Blog
Over the last decade, the amount of data that organisations generate and need to manage has grown exponentially. With the rise of the cloud, Internet of Things (IoT), edge computing and artificial intelligence (AI), enterprises face the challenge of integrating and governing data from multiple sources and environments. In this context, two key approaches to data management have emerged that seek to solve the problems associated with data centralisation: Data Mesh y Data Fabric. Although these concepts complement each other, each offers a different approach to solving the data challenges of modern organisations.
Why is a data lake not enough?
Many companies have implemented data lakes or centralised data warehouses with dedicated teams as a strategy to drive company data analytics. However, this approach often creates problems as the company scales up, for example:
- Centralised data equipment becomes a bottleneck. These teams cannot respond quickly enough to the variety and volume of questions that arise from different areas of the business.
- Centralisation creates a dependency that limits the autonomy of domain teams, who know their data needs best.
This is where the Data Meshapproach comes in.
Data Mesh: a decentralised, domain-driven approach
Data Mesh breaks the centralisation of data and distributes it across specific domains, allowing each business team (or domain team) to manage and control the data it knows and uses most. This approach is based on four basic principles:
- Domain ownership: instead of a central data computer having all the control, each computer is responsible for the data it generates. That is, if you are the sales team, you manage the sales data; if you are the marketing team, you manage the marketing data. Nobody knows this data better than the team that uses it on a daily basis.
- Data as a product: this idea reminds us that data is not only for the use of the domain that generates it, but can be useful for the entire enterprise. So each team should think of its data as a "product" that other teams can also use. This implies that the data must be accessible, reliable and easy to find, almost as if it were a public API.
- Self-service platform: decentralisation does not mean that every team has to reinvent the wheel. To prevent each domain team from specialising in complex data tools, the Data Mesh is supported by a self-service infrastructure that facilitates the creation, deployment and maintenance of data products. This platform should allow domain teams to consume and generate data without relying on high technical expertise.
- Federated governance: although data is distributed, there are still common rules for all. In a Data Mesh, governance is "federated", i.e. each device follows globally defined interoperability standards. This ensures that all data is secure, high quality and compliant.
These principles make Data Mesh an ideal architecture for organisations seeking greater agility and team autonomy without losing sight of quality and compliance. Despite decentralisation, Data Mesh does not create data silos because it encourages collaboration and standardised data sharing between teams, ensuring common access and governance across the organisation.
Data Fabric: architecture for secure and efficient access to distributed data
While the Data Mesh focuses on organising and owning data around domains, the Data Fabric is an architecture that allows connecting and exposing an organisation''s data, regardless of its location. Unlike approaches based on data centralisation, such as the data lake, the Data Fabric acts as a unified layer, providing seamless access to data distributed across multiple systems without the need to physically move it to a single repository.
In general terms, the Data Fabric is based on three fundamental aspects:
- Access to data: in a modern enterprise, data is scattered across multiple locations, such as data lakes, data warehouses, relational databases and numerous SaaS (Software as-a-Service) applications. Instead of consolidating all this data in one place, the Data Fabric employs a virtualisation layer that allows it to be accessed directly from its original sources. This approach minimises data duplication and enables real-time access, thus facilitating agile decision-making. In cases where an application requires low latencies, the Data Fabric also has robust integration tools, such as ETL (extract, transform and load), to move and transform data when necessary.
- Data lifecycle management: the Data Fabric not only facilitates access, but also ensures proper management throughout the entire data lifecycle. This includes critical aspects such as governance, privacy and compliance. The architecture of the Data Fabric relies on active metadata that automates the application of security and access policies, ensuring that only users with the appropriate permissions access the corresponding information. It also offers advanced traceability (lineage) functionalities, which allow tracking the origin of data, knowing its transformations and assessing its quality, which is essential in environments regulated under regulations such as the General Data Protection Regulation (GDPR).
- Data exposure: after connecting the data and applying the governance and security policies, the next step of the Data Fabric is to make that data available to end users. Through enterprise catalogues, data is organised and presented in a way that is accessible to analysts, data scientists and developers, who can locate and use it efficiently.
In short, the Data Fabric does not replace data lakes or data warehouses, but facilitates the integration and management of the organisation''s existing data. It aims to create a secure and flexible environment that enables the controlled flow of data and a unified view, without the need to physically move it, thus driving more agile and informed decision-making.
Data Mesh vs. Data Fabric. Competitors or allies?
