Blog
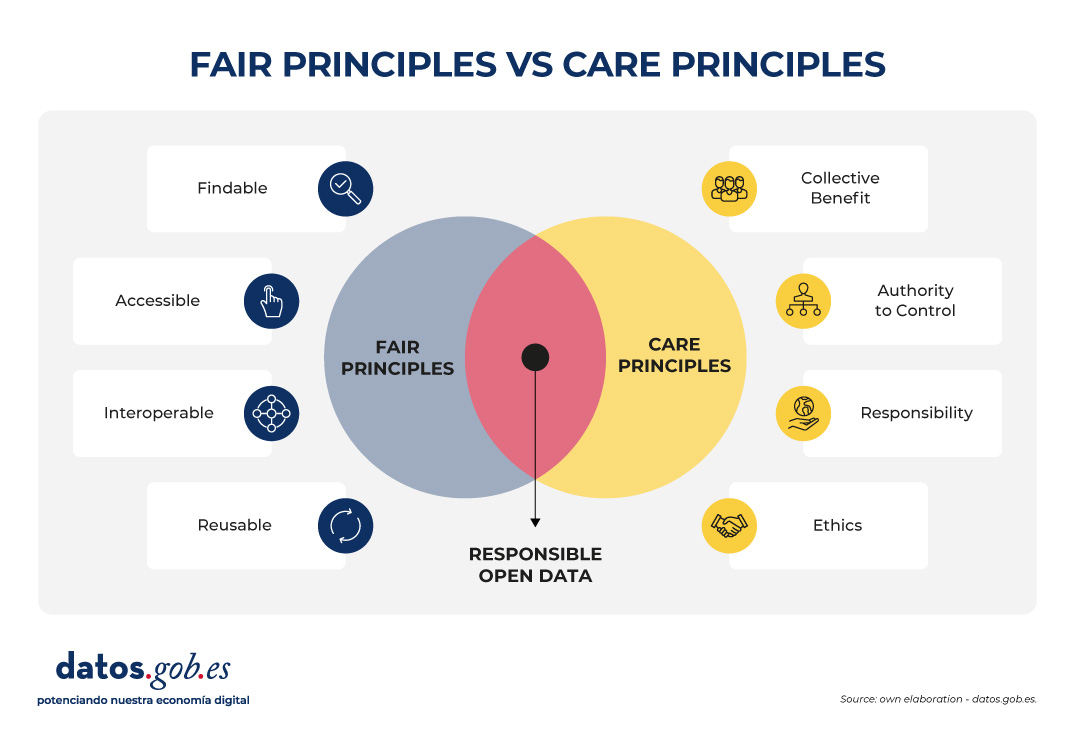
In recent years, open data initiatives have transformed the way in which both public institutions and private organizations manage and share information. The adoption of FAIR (Findable, Accessible, Interoperable, Reusable) principles has been key to ensuring that data generates a positive impact, maximizing its availability and reuse.
However, in contexts of vulnerability (such as indigenous peoples, cultural minorities or territories at risk) there is a need to incorporate an ethical framework that guarantees that the opening of data does not lead to harm or deepen inequalities. This is where the CARE principles (Collective Benefit, Authority to Control, Responsibility, Ethics), proposed by the Global Indigenous Data Alliance (GIDA), come into play, which complement and enrich the FAIR approach.
It is important to note that although CARE principles arise in the context of indigenous communities (to ensure indigenous peoples' effective sovereignty over their data and their right to generate value in accordance with their own values), these can be extrapolated to other different scenarios. In fact, these principles are very useful in any situation where data is collected in territories with some type of social, territorial, environmental or even cultural vulnerability.
This article explores how CARE principles can be integrated into open data initiatives generating social impact based on responsible use that does not harm vulnerable communities.
The CARE principles in detail
The CARE principles help ensure that open data initiatives are not limited to technical aspects, but also incorporate social, cultural and ethical considerations. Specifically, the four CARE principles are as follows:
-
Collective Benefit: data must be used to generate a benefit that is shared fairly between all parties involved. In this way, open data should support the sustainable development, social well-being and cultural strengthening of a vulnerable community, for example, by avoiding practices related to open data that only favour third parties.
-
Authority to Control: vulnerable communities have the right to decide how the data they generate is collected, managed, shared, and reused. This principle recognises data sovereignty and the need to respect one’s own governance systems, rather than imposing external criteria.
-
Responsibility: those who manage and reuse data must act responsibly towards the communities involved, recognizing possible negative impacts and implementing measures to mitigate them. This includes practices such as prior consultation, transparency in the use of data, and the creation of accountability mechanisms.
-
Ethics: the ethical dimension requires that the openness and re-use of data respects the human rights, cultural values and dignity of communities. It is not only a matter of complying with the law, but of going further, applying ethical principles through a code of ethics.
