Entrevista
Publishing open data following the best practices of linked data allows to boost its reuse. Data and metadata are described using RDF standards that allow representing relationships between entities, properties and values. In this way, datasets are interconnected with each other, regardless of the digital repository where they are located, which facilitates their contextualization and exploitation.
If there is a field where this type of data is especially valued, it is research. It is therefore not surprising that more and more universities are beginning to use this technology. This is the case of the University of Extremadura (UEX), which has a research portal that automatically compiles the scientific production linked to the institution. Adolfo Lozano, Director of the Office of Transparency and Open Data at the University of Extremadura and collaborator in the preparation of the "Practical guide for the publication of linked data in RDF", tells us how this project was launched.
Full interview:
1. The research portal of the University of Extremadura is a pioneering initiative in our country. How did the project come about?
The research portal of the University of Extremadura has been launched about a year ago, and has had a magnificent reception among UEX researchers and external entities looking for the lines of work of our researchers.
But the UEX open data portal initiative started in 2015, applying the knowledge of our research group Quercus of the University of Extremadura on semantic representation, and with the experience we had in the open data portal of the City Council of Cáceres. The biggest boost came about 3 years ago when the Vice-Rectorate for Digital Transformation created the UEX Office of Transparency and Open Data.
From the beginning, we were clear that we wanted a portal with quality data, with the highest level of reusability, and where international standards would be applied. Although it was a considerable effort to publish all the datasets using ontological schemas, always representing the data in RDF, and linking the resources as usual practice, we can say that in the medium term the benefits of organizing the information in this way gives us great potential to extract and manage the information for multiple purposes.
We wanted a portal with quality data, with the highest level of reusability, and where international standards. [...] it was a considerable effort to publish all the datasets using ontological schemas, always representing the data in RDF, and linking the resources.
2. One of the first steps in a project of this type is to select vocabularies, that allow conceptualizing and establishing semantic relationships between data. Did you have a good starting point or did you need to develop a vocabulary ex-profeso for this context? Does the availability of reference vocabularies constitute a brake on the development of data interoperability?
One of the first steps in following ontology schemas in an open data portal is to identify the most appropriate terms to represent the classes, attributes and relationships that will configure the datasets. And it is also a practice that continues as new datasets are incorporated.
In our case, we have tried to reuse the most extended vocabularies as possible such as foaf, schema, dublin core and also some specific ones such as vibo or bibo. But in many cases we have had to define our own terms in our ontology because those components did not exist. In our opinion, when the CRUE-TIC Hercules project would be operational and the generic ontology schemas for universities would be defined, it will greatly improve the interoperability between our data, and above all it will encourage other universities to create their open data portals with these models.
One of the first steps in following ontology schemas in an open data portal is to identify the most appropriate terms to represent the classes, attributes and relationships that will configure the datasets.
3. How did you approach the development of this initiative, what difficulties did you encounter and what profiles are necessary to carry out a project of this type?
In our opinion, if you want to make a portal that is useful in the medium term, it is clear that an initial effort is required to organize the information. Perhaps the most complicated thing at the beginning is to collect the data that are scattered in different services of the University in multiple formats, understand what they consist of, find the best way to represent them, and then coordinate how to access them periodically for updates.
In our case, we have developed specific scripts for different data source formats, from different UEX Services (such as the IT Service, the Transfer Service, or from external publication servers) and that transform them into RDF representation. In this sense, it is essential to have Computer Engineers specialized in semantic representation and with extensive knowledge of RDF and SPARQL. In addition, of course, different services of the University must be involved to coordinate this information maintenance.
4. How do you assess the impact of the initiative? Can you tell us with some success stories of reuse of the provided datasets?
From the logs of queries, especially to the research portal, we see that many researchers use the portal as a data collection point that they use to prepare their resumes. In addition, we know that companies that need some specific development, use the portal to obtain the profile of our researchers.
But, on the other hand, it is common that some users (inside and outside the UEX) ask us for specific queries to the portal data. And curiously, in many cases, it is the University's own services that provide us with the data that ask us for specific lists or graphs where they are linked and crossed with other datasets of the portal.
By having the data linked, a UEX professor is linked to the subject he/she teaches, the area of knowledge, the department, the center, but also to his/her research group, to each of his/her publications, the projects in which he/she participates, the patents, etc. The publications are linked to journals and these in turn with their impact indexes.
On the other hand, the subjects are linked to the degrees where they are taught, the centers, and we also have the number of students enrolled in each subject, and quality and user satisfaction indexes. In this way, complex queries and reports can be made by handling all this information together.
As use cases, for example, we can mention that the Word documents of the 140 quality commissions of the degrees are automatically generated (including annual evolution graphs and lists) by means of queries to the opendata portal. This has saved dozens of hours of joint work for the members of these commissions.
Another example, which we have completed this year, is the annual research report, which has also been generated automatically through SPARQL queries. We are talking about more than 1,500 pages where all the scientific production and transfer of the UEX is exposed, grouped by research institutes, groups, centers and departments.
As use cases, for example, we can mention that the Word documents of the 140 quality commissions of the degrees are automatically generated (including annual evolution graphs and lists) by means of queries to the opendata portal. This has saved dozens of hours of joint work for the members of these commissions.
5. What are the future plans of the University of Extremadura in terms of open data?
Much remains to be done. For now we are addressing first of all those topics that we have considered to be most useful for the university community, such as scientific production and transfer, and academic information of the UEX. But in the near future we want to develop datasets and applications related to economic issues (such as public contracts, evolution of expenditure, hiring tables) and administrative issues (such as the teaching organization plan, organization chart of Services, compositions of governing bodies, etc.) to improve the transparency of the institution.
Documentación
It is important to publish open data following a series of guidelines that facilitate its reuse, including the use of common schemas, such as standard formats, ontologies and vocabularies. In this way, datasets published by different organizations will be more homogeneous and users will be able to extract value more easily.
One of the most recommended families of formats for publishing open data is RDF (Resource Description Framework). It is a standard web data interchange model recommended by the World Wide Web Consortium, and highlighted in the F.A.I.R. principles or the five-star schema for open data publishing.
