Application
Precioil.es is a web platform where it is possible to consult information about gas stations located in Spain and their current prices.
Through a search engine, it is possible to locate gas stations in a given area and select the type of fuel and brand. In the information of each of the stations you can find not only the prices, but also the address, opening hours, location and other details of interest, as well as the price history of the last week.
Precioil.es also shows the evolution of the average prices per type of fuel in Spain for the last seven days, the data of the daily average prices per brand and the average prices per province. It also has a directory of all service stations in the country.
Open data on fuel prices in Spain have been used for its development.
The open data sources are:
Documentación
1. Introduction
Visualizations are graphical representations of data that allow you to communicate, in a simple and effective way, the information linked to it. The visualization possibilities are very extensive, from basic representations such as line graphs, bar graphs or relevant metrics, to visualizations configured on interactive dashboards.
In the section of “Step-by-step visualizations” we are periodically presenting practical exercises making use of open data available in datos.gob.es or other similar catalogs. They address and describe in a simple way the steps necessary to obtain the data, carry out the transformations and analyses that are pertinent to finally obtain conclusions as a summary of this information.
In each of these hands-on exercises, conveniently documented code developments are used, as well as free-to-use tools. All generated material is available for reuse in the datos.gob.es GitHub repository.
Accede al repositorio del laboratorio de datos en Github.
Ejecuta el código de pre-procesamiento de datos sobre Google Colab.
2. Objetive
The main objective of this exercise is to show how to carry out, in a didactic way, a predictive analysis of time series based on open data on electricity consumption in the city of Barcelona. To do this, we will carry out an exploratory analysis of the data, define and validate the predictive model, and finally generate the predictions together with their corresponding graphs and visualizations.
Predictive time series analytics are statistical and machine learning techniques used to forecast future values in datasets that are collected over time. These predictions are based on historical patterns and trends identified in the time series, with their primary purpose being to anticipate changes and events based on past data.
The initial open dataset consists of records from 2019 to 2022 inclusive, on the other hand, the predictions will be made for the year 2023, for which we do not have real data.
Once the analysis has been carried out, we will be able to answer questions such as the following:
- What is the future prediction of electricity consumption?
- How accurate has the model been with the prediction of already known data?
- Which days will have maximum and minimum consumption based on future predictions?
- Which months will have a maximum and minimum average consumption according to future predictions?
These and many other questions can be solved through the visualizations obtained in the analysis, which will show the information in an orderly and easy-to-interpret way.
3. Resources
3.1. Datasets
The open datasets used contain information on electricity consumption in the city of Barcelona in recent years. The information they provide is the consumption in (MWh) broken down by day, economic sector, zip code and time slot.
These open datasets are published by Barcelona City Council in the datos.gob.es catalogue, through files that collect the records on an annual basis. It should be noted that the publisher updates these datasets with new records frequently, so we have used only the data provided from 2019 to 2022 inclusive.
These datasets are also available for download from the following Github repository.
3.2. Tools
To carry out the analysis, the Python programming language written on a Jupyter Notebook hosted in the Google Colab cloud service has been used.
"Google Colab" or, also called Google Colaboratory, is a cloud service from Google Research that allows you to program, execute and share code written in Python or R on top of a Jupyter Notebook from your browser, so it requires no configuration. This service is free of charge.
The Looker Studio tool was used to create the interactive visualizations.
"Looker Studio", formerly known as Google Data Studio, is an online tool that allows you to make interactive visualizations that can be inserted into websites or exported as files.
If you want to know more about tools that can help you in data processing and visualization, you can refer to the "Data processing and visualization tools" report.
4. Predictive time series analysis
Predictive time series analysis is a technique that uses historical data to predict future values of a variable that changes over time. Time series is data that is collected at regular intervals, such as days, weeks, months, or years. It is not the purpose of this exercise to explain in detail the characteristics of time series, as we focus on briefly explaining the prediction model. However, if you want to know more about it, you can consult the following manual.
This type of analysis assumes that the future values of a variable will be correlated with historical values. Using statistical and machine learning techniques, patterns in historical data can be identified and used to predict future values.
The predictive analysis carried out in the exercise has been divided into five phases; data preparation, exploratory data analysis, model training, model validation, and prediction of future values), which will be explained in the following sections.
The processes described below are developed and commented on in the following Notebook executable from Google Colab along with the source code that is available in our Github account.
It is advisable to run the Notebook with the code at the same time as reading the post, since both didactic resources are complementary in future explanations.
4.1 Data preparation
This section can be found in point 1 of the Notebook.
In this section, the open datasets described in the previous points that we will use in the exercise are imported, paying special attention to obtaining them and validating their content, ensuring that they are in the appropriate and consistent format for processing and that they do not contain errors that could condition future steps.
4.2 Exploratory Data Analysis (EDA)
This section can be found in point 2 of the Notebook.
In this section we will carry out an exploratory data analysis (EDA), in order to properly interpret the source data, detect anomalies, missing data, errors or outliers that could affect the quality of subsequent processes and results.
Then, in the following interactive visualization, you will be able to inspect the data table with the historical consumption values generated in the previous point, being able to filter by specific period. In this way, we can visually understand the main information in the data series.
