Empresa reutilizadora
EpData es la plataforma creada por Europa Press para facilitar el uso de datos públicos por parte de los periodistas, con el objetivo tanto de enriquecer las noticias con gráficos y análisis de contexto como de contrastar las cifras ofrecidas por las diversas fuentes. La base de datos de la que se alimenta EpData está mantenida por un equipo multidisciplinar de informáticos y periodistas que se valen de las nuevas tecnologías y el análisis de datos para mejorar la eficiencia en el consumo de datos y encontrar patrones relevantes e informativos en los datos.
Evento
En 2018 se cumplen 25 años de hermanamiento de las ciudades de Barcelona y Kobe, y para celebrarlo ambos ayuntamientos han puesto en marcha el World Data Viz Challenge 2018 Barcelona-Kobe.
Promoviendo mejoras políticas a través de visualizaciones de datos
En cada ciudad se han lanzado retos similares: los participantes tendrán que generar visualizaciones basadas en datos abiertos que muestren los desafíos de una ciudad inteligente y que puedan ser de utilidad para optimizar las políticas públicas. En el caso de Barcelona, será necesario utilizar al menos uno de los más de 440 conjuntos de datos incluidos en el portal Open Data BCN. Dichos conjuntos de datos están clasificados en cinco grandes temas: ciudad y servicios, territorio, población, administración y economía y empresa.
Un grupo de expertos seleccionara los 10 mejores dataviz o infografías, que serán presentados en el Smart City Expo World Congress 2018, el 14 de noviembre. Este evento internacional viene celebrándose en Barcelona desde 2011, con el objetivo de promover la innovación e identificar oportunidades para crear ciudades inteligentes que respondan a las necesidades de los ciudadanos.
La preinscripción está abierta hasta el 26 de octubre
Cualquier ciudadano puede participar. Solo es necesario tener “habilidades y capacidades para trabajar con datos abiertos, analizarlos y visualizarlos.”
Aquellas personas interesadas en formar parte del World Data Viz Challenge 2018 Barcelona-Kobe deberán realizar la preinscripción antes del 26 de octubre, rellenando este formulario. El plazo para presentar las visualizaciones será del 2 de octubre al 2 de noviembre a través de este otro formulario. Los trabajos, que podrán ser presentados en catalán, castellano o inglés, no podrán haber sido realizados por más de dos personas. Puedes consultar el detalle completo de las condiciones de participación en este enlace.
Con este reto, el Ayuntamiento de Barcelona busca fomentar el uso de los datos abiertos de las ciudades inteligentes y de herramientas y técnicas de análisis y visualización de datos. Además, el concurso también servirá para desarrollar el espíritu crítico de los ciudadanos, que pasan a convertirse en una pieza fundamental a la hora de promover políticas que mejoren nuestro entorno.
Evento
DataLab Madrid organiza una nueva edición del taller de visualización de datos Visualizar´18. Su objetivo es crear un espacio de trabajo colaborativo, intercambio de conocimientos y formación teórico-práctica para investigar las implicaciones sociales, culturales y artísticas de la cultura de los datos, abriendo caminos para la participación y la crítica.
La cita tendrá lugar del 21 de septiembre al 5 de octubre en la sede de Medialab Prado. En esta ocasión, el evento girará en torno al poder de los datos personales. La preocupación de los ciudadanos por este asunto no ha dejado de crecer en un año marcado por la entrada en vigor del GDPR o por escándalos como el de Cambridge Analytica. Por ello, es una buena oportunidad para desarrollar proyectos que enriquezcan el debate sobre la privacidad y el uso de nuestros datos personales.
El taller se desarrollará en 3 partes: una jornada inaugural, un taller de desarrollo de ideas y una presentación final. La jornada inaugural tendrá lugar durante el viernes 21 y el sábado 22 de septiembre. En ella se presentará el propio taller, los proyectos seleccionados y los integrantes de los equipos, y se inaugurará la exposición The Glass Room. Los días siguientes tendrá lugar el taller de desarrollo de ideas, donde los distintos grupos trabajarán en común en el desarrollo de sus proyectos. Los resultados se presentarán el viernes 5 de octubre.
Los 6 proyectos seleccionados sobre los que trabajarán los distintos participantes son:
-
A-9. Black Eyes. El proyecto consiste en una video-instalación donde se mostrará un mapa que integra carreteras de todo el mundo. El usuario podrá interaccionar de manera directa con la obra seleccionando cualquier punto del mapa para visualizar imágenes en tiempo real del mismo. El objetivo es concienciar sobre el poder de la información y su influencia en un mundo globalizado.
-
Microblogs y micropolítica. Los participantes podrán exportar, scrapear, codificar y visualizar, de manera original, los datos personales que ellos mismos producen diariamente en su timeline público de Twitter. Si el tiempo lo permite, se repetirá el proceso con los datos de instituciones públicas y políticos electos.
-
My [inte] gration. Este proyecto busca cambiar la percepción de la crisis migratoria en base a los datos. A través de tecnologías big data y thick data se analizarán los derechos y necesidades de los migrantes, refugiados, minorías y comunidades vulnerables, con el objetivo final de crear espacios, ciudades y políticas inclusivas. Aunque la propuesta se centra en la ciudad de Madrid, está pensado para ser escalado a otras ciudades y regiones.
-
Bad Data Challenge. Durante este proyecto los participantes investigarán problemas de datos erróneos (es decir, conjuntos de datos que contengan datos perdidos, datos incompatibles, datos corruptos, datos desactualizados, etc.), utilizando diversas herramientas y metodologías.
-
Juego de Datos Personales. Este proyecto propone realizar un juego de mesa con visualizaciones modeladas de los datos personales para concienciar sobre su importancia. Los datos (características físicas, propiedades de identificación, rasgos sociales, ideas políticas, etc.) darán lugar a objetos atractivos al tacto que se complementen o no encajen. El objetivo del juego es atravesar el tablero conservando la mayor cantidad de datos personales, protegiendolos del enemigo (que los puede robar o intercambiar).
