Documentación
Introduction
In previous content, we have explored in depth the exciting world of Large Language Models (LLM) and, in particular, the Retrieval Augmented Generation (RAG) techniques that are revolutionising the way we interact with conversational agents. This exercise marks a milestone in our series, as we will not only explain the concepts, but also guide you step-by-step in building your own RAG-powered conversational agent. For this, we will use a Google Colabnotebook.
Access the data lab repository on Github.
Execute the data pre-processing code on Google Colab.
Through this notebook, we will build a chat that uses RAG to improve its responses, starting from scratch. The notebook will guide the user through the whole process:
- Installation of dependencies.
- Setting up the environment.
- Integration of a source of information in the form of a post.
- Incorporation of this source into the chat knowledge base using RAG techniques.
- Finally, we can see how the model's response changes before and after providing the post and asking a specific question about its content.
Tools used
Before starting, it is necessary to introduce and explain which tools we have used and why we have chosen them. For the construction of this RAG application we have used 3 pieces of technology or tools: Google Colab, OpenAI y LangChain. Both Google Colab and OpenAI are old acquaintances and we have used them several times in previous content. Therefore, in this section, we pay special attention to explaining what LangChain is, as it is a new tool that we have not used in previous posts.
- Google Colab. As usual in our exercises, when computing resources are needed, as well as a user-friendly programming environment, we use Google Colab, as far as possible. Google Colab guarantees that any user who wants to reproduce the exercise can do so without complications derived from the configuration of the particular environments of each programmer. It should be noted that adapting this exercise inspired by previous resources available in LangChain to the Google Colab environment has been a challenge.
- OpenAI. As a provider of the Chat GPT large language model (LLM), OpenAI offers a variety of powerful language models, such as GPT-4, GPT-4o, GPT-4o mini, etc. that are used to process and generate natural language text. In this case, the OpenAI language model is used in the answer generation area, where the user's question and the retrieved documents are combined to produce an accurate answer.
- LangChain. It is an open source framework (set of libraries) designed to facilitate the development of large-scale language model (LLM) based applications. This framework is especially useful for integrating and managing complex flows that combine multiple components, such as language models, vector databases, and information retrieval tools, among others.
LangChain is widely used in the development of applications such as:
- Question and answer systems (QA systems).
- Virtual assistants with specific knowledge.
- Customised text generation systems.
- Data analysis tools based on natural language.
Key features of LangChain
- Modularity and flexibility. LangChain is designed with a modular architecture that allows developers to connect different tools and services. This includes language models (such as OpenAI, Hugging Face, or local LLM) and vector databases (such as Pinecone, ChromaDB or Weaviate). The List of chat models that can be interacted with through Langchain is extensive.
- Support for AGR (Generation Augmented Retrieval) techniques. Langhain facilitates the implementation of RAG techniques by enabling the direct integration of information retrieval and text generation models. This improves the accuracy of responses by enabling LLMs to work with up-to-date and specific knowledge.
- Optimising the handling of prompts. Langhain helps to design and manage complex prompts efficiently. It allows to dynamically build a relevant context that works with the model, optimising the use of tokens and ensuring that responses are accurate and useful.
- Tokens represent the basic units that an AI model uses to process text. A token can be a whole word, a part of a word or a punctuation mark. In the sentence "Hello world!" there are, for example, four different tokens: "Hello", "Hello", "World", "! Text processing requires more computational resources as the number of tokens increases. Free versions of AI models, including the one we use in this exercise, set limits on the number of tokens that can be processed.
- Integrate multiple data sources. The framework can connect to various data sources, such as databases, APIs or user uploaded documents. This makes it ideal for building applications that need access to large volumes of structured or unstructured information.
- Interoperability with multiple LLMs. LangChain is agnostic (can be adapted to various language model providers) with respect to the language model provider, which means that you can use OpenAI, Cohere, Anthropic or even locally hosted language models.
To conclude this section, it is worth noting the open source nature of Langhain, which facilitates collaboration and innovation in the development of applications based on language models. In addition, LangChain gives us incredible flexibility because it allows developers to easily integrate different LLMs, vectorisers and even final web interfaces into their applications.
Step-by-step exploration of the exercise: introduction to the Repository
The Github repository that we will use contains all the resources needed to build our RAG application. Inside, you will find:
- README: this file provides an overview of the project, instructions for use and additional resources.
- Jupyter Notebook: the example has been developed using a Jupyter Notebook format that we have already used in the past to code practical exercises combining a text document with code snippets executable in Google Colab. Here is the detailed implementation of the application, including data loading and processing, integration with language models such as GPT-44, configuration of information retrieval systems and generation of responses based on the retrieved data.
Notebook: preparing the Environment
Before starting, it is advisable to have the following requirements.
- Basic knowledge of Python and Natural Language Processing (NLP): although the notebook is self-explanatory, a basic understanding of these concepts will facilitate learning.
- Access to Google Colab: the notebook runs in this environment, which provides the necessary infrastructure.
- Accounts active in OpenAI and LangChain with valid API keys. These services are free and essential for running the notebook. Once you register with these services, you will need to generate an API Key to interact with the services. You will need to have this key handy so that you can paste it when executing the corresponding code snippet. If you need help to get these keys, any conversational assistant such as chatGPT or Google Gemini can help you step-by-step to get the keys. If you need visual guidance on youtube you will find thousands of tutorials.
- OpenAI API: https://openai.com/api/
- Lanchain API: https://www.langchain.com/
Exploring the Notebook: block by block
The notebook is divided into several blocks, each dedicated to a specific stage of the development of our RAG application. In the following, we will describe each block in detail, including the code used and its explanation.
Note to user. In the following, we are going to reproduce blocks of the code present in the Colab notebook. For clarity we have divided the code into self-contained units and formatted the code to highlight the syntax of the Python programming language. In addition, the outputs provided by the Notebook have been formatted and highlighted in JSON format to make them more readable. Note that this Notebook invokes language model APIs and therefore the model response changes with each run. This means that the outputs (the answers) presented in this post may not be exactly the same as what the user receives when running the Notebook in Colab.
Block 1: Installation and initial configuration
|
import os |
It is very important that you run these two lines at the beginning of the exercise and then do not run it again until you close and exit Google Colab.
|
%%capture |
|
!pip install langchain --quiet |
|
import getpass os.environ["LANGCHAIN_TRACING_V2"] = "true" |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your Langchain API Key.
|
!pip install -qU langchain-openai |
|
import getpass |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your OpenAI API Key.
In this first block, we have installed the necessary libraries for our project. Some of the most relevant are:
- openai: To interact with the OpenAI API and access models such as GPT-4.
- langchain: A framework that simplifies LLM application development.
- langchain-text-splitters: To break up long texts into smaller fragments that can be processed by language models.
- langchain-community: A collection of additional tools and components for LangChain.
- langchain-openai: To integrate LangChain with the OpenAI API.
- langgraph: To visualise the workflow of our RAG application.
- In addition to installing the libraries, we also set up the API keys for OpenAI and LangChain, using the getpass.getpass() function to enter them securely.
Block 2: Initialising the interaction with the LLM
Next, we start the first programmatic interaction (we pass our first prompt) with the language model. To check that everything works, we ask you to translate a simple sentence.
|
import getpass import os ] |
If everything went well we will get an output like this:
|
{ |
This block is a basic introduction to using an LLM for a simple task: translation. The OpenAI API key is configured and a gpt-4o-mini language model is instantiated using ChatOpenAI.
