Blog
A la hora de realizar un proyecto de análisis de datos, lo habitual es trabajar con distintas fuentes, que en muchas ocasiones incluyen datasets con formatos y estructuras heterogéneas que no siempre comparten la misma calidad. Por ello, una de las primeras fases en cualquier proceso de análisis de datos es la conocida como depuración de datos o data cleaning.
¿Qué es la depuración de datos?
Cuando hablamos de depuración de datos nos referimos al conjunto de procesos necesarios para la preparación y transformación de datos procedentes de distintas fuentes para su análisis. Fruto de estos procesos se genera una estructura homogénea, libre de errores y en el formato adecuado, que será procesable en las posteriores etapas de análisis. A este conjunto de datos resultante se le conoce como vista minable de datos.
La depuración es esencial en el procesado de los datos, ya que los estandariza y los formatea antes de introducirlos en el sistema de destino, de tal forma que podamos trabajar con ellos de manera apropiada.
Dentro de los distintos procesos que conforman la fase de depuración de datos se incluye la conversión de los mismos, que supone la transformación de los datos a un formato concreto. De esta forma pueden ser utilizados por herramientas que solo aceptan determinados formatos.
En el mercado encontramos muchas herramientas de depuración de datos que también realizan su conversión a otros formatos, aunque igualmente existen herramientas que realizan cada una de estas tareas de manera exclusiva. A continuación, se recogen algunos ejemplos seleccionados en fase a su popularidad, aunque te invitamos a dejar en comentarios cualquier mención a otras herramientas que sean de tu interés.
Principales ejemplos de herramientas de depuración de datos
Dos de las herramientas más utilizadas en el campo de la depuración de datos son Open Refine y Talend Open Studio.
OpenRefine
Funcionalidad:
OpenRefine es una herramienta gratuita, que busca mejorar la calidad y estructura de los datos corrigiendo errores comunes como duplicidades de los datos, datos incompletos o inconsistencias. Gracias a ella los usuarios pueden organizar, limpiar, aplicar transformaciones, convertir en diferentes formatos y enriquecer los datos mediante el uso de servicios web y otras fuentes externas de datos.
Principales ventajas:
Una de sus principales ventajas es que utiliza el lenguaje GREL (Google Refine Expression Languaje), que permite realizar tareas de depuración avanzadas aplicando un importante número de funciones utilizando expresiones regulares. Además, permite incorporar extensiones adicionales mediante el acceso a funciones para georreferenciar información, vincular datos de la DBpedia u otras fuentes, generando datos enlazados en RDF.
¿Quieres saber más?
- Materiales de ayuda: En este manual de usuario se recorren todos los aspectos de la configuración y el uso de Open Refine 3.4.1, incluidas todas las funciones y características de la interfaz y esta cuenta de Youtube distintos video-tutoriales.
- Repositorio: En este GitHub se encuentran los recursos necesarios para que puedas operar OpenRefine desde Mac OS, Linux y Windows.
- Comunidad de usuarios: Los usuarios de OpenRefine pueden encontrar grupos de discusión en Google, Gitter y Stackoverflow.
- Redes sociales: En la cuenta de Twitter de @OpenRefine puedes encontrar vídeos, guías, información sobre las últimas novedades o próximos eventos relacionados con OpenRefine.
Talend Open Studio
Funcionalidad:
Talend Open Studio es una solución de código abierto que integra un conjunto de herramientas ETL (Extraer, Transformar y Cargar) diseñadas para extraer, depurar y transformar conjuntos de datos para su posterior análisis. Como resultado genera código estandarizado en Perl y Java que puede ser reutilizado en diferentes proyectos.
Principales ventajas:
Esta herramienta destaca por su interfaz intuitiva basada en la programación por componentes, una técnica que consiste en concatenar procesos con diversas funcionalidades mediante flujos de entrada y salida.
¿Quieres saber más?
- Materiales de ayuda: En la propia web de Talend puedes encontrar distintos manuales de usuario y tutoriales para descubrir Talend Studio y su interfaz, y crear un proyecto, junto con sencillos trabajos de ejemplo.
- Repositorio: Este GitHub contiene los archivos fuente de Talend Open Studio, los cuales archivos deben utilizarse junto con el código común contenido en tcommon-studio-se.
- Comunidad de usuarios: En Stackoverflow existen canales donde usuarios cuentas su experiencia y plantean distintas dudas.
- Redes sociales: Talend Open Studio cuenta con una página de LinkedIn y el perfil @Talend en Twitter, donde comparten novedades, experiencias y casos de uso, entre otros.
Principales ejemplos de Herramientas de conversión de datos
En el caso de la conversión de datos, destacan por su popularidad Mr Data Converter, Beautify Converters y Tabula.
Mr Data Converter
Funcionalidad:
Mr Data Converter es una aplicación web que permite convertir datos que se encuentran en formato CSV o Excel a otros formatos como CSV, JSON, HTML y XML de manera sencilla.
Principales ventajas:
Uno de sus puntos fuertes es que los datos se incorporan copiando y pegando sobre la interfaz de la aplicación, sin necesidad de subir ningún archivo. Lo mismo sucede a la hora de exportar, donde basta con copiar y pegar el código generado. En el lado negativo de la balanza, encontramos una limitación en el tamaño máximo de los datos, que no deben superar los 300 MB.
¿Quieres saber más?
- Repositorio: Puedes encontrar información sobre la licencia y distintos materiales en este GitHub.
Beautify Converters
Funcionalidad:
Beautify Converters es una aplicación web, que permite convertir datos a formatos JSON, SQL, CSV o Excel, entre otros. Pertenece a la colección de herramientas online gratuitas de Beautify Tools.
Principales ventajas:
Al igual que sucedía con Mr Data Converter, el usuario puede incorporar los datos copiando y pegando sobre la interfaz de la aplicación. También se puede realizar esta acción subiendo el archivo desde un equipo local. A diferencia de la herramienta anterior, admite un número significativamente mayor de formatos, SQL, YAML o RSS.
¿Quieres saber más?
- Repositorio: En este repositorio GitHub tienes información sobre la licencia y el resto de herramientas de la colección Beautify Tools.
Tabula
Funcionalidad:
Tabula permite extraer tablas de informes PDF -excepto en aquellos que son solo imagen-, en formatos reutilizables por herramientas de análisis y visualización de datos.
Principales ventajas:
Su principal ventaja es una interfaz muy sencilla. Únicamente será necesario subir el PDF, seleccionar las tablas que queramos extraer y finalmente seleccionar el formato deseado, Excel, CSV o JSON.
¿Quieres saber más?
- Materiales de ayuda: La Junta de Andalucía ha desarrollado este tutorial donde cuenta cómo subir un archivo PDF a Tabula y extraer los datos tabulares en formato CSV, listos para su uso en hojas de cálculo. El proceso lo ejemplifican con el conjunto de datos Calidad sanitaria de las aguas de baño.
- Repositorio: Puedes descargar los materiales desde este enlace o GitHub.
- Redes sociales: La cuenta @TabulaPDF, aunque no está muy actualizada, ofrece, entre otros, información sobre corrección de errores y mantenimiento, guías y comentarios de usuarios que utilizan esta herramienta.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:

La adecuación y conversión de los datos puede consumir una gran cantidad de recursos, económicos y temporales, de cualquier proyecto. Este tipo de herramientas ayudan a realizar estas actividades con agilidad y eficiencia, liberando a los científicos de datos para poder centrarse en otras actividades.
Para aquellos que quieran saber más sobre estas herramientas y otras que nos pueden ayudar durante las distintas fases del procesamiento de los datos, desde datos.gob.es ponemos a vuestra disposición el informe “Herramientas de procesado y visualización de datos “recientemente actualizado. Puedes ver el informe completo aquí. Puedes ver más herramientas relacionadas con este campo en los siguientes monográficos:
- Las herramientas de análisis de datos más populares
- Las herramientas de visualización de datos más populares
- Las librerías y APIs de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.
Documentación
La visualización es crítica para el análisis de datos. Aporta una primera línea de ataque, revelando estructuras intrincadas en datos que no pueden ser absorbidas de otro modo. Descubrimos efectos inimaginables y cuestionamos aquellos que han sido imaginados.”
William S. Cleveland (de Visualizing Data, Hobart Press)
A lo largo de los años se ha generado y almacenado una enorme cantidad de información pública. Esta información, si se observa de forma lineal, consta de una gran cantidad de números y hechos inconexos que, fuera de contexto, carecen de cualquier significado. Por ello, la visualización se presenta como una fácil solución hacia la comprensión e interpretación de la información.
