Documentación
La compartición de datos o data sharing se ha convertido en un pilar imprescindible para el avance de la analítica y el intercambio de conocimiento, tanto en el ámbito privado como en el público. Las organizaciones de cualquier tamaño y sector –empresas, administraciones públicas, instituciones de investigación, comunidades de desarrolladores o individuos– encuentran un fuerte valor en la capacidad de compartir información de forma segura, fiable y eficiente. Este intercambio no se limita a datos en crudo o datasets estructurados; también se extiende a productos de datos más avanzados, tales como modelos de machine learning entrenados, dashboards analíticos, resultados de experimentos científicos y otros artefactos complejos que generan un gran impacto a través de su reutilización.
En este contexto, la importancia de la gobernanza de estos recursos cobra un papel crítico. No es suficiente con disponer de un método para mover ficheros de un sitio a otro; es necesario garantizar aspectos clave como el control de acceso (quién puede leer o modificar cierto recurso), la trazabilidad y la auditoría (saber quién ha accedido, cuándo y con qué finalidad) o el cumplimiento de regulaciones o estándares, especialmente en entornos empresariales y gubernamentales.
Con el fin de unificar estos requisitos, Unity Catalog surge como un almacén de metadatos (metastore) de próxima generación, pensado para centralizar y simplificar la gobernanza de datos y recursos de datos. Originalmente, Unity Catalog formaba parte de los servicios ofrecidos por la plataforma Databricks, pero el proyecto ha dado un salto a la comunidad de código abierto para convertirse en un estándar de referencia. Esto implica que ahora es posible utilizarlo, modificarlo y, en definitiva, contribuir a su evolución desde un entorno libre y colaborativo. Con ello, se espera que más organizaciones adopten sus modelos de catálogo y compartición, impulsando la reutilización de datos y la creación de flujos analíticos e innovaciones tecnológicas.

Fuente: https://docs.unitycatalog.io/
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Objetivos
En este ejercicio, aprenderemos a configurar Unity Catalog, una herramienta que nos ayuda a organizar y compartir datos en la nube de manera segura. Aunque utilizaremos algo de código, explicaremos cada paso para que incluso personas con poca experiencia en programación puedan seguirlo a través de un laboratorio práctico.
Trabajaremos con un escenario realista donde gestionaremos datos sobre transporte público en diferentes ciudades. Crearemos catálogos de datos, configuraremos una base de datos y aprenderemos a interactuar con la información usando herramientas como Docker, Apache Spark y MLflow.
Nivel de dificultad: Intermedio.

Figura 1. Esquema Unity Catalog
Recursos Necesarios
En esta sección explicaremos los requisitos previos y recursos necesarios para poder desarrollar este laboratorio. El laboratorio está pensado para desarrollarse en un ordenador personal estándar (Windows, MacOS, Linux).
Adicionalmente utilizaremos las siguientes herramientas y entornos de trabajo:
- Docker Desktop: Docker es una herramienta que nos permite ejecutar aplicaciones en un entorno aislado llamado contenedor. Un contenedor es como una "caja" que contiene todo lo necesario para que una aplicación funcione correctamente, sin importar el sistema operativo que estés usando.
- Visual Studio Code: Nuestro entorno de trabajo será un Notebook Python que ejecutaremos y manipularemos a través del editor de código ampliamente utilizado Visual Studio Code (VS Code).
- Unity Catalog: Es una herramienta de gobernanza de datos que permite organizar y controlar el acceso a recursos como tablas, volúmenes de datos, funciones o modelos de machine learning. A lo largo del laboratorio, utilizaremos su versión open source, que puede desplegarse localmente, para aprender a gestionar catálogos de datos con control de permisos, trazabilidad y estructura jerárquica. Unity Catalog actúa como un metastore centralizado, facilitando la colaboración y la reutilización de datos de forma segura.
- Amazon Web Services: AWS será el proveedor cloud que utilizaremos para alojar ciertos datos del laboratorio, en concreto los datos en crudo (como archivos JSON) que gestionaremos mediante volúmenes de datos. Aprovecharemos su servicio Amazon S3 para almacenar estos archivos y configuraremos las credenciales y permisos necesarios para que Unity Catalog pueda interactuar con ellos de forma controlada.
Desarrollo del ejercicio
A lo largo del ejercicio, los participantes desplegarán la aplicación, comprenderán su arquitectura e irán construyendo un catálogo de datos paso a paso, aplicando buenas prácticas de organización, control de acceso y trazabilidad.
Despliegue y primeros pasos
- Clonamos el repositorio de Unity Catalog y lo levantamos con Docker.
- Exploramos su arquitectura: un backend accesible por API y CLI, y una interfaz gráfica intuitiva.
- Navegamos por los recursos que gestiona Unity Catalog: catálogos, esquemas, tablas, volúmenes, funciones y modelos.
Figura 2. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo levantar la aplicación, sus componentes principales, y cómo empezar a interactuar con ella desde distintos puntos: web, API y CLI.
Organización de recursos
- Configuramos una base de datos MySQL externa como repositorio de metadatos.
- Creamos catálogos para representar distintas ciudades y esquemas para distintos servicios públicos.

Figura 3. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo estructurar el gobierno de datos a distintos niveles (ciudad, servicio, dataset) y cómo gestionar los metadatos de forma centralizada y persistente.
Construcción de datos y uso real
- Creamos tablas estructuradas para representar rutas, autobuses o paradas.
- Cargamos datos reales en estas tablas usando PySpark.Habilitamos un bucket en AWS S3 como almacenamiento de datos en crudo (volúmenes).
- Subimos ficheros JSON con eventos de telemetría y los gobernamos desde Unity Catalog.
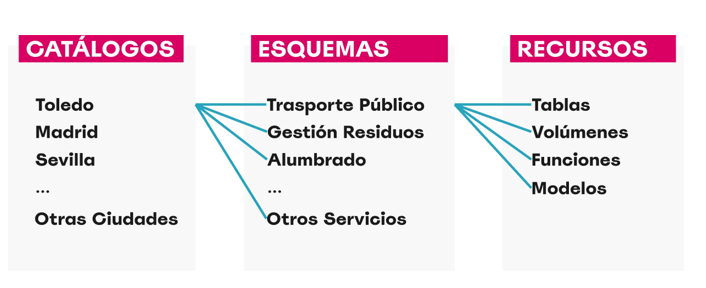
Figura 4. Esquema
¿Qué aprenderemos aquí?