While Data Mesh and Data Fabric have some objectives in common, each solves different problems and, in fact, benefits can be found in applying mechanisms from both approaches in a complementary manner. The following table shows a comparison of the two approaches:
| APEARANCE | DATA MESH | DATA FABRIC |
|---|---|---|
| Approach | Organisational and structural, domain-oriented. | Technical, focusing on data integration. |
| Purpose | Decentralise ownership and responsibility for data to domain teams. | Create a unified data access layer distributed across multiple environments. |
| Data management | Each domain manages its own data and defines quality standards. | Data is integrated through services and APIs, allowing a unified view without physically moving data. |
| Governance | Federated, with rules established by each domain, maintaining common standards. | Centralised at platform level, with automation of access and security policies through active metadata. |
Figure 1. Comparative table of Data Mesh VS. Data Fabric. Source: Own elaboration.
Conclusion
Both Data Mesh and Data Fabric are designed to solve the challenges of data management in modern enterprises. Data Mesh brings an organisational approach that empowers domain teams, while Data Fabric enables flexible and accessible integration of distributed data without the need to physically move it. The choice between the two, or a combination of the two, will depend on the specific needs of each organisation, although it is important to consider the investment in infrastructure, training and possible organisational changes that these approaches require. For small to medium-sized companies, a traditional data warehouse can be a practical and cost-effective alternative, especially if their data volumes and organisational complexity are manageable. However, given the growth of data ecosystems in organisations, both models represent a move towards a more agile, secure and useful data environment, facilitating data management that is better aligned with strategic objectives in an environment.
Definitions
- Data Lake: it is a storage repository that allows large volumes of data to be stored in their original format, whether structured, semi-structured or unstructured. Its flexible structure allows raw data to be stored and used for advanced analytics and machine learning.
- Data Warehouse: it is a structured data storage system that organises, processes and optimises data for analysis and reporting. It is designed for quick queries and analysis of historical data, following a predefined scheme for easy access to information.
References
- Dehghani, Zhamak. Data Mesh Principles and Logical Architecture. https://martinfowler.com/articles/data-mesh-principles.html.
- Dehghani, Zhamak. Data Mesh: Delivering Data-Driven Value at Scale. O''Reilly Media. Book detailing the implementation and fundamental principles of Data Mesh in organisations.
- Data Mesh Architecture. Website about Data Mesh and data architectures. https://www.datamesh-architecture.com/
- IBM Data Fabric. IBM Topics. https://www.ibm.com/topics/data-fabric
- IBM Technology. Data Fabric. Unifying Data Across Hybrid and Multicloud Environments. YouTube. https://www.youtube.com/watch?v=0Zzn4eVbqfk&t=4s&ab_channel=IBMTechnology
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
There is such a close relationship between data management, data quality management and data governance that the terms are often used interchangeably or confused. However, there are important nuances.
The overall objective of data management is to ensure that data meets the business requirements that will support the organisation's processes, such as collecting, storing, protecting, analysing and documenting data, in order to implement the objectives of the data governance strategy. It is such a broad set of tasks that there are several categories of standards to certify each of the different processes: ISO/IEC 27000 for information security and privacy, ISO/IEC 20000 for IT service management, ISO/IEC 19944 for interoperability, architecture or service level agreements in the cloud, or ISO/IEC 8000-100 for data exchange and master data management.
Data quality management refers to the techniques and processes used to ensure that data is fit for its intended use. This requires a Data Quality Plan that must be in line with the organisation's culture and business strategy and includes aspects such as data validation, verification and cleansing, among others. In this regard, there is also a set of technical standards for achieving data quality] including data quality management for transaction data, product data and enterprise master data (ISO 8000) and data quality measurement tasks (ISO 25024:2015).
Data governance, according to Deloitte's definition, consists of an organisation's set of rules, policies and processes to ensure that the organisation's data is correct, reliable, secure and useful. In other words, it is the strategic, high-level planning and control to create business value from data. In this case, open data governance has its own specificities due to the number of stakeholders involved and the collaborative nature of open data itself.
