Empresa reutilizadora
Estudio Alfa is a technology company dedicated to offering services that promote the image of companies and brands on the Internet, including the development of apps. To carry out these services, they use techniques and strategies that comply with usability standards and favour positioning in search engines, thus helping their clients' websites to receive more visitors and thus potential clients. They also have special experience in the production and tourism sectors.
Noticia
How time flies! It seems like only yesterday when, at this time of year, we were writing our letter to Santa Claus and the Three Wise Men asking them for our most sincere wishes. Once again, Christmas is here to remind us of the magic of reuniting with our loved ones, but it is also the perfect time to enjoy and rest.
For many, within that Christmas happiness is the passion for reading. What better time to enjoy a good book than these winter days under the warmth of home? Novels, comics, essays... but also guides or theoretical books that can help you expand your knowledge related to your field of work. Therefore, as every year, we have asked our pages -the collaborators of datos.gob.es- the best recommendations on books related to data and technology to offer you some ideas that you can include in your letter this year, if you have behaved well.
Telling your Data Story: Data Storytelling for Data Management, Scott Taylor (The Data Whisperer)
What is it about? The author of this book offers us a practical guide to explain and make us understand the strategic value of data management within the business environment.
Who is it for? It is focused on working professionals interested in improving their skills both in managing and carrying out a company's data plan, as well as in handling tools to be able to clearly explain their actions to third parties. Its target audience also includes data scientists interested in bringing this discipline closer to the business sector.
Language: English
The art of statistics: Learning from data, David Spiegelhalter
What is it about? This book shows readers how to derive knowledge from raw data and mathematical concepts. Through real-world examples, the author tells us how data and statistics can help us solve different problems, such as determining the luckiest passenger on the Titanic or whether a serial killer could have been caught earlier, among others.
Who is it for? If you are passionate about the world of statistics and curious data, this book is for you. Its readability and full of examples taken from the world around us makes this book an interesting idea to include in your letter to the Three Wise Men this year.
Language: English
Big Data. Conceptos, tecnologías y aplicaciones, David Ríos Insúa y David Gómez Ullate Oteiza
What is it about? This new CSIC book brings readers closer to big data and its applications in politics, healthcare and cybersecurity. Its authors, David Ríos and David Gómez-Ullate describe the technology and methods used by data science, explaining its potential in various fields.
Who is it for? Anyone interested in expanding their knowledge of current scientific and technological issues will find this book more than interesting. Its simple and accessible explanations make this manual a pleasant and friendly text for all types of readers.
Language: Spanish
Data Analytics with R: A Recipe book, Ryan Garnett
What is it about? As if it were a recipe book! This is how Ryan Garnet presents this book dedicated to explaining in an entertaining and very practical way to the readers the data analysis focused on the R language.
Who is it for? This book is a very interesting option for both programmers and data analysis enthusiasts who want to discover more about R. Its structure in the form of recipes to explain this field makes it easy to understand. In addition, you can download it for free.
Language: English
Datanomics, Paloma Llaneza
What is it about? This book reveals with data, reports and proven facts what technology companies are really doing with the personal data we give them and how they profit from it.
Who is it for? It is a document of great interest to all citizens. The fact that the information it contains is reinforced with supporting reports makes it lighter and more enjoyable to read.
Language: Spanish
Everybody Lies: Big Data, New Data, and What the Internet Can Tell Us about Who We Really Are, Seth Stephens-Davidowitz
What is it about? Did you know that users surfing the Internet expose a total of 8 billion gigabytes of data every day? The author shows us in this book how the data we provide about our searches reveal our fears, desires and behaviors, but also conscious and unconscious biases.
Who is it for? This book is aimed at anyone looking to expand their knowledge about how we express ourselves in the digital age. If you would like answers to questions such as whether where we go to school can influence our future success, this book is for you.
