Documentación
Introducción
En anteriores contenidos, hemos explorado a fondo el apasionante mundo de los Modelos Grandes de Lenguaje (LLM) y, en particular, las técnicas de Generación Aumentada por Recuperación (RAG) que están revolucionando la forma en que interactuamos con los agentes conversacionales. Este ejercicio marca un hito en nuestra serie, ya que no solo explicaremos los conceptos, sino que también te guiaremos paso a paso en la construcción de tu propio agente conversacional potenciado con RAG. Para ello, utilizaremos un notebook de Google Colab.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
A través de este notebook, construiremos un chat que utiliza RAG para mejorar sus respuestas, partiendo desde cero. El notebook guiará al usuario a través de todo el proceso:
- Instalación de dependencias.
- Configuración del entorno.
- Integración de una fuente de información en forma de post.
- Incorporación de dicha fuente a la base de conocimiento del chat utilizando técnicas RAG.
- Finalmente, podremos observar cómo la respuesta del modelo cambia antes y después de proporcionar el post y realizar una pregunta específica sobre su contenido.
Herramientas utilizadas
Antes de comenzar, es necesario introducir y explicar qué herramientas hemos utilizado y por qué hemos escogido estas. Para la construcción de esta aplicación RAG hemos utilizado 3 piezas de tecnología o herramientas: Google Colab, OpenAI y LangChain. Tanto Google Colab como OpenAI son viejos conocidos y los hemos utilizado varias veces en contenidos previos. Por eso, en esta sección, ponemos especial atención en explicar qué es LangChain puesto que es una nueva herramienta que no hemos utilizado en anteriores posts.
- Google Colab. Como es habitual en nuestros ejercicios, cuando son necesarios recursos de computación, así como un entorno de programación amigable, empleamos Google Colab, en la medida de lo posible. Google Colab nos garantiza que cualquier usuario que quiera reproducir el ejercicio lo pueda hacer sin complicaciones derivadas de la configuración de los entornos particulares de cada programador. Cabe destacar que adecuar este ejercicio inspirado en recursos previos disponibles en LangChain al entorno de Google Colab ha sido un reto.
- OpenAI. Como proveedor del modelo grande del lenguaje (LLM) Chat GPT, OpenAI ofrece una variedad de modelos de lenguaje potentes, como GPT-4, GPT-4o, GPT-4o mini, etc. que se utilizan para procesar y generar texto en lenguaje natural. En este caso, el modelo de lenguaje de OpenAI se utiliza en la zona de generación de la respuesta, donde se combinan la pregunta del usuario y los documentos recuperados para producir una respuesta precisa.
- LangChain. Es un framework (conjunto de bibliotecas) de código abierto diseñado para facilitar el desarrollo de aplicaciones basadas en modelos de lenguaje de gran escala (LLM). Este framework es especialmente útil para integrar y gestionar flujos complejos que combinan múltiples componentes, como modelos de lenguaje, bases de datos vectoriales, y herramientas de recuperación de información, entre otros.
LangChain es ampliamente utilizado en el desarrollo de aplicaciones como:
- Sistemas de preguntas y respuestas (QA systems).
- Asistentes virtuales con conocimiento específico.
- Sistemas de generación de texto personalizados.
- Herramientas de análisis de datos basadas en lenguaje natural.
Características principales de LangChain
- Modularidad y flexibilidad. LangChain está diseñado con una arquitectura modular que permite a los desarrolladores conectar diferentes herramientas y servicios. Esto incluye modelos de lenguaje (como OpenAI, Hugging Face, o LLM locales) y bases de datos vectoriales (como Pinecone, ChromaDB o Weaviate). La La lista de modelos de chat con los que se puede interactuar a través de Langchain es muy amplia.
- Soporte para técnicas RAG (Recuperación Aumentada por Generación). Langhain facilita la implementación de técnicas RAG al permitir la integración directa de modelos de recuperación de información y generación de texto. Esto mejora la precisión de las respuestas al permitir que los LLM trabajen con conocimiento actualizado y específico.
- Optimización del manejo de prompts. Langhain ayuda a diseñar y gestionar prompts complejos de manera eficiente. Permite construir dinámicamente un contexto relevante que se trabaja con el modelo, optimizando el uso de tokens y asegurando que las respuestas sean precisas y útiles.
- Los tokens representan las unidades básicas que un modelo de IA utiliza para procesar texto. Un token puede ser una palabra completa, una parte de una palabra o un signo de puntuación. En la frase "¡Hola mundo!" existen, por ejemplo, cuatro tokens distintos: "¡", "Hola", "mundo", "!". El procesamiento de texto requiere más recursos computacionales a medida que aumenta el número de tokens. Las versiones gratuitas de modelos de IA, incluida la que usamos en este ejercicio, establecen límites en la cantidad de tokens procesables.
- Integración con múltiples fuentes de datos. El framework puede conectarse a diversas fuentes de datos, como bases de datos, API o documentos cargados por los usuarios. Esto lo hace ideal para construir aplicaciones que necesitan acceso a grandes volúmenes de información estructurada o no estructurada.
- Interoperabilidad con múltiples LLM. LangChain es agnóstico (se puede adaptar a varios proveedores de modelos de lenguaje) respecto al proveedor del modelo de lenguaje, lo que significa que puedes utilizar OpenAI, Cohere, Anthropic o incluso modelos de lenguaje alojados localmente.
Para terminar con esta sección, cabe destacar el carácter open source de Langhain, algo que facilita la colaboración y la innovación en el desarrollo de aplicaciones basadas en modelos de lenguaje. Además, LangChain nos aporta una increíble flexibilidad porque permite a los desarrolladores integrar fácilmente diferentes LLM, vectorizadores y hasta interfaces web finales en sus aplicaciones.
Exploración del ejercicio paso a paso
Introducción al Repositorio
El repositorio de Github que utilizaremos contiene todos los recursos necesarios para construir nuestra aplicación RAG. En su interior, encontrarás:
- README: este archivo proporciona una descripción general del proyecto, instrucciones de uso y recursos adicionales.
- Jupyter Notebook: el ejemplo lo hemos desarrollado usando un formato de Jupyter Notebook que ya hemos empleado en el pasado para codificar ejercicios prácticos combinando un documento de texto con fragmentos de código ejecutable en Google Colab. Aquí se encuentra la implementación detallada de la aplicación, incluyendo la carga y procesamiento de datos, la integración con modelos de lenguaje como GPT-44, la configuración de sistemas de recuperación de información y la generación de respuestas basadas en los datos recuperados.
Notebook: preparando el entorno
Antes de comenzar, es recomendable contar con los siguientes requisitos.
- Conocimientos básicos de Python y Procesamiento de Lenguaje Natural (PLN): si bien el notebook es autoexplicativo, una comprensión básica de estos conceptos facilitará el aprendizaje.
- Acceso a Google Colab: el notebook se ejecuta en este entorno, que nos proporciona la infraestructura necesaria.
- Cuentas activas en OpenAI y LangChain con claves de API válidas. Estos servicios son gratuitos y esenciales para la ejecución del notebook. Una vez que te registres en estos servicios, necesitarás generar una API Key para interactuar con los servicios. Deberás tener a mano esta clave para poder pegarla en el momento de ejecutar el fragmento de código correspondiente. Si necesitas ayuda para obtener estas claves, cualquier asistente conversacional como chatGPT o Google Gemini te pueden ayudar paso a paso a conseguir las claves. Si necesitas guía visual en youtube encontraras miles de tutoriales
- OpenAI API: https://openai.com/api/
- Lanchain API: https://www.langchain.com/
Explorando el Notebook: bloque por bloque
El notebook se divide en varios bloques, cada uno dedicado a una etapa específica del desarrollo de nuestra aplicación RAG. A continuación, describiremos cada bloque en detalle, incluyendo el código utilizado y su explicación.
Nota para el usuario. A continuación, vamos a ir reproduciendo bloques del código presentes en el notebook de Colab. Por claridad hemos dividido el código en unidades autocontenidas y hemos formateado el código para resaltar la sintaxis del lenguaje de programación Python. Además, las salidas que el Notebook proporciona, las hemos formateado y resaltado en formato JSON para que sean más legibles. Ha de tenerse en cuenta que este Notebook invoca API de modelos del lenguaje y por lo tanto, la respuesta del modelo cambia con cada ejecución. Esto hace que las salidas (las respuestas) que presentamos en este post puedan no ser exactamente iguales a las que el usuario reciba cuándo ejecute el Notebook en Colab
Bloque 1: instalación y configuración inicial
|
import os |
Es muy importante que ejecutes estas dos líneas al principio del ejercicio y luego ya no lo vuelvas a ejecutar más hasta que cierres y salgas de Google Colab.
|
%%capture |
|
!pip install langchain --quiet |
|
import getpass os.environ["LANGCHAIN_TRACING_V2"] = "true" |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de Langchain.
|
!pip install -qU langchain-openai |
|
import getpass |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de OpenAI.
En este primer bloque, hemos instalado las bibliotecas necesarias para nuestro proyecto. Algunas de las más relevantes son:
- openai: Para interactuar con la API de OpenAI y acceder a modelos como GPT-4.
- langchain: Un framework que simplifica el desarrollo de aplicaciones con LLM.
- langchain-text-splitters: Para dividir textos largos en fragmentos más pequeños que puedan ser procesados por los modelos de lenguaje.
- langchain-community: Una colección de herramientas y componentes adicionales para LangChain.