-
El gran G y sus secuaces. Aquellas personas que participen en este proyecto podrán desarrollar una herramienta web para conocer qué información personal almacenan las diferentes aplicaciones sobre ellos. Una vez recopilada esta información, los participantes desarrollarán un webcomic donde se cuente cómo los dispositivos recopilan datos de los usuarios a través de los dispositivos móviles.
Además, durante el transcurso del evento tendrán lugar diversas charlas y talleres prácticos, así como un encuentro de iniciativas ciudadanas por la privacidad y seguridad de los datos personales.
Aquellas personas que deseen participar en visualizar´18, todavía pueden apuntarse como colaboradores. La inscripción, que es gratuita hasta un máximo de 30 participantes, estará abierta hasta el miércoles 19 a las 23:59 CEST.
Noticia
Si lo analizamos con perspectiva, el concepto de datos abiertos no es realmente tan revolucionario o novedoso en sí mismo. Por un lado, la filosofía de apertura y/o reutilización en la que se basan los datos abiertos llevaba ya mucho tiempo establecida entre nosotros antes de su definición formal. Por otro lado, los objetivos del movimiento de los datos abiertos son también muy similares a aquellos que promueven otras comunidades con mayor recorrido y que podrían en cierto modo considerarse también afines, tales como el código abierto, el hardware abierto, el contenido abierto, el gobierno abierto o la ciencia abierta, entre muchos otros.
No obstante, tanto el término “open data” como la comunidad asociada a él pueden ambos considerarse relativamente recientes, empezando a ganar en popularidad hace ya unos diez años cuando un grupo de defensores del gobierno abierto establecieron los ocho principios de los datos abiertos gubernamentales durante la reunión que tuvo lugar en Sebastopol (California) en Diciembre de 2007. Acto seguido se lanzaron las iniciativas oficiales de datos abiertos de referencia por parte de los gobiernos de Estados Unidos (data.gov) y Reino Unido (data.gov.uk), dándole el empujón final que necesitaba esta nueva corriente para convertirse en un nuevo movimiento con identidad propia.
Desde entonces la comunidad global de los datos abiertos ha progresado enormemente, pero también se encuentra todavía muy lejos de sus objetivos iniciales. Al mismo tiempo, los datos en general se están consolidando como el activo más valioso con el que cuentan la mayoría de las organizaciones hoy en día. Es por ello que, en el décimo aniversario desde su formalización, la comunidad de los datos abiertos se plantea ahora una reflexión sobre su papel en el pasado - mirando hacia los logros obtenidos hasta el momento - y también sobre su rol en un futuro próximo dominado por los datos.
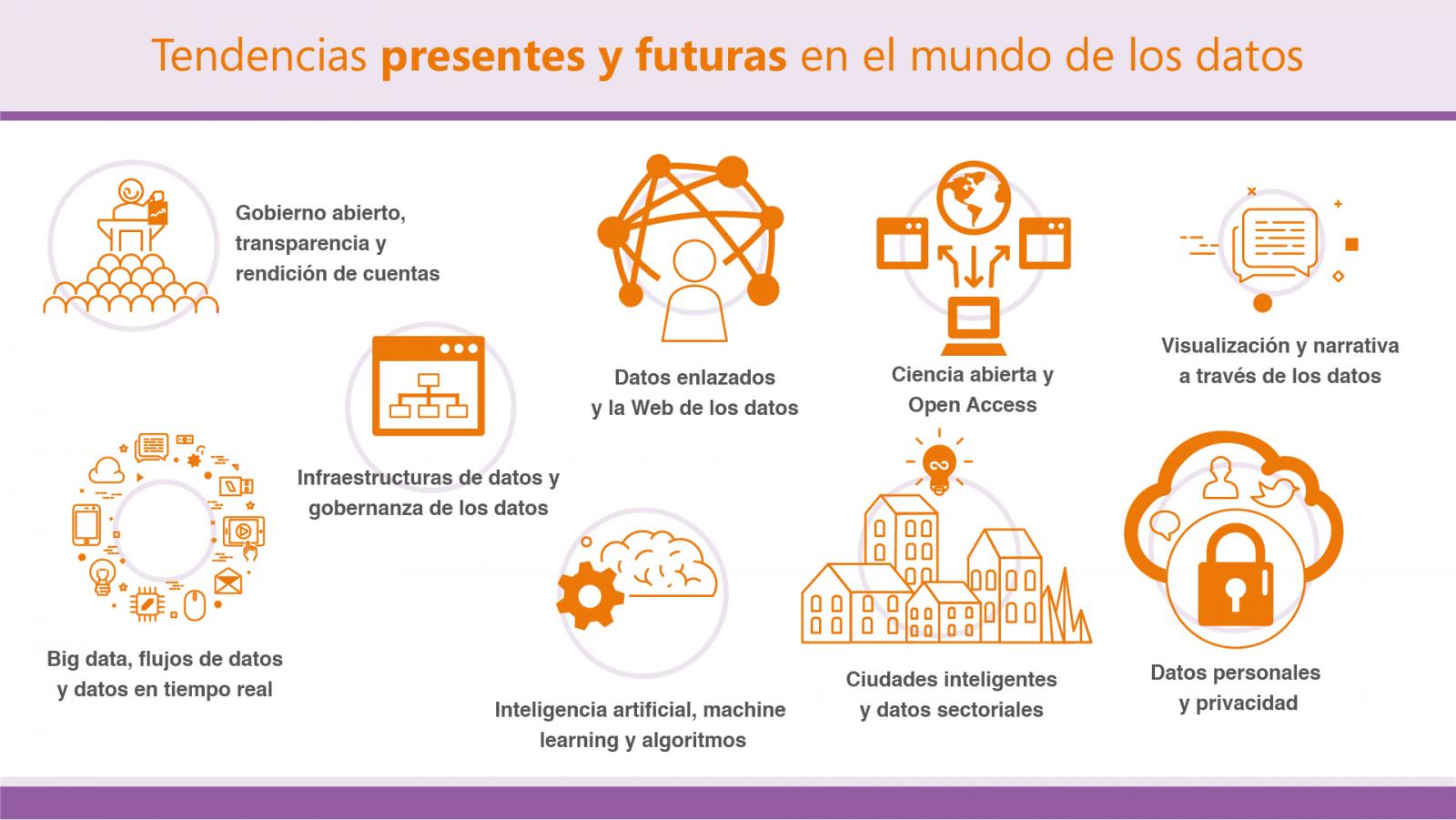
En este contexto tiene sentido hacer un breve repaso sobre algunas de las tendencias actuales en el mundo de los datos y cuál es el papel que podrían jugar los datos abiertos en cada una de ellas, empezando por las que sean quizás más afines:
Gobierno abierto, transparencia y rendición de cuentas
Aunque las comunidades de la libertad de información y datos abiertos a veces difieren en sus estrategias, ambas comparten el objetivo común de facilitar el acceso de los ciudadanos a la información necesaria para mejorar la transparencia y los servicios públicos. El potencial beneficio que se puede obtener de la colaboración entre ambos grupos es por tanto muy significativo, evolucionando del derecho a la información al derecho a los datos. Sin embargo después de varios esfuerzos no se ha conseguido todavía que la colaboración sea tan efectiva como sería deseable y existen también dudas acerca de si los datos abiertos se están utilizando realmente como una herramienta efectiva para la transparencia o precisamente como una excusa para no tener que hacer un ejercicio de transparencia más profundo.
Datos enlazados y la Web de los datos