RDFs are the foundation of the semantic web, as they allow representing relationships between entities, properties and values, forming graphs. In this way, data and metadata are automatically interconnected, generating a network of linked data that facilitates their exploitation by reusers. This also requires the use of agreed data schemas (vocabularies or ontologies), with common definitions to avoid misunderstandings or ambiguities.
In order to promote the use of this model, from datos.gob.es we provide users with the "Practical guide for the publication of linked data", prepared in collaboration with the Ontology Engineering Group team - Artificial Intelligence Department, ETSI Informáticos, Polytechnic University of Madrid-.
The guide highlights a series of best practices, tips and workflows for the creation of RDF datasets from tabular data, in an efficient and sustainable way over time.
Who is the guide aimed at?
The guide is aimed at those responsible for open data portals and those preparing data for publication on such portals. No prior knowledge of RDF, vocabularies or ontologies is required, although a technical background in XML, YAML, SQL and a scripting language such as Python is recommended.
What does the guide include?
After a short introduction, some necessary theoretical concepts (triples, URIs, controlled vocabularies by domain, etc.) are addressed, while explaining how information is organized in an RDF or how naming strategies work.
Next, the steps to be followed to transform a CSV data file, which is the most common in open data portals, into a normalized RDF dataset based on the use of controlled vocabularies and enriched with external data that enhance the context information of the starting data are described in detail. These steps are as follows:

The guide ends with a section oriented to more technical profiles that implements an example of the use of RDF data generated using some of the most common programming libraries and databases for storing triples to exploit RDF data.
Additional materials
The practical guide for publishing linked data is complemented by a cheatsheet that summarizes the most important information in the guide and a series of videos that help to understand the set of steps carried out for the transformation of CSV files into RDF. The videos are grouped in two series that relate to the steps explained in the practical guide:
1) Series of explanatory videos for the preparation of CSV data using OpenRefine. This series explains the steps to be taken to prepare a CSV file for its subsequent transformation into RDF:
- Video 1: Pre-loading tabular data and creating an OpenRefine project.
- Video 2: Modifying column values with transformation functions.
- Video 3: Generating values for controlled lists or SKOS.
- Video 4: Linking values with external sources (Wikidata) and downloading the file with the new modifications.
2) Series of explanatory videos for the construction of transformation rules or CSV to RDF mappings. This series explains the steps to be taken to transform a CSV file into RDF by applying transformation rules.
- Video 1: Downloading the basic template for the creation of transformation rules and creating the skeleton of the transformation rules document.
- Video 2: Specifying the references for each property and how to add the Wikidata reconciled values obtained through OpenRefine.
Below you can download the complete guide, as well as the cheatsheet. To watch the videos you must visit our Youtube channel.
Noticia
The Cross-Forest project combines two areas of great interest to Europe, as set out in the Green Deal. On the one hand, the care and protection of the environment - in particular our forests-. On the other hand, the promotion of an interoperable European digital ecosystem.
The project started in 2018 and ended on 23 June, resulting in different tools and resources, as we will see below.
What is Cross-Forest?
Cross-Forest is a project co-funded by the European Commission through the CEF (Connecting Europe Facility) programme, which seeks to publish and combine open and linked datasets of forest inventories and forest maps, in order to promote models that facilitate forest management and protection.
The project has been carried out by a consortium formed by the Tragsa Public Group, the University of Valladolid and Scayle Supercomputacion of Castilla y León, with the institutional support of the Ministry for Ecological Transition and the Demographic Challenge (MITECO, in Spanish acronyms). On the Portuguese side, the Direção-Geral do Território of Portugal has participated.
The project has developed:
- A Digital Services Infrastructure (DSI) for open forest data, oriented towards modelling forest evolution at country level, as well as predicting forest fire behaviour and spread. Data on fuel materials, forest maps and spread models have been used. High Performance Computing (HPC) resources have been used for their execution, due to the complexity of the models and the need for numerous simulations.
- An ontological model of forest data common to public administrations and academic institutions in Portugal and Spain, for the publication of linked open data. Specifically, a set of eleven ontologies has been created. These ontologies, which are aligned with the INSPIRE Directive, interrelate with each other and are enriched by linking to external ontologies. Although they have been created with a focus on these two countries, the idea is that any other territory can use them to publish their forest data, in an open and standard format.
The different datasets used in the project are published separately, so that users can use the ones they want. All the data, which are published under CC BY 4.0 licence, can be accessed through this Cross-Forest Github repository and the IEPNB Data Catalogue.
4 flagship projects in Linked Open Data format
Thanks to Cross-Forest, a large part of the information of 4 flagship projects of the General Directorate of Biodiversity, Forests and Desertification of the Ministry for Ecological Transition and the Demographic Challenge has been published in linked open data format:
- National Forest Inventory (IFN-3). It includes more than 100 indicators of the state and evolution of the forests. These indicators range from their surface area or the tree and shrub species that inhabit them, to data related to regeneration and biodiversity. It also incorporates the value in monetary terms of the environmental, recreational and productive aspects of forest systems, among other aspects. It has more than 90,000 plots. Two databases corresponding to a subset of the NFI indicators have been published openly.
- Forest Map of Spain (Scale 1:50.000). It consists of the mapping of the situation of forest stands, following a conceptual model of hierarchical land uses.
- National Soil Erosion Inventory (INES). This is a study that detects, quantifies and cartographically reflects the main erosion processes affecting the Spanish territory, both forest and agricultural. Its objective is to know its evolution over time thanks to continuous data collection and it has more than 20,000 plots.
- General Forest Fire Statistics. It includes the information collected in the Fire Reports that are completed by the Autonomous Communities for each of the forest fires that take place in Spain.
These datasets, along with others from this Ministry, have been federated with datos.gob.es, so that they are also available through our data catalogue. Like any other dataset that is published on datos.gob.es, they will automatically be federated with the European portal as well.
