Blog
En la última década, la cantidad de datos que las organizaciones generan y necesitan gestionar ha crecido de manera exponencial. Con el auge del cloud, Internet de las Cosas (IoT, por sus siglas en inglés), edge computing y la inteligencia artificial (IA), las empresas se enfrentan al reto de integrar y gobernar datos que provienen de múltiples fuentes y entornos. En este contexto, han surgido dos enfoques clave para la gestión de datos que buscan solucionar los problemas asociados a la centralización de datos: Data Mesh y Data Fabric. Aunque estos conceptos se complementan, cada uno ofrece una aproximación distinta para resolver los desafíos de datos de las organizaciones modernas.
¿Por qué un data lake no es suficiente?
Muchas empresas han implementado data lakes o data warehouses centralizados con equipos dedicados como estrategia para impulsar el análisis de datos de compañía. Sin embargo, este enfoque suele generar problemas a medida que la empresa escala, como por ejemplo:
- Los equipos de datos centralizados se convierten en un cuello de botella. Estos equipos no pueden responder con la rapidez necesaria ante la variedad y volumen de preguntas que surgen desde diferentes áreas del negocio.
- La centralización crea una dependencia que limita la autonomía de los equipos de dominio, quienes conocen mejor sus necesidades de datos.
Aquí es donde entra en escena el enfoque Data Mesh.
Data Mesh: un enfoque descentralizado y orientado a dominios
Data Mesh rompe con la centralización de los datos y los distribuye en dominios específicos, permitiendo que cada equipo de negocio (o equipo de dominio) gestione y controle los datos que más conoce y utiliza. Este enfoque se basa en cuatro principios básicos:
- Propiedad de dominio: en lugar de que un equipo central de datos tenga todo el control, cada equipo es responsable de los datos que genera. Es decir, si eres el equipo de ventas, tú gestionas los datos de ventas; si eres el de marketing, gestionas los datos de marketing. Nadie conoce mejor esos datos que el propio equipo que los usa día a día.
- Datos como producto: esta idea nos recuerda que los datos no son solo para el uso del dominio que los genera, sino que pueden ser útiles para toda la empresa. Así que cada equipo debe pensar en sus datos como un “producto” que otros equipos también puedan usar. Esto implica que los datos deben ser accesibles, confiables y fáciles de encontrar, casi como si fueran una API pública.
- Plataforma autoservicio: la descentralización no significa que cada equipo tenga que reinventar la rueda. Para evitar que cada equipo de dominio se especialice en herramientas complejas de datos, el Data Mesh se apoya en una infraestructura de autoservicio que facilita la creación, despliegue y mantenimiento de productos de datos. Esta plataforma debe permitir a los equipos de dominio consumir y generar datos sin depender de una alta especialización técnica.
- Gobernanza federada: aunque los datos están distribuidos, sigue habiendo reglas comunes para todos. En un Data Mesh, la gobernanza es “federada”, es decir, cada equipo sigue unos estándares de interoperabilidad definidos globalmente. Esto asegura que todos los datos sean seguros, de alta calidad y cumplan con las normativas.
Estos principios hacen que el Data Mesh sea una arquitectura ideal para organizaciones que buscan mayor agilidad y que los equipos tengan autonomía sin perder de vista la calidad y el cumplimiento. A pesar de la descentralización, Data Mesh no crea silos de datos porque fomenta la colaboración y el intercambio estandarizado de datos entre equipos, asegurando acceso y gobernanza comunes en toda la organización.
Data Fabric: arquitectura para el acceso seguro y eficiente a datos distribuidos
Mientras que el Data Mesh se enfoca en la organización y propiedad de los datos en torno a dominios, el Data Fabric es una arquitectura que permite conectar y exponer los datos de una organización, independientemente de su ubicación. A diferencia de enfoques basados en la centralización de datos, como el data lake, el Data Fabric actúa como una capa unificada, ofreciendo acceso fluido a los datos distribuidos en múltiples sistemas sin necesidad de trasladarlos físicamente a un único repositorio.