Two messages are defined:
- SystemMessage: Instruction to the model for translating from English into Italian.
- HumanMessage: The text to be translated ("hi!").
Finally, the model is invoked with llm.invoke(messages) to get the translation.
Block 3: Creating Embeddings
To understand the concept of Embeddings applied to the context of natural language processing, we recommend reading this post.
|
import getpass pip install -qU langchain-core from langchain_core.vectorstores import InMemoryVectorStore |
When you run this snippet, a small dialogue box will appear below the snippet. There you must paste your OpenAI API Key.
This block focuses on the creation of embeddings (vector representations of text) that capture their semantic meaning. We use the OpenAIEmbeddings class to access OpenAI's text-embedding-3-large model, which generates high-quality embeddings .
The embeddings will be stored in an InMemoryVectorStore, an in-memory data structure that allows efficient searches based on semantic similarity.
Block 4: Implementing RAG
|
#RAG import bs4 from langchain_community.document_loaders import WebBaseLoader # Manten únicamente el título del post, los encabezados y el contenido del HTML bs4_strainer = bs4.SoupStrainer(class_=("post-title", "post-header", "post-content")) loader = WebBaseLoader( web_paths=("https://datos.gob.es/es/blog/slm-llm-rag-y-fine-tuning-pilares-de-la-ia…",) ) docs = loader.load() assert len(docs) == 1 print(f"Total characters: {len(docs.page_content)}") from langchain_text_splitters import RecursiveCharacterTextSplitter text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200, add_start_index=True, ) all_splits = text_splitter.split_documents(docs) print(f"Split blog post into {len(all_splits)} sub-documents.") document_ids = vector_store.add_documents(documents=all_splits) print(document_ids[:3]) |
This block is the heart of the RAG implementation. Start loading the content of a post, using WebBaseLoader and the URL of the post on SLM, LLM, RAG and Fine-tuning..
To prepare our Generation Augmented Retrieval (GAR) system, we start by processing the text of the post using segmentation techniques. This initial step is crucial, as we break down the content into smaller fragments that are complete in meaning. We use LangChain tools to perform this segmentation, assigning each fragment a unique identifier (id). This prior preparation allows us to subsequently perform efficient and accurate searches when the system needs to retrieve relevant information to answer queries.
The bs4.SoupStrainer is used to extract only the relevant sections of the HTML. The text of the post is split into smaller fragments with RecursiveCharacterTextSplitter, ensuring overlap between fragments to maintain context. These fragments are added to the vector_store created in the previous block, generating embeddings for each one.
We see that the result of one of the fragments informs us that it has split the document into 21 sub-documents.
|
Split blog post into 21 sub-documents. |
Documents have their own identifier. For example, the first 3 are identified as:.
|
["409f1bcb-1710-49b0-80f8-e45b7ca51a96", "e242f16c-71fd-4e7b-8b28-ece6b1e37a1c", "9478b11c-61ab-4dac-9903-f8485c4770c6"] |
Block 5: Defining the Prompt and visualising the workflow
|
from langchain import hub prompt = hub.pull("rlm/rag-prompt") example_messages = prompt.invoke( {"context": "(context goes here)", "question": "(question goes here)"} ).to_messages() assert len(example_messages) == 1 print(example_messages.content) from langchain_core.documents import Document from typing_extensions import List, TypedDict class State(TypedDict): question: str context: List[Document] answer: str def retrieve(state: State): retrieved_docs = vector_store.similarity_search(state["question"]) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} from langgraph.graph import START, StateGraph graph_builder = StateGraph(State).add_sequence([retrieve, generate]) graph_builder.add_edge(START, "retrieve") graph = graph_builder.compile() from IPython.display import Image, display display(Image(graph.get_graph().draw_mermaid_png())) result = graph.invoke({"question": "What is Task Decomposition?"}) print(f"Context: {result["context"]}\n\n") print(f"Answer: {result["answer"]}") for step in graph.stream( {"question": "¿Cual es el futuro de la IA Generativa?"}, stream_mode="updates" ): print(f"{step}\n\n----------------\n") |
This block defines the prompt to be used to interact with the LLM. A predefined LangChain Hub prompt (rlm/rag-prompt) is used which is designed for RAG tasks.
Two functions are defined:
- retrieve: search the vector_store for snippets most similar to the user's question.
- generate: generates a response using the LLM, taking into account the context provided by the retrieved fragments.
langgraph is used to visualise the RAG workflow.
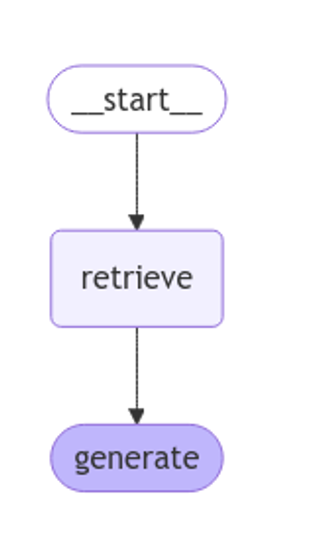
Figure 1: RAG workflow. Own elaboration.
Finally, the system is tested with two questions: one in English ("What is Task Decomposition?") and one in Spanish ("¿Cual es el futuro de la AI Generativa?").
The first question, "What is Task Decomposition?", is in English and is a generic question, unrelated to our content post. Therefore, although the system searches in its knowledge base previously created with the vectorisation of the document (post), it does not find any relation between the question and this context.
This text may vary with each execution
|
Answer: There is no explicit mention of the concept of "Task Decomposition" in the context provided. Therefore, I have no information on what Task Decomposition is. |
|
Answer: Task Decomposition is a process that decomposes a complex task into smaller, more manageable sub-tasks. This allows each subtask to be addressed independently, facilitating their resolution and improving overall efficiency. Although the context provided does not explicitly define Task Decomposition, this concept is common in AI and task optimisation. |
Answer: Task Decomposition is a process that decomposes a complex task into smaller, more manageable sub-tasks. This allows each subtask to be addressed independently, facilitating their resolution and improving overall efficiency. Although the context provided does not explicitly define Task Decomposition, this concept is common in AI and task optimisation.
|
{ |
As you can see in the response, the system retrieves 4 documents (in the diagram above, this corresponds to the "Retrieve" stage) with their corresponding "id" (identifiers), for example, the first document "id":. "53962c40-c08b-4547-a74a-26f63cced7e8" which corresponds to a fragment of the original post "title":. "SLM, LLM, RAG and Fine-tuning: Pillars of Modern Generative AI | datos.gob.es".
With these 4 fragments the system considers that it has enough relevant information to provide (in the diagram above, the "generate" stage) a satisfactory answer to the question.
|
{ |
Bloque 6: personalizando el prompt
|
from langchain_core.prompts import PromptTemplate template = """Use the following pieces of context to answer the question at the end. If you don"t know the answer, just say that you don"t know, don"t try to make up an answer. Use three sentences maximum and keep the answer as concise as possible. Always say "thanks for asking!" at the end of the answer. {context} Question: {question} Helpful Answer:""" custom_rag_prompt = PromptTemplate.from_template(template) |
This block customises the prompt to make answers more concise and add a polite sentence at the end. PromptTemplate is used to create a new prompt with the desired instructions.