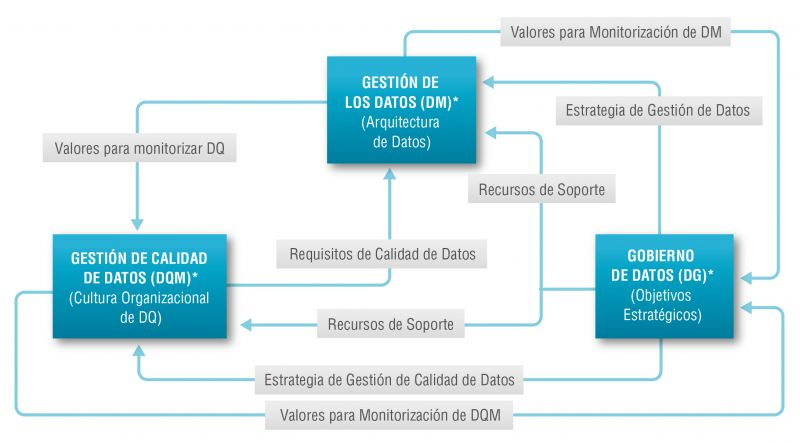
The Alarcos Model
In this context, the Alarcos Model for Data Improvement (MAMD), currently in its version 3, aims to collect the necessary processes to achieve the quality of the three dimensions mentioned above: data management, data quality management and data governance. This model has been developed by a group of experts coordinated by the Alarcos research group of the University of Castilla-La Mancha in collaboration with the specialised companies DQTeam and AQCLab.
The MAMD Model is aligned with existing best practices and standards such as Data Management Community (DAMA), Data management maturity (DMM) or the ISO 8000 family of standards, each of which addresses different aspects related to data quality and master data management from different perspectives. In addition, the Alarcos model is based on the family of standards to define the maturity model so it is possible to achieve AENOR certification for ISO 8000-MAMD data governance, management and quality.
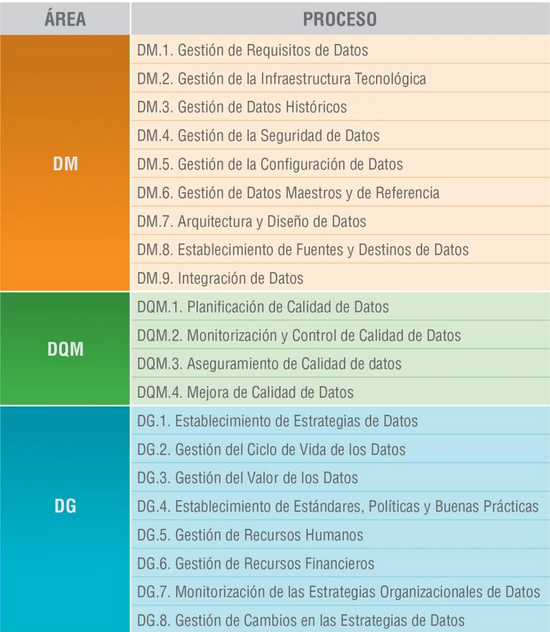
The MAMD model consists of 21 processes, 9 processes correspond to data management (DM), data quality management (DQM) includes 4 more processes and data governance (DG), which adds another 8 processes.
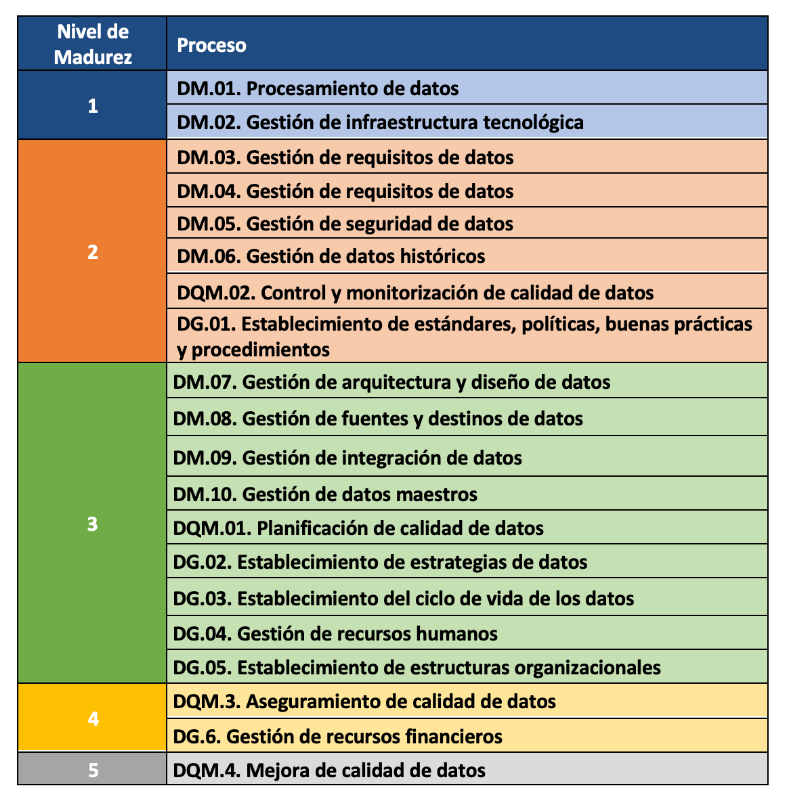
The progressive incorporation of the 21 processes allows the definition of 5 maturity levels that contribute to the organisation improving its data management, data quality and data governance. Starting with level 1 (Performed) where the organisation can demonstrate that it uses good practices in the use of data and has the necessary technological support, but does not pay attention to data governance and data quality, up to level 5 (Innovative) where the organisation is able to achieve its objectives and is continuously improving.
