Documentación
Introducción
Cada año se producen en España decenas de miles de accidentes, en los que miles de personas resultan heridas de diversa consideración, y que ocurren en circunstancias muy diversas, tanto de tipo de vía, como por el tipo de accidente.
Muchas de las estadísticas relacionadas con estos parámetros están recogidas en las bases de datos de la Dirección General de Tráfico (DGT) y algunas de ellas en el catálogo albergado en datos.gob.es.
En este ejercicio examinaremos el contenido de la base de datos de siniestralidad de la DGT para el año 2024 con el fin de realizar una serie de visualizaciones básicas que nos permitan ver de forma rápida e intuitiva cuáles son los hechos a destacar respecto a la incidencia de accidentes y sus consecuencias en ese año.
Para ello vamos a desarrollar código en Python que nos permita la lectura y cálculo de métricas básicas respecto al número total de víctimas, las particularidades de las infraestructuras así como las diferentes casuísticas de los accidentes. Y una vez tengamos disponibles esos datos, los visualizaremos utilizando la librería de Javascript D3.js, que nos permite tanto la representación de datos en su forma más tradicional como en diseños más contemporáneos, habituales en la prensa, favoreciendo así una narrativa fluída en estilo y coherente en contenido.
En el entorno de Python utilizaremos librerías de uso común y frecuente como son Numpy, para el cálculo básico - sumas, máximos y mínimos-, y Pandas, para estructurar los datos de forma intuitiva, facilitando tanto su organización como su transformación. Igualmente trabajaremos con Datetime, tanto para el formateo de los datos de entrada en tipos de fecha estándares dentro del mundo de la programación en Python, como para agregar los datos de forma fácil e intuitiva. De esta forma aprenderemos a abrir cualquier tipo de fichero de datos en formato .CSV, a estructurarlo de forma ordenada y a realizar transformaciones y operaciones básicas de forma sencilla.
En el entorno de Javascript desarrollaremos notebooks en D3.js gracias al uso de Observable, una iniciativa abierta y gratuita, para poder ejecutar código de Javascript directamente en un interfaz web, y sin tener que recurrir a servidores locales o complejas instalaciones. En diferentes notebooks crearemos visualizaciones clásicas -como las series temporales en ejes cartesianos o mapas- junto con otras propuestas tales como distribuciones de burbujas o elementos apilados por categorías.
En la Figura 1 se pueden ver las principales etapas de este ejercicio, desde la lectura de los datos dentro del fichero de la DGT, hasta las operaciones y las variables de salida en formato JSON, que nos servirán a su vez en un entorno Javascript para poder desarrollar las visualizaciones en D3.js.
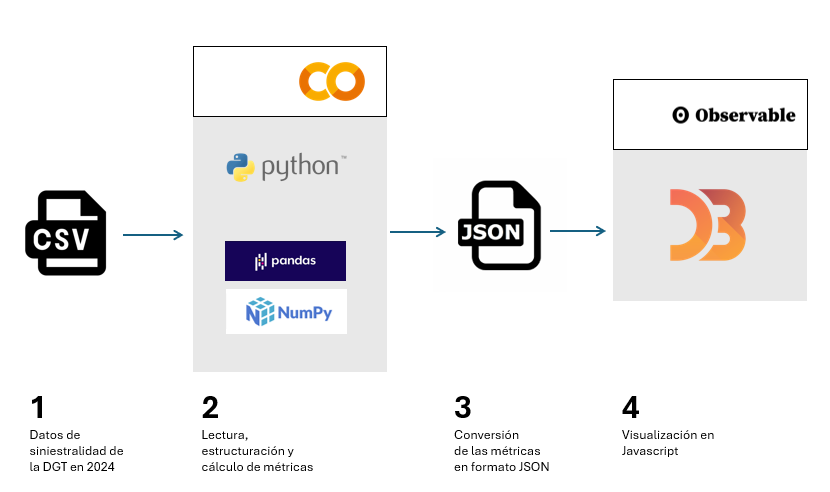
Figura 1. Pasos en los cuales se estructura este ejercicio, con punto de partida en la base de datos de la DGT, el procesado y manipulación de esos datos en Python, la creación de ficheros de salida en formato JSON y su uso en Javascript para visualizar los resultados.
El acceso al repositorio de Github, el notebook de Google Colab y los notebooks de Observable se pueden realizar a través de los siguientes enlaces:
Accede al repositorio del laboratorio de datos en GitHub
Accede al notebook de GoogleColab
Accede a los notebooks de Observable
Proceso de Desarrollo
1. Lectura del fichero de datos
El primer paso será leer el fichero de la DGT que contiene todos los registros de accidentes del año 2024. Este paso nos permitirá identificar los campos de interés y sobre todo en qué formato se encuentran. Podremos identificar si se precisa de alguna transformación sobre todo en la información de la fecha, tal y como está estructurada en el fichero de origen.
Igualmente veremos cómo traducir los códigos de muchas de las categorías que nos ofrece la DGT, de modo que podamos hacer una interpretación real más allá de los números de categorías como tipo de accidente, tipo de vía o titularidad de la vía.
Una vez entendemos la estructura y contenido de los datos podemos empezar a operar con ellos.
2. Cálculo de métricas
La librería Pandas de Python nos permite operar con las diferentes columnas de datos y realizar cálculos básicos que serán suficientemente representativos para entender mínimamente la casuística de los accidentes en las carreteras españolas.
En este apartado se realizarán tres tipos de cálculos.
- El primero de ellos será el cálculo del número total de víctimas por hora del día para cada uno de los días de la semana. La base de datos de la DGT viene estructurada por día de la semana, de forma que utilizaremos también esa escala temporal para representar los datos en una serie. Cabe hacer notar que por víctima se considera toda aquella persona que ha fallecido o que sea diagnosticada como herida grave o leve.
- El segundo cálculo será la suma total de accidentes para diferentes categorías, tales como la titularidad de la vía, el tipo de accidente o el tipo de vía. Esto nos permitirá ver cuáles son las condiciones en las cuales los accidentes son más frecuentes.
- El tercer cálculo será el de número de accidentes por municipio. En este caso realizaremos el cálculo restringido a la provincia de Valencia como ejemplo, y que sería aplicable a cualquier provincia o municipio de nuestro interés. En este caso observaremos las diferencias entre los núcleos urbanos y no urbanos, así como aquellos municipios por los que pasan las principales vías de comunicación.
3. Diseño de las visualizaciones
Una vez hemos calculado las métricas de interés, desarrollaremos cinco ejercicios de visualización en D3.js. Para ello exportaremos en formato JSON el resultado de las métricas y crearemos notebooks en Observable. En concreto realizamos las siguientes visualizaciones:
- Serie temporal con el número total de víctimas en cada hora y día de la semana, con un menú desplegable interactivo para seleccionar el día de la semana de interés. A mayores de la curva que describe el número de víctimas dibujaremos sobre el fondo de la gráfica la incertidumbre de todos los días de la semana, de forma que la serie temporal diaria queda enmarcada en el contexto de toda la semana como referencia.
- Mapa de la provincia de Valencia con el número total de accidentes por municipio.
- Diagrama de burbujas, con las diferentes magnitudes de los diferentes tipos de accidentes con el número total de accidentes en cada caso escrita de forma detallada.
- Diagrama de puntos apilados, donde acumulamos círculos o cualquier otra forma geométrica para las diferentes titularidades de la vía y su número total de accidentes dentro del marco de cada titularidad.
- Diagrama de sierra, con la altura de cada montaña correspondiente al número de accidentes en cada tipo de vía en escala logarítmica.
Visualización de las métricas
El resultado de este ejercicio se podrá ver de forma gráfica y explícita en forma de visualizaciones realizadas para el formato web y accesibles desde una interfaz también web, tanto para su desarrollo como para su posterior publicación. Todo el conjunto de visualizaciones se encuentra en el repositorio de Datos.gob.es en Observable:
Accede a los notebooks de Observable
En la Figura 2 tenemos el resultado de la serie temporal del total de víctimas respecto a la hora del día para diferentes días de la semana. La serie temporal está enmarcada dentro de la incertidumbre del total de días de la semana, para dar una idea del margen de variabilidad que podemos tener dependiendo de la hora del día.
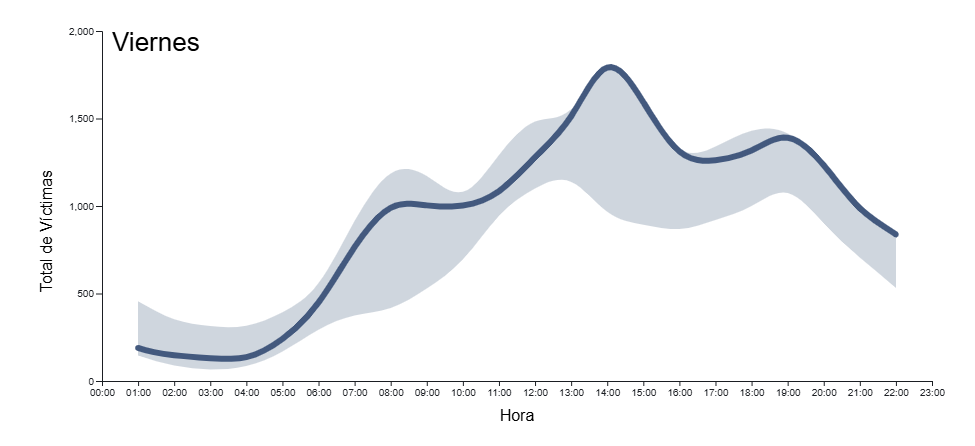
Figura 2. Serie temporal del total de víctimas en accidentes por hora del día para todos los días de la semana en 2024. En el fondo en color azul claro se indica la incertidumbre asociada a todos los días de la semana como contexto, con menú desplegable para seleccionar el día de la semana.
En la Figura 3 podemos observar el mapa de la provincia de Valencia con una intensidad de color proporcional al número de accidentes en cada municipio. Aquellos municipios en los cuales no se han registrado accidentes aparecen en color blanco. De forma intuitiva se puede adivinar el trazado de las principales carreteras que atraviesan la provincia, tanto la carretera hacia el este de la ciudad de Valencia en dirección Madrid como la carretera del interior hacia el sur de la ciudad en dirección a Alicante.
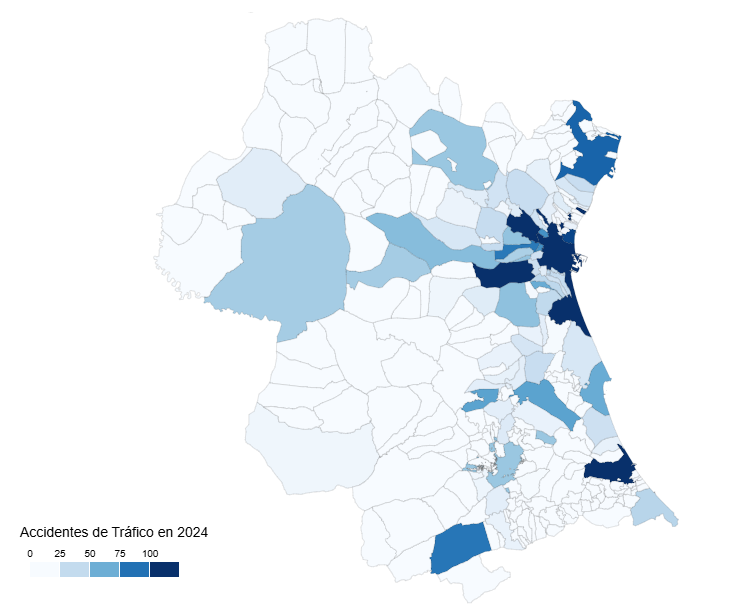
Figura 3. Mapa del número de accidentes por municipio en la provincia de Valencia en 2024.
En la Figura 4 vemos una forma geométrica, el círculo, asociada a los tipos de accidente, con el detalle del número de accidentes asociada a cada categoría. En este tipo de visualización emerge de forma natural aquellos accidentes más frecuentes en torno al centro del diagrama, mientras que aquellos minoritarios o residuales ocupan el perímetro del diagrama para dar igualmente una forma redonda al conjunto de formas.
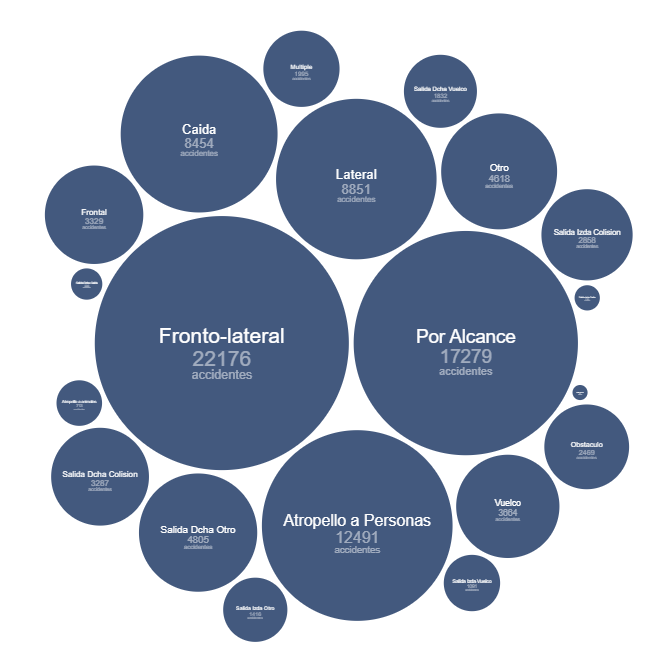
Figura 4. Diagrama de burbujas del número de accidentes por tipo de accidente en 2024.
En la Figura 5 se puede contemplar el tradicional diagrama de barras pero esta vez descompuesto en unidades más pequeñas, para afinar la cantidad de accidentes asociada a la titularidad de la vía donde han sucedido. Este tipo de diagramas permite discernir pequeñas diferencias entre magnitudes parecidas, preservando el mensaje general que obtenemos de un cálculo de estas características.
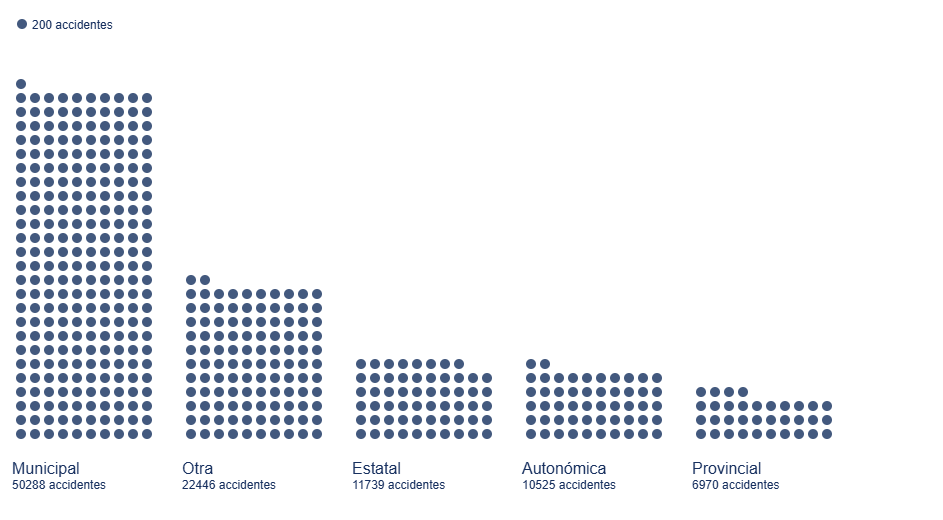
Figura 5. Diagrama de barras con discretización de puntos para el número de accidentes por titularidad de la vía en el 2024.
En la Figura 6 creamos una serie de formas geométricas que replican una cordillera o sierra donde los diferentes picos apuntan a la diferencia de número de accidentes por tipo de vía. Dada la diferencia en órdenes de magnitud establecemos una escala logarítmica, que permita comparar en el mismo diagrama diferentes casuísticas.
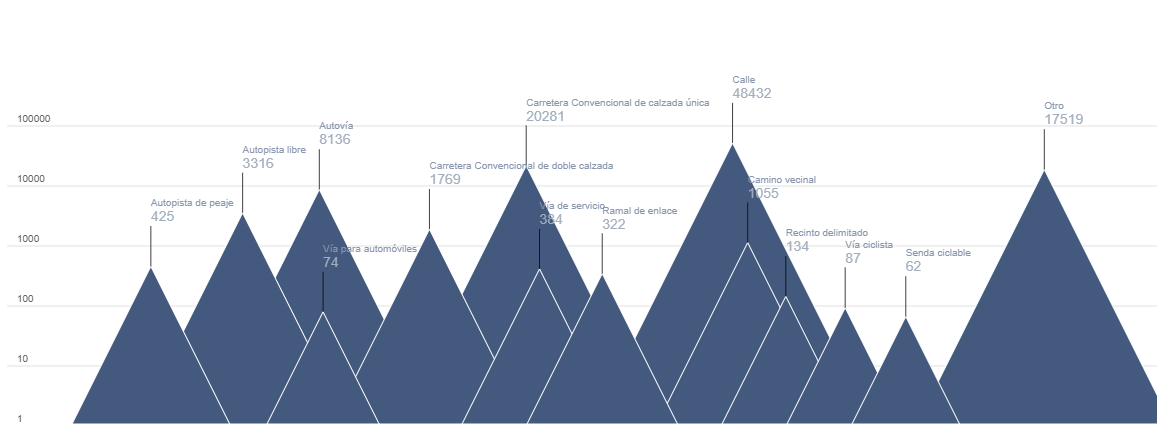
Figura 6. Diagrama en cordillera para los diferentes órdenes de magnitud del número de accidentes por tipo de vía en el 2024.
Lecciones aprendidas
A través de estos pasos aprenderemos toda una serie de habilidades transversales que nos permiten trabajar con aquellos conjunto de datos que se nos presentan en formato CSV en columnas, un formato muy popular para el cual podremos realizar tanto su análisis como su visualización. Estas lecciones son en concreto:
- Universalidad de lectura y estructuración de datos: el uso de herramientas como Python, con sus librerías Numpy y Pandas, permiten acceder a los datos en detalle y estructurarlos de forma ordenada e intuitiva con pocas líneas de código.
- Cálculos sencillos en Pandas: la propia librería de Python permite cálculos sencillos pero esenciales para la interpretación preliminar de resultados.
- Formato Datetime: a través de esta librería de Python podemos familiarizarnos con el estándar del formato de fecha, y así realizar todo tipo de transformaciones, filtros y selecciones que más nos interesen en cualquier intervalo temporal.
- Formato JSON: una vez que decidimos dar espacio a nuestras visualizaciones en la web, aprender la estructura y uso del formato JSON es de gran utilidad dado su amplio uso en todo tipo de aplicaciones y arquitecturas web.
- Espectro de posibilidades de D3.js: esta librería de Javascript nos permite explorar de lo más tradicional y conservador a lo más creativo gracias a sus principios basados en las formas más básicas, sin plantillas, templates o diagramas predefinidos.
Conclusiones y próximos pasos
Hemos aprendido a leer y a estructurar datos según los estándares de los formatos más utilizados en el mundo del análisis y visualización. Este ejercicio también sirve como módulo introductorio al mundo de D3.js, una herramienta muy versátil, vigente y popular dentro del mundo del storytelling y la visualización de datos a todos los niveles.
Para poder avanzar en este ejercicio se recomienda:
- Para los analistas y desarrolladores, se puede prescindir de la librería Pandas y estructurar los datos con objetos más elementales de Python como arrays y matrices, buscando qué funciones y qué operadores permiten realizar las mismas tareas que hace Pandas pero de una forma más fundamental, sobre todo si pensamos en entornos de producción para los cuales necesitamos el menor número de librerías posibles para aligerar la aplicación.
- Para los creadores de visualizaciones, la información sobre los municipios puede proyectarse igualmente sobre bases cartográficas ya existentes como OpenStreetMap y de esta forma vincular la incidencia de accidentes a características orográficas o infraestructuras ya reflejadas en esas bases cartográficas. Para las magnitudes de los números de accidentes se pueden explorar diagramas de tipo Treemap o diagramas de Voronoi y ver si transmiten el mismo mensaje que los que presentamos en este ejercicio.
Ámbitos de aplicación
Los pasos descritos en este ejercicio pueden pasar a formar parte de cualquier caja de herramientas de uso habitual para los siguientes perfiles:
- Analistas de datos: aquí se encuentran los pasos básicos para la descripción de un fichero de datos en formato CSV y los cálculos básicos a realizar tanto en el campo de la fecha como de operaciones entre variables de diferentes columnas. Estas herramientas pueden servir para introducirse en el mundo del análisis de datos y ayuda en esos primeros pasos a la hora de enfrentarse a un dataset.
- Científicos y personal investigador: la universalidad de las herramientas aquí descritas aplican a una gran variedad de origen de datos, como el que se experimenta en las ciencias experimentales y de observaciones o medidas de todo tipo. Estas herramientas permiten un análisis rápido a la vez que riguroso sin importar el campo de conocimiento en el que se trabaje.
- Desarrolladores web: la exportación de datos en formato JSON así como el código en Javascript que se ofrece en los notebooks de Observable son fácilmente integrables en todo tipo de entornos (Svelte, React, Angular, Vue) y permite la creación de visualizaciones en una web de forma sencilla e intuitiva.
- Periodistas: abarcar todo el proceso de vida de un fichero de datos, desde su lectura a su visualización, otorga al periodista o investigador independencia a la hora de evaluar e interpretar los datos por sí mismo sin depender de recursos técnicos ajenos. La creación del mapa por municipios abre la puerta a utilizar cualquier otro dato similar, como por ejemplo procesos electorales, con el mismo formato de salida para mostrar variabilidad geográfica respecto a cualquier tipo de magnitud.
- Diseñadores Gráficos: el manejo de herramientas de visualización con un amplio grado de libertad permite a los diseñadores cultivar toda su creatividad dentro del rigor y la exactitud que los datos necesitan.
Documentación
En el panorama actual del análisis de datos y la inteligencia artificial, la generación automática de informes completos y coherentes representa un desafío significativo. Mientras que las herramientas tradicionales permiten visualizar datos o generar estadísticas aisladas, existe la necesidad de sistemas que puedan investigar un tema a fondo, recopilar información de diversas fuentes, y sintetizar hallazgos en un informe estructurado y coherente.
En este ejercicio práctico, exploraremos el desarrollo de un agente de generación de reportes basado en LangGraph e inteligencia artificial. A diferencia de los enfoques tradicionales basados en plantillas o análisis estadísticos predefinidos, nuestra solución aprovecha los últimos avances en modelos de lenguaje para:
- Crear equipos virtuales de analistas especializados en diferentes aspectos de un tema.
- Realizar entrevistas simuladas para recopilar información detallada.
- Sintetizar los hallazgos en un informe coherente y bien estructurado.
Accede al repositorio del laboratorio de datos en Github
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
Como se muestra en la Figura 1, el flujo completo del agente sigue una secuencia lógica que va desde la generación inicial de preguntas hasta la redacción final del informe.