Once you have inspected the interactive visualization of the time series, you will have observed several values that could potentially be considered outliers, as shown in the figure below. We can also numerically calculate these outliers, as shown in the notebook.

Once the outliers have been evaluated, for this year it has been decided to modify only the one registered on the date "2022-12-05". To do this, the value will be replaced by the average of the value recorded the previous day and the day after.
The reason for not eliminating the rest of the outliers is because they are values recorded on consecutive days, so it is assumed that they are correct values affected by external variables that are beyond the scope of the exercise. Once the problem detected with the outliers has been solved, this will be the time series of data that we will use in the following sections.
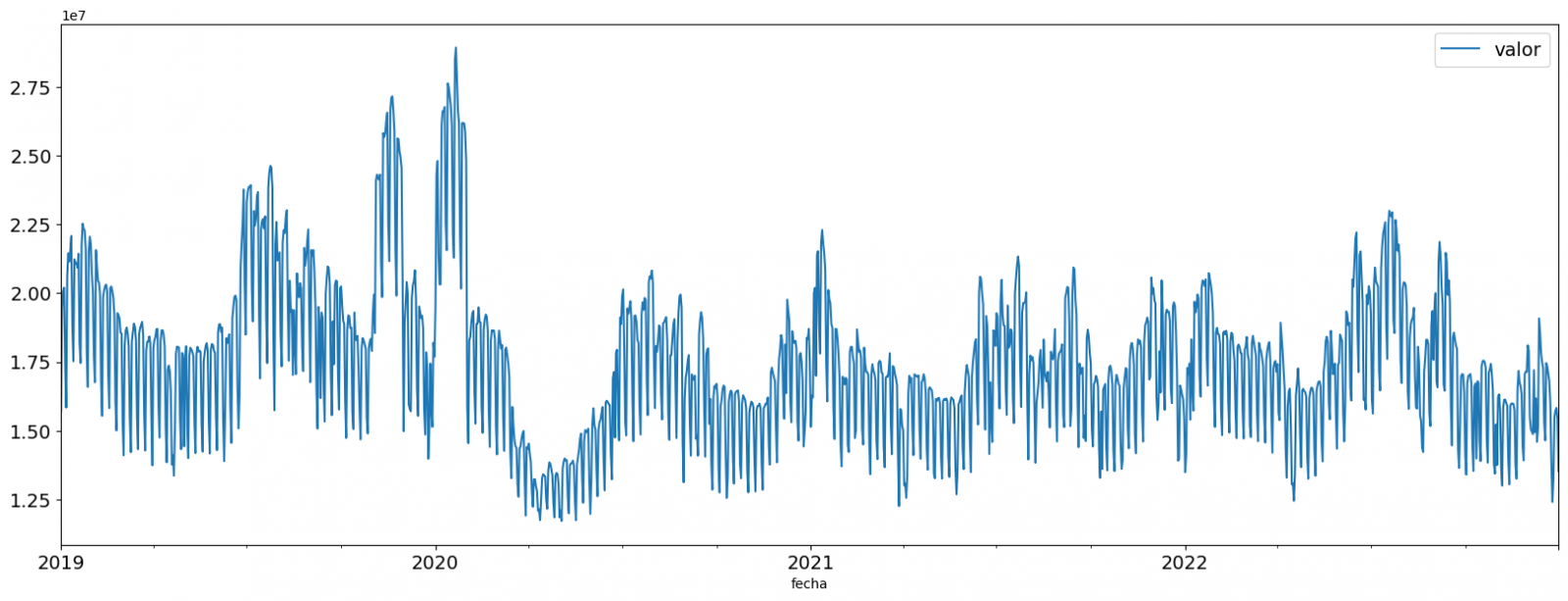
Figure 2. Time series of historical data after outliers have been processed.
If you want to know more about these processes, you can refer to the Practical Guide to Introduction to Exploratory Data Analysis.
4.3 Model training
This section can be found in point 3 of the Notebook.
First, we create within the data table the temporal attributes (year, month, day of the week, and quarter). These attributes are categorical variables that help ensure that the model is able to accurately capture the unique characteristics and patterns of these variables. Through the following box plot visualizations, we can see their relevance within the time series values.