Cómo convivir con distintos tipos de datos (estructurados y no estructurados), y cómo integrarlos con fuentes externas (como AWS S3).
Funciones reutilizables y modelos de IA
- Registramos funciones personalizadas (como el cálculo de distancias) reutilizables desde el catálogo.
- Creamos y registramos modelos de machine learning con MLflow.
- Ejecutamos predicciones desde Unity Catalog como si fueran cualquier otro recurso del ecosistema.
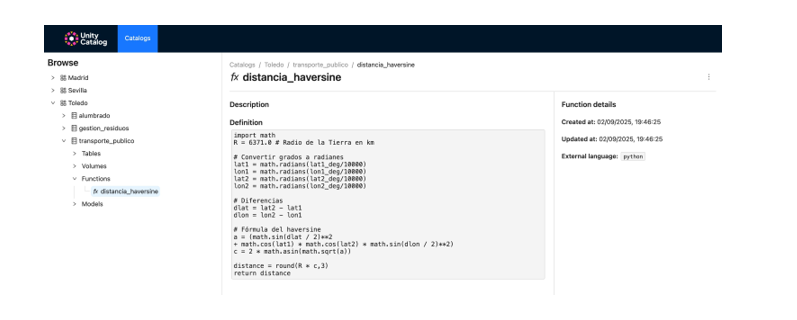
Figura 5. Captura de pantalla
¿Qué aprenderemos aquí?
Cómo ampliar el gobierno de datos a funciones y modelos, y cómo facilitar su reutilización y trazabilidad en entornos colaborativos.
Resultados y conclusiones
Como resultado de este laboratorio práctico, vamos a poner conocer la herramienta Unity Catalog como plataforma abierta para la gobernanza de datos y recursos de datos como modelos de machine learning. Exploraremos, además, el contexto de un caso de uso concreto y con un ecosistema de herramientas similar al que podemos encontrar en una organización real, sus capacidades, su modo de despliegue y su uso.
Mediante este ejercicio configuraremos y utilizaremos Unity Catalog para organizar datos de transporte público. En concreto, podrás:
- Aprender a instalar herramientas como Docker o Spark.
- Crear catálogos, esquemas y tablas en Unity Catalog.
- Cargar datos y almacenarlos en un bucket de Amazon S3.
- Implementar un modelo de machine learning con MLflow.
Veremos, en los próximos años, si este tipo de herramientas alcanzan el nivel de estandarización necesario para transformar la forma en que se administran y comparten los recursos de datos en múltiples sectores.
¡Te animamos a realizar más ejercicios de ciencia de datos! Accede al repositorio aquí
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en tecnologías ligadas a la economía del dato. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
En el panorama actual del análisis de datos y la inteligencia artificial, la generación automática de informes completos y coherentes representa un desafío significativo. Mientras que las herramientas tradicionales permiten visualizar datos o generar estadísticas aisladas, existe la necesidad de sistemas que puedan investigar un tema a fondo, recopilar información de diversas fuentes, y sintetizar hallazgos en un informe estructurado y coherente.
En este ejercicio práctico, exploraremos el desarrollo de un agente de generación de reportes basado en LangGraph e inteligencia artificial. A diferencia de los enfoques tradicionales basados en plantillas o análisis estadísticos predefinidos, nuestra solución aprovecha los últimos avances en modelos de lenguaje para:
- Crear equipos virtuales de analistas especializados en diferentes aspectos de un tema.
- Realizar entrevistas simuladas para recopilar información detallada.
- Sintetizar los hallazgos en un informe coherente y bien estructurado.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
Como se muestra en la Figura 1, el flujo completo del agente sigue una secuencia lógica que va desde la generación inicial de preguntas hasta la redacción final del informe.

Figura 1. Diagrama de flujo del agente.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en un diseño modular implementado como un grafo de estados interconectados, donde cada módulo representa una funcionalidad específica en el proceso de generación de reportes. Esta estructura permite un flujo de trabajo flexible, recursivo cuando es necesario, y con capacidad de intervención humana en puntos estratégicos.
Componentes principales
El sistema se compone de tres módulos fundamentales que trabajan en conjunto:
1. Generador de Analistas Virtuales
Este componente crea un equipo diverso de analistas virtuales especializados en diferentes aspectos del tema a investigar. El flujo incluye:
- Creación inicial de perfiles basados en el tema de investigación.
- Punto de retroalimentación humana que permite revisar y refinar los perfiles generados.
- Regeneración opcional de analistas incorporando sugerencias.
Este enfoque garantiza que el informe final incluya perspectivas diversas y complementarias, enriqueciendo el análisis.
2. Sistema de Entrevistas
Una vez generados los analistas, cada uno participa en un proceso de entrevista simulada que incluye:
- Generación de preguntas relevantes basadas en el perfil del analista.
- Búsqueda de información en fuentes vía Tavily Search y Wikipedia.
- Generación de respuestas informativas combinando la información obtenida.
- Decisión automática sobre continuar o finalizar la entrevista en función de la información recopilada.
- Almacenamiento de la transcripción para su procesamiento posterior.
El sistema de entrevistas representa el corazón del agente, donde se obtiene la información que nutrirá el informe final. Tal y como se muestra en la Figura 2, este proceso puede monitorizarse en tiempo real mediante LangSmith, una herramienta abierta de observabilidad que permite seguir cada paso del flujo.

Figura 2. Monitorización del sistema vía LangGraph. Ejemplo concreto de una interacción analista-entrevistador.
3. Generador de Informes
Finalmente, el sistema procesa las entrevistas para crear un informe coherente mediante:
- Redacción de secciones individuales basadas en cada entrevista.
- Creación de una introducción que presente el tema y la estructura del informe.
- Organización del contenido principal que integra todas las secciones.
- Generación de una conclusión que sintetiza los hallazgos principales.
- Consolidación de todas las fuentes utilizadas.
La Figura 3 muestra un ejemplo del informe resultante del proceso completo, demostrando la calidad y estructura del documento final generado automáticamente.

Figura 3. Vista del informe resultante del proceso de generación automática al prompt de “Datos abiertos en España”.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
Integración de IA avanzada en sistemas de procesamiento de información:
- Cómo comunicarse efectivamente con modelos de lenguaje.
- Técnicas para estructurar prompts que generen respuestas coherentes y útiles.
- Estrategias para simular equipos virtuales de expertos.
Desarrollo con LangGraph:
- Creación de grafos de estados para modelar flujos complejos.
