Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como los gráficos de líneas, de barras o de sectores, hasta visualizaciones configuradas sobre cuadros de mando interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y los análisis que resulten pertinentes para, finalmente, posibilitar la creación de visualizaciones interactivas que nos permitan obtener unas conclusiones finales a modo de resumen de dicha información. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio Laboratorio de datos de GitHub.
A continuación, y como complemento a la explicación que encontrarás seguidamente, puedes acceder al código que utilizaremos en el ejercicio y que iremos explicando y desarrollando en los siguientes apartados de este post.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este ejercicio es mostrar como generar un cuadro de mando interactivo que, partiendo de datos abiertos, nos muestre información relevante sobre el consumo en alimentación de los hogares españoles partiendo de datos abiertos. Para ello realizaremos un preprocesamiento de los datos abiertos con la finalidad de obtener las tablas que utilizaremos en la herramienta generadora de las visualizaciones para crear el cuadro de mando interactivo.
Los cuadros de mando son herramientas que permiten presentar información de manera visual y fácilmente comprensible. También conocidos por el témino en inglés "dashboards", son utilizados para monitorizar, analizar y comunicar datos e indicadores. Su contenido suele incluir gráficos, tablas, indicadores, mapas y otros elementos visuales que representan datos y métricas relevantes. Estas visualizaciones ayudan a los usuarios a comprender rápidamente una situación, identificar tendencias, detectar patrones y tomar decisiones informadas.
Una vez analizados los datos, mediante esta visualización podremos contestar a preguntas como las que se plantean a continuación:
-
¿Cuál es la tendencia de los últimos años en el gasto y del consumo per cápita en los distintos alimentos que componen la cesta básica?
-
¿Qué alimentos son los más y menos consumidos en los últimos años?
-
¿En qué Comunidades Autónomas se produce un mayor gasto y consumo en alimentación?
-
¿El aumento en el coste de ciertos alimentos en los últimos años ha significado una reducción de su consumo?
Éstas, y otras muchas preguntas pueden ser resueltas mediante el cuadro de mando que mostrará información de forma ordenada y sencilla de interpretar.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos abiertos utilizados en este ejercicio contienen distinta información sobre el consumo per cápita y el gasto per cápita de los principales grupos de alimentos desglosados por Comunidad Autónoma. Los conjuntos de datos abiertos utilizados, pertenecientes al Ministerio de Agricultura, Pesca y Alimentación (MAPA), se proporcionan en series anuales (utilizaremos las series anuales desde el 2010 hasta el 2021)
Estos conjuntos de datos también se encuentran disponibles para su descarga en el siguiente repositorio de Github.
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o, también llamado Google Colaboratory, es un servicio en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R sobre un Jupyter Notebook desde tu navegador, por lo que no requiere configuración. Este servicio es gratuito.
Para la creación del cuadro de mando se ha utilizado la herramienta Looker Studio.
"Looker Studio" antiguamente conocido como Google Data Studio, es una herramienta online que permite realizar cuadros de mandos interactivos que pueden insertarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el siguiente Notebook que podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a su obtención y a la validación de su contenido, asegurándonos que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso, una vez cargados los conjuntos de datos iniciales, es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es generar la tabla de datos preprocesada que usaremos para alimentar la herramienta de visualización (Looker Studio). Para ello modificaremos, filtraremos y uniremos los datos según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en el siguiente Notebook de Google Colab, son los siguientes:
-
Instalación de librerías y carga de los conjuntos de datos
-
Análisis exploratorio de los datos (EDA)
-
Generación de tablas preprocesadas
Podrás reproducir este análisis con el código fuente que está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Visualización del cuadro de mandos interactivo
Una vez hemos realizado el preprocesamiento de los datos, vamos con la generación del cuadro de mandos. Un cuadro de mandos es una herramienta visual que proporciona una visión resumida de los datos y métricas clave. Es útil para el monitoreo, la toma de decisiones y la comunicación efectiva, al proporcionar una vista clara y concisa de la información relevante.
Para la realización de las visualizaciones interactivas que componen el cuadro de mando se ha usado la herramienta Looker Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí se necesita que la tabla de datos que le proporcionamos esté estructurada adecuadamente, razón por la que hemos realizado los pasos anteriores relativos al preprocesamiento de los datos. Si quieres saber más sobre cómo utilizar Looker Studio, en el siguiente enlace puedes acceder a formación sobre el uso de la herramienta.
El cuadro de mandos se puede abrir en una nueva pestalla en el siguiente link. En los próximos apartados desglosaremos cada uno de los componentes que lo integran.
5.1. Filtros
Los filtros en un cuadro de mando son opciones de selección que permiten visualizar y analizar datos específicos mediante la aplicación de varios criterios de filtrado a los conjuntos de datos presentados en el panel de control. Ayudan a enfocarse en información relevante y a obtener una visión más precisa de los datos.

Los filtros incluidos en el cuadro de mando generado permiten elegir el tipo de análisis a mostrar, el territorio o Comunidad Autónoma, la categoría de alimentos y los años de la muestra.
También incorpora diversos botones para facilitar el borrado de los filtros elegidos, descargar el cuadro de mandos como un informe en formato PDF y acceder a los datos brutos con los que se ha elaborado este cuadro de mando.
5.2. Visualizaciones interactivas
El cuadro de mandos está compuesto por diversos tipos de visualizaciones interactivas, que son representaciones gráficas de datos que permiten a los usuarios explorar y manipular la información de forma activa.
A diferencia de las visualizaciones estáticas, las visualizaciones interactivas brindan la capacidad de interactuar con los datos, permitiendo a los usuarios realizar diferentes e interesantes acciones como hacer clic en elementos, arrastrarlos, ampliar o reducir el enfoque, filtrar datos, cambiar parámetros y ver los resultados en tiempo real.
Esta interacción es especialmente útil cuando se trabaja con conjuntos de datos grandes y complejos, pues facilitan a los usuarios el examen de diferentes aspectos de los datos así como descubrir patrones, tendencias y relaciones de una manera más intuitiva.
De cara a la definición de cada tipo de visualización, nos hemos basado en la guía de visualización de datos para entidades locales presentada por la RED de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP.
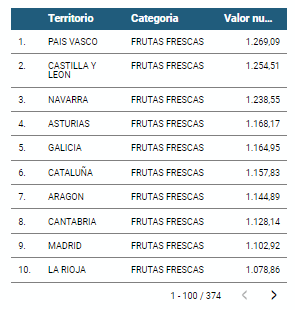
5.2.1 Tabla de datos
Las tablas de datos permiten la presentación de una gran cantidad de datos de forma organizada y clara, con un alto rendimiento de espacio/información.
Sin embargo, pueden dificultar la presentación de patrones o interpretaciones respecto a otros objetos visuales de carácter más gráfico.
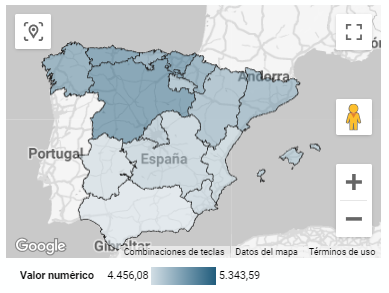
5.2.2 Mapa de cloropetas
Se trata de un mapa en el que se muestran datos numéricos por territorios marcando con intensidad de colores diferentes las distintas áreas. Para su elaboración se requiere de una medida o dato numérico, un dato categórico para el territorio y un dato geográfico para delimitar el área de cada territorio.
5.2.3 Gráfico de sectores
Se trata de un gráfico que muestra los datos a partir de unos ejes polares en los que el ángulo de cada sector marca la proporción de una categoría respecto al total. Su funcionalidad es mostrar las diferentes proporciones de cada categoría respecto a un total utilizando gráficos circulares.
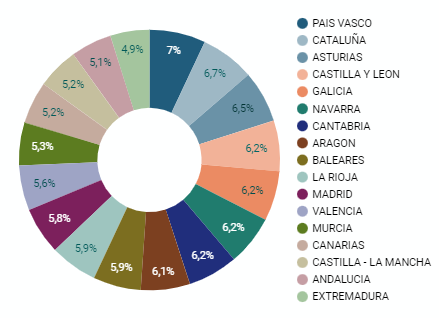
Figura 4. Gráfico de sectores del cuadro de mando
5.2.4 Gráfico de líneas
Se trata de un gráfico que muestra la relación entre dos o más medidas de una serie de valores en dos ejes cartesianos, reflejando en el eje X una dimensión temporal, y una medida numérica en el eje Y. Estos gráficos son idóneos para representar series de datos temporales con un elevado número de puntos de datos u observaciones.
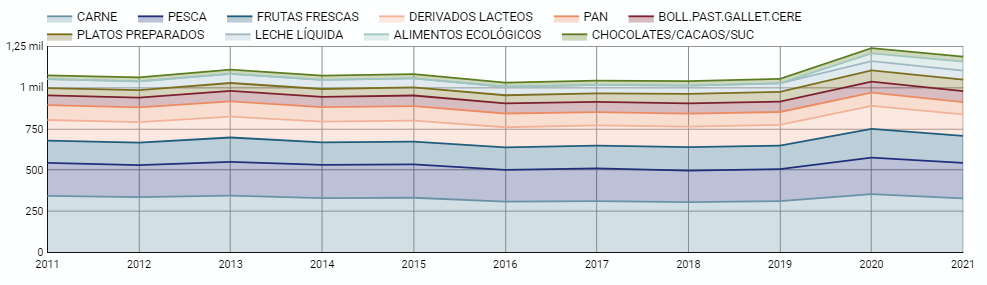
Figura 5. Gráfico de lineas del cuadro de mando
5.2.5 Gráfico de barras
Se trata de un gráfico de los más utilizados por la claridad y simplicidad de preparación. Facilita la lectura de valores a partir de la proporción de la longitud de las barras. El gráfico muestra los datos mediante un eje que representa los valores cuantitativos y otro que incluye los datos cualitativos de las categorías o de tiempo.
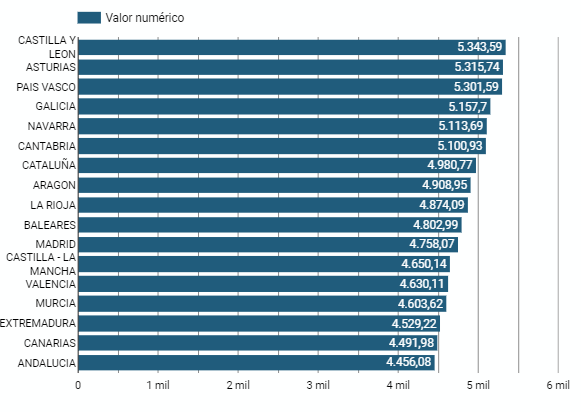
Figura 6. Gráfico de barras del cuadro de mando
5.2.6 Gráfico de jerarquías
Se trata de un gráfico formado por distintos rectángulos que representan categorías, y que permite agrupaciones jerárquicas de los sectores de cada categoría. La dimensión de cada rectángulo y su colocación varía en función del valor de la medida de cada una de las categorías que se muestran respecto del valor total de la muestra.
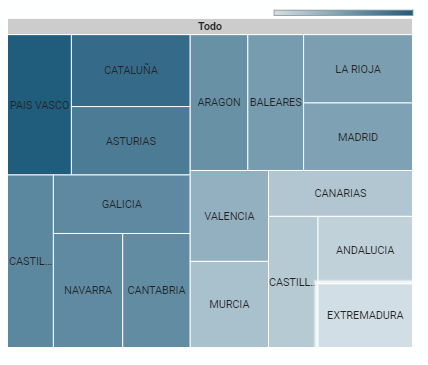
Figura 7. Gráfico de jerarquías del cuadro de mando
6. Conclusiones del ejercicio
Los cuadros de mando son uno de los mecanismos más potentes para explotar y analizar el significado de los datos. Cabe destacar la importancia que nos ofrecen a la hora de monitorear, analizar y comunicar datos e indicadores de una manera clara, sencilla y efectiva.
Como resultado, hemos podido responder a las preguntas originalmente planteadas:
-
La tendencia del consumo per cápita se encuentra en disminución desde el 2013, año en el que llegó a su máximo, con un pequeño repunte en los años 2020 y 2021.
-
La tendencia del gasto per cápita se ha mantenido estable desde el 2011 hasta que en 2020 ha sufrido una subida del 17,7% pasando de ser el gasto medio anual de 1052 euros a 1239 euros, produciéndose una leve disminución del 4,4% de los datos del 2020 a los del 2021.
-
Los tres alimentos más consumidos durante todos los años analizados son: frutas frescas, leche líquida y carne (valores en kgs)
-
Las Comunidades Autónomas donde el gasto per cápita es mayor son País Vasco, Cataluña y Asturias, mientras que Castilla la Mancha, Andalucía y Extremadura son las que menos gasto tienen.
-
Las Comunidad Autónomas donde un mayor consumo per cápita se produce son Castilla y León, Asturias y País Vasco, mientras que en las que menor son: Extremadura, Canarias y Andalucía.
También hemos podido observar ciertos patrones interesantes, como un aumento de un 17,33% en el consumo de alcohol (cervezas, vino y bebidas espirituosas) en los años 2019 y 2020 .
Puedes utilizar los distintos filtros para averiguar y buscar más tendencias o patrones en los datos según tus intereses e inquietudes.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas, de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos, se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio de GitHub.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo generar un mapa personalizado de Google Maps mediante la herramienta "My Maps" partiendo de datos abiertos. Este tipo de mapas son altamente populares en páginas, blogs y aplicaciones del sector turístico, no obstante, la información útil proporcionada al usuario suele ser escasa.
En este ejercicio, utilizaremos el potencial de los datos abiertos para ampliar la información a mostrar en nuestro mapa y hacerlo de una forma automática. También mostraremos como realizar un enriquecimiento de los datos abiertos para añadir información de contexto que mejore significativamente la experiencia de usuario.
Desde un punto de vista funcional, el objetivo del ejercicio es la creación de un mapa personalizado para planificar rutas turísticas por los espacios naturales de la Comunidad Autónoma de Castilla y León. Para ello se han utilizado conjuntos de datos abiertos publicados por la Junta de Castilla y León, que hemos preprocesado y adaptado a nuestras necesidades de cara a generar el mapa personalizado.
3. Recursos
3.1. Conjuntos de datos
Los conjuntos de datos contienen distinta información turística de interés geolocalizada. Dentro del catálogo de datos abiertos de la Junta de Castilla y León, encontramos el “diccionario de entidades” (sección información adicional), documento de vital importancia, ya que nos define la terminología utilizada en los distintos conjuntos de datos.
Estos conjuntos de datos también se encuentran disponibles en el repositorio de Github
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
"Google Colab" o también llamado "Google Colaboratory", es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google My Maps.
"Google My Maps" es una herramienta online que permite crear mapas interactivos que pueden ser incrustados en sitios web o exportarse como archivos. Esta herramienta es gratuita, sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe "Herramientas de procesado y visualización de datos".
4. Tratamiento o preparación de los datos
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que podrás ejecutar desde Google Colab.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso a dar es generar las tablas de datos preprocesados que usaremos para alimentar el mapa. Para ello, transformaremos los sistemas de coordenadas, modificaremos y filtraremos la información según nuestras necesidades.
Los pasos que se siguen en este preprocesamiento de los datos, explicados en el Notebook, son los siguientes:
- Instalación y carga de librerías
- Carga de los conjuntos de datos
- Análisis exploratorio de datos (EDA)
- Preprocesamiento de los conjuntos de datos
- Transformación de coordenadas
- Filtrado de la información
- Representación gráfica de los conjuntos de datos
- Almacenamiento de las nuevas tablas de datos transformadas
Durante el preprocesado de las tablas de datos, hay que hacer un cambio de sistema de coordenadas ya que en los conjuntos de datos de origen el sistema en el que se encuentran es ESTR89 (sistema estándar que se usa en la Unión Europea), mientras que las necesitaremos en el sistema WGS84 (sistema usado por Google My Maps entre otras aplicaciones geográficas). La forma de realizar este cambio de coordenadas se encuentra explicado en el Notebook. Si quieres saber más sobre tipos y sistemas de coordenadas, puedes recurrir a la “Guía de datos espaciales”
Una vez terminado el preprocesamiento, obtendremos las tablas de datos "recreativas_parques_naturales.csv", "alojamientos_rurales_2estrellas.csv", "refugios_parques_naturales.csv", "observatorios_parques_naturales.csv", "miradores_parques_naturales.csv", "casas_del_parque.csv", "arboles_parques_naturales.csv" las cuales incluyen campos de información genéricos y comunes como: nombre, observaciones, geoposición, … junto a campos de información específicos, los cuales se definen en detalle en el apartado 6.2 Personalización de la información a mostrar en el mapa.
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada, se realiza un proceso de enriquecimiento de datos sobre el conjunto de datos “registro de alojamientos hoteleros” explicado a continuación. Con este paso vamos a lograr añadir de forma automática información complementaria que no está inicialmente incluida. Con ello, conseguiremos mejorar la experiencia del usuario durante su uso del mapa al proporcionar información de contexto relacionada con cada punto de interés.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador.
A continuación, se detallan los pasos a seguir.
Paso 1
Carga del CSV en el sistema (Figura 1). En esta caso, el conjunto de datos “Registro de alojamientos hoteleros”.
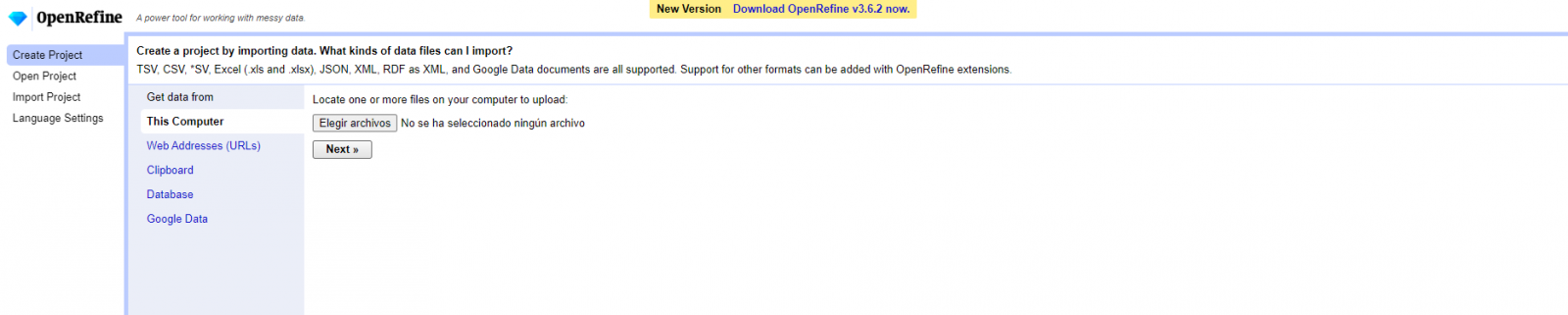
Figura 1. Carga de archivo CSV en OpenRefine
Paso 2
Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.