En términos generales, el Data Fabric se basa en tres aspectos fundamentales:
- Acceso a los datos: en una empresa moderna, los datos se encuentran dispersos en diversas ubicaciones, tales como data lakes, data warehouses, bases de datos relacionales y numerosas aplicaciones SaaS (Software como servicio). En lugar de consolidar todos estos datos en un solo lugar, el Data Fabric emplea una capa de virtualización que permite acceder a ellos directamente desde sus fuentes de origen. Este enfoque minimiza la duplicación de datos y permite el acceso en tiempo real, facilitando así la toma de decisiones ágil. En los casos en que una aplicación requiera latencias bajas, el Data Fabric también dispone de herramientas de integración robusta, como ETL (extracción, transformación y carga), para mover y transformar los datos cuando sea necesario.
- Gestión del ciclo de vida de los datos: el Data Fabric no solo facilita el acceso, sino que también garantiza una gestión adecuada a lo largo de todo el ciclo de vida de los datos. Esto incluye aspectos críticos como la gobernanza, la privacidad y el cumplimiento de normativas. La arquitectura del Data Fabric se apoya en metadatos activos que automatizan la aplicación de políticas de seguridad y acceso, asegurando que solo los usuarios con los permisos adecuados accedan a la información correspondiente. Asimismo, ofrece funcionalidades avanzadas de trazabilidad (linaje), que permiten rastrear el origen de los datos, conocer sus transformaciones y evaluar su calidad, lo cual resulta esencial en entornos regulados bajo normativas como el Reglamento General de Protección de Datos (GDPR en sus siglas en inglés).
- Exposición de los datos: tras conectar los datos y aplicar las políticas de gobernanza y seguridad, el siguiente paso del Data Fabric es poner esos datos a disposición de los usuarios finales. A través de catálogos empresariales, los datos se organizan y presentan de forma accesible para analistas, científicos de datos y desarrolladores, quienes pueden localizarlos y utilizarlos de manera eficiente.
En resumen, el Data Fabric no reemplaza a los data lakes o data warehouses, sino que facilita la integración y gestión de los datos ya existentes en la organización. Su objetivo es crear un entorno seguro y flexible que permita el flujo controlado de datos y una visión unificada, sin la necesidad de trasladarlos físicamente, impulsando así una toma de decisiones más ágil y bien fundamentada.
Data Mesh vs. Data Fabric: ¿Competidores o aliados?
Si bien el Data Mesh y el Data Fabric tienen algunos objetivos en común, cada uno resuelve problemas diferentes y, de hecho, pueden encontrarse beneficios al aplicar mecanismos de ambos enfoques de forma complementaria. La siguiente tabla muestra una comparativa de ambos enfoques:
| ASPECTO | DATA MESH | DATA FABRIC |
|---|---|---|
| Enfoque | Organizacional y estructural, orientado a dominios. | Técnico, centrado en la integración de datos. |
| Propósito | Descentralizar la propiedad y la responsabilidad de los datos a los equipos de dominio. | Crear una capa unificada de acceso a datos distribuida en múltiples entornos. |
| Gestión de datos | Cada dominio gestiona sus propios datos y define los estándares de calidad. | Los datos se integran mediante servicios y APIs, lo que permite una visión unificada sin mover físicamente los datos. |
| Gobernanza | Federada, con reglas establecidas por cada dominio, manteniendo estándares comunes. | Centralizada a nivel de plataforma, con automatización de políticas de acceso y seguridad mediante metadatos activos. |
Figura 1. Tabla comparativa de Data Mesh VS. Data Fabric. Fuente: Elaboración propia.
Conclusión
Tanto el Data Mesh como el Data Fabric están diseñados para resolver los desafíos de la gestión de datos en empresas modernas. El Data Mesh aporta un enfoque organizacional que empodera a los equipos de dominio, mientras que el Data Fabric permite una integración flexible y accesible de datos distribuidos sin necesidad de moverlos físicamente. La elección entre ambos, o la combinación de los dos, dependerá de las necesidades específicas de cada organización, aunque es importante considerar la inversión en infraestructura, formación y posibles cambios organizativos que estos enfoques requieren. Para empresas pequeñas o medianas, un data warehouse tradicional puede ser una alternativa práctica y rentable, especialmente si sus volúmenes de datos y la complejidad organizativa son manejables. De cualquier modo, dado el crecimiento de los ecosistemas de datos en las organizaciones, ambos modelos representan un avance hacia un entorno de datos más ágil, seguro y útil, facilitando una gestión de datos mejor alineada con los objetivos estratégicos en un entorno.