Language: English
As in previous years, this list is just a small selection that we have made based on the recommendations suggested by some of the experts who collaborate in datos.gob.es, as well as some of the members of this team. Undoubtedly, the world is full of really interesting books on data and technology.
Do you know of any more that we should not forget in our letter to the Three Wise Men? Leave us a comment or send us an email to dinamizacion@datos.gob.es, we will be happy to read it!
Blog
Artificial intelligence is increasingly present in our lives. However, its presence is increasingly subtle and unnoticed. As a technology matures and permeates society, it becomes more and more transparent, until it becomes completely naturalized. Artificial intelligence is rapidly going down this path, and today, we tell you about it with a new example.
Introduction
In this communication and dissemination space we have often talked about artificial intelligence (AI) and its practical applications. On other occasions, we have communicated monographic reports and articles on specific applications of AI in real life. It is clear that this is a highly topical subject with great repercussions in the technology sector, and that is why we continue to focus on our informative work in this field.
On this occasion, we talk about the latest advances in artificial intelligence applied to the field of natural language processing. In early 2020 we published a report in which we cited the work of Paul Daugherty and James Wilson - Human + Machine - to explain the three states in which AI collaborates with human capabilities. Daugherty and Wilson explain these three states of collaboration between machines (AI) and humans as follows (see Figure 1). In the first state, AI is trained with genuinely human characteristics such as leadership, creativity and value judgments. In the opposite state, characteristics where machines demonstrate better performance than humans are highlighted. We are talking about repetitive, precise and continuous activities. However, the most interesting state is the intermediate one. In this state, the authors identify activities or characteristics in which humans and machines perform hybrid activities, in which they complement each other. In this intermediate state, in turn, two stages of maturity are distinguished.
- In the first stage - the most immature - humans complement machines. We have numerous examples of this stage today. Humans teach machines to drive (autonomous cars) or to understand our language (natural language processing).
- The second stage of maturity occurs when AI empowers or amplifies our human capabilities. In the words of Daugherty and Wilson, AI gives us humans superpowers.

Figure 1: States of human-machine collaboration. Original source.
In this post, we show you an example of this superpower returned by AI. The superpower of summarizing books from tens of thousands of words to just a few hundred. The resulting summaries are similar to how a human would do it with the difference that the AI does it in a few seconds. Specifically, we are talking about the latest advances published by the company OpenAI, dedicated to research in artificial intelligence systems.
Summarizing books as a human
OpenAI similarly defines Daugherty and Wilson's reasoning on models of AI collaboration with humans. The authors of the latest OpenAI paper explain that, in order to implement such powerful AI models that solve global and genuinely human problems, we must ensure that AI models act in alignment with human intentions. In fact, this challenge is known as the alignment problem.
The authors explain that: To test scalable alignment techniques, we train a model to summarize entire books [...] Our model works by first summarizing small sections of a book, then summarizing those summaries into a higher-level summary, and so on.
Let's look at an example.
The authors have refined the GPT-3 algorithm to summarize entire books based on an approach known as recursive task decomposition accompanied by reinforcement from human comments. The technique is called recursive decomposition because it is based on making multiple summaries of the complete work (for example, a summary for each chapter or section) and, in subsequent iterations, making, in turn, summaries of the previous summaries, each time with a smaller number of words. The following figure explains the process more visually.

Fuente original: https://openai.com/blog/summarizing-books/
Final result:

Original source: https://openai.com/blog/summarizing-books/
As we have mentioned before, the GPT-3 algorithm has been trained thanks to the set of books digitized under the umbrella of Project Gutenberg. The vast Project Gutenberg repository includes up to 60,000 books in digital format that are currently in the public domain in the United States. Just as Project Gutenberg has been used to train GPT-3 in English, other open data repositories could have been used to train the algorithm in other languages. In our country, the National Library has an open data portal to exploit the available catalog of works under public domain in Spanish.
The authors of the paper state that recursive decomposition has certain advantages over more comprehensive approaches that try to summarize the book in a single step.
