Documentación
La RED de Entidades Locales por la Transparencia y Participación Ciudadana de la FEMP acaba de presentar una guía centrada en la visualización de datos. El documento, que toma como referencia la Guía de visualización de datos elaboradora por el Ayuntamiento de L’Hospitalet, ha sido elaborado a partir de la búsqueda de buenas prácticas impulsada por organismos públicos y privados.
La guía incluye recomendaciones y criterios básicos para representar datos gráficamente, facilitando su comprensión. En principio, está dirigida al conjunto de las entidades adheridas a la Red de Entidades locales por la transparencia y la participación ciudadana de la FEMP. No obstante, también es de utilidad para todo aquel que desee adquirir un conocimiento general sobre la visualización de datos.
En concreto, la guía ha sido elaborada con tres objetivos en mente:
- Facilitar principios y buenas prácticas en el ámbito de la visualización de datos.
- Disponer de un modelo de visualización y comunicación de los datos de las entidades locales gracias a la estandarización del uso de diferentes recursos visuales.
- Promover los principios de calidad, sencillez, inclusión y ética en la comunicación de datos.
¿Qué incluye la guía?
Tras una breve introducción, la guía comienza con una serie de conceptos básicos y principios generales a seguir en la visualización de datos, como el principio de simplificación, de aprovechamiento del espacio o de accesibilidad y diseño exclusivo. A través de ejemplos gráficos, el lector aprende lo que se debe y no se debe hacer si queremos que nuestra visualización se entienda fácilmente.
A continuación, la guía se centra en las diferentes etapas del diseño de una visualización de datos a través de un proceso metodológico secuencial, como el que muestra la siguiente imagen:
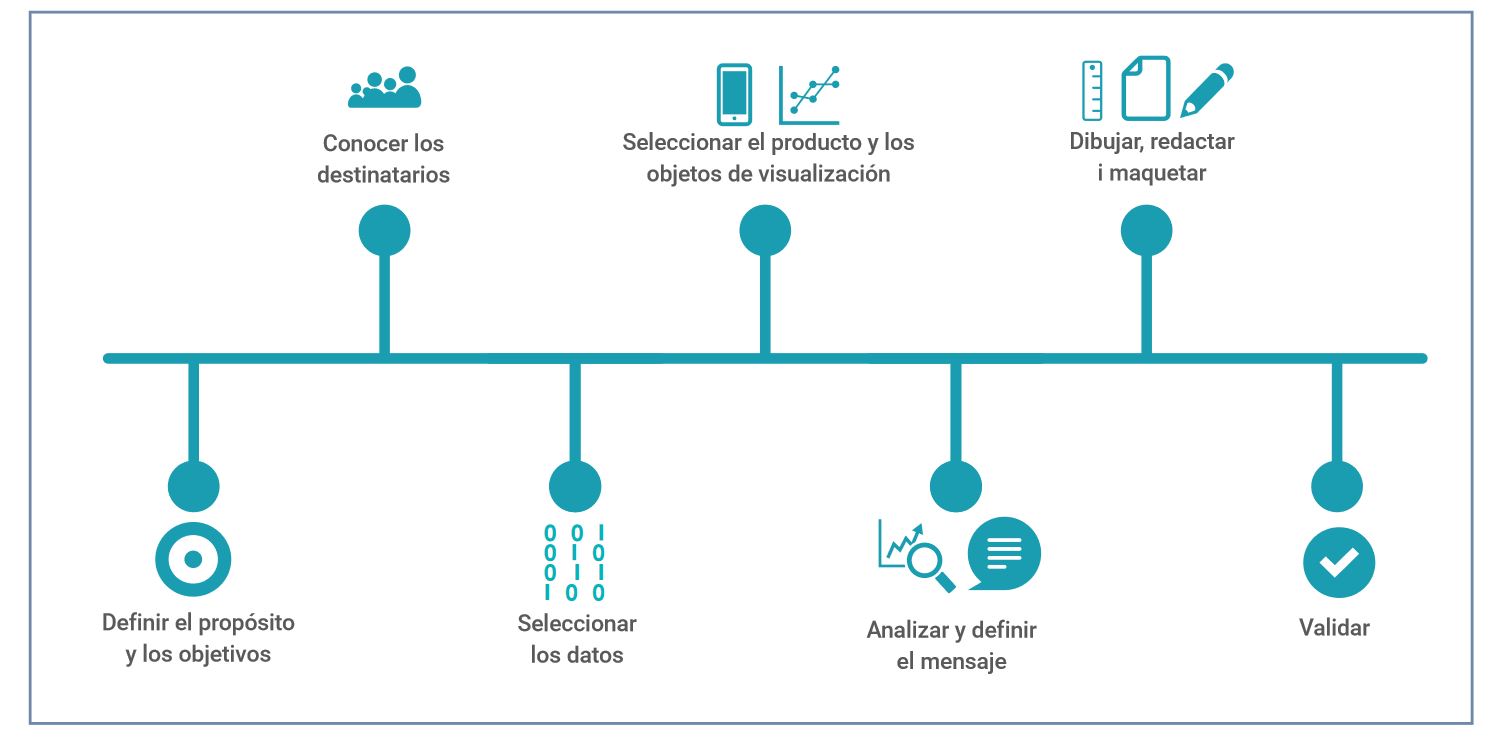
Como muestra la imagen, antes de elabora la visualización es fundamental dedicar tiempo a establecer los objetivos que queremos alcanzar y el público al que nos dirigimos, para poder adaptar el mensaje y seleccionar la visualización más adecuada en base a aquello que queramos representar.
A la hora de representar datos, los usuarios tienen a su disposición una amplia variedad de objetos de visualización con distintas funciones y rendimiento. No todos los objetos son apropiados para todos los casos y habrá que determinar el más adecuado en cada situación concreta. En este sentido, la guía ofrece diversas recomendaciones y pautas para que el lector sea capaz de elegir el elemento adecuado en base a sus objetivos y audiencia, así como a los datos que quiere mostrar.
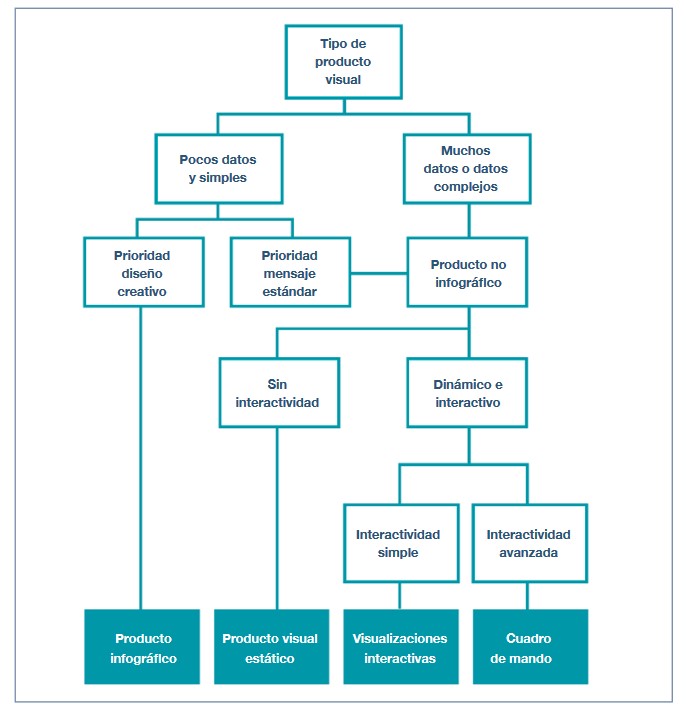
Los siguientes capítulos se centran en los diversos elementos disponibles (infografías, cuadros de mandos, indicadores, tablas, mapas, etc.) mostrando las distintas subcategorías que existen y las buenas prácticas a seguir en su elaboración, mostrando numerosos ejemplos que facilitan su comprensión. También se ofrecen recomendaciones sobre el uso del texto.
La guía finaliza con una selección de recursos, que permiten ampliar el conocimiento, y de herramientas de visualización de datos a considerar por todo aquel que quiera empezar a elaborar sus propias visualizaciones.
Puedes descargar la guía completa a continuación, en el aparatado de “Documentación”.
Aplicación
El Ayuntamiento de Madrid ha creado un portal de visualizaciones llamado "Visualiza Madrid con Datos Abiertos". A través de esta plataforma, en formato web, los usuarios pueden consultar diversas visualizaciones que se han desarrollado con datos abiertos del portal del Ayuntamiento.
Las visualizaciones se encuentran clasificadas por diversas temáticas de la Ciudad de Madrid y sus cuadros de mando interactivos están elaborados con datos disponibles para la ciudadanía en el Portal de Datos Abiertos datos.madrid.es.
Algunas de las principales temáticas sobre las que los usuarios pueden consultar visualizaciones son:
- Accidentes de tráfico
- Avisos del Ayuntamiento
- Aparcamiento en la ciudad
- Bibliotecas
- Covid-19
- Datos meteorológicos
- Energía
- Presupuestos del Ayuntamiento
- Etc.
Blog
Las librerías de programación son conjuntos de archivos de código que se utilizan para desarrollar software. Su objetivo es facilitar la programación, al proporcionar funcionalidades comunes, que ya han sido resueltas previamente por otros programadores. Como curiosidad, el término proviene de una mala traducción de la palabra inglesa library, que en realidad significa biblioteca.
Las librerías (o bibliotecas) son un componente esencial para que los desarrolladores puedan programar de forma sencilla, evitando la duplicidad de código y minimizando errores. También permiten una mayor agilidad, al reducir el tiempo de desarrollo, así como los costes.
Estas ventajas se reflejan a la hora de usar librerías para realizar visualizaciones utilizando lenguajes tan populares como Python, R y JavaScript.
Librerías para Python
Python es uno de lenguajes de programación más utilizados. Se trata de un lenguaje interpretado (fácil de leer y escribir gracias a la semejanza que presenta con el lenguaje humano), multiplataforma, gratuito y de código abierto. En este artículo previo puedes encontrar cursos para aprender más sobre él.
Dada su popularidad, no es de extrañar que encontremos en la red múltiples librerías que nos facilitarán la creación de visualizaciones con este lenguaje, como por ejemplo:
Matplotlib
- Descripción:
Matplotlib es una biblioteca completa para la generación de visualizaciones estáticas, animadas e interactivas a partir de datos contenidos en listas o arrays en el lenguaje de programación Python y su extensión matemática NumPy.
- Materiales de apoyo:
En su web se recogen ejemplos de visualizaciones con el código fuente, para inspirar a nuevos usuarios, y diversas guías dirigidas tanto a usuarios principiantes como a aquellos más avanzados. En la web también hay disponible una sección de recursos externos que redirige a libros, artículos, vídeos y tutoriales elaborados por terceros.
Seaborn
- Descripción:
Seaborn es una biblioteca de visualización de datos en Python basada en matplotlib. Proporciona una interfaz de alto nivel que permite dibujar gráficos estadísticos atractivos e informativos.