Definiciones
- Data Lake: Es un repositorio de almacenamiento que permite guardar grandes volúmenes de datos en su formato original, ya sean estructurados, semiestructurados o no estructurados. Su estructura flexible permite almacenar datos sin procesar y usarlos para análisis avanzados y machine learning.
- Data Warehouse: Es un sistema de almacenamiento de datos estructurados que organiza, procesa y optimiza los datos para realizar análisis y generar reportes. Está diseñado para consultas rápidas y análisis de datos históricos, siguiendo un esquema predefinido para facilitar el acceso a la información.
Referencias
- Dehghani, Zhamak. Data Mesh Principles and Logical Architecture. https://martinfowler.com/articles/data-mesh-principles.html
- Dehghani, Zhamak. Data Mesh: Delivering Data-Driven Value at Scale. O''Reilly Media. Libro que detalla la implementación y los principios fundamentales del Data Mesh en organizaciones.
- Data Mesh Architecture. Sitio web sobre Data Mesh y arquitecturas de datos. https://www.datamesh-architecture.com/
- IBM. Data Fabric. IBM Topics. https://www.ibm.com/topics/data-fabric
- IBM Technology. Data Fabric: Unifying Data Across Hybrid and Multicloud Environments. YouTube. https://www.youtube.com/watch?v=0Zzn4eVbqfk&t=4s&ab_channel=IBMTechnology
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Existe una tan estrecha relación entre la gestión del dato, la gestión de calidad del dato y el gobierno del dato que en muchas ocasiones los términos se utilizan de forma indistinta o directamente se confunden. Sin embargo, existen importantes matices.
El objetivo general de la gestión de datos es asegurar que los datos satisfacen los requisitos de negocio que darán soporte a los procesos de la organización, tales como recopilar, almacenar, proteger, analizar y documentar los datos, con el objetivo de implementar los objetivos de la estrategia de gobierno del dato. Se trata de un conjunto de tareas tan amplio que existen diversas categorías de normas para certificar cada uno de los diferentes procesos: ISO/IEC 27000 para la seguridad y privacidad de la información, ISO/IEC 20000 para la gestión de servicios de TI, ISO/IEC 19944 para interoperabilidad, arquitectura o acuerdos de nivel de servicio en la nube, o ISO/IEC 8000-100 para el intercambio de datos y la gestión de datos maestros.
La gestión de calidad de datos, por su parte, se refiere a las técnicas y procesos utilizados para asegurar que los datos son adecuados para el uso que se pretende hacer de ellos. Para ello se requiere un Plan de calidad de los datos que debe ser acorde con la cultura de la organización y con la estrategia de negocio e incluye aspectos como la validación, verificación y limpieza de datos, entro otros. En este sentido también existe un conjunto de normas técnicas para conseguir que los datos tengan calidad] entre las que se incluyen la propia gestión de la calidad de los datos de transacción, los datos de producto y los datos maestros empresariales (ISO 8000) y las tareas de medición de la calidad de los datos (ISO 25024:2015).
Por su parte, el gobierno del dato, de acuerdo con la definición de Deloitte, está formado por conjunto de normas, políticas y procesos de una organización que permiten asegurar que los datos de la organización sean correctos, fiables, seguros y útiles. Es decir, es la parte estratégica y de planificación y control a alto nivel para conseguir crear valor para el negocio a partir de los datos. En este caso, el gobierno de los datos abiertos tiene sus propias especificidades debido al número de partes interesadas que intervienen y la propia naturaleza colaborativa de los datos abiertos.