- Implementación de puntos de decisión condicionales.
- Diseño de sistemas con intervención humana en puntos estratégicos.
Procesamiento paralelo con LLMs:
- Técnicas de paralelización de tareas con modelos de lenguaje.
- Coordinación de múltiples subprocesos independientes.
- Métodos de consolidación de información dispersa.
Buenas prácticas de diseño:
- Estructuración modular de sistemas complejos.
- Manejo de errores y reintentos.
- Seguimiento y depuración de flujos de trabajo mediante LangSmith.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos y los usuarios finales. A través del caso práctico desarrollado, podemos observar cómo la combinación de modelos de lenguaje avanzados con arquitecturas flexibles basadas en grafos abre nuevas posibilidades para la generación automática de informes.
La capacidad de simular equipos de expertos virtuales, realizar investigaciones paralelas y sintetizar hallazgos en documentos coherentes, representa un paso significativo hacia la democratización del análisis de información compleja.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de mecanismos de verificación automática de datos para garantizar la precisión.
- Implementación de capacidades multimodales que permitan incorporar imágenes y visualizaciones.
- Integración con más fuentes de información y bases de conocimiento.
- Desarrollo de interfaces de usuario más intuitivas para la intervención humana.
- Expansión a dominios especializados como medicina, derecho o ciencias.
En resumen, este ejercicio no solo demuestra la viabilidad de automatizar la generación de informes complejos mediante inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el análisis profundo de cualquier tema esté al alcance de todos, independientemente de su nivel de experiencia técnica. La combinación de modelos de lenguaje avanzados, arquitecturas de grafos y técnicas de paralelización abre un abanico de posibilidades para transformar la forma en que generamos y consumimos información.
Blog
La creciente complejidad de los modelos de aprendizaje automático y la necesidad de optimizar su rendimiento lleva años impulsando el desarrollo del AutoML (Automated Machine Learning). Esta disciplina busca automatizar tareas clave en el ciclo de vida del desarrollo de modelos, como la selección de algoritmos, el procesamiento de datos y la optimización de hiperparámetros.
El AutoML permite a los usuarios desarrollar modelos de manera más sencilla y rápida. Se trata de un enfoque que facilita el acceso a la disciplina, haciéndola accesible a los profesionales con menos experiencia en programación y acelerando los procesos para aquellos que cuentan con más experiencia. Así, para un usuario con conocimientos profundos de programación, el AutoML también puede ser interesante. Gracias al auto machine learning, este usuario podría aplicar automáticamente las configuraciones técnicas necesarias, como definir variables o interpretar los resultados de manera más ágil.
En este post, abordaremos las claves de estos procesos de automatización y recopilaremos una serie de herramientas de código abierto gratuitas y/o con modelo freemium, que te pueden servir para profundizar en el AutoML.
Aprende a crear tu propio modelado de aprendizaje automático
Como se indicaba anteriormente, gracias a la automatización, el proceso de entrenamiento y evaluación de modelos en base a herramientas de AutoML es más rápido que en un proceso de machine learning (ML) habitual, si bien las etapas para la creación de modelos son similares.
En general, los componentes clave del AutoML son:
- Preprocesamiento de datos: automatiza tareas como la limpieza, transformación y selección de características de los datos.
- Selección de modelos: examina una variedad de algoritmos de machine learning y elige el más adecuado para la tarea específica.
- Optimización de hiperparámetros: ajusta automáticamente los parámetros de los modelos para mejorar su rendimiento.
- Evaluación de modelos: proporciona métricas de rendimiento y valida modelos utilizando técnicas como la validación cruzada.
- Implementación y mantenimiento: facilita la implementación de modelos en producción y, en algunos casos, su actualización.
Todos estos elementos ofrecen, en su conjunto, una serie de ventajas como las que vemos en la imagen
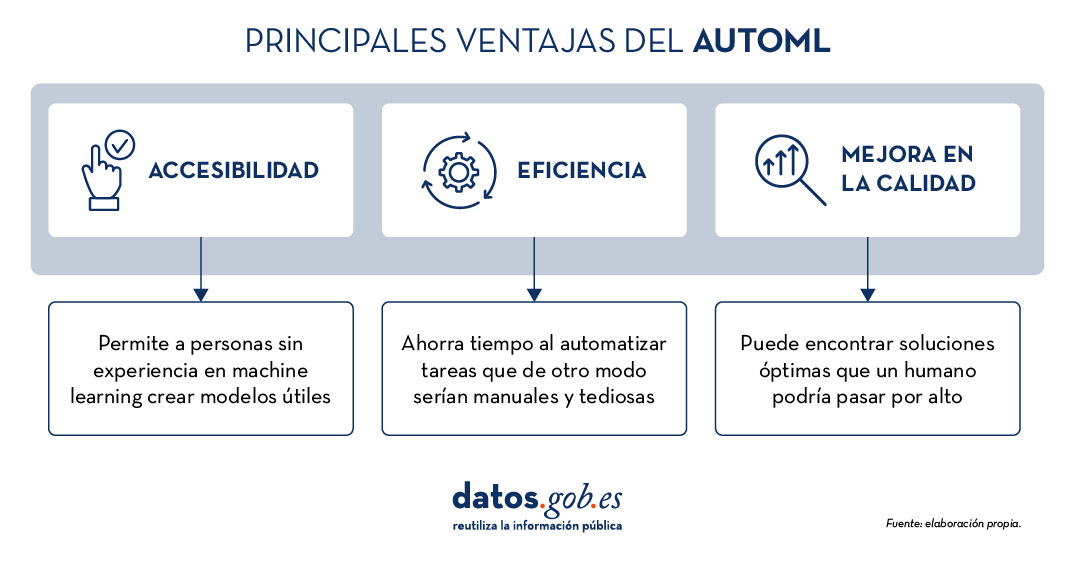
Figura 1. Fuente: elaboración propia.
Ejemplos de herramientas de AutoML
A pesar que el AutoML puede llegar a ser muy útil, es importante destacar algunas de sus limitaciones como el riesgo de overfitting (cuando el modelo se ajusta demasiado a los datos de entrenamiento y no generaliza bien el conocimiento), la pérdida de control sobre el proceso de modelado o la interpretabilidad de ciertos resultados.