Para obtener buenas visualizaciones es preciso trabajar con datos que cumplan dos características:
- Tienen que ser datos de calidad. Es necesario que sean precisos, completos, fiables, actuales y relevantes.
- Tienen que estar bien tratados. Es decir, convenientemente identificados, correctamente extraídos, de forma estructurada, etc.
Por tanto, es importante procesar adecuadamente la información antes de su tratamiento gráfico. El tratamiento de los datos y su visualización forman un tándem atractivo para el usuario que demanda, cada vez más, poder interpretar datos de forma ágil y rápida.
Existen un gran número de herramientas destinado a este fin. El informe “Herramientas de procesado y visualización de datos” nos ofrece un listado de diferentes herramientas que nos ayudan en el procesamiento de los datos, desde la obtención de los mismos hasta la creación de una visualización que nos permita interpretarlos de manera sencilla.
¿Qué puedes encontrar en el informe?
La guía incluye una recopilación de herramientas de:
- Web scraping
- Depuración de datos
- Conversión de datos
- Análisis de datos para programadores y no programadores
- Servicios de visualización genéricos, geoespaciales y librerías y APIs.
- Análisis de redes
Todas las herramientas presentes en la guía tienen una versión de libre disposición para que cualquier usuario pueda acceder a ellas.
Nueva edición 2021: incorporación de nuevas herramientas
La primera versión de este informe vio la luz en 2016. Cinco años después se ha procedido a su actualización. Las novedades y cambios efectuados son:
- Se han incorporado nuevas herramientas de procesado y visualización de datos actualmente populares como Talend Open Studio, Python, Kibana o Knime.
- Se han eliminado algunas herramientas desfasadas.
- Se ha actualizado la maquetación.
Si conoces alguna herramienta adicional, no incluida actualmente en la guía, te invitamos a compartir la información en los comentarios.
Además, hemos preparado una serie de post donde se explican los distintos tipos de herramientas que pueden encontrar en el informe:
Documentación
El dicho “una imagen vale más que mil palabras” es un claro ejemplo de sabiduría popular basada en la ciencia. El 90% de la información que procesamos es visual, gracias a un millón de fibras nerviosas que unen el ojo con el cerebro y a más de 20.000 millones de neuronas que realizan el procesamiento de los impulsos recibidos a gran velocidad. Por ello somos capaces de recordar el 80% de las imágenes que vemos, mientras que en el caso del texto y el sonido los porcentajes se reducen al 20% y al 10%, respectivamente.
Estos datos explican la importancia de la visualización de datos en cualquier sector de actividad. No es lo mismo contar cómo evoluciona un indicador, que verlo a través de elementos visuales, como gráficos o mapas. La visualización de datos nos ayuda a comprender conceptos complejos y supone una manera accesible para detectar y comprender tendencias y patrones en los datos.
Visualización de datos y Smart cities
En el caso de las Smart cities, donde se genera y captura tanta información, la visualización de datos es fundamental. A lo largo y ancho de una ciudad inteligente, hay un gran número de sensores y dispositivos inteligentes, con diferentes capacidades de detección, que generan una gran cantidad de datos en bruto. Por poner un ejemplo, solo la ciudad de Barcelona, dispone de más de 18.000 sensores repartidos por toda la ciudad que captan millones de datos. Esto datos permiten desde la vigilancia en tiempo real del entorno hasta la toma de decisiones informada o la rendición de cuentas. Visualizar estos datos a través de cuadros de mando visuales agiliza todos estos procesos.
Para ayudar a las Smart cities en esta tarea, desde el proyecto Ciudades abiertas, liderado por Red.es y cuatro ayuntamientos (A Coruña, Madrid, Santiago de Compostela y Zaragoza), se han seleccionado una serie de herramientas de visualización y se ha desarrollado una extensión para CKAN similar a la funcionalidad “Open With Apps”, inicialmente ideada para el portal Data.gov, que facilita la integración con este tipo de herramientas.
El método de integración inspirado en “Open with Apps”
La idea tras “Open With Apps” es permitir la integración con algunos servicios de terceros, para algunos formatos publicados en los portales de datos abiertos, como por ejemplo CSV o XLS, sin necesidad de descargar y cargar datos manualmente, a través de las APIs o URIs del servicio externo.
Pero no todos los sistemas de visualización permiten esta funcionalidad. Por ello, desde el proyecto ciudades abiertas han analizado varias plataformas y herramientas online de creación de visualizaciones y análisis de datos, y han seleccionado 3 que cumplen con las características necesarias para el funcionamiento descrito:
-
La integración se realiza a través de enlaces a sitios web sin necesidad de descargar ningún software.
-
En la invocación sólo es necesario pasar como parámetro la URL de descarga del fichero de los datos.
El resultado de dicho análisis ha dado lugar al informe “Análisis y definición de especificaciones de integración con sistemas externos de visualización”, donde se destacan 3 herramientas que cumplen estas funcionalidades.
3 herramientas de visualización y análisis de datos sencillas
De acuerdo con el citado informe, las 3 plataformas que cumplen las características necesarias para lograr dicho funcionamiento son:
-
Plotly: facilita la creación de visualizaciones interactivas de datos y paneles de control para compartir en línea con la audiencia. Los usuarios más avanzados pueden procesar datos con cualquier función personalizada, así como crear simulaciones con scripts de Python. Los formatos que acepta son CSV, TSV, XLS y XLSX.
-
Carto: antes conocida como CartoDB, genera mapas interactivos a partir de datos geoespaciales. Los mapas se crean automáticamente y el usuario puede filtrar y refinar los datos para obtener más información. Acepta ficheros en formatos CSV, XLS, XLSX, KML (Google Earth), KMZ, GeoJSON y SHP.
-
Geojson.io: permite visualizar y editar datos geográficos en formato GeoJSON, así como exportar a un gran número de formatos.

Para cada una de estas herramientas el informe incluye una descripción de sus requisitos y limitaciones, su modo de uso, una llamada genérica y ejemplos concretos de llamadas junto con el resultado obtenido.
La extensión “Abrir con”
Como se mencionó anteriormente, dentro del proyecto también se ha desarrollado una extensión para CKAN denominada “Abrir con”. Esta extensión permite visualizar los ficheros de datos utilizando los sistemas externos de visualización antes descritos. Se puede acceder a ella a través de la cuenta de GitHub del proyecto.
El informe explica cómo llevar a cabo su instalación de manera sencilla, aunque si surge alguna duda acerca de su funcionamiento, los usuarios pueden ponerse en contacto con Ciudades abiertas a través del correo electrónico contacto@ciudadesabiertas.es.
Aquellos interesados en otras extensiones de CKAN relacionadas con la visualización de datos tienen a su disposición el informe Análisis de las Extensiones de Visualización para CKAN, realizado en el marco de la misma iniciativa. En la cuenta de Gighub, se espera que vayan publicando ejemplos de visualizaciones realizadas.
En definitiva, la visualización de datos es una pata fundamental de las Smart cities, y gracias al trabajo del equipo de Ciudades Abiertas ahora le resultará más fácil a cualquier iniciativa integrar soluciones sencillas de visualización de datos en sus plataformas de gestión de la información.
Blog
Introducción
En este nuevo post introducimos un tema importante en el sector del análisis de datos y que, sin embargo, suele pasar desapercibido a la mayor parte de la audiencia no especialista. Cuando hablamos de analítica avanzada de datos tendemos a pensar en sofisticadas herramientas y avanzados conocimientos en materia de aprendizaje automático e inteligencia artificial. Sin desmerecer estas habilidades tan demandadas en la actualidad, existen aspectos mucho más básicos del análisis de datos que tienen un impacto mucho mayor en el usuario o consumidor final de resultados. En esta ocasión hablamos de la comunicación del análisis de datos. Una buena comunicación de los resultados y el proceso de un análisis de datos puede marcar la diferencia entre el éxito o el fracaso de un proyecto de analítica de datos.