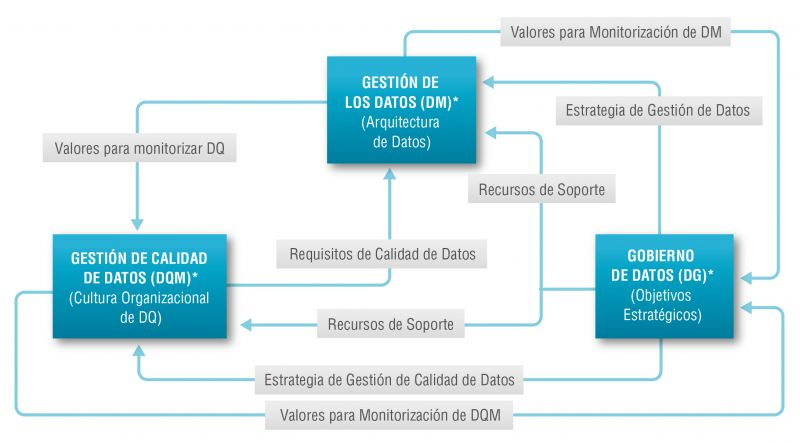
El modelo Alarcos
En este contexto el Modelo Alarcos de Mejora de Datos (MAMD), actualmente en su versión 3, tiene como objetivo recoger los procesos necesarios para alcanzar la calidad de las tres citadas dimensiones: la gestión de los datos, la gestión de la calidad de los datos y el gobierno de los datos. Este modelo ha sido desarrollado por un grupo de expertos coordinado por el grupo de investigación Alarcos de la Universidad de Castilla-La Mancha.
El Modelo MAMD está alineado con las mejores prácticas y estándares existentes tales como Data Management Community (DAMA), Data management maturity (DMM) o la propia familia de normas ISO 8000, cada una de las cuáles aborda diferentes aspectos relacionados con la calidad de los datos y la gestión de los datos maestros desde diferentes perspectivas. Además, el modelo Alarcos está basado en la familia de estándares para definir el modelo de madurez por lo que es posible conseguir la certificación de AENOR para el gobierno, gestión y calidad de datos ISO 8000-MAMD.
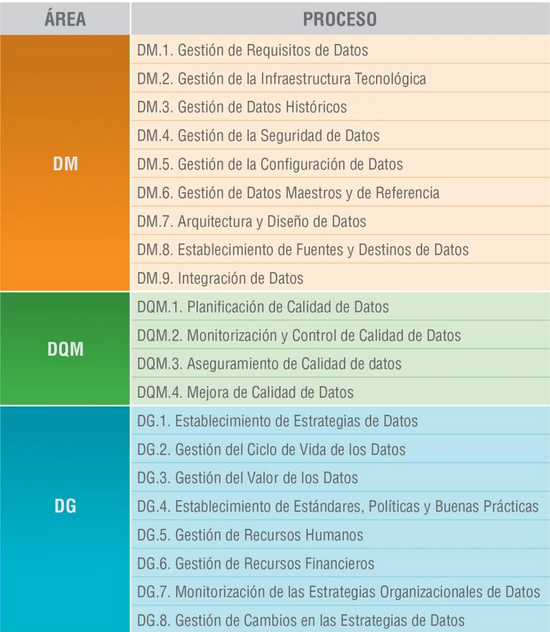
El modelo MAMD consiste de 21 procesos, 9 procesos corresponden a la gestión de los datos (DM), la gestión de la calidad de datos (DQM) incluye 4 procesos más y el gobierno del dato (DG), que añade otros 8 procesos.
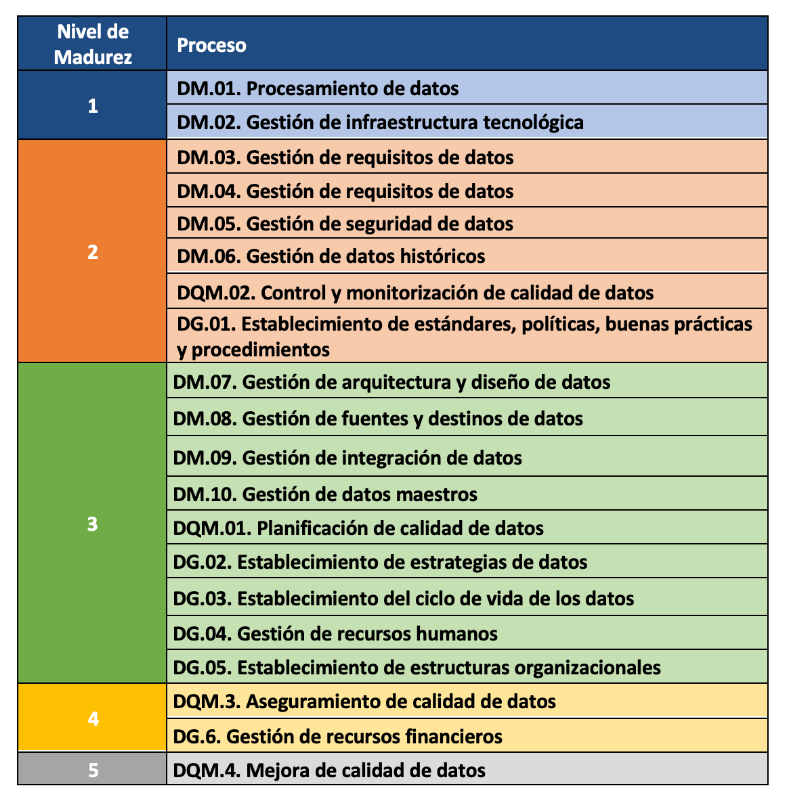
La incorporación progresiva de los 21 procesos permite la definición de 5 niveles de madurez que contribuyen a que la organización mejore su gestión, calidad y gobierno de datos. Comenzando con el nivel 1 (Realizado) en el que el organismo puede demostrar que utiliza buenas prácticas en el uso de los datos y tiene el soporte tecnológico necesario, pero no presta atención al gobierno ni a la calidad de los datos, hasta el nivel 5 (Innovado) en el que el organismo es capaz de alcanzar sus objetivos y está continuamente mejorando.