Figura 1. Diagrama de flujo del agente.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en un diseño modular implementado como un grafo de estados interconectados, donde cada módulo representa una funcionalidad específica en el proceso de generación de reportes. Esta estructura permite un flujo de trabajo flexible, recursivo cuando es necesario, y con capacidad de intervención humana en puntos estratégicos.
Componentes principales
El sistema se compone de tres módulos fundamentales que trabajan en conjunto:
1. Generador de Analistas Virtuales
Este componente crea un equipo diverso de analistas virtuales especializados en diferentes aspectos del tema a investigar. El flujo incluye:
- Creación inicial de perfiles basados en el tema de investigación.
- Punto de retroalimentación humana que permite revisar y refinar los perfiles generados.
- Regeneración opcional de analistas incorporando sugerencias.
Este enfoque garantiza que el informe final incluya perspectivas diversas y complementarias, enriqueciendo el análisis.
2. Sistema de Entrevistas
Una vez generados los analistas, cada uno participa en un proceso de entrevista simulada que incluye:
- Generación de preguntas relevantes basadas en el perfil del analista.
- Búsqueda de información en fuentes vía Tavily Search y Wikipedia.
- Generación de respuestas informativas combinando la información obtenida.
- Decisión automática sobre continuar o finalizar la entrevista en función de la información recopilada.
- Almacenamiento de la transcripción para su procesamiento posterior.
El sistema de entrevistas representa el corazón del agente, donde se obtiene la información que nutrirá el informe final. Tal y como se muestra en la Figura 2, este proceso puede monitorizarse en tiempo real mediante LangSmith, una herramienta abierta de observabilidad que permite seguir cada paso del flujo.

Figura 2. Monitorización del sistema vía LangGraph. Ejemplo concreto de una interacción analista-entrevistador.
3. Generador de Informes
Finalmente, el sistema procesa las entrevistas para crear un informe coherente mediante:
- Redacción de secciones individuales basadas en cada entrevista.
- Creación de una introducción que presente el tema y la estructura del informe.
- Organización del contenido principal que integra todas las secciones.
- Generación de una conclusión que sintetiza los hallazgos principales.
- Consolidación de todas las fuentes utilizadas.
La Figura 3 muestra un ejemplo del informe resultante del proceso completo, demostrando la calidad y estructura del documento final generado automáticamente.

Figura 3. Vista del informe resultante del proceso de generación automática al prompt de “Datos abiertos en España”.
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
Integración de IA avanzada en sistemas de procesamiento de información:
- Cómo comunicarse efectivamente con modelos de lenguaje.
- Técnicas para estructurar prompts que generen respuestas coherentes y útiles.
- Estrategias para simular equipos virtuales de expertos.
Desarrollo con LangGraph:
- Creación de grafos de estados para modelar flujos complejos.
- Implementación de puntos de decisión condicionales.
- Diseño de sistemas con intervención humana en puntos estratégicos.
Procesamiento paralelo con LLMs:
- Técnicas de paralelización de tareas con modelos de lenguaje.
- Coordinación de múltiples subprocesos independientes.
- Métodos de consolidación de información dispersa.
Buenas prácticas de diseño:
- Estructuración modular de sistemas complejos.
- Manejo de errores y reintentos.
- Seguimiento y depuración de flujos de trabajo mediante LangSmith.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos y los usuarios finales. A través del caso práctico desarrollado, podemos observar cómo la combinación de modelos de lenguaje avanzados con arquitecturas flexibles basadas en grafos abre nuevas posibilidades para la generación automática de informes.
La capacidad de simular equipos de expertos virtuales, realizar investigaciones paralelas y sintetizar hallazgos en documentos coherentes, representa un paso significativo hacia la democratización del análisis de información compleja.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de mecanismos de verificación automática de datos para garantizar la precisión.
- Implementación de capacidades multimodales que permitan incorporar imágenes y visualizaciones.
- Integración con más fuentes de información y bases de conocimiento.
- Desarrollo de interfaces de usuario más intuitivas para la intervención humana.
- Expansión a dominios especializados como medicina, derecho o ciencias.
En resumen, este ejercicio no solo demuestra la viabilidad de automatizar la generación de informes complejos mediante inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el análisis profundo de cualquier tema esté al alcance de todos, independientemente de su nivel de experiencia técnica. La combinación de modelos de lenguaje avanzados, arquitecturas de grafos y técnicas de paralelización abre un abanico de posibilidades para transformar la forma en que generamos y consumimos información.
Documentación
Los portales de datos abiertos son una fuente invaluable de información pública. Sin embargo, extraer insights significativos de estos datos puede resultar desafiante para usuarios sin conocimientos técnicos avanzados.
En este ejercicio práctico, exploraremos el desarrollo de una aplicación web que democratiza el acceso a estos datos mediante el uso de inteligencia artificial, permitiendo realizar consultas en lenguaje natural.
La aplicación, desarrollada utilizando el portal datos.gob.es como fuente de datos, integra tecnologías modernas como Streamlit para la interfaz de usuario y el modelo de lenguaje Gemini de Google para el procesamiento de lenguaje natural. La naturaleza modular permite que se pueda utilizar cualquier modelo de Inteligencia Artificial con mínimos cambios. El proyecto completo está disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Arquitectura de la aplicación
El núcleo de la aplicación se basa en cuatro apartados principales e interconectados que trabajan para procesar las consultas de la persona usuaria:
- Generación del Contexto
- Analiza las características del dataset elegido.
- Genera una descripción detallada incluyendo dimensiones, tipos de datos y estadísticas.
- Crea una plantilla estructurada con guías específicas para la generación de código.
- Combinación de Contexto y Consulta
- Une el contexto generado con la pregunta de la persona usuaria creando el prompt que recibirá el modelo de inteligencia artificial.
- Generación de Respuesta
- Envía el prompt al modelo y obtiene el código Python que permite resolver la cuestión generada.
- Ejecución del Código
- Ejecuta de manera segura el código generado con un sistema de reintentos y correcciones automáticas.
- Captura y expone los resultados en el frontal de la aplicación.

Figura 1. Flujo de procesamiento de solicitudes
Proceso de desarrollo
El primer paso es establecer una forma de acceder a los datos públicos. El portal datos.gob.es ofrece vía API los datasets. Se han desarrollado funciones para navegar por el catálogo y descargar estos archivos de forma eficiente.
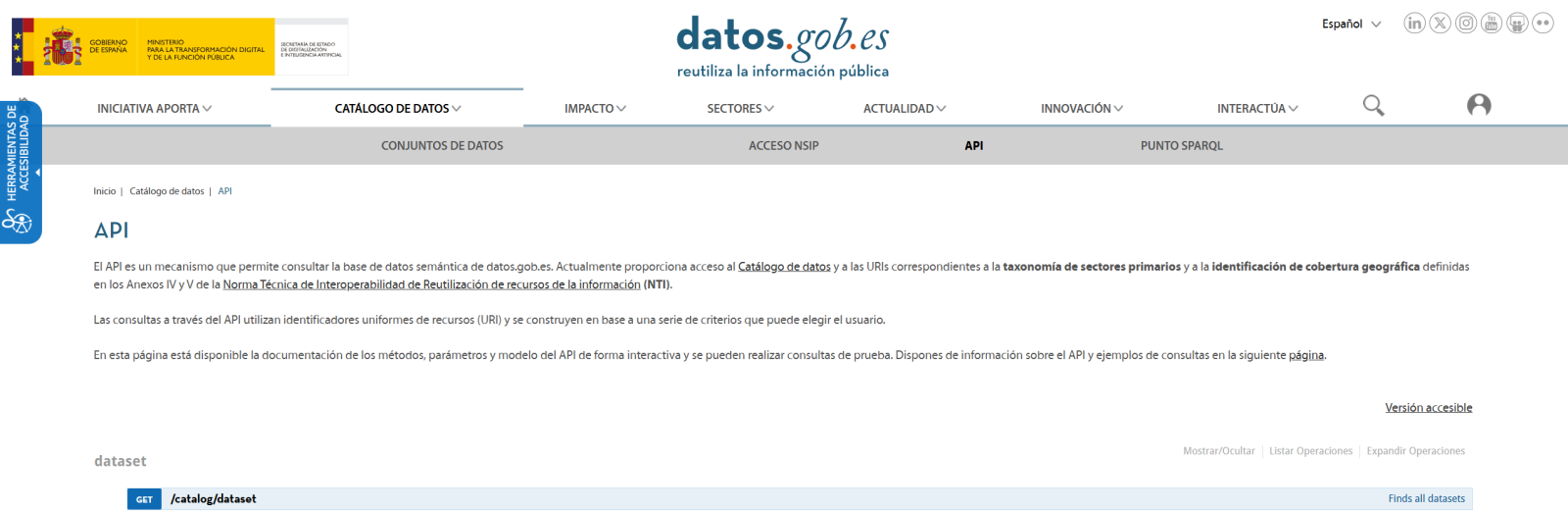
Figura 2. API de datos.gob
El segundo paso aborda la cuestión: ¿cómo convertir preguntas en lenguaje natural en análisis de datos útiles? Aquí es donde entra Gemini, el modelo de lenguaje de Google. Sin embargo, no basta con simplemente conectar el modelo; es necesario enseñarle a entender el contexto específico de cada dataset.
Se ha desarrollado un sistema en tres capas:
- Una función que analiza el dataset y genera una "ficha técnica" detallada.
- Otra que combina esta ficha con la pregunta del usuario.
- Y una tercera que traduce todo esto en código Python ejecutable.
Se puede ver en la imagen inferior como se desarrolla este proceso y, posteriormente, se muestran los resultados del código generado ya ejecutado.

Figura 3. Visualización del procesamiento de respuesta de la aplicación
Por último, con Streamlit, se ha construido una interfaz web que muestra el proceso y sus resultados al usuario. La interfaz es tan simple como elegir un dataset y hacer una pregunta, pero también lo suficientemente potente como para mostrar visualizaciones complejas y permitir la exploración de datos.
El resultado final es una aplicación que permite a cualquier persona, independientemente de sus conocimientos técnicos, realizar análisis de datos y aprender sobre el código ejecutado por el modelo. Por ejemplo, un funcionario municipal puede preguntar "¿Cuál es la edad media de la flota de vehículos?" y obtener una visualización clara de la distribución de edades.