- langchain-openai: Para integrar LangChain con la API de OpenAI.
- langgraph: Para visualizar el flujo de trabajo de nuestra aplicación RAG.
- Además de instalar las bibliotecas, también configuramos las claves de API para OpenAI y LangChain, utilizando la función getpass.getpass() para introducirlas de forma segura.
Bloque 2: inicializamos la interacción con el LLM
A continuación, iniciamos la primera interacción programática (le pasamos nuestro primer prompt) con el modelo del lenguaje. Para comprobar que todo funciona le pedimos traducir una sencilla frase.
|
import getpass import os ] |
Si todo ha ido bien obtendremos una salida como esta:
|
{ |
Este bloque es una introducción básica a la utilización de un LLM para una tarea sencilla: la traducción. Se configura la clave de API de OpenAI y se instancia un modelo de lenguaje gpt-4o-mini utilizando ChatOpenAI.
Se definen dos mensajes:
- SystemMessage: Instrucción al modelo para traducir del inglés al italiano.
- HumanMessage: El texto que se desea traducir ("hi!").
Finalmente, se invoca al modelo con llm.invoke(messages) para obtener la traducción.
Bloque 3: creando Embeddings
Para entender el concepto del Embeddings aplicado al contexto del procesamiento del lenguaje natural recomendamos leer este post.
|
import getpass pip install -qU langchain-core from langchain_core.vectorstores import InMemoryVectorStore |
Cuando ejecutes este fragmento, aparecerá un pequeño cuadro de diálogo debajo del fragmento. Ahí debes de pegar tu API Key de OpenAI.
Este bloque se centra en la creación de embeddings (representaciones vectoriales de texto) que capturan su significado semántico. Utilizamos la clase OpenAIEmbeddings para acceder al modelo text-embedding-3-large de OpenAI, que genera embeddings de alta calidad.
Los embeddings se almacenarán en un InMemoryVectorStore, una estructura de datos en memoria que permite realizar búsquedas eficientes basadas en similitud semántica.
Bloque 4: implementando RAG
|
#RAG import bs4 from langchain_community.document_loaders import WebBaseLoader # Manten únicamente el título del post, los encabezados y el contenido del HTML bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://datos.gob.es/es/blog/slm-llm-rag-y-fine-tuning-pilares-de-la-ia…",) ) docs = loader.load() assert len(docs) == 1 print(f"Total characters: {len(docs.page_content)}") from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True, ) all_splits = text_splitter.split_documents(docs) print(f"Split blog post into {len(all_splits)} sub-documents.") document_ids = vector_store.add_documents(documents=all_splits) print(document_ids[:3]) |
Este bloque es el corazón de la implementación RAG. Comienza cargando el contenido de un post, utilizando WebBaseLoader y la URL del post sobre SLM, LLM, RAG y Fine-tuning.
Para preparar nuestro sistema de Recuperación Aumentada por Generación (RAG), comenzamos procesando el texto del post mediante técnicas de segmentación. Este paso inicial resulta fundamental, ya que dividimos el contenido en fragmentos más pequeños pero completos en significado. Utilizamos las herramientas de LangChain para realizar esta segmentación, asignando a cada fragmento un identificador único (id). Esta preparación previa nos permite posteriormente realizar búsquedas eficientes y precisas cuando el sistema necesite recuperar información relevante para responder a las consultas.
Se utiliza bs4.SoupStrainer para extraer solo las secciones relevantes del HTML. El texto del post se divide en fragmentos más pequeños con RecursiveCharacterTextSplitter, asegurando un solapamiento entre fragmentos para mantener el contexto. Estos fragmentos se añaden al vector_store creado en el bloque anterior, generando embeddings para cada uno.
Vemos que el resultado de uno de los fragmentos nos informa que ha dividido el documento en 21 sub-documentos.
|
Split blog post into 21 sub-documents. |
Los documentos tienen un identificador propio. Por ejemplo, los 3 primeros se identifican como:
|
["409f1bcb-1710-49b0-80f8-e45b7ca51a96", "e242f16c-71fd-4e7b-8b28-ece6b1e37a1c", "9478b11c-61ab-4dac-9903-f8485c4770c6"] |
Bloque 5: definiendo el Prompt y visualizando el flujo de trabajo
|
from langchain import hub prompt = hub.pull("rlm/rag-prompt") example_messages = prompt.invoke( {"context": "(context goes here)", "question": "(question goes here)"} ).to_messages() assert len(example_messages) == 1 print(example_messages.content) from langchain_core.documents import Document from typing_extensions import List, TypedDict class State(TypedDict): question: str context: List[Document] answer: str def retrieve(state: State): retrieved_docs = vector_store.similarity_search(state["question"]) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} from langgraph.graph import START, StateGraph graph_builder = StateGraph(State).add_sequence([retrieve, generate]) graph_builder.add_edge(START, "retrieve") graph = graph_builder.compile() from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png())) result = graph.invoke({"question": "What is Task Decomposition?"}) print(f"Context: {result["context"]}\n\n") print(f"Answer: {result["answer"]}") for step in graph.stream( {"question": "¿Cual es el futuro de la IA Generativa?"}, stream_mode="updates" ): print(f"{step}\n\n----------------\n") |
Este bloque define el prompt que se utilizará para interactuar con el LLM. Se utiliza un prompt predefinido de LangChain Hub (rlm/rag-prompt) que está diseñado para tareas RAG.
Se definen dos funciones:
- retrieve: busca en el vector_store los fragmentos más similares a la pregunta del usuario.
- generate: genera una respuesta utilizando el LLM, teniendo en cuenta el contexto proporcionado por los fragmentos recuperados.
Se utiliza langgraph para visualizar el flujo de trabajo RAG.
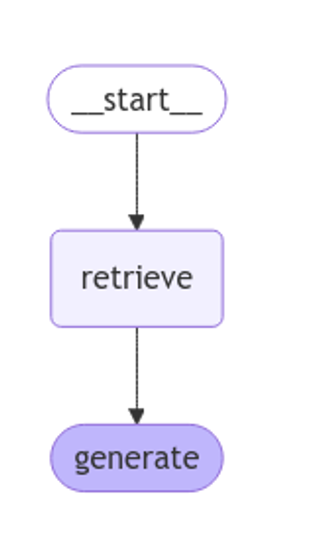
Figura 1: flujo de trabajo RAG. Elaboración propia.
Finalmente, se prueba el sistema con dos preguntas: una en inglés ("What is Task Decomposition?") y otra en español ("¿Cual es el futuro de la IA Generativa?").
La primera pregunta, "What is Task Decomposition?, está en inglés y es una pregunta genérica, sin relación con nuestro post de contenido. Por esto, pese a que el sistema, busca en su base de conocimiento previamente creada con la vectorización del documento (post) no encuentra relación entre la pregunta y este contexto.
Este texto puede variar con cada ejecución
|
Answer: No se menciona explícitamente el concepto de "Task Decomposition" en el contexto proporcionado. Por lo tanto, no tengo información sobre qué es Task Decomposition. |
|
Answer: Task Decomposition es un proceso que descompone una tarea compleja en subtareas más pequeñas y manejables. Esto permite abordar cada subtarea de manera independiente, facilitando su resolución y mejorando la eficiencia general. Aunque el contexto proporcionado no define explícitamente Task Decomposition, este concepto es común en la IA y optimización de tareas. |
Esta respuesta es la que proporciona el modelo del lenguaje sin ninguna base de conocimiento específica. Ahora bien, cuando preguntamos por algo que tiene que ver con el post que hemos cargado como base de conocimiento, la técnica RAG entra en funcionamiento y ejecuta los mecanismos secuenciales de retrieve y generate.
|
{ |
Cómo se ve en la respuesta, el sistema recupera 4 documentos (en el diagrama anterior, esto corresponde a la etapa de “Retrieve”) con sus correspondientes “id” (identificadores) cómo por ejemplo, el primer documento "id": "53962c40-c08b-4547-a74a-26f63cced7e8" que se corresponde con un fragmento del post original "title": "SLM, LLM, RAG y Fine-tuning: Pilares de la IA Generativa Moderna | datos.gob.es"
Con esos 4 fragmentos el sistema considera que tiene suficiente información relevante para proporcionar (en el diagrama anterior, la etapa “generate”) una respuesta satisfactoria a la pregunta.
|
{ |
Bloque 6: personalizando el prompt
|
from langchain_core.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don"t know the answer, just say that you don"t know, don"t try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template) |
Este bloque personaliza el prompt para que las respuestas sean más concisas y añadan una frase de cortesía al final. Se utiliza PromptTemplate para crear un nuevo prompt con las instrucciones deseadas.
Bloque 7: añadiendo metadatos y refinando la búsqueda
|
total_documents = len(all_splits) third = total_documents // 3 for i, document in enumerate(all_splits): if i < third: document.metadata["section"] = "beginning" elif i < 2 * third: document.metadata["section"] = "middle" else: document.metadata["section"] = "end" all_splits.metadata from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings) _ = vector_store.add_documents(all_splits) from typing import Literal from typing_extensions import Annotated class Search(TypedDict): """Search query.""" query: Annotated[str, ..., "Search query to run."] section: Annotated( Literal["beginning", "middle", "end"], ..., "Section to query.", ] class State(TypedDict): question: str query: Search context: List[Document] answer: str def analyze_query(state: State): structured_llm = llm.with_structured_output(Search) query = structured_llm.invoke(state["question"]) return {"query": query} def retrieve(state: State): query = state["query"] retrieved_docs = vector_store.similarity_search( query["query"], filter=lambda doc: doc.metadata.get("section") == query["section"], ) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate]) graph_builder.add_edge(START, "analyze_query") graph = graph_builder.compile() display(Image(graph.get_graph().draw_mermaid_png())) for step in graph.stream( {"question": "¿Cual es el furturo de la IA Generativa en palabras del autor?"}, stream_mode="updates", ): print(f"{step}\n\n----------------\n") |
En este bloque, se añaden metadatos a los fragmentos del post, dividiéndolos en tres secciones: "beginning", "middle" y "end". Esto permite realizar búsquedas más refinadas, limitando la búsqueda a una sección específica del post.