Comunicación. Un proceso integrado
Podríamos pensar que la comunicación del análisis de datos es un proceso posterior y desacoplado al propio análisis técnico. En definitiva, es algo que se deja para el final. Esto es un error muy común entre los analistas y científicos de datos. La comunicación debe de estar integrada con el proceso de análisis. Desde la perspectiva más táctica de la documentación del código y el proceso de análisis, hasta la comunicación al público final (en forma de presentaciones y/o informes). Todo debe de ser un proceso integrado. De la misma forma que en el mundo del desarrollo de software se ha impuesto la filosofía DevOps, en el espacio del análisis de datos ha de imponerse la filosofía DataOps. En ambos casos, el objetivo es la entrega de valor continua y ágil en forma de software y datos
Gartner define DataOps como “una práctica colaborativa de gestión de datos centrada en la mejora de la comunicación, la integración y la automatización de los flujos de datos entre los responsables de la gestión de datos y los consumidores en una empresa\".
Innovation Insight for DataOps
Beneficios de emplear una metodología integrada de análisis y comunicación de datos.
- Un único proceso controlado y gobernado. Cuando adoptamos DataOps podemos estar seguros de que todas las etapas de análisis de datos se encuentran bajo control, gobernadas y altamente automatizadas. Esto redunda en el control y la seguridad del pipeline de datos.
- Ciencia de datos reproducible. Cuando comunicamos resultados y/o parte del proceso de análisis de datos, es habitual que otros colaboradores partan de tu trabajo para intentar mejorar o modificar los resultados. A veces, tan solo tratarán de reproducir tus mismos resultados. Si la comunicación final ha formado parte del proceso de una forma integrada y automatizada, tus colaboradores no tendrán problema a la hora de reproducir esos mismos resultados por ellos mismos. De lo contrario, si la comunicación se ha realizado al final del proceso y de forma desacoplada (tanto en el tiempo como en el uso de herramientas diferentes) del análisis, existe una alta probabilidad de que el intento de reproducción falle. Los procesos de desarrollo de software, incluyan o no datos, son altamente iterativos. Esto es, se efectúan cientos si no miles de cambios en los códigos antes de obtener los resultados deseados. Si estos cambios iterativos, por pequeños que sean se desacoplan de la comunicación final, con toda seguridad, el resultado obtenido habrá obviado cambios que harán imposible su reproducción directa.
- Entrega de valor continua. En multitud de ocasiones he vivido situaciones en las que la preparación de resultados se deja como última fase de un proyecto o proceso de análisis de datos. La mayor parte de los esfuerzos se centran en el desarrollo del análisis de los datos y el desarrollo de algoritmos (cuando corresponde). Este hecho tiene una consecuencia clara. La última tarea es la de preparar la comunicación y por lo tanto es la que menos foco acaba concentrando. Todos los esfuerzos del equipo se han gastado en fases previas. Estamos exhaustos y la documentación y comunicación es lo que nos separa de la entrega del proyecto. Como consecuencia, la documentación del proyecto será insuficiente y la comunicación mediocre. Sin embargo, cuando presentemos los resultados a nuestros clientes, intentaremos desesperadamente convencer de que se ha hecho un trabajo excelente de análisis (y así será) pero nuestra arma es la comunicación que hemos preparada y está será previsiblemente muy mejorable.
- Mejora en la calidad de la comunicación. Cuando integramos desarrollo y comunicación estamos monitorizando en todo momento lo que finalmente van a consumir nuestros clientes. De esta forma, durante el proceso de análisis, contamos con la agilidad de modificar los resultados que estamos produciendo (en forma de gráficos, tablas, etc.) en tiempo de análisis. En múltiples ocasiones he visto como después de cerrar la fase de análisis y revisar los resultados producidos, nos damos cuenta de que algo no se entiende bien o es mejorable en términos de comunicación. Pueden ser cosas sencillas como los colores de una leyenda o los dígitos decimales en una tabla. Sin embargo, si el análisis se ha realizado con herramientas muy diferentes y desacopladas de la producción de resultados (por ejemplo, una presentación), la sola idea de volver a ejecutar el proyecto de análisis para modificar pequeños detalles le hará saltar las alarmas a cualquier analista o científico de datos. Con la metodología DataOps y las herramientas adecuadas, tan solo tenemos que volver a ejecutar la pipeline de datos con los cambios correspondientes y todo se re-creará de forma automática.
Herramientas de comunicación integrada
Hemos hablado de la metodología y sus beneficios, pero debemos saber que las herramientas para implementar de forma correcta la estrategia juegan un papel importante. Sin ir más lejos, este post se ha realizado íntegramente con un pipeline de datos que en el mismo proceso integra: (1) la redacción de este post, (2) la creación de un sitio web para su publicación, (3) el versionado del código y (4) el análisis de datos, aunque en este caso, no es relevante, pues tan solo sirve para ilustrar que es una parte más del proceso.
Sin entrar en demasiados detalles técnicos, en el mismo entorno de trabajo (y programación y redacción de documentos) RStudio y utilizando los complementos de Markdown y Blogdown podemos crear un sitio web completo en el que podemos ir publicando nuestros posts, en este caso sobre análisis de datos. La explicación detallada sobre la creación del sitio web que alojará los siguientes posts de contenido lo dejaremos para otro momento. En estos momentos vamos a centrarnos en la generación de este post de contenido en el que mostraremos un ejemplo de análisis de datos.
Para ilustrar el proceso vamos a utilizar este conjunto de datos disponible en datos.gob.es. Se trata de un conjunto de datos que recoge los usos de la tarjeta ciudadana del Ayuntamiento de Gijón, durante 2019 en los diferentes servicios disponibles en la ciudad.
Como podemos comprobar, en este punto, estamos ya integrando la comunicación de un análisis de datos con su propio análisis. Lo primero que vamos a hacer es cargar el conjunto de datos y ver una previsualización del mismo.
file <- \"http://opendata.gijon.es/descargar.php?id=590&tipo=EXCEL\"\r\n Citicard <- read_csv2(file, col_names = TRUE)\r\n head(Citicard)| Fecha | Servicio | Instalacion | Usos |
|---|---|---|---|
| 2019-01-01 | Aseos públicos | Avda Carlos Marx | 642 |
| 2019-01-01 | Aseos públicos | Avda del Llano | 594 |
| 2019-01-01 | Aseos públicos | C/ Puerto el Pontón | 139 |
| 2019-01-01 | Aseos públicos | Cerro Santa Catalina | 146 |
| 2019-01-01 | Aseos públicos | Donato Argüelles | 1095 |
| 2019-01-01 | Aseos públicos | El Rinconín | 604 |
A continuación vamos a generar un análisis obvio y sencillo en cualquier fase exploratoria (EDA - Exploratory Data Analysis) de un conjunto de datos nuevo. Vamos a agregar el conjunto de datos por Fecha y Servicios, obteniendo así la suma de usos de la tarjeta por fecha y tipo de servicio.
Citi_agg <- Citicard %>%\r\n group_by(Fecha, Servicio) %>%\r\n summarise(Usos = sum(Usos)) \r\n \r\n head(Citi_agg)| Fecha | Servicio | Usos |
|---|---|---|
| 2019-01-01 | Aseos públicos | 17251 |
| 2019-01-01 | Préstamos bibliotecas | 15369 |
| 2019-01-01 | Transporte | 1201471 |
| 2019-02-01 | Aseos públicos | 18186 |
| 2019-02-01 | Préstamos bibliotecas | 14716 |
| 2019-02-01 | Transporte | 1158109 |
Graficamos el resultado y observamos como el uso mayoritario de la tarjeta ciudadana es el pago del transporte público. Dado que hemos generado un gráfico interactivo, podemos seleccionar en los controles Autoescala y hacer click sobre la leyenda para eliminar la columna del transporte y analizar con detalles las diferencias entre el uso de Aseos públicos y Préstamos en bibliotecas.
Citi_fig <- ggplot(Citi_agg, aes(x=Fecha, y=Usos/1000, fill=Servicio)) +\r\n geom_bar(stat=\"identity\", colour=\"white\") + labs(x = \"Servicio\", y = \"Uso Tarjeta (en miles)\") + \r\n theme(\r\n axis.title.x = element_text(color = \"black\", size = 14, face = \"bold\"),\r\n axis.title.y = element_text(color = \"black\", size = 10, face = \"bold\")\r\n ) \r\n \r\n ggplotly(Citi_fig)Cuando descartamos por un momento el uso de la tarjeta como medio de pago en el transporte público, observamos el mayor uso de la tarjeta para el acceso a los aseos públicos y en menor medida para el préstamo de medios en bibliotecas públicas. De la misma forma, el uso del zoom, nos permite ver con mayor comodidad y detalles estas diferencias en meses concretos.