The predecessor of this project was CrossNature. This project resulted in the Eidos database, which includes linked data on wild species of fauna and flora in Spain and Portugal. It is also available on datos.gob.es and is reflected in the European portal.
Both projects are an example of innovation and collaboration between countries, with the aim of achieving more harmonised and interoperable data, facilitating to compare indicators and improve actions, in this case, in the field of forest protection.
Blog
The Hercules initiative was launched in November 2017, through an agreement between the University of Murcia and the Ministry of Economy, Industry and Competitiveness, with the aim of developing a Research Management System (RMS) based on semantic open data that offers a global view of the research data of the Spanish University System (SUE), to improve management, analysis and possible synergies between universities and the general public.
This initiative is complementary to UniversiDATA, where several Spanish universities collaborate to promote open data in the higher education sector by publishing datasets through standardised and common criteria. Specifically, a Common Core is defined with 42 dataset specifications, of which 12 have been published for version 1.0. Hercules, on the other hand, is a research-specific initiative, structured around three pillars:
- Innovative SGI prototype
- Unified knowledge graph (ASIO) 1],
- Data Enrichment and Semantic Analysis (EDMA)
The ultimate goal is the publication of a unified knowledge graph integrating all research data that participating universities wish to make public. Hercules foresees the integration of universities at different levels, depending on their willingness to replace their RMS with the Hercules RMS. In the case of external RMSs, the degree of accessibility they offer will also have an impact on the volume of data they can share through the unified network.
General organisation chart of the Hercule initiative
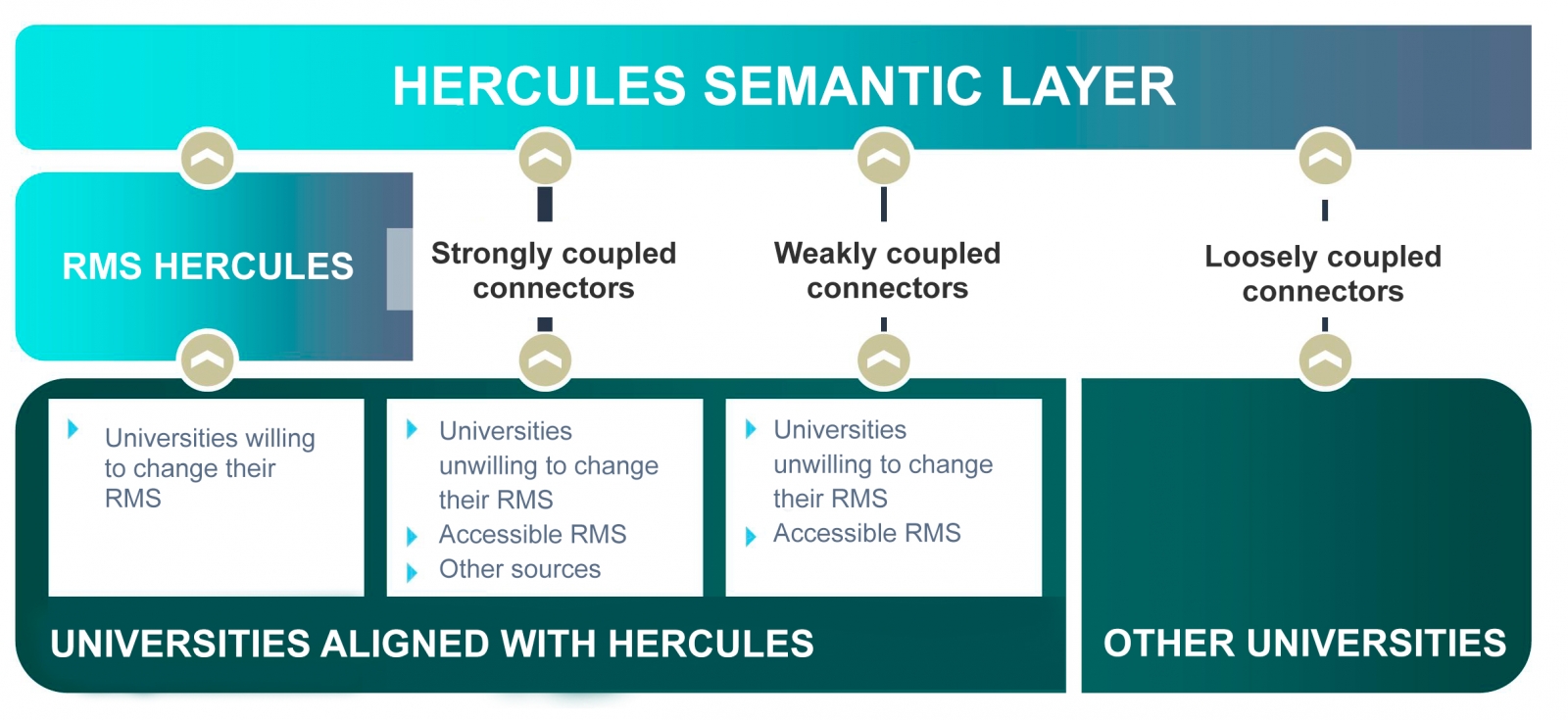
Within the Hercules initiative, the ASIO Project (Semantic Architecture and Ontology Infrastructure) is integrated. The purpose of this sub-project is to define an Ontology Network for Research Management (Ontology Infrastructure). An ontology is a formal definition that describes with fidelity and high granularity a particular domain of discussion. In this case, the research domain, which can be extrapolated to other Spanish and international universities (at the moment the pilot is being developed with the University of Murcia). In other words, the aim is to create a common data vocabulary.
Additionally, through the Semantic Data Architecture module, an efficient platform has been developed to store, manage and publish SUE research data, based on ontologies, with the capacity to synchronise instances installed in different universities, as well as the execution of distributed federated queries on key aspects of scientific production, lines of research, search for synergies, etc.
As a solution to this innovation challenge, two complementary lines have been proposed, one centralised (synchronisation in writing) and the other decentralised (synchronisation in consultation). The architecture of the decentralised solution is explained in detail in the following sections.