Se introduce una nueva función analyze_query que utiliza el LLM para determinar la sección del post más relevante para la pregunta del usuario. El flujo de trabajo RAG se actualiza para incluir esta nueva etapa.
Finalmente, se prueba el sistema con una pregunta en español ("¿Cuál es el futuro de la IA Generativa en palabras del autor?"), observando cómo el sistema utiliza la información de la sección "end" del post para generar una respuesta más precisa.
Veamos el resultado:

Figura 2: flujo de trabajo RAG. Elaboración propia.
|
{ ---------------- { |
|
{ |
Conclusiones
A través de este recorrido por el notebook de Google Colab, hemos experimentado de primera mano la construcción de un agente conversacional con RAG. Hemos aprendido a:
- Instalar las bibliotecas necesarias.
- Configurar el entorno de desarrollo.
- Cargar y procesar datos.
- Crear embeddings y almacenarlos en un vector_store.
- Implementar las etapas de recuperación y generación de RAG.
- Personalizar el prompt para obtener respuestas más específicas.
- Añadir metadatos para refinar la búsqueda.
Este ejercicio práctico te proporciona las herramientas y conocimientos necesarios para comenzar a explorar el potencial de RAG y desarrollar tus propias aplicaciones.
¡Anímate a experimentar con diferentes fuentes de información, modelos de lenguaje y prompts para crear agentes conversacionales cada vez más sofisticados!
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
En el vertiginoso mundo de la Inteligencia Artificial (IA) Generativa, encontramos diversos conceptos que se han convertido en fundamentales para comprender y aprovechar el potencial de esta tecnología. Hoy nos centramos en cuatro: los Modelos de Lenguaje Pequeños (SLM, por sus siglas en inglés), los Modelos de Lenguaje Grandes (LLM), la Generación Aumentada por Recuperación (RAG) y el Fine-tuning. En este artículo, exploraremos cada uno de estos términos, sus interrelaciones y cómo están moldeando el futuro de la IA generativa.
Empecemos por el principio. Definiciones.
Antes de sumergirnos en los detalles, es importante entender brevemente qué representa cada uno de estos términos. Los dos primeros conceptos (SLM y LLM) que abordamos, son lo que se conoce cómo modelos del lenguaje. Un modelo de lenguaje es un sistema de inteligencia artificial que entiende y genera texto en lenguaje humano, como lo hacen los chatbots o los asistentes virtuales. Los siguientes dos conceptos (Fine Tuning y RAG), podríamos definirlos cómo técnicas de optimización de estos modelos del lenguaje previos. En definitiva, estás técnicas, con sus respectivos enfoques, que veremos más adelante, mejoran las respuestas y el contenido que devuelven al que pregunta. Vamos a por los detalles:
- SLM (Small Language Models): Modelos de lenguaje más compactos y especializados, diseñados para tareas específicas o dominios concretos.
- LLM (Large Language Models): Modelos de lenguaje de gran escala, entrenados con vastas cantidades de datos y capaces de realizar una amplia gama de tareas lingüísticas.
- RAG (Retrieval-Augmented Generation): Una técnica que combina la recuperación de información relevante con la generación de texto para producir respuestas más precisas y contextualizadas.
- Fine-tuning: El proceso de ajustar un modelo pre-entrenado para una tarea o dominio específico, mejorando su rendimiento en aplicaciones concretas.
Ahora, profundicemos en cada concepto y exploremos cómo se interrelacionan en el ecosistema de la IA Generativa.
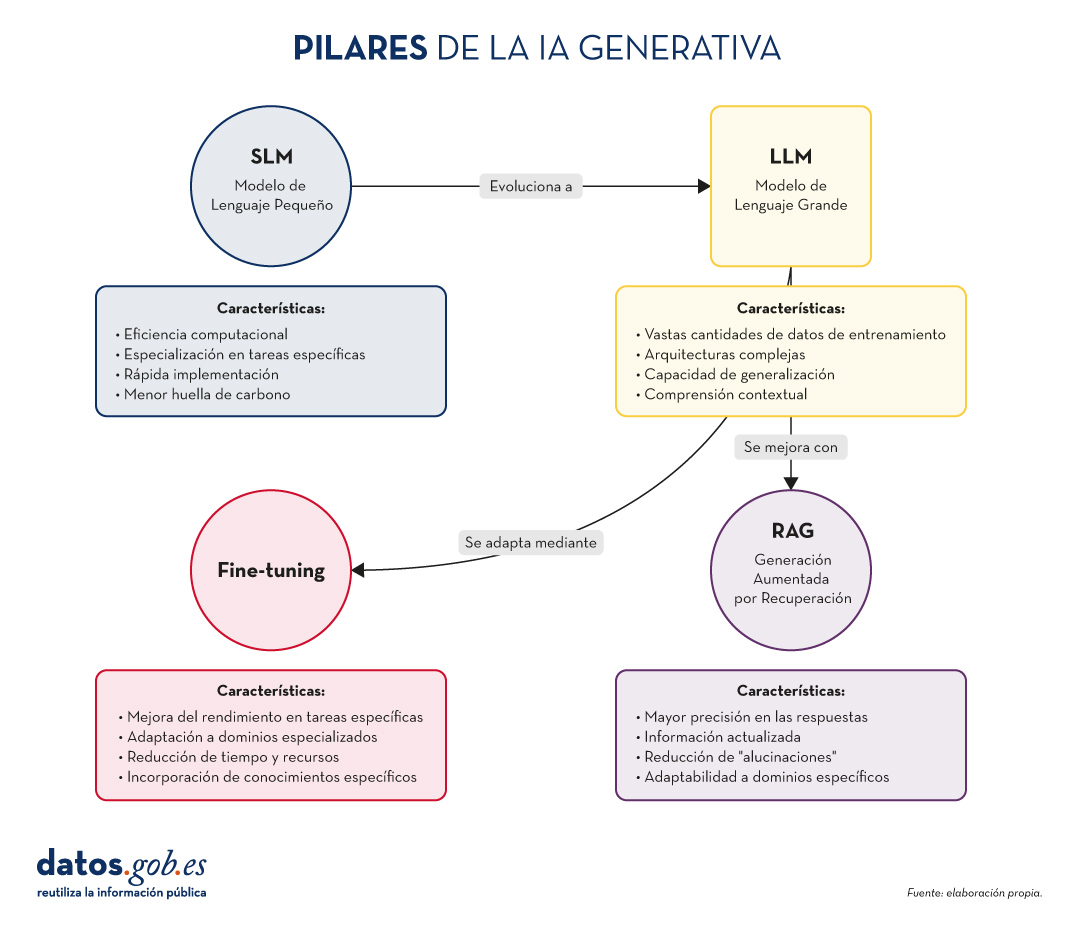
Figura 1. Pilares de la IA genrativa. Elaboración propia.
SLM: La potencia en la especialización
Mayor eficiencia para tareas concretas
Los Modelos de Lenguaje Pequeños (SLM) son modelos de IA diseñados para ser más ligeros y eficientes que sus contrapartes más grandes. Aunque tienen menos parámetros, están optimizados para tareas específicas o dominios concretos.
Características clave de los SLM:
- Eficiencia computacional: requieren menos recursos para su entrenamiento y ejecución.
- Especialización: se centran en tareas o dominios específicos, logrando un alto rendimiento en áreas concretas.
- Rápida implementación: ideal para dispositivos con recursos limitados o aplicaciones que requieren respuestas en tiempo real.
- Menor huella de carbono: al ser más pequeños, su entrenamiento y uso consumen menos energía.
Aplicaciones de los SLM:
- Asistentes virtuales para tareas específicas (por ejemplo, reserva de citas).
- Sistemas de recomendación personalizados.
- Análisis de sentimientos en redes sociales.
- Traducción automática para pares de idiomas específicos.
LLM: El poder de la generalización
La revolución de los Modelos de Lenguaje Grandes
Los LLM han transformado el panorama de la IA Generativa, ofreciendo capacidades sorprendentes en una amplia gama de tareas lingüísticas.
Características clave de los LLM:
- Vastas cantidades de datos de entrenamiento: se entrenan con enormes corpus de texto, abarcando diversos temas y estilos.
- Arquitecturas complejas: utilizan arquitecturas avanzadas, como Transformers, con miles de millones de parámetros.
- Capacidad de generalización: pueden abordar una amplia variedad de tareas sin necesidad de entrenamiento específico para cada una.
- Comprensión contextual: son capaces de entender y generar texto considerando contextos complejos.
Aplicaciones de los LLM:
- Generación de texto creativo (historias, poesía, guiones).
- Respuesta a preguntas complejas y razonamientos.
- Análisis y resumen de documentos extensos.