- Materiales de apoyo:
En su web hay disponibles tutoriales, con información sobre la API y los distintos tipos de funciones, así como una galería de ejemplos. También es recomendable echar un vistazo a este paper elaborado por The Journal of Open Source Software.
Bokeh
- Descripción:
Bokeh es una librería para la visualización de datos de forma interactiva en un navegador web. Entre sus funciones está desde la creación de gráficos simples hasta la elaboración de cuadros de mando interactivos.
- Materiales de apoyo:
Los usuarios pueden encontrar en su guía descripciones detalladas y ejemplos que describen las tareas más comunes. La guía incluye la definición de conceptos básicos, el trabajo con datos geográficos o cómo generar interacciones, entre otros.
La web también cuenta con una galería con ejemplos, tutoriales y un apartado de comunidad, donde plantear y resolver dudas.
Geoplotlib
- Descripción:
Geoplotlib es una librería de código abierto en python para la visualización de datos geográficos. Se trata de una sencilla API que produce visualizaciones sobre mosaicos de OpenStreetMap. Permite la creación de mapas de puntos, estimadores de densidad de datos, gráficos espaciales y archivos ”shapes”, entre muchas otras visualizaciones espaciales.
- Materiales de apoyo:
En Github tienes disponible esta guía de usuarios, donde se explica cómo cargar datos, crear mapas de colores o añadir interactividad a las capas, entre otros. También hay disponibles ejemplos de código.
Librerías para R
R también es un lenguaje interpretado para la computación estadística y la creación de representaciones gráficas (puedes aprender más sobre ello siguiendo alguno de estos cursos). Cuenta con su propio entorno de programación, R-Studio, y con un conjunto de herramientas muy flexibles y versátiles que se pueden ampliar fácilmente mediante la instalación de librerías o paquetes –usando su propia terminología-, como las que se detallan a continuación:
ggplot 2
- Descripción:
Ggplot es una de las librerías más populares y utilizadas en R para la creación de visualizaciones interactivas de datos. Su funcionamiento se basa en el paradigma descrito en The Grammar of Graphics para la creación de visualizaciones con 3 capas de elementos: datos (data frame), la lista de relaciones entre las variables (aesthetics) y los elementos geométricos que se van a representar (geoms).
- Materiales de apoyo:
En su web puedes encontrar diversos materiales, como esta cheatsheet que recoge de manera resumida las principales funcionalidades de ggplot2. Por su parte, esta guía comienza explicando las características generales del sistema utilizando como ejemplo los diagramas de dispersión para detallar, a continuación, cómo representar algunos de los gráficos más conocidos. También se incluyen diversas FAQ que pueden ser de ayuda.
Lattice
- Descripción:
Lattice es un sistema de visualización de datos inspirado en los gráficos Trellis o de trama, prestando especial atención a los datos multivariantes. La interfaz de usuario de Lattice consiste en varias funciones genéricas de "alto nivel", cada una de ellas diseñada para crear un tipo particular de gráfico por defecto.
- Materiales de apoyo:
En este manual puedes encontrar información sobre las diversas funcionalidades, aunque si quieres profundizar en ellas, en esta sección de la web puedes encontrar diversos manuales como R Graphics de Paul Murrell o Lattice de Deepayan Sarkar.
Esquisse
- Descripción:
Esquise permite explorar interactivamente los datos y crear visualizaciones detalladas con el paquete ggplot2 a través de una interfaz de arrastrar y soltar. Incluye multitud de elementos: gráficos de dispersión, de líneas, de cajas, con ejes múltiples, sparklines, dendogramas, gráficos 3D, etc.
- Materiales de apoyo:
La documentación está disponible a través de este enlace, incluyendo información sobre la instalación y las diversas funciones. También tienes información en la web de R.
Leaflet
- Descripción:
Leaflet permite la creación de mapas altamente detallados, interactivos y personalizados. Está basado en la biblioteca de JavaScript del mismo nombre.
- Materiales de apoyo:
En esta web tienes documentación sobre las diversas funcionalidades: el funcionamiento del widget, marcadores, cómo trabajar con GeoJSON & TopoJSON, cómo integrarse con Shiny, etc.
Librerías para JavaScript
JavaScript también es un lenguaje de programación interpretado, responsable de dotar de mayor interactividad y dinamismo a las páginas web. Es un lenguaje orientado a objetos, basado en prototipos y dinámico.
Algunas de las principales librerías para JavaScript son:
D3.js
- Descripción:
D3.js está dirigida a la creación de visualizaciones de datos y animaciones utilizando estándares web, como SVG, Canvas y HTML. Es una librería muy potente y de cierta complejidad.
- Materiales de apoyo:
En Github puedes encontrar una galería con ejemplos de los diversos gráficos y visualizaciones que se pueden obtener con esta librería, así como diversos tutoriales e información sobre técnicas específicas.
Chart.js
- Descripción:
Chart.js es una librería de JavaScript que utiliza canvas de HTML5 para la creación de gráficos interactivos. En concreto, admite 9 tipos de gráficos: barra, línea, área, circular, burbuja, radar, polar, dispersión y mixtos.
- Materiales de apoyo:
En su propia web tienes información sobre la instalación y configuración, y ejemplos de los distintos tipos de gráficos. También hay un apartado para desarrolladores con diversa documentación.
Otras librerias
Plotly
- Descripción:
Plotly es una biblioteca de gráficos de alto nivel, que permite la creación de más de 40 tipos de gráficos, incluidos gráficos 3D, estadísticos y mapas SVG. Es una librería Open Source, pero tiene versiones de pago.
Plotly no está ligada a un único lenguaje de programación, si no que permite la integración con R, Python y JavaScript.
- Materiales de apoyo:
Cuenta con una completa página web donde los usuarios pueden encontrar guías, casos de uso por ámbitos de aplicación, ejemplos prácticos, webinars y una sección de comunidad donde compartir conocimiento.
Cualquier usuario que lo desee puede contribuir con cualquiera de estas librerías, escribiendo código, generando nueva documentación o reportando errores, entre otros. De esta forma se enriquecen y perfeccionan, mejorando sus resultados de manera continua.
¿Conoces alguna otra librería que quieras recomendar? Déjanos un mensaje en comentarios o envíanos un correo electrónico a dinamizacion@datos.gob.es.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
Las capacidades relacionadas con los datos son cada vez más transversales. La analítica de datos se ha vuelto fundamental para la toma de decisiones en organizaciones de todos los tamaños y sectores. Pero para transmitir bien el resultado de los análisis a los diversos interlocutores, es necesario trabajar con gráficas, visualizaciones y narrativas que permitan apreciar de manera sencilla las conclusiones. Fruto de ello, ha crecido la demanda de perfiles capaces de trabajar con las principales herramientas de visualización de datos.
Para desarrollarse en este campo es necesario tener una base de estadística y analítica, pero también conocer las tendencias de diseño y comunicación visual. En el mercado podemos encontrar multitud de cursos que nos ayudan a formarnos en estas habilidades de manera flexible y online. A continuación, recogemos algunos ejemplos.
Cursos generales de visualización de datos
Son muchas las escuelas que ofrecen cursos para aquellos que no quieran especializarse en una herramienta concreta, sino que prefieran adquirir una visión general sobre la visualización de datos.
Big Data: Visualización de datos
- Impartido por: Universidad Autónoma de Barcelona (a través de Coursera)
- Duración: 9 horas, a lo largo de 4 semanas.
- Idioma: Español
- Precio: Gratuito
Se trata de un curso introductorio que explica los conceptos clave de la visualización de datos masivos, mostrando ejemplos en distintos contextos. Con el curso se busca que el estudiante aprenda a formular el problema y elegir las herramientas más adecuadas. Se distribuye en 4 módulos (uno por semana): contexto para la visualización de datos hoy, herramientas de análisis y visualización de datos, el proceso de creación de una visualización de datos y otros aspectos de la visualización de datos.
Fundamentos de visualización de datos
- Impartido por: Marco Russo (a través de Udemy)
- Duración: 2 horas
- Idioma: Español
- Precio: Gratuito
Esta formación está diseñada para enseñar a sus alumnos a crear visualizaciones de datos modernas y completas. Este curso comienza con unas nociones básicas sobre la aplicación de la visualización de datos y para qué sirve esta técnica. Tras una breve introducción, los alumnos podrán aprender a interactuar con los diferentes gráficos, a diferenciar entre Business Analytics y Data Analytics o a entender la correcta visualización de datos a través de ejemplos prácticos.
Periodismo de datos y visualización con herramientas gratuitas
- Impartido por: Centro Knight para el Periodismo en las Américas
- Duración: 30 horas (6 semanas)
- Idioma: Español
- Precio: Gratuito
Este curso está disponible de manera gratuita para todos aquellos que estén interesados en el periodismo de datos, la visualización y las herramientas que ofrece el mercado de manera gratuita. Gracias a esta formación, los alumnos pueden aprender a buscar y conseguir datos, a encontrar historias dentro de ellos, así como a prepararlos y a realizar visualizaciones.
Cursos específicos sobre diferentes herramientas de visualización
Aquellos que, por el contrario, prefieran formarse de manera más específica en alguna de las herramientas más populares de visualización de datos, también dispones de multitud de opciones en la red.
Fundamentos de la visualización de datos con Tableau
- Impartido por: Universidad Austral (a través de Coursera)
- Duración: 8 horas
- Idioma: Español
- Precio: Gratuito
Tableau combina una interfaz gráfica con elementos habituales de las herramientas de Bussiness Integillence. Este curso está dirigido a usuarios que no han trabajado nunca con esta herramienta o quieren profundizar en ella, sin ser necesarios conocimientos técnicos o analíticos previos. En él se explican conceptos fundamentales de visualización de datos y se aprende a utilizar las diversas herramientas que ofrece Tableau.
¡Crea y comparte reportes con Tableau Public!
- Impartido por: Adrián Javier Tagüico (a través de Udemy)
- Duración: 1,5 horas
- Idioma: Español
- Precio: De pago
Este curso muestra cómo crear reportes dinámicos e intuitivos, dashboards y stories paso a paso utilizando Tableau Public. En él se aprende cómo importar fuentes de datos (utilizando para ello datos públicos de ejemplo), cómo preparar los datos, en qué consiste su modelado y cómo crear visualizaciones, utilizando filtros (segmentación de datos, interacción de visualizaciones u diversas opciones en cada visualización). Son necesarios conocimientos previos básicos sobre los tipos de datos.
Google Data Studio – Visualización de Datos y Cuadros de Mando
- Impartido por: Start-Tech Academy (a través de Udemy)
- Duración: 4 horas de video. El curso puede ser completado en 6 horas.
- Idioma: Español
- Precio: De pago
Data Studio es una herramienta gratuita de Google para elaborar informes muy visuales con datos analíticos, permitiendo su automatización. El objetivo de este curso es que el estudiante aprenda a elaborar todo tipo de gráficos en Google Data Studio, así como profundizar en las características específicas avanzadas de la herramienta. Se trata de un curso para principiantes en el que no es necesario ningún conocimiento previo.