Block 7: Adding metadata and refining your search
|
total_documents = len(all_splits) third = total_documents // 3 for i, document in enumerate(all_splits): if i < third: document.metadata["section"] = "beginning" elif i < 2 * third: document.metadata["section"] = "middle" else: document.metadata["section"] = "end" all_splits.metadata from langchain_core.vectorstores import InMemoryVectorStore vector_store = InMemoryVectorStore(embeddings) _ = vector_store.add_documents(all_splits) from typing import Literal from typing_extensions import Annotated class Search(TypedDict): """Search query.""" query: Annotated[str, ..., "Search query to run."] section: Annotated( Literal["beginning", "middle", "end"], ..., "Section to query.", ] class State(TypedDict): question: str query: Search context: List[Document] answer: str def analyze_query(state: State): structured_llm = llm.with_structured_output(Search) query = structured_llm.invoke(state["question"]) return {"query": query} def retrieve(state: State): query = state["query"] retrieved_docs = vector_store.similarity_search( query["query"], filter=lambda doc: doc.metadata.get("section") == query["section"], ) return {"context": retrieved_docs} def generate(state: State): docs_content = "\n\n".join(doc.page_content for doc in state["context"]) messages = prompt.invoke({"question": state["question"], "context": docs_content}) response = llm.invoke(messages) return {"answer": response.content} graph_builder = StateGraph(State).add_sequence([analyze_query, retrieve, generate]) graph_builder.add_edge(START, "analyze_query") graph = graph_builder.compile() display(Image(graph.get_graph().draw_mermaid_png())) for step in graph.stream( {"question": "¿Cual es el furturo de la IA Generativa en palabras del autor?"}, stream_mode="updates", ): print(f"{step}\n\n----------------\n") |
In this block, metadata is added to the post fragments, dividing them into three sections: "beginning", "middle" and "end". This allows for more refined searches, limiting the search to a specific section of the post.
A new analyze_query function is introduced that uses the LLM to determine the section of the post most relevant to the user's question. The RAG workflow is updated to include this new step.
Finally, the system is tested with a question in Spanish ("What is the future of Generative AI in the author's words?"), observing how the system uses the information in the "end" section of the post to generate a more accurate answer.
Let's look at the result:

Figure 2: RAG workflow. Own elaboration.
|
{ ---------------- { |
|
{ |
Conclusions
Through this notebook tour of Google Colab, we have experienced first-hand the construction of a conversational agent with RAG. We have learned to:
- Install the necessary libraries.
- Configure the development environment.
- Upload and process data.
- Create embeddings and store them in a vector_store.
- Implement the RAG recovery and generation stages.
- Customise the prompt to get more specific answers.
- Add metadata to refine the search.
This practical exercise provides you with the tools and knowledge you need to start exploring the potential of RAG and develop your own applications.
Dare to experiment with different information sources, language models and prompts to create increasingly sophisticated conversational agents!
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
In the fast-paced world of Generative Artificial Intelligence (AI), there are several concepts that have become fundamental to understanding and harnessing the potential of this technology. Today we focus on four: Small Language Models(SLM), Large Language Models(LLM), Retrieval Augmented Generation(RAG) and Fine-tuning. In this article, we will explore each of these terms, their interrelationships and how they are shaping the future of generative AI.
Let us start at the beginning. Definitions
Before diving into the details, it is important to understand briefly what each of these terms stands for:
The first two concepts (SLM and LLM) that we address are what are known as language models. A language model is an artificial intelligence system that understands and generates text in human language, as do chatbots or virtual assistants. The following two concepts (Fine Tuning and RAG) could be defined as optimisation techniques for these previous language models. Ultimately, these techniques, with their respective approaches as discussed below, improve the answers and the content returned to the questioner. Let's go into the details:
- SLM (Small Language Models): More compact and specialised language models, designed for specific tasks or domains.
- LLM (Large Language Models): Large-scale language models, trained on vast amounts of data and capable of performing a wide range of linguistic tasks.
- RAG (Retrieval-Augmented Generation): A technique that combines the retrieval of relevant information with text generation to produce more accurate and contextualised responses.
- Fine-tuning: The process of tuning a pre-trained model for a specific task or domain, improving its performance in specific applications.
Now, let's dig deeper into each concept and explore how they interrelate in the Generative AI ecosystem.
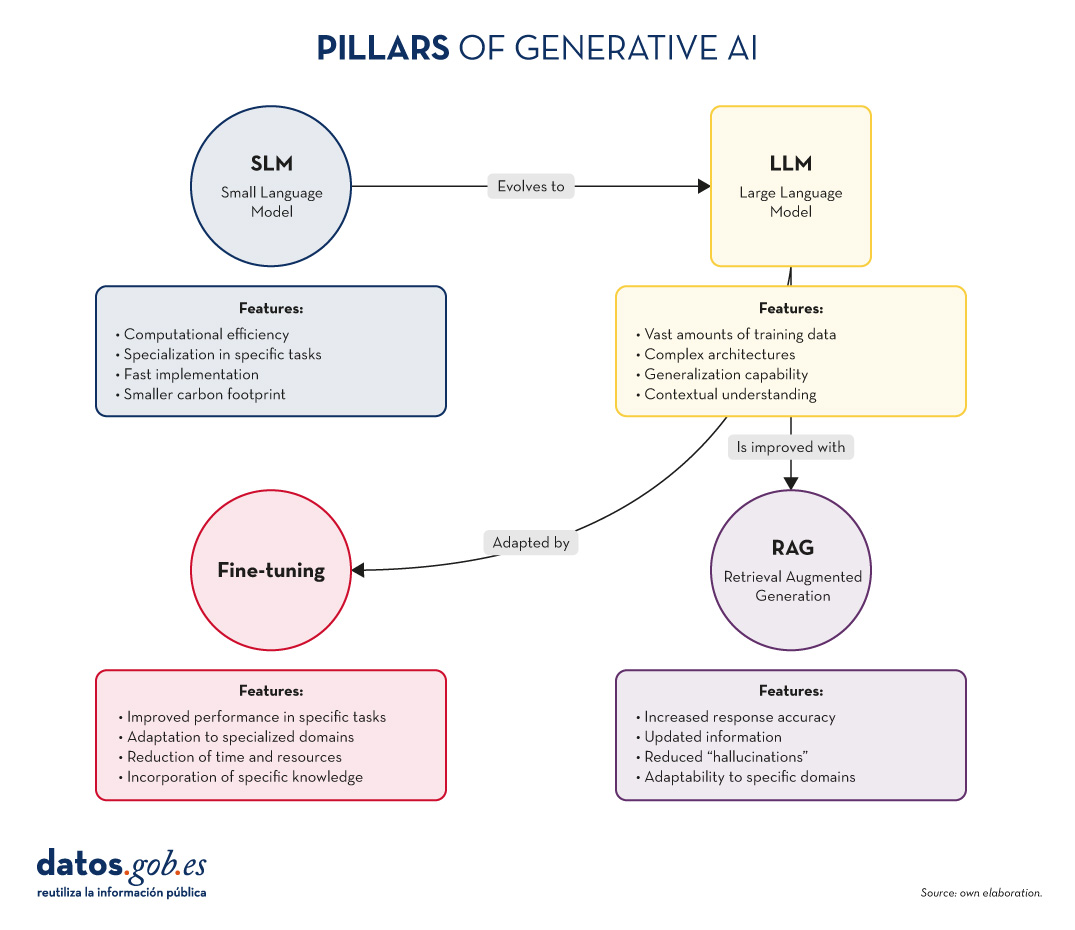
Figure 1. Pillars of Generative AI. Own elaboration.