Domain Driven Design
The data model follows the Domain Driven Design approach, modelling common entities and vocabulary, which can be understood by both developers and domain experts. This model is independent of the database, the user interface and the development environment, resulting in a clean software architecture that can adapt to changes in the model.
This is achieved by using Shape Expressions (ShEx), a language for validating and describing RDF datasets, with human-readable syntax. From these expressions, the domain model is automatically generated and allows orchestrating a continuous integration (CI) process, as described in the following figure.
Continuous integration process using Domain Driven Design (just available in Spanish)
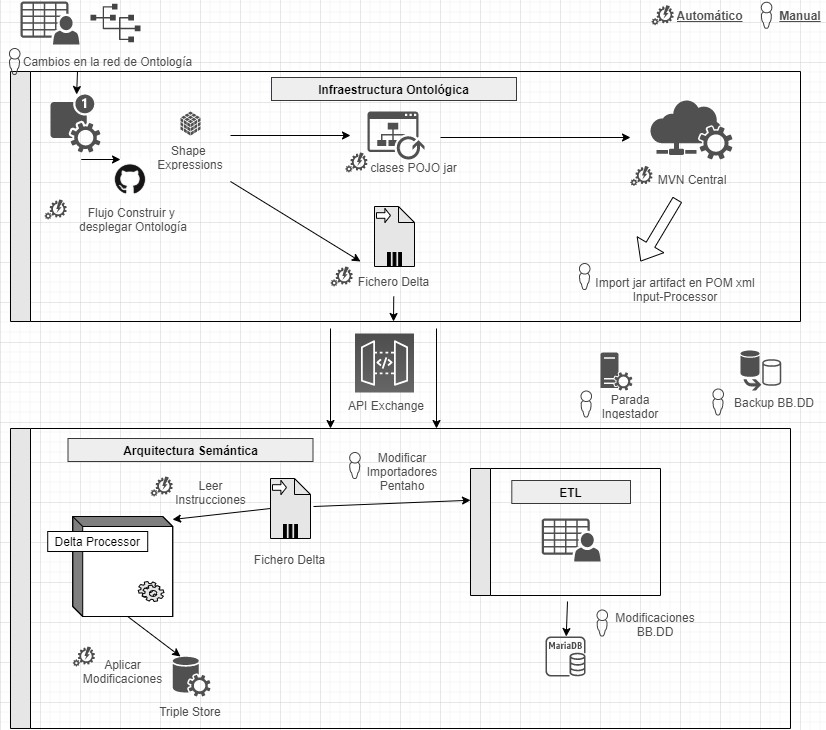
By means of a system based on version control as a central element, it offers the possibility for domain experts to build and visualise multilingual ontologies. These in turn rely on ontologies both from the research domain: VIVO, EuroCRIS/CERIF or Research Object, as well as general purpose ontologies for metadata tagging: Prov-O, DCAT, etc.
Linked Data Platform
The linked data server is the core of the architecture, in charge of rendering information about all entities. It does this by collecting HTTP requests from the outside and redirecting them to the corresponding services, applying content negotiation, which provides the best representation of a resource based on browser preferences for different media types, languages, characters and encoding.
All resources are published following a custom-designed persistent URI scheme. Each entity represented by a URI (researcher, project, university, etc.) has a series of actions to consult and update its data, following the patterns proposed by the Linked Data Platform (LDP) and the 5-star model.
This system also ensures compliance with the FAIR (Findable, Accessible, Interoperable, Reusable) principles and automatically publishes the results of applying these metrics to the data repository.
Open data publication
The data processing system is responsible for the conversion, integration and validation of third-party data, as well as the detection of duplicates, equivalences and relationships between entities. The data comes from various sources, mainly the Hercules unified RMS, but also from alternative RMSs, or from other sources offering data in FECYT/CVN (Standardised Curriculum Vitae), EuroCRIS/CERIF and other possible formats.
The import system converts all these sources to RDF format and registers them in a specific purpose repository for linked data, called Triple Store, because of its capacity to store subject-predicate-object triples.
Once imported, they are organised into a knowledge graph, easily accessible, allowing advanced searches and inferences to be made, enhanced by the relationships between concepts.
Example of a knowledge network describing the ASIO project
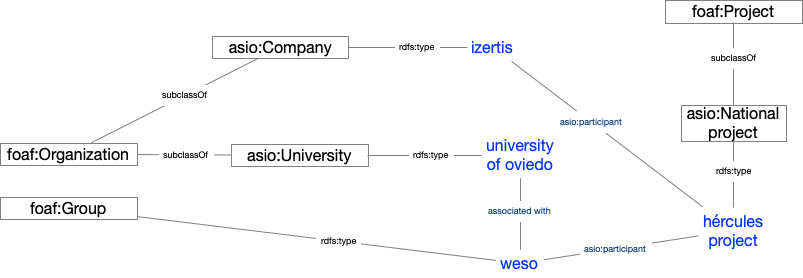
Results and conclusions
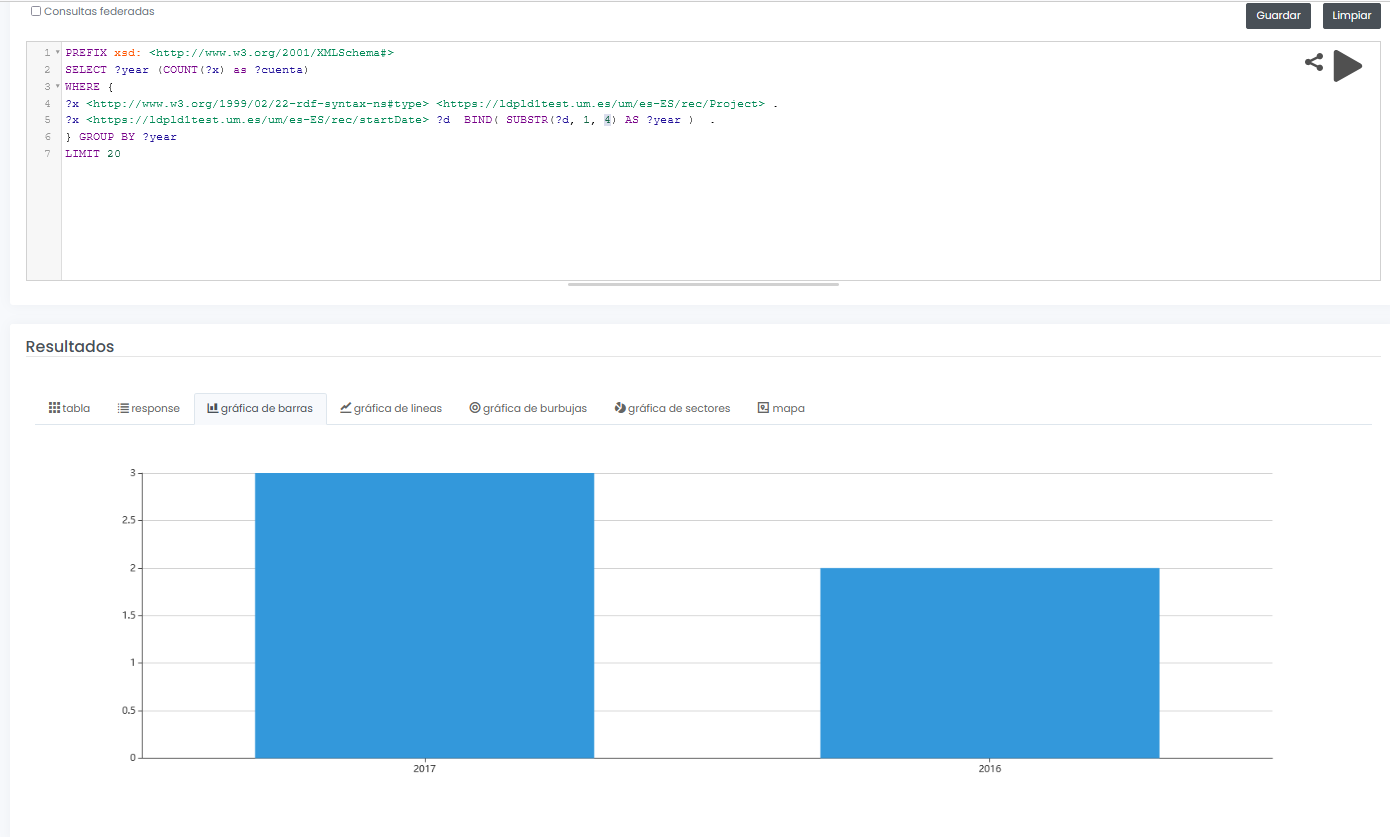
The final system not only allows to offer a graphical interface for interactive and visual querying of research data, but also to design SPARQL queries, such as the one shown below, even with the possibility to run the query in a federated way on all nodes of the Hercules network, and to display results dynamically in different types of graphs and maps.