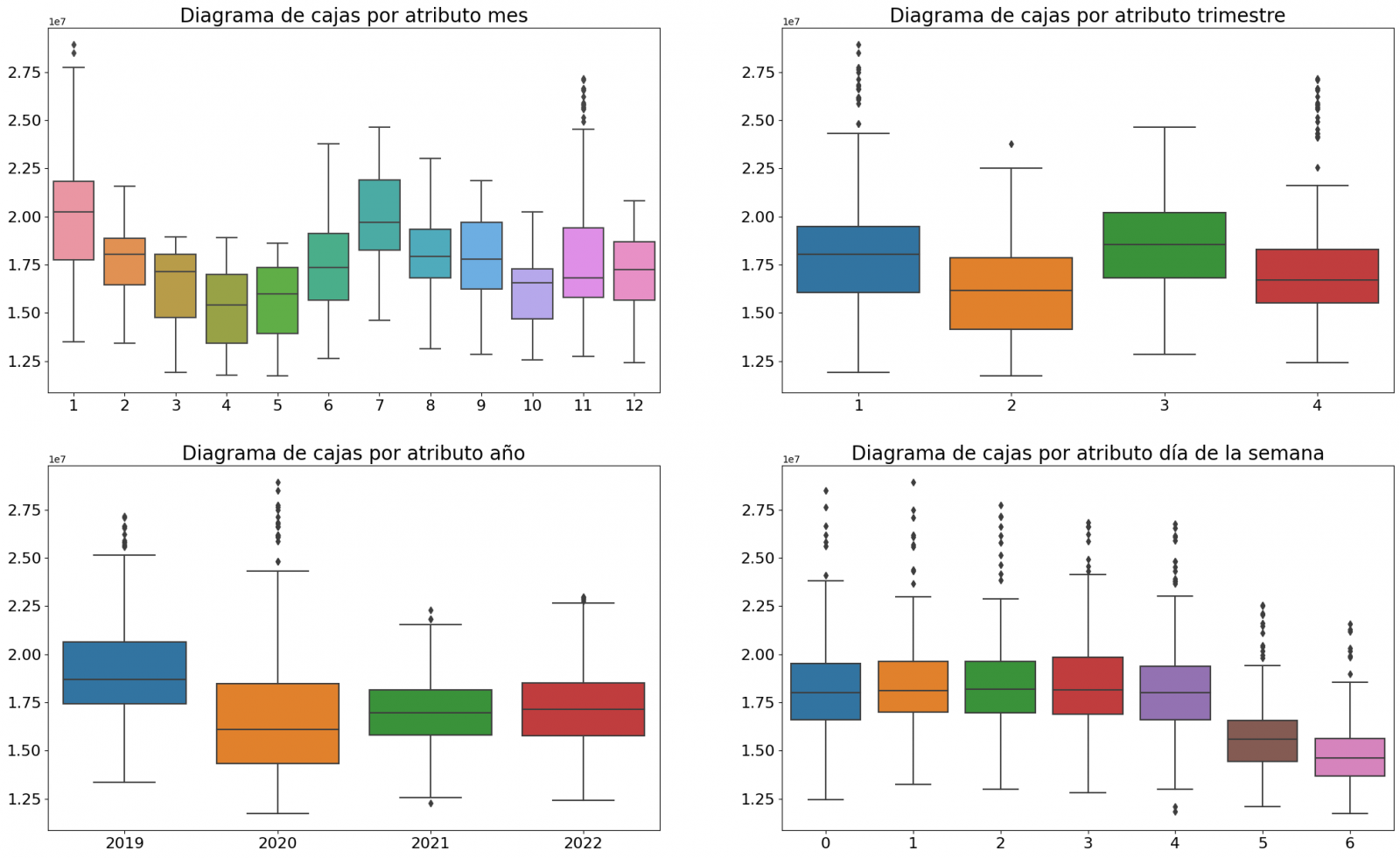
Figure 3. Box Diagrams of Generated Temporal Attributes
We can observe certain patterns in the charts above, such as the following:
- Weekdays (Monday to Friday) have a higher consumption than on weekends.
- The year with the lowest consumption values is 2020, which we understand is due to the reduction in service and industrial activity during the pandemic.
- The month with the highest consumption is July, which is understandable due to the use of air conditioners.
- The second quarter is the one with the lowest consumption values, with April standing out as the month with the lowest values.
Next, we divide the data table into training set and validation set. The training set is used to train the model, i.e., the model learns to predict the value of the target variable from that set, while the validation set is used to evaluate the performance of the model, i.e., the model is evaluated against the data from that set to determine its ability to predict the new values.
This splitting of the data is important to avoid overfitting, with the typical proportion of the data used for the training set being 70% and the validation set being approximately 30%. For this exercise we have decided to generate the training set with the data between "01-01-2019" to "01-10-2021", and the validation set with those between "01-10-2021" and "31-12-2022" as we can see in the following graph.