El objetivo de la Web de los datos es poder crear conexiones explícitas entre aquellos datos que están relacionados entre sí y que ya están disponibles en la web, pero no convenientemente relacionados. No todos los datos enlazados necesitan forzosamente ser también abiertos, pero por el propio objetivo de los datos enlazados está claro que la combinación de ambos es lo que permitiría alcanzar su máximo potencial conjunto, como sucede ya por ejemplo con algunas grandes bases de datos globales de referencia como DBPedia, LexInfo, Freebase, NUTS o BabelNet.
Ciencia abierta y Open Access
Son muchas ya las ocasiones en las que se ha comentado la ironía de que en este mismo momento de la historia en el que contamos con las mejores herramientas y tecnologías para poder distribuir la ciencia y el conocimiento a lo largo del mundo, estamos precisamente muy ocupados poniendo nuevas barreras al uso de esos valiosos datos y ese conocimiento. El pujante movimiento del open access apuesta precisamente por aplicar nuevamente los criterios de los datos abiertos a la producción científica, de forma que pase a ser un bien intangible y acelerar así la nuestra capacidad de colaboración y descubrimiento conjunto para que genere nuevos logros para la humanidad.
Visualización y narrativa a través de los datos
A medida que más y más datos están disponibles para cualquier organización o individuo el siguiente paso indispensable será el de proporcionar también los medios para que se pueda extraer todo el valor de ellos. La capacidad de, partiendo de unos datos concretos, ser capaces de comprenderlos, procesarlos, extraer su valor y comunicarlo adecuadamente, va a ser una habilidad muy demandada en la próxima década. La elaboración de historias a partir de los datos no es más que una aproximación estructurada a la hora de comunicar el conocimiento que nos transmiten los datos a través de tres elementos clave combinados, capaces en conjunto de generar la influencia necesaria para dar lugar a cambios: datos, visualizaciones y narrativa.
Big data, flujos de datos y datos en tiempo real
En el presente las organizaciones tienen que lidiar con un volumen y variedad cada vez mayor de datos. Las técnicas de tratamiento de big data les permite analizar estos grandes volúmenes de información para aflorar distintos patrones y correlaciones que servirán para mejorar los procesos de toma de decisión. No obstante, el gran reto continua siendo cómo realizar este proceso de forma eficiente sobre flujos continuos de datos en tiempo real. Si bien el big data promete una capacidad de análisis sin precedentes, su combinación con la filosofía de los datos abiertos permitirá que ese poder pueda ser compartido por todos mejorando los servicios públicos.
{kind=link}
Inteligencia artificial, machine learning y algoritmos
Aunque la inteligencia artificial está cada vez más presente en varios aspectos de nuestras vidas cotidianas, podríamos considerar que todavía nos encontramos en una etapa muy temprana de lo que podría llegar a ser una revolución global. La inteligencia artificial cuenta ya con un éxito relativo en alguna tareas que tradicionalmente habían siempre requerido de lo que consideramos inteligencia humana para poder llevarse a cabo. Para que esto sea posible son también necesarios algoritmos alimentados por datos que sostengan estos sistemas automatizados. Una mayor disponibilidad y calidad de los datos abiertos servirá para alimentar esos algoritmos y a la vez poder también mejorarlos y auditar su correcto funcionamiento.
Ciudades inteligentes y datos sectoriales
El movimiento de los datos abiertos se encuentra también en un periodo de transición en el que se están empezando a focalizar los esfuerzos en publicar los datos necesarios para dar respuesta a problemas concretos en lugar de simplemente intentar publicar cualquier dato en general. Esta aproximación temática o sectorial resulta generalmente más eficiente porque no solo requiere de menos recursos para su ejecución, sino que también está más centrada en la necesidades de los usuarios y beneficiarios finales de los datos. En este sentido destaca el área concreta de las ciudades inteligentes o las open cities como ejemplo de integración de las distintas tecnologías y filosofías de datos para la mejora de los servicios que se ofrecen a los ciudadanos.