Data Visualization with Kibana
- Impartido por: Start-Tech Academy (a través de Udemy)
- Duración: 5,5 horas
- Idioma: Inglés
- Precio: De pago
Curso para aprender los fundamentos de Kibana, un software de código abierto que forma parte del paquete de productos Elastic Stack. Los estudiantes aprenden desde cuestiones básicas de seguridad (usuarios, roles y espacios), hasta cómo crear visualizaciones avanzadas o dashboards, utilizando el lenguaje de consulta de Kibana (KQL).
Grafana
- Impartido por: Sean Bradley (a través de Udemy)
- Duración: 6 horas
- Idioma: Inglés
- Precio: De pago
Grafana empezó siendo un componente de Kibana, pero en la actualidad se trata de herramientas completamente independientes. En este curso se aprende a explorar los paneles de gráficos, estadísticas, indicadores, barras, tablas, textos, mapas de calor y registros. Incluye desde la instalación de distintas fuentes de datos (MySQL, Zabbix, InfluxDB, etc.) y la creación de tableros dinámicos con colocación automática de visualización, hasta la instalación de un servidor SMTP y o la configuración de un canal de notificaciones por correo electrónico o Telegram.
Cursos de librerías de visualización de datos
Además de las herramientas genéricas previas, en el mercado también encontramos librerías específicas de visualización. Estas librerías son más versátiles, pero necesitan que el usuario conozca el lenguaje de programación donde se implemente la librería. Algunos ejemplos de cursos en este campo son:
Curso de visualización de datos con Python
- Impartido por: Abraham Requena (a través de Open webinars)
- Duración: 3 horas
- Idioma: Español
- Precio: Gratuito
Este curso se enfoca en dos librerías de Python: Matplotlib y Seaborn. El curso comienza con una introducción donde se habla de la importancia de la visualización y los tipos de gráficos. A continuación se aborda el trabajo con cada una de las librerías, incluyendo ejercicios.
Visualización de datos con Python
- Impartido por: Universidad Complutense de Madrid
- Duración: 40 horas (8 semanas)
- Idioma: Español
- Precio: De Pago
Se trata de un curso centrado en la elaboración de visualización utilizando Python. Tras una introducción en la que se abordan los aspectos clave a considerar para crear visualizaciones de datos efectivas, el curso se centra en el desarrollo de visualizaciones de datos en Python utilizando Matplotlib y Plotly. En el curso se utiliza en entorno Jupyter Notebook. Es necesario tener conocimientos mínimos de Python y de análisis de datos con Pandas.
Big Data: visualización de datos. Introducción a R y ggplot2
- Impartido por: Universitat Autónoma de Barcelona (a través de Coursera)
- Duración: 9 horas
- Idioma: Español
- Precio: Gratuito
Se trata del cuarto curso del programa especializado “Big Data – Introducción al uso práctico de datos masivos”. Este programa ha sido diseñado para motivar y enseñar a sus alumnos conceptos clave acerca de la visualización de datos, así como a proporcionarles criterios para formular los problemas y elegir adecuadamente la herramienta para cada visualización. Este curso se divide en cuatro módulos principales que comprenden materias como contextos, herramientas o procesos de creación para las visualizaciones de datos.
Los cursos anteriores son solo un ejemplo de la oferta disponible en el mercado. Si conoces algún otro que quieras recomendarnos, envíanos un email a dinamizacion@datos.gob.es o deja un comentario.
Lo que no se puede negar es que con este tipo de cursos reforzarás tu perfil laboral y ampliarás tus ventajas competitivas en el mercado laboral.
Blog
Nadie puede negar hoy en día el valor que esconden los datos: tendencias, áreas de mejora u oportunidades de negocio son solo algunos de los conocimientos que puede haber tras una serie de cifras. Un correcto análisis de los datos internos y externos de una organización, puede suponer una gran ventaja competitiva e impulsar una toma de decisiones más acertada.
Sin embargo, extraer ese valor no siempre es fácil. Los datos pueden ser difíciles de comprender y los análisis realizados a partir de ellos necesitan ser comunicados de una forma efectiva. En este sentido, el mecanismo habitual para mostrar datos son las visualizaciones. Pero en un mundo tan saturado de datos y conocimiento, las visualizaciones por sí solas pueden no alcanzar el resultado esperado. A menudo es necesario sumar también una buena explicación en forma de historia para impactar en el receptor.
La importancia de la narrativa
A todos nos gustan que nos cuenten historias que llamen nuestra atención. Recordamos mejor las cosas si están integradas en una narrativa. Prueba de ello es este estudio recogido en el libro Made to Stick): tras una serie de intervenciones de un minuto en las que se proporcionaban una media de 2,5 estadísticas, sólo el 5% de los oyentes era capaz de recordar una cifra individual. Sin embargo, el 63% se acordaba de la historia narrada.
Las historias consiguen involucrarnos, dotando a los datos de un contexto relacionado con nuestros intereses y preocupaciones. De esta forma los datos adquieren un mayor significado, y es más fácil que lleguen a impulsar la puesta en marcha de acciones relacionadas.
Es en este contexto donde nace el data storytelling.
¿Qué es el data storytelling?
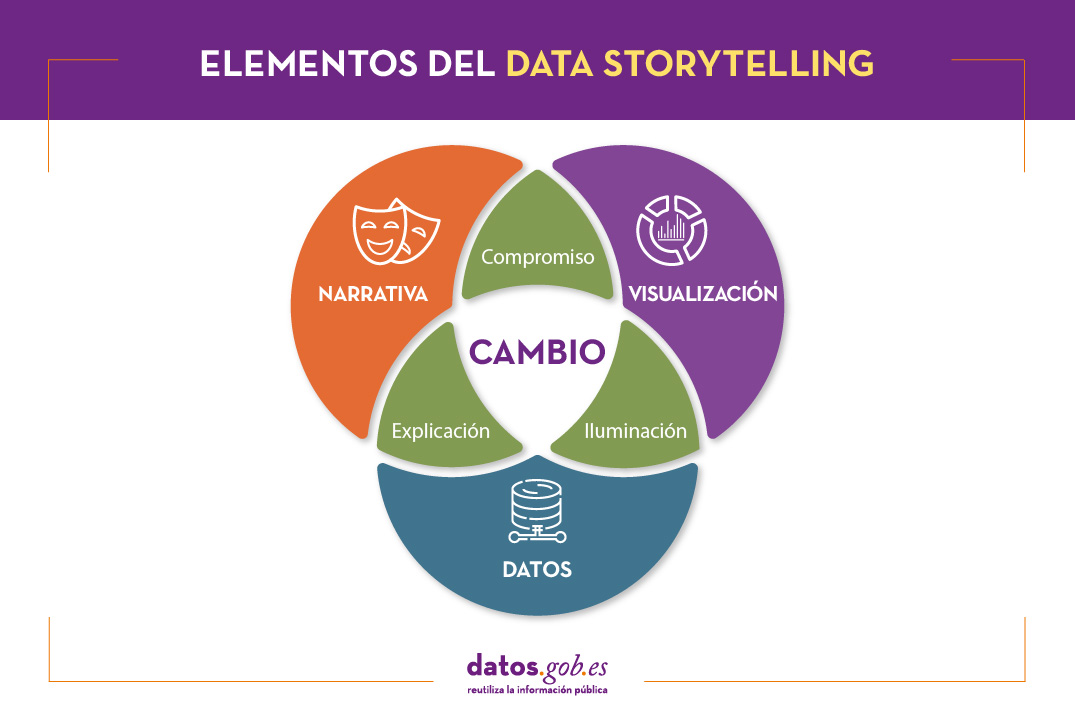
El data storytelling consiste en comunicar la información resultante del análisis de datos a través de una historia. Para ello involucra tres ingredientes: datos, visualización y narrativa. Estos tres elementos se combinan para dar como resultado una comunicación efectiva:
-
Al combinar la narrativa y los datos nos movemos en el terreno de la explicación: gracias al contexto la audiencia comprende qué ocurre (o va a ocurrir) y por qué es importante.
-
Al combinar los elementos visuales con los datos, sucede lo que podemos llamar “iluminación” (enlighten, en inglés): los conocimientos se muestran de una forma llamativa y fácil de comprender, permitiendo observar relaciones y patrones.
-
Al combinar la narrativa y los elementos visuales, se conecta con la audiencia generando un compromiso (engagement, en inglés): gracias a fórmulas ligadas al sector del entretenimiento se consigue la atención de la audiencia.
Cuando se combina todo ello, se logra una historia basada en datos que puede influir e impulsar el cambio.
El data storytelling es la base del periodismo de datos, pero también se utiliza cada vez más dentro de las organizaciones públicas y privadas para transmitir las ideas que hay detrás de los datos tanto de manera interna como externa.
¿Qué es necesario tener en cuenta para poder contar una historia con datos?
Para transformar los datos en información de valor y contar una historia es necesario tener conocimientos de las tres áreas anteriores.
El primer paso es pensar cuál es nuestro objetivo. En base a ello determinaremos el mensaje que queremos lanzar, que debe ser claro y sencillo. Para poder comunicarlo efectivamente, es necesario conocer a la audiencia y saber cuál es su grado de conocimiento sobre la materia. De ello dependerá el enfoque, el tono, el medio y los datos que utilicemos.
También hay que conocer los fundamentos del análisis y la visualización de los datos. Existen multitud de herramientas a nuestro alcance que podemos utilizar. Es importante elegir bien el tipo de gráfico a utilizar, según lo que queremos mostrar (comparativas, tendencias, distribuciones, etc.), así como prestar una gran atención al uso del color y de las jerarquías en la información.
Para dar respuesta a estas necesidades, a veces es necesario contar con equipos multidisciplinares donde se mezclan distintos tipos de habilidades. No obstante, también están surgiendo herramientas sencillas pensadas para que las pueda utilizar cualquier persona, como veremos a continuación.
La integración del data storytelling en los portales de datos abiertos: el ejemplo de Aragon Open Data
El data storytelling también está llegando a los portales de datos abiertos como una forma de acercar los datos a la ciudadanía e impulsar su reutilización, amplificando su impacto.
El portal de datos abiertos de Aragón ha desarrollado Open Data Focus, un servicio gratuito que permite a los usuarios del portal desarrollar y compartir sus propias historias a partir de los datos abiertos de la región. Se trata de una herramienta muy intuitiva, para la que no es necesario tener conocimientos técnicos. En el portal se pueden ver algunas de las narrativas digitales elaboradas en torno a distintas temáticas de interés. En este documento puedes profundizar más sobre el contexto, objetivos, metodología y resultados del proyecto.
Aragón Open Data Focus es una experiencia innovadora y pionera en nuestro país, que acerca a la ciudanía la información del sector público. Dada la importancia de la narrativa y la visualización en la comprensión de los datos, no es de extrañar que próximamente conozcamos más historias de éxito en este sentido.
Contenido elaborado por el equipo de datos.gob.es.
Noticia
R es uno de los lenguajes de programación más populares en el mundo de la ciencia de datos.
Es un lenguaje interpretado que además dispone de un entorno de programación, R-Studio y un conjunto de herramientas muy flexibles y versátiles para la computación estadística y creación de representaciones gráficas.