En caso de preguntarnos cual es la distribución del uso total de la Tarjeta Ciudadana a lo largo del 2019, podemos generar la siguiente visualización y constatar el resultado evidente de que el uso en el trasnporte público representa el 97%.
Tot_2019_uses <- sum(Citi_agg$Usos)\r\n Citi_agg_tot <- Citicard %>%\r\n group_by(Servicio) %>%\r\n summarise(Usos = 100*sum(Usos)/Tot_2019_uses) %>%\r\n arrange(desc(Usos))\r\n \r\n knitr::kable(Citi_agg_tot, \"pipe\", digits=0, col.names=(c(\"Servicio Usado\", \"Uso Tarjeta en %\")))| Servicio Usado | Uso Tarjeta en % |
|---|---|
| Transporte | 97 |
| Aseos públicos | 2 |
| Préstamos bibliotecas | 1 |
ggplot(Citi_agg_tot,aes(x=Servicio, y=Usos, fill=Servicio)) + \r\n geom_bar(stat=\"identity\", colour=\"white\") + labs(x = \"Servicio\", y = \"Uso en %\") + \r\n theme(\r\n axis.title.x = element_text(color = \"black\", size = 14, face = \"bold\"),\r\n axis.title.y = element_text(color = \"black\", size = 14, face = \"bold\")\r\n ) -> Citi_fig2\r\n \r\n \r\n ggplotly(Citi_fig2)Terminamos. En este post, hemos visto como una estrategia integrada de comunicación nos permite integrar nuestro análisis técnico con la generación de resultados consumibles en forma de tablas y gráficos listos para el usuario final. En el mismo proceso integramos los cálculos (agregaciones, normalizaciones, etc.) con la producción de resultados de calidad y con un formato adaptado al lector no especialista. En una estrategia no integrada de comunicación, hubieramos post-procesado los resultados del análisis técnico en otro momento del tiempo posterior y, probablemente, en una herramienta diferente. Esto nos hubiera hecho ser menos productivos a la vez que perderíamos la traza de los pasos que hemos seguido para generar el resultado final.
Conclusiones
La comunicación es un aspecto fundamental del análisis de datos. Una mala comunicación puede echar por tierra un excelente trabajo de análisis de datos, por muy sofisticado que este sea. Para realizar una buena comunicación es necesario implementar una estrategia integrada de comunicación. Esto pasa por adoptar la filosofía DataOps para desarrollar un trabajo excelente, reproducible y automatizado de los flujos de datos. Esperamos que os haya gustado el tema de este post y volveremos más adelante con contenidos sobre DataOps y comunicación de datos. ¡Hasta pronto!
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Dentro de esta vorágine tecnológica en la que estamos constantemente sumergidos, cada día que pasa, la humanidad está creando una gran cantidad de información que en muchos casos somos incapaces de tratar.
Las administraciones públicas también generan grandes volúmenes de información, que ponen a disposición de los ciudadanos para que podamos reutilizarla a partir de los portales de datos abiertos, pero, ¿cómo podemos sacar partido a estos datos?
En muchas ocasiones, pensamos que solo los expertos pueden analizar estas grandes cantidades de información, pero no es así. En este artículo vamos a ver qué oportunidades presentan los datos abiertos para usuarios sin conocimientos técnicos ni experiencia en el análisis y visualización de datos.
Generado conocimiento en 4 sencillos pasos con un caso de uso
Dentro de la plataforma de datos abiertos del Gobierno de España, podemos encontrar multitud de datos a nuestra disposición. Estos datos están agrupados por categoría, temática, administración que publica el dato, formato o con otros tags que nos etiquetan el contenido de los mismos.
Estos datos, podemos cargarlos en aplicativos de análisis informacional, como por ejemplo PowerBI, Qlik, Tableau, Tipco, Excel, etc., que nos ayudarán a crear nuestros propios gráficos y tablas sin tener apenas conocimientos informáticos. La utilización de estas herramientas nos permitirá desarrollar nuestro propio producto de análisis informacional, con el que podremos crear filtros o consultas no planificadas. Todo ello sin contar con otros elementos informáticos como bases de datos o herramientas de ETL (Abreviatura de Extracción, Transformación y Carga de datos).
A continuación veremos cómo podemos construir un primer cuadro de mando de una manera muy sencilla.
1.- Selección de datos
Antes de empezar a recoger datos sin sentido, lo primero que debemos decidir es con qué finalidad usaremos los datos. El catálogo de datos.gob.es es muy amplio y es muy fácil perderse dentro de ese mar de datos, por lo que debemos centrarnos en la temática que buscamos y la administración que lo publica, si la conocemos. Con esta simple acción reduciremos mucho el alcance de nuestra búsqueda.
Una vez que sabemos qué buscar, debemos centrarnos en el formato de los datos:
- Si queremos recoger la información directamente para redactar nuestra tesis doctoral, escribir un artículo para un medio de comunicación con datos estadísticos, o simplemente adquirir nuevos conocimientos para nuestro propio interés, nos centraremos en coger información que ya esté preparada y trabajada. Debemos entonces acudir a formatos de datos tipo pdf, html, jpg, docx, etc. Estos formatos nos permitirán recoger ese conocimiento sin necesidad de herramientas tecnológicas adicionales, ya que la información se sirve en formatos visuales, los conocidos como no estructurados.
- Si queremos trabajar la información aplicando diferentes métricas de cálculo y cruzarlas con otros datos que tengamos en nuestro poder, en ese caso deberemos utilizar información estructurada, o sea, formatos XLS, CSV, JSON, XML.
Como ejemplo, imaginemos que queremos analizar la población de cada uno de los distritos de la ciudad de Madrid. En este caso el conjunto de datos que necesitamos es el padrón del ayuntamiento de Madrid.
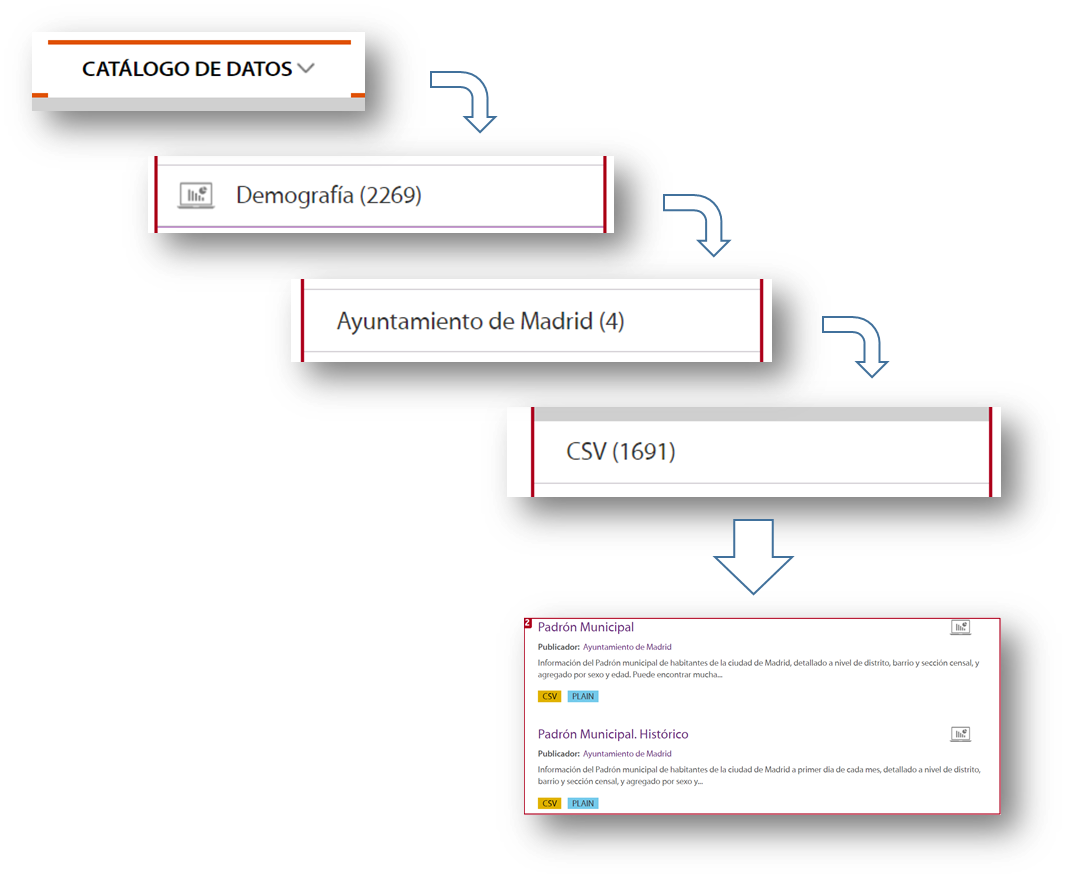
Para localizar este conjunto de datos, seleccionamos Catalogo de datos, categoría Demografía, que el publicador sea el Ayuntamiento de Madrid, el formato CSV y ya me aparece la información que necesito en la parte derecha de la pantalla. Otra forma sencilla y complementaria de la anterior de localizar la información, es utilizar el buscador incluido dentro de la plataforma y teclear “Padrón”+“Madrid”.