No obstante, a medida que el AutoML continúa ganando terreno en el ámbito del aprendizaje automático, diversas herramientas han surgido para facilitar su implementación y uso. A continuación, exploraremos algunas de las herramientas de AutoML de código abierto más destacadas:
H2O.ai, versátil y escalable, ideal para empresas
H2O.ai es una plataforma de AutoML que incluye modelos de deep learning y machine learning como XGBoost (biblioteca de machine learning diseñada para mejorar la eficiencia de los modelos) y una interfaz de usuario gráfica. Esta herramienta se utiliza en proyectos a gran escala y permite un alto nivel de personalización. H2O.ai incluye opciones para modelos de clasificación, regresión y series temporales, y se destaca por su capacidad para manejar grandes volúmenes de datos.
Aunque H2O facilita el acceso al machine learning a no expertos, sí son necesarios algunos conocimientos y experiencia en ciencia de datos para sacarle el máximo partido a la herramienta. Además, permite realizar un gran número de tareas relacionadas con el modelado que normalmente requerirían muchas líneas de código, facilitando la tarea del analista de datos. H2O ofrece un modelo freemium y también cuenta con una versión comunitaria de código abierto.
TPOT, basado en algoritmos genéticos, buena opción para experimentar
TPOT (Tree-based Pipeline Optimization Tool) es una herramienta gratuita y de código abierto para el aprendizaje automático con Python que optimiza los procesos mediante programación genética.
Esta solución busca la mejor combinación de preprocesamiento de datos y modelos de aprendizaje automático para un conjunto de datos específico. Para ello, utiliza algoritmos genéticos que le permiten explorar y optimizar diferentes pipelines, transformación de datos y modelos. Se trata de una opción más experimental que puede resultar menos intuitiva, pero ofrece soluciones innovadoras.
Además, TPOT está construido sobre la popular biblioteca scikit-learn, así que los modelos generados por TPOT se pueden utilizar y ajustar con las mismas técnicas que se usarían en scikit-learn.
Auto-sklearn, accesible para usuarios de scikit-learn y eficiente en problemas estructurados
Como TPOT, Auto-sklearn está basada en scikit-learn y sirve para automatizar la selección de algoritmos y la optimización de hiperparámetros en modelos de aprendizaje automático en Python.
Además de ser una opción gratuita y de código abierto, incluye técnicas para manejar datos ausentes, una funcionalidad muy útil a la hora de trabajar con conjuntos de datos del mundo real. Por otro lado, Auto-sklearn ofrece una API sencilla y fácil de usar, lo que permite a los usuarios iniciar el proceso de modelado con pocas líneas de código.
BigML, integración mediante API REST y modelos de precios flexibles
BigML es una plataforma de aprendizaje automático consumible, programable y escalable que, como el resto de herramientas mencionadas, facilita la resolución y automatización de tareas de clasificación, regresión, pronóstico de series de tiempo, análisis de clústeres, detección de anomalías, descubrimiento de asociaciones y modelado de temas. Cuenta con una interfaz intuitiva y un enfoque hacia la visualización que facilita la creación y gestión de modelos de ML, incluso para usuarios con pocas nociones de programación.
Además, BigML tiene una API REST que posibilita la integración con diversas aplicaciones y lenguajes, y es escalable para manejar grandes volúmenes de datos. Por otro lado, ofrece un modelo de precios flexible basado en el uso, y cuenta con una comunidad activa que actualiza regularmente los recursos didácticos disponibles.
La siguiente tabla muestra una comparativa entre estas herramientas:
| H2O.ai | TPOT | Auto-sklearn | BigML | |
|---|---|---|---|---|
| Uso | Para proyectos a gran escala. | Para experimentar con algoritmos genéticos y optimizar pipelines. | Para usuarios de scikit-learn que desean automatizar el proceso de selección de modelos y para tareas estructuradas. | Para crear y desplegar modelos de ML de forma accesible y sencilla. |
| Dificultad de configuración | Sencilla, con opciones avanzadas. | Dificultad media. Una opción más técnica por los algoritmos genéticos. | Dificultad media. Precisa una configuración técnica, pero es fácil para usuarios de scikit-learn. | Sencilla. Interfaz intuitiva con opciones de personalización. |
| Facilidad de uso | Fácil de usar con los lenguajes de programación más habituales. Tiene interfaz gráfica y APIs para R y Python. | Fácil de usar, pero requiere conocimientos de Python. | Fácil de usar, pero requiere conocimientos previos. Opción sencilla para usuarios de scikit-learn. | Fácil de usar, enfocada a la visualización, no requiere grandes conocimientos de programación. |
| Escalabilidad | Escalable a grandes volúmenes de datos. | Enfocada en conjuntos de datos pequeños y medianos. Menos eficiente en datasets grandes. | Efectivo en conjuntos de datos tamaño pequeño y medio. | Escalable para diferentes tamaños de datasets. |
| Interoperabilidad | Compatible con varias bibliotecas y lenguajes, como Java, Scala, Python y R. | Basado en Python. | Basado en Python integrando scikit-learn. | Compatible con API REST y varios lenguajes. |
| Comunidad | Amplia y activa que comparte documentación de referencia. | Menos extensa, pero en proceso de crecimiento. | Cuenta con el soporte de la comunidad scikit-learn. | Comunidad activa y soporte disponible. |
| Desventajas | Aunque es versátil, su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. | Puede ser menos eficiente en grandes conjuntos de datos debido a la naturaleza intensiva de los algoritmos genéticos. | Su rendimiento está optimizado para tareas estructuradas (datos estructurados), lo que podría limitar su uso en otros tipos de problemas. | Su personalización avanzada podría ser desafiante para principiantes sin experiencia técnica. |
Figura 2. Tabla comparativa de herramientas de autoML. Fuente:elaboración propia.
Cada herramienta tiene su propia propuesta de valor, y la elección dependerá de las necesidades específicas y del entorno en el que trabaje el usuario.
Estos son algunos ejemplos de herramientas gratuitas y de código abierto que puedes explorar para adentrarte en el AutoML. Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, así como los siguientes artículos monográficos:
Blog
Como cada año, desde el equipo de datos.gob.es te deseamos unas felices fiestas. Si esta Navidad te apetece regalar o autorregalarte conocimiento, te traemos nuestra tradicional carta navideña con ideas para pedir a Papá Noel o a los Reyes Magos.
Tenemos una selección de libros sobre temáticas variadas como la protección de datos, las novedades en IA o los grandes descubrimientos científicos del siglo XX. Todas estas recomendaciones que van del género ensayístico a la novela serán un acierto seguro para colocar debajo del árbol.