The model can be certified with an audit equivalent to that of other AENOR standards, so there is the possibility of including it in the cycle of continuous improvement and internal control of regulatory compliance of organisations that already have other certificates.
Practical exercises
The Library of the University of Castilla-La Mancha (UCLM), which supports more than 30,000 students and 3,000 professionals including teachers and administrative and service staff, is one of the first organisations to pass the certification audit and therefore obtain level 2 maturity in ISO/IEC 33000 - ISO 8000 (MAMD).
The strengths identified in this certification process were the commitment of the management team and the level of coordination with other universities. As with any audit, improvements were proposed such as the need to document periodic data security reviews which helped to feed into the improvement cycle.
The fact that organisations of all types place an increasing value on their data assets means that technical certification models and standards have a key role to play in ensuring the quality, security, privacy, management or proper governance of these data assets. In addition to existing standards, a major effort continues to be made to develop new standards covering aspects that have not been considered central until now due to the reduced importance of data in the value chains of organisations. However, it is still necessary to continue with the formalisation of models that, like the Alarcos Data Improvement Model, allow the evaluation and improvement process of the organisation in the treatment of its data assets to be addressed holistically, and not only from its different dimensions.
Content prepared by Jose Luis Marín, Senior Consultant in Data, Strategy, Innovation & Digitalization.
The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
In the current environment, organisations are trying to improve the exploitation of their data through the use of new technologies, providing the business with additional value and turning data into their main strategic asset.
However, we can only extract the real value of data if it is reliable and for this, the function of Data Governance arises, focused on the efficient management of information assets. Open data cannot be alien to these practices due to its characteristics, mainly of availability and access.
To answer the question of how we should govern data, there are several international methodologies, such as DCAM, MAMD, DGPO or DAMA. In this post, we will base ourselves on the guidelines offered by the latter.
What is DAMA?
DAMA, by its acronym Data Management Association, is an international association for data management professionals. It has a chapter in Spain, DAMA Spain, since March 2019.
Its main mission is to promote and facilitate the development of the data management culture, becoming the reference for organisations and professionals in information management, providing resources, training and knowledge on the subject.
The association is made up of data management professionals from different sectors.
Data governance according to DAMA's reference framework
“A piece of data placed in a context gives rise to information. Add intelligence and you get knowledge that, combined with a good strategy, generates power”
Although it is just a phrase, it perfectly sums up the strategy, the search for power from data. To achieve this, it is necessary to exercise authority, control and shared decision-making (planning, monitoring and implementation) over the management of data assets or, in other words, to apply Data Governance.