Together, these four principles provide a guide to managing open data more fairly and responsibly, respecting the sovereignty and interests of the communities to which that data relates.
CARE and FAIR: complementary principles for open data that transcend
The CARE and FAIR principles are not opposite, but operate on different and complementary levels:
-
FAIR focuses on making data consumption technically easier.
-
CARE introduces the social and ethical dimension (including cultural considerations of specific vulnerable communities).
The FAIR principles focus on the technical and operational dimensions of data. In other words, data that comply with these principles are easily locatable, available without unnecessary barriers and with unique identifiers, use standards to ensure interoperability, and can be used in different contexts for purposes other than those originally intended.
However, the FAIR principles do not directly address issues of social justice, sovereignty or ethics. In particular, these principles do not contemplate that data may represent knowledge, resources or identities of communities that have historically suffered exclusion or exploitation or of communities related to territories with unique environmental, social or cultural values. To do this, the CARE principles, which complement the FAIR principles, can be used, adding an ethical and community governance foundation to any open data initiative.
In this way, an open data strategy that aspires to be socially just and sustainable must articulate both principles. FAIR without CARE risks making collective rights invisible by promoting unethical data reuse. On the other hand, CARE without FAIR can limit the potential for interoperability and reuse, making the data useless to generate a positive benefit in a vulnerable community or territory.
An illustrative example is found in the management of data on biodiversity in a protected natural area. While the FAIR principles ensure that data can be integrated with various tools to be widely reused (e.g., in scientific research), the CARE principles remind us that data on species and the territories in which they live can have direct implications for communities who live in (or near) that protected natural area. For example, making public the exact points where endangered species are found in a protected natural area could facilitate their illegal exploitation rather than their conservation, which requires careful definition of how, when and under what conditions this data is shared.
Let's now see how in this example the CARE principles could be met:
-
First, biodiversity data should be used to protect ecosystems and strengthen local communities, generating benefits in the form of conservation, sustainable tourism or environmental education, rather than favoring isolated private interests (i.e., collective benefit principle).
-
Second, communities living near or dependent on the protected natural area have the right to decide how sensitive data is managed, for example, by requiring that the location of certain species not be published openly or published in an aggregated manner (i.e., principle of authority).
-
On the other hand, the people in charge of the management of these protected areas of the park must act responsibly, establishing protocols to avoid collateral damage (such as poaching) and ensuring that the data is used in a way that is consistent with conservation objectives (i.e. the principle of responsibility).
-
Finally, the openness of this data must be guided by ethical principles, prioritizing the protection of biodiversity and the rights of local communities over economic (or even academic) interests that may put ecosystems or the populations that depend on them at risk (principle of ethics).
Notably, several international initiatives, such as Indigenous Environmental Data Justice related to the International Indigenous Data Sovereignty Movement and the Research Data Alliance (RDA) through the Care Principles for Indigenous Data Governance, are already promoting the joint adoption of CARE and FAIR as the foundation for more equitable data initiatives.
Conclusions
Ensuring the FAIR principles is essential for open data to generate value through its reuse. However, open data initiatives must be accompanied by a firm commitment to social justice, the sovereignty of vulnerable communities, and ethics. Only the integration of the CARE principles together with the FAIR will make it possible to promote truly fair, equitable, inclusive and responsible open data practices.
Jose Norberto Mazón, Professor of Computer Languages and Systems at the University of Alicante. The contents and views reflected in this publication are the sole responsibility of the author.
Blog
The concept of data commons emerges as a transformative approach to the management and sharing of data that serves collective purposes and as an alternative to the growing number of macrosilos of data for private use. By treating data as a shared resource, data commons facilitate collaboration, innovation and equitable access to data, emphasising the communal value of data above all other considerations. As we navigate the complexities of the digital age - currently marked by rapid advances in artificial intelligence (AI) and the continuing debate about the challenges in data governance- the role that data commons can play is now probably more important than ever.
What are data commons?
The data commons refers to a cooperative framework where data is collected, governed and shared among all community participants through protocols that promote openness, equity, ethical use and sustainability. The data commons differ from traditional data-sharing models mainly in the priority given to collaboration and inclusion over unitary control.
Another common goal of the data commons is the creation of collective knowledge that can be used by anyone for the good of society. This makes them particularly useful in addressing today's major challenges, such as environmental challenges, multilingual interaction, mobility, humanitarian catastrophes, preservation of knowledge or new challenges in health and health care.
In addition, it is also increasingly common for these data sharing initiatives to incorporate all kinds of tools to facilitate data analysis and interpretation , thus democratising not only the ownership of and access to data, but also its use.