Con esta búsqueda, la plataforma ofrece, entre otros, dos conjuntos de datos: el padrón histórico y el padrón del último mes publicado. Para este ejemplo cogeremos el documento correspondiente a la actualización de agosto de 2020.
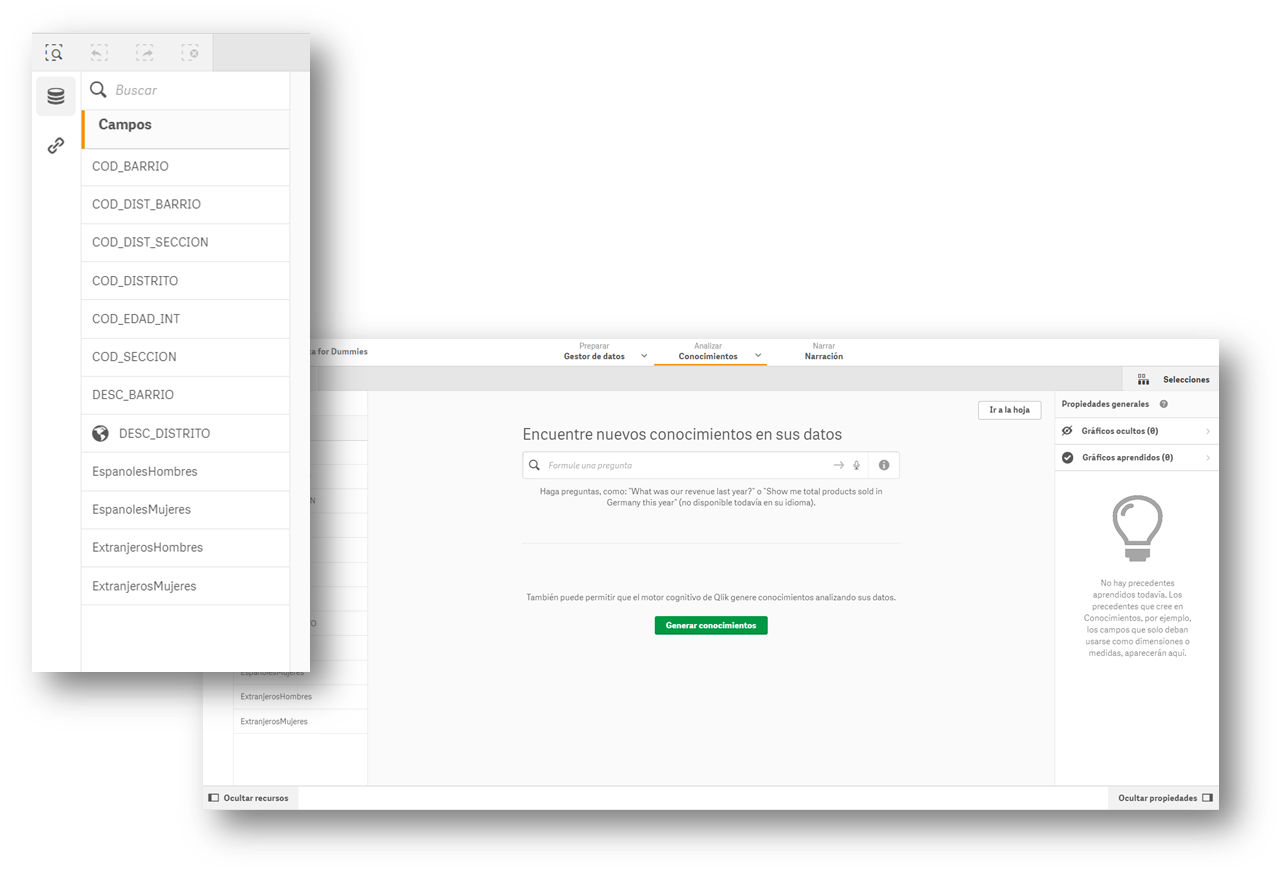
2.- Carga de la información en una herramienta de visualización de información
Buena parte de las herramientas de visualización de información suelen llevar asistentes incorporados para recoger los datos que nos podemos descargar de un portal de datos abiertos. Las imágenes que acompañan a este artículo corresponden a la versión Business de QlikSense (que cuenta con una versión gratuita de prueba de 30 días), pero cualquiera de las herramientas anteriormente mencionadas funciona de manera similar. Con un sencillo “arrastrar y soltar”, ya tendremos la información dentro de la herramienta, para empezar a crear indicadores y así generar el conocimiento.

La mayoría de estas herramientas interpretan directamente el contenido de los campos y proponen un uso para esos valores, diferenciándolos por datos que pueden ser usados como filtros, datos geográficos y datos con lo que poder formular.
3.- Creación del primer gráfico o indicador
Ahora solo nos queda arrastrar los campos sobre los que queremos generar conocimiento y crear el primer indicador de nuestro cuadro de mando. Arrastraremos el campo DESC_DISTRITO, que contiene la descripción del distrito, para ver qué sucede.
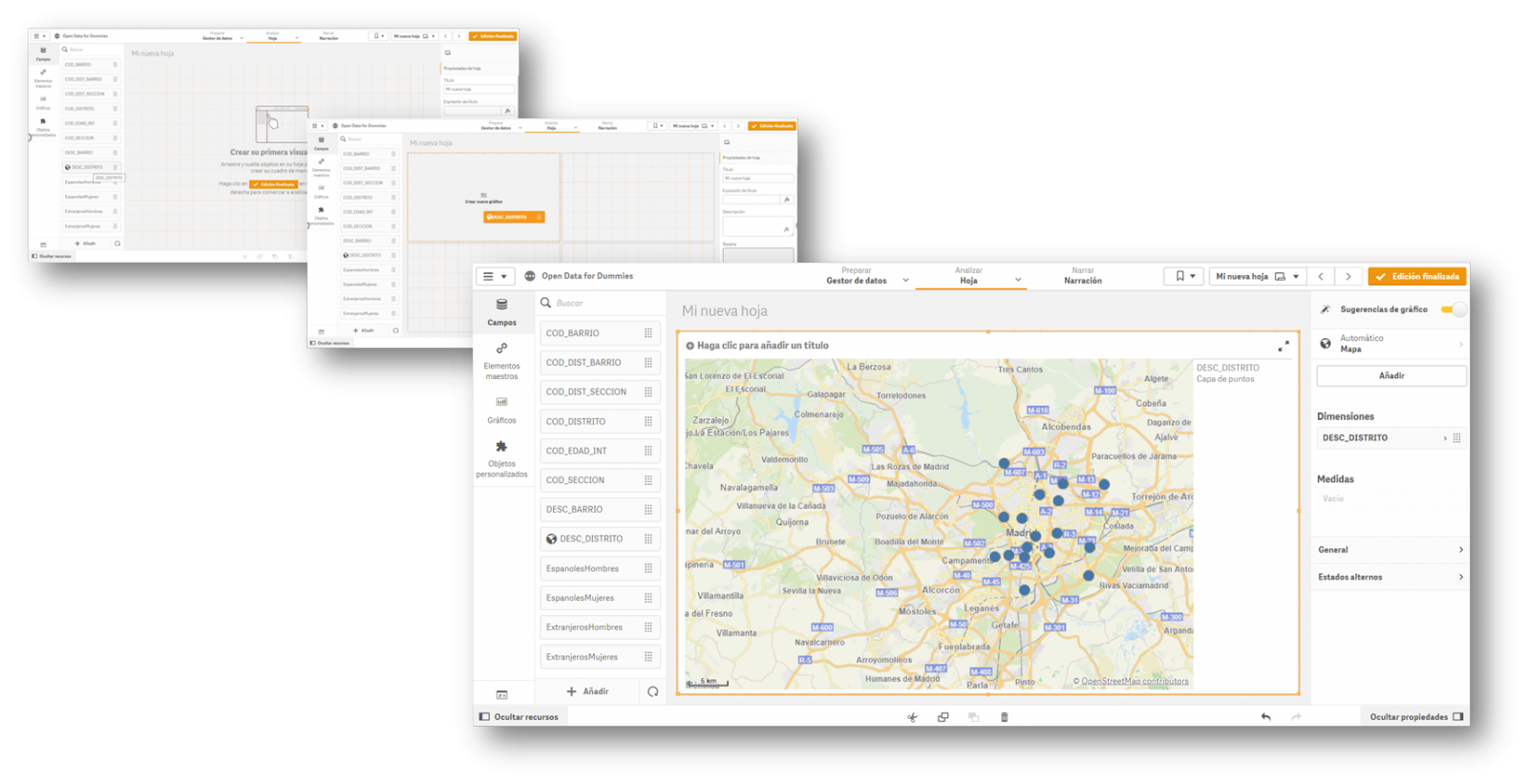
Una vez realizada la acción, vemos que nos ha geo-posicionado en un mapa todos los distritos de Madrid, aunque en un primer momento no tenemos ningún tipo de información que analizar. En esta primera visualización automática nos muestra un punto en el centro del distrito, pero no nos proporciona ningún otro tipo de información adicional.