In this example, a query is shown (with limited test data) of all available research projects grouped graphically by year:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
SELECT ?year (COUNT(?x) as ?cuenta)
WHERE {
?x <http://www.w3.org/1999/02/22-rdf-syntax-nes#type> <https://ldpld1test.um.es/um/es-ES/rec/Project> .
?x <https://ldpld1test.um.es/um/es-ES/rec/startDate> ?d BIND(SUBSTR(?d, 1, 4) as ?year) .
} GROUP BY ?year LIMIT 20
LIMIT 20
Ejemplo de consulta SPARQL con resultado gráfico
In short, ASIO offers a common framework for publishing linked open data, offered as open source and easily adaptable to other domains. For such adaptation, it would be enough to design a specific domain model, including the ontology and the import and validation processes discussed in this article.
Currently the project, in its two variants (centralised and decentralised), is in the process of being put into pre-production within the infrastructure of the University of Murcia, and will soon be publicly accessible.
[1 Graphs are a form of knowledge representation that allow concepts to be related through the integration of data sets, using semantic web techniques. In this way, the context of the data can be better understood, which facilitates the discovery of new knowledge.
Content prepared by Jose Barranquero, expert in Data Science and Quantum Computing.
The contents and views expressed in this publication are the sole responsibility of the author.
Blog
An important part of the data which is published on the Semantic Web, where resources are identified by URIs, is stored within triple store databases. This data can only be accessed through SPARQL queries via a SPARQL endpoint.
Moreover, the URIs used, usually designed in a pattern, in most of the datasets which are stored in those databases are not dereferenced, meaning that requests made to that identifier are met with no response (an ‘error 404’ message).
Given the current situation, in which this data is only accessible by machines, and combined with the push of the Linked Data movement, various projects have emerged in which the main objective is to generate human views of the data through web interfaces (where the views of the resources are interlinked), as well as offering a service where the URIs are dereferenced.
Pubby is perhaps the best-known of the projects which have been created for this purpose. It is a Java developed web application, whose code is shared under the open source license Apache Version 2.0. It is designed to be deployed on a system that has SPARQL access to the database of triplets that you wish to apply.
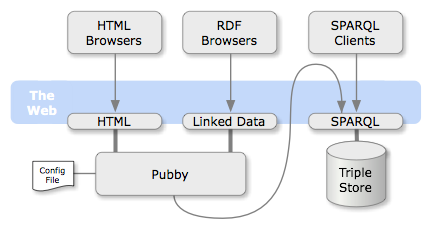
The non-dereferenced URIs and the dereferenced URIs are mapped through a configuration file which is managed by the Pubby server. The application uses this to process the requests to the mapped URIs, requesting the information of the original URI to the associated database (via a SPARQL ‘DESCRIBE’ query) and returning the results to the client in the requested format.
In addition, Pubby provides a simple HTML view of the stored data and manages content negotiation between the different representations. Users can navigate between the HTML views of the linked resources (Linked Data) via the web interface. These views show all the information of the resources, including their attributes and relationships with other resources.