Figura 2. Creación de un proyecto en OpenRefine
Paso 3
Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones:
- Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, de forma genérica se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, disponemos de la columna “municipios” que contiene el nombre de los municipios españoles.
- Comienzo de la reconciliación. (Figura 3) Comenzamos la reconciliación y seleccionamos la fuente por defecto que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.
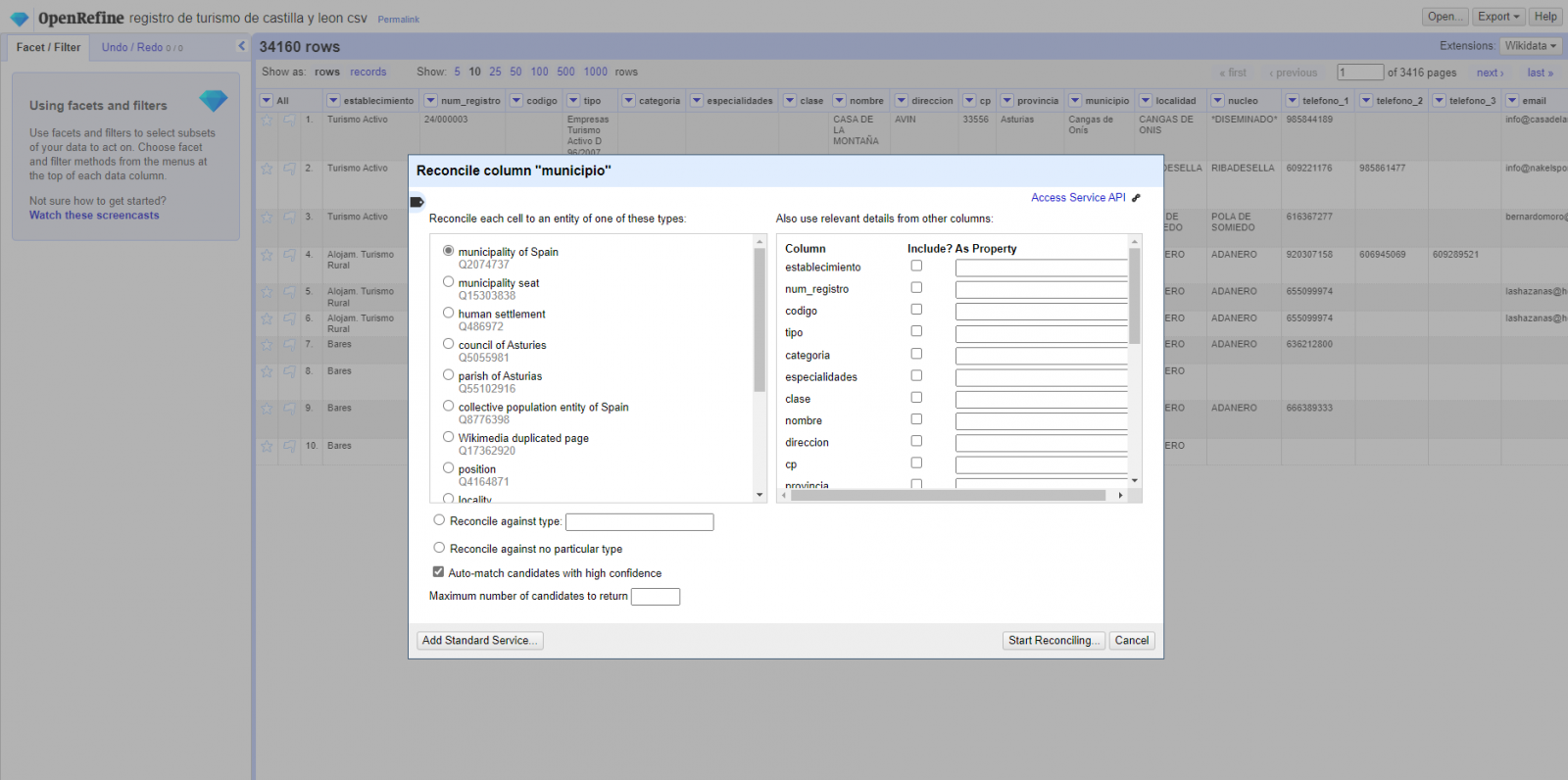
Figura 3. Selección de la clase que mejor representa los valores de la columna "municipio"
- Obtención de los valores de la reconciliación. OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión.
Paso 4
Generar una nueva columna con los valores reconciliados o enlazados. (Figura 4) Para ello debemos pulsar en la columna “municipio” e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser “wikidata”). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“Adanero”) = Q1404668
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
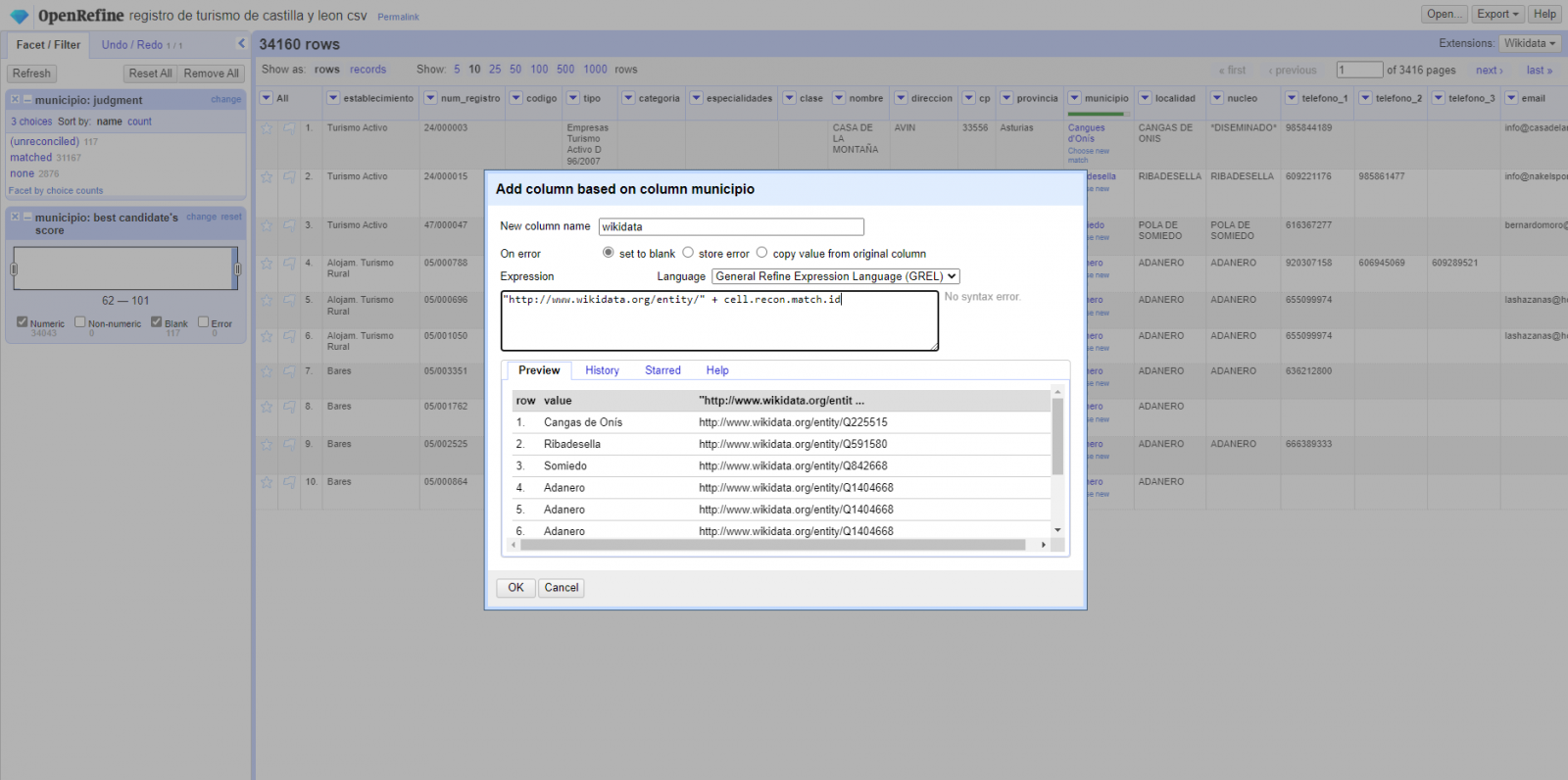
Figura 4. Generación de nueva columna con valores reconciliados
Paso 5
El proceso lo repetimos modificando en el paso 4 el “Edit Column → Add column based in this column” por “Add columns from reconciled values” (Figura 5). De esta forma, podremos elegir la propiedad de la columna reconciliada.
En este ejercicio hemos elegido la propiedad “image” con identificador P18 y la propiedad “population” con identificador P1082. No obstante, podríamos añadir todas las propiedades que consideremos útiles, como el número de habitantes, el listado de monumentos de interés, etc. Cabe destacar que al igual que enriquecemos los datos con Wikidata, podemos hacerlo con otros servicios de reconciliación.
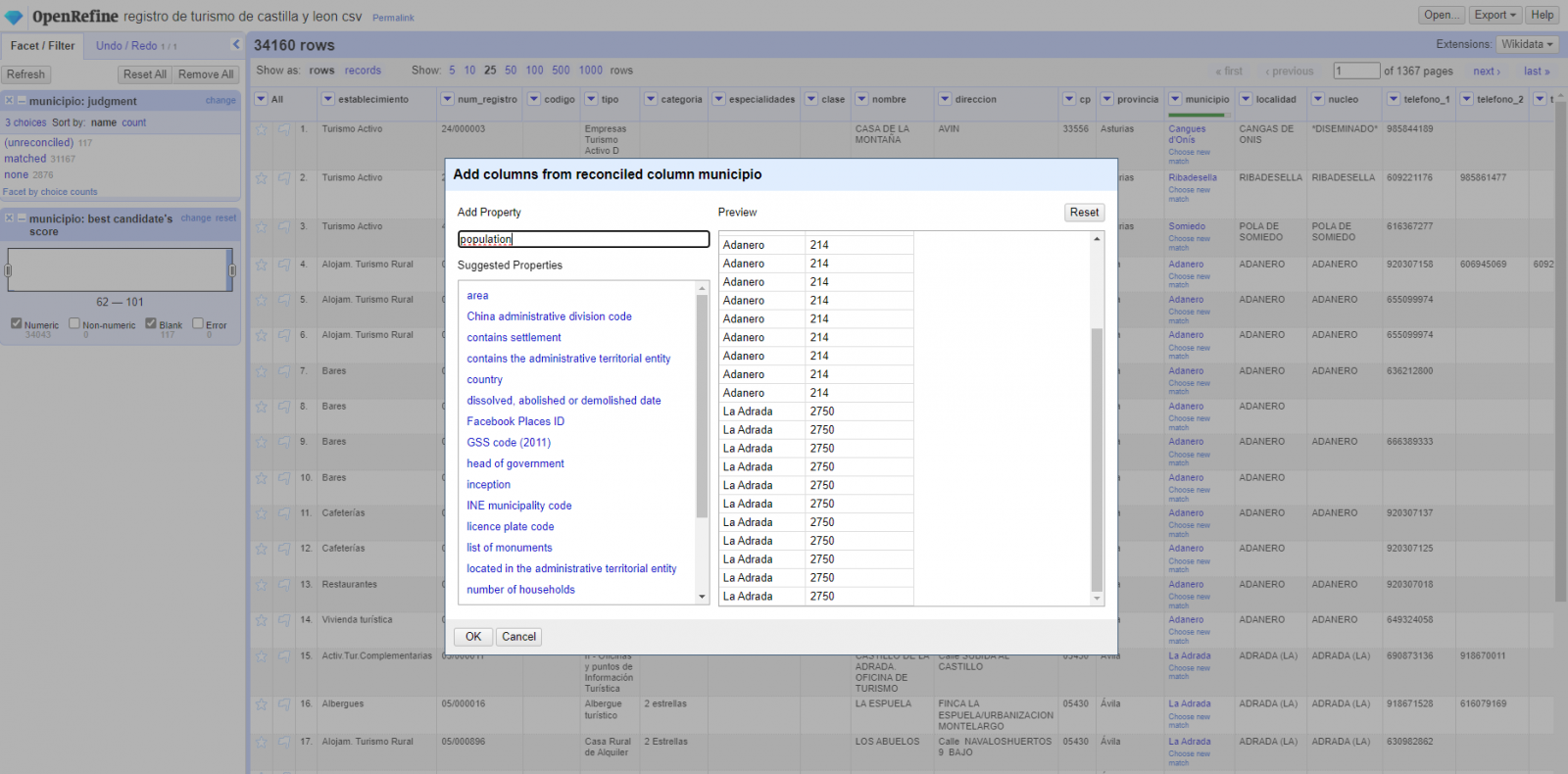
Figura 5. Elección propiedad para reconciliación
En el caso de la propiedad “image”, debido a la visualización, queremos que el valor de las celdas tenga forma de link, por lo que hemos realizado varios ajustes. Estos ajustes han sido la generación de varias columnas según los valores reconciliados, adecuación de las columnas mediante comandos en lenguaje GREL (lenguaje propio de OpenRefine) y unión de los diferentes valores de ambas columnas. Puedes consultar estos ajustes y más técnicas para mejorar tu manejo de OpenRefine y adaptarlo a tus necesidades en el siguiente User Manual.
6. Visualización del mapa
6.1 Generación del mapa con "Google My Maps"
Para generar el mapa personalizado mediante la herramienta My Maps, hemos seguidos los siguientes pasos:
- Iniciamos sesión con una cuenta Google y vamos a "Google My Maps", teniendo acceso de forma gratuita sin tener que descargar ningún tipo de software.
- Importamos las tablas de datos preprocesados, uno por cada nueva capa que añadimos al mapa. Google My Maps permite importar archivos CSV, XLSX, KML y GPX (Figura 6), los cuales deberán tener asociada información geográfica. Para realizar este paso, primero se debe crear una capa nueva desde el menú de opciones lateral.
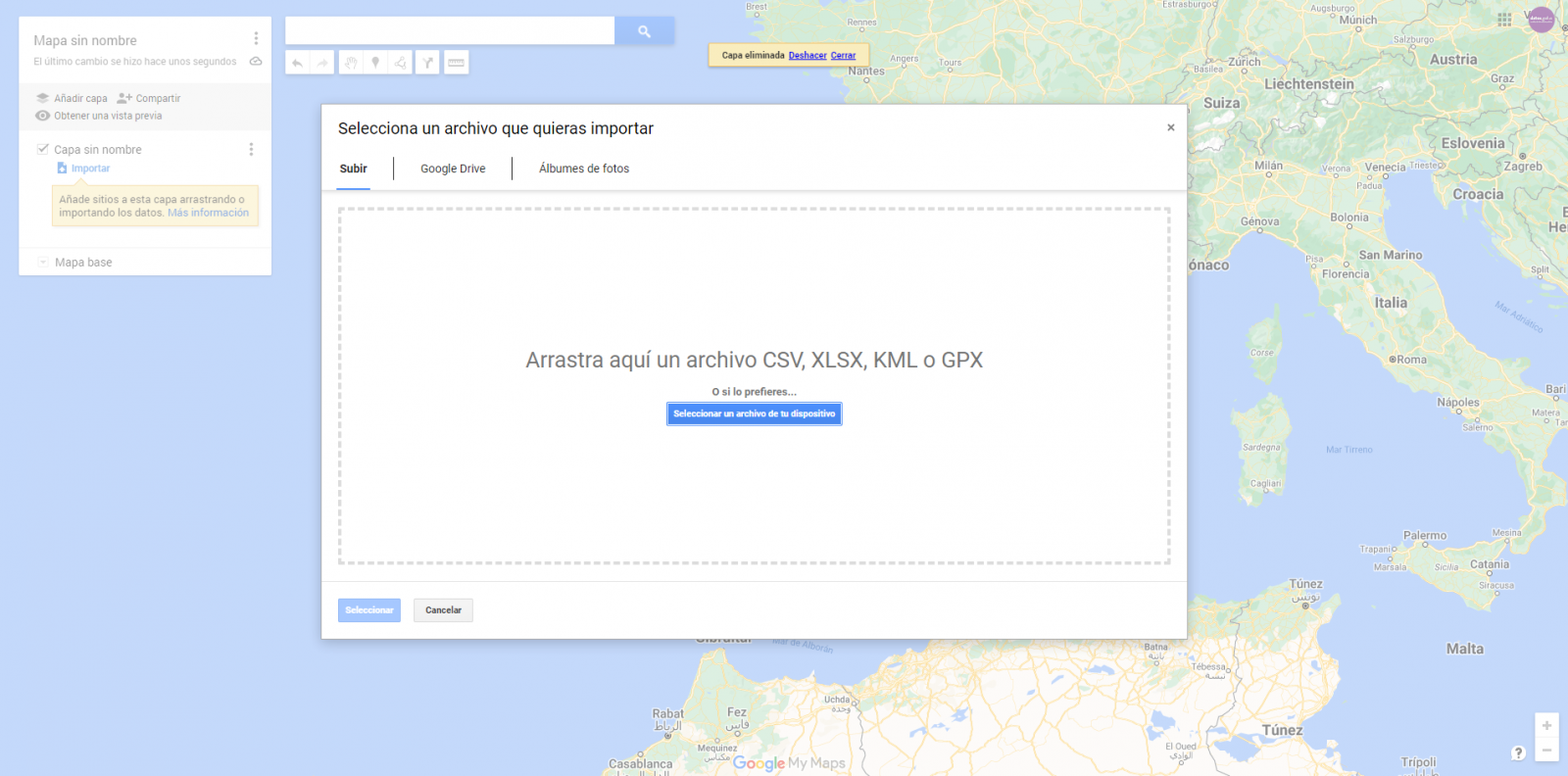
Figura 6. Importación de archivos en "Google My Maps"
- En este caso práctico, importaremos tablas de datos preprocesados que contienen una variable con la latitud y otra con la longitud. Esta información geográfica se reconocerá automáticamente. My Maps también reconoce direcciones, códigos postales, países, ...