SLM: The power of specialisation
Increased efficiency for specific tasks
Small Language Models (SLMs) are AI models designed to be lighter and more efficient than their larger counterparts. Although they have fewer parameters, they are optimised for specific tasks or domains.
Key characteristics of SLMs:
- Computational efficiency: They require fewer resources for training and implementation.
- Specialisation: They focus on specific tasks or domains, achieving high performance in specific areas.
- Rapid implementation: Ideal for resource-constrained devices or applications requiring real-time responses.
- Lower carbon footprint: Being smaller, their training and use consumes less energy.
SLM applications:
- Virtual assistants for specific tasks (e.g. booking appointments).
- Personalised recommendation systems.
- Sentiment analysis in social networks.
- Machine translation for specific language pairs.
LLM: The power of generalisation
The revolution of Large Language Models
LLMs have transformed the Generative AI landscape, offering amazing capabilities in a wide range of language tasks.
Key characteristics of LLMs:
- Vast amounts of training data: They train with huge corpuses of text, covering a variety of subjects and styles.
- Complex architectures: They use advanced architectures, such as Transformers, with billions of parameters.
- Generalisability: They can tackle a wide variety of tasks without the need for task-specific training.
- Contextual understanding: They are able to understand and generate text considering complex contexts.
LLM applications:
- Generation of creative text (stories, poetry, scripts).
- Answers to complex questions and reasoning.
- Analysis and summary of long documents.
- Advanced multilingual translation.
RAG: Boosting accuracy and relevance
The synergy between recovery and generation
As we explored in our previous article, RAG combines the power of information retrieval models with the generative capacity of LLMs. Its key aspects are:
Key features of RAG:
- Increased accuracy of responses.
- Capacity to provide up-to-date information.
- Reduction of "hallucinations" or misinformation.
- Adaptability to specific domains without the need to completely retrain the model.
RAG applications:
- Advanced customer service systems.
- Academic research assistants.
- Fact-checking tools for journalism.
- AI-assisted medical diagnostic systems.
Fine-tuning: Adaptation and specialisation
Refining models for specific tasks
Fine-tuning is the process of adjusting a pre-trained model (usually an LLM) to improve its performance in a specific task or domain. Its main elements are as follows:
Key features of fine-tuning:
- Significant improvement in performance on specific tasks.
- Adaptation to specialised or niche domains.
- Reduced time and resources required compared to training from scratch.
- Possibility of incorporating specific knowledge of the organisation or industry.
Fine-tuning applications:
- Industry-specific language models (legal, medical, financial).
- Personalised virtual assistants for companies.
- Content generation systems tailored to particular styles or brands.
- Specialised data analysis tools.
Here are a few examples
Many of you familiar with the latest news in generative AI will be familiar with these examples below.
SLM: The power of specialisation
Ejemplo: BERT for sentiment analysis
BERT (Bidirectional Encoder Representations from Transformers) is an example of SLM when used for specific tasks. Although BERT itself is a large language model, smaller, specialised versions of BERT have been developed for sentiment analysis in social networks.
For example, DistilBERT, a scaled-down version of BERT, has been used to create sentiment analysis models on X (Twitter). These models can quickly classify tweets as positive, negative or neutral, being much more efficient in terms of computational resources than larger models.
LLM: The power of generalisation
Ejemplo: OpenAI GPT-3
GPT-3 (Generative Pre-trained Transformer 3) is one of the best known and most widely used LLMs. With 175 billion parameters, GPT-3 is capable of performing a wide variety of natural language processing tasks without the need for task-specific training.
A well-known practical application of GPT-3 is ChatGPT, OpenAI's conversational chatbot. ChatGPT can hold conversations on a wide variety of topics, answer questions, help with writing and programming tasks, and even generate creative content, all using the same basic model.
Already at the end of 2020 we introduced the first post on GPT-3 as a great language model. For the more nostalgic ones, you can check the original post here.
RAG: Boosting accuracy and relevance
Ejemplo: Anthropic's virtual assistant, Claude
Claude, the virtual assistant developed by Anthropic, is an example of an application using RAGtechniques. Although the exact details of its implementation are not public, Claude is known for his ability to provide accurate and up-to-date answers, even on recent events.
In fact, most generative AI-based conversational assistants incorporate RAG techniques to improve the accuracy and context of their responses. Thus, ChatGPT, the aforementioned Claude, MS Bing and the like use RAG.
Fine-tuning: Adaptation and specialisation
Ejemplo: GPT-3 fine-tuned for GitHub Copilot
GitHub Copilot, the GitHub and OpenAI programming assistant, is an excellent example of fine-tuning applied to an LLM. Copilot is based on a GPT model (possibly a variant of GPT-3) that has been specificallyfine-tunedfor scheduling tasks.
The base model was further trained with a large amount of source code from public GitHub repositories, allowing it to generate relevant and syntactically correct code suggestions in a variety of programming languages. This is a clear example of how fine-tuning can adapt a general purpose model to a highly specialised task.
Another example: in the datos.gob.es blog, we also wrote a post about applications that used GPT-3 as a base LLM to build specific customised products.
Interrelationships and synergies
These four concepts do not operate in isolation, but intertwine and complement each other in the Generative AI ecosystem:
- SLM vs LLM: While LLMs offer versatility and generalisability, SLMs provide efficiency and specialisation. The choice between one or the other will depend on the specific needs of the project and the resources available.
- RAG and LLM: RAG empowers LLMs by providing them with access to up-to-date and relevant information. This improves the accuracy and usefulness of the answers generated.
- Fine-tuning and LLM: Fine-tuning allows generic LLMs to be adapted to specific tasks or domains, combining the power of large models with the specialisation needed for certain applications.
- RAG and Fine-tuning: These techniques can be combined to create highly specialised and accurate systems. For example, a LLM with fine-tuning for a specific domain can be used as a generative component in a RAGsystem.
- SLM and Fine-tuning: Fine-tuning can also be applied to SLM to further improve its performance on specific tasks, creating highly efficient and specialised models.
Conclusions and the future of AI
The combination of these four pillars is opening up new possibilities in the field of Generative AI:
- Hybrid systems: Combination of SLM and LLM for different aspects of the same application, optimising performance and efficiency.
- AdvancedRAG : Implementation of more sophisticated RAG systems using multiple information sources and more advanced retrieval techniques.
- Continuousfine-tuning : Development of techniques for the continuous adjustment of models in real time, adapting to new data and needs.
- Personalisation to scale: Creation of highly customised models for individuals or small groups, combining fine-tuning and RAG.
- Ethical and responsible Generative AI: Implementation of these techniques with a focus on transparency, verifiability and reduction of bias.
SLM, LLM, RAG and Fine-tuning represent the fundamental pillars on which the future of Generative AI is being built. Each of these concepts brings unique strengths:
- SLMs offer efficiency and specialisation.
- LLMs provide versatility and generalisability.
- RAG improves the accuracy and relevance of responses.