Figura 4. Caso de uso completo. Visualizar la distribución de los años de matriculación de la flota automovilística del ayuntamiento de Almendralejo en 2018
¿Qué puedes aprender?
Este ejercicio práctico te permite aprender:
- Integración de IA en Aplicaciones Web:
- Cómo comunicarse efectivamente con modelos de lenguaje como Gemini.
- Técnicas para estructurar prompts que generen código preciso.
- Estrategias para manejar y ejecutar código generado por IA de forma segura.
- Desarrollo Web con Streamlit:
- Creación de interfaces interactivas en Python.
- Manejo de estado y sesiones en aplicaciones web.
- Implementación de componentes visuales para datos.
- Trabajo con Datos Abiertos:
- Conexión y consumo de APIs de datos públicos.
- Procesamiento de archivos Excel y DataFrames.
- Técnicas de visualización de datos.
- Buenas Prácticas de Desarrollo:
- Estructuración modular de código Python.
- Manejo de errores y reintentos.
- Implementación de sistemas de feedback visual.
- Despliegue de aplicaciones web usando ngrok.
Conclusiones y futuro
Este ejercicio demuestra el extraordinario potencial de la inteligencia artificial como puente entre los datos públicos y los usuarios finales. A través del caso práctico desarrollado, hemos podido observar cómo la combinación de modelos de lenguaje avanzados con interfaces intuitivas permite democratizar el acceso al análisis de datos, transformando consultas en lenguaje natural en análisis significativos y visualizaciones informativas.
Para aquellas personas interesadas en expandir las capacidades del sistema, existen múltiples direcciones prometedoras para su evolución:
- Incorporación de modelos de lenguaje más avanzados que permitan análisis más sofisticados.
- Implementación de sistemas de aprendizaje que mejoren las respuestas basándose en el feedback del usuario.
- Integración con más fuentes de datos abiertos y formatos diversos.
- Desarrollo de capacidades de análisis predictivo y prescriptivo.
En resumen, este ejercicio no solo demuestra la viabilidad de democratizar el análisis de datos mediante la inteligencia artificial, sino que también señala un camino prometedor hacia un futuro donde el acceso y análisis de datos públicos sea verdaderamente universal. La combinación de tecnologías modernas como Streamlit, modelos de lenguaje y técnicas de visualización abre un abanico de posibilidades para que organizaciones y ciudadanos aprovechen al máximo el valor de los datos abiertos.
Documentación
Los portales de datos abiertos juegan un papel fundamental en el acceso y reutilización de la información pública. Un aspecto clave en estos entornos es el etiquetado de los conjuntos de datos, que facilita su organización y recuperación.
Los word embeddings representan una tecnología transformadora en el campo del procesamiento del lenguaje natural, permitiendo representar palabras como vectores en un espacio multidimensional donde las relaciones semánticas se preservan matemáticamente. En este ejercicio se explora su aplicación práctica en un sistema de recomendación de etiquetas, utilizando como caso de estudio el portal de datos abiertos datos.gob.es.
El ejercicio se desarrolla en un notebook que integra la configuración del entorno, la adquisición de datos y el procesamiento del sistema de recomendación, todo ello implementado en Python. El proyecto completo se encuentra disponible en el repositorio de Github.
Accede al repositorio del laboratorio de datos en Github
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
Entendiendo los word embeddings
Los word embeddings son representaciones numéricas de palabras que revolucionan el procesamiento del lenguaje natural al transformar el texto en un formato matemáticamente procesable. Esta técnica codifica cada palabra como un vector numérico en un espacio multidimensional, donde la posición relativa entre vectores refleja relaciones semánticas y sintácticas entre palabras. La verdadera potencia de los embeddings radica en tres aspectos fundamentales:
- Captura de contexto: a diferencia de técnicas tradicionales como one-hot encoding, los embeddings aprenden del contexto en el que aparecen las palabras, permitiendo capturar matices de significado.
- Algebra semántica: los vectores resultantes permiten operaciones matemáticas que preservan relaciones semánticas. Por ejemplo, vector('Madrid') - vector('España') + vector('Francia') ≈ vector('París'), demostrando la captura de relaciones capital-país.
- Similitud cuantificable: la similitud entre palabras se puede medir mediante métricas, permitiendo identificar no solo sinónimos exactos sino también términos relacionados en diferentes grados y generalizar estas relaciones a nuevas combinaciones de palabras.
En este ejercicio se han utilizado embeddings pre-entrenados GloVe (Global Vectors for Word Representation), un modelo desarrollado por Stanford que destaca por su capacidad de capturar relaciones semánticas globales en el texto. En nuestro caso, empleamos vectores de 50 dimensiones, un equilibrio entre complejidad computacional y riqueza semántica. Para evaluar exhaustivamente su capacidad de representar el lenguaje castellano, se han realizado múltiples pruebas:
- Se ha analizado la similitud entre palabras mediante la similitud coseno, una métrica que evalúa el ángulo entre los vectores de dos palabras. Esta medida resulta en valores entre -1 y 1, donde valores cercanos a 1 indican alta similitud semántica, mientras que valores cercanos a 0 indican poca o ninguna relación. Se evaluaron términos como "amor", "trabajo" y "familia" para verificar que el modelo identificara correctamente palabras semánticamente relacionadas.
- Se ha probado la capacidad del modelo para resolver analogías lingüísticas, por ejemplo, "hombre es a mujer lo que rey es a reina", confirmando su habilidad para capturar relaciones semánticas complejas.
- Se han realizado operaciones vectoriales (como "rey - hombre + mujer") para comprobar si los resultados mantenían coherencia semántica.
- Finalmente, se han aplicado técnicas de reducción de dimensionalidad sobre una muestra representativa de 40 palabras en español, permitiendo visualizar las relaciones semánticas en un espacio bidimensional. Los resultados revelaron patrones de agrupación natural entre términos semánticamente relacionados, como se observa en la figura:
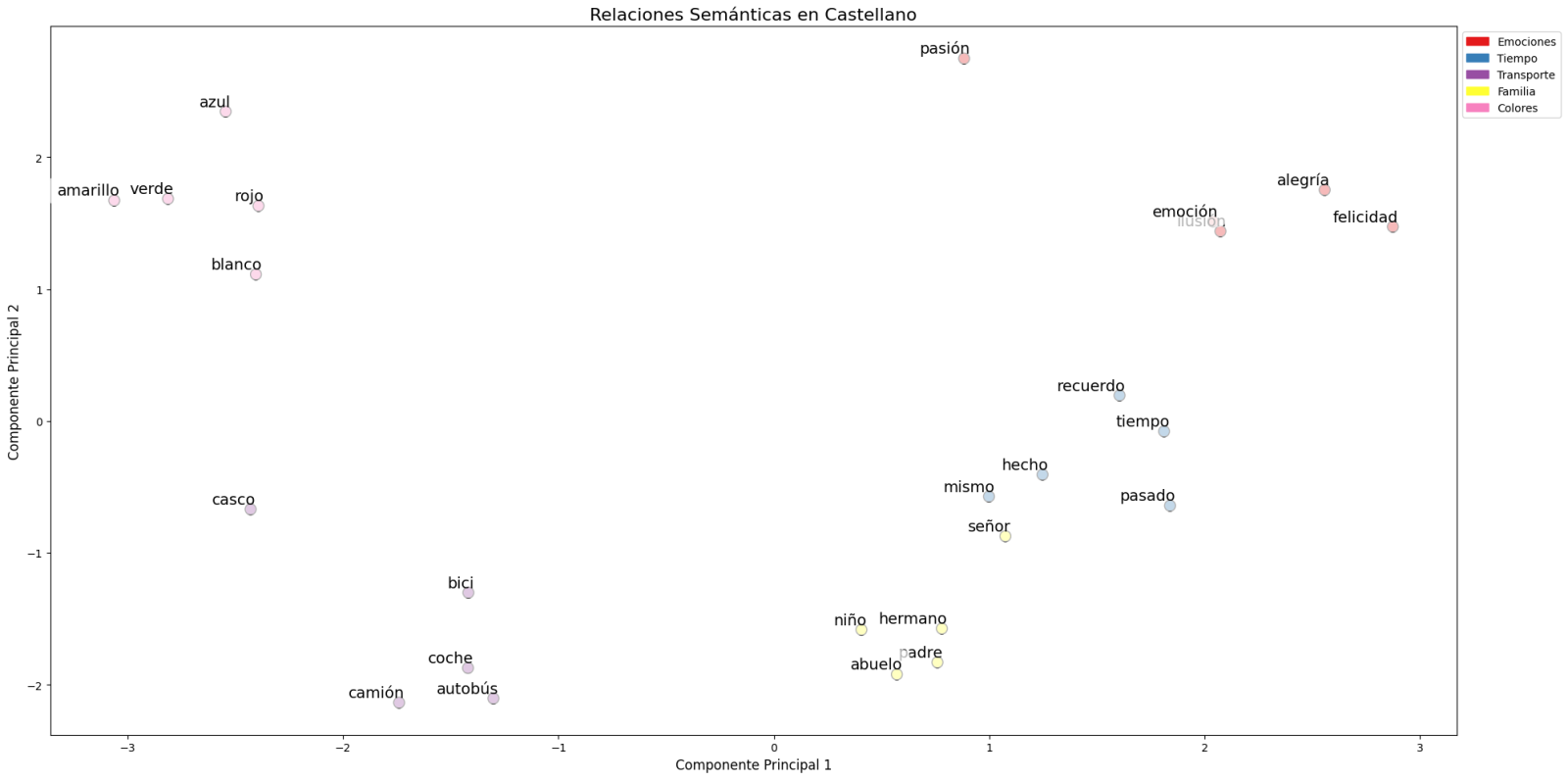
Figura 1. Análisis de Componentes principales sobre 50 dimensiones (embeddings) con un porcentaje de variabilidad explicada por los dos componentes de 0.46
- Los términos relacionados con familia (padre, hermano, abuelo) se concentran en la parte inferior.
- Los medios de transporte (coche, autobús, camión) forman un grupo distintivo.
- Los colores (azul, verde, rojo) aparecen próximos entre sí.
Para sistematizar este proceso de evaluación, se ha desarrollado una función unificada que encapsula todas las pruebas descritas anteriormente. Esta arquitectura modular permite evaluar de manera automática y reproducible diferentes modelos de embeddings pre-entrenados, facilitando así la comparación objetiva de su rendimiento en el procesamiento del lenguaje castellano. La estandarización de estas pruebas no solo optimiza el proceso de evaluación, sino que también establece un marco consistente para futuras comparaciones y validaciones de nuevos modelos por parte del público.
La buena capacidad para capturar relaciones semánticas en el lenguaje castellano es la que aprovechamos en nuestro sistema de recomendación de etiquetas.
Sistema de recomendación basado en embeddings
Aprovechando las propiedades de los embeddings, desarrollamos un sistema de recomendación de etiquetas que sigue un proceso de tres fases:
- Generación de embeddings: para cada conjunto de datos del portal, generamos una representación vectorial combinando el título y la descripción. Esto nos permite comparar datasets por su similitud semántica.
- Identificación de datasets similares: utilizando la similitud coseno entre los vectores, identificamos los conjuntos de datos más similares semánticamente.
- Extracción y estandarización de etiquetas: a partir de los conjuntos similares, extraemos sus etiquetas asociadas y las mapeamos con términos del tesauro Eurovoc. Este tesauro, desarrollado por la Unión Europea, es un vocabulario controlado multilingüe que proporciona una terminología estandarizada para la catalogación de documentos y datos en el ámbito de las políticas europeas. Aprovechando nuevamente la potencia de los embeddings, identificamos los términos de Eurovoc semánticamente más cercanos a nuestras etiquetas, garantizando así una estandarización coherente y una mejor interoperabilidad entre sistemas de información europeos.
Los resultados muestran que el sistema es capaz de generar recomendaciones de etiquetas coherentes y estandarizadas. Para ilustrar el funcionamiento del sistema, tomemos el caso del conjunto de datos “Agenda de Actividades Ciudad de Tarragona”:
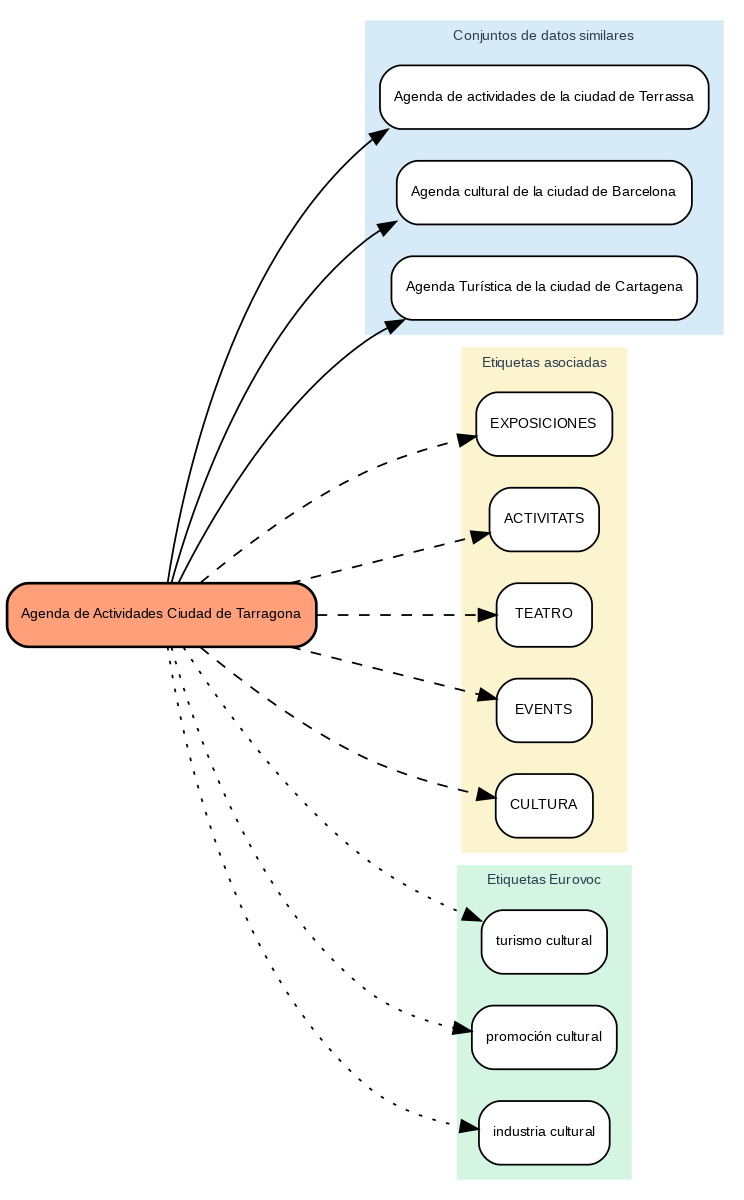
Figura 2. Agenda de Actividades Ciudad de Tarragona
El sistema:
- Encuentra conjuntos de datos similares como "Agenda de actividades de Terrassa" y "Agenda cultural de Barcelona".
- Identifica etiquetas comunes de estos conjuntos de datos, como "EXPOSICIONES", "TEATRO" y "CULTURA".
- Sugiere términos Eurovoc relacionados: "turismo cultural", "promoción cultural" e "industria cultural".
Ventajas del enfoque
Este enfoque ofrece ventajas significativas:
- Recomendaciones Contextuales: el sistema sugiere etiquetas basándose en el significado real del contenido, no solo en coincidencias textuales.
- Estandarización Automática: la integración con Eurovoc garantiza un vocabulario controlado y coherente.
- Mejora Continua: el sistema aprende y mejora sus recomendaciones a medida que se añaden nuevos datasets.
- Interoperabilidad: el uso de Eurovoc facilita la integración con otros sistemas europeos.
Conclusiones
Este ejercicio demuestra el gran potencial de los embeddings como herramienta para la asociación de textos en función de su naturaleza semántica. A través del caso práctico analizado, se ha podido observar cómo, mediante la identificación de títulos y descripciones similares entre datasets, es posible generar recomendaciones precisas de etiquetas o keywords. Estas etiquetas, a su vez, pueden vincularse con palabras clave de un tesauro estandarizado como Eurovoc, aplicando el mismo principio.
A pesar de los retos que pueden surgir, la implementación de este tipo de sistemas en entornos de producción presenta una valiosa oportunidad para mejorar la organización y recuperación de información. La precisión en la asignación de etiquetas puede verse influenciada por diversos factores interrelacionados del proceso:
- La especificidad de los títulos y descripciones de los datasets es fundamental, ya que de ella depende una correcta identificación de contenidos similares y, por tanto, una adecuada recomendación de etiquetas.
- La calidad y representatividad de las etiquetas existentes en los datasets similares determina directamente la relevancia de las recomendaciones generadas.
- La cobertura temática del tesauro Eurovoc, que, si bien es extensa, puede no abarcar términos específicos necesarios para describir ciertos datasets de manera precisa.
- La capacidad de los vectores para capturar fielmente las relaciones semánticas entre los contenidos, lo cual impacta directamente en la precisión de las etiquetas asignadas.
Para aquellos que deseen profundizar en el tema, existen otras aproximaciones interesantes al uso de embeddings que complementan lo visto en este ejercicio, tales como:
- Utilización de modelos de embeddings más complejos y computacionalmente costosos (como BERT, GPT, etc.).
- Entrenamiento de modelos en un corpus propio adaptado al dominio.
- Aplicación de técnicas más profundas de limpieza de datos.
En resumen, este ejercicio no solo demuestra la eficacia de los embeddings para la recomendación de etiquetas, sino que abre la puerta a que el lector explore todas las posibilidades que esta poderosa herramienta ofrece.
Documentación
Se presenta a continuación una nueva guía de Análisis Exploratorio de Datos (AED) implementada en Python, que evoluciona y complementa la versión publicada en R en el año 2021. Esta actualización responde a las necesidades de una comunidad cada vez más diversa en el ámbito de la ciencia de datos.
El Análisis Exploratorio de Datos (AED o EDA, por sus siglas en inglés) representa un paso crítico previo a cualquier análisis estadístico, ya que permite:
- Comprender exhaustivamente los datos antes de analizarlos.
- Verificar el cumplimiento de los requisitos estadísticos que garantizarán la validez de los análisis posteriores.
Para ejemplificar su importancia, tomemos el caso de la detección y tratamiento de valores atípicos, una de las tareas a realizar en un AED. Esta fase tiene un impacto significativo en estadísticos fundamentales como la media, la desviación estándar o el coeficiente de variación.
Además de explicar las distintas fases de un AED, la guía las ilustra con un caso práctico. En este sentido, se mantiene como caso práctico el análisis de datos de calidad del aire de Castilla y León. A través de explicaciones que el usuario podrá replicar, se transforman los datos públicos en información valiosa mediante el uso de bibliotecas Python fundamentales como pandas, matplotlib y seaborn, junto con herramientas modernas de análisis automatizado como ydata-profiling.
¿Por qué una nueva guía en Python?
La elección de Python como lenguaje para esta nueva guía refleja su creciente relevancia en el ecosistema de la ciencia de datos. Su sintaxis intuitiva y su extenso catálogo de bibliotecas especializadas lo han convertido en una herramienta fundamental para el análisis de datos. Al mantener el mismo conjunto de datos y estructura analítica que la versión en R, se facilita la comprensión de las diferencias entre ambos lenguajes. Esto resulta especialmente valioso en entornos donde coexisten múltiples tecnologías. Este enfoque es particularmente relevante en el contexto actual, donde numerosas organizaciones están migrando sus análisis desde lenguajes/herramientas tradicionales como R, SAS o SPSS hacia Python. La guía busca facilitar estas transiciones y garantizar la continuidad en la calidad de los análisis durante el proceso de migración.
Novedades y mejoras
Se ha enriquecido el contenido con la introducción al AED automatizado y las herramientas de perfilado de datos, respondiendo así a una de las últimas tendencias en el campo. El documento profundiza en aspectos esenciales como la interpretación de datos medioambientales, ofrece un tratamiento más riguroso de los valores atípicos y presenta un análisis más detallado de las correlaciones entre variables. Además, incorpora buenas prácticas en la escritura de código.
La aplicación práctica de estos conceptos se ilustra a través del análisis de datos de calidad del aire, donde cada técnica cobra sentido en un contexto real. Por ejemplo, al analizar las correlaciones entre contaminantes, no solo se muestra cómo calcularlas, sino que se explica cómo estos patrones reflejan procesos atmosféricos reales y qué implicaciones tienen para la gestión de la calidad del aire.
Estructura y contenidos
La guía sigue un enfoque práctico y sistemático, cubriendo las cinco etapas fundamentales del AED:
- Análisis descriptivo para obtener una visión representativa de los datos
- Ajuste de los tipos de variables para garantizar la consistencia
- Detección y tratamiento de datos ausentes
- Identificación y gestión de datos atípicos
- Análisis de correlación entre variables
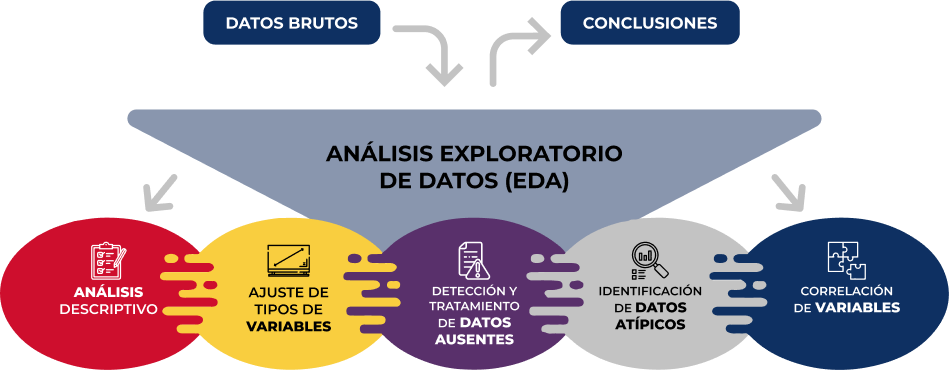
Figura 1. Fases del análisis exploratorio de datos. Fuente: elaboración propia.
Como novedad en la estructura, se incluye una sección sobre análisis exploratorio automatizado, presentando herramientas modernas que facilitan la exploración sistemática de grandes conjuntos de datos.
¿A quién va dirigida?
Esta guía está diseñada para usuarios de datos abiertos que deseen realizar análisis exploratorios y reutilizar las valiosas fuentes de información pública que se encuentran en este y otros portales de datos a nivel mundial. Si bien es recomendable tener conocimientos básicos del lenguaje, la guía incluye recursos y referencias para mejorar las competencias en Python, así como ejemplos prácticos detallados que facilitan el aprendizaje autodidacta.
El material completo, que incluye tanto la documentación como el código fuente, se encuentra disponible en el repositorio de GitHub del portal. La implementación se ha realizado utilizando herramientas de código abierto como Jupyter Notebook en Google Colab, lo que permite reproducir los ejemplos y adaptar el código según las necesidades específicas de cada proyecto.
Se invita a la comunidad a explorar esta nueva guía, experimentar con los ejemplos proporcionados y aprovechar estos recursos para desarrollar sus propios análisis de datos abiertos.
Haz click para ver la infografía completa, en versión accesible

Figura 2. Captura de la infografía. Fuente: elaboración propia.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos, se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos los flujos de turistas a nivel nacional, creando visualizaciones de los turistas que se mueven entre las comunidades autónomas (CCAA) y provincias.
Accede al repositorio del laboratorio de datos en Github
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto
Analizar los flujos de turistas nacionales nos permite observar ciertos movimientos ya muy conocidos, como, por ejemplo, que la provincia de Alicante es un destino muy popular del turismo veraniego. Además, este análisis es interesante para observar tendencias en el impacto económico que el turismo pueda tener, año tras año, en ciertas CCAA o provincias. El artículo sobre experiencias para la gestión de los flujos de visitantes en destinos turísticos ilustra el impacto de los datos en el sector.
3. Objetivo
El objetivo principal del ejercicio es crear visualizaciones interactivas en Python que permitan visualizar información compleja de manera comprensible y atractiva. Se cumplirá este objetivo usando un conjunto de datos abiertos que contiene información sobre flujos de turistas nacionales, planteando varias preguntas sobre los datos y contestándolas gráficamente. Podremos responder a preguntas como las que se plantean a continuación:
- ¿En qué CCAA hay más turismo procedente de la misma CA?
- ¿Cuál es la CA que más sale de su propia CA?
- ¿Qué diferencias hay entre los flujos de turistas a lo largo del año?
- ¿Cuál es la provincia valenciana que más turistas recibe?
La comprensión de las herramientas propuestas aportará al lector la capacidad para poder modificar el código contenido en el notebook que acompaña a este ejercicio para seguir explorando los datos por su cuenta y detectar más comportamientos interesantes a partir del conjunto de datos utilizado.
Para poder crear visualizaciones interactivas y contestar a las preguntas sobre los flujos de turistas, será necesario un proceso de limpieza y reformateado de datos que está descrito en el notebook que acompaña este ejercicio.
4. Recursos
Conjunto de datos
El conjunto de datos abiertos utilizado contiene información sobre los flujos de turistas en España a nivel de CCAA y provincias, indicando también los valores totales a nivel nacional. El conjunto de datos ha sido publicado por el Instituto Nacional de Estadística, a través de varios tipos de ficheros. Para el presente ejercicio utilizamos únicamente el fichero .csv separado por “;”. Los datos datan de julio de 2019 a marzo de 2024 (a la hora de redactar este ejercicio) y se actualizan mensualmente.
Número de turistas por CCAA y provincia de destino desagregados por PROVINCIA de origen
El conjunto de datos también se encuentra disponible para su descarga en este repositorio de Github.
Herramientas analíticas
Para la limpieza de los datos y la creación de las visualizaciones se ha utilizado el lenguaje de programación Python. El código creado para este ejercicio se pone a disposición del lector a través de un notebook de Google Colab.
Las librerías de Python que utilizaremos para llevar a cabo el ejercicio son:
- pandas: es una librería que se utiliza para el análisis y manipulación de datos.
- holoviews: es una librería que permite crear visualizaciones interactivas, combinando las funcionalidades de otras librerías como Bokeh y Matplotlib.
5. Desarrollo del ejercicio
Para visualizar los datos sobre flujos de turistas interactivamente crearemos dos tipos de diagramas, los diagramas de cuerdas y los diagramas de Sankey.
Los diagramas de cuerdas son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 1. Los nodos se sitúan en un círculo y las aristas simbolizan las relaciones entre los nodos del círculo. Estos diagramas suelen utilizarse para mostrar tipos de flujos, por ejemplo, flujos migratorios o monetarios. El volumen diferente de las aristas se visualiza de manera comprensible y refleja la importancia de un flujo o de un nodo. Por su forma de círculo, el diagrama de cuerdas es una buena opción para visualizar las relaciones entre todos los nodos de nuestro análisis (relación del tipo “varios a varios”).
Figura 1. Diagrama de cuerdas (Migración global). Fuente.
Los diagramas de Sankey, igual que los diagramas de cuerdas, son un tipo de diagrama que está compuesto por nodos y aristas, véase la figura 2. Los nodos se representan en los márgenes de la visualización, estando las aristas entre los márgenes. Por esta agrupación lineal de los nodos, los diagramas de Sankey son mejores que los diagramas de cuerdas para análisis en los cuales queramos visualizar la relación entre:
- varios nodos y otros nodos (tipo varios a varios, o varios a pocos, o viceversa)
- varios nodos y un solo nodo (varios a uno, o viceversa)