Maniac de Benjamín Labatut
- ¿De qué va? Guiado por la figura de John von Neumann, uno de los grandes genios del siglo XX, el libro recorre temas como la creación de las bombas atómicas, la Guerra Fría, el nacimiento del universo digital y el auge de la inteligencia artificial. La historia comienza con el trágico suicidio de Paul Ehrenfest y avanza a través de la vida de von Neumann, quien presagió la llegada de una singularidad tecnológica. El libro culmina con la confrontación entre un hombre y una máquina, en un enfrentamiento épico en el juego de Go, que sirve como advertencia sobre el futuro de la humanidad y sus creaciones.
- ¿A quién va dirigido? Esta novela de ciencia ficción está dirigida a toda persona interesada en la historia de la ciencia, la tecnología y sus implicaciones filosóficas y sociales. Es ideal para quienes disfrutan de narrativas que combinan el thriller con profundas reflexiones sobre el futuro de la humanidad y el avance tecnológico. También es adecuado para aquellos que buscan una obra literaria que se adentre en los límites del pensamiento, la razón y la inteligencia artificial.
Toma el control de tus datos, de Alicia Asin
- ¿De qué va? Este libro recopila recursos para comprender mejor el entorno digital en el que vivimos, utilizando ejemplos prácticos y definiciones claras que facilitan que cualquiera pueda entender cómo las tecnologías afectan nuestra vida personal y social. Además, nos invita a ser más conscientes de las consecuencias del uso indiscriminado de nuestros datos, desde el rastro digital que dejamos o el manejo de nuestra privacidad en las redes sociales, hasta el comercio en la dark web. También alerta sobre el uso legítimo, pero a veces invasivo que muchas empresas hacen de nuestros comportamientos en línea.
- ¿A quién va dirigido? La autora de este libro es CEO de la empresa reutilizadora de datos Libelium que participó en uno de nuestros Encuentros Aporta y es una experta referente en privacidad, uso apropiado de los datos y espacios de datos, entre otros. En este libro ofrece una perspectiva empresarial a través de una obra dirigida al público general.
Gobierno, gestión y calidad de la inteligencia artificial de Mario Geraldo Piattini
- ¿De qué va? La inteligencia artificial está cada vez más presente en nuestra vida diaria y en la transformación digital de empresas y organismos públicos ofreciendo tanto beneficios como posibles riesgos. Para aprovechar correctamente las ventajas de la IA y evitar problemáticas es muy importante contar con sistemas éticos, legales y responsables. En este libro se ofrece una visión general de las principales normas y herramientas para gestionar y asegurar la calidad de los sistemas inteligentes. Para ello, aporta ejemplos claros sobre las mejores prácticas disponibles.
- ¿A quién va dirigido? Aunque cualquier persona puede leerlo, el libro proporciona herramientas para ayudar a las empresas a afrontar los desafíos de la IA, creando sistemas que respeten principios éticos y se alineen con las mejores prácticas ingenieriles.
Nexus, de Yuval Noah
- ¿De qué va? En esta nueva entrega, uno de los escritores de moda, analiza cómo las redes de la información han moldeado la historia humana, desde la Edad de Piedra hasta la era actual. Este ensayo explora la relación entre la información, la verdad, la burocracia, la mitología, la sabiduría y el poder, y cómo diferentes sociedades han utilizado la información para imponer orden, con consecuencias tanto positivas como negativas. En este contexto, el autor plantea las urgentes decisiones que debemos tomar frente a las amenazas actuales, como el impacto de la inteligencia no humana en nuestra existencia.
- ¿A quién va dirigido? Es una obra mainstream, es decir, cualquier persona puede leerlo y lo más probable es que disfrute de su lectura. Es una opción especialmente atractiva para lectores que buscan reflexionar sobre el papel de la información en la sociedad moderna y sus implicaciones para el futuro de la humanidad, en un contexto donde las tecnologías emergentes, como la inteligencia artificial, están desafiando nuestra forma de vida.
Generative Deep Learning: Teaching Machines to Paint, Write, Compose, and Play de David Foster (segunda edición 2024)
- ¿De qué va? Este libro práctico nos sumerge en el fascinante mundo del aprendizaje profundo generativo, explorando cómo las máquinas pueden crear arte, música y texto. A través de sus páginas, Foster nos guía por las arquitecturas más innovadoras como VAEs, GANs y modelos de difusión, explicando cómo estas tecnologías pueden transformar fotografías, generar música e incluso escribir textos. El libro comienza con los fundamentos del deep learning y progresa hacia aplicaciones de vanguardia, incluyendo la creación de imágenes con Stable Diffusion, la generación de texto con GPT y la composición musical con MuSEGAN. Es una obra que combina el rigor técnico con la creatividad artística.
- ¿A quién va dirigido? Este manual técnico está pensado para ingenieros de machine learning, científicos de datos y desarrolladores que quieran adentrarse en el campo del aprendizaje profundo generativo. Es ideal para aquellos que ya tienen una base en programación y machine learning, y desean explorar cómo las máquinas pueden crear contenido original. También resultará valioso para profesionales creativos interesados en entender cómo la IA puede amplificar sus capacidades artísticas. El libro encuentra el equilibrio perfecto entre la teoría matemática y la implementación práctica, haciendo accesibles conceptos complejos mediante ejemplos concretos y código funcional.
Information is beautiful, de David McCandless
- ¿De qué va? Esta guía visual en inglés nos ayuda a entender cómo funciona el mundo a través de impactantes infografías y visualizaciones de datos. Esta nueva edición ha sido completamente revisada, con más de 20 actualizaciones y 20 nuevas visualizaciones. Presenta la información de una manera que se puede hojear fácilmente, pero que también invita a una exploración más profunda.
- ¿A quién va dirigido? Este libro está dirigido a cualquier persona interesada en ver y comprender la información de una manera diferente. Es perfecto para aquellos que buscan una forma innovadora y visualmente atractiva de entender el mundo que nos rodea. Además, es ideal para quienes disfrutan de explorar datos, hechos y sus interrelaciones de una forma entretenida y accesible.
Collecting Field Data with QGIS and Mergin Maps, de Kurt Menke y Alexandra Bucha Rasova.
- ¿De qué va? Este libro en inglés te enseña a dominar la plataforma Mergin Maps para recopilar, compartir y gestionar datos de campo utilizando QGIS. La obra abarca desde los conceptos básicos, como la configuración de proyectos en QGIS y la realización de encuestas de campo, hasta flujos de trabajo avanzados para personalizar proyectos y gestionar colaboraciones. Además, se incluyen detalles sobre cómo crear mapas, configurar capas de encuesta y trabajar con formularios inteligentes para la recolección de datos.