Una de sus ventajas es que las funciones pueden ampliarse fácilmente, mediante la instalación de librerías -denominados paquetes en el entorno de R- o la definición de funciones personalizadas. Además, está permanentemente actualizado, ya que su amplia comunidad de usuarios desarrolla constantemente nuevos paquetes, funciones y actualizaciones disponibles gratuitamente.
Por este motivo, R es uno de los lenguajes más demandados y existe un gran número de recursos para aprender más sobre ello. A continuación, te mostramos una selección basada en las recomendaciones de los expertos que colaboran con datos.gob.es y las comunidades de usuarios R-Hispano y R-Ladies, que reúnen a gran cantidad de usuarios de este lenguaje en nuestro país.
Cursos online
En la red podemos encontrar numerosos cursos online que introducen R a aquellos usuarios noveles.
Curso de R básico
- Impartido por: Universidad de Cádiz
- Duración: No disponible.
- Idioma: Español
- Gratuito.
Enfocado a estudiantes que están realizando un trabajo fin de grado o master, el curso busca proporcionar los elementos básicos para empezar a trabajar con el lenguaje de programación R en el ámbito de la estadística. Incluye conocimientos sobre estructura de datos (vectores, matrices, data frames…), gráficos, funciones y elementos de programación, entre otros.
Introducción a R
- Impartido por: Datacamp
- Duración: 4 horas.
- Idioma: Inglés.
- Gratuito
El curso comienza con conceptos básicos, empezando por cómo utilizar la consola como una calculadora y cómo asignar variables. A continuación, se aborda la creación de vectores en R, cómo trabajar con matrices, cómo comparar factores y el uso de data frames o listas.
Introducción a R
- Impartido por: Red de Universidades Anáhuac
- Duración: 4 semanas (5-8 horas por semana).
- Idioma: Español.
- Modalidad gratuita y de pago.
A través de un enfoque práctico, con este curso aprenderás a crear un ambiente de trabajo para R con R Studio, clasificar y manipular datos, así como realizar gráficas. También aporta nociones básicas de programación en R, abarcando condicionales, ciclos y funciones.
R Programming Fundamentals
- Impartido por: Stanford School of Engineering
- Duración: 6 semanas (2-3 horas por semana).
- Idioma: Inglés
- Gratuito, aunque el certificado tiene un coste de 79$.
Este curso cubre una introducción a R, desde la instalación hasta las funciones estadísticas básicas. Los estudiantes aprenden a trabajar con conjuntos de datos dinámicos y externos, así como a escribir funciones. En el curso podrás escuchar a uno de los co-creadores del lenguaje R, Robert Gentleman.
Programación R
- Impartido por: Johns Hopkins University
- Duración: 57 horas
- Idioma: Inglés, con subtítulos en español.
- De pago.
Este curso forma parte de los programas de Ciencia de Datos y Ciencia de los datos: bases utilizando R. Se puede cursar por separado o como parte de dichos programas. Con él aprenderás a comprender los conceptos fundamentales del lenguaje de programación, a utilizar las funciones de loop de R y las herramientas de depuración o a recoger información detallada con R profiler, entre otras cuestiones.
Data Visualization & Dashboarding with R
- Impartido por: Johns Hopkins University
- Duración: 4 meses (5 horas por semana)
- Idioma: Inglés.
- De pago.
La Universidad John Hopkins también ofrece este curso donde los alumnos generarán diferentes tipos de visualizaciones para explorar los datos, desde figuras sencillas como gráficos de barras y de dispersión hasta cuadros de mando interactivos. Los estudiantes integrarán estas figuras en productos de investigación reproducibles y los compartirán online.
Introducción al software estadístico R
- Impartido por: Asociación Española para la Calidad (AEC)
- Duración: Del 5 de octubre al 3 de diciembre de 2021 (50 horas)
- Idioma: Español
- De pago.
Se trata de una formación inicial práctica en el uso del software R para el tratamiento de datos y su análisis estadístico a través de las técnicas más sencillas y habituales: análisis exploratorio y relación entre variables. Entre otras cuestiones, los estudiantes adquirirán la capacidad de extraer información valiosa de los datos a través del análisis exploratorio, la regresión y el análisis de la varianza.
Introducción a la programación en R
- Impartido por: Abraham Requena
- Duración: 6 horas
- Idioma: Español
- De pago (por suscripción)
Diseñado para iniciarse en el mundo de R y aprender a programar con este lenguaje. Podrás aprender los diferentes tipos de datos y objetos que hay en R, a trabajar con ficheros y a utilizar condicionales, así como a crear funciones y gestionar errores y excepciones.
Programación y análisis de datos con R
- Impartido por: Universidad de Salamanca
- Duración: Del 25 de octubre de 2021 - 22 de abril de 2022 (80 horas lectivas)
- Idioma: Español
- De pago
Empieza desde un nivel básico, con información sobre los primeros comandos y la instalación de paquetes, para continuar con las estructuras de datos (variables, vectores, factores, etc.), funciones, estructuras de control, funciones gráficas y representaciones interactivas, ente otros temas. Incluye un trabajo de fin de curso.
- Impartido por: Harvard University
- Duración: 4 semanas (2-4 horas por semana).
- Idioma: Inglés
- De pago
Una introducción a los conceptos estadísticos básicos y a los conocimientos de programación en R necesarios para el análisis de datos en biociencia. A través de ejemplos de programación en R se establece la conexión entre los conceptos y la aplicación.
Para aquellos que quieran aprender más sobre álgebra matricial, la Universidad de Harvard también ofrece de forma online el curso Introduction to Linear Models and Matrix Algebra, donde se utiliza el lenguaje de programación R para llevar a cabo los análisis.
Curso de R gratuito
- Impartido por: Afi Escuela
- Duración: 7,5 horas
- Idioma: Español
- Gratuito
Este curso fue impartido por Rocío Parrilla, responsable de Data Science en Atresmedia, en formato presencial virtual. La sesión se grabó y está disponible a través de Youtube. Se estructura en tres clases donde se explican los elementos básicos de la programación en R, se hace una introducción al análisis de datos y se aborda la visualización con este lenguaje (visualización estática, visualización dinámica, mapas con R y materiales).
Programación R para principiantes
- Impartido por: Keepcoding
- Duración: 12 horas de contenido en video
- Idioma: Español
- Gratuito
Consta de 4 capítulos, cada uno de ellos integrado por varios vídeos de corta duración. El primero “Introducción”, aborda la instalación. El segundo, llamado “primeros pasos en R” explica ejecuciones básicas, así como vectores, matrices o data frames, entre otros. El tercero aborda el “Flujo Programa R” y el último los gráficos.
Curso online autónomo Introducción a R
- Impartido por: Universidad de Murcia
- Duración: 4 semanas (4-7 horas por semana)
- Idioma: Español
- Gratuito
Se trata de un curso práctico dirigido a jóvenes investigadores que necesitan realizar el análisis de los datos de su trabajo y buscan una metodología de que optimice su esfuerzo.
El curso forma parte de un conjunto de cursos relacionados con R que ofrece la Universidad de Murcia, sobre Métodos de análisis de datos multivariantes, Elaboración de documentos e informes técnico–científicos o Métodos de contraste de hipótesis y diseño de experimentos, entre otros.
Libros online relacionados con R
Si en vez de un curso, prefiere un manual o documentación que te pueda ayudar a mejorar tus conocimientos de una manera más amplia, también existen opciones, como las que te detallamos a continuación.
R para profesionales de Datos. Una Introducción
- Autor: Carlos Gil Bellosta
- Gratuito
El libro cubre 3 aspectos básicos muy demandados por los profesionales de los datos: la creación de visualizaciones de datos de alta calidad, la creación de dashboards para visualizar y analizar datos, y la creación de informes automáticos. Su objetivo es que el lector puede comenzar a aplicar métodos estadísticos (y de la llamada ciencia de datos) por su cuenta.
Aprendiendo R sin morir en el intento
- Autor: Javier Álvarez Liébana
- Gratuito
El objetivo de este tutorial es introducir en la programación y análisis estadístico en R a personas sin necesidad de conocimientos previos de programación. Su objetivo es entender los conceptos básicos de R y dotar al usuario de trucos sencillos y de autonomía básica para poder trabajar con datos.
Aprendizaje Estadístico
- Autor: Rubén F. Casal
- Gratuito
Se trata de un documento con los apuntes de la asignatura de Aprendizaje Estadístico del Máster en Técnicas Estadísticas. Ha sido escrito en R-Markdown empleando el paquete bookdown y está disponible en Github. El libro no trata directamente de R, si no que aborda desde una introducción al aprendizaje estadístico, hasta las redes neuronales, pasando por los arboles de decisión o los modelos lineales, entre otros.
Simulación Estadística
- Autor: Rubén F. Casal y Ricardo Cao
- Gratuito
Al igual que en el caso anterior, este libro es el manual de una asignatura, en este caso de Simulación Estadística del Máster en Técnicas Estadísticas. También ha sido escrito en R-Markdown empleando el paquete bookdown y está disponible en el repositorio Github. Tras una introducción a la simulación, el libro aborda la generación de números pseudoaleatorios en R, el análisis de resultados de simulación o la simulación de variables continuas y discretas, entre otros.
Estadística con R
- Autor: Joaquín Amat Rodrigo
- Gratuito
No es un libro directamente, sino una web donde podrás encontrar diversos recursos y trabajos que te pueden servir de ejemplo a la hora de practicar con R. Su autor es Joaquín Amat Rodrigo también responsable de Machine Learning con R.
la página oficial de R-Studio también disponen de recursos para aprender diferentes paquetes o funciones de R, utilizando diversas cheatsheet.
Masters
Además de cursos, cada vez es más habitual encontrar en universidades masters relacionados con esta materia, como por ejemplo:
Master en Estadística Aplicada con R / Máster en Machine Learning con R
- Impartido por: Máxima Formación
- Duración: 10 meses
- Idioma: Español
La Escuela Máxima Formación ofrece dos masters que comienzan en octubre de 2021 relacionados con R. El Máster en Estadística Aplicada para la Ciencia de Datos con R Software (13ª edición) está dirigido a profesionales que quieran desarrollar desarrolla competencias prácticas avanzadas para solucionar los problemas reales relacionados con el análisis, la manipulación y la representación gráfica de los datos. El Máster en Machine Learning con R Software (2ª edición) está enfocado en el trabajo con datos en tiempo real para crear modelos de análisis y algoritmos con aprendizaje supervisado, no supervisado y aprendizaje profundo.
Además, cada vez más centros de estudio ofrecen masters o programas relacionados con la ciencia de datos que recogen en su temario conocimientos sobre R, tanto generalistas como enfocados en sectores concretos. Algunos ejemplos son:
- Máster en Data Science, de la Universidad Rey Juan Carlos, que integra aspectos de ingeniería de datos (Spark, Hadoop, arquitecturas cloud, obtención y almacenamiento de datos) y analítica de datos (modelos estadísticos, minería de datos, simulación, análisis de grafos o visualización y comunicación).
- Master en Big Data, de la Universidad Nacional de Educación a Distancia (UNED), incluye un módulo de Introducción al Machine Learning con R y otro de paquetes avanzados con R.