- The evaluation of the quality of human summaries is easier when it comes to evaluating summaries of specific parts of a book than when it comes to the entire work.
- A summary always tries to identify the key parts of a book or a chapter of a book, keeping the fundamental data and discarding those that do not contribute to the understanding of the content. Evaluating this process to understand if those fundamental details have really been captured is much easier with this approach based on the decomposition of the text into smaller units.
- This decompositional approach mitigates the limitations that may exist when the works to be summarized are very large.
In addition to the main example we have exposed in this post on Shakespeare's Romeo and Juliet, readers can experience for themselves how this AI works in the openAI summary browser. This website makes available two open repositories of books (classic works) on which one can experience the summarization capabilities of this AI by navigating from the final summary of the book to the previous summaries in the recursive decomposition process.
In conclusion, natural language processing is a key human capability that is being dramatically enhanced by the development of AI in recent years. It is not only OpenAI that is making major contributions in this field. Other technology giants, such as Microsoft and NVIDIA, are also making great strides as evidenced by the latest announcement from these two companies and their new Megatron-Turing NLG model. This new model shows great advances in tasks such as: the generation of predictive text or the understanding of human language for the interpretation of voice commands in personal assistants. With all this, there is no doubt that we will see machines doing incredible things in the coming years.
Content prepared by Alejandro Alija, expert in Digital Transformation and Innovation.
The contents and views expressed in this publication are the sole responsibility of the author.
Noticia
A symptom of the maturity of an open data ecosystem is the possibility of finding datasets and use cases across different sectors of activity. This is considered by the European Open Data Portal itself in its maturity index. The classification of data and their uses by thematic categories boosts re-use by allowing users to locate and access them in a more targeted way. It also allows needs in specific areas to be detected, priority sectors to be identified and impact to be estimated more easily.
In Spain we find different thematic repositories, such as UniversiData, in the case of higher education, or TURESPAÑA, for the tourism sector. However, the fact that the competences of certain subjects are distributed among the Autonomous Communities or City Councils complicates the location of data on the same subject.
Datos.gob.es brings together the open data of all the Spanish public bodies that have carried out a federation process with the portal. Therefore, in our catalogue you can find datasets from different publishers segmented by 22 thematic categories, those considered by the Technical Interoperability Standard.