4.- Crear valor en nuestro indicador
Una vez tenemos los puntos sobre el mapa, necesitamos saber qué queremos ver dentro de esos puntos. Vamos a seguir con el “Arrastrar y Soltar” para contabilizar los hombres y mujeres de nacionalidad española. Veamos que sucede…
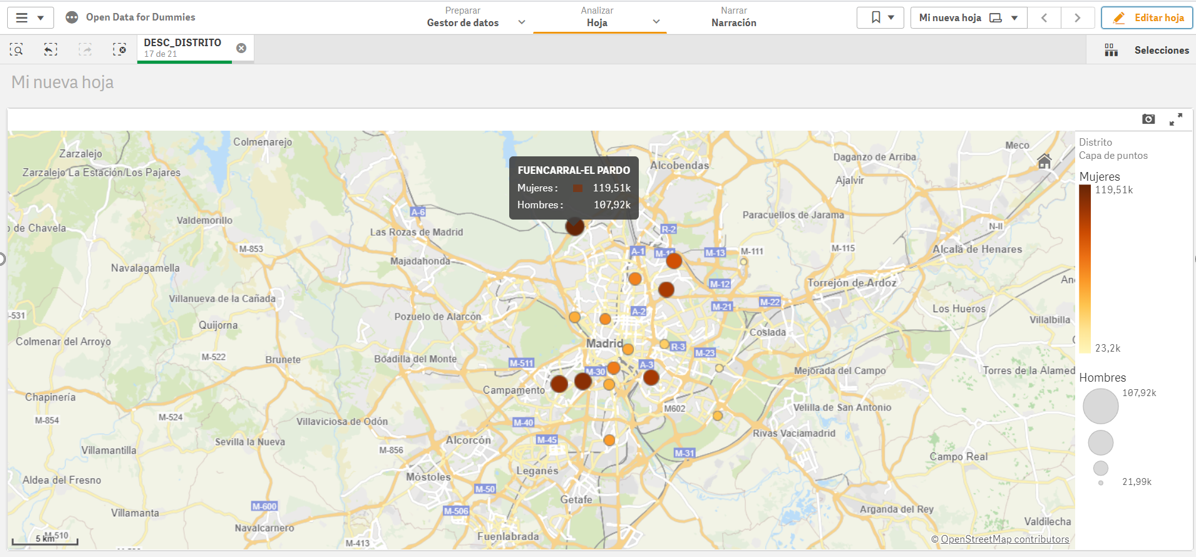
Vemos que para cada uno de los puntos nos ha sumado por sexo los ciudadanos en cada uno de los distritos donde están empadronados.
En definitiva, con cuatro sencillos pasos en los que solo hemos seleccionado el conjunto de datos y hemos arrastrado y soltado el archivo dentro de una herramienta de visualización, nos hemos creado el primer indicador del nuestro cuadro de mando, donde podremos seguir generando conocimiento.
Si seguimos profundizando en el uso de estas herramientas, podremos crear nuevos gráficos, como tablas dinámicas, gráficos de tarta o visualizaciones interactivas.
Lo interesante de este tipo de análisis, es poder incorporar nuevos conjuntos de datos abiertos, como la cantidad de Farmacias que hay en un distrito, o el número y tipología de accidentes en una zona en concreto. Cruzando los distintos datos podremos ir adquiriendo más conocimiento sobre la ciudad y tomar decisiones informadas, como cuál es la mejor zona para poner una nueva farmacia en función de la población o instalar un nuevo semáforo.
Contenido elaborado por David Puig, Graduado en Información y Documentación y responsable del grupo de trabajo de Datos Maestros y de Referencia en DAMA ESPAÑA.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
La representación de datos de forma visual ayuda a nuestro cerebro a digerir grandes cantidades de información de una manera rápida y sencilla. Las visualizaciones interactivas facilitan a personas no expertas el análisis de situaciones complejas representadas en forma de datos.
Cómo introdujimos en nuestro último post sobre este tema, la visualización gráfica de datos constituye una disciplina propia dentro del universo de la ciencia de datos. En este nuevo post queremos poner el foco sobre las visualizaciones de datos interactivas. Las visualizaciones dinámicas permiten al usuario interactuar con los datos y transformarlos en gráficos, tablas e indicadores que tienen la capacidad de mostrar información diferente según los filtros establecidos por el usuario. En cierta medida, las visualizaciones interactivas son una evolución de las visualizaciones clásicas, permitiéndonos condensar mucha más información en un espacio similar al de los informes y presentaciones habituales.
La evolución de las tecnologías digitales ha desplazado el foco de la analítica visual de datos hacia los entornos web y móviles. Las herramientas y librerías que permiten generar y convertir visualizaciones clásicas o estáticas en dinámicas o interactivas son incontables. Sin embargo, a pesar de los nuevos formatos de representación y generación de visualizaciones, a veces se corre el riesgo de olvidar las buenas prácticas de diseño y composición, que siempre deben estar presentes. La facilidad que las visualizaciones interactivas brindan para condensar gran cantidad de información hace que, en muchas ocasiones, los usuarios intenten incluir mucha información en un único gráfico y conviertan en ilegible hasta el más sencillo de los informes. Pero, volvamos a la parte positiva de las visualizaciones interactivas y analicemos algunas de sus ventajas más significativas.
Beneficios de las visualizaciones interactivas
Los beneficios de las visualizaciones interactivas de los datos son varios:
- Tecnologías web y móvil principalmente. Las visualizaciones interactivas están diseñadas para su consumo desde aplicaciones de software modernas, muchas de ellas, con orientación 100% web y móvil. Esto facilita su lectura desde cualquier dispositivo.
- Más información en el mismo espacio. Las visualizaciones interactivas muestran información diferente en función de los filtros aplicados por el usuario. Así, si queremos mostrar la evolución mensual de las ventas de una empresa en función de la geografía, en una visualización clásica, utilizaríamos un gráfico de barras (meses en el eje horizontal y ventas en el eje vertical) por cada geografía. Por el contrario, en una visualización interactiva, utilizamos un solo gráfico de barras con un filtro al lado, donde seleccionamos la geografía que queremos visualizar en cada momento.
- Personalizaciones. Con las visualizaciones interactivas, un mismo informe o cuadro de mando puede estar personalizado para cada usuario o grupos de usuario. De esta forma, utilizando filtros a modo de menú, podemos seleccionar unos datos u otros, dependiendo del tipo y nivel del usuario consumidor.
- Autoservicio. Existen tecnologías de visualización interactivas muy sencillas, que permite a los usuarios configurar sus propios gráficos y paneles a la carta con tan solo tener accesibles los datos origen a representar. De esta forma, un usuario no experto en visualización, puede configurar su propio informe con tan solo arrastrar y soltar los campos que quiere representar.