- Máster en Big Data y Data Science Aplicado a la Economía, de la Universidad Nacional de Educación a Distancia (UNED), introduce conceptos de R como uno de los programas de software más utilizados.
- Máster Big Data - Business – Analytics, de la Universidad Complutense de Madrid, incluye un tema de Minería de datos y modelización predictiva con R.
- Master en Big Data y Data Science aplicado a la Economía y Comercio, también de la Universidad Complutense de Madrid, donde se estudia programación en R, por ejemplo, para el diseño de mapas, entre otros.
- Máster en Humanidades Digitales para un Mundo Sostenible, de la Universidad Autónoma de Madrid, donde los alumnos serán capaces de programar en Python y R para conseguir datos estadísticos a partir de textos (PLN).
- Máster en Data Science & Business Analytics, de la Universidad de Castilla-La Mancha, cuyo ojetivo es aprender y/o profundizar en la Ciencia de Datos, la Inteligencia Artificial y el Business Analytics, utilizando el software estadístico R.
- Experto en Modeling & Data Mining, de la Universidad de Castilla-La Mancha, donde al igual que en el caso anterior también se trabaja con R para transformar datos no estructurados en conocimiento.
- Máster de Big Data Finanzas, donde se habla de Programación para data science / big data o visualización de información con R.
- Programa en Big Data y Business Intelligence, de la universidad de Deusto, que capacita para realizar ciclos completos de análisis de datos (extracción, gestión, procesamiento (ETL) y visualización).
Esperamos que alguno de estos cursos responda a tus necesidades y puedas convertirte en un experto en R. Si conoces algún otro curso que quieras recomendar, déjanos un comentario o escríbenos a dinamizacion@datos.gob.es.
Blog
Los mapas ayudan a comprender el mundo en el que vivimos y por ello han sido fundamentales en el desarrollo de la humanidad. Nos permiten conocer las características de un lugar y comprender fenómenos sociales, como el comportamiento espacial de una enfermedad o la trazabilidad de flujos comerciales.
Si mostramos datos a través de un mapa, facilitamos su comprensión e interpretabilidad. Pero para poder construir este tipo de visualizaciones geoespaciales, necesitamos datos georreferenciados.
¿Qué es la georreferenciación?
La georreferenciación es un método que consiste en determinar la posición de un elemento en base a un sistema de coordenadas espacial.
Muchos de los datos abiertos que ofrecen las administraciones públicas están georreferenciados o se pueden georreferenciar, aumentando así su valor. A través de servicios online georreferenciados de visualización o descarga de datos como Infraestructuras de Datos Espaciales (IDE) o geoportales, los usuarios pueden acceder a una gran cantidad de datos de este tipo. Pero manejar este tipo de información no es sencillo.
El usuario de datos georreferenciados necesita entender conceptos clave vinculados con la visualización de información geográfica como son los sistemas de referencia de coordenadas, las proyecciones cartográficas o los diferentes modelos de representación de datos con los que se trabaja: raster - imágenes de mapa de píxeles- o vectoriales - puntos, líneas, etc. en representación de los distintos objetos-. Estos elementos se pueden combinar entre sí sobre Sistemas de Información Geográfica (SIG).
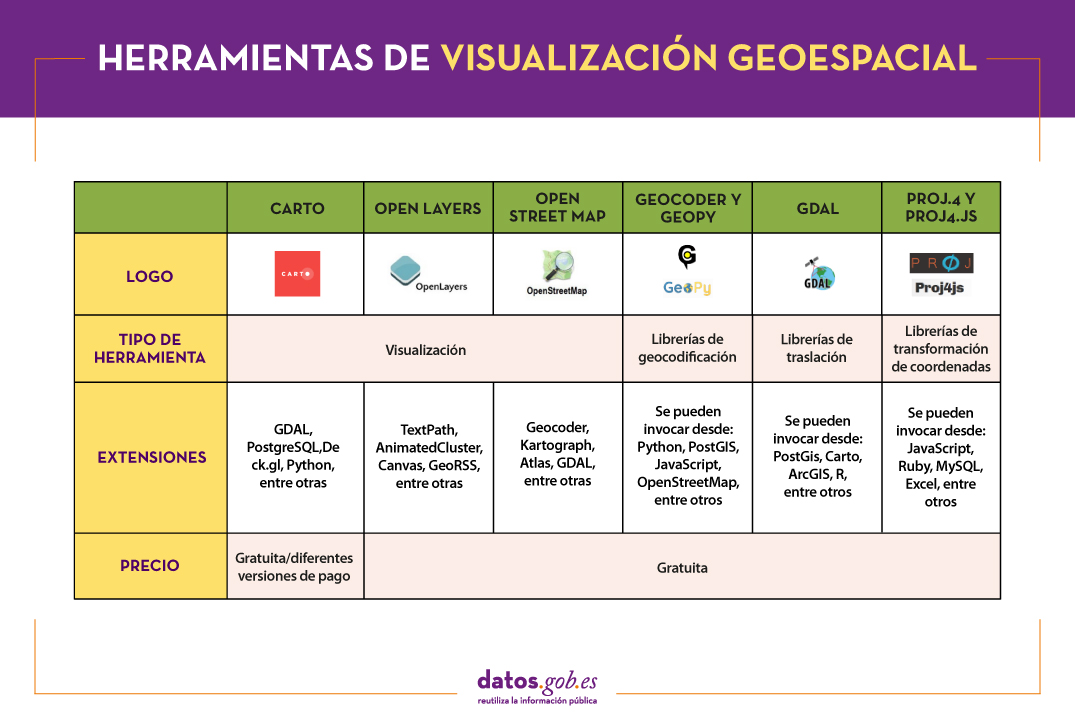
En este artículo se recogen un conjunto de herramientas útiles para abordar las tareas necesarias para desarrollar visualizaciones de datos geoespaciales, así como librerías basadas en diferentes lenguajes de programación para el tratamiento de información geográfica.
Herramientas de visualización geoespacial
Carto
Funcionalidad:
Carto es una plataforma de análisis de datos geoespaciales, orientada a desarrolladores sin experiencia previa en sistemas de información geoespacial, que facilita la creación de aplicaciones interactivas geolocalizadas.
Principales ventajas:
Su principal ventaja es que permite diseñar y desarrollar mapas en tiempo real que funcionan en plataformas web y dispositivos móviles. También permite la vinculación con servicios cartográficos como Google Maps o MapBox, de tal forma que se pueden aprovechar algunas de sus funcionalidades, como el zoom o la función de desplazamiento.
Mediante el uso de la librería PostGIS, Carto permite consultar y combinar conjuntos de datos geoespaciales, y es posible utilizar CartoCSS en las capas de datos para editar fácilmente el formato y la apariencia que presentan los mapas.
¿Quieres saber más?
- Materiales de ayuda: En su web, Carto ofrece manuales de usuario, tanto para usuarios que quieran utilizar la plataforma para realizar análisis espaciales como para aquellos que quieren desarrollar apps usando su paquete de herramientas. También ofrece tutoriales para gestionar la cuenta o configurar la seguridad, webinars periódicos con ejemplos prácticos, un blog y distintos vídeos a través de su canal de YouTube.
- Repositorio: En Github encontramos multitud de repositorios con recursos para Carto.
- Comunidad de usuarios: Los usuarios pueden entrar en contacto a través de Stackoverflow.
- Redes sociales: Puedes estar al día de las novedades de Carto si sigues su perfil en Twitter (@CARTO) o LinkedIn.
OpenLayers
Funcionalidad:
OpenLayers es la librería de JavaScript de código abierto que permite la inclusión de componentes tipo mapa en cualquier página web.
Principales ventajas:
OpenLayers permite superponer distintas capas y añadir diferentes características como puntos, líneas, polígonos e iconos sobre los que vincular una leyenda. Incorpora un set de controles básicos y una barra de herramientas de controles avanzados, lo cual permite embeber la funcionalidad necesaria haciendo uso de la API. También destaca porque renderiza elementos DOM en cualquier lugar del mapa.
¿Quieres saber más?
- Materiales de ayuda: En la web de OpenLayers hay un manual de usuario que te explica rápidamente cómo poner un mapa sencillo en una página web, o guías más avanzadas sobre los distintos componentes. También hay disponibles tutoriales que abarcan conceptos básicos, los antecedentes de OpenLayers o cómo crear una aplicación. Fuera de su web también puedes encontrar otros recursos de ayuda, algunos de los cuales se enumeran en este artículo. Si eres principiante, también te recomendamos este vídeo que explica funcionalidades básicas en solo 12 minutos.
- Comunidad de usuarios: Si quieres conocer la experiencia de otros usuarios, y plantear cualquier duda, puedes acudir a Stackoverflow.
- Redes sociales: En su canal de Twitter (@openlayers) puedes participar en encuestas o enterarte de noticias relacionadas. También disponen de un grupo de LinkedIn.
OpenStreetMap
Funcionalidad:
OpenStreetMap es un proyecto colaborativo enfocado en la creación de mapas libres y editables. Estos mapas se crean utilizando información geográfica capturada con dispositivos GPS, ortofotos y otras fuentes de dominio público.
Principales ventajas:
Los usuarios registrados de OpenStreetMap pueden subir sus trazas desde el GPS, crear y corregir datos vectoriales mediante herramientas de edición creadas por la comunidad. También destaca porque utiliza una estructura de datos topológica que se almacena en el datum WGS84 lat/lon (EPSG:4326) como sistema de referencia de coordenadas.
¿Quieres saber más?
- Materiales de ayuda: En esta wiki puedes encontrar información sobre cómo utilizar OpenStreetMap o una guía para principiantes sobre cómo empezar a contribuir. También hay disponibles video tutoriales.
- Repositorio: En Github hay distintos repositorios y recursos para seguir avanzando en la creación de mapas.
- Comunidad de usuarios: OpenStreetMap cuenta con un foro oficial de ayuda, aunque los usuarios también tienen un punto de encuentro en Stackoverflow.
- Redes sociales: Para conocer las novedades y tendencias, puedes seguir la cuenta en Twitter @openstreetmap o su perfil en LinkedIn.
Herramientas para el tratamiento de información geográfica
Aunque no se trata de herramientas de visualización geoespacial propiamente dichas, conviene destacar la existencia de librerías de diferentes lenguajes de programación diseñadas para el tratamiento de información geográfica.
Geocoder y Geopy:
Funcionalidad
Geocoder y Geopy son librerías de Python diseñadas para resolver el problema de la geocodificación. Convierten direcciones postales en coordenadas espaciales o viceversa.
Principales ventajas:
Ambas librerías incorporan la capacidad de calcular la distancia entre puntos geolocalizados.
¿Quieres saber más?
- Materiales de ayuda: Los usuarios que quieran trabajar con Geopy, tienen a su disposición este manual que incluye la instalación, el uso de distintos geocodificadores o cómo calcular distancias, entre otras cuestiones. Si prefieres, Godecoder, en esta guía encontrarás cómo instalarlo y ejemplos de uso.
- Repositorio: En Github hay repositorios con recursos tanto para Geopy como para Geocoder.