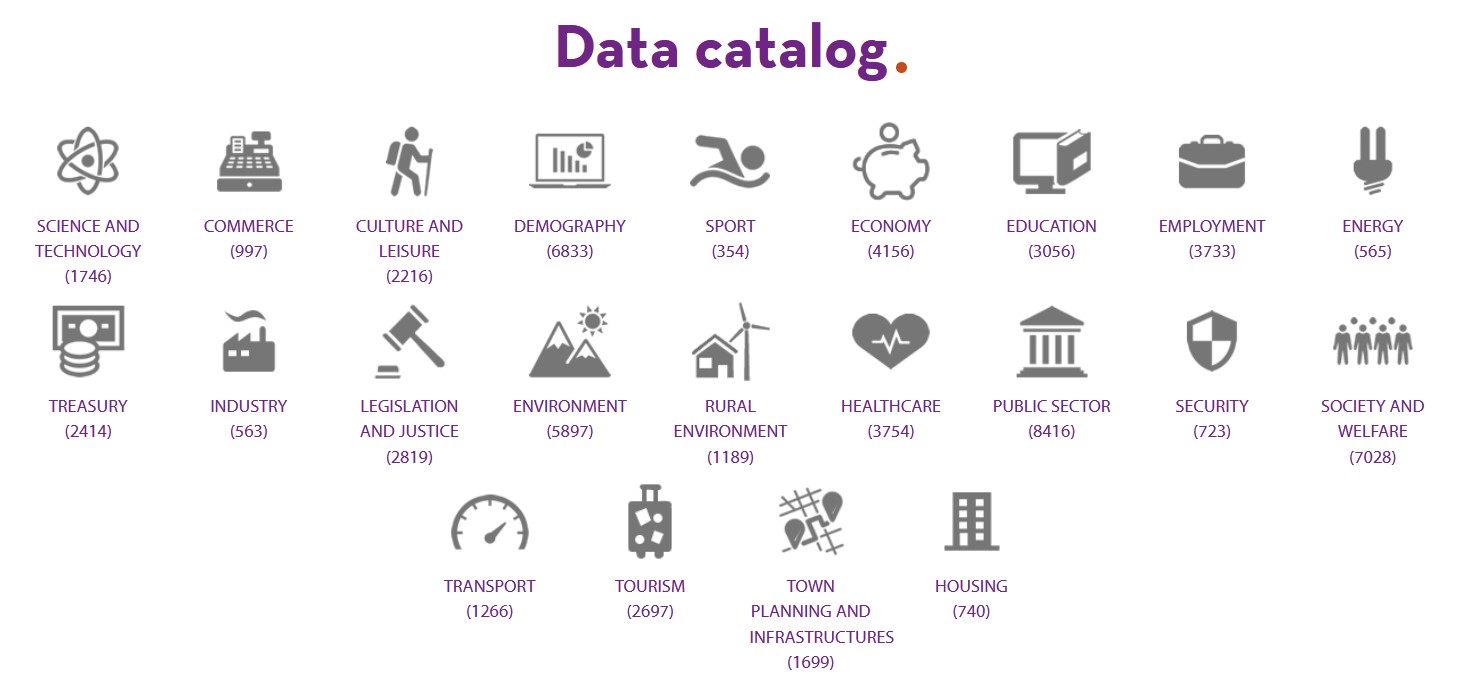
Number of datasets by category as of June 2021
But in addition to showing the datasets divided by subject area, it is also important to show highlighted datasets, use cases, guides and other help resources by sector, so that users can more easily access content related to their areas of interest. For this reason, at datos.gob.es we have launched a series of web sections focused on different sectors of activity, with specific content for each area.
4 sectorial sections that will be gradually extended to other areas of interest
Currently in datos.gob.es you can find 4 sectors: Environment, Culture and leisure, Education and Transport. These sectors have been highlighted for different strategic reasons:
- Environment: Environmental data are essential to understand how our environment is changing in order to fight climate change, pollution and deforestation. The European Commission itself considers environmental data to be highly valuable data in Directive 2019/1024. At datos.gob.es you can find data on air quality, weather forecasting, water scarcity, etc. All of them are essential to promote solutions for a more sustainable world.
- Transport: Directive 2019/1024 also highlights the importance of transport data. Often in real time, this data facilitates decision-making aimed at efficient service management and improving the passenger experience. Transport data are among the most widely used data to create services and applications (e.g. those that inform about traffic conditions, bus timetables, etc.). This category includes datasets such as real-time traffic incidents or fuel prices.
- Education: With the advent of COVID-19, many students had to follow their studies from home, using digital solutions that were not always ready. In recent months, through initiatives such as the Aporta Challenge, an effort has been made to promote the creation of solutions that incorporate open data in order to improve the efficiency of the educational sphere, drive improvements - such as the personalisation of education - and achieve more universal access to knowledge. Some of the education datasets that can be found in the catalogue are the degrees offered by Spanish universities or surveys on household spending on education.
- Culture and leisure: Culture and leisure data is a category of great importance when it comes to reusing it to develop, for example, educational and learning content. Cultural data can help generate new knowledge to help us understand our past, present and future. Examples of datasets are the location of monuments or listings of works of art.
Structure of each sector
Each sector page has a homogeneous structure, which facilitates the location of contents also available in other sections.
It starts with a highlight where you can see some examples of outstanding datasets belonging to this category, and a link to access all the datasets of this subject in the catalogue.