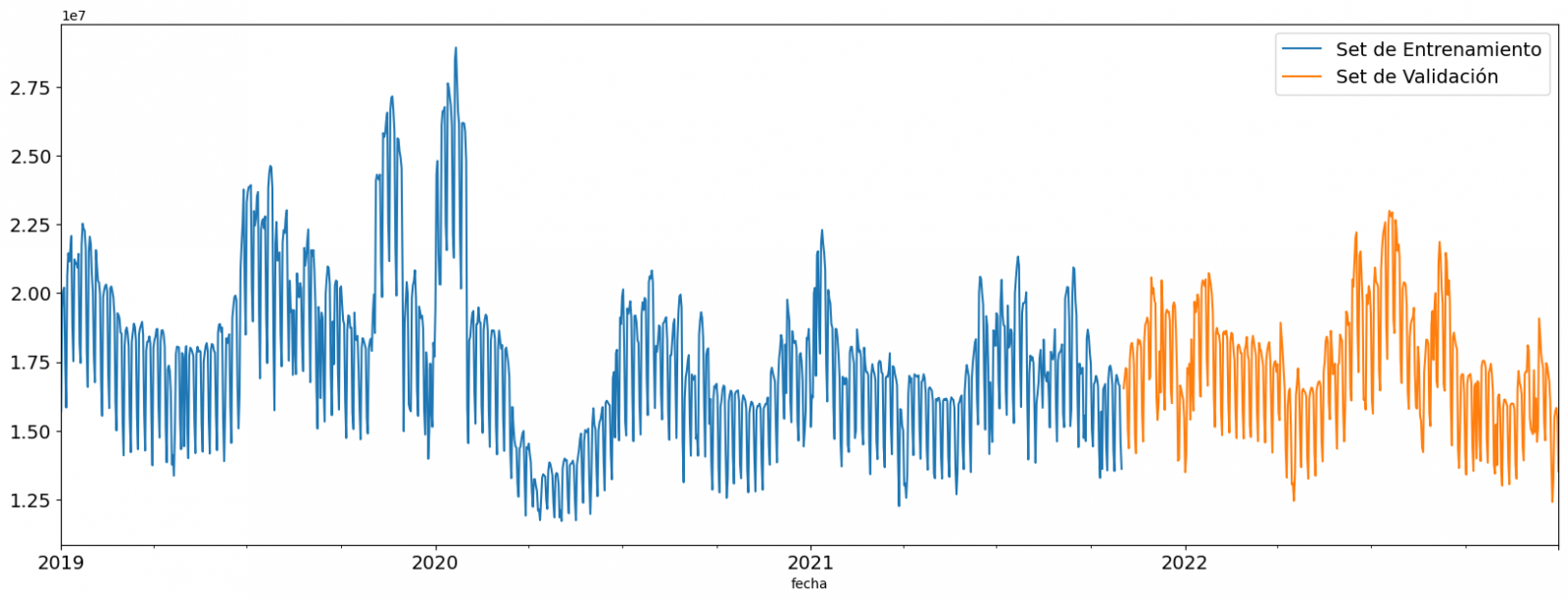
Figure 4. Historical data time series divided into training set and validation set
For this type of exercise, we have to use some regression algorithm. There are several models and libraries that can be used for time series prediction. In this exercise we will use the "Gradient Boosting" model, a supervised regression model that is a machine learning algorithm used to predict a continuous value based on the training of a dataset containing known values for the target variable (in our example the variable "value") and the values of the independent variables (in our exercise the temporal attributes).
It is based on decision trees and uses a technique called "boosting" to improve the accuracy of the model, being known for its efficiency and ability to handle a variety of regression and classification problems.
Its main advantages are the high degree of accuracy, robustness and flexibility, while some of its disadvantages are its sensitivity to outliers and that it requires careful optimization of parameters.
We will use the supervised regression model offered in the XGBBoost library, which can be adjusted with the following parameters:
- n_estimators: A parameter that affects the performance of the model by indicating the number of trees used. A larger number of trees generally results in a more accurate model, but it can also take more time to train.
- early_stopping_rounds: A parameter that controls the number of training rounds that will run before the model stops if performance in the validation set does not improve.
- learning_rate: Controls the learning speed of the model. A higher value will make the model learn faster, but it can lead to overfitting.
- max_depth: Control the maximum depth of trees in the forest. A higher value can provide a more accurate model, but it can also lead to overfitting.
- min_child_weight: Control the minimum weight of a sheet. A higher value can help prevent overfitting.
- Gamma: Controls the amount of expected loss reduction needed to split a node. A higher value can help prevent overfitting.
- colsample_bytree: Controls the proportion of features that are used to build each tree. A higher value can help prevent overfitting.
- Subsample: Controls the proportion of the data that is used to construct each tree. A higher value can help prevent overfitting.
These parameters can be adjusted to improve model performance on a specific dataset. It's a good idea to experiment with different values of these parameters to find the value that provides the best performance in your dataset.
Finally, by means of a bar graph, we will visually observe the importance of each of the attributes during the training of the model. It can be used to identify the most important attributes in a dataset, which can be useful for model interpretation and feature selection.