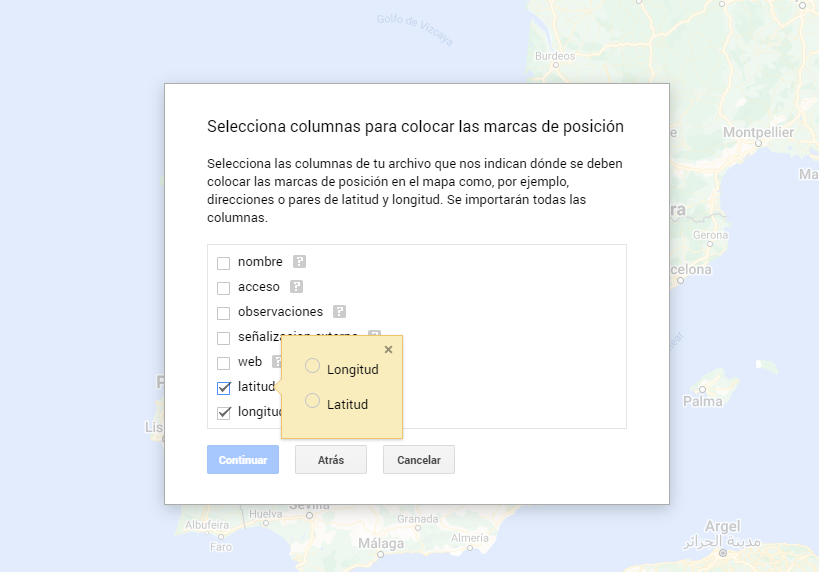
Figura 7. Selección columnas con valores de posición
- Mediante la opción de editar estilo que aparece en el menú lateral izquierdo, en cada una de las capas, podemos personalizar los pines, editando el color y su forma.

Figura 8. Edicción de pines de posición
- Por último, podemos elegir el mapa base que queremos visualizar en la parte inferior de la barra lateral de opciones.
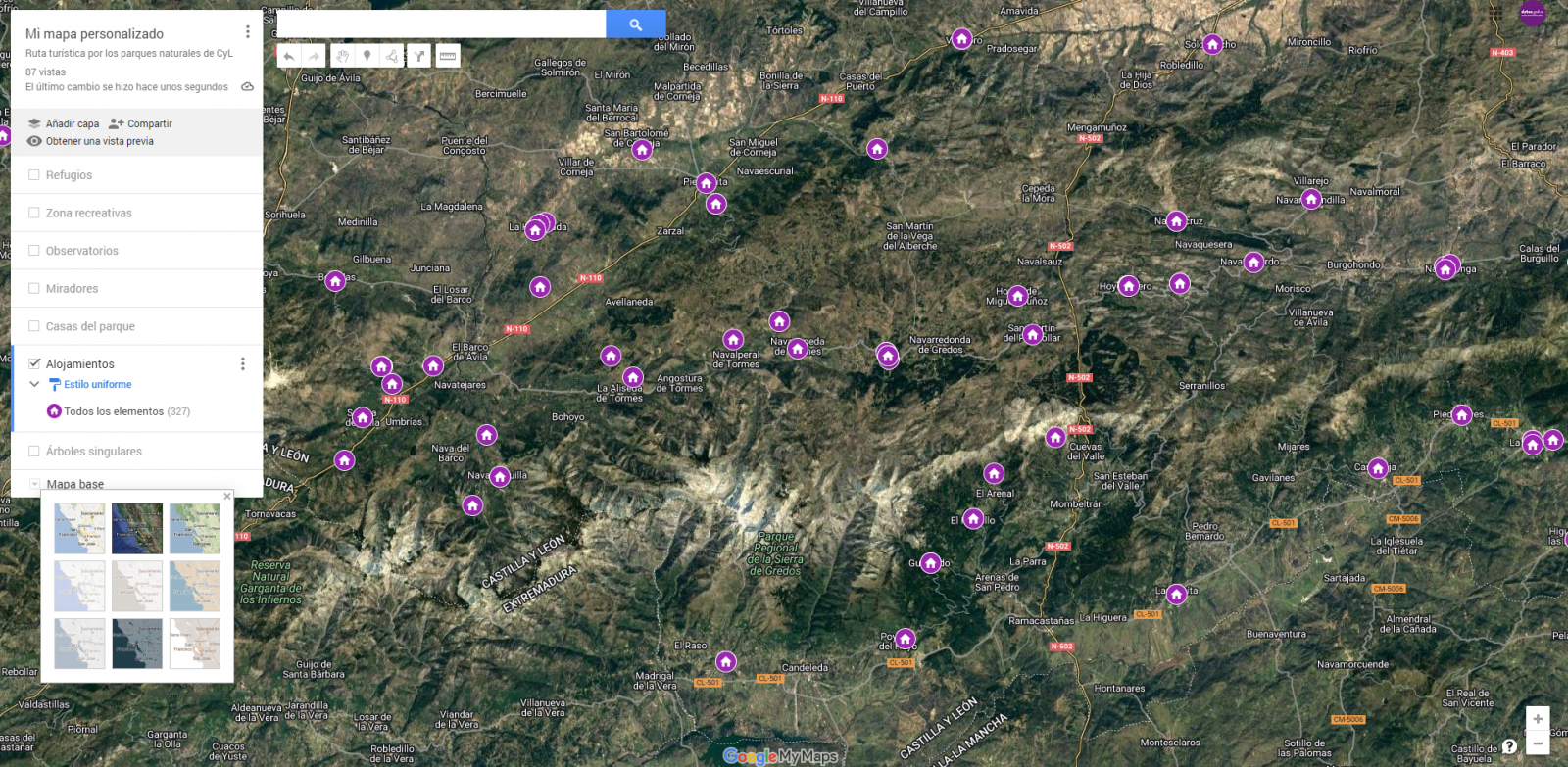
Figura 9. Selección de mapa base
Si quieres conocer más sobre los pasos para la generación de mapas con “Google My Maps”, consulta el siguiente tutorial paso a paso.
6.2 Personalización de la información a mostrar en el mapa
Durante el preprocesamiento de las tablas de datos, hemos realizado un filtrado de la información según el enfoque del ejercicio, que es la generación de un mapa para realizar rutas tusísticas por los espacios naturales de Castilla y León. A continuación, se describe la personalización de la información que hemos llevado a cabo para cada uno de los conjuntos de datos.
- En el conjunto de datos perteneciente a los árboles singulares de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a las casas del parque de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso, la web y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los miradores de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los observatorios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización y la posición (latitud/longitud)
- En el conjunto de datos perteneciente a los refugios de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Dado que los refugios pueden encontrarse en estados muy diferentes y que algunos registros no ofrecen información en el campo “observaciones”, hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en dicho campo.
- En el conjunto de datos perteneciente a las áreas recreativas de los espacios naturales, la información a mostrar para cada registro es el nombre, las observaciones, la señalización, el acceso y la posición (latitud/longitud). Hemos decidido filtrar para que nos muestre solamente aquellos que tengan información en los campos de “observaciones” y “acceso”.
- En el conjunto de datos perteneciente a los alojamientos, la información a mostrar para cada registro es el nombre, tipo de establecimiento, categoría, municipio, web, teléfono y la posición (latitud/longitud). Hemos filtrado el “tipo” de establecimiento para que nos muestre solamente los que están categorizados como alojamientos de turismo rural y hemos filtrado para que nos muestre los que son de 2 estrellas.
A continuación, tenemos la visualización del mapa personalizado que hemos creado. Seleccionando el icono para agrandar el mapa que aparece en la esquina superior derecha, podrás acceder su visualización en pantalla completa.
6.3 Funcionalidades sobre el mapa (capas, pines, rutas y vista inmersiva 3D)
En este punto, una vez creado el mapa personalizado, explicaremos diversas funcionalidades que nos ofrece "Google My Maps" durante la visualización de los datos.
-
Capas
Mediante el menú desplegable de la izquierda, podemos activar y desactivar las capas a mostrar según nuestras necesidades.
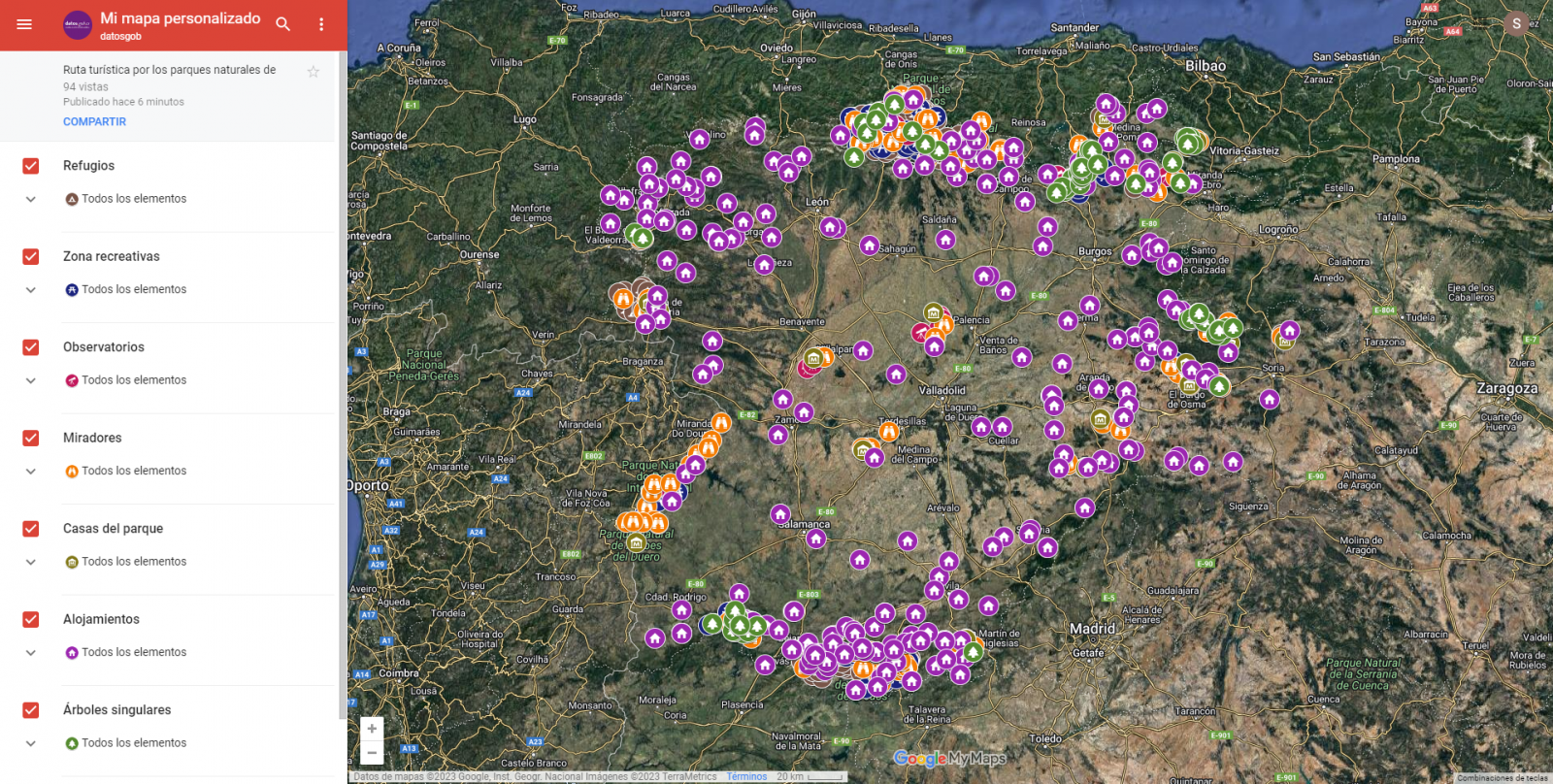
Figura 10. Capas en "My Maps"
-
Pines
Pinchando en cada uno de los pines del mapa podemos acceder a la información asociada a esa posición geográfica.
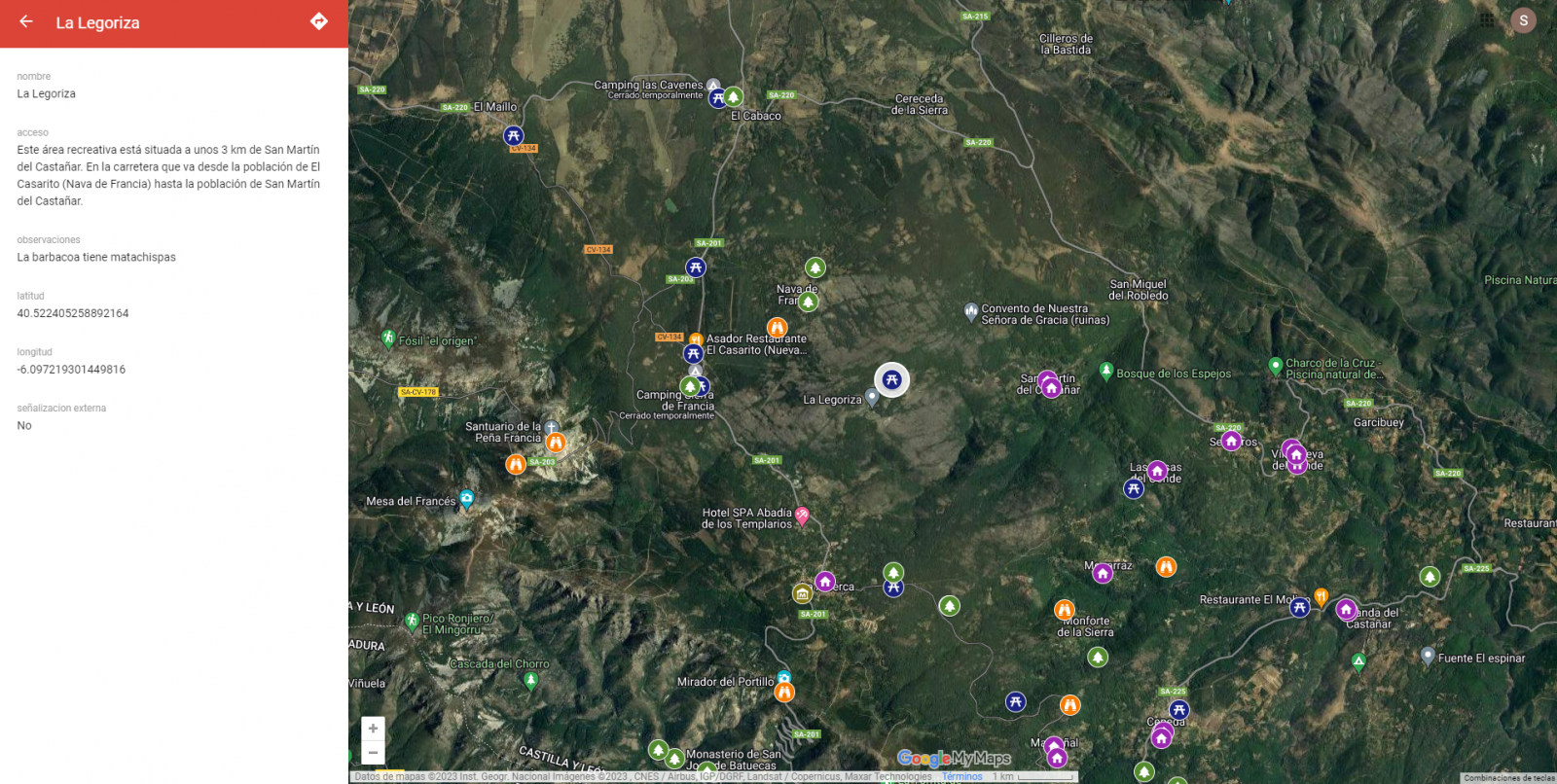
Figura 11. Pines en "My Maps"
-
Rutas
Podemos crear una copia del mapa sobre la que añadir nuestros recorridos personalizados.
En las opciones del menú lateral izquierdo, seleccionamos “copiar mapa”. Una vez copiado el mapa, mediante el símbolo de añadir indicaciones, situado debajo de la barra buscador, generaremos una nueva capa. A esta capa podremos indicarle dos o más puntos, junto al medio de transporte y nos creará el trazado junto a las indicaciones de trayecto.

Figura 12. Rutas en "My Maps"
-
Mapa inmersivo en 3D
Mediante el símbolo de opciones que aparece en el menú lateral, podemos acceder a Google Earth, desde donde podemos realizar una exploración del mapa inmersiva en 3D, destacando el poder observar la altitud de los distintos puntos de interés. También puedes acceder mediante el siguiente enlace.