- Traducción multilingüe avanzada.
RAG: Potenciando la precisión y relevancia
La sinergia entre recuperación y generación
Como ya exploramos en nuestro artículo anterior, RAG combina la potencia de los modelos de recuperación de información con la capacidad generativa de los LLM. Sus aspectos fundamentales son:
Características clave de RAG:
- Mayor precisión en las respuestas.
- Capacidad de proporcionar información actualizada.
- Reducción de "alucinaciones" o información incorrecta.
- Adaptabilidad a dominios específicos sin necesidad de reentrenar completamente el modelo.
Aplicaciones de RAG:
- Sistemas de atención al cliente avanzados.
- Asistentes de investigación académica.
- Herramientas de fact-checking para periodismo.
- Sistemas de diagnóstico médico asistido por IA.
Fine-tuning: Adaptación y especialización
Perfeccionando modelos para tareas específicas
El fine-tuning es el proceso de ajustar un modelo pre-entrenado (generalmente un LLM) para mejorar su rendimiento en una tarea o dominio específico. Sus elementos principales son los siguientes:
Características clave del fine-tuning:
- Mejora significativa del rendimiento en tareas específicas.
- Adaptación a dominios especializados o nichos.
- Reducción del tiempo y recursos necesarios en comparación con el entrenamiento desde cero.
- Posibilidad de incorporar conocimientos específicos de la organización o industria.
Aplicaciones del fine-tuning:
- Modelos de lenguaje específicos para industrias (legal, médica, financiera).
- Asistentes virtuales personalizados para empresas.
- Sistemas de generación de contenido adaptados a estilos o marcas particulares.
- Herramientas de análisis de datos especializadas.
Pongamos algunos ejemplos
A muchos de los que estéis familiarizados con las últimas noticias en IA generativa os sonarán estos ejemplos que citamos a continuación.
SLM: La potencia en la especialización
Ejemplo: BERT para análisis de sentimientos
BERT (Bidirectional Encoder Representations from Transformers) es un ejemplo de SLM cuando se utiliza para tareas específicas. Aunque BERT en sí es un modelo de lenguaje grande, versiones más pequeñas y especializadas de BERT se han desarrollado para análisis de sentimientos en redes sociales.
Por ejemplo, DistilBERT, una versión reducida de BERT, se ha utilizado para crear modelos de análisis de sentimientos en X (Twitter). Estos modelos pueden clasificar rápidamente tweets como positivos, negativos o neutros, siendo mucho más eficientes en términos de recursos computacionales que modelos más grandes.
LLM: El poder de la generalización
Ejemplo: GPT-3 de OpenAI
GPT-3 (Generative Pre-trained Transformer 3) es uno de los LLM más conocidos y utilizados. Con 175 mil millones de parámetros, GPT-3 es capaz de realizar una amplia variedad de tareas de procesamiento de lenguaje natural sin necesidad de un entrenamiento específico para cada tarea.
Una aplicación práctica y conocida de GPT-3 es ChatGPT, el chatbot conversacional de OpenAI. ChatGPT puede mantener conversaciones sobre una gran variedad de temas, responder preguntas, ayudar con tareas de escritura y programación, e incluso generar contenido creativo, todo ello utilizando el mismo modelo base.
Ya a finales de 2020 introducimos en este espacio el primer post sobre GPT-3 como gran modelo del lenguaje. Para los más nostálgicos, podéis consultar el post original aquí.
RAG: Potenciando la precisión y relevancia
Ejemplo: El asistente virtual de Anthropic, Claude
Claude, el asistente virtual desarrollado por Anthropic, es un ejemplo de aplicación que utiliza técnicas RAG. Aunque los detalles exactos de su implementación no son públicos, Claude es conocido por su capacidad para proporcionar respuestas precisas y actualizadas, incluso sobre eventos recientes.
De hecho, la mayoría de asistentes conversacionales basados en IA generativa incorporan técnicas RAG para mejorar la precisión y el contexto de sus respuestas. Así, ChatGPT, la citada Claude, MS Bing y otras similares usan RAG.
Fine-tuning: Adaptación y especialización
Ejemplo: GPT-3 fine-tuned para GitHub Copilot
GitHub Copilot, el asistente de programación de GitHub y OpenAI, es un excelente ejemplo de fine-tuning aplicado a un LLM. Copilot está basado en un modelo GPT (posiblemente una variante de GPT-3) que ha sido específicamente ajustado (fine-tuned) para tareas de programación.
El modelo base se entrenó adicionalmente con una gran cantidad de código fuente de repositorios públicos de GitHub, lo que le permite generar sugerencias de código relevantes y sintácticamente correctas en una variedad de lenguajes de programación. Este es un claro ejemplo de cómo el fine-tuning puede adaptar un modelo de propósito general a una tarea altamente especializada.
Otro ejemplo: en el blog de datos.gob.es, también escribimos un post sobre aplicaciones que utilizaban GPT-3 como LLM base para construir productos concretos ajustados específicamente.
Interrelaciones y sinergias
Estos cuatro conceptos no operan de forma aislada, sino que se entrelazan y complementan en el ecosistema de la IA Generativa:
- SLM y LLM: Mientras que los LLM ofrecen versatilidad y capacidad de generalización, los SLM proporcionan eficiencia y especialización. La elección entre uno u otro dependerá de las necesidades específicas del proyecto y los recursos disponibles.
- RAG y LLM: RAG potencia las capacidades de los LLM al proporcionarles acceso a información actualizada y relevante. Esto mejora la precisión y utilidad de las respuestas generadas.
- Fine-tuning y LLM: El fine-tuning permite adaptar LLM genéricos a tareas o dominios específicos, combinando la potencia de los modelos grandes con la especialización necesaria para ciertas aplicaciones.
- RAG y Fine-tuning: Estas técnicas pueden combinarse para crear sistemas altamente especializados y precisos. Por ejemplo, un LLM con fine-tuning para un dominio específico puede utilizarse como componente generativo en un sistema RAG.
- SLM y Fine-tuning: El fine-tuning también puede aplicarse a SLM para mejorar aún más su rendimiento en tareas específicas, creando modelos altamente eficientes y especializados.
Conclusiones y futuro de la IA
La combinación de estos cuatro pilares está abriendo nuevas posibilidades en el campo de la IA Generativa:
- Sistemas híbridos: combinación de SLM y LLM para diferentes aspectos de una misma aplicación, optimizando rendimiento y eficiencia.
- RAG avanzado: implementación de sistemas RAG más sofisticados que utilicen múltiples fuentes de información y técnicas de recuperación más avanzadas.
- Fine-tuning continuo: desarrollo de técnicas para el ajuste continuo de modelos en tiempo real, adaptándose a nuevos datos y necesidades.
- Personalización a escala: creación de modelos altamente personalizados para individuos o pequeños grupos, combinando fine-tuning y RAG.
- IA Generativa ética y responsable: implementación de estas técnicas con un enfoque en la transparencia, la verificabilidad y la reducción de sesgos.
SLM, LLM, RAG y Fine-tuning representan los pilares fundamentales sobre los que se está construyendo el futuro de la IA Generativa. Cada uno de estos conceptos aporta fortalezas únicas:
- Los SLM ofrecen eficiencia y especialización.
- Los LLM proporcionan versatilidad y capacidad de generalización.
- RAG mejora la precisión y relevancia de las respuestas.
- El Fine-tuning permite la adaptación y personalización de modelos.
La verdadera magia ocurre cuando estos elementos se combinan de formas innovadoras, creando sistemas de IA Generativa más potentes, precisos y adaptables que nunca. A medida que estas tecnologías continúen evolucionando, podemos esperar ver aplicaciones cada vez más sofisticadas y útiles en una amplia gama de campos, desde la atención médica hasta la creación de contenido creativo.
El desafío para los desarrolladores e investigadores será encontrar el equilibrio óptimo entre estos elementos, considerando factores como la eficiencia computacional, la precisión, la adaptabilidad y la ética. El futuro de la IA Generativa promete ser fascinante, y estos cuatro conceptos estarán sin duda en el centro de su desarrollo y aplicación en los años venideros.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La inteligencia artificial (IA) está revolucionando la manera en que creamos y consumimos contenido. Desde la automatización de tareas repetitivas hasta la personalización de experiencias, la IA ofrece herramientas que están cambiando el panorama del marketing, la comunicación y la creatividad.
Estas inteligencias artificiales necesitan ser entrenadas con datos acordes a los objetivos, sobre los que no discurran derechos de autor. Por ello, los datos abiertos se alzan como una herramienta de gran utilidad de cara al futuro de la IA.
Para profundizar sobre esta temática, The Govlab ha publicado el informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI” (¿Una cuarta ola de datos abiertos? Explorando el espectro de escenarios para los datos abiertos y la IA generativa). En él se analiza la relación emergente entre los datos abiertos y la IA generativa, presentado diversos escenarios y recomendaciones. A continuación, se recogen sus claves.
El papel de los datos en la IA generativa
Los datos son la base fundamental de los modelos generativos de inteligencia artificial. Construir y entrenar dichos modelos requiere un gran volumen de datos, cuya escala y variedad está condicionada por los objetivos y los casos de uso del modelo.
El siguiente gráfico explica cómo los datos funcionan como una pieza clave tanto de entrada de un sistema de IA generativa, como de salida. Los datos se recopilan de diversas fuentes, incluyendo portales de datos abiertos, con el fin de entrenar un modelo de IA de propósito general. Este modelo, posteriormente, será adaptado para realizar funciones específicas y diferentes tipos de análisis, que generan, a su vez, nuevos datos, que pueden utilizarse para seguir entrenando modelos.