Multiple parallel projects (forks) and inspired projects have emerged from the Pubby project. One of the most recent is the Linked Open Data Inspector (LODI) project, developed by the Quercus software engineering group at the University of Extremadura under Creative Commons 3.0. This project is developed in Node.js and features some positive differences with respect to Pubby:
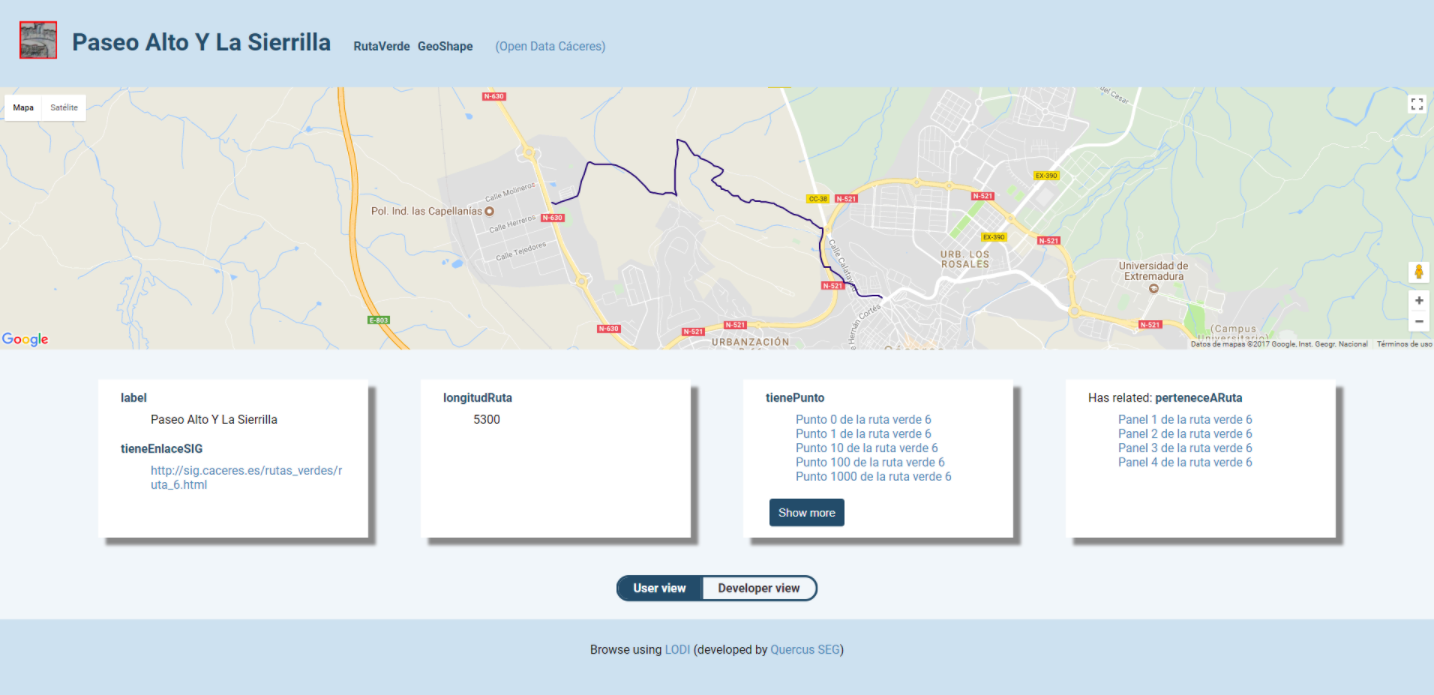
● It provides a simple HTML view for a general audience, and a more detailed view for programmers.
● It provides resource information in N3 format (but not RDF/XML or Turtle).
● In the case of resources with geospatial information, it displays a map detailing the location.
● In the case of detected images (.jpg, .jpeg or .png), these images are shown automatically.
There are currently two open data portals which are using LODI: Open Data Cáceres and Open Data UEx.
Pubby, LODI and other similar projects (such as LODDY), using the AGROVOC thesaurus, have managed to expose information that was retained within RDF databases which was not accessible to humans. Projects like these help the linked data web continue to grow, both in quantity and quality, putting human interaction at the centre of this progress.
Noticia
The Spanish National Library (BNE) continues promoting the dissemination and reuse of its documentary collections. In addition to contributing to the preservation of Spanish cultural heritage, through the digitization and digital preservation of its collections, the BNE also seeks to facilitate citizen access to cultural data, enrich it and encourage its reuse across all fields, beyond research, such as tourism, fashion or video games, among others.
Since launching the first version of its linked data portal, datos.bne.es, in 2014, BNE has opted to offer a new approach to the large amount of data that they generates: data related to the works they preserve but also to authors, vocabularies, geographical terms, etc. These data have a high level of standardization and meet the international standards of description and interoperability. The data are also identified through URIs and new conceptual models, linked through semantic technologies and offered in open and reusable formats.
In addition, datos.bne.es is a clear example of how the application of Linked Open Data techniques and standards facilitates the enrichment of data with other sources, becoming a tool and basis for research projects that incorporates big data or machine learning. This opens up numerous possibilities for searching and visualizing information (through graphs, georeferences, etc.). In short, datos.bne.es is the transit from a tool to locate copies to a tool to locate and use data, enriching and integrating the data into the Linked Open Data universe.
Since 2014, steps have been taken in this direction, seeking to bring the BNE data to citizens and reusers. For this, BNE has just launched a new version of datos.bne.es. This new version means, on the one hand, a complete data update, and on the other hand, new functionalities that facilitate access to information.
Among these developments, we can find:
- Incorporation of a new specialized search engine. From now on, users can carry out advanced searches related to works editions, as well as the people and entities that have taken part in their creation. In this way, authors can be searched based on their date and place of birth or death, their gender or profession. It is important to note that these data are not yet available in the catalogue for all people and entities, so the results should be considered a sample that will be progressively expanded.