It continues with news related to the data and the sector in question, which can range from events or information on specific initiatives (such as Procomún in the field of educational data or the Green Deal in the environment) to the latest developments at strategic and operational level.
Finally, there are three sections related to use cases: innovation, reusing companies and applications. In the first section, articles provide examples of innovative uses, often linked to disruptive technologies such as Artificial Intelligence. In the last two sections, we find specific files on companies and applications that use open data from this category to generate a benefit for society or the economy.
Highlights section on the home page
In addition to the creation of sectoral pages, over the last year, datos.gob.es has also incorporated a section of highlighted datasets. The aim is to give greater visibility to those datasets that meet a series of characteristics: they have been updated, are in CSV format or can be accessed via API or web services.
What other sectors would you like to highlight?
The plans of datos.gob.es include continuing to increase the number of sectors to be highlighted. Therefore, we invite you to leave in comments any proposal you consider appropriate.
Noticia
2020 is coming to an end and in this unusual year we are going to have to experience a different, calmer Christmas with our closest nucleus. What better way to enjoy those moments of calm than to train and improve your knowledge of data and new technologies?
Whether you are looking for a reading that will make you improve your professional profile to which to dedicate your free time on these special dates, or if you want to offer your loved ones an educational and interesting gift, from datos.gob.es we want to propose some book recommendations on data and disruptive technologies that we hope will be of interest to you. We have selected books in Spanish and English, so that you can also put your knowledge of this language into practice.
Take note because you still have time to include one in your letter to Santa Claus!
INTELIGENCIA ARTIFICIAL, naturalmente. Nuria Oliver, ONTSI, red.es (2020)
What is it about?: This book is the first of the new collection published by the ONTSI called “Pensamiento para la sociedad digital”. Its pages offer a brief journey through the history of artificial intelligence, describing its impact today and addressing the challenges it presents from various points of view.
Who is it for?: It is aimed especially at decision makers, professionals from the public and private sector, university professors and students, third sector organizations, researchers and the media, but it is also a good option for readers who want to introduce themselves and get closer to the complex world of artificial intelligence.
Artificial Intelligence: A Modern Approach, Stuart Russell
What is it about?: Interesting manual that introduces the reader to the field of Artificial Intelligence through an orderly structure and understandable writing.
Who is it for?: This textbook is a good option to use as documentation and reference in different courses and studies in Artificial Intelligence at different levels. For those who want to become experts in the field.
Situating Open Data: Global Trends in Local Contexts, Danny Lämmerhirt, Ana Brandusescu, Natalia Domagala – African Minds (October 2020)
What is it about?: This book provides several empirical accounts of open data practices, the local implementation of global initiatives, and the development of new open data ecosystems.
Who is it for?: It will be of great interest to researchers and advocates of open data and to those in or advising government administrations in the design and implementation of effective open data initiatives. You can download its PDF version through this link.
The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Second Edition (Springer Series in Statistics), Trevor Hustle, Jerome Friedman. – Springer (May 2017)
What is it about?: This book describes various statistical concepts in a variety of fields such as medicine, biology, finance, and marketing in a common conceptual framework. While the focus is statistical, the emphasis is on definitions rather than mathematics.
Who is it for?: It is a valuable resource for statisticians and anyone interested in data mining in science or industry. You can also download its digital version here.
Europa frente a EEUU y China: Prevenir el declive en la era de la inteligencia artificial, Luis Moreno, Andrés Pedreño – Kdp (2020)
What is it about?: This interesting book addresses the reasons for the European delay with respect to the power that the US and China do have, and its consequences, but above all it proposes solutions to the problem that is exposed in the work.
Who is it for?: It is a reflection for those interested in thinking about the change that Europe would need, in the words of its author, "increasingly removed from the revolution imposed by the new technological paradigm".
What is it about?: This book calls attention to the problems that can lead to the misuse of algorithms and proposes some ideas to avoid making mistakes.