Figura 1. El Rol de los datos abiertos en la IA generativa, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
5 escenarios donde convergen los datos abiertos y la Inteligencia artificial
Con el fin de ayudar a los proveedores de datos abiertos a “preparar” dichos datos para la IA generativa, The Govlab ha definido cinco escenarios que resumen cinco formas distintas en las que los datos abiertos y la IA generativa pueden cruzarse. Estos escenarios pretenden ser un punto de partida, que se irá ampliando en el futuro, en base a los casos de uso disponibles.
| Escenario | Función | Requisitos de calidad | Necesidades de metadatos | Ejemplo |
|---|---|---|---|---|
| Preentrenamiento (Pretraining) | Entrenamiento de las capas fundacionales de un modelo de IA generativa con grandes cantidades de datos abiertos. | Alto volumen de datos, diversos y representativos del dominio de aplicación y uso no estructurado. | Información clara sobre la fuente de los datos. | Los datos del proyecto Harmonized Landsat Sentinel-2 (HLS) de la NASA se utilizaron para entrenar el modelo fundacional geoespacial watsonx.ai. |
| Adaptación (Adaptation) | Perfeccionamiento de un modelo preentrenado con datos abiertos específicos para tareas concretas, utilizando técnicas de fine-tuning or RAG. | Datos tabulares y/o no estructurados de alta precisión y relevancia para la tarea objetivo, con una distribución equilibrada. | Metadatado centrado en la anotación y procedencia de los datos para aportar enriquecimiento contextual. | Partiendo del modelo LLaMA 70B, el Gobierno de Francia creó LLaMandement, un modelo de lenguaje grande perfeccionado para el análisis y la redacción de resúmenes de proyectos jurídicos. Para ello usaron datos de SIGNALE, la plataforma legislativa del Gobierno francés. |
| Inferencia y generación de hechos relevantes (Inference and Insight Generation) | Extracción de información y patrones a partir de datos abiertos mediante un modelo entrenado de IA generativa. | Datos tabulares de alta calidad, completos y coherentes. | Metadatado descriptivo de los métodos de recogida de datos, información de origen y control de versiones. | Wobby es una interfaz generativa que acepta consultas en lenguaje natural y produce respuestas en forma de resúmenes y visualizaciones, utilizando conjuntos de datos de distintas oficinas como Eurostat o el Banco Mundial. |
| Incremento de datos (Data Augmentation) | Aprovechamiento de los datos abiertos para generar datos sintéticos o proporcionar ontologías para extender la cantidad de datos de entrenamiento. | Datos tabulares y/o no estructurados que sean una representación cercana a la realidad, asegurando el cumplimiento de consideraciones éticas. | Transparencia sobre el proceso de generación y posibles sesgos. | Un equipo de investigadores adaptó el modelo Synthea de EE.UU. para incluir datos demográficos y hospitalarios de Australia. Utilizando este modelo, el equipo pudo generar aproximadamente 117.000 historiales médicos sintéticos específicos, aplicados a su región. |
| Exploración abierta (Open-Ended Exploration) | Exploración y descubrimiento de nuevos conocimientos y patrones en datos abiertos mediante modelos generativos. | Datos tabulares y/o no estructurados, diversos y completos. | Información clara sobre fuentes y derechos de autor, comprensión de posibles sesgos y limitaciones, identificación de entidades. | NEPAccess es un piloto para desbloquear el acceso datos relacionados con la Ley Nacional de Política Medioambiental (NEPA) de EE.UU. mediante un modelo generativo de IA. Incluirá funciones para redactar evaluaciones de impacto ambiental, análisis de datos, etc. |
Figura 2. Cinco escenarios donde convergen los datos abiertos y la Inteligencia artificial, adaptado del informe “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, de The Govlab, 2024.
Puedes leer el detalle de estos escenarios en el informe, donde se explican más ejemplos. Además, The Govlab también ha puesto en marcha un observatorio donde recopila ejemplos de intersecciones entre datos abiertos e inteligencia artificial generativa (los incluidos en el informe junto con otros adicionales). Cualquier usuario puede proponer nuevos casos a través de este formulario. Dichos ejemplos se utilizarán para continuar estudiando este campo y mejorar los escenarios actualmente definidos.
Entre los casos que se pueden ver en la web, encontramos una empresa española: Tendios. Se trata de una compañía de software como servicio que ha desarrollado un chatbot para ayudar en el análisis de licitaciones y concursos públicos con el fin de facilitar la concurrencia. Esta herramienta está entrenada con documentos públicos de licitaciones gubernamentales.
Recomendaciones para publicadores de datos
Para extraer el máximo potencial de IA generativa, mejorando su eficiencia y eficacia, el informe destaca que los proveedores de datos abiertos deben hacer frente a algunos retos, como la mejora de la gobernanza y la gestión de los datos. En este sentido, recogen cinco recomendaciones:
- Mejorar la transparencia y la documentación. A través del uso de estándares, diccionarios de datos, vocabularios, plantillas de metadatos, etc. se ayudará a aplicar prácticas de documentación sobre el linaje, la calidad, las consideraciones éticas y el impacto de los resultados.
- Mantener la calidad y la integridad. Se necesita formación y procesos rutinarios que aseguren la calidad, incluida la validación automatizada o manual, así como herramientas para actualizar los conjuntos de datos rápidamente cuando sea necesario. Además, son necesarios mecanismos para informar y abordar problemas que puedan surgir relacionados con los datos, a fin de impulsar la transparencia y facilitar la creación de una comunidad en torno a los conjuntos de datos abiertos.
- Fomentar la interoperabilidad y los estándares. Implica adoptar y promover normas internacionales de datos, con especial foco en los datos sintéticos y los contenidos generados por IA.
- Mejorar la accesibilidad y la facilidad de uso. Supone la mejora de los portales de datos abiertos mediante algoritmos de búsqueda inteligentes y herramientas interactivas. También es imprescindible establecer un espacio compartido donde los publicadores de los datos y los usuarios puedan intercambiar opiniones y manifestar necesidades, con el fin de hacer coincidir oferta y demanda.
- Abordar las consideraciones éticas. Proteger a los titulares de los datos es de máxima prioridad al hablar de datos abiertos e IA generativa. Se necesitan comités éticos y directrices éticas exhaustivas en torno a la recopilación, el intercambio y el uso de datos abiertos, así como tecnologías avanzadas de preservación de la intimidad.
Estamos ante un campo en continua evolución que necesita de actualización constante por parte de los publicadores de datos. Estos deben proporcionar conjuntos de datos adecuados tanto técnica como éticamente, para que los sistemas de IA generativa puedan alcanzar todo su potencial.
Blog
En los últimos meses hemos visto cómo los grandes modelos del lenguaje (LLM en sus siglas en inglés) que habilitan las aplicaciones de Inteligencia artificial generativa (GenAI) han ido mejorando en cuanto a su precisión y confiabilidad. Las técnicas de RAG (Retrieval Augmented Generation) nos han permitido utilizar toda la potencia de la comunicación en lenguaje natural (NLP) con las máquinas para explorar bases de conocimiento propias y extraer información procesada en forma de respuestas a nuestras preguntas. En este artículo profundizamos en las técnicas RAG con el objetivo de conocer mejor su funcionamiento y todas las posibilidades que nos ofrecen en el contexto de la IA generativa.
¿Qué son las técnicas RAG?
No es la primera vez que hablamos de las técnicas RAG. En este artículo ya introdujimos el tema, explicando de forma sencilla en qué consisten, cuáles son sus principales ventajas y qué beneficios aporta en el uso de la IA Generativa.
Recordemos por un momento sus principales claves. RAG, del inglés, Retrieval Augmented Generation, viene a traducirse cómo Generación Aumentada por Recuperación (de información). Es decir, RAG consiste en lo siguiente: cuando un usuario realiza una pregunta -normalmente en un interfaz conversacional-, la Inteligencia Artificial (IA), antes de proporcionar la respuesta directa -que podría dar haciendo uso de la base de conocimiento (fijo) con la que ha sido entrenada-, realiza un proceso de búsqueda y procesamiento de información en una base de datos específica proporcionada previamente, complementaria a la del entrenamiento. Cuando hablamos de una base de datos nos referimos a una base de conocimiento previamente preparada a partir de un conjunto de documentos que el sistema utilizará para proporcionar respuestas más precisas. De esta forma, cuando hacen uso de las técnicas RAG, las interfaces conversacionales producen respuestas más precisas y adaptadas a un contexto concreto.