Ejemplo práctico
Para ilustrar con un ejemplo práctico el razonamiento anterior vamos a seleccionar un conjunto de datos disponibles en el catálogo de datos.gob.es. En particular, hemos escogido los datos de calidad del aire del ayuntamiento de Madrid en el año 2020. Este conjunto de datos contiene las medidas (granularidad horaria) de agentes contaminantes recogidas por la red de calidad de aire del Ayto. de Madrid. En este conjunto de datos, disponemos de la serie temporal horaria para cada contaminante en cada estación de medida del Ayto. de Madrid, para los meses comprendidos entre enero y mayo de 2020. Para la interpretación del conjunto de datos es necesario obtener también el fichero de interpretación en formato pdf. Ambos ficheros pueden descargarse desde el siguiente sitio web (También está disponible a través de datos.gob.es).
Herramientas de visualización interactiva de los datos
Gracias al uso de herramientas modernas de visualización de datos (en este caso Microsoft Power BI, una herramienta gratuita y de fácil acceso) en tan solo 30 minutos hemos podido descargar los datos de calidad del aire de todo el 2020 (aproximadamente medio millón de registros) y crear un informe interactivo. En este informe, el usuario final puede escoger la estación de medida, bien haciendo uso del filtro de la izquierda o bien seleccionando la estación en mapa inferior. Además, el usuario puede escoger el contaminante en el que esté interesado y un rango de fechas. En esta captura estática del informe, hemos representado todas las estaciones y todos los contaminantes. El objetivo es ver la significativa reducción de la contaminación en todos los contaminantes (excepto el ozono debido a la supresión de los óxidos de nitrógeno) debido a la situación de brusco confinamiento ocasionado por la pandemia del Covid-19 desde mediados del mes de marzo. Para realizar este ejercicio podríamos haber utilizado otras herramientas como MS Excel, Qlik, Tableau o paquetes de visualización interactivos sobre entornos de programación como R y Python. Estas herramientas son perfectas para comunicar los datos sin necesidad de disponer de competencias en programación o codificación.
En conclusión, la disciplina de visualización de datos (Visual Analytics en inglés) es un campo inmenso que cobra gran relevancia hoy en día gracias a la proliferación de las interfaces web y móvil donde quiera que miremos. Las visualizaciones interactivas, empoderan al usuario final y democratizan el acceso al análisis de datos con herramientas libres de código (codeless), mejorando la transparencia y el rigor en la comunicación en cualquier aspecto de la vida y la sociedad, cómo la ciencia, la política y la educación.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
"The simple graph has brought more information to the data analyst’s mind than any other device.” — John Tukey
La visualización gráfica de datos constituye una disciplina propia dentro del universo de la ciencia de datos. Esta práctica ha marcado hitos importantes a lo largo de la história en la analítica de datos. En este post te ayudamos a descubrir y entender su importancia y repercusión de una forma amena y práctica.
Pero, empecemos la historia por el principio. En 1975, un joven de 33 años comienza a impartir un curso de estadística en la universidad de Princeton, sentando las bases de lo que sería la disciplina del visual analytics varias décadas después. Ese joven, llamado Edward Tufte, es considerado el Leonardo da Vinci de los datos. Tufte es, actualmente, profesor emérito de ciencias políticas, estadística y ciencias de la computación en la universidad de Yale. Entre 2001 y 2006, el profesor Tufte escribió una serie de 4 libros - considerados ya clásicos- sobre la visualización gráfica de datos. Algunas ideas centrales de las tesis de Tufte hacen referencia a la eliminación de los elementos inútiles y no informativos en los gráficos. Tufte, aboga por la eliminación de elementos no cuantitativos y decorativos de las visualizaciones, argumentando que éstos distraen la atención de los elementos realmente explicativos y de valor.
Desde el gráfico más sencillo hasta el más complejo (figura 1) y refinado, todos ofrecen alto valor tanto al analista, durante su proceso de ciencia de datos, como al usuario final, al cual estamos comunicando una historia basada en datos.
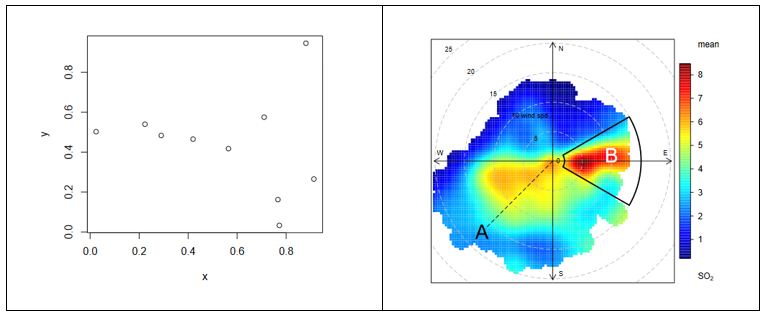
Figura1. La imagen muestra la diferencia entre dos visualizaciones gráficas de datos. A la izquierda, un ejemplo de la visualización de datos más sencilla que se puede realizar. Representación de puntos en coordenadas cartesianas x|y. A la derecha, un ejemplo de visualización de datos compleja en el que se representa en coordenadas polares la distribución de un contaminante (SO2). Los ejes representan las direcciones del viento N|S E|W (en grados) mientras que el radio de la distribución representa la velocidad del viento según la dirección en m/s. La escala de colores representa la concentración promedio de SO2 (en ppb) para esas direcciones y velocidades del viento. Con este tipo de visualización se pueden representar gráficamente tres variables (dirección del viento, velocidad del viento y concentración de contaminantes) en un gráfico "plano" en dos dimensiones (2D). La visualización en 2D es muy conveniente pues resulta más fácil de interpretar para el cerebro humano.
¿Por qué es tan importante la visualización gráfica de los datos?
En la ciencia de datos existen muchos tipos diferentes de datos para analizar. Una forma de clasificación de los datos atiende al nivel de estructuración lógica que éstos tienen. Por ejemplo, se entiende que los datos en formatos similares a hojas de cálculo -aquellos datos que se estructuran en forma de filas y columnas- son datos con una estructura bien definida - o datos estructurados- Sin embargo, aquellos datos como los 140 caracteres de un feed de twitter se consideran datos sin estructura - o desestructurados-. En medio de estos dos extremos se encuentra toda una gama de grises, que va desde los ficheros delimitados por caracteres especiales (comas, puntos y comas, espacios, etc.) hasta las imágenes o los videos de Youtube. Es evidente que las imágenes y los videos solamente cobran sentido humano una vez representadas visualmente. De nada serviría (para un humano) que presentaremos una imagen como una matriz de números que representan una combinación de colores RGB (Red, Green, Blue). En el caso de los datos estructurados, su representación gráfica es necesaria en todas las etapas del proceso de análisis, desde la etapa exploratoria, hasta la presentación final de resultados. Veamos un ejemplo:
En 1963, la compañía de aerolíneas norteamericana Pam Am utilizó la representación gráfica (la serie temporal entre 1949 y 1960) del número mensual de pasajeros internacionales para pronosticar la demanda futura de aviones y realizar un pedido de compra. En el ejemplo, vemos la diferencia entre la representación matricial de los datos y su representación gráfica. La ventaja de representar gráficamente los datos salta a la vista con el ejemplo de la figura 2.
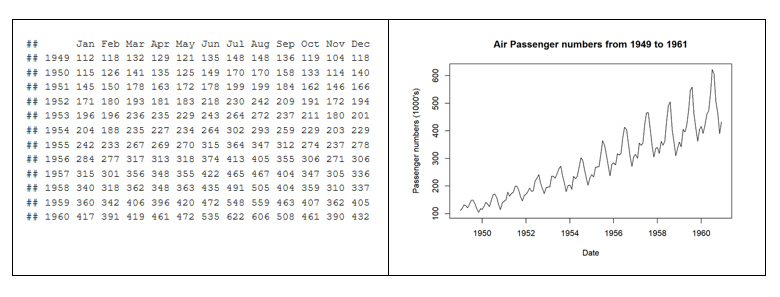
Figura 2. Diferencia entre la representación tabular de los datos y la representación gráfica o visualización.