- Fine-tuning allows the adaptation and customisation of models.
The real magic happens when these elements combine in innovative ways, creating Generative AI systems that are more powerful, accurate and adaptive than ever before. As these technologies continue to evolve, we can expect to see increasingly sophisticated and useful applications in a wide range of fields, from healthcare to creative content creation.
The challenge for developers and researchers will be to find the optimal balance between these elements, considering factors such as computational efficiency, accuracy, adaptability and ethics. The future of Generative AI promises to be fascinating, and these four concepts will undoubtedly be at the heart of its development and application in the years to come.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Artificial intelligence (AI) is revolutionising the way we create and consume content. From automating repetitive tasks to personalising experiences, AI offers tools that are changing the landscape of marketing, communication and creativity.
These artificial intelligences need to be trained with data that are fit for purpose and not copyrighted. Open data is therefore emerging as a very useful tool for the future of AI.
The Govlab has published the report "A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI" to explore this issue in more detail. It analyses the emerging relationship between open data and generative AI, presenting various scenarios and recommendations. Their key points are set out below.
The role of data in generative AI
Data is the fundamental basis for generative artificial intelligence models. Building and training such models requires a large volume of data, the scale and variety of which is conditioned by the objectives and use cases of the model.
The following graphic explains how data functions as a key input and output of a generative AI system. Data is collected from various sources, including open data portals, in order to train a general-purpose AI model. This model will then be adapted to perform specific functions and different types of analysis, which in turn generate new data that can be used to further train models.
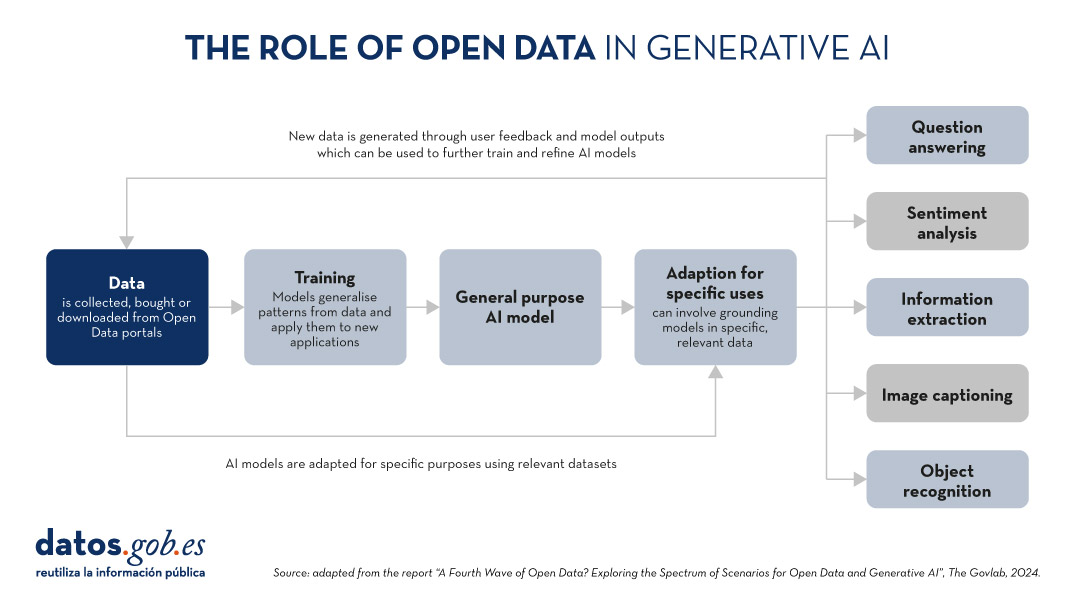
Figure 1. The role of open data in generative AI, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
5 scenarios where open data and artificial intelligence converge
In order to help open data providers ''prepare'' their data for generative AI, The Govlab has defined five scenarios outlining five different ways in which open data and generative AI can intersect. These scenarios are intended as a starting point, to be expanded in the future, based on available use cases.
| Scenario | Function | Quality requirements | Metadata requirements | Example |
|---|---|---|---|---|
| Pre-training | Training the foundational layers of a generative AI model with large amounts of open data. | High volume of data, diverse and representative of the application domain and non-structured usage. | Clear information on the source of the data. | Data from NASA''s Harmonized Landsat Sentinel-2 (HLS) project were used to train the geospatial foundational model watsonx.ai. |
| Adaptation | Refinement of a pre-trained model with task-specific open data, using fine-tuning or RAG techniques. | Tabular and/or unstructured data of high accuracy and relevance to the target task, with a balanced distribution. | Metadata focused on the annotation and provenance of data to provide contextual enrichment. | Building on the LLaMA 70B model, the French Government created LLaMandement, a refined large language model for the analysis and drafting of legal project summaries. They used data from SIGNALE, the French government''s legislative platform. |
| Inference and Insight Generation | Extracting information and patterns from open data using a trained generative AI model. | High quality, complete and consistent tabular data. | Descriptive metadata on the data collection methods, source information and version control. | Wobby is a generative interface that accepts natural language queries and produces answers in the form of summaries and visualisations, using datasets from different offices such as Eurostat or the World Bank. |
| Data Augmentation | Leveraging open data to generate synthetic data or provide ontologies to extend the amount of training data. | Tabular and/or unstructured data which is a close representation of reality, ensuring compliance with ethical considerations. | Transparency about the generation process and possible biases. | A team of researchers adapted the US Synthea model to include demographic and hospital data from Australia. Using this model, the team was able to generate approximately 117,000 region-specific synthetic medical records. |
| Open-Ended Exploration | Exploring and discovering new knowledge and patterns in open data through generative models. | Tabular data and/or unstructured, diverse and comprehensive. | Clear information on sources and copyright, understanding of possible biases and limitations, identification of entities. | NEPAccess is a pilot to unlock access to data related to the US National Environmental Policy Act (NEPA) through a generative AI model. It will include functions for drafting environmental impact assessments, data analysis, etc. |
Figure 2. Five scenarios where open data and Artificial Intelligence converge, adapted from the report “A Fourth Wave of Open Data? Exploring the Spectrum of Scenarios for Open Data and Generative AI”, The Govlab, 2024.
You can read the details of these scenarios in the report, where more examples are explained. In addition, The Govlab has also launched an observatory where it collects examples of intersections between open data and generative artificial intelligence. It includes the examples in the report along with additional examples. Any user can propose new examples via this form. These examples will be used to further study the field and improve the scenarios currently defined.
Among the cases that can be seen on the web, we find a Spanish company: Tendios. This is a software-as-a-service company that has developed a chatbot to assist in the analysis of public tenders and bids in order to facilitate competition. This tool is trained on public documents from government tenders.
Recommendations for data publishers
To extract the full potential of generative AI, improving its efficiency and effectiveness, the report highlights that open data providers need to address a number of challenges, such as improving data governance and management. In this regard, they contain five recommendations:
- Improve transparency and documentation. Through the use of standards, data dictionaries, vocabularies, metadata templates, etc. It will help to implement documentation practices on lineage, quality, ethical considerations and impact of results.
- Maintaining quality and integrity. Training and routine quality assurance processes are needed, including automated or manual validation, as well as tools to update datasets quickly when necessary. In addition, mechanisms for reporting and addressing data-related issues that may arise are needed to foster transparency and facilitate the creation of a community around open datasets.