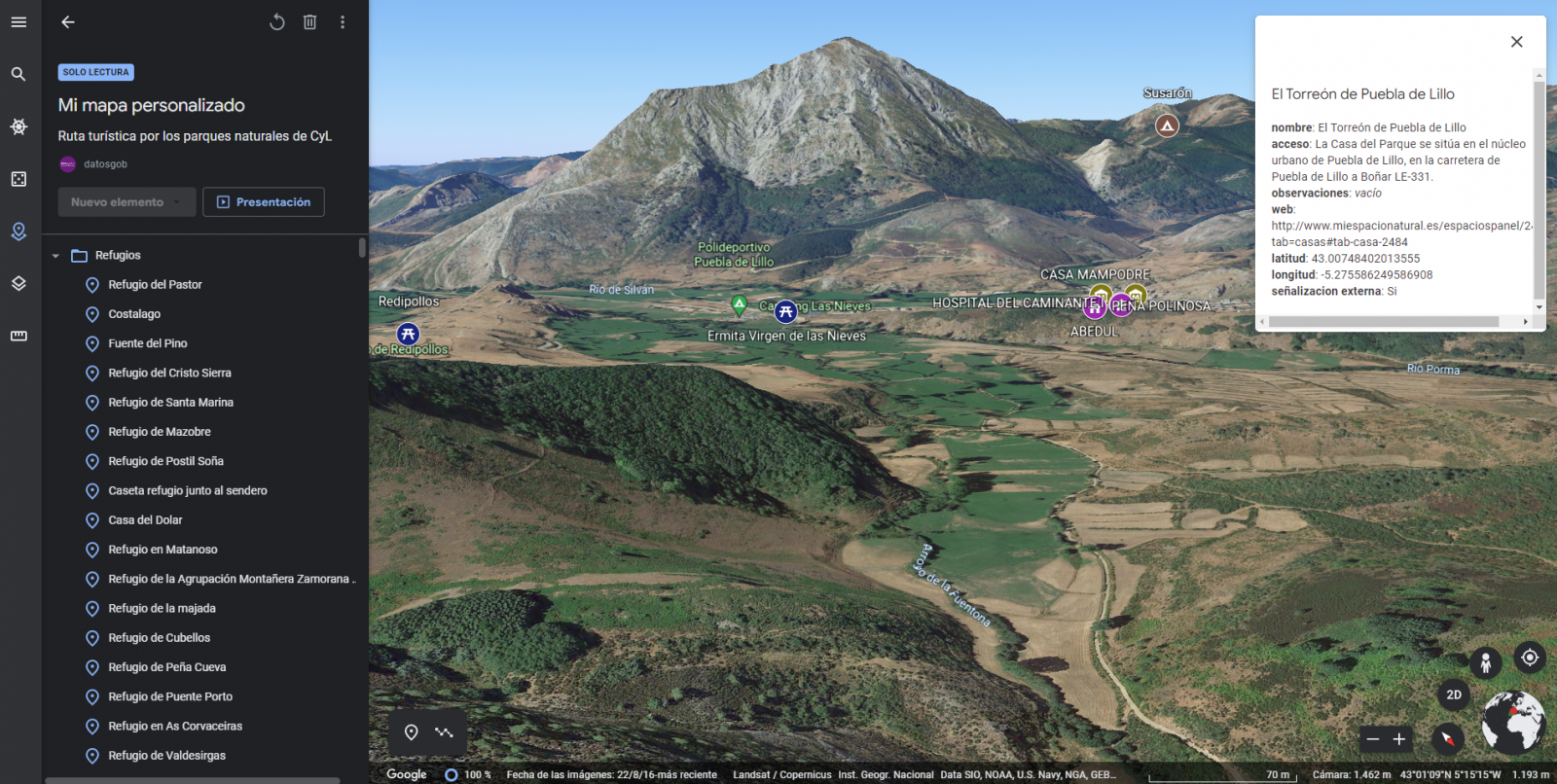
Figura 13. Vista inmersiva en 3D
7. Conclusiones del ejercicio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos. Cabe destacar la vital importancia que los datos geográficos tienen en el sector del turismo, lo cual hemos podido comprobar en este ejercicio.
Como resultado, hemos desarrollado un mapa interactivo con información aportada por los datos abiertos enriquecidos (Linked Data), la cual hemos personalizado según nuestros intereses.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones utilizando el lenguaje visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
En esta sección de “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos disponibles en datos.gob.es u otros catálogos similares. En ellos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, la creación de visualizaciones interactivas de las que podemos extraer información resumida en unas conclusiones finales. En cada uno de estos ejercicios prácticos se utilizan sencillos desarrollos de código convenientemente documentados, así como herramientas de uso gratuito. Todo el material generado está disponible para su reutilización en el repositorio del laboratorio de datos de Github perteneciente a datos.gob.es.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es mostrar cómo realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos utilizado un dataset proporcionado por el Ministerio de Justicia que contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico, que cruzaremos con los datos que publica la Jefatura Central de Tráfico que contienen el detalle sobre el parque de vehículos matriculados en España.
A partir de este cruce de datos analizaremos y podremos observar las ratios de resultados toxicológicos positivos en relación con el parque de vehículos matriculados.
Cabe destacar que el Ministerio de Justicia pone a disposición de los ciudadanos diversos cuadros de mando donde visualizar los datos sobre los resultados toxicológicos realizados en accidentes de tráfico. La diferencia radica en que este ejercicio práctico hace hincapié en la parte didáctica, mostraremos cómo procesar los datos y cómo diseñar y construir las visualizaciones.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se ha utilizado un conjunto de datos proporcionado por el Ministerio de Justicia, el cual contiene información sobre los resultados toxicológicos realizados en accidentes de tráfico. Este conjunto de datos se encuentra en el siguiente repositorio de Github:
También se han utilizado los conjuntos de datos del parque de vehículos matriculados en España. Estos conjuntos de datos son publicados por parte de la Jefatura Central de Tráfico, organismo dependiente del Ministerio del Interior. Se encuentran disponibles en la siguiente página del catálogo de datos de datos.gob.es:
3.2. Herramientas
Para la realización de las tareas de preprocesado de los datos se ha utilizado el lenguaje de programación Python escrito sobre un Notebook de Jupyter alojado en el servicio en la nube de Google Colab.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Tratamiento o preparación de los datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y que no contienen errores.
Los procesos que te describimos a continuación los encontrarás comentados en el Notebook que también podrás ejecutar desde Google Colab. Link al notebook de Google Colab
Como primer paso del proceso es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creados posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
El siguiente paso es la generación de las tablas de datos preprocesados que usaremos para generar las visualizaciones. Para ello ajustaremos las variables, realizaremos el cruce de datos entre ambos conjuntos y filtraremos o agruparemos según sea conveniente.
Los pasos que se siguen en este preprocesamiento de los datos son los siguientes:
- Importación de librerías
- Carga de archivos de datos a utilizar
- Detención y tratamiento de datos ausentes (NAs)
- Modificación y ajuste de las variables
- Generación de tablas con datos preprocesados para las visualizaciones
- Almacenamiento de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en nuestra cuenta de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y para favorecer el entendimiento de los lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
5. Generación de las visualizaciones
Una vez hemos realizado el preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente, para ello hemos realizado los pasos anteriores para la preparación de los datos.
El punto de partida es el planteamiento de una serie de preguntas que la visualización nos ayudará a resolver. Proponemos las siguientes:
-
¿Cómo está distribuido el parque de vehículos en España por comunidades autónomas?
-
¿Qué tipo de vehículo está implicado en mayor y en menor medida en accidentes de tráfico con resultados toxicológicos positivos?
-
¿Dónde se producen más hallazgos toxicológicos en víctimas mortales de accidentes de tráfico?
¡Vamos a buscar las respuestas viendo los datos!
5.1. Parque de vehículos matriculados por CCAA y por típo de vehículo
Esta representación visual se ha realizado teniendo en cuenta el número de vehículos matriculados en las distintas comunidades autónomas, desglosando el total por tipo de vehículo. Los datos, correspondientes a la media de los registros mes a mes de los años 2020 y 2021, están almacenados en la tabla “parque_vehiculos.csv” generada en el preprocesamiento de los datos de partida.
Mediante un mapa coroplético podemos visualizar qué CCAAs son las que poseen un mayor parque de vehículos. El mapa se complementa con un gráfico de anillo que aporta información de los porcentajes sobre el total por cada CCAA.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los mapas coropléticos o de coropletas muestran los valores de una variable sobre un mapa pintando las áreas de cada región afectada de un color determinado. Son utilizados cuando se quieren encontrar patrones geográficos en los datos que están categorizados por zonas o regiones.
Los gráficos de anillo, englobados en los gráficos de sectores, utilizan una representación circular que muestra cómo se distribuyen proporcionalmente los datos.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de vehículo.
Ver la visualización en pantalla completa
5.2. Ratio resultados toxicológicos positivos para los distintos tipos de vehículos
Esta representación visual se ha realizado teniendo en cuanta las ratios de los resultados toxicológicos positivos por número de vehículos a nivel nacional. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_vehiculos.csv”
Mediante un gráfico de barras apiladas, podemos evaluar los ratios de los resultados toxicológicos positivos por número de vehículos para las distintas sustancias y los distintos tipos de vehículos.
Según se definen en la “Guía de visualización de datos de la Generalitat Catalana” los gráficos de barras se utilizan cuando se quiere comparar el valor total de la suma de los segmentos que forman cada una de las barras. Al mismo tiempo, ofrecen información sobre cómo son de grandes estos segmentos.
Cuando las barras apiladas suman un 100%, es decir, que cada barra segmenteada ocupa la altura de la representación, el gráfico se puede considerar un gráfico que permite representar partes de un total.
La tabla aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña desplegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
5.3. Ratio resultados toxicológicos positivos para las CCAAs
Esta representación visual se ha realizado teniendo en cuenta las ratios de los resultados toxicológicos positivos por el parque de vehículos de cada CCAA. Contabilizamos como resultado positivo cada vez que un sujeto da positivo en el análisis de cada una de las sustancias, es decir, un mismo sujeto puede contabilizar varias veces en el caso de que sus resultados sean positivos para varias sustancias. Para ello se ha generado durante el preprocesamiento de datos la tabla “resultados_ccaa.csv”.
Hay que remarcar que no tiene por qué coincidir la CCAA de matriculación del vehículo con la CCAA donde se ha registrado el accidente, no obstante, ya que este es un ejercicio didáctico y se presupone que en la mayoría de los casos coinciden, se ha decido partir de la base de que ambos coinciden.
Mediante un mapa coroplético podemos visualizar que CCAAs son las que poseen las mayores ratios. A la información aportada en la primera visualización sobre este tipo de gráficos, hay que añadir lo siguiente.
Según se define en la “Guía de visualización de datos para Entidades Locales” uno de los requisitos de los mapas coropléticos o de coropletas es utilizar una medida o dato numérico, un dato categórico para el territorio y un dato geográfico de polígono.
La tabla y el gráfico de barras aportan la misma información de una forma complementaria.
Una vez obtenida la visualización, mediante la pestaña despegable, aparece la opción de filtrar por tipo de sustancia.
Ver la visualización en pantalla completa
6. Conclusiones del estudio
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
El parque de vehículos de las Comunidades Autónomas de Andalucía, Cataluña y Madrid corresponde a cerca del 50% del total del país.
-
Las ratios de resultados toxicológicos positivos más altas se presentan en las motocicletas, siendo del orden de tres veces superior a la siguiente ratio, los turismos, para la mayoría de las sustancias.
-
Las ratios de resultados toxicológicos positivos más bajas se presentan en los camiones.
-
Los vehículos de dos ruedas (motocicletas y ciclomotores) presentan ratios en \"cannabis\" superiores a los obtenidos en \"cocaina\", mientras que los vehículos de cuatro ruedas (turismos, furgonetas y camiones) presentan ratios en \"cocaina\" superiores a los obtenidos en \"cannabis\".
-
La comunidad autónoma donde mayor es la ratio para el total de sustancias es La Rioja.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por tipo de vehículo y tipo de sustancia. Te animamos a lo que lo hagas para sacar conclusiones más específicas sobre la información concreta en la que estés más interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
Python, R, SQL, JavaScript, C++, HTML... Hoy en día podemos encontrar multitud de lenguajes de programación que nos permiten desarrollar programas de software, aplicaciones, páginas webs, etc. Cada uno tiene características únicas que lo diferencian del resto y que lo hacen más apropiado para determinadas tareas. Pero, ¿cómo sabemos cuándo y dónde utilizar cada lenguaje? En este artículo te damos algunas pistas.
Tipos de lenguajes de programación
Los lenguajes de programación son reglas sintácticas y semánticas que nos permiten ejecutar una serie de instrucciones. Según su nivel de complejidad, podemos hablar de distintos niveles:
- Lenguajes de bajo nivel: utilizan instrucciones básicas que la máquina interpreta directamente y que son difíciles de entender por las personas. Están diseñados a medida de cada hardware y no se pueden migrar, pero son muy eficaces, ya que aprovechan al máximo las características de cada máquina.
- Lenguajes de alto nivel: utilizan instrucciones claras usando un lenguaje natural, más entendible por los humanos. Estos lenguajes emulan nuestra forma de pensar y razonar, pero después deben ser traducidos a lenguaje máquina a través de traductores/intérpretes o compiladores. Se pueden migrar y no dependen del hardware.
En ocasiones también se habla de lenguajes de nivel medio para aquellos que, aunque funcionan como un lenguaje de bajo nivel, permiten cierto manejo abstracto independiente de la máquina.
Los lenguajes de programación más utilizados
En este artículo nos vamos a centrar en los lenguajes de alto nivel más utilizados en la ciencia de datos. Para ello nos vamos a fijar en esta encuesta, realizada por Anaconda en 2021, y en el artículo elaborado por KD Nuggets.
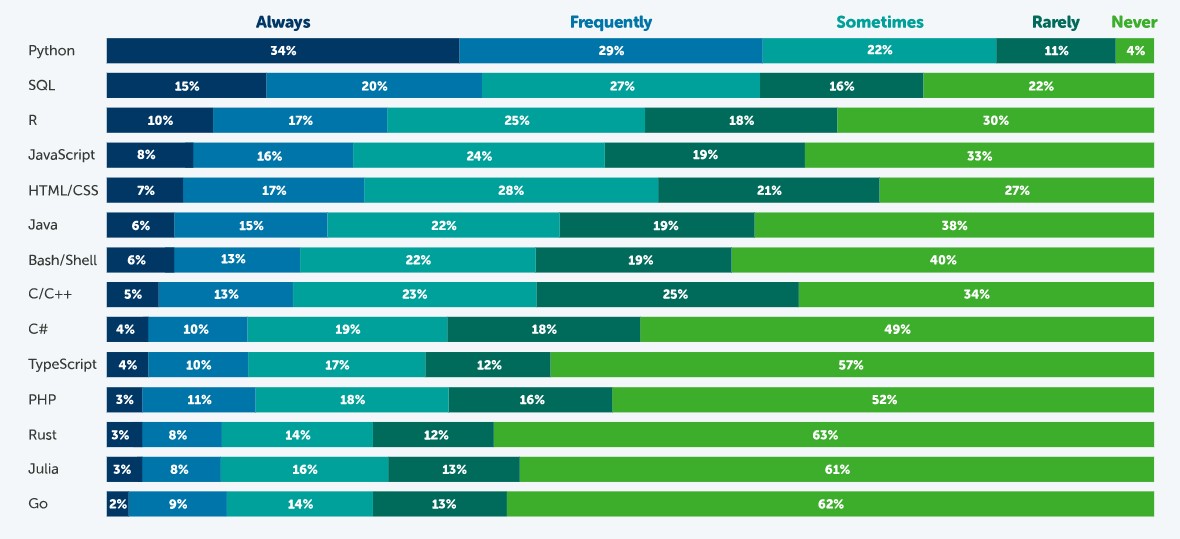
Fuente: Estado de la Ciencia de Datos en 2021, Anaconda.
Según esta encuesta, el lenguaje más popular es Python. El 63% de los encuestados – 3.104 científicos de datos, investigadores, estudiantes y profesionales del dato de todo el mundo- indicó que utiliza Python siempre o frecuentemente y solo un 4% indicó que nunca. Esto se debe a que es un lenguaje muy versátil, que se puede utilizar en las distintas tareas que existen a lo largo de un proyecto de ciencia de datos.
Un proyecto de ciencia de datos cuenta con distintas fases y tareas. Algunos lenguajes pueden ser utilizados para ejecutar distintas labores, pero con desigual rendimiento. La siguiente tabla, elaborada por KD Nuggets, muestra qué lenguaje es más recomendado para algunas de las tareas más populares:

Como vemos Python es el único lenguaje que resulta apropiado para todas las áreas analizadas por KD Nuggets, aunque existen otras opciones que también son muy interesantes, según la tarea a realizar, como veremos a continuación:
- Extracción y manipulación de datos. Estas tareas están dirigidas a obtener los datos y depurarlos con el fin de conseguir una estructura homogénea, sin datos incompletos, libre de errores y en el formato adecuado. Para ello se recomienda realizar un Análisis Exploratorio de Datos. SQL es el lenguaje de programación que más destaca con respecto a la extracción de datos, sobre todo cuando se trabaja con bases de datos relacionales. Es rápido en la recuperación de datos y cuenta con una sintaxis estandarizada, lo cual lo hace relativamente sencillo. Sin embargo, es más limitado a la hora de manipular datos. Una tarea en la que dan mejores resultados Python y R, dos programas que cuentan con una gran cantidad de librerías para estas tareas.
- Análisis estadístico y visualización de datos. Supone el tratamiento de los datos para encontrar patrones que luego se convierten en conocimiento. Existen distintos tipo de análisis según su propósito: conocer mejor nuestro entorno, realizar predicciones u obtener recomendaciones. El mejor lenguaje para ello es R, un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística. Python, Java y Julia son otras herramientas que dan un buen rendimiento en esta tarea, para la cual también se puede utilizar JavaScript. Los lenguajes anteriores permiten, además de realizar análisis, elaborar visualizaciones gráficas que facilitan la comprensión de la información.
- Modelización/aprendizaje automático (ML). Si queremos trabajar con machine learning y construir algoritmos, Python, Java, Java/JavaScript, Julia y TypeScript son las mejores opciones. Todas ellas simplifican la tarea de escribir código, aunque es necesario tener conocimientos amplios para poder trabajar con las diferentes técnicas de aprendizaje automático. Aquellos usuarios más expertos pueden trabajar con C/C++, un lenguaje de programación muy fácil de leer por máquinas, pero con mucho código, que puede ser difícil de aprender. Por el contrario, R puede ser una buena opción para aquellos menos expertos, aunque es más lento y poco apropiado para redes neuronales complejas.
- Despliegue de modelos. Una vez creado un modelo, es necesario su despliegue, teniendo en cuenta todos los requisitos necesarios para su entrada en producción en un entorno real. Para ello, los lenguajes más adecuados son Python, Java, JavaScript y C#, seguido de PHP, Rust, GoLang y, si trabajamos con aplicaciones básicas, HTML/CSS.
- Automatización. Aunque no todas las partes del trabajo de un científico de datos pueden automatizarse, hay algunas tareas tediosas y repetitivas cuya automatización agiliza el rendimiento. Python, por ejemplo, cuenta con una gran cantidad de librerías para la automatización de tareas de machine learning. Si trabajamos con aplicaciones móviles, entonces nuestra mejor opción será Java. Otras opciones son C# (especialmente útil para automatizar la construcción de modelos), Bash/Shell (para extracción y manipulación de datos) y R (para análisis estadísticos y visualizaciones).