Datos personales y privacidad
Hoy en día pasamos una buen parte de nuestras vidas online y eso está contribuyendo a generar una cantidad de información sobre nosotros que no tiene precedente. Gracias a estos datos podemos disfrutar de nuevos servicios de gran utilidad, pero también cuentan con una parte negativa importante. En caso de que exista por ejemplo algún fallo en la cadena de custodia de nuestros datos se podría revelar importante información personal sobre nuestra capacidad económica, posicionamiento político o hábitos de consumo entre otros. Por otra parte, existen también cada vez más usos poco éticos por parte de algunas empresas. Usando los mismos principios de los datos abiertos se está experimentando con nuevas formas de autogestión de nuestros datos personales para conseguir un balance entre retomar el control de nuestros propios datos y los beneficios que podemos obtener mediante su explotación, siempre con nuestro expreso conocimiento y consentimiento.
Infraestructuras de datos y gobernanza de los datos
La gestión del día a día de los datos comienza a ser una tarea tan valiosa como compleja para cualquier organización en general, pero particularmente complicada para la administración debido a su propio volumen y la necesidad de combinar distintos modelos de gestión que se corresponden también con los distintos niveles administrativos. Para afrontar esta tarea de gestión con garantías será necesario invertir en las infraestructuras de datos adecuadas, tanto a nivel físico como de gestión. Establecer los frameworks tecnológicos y los modelos de gobernanza de los datos necesarios para que puedan ser compartidos con agilidad será un requisito indispensable para conseguir un modelo de administración eficiente en el futuro.
Con todo lo anterior, es posible que en un futuro no muy lejano dejemos de tratar los datos abiertos como la única solución posible para los retos que se plantean a los gobiernos y empecemos a tratarlos como otra herramienta clave a nuestra disposición que utilizaremos de forma más diluida e integrada junto a las otras tendencias actuales en el mundo de los datos y la apertura que hemos repasado.
Evento
El programa internacional de visualización de datos Visualizar, organizado por MediaLab Prado, celebra este año su décimo aniversario con un simposio abierto al público los días 15 y 16 de septiembre y un taller práctico dedicado a las Migraciones que se desarrollará durante la segunda quincena de este mes de septiembre.
Este viernes 15 de septiembre arranca el simposio de carácter público, que se extenderá al sábado 16, y que incluye presentación de proyectos, presentación de colaboradores y formación de equipos. El simposio contará con una charla sobre Visualizar: 10 años, por José Luis de Vicente, fundador de Visualizar. la presentación del Festival Transeuropa, sendas charlas sobre "Visualización artística de datos: nuevas formas de narrativa" y "Code for Southafrica", a cargo de Lucila Rodríguez Alarcón y Hannah Williams, respectivamente, así como con la intervención de Julie Freeman, miembro del Open Data Institute.
El sábado 16 de septiembre tendrá lugar la presentación de proyectos y colaboradores, así como la metodología de los proyectos: editor de texto, Markdown y Github. Durante este segundo día del simposio Visualizar`17 intervendrán diversos especialistas en visualización de datos nacionales e internacionales como Pau García y Polo Trías Coca (Domestic Data Streamers), José Luis Esteban Aparicio (Grupo Haskell Madrid), Álvaro Anguix y Javier Rodrigo (gvSIG), Gonzalo Fanjul (PorCausa), Samuel Granados (editor gráfico en The Washington Post) y Alison Killing (arquitecta y artista visual).
El taller posterior, dedicado a las migraciones de personas y migraciones de datos y realizado en colaboración con PorCausa, tiene como objetivo desarrollar los ocho proyectos seleccionados entre el 17 al 29 de septiembre, cuyo resultado será presentado públicamente el 30 de septiembre. Para el desarrollo de los proyectos se cuenta con un equipo de mentores internacionales y nacionales: editores gráficos, data sciencist, visualizadores, cartógrafos y diseñadores de interacción, entre otros. Dicho taller está enfocado a los rasgos, procesos y comportamientos de la migración entendida como movimiento sobre el territorio mundo -local, global o glocal- por especies (flora y fauna), personas, datos o sustancias, con el objetivo de dar mayor visibilidad a las migraciones, descifrar las historias que ocultan los números y unir los datos con la creatividad y la tecnología.
Visualizar es un taller internacional de prototipado de proyectos de visualización de datos de Medialab-Prado que aboga por desarrollar la disciplina de la visualización de dato. Desde 2007, el programa Visualizar investiga las implicaciones sociales, culturales y artísticas de la cultura de los datos, y propone metodologías para hacerlos más comprensibles y abrir caminos para la participación y la crítica.
Más información: Visualizar´17
Aplicación
Mapa interactivo que permite consultar a tiempo real cuáles son las emisiones de CO2 que cada país emite a la atmósfera y recoge las fuentes de electricidad de cada lugar, extraídas de sus datos públicos. Muestra la electricidad importada y exportada entre países y utiliza datos abiertos energéticos de cada país.
Junto a datos públicos ofrecidos por cada país, este mapa interactivo – se puede consultar en este enlace- incluye otras variables interesantes para los usuarios como la dirección del viento, la potencia instalada de cada tipo de energía, la intensidad de las emisiones de CO2 durante las últimas 24 horas o el intercambio de electricidad entre diversos países. El mapa recibe actualizaciones constantes cada día.
Esta visualización a tiempo real de la huella del consumo de electricidad se ha realizado con d3.js, está optimizada para Google Chrome y se ha generado como aplicación móvil para su descarga en los sistemas operativos IOS y Google Play. Al ser un proyecto de código abierto, los usuarios pueden contribuir agregando un nuevo país en el mapa, corrigiendo fuentes de datos o proponiendo ideas.