Who is it for?: These pages do not appear overly technical concepts, nor are there formulas or complex explanations, although they do deal with dense problems that need the author's attention.
Data Feminism (Strong Ideas), Catherine D’Ignazio, Lauren F. Klein. MIT Press (2020)
What is it about?: These pages address a new way of thinking about data science and its ethics based on the ideas of feminist thought.
Who is it for?: To all those who are interested in reflecting on the biases built into the algorithms of the digital tools that we use in all areas of life.
Open Cities | Open Data: Collaborative Cities in the Information, Scott Hawken, Hoon Han, Chris Pettit – Palgrave Macmillan, Singapore (2020)
What is it about?: This book explains the importance of opening data in cities through a variety of critical perspectives, and presents strategies, tools, and use cases that facilitate both data openness and reuse..
Who is it for?: Perfect for those integrated in the data value chain in cities and those who have to develop open data strategies within the framework of a smart city, but also for citizens concerned about privacy and who want to know what happens - and what can happen- with the data generated by cities.
Although we would love to include them all on this list, there are many interesting books on data and technology that fill the shelves of hundreds of bookstores and online stores. If you have any extra recommendations that you want to make us, do not hesitate to leave us your favorite title in comments. The members of the datos.gob.es team will be delighted to read your recommendations this Christmas.
Noticia
In the last few months we have spent so much time at home, and we have realized the importance of culture. Music, movies, reading or painting have made those hours spent at home much more bearable.
Cultural institutions have a lot of valuable information. This information includes the collections managed by cultural institutions, i.e. works that have been digitally shared free of charge by museums or libraries. But it also includes the knowledge available about those collections. All this material, if shared in open format, can be reused to develop, for example, educational and learning content, documentaries or animations.
What types of cultural data can I find in datos.gob.es?
At datos.gob.es we have an extensive catalogue of cultural data. There are currently 2,300 datasets that have been grouped under a category called "culture and leisure". Among these datasets we find state, regional and local information. The publishers that share the most data of this type are the Autonomous Community of the Basque Country, the Centre for Sociological Research, the National Institute of Statistics and the National Library of Spain.
Of these datasets, some of the most popular are:

You can access these datasets through the following links:
- Spanish authors in the public domain
- Archive of the Spanish website: thematic collection: feminism
- Cultural Parks of Aragon
- Agenda of the museums in the province of Barcelona
- Free activities in Madrid's Municipal Libraries
As we can see, most of these datasets are related to the literary field, one of the most prolific and advanced when it comes to opening its data. However, in the catalogue we can also find data related to the pictorial, cinematographic or musical field.
One advantage of cultural datasets is their cross-sectional nature. For example, datasets such as the thematic collection on feminism or those on immigration provide us with information on our society, something important for understanding how we were and are.
From datos.gob.es we invite you to visit our data catalogue and dive into all the datasets.
Blog
Did you know that open digital heritage is fundamental to understanding the world around us, to boosting a more creative economy and to meeting agreed educational goals? It is estimated that around 90% of the world's cultural heritage has not yet been digitized. Of the remaining 10% that has been digitized, just 34% is available online while only 3% of that work is open
Most cultural institutions have a great deal of valuable information. This information is usually found mainly in the form of collections, but also in the files of authors, dates, technique, etc. Both the works and their information are susceptible to being converted into open data.
Some examples of museums that have digitized and opened their collection are The Rijksmuseum (Netherlands), the Statens Museum for Kunst (Denmark) or the Metropolitan Museum (USA).
What new products can be created by reusing cultural data?
New technologies offer us endless possibilities when it comes to creating new products through the reuse of cultural data. This is the case of new educational platforms such as BNEscolar, which allow for the learning of art from a different point of view. Open cultural data can even be used to generate scaperoom games or new art pieces. They can also be used as design tools or to complement films and documentaries.
In short, it can be established that cultural data are endowed with a great value that, through greater openness, could be of great benefit for the creation of new initiatives that provide benefits for the whole society.