- ¿A quién va dirigido? Aunque es una opción algo más técnica que las propuestas anteriores, el libro está dirigido a nuevos usuarios de Mergin Maps y QGIS. También es útil para quienes ya estén familiarizados con estas herramientas y buscan profundizar en flujos de trabajo más avanzados.
Un verdor terrible de Benjamin Labatut
- ¿De qué va? Este libro es una fascinante mezcla de ciencia y literatura, que narra descubrimientos científicos y sus implicaciones, tanto positivas como negativas. A través de historias impactantes, como la creación del azul de Prusia y su conexión con la guerra química, las exploraciones matemáticas de Grothendieck y la lucha entre científicos como Schrödinger y Heisenberg, el autor, Benjamín Labatut, nos lleva a explorar los límites de la ciencia, las locuras del conocimiento y las consecuencias imprevistas de los avances científicos. La obra convierte la ciencia en literatura, presentando a los científicos como personajes complejos y humanos.
- ¿A quién va dirigido? El libro está dirigido a un público general interesado en la ciencia, la historia de los descubrimientos y las historias humanas detrás de ellos, con un enfoque en aquellos que buscan una aproximación literaria y profunda a temas científicos. Es ideal para quienes disfrutan de obras que exploran la complejidad del conocimiento y sus efectos en el mundo.
Designing Better Maps: A Guide for GIS Users, de Cynthia A. Brewer.
- ¿De qué va? Es una guía en inglés escrita por la experta cartógrafa que enseña a crear mapas exitosos utilizando cualquier herramienta GIS o de ilustración. A través de sus 400 ilustraciones a todo color, el libro cubre las mejores prácticas de diseño cartográfico aplicadas tanto a mapas de referencia como a mapas estadísticos. Los temas incluyen planificación de mapas, uso de mapas base, manejo de escala y tiempo, explicación de mapas, publicación y compartición, uso de tipografía y etiquetas, comprensión y uso del color, y personalización de símbolos.
- ¿A quién va dirigido? Este libro está dirigido a todos los usuarios de sistemas de información geográfica (GIS), desde principiantes hasta cartógrafos avanzados, que deseen mejorar sus habilidades en diseño de mapas.
Aunque en el post vinculamos muchos enlaces de compra. Si te interesa alguna opción, te animamos que preguntes en la librería de tu barrio para apoyar al pequeño comercio durante las fiestas. ¿Conoces algún otro título interesante? Escríbelo en comentarios o envíanoslo a dinamizacion@datos.gob.es. ¡Te leemos!
Evento
Nunca se acaban las oportunidades para debatir, aprender y compartir experiencias sobre datos abiertos y tecnologías relacionadas. En este post, seleccionamos algunas de las que tendrán lugar próximamente, y te contamos todo lo que tienes que saber: de qué va, cuándo y dónde se celebra y cómo puedes inscribirte.
No te pierdas esta selección de eventos sobre temáticas de vanguardia como los datos geoespaciales, las estrategias de reutilización de datos accesibles e incluso las tendencias innovadoras de periodismo de datos. ¿Lo mejor? Todos son gratuitos.
Hablemos del dato en Alicante
La Asociación Nacional de Big Data y Analytics (ANBAN) organiza un evento abierto y gratuito en Alicante para debatir e intercambiar opiniones sobre datos e inteligencia artificial. Durante el encuentro no solo se presentarán casos de uso que relacionen datos con IA, sino que también se dedicará una parte a incentivar el networking entre los asistentes.
- ¿De qué trata?: 'Hablemos del dato’ empezará con dos charlas sobre proyectos de inteligencia artificial que ya estén creando impacto. Posteriormente, se explicará en qué va a consistir el curso sobre IA que ha organizado la Universidad de Alicante junto a ANBAN. La parte final del evento será más distendida para animar a los asistentes a establecer conexiones de valor.
- ¿Cuándo y dónde?: El jueves 29 de febrero a las 20.30h en ULAB (Pza. San Cristóbal, 14) en Alicante.
- ¿Cómo me inscribo?: Reserva tu lugar apuntándote aquí: https://www.eventbrite.es/e/entradas-hablemos-del-dato-beers-alicante-823931670807?aff=oddtdtcreator&utm_source=rrss&utm_medium=colaborador&utm_campaign=HDD-ALC-2902
Open Data Day en Barcelona: Reutilización de datos para mejorar la ciudad
El Open Data Day es un evento internacional que agrupa actividades sobre los datos abiertos alrededor del mundo. En este marco, la iniciativa Barcelona Open Data ha organizado un acto para dialogar sobre proyectos y estrategias de publicación y reutilización de datos abiertos para hacer posible una ciudad limpia, segura, amigable y accesible.
- ¿De qué trata?: A través de proyectos con datos abiertos y estrategias basadas en ellos, se abordará el reto de la seguridad, la coexistencia de usos y el mantenimiento de espacios compartidos en los municipios. El objetivo es generar diálogo entre las organizaciones que publican datos y los reutilizan para aportar valor y desarrollar estrategias de manera conjunta.
- ¿Cuándo y dónde?: El día 6 de marzo de 17h a 19.30h en Ca l’Alier (C/ de Pere IV, 362).
- ¿Cómo me inscribo?: A través de este enlace: https://www.eventbrite.es/e/entradas-open-data-day-2024-819879711287?aff=oddtdtcreator
Presentación de la “Guía de Buenas Prácticas para Periodistas de Datos”
El Observatori Valencià de Dades Obertes i Transparència de la Universitat Politècnica de València ha creado una guía dirigida a periodistas y profesionales del dato con consejos prácticos para convertir los datos en historias periodísticas atractivas y relevantes para la sociedad. La autora de este material de referencia dialogará con un periodista de datos sobre los retos y oportunidades que los datos ofrecen en el ámbito periodístico.
- ¿De qué trata?: Es un evento que abordará conceptos clave de la Guía de Buenas Prácticas para Periodistas de Datos mediante ejemplos prácticos y casos para analizar y visualizar datos correctamente. La ética también será un tema que se abordará durante la presentación.
- ¿Cuándo y dónde?: El viernes 8 de marzo de 12h a 13h en el Salón de Actos de la Facultad de ADE de la UPV (Avda. Tarongers s/n) en Valencia.