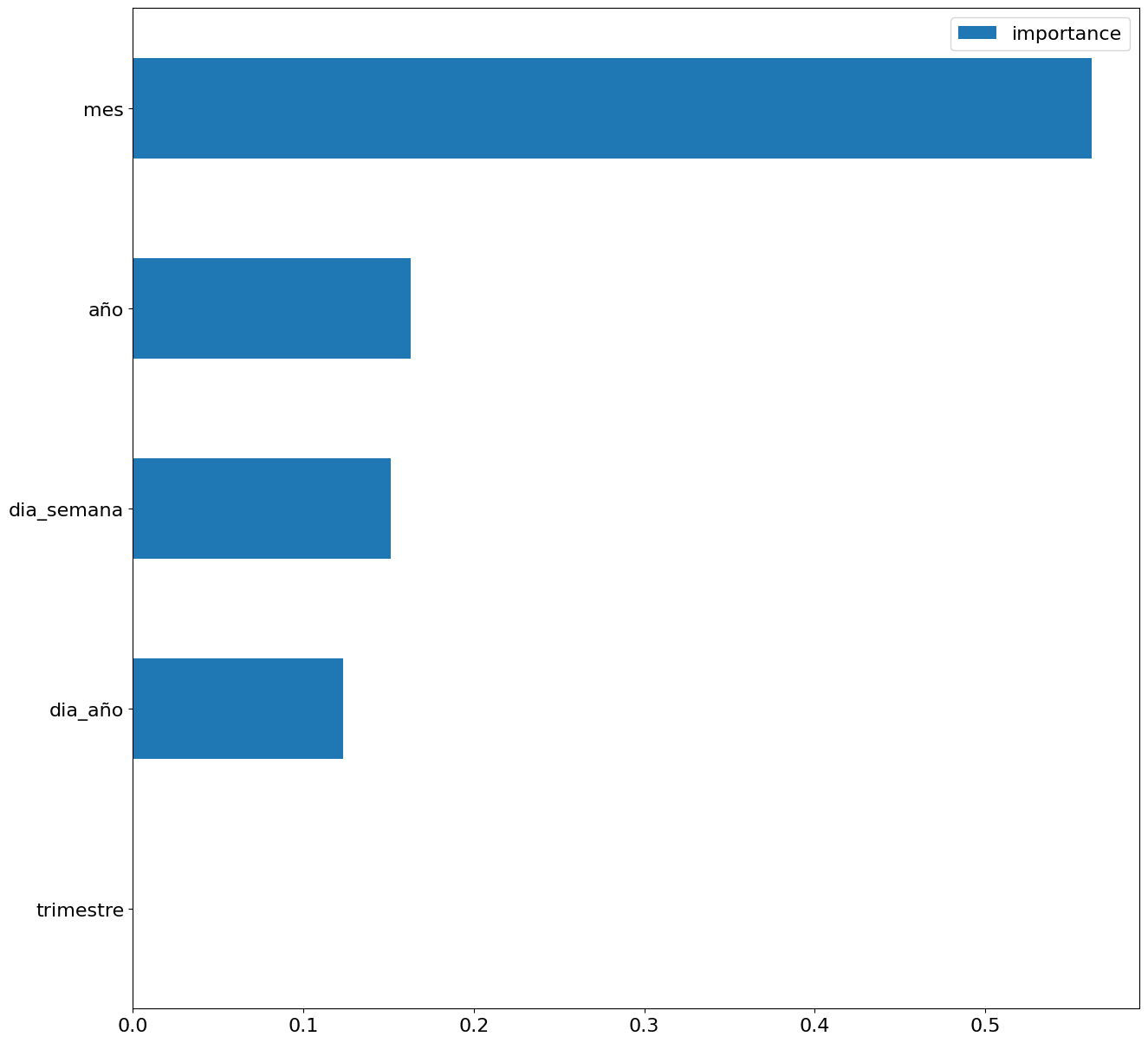
Figure 5. Bar Chart with Importance of Temporal Attributes
4.4 Model training
This section can be found in point 4 of the Notebook.
Once the model has been trained, we will evaluate how accurate it is for the known values in the validation set.
We can visually evaluate the model by plotting the time series with the known values along with the predictions made for the validation set as shown in the figure below.
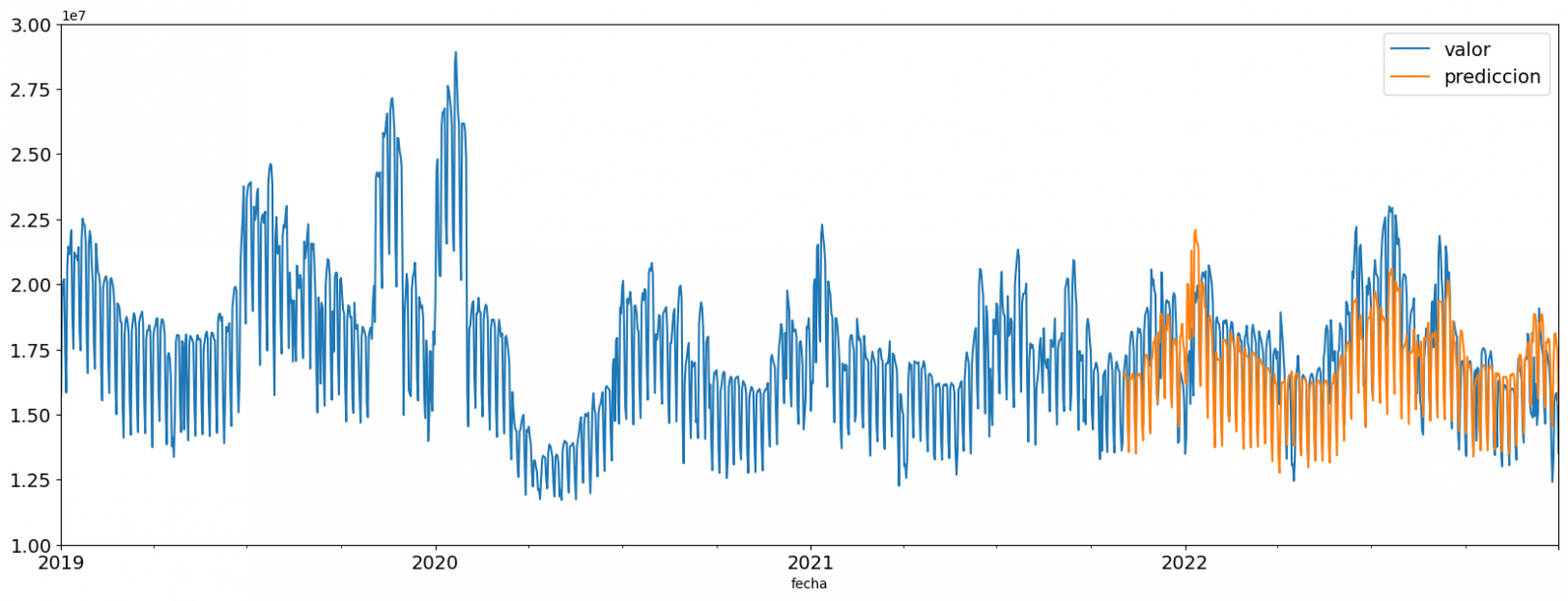
Figure 6. Time series with validation set data next to prediction data.