Blog
Can we consider a work of as a data? When talking about open data, we usually think of statistical, meteorological, geospatial data... but we do not have in mind a painting, a song or a book. Resources also susceptible to becoming open data.
When we talk about open cultural data we refer to publications, photographs or musical collections created and distributed by institutions belonging to the cultural sector. It is not just the digitalization of the funds, but also enriching them with metadata that provide the maximum possible information (author, date, technique, etc.) and facilitate access in conditions that favour their reuse.
In this sense, libraries seem to have taken the lead in opening information. We have the example of the National Library of Spain, which launched the open data portal datos.bne.es and has launched different projects based on the reuse of its data, such as BNEscolar. Another example is the Miguel de Cervantes Virtual Library Foundation, whose catalogue consists of more than 230,000 records open for reuse.
Museums, meanwhile, are slowly embracing the commitment to open data, although there are an increasing number of institutions that are committed to sharing their collections openly.
Two examples of museums that have opened their collections
On February 7, 2017, the New York Metropolitan Museum implemented a new open data policy. The museum creates, organizes and disseminates a wide range of images and digital data that document the history of the museum and its collection - made up of more than two million works of art, from ancient Greece to European masters such as Rafael, Rembrandt or Velázquez-. With this policy, the images of selected works of art that are in the public domain – and, therefore, with lack of copyright - have been made available to users without restrictions or cost, in accordance with the Creative Commons Zero designation (CC0 ).
The museum's website has a search engine, which shows the different pieces of the collection. The user can separate those that are under the CC0 license, thanks to a filtering tool. In total there are 406,000 high resolution images, accompanied by basic information such as title, artist, date, medium and dimensions.
Another example is the National Museum of Amsterdam or Rijksmuseum, dedicated to the art, crafts and history of this region, which has a large collection of Dutch Golden Age paintings. The Rijksmuseum has an open data space where digital reproductions and associated data are collected. These data are made available to the public free of charge for all types of purposes, also commercial. When the works are free of copyright, it is explicitly indicated in the corresponding descriptive metadata. In these cases, the copyright notice establishes "Public domain", with a reference to the Creative Commons Zero (CC0) license.


Web pages of the Metropolitan Museum of New York and the Rijksmuseum
Why should museums open their collections?
In this interview with the people in charge of the Musée de Bretagne, pioneer in the opening of data among French museums, the interviewees highlight how thanks to the opening of their collection they have achieved greater visibility. The opening of data gives the museum “a positive and innovative image in the French culture sector. It also generates new knowledge about the museum’s collections, thanks to feedback from online visitors”. This museum has a collection of 700,000 pieces, of which more than 200,000 are now visible and reusable online, including free high-resolution public domain images to download and use.
In the same plot line, we can find this study that analyse the impact of the paintings and their metadata included in wikidata and Wikipedia in English. The study shows how the paintings included in Wikipedia are not only used to illustrate content related to art, but also to enrich other types of entries on diverse themes, such as history (for example, the paintings of kings that show us the aspect that they had) or basic concepts (show what a mermaid looks like through a pictorial representation of it). These paintings help complement textual information while attracting users' attention to museum collections, driving a views increase.
A field full of challenges, but also opportunities
Opening the works of the museums entails a series of challenges, such as the need to carry out a legal evaluation to know who are the rights holders and the contracts in force, so that copyright is always respected, or the technical challenges that entails. Museums will need a technological infrastructure, as well as resources to correctly catalogue all the works with their corresponding metadata (you can learn about the Prado Museum's experience in this interview).
But, on the other hand, if these challenges are overcome, the museum will gain multiple benefits, starting with the increase in visibility and the possibilities of its reuse to create valuable products and services.