- Possibility of carrying out multilingual searches. The Themes search engine allows the multilingual search of concepts in English and French. For example, a search for "Droit à l'éducation" will return the concept "Derecho a la educación". This functionality has been achieved by semantically exploiting the relationship between the vocabularies of BNE, Library of Congress and the National Library of France. In subsequent updates the number of languages will increase.
- Improvement of access to Hispanic Digital Library resources. From now on, digitized editions of music and press resources will include direct access to the digitized resource.
All these updates represent a great step in the path that the National Library of Spain is carrying out in favour of cultural open data promotion, but efforts continues. During the next months they will continue working to improve usability, focusing on a visual and intuitive portal, with easy-to-reuse datasets (for example, incorporating new formats or enriching the data through semantic technologies). In addition, they will go for interoperability and standardization improvements. All these are necessary actions to facilitate that users can reuse the available data and create new products and services that add value to society.
To ensure that all the actions carried out are aligned with users’ needs, the National Library of Spain has also opted for the creation of an Open Data Community. The objective is that citizens could share a dialogue space to propose new improvements, updates and uses of cultural open data. This community will be formed by a combination of professional librarian and technical profiles, which will help to extract all the value from the BNE´s data.
Noticia
High diplomacy traditionally plays a role in helping cultures and nations to dialogue with each other. But when it comes to strengthening the right to land, it is the local communities themselves that have to get involved.
This is the vision of the Land Portal Foundation, and the main reason to create the web landportal.org, a place where interested groups can gather and consult information about land governance. This information comes from diverse sources (fragmented and sometimes not accessible) and produced by governments, academia, international organizations, indigenous peoples and non-governmental organizations. Appart from gathering information, the platform promotes the generation of debates, the exchange of information and the creation of networks of contacts.
The organization, and therefore the platform, is based on the idea of the "open movement", which are embodied in concrete realities such as establishing by default open source licenses in all its computer developments, the consumption of open data and the publication of linked open data, or the use of open licenses when sharing information.
The portal collects statistical data, bibliographic data, or data on different resources (organizations, events, news, projects) and republishes them as LOD in a machine-readable format (RDF), using a standards-based and shared data model under an open license. With this, the foundation aims to create an information ecosystem and reuse it.
To access this data published under the criteria of the Linked Open Data, a SPARQL endpoint has been deployed where semantic queries can be made to the different graphs in which the knowledge is grouped.
Another project of the organization is LandVoc,, a controlled vocabulary that gathers concepts related to the land governance. This vocabulary comes from the AGROVOC thesaurus, and was born as an attempt to standardize the concepts related to the land governance. In this way the different organizations of the domain can use the concepts to label content and thus favor the information exchange and the integration of systems. LandVoc currently consists of 270 concepts, is available in 4 languages (English, French, Spanish and Portuguese), and is published under the open license Creative Commons Attribution-Noncommercial-ShareAlike 3.0 IGO (CC BY-NC-SA 3.0 IGO).
The Land Portal Foundation carries out all this with the aim of improving the land governance and thus benefit the groups with greater insecurity in their right to land. The theory of change of the organization predicts an increase in the quality of life of the most vulnerable groups, if their right to live and cultivate without fear of forced or illegal evictions is achieved; and with the security of land tenure, it also predicts progress of the food security for the most vulnerable communities in the world.
Noticia
If we analyze it with perspective, the concept of open data is not so revolutionary or novel in itself. On one hand, the philosophy of openness and/ or re-use on which open data are based had long been established between us before its formal definition. On the other hand, the objectives of the open data movement are also very similar to those promoted by other communities which could in a certain way be considered similar, such as open source, open hardware, open content, open government or open science, among many others..
However, both the term "open data" and the community associated with it can both be considered relatively recent, beginning to gain popularity about ten years ago when a group of open government advocates established the eight principles of government open data during the meeting that took place in Sebastopol (California) in December 2007. Next, official open data initiatives of reference were launched by the United States (data.gov)) and the United Kingdom (data.gov.uk) , giving it the final push needed to become a new movement with its own identity.
Since then, the global open data community has made enormous progress, but it is also still far away from its initial objectives. At the same time, data in general is consolidating itself as the most valuable asset that most organizations have today. That is why, on the tenth anniversary since its formalization, the open data community reflects on its role in the past - looking at the achievements obtained so far - and also on its role in the upcoming future dominated for the data.

In this context, it makes sense to briefly review some of the current trends in the data world and what role open data could play in each of them, starting with those that are more related:
Open government, transparency and accountability
Although freedom of information and open data communities sometimes differ in their strategies, both share the common goal of facilitating citizens access to the information needed to improve transparency and public services. The potential benefit that can be obtained from the collaboration between both groups is, therefore, very significant, evolving from the right to information to the right to data. Nevertheless, after several efforts, collaboration has not yet been achieved as effectively as it would be desirable and there are also doubts about whether open data is really being used as an effective tool for transparency or as an excuse for not making a deeper transparency exercise.
Linked data and web of data
The goal of the Web of data is being able to create explicit connections between those data that are related to each other and those already available on the web, but not conveniently related. Not all linked data necessarily needs to be open, but it is clear from the very purpose of the linked data that the combination of both is what would let reach its maximum joint potential, as it is already the case, for example, with some large global data bases such as DBPedia, LexInfo, Freebase, NUTS or BabelNet.
Open Science and Open Access
Ironically, at this very moment in history when we have the best tools and technologies to distribute science and knowledge throughout the world, we are very busy putting new barriers to the use of those valuable data and that knowledge. The thriving movement of open access bet precisely to apply again the criteria of open data to scientific production, so that it becomes an intangible asset and thus accelerate our collaborations ability to generate new achievements for humanity.
Visualization and narrative through data
As more and more data is available to any organization or individual, the next key step will be providing the means so the value can be extracted from them. The ability, based on specific data, to be able to understand them, process them, extract their value and communicate it adequately, will be a very demanded skill in the next decade. The elaboration of stories from data is nothing more than a structured approach when communicating the knowledge that the data transmit uthrough three key elements: data, visualizations and narrative.