- Promote interoperability and standards. It involves adopting and promoting international data standards, with a special focus on synthetic data and AI-generated content.
- Improve accessibility and user-friendliness. It involves the enhancement of open data portals through intelligent search algorithms and interactive tools. It is also essential to establish a shared space where data publishers and users can exchange views and express needs in order to match supply and demand.
- Addressing ethical considerations. Protecting data subjects is a top priority when talking about open data and generative AI. Comprehensive ethics committees and ethical guidelines are needed around the collection, sharing and use of open data, as well as advanced privacy-preserving technologies.
This is an evolving field that needs constant updating by data publishers. These must provide technically and ethically adequate datasets for generative AI systems to reach their full potential.
Blog
In recent months we have seen how the large language models (LLMs ) that enable Generative Artificial Intelligence (GenAI) applications have been improving in terms of accuracy and reliability. RAG (Retrieval Augmented Generation) techniques have allowed us to use the full power of natural language communication (NLP) with machines to explore our own knowledge bases and extract processed information in the form of answers to our questions. In this article we take a closer look at RAG techniques in order to learn more about how they work and all the possibilities they offer in the context of generative AI.
What are RAG techniques?
This is not the first time we have talked about RAG techniques. In this article we have already introduced the subject, explaining in a simple way what they are, what their main advantages are and what benefits they bring in the use of Generative AI.
Let us recall for a moment its main keys. RAG is translated as Retrieval Augmented Generation . In other words, RAG consists of the following: when a user asks a question -usually in a conversational interface-, the Artificial Intelligence (AI), before providing a direct answer -which it could give using the (fixed) knowledge base with which it has been trained-, carries out a process of searching and processing information in a specific database previously provided, complementary to that of the training. When we talk about a database, we refer to a knowledge base previously prepared from a set of documents that the system will use to provide more accurate answers. Thus, when using RAGtechniques, conversational interfaces produce more accurate and context-specific responses.
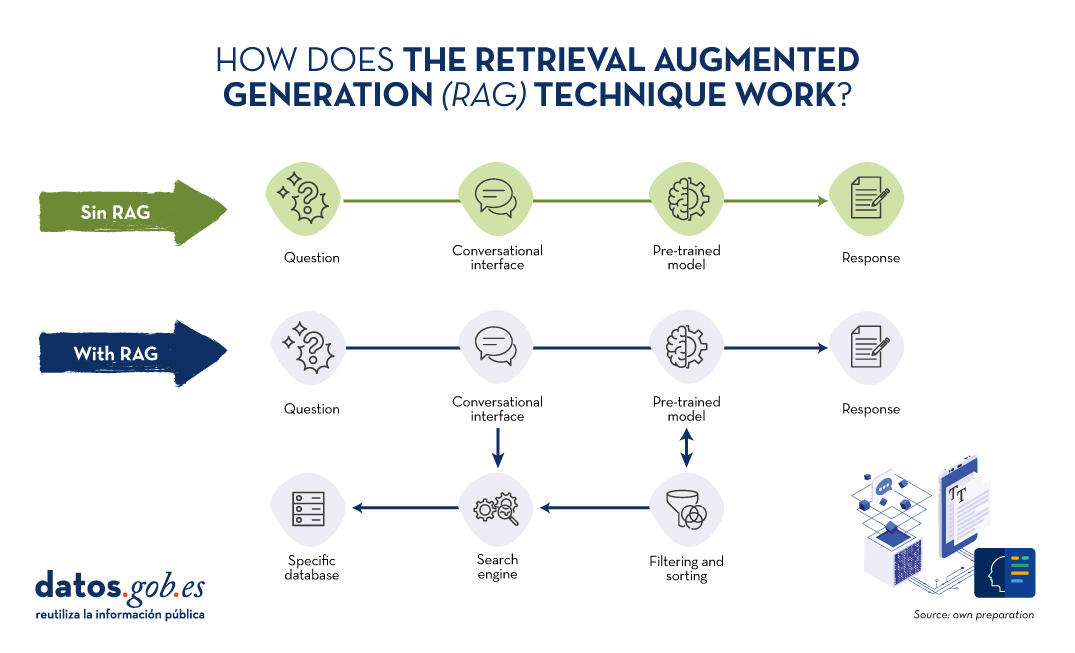
Source: Own preparation.
Conceptual diagram of the operation of a conversational interface or assistant without using RAG (top) and using RAG (bottom).
Drawing a comparison with the medical field, we could say that the use of RAG is as if a doctor, with extensive experience and therefore highly trained, in addition to the knowledge acquired during his academic training and years of experience, has quick and effortless access to the latest studies, analyses and medical databases instantly, before providing a diagnosis. Academic training and years of experience are equivalent to large language model (LLM) training and the "magic" access to the latest studies and specific databases can be assimilated to what RAG techniques provide.
Evidently, in the example we have just given, good medical practice makes both elements indispensable, and the human brain knows how to combine them naturally, although not without effort and time, even with today's digital tools, which make the search for information easier and more immediate.
RAG in detail
RAG Fundamentals
RAG combines two phases to achieve its objective: recovery and generation. In the first, relevant documents are searched for in a database containing information relevant to the question posed (e.g. a clinical database or a knowledge base of commonly asked questions and answers). In the second, an LLM is used to generate a response based on the retrieved documents. This approach ensures that responses are not only consistent but also accurate and supported by verifiable data.
Components of the RAG System
In the following, we will describe the components that a RAG algorithm uses to fulfil its function. For this purpose, for each component, we will explain what function it fulfils, which technologies are used to fulfil this function and an example of the part of the RAG process in which that component is involved.
- Recovery Model:
- Function: Identifies and retrieves relevant documents from a large database in response to a query.
- Technology: It generally uses Information Retrieval (IR) techniques such as BM25 or embedding-based retrieval models such as Dense Passage Retrieval (DPR).
- Process: Given a question, the retrieval model searches a database to find the most relevant documents and presents them as context for answer generation.
- Generation Model:
- Function: Generate coherent and contextually relevant answers using the retrieved documents.
- Technology: Based on some of the major Large Language Models (LLM) such as GPT-3.5, T5, or BERT, Llama.
- Process: The generation model takes the user's query and the retrieved documents and uses this combined information to produce an accurate response.
Detailed RAG Process
For a better understanding of this section, we recommend the reader to read this previous work in which we explain in a didactic way the basics of natural language processing and how we teach machines to read. In detail, a RAG algorithm performs the following steps:
- Reception of the question. The system receives a question from the user. This question is processed to extract keywords and understand the intention.
- Document retrieval. The question is sent to the recovery model.
- Example of Retrieval based on embeddings:
- The question is converted into a vector of embeddings using a pre-trained model.
- This vector is compared with the document vectors in the database.
- The documents with the highest similarity are selected.
- Example of BM25:
- The question is tokenised and the keywords are compared with the inverted indexes in the database.
- The most relevant documents are retrieved according to a relevance score.
- Example of Retrieval based on embeddings:
- Filtering and sorting. The retrieved documents are filtered to eliminate redundancies and to classify them according to their relevance. Additional techniques such as reranking can be applied using more sophisticated models.