En definitiva, el lenguaje de programación que utilicemos dependerá completamente de la tarea a realizar y de nuestras capacidades. No todos los profesionales de la ciencia de datos necesitan saber de todos los lenguajes, sino que deberán optar por profundizar en aquel más adecuado en base a su trabajo diario.
Algunos recursos adicionales para aprender más sobre estos lenguajes
En datos.gob.es hemos elaborado algunas guías y recursos que pueden ser de tu utilidad para aprender algunos de estos lenguajes:
- Informe sobre Herramientas de procesado y visualización de datos
- Cursos para aprender más sobre R
- Cursos para aprender más sobre Python
- Cursos online para aprender más sobre visualización de datos
- Comunidades de desarrolladores en R y Python
Contenido elaborado por el equipo de datos.gob.es.
Blog
El avance de la supercomputación y la analítica de datos en campos tan dispares como las redes sociales o la atención al cliente está fomentando que una parte de la inteligencia artificial (IA) se enfoque en desarrollar algoritmos capaces de procesar y generar un lenguaje natural.
Para poder llevar a cabo esta tarea en un contexto como el actual, tener acceso a un heterogéneo listado de bibliotecas de procesamiento de lenguaje natural es clave para diseñar soluciones IA eficaces y funcionales de forma ágil. Estos archivos de código fuente, que se utilizan para desarrollar software, facilitan la programación al proporcionar funcionalidades comunes, resueltas previamente por otros desarrolladores, evitando duplicidades y minimizando los errores.
Así y con el objetivo de fomentar la compartición y reutilización para diseñar aplicaciones y servicios que aporten valor económico y social, desglosamos cuatro conjuntos de bibliotecas de procesamiento de lenguaje natural, divididas en base al lenguaje de programación utilizado.
Librerías para Python
Idóneas para codificar utilizando el lenguaje de programación Python. Al igual que sucede con los ejemplos disponibles para otros lenguajes, estas librerías cuentan con gran variedad de implementaciones que permiten al desarrollador crear una nueva interfaz por su propia cuenta.
Algunos ejemplos son:
NLTK: Natural Language Toolkit
- Descripción: NLTK ofrece interfaces fáciles de usar para más de 50 corpus y recursos léxicos como WordNet, junto con un conjunto de bibliotecas de procesamiento de textos. Permite realizar tareas de preprocesado de texto, entre las que encontramos, la clasificación, tokenización, lematización o la exclusión de stop words, el análisis sintáctico y el razonamiento semántico.
- Materiales de apoyo: Una de las secciones más interesantes para consultar información y resolver dudas es el apartado dedicado a las preguntas frecuentes. Puedes encontrarlo en este enlace. También tiene disponible ejemplos de uso y una wiki.
Gensim
- Descripción: Gensim es una biblioteca Python de código abierto para representar documentos como vectores semánticos. La diferencia principal respecto al resto de librerías de lenguaje natural para Python reside en que Gensim es capaz de identificar automáticamente la temática del conjunto de documentos a tratar. También permite analizar la similitud entre ficheros, algo realmente útil cuando utilizamos la librería para realizar búsquedas.
- Materiales de apoyo: En la sección de Documentación de su página web, es posible encontrar materiales didácticos enfocados a tres áreas muy concretas. Por un lado, hay una serie de tutoriales dirigidos a aquellos programadores que nunca antes han utilizado este tipo de bibliotecas. Existen lecciones formativas orientadas a cuestiones específicas del lenguaje de programación, una serie de guías cuyo objetivo es resolver las dudas que surgen ante determinados problemas y también una sección dedicada únicamente a las preguntas frecuentes
Librerías para JavaScript
Las librerías de JavaScript sirven para diversificar el abanico de recursos que pueden utilizar los programadores y desarrolladores web que hacen uso de este lenguaje. Puedes elegir entre los siguientes ejemplos propuestos a continuación:
Apache OpenNLP
- Descripción: La biblioteca Apache OpenNLP es un conjunto de herramientas basadas en el aprendizaje automático para el procesamiento de textos en lenguaje natural. Es compatible con las tareas básicas de programación de lenguaje natural, tokenización, segmentación de frases, el etiquetado de las partes de un discurso, la extracción de entidades con nombre o la detección de idiomas, entre otras muchas.
- Materiales de apoyo: Dentro de la categoría General de su web, encontramos un subapartado denominado Books, Tutorials and Talks donde se proporcionan una serie de charlas, tutoriales y publicaciones destinadas a resolver las dudas de los programadores. Igualmente, en la categoría Documentation disponen de distintos manuales de uso.
NLP.js
- Descripción: NLP.js está dirigida a node.js, un entorno de ejecución de JavaScript de código abierto. Admite 41 idiomas de forma nativa e, incluso, puede ampliarse hasta 104 idiomas con el uso de Bert embeddings. Se trata de una librería utilizada principalmente para la construcción de bots, el análisis de sentimiento o la identificación automática del lenguaje, entre otras funciones. Precisamente por esta razón, es una librería a tener en cuenta para la construcción de chatbots.
- Materiales de apoyo: Dentro de su perfil alojado en el portal de código Github ofrecen un apartado de preguntas frecuentes y otro de ejemplos de uso que pueden resultar útiles a la hora de hacer uso de la librería para desarrollar una app o servicio.
Natural
- Descripción: Al igual que NLP.js, Natural también facilita el procesamiento del lenguaje natural para node.js. Ofrece una variada gama de funcionalidades como la tokenización, coincidencia fonética, frecuencia de términos (TF-IDF) y la integración con la base de datos WordNet, entre otras.
- Materiales de apoyo: Al igual que la anterior biblioteca, esta librería tampoco tiene web propia. En su perfil de Github, dispone de contenidos de apoyo como ejemplos de casos de uso desarrollados anteriormente por otros programadores.
Wink
- Descripción: Wink es una familia de paquetes de código abierto para el análisis estadístico, el procesamiento del lenguaje natural y el aprendizaje automático en NodeJS. Ha sido optimizada para lograr un equilibrio entre rendimiento y precisión, lo que hace que el paquete pueda manejar grandes cantidades de texto en bruto a una alta velocidad.
- Materiales de apoyo: Acceder a los tutoriales desde su página web resulta muy intuitivo ya que una de las categorías que tiene el mismo nombre recoge precisamente este tipo de contenido divulgativo. En ella es posible encontrar guías de aprendizaje divididas según el nivel de experiencia del programador o de la parte del proceso en el que esté inmerso.
Librerías para R
En este último apartado aglutinamos las bibliotecas específicas para construir una web, aplicación o servicio utilizando el lenguaje de codificación R. Algunas de ellas son:
koRpus
- Descripción: Se trata de un paquete de análisis de textos capaz de detectar el idioma de manera automática y diversos índices de diversidad léxica o legibilidad, entre otras funciones. Además, incluye el plugin RKWard que proporciona cuadros de diálogo gráficos para sus funciones básicas.
- Materiales de apoyo: koRpus ofrece una serie de directrices enfocadas a su instalación y aglutinadas en el documento Read me que puedes encontrar en este enlace. Igualmente, en el aparado News están disponibles las actualizaciones y cambios que se han ido realizando en las sucesivas versiones de la librería.
Quanteda
- Descripción: Esta biblioteca ha sido diseñada para que los programadores que utilizan R apliquen técnicas de procesamiento de lenguaje natural a sus textos desde la versión original hasta la obtención de los resultados finales. Por ello, su API ha sido desarrollada para permitir un análisis potente y eficiente con un mínimo de pasos, reduciendo así las barreras de aprendizaje, al procesamiento del lenguaje natural y el análisis cuantitativo de textos.
- Materiales de apoyo: Ofrece como material de apoyo principal esta guía de inicio rápido. A través de ella, es posible seguir las instrucciones principales para no cometer ningún error. Incluye también varios ejemplos que pueden servir para comparar resultados.
Isa - Natural Language Processing
- Descripción: Esta librería se basa en el análisis semántico latente que consiste en crear datos estructurados a partir de una colección de textos no estructurados.
- Materiales de apoyo: En el apartado dedicado a la documentación, podemos encontrar información útil para el desarrollo.
Librerías para Python y R
Hablamos de librerías para Python y R para referirnos a aquellas que son compatibles para codificar utilizando ambos lenguajes de programación.
spaCy
- Descripción: Es una herramienta muy útil para preparar textos que, posteriormente, serán empleados en otras tareas de aprendizaje automático. Además, permite aplicar modelos lingüísticos estadísticos para resolver diferentes problemas de procesamiento del lenguaje natural.
- Materiales de apoyo: spaCy ofrece una serie de cursos online divididos en distintos capítulos y que podrás encontrar aquí. A través de los contenidos compartidos en NLP Advanced podrás seguir paso a paso las utilidades de esta biblioteca, ya que cada capítulo se centra en una parte del procesamiento del texto. Si aún quieres aprender más sobre esta librería, te recomendamos leer este artículo de Alejandro Alija sobre su experiencia probando esta biblioteca.
En este artículo hemos compartido una muestra de algunas de las librerías más populares para el procesamiento del lenguaje natural. Aun así, conviene subrayar que se trata de una mera selección.
Por todo ello, si conoces de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Documentación
1. Introducción
Las visualizaciones son representaciones gráficas de datos que permiten comunicar de manera sencilla y efectiva la información ligada a los mismos. Las posibilidades de visualización son muy amplias, desde representaciones básicas, como puede ser un gráfico de líneas, barras o sectores, hasta visualizaciones configuradas sobre cuadros de mando o dashboards interactivos. Las visualizaciones juegan un papel fundamental en la extracción de conclusiones a partir de información visual, permitiendo además detectar patrones, tendencias, datos anómalos o proyectar predicciones, entre otras muchas funciones.
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos, prestando especial atención a la obtención de los mismos y validando su contenido, asegurando que se encuentran en el formato adecuado y consistente para su procesamiento y no contienen errores. Un tratamiento previo de los datos es primordial para realizar cualquier tarea relacionada con el análisis de datos y la realización de visualizaciones efectivas.
En la sección “Visualizaciones paso a paso” estamos presentando periódicamente ejercicios prácticos de visualizaciones de datos abiertos que están disponibles en el catálogo datos.gob.es u otros catálogos similares. En ellos abordamos y describimos de manera sencilla las etapas necesarias para obtener los datos, realizar las transformaciones y análisis que resulten pertinentes para, finalmente, crear visualizaciones interactivas, de las que podemos extraer información en forma de conclusiones finales.
En este ejercicio práctico, hemos realizado un sencillo desarrollo de código que está convenientemente documentado apoyandonos en herramientas de uso gratuito.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetivo
El objetivo principal de este post es aprender a realizar una visualización interactiva partiendo de datos abiertos. Para este ejercicio práctico hemos escogido conjuntos de datos que contienen información relevante sobre los embalses nacionales. A partir de estos datos realizaremos el análisis de su estado y de su evolución temporal en los últimos años.
3. Recursos
3.1. Conjuntos de datos
Para este caso práctico se han seleccionado conjuntos de datos publicados por el Ministerio para la Transición Ecológica y el Reto Demográfico, que dentro del boletín hidrológico recoge series temporales de datos sobre él volumen de agua embalsada de los últimos años para todos los embalses nacionales con una capacidad superior a 5hm3. Datos históricos del volumen de agua embalsada disponibles en:
También se ha seleccionado un conjunto de datos geoespaciales. Durante su búsqueda, se han encontrado dos posibles archivos con datos de entrada, el que contiene las áreas geográficas correspondientes a los embalses de España y el que contiene las presas que incluye su geoposicionamiento como un punto geográfico. Aunque evidentemente no son lo mismo, embalses y presas guardan relación y para simplificar este ejercicio práctico optamos por utilizar el archivo que contiene la relación de presas de España. Inventario de presas disponible en: https://www.mapama.gob.es/ide/metadatos/index.html?srv=metadata.show&uuid=4f218701-1004-4b15-93b1-298551ae9446 , concretamente:
Este conjunto de datos contiene geolocalizadas (Latitud, Longitud) las presas de toda España con independencia de su titularidad. Se entiende por presa, aquellas estructuras artificiales que, limitando en todo o en parte el contorno de un recinto enclavado en el terreno, esté destinada al almacenamiento de agua dentro del mismo.
Para generar los puntos geográficos de interés se realiza un procesamiento mediante la herramienta QGIS, cuyos pasos son los siguientes: descargar el archivo ZIP, cargarlo en QGIS y guardarlo como CSV incluyendo la geometría de cada elemento como dos campos que especifican su posición como un punto geográfico (Latitud y Longitud).
También se he realizado un filtrado para quedarnos con los datos correspondientes a las presas de los embalses que tengan una capacidad mayor a 5hm3
3.2. Herramientas
Para la realización del preprocesamiento de los datos se ha utilizado el lenguaje de programación Python desde el servicio cloud de Google Colab, que permite la ejecución de Notebooks de Jupyter.
Google Colab o también llamado Google Colaboratory, es un servicio gratuito en la nube de Google Research que permite programar, ejecutar y compartir código escrito en Python o R desde tu navegador, por lo que no requiere la instalación de ninguna herramienta o configuración.
Para la creación de la visualización interactiva se ha usado la herramienta Google Data Studio.
Google Data Studio es una herramienta online que permite realizar gráficos, mapas o tablas que pueden incrustarse en sitios web o exportarse como archivos. Esta herramienta es sencilla de usar y permite múltiples opciones de personalización.
Si quieres conocer más sobre herramientas que puedan ayudarte en el tratamiento y la visualización de datos, puedes recurrir al informe \"Herramientas de procesado y visualización de datos\".
4. Enriquecimiento de los datos
Con la finalidad de aportar mayor información relacionada a cada una de las presas en el dataset con datos geoespaciales, se realiza un proceso de enriquecimiento de datos explicado a continuación.
Para ello vamos a utilizar una herramienta útil para este tipo de tarea, OpenRefine. Esta herramienta de código abierto permite realizar múltiples acciones de preprocesamiento de datos, aunque en esta ocasión la usaremos para llevar a cabo un enriquecimiento de nuestros datos mediante la incorporación de contexto enlazando automáticamente información que reside en el popular repositorio de conocimiento Wikidata.
Una vez instalada la herramienta en nuestro ordenador, al ejecutarse se abrirá una aplicación web en el navegador, en caso de que eso no ocurriese, se accedería a dicha aplicación tecleando en la barra de búsqueda del navegador \"localhost:3333\".
Pasos a seguir:
- Paso 1: Carga del CSV en el sistema (Figura 1).

Figura 1 - Carga de un archivo CSV en OpenRefine
- Paso 2: Creación del proyecto a partir del CSV cargado (Figura 2). OpenRefine se gestiona mediante proyectos (cada CSV subido será un proyecto), que se guardan en el ordenador dónde se esté ejecutando OpenRefine para un posible uso posterior. En este paso debemos dar un nombre al proyecto y algunos otros datos, como el separador de columnas, aunque lo más habitual es que estos últimos ajustes se rellenen automáticamente.

Figura 2 - Creación de un proyecto en OpenRefine
- Paso 3: Enlazado (o reconciliación, usando la nomenclatura de OpenRefine) con fuentes externas. OpenRefine nos permite enlazar recursos que tengamos en nuestro CSV con fuentes externas como Wikidata. Para ello se deben realizar las siguientes acciones (pasos 3.1 a 3.3):
- Paso 3.1: Identificación de las columnas a enlazar. Habitualmente este paso suele estar basado en la experiencia del analista y su conocimiento de los datos que se representan en Wikidata. Como consejo, habitualmente se podrán reconciliar o enlazar aquellas columnas que contengan información de carácter más global o general como nombres de países, calles, distritos, etc., y no se podrán enlazar aquellas columnas como coordenadas geográficas, valores numéricos o taxonomías cerradas (tipos de calles, por ejemplo). En este ejemplo, hemos encontrado la columna NOMBRE que contiene el nombre de cada embalse que puede servir como identificador único de cada ítem y puede ser un buen candidato para enlazar.
- Paso 3.2: Comienzo de la reconciliación. Comenzamos la reconciliación como se indica en la figura 3 y seleccionamos la única fuente que estará disponible: Wikidata(en). Después de hacer clic en Start Reconciling, automáticamente comenzará a buscar la clase del vocabulario de Wikidata que más se adecue basado en los valores de nuestra columna.

Figura 3 – Inicio del proceso de reconciliación de la columna NOMBRE en OpenRefine
- Paso 3.3: Selección de la clase de Wikidata. En este paso obtendremos los valores de la reconciliación. En este caso como valor más probable, seleccionamos el valor de la propiedad “reservoir” cuya descripción se puede ver en https://www.wikidata.org/wiki/Q131681, que corresponde a la descripción de un “lago artificial para acumular agua”. Únicamente habrá que pulsar otra vez en Start Reconciling.
OpenRefine nos ofrece la posibilidad de mejorar el proceso de reconciliación agregando algunas características que permitan orientar el enriquecimiento de la información con mayor precisión. Para ello ajustamos la propiedad P4568 cuya descripción se corresponde con el identificador de un embalse en España, en el SNCZI-Inventario de Presas y Embalses, como se observa en la figura 4.

Figura 4 - Selección de la clase de Wikidata que mejor representa los valores de la columna NOMBRE
- Paso 4: Generar una nueva columna con los valores reconciliados o enlazados. Para ello debemos pulsar en la columna NOMBRE e ir a “Edit Column → Add column based in this column”, dónde se mostrará un texto en la que tendremos que indicar el nombre de la nueva columna (en este ejemplo podría ser WIKIDATA_EMBALSE). En la caja de expresión deberemos indicar: “http://www.wikidata.org/entity/”+cell.recon.match.id y los valores aparecen como se previsualiza en la Figura 6. “http://www.wikidata.org/entity/” se trata de una cadena de texto fija para representar las entidades de Wikidata, mientras el valor reconciliado de cada uno de los valores lo obtenemos a través de la instrucción cell.recon.match.id, es decir, cell.recon.match.id(“ALMODOVAR”) = Q5369429.
Mediante la operación anterior, se generará una nueva columna con dichos valores. Con el fin de comprobar que se ha realizado correctamente, haciendo clic en una de las celdas de la nueva columna, está debería conducir a una página web de Wikidata con información del valor reconciliado.