El modelo puede certificarse con una auditoría equivalente a la de otras normas de AENOR por lo que existe la posibilidad de incluirlo en el ciclo de mejora continua y control interno de cumplimiento normativo de las organizaciones que ya cuentan con otros certificados.
Experiencias prácticas
La Biblioteca de la Universidad de Castilla-La Mancha (UCLM), que da soporte a más de 30.000 alumnos y 3.000 profesionales entre profesores y personal de administración y servicios, es una de las primeras organizaciones que pudo superar la auditoría de certificación y por tanto obtener el nivel 2 de madurez en ISO/IEC 33000 – ISO 8000 (MAMD).
Los puntos más fuertes que se identificaron en este proceso de certificación fueron el compromiso del equipo directivo y el nivel de coordinación con otras universidades. Como en toda auditoría, se propusieron mejoras como la necesidad de documentar las revisiones periódicas de seguridad de datos que contribuyeron a alimentar el ciclo de mejora.
El hecho de que las organizaciones de todo tipo otorguen un valor cada vez mayor a sus activos de datos hace que los modelos y normas técnicas de certificación tengan un papel fundamental en garantizar la calidad, la seguridad, la privacidad, la gestión o el adecuado gobierno de estos activos de datos. Además de los estándares ya existentes se sigue haciendo un importante esfuerzo para desarrollar nuevas normas que cubran aspectos que hasta ahora no se habían considerado centrales debido a la menor importancia de los datos en las cadenas de valor de las organizaciones. Sin embargo, aún es necesario continuar con la formalización de modelos que como el Modelo Alarcos de Mejora de Datos permitan abordar de forma holística, y no sólo desde sus diferentes dimensiones, la evaluación y el proceso de mejora de la organización en el tratamiento de sus activos de datos.
Contenido elaborado por Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el entorno actual, las organizaciones tratan de mejorar la explotación de sus datos mediante el uso de nuevas tecnologías, dotando al negocio de un valor adicional y convirtiendo al dato en el principal activo estratégico de las mismas.
Sin embargo, únicamente podremos extraer el valor real de los datos si estos son confiables y para ello, surge la función del Gobierno del Dato, enfocada en la gestión eficiente de los activos de información. Los datos abiertos no pueden ser ajenos a estas prácticas debido a sus características, principalmente de disponibilidad y acceso.
Para dar respuesta a la pregunta de cómo debemos gobernar los datos, existen diversas metodologías internacionales, como DCAM, MAMD, DGPO o DAMA. En este post, nos basaremos en las guías ofrecidas por este último.
¿Qué es DAMA?
DAMA, por sus siglas en inglés Data Management Association, es una asociación internacional para profesionales de la gestión de datos. Cuenta con un capítulo en España, DAMA España, desde marzo de 2019.
Su principal misión consiste en promover y facilitar el desarrollo de la cultura de gestión de los datos, convirtiéndose en la referencia para las organizaciones y profesionales en la gestión de la información, aportando recursos, formación y conocimiento sobre la materia.
La asociación se compone de profesionales de la gestión de datos en diferentes sectores.