- ¿Cómo me inscribo?: Más información e inscripción aquí: https://www.eventbrite.es/e/entradas-presentacion-de-la-guia-de-buenas-practicas-para-periodistas-de-datos-835947741197
Jornadas de Geodatos del Geoportal del Ayuntamiento de Madrid
Madrid acoge la sexta edición de este evento que reúne responsables de instituciones y empresas de referencia en cartografía, sistemas de información geográfica, gemelo digital, BIM, Big Data e inteligencia artificial. También se aprovechará el evento para hacer entrega de los premios del Estand del Geodato.
- ¿De qué trata?: Siguiendo la estela de otros años, las Jornadas de Geodatos de Madrid presentan casos prácticos y novedades sobre cartografía, gemelo digital, reutilización de datos georreferenciados, así como los mejores trabajos presentados al Estand del Geodato.
- ¿Cuándo y dónde?: El evento empieza el día 12 de marzo a las 9h en Auditorio de La Nave en Madrid y durará hasta las 14h. El día siguiente, 13 de marzo la sesión será virtual y se presentarán los proyectos y las novedades de la producción de geo información y de la distribución a través del Geoportal de Madrid.
- ¿Cómo me inscribo?: A través del portal del evento. Las plazas son limitadas https://geojornadas.madrid.es/
III Jornadas de Cultura Libre de la URJC
Las Jornadas de Cultura Libre de la Universidad Rey Juan Carlos son un punto de encuentro, aprendizaje e intercambio de experiencias en torno a la cultura libre en la universidad. Se abordarán temas como la publicación abierta de materiales docentes e investigativos, la ciencia abierta, los datos abiertos, y el software libre.
- ¿De qué trata?: Son dos días durante los que se ofrecerán presentaciones a cargo de expertos, talleres sobre temas específicos y se dará la oportunidad a la comunidad universitaria de presentar ponencias. Además, habrá un espacio ferial donde se compartirán herramientas y novedades relacionadas con la cultura y el software libre, así como un área de exposición de poster
- ¿Cuándo y dónde?: El 20 y 21 de marzo en el Campus de Fuenlabrada de la URJC
- ¿Cómo me inscribo?: La inscripción es gratuita mediante este enlace: https://eventos.urjc.es/109643/tickets/iii-jornadas-de-cultura-libre-de-la-urjc.html
Estos son algunos de los eventos que sucederán próximamente. De todas formas, no olvides seguirnos en redes sociales para no perderte ninguna novedad sobre innovación y datos abiertos. Estamos en Twitter y LinkedIn, también nos puedes escribir a dinamizacion@datos.gob.es si quieres que incluyamos algún otro evento a la lista o si necesitas información extra.
Blog
2023 fue un año cargado de novedades en materia de inteligencia artificial, algoritmos y tecnologías relacionadas con los datos. Por ello, estas fiestas navideñas se configuran como un buen momento para aprovechar la llegada de los Reyes Magos y pedirles un libro para disfrutar de su lectura en los días de fiesta, el descanso merecido y la vuelta a la rutina tras el periodo vacacional.
Tanto si estás buscando una lectura que haga mejorar tu perfil profesional, conocer novedades y aplicaciones tecnológicas ligadas al mundo de los datos y la inteligencia artificial, como si quieres ofrecer a tus seres más queridos un regalo didáctico e interesante, desde datos.gob.es queremos proponerte algunos ejemplos. Para la elaboración de la lista hemos contado con la opinión de expertos en la materia.
¡Coge papel y lápiz porque todavía estás a tiempo de incluirlos en tu carta a los Reyes Magos!
1. Inteligencia Artificial: Ficción, Realidad y... sueños, Nuria Oliver, Real Academia de Ingeniería GTT (2023)
¿De qué trata?: El libro tiene su origen en el discurso de ingreso en la Real Academia de Ingeniería de la autora. En él, explora la historia de la IA, sus implicaciones y desarrollo, describe su impacto actual y plantea diversas perspectivas.
¿A quién va dirigido?: Está pensado para personas con interés en introducirse en el mundo de la Inteligencia Artificial, conocer su historia y aplicaciones prácticas. También se dirige a aquellas personas que quieren adentrarse en el mundo de la IA ética y aprender cómo utilizarla para un bien social.
2. A Data-Driven Company. 21 Claves para crear valor a través de los datos y de la Inteligencia Artificial, Richard Benjamins, Lid Editorial (2022)
¿De qué trata?: A Data-Driven Company analiza 21 decisiones clave a las que tienen que hacer frente las compañías para convertirse en una empresa orientada hacia los datos y la IA. En él se abordan las típicas decisiones organizativas, tecnológicas, empresariales, de personal y éticas que las organizaciones deben afrontar para empezar a tomar decisiones basadas en datos, incluyendo cómo financiar su estrategia de datos, organizar equipos, medir los resultados y escalar.
¿A quién va dirigido?: Sirve tanto para profesionales que empiezan a trabajar con datos, como para aquellos que ya tienen experiencia, pero necesitan adaptarse para trabajar con big data, analítica o inteligencia artificial.
3. Digital Empires: The Global Battle to Regulate Technology, Anu Bradford, OUP USA (2023)
¿De qué trata?: Ante los avances tecnológicos en todo el mundo y la llegada de gigantes empresariales repartidos en las potencias internacionales, Bradford examina tres enfoques regulatorios que compiten entre sí: el modelo estadounidense donde lo que prima es el mercado, el modelo chino condicionado por el Estado y el modelo regulatorio europeo, centrado en los derechos. A través de sus páginas, se analiza cómo los gobiernos y las empresas tecnológicas navegan por los inevitables conflictos que surgen cuando estos enfoques regulatorios chocan en el ámbito internacional.
¿A quién va dirigido?: Es un libro pensado para quienes desean conocer más sobre el enfoque regulador de las tecnologías alrededor del mundo y cómo afecta al ámbito empresarial. Está redactado de manera clara y comprensible, a pesar de la complejidad del tema. Sin embargo, el lector deberá saber inglés, porque aún no se ha traducido a nuestro idioma.
4. El mito del algoritmo, Richard Benjamins e Idoia Salazar, Anaya Multimedia (2020)
¿De qué trata?: La inteligencia artificial y su uso exponencial en múltiples disciplinas está provocando un cambio social sin precedentes. Con ello, empiezan a surgir pensamientos filosóficos tan profundos como la existencia del alma o debates relacionados con la posibilidad de que las máquinas tengan sentimientos. Se trata de un libro para conocer los desafíos, retos y oportunidades de esta tecnología.