El proceso lo repetimos para añadir otro tipo de información enriquecida como la referencia en Google u OpenStreetMap.

Figura 5 - Generación de las entidades de Wikidata gracias a la reconciliación a partir de una nueva columna
- Paso 5: Descargar el CSV enriquecido. Utilizamos la función Export → Custom tabular exporter situada en la parte superior derecha de la pantalla y seleccionamos las características como se indica en la Figura 6.

Figura 6 - Opciones de descarga del fichero CSV a través de OpenRefine
5. Preprocesamiento de datos
Durante el preprocesamiento es necesario realizar un análisis exploratorio de los datos (EDA) con el fin de interpretar adecuadamente los datos de partida, detectar anomalías, datos ausentes o errores que pudieran afectar a la calidad de los procesos posteriores y resultados, además de realizar las tareas de transformación y preparación de las variables necesarias. Un tratamiento previo de los datos es esencial para garantizar que los análisis o visualizaciones creadas posteriormente a partir de ellos son confiables y consistentes. Si quieres conocer más sobre este proceso puedes recurrir a la Guía Práctica de Introducción al Análisis Exploratorio de Datos.
Los pasos que se siguen en esta fase de preprocesamiento son los siguientes:
- Instalación y carga de librerías
- Carga de archivos de datos de origen
- Modificación y ajuste de las variables
- Detención y tratamiento de datos ausentes (NAs)
- Generación de nuevas variables
- Creación de tabla para visualización \"Evolución histórica de la reserva hídrica entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (hm3) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Reserva hídrica (%) entre los años 2012 y 2022\"
- Creación de tabla para visualización \"Evolución mensual de la reserva hídrica (hm3) para distintas series temporales\"
- Guardado de las tablas con los datos preprocesados
Podrás reproducir este análisis, ya que el código fuente está disponible en este repositorio de GitHub. La forma de proporcionar el código es a través de un documento realizado sobre un Jupyter Notebook que una vez cargado en el entorno de desarrollo podrás ejecutar o modificar de manera sencilla. Debido al carácter divulgativo de este post y con el fin de favorecer el aprendizaje de lectores no especializados, el código no pretende ser el más eficiente, sino facilitar su comprensión por lo que posiblemente se te ocurrirán muchas formas de optimizar el código propuesto para lograr fines similares. ¡Te animamos a que lo hagas!
Puedes seguir los pasos y ejecutar el código fuente sobre este notebook en Google Colab.
6. Visualización de datos
Una vez hemos realizado un preprocesamiento de los datos, vamos con las visualizaciones. Para la realización de estas visualizaciones interactivas se ha usado la herramienta Google Data Studio. Al ser una herramienta online, no es necesario tener instalado un software para interactuar o generar cualquier visualización, pero sí es necesario que las tablas de datos que le proporcionemos estén estructuradas adecuadamente.
Para abordar el proceso de diseño del conjunto de representaciones visuales de los datos, el primer paso es plantearnos las preguntas que queremos resolver. Proponemos las siguientes:
- ¿Cuál es la localización de los embalses dentro del territorio nacional?
-
¿Qué embalses son los de mayor y menor aporte de volumen de agua embalsada (reserva hídrica en hm3) al conjunto del país?
-
¿Qué embalses poseen el mayor y menor porcentaje de llenado (reserva hídrica en %)?
-
¿Cuál es la tendencia en la evolución de la reserva hídrica en los últimos años?
¡Vamos a buscar las respuestas viendo los datos!
6.1. Localización geográfica y principal información de cada embalse
Esta representación visual se ha realizado teniendo en cuenta las coordenadas geográficas de los embalses y distinta información asociada a cada uno de ellos. Para ello se ha generado durante el preprocesamiento de datos la tabla “geo.csv”
Mediante un mapa de puntos geográficos se visualiza la localización de los embalses en el territorio nacional.
Una vez obtenido el mapa, pinchando en cada uno de los embalses podemos acceder a información complementaria sobre dicho embalse en la tabla inferior. También, mediante las pestañas despegables, aparece la opción de filtrar el mapa por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.2. Reserva hídrica (hm3) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) por embalse entre los años los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “volumen.csv”
Mediante un gráfico de jerarquía rectangular se visualiza de forma intuitiva la importancia de cada embalse en cuanto a volumen embalsado dentro del conjunto nacional para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.3. Reserva hídrica (%) entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (%) por embalse entre los años 2012 (inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “porcentaje.csv”
Mediante un gráfico de barras se visualiza de forma intuitiva el porcentaje de llenado de cada embalse para el periodo temporal anteriormente indicado.
Una vez obtenido el gráfico, mediante las pestañas despegables, aparece la opción de filtrar la visualización por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.4. Evolución histórica de la reserva hídrica entre los años 2012 y 2022
Esta representación visual se ha realizado teniendo en cuenta los datos históricos de la reserva hídrica (hm3 y %) para todas las mediciones semanales registradas entre los años 2012(inclusive) y 2022. Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas.csv”
Mediante gráficos de líneas y sus líneas de tendencia se visualiza la evolución temporal de la reserva hídrica (hm3 y %).
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos modificar la serie temporal, filtrar por demarcación hidrográfica y por embalse.
Ver la visualización en pantalla completa
6.5. Evolución mensual de la reserva hídrica (hm3) para distintas series temporales
Esta representación visual se ha realizado teniendo en cuenta la reserva hídrica (hm3) de los distintos embalses desglosada por meses para distintas series temporales (cada uno de los años desde el 2012 hasta el 2022). Para ello se ha generado durante el preprocesamiento de datos la tabla “lineas_mensual.csv”
Mediante un gráfico de líneas se visualízala la reserva hídrica mes a mes para cada una de las series temporales.
Una vez obtenido el gráfico, mediante las pestañas desplegables, podemos filtrar por demarcación hidrográfica y por embalse. También tenemos la opción de elegir la serie o series temporales (cada uno de los años desde el 2012 hasta el 2022) que queremos visualizar mediante el icono que aparece en la parte superior derecha del gráfico.
Ver la visualización en pantalla completa
7. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica. En el conjunto de representaciones gráficas de datos que acabamos de implementar se puede observar lo siguiente:
-
Se observa una tendencia significativa en la disminución del volumen de agua embalsada por el conjunto de embalses nacionales entre los años 2012 y 2022.
-
El año 2017 es el que presenta valores más bajos de porcentaje de llenado total de los embalses, llegando a ser este inferior al 45% en ciertos momentos del año.
-
El año 2013 es el que presenta valores más altos de porcentaje de llenado total de los embalses, llegando a ser este superior al 80% en ciertos momentos del año.
Cabe destacar que en las visualizaciones tienes la opción de filtrar por demarcación hidrográfica y por embalse. Te animamos a lo que lo hagas para sacar conclusiones más específicas de las demarcaciones hidrográficas y embalses que estés interesado.
Esperemos que esta visualización paso a paso te haya resultado útil para el aprendizaje de algunas técnicas muy habituales en el tratamiento y representación de datos abiertos. Volveremos para mostraros nuevas reutilizaciones. ¡Hasta pronto!
Blog
Las librerías de programación hacen referencia a los conjuntos de archivos de código que han sido creados para desarrollar software de manera sencilla. Gracias a ellas, los desarrolladores pueden evitar la duplicidad de código y minimizar errores con mayor agilidad y menor coste. Existen multitud de librerías, enfocadas en distintas actividades. Hace unas semanas vimos algunos ejemplos de librerías para la creación de visualizaciones, y en esta ocasión nos vamos a centrar en librerías de utilidad para tareas de aprendizaje automático (Machine Learning).
Estas librerías son altamente prácticas a la hora de implementar flujos de Machine Learning. Esta disciplina, perteneciente al campo de la Inteligencia Artificial, utiliza algoritmos que ofrecen, por ejemplo, la capacidad de identificar patrones de datos masivos o la capacidad de ayudar a elaborar análisis predictivos.
A continuación, te mostramos algunas de las librerías de análisis de datos y Machine Learning más populares que existen en la actualidad para los principales lenguajes de programación, como Python o R:
Librerías para Python
NumPy
- Descripción:
Esta librería de Python está especializada en el cálculo matemático y en el análisis de grandes volúmenes de datos. Permite trabajar con arrays que permiten representar colecciones de datos de un mismo tipo en varias dimensiones, además de funciones muy eficientes para su manipulación.
- Materiales de apoyo:
Aquí encontramos la Guía para principiantes, con conceptos básicos y tutoriales, la Guía del usuario, con información sobre las características generales, o la Guía del colaborador, para contribuir al mantenimiento y desarrollo del código o en la redacción de documentación técnica. NumPy también cuenta con una Guía de referencia que detalla funciones, módulos y objetos incluidos en esta librería, así como una serie de tutoriales para aprender a utilizarla de forma sencilla.
Pandas
- Descripción:
Se trata de una de las librerías más utilizadas para el tratamiento de datos en Python. Esta herramienta de análisis y manipulación de datos se caracteriza, entre otros aspectos, por definir nuevas funcionalidades de datos basadas en los arrays de la librería NumPy. Permite leer y escribir fácilmente ficheros en formato CSV, Excel y especificar consultas a bases de datos SQL.
- Materiales de apoyo:
Su web cuenta con diferentes documentos como la Guía del usuario, con información básica detallada y explicaciones útiles, la Guía del desarrollador, que detalla los pasos a seguir ante la identificación de errores o sugerencia de mejoras en las funcionalidades, así como la Guía de referencia, con descripción detallada de su API. Además, ofrece una serie de tutoriales aportados por la comunidad y referencias sobre operaciones equivalentes en otros softwares y lenguajes como SAS, SQL o R.
Scikit-learn
- Descripción:
Scikit-Learn es una librería que implementa una gran cantidad de algoritmos de Machine Learning para tareas de clasificación, regresión, clustering y reducción de dimensionalidad. Además, es compatible con otras librerías de Python como NumPy, SciPy y Matplotlib (Matpotlib es una librería de visualización de datos y como tal está incluida en el artículo anterior).
- Materiales de apoyo:
Esta librería cuenta con diferentes documentos de ayuda como un Manual de instalación, una Guía del Usuario o un Glosario de términos comunes y elementos de su API. Además, ofrece una sección con diferentes ejemplos que ilustran las características de la librería, así como otras secciones de interés con tutoriales, preguntas frecuentes o acceso a su GitHub.
Scipy
- Descripción:
Esta librería presenta una colección de algoritmos matemáticos y funciones construidas sobre la extensión de NumPy. Incluye módulos de extensión para Python sobre estadística, optimización, integración, álgebra lineal o procesamiento de imágenes, entre otros.
- Materiales de apoyo:
Al igual que los ejemplos anteriores, esta librería también cuenta con materiales como Guías de instalación, Guías para usuarios, para desarrolladores o un documento con descripciones detalladas sobre su API. Además, ofrece información sobre act, una herramienta para ejecutar acciones de GitHub de forma local.
Librerías para R
mlr
- Descripción:
Esta librería ofrece componentes fundamentales para desarrollar tareas de aprendizaje automático, entre otros, preprocesamiento, pipelining, selección de características, visualización e implementación de técnicas supervisadas y no supervisadas utilizando un amplio abanico de algoritmos.
- Materiales de apoyo:
En su web cuenta con múltiples recursos para usuarios y desarrolladores, entre los que destaca un tutorial de referencia que presenta un extenso recorrido que abarca los aspectos básicos sobre tareas, predicciones o preprocesamiento de datos hasta la implementación de proyectos complejos utilizando funciones avanzadas.
Además, cuenta con un apartado que redirige a GitHub en el que ofrece charlas, vídeos y talleres de interés sobre el funcionamiento y los usos de esta librería.
Tidyverse
- Descripción:
Esta librería ofrece una colección de paquetes de R diseñados para la ciencia de datos que aporta funcionalidades muy útiles para importar, transformar, visualizar, modelar y comunicar información a partir de datos. Todos ellos comparten una misma filosofía de diseño, gramática y estructuras de datos subyacentes. Los principales paquetes que lo componen son: dplyr, ggplot2, forcats, tibble, readr, stringr, tidyr y purrr.
- Materiales de apoyo:
Tidyverse cuenta con un blog en el que podrás encontrar posts sobre programación, paquetes o trucos y técnicas para trabajar con esta librería. Además, cuenta con una sección que recomienda libros y workshops para aprender a utilizar esta librería de una manera más sencilla y amena.
Caret
- Descripción:
Esta popular librería contiene una interfaz que unifica bajo un único marco de trabajo cientos de funciones para entrenar clasificadores y regresores, facilitando en gran medida todas las etapas de preprocesado, entrenamiento, optimización y validación de modelos predictivos.
- Materiales de apoyo:
La web del proyecto contine exhaustiva información que facilita al usuario abordar tareas mencionadas. También se puede encontrar referencias en CRAN y el proyecto está alojado en GitHub. Algunos recursos de interés para el manejo de esta librería se pueden encontrar a través de libros como Applied Predictive Modeling, artículos, seminarios o tutoriales, entre otros.
Librerías para abordar tareas de Big Data
TensorFlow
- Descripción:
Además de Python y R, esta librería también es compatible con otros lenguajes como JavaScript, C++ o Julia. TensorFlow ofrece la posibilidad de compilar y entrenar modelos de ML utilizando APIs. La API más destacada es Keras, que permite construir y entrenar modelos de aprendizaje profundo (Deep Learning).
- Materiales de apoyo:
En su web se pueden encontrar recursos como modelos y conjuntos de datos previamente establecidos y desarrollados, herramientas, bibliotecas y extensiones, programas de certificación, conocimientos sobre aprendizaje automático o recursos y herramientas para integrar las prácticas de IA responsable. Puedes acceder a su página de GitHub aquí.
Dmlc XGBoost
- Descripción:
Librería de "Gradient Boosting" (GBM, GBRT, GBDT) escalable, portátil y distribuida es compatible con los lenguajes de programación C++, Python, R, Java, Scala, Perl y Julia. Esta librería permite resolver muchos problemas de ciencia de datos de una manera rápida y precisa y se puede integrar con Flink, Spark y otros sistemas de flujo de datos en la nube para abordar tareas Big Data.
- Materiales de apoyo:
En su web cuenta con un blog con temáticas relacionadas como actualizaciones de algoritmos o integraciones, además de una sección de documentación que cuenta con guías de instalación, tutoriales, preguntas frecuentes, foro de usuarios o paquetes para los distintos lenguajes de programación. Puedes acceder a su página de GitHub a través de este enlace.
H20
- Descripción:
Esta librería combina los principales algoritmos de Machine Learning y aprendizaje estadístico con Big Data, además de ser capaz de trabajar con millones de registros. H20 está escrita en Java, y sigue el paradigma Key/Value para almacenar datos y Map/Reduce para implementar algoritmos. Gracias a su API, se puede acceder desde R, Python o Scala.
- Materiales de apoyo:
Cuenta con una serie de vídeos en forma de tutorial para enseñar y facilitar su uso a los usuarios. En su página de GitHub podrás encontrar recursos adicionales como blogs, proyectos, recursos, trabajos de investigación, cursos o libros sobre H20.
En este artículo hemos ofrecido una muestra de algunas de las librerías más populares que ofrecen funcionalidades versátiles para abordar tareas típicas de ciencia de datos y aprendizaje automático, aunque hay muchas otras. Este tipo de librerías está en constante evolución gracias a la posibilidad que ofrece a sus usuarios de participar en su mejora a través de acciones como la contribución a la escritura de código, la generación de nueva documentación o el reporte de errores. Todo ello permite enriquecer y perfeccionar sus resultados continuamente.
Si sabes de alguna otra librería de interés que quieras recomendarnos, puedes dejarnos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es
Contenido elaborado por el equipo de datos.gob.es.
Blog
Las librerías de programación son conjuntos de archivos de código que se utilizan para desarrollar software. Su objetivo es facilitar la programación, al proporcionar funcionalidades comunes, que ya han sido resueltas previamente por otros programadores. Como curiosidad, el término proviene de una mala traducción de la palabra inglesa library, que en realidad significa biblioteca.
Las librerías (o bibliotecas) son un componente esencial para que los desarrolladores puedan programar de forma sencilla, evitando la duplicidad de código y minimizando errores. También permiten una mayor agilidad, al reducir el tiempo de desarrollo, así como los costes.
Estas ventajas se reflejan a la hora de usar librerías para realizar visualizaciones utilizando lenguajes tan populares como Python, R y JavaScript.
Librerías para Python
Python es uno de lenguajes de programación más utilizados. Se trata de un lenguaje interpretado (fácil de leer y escribir gracias a la semejanza que presenta con el lenguaje humano), multiplataforma, gratuito y de código abierto. En este artículo previo puedes encontrar cursos para aprender más sobre él.
Dada su popularidad, no es de extrañar que encontremos en la red múltiples librerías que nos facilitarán la creación de visualizaciones con este lenguaje, como por ejemplo:
Matplotlib
- Descripción:
Matplotlib es una biblioteca completa para la generación de visualizaciones estáticas, animadas e interactivas a partir de datos contenidos en listas o arrays en el lenguaje de programación Python y su extensión matemática NumPy.
- Materiales de apoyo:
En su web se recogen ejemplos de visualizaciones con el código fuente, para inspirar a nuevos usuarios, y diversas guías dirigidas tanto a usuarios principiantes como a aquellos más avanzados. En la web también hay disponible una sección de recursos externos que redirige a libros, artículos, vídeos y tutoriales elaborados por terceros.
Seaborn
- Descripción:
Seaborn es una biblioteca de visualización de datos en Python basada en matplotlib. Proporciona una interfaz de alto nivel que permite dibujar gráficos estadísticos atractivos e informativos.
- Materiales de apoyo:
En su web hay disponibles tutoriales, con información sobre la API y los distintos tipos de funciones, así como una galería de ejemplos. También es recomendable echar un vistazo a este paper elaborado por The Journal of Open Source Software.
Bokeh
- Descripción:
Bokeh es una librería para la visualización de datos de forma interactiva en un navegador web. Entre sus funciones está desde la creación de gráficos simples hasta la elaboración de cuadros de mando interactivos.
- Materiales de apoyo:
Los usuarios pueden encontrar en su guía descripciones detalladas y ejemplos que describen las tareas más comunes. La guía incluye la definición de conceptos básicos, el trabajo con datos geográficos o cómo generar interacciones, entre otros.