We can also numerically evaluate the accuracy of the model using different metrics. In this exercise, we have chosen to use the mean absolute percentage error (ASM) metric, which has been 6.58%. The accuracy of the model is considered high or low depending on the context and expectations in such a model, generally an ASM is considered low when it is less than 5%, while it is considered high when it is greater than 10%. In this exercise, the result of the model validation can be considered an acceptable value.
If you want to consult other types of metrics to evaluate the accuracy of models applied to time series, you can consult the following link.
4.5 Predictions of future values
This section can be found in point 5 of the Notebook.
Once the model has been generated and its MAPE = 6.58% performance has been evaluated, we will apply this model to all known data, in order to predict the unknown electricity consumption values for 2023.
First of all, we retrain the model with the known values until the end of 2022, without dividing it into a training and validation set. Finally, we calculate future values for the year 2023.

Figure 7. Time series with historical data and prediction for 2023
In the following interactive visualization you can see the predicted values for the year 2023 along with their main metrics, being able to filter by time period.
Improving the results of predictive time series models is an important goal in data science and data analytics. Several strategies that can help improve the accuracy of the exercise model are the use of exogenous variables, the use of more historical data or generation of synthetic data, optimization of parameters, ...
Due to the informative nature of this exercise and to promote the understanding of less specialized readers, we have proposed to explain the exercise in a way that is as simple and didactic as possible. You may come up with many ways to optimize your predictive model to achieve better results, and we encourage you to do so!
5. Conclusions of the exercise
Once the exercise has been carried out, we can see different conclusions such as the following:
- The maximum values for consumption predictions in 2023 are given in the last half of July, exceeding values of 22,500,000 MWh
- The month with the highest consumption according to the predictions for 2023 will be July, while the month with the lowest average consumption will be November, with a percentage difference between the two of 25.24%
- The average daily consumption forecast for 2023 is 17,259,844 MWh, 1.46% lower than that recorded between 2019 and 2022.
We hope that this exercise has been useful for you to learn some common techniques in the study and analysis of open data. We'll be back to show you new reuses. See you soon!
Application
This application is a tool that presents in real time the costs of electricity in Spain for the Regulated Tariff PVPC (Voluntary Price for Small Consumers). The objective is that any user can check the hours with the lowest electricity costs in order to save on their electricity bill.
Different graphs of the price of electricity hour by hour are offered, as well as useful data for users obtained from the open API of ESIOS (Red Eléctrica de España). All these graphs and data show information about fluctuations in the price of electricity in Spain.
The user can easily find out at what time electricity is cheapest at any given moment and the exact price, as well as an estimate of the next day's prices as of 8:30 p.m. the previous day.
Open data sources are:
-
Data from Red Eléctrica: https://api.esios.ree.es/
Blog
Aspects as relevant to our society as environmental sustainability, climate change mitigation or energy security have led to the energy transition taking on a very important role in the daily lives of nations, private and public organisations, and even in our daily lives as citizens of the world. The energy transition refers to the transformation of our energy production and consumption patterns towards less dependence on fossil fuels through low or zero carbon sources, such as renewable sources.
The measures needed to achieve a real transition are far-reaching and therefore complex. In this process, open data initiatives can contribute enormously by facilitating public awareness, improving the standardisation of metrics and mechanisms to measure the impact of measures taken to mitigate climate change globally, promoting the transparency of governments and companies in terms ofCO2emission reductions, or increasing the participation of citizens in the process citizen and scientific and scientific participation for the creation of new digital solutions, as well as the advancement of knowledge and innovation.
What initiatives are providing guidance?
The best way to understand how open data helps us to observe the effects of highCO2 emissions as well as the impact of different measures taken by all kinds of actors in favour of the energy transition is by looking at real examples.