Figura 2. Diagrama de Sankey (Migración interna Reino Unido). Fuente.
El ejercicio está dividido en 5 partes, siendo la parte 0 (“configuración inicial”) solo de montar el entorno de programación. A continuación, describimos las cinco partes y los pasos que se llevan a cabo.
5.1. Cargar datos
Este apartado podrás encontrarlo en el punto 1 del notebook.
En este parte cargamos el conjunto de datos para poder procesarlo en el notebook. Comprobamos el formato de los datos cargados y creamos un pandas.DataFrame que utilizaremos para el procesamiento de los datos en los siguientes pasos.
5.2. Exploración inicial de los datos
Este apartado podrás encontrarlo en el punto 2 del notebook.
En esta parte realizamos un análisis exploratorio de los datos para entender el formato del conjunto de datos que hemos cargado y para tener una idea más clara de la información que contiene. Mediante esta exploración inicial, podemos definir los pasos de limpieza que tenemos que llevar a cabo para poder crear las visualizaciones interactivas.
Si quieres aprender más sobre cómo abordar esta tarea, tienes a tu disposición esta guía introductoria sobre análisis exploratorio de datos.
5.3. Análisis del formato de los datos
Este apartado podrás encontrarlo en el punto 3 del notebook.
En esta parte resumimos las observaciones que hemos podido hacer durante la exploración inicial de los datos. Recapitulamos aquí las observaciones más importantes:
| Provincia de origen | Provincia de origen | CCAA y provincia de destino | CCAA y provincia de destino | CCAA y provincia de destino | Concepto turístico | Periodo | Total |
|---|---|---|---|---|---|---|---|
| Total Nacional | Total Nacional | Turistas | 2024M03 | 13.731.096 | |||
| Total Nacional | Ourense | Total Nacional | Andalucía | Almería | Turistas | 2024M03 | 373 |
Figura 3. Fragmento del conjunto de datos original.
Podemos observar en las columnas uno a cuatro que los orígenes de los flujos de turistas están desagregados por provincia mientras que, para los destinos, las provincias están agregadas por CCAA. Aprovecharemos el mapeado de las CCAA y de sus provincias que podemos extraer de la cuarta y quinta columna para agregar las provincias de origen por CCAA.
También podemos ver que la información contenida en la primera columna a veces es superflua, por lo cual, la combinaremos con la segunda columna. Además, hemos constatado que la quinta y sexta columna no aportan valor para nuestro análisis, por lo cual, las eliminaremos. Renombraremos algunas columnas para tener un pandas. DataFrame más comprensible.
5.4. Limpieza de los datos
Este apartado podrás encontrarlo en el punto 4 del notebook.
En esta parte llevamos a cabo los pasos necesarios para darle mejor formato a nuestros datos. Para ello aprovechamos varias funcionalidades que nos ofrece pandas, por ejemplo, para renombrar las columnas. También definimos una función reutilizable que necesitamos para concatenar los valores de la primera y segunda columna con el objetivo de no tener una columna que exclusivamente indique “Total Nacional” en todas las filas del pandas.DataFrame. Además, extraeremos de las columnas de destino un mapeado de CCAA a provincias que aplicaremos a las columnas de origen.
Queremos obtener una versión del conjunto de datos más comprimida con mayor transparencia de los nombres de las columnas y que no contenga información que no vamos a procesar. El resultado final del proceso de limpieza de datos es el siguiente:
| Origen | Provincia de origen | Destino | Provincia de destino | Periodo | Total |
|---|---|---|---|---|---|
| Total Nacional | Total Nacional | 2024M03 | 13731096.0 | ||
| Galicia | Ourense | Andalucía | Almería | 2024M03 | 373.0 |
Figura 4. Fragmento del conjunto de datos limpio.
5.5. Crear visualizaciones
Este apartado podrás encontrarlo en el punto 5 del notebook
En esta parte creamos nuestras visualizaciones interactivas utilizando la librería Holoviews. Para poder dibujar gráficos de cuerdas o de Sankey que visualicen el flujo de personas entre CCAA y CCAA y/o provincias, tenemos que estructurar la información de nuestros datos de tal forma que dispongamos de nodos y aristas. En nuestro caso, los nodos son los nombres de CCAA o provincia y las aristas, es decir, la relación entre los nodos, son el número de turistas. En el notebook definimos una función para obtener los nodos y aristas que podemos reutilizar para los diferentes diagramas que queramos realizar, cambiando el período de tiempo según la estación del año que nos interese analizar.
Vamos a crear primero un diagrama de cuerdas usando exclusivamente los datos sobre flujos de turistas de marzo de 2024. En el notebook, este diagrama de cuerdas es dinámico. Te animamos a probar su interactividad.
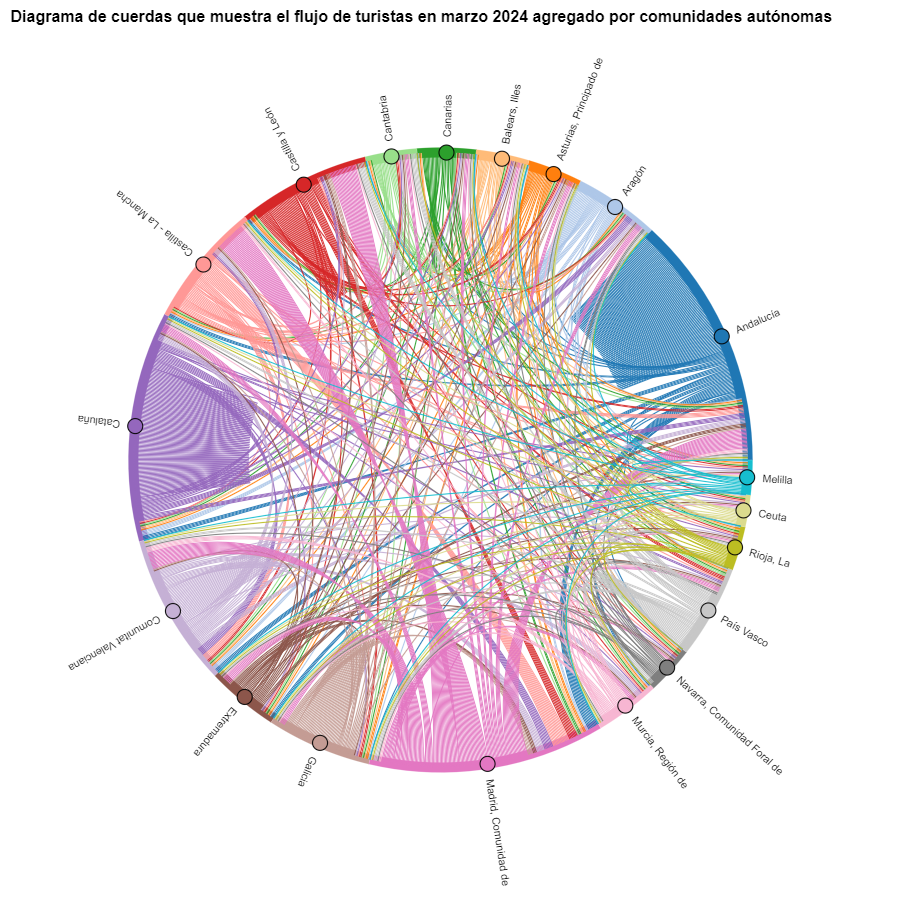
Figura 5. Diagrama de cuerdas que muestra el flujo de turistas en marzo 2024 agregado por comunidades autónomas.
En el diagrama de cuerdas se visualizan los flujos de turistas entre todas las CCAA. Cada CA tiene un color y los movimientos que hacen los turistas provenientes de esta CA se simbolizan con el mismo color. Podemos observar que los turistas de Andalucía y Cataluña viajan mucho dentro de sus propias CCAA. En cambio, los turistas de Madrid salen mucho de su propia CA.
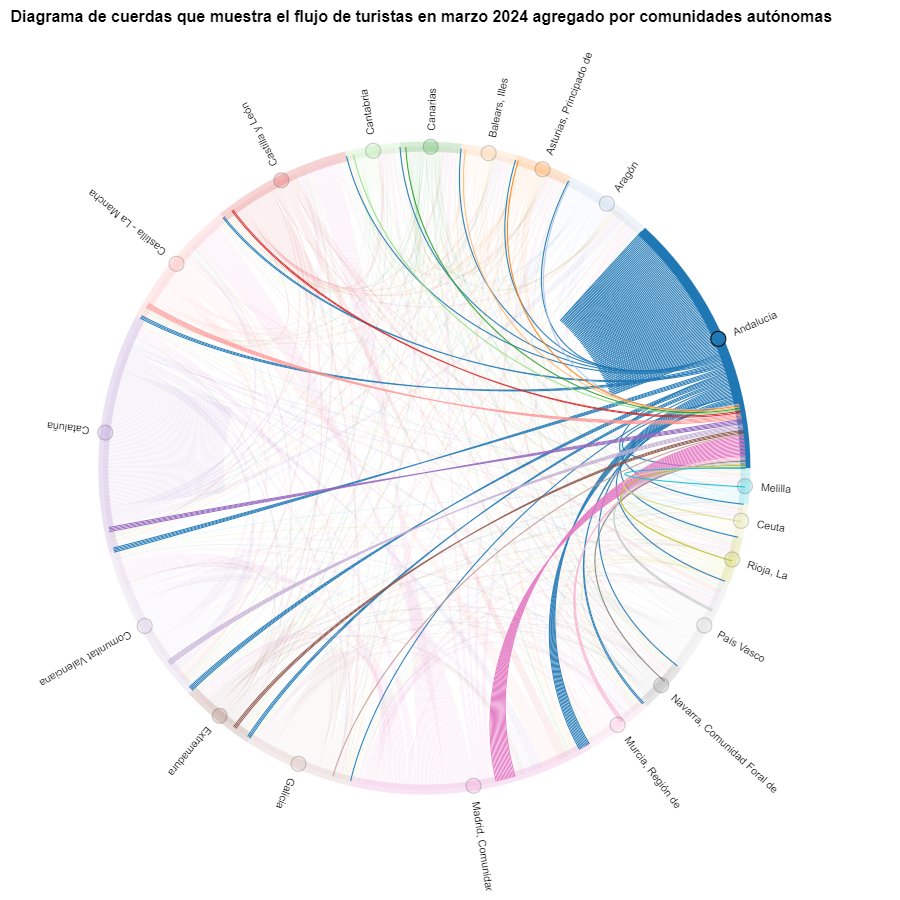
Figura 6. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de Andalucía en marzo 2024 agregado por comunidades autónomas.
Creamos otro diagrama de cuerdas utilizando la función que hemos creado y visualizamos los flujos de turistas en agosto de 2023.
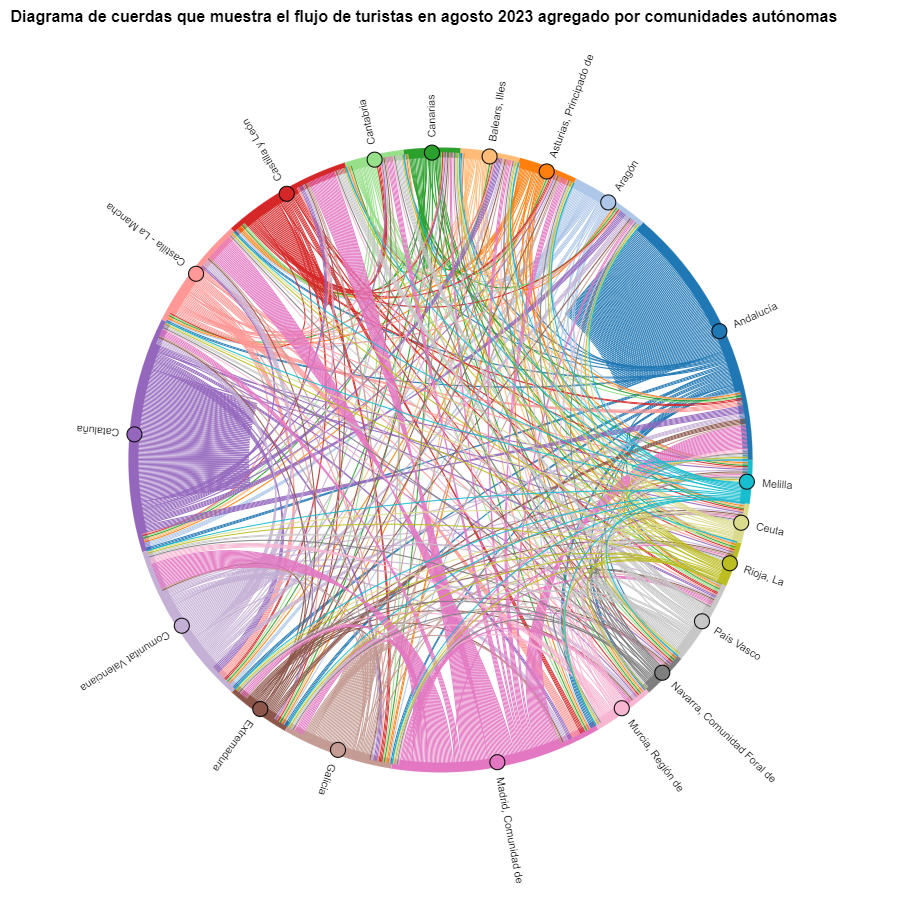
Figura 7. Diagrama de cuerdas que muestra el flujo de turistas en agosto 2023 agregado por comunidades autónomas.
Podremos observar que, a grandes rasgos, no cambian los movimientos de los turistas, solo que se intensifican los movimientos que ya hemos podido observar para marzo 2024.
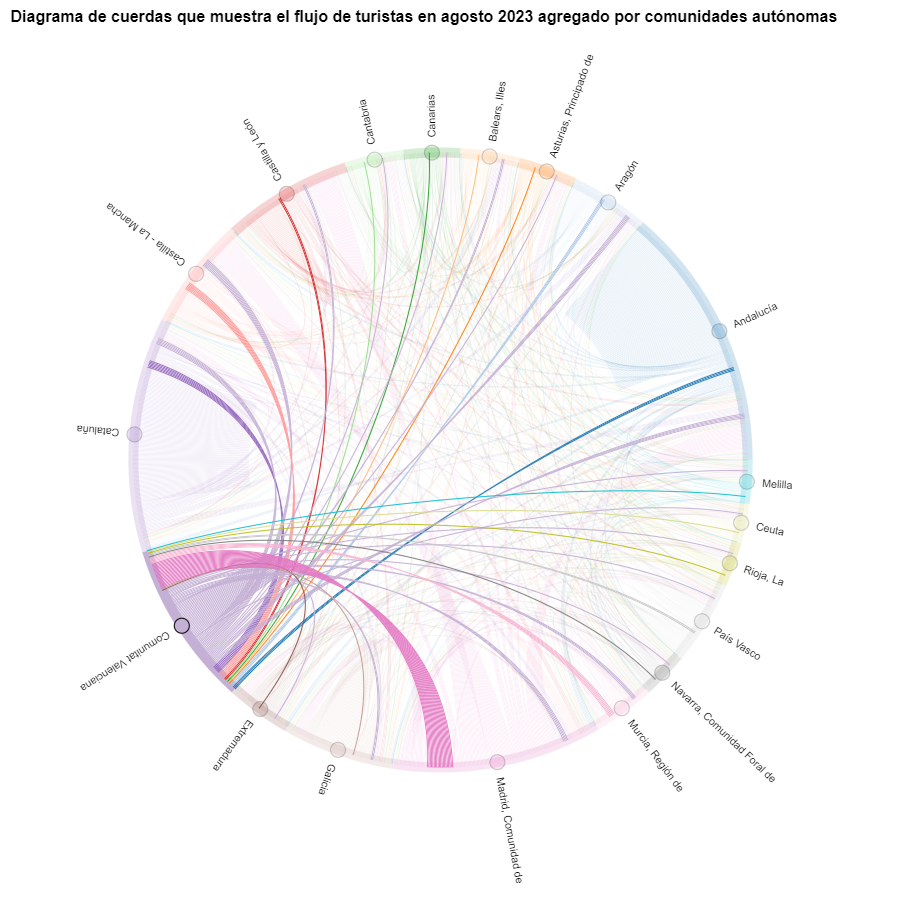
Figura 8. Diagrama de cuerdas que muestra el flujo de turistas entrando y saliendo de la Comunitat Valenciana en agosto 2023 agregado por comunidades autónomas.
El lector puede crear el mismo diagrama para otros períodos de tiempo, por ejemplo, para el verano del año 2020, con el fin de visualizar el impacto de la pandemia en el turismo veraniego, reutilizando la función que hemos creado.
Para los diagramas de Sankey nos vamos a centrar en la Comunitat Valenciana, ya que es un destino vacacional popular. Filtramos las aristas que hemos creado para el diagrama de cuerdas anterior de manera que solo contengan flujos que terminen en la Comunitat Valenciana. El mismo procedimiento se podría aplicar para estudiar cualquier otra CA o se podría invertir para analizar dónde van a veranear los valencianos. Visualizamos el diagrama de Sankey que, igual que los diagramas de cuerdas, es interactivo dentro del notebook. El aspecto visual quedaría así:
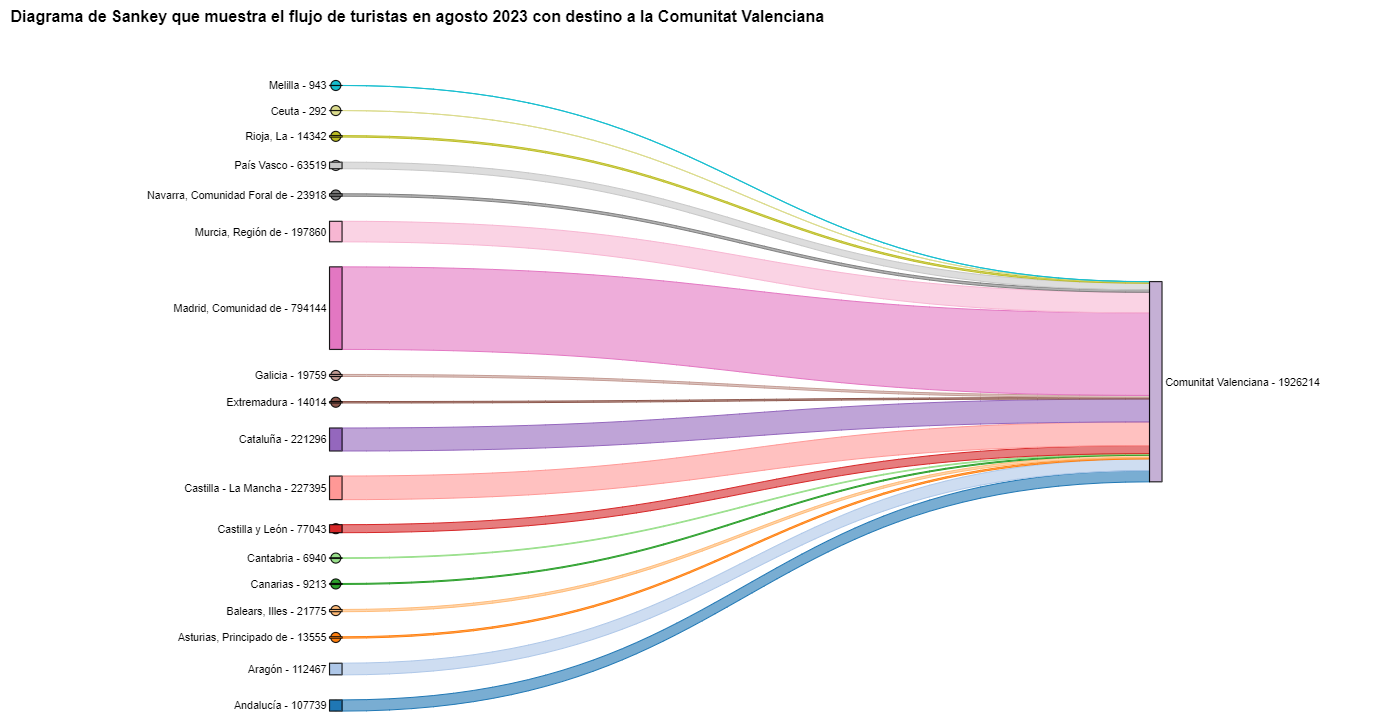
Figura 9. Diagrama de Sankey que muestra el flujo de turistas en agosto 2023 con destino a la Comunitat Valenciana.
Como ya hemos podido intuir por el diagrama de cuerdas de arriba, véase la figura 8 el mayor grupo de turistas que llegan a la Comunitat Valenciana proviene de Madrid. Vemos que también hay un elevado número de turistas que visitan la Comunitat Valenciana desde las CCAA vecinas como Murcia, Andalucía y Cataluña.
Para comprobar que estas tendencias se dan en las tres provincias de la Comunitat Valenciana, vamos a crear un diagrama de Sankey que muestre en el margen izquierdo todas las CCAA y en el margen derecho las tres provincias de la Comunitat Valenciana.
Para crear este diagrama de Sankey a nivel de provincias tenemos que filtrar nuestro pandas. DataFrame inicial para extraer de él las filas que contienen la información relevante. Los pasos en el notebook se pueden adaptar para realizar este análisis a nivel de provincias para cualquier otra CA. Aunque no estamos reutilizando la función que hemos usado anteriormente, también podemos cambiar el período de análisis.
El diagrama de Sankey que visualiza los flujos de turistas que llegaron en agosto de 2023 a las tres provincias valencianas quedaría así:
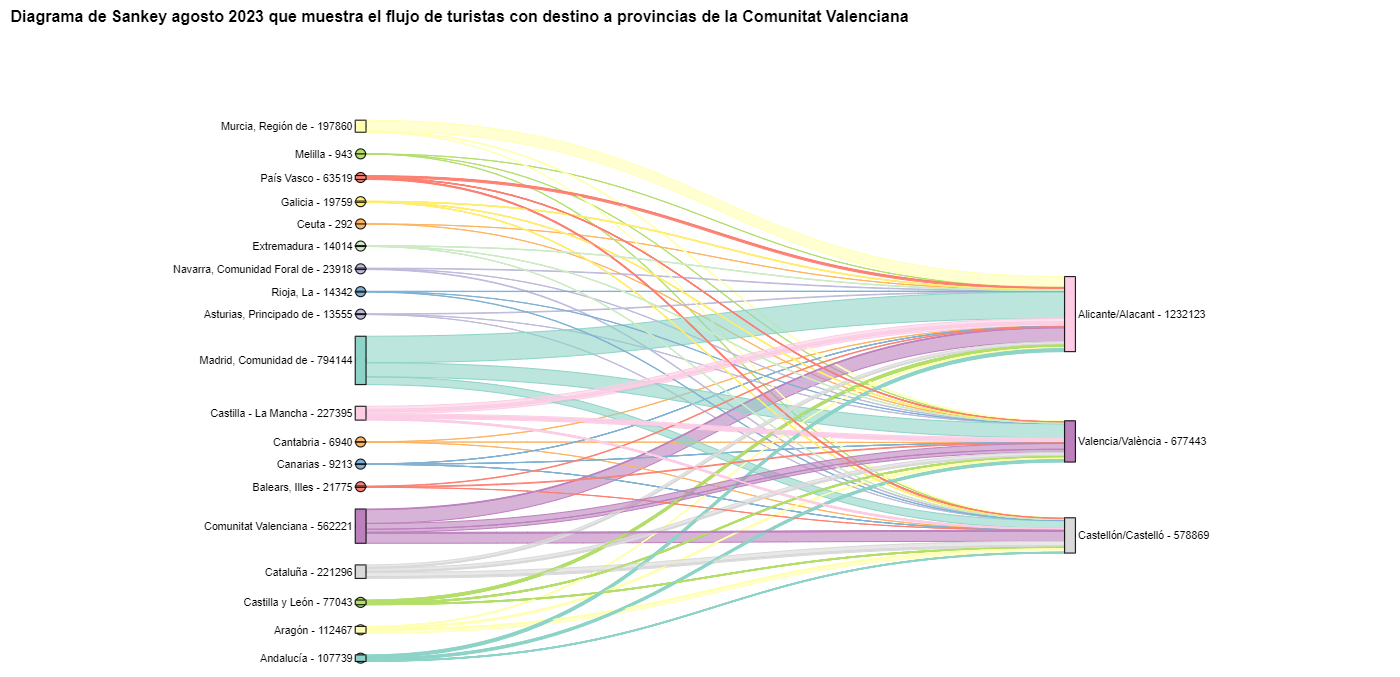
Figura 10. Diagrama de Sankey agosto 2023 que muestra el flujo de turistas con destino a provincias de la Comunitat Valenciana.
Podemos observar que, como ya suponíamos, el mayor número de turistas que llega a la Comunitat Valenciana en agosto proviene de la Comunidad de Madrid. Sin embargo, podemos comprobar que esto no es cierto para la provincia de Castellón, donde en agosto de 2023 la mayoría de los turistas fueron valencianos que se desplazaron dentro de su propia CA.
6. Conclusiones del ejercicio
Gracias a las técnicas de visualización empleadas en este ejercicio, hemos podido observar los flujos de turistas que se desplazan dentro del territorio nacional, enfocándonos en hacer comparaciones entre diversas épocas del año y tratando de identificar patrones. Tanto en los diagramas de cuerdas como en los diagramas de Sankey que hemos creado, hemos podido observar la afluencia de los turistas madrileños en las costas valencianas en verano. También hemos podido identificar las comunidades autónomas donde los turistas salen menos de su propia comunidad autónoma, como Cataluña y Andalucía.
7. ¿Quieres realizar el ejercicio?
Invitamos al lector a ejecutar el código contenido en el notebook de Google Colab que acompaña a este ejercicio para seguir con el análisis de los flujos de turistas. Dejamos aquí algunas ideas de posibles preguntas y de cómo se podrían contestar:
- El impacto de la pandemia: ya lo hemos mencionado brevemente arriba, pero una pregunta interesante sería medir el impacto que ha tenido la pandemia del coronavirus sobre el turismo. Podemos comparar los datos de los años anteriores con el 2020 y también analizar los años siguientes para detectar tendencias de estabilización. Visto que la función que hemos creado permite cambiar fácilmente el período de tiempo bajo análisis, te proponemos hacer este análisis por tu cuenta.
- Intervalos de tiempo: también es posible modificar la función que hemos estado usando de tal manera que no solo permita seleccionar un periodo de tiempo concreto, sino que también permita intervalos de tiempos.
- Análisis a nivel de provincias: igualmente, un lector avanzado con Pandas puede imponerse el reto de crear un diagrama de Sankey que visualice a qué provincias viajan los habitantes de una determinada región, por ejemplo, Ourense. Para no tener demasiadas provincias de destino que podrían hacer ilegible el diagrama de Sankey, se podrían visualizar solo las 10 más visitadas. Para obtener los datos para crear esta visualización, el lector tendría que jugar con los filtros que pone sobre el dataset y con el método de groupby de pandas, dejándose inspirar por el código ya ejecutado.
Esperamos que este ejercicio práctico te haya aportado conocimiento suficiente para desarrollar tus propias visualizaciones. Si tienes algún tema sobre ciencia de datos que quieras que tratemos próximamente, no dudes en proponer tu interés a través de nuestros canales de contacto.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Ejercicios de ciencia de datos”.
Noticia
Hoy, 23 de abril, se celebra el Día del Libro, una ocasión para resaltar la importancia de la lectura, la escritura y la difusión del conocimiento. La lectura activa promueve la adquisición de habilidades y el pensamiento crítico, al acercarnos a información especializada y detallada sobre cualquier tema que nos interese, incluido el mundo de los datos.
Por ello, queremos aprovechar la ocasión para mostrar algunos ejemplos de libros y manuales relacionados con los datos y tecnologías relacionadas que se pueden encontrar en la red de manera gratuita.
1. Fundamentos de ciencia de datos con R, editado por Gema Fernandez-Avilés y José María Montero (2024)
Accede al libro aquí.
- ¿De qué trata? El libro guía al lector desde el planteamiento de un problema hasta la realización del informe que contiene su solución. Para ello, explica una treintena de técnicas de ciencia de datos en el ámbito de la modelización, análisis de datos cualitativos, discriminación, machine learning supervisado y no supervisado, etc. En él se incluyen más de una docena de casos de uso en sectores tan dispares como la medicina, el periodismo, la moda o el cambio climático, entre otros. Todo ello, con un gran énfasis en la ética y en el fomento de la reproductibilidad de los análisis.
-
¿A quién va dirigido? Está dirigido a usuarios que quieran iniciarse en la ciencia de datos. Parte de preguntas básicas, como qué es la ciencia de datos, e incluye breves secciones con explicaciones sencillas sobre la probabilidad, la inferencia estadística o el muestreo, para aquellos lectores no familiarizados con estas cuestiones. También incluye ejemplos replicables para practicar.
-
Idioma: Español
2. Contar historias con datos, Rohan Alexander (2023).
Accede al libro aquí.
-
¿De qué trata? El libro explica una amplia gama de temas relacionados con la comunicación estadística y el modelado y análisis de datos. Abarca las distintas operaciones desde la recopilación de datos, su limpieza y preparación, hasta el uso de modelos estadísticos para analizarlos, prestando especial importancia a la necesidad de extraer conclusiones y escribir sobre los resultados obtenidos. Al igual que el libro anterior, también pone el foco en la ética y la reproductibilidad de resultados.
-
¿A quién va dirigido? Es perfecto para estudiantes y usuarios con conocimientos básicos, a los que dota de capacidades para realizar y comunicar de manera efectiva un ejercicio de ciencia de datos. Incluye extensos ejemplos de código para replicar y actividades a realizar a modo de evaluación.
-
Idioma: Inglés.
3. El gran libro de los pequeños proyectos con Python, Al Sweigart (2021)
Accede al libro aquí.
- ¿De qué trata? Es una colección de sencillos proyectos en Python para aprender a crear arte digital, juegos, animaciones, herramientas numéricas, etc. a través de un enfoque práctico. Cada uno de sus 81 capítulos explica de manera independiente un proyecto sencillo paso a paso -limitados a máximo 256 líneas de código-. Incluye una ejecución de muestra del resultado de cada programa, el código fuente y sugerencias de personalización.
-
¿A quién va dirigido? El libro está escrito para dos grupos de personas. Por un lado, aquellos que ya han aprendido los conceptos básicos de Python, pero todavía no están seguros de cómo escribir programas por su cuenta. Por otro, aquellos que se inician en la programación, pero son aventureros, cuentan con grandes dosis de entusiasmo y quieren ir aprendiendo sobre la marcha. No obstante, el mismo autor tiene otros recursos para principiantes con los que aprender conceptos básicos.
-
Idioma: Inglés.
4. Matemáticas para Machine Learning, Marc Peter Deisenroth A. Aldo Faisal Cheng Soon Ong (2024)
Accede al libro aquí.
-
¿De qué trata? La mayoría de libros sobre machine learning se centran en algoritmos y metodologías de aprendizaje automático, y presuponen que el lector es competente en matemáticas y estadística. Este libro pone en primer plano los fundamentos matemáticos de los conceptos básicos detrás del aprendizaje automático
-
¿A quién va dirigido? El autor asume que el lector tiene conocimientos matemáticos comúnmente aprendidos en las materias de matemáticas y física de la escuela secundaria, como por ejemplo derivadas e integrales o vectores geométricos. A partir de ahí, el resto de conceptos se explican de manera detallada, pero con un estilo académico, con el fin de ser precisos.
-
Idioma: Inglés.
5. Profundizando en el aprendizaje profundo, Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola (2021, se actualiza continuamente)
Accede al libro aquí.
-
¿De qué trata? Los autores son empleados de Amazon que utilizan la biblioteca MXNet para enseñar Deep Learning. Su objetivo es hacer accesible el aprendizaje profundo, enseñando los conceptos básicos, el contexto y el código de forma práctica a través de ejemplos y ejercicios. El libro se divide en tres partes: conceptos preliminares, técnicas de aprendizaje profundo y temas avanzados centrados en sistemas y aplicaciones reales.
-
¿A quién va dirigido? Este libro está dirigido a estudiantes (de grado o posgrado), ingenieros e investigadores, que buscan un dominio sólido de las técnicas prácticas del aprendizaje profundo. Cada concepto se explica desde cero, por lo que no es necesario tener conocimientos previos de aprendizaje profundo o automático. No obstante, sí son necesario conocimientos de matemáticas y programación básicas, incluyendo álgebra lineal, cálculo, probabilidad y programación en Python.
-
Idioma: Inglés.
6. Inteligencia artificial y sector público: retos límites y medios, Eduardo Gamero y Francisco L. Lopez (2024)
Accede al libro aquí.
-
¿De qué trata? Este libro se centra en analizar los retos y oportunidades que presenta el uso de la inteligencia artificial en el sector público, especialmente cuando se usa como soporte a la toma de decisiones. Comienza explicando qué es la inteligencia artificial y cuáles son sus aplicaciones en el sector público, para pasar a abordar su marco jurídico, los medios disponibles para su implementación y aspectos ligados a la organización y gobernanza.
-
¿A quién va dirigido? Es un libro útil para todos aquellos interesados en la temática, pero especialmente para responsables políticos, trabajadores públicos y operadores jurídicos relacionados con la aplicación de la IA en el sector público.
-
Idioma: español
7. Introducción del analista de negocio a la analítica empresarial, Adam Fleischhacker (2024)
Accede al libro aquí.
-
¿De qué trata? El libro aborda un flujo de trabajo de análisis empresarial completo, que incluye la manipulación de datos, su visualización, el modelado de problemas empresariales, la traducción de modelos gráficos a código y la presentación de resultados ante las partes interesadas. El objetivo es aprender a impulsar cambios dentro de una organización gracias al conocimiento basado en datos, modelos interpretables y visualizaciones persuasivas.
-
¿A quién va dirigido? Según su autor, se trata de un contenido accesible para todos, incluso para principiantes en la realización de trabajos de análisis. El libro no asume ningún conocimiento del lenguaje de programación, sino que proporciona una introducción a R, RStudio y al “tidyverse”, una serie de paquetes de código abierto para la ciencia de datos.
-
Idioma: Inglés.