La web también cuenta con una galería con ejemplos, tutoriales y un apartado de comunidad, donde plantear y resolver dudas.
Geoplotlib
- Descripción:
Geoplotlib es una librería de código abierto en python para la visualización de datos geográficos. Se trata de una sencilla API que produce visualizaciones sobre mosaicos de OpenStreetMap. Permite la creación de mapas de puntos, estimadores de densidad de datos, gráficos espaciales y archivos ”shapes”, entre muchas otras visualizaciones espaciales.
- Materiales de apoyo:
En Github tienes disponible esta guía de usuarios, donde se explica cómo cargar datos, crear mapas de colores o añadir interactividad a las capas, entre otros. También hay disponibles ejemplos de código.
Librerías para R
R también es un lenguaje interpretado para la computación estadística y la creación de representaciones gráficas (puedes aprender más sobre ello siguiendo alguno de estos cursos). Cuenta con su propio entorno de programación, R-Studio, y con un conjunto de herramientas muy flexibles y versátiles que se pueden ampliar fácilmente mediante la instalación de librerías o paquetes –usando su propia terminología-, como las que se detallan a continuación:
ggplot 2
- Descripción:
Ggplot es una de las librerías más populares y utilizadas en R para la creación de visualizaciones interactivas de datos. Su funcionamiento se basa en el paradigma descrito en The Grammar of Graphics para la creación de visualizaciones con 3 capas de elementos: datos (data frame), la lista de relaciones entre las variables (aesthetics) y los elementos geométricos que se van a representar (geoms).
- Materiales de apoyo:
En su web puedes encontrar diversos materiales, como esta cheatsheet que recoge de manera resumida las principales funcionalidades de ggplot2. Por su parte, esta guía comienza explicando las características generales del sistema utilizando como ejemplo los diagramas de dispersión para detallar, a continuación, cómo representar algunos de los gráficos más conocidos. También se incluyen diversas FAQ que pueden ser de ayuda.
Lattice
- Descripción:
Lattice es un sistema de visualización de datos inspirado en los gráficos Trellis o de trama, prestando especial atención a los datos multivariantes. La interfaz de usuario de Lattice consiste en varias funciones genéricas de "alto nivel", cada una de ellas diseñada para crear un tipo particular de gráfico por defecto.
- Materiales de apoyo:
En este manual puedes encontrar información sobre las diversas funcionalidades, aunque si quieres profundizar en ellas, en esta sección de la web puedes encontrar diversos manuales como R Graphics de Paul Murrell o Lattice de Deepayan Sarkar.
Esquisse
- Descripción:
Esquise permite explorar interactivamente los datos y crear visualizaciones detalladas con el paquete ggplot2 a través de una interfaz de arrastrar y soltar. Incluye multitud de elementos: gráficos de dispersión, de líneas, de cajas, con ejes múltiples, sparklines, dendogramas, gráficos 3D, etc.
- Materiales de apoyo:
La documentación está disponible a través de este enlace, incluyendo información sobre la instalación y las diversas funciones. También tienes información en la web de R.
Leaflet
- Descripción:
Leaflet permite la creación de mapas altamente detallados, interactivos y personalizados. Está basado en la biblioteca de JavaScript del mismo nombre.
- Materiales de apoyo:
En esta web tienes documentación sobre las diversas funcionalidades: el funcionamiento del widget, marcadores, cómo trabajar con GeoJSON & TopoJSON, cómo integrarse con Shiny, etc.
Librerías para JavaScript
JavaScript también es un lenguaje de programación interpretado, responsable de dotar de mayor interactividad y dinamismo a las páginas web. Es un lenguaje orientado a objetos, basado en prototipos y dinámico.
Algunas de las principales librerías para JavaScript son:
D3.js
- Descripción:
D3.js está dirigida a la creación de visualizaciones de datos y animaciones utilizando estándares web, como SVG, Canvas y HTML. Es una librería muy potente y de cierta complejidad.
- Materiales de apoyo:
En Github puedes encontrar una galería con ejemplos de los diversos gráficos y visualizaciones que se pueden obtener con esta librería, así como diversos tutoriales e información sobre técnicas específicas.
Chart.js
- Descripción:
Chart.js es una librería de JavaScript que utiliza canvas de HTML5 para la creación de gráficos interactivos. En concreto, admite 9 tipos de gráficos: barra, línea, área, circular, burbuja, radar, polar, dispersión y mixtos.
- Materiales de apoyo:
En su propia web tienes información sobre la instalación y configuración, y ejemplos de los distintos tipos de gráficos. También hay un apartado para desarrolladores con diversa documentación.
Otras librerias
Plotly
- Descripción:
Plotly es una biblioteca de gráficos de alto nivel, que permite la creación de más de 40 tipos de gráficos, incluidos gráficos 3D, estadísticos y mapas SVG. Es una librería Open Source, pero tiene versiones de pago.
Plotly no está ligada a un único lenguaje de programación, si no que permite la integración con R, Python y JavaScript.
- Materiales de apoyo:
Cuenta con una completa página web donde los usuarios pueden encontrar guías, casos de uso por ámbitos de aplicación, ejemplos prácticos, webinars y una sección de comunidad donde compartir conocimiento.
Cualquier usuario que lo desee puede contribuir con cualquiera de estas librerías, escribiendo código, generando nueva documentación o reportando errores, entre otros. De esta forma se enriquecen y perfeccionan, mejorando sus resultados de manera continua.
¿Conoces alguna otra librería que quieras recomendar? Déjanos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
Hace algún tiempo os presentamos algunos cursos de interés sobre R. En esta ocasión, realizamos una segunda entrega de formaciones online, pero esta vez sobre otro de los lenguajes de programación más populares en el mundo de la ciencia de datos: Python.
Python es un lenguaje de programación de alto nivel que se utiliza para desarrollar aplicaciones de diversas clases. Este lenguaje presenta una gran diferencia respecto a otros lenguajes como Java o .NET, ya que Python es un lenguaje interpretado.
Python es un lenguaje fácil de leer y escribir gracias a la semejanza que presenta con el lenguaje humano. Es un lenguaje multiplataforma gratuito y de código abierto, lo que fomenta la posibilidad de desarrollar software sin límites.
En los últimos años, este lenguaje ha ganado adeptos gracias a su sencillez y a las amplias posibilidades que ofrece para colaborar con otros campos como: inteligencia artificial, big data, machine learning o data science, entre otros.
A continuación, te mostramos una selección de cursos y formaciones basada en las recomendaciones de los expertos que colaboran con datos.gob.es y algunas comunidades de usuarios como Python Canarias que han colaborado en la realización de este listado.
Cursos online
Programación en Python: Aprende Python desde cero (Mayo 2021)
- Impartido por: Santiago Hernández (Udemy)
- Duración: No especificada
- Idioma: Español
- Precio: 94,99€
Curso eminentemente práctico dirigido a cualquier persona que quiera iniciarse en el mundo del lenguaje de programación con Python. Además, aborda la aplicación de Python a diferentes disciplinas como machine learning, ciberseguridad o el desarrollo de videojuegos.
Curso completo de Machine Learning: Data Science en Python (Noviembre 2021)
- Impartido por: Juan Gabriel Gomila, Frogrames SL (Udemy)
- Duración: 50 horas (aproximadamente)
- Idioma: Español
- Precio: 99,99€
Orientado a todo tipo de usuarios que tengan interés en saber más sobre Python, este curso aborda las matemáticas y algoritmos que tiene detrás este lenguaje de programación, así como las librerías de programación con Python. Su enfoque práctico permite a los alumnos trabajar con ejemplos basados en la vida real, además de practicar para construir sus propios modelos de machine learning.
Python for Data Science, AI & Development (Diciembre 2021)
- Impartido por: Coursera (IBM)
- Duración: 20 horas
- Idioma: Inglés
- Precio: Gratuito
Gracias a este curso podrás iniciarte en el aprendizaje de Python para la ciencia de datos, así como en la programación en general. Partirás desde cero a programar en Python, sin necesidad de tener experiencia previa en programación.
Python for Beginners (Enero 2020)
- Impartido por: Microsoft Developer (YouTube)
- Duración: 5 horas
- Idioma: Inglés
- Precio: Gratuito
Este curso online disponible en YouTube de manera gratuita, ofrece las bases de la programación en Python, empezando por el código y los escenarios cotidianos más comunes.
Anylize data with Python
- Impartido por: Codecademy
- Duración: 10 semanas
- Idioma: Inglés
- Precio: Contenido básico gratuito y contenido completo sujeto a suscripción
Gracias a este curso podrás potenciar y perfeccionar los fundamentos básicos del análisis de datos mientras desarrollas habilidades en el lenguaje de programación Python. Al terminar el curso, podrás utilizar las habilidades sobre Python adquiridas para presentar mejor los datos a través de visualizaciones, entre otros muchos aspectos.
Aprende Python (2020)
- Impartido por: Sergio Delgado Quintero
- Duración: No especificada
- Idioma: Español
- Precio: Gratuito
Curso gratuito que permite aprender el lenguaje de programación Python con un enfoque práctico. Incluye ejercicios y cobertura para distintos niveles de conocimiento.
- Impartido por: Junta de Andalucía
- Duración: 20 horas
- Idioma: Español
- Precio: Gratuito
Con este curso gratuito en Python podrás iniciarte en esta herramienta y contar con los conocimientos básicos de programación. Si no cuentas con mucha experiencia con Python, no te preocupes. Este curso parte de un nivel cero.
Másters
No toda la oferta formativa sobre Python viene recogida en cursos. Cada vez más centros de estudio ofrecen masters o programas relacionados con la ciencia de datos que recogen en su temario conocimientos sobre Python. A continuación, te mostramos algunos ejemplos:
- Máster de Data Science con Python (120 horas): Impartido por la Asociación Española de Programadores Informáticos, este máster ofrece a los estudiantes conocimientos de modelaje y tecnología para soportar la toma de decisiones fundamentada en datos.
- Máster en Big Data, de la Universidad Nacional de Educación a Distancia (UNED) (Duración no especificada): tiene entre sus objetivos que los alumnos aprendan a programar en Python y a almacenar en Hadoop o en bases de datos NoSQL.
- Máster en Big Data y Data Science Aplicado a la Economía (12 meses): de la Universidad Nacional de Educación a Distancia (UNED), introduce conceptos de Python como uno de los programas de software más utilizados.
- Máster Big Data - Business – Analytics (520 horas): de la Universidad Complutense de Madrid, incluye un tema de Introducción y fundamentos de programación en Python, así como otro de Machine Learning con R y Python.
- Máster en Big Data y Data Science aplicado a la Economía y Comercio: (520 horas) también de la Universidad Complutense de Madrid, incluye un módulo de lenguajes de programación en Python y R.
- Máster en Humanidades Digitales para un Mundo Sostenible (Duración no especificada): de la Universidad Autónoma de Madrid, donde los alumnos serán capaces de programar en Python y R para conseguir datos estadísticos a partir de textos (procesamiento del lenguaje natural).
- Máster en programación avanzada en Python para Hacking, Big Data y Machine Learning (1.500 horas): impartido por la Universidad Europea Miguel de Cervantes, este máster preparará al alumno para realizar trabajos de programación en Python especializado en áreas destacadas como Big Data, Hacking y Machine Learning.
- Experto Universitario en Programación en Python (4 meses): este Curso en Programación en Python, impartido por la Universidad Internacional de Valencia, ofrece a sus alumnos una formación completa en el ámbito de la programación, partiendo desde los fundamentos más básicos hasta las especializaciones más demandadas.
- Master en Data Science (14 semanas): ofertado por la Universidad Europea, está dirigido a aquellos estudiantes que quieran aprender a desarrollar proyectos basados en datos. El primero módulo está enfocado en el aprendizaje de Python. La Universidad Europea también ofrece un máster en Análisis de datos masivos (Big Data) de 10 meses, un máster en Business Analytics de 8 meses y un curso online sobre los fundamentos del Big Data.
Si quieres saber más, en la web de Pyhton España, cuentan con una sección con tutoriales, libros y cursos, ordenados por niveles. También incluyen el enlace a varias comunidades de Python en español (Discord , Telegram y Stack Overflow) donde podrán resolver tus dudas con esta potente herramienta.
Esta ha sido tan solo una pequeña recopilación de formaciones relacionadas con el lenguaje Python que esperamos puedan ser de tu interés. Si conoces algún otro curso que quieras recomendar, puedes dejarnos un comentario o escribirnos un correo electrónico a dinamizacion@datos.gob.es.
Documentación
1. Introducción
Las visualizaciones son una representación gráfica que nos permite comunicar de una manera sencilla la información ligada a los datos. Mediante elementos visuales, como gráficos, mapas o nubes de palabras, las visualizaciones, también nos ayudan a comprender tendencias, patrones o valores atípicos que pueden presentar los datos.
Las visualizaciones se pueden generar a partir de datos de diferente naturaleza, como pueden ser las palabras que conforman una noticia, un libro o una canción. Para realizar visualizaciones a partir de este tipo de datos, es necesario que las maquinas, mediante programas de software, sean capaces de entender, interpretar y reconocer las palabras que configuran el lenguaje humano (escrito o hablado) en múltiples idiomas. El campo de estudio enfocado en el tratamiento de estos datos se denomina Procesamiento del Lenguaje Natural (PLN). Es un campo interdisciplinar que combina el poder de la inteligencia artificial, la lingüística computacional y la informática. Los sistemas basados en PLN han permitido grandes innovaciones como el buscador de Google, el asistente de voz de Amazon, los traductores automáticos, el análisis de sentimientos de diferentes redes sociales o incluso detección de spam en una cuenta de correo electrónico.
En este ejercicio práctico, vamos a implementar una visualización gráfica de un resumen de palabras clave representativas de varios textos extraídas mediante la aplicación de técnicas de PLN. En concreto, vamos a crear una nube de palabras que resuma cuál son los términos que más se repiten en varios posts del portal.
Esta visualización se engloba dentro de la serie de ejercicios prácticos, en los cuales se utilizan datos abiertos disponibles en el portal datos.gob.es. En estos se abordan y describen de manera sencilla las etapas necesarias para obtener los datos, realizar transformaciones y análisis que resulten pertinentes para la creación de la visualización, extrayendo la máxima información. En cada uno de los ejercicios prácticos se usan sencillos desarrollos de código que estarán convenientemente documentados, así como herramientas de uso libre y gratuito. Todo el material generado estará disponible para su reutilización en el repositorio Laboratorio de datos en GitHub.
2. Objetivos
El objetivo principal de este post es aprender a realizar una visualización que incluya imágenes, generadas a partir de conjuntos de palabras representativas de diversos textos, conocidas popularmente como “nubes de palabras”. Para este ejercicio práctico hemos escogido 6 post publicados en la sección de blog del portal de datos.gob.es. A partir de estos textos y utilizando técnicas de PLN generaremos una nube de palabras para cada texto que nos permitirá detectar de manera sencilla y visual la frecuencia e importancia de cada palabra, facilitando la identificación de las palabras clave y la temática principal de cada uno de los posts.

A partir de un texto construimos una nube de palabras aplicando técnicas de Procesamiento de Lenguaje Natural (PLN)
3. Recursos
3.1. Herramientas
Para la realización del tratamiento previo de los datos (entorno de trabajo, programación y redacción del mismo), como la visualización propiamente dicha, se utiliza Python (versión 3.7) y Jupyter Notebook (versión 6.1), herramientas que encontraras integradas en, junto con muchas otras, en Anaconda, una de las plataformas más populares para instalar, actualizar y administrar software para trabajar en ciencia de datos. Para abordar las tareas relacionadas con el Procesamiento del Lenguaje Natural, utilizamos dos librerías, Scikit-Learn (sklearn) y wordcloud. Todas estas herramientas son Open Source y están disponibles de manera gratuita.
Scikit-Learn es una amplia librería muy popular, diseñada principalmente para llevar a cabo tareas de aprendizaje automático sobre datos en forma de texto. Entre otros, cuenta con algoritmos para realizar tareas de clasificación, regresión, clustering y reducción de dimensionalidades. Además, está diseñada para el aprendizaje profundo sobre datos textuales, siendo útil para el manejo de conjuntos de características textuales en forma de matrices, la realización de tareas como el cálculo de similitudes, la clasificación de texto y la agrupación de clústeres. En Python, para realizar este tipo de tareas, también es posible trabajar con otras librerías igualmente populares como NLTK o spacy, entre otras.
wordcloud es una librería especializada en la creación de nubes de palabras utilizando un algoritmo simple y que puede ser modificado fácilmente.
Para favorecer el entendimiento de los lectores no especializados en programación, el código en Python que se incluye a continuación, al que puedes acceder haciendo click en el botón “Código” de cada sección, no está diseñado para maximizar su eficiencia, sino para facilitar su comprensión, por lo que es posible que lectores más avanzados en este lenguaje consideren formas alternativas más eficientes para codificar algunas funcionalidades. El lector podrá reproducir este análisis si lo desea, ya que el código fuente está disponible en la cuenta de GitHub de datos.gob.es. La forma de proporcionar el código es a través de un Jupyter Notebook, que una vez cargado en el entorno de desarrollo podrá ejecutarse o modificarse de manera sencilla si se desea.
3.2. Conjuntos de datos
Para este análisis se han seleccionado 6 posts publicados recientemente en el portal de datos abiertos datos.gob.es, en su sección de blog. Estos posts están relacionado con diferentes temáticas relativas a los datos abiertos:
- Lo último en el procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cientos de palabras.
- La importancia de la anonimización y la privacidad de datos.
- El valor de los datos en tiempo real a través de un ejemplo práctico.
- Nuevas iniciativas para abrir y aprovechar datos para investigación en salud.
- Kaggle y otras plataformas alternativas para aprender ciencia de datos.
- La infraestructura de Datos Espaciales de España (IDEE), un referente de la información geoespacial.
4. Tratamiento de datos
Antes de lanzarnos a construir una visualización efectiva, debemos realizar un tratamiento previo de los datos o preprocesamiento de los datos, prestando atención a la obtención de los mismos, asegurando que no contienen errores y se encuentran en un formato adecuado para su procesamiento. Un tratamiento previo de los datos es esencial para construir cualquier representación visual efectiva y consistente.