DAMA presents what it considers to be the best practices for guaranteeing control over information, regardless of the application business, and to this end, it positions Data Governance as the main activity around which all other activities are managed, such as architecture, interoperability, quality or metadata, as shown in the following figure:
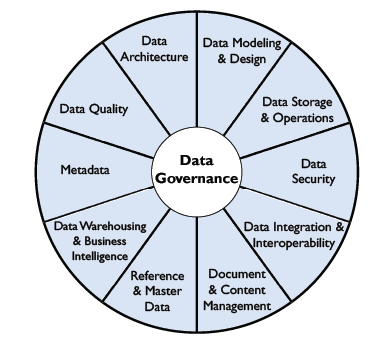
The Data Government's implementation of open data
Based on the wheel outlined in the previous section, data governance, control, quality, management and knowledge are the key to success and, to this end, the following principles must be complied with:
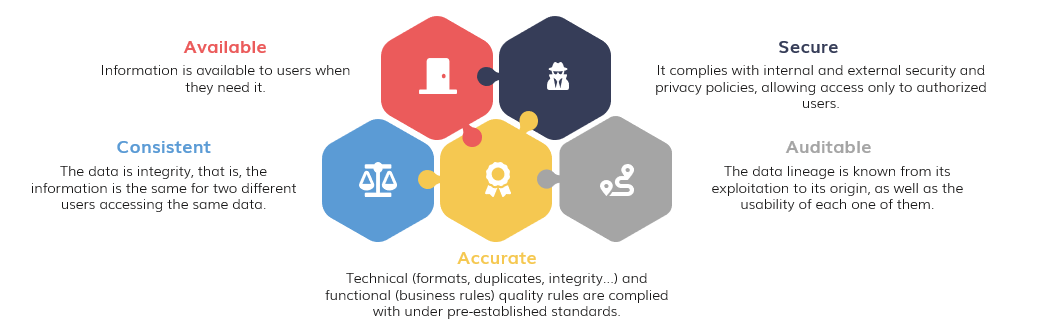
To achieve data compliance with these principles, it will be necessary to establish a data governance strategy, through the implementation of a Data Office capable of defining the policies and procedures that dictate the guidelines for data management. These should include the definition of roles and responsibilities, the relationship model for all of them and how they will be enforced, as well as other data-related initiatives.
In addition to data governance, some of the recommended features of open data management include the following:
- An architecture capable of ensuring the availability of information on the portal. In this sense, CKAN has become one of the reference architecture for open data. CKAN is a free and open source platform, developed by the Open Knowledge Foundation, which serves to publish and catalogue data collections. This link provides a guide to learn more about how to publish open data with CKAN.
- The interoperability of data catalogues. Any user can make use of the information through direct download of the data they consider. This highlights the need for easy integration of information, regardless of which open data portal it was obtained from.
- Recognised standards should be used to promote the interoperability of data and metadata catalogues across Europe, such as the Data Catalogue Vocabulary (DCAT) defined by the W3C and its application profile DCAT-AP. In Spain, we have the Technical Interoperability Standard (NTI), based on this vocabulary. You can read more about it in this report.
- The metadata, understood as the data of the data, is one of the fundamental pillars when categorising and labelling the information, which will later be reflected in an agile and simple navigation in the portal for any user. Some of the metadata to be included are the title, the format or the frequency of updating, as shown in the aforementioned NTI.
- As this information is offered by public administrations for reuse, it is not necessary to comply with strict privacy measures for its exploitation, as it has been previously anonymised. On the contrary, there must be activities to ensure the security of the data. For example, improper or fraudulent use can be prevented by monitoring access and tracking user activity.
- Furthermore, the information available on the portal will meet the technical and functional quality criteria required by users, guaranteed by the application of quality indicators.
- Finally, although it is not one of the characteristics of the reference framework as such, DAMA speaks transversally to all of them about data ethics, understood as social responsibility with respect to data processing. There is certain sensitive information whose improper use could have an impact on individuals.
The evolution of Data Government
Due to the financial crisis of 2008, the focus was placed on information management in financial institutions: what information is held, how it is exploited... For this reason, it is currently one of the most regulated sectors, which also makes it one of the most advanced with regard to the applicability of these practices.
However, the rise of new technologies associated with data processing began to change the conception of these management activities. They were no longer seen so much as a mere control of information, but considering data as strategic assets meant great advances in the business.
Thanks to this new concept, private organisations of all kinds have taken an interest in this area and, even in some public bodies, it is not unusual to see how data governance is beginning to be professionalised through initiatives focused on offering citizens a more personalised and efficient service based on data. For example, the city of Edmonton uses this methodology and has been recognised for it.
In this webinar you can learn more about data management in the DAMA framework. You can also watch the video of their annual event where different use cases are explained or follow their blog.
The road to data culture
We are immersed in a globalised digital world that is constantly evolving and data is no stranger to this. New data initiatives are constantly emerging and an efficient data governance capable of responding to these changes is necessary.
Therefore, the path towards a data culture is a reality that all organisations and public bodies must take in the short term. The use of a data governance methodology, such as DAMA's, will undoubtedly be a great support along the way.
Content prepared by David Puig, Graduate in Information and Documentation and head of the Master and Reference Data working group at DAMA SPAIN, and Juan Mañes, expert in Data Governance.
The contents and points of view reflected in this publication are the sole responsibility of its author.