Te invitamos a ojear esta selección de libros. Asimismo, recordamos que solo se trata de una lista con ejemplos de las posibilidades de materiales que puedes encontrar en la red. ¿Conoces algún otro libro que quieras recomendar? ¡Indícanoslo en los comentarios o manda un email a dinamizacion@datos.gob.es!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada ejercicio práctico se utilizan desarrollos de código documentados y herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
En este ejercicio concreto, exploraremos la actual situación de la penetración de los vehículos eléctricos en España y las perspectivas de futuro de esta tecnología disruptiva en el transporte.
Accede al repositorio del laboratorio de datos en Github
Ejecuta el código de pre-procesamiento de datos sobre Google Colab
En este vídeo, el autor te explica que vas a encontrar tanto en el Github como en Google Colab.
2. Contexto: ¿Por qué es importante el vehículo eléctrico?
La transición hacia una movilidad más sostenible se ha convertido en una prioridad global, situando al vehículo eléctrico (VE) en el centro de numerosas discusiones sobre el futuro del transporte. En España, esta tendencia hacia la electrificación del parque automovilístico no solo responde a un creciente interés por parte de los consumidores en tecnologías más limpias y eficientes, sino también a un marco regulatorio y de incentivos diseñado para acelerar la adopción de estos vehículos. Con una creciente oferta de modelos eléctricos disponibles en el mercado, los vehículos eléctricos representan una pieza clave en la estrategia del país para reducir las emisiones de gases de efecto invernadero, mejorar la calidad del aire en las ciudades y fomentar la innovación tecnológica en el sector automotriz.
Sin embargo, la penetración de los vehículos eléctricos en el mercado español enfrenta una serie de desafíos, desde la infraestructura de carga hasta la percepción y el conocimiento del consumidor sobre estos vehículos. La expansión de la red de carga, junto con las políticas de apoyo y los incentivos fiscales, son fundamentales para superar las barreras existentes y estimular la demanda. A medida que España avanza hacia sus objetivos de sostenibilidad y transición energética, el análisis de la evolución del mercado de vehículos eléctricos se convierte en una herramienta esencial para entender el progreso realizado y los obstáculos que aún deben superarse.
3. Objetivo
Este ejercicio se centra en mostrar al lector técnicas para el tratamiento, visualización y análisis avanzado de datos abiertos mediante Python. Adoptaremos para ello el enfoque “aprender haciendo”, de tal forma que el lector pueda comprender la utilización de estas herramientas en el contexto de la resolución de un reto real y de actualidad como es el estudio de la penetración del VE en España. Este enfoque práctico no solo mejora la comprensión de las herramientas de ciencia de datos, sino que también prepara a los lectores para aplicar estos conocimientos en la resolución de problemas reales, ofreciendo una experiencia de aprendizaje rica y directamente aplicable a sus propios proyectos.
Las preguntas a las que trataremos de dar respuesta a través de nuestro análisis son:
- ¿Qué marcas de vehículos lideraron el mercado en 2023?
- ¿Qué modelos de vehículos fueron los más vendidos en el 2023?
- ¿Qué cuota de mercado absorbieron los vehículos eléctricos en el 2023?
- ¿Qué modelos de vehículos eléctricos fueron los más vendidos en el 2023?
- ¿Cómo han evolucionado las matriculaciones de vehículos a lo largo del tiempo?
- ¿Observamos algún tipo de tendencia respecto a la matriculación de vehículos eléctricos?
- ¿Cómo esperamos que evolucionen las matriculaciones de vehículos eléctricos el próximo año?
- ¿Cuál es la reducción de emisiones de CO2 que podemos esperar gracias a las matriculaciones obtenidas durante el próximo año?
4. Recursos
Para completar el desarrollo de este ejercicio requeriremos el uso de dos categorías de recursos: Herramientas Analíticas y Conjuntos de Datos.
4.1. Conjunto de datos
Para completar este ejercicio utilizaremos un conjunto de datos provisto por la Dirección General de Tráfico (DGT) a través de su portal estadístico, también disponible desde el catálogo Nacional de Datos Abiertos (datos.gob.es). El portal estadístico de la DGT es una plataforma en línea destinada a ofrecer acceso público a una amplia gama de datos y estadísticas relacionadas con el tráfico y la seguridad vial. Este portal incluye información sobre accidentes de tráfico, infracciones, matriculaciones de vehículos, permisos de conducción y otros datos relevantes que pueden ser útiles para investigadores, profesionales del sector y el público en general.
En nuestro caso, utilizaremos su conjunto de datos de matriculaciones de vehículos en España disponibles vía:
- Catálogo de Datos Abiertos del Gobierno de España.
- Portal estadístico de la DGT.
Aunque durante el desarrollo del ejercicio mostraremos al lector los mecanismos necesarios para su descarga y procesamiento, incluimos en el repositorio de GitHub asociado los datos preprocesados*, de tal forma que el lector pueda proceder directamente al análisis de los mismos en el caso de que lo desee.
*Los datos utilizados en este ejercicio fueron descargados el 04 de marzo de 2024. La licencia aplicable a este conjunto de datos puede encontrarse en https://datos.gob.es/avisolegal.
4.2. Herramientas analíticas
- Lenguaje de programación: Python – es un lenguaje de programación ampliamente utilizado en análisis de datos debido a su versatilidad y a la amplia gama de bibliotecas disponibles. Estas herramientas permiten a los usuarios limpiar, analizar y visualizar grandes conjuntos de datos de manera eficiente, lo que hace de Python una elección popular entre los científicos de datos y analistas.
- Plataforma: Jupyter Notebooks – es una aplicación web que permite crear y compartir documentos que contienen código vivo, ecuaciones, visualizaciones y texto narrativo. Se utiliza ampliamente para la ciencia de datos, análisis de datos, aprendizaje automático y educación interactiva en programación.
- Principales librerías y módulos:
- Manipulación de datos: Pandas – es una librería de código abierto que proporciona estructuras de datos de alto rendimiento y fáciles de usar, así como herramientas de análisis de datos.
- Visualización de datos:
- Matplotlib: es una librería para crear visualizaciones estáticas, animadas e interactivas en Python.
- Seaborn: es una librería basada en Matplotlib. Proporciona una interfaz de alto nivel para dibujar gráficos estadísticos atractivos e informativos.
- Estadística y algoritmia:
- Statsmodels: es una librería que proporciona clases y funciones para la estimación de muchos modelos estadísticos diferentes, así como para realizar pruebas y exploración de datos estadísticos.
- Pmdarima: es una librería especializada en la modelización automática de series temporales, facilitando la identificación, el ajuste y la validación de modelos para pronósticos complejos.
5. Desarrollo del ejercicio
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
El ejercicio propuesto se divide en cuatro fases principales.
5.1 Configuración inicial
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este breve primer apartado, configuraremos nuestro Jupyter Notebook y nuestro entorno de trabajo para poder trabajar con el conjunto de datos seleccionado. Importaremos las librerías Python necesarias y crearemos algunos directorios donde almacenaremos los datos descargados.
5.2 Preparación de datos
Este apartado podrás encontrarlo en el punto 2 del Notebook.
Todo análisis de datos requiere una fase de acceso y tratamiento de los mismos hasta obtener los datos adecuados en el formato deseado. En esta fase, descargaremos los datos del portal estadístico y los transformaremos al formato Apache Parquet antes de proceder a su análisis.
Aquellos usuarios que quieran profundizar en esta tarea, tienen a su disposición la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
5.3 Análisis de datos
Este apartado podrás encontrarlo en el punto 3 del Notebook.
5.3.1 Análisis descriptivo
En esta tercera fase, comenzaremos nuestro análisis de datos. Para ello, responderemos las primeras preguntas apoyándonos en herramientas de visualización de datos que además nos permitirán familiarizarnos con los mismos. Mostramos a continuación algunos ejemplos del análisis:
- Top 10 Vehículos matriculados en el 2023: En esta visualización representamos los diez modelos de vehículos con mayor número de matriculaciones durante el año 2023, indicando además el tipo de combustión de estos. Las principales conclusiones son:
- Los únicos vehículos de fabricación europea que aparecen en el Top 10 son el Arona y el Ibiza de la marca española SEAT. El resto son asiáticos.
- Nueve de los diez vehículos están propulsados por Gasolina.
- El único vehículo del Top 10 con un tipo de propulsión diferente es el DACIA Sandero GLP (Gas Licuado de Petróleo).
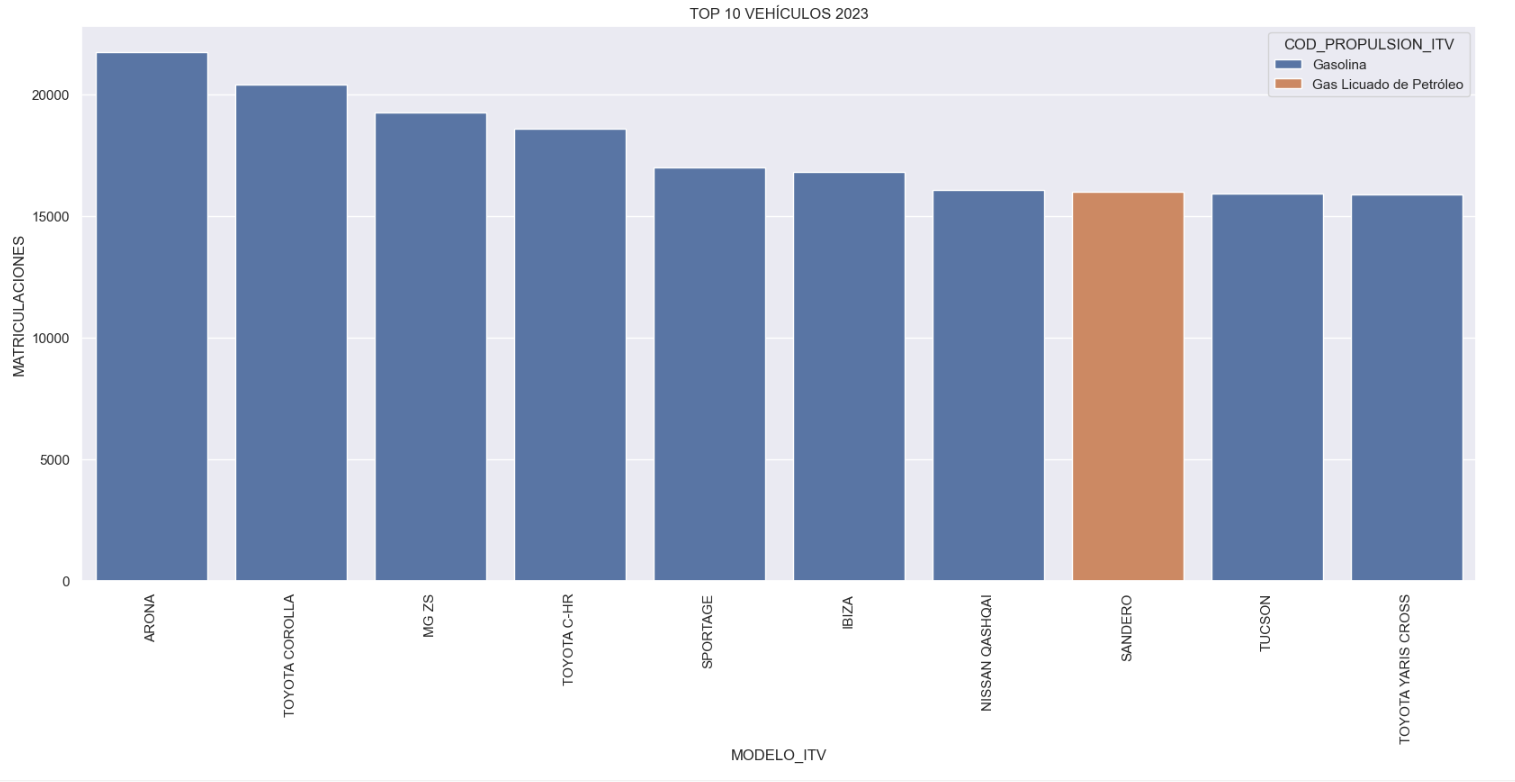
Figura 1. Gráfica "Top 10 Vehículos matriculados en el 2023"
- Cuota de mercado por tipo de propulsión: En esta visualización representamos el porcentaje de vehículos matriculado por cada tipo de propulsión (vehículos de gasolina, diésel, eléctricos u otros). Vemos cómo la inmensa mayoría del mercado (>70%) la absorbieron vehículos de gasolina, siendo los diésel la segunda opción, y como los vehículos eléctricos alcanzaron el 5.5%.
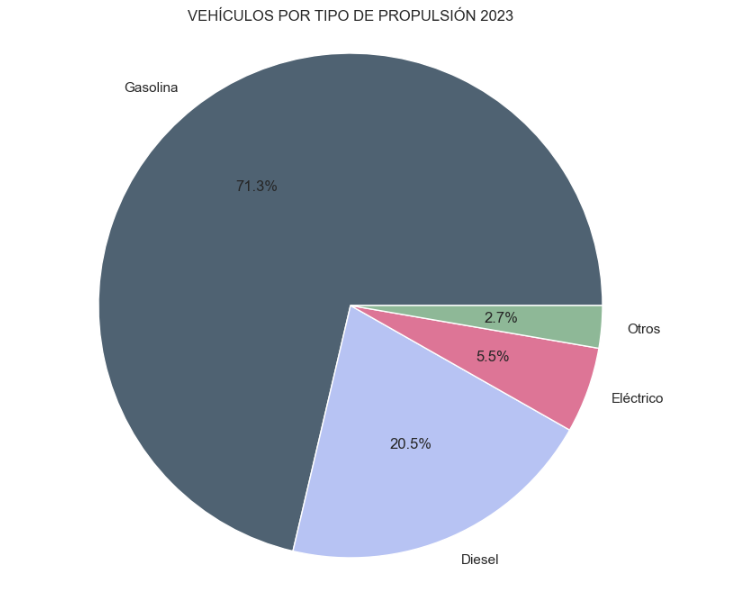
Figura 2. Gráfica "Cuota de mercado por tipo de propulsión".
- Evolución histórica de las matriculaciones: Esta visualización representa la evolución de las matriculaciones de vehículos en el tiempo. En ella se muestra el número de matriculaciones mensual entre enero de 2015 y diciembre de 2023 distinguiendo entre los tipos de propulsión de los vehículos matriculados.Podemos observar varios aspectos interesantes en este gráfico:
- Apreciamos un comportamiento estacional anual, es decir, observamos patrones o variaciones que se repiten a intervalos regulares de tiempo. Vemos cómo recurrentemente en junio/julio aparecen altos niveles de matriculación mientras que en agosto/septiembre decrecen drásticamente. Esto es muy relevante, pues el análisis de series temporales con factor estacional tiene ciertas particularidades.
- Es muy notable también la enorme caída de matriculaciones producida durante los primeros meses del COVID.
- Vemos también como los niveles de matriculación post-covid son inferiores a los previos.
- Por último, podemos observar cómo entre los años 2015 y 2023 la matriculación de vehículos eléctricos va creciendo paulatinamente.
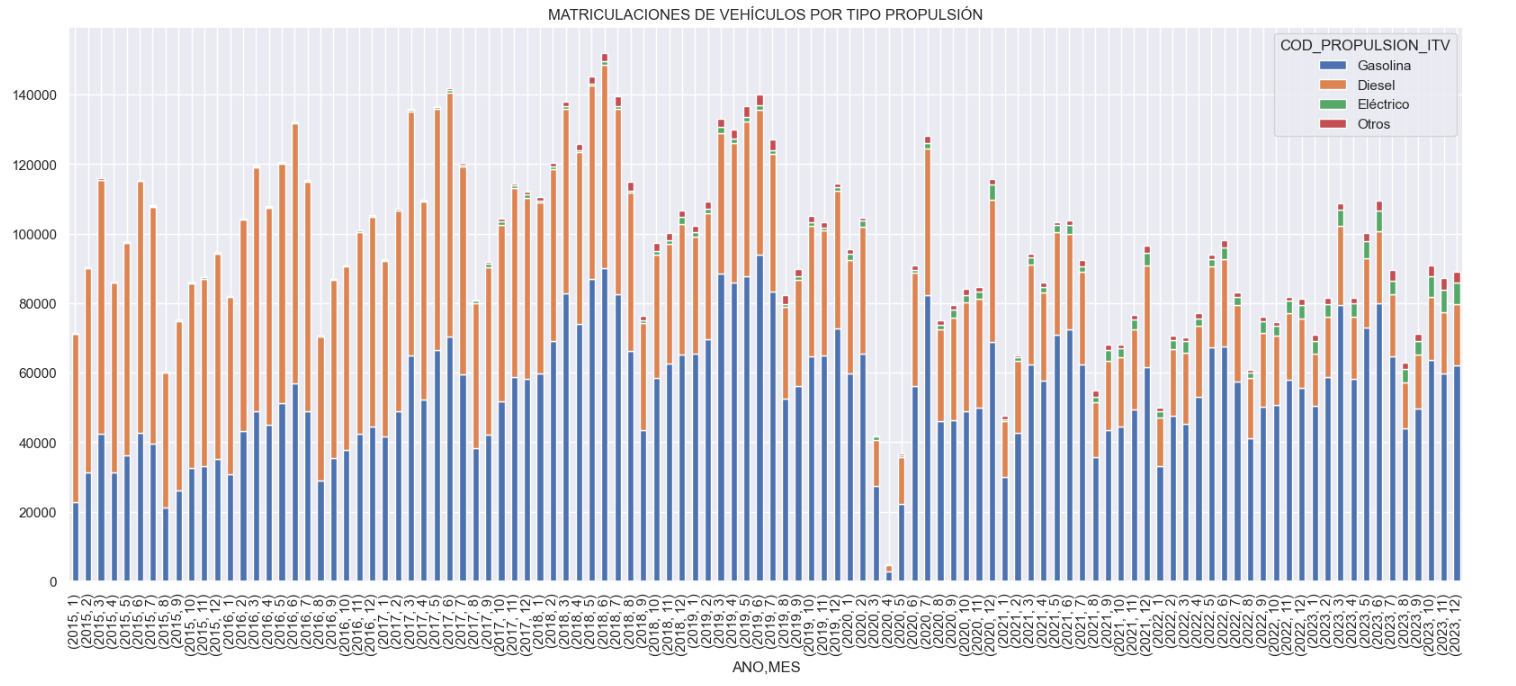
Figura 3. Gráfica "Matriculaciones de vehículos por tipo de propulsión".
- Tendencia en la matriculación de vehículos eléctricos: Analizamos ahora por separado la evolución de vehículos eléctricos y no eléctricos utilizando mapas de calor como herramienta visual. Podemos observar comportamientos muy diferenciados entre ambos gráficos. Observamos cómo el vehículo eléctrico presenta una tendencia de incremento de matriculaciones año a año y, a pesar de suponer el COVID un parón en la matriculación de vehículos, los años posteriores han mantenido la tendencia creciente.
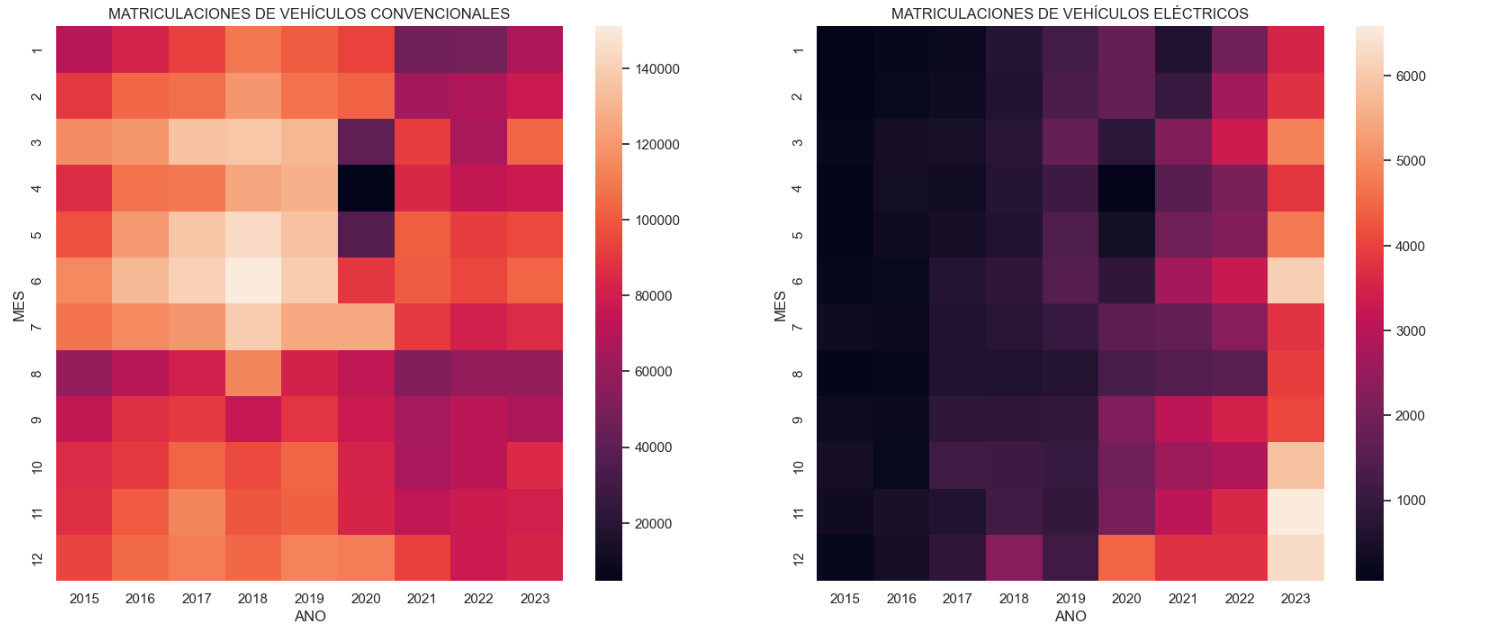
Figura 4. Gráfica "Tendencia en la matriculación de vehículos convencionales vs eléctricos".
5.3.2. Analítica predictiva
Para dar respuesta a la última de las preguntas de forma objetiva, utilizaremos modelos predictivos que nos permitan realizar estimaciones respecto a la evolución del vehículo eléctrico en España. Como podemos observar, el modelo construido nos propone una continuación del crecimiento en las matriculaciones esperadas a lo largo del año serán de 70.000, alcanzando valores cercanos a las 8.000 matriculaciones solo en el mes de diciembre del 2024.
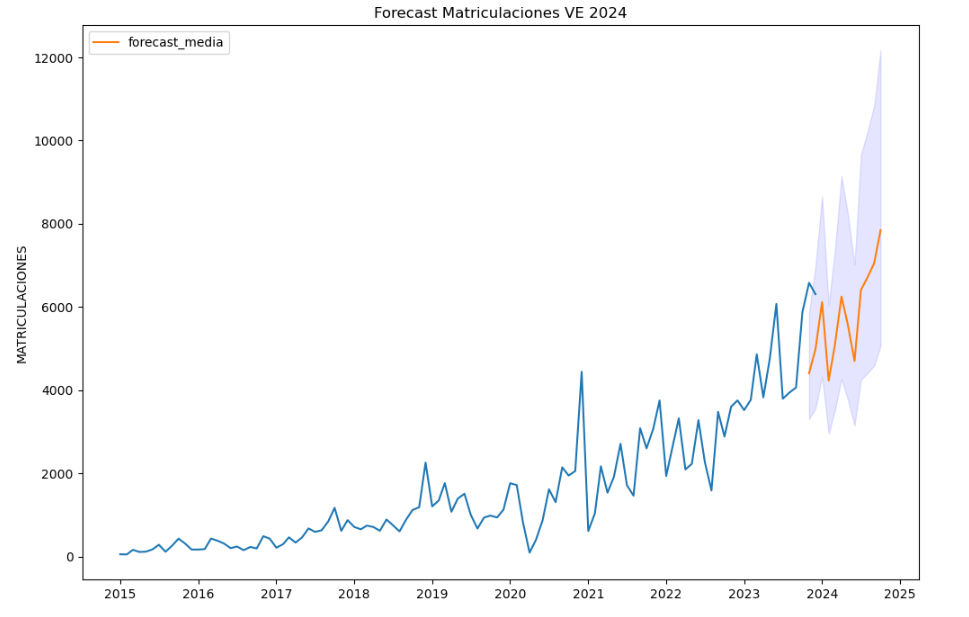
Figura 5. Gráfica "Predicción de matriculaciones de vehículos electricos".
5. Conclusiones del ejercicio
Como conclusión del ejercicio, podremos observar gracias a las técnicas de análisis empleadas como el vehículo eléctrico está penetrando cada vez a mayor velocidad en el parque móvil español aunque aún se encuentre a una distancia grande de otras alternativas como el Diésel o la Gasolina, por ahora liderado por el fabricante Tesla. Veremos en los próximos años si el ritmo crece al nivel necesario para alcanzar los objetivos de sostenibilidad fijados y si Tesla sigue siendo líder a pesar de la fuerte entrada de competidores asiáticos.
6. ¿Quieres realizar el ejercicio?
Si quieres conocer más sobre el Vehículo Eléctrico y poner a prueba tus capacidades analíticas, accede a este repositorio de código donde podrás desarrollar este ejercicio paso a paso.
Además, recuerda que tienes a tu disposición más ejercicios en el apartado sección de “Visualizaciones paso a paso”.
Contenido elaborado por Juan Benavente, ingeniero superior industrial y experto en Tecnologías ligadas a la economía del dato.Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar, de manera sencilla y efectiva, la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas como los gráficos de líneas, de barras o métricas relevantes, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos haciendo uso de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente obtener unas conclusiones a modo de resumen de dicha información.
En cada uno de estos ejercicios prácticos, se utilizan desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub de datos.gob.es.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El principal objetivo de este ejercicio es mostrar cómo realizar, de una forma didáctica, un análisis predictivo de series temporales partiendo de datos abiertos sobre el consumo de electricidad en la ciudad de Barcelona. Para ello realizaremos un análisis exploratorio de los datos, definiremos y validaremos el modelo predictivo, para por último generar las predicciones junto a sus gráficas y visualizaciones correspondientes.
Los análisis predictivos de series temporales son técnicas estadísticas y de aprendizaje automático que se utilizan para prever valores futuros en conjuntos de datos que se recopilan a lo largo del tiempo. Estas predicciones se basan en patrones y tendencias históricas identificadas en la serie temporal, siendo su objetivo principal anticipar cambios y eventos en función de datos pasados.
El conjunto de datos abiertos inicial consta de registros desde el año 2019 hasta el año 2022 ambos inclusive, por otra parte, las predicciones las realizaremos para el año 2023, del cual no tenemos datos reales.
Una vez realizado el análisis, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la predicción futura de consumo eléctrico?
- ¿Cómo de preciso ha sido el modelo con la predicción de datos ya conocidos?
- ¿Qué días tendrán un consumo máximo y mínimo según las predicciones futuras?
- ¿Qué meses tendrán un consumo medio máximo y mínimo según las predicciones futuras?
Estas y otras muchas preguntas pueden ser resueltas mediante las visualizaciones obtenidas en el análisis que mostrarán la información de una forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre el consumo eléctrico en la ciudad de Barcelona en los últimos años. La información que aportan es el consumo en (MWh) desglosados por día, sector económico, código postal y tramo horario.
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Barcelona en el catálogo de datos.gob.es, mediante ficheros que recogen los registros de forma anual. Cabe destacar que el publicador actualiza estos conjuntos de datos con nuevos registros con frecuencia, por lo que hemos utilizado solamente los datos proporcionados desde el 2019 hasta el 2022 ambos inclusive.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización del análisis se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de las visualizaciones interactivas se ha usado la herramienta Looker Studio.
"Looker Studio", antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar visualizaciones interactivas que pueden insertarse en sitios web o exportarse como archivos.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Análisis predictivo de series temporales
El análisis predictivo de series temporales es una técnica que utiliza datos históricos para predecir valores futuros de una variable que cambia con el tiempo. Las series temporales son datos que se recopilan en intervalos regulares, como días, semanas, meses o años. No es el objetivo de este ejercicio explicar en detalle las características de las series temporales, ya que nos centramos en explicar brevemente el modelo de predicción. No obstante, si quieres saber más al respecto, puedes consultar el siguiente manual.
Este tipo de análisis se basa en el supuesto de que los valores futuros de una variable estarán correlacionados con los valores históricos. Utilizando técnicas estadísticas y de aprendizaje automático, se pueden identificar patrones en los datos históricos y utilizarlos para predecir valores futuros.
El análisis predictivo realizado en el ejercicio ha sido dividido en cinco fases; preparación de los datos, análisis exploratorio de los datos, entrenamiento del modelo, validación del modelo y predicción de valores futuros), las cuales se explicarán en los próximos apartados.
Los procesos que te describimos a continuación los encontrarás desarrollados y comentados en el siguiente Notebook ejecutable desde Google Colab junto al código fuente que está disponible en nuestra cuenta de Github.
Es aconsejable ir ejecutando el Notebook con el código a la vez que se realiza la lectura del post, ya que ambos recursos didácticos son complementarios en las futuras explicaciones
4.1 Preparación de los datos
Este apartado podrás encontrarlo en el punto 1 del Notebook.
En este apartado se importan los conjuntos de datos abiertos descritos en los puntos anteriores que utilizaremos en el ejercicio, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores que puedan condicionar los pasos futuros.
4.2 Análisis exploratorio de los datos (EDA)
Este apartado podrás encontrarlo en el punto 2 del Notebook.
En este apartado realizaremos un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de origen, detectar anomalías, datos ausentes, errores u outliers que pudieran afectar a la calidad de los procesos posteriores y resultados.
A continuación, en la siguiente visualización interactiva, podrás inspeccionar la tabla de datos con los valores de consumo históricos generada en el punto anterior pudiendo filtrar por periodo temporal concreto. De esta forma podemos comprender, de una forma visual, la principal información de la serie de datos.
Una vez inspeccionada la visualización interactiva de la serie temporal, habrás observado diversos valores que potencialmente podrían ser considerados como outliers, como se muestra en la siguiente figura. También podemos calcular de forma numérica estos outliers, como se muestra en el notebook.