- Comunidad de usuarios: En Stackoverflow puedes encontrar grupos de usuarios de Geopy y Geocoder.
GDAL
Funcionalidad
GDAL es una librería de código abierto disponible para diferentes lenguajes de programación como son Python, Java, Ruby, VB6, Perl y R.
Principales ventajas:
Esta librería permite la traslación entre datos geoespaciales vectoriales y raster. Un buen número de herramientas que incorporan funciones de Sistema de Información Geográfica (SIG o GIS), como PostGIS, Carto o ArcGIS, integran GDAL para realizar este proceso.
¿Quieres saber más?
- Materiales de ayuda: En este manual de usuario puedes encontrar preguntas frecuentes e información sobre los programas y drivers. Puedes complementar su lectura con este tutorial.
- Repositorio: Puedes descargar todo lo necesario para su uso desde Github.
- Comunidad de usuarios: Una vez más, es en Stackoverflow donde nos encontramos distintos debates abiertos sobre esta herramienta.
- Redes sociales: En el perfil @GdalOrg se comparten noticias de interés para todos sus usuarios.
PROJ.4 y PROJ4.JS
Funcionalidad
PROJ.4 es una librería disponible para varias plataformas, como Python, Ruby, Rust, Go o Julia, entre otros. PROJ4.JS es la implementación de PROJ.4 para JavaScript.
Principales ventajas:
PROJ.4 permite la transformación de coordenadas geoespaciales de un sistema de referencia de coordenadas a otro, así como invocar desde línea de comandos para una fácil conversión de coordenadas en archivos de texto.
¿Quieres saber más?
- Materiales de ayuda: Este manual incluye información sobre proyección cartográfica, transformación geodésica o las diferencias conocidas entre versiones, entre otros aspectos.
- Repositorio: En GitHub hay un espacio para PROJ.4 y otro para PROJ4.JS.
- Comunidad de usuarios: En Stackoverflow también hay grupos de discusión de PROJ.4 y PROJ4.JS.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:
El criterio elegido para seleccionar estas herramientas, ha sido su popularidad, pero nos gustaría conocer tú opinión. No dudes en dejarnos un comentario.
Estas herramientas están incluidas en el informe “Herramientas de procesado y visualización de datos”, recientemente actualizado. Puedes ver más herramientas ligadas a este ámbito en los siguientes monográficos:
Contenido elaborado por el equipo de datos.gob.es.
Blog
Hace un par de semanas, comentamos a través de este artículo la importancia de las herramientas de análisis de datos para generar representaciones que permitan comprender mejor la información y tomar decisiones más acertadas. En dicho artículo dividimos estas herramientas en 2 categorías: herramientas de visualización de datos genéricas - como son Kibana, Tableau Public, SpagoBI (actual Knowage) y Grafana - y las librerías y APIs de visualización. Este nuevo post se lo vamos a dedicar a las segundas.
Las librerías y APIs de visualización son más versátiles que las herramientas de visualización genéricas, pero para poder trabajar con ellas es necesario que el usuario conozca del lenguaje de programación donde se implemente la librería.
Existe una amplia gama de librerías y APIs para diferentes lenguajes de programación o plataformas, que implementan funcionalidades relacionadas con la visualización de datos. A continuación, os mostraremos una selección tomando como criterio fundamental la popularidad que les otorga la Comunidad de usuarios.
Google Chart Tools
Funcionalidad:
Google Chart Tools es la API de Google para la creación de visualizaciones interactivas. Permite la creación de dashboards utilizando diferentes tipos de widgets, como selectores de categoría, rangos temporales o autocompletadores, entre otros.
Principales ventajas:
Se trata de una herramienta muy fácil de usar e intuitiva, que permite la interacción con datos en tiempo real. Además, las visualizaciones generadas pueden ser integradas en portales webs utilizando tecnología HTML5/SVG.
¿Quieres saber más?
-
Materiales de ayuda: En Youtube encontramos diversos tutoriales elaborados por usuarios de la API.
-
Repositorio: En Github podemos acceder a una biblioteca común para los paquetes de gráficos, así como conocer los tipos de gráficos compatibles y ejemplos de cómo personalizar los componentes de cada gráfico, entre otros.
-
Comunidad de usuarios: Los usuarios de Google Chart Tools pueden plantear sus dudas en la comunidad de Google, en el espacio habilitado para ello.
JavaScript InfoVis Toolkit
Funcionalidad:
JavaScript InfoVis Toolkit es la librería de JavaScript que proporciona funciones para la creación de múltiples visualizaciones interactivas como mapas, árboles jerárquicos o gráficos de líneas.
Principales ventajas:
Es eficiente en el manejo de estructuras de datos complejas y dispone de una gran diversidad de opciones de visualización, por lo que se adapta a cualquier necesidad del desarrollador.
¿Quieres saber más?
-
Materiales de ayuda: Este manual de usuario explica las principales opciones de visualización y cómo trabajar con la librería. También hay disponibles demos para la creación de diferentes tipos de gráficos.
-
Repositorio: Los usuarios deben descargar el proyecto de http://thejit.org, aunque también tienen disponible un repositorio en Github donde, entre otras cosas, pueden descargar extras.
-
Comunidad de usuarios: Tanto en la comunidad de usuarios de Google como en Stackoverflow encontramos espacios dedicados a JavaScript InfoVis Tookit para que los usuarios compartan dudas y experiencias.
Data-Driven Documents (D3.js)
Funcionalidad:
Data-Driven Documents (D3.js) es la librería de Javascript que permite la creación de gráficos interactivos y visualizaciones complejas. Gracias a ella se pueden manipular documentos basados en datos usando estándares abiertos de la web (HTML. SVG y CSS), de forma que los navegadores puedan interpretarlos para crear visualizaciones independientemente del software propietario.
Principales ventajas:
Esta librería permite la manipulación de un DOM (Modelo en Objetos para la Representación de Documentos) aplicando las transformaciones necesarias a la estructura en función de los datos vinculados a un documento HTML o XML. Esto proporciona una versatilidad prácticamente ilimitada.
¿Quieres saber más?
-
Materiales de ayuda: En Github puedes encontrar numerosos tutoriales, aunque principalmente dedicados a las versiones antiguas (actualmente están en proceso de actualizar esta sección de la wiki y escribir nuevos tutoriales sobre la versión 4.0 de D3).
-
Repositorio: También en Github encontramos hasta 53 repositorios, que abarcan distintos materiales para gestionar miles de animaciones simultáneas, agrupar puntos bidimensionales en bandejas hexagonales o trabajar con el módulo d3-color, entre otros. En esta galería puedes ver algunos de los trabajos realizados.
-
Comunidad de usuarios: Existen espacios de discusión sobre D3 en la Comunidad de Google, Stackoverflow, Gitter y Slack.
-
Redes sociales: En la cuenta de Twitter @d3js_org se comparten experiencias, novedades y casos de uso. También existe un grupo en LinkedIn.
Matplotlib
Funcionalidad:
Matplotlib es una de las librerías más populares en Python para la creación de visualizaciones y gráficos de alta calidad. Se caracteriza por presentar una organización jerárquica que va desde el nivel más general, como puede ser el contorno de una matriz 2D, hasta un nivel muy específico, como puede ser colorear un pixel determinado.
Principales ventajas:
Matplotlib soporta texto y etiquetas en formato LaTeX. Además, los usuarios pueden personalizar su funcionalidad a través de paquetes diseñados por terceros (Cartopy, Ridge Map, holoviews, entre otros).
¿Quieres saber más?
-
Materiales de ayuda: En su propia web encontramos una guía de usuario que incluye información sobre la instalación y el uso de las diversas funcionalidades. También hay disponibles tutoriales para usuarios tanto principiantes, como intermedios o avanzados.
-
Repositorio: En este repositorio Github están los materiales que necesitas para su instalación. En la web puedes ver una galería con ejemplos de trabajos para tu inspiración.
-
Comunidad de usuarios: La web oficial dispone de una sección de comunidad, aunque también puedes encontrar grupos de usuarios que te ayuden con tus dudas en Stackoverflow y Gitter.
-
Redes sociales: En el perfil de Twitter @matplotlib también se comparten ejemplos de visualizaciones y trabajos de usuarios, así como información sobre las últimas novedades de la herramienta.
Bokeh
Funcionalidad:
Bokeh es la librería de Python orientada a la creación de gráficas interactivas basadas en HTML/JS. Tiene la capacidad de generar visualizaciones interactivas con características como, texto flotante, zoom, filtros o selecciones, entre otros.
Principales ventajas:
Su principal ventaja es la simplicidad en la implementación: con pocas líneas de código se pueden crear visualizaciones interactivas complejas. Además, permite embeber código JavaScript para implementar funcionalidades específicas.
¿Quieres saber más?
-
Materiales de ayuda: Esta guía del usuario proporciona descripciones detalladas y ejemplos que describen muchas tareas comunes que se puede realizar con Bokeh. En la web de Bokeh también encontramos este tutorial y ejemplos de aplicaciones construidas con esta herramienta.
-
Repositorio: En este repositorio Github están los materiales e instrucciones para su instalación, así como ejemplos de uso. También hay ejemplos disponibles en esta galería.
-
Comunidad de usuarios: La comunidad oficial se encuentra en la propia web de Bokeh, aunque los usuarios de esta herramienta también se reúnen en Stackoverflow.
-
Redes sociales: Para estar al día de las novedades, puedes seguir la cuenta de Twitter @bokeh o su perfil en LinkedIn.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:
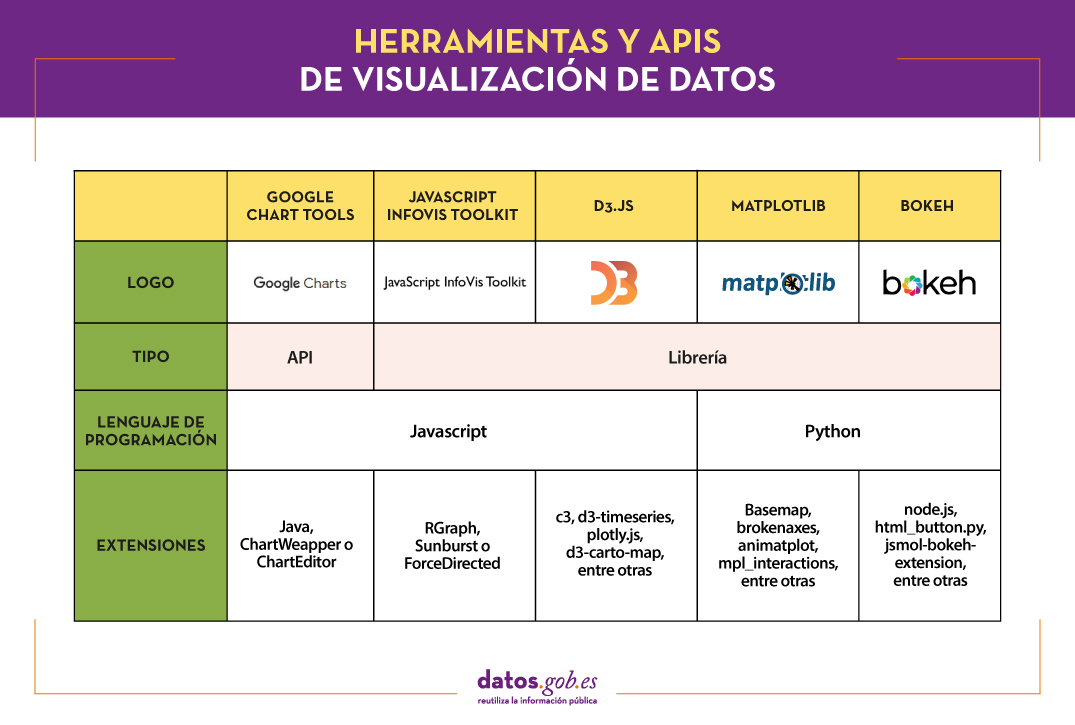
¿Estás de acuerdo con nuestra selección? Te invitamos a compartir tu experiencia con estas u otras herramientas en la sección de comentarios.