- Response generation. The filtered documents are concatenated with the user's question and fed into the generation model. The LLM uses the combined information to generate an answer that is coherent and directly relevant to the question. For example, if we use GPT-3.5 as LLM, the input to the model includes both the user's question and fragments of the retrieved documents. Finally, the model generates text using its ability to understand the context of the information provided.
In the following section we will look at some applications where Artificial Intelligence and large language models play a differentiating role and, in particular, we will analyse how these use cases benefit from the application of RAGtechniques.
Examples of use cases that benefit substantially from using RAG vs. not using RAG
1. ECommerceCustomer Service
- No RAG:
- A basic chatbot can give generic and potentially incorrect answers about return policies.
- Example: Please review our returns policy on the website.
- With RAG:
- The chatbot accesses the database of updated policies and provides a specific and accurate response.
- Example: You may return products within 30 days of purchase, provided they are in their original packaging. See more details [here].
2. Medical Diagnosis
- No RAG:
- A virtual health assistant could offer recommendations based only on their previous training, without access to the latest medical information.
- Example: You may have the flu. Consult your doctor
- With RAG:
- The wizard can retrieve information from recent medical databases and provide a more accurate and up-to-date diagnosis.
- Example: Based on your symptoms and recent studies published in PubMed, you could be dealing with a viral infection. Consult your doctor for an accurate diagnosis.
3. Academic Research Assistance
- No RAG:
- A researcher receives answers limited to what the model already knows, which may not be sufficient for highly specialised topics.
- Example: Economic growth models are important for understanding the economy.
- With RAG:
- The wizard retrieves and analyses relevant academic articles, providing detailed and accurate information.
- Example: According to the 2023 study in the Journal of Economic Growth, the XYZ model has been shown to be 20% more accurate in predicting economic trends in emerging markets.
4. Journalism
- No RAG:
- A journalist receives generic information that may not be up to date or accurate.
- Example Artificial intelligence is changing many industries.
- With RAG:
- The wizard retrieves specific data from recent studies and articles, providing a solid basis for the article.
- Example: According to a 2024 report by 'TechCrunch', AI adoption in the financial sector has increased by 35% in the last year, improving operational efficiency and reducing costs.
Of course, for most of us who have experienced the more accessible conversational interfaces, such as ChatGPT, Gemini o Bing we can see that the answers are usually complete and quite precise when it comes to general questions. This is because these agents make use of AGN methods and other advanced techniques to provide the answers. However, it is not long before conversational assistants, such as Alexa, Siri u OK Google provided extremely simple answers and very similar to those explained in the previous examples when not making use of RAG.
Conclusions
Retrieval Augmented Generation (RAG) techniques improve the accuracy and relevance of language model answers by combining document retrieval and text generation. Using retrieval methods such as BM25 or DPR and advanced language models, RAG provides more contextualised, up-to-date and accurate responses.Today, RAG is the key to the exponential development of AI in the private data domain of companies and organisations. In the coming months, RAG is expected to see massive adoption in a variety of industries, optimising customer care, medical diagnostics, academic research and journalism, thanks to its ability to integrate relevant and current information in real time.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation. The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
The era of digitalisation in which we find ourselves has filled our daily lives with data products or data-driven products. In this post we discover what they are and show you one of the key data technologies to design and build this kind of products: GraphQL.
Introduction
Let's start at the beginning, what is a data product? A data product is a digital container (a piece of software) that includes data, metadata and certain functional logics (what and how I handle the data). The aim of such products is to facilitate users' interaction with a set of data. Some examples are:
- Sales scorecard: Online businesses have tools to track their sales performance, with graphs showing trends and rankings, to assist in decision making.
- Apps for recommendations: Streaming TV services have functionalities that show content recommendations based on the user's historical tastes.
- Mobility apps. The mobile apps of new mobility services (such as Cabify, Uber, Bolt, etc.) combine user and driver data and metadata with predictive algorithms, such as dynamic fare calculation or optimal driver assignment, in order to offer a unique user experience.
- Health apps: These applications make massive use of data captured by technological gadgets (such as the device itself, smart watches, etc.) that can be integrated with other external data such as clinical records and diagnostic tests.
- Environmental monitoring: There are apps that capture and combine data from weather forecasting services, air quality systems, real-time traffic information, etc. to issue personalised recommendations to users (e.g. the best time to schedule a training session, enjoy the outdoors or travel by car).
As we can see, data products accompany us on a daily basis, without many users even realising it. But how do you capture this vast amount of heterogeneous information from different technological systems and combine it to provide interfaces and interaction paths to the end user? This is where GraphQL positions itself as a key technology to accelerate the creation of data products, while greatly improving their flexibility and adaptability to new functionalities desired by users.
What is GraphQL?
GraphQL saw the light of day on Facebook in 2012 and was released as Open Source in 2015. It can be defined as a language and an interpreter of that language, so that a developer of data products can invent a way to describe his product based on a model (a data structure) that makes use of the data available through APIs.
Before the advent of GraphQL, we had (and still have) the technology REST, which uses the HTTPs protocol to ask questions and get answers based on the data. In 2021, we introduced a post where we presented the technology and made a small demonstrative example of how it works. In it, we explain REST API as the standard technology that supports access to data by computer programs. We also highlight how REST is a technology fundamentally designed to integrate services (such as an authentication or login service).
In a simple way, we can use the following analogy. It is as if REST is the mechanism that gives us access to a complete dictionary. That is, if we need to look up any word, we have a method of accessing the dictionary, which is alphabetical search. It is a general mechanism for finding any available word in the dictionary. However, GraphQL allows us, beforehand, to create a dictionary model for our use case (known as a "data model"). So, for example, if our final application is a recipe book, what we do is select a subset of words from the dictionary that are related to recipes.
To use GraphQL, data must always be available via an API. GraphQL provides a complete and understandable description of the API data, giving clients (human or application) the possibility to request exactly what they need. As quoted in this post, GraphQL is like an API to which we add a SQL-style "Where" statement.
Below, we take a closer look at GraphQL's strengths when the focus is on the development of data products.
Benefits of using GraphQL in data products:
- With GraphQL, the amount of data and queries on the APIs is considerably optimised . APIs for accessing certain data are not intended for a specific product (or use case) but as a general access specification (see dictionary example above). This means that, on many occasions, in order to access a subset of the data available in an API, we have to perform several chained queries, discarding most of the information along the way. GraphQL optimises this process, as it defines a predefined (but adaptable in the future) consumption model over a technical API. Reducing the amount of data requested has a positive impact on the rationalisation of computing resources, such as bandwidth or caches, and improves the speed of response of systems.
- This has an immediate effect on the standardisation of data access. The model defined thanks to GraphQL creates a data consumption standard for a family of use cases. Again, in the context of a social network, if what we want is to identify connections between people, we are not interested in a general mechanism of access to all the people in the network, but a mechanism that allows us to indicate those people with whom I have some kind of connection. This kind of data access filter can be pre-configured thanks to GraphQL.
- Improved safety and performance: By precisely defining queries and limiting access to sensitive data, GraphQL can contribute to a more secure and better performing application.
Thanks to these advantages, the use of this language represents a significant evolution in the way of interacting with data in web and mobile applications, offering clear advantages over more traditional approaches such as REST.
Generative Artificial Intelligence. A new superhero in town.
If the use of GraphQL language to access data in a much more efficient and standard way is a significant evolution for data products, what will happen if we can interact with our product in natural language? This is now possible thanks to the explosive evolution in the last 24 months of LLMs (Large Language Models) and generative AI.