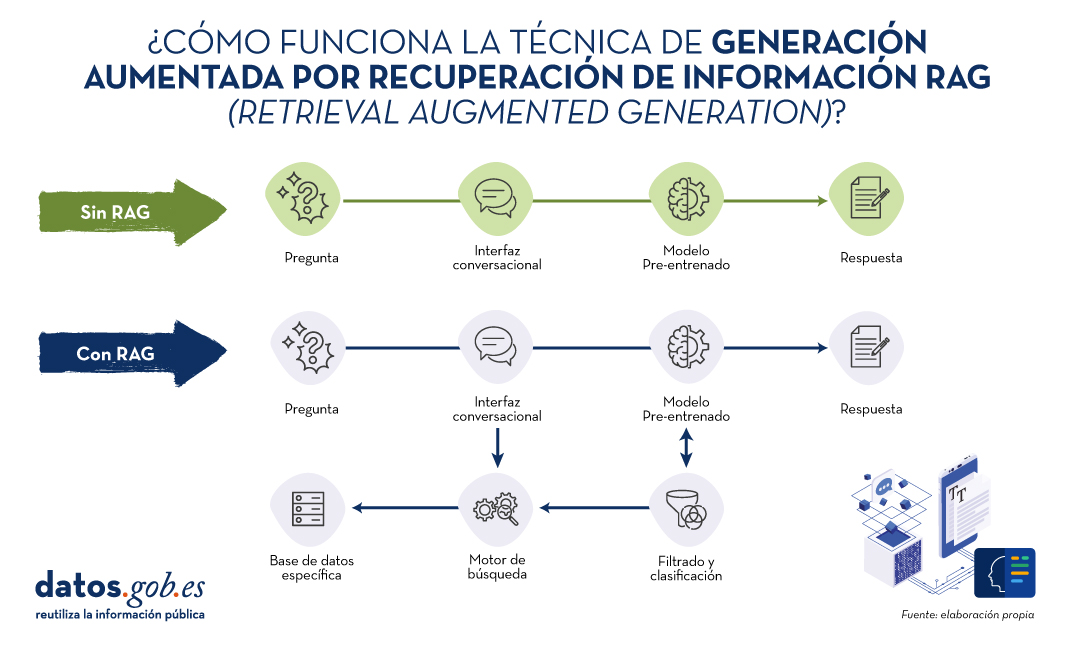
Fuente: Elaboración propia
Diagrama conceptual del funcionamiento de un asistente o interfaz conversacional sin hacer uso de RAG (arriba) y haciendo uso de RAG (abajo).
Haciendo un símil con el ámbito médico, podríamos decir que el uso de RAG es como si un médico, con amplia experiencia y, por lo tanto, altamente entrenado, además de los conocimientos adquiridos durante su formación académica y años de experiencia, tuviera acceso rápido y sin esfuerzo a los últimos estudios, análisis y bases de datos médicas al instante, antes de proporcionar un diagnóstico. La formación académica y los años de experiencia equivalen al entrenamiento del modelo grande del lenguaje (LLM) y el “mágico” acceso a los últimos estudios y bases de datos específicas pueden asimilarse a lo que proporciona las técnicas RAG.
Evidentemente, en el ejemplo que acabamos de poner, la buena práctica médica hace indispensables ambos elementos que el cerebro humano sabe combinar de forma natural, aunque no sin esfuerzo y tiempo, incluso disponiendo de las herramientas digitales actuales, que hacen más sencilla e inmediata la búsqueda de información.
RAG en detalle
Fundamentos de RAG
RAG combina dos fases para conseguir su objetivo: la recuperación y la generación. En la primera, se buscan documentos relevantes en una base de datos que contiene información pertinente a la pregunta planteada (por ejemplo, una base de datos clínicos o una base de conocimiento de preguntas y respuestas más habituales). En la segunda, se utiliza un LLM para generar una respuesta basada en los documentos recuperados. Este enfoque asegura que las respuestas no solo sean coherentes sino también precisas y respaldadas por datos verificables.
Componentes del Sistema RAG
A continuación, vamos a describir los componentes que utiliza un algoritmo de RAG para cumplir con su función. Para ello, en cada componente, vamos a explicar qué función cumple, qué tecnologías se utilizan para cumplir esta función y un ejemplo de la parte del proceso RAG en el que interviene ese componente.
1. Modelo de Recuperación:
- Función: Identifica y recupera documentos relevantes de una base de datos grande en respuesta a una consulta.
- Tecnología: Generalmente utiliza técnicas de recuperación de información (Information Retrieval en inglés o IR) como BM25 o modelos de recuperación basados en embeddings como Dense Passage Retrieval (DPR).
- Proceso: Dada una pregunta, el modelo de recuperación busca en una base de datos para encontrar los documentos más relevantes y los presenta como contexto para la generación de la respuesta.
2. Modelo de Generación:
- Función: Generar respuestas coherentes y contextualmente relevantes utilizando los documentos recuperados.
- Tecnología: Basado en algunos de los principales grandes modelos de Lenguaje (LLM) como GPT-3.5, T5, o BERT, Llama.
- Proceso: El modelo de generación toma la consulta del usuario y los documentos recuperados y utiliza esta información combinada para producir una respuesta precisa.
Proceso Detallado de RAG1
En detalle, un algoritmo RAG realiza las siguientes etapas:
1. Recepción de la pregunta. El sistema recibe una pregunta del usuario. Esta pregunta se procesa para extraer las palabras clave y entender la intención.
2. Recuperación de documentos. La pregunta se envía al modelo de recuperación.
- Ejemplo de Recuperación basada en embeddings:
- La pregunta se convierte en un vector de embeddings utilizando un modelo pre-entrenado.
- Este vector se compara con los vectores de documentos en la base de datos.
- Se seleccionan los documentos con mayor similitud.
- Ejemplo de BM25:
- Se tokeniza la pregunta y se comparan las palabras clave con los índices invertidos de la base de datos.
- Se recuperan los documentos más relevantes según una puntuación de relevancia.
3. Filtrado y clasificación. Los documentos recuperados se filtran para eliminar redundancias y clasificarlos según su relevancia. Pueden aplicarse técnicas adicionales como reranking utilizando modelos más sofisticados.
4. Generación de la respuesta. Los documentos filtrados se concatenan con la pregunta del usuario y se introducen en el modelo de generación. El LLM utiliza la información combinada para generar una respuesta que es coherente y directamente relevante a la pregunta. Por ejemplo, si utilizamos GPT-3.5 como LLM, la entrada al modelo incluye tanto la pregunta del usuario como fragmentos de los documentos recuperados. Finalmente, el modelo genera texto utilizando su capacidad para comprender el contexto de la información proporcionada.
En la siguiente sección vamos a ver algunas aplicaciones en las que la Inteligencia Artificial y los modelos grandes del lenguaje juegan un papel diferenciador y, en concreto, vamos a analizar cómo se benefician estos casos de usos de la aplicación de las técnicas RAG.
Ejemplos de casos de uso que se benefician sustancialmente de usar RAG frente a no usar RAG
1. Atención al Cliente en eCommerce
- Sin RAG:
- Un chatbot básico puede dar respuestas genéricas y potencialmente incorrectas sobre políticas de devolución.
- Ejemplo: Por favor, revise nuestra política de devoluciones en el sitio web.
- Con RAG:
- El chatbot accede a la base de datos de políticas actualizadas y proporciona una respuesta específica y precisa.
- Ejemplo: Puede devolver los productos dentro de 30 días desde la compra, siempre que estén en su embalaje original. Consulte más detalles [aquí].
2. Diagnóstico Médico
- Sin RAG:
- Un asistente virtual de salud podría ofrecer recomendaciones basadas solo en su entrenamiento previo, sin acceso a la información médica más reciente.
- Ejemplo: Es posible que tenga gripe. Consulte a su médico
- Con RAG:
- El asistente puede recuperar información de bases de datos médicas recientes y proporcionar un diagnóstico más preciso y actualizado.
- Ejemplo: Según los síntomas y los estudios recientes publicados en PubMed, podría estar enfrentando una infección viral. Consulte a su médico para un diagnóstico preciso.
3. Asistencia en Investigación Académica
- Sin RAG:
- Un investigador recibe respuestas limitadas a lo que el modelo ya sabe, lo que puede no ser suficiente para temas altamente especializados.
- Ejemplo: Los modelos de crecimiento económico son importantes para entender la economía.
- Con RAG:
- El asistente recupera y analiza artículos académicos relevantes, proporcionando información detallada y precisa.
- Ejemplo: Según el estudio de 2023 en 'Journal of Economic Growth', el modelo XYZ ha mostrado un 20% más de precisión en la predicción de tendencias económicas en mercados emergentes.
4. Periodismo
- Sin RAG:
- Un periodista recibe información genérica que puede no estar actualizada ni ser precisa.
- Ejemplo: La inteligencia artificial está cambiando muchas industrias.
- Con RAG:
- El asistente recupera datos específicos de estudios y artículos recientes, ofreciendo una base sólida para el artículo.
- Ejemplo: Según un informe de 2024 de 'TechCrunch', la adopción de IA en el sector financiero ha aumentado en un 35% en el último año, mejorando la eficiencia operativa y reduciendo costos.
Por supuesto, para la mayoría de los usuarios que hemos experimentado los interfaces conversacionales más accesibles, como ChatGPT, Gemini o Bing, podemos constatar que las respuestas suelen ser completas y bastante precisas cuando se trata de preguntas de ámbito general. Esto es porque estos agentes hacen uso de métodos RAG y otras técnicas avanzadas para proporcionar las respuestas. Sin embargo, no hay que remontarse mucho tiempo atrás en el que los asistentes conversacionales, como Alexa, Siri u OK Google, proporcionaban respuestas extremadamente simples y muy similares a las que explicamos en los ejemplos anteriores cuando no se hace uso de RAG.