En PLN, el preprocesamiento de los datos consiste fundamentalmente en una serie de transformaciones que se realizan sobre los datos de entrada, en nuestro caso varios posts en formato TXT, con el objetivo de obtener datos uniformes y sin elementos que puedan afectar a la calidad de los resultados, con el fin de facilitar su posterior procesamiento para realizar tareas como, generar una nube de palabras, realizar minería de opiniones/sentimientos o generar resúmenes automatizados a partir de textos de entrada. De forma general, el flujograma que se sigue para realizar un preprocesamiento de texto incluye las siguientes etapas:
- Limpieza: eliminación de los caracteres y símbolos especiales que contribuyen a distorsionar los resultados, por ejemplo, los signos de puntuación.
- Tokenizar: la tokenización es el proceso de separar un texto en unidades más pequeñas, tokens. Los tokens pueden ser oraciones, palabras o incluso caracteres.
- Derivación y Lematización: este proceso consiste en transformar las palabras a su forma básica, es decir a su forma canónica o lema, eliminando plurales, tiempos verbales o géneros. Esta acción en ocasiones no es necesaria ya que no siempre se requiere para el procesamiento posterior saber la similitud semántica entre las diferentes palabras del texto.
- Eliminación de stop words: las stop words o palabras vacías son aquellas palabras de uso común pero que no contribuyen de una manera significativa en el texto. Estas palabras deben eliminarse antes del procesamiento del texto ya que no aportan ninguna información única que pueda ser usada para la clasificación o agrupación del texto, por ejemplo, los artículos determinantes como ‘los’, ‘las’, ‘una’ ‘unos’, etc.
- Vectorización: en este paso transformamos cada uno de los tokens obtenidos en el paso anterior a un vector de números reales que se genera en base a la frecuencia de la aparición de cada palabra en el texto. La vectorización permite que las maquinas sean capaces de procesar texto y aplicar, entre otras, técnicas de aprendizaje automático.
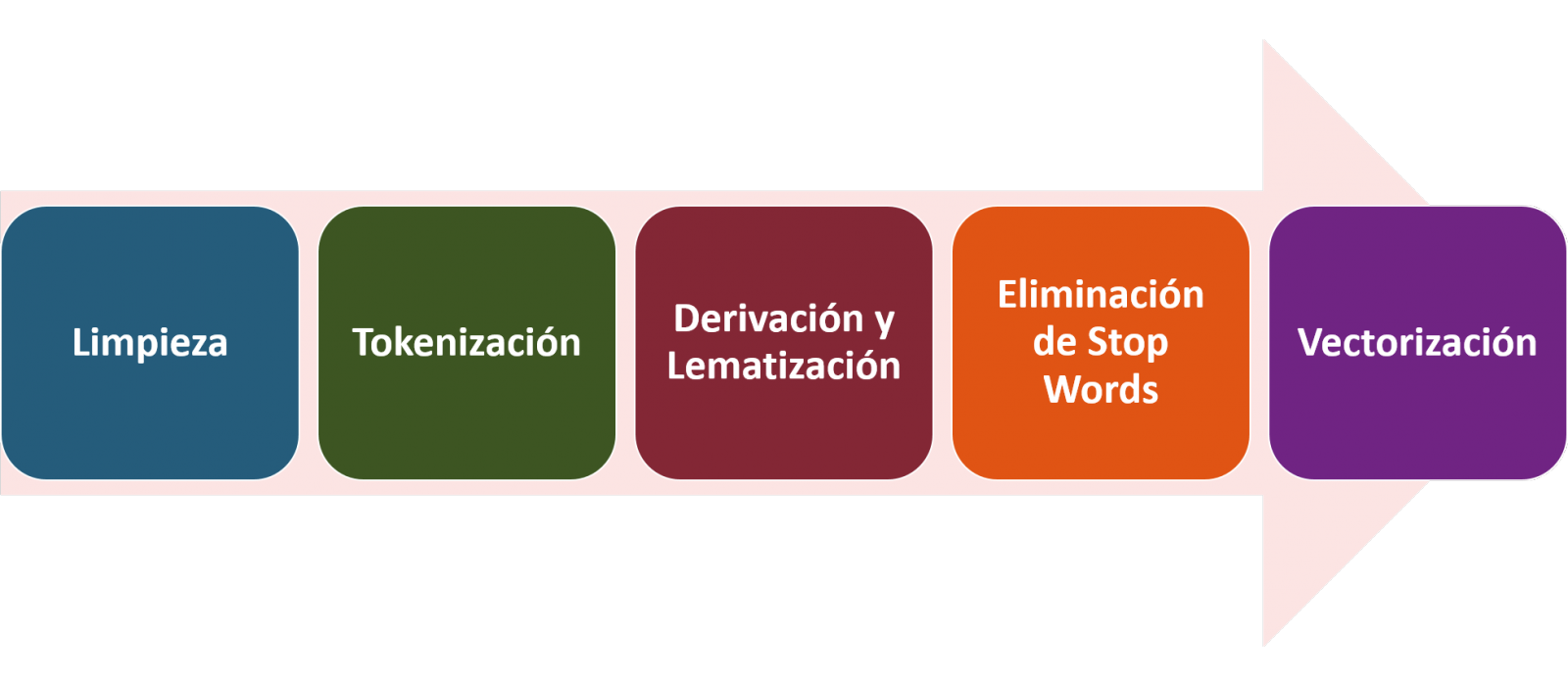
4.1. Instalación y carga de librerías
Antes de empezar con el preprocesamiento de datos, debemos importar las librerías con las cuales vamos a trabajar. Python dispone de una gran cantidad de librerías que permiten implementar funcionalidades para muchas tareas, como visualización de datos, Machine Learning, Deep Learning o Procesamiento del Lenguaje Natural, entre muchas otras. Las librerías que utilizaremos para este análisis y visualización son:
- os, que permite acceder a funcionalidades dependientes del sistema operativo, como manipular la estructura de directorios.
- re, proporciona funciones para procesar expresiones regulares.
- pandas, es una librería muy popular y esencial para procesar tablas de datos.
- string, proporciona una serie de funciones muy útiles para el manejo de cadenas de caracteres.
- matplotlib.pyplot, contiene una colección de funciones que nos permitirán generar las representaciones gráficas de las nubes de palabras.
- sklearn.feature_extraction.text (librería Scikit-Learn), convierte una colección de documentos de texto en una matriz de vectores. De esta librería usaremos algunos comandos que comentaremos más adelante.
- wordcloud, librería con la cual podremos generar la nube de palabras.
# Importaremos las librerías necesarias para realizar este análisis y la visualización. import os import re import pandas as pd import string import matplotlib.pyplot as plt from sklearn.feature_extraction.text import CountVectorizer from sklearn.feature_extraction.text import TfidfTransformer from wordcloud import WordCloud4.2. Carga de datos
Una vez cargadas las librerías, preparamos los datos con los cuales vamos a trabajar. Antes de comenzar a cargar los datos, en el directorio de trabajo debemos tener: (a) una carpeta denominada “post” que contendrá todos los archivos en formato TXT con los cuales vamos a trabajar y que están disponibles en el repositorio de este proyecto del GitHub de datos.gob.es; (b) un archivo denominado “stop_words_spanish.txt” que contiene el listado de las stop words en español, que también está disponible en dicho repositorio y (c) una carpeta llamada “imagenes” donde guardaremos las imágenes de las nubes de palabras en formato PNG, que crearemos a continuación.
# Generamos la carpeta \"imagenes\".nueva_carpeta = \"imagenes/\" try: os.mkdir(nueva_carpeta)except OSError: print (\"Ya existe una carpeta llamada %s\" % nueva_carpeta)else: print (\"Se ha creado la carpeta: %s\" % nueva_carpeta)Seguidamente, procederemos a cargar los datos. Los datos de entrada, como ya hemos comentado anteriormente, se encuentran en ficheros TXT y cada fichero contiene un post. Como queremos realizar el análisis y la visualización de varios posts al mismo tiempo, cargaremos en nuestro entorno de desarrollo todos los textos que nos interesen, para posteriormente insertarlos en una única tabla o dataframe.
# Generamos una lista donde incluiremos todos los archivos que debe leer, indicándole la carpeta donde se encuentran.filePath = []for file in os.listdir(\"./post/\"): filePath.append(os.path.join(\"./post/\", file))# Generamos un dataframe en el cual incluiremos una fila por cada post.post_df = pd.DataFrame()for file in filePath: with open (file, \"rb\") as readFile: post_df = pd.DataFrame([readFile.read().decode(\"utf8\")], append(post_df)# Nombramos la columna que contiene los textos en el dataframe.post_df.columns = [\"texto\"]4.3. Preprocesamiento de datos
Para el objetivo que nos hemos planteado, generar nubes de palabras para cada post, vamos a realizar las siguientes tareas de preprocesamiento.
a) Limpieza de datos
Una vez generada la tabla que contiene los textos con los cuales vamos a trabajar, debemos eliminar el ruido ajeno al texto que nos interesa: caracteres especiales, signos de puntuación y retornos de carro.
En primer lugar, ponemos en minúscula todos los caracteres para evitar cualquier error en los procesos que distinguen entre mayúsculas y minúsculas, mediante el uso del comando lower().
Seguidamente eliminamos los signos de puntuación, como puntos, comas, exclamaciones, interrogaciones, entre muchos otros. Para la eliminación de estos recurriremos a la cadena preinicializada string.punctuacion de la librería string, que devuelve un conjunto de símbolos considerados signos de puntuación. Además, debemos eliminar las tabulaciones, saltos de carro y espacios extra, que no aportan información en este análisis, mediante el uso de expresiones regulares.
Es fundamental aplicar todos estos pasos en una única función para que se procesen de forma secuencial, debido a que todos los procesos están altamente relacionados.
# Eliminamos los signos de puntuación, los saltos de carro/tabulaciones y espacios en blanco extra.# Para ello generamos una función en la cual indicamos todos los cambios que queremos aplicar al texto.def limpiar_texto(texto): texto = texto.lower() texto = re.sub(\"\\[.*?¿\\]\\%\", \" \", texto) texto = re.sub(\"[%s]\" % re.escape(string.punctuation), \" \", texto) texto re.sub(\"\\w*\\d\\w*\", \" \", texto) return texto# Aplicamos los cambios al texto.limpiar_texto = lambda x: limpiar_texto(x)post_clean = pd.DataFrame(post_clean.texto.apply/limpiar_texto)b) Tokenizar
Una vez que hemos eliminado el ruido en los textos con los cuales vamos a trabajar, “tokenizaremos” en palabras cada uno de los textos. Para ello utilizaremos la funció split(), usando como separador entre palabras, el espacio. Esto permitirá separar las palabras de manera independiente (tokens) para análisis futuros.
# Tokenizar los textos. Se crea una nueva columna en la tabla con los tokens con el texto \"tokenizado\".def tokenizar(text): text = texto.split(sep = \" \") return(text)post_df[\"texto_tokenizado\"] = post_df[\"texto\"].apply(lambda x: tokenizar(x))c) Eliminación de \"stop words\"
Después de eliminar los signos de puntuación y otros elementos que pueden distorsionar la visualización objetivo, eliminaremos las “stop words” o palabras vacías. Para la realización de este paso usamos una lista de stop words del castellano dado que cada idioma posee su propia lista. Esta lista consta de un total de 608 palabras, en las que se incluyen artículos, preposiciones, verbos copulativos, adverbios, entre otros y está actualizada recientemente. Esta lista puede descargarse desde la cuenta de GitHub de datos.gob.es en formato TXT y debe estar ubicada en el directorio de trabajo.
# Leemos el archivo que contiene las palabras vacías en castellano.with open \"stop_words_spanish.txt\", encoding = \"UTF8\") as f: lines = f.read().splitlines()En esta lista de palabras, incluiremos nuevas palabras que no aportan información relevante a nuestros textos o aparecen recurrentemente debido al contexto de los mismos. En este caso, existe una serie de palabras, que nos conviene eliminar ya que están presentes en todos los posts de manera repetitiva dado que todos tratan sobre el tema de datos abiertos y existe una alta probabilidad de que éstas sean las palabras más significativas. Algunas de estas palabras son, “datos”, “dato”, “abiertos”, “caso”, entre otras. Esto permitirá obtener una representación gráfica más representativa del contenido de cada post.
Por otro lado, una inspección visual de los resultados obtenidos permite detectar palabras o caracteres derivados de errores incluidos en los textos, que evidentemente no tienen significado y que no han sido eliminados en los pasos anteriores. Estos, deben ser retirados del análisis para que no distorsionen los resultados posteriores. Se trata de palabras como, “nen”, “nun” o “nla”.
# Actualizamos nuestra lista de stop words.stop_words.extend((\"caso\", \"forma\",\"unido\", \"abiertos\", \"post\", \"espera\", \"datos\", \"dato\", \"servicio\", \"nun\", \"día\", \"nen\", \"data\", \"conjuntos\", \"importantes\", \"unido\", \"unión\", \"nla\", \"r\", \"n\"))# Eliminamos las stop words de nuestra tabla.post_clean = post_clean [~(post_clean[\"texto_tokenizado\"].isin(stop_words))]d) Vectorización
Las maquinas no son capaces de comprender palabras y oraciones, por lo que estas deben convertirse en alguna estructura numérica. El método consiste en generar vectores a partir de cada token. En este post utilizamos una técnica sencilla conocida como bolsa de palabras (BoW). Consiste en asignar un peso a cada token proporcional a la frecuencia de aparición de dicho token en el texto. Para ello, trabajamos sobre una matriz en la que cada fila representa un texto y cada columna un token. Para realizar la vectorización recurriremos a los comandos CountVectorizer() y TfidTransformer() de la lirería Scikit-Learn.
La función CountVectorizer() permite transformar un texto en un vector de frecuencias o recuentos de palabras. En este caso obtendremos 6 vectores con tantas dimensiones como tokens hay en cada texto, uno por cada post, que integraremos en una única matriz, donde las columnas serán los tokens o palabras y las filas serán los posts.
# Calculamos la matriz de frecuencia de palabras del texto.vectorizador = CountVectorizer()post_vec = vectorizador.fit_transform(post_clean.texto_tokenizado)Una vez generada la matriz de frecuencia de palabras, es necesario convertirla en una forma vectorial normalizada con el objetivo de reducir el impacto de los tokens que ocurren con mucha frecuencia en el texto. Para ello utilizaremos la función TfidfTransformer().
# Convertimos una matriz de frecuencia de palabras en una forma vectorial regularizada.transformer = TfidfTransformer()post_trans = transformer.fit_transform(post_vec).toarray()Si quieres saber más sobre la importancia de aplicar está técnica, encontrarás numerosos artículos en Internet que hablan sobre ello y lo relevante que es, entre otras cuestiones, para la optimización de SEO.
5. Creación de la nube de palabras
Una vez que hemos realizado un preprocesamiento del texto, como indicábamos al inicio del post, es posible realizar tareas propias de PLN. En este ejercicio crearemos una nube de palabras o “WordCloud” para cada uno de los textos analizados.
Una nube de palabras, es una representación visual de las palabras con mayor número de ocurrencias en el texto. Permite detectar de manera sencilla la frecuencia e importancia de cada una de las palabras, facilitando la identificación de las palabras clave y descubriendo con un solo golpe de vista la temática principal tratada en el texto.
Para ello vamos a utilizar la librería “wordcloud” que incorpora las funciones necesarias para construir cada representación. En primer lugar, debemos indicar las características que presentará cada nube de palabras, como es el color de fondo (función background_color), el mapa de colores que tomaran las palabras (función colormap), el tamaño máximo de letra (función max_font_size) o fijar una semilla para que la nube de palabras generada siempre sea igual (función random_state) en futuras ejecuciones. Podemos aplicar estas y muchas otras funciones para personalizar cada nube de palabras.
# Indicamos las características que presentará cada nube de palabras.wc = WordCloud(stopwords = stop_words, background_color = \"black\", colormap = \"hsv\", max_font_size = 150, random_state = 123)Una vez que hemos indicado las características que queremos que presente cada nube de palabras, procedemos a crearla y guardarla como imagen en formato PNG. Para generar la nube de palabras, usaremos un bucle en el cual le indicaremos diferentes funciones de la librería matplotlib (representada por el prefijo plt) necesarias para generar gráficamente la nube de palabras según la especificación definida en el paso anterior. Debemos indicarle que debe realizar una nube de palabras por cada fila de la tabla, es decir por cada texto, con la función plt.subplot(). Con el comando plt.imshow() indicamos que el resultado es una imagen en 2D. Si queremos que no se muestren los ejes debemos indicárselo con la función plt.axis(). Por último, con la función plt.savefig() guardaremos la visualización generada.
# Generamos las nubes de palabras para cada uno de los posts.for index, i in enumerate(post.columns): wc.generate(post.texto_tokenizado[i]) plt.subplot(3, 2, index+1 plt.imshow(wc, interpolation = \"bilinear\") plt.axis(\"off\") plt.savefig(\"imagenes/.png\")# Mostramos las nubes de palabras resultantes.plt.show()La visualización obtenida es:

Visualización de las nubes de palabras obtenidas a partir de los textos de diferentes posts de la sección de blog de datos.gob.es
5. Conclusiones
La visualización de datos es uno de los mecanismos más potentes para explotar y analizar el significado implícito de los datos, independientemente del tipo de dato y el grado de conocimiento tecnológico del usuario. Las visualizaciones nos permiten construir significado sobre los datos y la creación de narrativas basadas en la representación gráfica.
Las nubes de palabras son una herramienta que permite agilizar el análisis de datos textuales, puesto que a través de ellas podemos identificar e interpretar de manera rápida y sencilla las palabras con mayor relevancia en el texto analizado, lo que nos da una idea de la temática.
Si quieres aprender más sobre el Procesamiento del Lenguaje Natural, puedes consultar la guía \"Tecnologías emergentes y datos abiertos: Procesamiento del lenguaje natural\" y los posts \"Procesamiento del lenguaje natural\" y \"Lo último en procesamiento del lenguaje natural: resúmenes de obras clásicas en tan solo unos cuentos de palabras\".
Esperemos que esta visualización paso a paso te haya enseñado algunas cosas sobre los entresijos del Procesamiento del Lenguaje Natural y la creación de nubes de palabras. Volveremos para mostraros nuevas reutilizaciones de datos. ¡Hasta pronto!