The Energy Institute (IE), an organisation dedicated to accelerating the energy transition, publishes its annual World Energy Statistical Review, which in its latest version includes up to 80 datasets, some dating back as far as 1965, describing the behaviour of different energy sources as well as the use of key minerals in the transition to sustainability. Using its own online reporting tool to represent those variables we want to analyse, we can see how, despite the exponential growth of renewable energy generation in recent years (figure 1), there is still an increasing trend inCO2emissions (figure 2), although not as drastic as in the first decade of the 2000s.
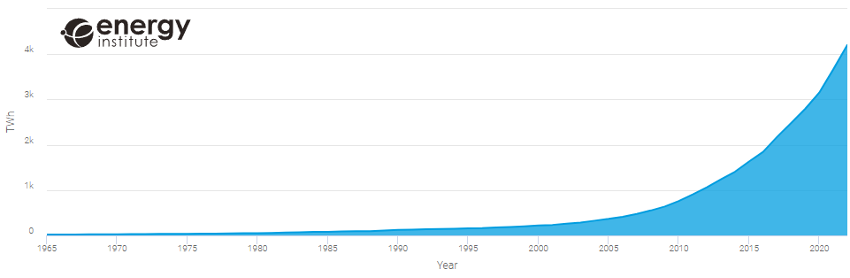
Figure 1: Evolution of global renewable generation in TWh.
Source: Energy Institute Statistical Review 2023
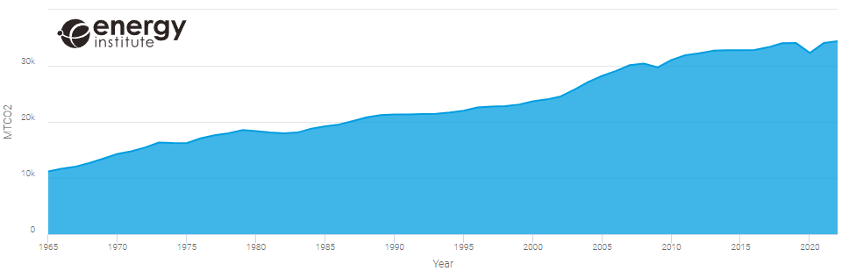
Figure 2: Evolution of global CO2 emissions in MTCO2
Source: Energy Institute Statistical Review 2023
Another international energy transition driver that offers an interesting catalogue of data is the International Energy Agency (IEA). In this case we can find more than 70 data sets, not all of them open without subscription, which include both historical energy data and future projections in order to reach the Net Zero 2050targets. The following is an example of this data taken from their library of graphical displays, in particular the expected evolution of energy generation to reach the Net Zero targets in 2050. In Figure 3 we can examine how, in order to achieve these targets, two main simultaneous processes must occur: reducing the total annual energy demand and progressively moving to lowerCO2emitting generation sources.
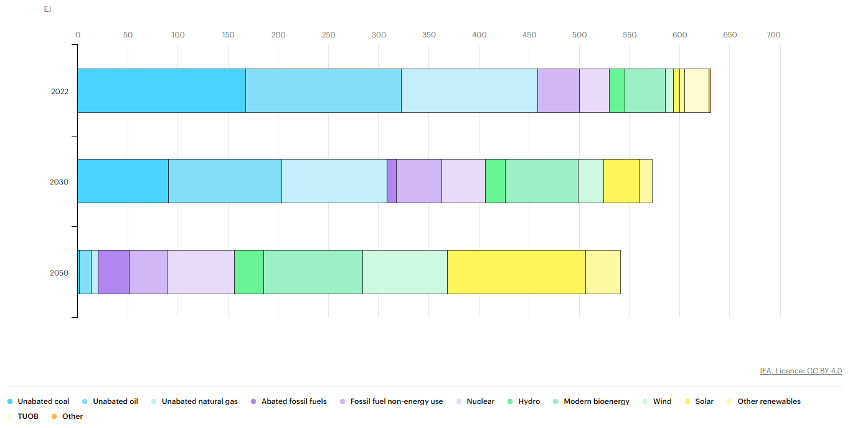
Figure 3: Energy generation 2020-2050 to achieve Net Zero emissions targets in Exajulios.
Source: IEA, Total energy supply by source in the Net Zero Scenario, 2022-2050, IEA, Paris, IEA. Licence: CC BY 4.0
To analyse in more detail how these two processes must happen in order to achieve the Net Zero objectives, IEA offers another very relevant visualisation (figure 4). In it, we can see how, in order to achieve the reduction of the total annual energy demand, it is necessary to make accelerated progress in the decade 2025-2035, thanks to measures such as electrification, technical improvements in the efficiency of energy systems or demand reduction. In this way, a reduction of close to 100EJs per year should be achieved by 2035, which should then be maintained throughout the rest of the period analysed. To try to understand the significance of these measures and taking as a reference the average electricity consumption of Spanish households, some 3,500kWh/year, the desired annual reduction would be equivalent to avoiding the consumption of some 7,937,000,000 households or, in other words, to avoiding in one year the electricity consumption that all Spanish households would consume for 418 years.
ith respect to the transition to lower emission sources, we can see in this figure how the expectation is that solar energy will be the leader in growth, ahead of wind energy, while unabated coal (energy from burning coal without usingCO2capture systems) is the source whose use is expected to be reduced the most.