Conclusiones
Las técnicas de Generación Aumentada por Recuperación (RAG) mejora la precisión y relevancia de las respuestas de los modelos de lenguaje al combinar recuperación de documentos y generación de texto. Utilizando métodos de recuperación como BM25 o DPR y modelos avanzados de lenguaje, RAG proporciona respuestas más contextualizadas, actualizadas y precisas. En la actualidad, RAG es la clave para el desarrollo exponencial de la IA en el ámbito de los datos privados de empresas y organizaciones. En los próximos meses se espera una adopción masiva de RAG en diversas industrias, optimizando la atención al cliente, diagnósticos médicos, investigación académica y periodismo, gracias a su capacidad para integrar información relevante y actual en tiempo real.
1. Para entender mejor esta sección, recomendamos al lector la lectura de este trabajo previo en el que explicamos de forma didáctica los fundamentos del procesamiento del lenguaje natural y cómo enseñamos a leer a las máquinas.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La era de la digitalización en la que nos encontramos ha llenado nuestra vida diaria de productos de datos o productos basados en datos. En este post te descubrimos en qué consisten y te mostramos una de las tecnologías de datos clave para diseñar y construir este tipo de productos: GraphQL.
Introducción
Empecemos por el principio, ¿qué es un producto de datos? Un producto de datos es un contenedor digital (una pieza de software) que incluye, datos, metadatos y ciertas lógicas funcionales (qué y cómo manejo los datos). El objetivo de este tipo de productos es facilitar la interacción de los usuarios con un conjunto de datos. Algunos ejemplos son:
- Cuadro de mando de ventas: Los negocios online cuentan con herramientas para conocer la evolución de sus ventas, con gráficos que muestran las tendencias y rankings, para ayudar en la toma de decisiones
- Apps de recomendaciones: Los servicios de TV en streaming disponen de funcionalidades que muestran recomendaciones de contenidos basándose en los gustos históricos del usuario.
- Apps de movilidad. Las aplicaciones móviles de los nuevos servicios de movilidad (como Cabify, Uber, Bolt, etc.) combinan datos y metadatos de usuarios y conductores con algoritmos predictivos, como el cálculo dinámico del precio del viaje o la asignación óptima de conductor, con el fin de ofrecer una experiencia única al usuario.
- Apps de salud: Estas aplicaciones hacen un uso masivo de los datos capturados por gadgets tecnológicos (como el propio dispositivo, los relojes inteligentes, etc.) que se pueden integrar con otros datos externos como registros clínicos y pruebas diagnósticas.
- Monitoreo ambiental: Existen apps que capturan y combinan datos de servicios de predicción meteorológica, sistemas de calidad del aire, información de tráfico en tiempo real, etc. para emitir recomendaciones personalizadas a los usuarios (por ejemplo, la mejor hora para programar una sesión de entrenamiento, disfrutar al aire libre o viajar en coche).
Como vemos, los productos de datos nos acompañan en el día a día, sin que muchos usuarios se den siquiera cuenta. Pero, ¿cómo se captura esa gran cantidad de información heterogénea de diferentes sistemas tecnológicos y se combina para proporcionar interfaces y vías de interacción con el usuario final? Aquí es donde GraphQL se posiciona como una tecnología clave para acelerar la creación de productos de datos, al mismo tiempo que mejora considerablemente su flexibilidad y la capacidad de adaptación a las nuevas funcionalidades deseadas por los usuarios.
¿Qué es GraphQL?
GraphQL vio la luz en Facebook en 2012 y se liberó como Open Source en 2015. Puede definirse como un lenguaje y un intérprete de ese lenguaje, de forma que un desarrollador de productos de datos puede inventarse una forma de describir su producto en base a un modelo (una estructura de datos) que hace uso de los datos disponibles mediante APIs.
Antes de la aparición de GraphQL, teníamos (y tenemos) la tecnología REST, que utiliza el protocolo HTTPs para hacer preguntas y obtener respuestas en base a los datos. En 2021, introducimos un post donde presentamos la tecnológica y realizamos un pequeño ejemplo demostrativo sobre su funcionamiento. En él, explicamos REST API como la tecnología estándar que soporta el acceso a datos por programas informáticos. También destacamos cómo REST es una tecnología fundamentalmente diseñada para integrar servicios (como un servicio de autenticación o login).
De forma sencilla, podemos utilizar la siguiente analogía. Es como si REST fuera el mecanismo que nos da acceso a un diccionario completo. Es decir, si necesitamos buscar cualquier palabra, tenemos un método de acceso al diccionario que es la búsqueda alfabética. Es un mecanismo general para encontrar cualquier palabra disponible en el diccionario. Sin embargo, GraphQL nos permite, previamente, crear un modelo de diccionario para nuestro caso de uso (lo que conocemos como “modelo de datos”). Así por ejemplo, si nuestra aplicación final es un recetario, lo que hacemos es seleccionar un subconjunto de palabras del diccionario que estén relacionadas con recetas de cocina.
Para utilizar GraphQL los datos tienen que estar siempre disponibles mediante una API. GraphQL facilita una descripción completa y comprensible de los datos de dicha API, ofreciendo a los clientes (humanos o aplicación) la posibilidad de solicitar exactamente lo que necesitan. Tal y como citan en este post, GraphQL es como un API al que le añadimos una sentencia “Dónde” al estilo SQL.
A continuación, analizamos en detalle las virtudes de GraphQL cuando el foco se pone en el desarrollo de productos de datos.
Beneficios de usar GraphQL en productos de datos:
- Con GraphQL se optimiza de forma considerable la cantidad de datos y consultas sobre las APIs. Las APIs de acceso a determinados datos no están pensadas para un producto (o un caso de uso) específico sino como una especificación general de acceso (véase el ejemplo anterior del diccionario). Esto hace que, en muchas ocasiones, para acceder a un subconjunto de datos disponibles en un API, tengamos que realizar varias consultas encadenadas, descartando la mayor parte de información por el camino. GraphQL optimiza este proceso, puesto que define un modelo de consumo predefinido (aunque adaptable a futuro) por encima de una API técnica. Reducir la cantidad de datos solicitados impacta positivamente en la racionalización de recursos informáticos, como el ancho de banda o el almacenamiento transitorio (cachés), y mejora la velocidad de respuesta de los sistemas.
- Lo anterior, tiene un efecto inmediato sobre la estandarización de acceso a datos. El modelo definido gracias a GraphQL crea un estándar de consumo de datos para una familia de casos de uso. De nuevo, en el contexto de una red social, si lo que queremos es identificar conexiones entre personas, no nos interesa un mecanismo general de acceso a todas las personas de la red, sino un mecanismo que nos permita indicar aquellas personas con las que tengo algún tipo de conexión. Esta especie de filtro en el acceso a los datos, se puede pre-configurar gracias a GraphQL.
- Mejora de seguridad y rendimiento: A través de la definición precisa de consultas y la limitación de acceso a datos sensibles, GraphQL puede contribuir a una aplicación más segura y de mejor rendimiento.
Gracias a estas ventajas, el uso de este lenguaje representa una evolución significativa en la manera de interactuar con datos en aplicaciones web y móviles, ofreciendo ventajas claras sobre enfoques más tradicionales como REST.
La Inteligencia Artificial generativa. Un nuevo superhéroe en la ciudad.
Si el uso del lenguaje GraphQL para acceder a los datos de forma mucho más eficiente y estándar es una evolución significativa para los productos de datos, ¿qué pasará si podemos interactuar con nuestro producto en lenguaje natural? Esto es ahora posible gracias a la explosiva evolución en los últimos 24 meses de los LLMs (Modelos Grandes del Lenguaje) y la IA generativa.
La siguiente imagen muestra el esquema conceptual de un producto de datos, integrado con LLMS: un contenedor digital que incluye datos, metadatos y funciones lógicas que se expresan como funcionalidades para el usuario, junto con las últimas tecnologías para exponer información de forma flexible, como GraphQL y las interfaces conversacionales construidas sobre Modelos Grandes del Lenguaje (LLMs).

¿Cómo se pueden beneficiar los productos de datos de la combinación de GraphQLy el uso de los LLMs?
- Mejora de la experiencia de usuario. Mediante la integración de LLMs, las personas puedan hacer preguntas a los productos de datos usando lenguaje natural. Esto representa un cambio significativo en cómo interactuamos con los datos, haciendo que el proceso sea más accesible y menos técnico. De forma práctica sustituiremos los clicks por frases en el momento de pedir un taxi.
- Mejoras en la seguridad a lo largo de la cadena de interacción en el uso de un producto de datos. Para que esta interacción sea posible, se necesita un mecanismo que conecte de manera eficaz el backend (donde residen los datos) con el frontend (donde se hacen las preguntas). GraphQL se presenta como la solución ideal debido a su flexibilidad y capacidad para adaptarse a las necesidades cambiantes de los usuarios, ofreciendo un enlace directo y seguro entre los datos y las preguntas realizadas en lenguaje natural. Es decir, GraphQL puede pre-seleccionar los datos que se van a mostrar en una consulta, evitando así que la consulta general pueda hacer visibles algunos datos privados o innecesarios para una aplicación particular.
- Potenciando las consultas con Inteligencia Artificial: La inteligencia artificial no solo juega un papel en la interacción en lenguaje natural con el usuario. Se puede pensar en escenarios donde el propio modelo que se define con GraphQL esté asistido por la propia inteligencia artificial. Esto enriquecería las interacciones con los productos de datos, permitiendo una comprensión más profunda y una exploración más rica de la información disponible. Por ejemplo, le podemos pedir a una IA generativa (como ChatGPT) que tome estos datos del catálogo que se exponen como un API y que nos cree un modelo y un endpoint de GraphQL.