Por el momento, los datos disponibles corresponden a Estados Unidos, Europa y una parte de Canadá y de Australia. El CO2 de cada país se muestra por colores, aunque existe la posibilidad de activar un modo específico para daltónicos.
Documentación
Cada vez se maneja mayor cantidad de información, hasta tal punto que podría decirse que la sociedad actual vive rodeada de datos. Sin embargo, una de las críticas más comunes en torno a la existencia de dicho volumen de información es su falta de usabilidad. No se trata únicamente de publicar datos en la red, sino que hay que poner el foco en cómo pueden tratarse, reutilizarse y ser consumidos por el usuario final. Solo cuando aplicamos fórmulas que permiten una interpretación a los datos, estos cobran sentido y se transforman en conocimiento.
En el contexto tecnológico, la explotación de datos ha evolucionado en las últimas décadas para diseñar mecanismos de interpretación cada vez más robustos y asequibles; siendo uno de los más importantes la visualización de datos.
En este marco Iniciativa Aporta ha elaborado el informe “Herramientas de visualización de datos abiertos”, un manual basado en el análisis en dos aspectos diferenciados pero complementarios. En primer lugar, se detallan las tecnologías de visualización como los frameworks y bibliotecas de programación que permiten la construcción de aplicaciones y servicios basados en datos; incluyendo exclusivamente la tecnología web de última generación y especialmente aquella que se construye sobre estándares, como HTML5 (Canvas), SVG y WebGL.
Por otro lado, en el documento se realiza un recorrido por las plataformas disponibles de visualización,estudiando las aplicaciones que permiten la construcción de cuadros de mando y visualizaciones interactivas completas. Se hace especial hincapié en aquellas plataformas más orientadas al mundo web, procedentes del mundo del Business Intelligence y el análisis de datos, que se pueden aplicar a la explotación de datos abiertos: Tableau Soft., Qlik y Tabulae. O, en su defecto, las herramientas de publicación open data que incorporan ciertas funcionalidades de visualización como CKAN y Socrata.
En la actualidad el número de herramientas y plataformas de visualización de datos al que se puede acceder es muy extenso. Por ello, el presente informe incorpora una serie de ejemplos reales, algunos de ellos más cercanos al ámbito del análisis y de la visualización de datos y otros de soporte a la publicación de datos que posteriormente incluyen funcionalidades de representación gráfica de datos para su consumo.
Con el fin de ayudar en el tratamiento de dicha información y su transformación en formatos más digeribles y legibles, el informe incluye siete muestras de visualización de datos, procedentes tanto del sector público como de entidades independientes a escala nacional e internacional, y concluye analizando las tendencias futuras en este campo del tratamiento de los datos: la visualización de grandes volúmenes de información; conseguir que el usuario cree sus propias visualizaciones y pueda explotar la información de manera dinámica y el desarrollo de la tecnología para la creación de visualizaciones 3D.

Entrevista
Tabulae es una plataforma de visualización y análisis de datos. Esta herramienta permite convertir la información en conocimiento, al poder crear de forma fácil y autónoma informes, presentaciones, mapas o cuadros de mando como aplicaciones web accesibles desde cualquier dispositivo.
1. ¿Cómo surgió la idea de crear esta plataforma y cómo han sido sus inicios?
Las personas que formamos parte de este proyecto empresarial venimos de diferentes ámbitos tecnológicos relacionados con la explotación y análisis de datos: inteligencia de negocio, data mining, gestión de conocimiento y open data. Nos dimos cuenta que una necesidad común que teníamos en nuestros proyectos era la falta de herramientas orientadas al usuario que facilitasen la interpretación de los datos y le proporcionasen mecanismos de navegación dinámicos y, sobre todo, fáciles de usar.
A partir de aquí, arrancamos nuestro proyecto empresarial con el objetivo de construir una plataforma de visualización orientada al mundo web y que tuviese como principal referente al usuario experto en datos dentro de las organizaciones. Quisimos dotarle de herramientas para el tratamiento de la información y la construcción personalizada de cuadros de mando e informes interactivos, sin necesidad de conocimientos programáticos. Todo se realiza mediante interfaces visuales intuitivas.
Una vez arrancado el proyecto, Tabulae ha ido creciendo y ganando en funcionalidad y potencia, entrando en competencia con plataformas, principalmente de B.I., más tradicionales, lo que nos ha permitido entrar en nichos de mercado que inicialmente no teníamos previsto. Nuestra propuesta y nuestra diferenciación sigue siendo la misma: acercar los datos al usuario y agilidad y dinamismo a la hora de construir cuadros de mando e informes.
Desde luego, los inicios nunca son fáciles y combinar el desarrollo tecnológico de un producto muy especializado y complejo con su comercialización es complicado. Nuestras primeras barreras fueron, a mi juicio, las naturales: producto poco maduro, falta de referencia de clientes importantes, escepticismo sobre la aproximación tecnológica y cómo encontrar el “matching” entre necesidades de los potenciales clientes y tus capacidades. A esto hay que añadir la falta de confianza en una empresa con menos de un año de vida. En esta parte da igual tu experiencia y tu pasado profesional. Afortunadamente, las cosas nos están funcionando bien a nivel de desarrollo de negocio, siendo este 2015 un año realmente positivo y esperamos que en el 2016 las cosas vayan incluso mejor.
2015 está siendo realmente positivo"
2. ¿Qué servicios concretos de tratamiento y visualización de datos abiertos ofrece?
Tabulae es una plataforma de análisis y visualización de datos. Como tal, se puede conectar con diferentes fuentes de datos: BD relacionales, carga ficheros CSV o Excel, integración con Google Analytics, Drive, etc. A partir de aquí, el usuario experto en datos dispone de mecanismos amigables para realizar diferentes operaciones: refinamiento de campos, correcciones, fórmulas, operaciones de agregación, definición de jerarquías para análisis drill-down, filtrados dinámico de datos, etc. Una de las funcionalidades más interesantes en el tratamiento de datos es la georreferenciación que permite al usuario la generación automática de mapas interactivos.