Si estás buscando herramientas para ayudarte en el procesamiento de datos, desde datos.gob.es ponemos a tu disposición el informe “Herramientas de procesado y visualización de datos”, recientemente actualizado, así como los siguientes artículos monográficos:
- Las herramientas de análisis de datos más populares
- Las herramientas de depuración y conversión de datos más populares
- Las herramientas de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.
Blog
Los datos son un pilar fundamental en la toma de decisiones empresariales. Antes de tomar cualquier decisión, es necesario analizar la situación para comprender el contexto y vislumbrar las posibles alternativas. Y para ello es necesario presentar los datos de una manera clara y comprensible.
El análisis de datos no sirve de nada si no conseguimos que el resultado se entienda. Y la mejor manera de entender los datos es visualizarlos.
¿Qué es la visualización de datos?
La visualización de datos es una tarea vinculada al análisis de datos cuyo objetivo es la representación gráfica de la información subyacente de los datos. Para ello se utilizan desde elementos gráficos básicos, como gráficos de líneas, de dispersión o mapas de calor, hasta visualizaciones complejas configuradas sobre un dashboard o cuadro de mando. La visualización de datos permite detectar patrones, tendencias o datos anómalos, proyectar predicciones o comunicar inferencias derivada del análisis de datos, entre otras cuestiones.
Gracias a estas representaciones, personas sin conocimientos avanzados de analítica pueden interpretar y comprender los datos de una manera más sencilla y tomar decisiones en base a ellos en ámbitos tan dispares como el marketing, la salud, la ciencia, la economía, el periodismo o incluso el arte.
Podemos dividir las herramientas de visualización de datos, en dos categorías. Por un lado, las herramientas de visualización genéricas y por otro, las librerías y APIs de visualización, más versátiles, pero que necesitan el manejo de lenguajes de programación. En este artículo nos vamos a centrar en las primeras.
Principales ejemplos de herramientas de visualización de datos genéricas
Kibana
Funcionalidad:
Kibana es un software de código abierto que forma parte del paquete de productos Elastic Stack. Proporciona capacidades de visualización y exploración de datos indexados sobre el motor de analítica Elasticsearch.
Principales ventajas:
Su principal ventaja es que presenta la información de manera visual a través de dashboards personalizables, mediante la integración de filtros facetados por rangos, categorías de información, cobertura geoespacial o intervalos temporales, entre otros. Además, dispone de un catálogo de herramientas de desarrollo (Dev Tools) para interactuar con los datos almacenados en Elasticsearch.
¿Quieres saber más?
- Materiales de ayuda: En la propia web de Elastic encontramos este manual de usuario que incluye conceptos básicos para configurar Kibana, cómo crear y personalizar los dashboards o cómo interactuar con las API de Kibana, entre otros. Elastic también ofrece vídeos cortos en su canal de Youtube y organiza, de manera periódica, webinars donde se explican diversos aspectos y casos de uso en Kibana.
- Repositorio: En este Github tienes distintos recursos para su configuración, incluyendo pluggins, tests y ejemplos.
- Comunidad de usuarios: Existe una comunidad de usuarios oficial en su página web, aunque también puedes encontrar grupos de discusión en Stackoverflow.
- Redes sociales: Puedes seguir la cuenta de Twitter @elastic para estar al día de las novedades de Kibana y descubrir experiencias de uso, o unirte a su grupo de LinkedIn.
Tableau Public
Funcionalidad:
Tableau Public es una herramienta diseñada para la realización de visualizaciones combinando una interfaz gráfica con elementos habituales de las herramientas de Bussiness Integillence, como el modelo de organización variable mediante el uso de dimensiones y la conexión con bases de datos o datasets.
Principales ventajas:
Destaca por su interfaz gráfica, eficiente y rápida, y por su integración sencilla de bases de datos u hojas de cálculo de cualquier tamaño. Además, permite la combinación de diversas fuentes de datos en una sola vista.
Como punto negativo, para poder usar la versión gratuita, tanto los datos como las visualizaciones deben ser publicados en su web de manera pública, eliminando la confidencialidad de la información.
¿Quieres saber más?
- Materiales de ayuda: Tableau ofrece un manual con 8 pasos para empezar a usar Tableau Desktop, que se incluye desde cómo conectarse a los datos hasta cómo compartir los hallazgos. En la web de Tableau también puedes encontrar tutoriales, una galería de visualizaciones, recursos para usuarios (como podcast o concursos) y un blog con artículos relacionados.
- Comunidad de usuarios: En el foro oficial de Tableau puedes encontrar más de 450 grupos de usuarios y respuestas a más de 195.000 cuestiones.
- Redes sociales: En la cuenta de Twitter @tableaupublic se incluyen ejemplos de visualizaciones, experiencias e información sobre novedades. También hay disponible un grupo de LinkedIn.
SpagoBI (Knowage)
Funcionalidad:
SpagoBI (actualmente llamada Knowage) es una plataforma de código abierto diseñada principalmente para aplicaciones de Inteligencia de negocios. Ofrece soluciones para la presentación de informes, análisis multidimensional, minería de datos, dashboards y consultas ad-hoc.
Principales ventajas:
SpagoBI permite crear informes personalizables y exportable en diferentes formatos (HTML, PDF, XLS, XML, TXT, CSV y RTF) que pueden contener tablas, tablas cruzadas, gráficos interactivos y texto.
¿Quieres saber más?
- Materiales de ayuda: En este documento puedes encontrar un manual de instalación, un manual de administración, una guía de usuario e información sobre las distintas funcionalidades. En su canal de youtube puedes encontrar distintas listas de reproducción con historias de éxito, ejemplos de visualizaciones, tutoriales sobre distintas funcionalidades o webinars, entre otros. En el caso de los webinars, también puedes acceder a ellos desde su página web, donde se incluye la agenda con las próximas citas.
- Repositorio: En Github hay distintos repositorios con material de interés para los usuarios de SpagoBI.
- Comunidad de usuarios: Puedes encontrar distintas preguntas planteadas por los usuarios -y sus respuestas- en Stackoverflow.
- Redes sociales: La comunidad de usuarios también tiene a su disposición un grupo de LinkedIn. En Twitter, conviven los canales @SpagoBI y @knowage_suite, que informan de las novedades y muestran ejemplos de trabajos realizado con esta herramienta.
Grafana
Funcionalidad:
Grafana permite crear visualizaciones interactivas y dinámicas. Originalmente empezó siendo un componente de Kibana, pero en la actualidad son herramientas completamente independientes.
Principales ventajas:
Esta herramienta permite a los usuarios interactuar, intercambiando datos o dashboards. Además, integra diferentes bases de datos como: PostgreSQL, MySQL y Elasticsearch, de las que se puede obtener métricas, filtrar datos o realizar anotaciones en tiempo real.
¿Quieres saber más?
- Materiales de ayuda: En la web de Grafana hay múltiple información sobre cómo instalar esta herramienta, crear un dashboard o gestionar alertas. Además cuentan con un blog, así como con webinars y videos, también disponible en su canal de Youtube.
- Repositorio: Desde este GitHub puedes descargar paquetes y recursos, como plugins.
- Comunidad de usuarios: Al igual que en algunos de los casos anteriores, encontramos una comunidad oficial en la propia web de Grafana, y comunidades informales en Gitter y Stackoverflow.
- Redes sociales: La cuenta de Twitter @grafana muestra ejemplos de uso y ayuda a difundir las novedades resaltadas en el blog. Los usuarios también se pueden unir a su grupo de LinkedIn.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:
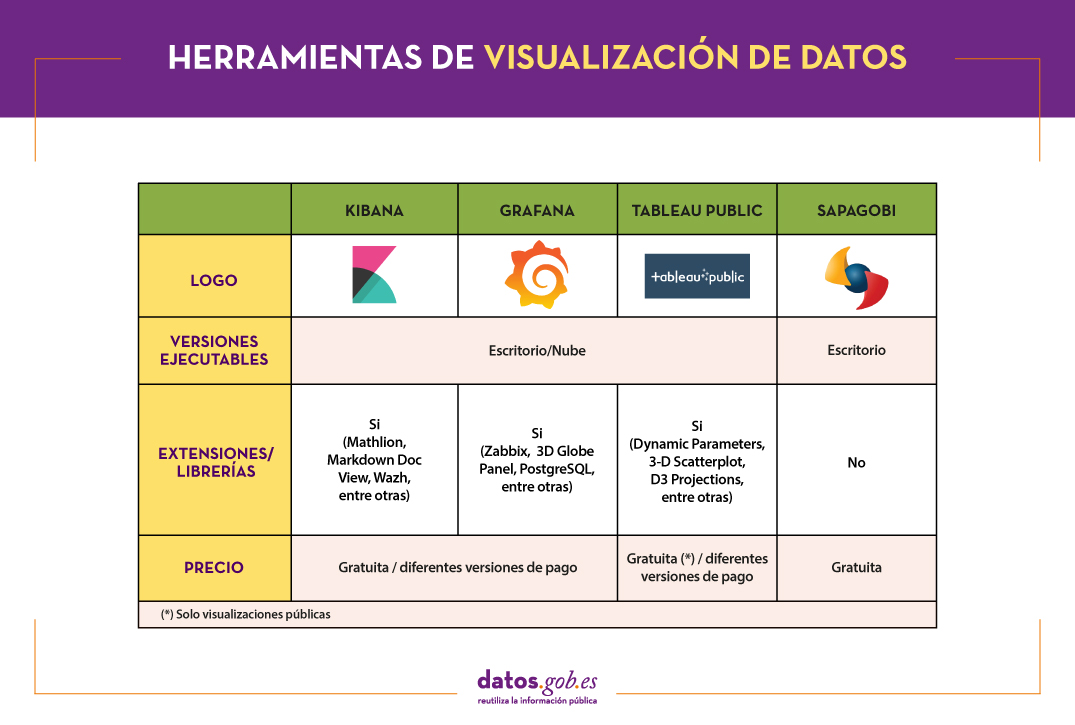
Estos son solo 4 ejemplos de herramientas populares de visualización de datos. Próximamente pondremos a tu disposición un artículo con ejemplos de librerías y APIs de visualización. Te invitamos a compartir tu experiencia con estas u otras herramientas en los comentarios.