Blog
The opening of data related to academic and research work entails multiple advantages, such as the improvement of transparency, the possibilities of replicating studies to verify their validity or greater visibility and impact that boost the recognition of the researcher. In this sense, Law 14/2011, of June 1, on Science, Technology and Innovation highlights the need to boost open access to research content, including mandatory when research has been funded with public funds.
This situation creates a series of challenges for researchers in fields such as humanities, who often lack the technical knowledge and resources necessary to publish their work in accessible, open, free and updated formats. Therefore, they often hire technical collaborators outside the research.
In order to provide a solution to this situation, the National Distance Education University (UNED) created LINHD, a research centre in Digital Humanities. LINHD - whose acronym means Laboratory of Innovation in Digital Humanities - seeks to create a new framework with interdisciplinary and hybrid work teams, with experts in technical and humanities areas who collaborate to foster innovation and share ideas. It also offers training, and advisory, consulting and technological services.
LINHD is one of the key elements of the dialogue in the Digital Humanities and a pioneer centre in Spain in this area. And it is because it deals with fundamental matters for the development of new technologies, competitiveness and productivity of humanities.
The laboratory started from an initiative that aimed to digitally connect the research data of the university itself, in order to improve transparency and visualize them through linked data technology (UNEDATA project), but soon grew by hosting and developing multiple projects and services, with institutions such as the Goethe Institute in Germany, the Thyssen Museum or the National Library. Thus, LINHD become the first digital humanities research centre in the Hispanic field of international reference and unique in its characteristics.
Through this philosophy, technology projects applied to the humanities are promoted, with special emphasis on fields such as art, philosophy, history, geography or education. This has led to projects that range from digital editions or visualizations of results to museums and virtual libraries.
In addition, the laboratory has been recognized as Clarin-K centre together with two centres of the UPF and the UPV, constituting the first “Knowledge Centre” of an ERIC-European Research Infrastructure Consortium in Spain.
LINHD también colabora con la Infraestructura de Investigación Digital en Artes y Humanidades DARIAH, que busca mejorar y desarrollar la investigación digital de humanidades en Europa.
Noticia
Every January 1, new writers, painters, musicians and artists from all areas enter the public domain. This means that their artistic works may be edited, reproduced or disseminated publicly, without the restrictions established by copyright.
In Spain, artistic works enter the public domain after 70 years after the death of their author, in accordance with the intellectual property law of 1987. However, for authors who died before that year, the term will be 80 years. Therefore, this year the works of those authors who died in 1939 enter the public domain.
The BNE and the free access to intellectual heritage
Each year, the National Library of Spain studies, publishes and digitizes the work of authors who are part of its catalogue and that year enter into the public domain. This year the list consists of 181 authors, among them Antonio Machado, Ciro Bayo or Agustín Espinosa. The works of these authors are available in the Hispanic Digital Library, the portal that gives access to the digitalized funds of the BNE.
The list of authors in the public domain is open and collaborative, so that any interested person can collaborate in its elaboration by proposing Spanish authors with works in the catalogue of the National Library of Spain, who died between 1900 and 1939, and that are not yet included in the listings.
In addition, in order to enrich the information, the BNE has launched a collaborative project entitled “From the public domain: Spanish authors who died in 1939”, within its comunidad.bne.es platform, developed in collaboration with Red.es. Users who wish to share their knowledge and experience will help increase the data that the BNE has related to these authors, adding information such as his/her place and year of birth, occupation and / or biographical sketch. This project joins others as “La mujer del XIX [escrito en femenino]”, where different authors prestige items are rescued as Blanca de los Rios, Pardo Bazán or Patrocinio Biedma, integrated into the work “Spanish, American and Lusitanas women, painted by themselves”, so users can sort the stereotypes presented, catalogue illustrations that accompany many of the texts and complete data on their authors.
With the available information, the BNE has created complete files, which have been published as open and reusable datasets, in different formats, in the data catalog.gob.es.
This action is part of the BNE's strategy for opening and promoting the reuse of its data and digital collections, along with other projects such as BNEscolar.