En definitiva, la combinación de GraphQL y los LLMs, supone una auténtica evolución en la forma en la que accedemos a los datos. La integración de GraphQL con los LLMs apunta hacia un futuro donde el acceso a los datos puede ser tan preciso como intuitivo, marcando un avance hacia sistemas de información más integrados, accesibles para todos y altamente reconfigurables para los diferentes casos de uso. Este enfoque abre la puerta a una interacción más humana y natural con las tecnologías de información, alineando la inteligencia artificial con nuestras experiencias cotidianas de comunicación usando productos de datos en nuestro día a día.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Enseñar a los ordenadores a entender cómo hablan y escriben los humanos es un viejo desafío en el campo de la inteligencia artificial, conocido como procesamiento de lenguaje natural (PLN). Sin embargo, desde hace poco más de dos años, estamos asistiendo a la caída de este antiguo bastión con la llegada de los modelos grandes del lenguaje (LLM) y los interfaces conversacionales. En este post, vamos a tratar de explicar una de las técnicas clave que hace posible que estos sistemas nos respondan con relativa precisión a las preguntas que les hacemos.
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog, varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del RAG. En este post vamos a tratar de explicarlo de la forma más sencilla posible.
Los modelos grandes del lenguaje o Large Language Models (hay cosas que es mejor no traducir…) son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los LLM por sí solos no proporcionarán respuestas específicas o habrá una alta probabilidad de que alucinen y se inventen completamente la respuesta. Que los LLM alucinen significa que generan texto inexacto, sin sentido o desconectado. Este efecto plantea riesgos y desafíos potenciales para las organizaciones que utilizan estos modelos fuera del entorno doméstico o cotidiano del uso personal de los LLM. La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para ChatGPT, puede tener implicaciones profundas para la reputación de las empresas y la fiabilidad de los sistemas de IA.
¿Qué es un RAG?
Precisamente, las técnicas RAG se han desarrollado para mejorar la calidad de las respuestas en contextos específicos, como por ejemplo, en una disciplina concreta o en base a repositorios de conocimiento privados como bases de datos de empresas.
RAG es una técnica extra dentro de los marcos de trabajo de la inteligencia artificial, cuyo objetivo es recuperar hechos de una base de conocimientos externa para garantizar que los modelos de lenguaje devuelven información precisa y actualizada. Un sistema RAG típico (ver imágen) incluye un LLM, una base de datos vectorial (para almacenar convenientemente los datos externos) y una serie de comandos o preguntas. Es decir, de forma simplificada, cuándo hacemos una pregunta en lenguaje natural a un asistente cómo ChatGPT, lo que ocurre entre la pregunta y la respuesta es algo como:
- El usuario realiza la consulta, también denominada técnicamente prompt.
- El RAG se encarga de enriquecer ese prompt o pregunta con datos y hechos que ha obtenido de una base de datos externa que contiene información relevante relativa a la pregunta que ha realizado el usuario. A esta etapa se le denomina retrieval.
- El RAG se encarga de enviar el prompt del usuario enriquecido o aumentado al LLM que se encarga de generar una respuesta en lenguaje natural aprovechando toda la potencia del lenguaje humano que ha aprendido con sus datos de entrenamiento genéricos, pero también con los datos específicos proporcionados en la etapa de retrieval.
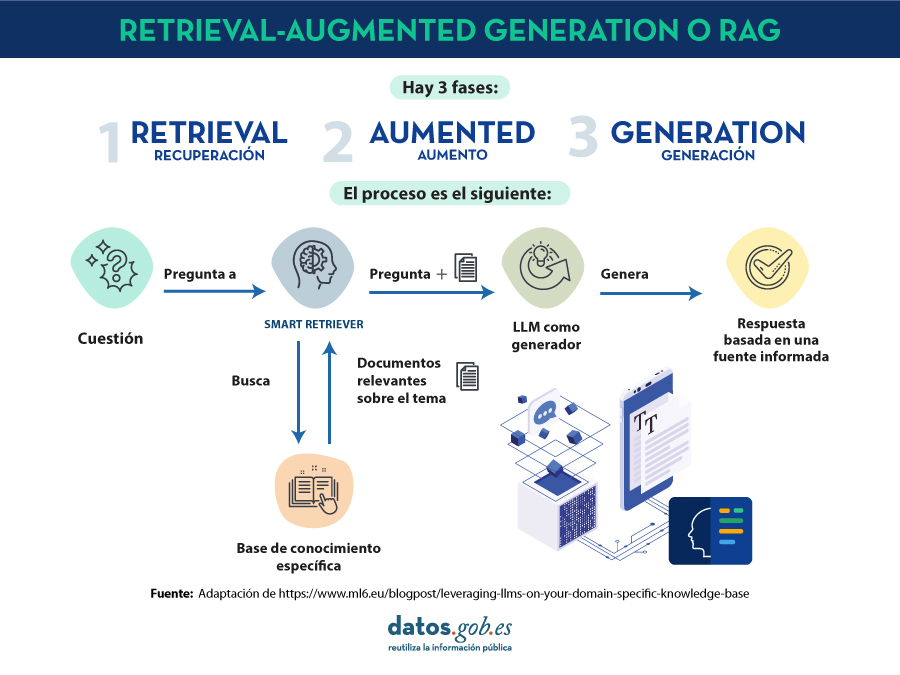
Entendiendo RAG con ejemplos
Pongamos un ejemplo concreto. Imagina que estás intentando responder una pregunta sobre dinosaurios. Un LLM generalista puede inventarse una respuesta perfectamente plausible, de forma que una persona no experta en la materia no la diferencia de una respuesta con base científica. Por el contrario, con el uso de RAG, el LLM buscaría en una base de datos de información sobre dinosaurios y recuperaría los hechos más relevantes para generar una respuesta completa.
Lo mismo ocurría si buscamos una información concreta en una base de datos privada. Por ejemplo, pensemos en un responsable de recursos humanos de una empresa. Éste desea recuperar información resumida y agregada sobre uno o varios empleados cuyos registros se encuentran en diferentes bases de datos de la empresa. Pensemos que podemos estar tratando de obtener información a partir de tablas salariales, encuestas de satisfacción, registros laborales, etc. Un LLM es de gran utilidad para generar una respuesta con un patrón humano. Sin embargo, es imposible que ofrezca datos coherentes y precisos puesto que nunca ha sido entrenado con esa información debido a su carácter privado. En este caso, RAG asiste al LLM para proporcionarle datos y contexto específico con el que poder devolver la respuesta adecuada.
De la misma forma, un LLM complementado con RAG sobre registros médicos podría ser un gran asistente en el ámbito clínico. También los analistas financieros se beneficiarían de un asistente vinculado a datos actualizados del mercado de valores. Prácticamente, cualquier caso de uso se beneficia de las técnicas RAG para enriquecer las capacidades de los LLM con datos de contexto específicos.
Recursos adicionales para entender mejor RAG
Cómo os podéis imaginar, tan pronto como nos asomamos por un momento a la parte más técnica de entender los LLM o RAG, las cosas se complican enormemente. En este post hemos tratado de explicar con palabras sencillas y ejemplos cotidianos cómo funciona la técnica de RAG para obtener respuestas más precisas y contextualizadas a las preguntas que le hacemos a un asistente conversacional como ChatGPT, Bard o cualquier otro. Sin embargo, para todos aquellos que tengáis ganas y fuerzas para profundizar en el tema, os dejamos una serie de recursos web disponibles para tratar de entender un poco más cómo se combinan los LLM con RAG y otras técnicas como la ingeniería de prompts para ofrecer las mejores apps de IA generativa posibles.
Videos introductorios:
Artículos de contenido de LLMs y RAG para principiantes:
- DEV - LLM for dummies
-
Digital Native - LLMs for Dummies
-
Hopsworks.ai - Retrieval Augmented Generation (RAG) for LLMs
-
Datalytyx - RAG For Dummies
¿Quieres pasar al siguiente nivel? Algunas herramientas para probar:
- LangChain. LangChain es un marco (framework) de desarrollo que facilita la construcción de aplicaciones usando LLMs, como GPT-3 y GPT-4. LangChain es para desarrolladores de software y permite integrar y gestionar varios LLMs, creando aplicaciones como chatbots y agentes virtuales. Su principal ventaja es simplificar la interacción y orquestación de LLMs para una amplia gama de aplicaciones, desde análisis de texto hasta asistencia virtual.
-
Hugging Face. Hugging Face es una plataforma con más de 350 mil modelos, 75 mil conjuntos de datos y 150 mil aplicaciones de demostración, todos ellos de código abierto y disponibles públicamente online donde la gente puede colaborar fácilmente y construir modelos de inteligencia artificial.
-
OpenAI. OpenAI es la plataforma más conocida en lo que a modelos de LLM e interfaces conversacionales se refiere. Los creadores de ChatGTP ponen a disposición de la comunidad de desarrolladores un conjunto de librerías para utilizar el API de OpenAI y poder crear sus propias aplicaciones utilizando los modelos GPT-3.5 y GPT- 4. Como ejemplo, os proponemos visitar la documentación de la librería de Python para entender cómo, con muy pocas líneas de código, podemos estar usando un LLM en nuestra propia aplicación. Aunque las interfaces conversacionales de OpenAI como ChatGPT, utilizan su propio sistema RAG, también podemos combinar los modelos GPT con nuestra propia RAG, como por ejemplo, lo que proponen en este artículo.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación. Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.