Si quieres saber más sobre las distintas fases del procesamiento de los datos, puedes ver el informe completo “Herramientas de procesado y visualización de datos”, recientemente actualizado. Además, tienes a tu disposición los siguientes artículos monográficos:
- Las herramientas de análisis de datos más populares
- Las herramientas de depuración y conversión de datos más populares
- Las librerías y APIs de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.
Blog
El análisis de datos es un proceso que nos permite obtener conocimiento de la información subyacente de los datos con el propósito de extraer conclusiones que permitan tomar decisiones informadas. Sin la analítica de datos, empresas y organizaciones se encuentran limitadas a la hora de examinar sus resultados y determinar la dirección a seguir para tener mayores probabilidades de éxito.
Tipos de analítica
Dentro del campo de la analítica encontramos distintos procesos que tratan de dar respuesta al pasado, presente y futuro de nuestras actividades:
- Análisis exploratorio, que somete a los datos a un tratamiento estadístico, para determinar por qué ha ocurrido un determinado evento.
- Análisis descriptivo, que explora los datos desde diferentes perspectivas para saber qué sucedió.
- Análisis predictivo, que permite predecir valores futuros de las variables de interés para conocer qué sucederá.
- Análisis prescriptivo, que ofrece recomendaciones al testear las variables del entorno y sugerir aquellas con mayor probabilidad de generar un resultado positivo.
En este artículo se recoge una selección de herramientas más populares de análisis de datos que te permitirán realizar estas tareas, divididas en base a dos públicos objetivos:
- Herramientas que no implican realizar tareas de programación, dirigidas a usuarios sin conocimientos técnicos avanzados.
- Herramientas que presentan una mayor versatilidad, pero necesitan el manejo de lenguajes de programación, por lo que están dirigidas a usuarios con estos conocimientos.
Es conveniente recordar que antes de realizar cualquier análisis de este tipo es necesario transformar los datos que utilicemos para que tengan la misma estructura y formato, libres de errores, algo que ya vimos en el artículo Herramientas de depuración y conversión de datos.
Herramientas de análisis de datos para no programadores
WEKA
Funcionalidad:
WEKA es un software multiplataforma de aprendizaje automático y minería de datos. Se puede acceder a sus funcionalidades a través de una interfaz gráfica, una línea de comandos o una API de Java.
Principales ventajas:
Una de sus principales ventajas es que contiene una gran cantidad de herramientas integradas para tareas estándar de aprendizaje automático y que permite el acceso a otras herramientas como son scikit-learn, R y Deeplearning.
¿Quieres saber más?
- Materiales de ayuda: Como apéndice al libro Data Mining: Practical Machine Learning: tools and techniques, encontramos este manual de WEKA que nos acerca a sus paneles y funcionalidades. Incluye métodos para los principales problemas de minería de datos: regresión, clasificación, clustering, reglas de asociación y selección de atributos. También tenemos a nuestra disposición en la red este manual y estos tutoriales elaborado por la Universidad de Waikato, entidad desarrolladora de la herramienta, que también ha puesto en marcha un blog sobre la materia.
- Repositorio: El código fuente oficial de WEKA está disponible en esta URL. También puedes acceder a ella desde este repositorio Github, así como a distintos paquetes o herramientas.
- Comunidad de usuarios: Puedes encontrar grupos de usuarios en Stackoverflow.
KNIME
Funcionalidad:
KNIME es un software de minería de datos, que permite el análisis de datos y la realización de visualizaciones a través de una interfaz gráfica.
Principales ventajas:
La interfaz gráfica sobre las que se modelan los flujos de análisis de datos utiliza nodos, que representan los diferentes algoritmos y flechas que muestran el flujo de los datos en el pipeline de procesamiento. Además, permite incorporar código desarrollado en R y Python, así como la interacción con WEKA.
¿Quieres saber más?
- Materiales de ayuda: En la propia web de KNIME puedes encontrar distintos documentos de ayuda, que te guían en su instalación, la creación de flujos de trabajo o el uso de nodos. Además, en su canal de Youtube puedes encontrar múltiples vídeos, incluyendo listas de reproducción con aspectos básicos para usuarios que se enfrentan a esta herramienta por primera vez.
- Repositorio: En GitHub se proporcionan herramientas para configurar el SDK (Kit de desarrollo de software, en sus siglas en inglés) de KNIME, para que puedas trabajar con el código fuente de las extensiones o desarrollar propias.
- Comunidad de usuarios: Los usuarios de KNIME tienen a su disposición grupos para resolver dudas en Gitter y Stackoverflow, así como un foro de discusión en la propia web de Knime.
- Redes sociales: Puedes seguir la cuenta de Twitter @knime y su perfil de LinkedIn para estar al día de las novedades de KNIME y de los eventos o charlas relacionados.
ORANGE
Funcionalidad:
Orange es un software abierto de aprendizaje automático y minería de datos, similar a Knime.
Principales ventajas:
Orange crea los análisis y visualizaciones de datos utilizando el paradigma drag and drop (arrastrar y soltar) a partir de un catálogo de widgets que representan diferentes tareas. Además, puede ser instalado como una librería de Python.
¿Quieres saber más?
- Materiales de ayuda: En este caso destacamos dos libros. En primer lugar, Introducción a la minería de datos con Orange, que recoge los flujos de trabajo y visualizaciones del curso on Introduction to Data Mining del propio Orange. En segundo, Orange Data Mining LibraryDocumentation, una ligera introducción al scripting en Orange. También puedes encontrar video tutoriales, en el canal de Youtube Orange Data Mining.
- Repositorio: Desde este GitHub puedes descargar los recursos necesarios para su instalación.
- Comunidad de usuarios: En Gitter, StackExchange y Stackoverflow los usuarios han creado espacios donde plantear dudas y contar experiencias.
- Redes sociales: En el perfil de twitter @OrangeDataMiner y su cuenta de LinkedIn se recogen informes, eventos, casos de uso y noticias relacionadas con esta herramienta.
Herramientas de análisis de datos para programadores
R (The R Project for statistical computing)
Funcionalidad:
R es un lenguaje de programación orientado a objetos e interpretado, creado inicialmente para computación estadística y creación de representaciones gráficas.
Principales ventajas:
R es uno de los lenguajes más usados en investigación científica y eso se debe a sus múltiples ventajas:
- Dispone de un entorno de programación, R-Studio.
- Está formado por un conjunto de funciones que pueden ampliarse fácilmente, mediante la instalación de librerías o la definición de funciones personalizadas.
- Está permanentemente actualizado debido a su extensa comunidad de usuarios y programadores, que desde sus inicios contribuyen al desarrollo de nuevas funciones, librerías y actualizaciones disponibles para todos los usuarios de forma libre y gratuita.
¿Quieres saber más?
- Materiales de ayuda: Debido a su popular, existen una gran cantidad de materiales de ayuda. Como ejemplo destacamos los libros R for Data Science y Manual de R. También puedes encontrar guías en el espacio web The R Manuals y los webinars que desde el propio R Studio organizan.
- Comunidad de usuarios: Existe un espacio de discusión en Stackoverflow. Además, a nivel España, encontramos dos grupos que realizan distintas actividades (hackathons, jornadas, cursos…) para promover el uso de R: la comunidad R-Hispano y R-Ladies. Puedes saber más sobre ellos en este artículo.
- Redes sociales: R cuenta con un grupo en LinkedIn con casi 150.000 miembros.
Python
Funcionalidad:
Python es un lenguaje de programación interpretado, dinámico, multiplataforma y multiparadigma, que soporta parcialmente programación orientada a objetos, programación estructurada, programación imperativa y programación funcional.
Principales ventajas:
Se trata de un lenguaje de programación cuya filosofía hace hincapié en ofrecer una sintaxis de código legible, fácil de usar y fácil de aprender. Además, permite la integración de librerías como Matplotlib, Bokeh, Numpy, Pandas o spaCy, para implementar funciones que posibilitan la realización de análisis estadísticos y gráficos interactivos complejos.
¿Quieres saber más?
- Materiales de ayuda: Al igual que ocurría con R, al ser u lenguaje muy popular encontramos gran cantidad de materiales y ayuda en la red como, los tutoriales The Python Tutorial y LearnPython.org, o el portal con videos Pyvideo, donde podrás encontrar diversos webinars.
- Repositorio: En Github puedes encontrar distintos repositorios relacionados con el lenguaje de programación Python.
- Comunidad de usuarios: Aquellos usuarios con preguntas pueden buscar la ayuda de personas en su misma situación en Stackoverflow o Gitter. En la propia web de Python también puedes encontrar un gran número de comunidades a nivel mundial.
- Redes sociales: El perfil oficial de twitter de la Python Software Foundation es @ThePSF. También hay grupo en Linkedin.
GNU Octave
Funcionalidad:
GNU Octave es un lenguaje de programación diseñado principalmente para resolver tareas de algebra computacional. Es la alternativa más conocida a la solución comercial MATLAB, pero de carácter libre y gratuito. Además, no dispone de una interfaz gráfica.
Principales ventajas:
GNU Octave dispone de potentes funciones matemáticas integradas (ecuaciones diferenciales, algebra lineal, cálculo con matrices) y pueden ampliarse con la incorporación de librerías, como Scientific Library, Dionysus o Bc. También dispone de un paquete index con numerosas extensiones que enriquecen la funcionalidad de la herramienta.
¿Quieres saber más?
- Materiales de ayuda: En este enlace tienes los apuntes del curso de GNU Octave de la Universidad Complutense de Madrid. En la propia web de GNU Octave también puedes encontrar manuales y en su perfil de youtube, video tutoriales.
- Repositorio: La comunidad de desarrolladores de GNU Octave tiene a su alcance distintos repositorios en Github con materiales de interés.
- Comunidad de usuarios: En Stackoverflow y en la web de GNU Octave hay un espacio para que los usuarios compartan opiniones y experiencia.
- Redes sociales: Puedes seguir las novedades ligadas a esta herramienta en la cuenta de Twitter @GnuOctave y este grupo de LinkedIn.
La siguiente tabla muestra un resumen de las herramientas mencionadas anteriormente:

Esta es solo una selección de herramientas de análisis de datos, pero hay muchas más. Te invitamos a compartir en los comentarios tu experiencia con estas u otras soluciones.
Para aquellos que quieran saber más sobre estas herramientas y otras que nos pueden ayudar durante las distintas fases del procesamiento de los datos, desde datos.gob.es ponemos a vuestra disposición el informe “Herramientas de procesado y visualización de datos “recientemente actualizado. Puedes ver el informe completo aquí. Puedes ver más herramientas relacionadas con este campo en los siguientes monográficos:
- Las herramientas de depuración y conversión de datos más populares
- Las herramientas de visualización de datos más populares
- Las librerías y APIs de visualización de datos más populares
- Las herramientas de visualización geoespacial más populares
- Las herramientas de análisis de redes más populares
Contenido elaborado por el equipo de datos.gob.es.