¿A quién va dirigido?: Está dirigido a personas con interés en la filosofía de la tecnología y el desarrollo de avances tecnológicos. Al usar un lenguaje sencillo y esclarecedor, es un libro al alcance de un público generalista.
5. ¿Cómo sobrevivir a la incertidumbre?, de Anabel Forte Deltell, Next Door Publishers
¿De qué trata?: Explica de forma sencilla y con ejemplos cómo la estadística y la probabilidad están más presentes en la vida diaria. El libro parte de la actualidad, en la que datos, números, porcentajes y gráficos se han adueñado del día a día y se han convertido en indispensables para tomar decisiones o para comprender el mundo que nos rodea.
¿A quién va dirigido?: A un público general que quiere entender cómo el análisis de los datos, la estadística y la probabilidad van configurando buena parte de las decisiones políticas, sociales, económicas...
6. Análisis espacial con R: Usa R como un Sistema de Información Geográfica, Jean François Mas, European Scientific Institute
¿De qué trata?: Se trata de un libro más técnico, en el que se realiza una breve introducción de los principales conceptos para el manejo del lenguaje y entorno de programación R (tipos de objetos y operaciones básicas) para posteriormente acercar al lector al uso de la librería o paquete sf, para datos espaciales en formato vector a través de sus principales funciones para lectura, escritura y análisis. El libro aborda, desde una perspectiva práctica y aplicativa con un lenguaje de fácil entendimiento, los primeros pasos para iniciarse con el manejo de R en aplicaciones de análisis espacial; para ello, es necesario que los usuarios tengan conocimientos básicos de Sistemas de Información Geográfica.
¿A quién va dirigido?: A un público con algún conocimiento en R y conocimientos básicos de GIS que desean introducirse en el mundo de las aplicaciones de análisis espacial.
Esta es solo una pequeña muestra de la gran variedad de literatura existente relacionada con el mundo de los datos. Seguro que nos dejamos algún libro interesante sin incluir por lo que, si tienes alguna recomendación extra que quieres hacer, no dudes en dejarnos tu título favorito en comentarios. Quienes formamos el equipo de datos.gob.es estaremos encantados de leer vuestras recomendaciones.
Evento
Vivimos en una era en la que la formación se ha vuelto un elemento imprescindible, tanto para ingresar y progresar en un mercado laboral cada vez más competitivo, como a la hora de formar parte de proyectos de investigación que puedan llegar a conseguir grandes mejoras en nuestra vida.
Se acerca el verano y con él nos llega una oferta formativa renovada que no descansa en absoluto en la época estival, sino todo lo contrario. Cada año, aumenta el número de cursos relacionados con la ciencia de datos, la analítica o los datos abiertos. El actual mercado laboral demanda y requiere profesionales especializados en este abanico de campos tecnológicos, tal y como refleja la CE en su Estrategia Europea de Datos, donde se destaca que la UE proporcionará financiación “para ampliar la reserva de talento digital a alrededor de 250.000 personas que sean capaces de implantar las últimas tecnologías en empresas de toda la UE”.
En este sentido, las posibilidades que ofrecen las nuevas tecnologías para realizar cualquier tipo de formación online, desde tu propio hogar con las máximas garantías, ayudan a que más profesionales apuesten por este tipo de cursos cada año.
Desde datos.gob.es hemos seleccionado una serie de cursos online, tanto gratuitos como de pago, relacionados con datos que pueden ser de tu interés:
- Comenzamos con el Curso de Aprendizaje automático y ciencia de datos impartido por la Universitat Politécnica de Valencia destaca por ofrecer a sus futuros alumnos el aprendizaje necesario para extraer conocimiento técnico a partir de los datos. Con un programa de 5 semanas de duración, en este curso podrás introducirte al lenguaje R y aprender, entre otras cosas, diferentes técnicas de preprocesamiento y visualización de datos.
- El curso de Métodos Modernos en el Análisis de Datos (Modern Methods in Data Analytics) es otra de las opciones si lo que buscas es ampliar tu formación sobre datos y aprender inglés al mismo tiempo. La Universidad de Utrecht comenzará a impartir este curso totalmente online a partir del 31 de agosto, totalmente centrado en el estudio de modelos lineares y análisis de datos longitudinal, entre otros campos.
- Otro de los cursos en inglés que dará comienzo el próximo 16 de junio es una formación de 9 semanas de duración enfocada a Data Analytics y que está impartido por la Ironhack International School. Se trata de un curso recomendable para quienes quieran aprender a cargar, limpiar, explorar y extraer información de una amplia gama de datasets, así como a utilizar Python, SQL y Tableau, entre otros aspectos.
- A continuación te descubrimos el curso de Digitalización Empresarial y Big Data: Datos, Información y Conocimiento en Mercados Altamente Competitivos, impartido por la FGUMA (Fundación General de la Universidad de Málaga). Su duración es de 25 horas y su fecha límite de matriculación es el 15 de junio. Si eres un profesional relacionado con la gestión empresarial y/o el emprendimiento, este curso seguro que resulta de tu interés.
- R para ciencia de Datos, es otro de los cursos que ofrece la FGUMA. Su principal objetivo es mostrar una visión introductoria al lenguaje de programación R para tareas de análisis de datos, incluyendo la realización de informes y visualizaciones avanzadas, presentando técnicas propias del aprendizaje computacional como un valor extra. Al igual que el curso anterior, el plazo límite de matrícula para esta formación es el 15 de junio.
- Por su parte, Google Cloud ofrece una ruta de aprendizaje totalmente online y gratuita destinada a profesionales de datos que buscan perfeccionar el diseño, compliación, análisis y optimización de soluciones de macrodatos. Seguro que este Programa especializado: Data Engineering, Big Data, and Machine Learning on GCP encaja dentro de la formación que tenías planeada.
Además, de estos cursos puntuales, cabe destacar la existencia de plataformas de formación online que ofrecen cursos relacionados con las nuevas tecnologías de manera continua. Estos cursos se conocen como MOOC y son una alternativa a la formación tradicional, en áreas como Machine Learning, Analítica del Dato, Business Intelligence o Deep Learning, unos conocimientos cada vez más demandados por las empresas.
Esta es tan solo una selección de los muchos cursos que existen como oferta formativa relacionada con datos. Sin embargo, nos encantaría contar con tu colaboración haciéndonos llegar, a través de los comentarios, otros cursos de interés en el campo de los datos y que puedan completar esta lista en el futuro.