El Gobierno del dato según el marco de referencia de DAMA
“Un dato ubicado en un contexto da lugar a información. Si le añadimos inteligencia obtenemos conocimiento que, combinado con una buena estrategia, genera poder”
Aunque sólo es una frase, sintetiza a la perfección la estrategia, la búsqueda de poder a partir de los datos. Para ello, es necesario realizar un ejercicio de autoridad, control y toma de decisiones compartida (planificación, vigilancia y aplicación) sobre la gestión de los activos de datos o, lo que es lo mismo, aplicar Gobierno del Dato.
DAMA nos presenta lo que entiende que son las mejores prácticas para garantizar el control sobre la información, independientemente del negocio de aplicación, y para ello, posiciona al Gobierno del Dato como principal actividad alrededor de la cual se gestionan el resto de actividades, como puedan ser arquitectura, interoperabilidad, calidad o metadatado, como muestra la siguiente figura:
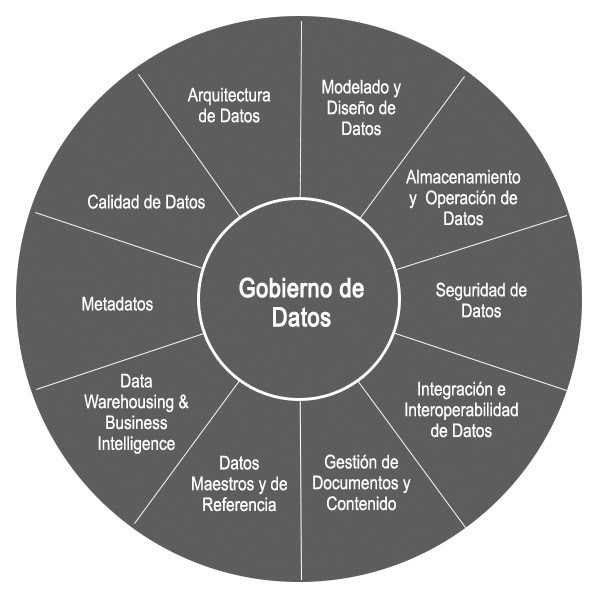
La aplicación del Gobierno del Dato en datos abiertos
Partiendo de la rueda expuesta en el apartado anterior, el gobierno, control, calidad, gestión y conocimiento de los datos son la clave del éxito y, para ello, se debe cumplir con los siguientes principios:
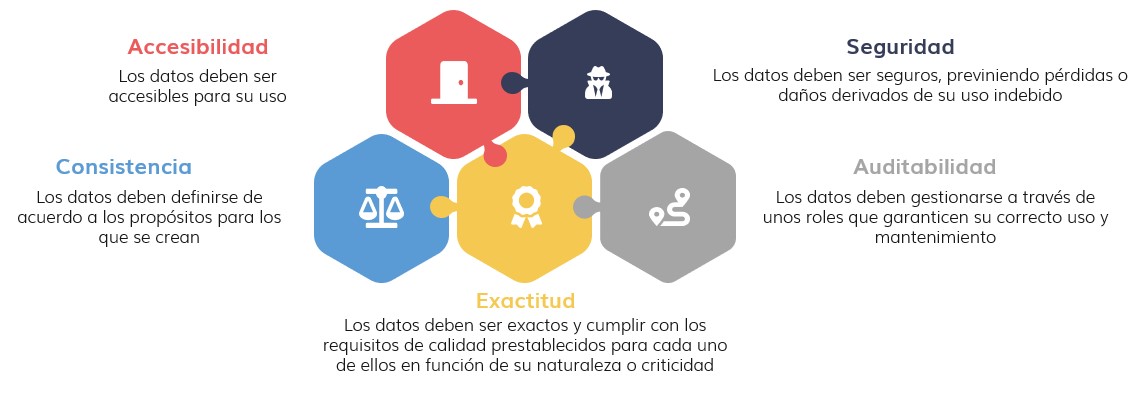
Para lograr que los datos cumplan con estos principios, será necesario establecer una estrategia de gobernanza de los mismos, mediante la implantación de una Oficina del Dato capaz de definir las políticas y procedimientos que dictaminen las pautas para su gestión. Deberán incluir la definición de los roles y sus responsabilidades, el modelo de relación de todos ellos y la forma en la que se velará por el cumplimiento de las mismas, así como otras iniciativas relacionadas con los datos.