Big data, data flows and real-time data
In the present, organizations have to deal with a growing volume and variety of data. Big data processing techniques allow them to analyze these large volumes of information to reveal different patterns and correlations that will serve to improve decision-making processes. However, the great challenge is still how to perform this process efficiently on continuous data flows in real time. While big data promises an unprecedented analytical capacity, its combination with the open data philosophy will allow that power to be shared by all improving public services.
{kind=link}
Artificial intelligence, machine learning and algorithms
Although artificial intelligence is increasingly present in several aspects of our daily lives, we could consider that we are still at a very early stage of what could become a global revolution. Artificial intelligence already has a relative success in some tasks that traditionally had always required of what we consider human intelligence to be carried out. For this to be possible, data-powered algorithms that support these automated systems are also necessary. A greater availability and quality of the open data will serve to feed these algorithms and, at the same time, also be able to improve them and audit their correct operation
Smart Cities and sector data
The open data movement is also in a period of transition in which they are beginning to focus efforts on publishing the data necessary to respond to specific problems instead of simply trying to publish any data in general. This thematic or sectorial approach is generally more efficient because it not only requires fewer resources for its execution, but is also more focused on the user needs and final beneficiaries of the data. In this regard, the specific area of Smart Cities or open cities stands out as an example of the integration of different technologies and data philosophies to improve the services offered to citizens.
Personal data and privacy
Today we spend a good part of our lives online and that is contributing to generate a lot of information about us. Thanks to these data we can enjoy new services of great utility, but this also have an important negative counterpart. In the case of a data leak, important personal information about our economic capacity, political positioning or consumption habits, among others, could be public. On the other hand, there are also increasingly unethical uses by some companies. Using the same principles of open data there are new forms of self-management of our personal data to achieve a balance between regaining control of our own data and the benefits we can obtain through exploitation, always with our express knowledge and consent.
Data infrastructures and data governance
The day-to-day management of data begins to be a task as valuable as complex for any organization in general, but particularly complicated for the administration due to its own volume and the need to combine different management models that also correspond to the different administrative levels. To face this management task with guarantees, it will be necessary to invest in the appropriate data infrastructures, both at a physical and management level. Establishing the technological frameworks and data governance models needed to be shared with agility will be an essential requirement to achieve an efficient management model in the future.
Taking into account the above aspects, it is possible that in the not too distant future we will stop treating open data as the only possible solution for the challenges posed to governments and begin to treat it as another key tool at our disposal that will be used in a more diluted and integrated way together with the other current trends in the data world and the openness that we have reviewed.
Noticia
One of the major concerns of international organisations is the dispersion in the categorisation and indexation of the knowledge created in each of the component parts (such as agencies, units, departments, venues or programmes). This is because, for example, when a person in a department wants to search for content on a particular topic in all the knowledge repositories of each of the parts of the organisation, they usually have to search in each individual repository. To do this, they use the keywords defined for each repository (which may vary), instead of using the same keywords, or even performing a single search (if there is a search system where all repositories are integrated). To solve this issue and facilitate the exchange of information between each of its parties, it is customary to create controlled vocabulary lists for the classification of the content generated.
The Food and Agriculture Organisation of the United Nations (FAO) was in this situation, and so in the early 1980s it created AGROVOC.
AGROVOC is a thesaurus that organises concepts related to the FAO's areas of interest, such as agriculture (mainly), food, nutrition, fisheries, forestry or the environment.
This thesaurus (and therefore, controlled vocabulary) which, as of August 2017, is currently composed of more than 33,000 terms, has followed an evolutionary process, going from being in 3 languages to 23 (Spanish being one of the first three), from being available only in a printed format to now being available as a SKOS-XL conceptual scheme.
In addition, AGROVOC is available as a Linked Open Data (LOD) set aligned with 16 other multilingual agricultural knowledge-management systems (such as DBPedia, EUROVOC, the U.S. thesaurus from the National Agricultural Library (NAL), the thesaurus from the International Centre for Agriculture and Biotechnology (ICAB)).
In fact, multiple organisations are working on projects, such as Global Agricultural Concept Scheme (GACS), which explores the possibility of creating a thesaurus of agricultural concepts and terminology, reusing the thesauri from the AGROVOC, ICAB and NAL.
The management of AGROVOC is divided into several parts. On the one hand, the FAO is responsible for its publication and final revision, while on the other hand, a community of external organisations and experts from different areas of knowledge are responsible for editing it (proposing new concepts, extending the terminology of the concepts already existing in other languages, reviewing and preserving the terminology already created...). To carry out this editing work, the community uses VocBench, an open source vocabulary management tool.
Undoubtedly, one of the key characteristics that has facilitated the extension of the use of AGROVOC in the community is that its access and use is free, being distributed under a Creative Commons 3.0 Attribution (CC-BY) license.
AGROVOC is commonly used by research personnel, librarians and knowledge managers for the indexing, retrieval and organisation of data in agricultural information systems and the FOA's other areas of interest mentioned above. As examples of dogfooding (when an organisation uses its own product to test and promote it) is the use of AGROVOC in AGRIS, the bibliographic information database on agricultural science and technology, or FAOLEX, a database of national legislation and policies on food, agriculture and natural resource management, both managed by the FAO.
The ways in which AGROVOC can be accessed, searched and reused are varied
- You can search for concepts or browse by hierarchy
- It can to download as an RDF dataset in two versions: Agrovoc Core (which includes all concepts in all languages but no links to external vocabulary lists) and Agrovoc LOD (which does include links to external vocabulary lists)
- Available web services can be used
- Searches can be performed through SPARQL queries, using a public SPARQL endpoint
The data on agriculture that are being generated are growing exponentially, by recording environmental data using sensors, by compiling legal regulations, or by using economic data on prices, crop production data, disease and pest data, etc... All this knowledge, if carefully catalogued, can be a source of future studies and discoveries, both in the public and private spheres. In this context, AGROVOC (and in the future, perhaps GACS) is a valuable tool for data to be classified homogeneously, facilitating the interoperability and reuse of the data, both within and beyond that organisation.