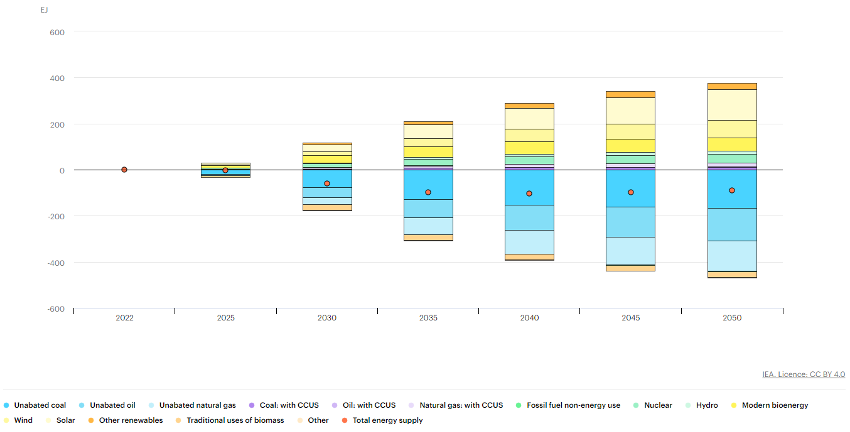
Figure 4: Changes in energy generation 2020-2050 to achieve Net Zero emissions targets in Exajulios.
Source: IEA, Changes in total energy supply by source in the Net Zero Scenario, 2022-2050, IEA, Paris, IEA. Licence: CC BY 4.0
Other interesting open data initiatives from an energy transition perspective are the catalogues of the European Commission (more than 1.5 million datasets) and of the Spanish Government through datos.gob.es (more than 70 thousand datasets). Both provide open datasets on topics such as environment, energy or transport.
In both portals, we can find a wide variety of information, such as energy consumption of cities and companies, authorised projects for the construction of renewable generation facilities or the evolution of hydrocarbon prices.
Finally, the REDatainitiative of Red Eléctrica Española (REE)offers a data area with a wide range of information related to the Spanish electricity system. Among others, information related to electricity generation, markets or the daily behaviour of the system.
Figure 5: Sections of information provided from REData
Source: El sistema eléctrico: Guía de uso de REData, November 2022. Red Eléctrica Española.
The website also offers an interactive viewer for consulting and downloading data, as shown below for electricity generation, as well as a programmatic interface (API - Application Programming Interface) for consulting the data repository provided by this entity.

Figure 6: REE REData Platform
Source: https://www.ree.es/es/datos/aldia
What conclusions can we draw from this movement?
As we have been able to observe, the enormous concern about the energy transition has motivated multiple organisations of different types to make data openly available for analysis and use by other organisations and the general public. Entities as varied as the Energy Institute, the International Energy Agency, the European Commission, the Spanish Government and Red Eléctrica Española publish valuable information through their data portals in search of greater transparency and awareness.
In this short article we have been able to examine how these data have been of great help to better understand the historical evolution ofCO2emissions, the installed wind power capacity or the expectations of energy demand to reach the Net Zero targets. Open data is a very good tool to improve the understanding of the need and depth of the energy transition, as well as the progress of the measures that are progressively being taken by multiple entities around the world, and we expect to see an increasing number of initiatives along these lines.
Content prepared by Juan Benavente, senior industrial engineer and expert in technologies linked to the data economy. The contents and points of view reflected in this publication are the sole responsibility of the author.
Blog
Open data is a valuable tool for making informed decisions that encourage the success of a process and enhance its effectiveness. From a sectorial perspective, open data provides relevant information about the legal, educational, or health sectors. All of these, along with many other areas, utilize open sources to measure improvement compliance or develop tools that streamline work for professionals.
The benefits of using open data are extensive, and their variety goes hand in hand with technological innovation: every day, more opportunities arise to employ open data in the development of innovative solutions. An example of this can be seen in urban development aligned with the sustainability values advocated by the United Nations (UN).
Cities cover only 3% of the Earth's surface; however, they emit 70% of carbon emissions and consume over 60% of the world's resources, according to the UN. In 2023, more than half of the global population lives in cities, and this figure is projected to keep growing. By 2030, it is estimated that over 5 billion people would live in cities, meaning more than 60% of the world's population.
Despite this trend, infrastructures and neighborhoods do not meet the appropriate conditions for sustainable development, and the goal is to "Make cities and human settlements inclusive, safe, resilient, and sustainable," as recognized in Sustainable Development Goal (SDG) number 11. Proper planning and management of urban resources are significant factors in creating and maintaining sustainability-based communities. In this context, open data plays a crucial role in measuring compliance with this SDG and thus achieving the goal of sustainable cities.
In conclusion, open data stands as a fundamental tool for the strengthening and progress of sustainable city development.
In this infographic, we have gathered use cases that utilize sets of open data to monitor and/or enhance energy efficiency, transportation and urban mobility, air quality, and noise levels. Issues that contribute to the proper functioning of urban centers.
Click on the infographic to view it in full size.