Tabulae es una plataforma de análisis y visualización de datos"
Una vez el experto en datos ha realizado los procesos de refinamiento pertinentes, Tabulae le permite construir cuadros de mando e informes de manera asistida mediante interfaces dedicados WYSIWYG (“what you see is what you get”). Todo se construye a partir de componentes de gráfica, mapas, filtros y diferentes tipos de tablas, que se pueden personalizar al detalle y son altamente interactivos. Esto enriquece las posibilidades de mostrar información y de jugar con la disposición de los elementos para comunicar mejor el mensaje.
Gráficos, mapas, filtros y diferentes tipos de tablas, que se pueden personalizar al detalle y son altamente interactivos"
3. ¿Con qué tipo de entidades y organizaciones suele trabajar conjuntamente Tabulae? ¿Qué beneficios les brinda?
El análisis y visualización datos es transversal a cualquier sector de actividad económica. Nuestra tecnología, por tanto, no está pensada para una aplicación específica, sino que Tabulae está diseñada con una perspectiva amplia y genérica para poder adaptarse a diferentes proyectos visualización.
Tabulae está diseñada con una perspectiva amplia y genérica"
Nuestros principales partners suelen ser empresas tecnológicas a las que nosotros complementamos tanto en la parte de producto de B.I. y visualización (Tabulae) como la de consultoría de datos, especialmente en todo lo que tiene que ver modelos de análisis estadístico y construcción de cuadros de mando.
Ahora mismo estamos principalmente en tres sectores. En primer lugar, el sector asegurador, especialmente en el canal de la mediación. En segundo lugar, el sector ligado a la transparencia y open data. Esto no es exclusivo de las administraciones, ya que muchas empresas por su tamaño y volumen tienen necesidades parecidas. Y, en tercer lugar, empresas y consultoras de estudios de mercado y marketing.
4. Con respecto al Sector público ¿En qué proyectos de open data y reutilización habéis colaborado?
Nuestra primera inmersión en el mundo open data viene de la mano de la AIMJB (Asociación Ibero-Macaronésica de Jardines Botánicos) en un proyecto para la construcción de un portal de acceso y gestión de especies botánicas silvestres conservados en bancos de germoplasma: OpenRedBag. Primero se publica la información en GBIF, la plataforma internacional open data de información de biodiversidad. Una vez la información está en GBIF y es pública para su consumo, Tabulae accede a esta información utilizando los servicios web disponibles, enriqueciéndola con datasets de terceros proveedores también accesibles en GBIF y con otras fuentes de datos nacionales (por ejemplo, con la legislación autonómica aplicable). Finalmente, Tabulae construye visualizaciones geográficas (básicamente, mapas interactivos) facilitando la realización de estudios. Este proyecto no sólo publica y facilita el acceso a la información, sino que proporciona herramientas de gestión y análisis.
No es sólo publicar, sino construir cosas útiles con los datos"
Actualmente estamos trabajando con el Gobierno del Principado de Asturias para construir el Portal de Transparencia, en el que aplicamos los principios del open data e introducimos elementos innovadores basados en la visualización y la accesibilidad de la información. El objetivo no es sólo cumplir la normativa vigente respecto a transparencia y apertura de datos, sino realmente facilitar el acceso y la interpretación de la información a los ciudadanos. Se tratar de que la gente pueda “usar” libremente los datos y la propia administración utilizar este servicio para consultas internas, en los medios de comunicación y, por supuesto, en las empresas infomediarias.
Además una de nuestras iniciativas actuales es impulsar, junto con nuestro partner ebroker, empresa tecnológica de referencia en el sector asegurador, una acción conjunta con la Administración en el ámbito de la Documentación Estadístico Contable (DEC): información que las entidades aseguradoras y las de mediación deben remitir a la Administración. La mejora de estos procesos de comunicación, de la publicación posterior de los datos y los informes resultantes puede tener un efecto muy positivo en el sector asegurador. El objetivo también es demostrar cómo la apertura de datos específica en un sector de negocio tiene un impacto real.
El objetivo también es demostrar cómo la apertura de datos específica en un sector de negocio tiene un impacto real"
5. ¿Os habéis encontrado algún obstáculo a la hora de reutilizar la información del sector público? ¿Cúales?
El primer proyecto en el que estuve involucrado estaba relacionado con la construcción de un buscador para un boletín oficial autonómico en el 2005. En aquella época, muchos de los boletines oficiales del estado no estaban accesibles digitalmente o eran básicamente PDFs generados a partir de imágenes. Desde luego, la situación ha cambiado sustancialmente para bien en los últimos años. Se publica información desde todos los niveles de la Administración: cada vez más, de mejor calidad y en formatos reusables.
Sin embargo, sigue habiendo ciertos problemas que dificultan su reutilización a gran escala y de una manera normalizada:
a. No hay una aproximación tecnológica y de vocabularios consensuada. Esto deriva en una fragmentación de soluciones a la hora de abordar la publicación. Desde luego, hay excepciones, como en el caso de la información geográfica.
b. Misma información en multitud de formatos. Personalmente considero esto una moda, que además no tiene un beneficio claro por parte de los reutilizadores y en parte introduce dificultades artificiales. Por ejemplo, formatos W3C estándar como RDF no son realmente conocidos en la industria y son costosos de procesar.
c. Muchos organismos siguen publicando la información en PDFs. Esto realmente es una barrera, aunque la información es pública. Lo mismo ocurre cuando se utilizan hojas de cálculo, ya que la mayor parte de las veces se introduce formato, lo que impide su tratamiento automático.
d. Formatos estándar como CSV, que son suficientes para gran parte de los procesos de publicación de datos estructurados, no son utilizados correctamente por parte de los publicadores, simulando formato cuando son ficheros planos.
e.En muchos casos, no hay una política de actualización y mantenimiento de los datos. La información se sube, se cumple el requisito y ya está. Otro problema derivado es que las URLs además pueden cambiar con este proceso de actualización.
f. Falta de endpoints donde acceder a los datos de una manera sistemática y programática. Quizás el objetivo no sea tener un servicio único de acceso a los datos, sino más bien un catálogo de servicios de la misma manera que existen los catálogos de datos. También creo que sería importante el uso de tecnologías estándar ampliamente conocidas y utilizadas por la mayor parte de las empresas. Uno de los riesgos del uso de ciertas aproximaciones es que el uso de esos servicios tienda a cero. En este sentido, me parece muy acertada la aproximación de GBIF para datos de biodiversidad.
