilización y compartir herramientas para la publicación de la información en formato de datos enlazados.
- Impulsar iniciativas que fomenten el uso de datos enlazados en la universidad.
Gracias a iniciativas como Linked Universities que promueven compartir, distribuir y reutilizar el conocimiento es posible mejorar los procesos de aprendizaje e investigación de las propias universidades mientras se generan nuevos servicios, productos y aplicaciones de los datos.