The following image shows the conceptual scheme of a data product, intLegrated with LLMS: a digital container that includes data, metadata and logical functions that are expressed as functionalities for the user, together with the latest technologies to expose information in a flexible way, such as GraphQL and conversational interfaces built on top of Large Language Models (LLMs).

How can data products benefit from the combination of GraphQL and the use of LLMs?
- Improved user experience. By integrating LLMs, people can ask questions to data products using natural language, . This represents a significant change in how we interact with data, making the process more accessible and less technical. In a practical way, we will replace the clicks with phrases when ordering a taxi.
- Security improvements along the interaction chain in the use of a data product. For this interaction to be possible, a mechanism is needed that effectively connects the backend (where the data resides) with the frontend (where the questions are asked). GraphQL is presented as the ideal solution due to its flexibility and ability to adapt to the changing needs of users,offering a direct and secure link between data and questions asked in natural language. That is, GraphQl can pre-select the data to be displayed in a query, thus preventing the general query from making some private or unnecessary data visible for a particular application.
- Empowering queries with Artificial Intelligence: The artificial intelligence not only plays a role in natural language interaction with the user. One can think of scenarios where the very model that is defined with GraphQL is assisted by artificial intelligence itself. This would enrich interactions with data products, allowing a deeper understanding and richer exploration of the information available. For example, we can ask a generative AI (such as ChatGPT) to take this catalogue data that is exposed as an API and create a GraphQL model and endpoint for us.
In short, the combination of GraphQL and LLMs represents a real evolution in the way we access data. GraphQL's integration with LLMs points to a future where access to data can be both accurate and intuitive, marking a move towards more integrated information systems that are accessible to all and highly reconfigurable for different use cases. This approach opens the door to a more human and natural interaction with information technologies, aligning artificial intelligence with our everyday experiences of communicating using data products in our day-to-day lives.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and points of view reflected in this publication are the sole responsibility of its author.
Blog
Teaching computers to understand how humans speak and write is a long-standing challenge in the field of artificial intelligence, known as natural language processing (NLP). However, in the last two years or so, we have seen the fall of this old stronghold with the advent of large language models (LLMs) and conversational interfaces. In this post, we will try to explain one of the key techniques that makes it possible for these systems to respond relatively accurately to the questions we ask them.
Introduction
In 2020, Patrick Lewis, a young PhD in the field of language modelling who worked at the former Facebook AI Research (now Meta AI Research) publishes a paper with Ethan Perez of New York University entitled: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks in which they explained a technique to make current language models more precise and concrete. The article is complex for the general public, however, in their blog, several of the authors of the article explain in a more accessible way how the RAG technique works. In this post we will try to explain it as simply as possible.
Large Language Models are artificial intelligence models that are trained using Deep Learning algorithms on huge sets of human-generated information. In this way, once trained, they have learned the way we humans use the spoken and written word, so they are able to give us general and very humanly patterned answers to the questions we ask them. However, if we are looking for precise answers in a given context, LLMs alone will not provide specific answers or there is a high probability that they will hallucinate and completely make up the answer. For LLMs to hallucinate means that they generate inaccurate, meaningless or disconnected text. This effect poses potential risks and challenges for organisations using these models outside the domestic or everyday environment of personal LLM use. The prevalence of hallucination in LLMs, estimated at 15% to 20% for ChatGPT, may have profound implications for the reputation of companies and the reliability of AI systems.
What is a RAG?
Precisely, RAG techniques have been developed to improve the quality of responses in specific contexts, for example, in a particular discipline or based on private knowledge repositories such as company databases.
RAG is an extra technique within artificial intelligence frameworks, which aims to retrieve facts from an external knowledge base to ensure that language models return accurate and up-to-date information. A typical RAG system (see image) includes an LLM, a vector database (to conveniently store external data) and a series of commands or queries. In other words, in a simplified form, when we ask a natural language question to an assistant such as ChatGPT, what happens between the question and the answer is something like this:
- The user makes the query, also technically known as a prompt.
- The RAG enriches the prompt or question with data and facts obtained from an external database containing information relevant to the user's question. This stage is called retrieval
- The RAG is responsible for sending the user's prompt enriched or augmented to the LLM which is responsible for generate a natural language response taking advantage of the full power of the human language it has learned with its generic training data, but also with the specific data provided in the retrieval stage.

Understanding RAG with examples
Let us take a concrete example. Imagine you are trying to answer a question about dinosaurs. A generalist LLM can invent a perfectly plausible answer, so that a non-expert cannot distinguish it from a scientifically based answer. In contrast, using RAG, the LLM would search a database of dinosaur information and retrieve the most relevant facts to generate a complete answer.
The same was true if we searched for a particular piece of information in a private database. For example, think of a human resources manager in a company. It wants to retrieve summarised and aggregated information about one or more employees whose records are in different company databases. Consider that we may be trying to obtain information from salary scales, satisfaction surveys, employment records, etc. An LLM is very useful to generate a response with a human pattern. However, it is impossible for it to provide consistent and accurate data as it has never been trained with such information due to its private nature. In this case, RAG assists the LLM in providing specific data and context to return the appropriate response.
Similarly, an LLM complemented by RAG on medical records could be a great assistant in the clinical setting. Financial analysts would also benefit from an assistant linked to up-to-date stock market data. Virtually any use case benefits from RAG techniques to enrich LLM capabilities with context-specific data.
Additional resources to better understand RAG
As you can imagine, as soon as we look for a moment at the more technical side of understanding LLMs or RAGs, things get very complicated. In this post we have tried to explain in simple words and everyday examples how the RAG technique works to get more accurate and contextualised answers to the questions we ask to a conversational assistant such as ChatGPT, Bard or any other. However, for those of you who have the desire and strength to delve deeper into the subject, here are a number of web resources available to try to understand a little more about how LLMs combine with RAG and other techniques such as prompt engineering to deliver the best possible generative AI apps.
Introductory videos:
LLMs and RAG content articles for beginners
- DEV - LLM for dummies
- Digital Native - LLMs for Dummies
- Hopsworks.ai - Retrieval Augmented Augmented Generation (RAG) for LLMs
- Datalytyx - RAG For Dummies
Do you want to go to the next level? Some tools to try out:
- LangChain. LangChain is a development framework that facilitates the construction of applications using LLMs, such as GPT-3 and GPT-4. LangChain is for software developers and allows you to integrate and manage multiple LLMs, creating applications such as chatbots and virtual agents. Its main advantage is to simplify the interaction and orchestration of LLMs for a wide range of applications, from text analysis to virtual assistance.
- Hugging Face. Hugging Face is a platform with more than 350,000 models, 75,000 datasets and 150,000 demo applications, all open source and publicly available online where people can easily collaborate and build artificial intelligence models.
- OpenAI. OpenAI is the best known platform for LLM models and conversational interfaces. The creators of ChatGTP provide the developer community with a set of libraries to use the OpenAI API to create their own applications using the GPT-3.5 and GPT-4 models. As an example, we suggest you visit the Python library documentation to understand how, with very few lines of code, we can be using an LLM in our own application. Although OpenAI conversational interfaces, such as ChatGPT, use their own RAG system, we can also combine GPT models with our own RAG, for example, as proposed in this article.
Content elaborated by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.