Una vez evaluados los outliers, para este ejercicio se ha decidido modificar únicamente el registrado en la fecha "2022-12-05". Para ello se sustituirá el valor por la media del registrado el día anterior y el día siguiente.
La razón de no eliminar el resto de outliers es debido a que son valores registrados en días consecutivos, por lo que se presupone que son valores correctos afectados por variables externas que se escapan del alcance del ejercicio. Una vez solucionado el problema detectado con los outliers, esta será la serie temporal de datos que utilizaremos en los siguientes apartados.
Figura 2. Serie temporal de datos históricos una vez tratados los outliers
Si quieres conocer más sobre estos procesos puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
4.3 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 3 del Notebook.
En primer lugar, creamos dentro de la tabla de datos los atributos temporales (año, mes, día de la semana y trimestre). Estos atributos son variables categóricas que ayudan a garantizar que el modelo sea capaz de capturar con precisión las características y patrones únicos de estas variables. Mediante las siguientes visualizaciones de diagramas de cajas, podemos ver su relevancia dentro de los valores de la serie temporal.
Figura 3. Diagramas de cajas de los atributos temporales generados
Podemos observar ciertos patrones en las gráficas anteriores como los siguientes:
- Los días laborales (lunes a viernes) presentan un mayor consumo que los fines de semana.
- El año que valores de consumo más bajos presenta es el 2020, esto entendemos que se debe a la reducción de actividad servicios e industrial durante la pandemia.
- El mes que mayor consumo presenta es julio, lo cual es entendible debido al uso de aparatos de aire acondicionado.
- El segundo trimestre es el que presenta valores más bajos de consumo, destacando abril como el mes con valores más bajos.
A continuación, dividimos la tabla de datos en set de entrenamiento y en set de validación. El set de entrenamiento se utiliza para entrenar el modelo, es decir, el modelo aprende a predecir el valor de la variable objetivo a partir de dicho set, mientras que el set de validación se utiliza para evaluar el rendimiento del modelo, es decir, el modelo se evalúa con los datos de dicho set para determinar su capacidad para predecir los nuevos valores.
Esta división de los datos es importante para evitar el sobreajuste siendo la proporción típica de los datos que se utilizan para el set de entrenamiento de un 70 % y el set de validación del 30% aproximadamente. Para este ejercicio hemos decidido generar el set de entrenamiento con los datos comprendidos entre el "01-01-2019" hasta el "01-10-2021", y el set de validación con los comprendidos entre el "01-10-2021" y el "31-12-2022" como podemos apreciar en la siguiente gráfica.
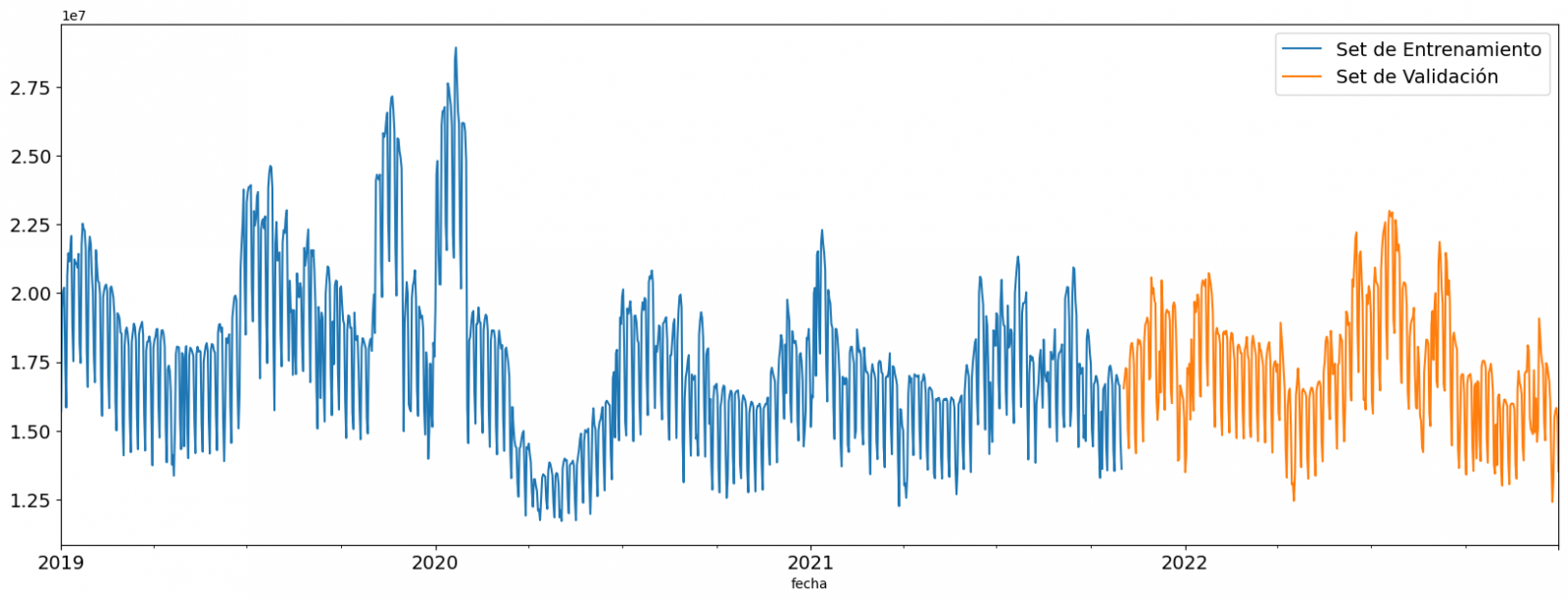
Figura 4. Serie temporal de datos históricos dividida en set de entrenamiento y set de validación
Para este tipo de ejercicio, tenemos que utilizar algún algoritmo de regresión. Existen diversos modelos y librerías que pueden utilizarse para predicción de series temporales. En este ejercicio utilizaremos el modelo “Gradient Boosting”, modelo de regresión supervisado que se trata de un algoritmo de aprendizaje automático utilizado para predecir un valor continúo basándose en el entrenamiento de un conjunto de datos que contienen valores conocidos para la variable objetivo (en nuestro ejemplo la variable “valor”) y los valores de las variables independientes (en nuestro ejercicio los atributos temporales).
Está basado en árboles de decisión y utiliza una técnica llamada "boosting" para mejorar la precisión del modelo siendo conocido por su eficiencia y capacidad para manejar una variedad de problemas de regresión y clasificación.
Sus principales ventajas son el alto grado de precisión, su robustez y flexibilidad, mientras que alguna de sus desventajas son la sensibilidad a valores atípicos y que requiere una optimización cuidadosa de los parámetros.
Utilizaremos el modelo de regresión supervisado ofrecido en la librería XGBBoost, el cuál puede ajustarse con los siguientes parámetros:
- n_estimators: parámetro que afecta al rendimiento del modelo indicando el número de árboles utilizados. Un mayor número de árboles generalmente resulta un modelo más preciso, pero también puede llevar más tiempo de entrenamiento.
- early_stopping_rounds: parámetro que controla el número de rondas de entrenamiento que se ejecutarán antes de que el modelo se detenga si el rendimiento en el conjunto de validación no mejora.
- learning_rate: controla la velocidad de aprendizaje del modelo. Un valor más alto hará que el modelo aprenda más rápido, pero puede provocar un sobreajuste.
- max_depth: controla la profundidad máxima de los árboles en el bosque. Un valor más alto puede proporcionar un modelo más preciso, pero también puede provocar un sobreajuste.
- min_child_weight: controla el peso mínimo de una hoja. Un valor más alto puede ayudar a prevenir el sobreajuste.
- gamma: controla la cantidad de reducción de la pérdida esperada que se necesita para dividir un nodo. Un valor más alto puede ayudar a prevenir el sobreajuste.
- colsample_bytree: controla la proporción de las características que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
- subsample: controla la proporción de los datos que se utilizan para construir cada árbol. Un valor más alto puede ayudar a prevenir el sobreajuste.
Estos parámetros se pueden ajustar para mejorar el rendimiento del modelo en un conjunto de datos específico. Se recomienda experimentar con diferentes valores de estos parámetros para encontrar el valor que proporciona el mejor rendimiento en tu conjunto de datos.
Por último, mediante una gráfica de barras observaremos de forma visual la importancia de cada uno de los atributos durante el entrenamiento del modelo. Se puede utilizar para identificar los atributos más importantes en un conjunto de datos, lo que puede ser útil para la interpretación del modelo y la selección de características.
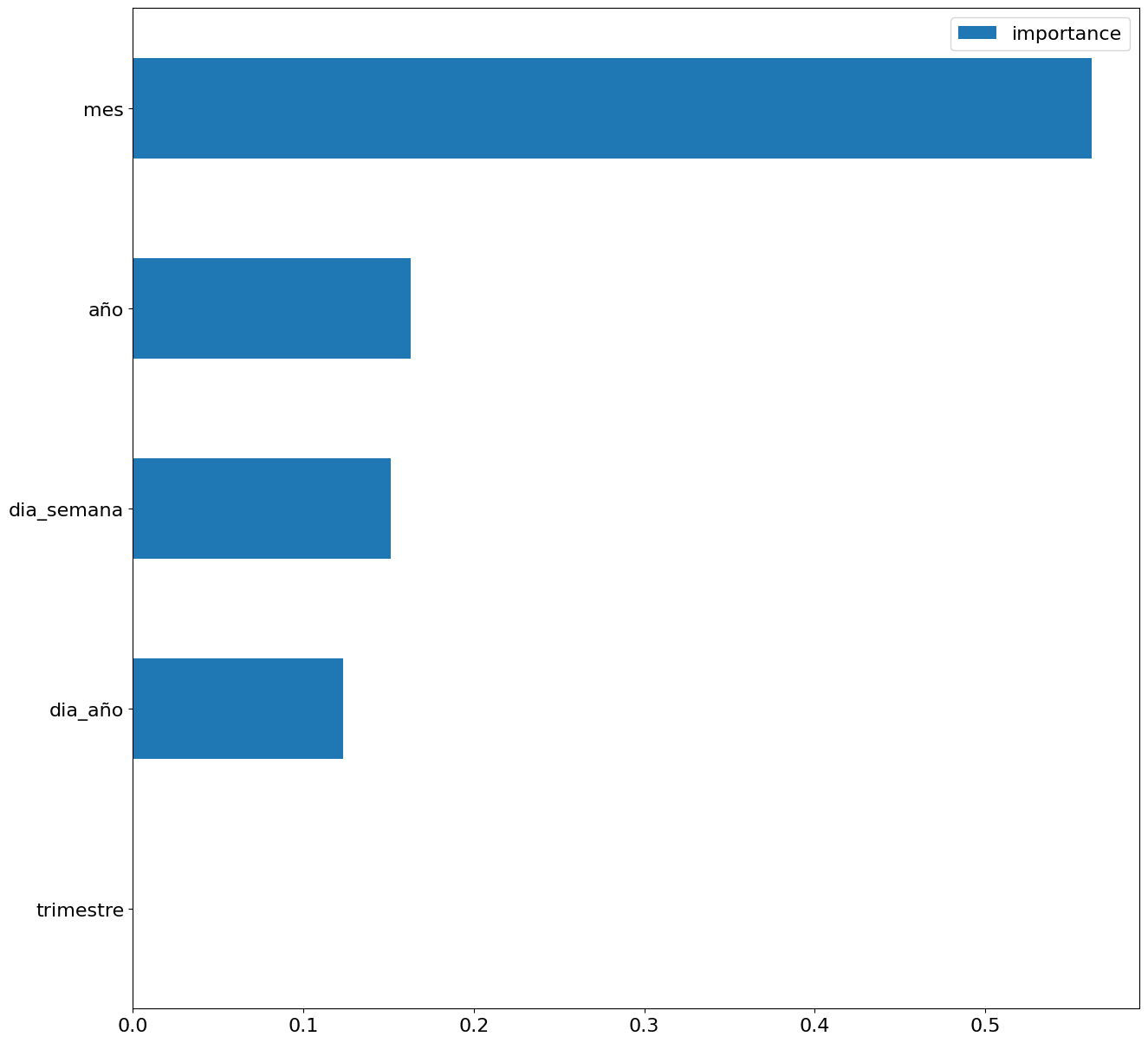
Figura 5. Gráfica de barras con importancia de los atributos temporales
4.4 Entrenamiento del modelo
Este apartado podrás encontrarlo en el punto 4 del Notebook.
Una vez entrenado el modelo, evaluaremos cómo de preciso es para los valores conocidos del set de validación.
Podemos evaluar de forma visual el modelo ploteando la serie temporal con los valores conocidos junto a las predicciones realizadas para el set de validación como se muestra en la siguiente figura.
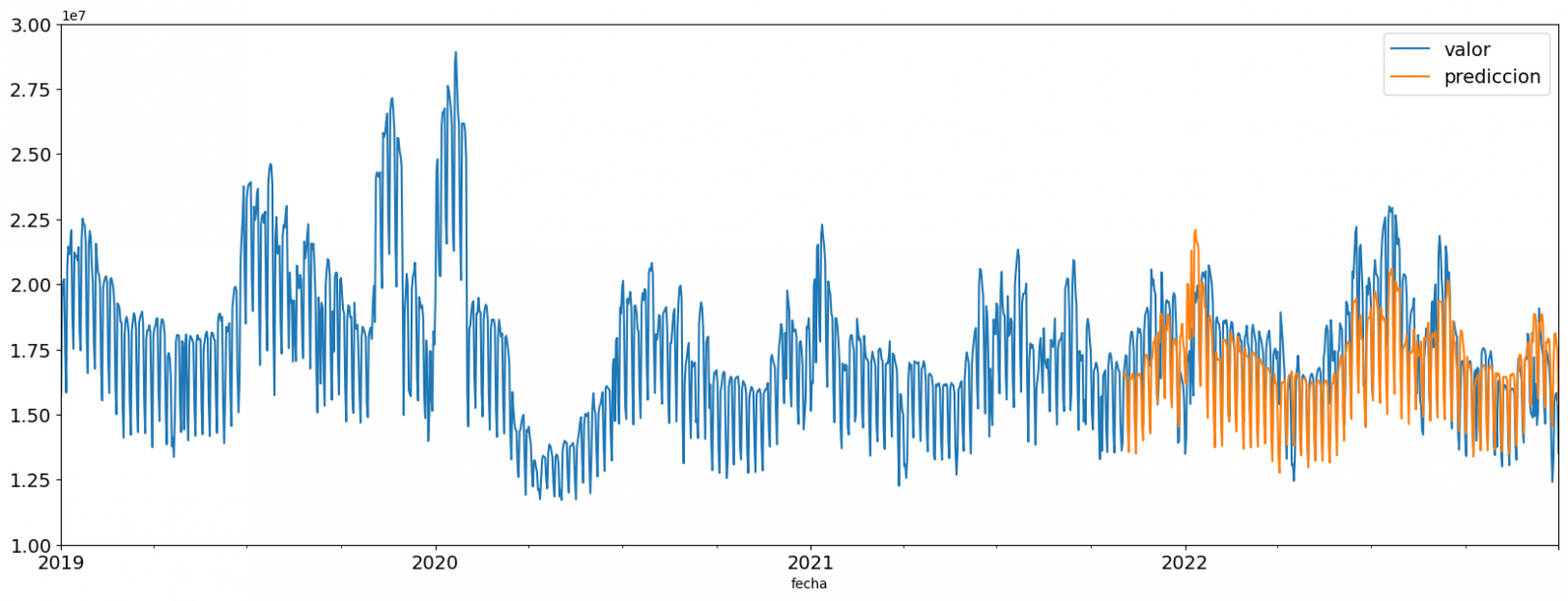
Figura 6. Serie temporal con los datos del set de validación junto a los de la predicción
También podemos evaluar de forma numérica la precisión del modelo mediante distintas métricas. En este ejercicio hemos optado por utilizar la métrica del error porcentual absoluto medio (MAPE), el cuál ha sido de un 6,58%. La precisión del modelo se considera alta o baja dependiendo del contexto y de las expectativas en dicho modelo, generalmente un MAPE se considera bajo cuando es inferior al 5%, mientras que se considera alto cuando es superior al 10%. En este ejercicio, el resultado de la validación del modelo puede ser considerado un valor aceptable.
Si quieres consultar otro tipo de métricas para evaluar la precisión de modelos aplicados a series temporales, puedes consultar el siguiente enlace.
4.5 Predicciones valores futuros
Este apartado podrás encontrarlo en el punto 5 del Notebook.
Una vez generado el modelo y evaluado su rendimiento MAPE = 6,58 %, pasamos a aplicar dicho modelo al total de datos conocidos, con la finalidad de predecir los valores de consumo eléctrico no conocidos del 2023.
En primer lugar, volvemos a entrenar el modelo con los valores conocidos hasta finales del 2022, sin dividir en set de entrenamiento y validación. Por último, calculamos los valores futuros para el año 2023.