La visualización gráfica de los datos tiene un papel fundamental en todos los estadios del análisis de datos. Existen múltiples aproximaciones sobre cómo realizar un proceso de análisis de datos de forma correcta y completa. De acuerdo con Garrett Grolemund y Hadley Wickham en su reciente libro R for Data Science, un proceso estándar en análitica de datos sería de la siguiente forma (figura 3):
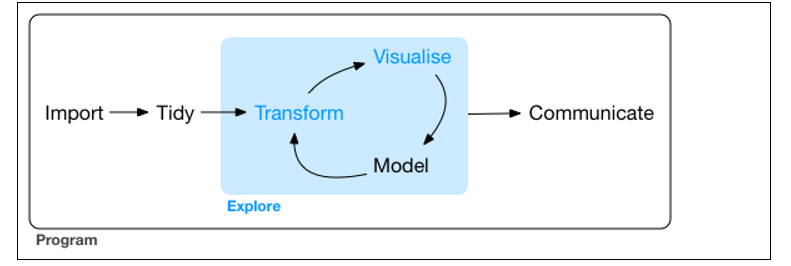
Figura 3. Representación de un proceso estándar en analítica avanzada de datos.
La visualización de datos está en el núcleo del proceso. Es una herramienta básica para el analista o científico de datos que -mediante un proceso iterativo- va transformando y componiendo un modelo lógico de los datos. Apoyándose en la visualización, el analista va descubriendo los secretos enterrados en los datos. La visualización permite de forma rápida:
-
Descartar aquellos datos poco representativos o erróneos.
-
Identificar aquellas variables que dependen unas de otras y por lo tanto contienen información redundante
-
Realizar cortes a los datos para poder observarlos desde diferentes perspectivas.
-
Finalmente, comprobar que aquellos modelos, tendencias, predicciones y agrupaciones que hemos aplicado sobre los datos, nos devuelven el resultado esperado.
Herramientas para el análisis visual de datos
Tan importante es la visualización gráfica de los datos en todos los ámbitos de la ciencia, ingeniería, negocios, banca, medio ambiente, etc. que existen multitud de herramientas para diseñar, desarrollar y comunicar la visualización gráfica de los datos.
Estas herramientas cubren un amplio espectro del público objetivo, desde desarrolladores de software, hasta científicos de datos pasando por periodistas y profesionales de la comunicación.
-
Para desarrolladores de software, existen cientos de librerías y paquetes de software que contienen miles de tipos de visualizaciones. Los desarrolladores tan solo tienen que cargar estas librerías en sus respectivos frameworks de programación y parametrizar el tipo de gráfico que deseen generar. El desarrollador tan solo ha de indicar los datos de origen que desea representar, el tipo de gráfico (líneas, barras, etc.) y la parametrización de dicho gráfico (escalas, colores, etiquetas, etc.). En los últimos años, la visualización web se impone con fuerza, y las librerías más populares se basan en frameworks JavaScript (la mayoría open source). Quizás una de las más populares por su potencia sea D3.JS, aunque existen muchas más.
-
El científico de datos acostumbra a trabajar con un framework de análisis concreto que, normalmente, incluye todos los componentes, entre ellos su motor de análisis visual de los datos. Los entornos más populares, hoy en día, para la ciencia de datos son R y Python, y ambos incluyen librerías nativas para la analítica visual. Quizás la librería más popular y potente en R sea ggplot2, mientras que en Python, matplotlib y Plotly son de las más populares.
-
Para comunicadores profesionales o personal no técnico de las distintas áreas de negocio (Marketing, Recursos Humanos, Producción, etc.) que necesita tomar decisiones basadas en datos, existen herramientas - que no son únicamente herramientas de visual analytics - con funcionalidades para generar representaciones gráficas de los datos. Herramientas modernas de Business Intelligence de autoservicio como MS Excel, MS Power BI, Qlik, Tableau, etc. son estupendas herramientas para comunicar los datos sin necesidad de disponer de competencias en programación o codificación.
En definitiva, las herramientas de visualización permiten a todos estos profesionales acceder a los datos de una manera más ágil y sencilla. En un universo donde la cantidad de datos útiles a analizar no deja de crecer, cada vez son más necesarias este tipo de herramientas, que facilitan la obtención de valor procedente de los datos y, con ello, la toma decisiones relativas al presente y al futuro de nuestro negocio o actividad.
Si quieren conocer más sobre herramientas de visualización de datos, te recomendamos el informe Visualización de datos: definición, tecnología y herramientas, así como el material formativo Uso de herramientas básicas de tratamiento de datos.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Blog
Hasta hace relativamente poco tiempo, hablar de arte y datos en la misma conversación podía parecer algo extraño. Sin embargo, los recientes avances en ciencia de datos e inteligencia artificial parecen abrir la puerta a una nueva disciplina en la que ciencia, arte y tecnología se dan la mano.

La imagen en portada ha sido extraida del blog https://www.r-graph-gallery.com y ha sido creada originalmente por Marcus Volz en su página web.
La imágen de arriba podría ser una pintura abstracta creada por algún autor de arte moderno y expuesto en el MoMA de Nueva York. Sin embargo es una imagen creada con unas cuentas líneas de código R que utilizan algunas expresiones matemáticas complejas. A pesar de la espectacularidad de la figura resultante, la bella forma de los trazos no representa una forma real. Pero la capacidad de crear arte con los datos no se limita a generar formas abstractas. Las posibilidades de crear arte con código van mucho más allá y, a continuación, mostramos dos ejemplos.
Arte real y representación de plantas

Con menos de 100 líneas de código R podemos crear esta planta e infinitas variaciones de ella en cuanto a ramaje, simetría y complejidad. Sin ser un experto en plantas y algas estoy seguro de haber visto en multitud de ocasiones plantas y algas prácticamente igual que estas. Lejos de parecer extraño, con estas representaciones no hacemos sino intentar reproducir lo que la naturaleza crea de forma natural teniendo en cuenta las leyes de la física y las matemáticas. Las figuras que se muestran a continuación han sido creadas utilizando código R originalmente extraído del blog de Antonio Sánchez Chinchón.

Variaciones de plantas creadas artificialmente mediante código R y expresiones fractales
A modo de ejemplo, estos son los datos que forman algunas de las figuras expuestas anteriormente:
Fotografía y arte con datos
Pero no solamente es posible construir figuras abstractas o representaciones que imitan las formas de las plantas. Con la ayuda de las herramientas de datos e inteligencia artificial podemos imitar, e incluso, crear nuevas obras. En el siguiente ejemplo, obtenemos versiones simplificadas de fotografías, utilizando subconjuntos de píxeles de la fotografía original. Veamos este ejemplo con más detalle.
Tomamos una fotografía de un banco de imágenes abiertas, en este caso del sitio web Wikimedia Commons, como la siguiente:

By Finetooth - Own work, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=11692574
A continuación ejecutamos un algoritmo relativamente sencillo que genera formas poligonales alrededor de los principales píxeles de la imágen original. A parte de un tratamiento sencillo de imágenes para convertir esta fotografía en una imagen plana en blanco y negro, este algoritmo aplica un método matemático denominado diagrama de Voronoid. Cuando el subconjunto de datos (sobre el que aplicamos el diagrama de Voronoid) es pequeño, el resultado del tratamiento es pobre y apenas podemos distinguir la forma subyacente de la figura.

Sin embargo, a medida que vamos aumentando el subconjunto de puntos para reproducir la fotografía inicial, comenzamos a encontrar resultados fascinantes. Finalmente, con menos de un 20% de todos los puntos que componen la imagen original, obtenemos un resultado realmente bello y artístico como el de la siguiente figura. Este experimento está basado en el post original de Antonio Sánchez Chinchón en su blog Fronkostin.

La capacidad de generar arte con la potente combinación de matemáticas y códigos de programación es absolutamente potente. En el siguiente enlace es posible apreciar algunas de las obras más impresionantes que existen en esta modalidad de arte. El autor de este blog es Marcus Volz, investigador de la Universidad de Melburne. Marcus trabaja con R para generar las figuras en dos dimensiones y con Houdini para las obras en 3D y de animación.
Contenido elaborado por Alejandro Alija,experto en Transformación Digital e Innovación.
Los contenidos y los puntos de vista reflejados en esta publicación son responsabilidad exclusiva de su autor.
Empresa reutilizadora
En Vizzuality utilizan datos geoespaciales y big data para crear productos digitales diseñados para capacitar a las personas a tomar las decisiones correctas y permitir y alentar cambios positivos.
Trabajan, junto con ONGs, gobiernos, corporaciones y ciudadanos, en desafíos relacionados con la emergencia climática, la pérdida global de biodiversidad, la transparencia de la cadena de suministro y la desigualdad.
Empresa reutilizadora
Empresa de desarrollo de soluciones y aplicaciones relacionadas con la gestión, integración y análisis de datos con componente geoespacial.