Además de la gobernanza del dato, algunas de las características recomendadas a la hora de gestionar datos abiertos, son las siguientes:
- Una arquitectura capaz de asegurar la disponibilidad de la información en el portal. En este sentido, CKAN se ha convertido en una de la arquitectura de referencia para la apertura de datos. CKAN es una plataforma de código abierto, gratuito y libre, desarrollada por la Open Knowledge Foundation, que sirve para publicar y catalogar colecciones de datos. En este enlace tienes una guía para conocer más sobre cómo publicar datos abiertos con CKAN.
- La interoperabilidad de los catálogos de datos. Cualquier usuario que lo desee, podrá hacer uso de la información mediante descarga directa de los datos que considere. Por ello, se pone de manifiesto la necesidad de una integración sencilla de la información, independientemente de qué portal de datos abiertos se haya obtenido. Se deben utilizar estándares reconocidos para fomentar la interoperabilidad de los catálogos de datos y metadatos en toda Europa, como el vocabulario para catálogos de datos (DCAT) definido por el W3C y su perfil de aplicación DCAT-AP. En España, tenemos la Norma Técnica de Interoperabilidad (NTI), basada en dicho vocabulario. Puedes profundizar más en este el informe.
- El metadatado, entendido como los datos de los datos, es uno de los pilares fundamentales a la hora de categorizar y etiquetar la información, lo que posteriormente se reflejará en una navegación ágil y sencilla en el portal para cualquier usuario. Algunos de los metadatos que debemos incluir son el título, el formato o la periodicidad de actualización, tal y como nos muestra la mencionada NTI.
- Al tratarse de información ofrecida por las administraciones públicas para su reutilización, no es necesario cumplir con estrictas medidas de privacidad para su explotación, ya que previamente han sido anonimizados. Por el contrario, deben existir actividades que garanticen la seguridad de los datos. Por ejemplo, se podrán evitar usos indebidos o fraudulentos mediante una monitorización de los accesos y el seguimiento de la actividad de los usuarios.
- Además, la información disponible en el portal cumplirá con los criterios de calidad tanto técnica como funcional requerida por los usuarios, garantizada mediante la aplicación de indicadores de calidad.
- Por último, aunque no es una de las características del marco de referencia como tal, DAMA nos habla de forma transversal a todas ellas sobre la ética del dato, entendida como la responsabilidad social respecto al tratamiento de los datos. Existe determinada información sensible cuyo uso indebido podría tener impacto en las personas.
La evolución del Gobierno del Dato
Debido a la crisis financiera del año 2008, se puso el foco en la gestión de la información en las entidades financieras: qué información se tiene, cómo se explota… Por ello, actualmente, es uno de los sectores más regulados, lo que le convierte también en uno de los más avanzados con respecto a la aplicabilidad de estas prácticas.
Sin embargo, el auge de las nuevas tecnologías asociadas al procesamiento de los datos, comenzaron a cambiar la concepción de estas actividades de gestión. Ya no se veían tanto como un mero control de la información, sino que considerar los datos como activos estratégicos suponía grandes avances en el negocio.
Gracias a esta nueva concepción, organizaciones privadas de todo tipo se han interesado por esta materia e, incluso, en algunos organismos públicos, no es extraño ver como se comienza a profesionalizar el gobierno del dato mediante iniciativas focalizadas en ofrecer al ciudadano una atención más personalizada y eficaz a partir del dato. Por ejemplo, la ciudad de Edmonton utiliza esta metodología y por ello ha sido reconocida.
En este webinar puedes ver más información sobre la gestión del dato en el marco de referencia de DAMA. También puedes ver el video de su evento anual donde se explican diversos casos de uso o seguir su blog.
El camino hacia la cultura del dato
Nos encontramos inmersos en un mundo digital globalizado en constante evolución y los datos no son ajenos a ello. Constantemente están surgiendo nuevas iniciativas de datos ante las que se hace necesario un gobierno del dato eficiente capaz de dar respuesta a estos cambios.
Por ello, el camino hacia una cultura del dato es una realidad que todas las organizaciones y organismos públicos deben tomar en el corto plazo. El uso de una metodología de gobierno del dato, como el de DAMA, sin duda, será un gran apoyo durante todo el trayecto.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA, y Juan Mañes, experto en Data Governance.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.