Figura 7. Serie temporal con los datos históricos y la predicción para el 2023
En la siguiente visualización interactiva puedes observar los valores predichos para el año 2023 junto a sus principales métricas, pudiendo filtrar por periodo temporal.
Mejorar los resultados de los modelos predictivos de series temporales es un objetivo importante en la ciencia de datos y el análisis de datos. Varias estrategias que pueden ayudar a mejorar la precisión del modelo del ejercicio son el uso de variables exógenas, la utilización de más datos históricos o generación de datos sintéticos, optimización de los parámetros, …
Debido al carácter divulgativo de este ejercicio y para favorecer el entendimiento de los lectores menos especializados, nos hemos propuesto explicar de una forma lo más sencilla y didáctica posible el ejercicio. Posiblemente se te ocurrirán muchas formas de optimizar el modelo predictivo para lograr mejores resultados, ¡Te animamos a que lo hagas!
5. Conclusiones ejercicio
Una vez realizado el ejercicio, podemos apreciar distintas conclusiones como las siguientes:
- Los valores máximos para las predicciones de consumo en el 2023 se dan en la última quincena de julio superando valores de 22.500.000 MWh
- El mes con un mayor consumo según las predicciones del 2023 será julio, mientras que el mes con un menor consumo medio será noviembre, existiendo una diferencia porcentual entre ambos del 25,24%
- La predicción de consumo medio diario para el 2023 es de 17.259.844 MWh, un 1,46% inferior a la registrada entre los años 2019 y 2022.
Esperemos que este ejercicio te haya resultado útil para el aprendizaje de algunas técnicas habituales en el estudio y análisis de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar cómo realizar un análisis de redes o de grafos partiendo de datos abiertos sobre viajes en bicicleta de alquiler en la ciudad de Madrid. Para ello, realizaremos un preprocesamiento de los datos con la finalidad de obtener las tablas que utilizaremos a continuación en la herramienta generadora de la visualización, con la que crearemos las visualizaciones del grafo.
Los análisis de redes son métodos y herramientas para el estudio y la interpretación de las relaciones y conexiones entre entidades o nodos interconectados de una red, pudiendo ser estas entidades personas, sitios, productos, u organizaciones, entre otros. Los análisis de redes buscan descubrir patrones, identificar comunidades, analizar la influencia y determinar la importancia de los nodos dentro de la red. Esto se logra mediante el uso de algoritmos y técnicas específicas para extraer información significativa de los datos de red.
Una vez analizados los datos mediante esta visualización, podremos contestar a preguntas como las que se plantean a continuación:
- ¿Cuál es la estación de la red con mayor tráfico de entrada y de salida?
- ¿Cuáles son las rutas entre estaciones más frecuentes?
- ¿Cuál es el número medio de conexiones entre estaciones para cada una de ellas?
- ¿Cuáles son las estaciones más interconectadas dentro de la red?
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados contienen información sobre los viajes en bicicleta de préstamo realizados en la ciudad de Madrid. La información que aportan se trata de la estación de origen y de destino, el tiempo del trayecto, la hora del trayecto, el identificador de la bicicleta, …
Estos conjuntos de datos abiertos son publicados por el Ayuntamiento de Madrid, mediante ficheros que recogen los registros de forma mensual.
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación de la visualización interactiva se ha usado la herramienta Gephi
"Gephi" es una herramienta de visualización y análisis de redes. Permite representar y explorar relaciones entre elementos, como nodos y enlaces, con el fin de entender la estructura y patrones de la red. El programa precisa descarga y es gratuito.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab.
Debido al alto volumen de viajes registrados en los conjuntos de datos, definimos los siguientes puntos de partida a la hora de analizarlos:
- Analizaremos la hora del día con mayor tráfico de viajes
- Analizaremos las estaciones con un mayor volumen de viajes
Antes de lanzarnos a analizar y construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, es necesario realizar un análisis exploratorio de los datos (EDA), con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de análisis de redes (Gephi) que de forma visual nos ayudará a comprender la información. Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en este Notebook de Google Colab, son los siguientes:
- Instalación de librerías y carga de los conjuntos de datos
- Análisis exploratorio de los datos (EDA)
- Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que, una vez cargado en el entorno de desarrollo, podrás ejecutar o modificar de manera sencilla.
Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente sino facilitar su comprensión, por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Análisis de la red
5.1. Definición de la red
La red analizada se encuentra formada por los viajes entre distintas estaciones de bicicletas en la ciudad de Madrid, teniendo como principal información de cada uno de los viajes registrados la estación de origen (denominada como “source”) y la estación de destino (denominada como “target”).
La red está formada por 253 nodos (estaciones) y 3012 aristas (interacciones entre las estaciones). Se trata de un grafo dirigido, debido a que las interacciones son bidireccionales y ponderado, debido a que cada arista entre los nodos tiene asociado un valor numérico denominado "peso" que en este caso corresponde al número de viajes realizados entre ambas estaciones.
5.2. Carga de la tabla preprocesada en Gephi
Mediante la opción “importar hoja de cálculo” de la pestaña archivo, importamos en formato CSV la tabla de datos previamente preprocesada. Gephi detectará que tipo de datos se están cargando, por lo que utilizaremos los parámetros predefinidos por defecto.