Esto lo vemos en un proyecto que estamos llevando acabo actualmente para la reutilización de datos públicos en un medio de comunicación, donde el objetivo es construir visualizaciones a partir de fuentes públicas como complemento y soporte a las noticias (data-driven journalism). Desde el punto de vista del periodista, surgieron las siguientes preguntas: ¿Dónde están los datos?, ¿Qué tipo de fichero puedo manejar?, ¿Este fichero lo puedo tratar de manera mecánica con un programa software?, en caso contrario, ¿Cuándo tiempo me lleva tratar el fichero original para que pueda ser procesado? Las respuestas, desafortunadamente, no están siendo fáciles de encontrar.
6. ¿Cómo puede ayudar Tabulae al sector reutilizador de datos abiertos?
Creemos que nuestra tecnología puede ayudar fundamentalmente en dos direcciones:
- A las Administraciones: en la fase de publicación de datos para construir servicios de valor añadido basados en la visualización. De esta manera, se ofrece un servicio de interpretación y análisis de la información que permite una comunicación transparente entre la Administración y la ciudadanía. Esta aproximación no sólo se queda como un ejercicio hacia el exterior, sino que en los mismos proyectos se pueden abordar necesidades internas de la Administración que pueden ser sustentadas por nuestra tecnología y experiencia en el análisis de datos.
Se ofrece un servicio de interpretación y análisis de la información"
- A las empresas infomediaria: nuestra tecnología permite la automatización de los procesos de carga, la combinación de fuentes y la construcción de conocimiento a partir de los datos. Podemos ayudar a enriquecer sus sistemas de información y en la oferta de un servicio enriquecido basado en el valor que proporciona nuestra tecnología. Si una imagen vale más que mil palabras, se puede decir que una visualización (una gráfica, un mapa…) bien construida vale más que mil datos.
Nuestra tecnología permite la automatización de los procesos de carga, la combinación de fuentes y la construcción de conocimiento a partir de los datos"
Noticia
En noviembre de 2013 nacía OpenDataMonitor, una iniciativa panaeuropea que permitirá identificar y caracterizar los conjuntos de datos públicos puestos a disposición en 25 países europeos a través de una serie de herramientas que están siendo desarrolladas en el marco del proyecto. Gracias a diferentes métodos de visualización y analítica, el usuario final tendrá la oportunidad de conocer en mayor profundidad los repositorios de datos abiertos a escala local, regional, nacional y europea.
Los equipos integrantes de OpenDataMonitor finalizarán sus trabajos en el plazo de un año. Hasta la fecha se han ido presentando los avances alcanzados a través de diferentes publicaciones disponibles en la página web del proyecto, entre las que cabe resaltar las siguientes:
- Armonización de topologías, catálogos y metadatos
Este estudio muestra una fotografía actualizada del movimiento de datos abiertos, principalmente en Europa, identifica buena parte de los retos a los que se enfrenta la comunidad open data y propone posible soluciones, especialmente en aspectos clave como son la necesaria armonización de vocabularios y de esquemas de representación de la información.
- Buenas prácticas de visualización, cuadros de mando y métricas
El documento presenta un conjunto de métricas que se entienden necesarias para la comprensión de las tendencias open data, detalla técnicas de visualización que se consideran relevantes para este fin, así como posibles combinaciones de las visualizaciones que se presentarán en el futuro cuadro de mandos a desarrollar.
- Informe de stakeholders en el campo de datos abiertos (1º parte, septiembre 2014).
Este informe ofrece una fotografía general de los agentes involucrados en el movimiento de datos abiertos: qué papel juegan, qué les interesa y qué requisitos debe cumplir el ecosistema open data para que los reutilizadores de los datos puedan obtener el máximo provecho de ellos.
En la iniciativa participan siete entidades europeas expertas en materia open data, visualización de la información e ingeniería de software. Entre los colaboradores se encuentra el Proyecto Aporta, encargado de la investigación de las topologías de datos abiertos; del control de las funcionalidades y usabilidad de la infraestructura, así como de la divulgación y formación de los usuarios finales de la herramienta de OpenDataMonitor.
Entrevista
Mari Luz Congosto es licenciada en Informática por la Universidad Politécnica de Madrid y Máster en Telemática por la Universidad Carlos III.
Ha trabajado en entornos de investigación en Telefónica I+D, ELIOP y Fujitsu y participado en la creación plataformas sociales dedicadas a la divulgación científica.
Actualmente es investigadora del Departamento de Telemática de la Universidad Carlos III. Está especializada en minería y visualización de datos.
¿Qué es, en su opinión, el periodismo de datos y la visualización de datos y en qué se diferencia de otros modelos de información?
El periodismo de datos se diferencia fundamentalmente en las fuentes. En el periodismo tradicional las fuentes suelen ser personas; en el de investigación, documentos que no se pueden procesar automáticamente. En el periodismo de datos las fuentes son datos que pueden ser procesados automáticamente hasta obtener información. La automatización permite escalar el volumen de datos hasta niveles inimaginables.