5.3. Opciones de visualización de la red
5.3.1 Ventana de distribución
En primer lugar, aplicamos en la ventana de distribución, el algoritmo Force Atlas 2. Este algoritmo utiliza la técnica de repulsión de nodos en función del grado de conexión de tal forma que los nodos escasamente conectados se separan respecto a los que tiene una mayor fuerza de atracción entre sí.
Para evitar que los componentes conexos queden fuera de la vista principal, fijamos el valor del parámetro "Gravedad en Puesta a punto" a un valor de 10 y para evitar que los nodos queden amontonados, marcamos la opción “Disuadir Hubs” y “Evitar el solapamiento”.

Dentro de la ventana de distribución, también aplicamos el algoritmo de Expansión con la finalidad de que los nodos no se encuentren tan juntos entre sí mismos.

Figura 3. Ventana distribución - algoritmo de Expansión
5.3.2 Ventana de apariencia
A continuación, en la ventana de apariencia, modificamos los nodos y sus etiquetas para que su tamaño no sea igualitario, sino que dependa del valor del grado de cada nodo (nodos con un mayor grado, mayor tamaño visual). También modificaremos el color de los nodos para que los de mayor tamaño sean de un color más llamativo que los de menor tamaño. En la misma ventana de apariencia modificamos las aristas, en este caso hemos optado por un color unitario para todas ellas, ya que por defecto el tamaño va acorde al peso de cada una de ellas.
Un mayor grado en uno de los nodos implica un mayor número de estaciones conectadas con dicho nodo, mientras que un mayor peso de las aristas implica un mayor número de viajes para cada conexión.

5.3.3 Ventana de grafo
Por último, en la zona inferior de la interfaz de la ventana de grafo, tenemos diversas opciones como activar/desactivar el botón para mostrar las etiquetas de los distintos nodos, adecuar el tamaño de las aristas con la finalizad de hacer más limpia la visualización, modificar el tipo de letra de las etiquetas, …

A continuación, podemos ver la visualización del grafo que representa la red una vez aplicadas las opciones de visualización mencionadas en los puntos anteriores.

Figura 6. Visualización del grafo
Activando la opción de visualizar etiquetas y colocando el cursor sobre uno de los nodos, se mostrarán los enlaces que corresponden al nodo y el resto de los nodos que están vinculados al elegido mediante dichos enlaces.
A continuación, podemos visualizar los nodos y enlaces relativos a la estación de bicicletas “Fernando el Católico". En la visualización se distinguen con facilidad los nodos que poseen un mayor número de conexiones, ya que aparecen con un mayor tamaño y colores más llamativos, como por ejemplo "Plaza de la Cebada" o "Quevedo".

5.4 Principales medidas de red
Junto a la visualización del grafo, las siguientes medidas nos aportan la principal información de la red analizada. Estas medias, que son las métricas habituales cuando se realiza analítica de redes, podremos calcularlas en la ventana de estadísticas.

- Nodos (N): son los distintos elementos individuales que componen una red, representando entidades diversas. En este caso las distintas estaciones de bicicletas. Su valor en la red es de 243
- Enlaces (L): son las conexiones que existen entre los nodos de una red. Los enlaces representan las relaciones o interacciones entre los elementos individuales (nodos) que componen la red. Su valor en la red es de 3014
- Número máximo de enlaces (Lmax): es el máximo posible de enlaces en la red. Se calcula mediante la siguiente fórmula Lmax= N(N-1)/2. Su valor en la red es de 31878
- Grado medio (k): es una medida estadística para cuantificar la conectividad promedio de los nodos de la red. Se calcula promediando los grados de todos los nodos de la red. Su valor en la red es de 23,8
- Densidad de la red (d): indica la proporción de conexiones existentes entre los nodos de la red con respecto al total de conexiones posibles. Su valor en la red es de 0,047
- Diámetro (dmax ): es la distancia de grafo más larga entre dos nodos cualquiera de la res, es decir, cómo de lejos están los 2 nodos más alejados. Su valor en la red es de 7
- Distancia media (d): es la distancia de grafo media promedio entre los nodos de la red. Su valor en la red es de 2,68
- Coeficiente medio de clustering (C): Índica cómo los nodos están incrustados entre sus nodos vecinos. El valor medio da una indicación general de la agrupación en la red. Su valor en la red es de 0,208
- Componente conexo: grupo de nodos que están directa o indirectamente conectados entre sí, pero no están conectados con los nodos fuera de ese grupo. Su valor en la red es de 24
5.5 Interpretación de los resultados
La probabilidad de grados sigue de forma aproximada una distribución de larga cola, donde podemos observar que existen unas pocas estaciones que interactúan con un gran número de ellas mientras que la mayoría interactúa con un número bajo de estaciones.
El grado medio es de 23,8 lo que indica que cada estación interacciona de media con cerca de otras 24 estaciones (entrada y salida).
En el siguiente gráfico podemos observar que, aunque tengamos nodos con grados considerados como altos (80, 90, 100, …), se observa que el 25% de los nodos tienen grados iguales o inferiores a 8, mientras que el 75% de los nodos tienen grados inferiores o iguales a 32.

La gráfica anterior se puede desglosar en las dos siguientes correspondientes al grado medio de entrada y de salida (ya que la red es direccional). Vemos que ambas tienen distribuciones de larga cola similares, siendo su grado medio el mismo de 11,9.
Su principal diferencia es que la gráfica correspondiente al grado medio de entrada tiene una mediana de 7 mientras que la de salida es de 9, lo que significa que existe una mayoría de nodos con grados más bajos en los de entrada que los de salida.


El valor del grado medio con pesos es de 346,07 lo cual nos indica la media de viajes totales de entrada y salida de cada estación.

La densidad de red de 0,047 es considerada una densidad baja indicando que la red es dispersa, es decir, contiene pocas interacciones entre distintas estaciones en relación con las posibles. Esto se considera lógico debido a que las conexiones entre estaciones estarán limitadas a ciertas zonas debido a la dificultad de llegar a estaciones que se encuentra a largas distancias.
El coeficiente medio de clustering es de 0,208 significando que la interacción de dos estaciones con una tercera no implica necesariamente la interacción entre sí, es decir, no implica necesariamente transitividad, por lo que la probabilidad de interconexión de esas dos estaciones mediante la intervención de una tercera es baja.
Por último, la red presenta 24 componentes conexos, siendo 2 de ellos componentes conexos débiles y 22 componentes conexos fuertes.
5.6 Análisis de centralidad
Un análisis de centralidad se refiere a la evaluación de la importancia de los nodos en una red utilizando diferentes medidas. La centralidad es un concepto fundamental en el análisis de redes y se utiliza para identificar nodos clave o influyentes dentro de una red. Para realizar esta tarea se parte de las métricas calculadas en la ventana de estadísticas.
- La medida de centralidad de grado indica que cuanto más alto es el grado de un nodo, más importante es. Las cinco estaciones con valores más elevados son: 1º Plaza de la Cebada, 2º Plaza de Lavapiés, 3º Fernando el Católico, 4º Quevedo, 5º Segovia 45.

- La media de centralidad de cercanía indica que cuanto más alto sea el valor de cercanía de un nodo, más central es, ya que puede alcanzar cualquier otro nodo de la red con el menor esfuerzo posible. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico 2º General Pardiñas, 3º Plaza de la Cebada, 4º Plaza de Lavapiés, 5º Puerta de Madrid.

Figura 13. Distribución medida centralidad de cercanía

- La medida de centralidad de intermediación indica que cuanto mayor sea la medida de intermediación de un nodo, más importante es dado que está presente en más rutas de interacción entre nodos que el resto de los nodos de la red. Las cinco estaciones que valores más elevados poseen son: 1º Fernando el Católico, 2º Plaza de Lavapiés, 3º Plaza de la Cebada, 4º Puerta de Madrid, 5º Quevedo.

 FIgura 16. Visualización grafo centralidad de intermediación
FIgura 16. Visualización grafo centralidad de intermediación
Con la herramienta Gephi se pueden calcular gran cantidad de métricas y parámetros que no se reflejan en este estudio ,como por ejemplo, la medida de vector propio o distribucción de centralidad "eigenvector".
5.7 Filtros
Mediante la ventana de filtrado, podemos seleccionar ciertos parámetros que simplifiquen las visualizaciones con la finalidad de mostrar información relevante del análisis de redes de una forma más clara visualmente.

A continuación, mostraremos varios filtrados realizados:
- Filtrado de rango (grado), en el que se muestran los nodos con un rango superior a 50, suponiendo un 13,44% (34 nodos) y un 15,41% (464 aristas)

- Filtrado de aristas (peso de la arista), en el que se muestran las aristas con un peso superior a 100, suponiendo un 0,7% (20 aristas)

Figura 19. VIsualización grafo filtrado de arista (peso)
Dentro de la ventana de filtros, existen muchas otras opciones de filtrado sobre atributos, rangos, tamaños de particiones, las aristas, … con los que puedes probar a realizar nuevas visualizaciones para extraer información del grafo. Si quieres conocer más sobre el uso de Gephi, puedes consultar los siguientes cursos y formaciones sobre la herramienta.
6. Conclusiones del ejercicio
Una vez realizado el ejercicio, podemos apreciar las siguientes conclusiones:
- Las tres estaciones más interconectadas con otras estaciones son Plaza de la Cebada (133), Plaza de Lavapiés (126) y Fernando el Católico (114).
- La estación que tiene un mayor número de conexiones de entrada es la Plaza de la Cebada (78), mientras que la que tiene un mayor número de conexiones de salida es la Plaza de Lavapiés con el mismo número que Fernando el Católico (57)
- Las tres estaciones con un mayor número de viajes totales son Plaza de la Cebada (4524), Plaza de Lavapiés (4237) y Fernando el Católico (3526).
- Existen 20 rutas con más de 100 viajes. Siendo las 3 rutas con un mayor número de ellos: Puerta de Toledo – Plaza Conde Suchil (141), Quintana Fuente del Berro – Quintana (137), Camino Vinateros – Miguel Moya (134).
- Teniendo en cuenta el número de conexiones entre estaciones y de viajes, las estaciones de mayor importancia dentro de la red son: Plaza la Cebada, Plaza de Lavapiés y Fernando el Católico.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!