La visualización es hija del periodismo infográfico del que hereda el lenguaje visual y la capacidad de síntesis para transmitir información. A diferencia de la infografía, la visualización se desarrolla en un medio digital, lo que le permite ser dinámica, interactiva y multimedia.
El periodismo de datos y la visualización pertenecen al mundo digital, se complementan y se realimentan. La visualización permite sintetizar los datos de forma visual y facilita descubrir nuevos patrones que mejoren el proceso de los datos.
El periodismo de datos y la visualización pertenecen al mundo digital, se complementan y se realimentan…"
¿Qué papel entiende que guardan los profesionales de este ámbito respecto de la información del sector público?
El sector público es depositario de una gran cantidad y variedad de datos de interés común. La explotación de estos datos por el sector público está enfocada al área administrativa pero puede tener muchísimas más aplicaciones y en ese punto el periodismo de datos puede generar información de valor.
¿Cómo surgió su interés por esta actividad?
Para mi Tesis empecé a trabajar con datos de la Red, primero en blogs y después en Twitter y utilicé la visualización como una herramienta de análisis que me ayudaba a mejorar el proceso de datos y a comprender mejor la información que estaba manejando.
¿Qué conocimientos, habilidades o herramientas precisa el tratamiento periodístico de los datos del sector público?
Hay tres conocimientos básicos: periodismo para saber comunicar información; programación para poder procesar datos automáticamente; y diseño para ser capaces de sintetizarlos de una forma visual.
Es muy difícil que una sola persona posea estos tres conocimientos aunque puede ser fuerte en uno de ellos y tener nociones de los otros dos. Lo más práctico es que haya equipos multidisciplinares que hablen un lenguaje común, como ocurre en The New York Times, que son líderes en periodismo de datos.
Lo más práctico es que haya equipos multidisciplinares que hablen un lenguaje común..."
¿Qué perfiles profesionales serían, a su juicio, los mejor situados para trabajar en el Periodismo o en la visualización de datos?
Hay tres perfiles profesionales: los periodistas, los informáticos y los diseñadores. Ellos son fuertes en uno de los conocimientos básicos; sólo tienen que complementar los dos restantes.
En su opinión, ¿cuál sería un buen ejemplo de lo que es este modelo de periodismo y de trabajo en el área del Open Data?
En España, el periódico La Información tiene un buen equipo de periodismo de datos y ha hecho trabajos muy interesantes, como los Presupuestos Generales del Estado, a través de los años; la evolución del paro; el patrimonio de los diputados; comparativas de IRPF por comunidades, etc. También existen iniciativas particulares como la Fundación CIVIO con Dónde van mis impuestos y España en llamas -con 10 años de incendios forestales-.
Todos estos ejemplos aportan información de valor basada en datos públicos y son de interés general.
En España, el periódico La Información tiene un buen equipo de periodismo de datos…"
¿Qué haría falta para que el conjunto de la sociedad, incluidos los gobiernos, valorasen todavía más el papel de los datos públicos?
Los ciudadanos deben tomar conciencia de que los datos públicos han sido generados con el dinero de los impuestos y, por tanto, son un bien común. Los gobiernos necesitan transmitir confianza a los ciudadanos y una manera de hacerlo es mediante una gestión transparente que incluya los datos abiertos.
Por otro lado, los datos públicos pueden ser una fuente de riqueza generadora de nuevos servicios para los ciudadanos.
Los gobiernos necesitan transmitir confianza a los ciudadanos…"
Si fuera una administración local, regional o nacional, ¿qué información consideraría más interesante para su apertura?
Debería ser obligatorio que todas las administraciones proporcionasen de una manera accesible las partidas presupuestarias desglosadas al máximo detalle y la ejecución del presupuesto indicando qué cantidades se han adjudicado en las distintas formas de licitación.
Además de los datos económicos, deberían irse incorporando datos como los de tráfico, transporte público, medio ambiente, sanidad, seguridad oferta cultural, etc., que pueden generar nuevas servicios de información que ayuden a la toma de decisiones.
datos como los de tráfico, transporte público, medio ambiente, sanidad, seguridad... pueden generar nuevos servicios de información que ayuden a la toma de decisiones…"
¿Por qué habría un lector de interesarse por este tipo de noticias basadas en los datos que custodian las administraciones?
Porque los lectores pueden acceder de una manera más relacionada, comprensible y sintetizada a una enorme cantidad de datos que ahora está oculta, dispersa o publicada en medios tan poco atractivos como los boletines oficiales.
¿Cómo ves ahora mismo el estado del Open Data en el ámbito estatal y en el conjunto de España?
En el ámbito estatal me parece una buena iniciativa datos.gob.es por su labor de catalogación de datos y de difusión de información relacionada con el Open Data. La mayoría de las administraciones autonómicas ha abierto su portal de Open Data siguiendo el camino de autonomías pioneras. La Administración Local está aún por desplegar.
De todas estas iniciativas echo en falta un criterio común en la forma de llevar a cabo la apertura de datos tanto en la prioridad de los temas como en los formatos de datos y en los métodos de acceso.
Un handicap para los portales de Open Data es la velocidad con que se desarrolla la tecnología y la rapidez con que unos formatos de datos pasan a ser obsoletos mientras que otros adquieren mucho auge. Por otro lado, la forma de acceder vía fichero puede ser insuficiente para cierto tipo de tratamientos de datos que requieran de información muy específica en tiempo real y en este punto los portales de Open Data deberían ir incorporando una alternativa de acceso a los datos vía APIs (application programming interface), como ya han empezado a realizar algunos portales.
No dudo de que la apertura de datos irá a más y a mejor, porque es algo beneficioso para todos.
Los portales de Open Data deberían ir incorporando una alternativa de acceso a los datos vía API's…"