For all these reasons, data commons could be considered today as a criticalpublic digital infrastructure for harnessing data and promoting social welfare.
Principles of the data commons
The data commons are built on a number of simple principles that will be key to their proper governance:
- Openness and accessibility: data must be accessible to all authorised persons.
- Ethical governance: balance between inclusion and privacy.
- Sustainability: establish mechanisms for funding and resources to maintain data as a commons over time.
- Collaboration: encourage participants to contribute new data and ideas that enable their use for mutual benefit.
- Trust: relationships based on transparency and credibility between stakeholders.
In addition, if we also want to ensure that the data commons fulfil their role as public domain digital infrastructure, we must guarantee other additional minimum requirements such as: existence of permanent unique identifiers , documented metadata , easy access through application programming interfaces (APIs), portability of the data, data sharing agreements between peers and ability to perform operations on the data.
The important role of the data commons in the age of Artificial Intelligence
AI-driven innovation has exponentially increased the demand for high-quality, diverse data sets a relatively scarce commodityat a large scale that may lead to bottlenecks in the future development of the technology and, at the same time, makes data commons a very relevant enabler for a more equitable AI. By providing shared datasets governed by ethical principles, data commons help mitigate common risks such as risks, data monopolies and unequal access to the benefits of AI.
Moreover, the current concentration of AI developments also represents a challenge for the public interest. In this context, the data commons hold the key to enable a set of alternative, public and general interest-oriented AI systems and applications, which can contribute to rebalancing this current concentration of power. The aim of these models would be to demonstrate how more democratic, public interest-oriented and purposeful systems can be designed based on public AI governance principles and models.
However, the era of generative AI also presents new challenges for data commons such as, for example and perhaps most prominently, the potential risk of uncontrolled exploitation of shared datasets that could give rise to new ethical challenges due to data misuse and privacy violations.
On the other hand, the lack of transparency regarding the use of the data commons by the AI could also end up demotivating the communities that manage them, putting their continuity at risk. This is due to concerns that in the end their contribution may be benefiting mainly the large technology platforms, without any guarantee of a fairer sharing of the value and impact generated as originally intended".
For all of the above, organisations such as Open Future have been advocating for several years now for Artificial Intelligence to function as a common good, managed and developed as a digital public infrastructure for the benefit of all, avoiding the concentration of power and promoting equity and transparency in both its development and its application.
To this end, they propose a set of principles to guide the governance of the data commons in its application for AI training so as to maximise the value generated for society and minimise the possibilities of potential abuse by commercial interests:
- Share as much data as possible, while maintaining such restrictions as may be necessary to preserve individual and collective rights.
- Be fully transparent and provide all existing documentation on the data, as well as on its use, and clearly distinguish between real and synthetic data.
- Respect decisions made about the use of data by persons who have previously contributed to the creation of the data, either through the transfer of their own data or through the development of new content, including respect for any existing legal framework.
- Protect the common benefit in the use of data and a sustainable use of data in order to ensure proper governance over time, always recognising its relational and collective nature.
- Ensuring the quality of data, which is critical to preserving its value as a common good, especially given the potential risks of contamination associated with its use by AI.
- Establish trusted institutions that are responsible for data governance and facilitate participation by the entire data community, thus going a step beyond the existing models for data intermediaries.
Use cases and applications
There are currently many real-world examples that help illustrate the transformative potential of data commons:
- Health data commons : projects such as the National Institutes of Health's initiative in the United States - NIH Common Fund to analyse and share large biomedical datasets, or the National Cancer Institute's Cancer Research Data Commons , demonstrate how data commons can contribute to the acceleration of health research and innovation.
- AI training and machine learning: the evaluation of AI systems depends on rigorous and standardised test data sets. Initiatives such as OpenML or MLCommons build open, large-scale and diverse datasets, helping the wider community to deliver more accurate and secure AI systems.
- Urban and mobility data commons : cities that take advantage of shared urban data platforms improve decision-making and public services through collective data analysis, as is the case of Barcelona Dades, which in addition to a large repository of open data integrates and disseminates data and analysis on the demographic, economic, social and political evolution of the city. Other initiatives such as OpenStreetMaps itself can also contribute to providing freely accessible geographic data.
- Culture and knowledge preservation: with such relevant initiatives in this field as Mozilla's Common Voice project to preserve and revitalise the world's languages, or Wikidata, which aims to provide structured access to all data from Wikimedia projects, including the popular Wikipedia.
Challenges in the data commons
Despite their promise and potential as a transformative tool for new challenges in the digital age, the data commons also face their own challenges:
- Complexity in governance: Striking the right balance between inclusion, control and privacy can be a delicate task.
- Sustainability: Many of the existing data commons are fighting an ongoing battle to try to secure the funding and resources they need to sustain themselves and ensure their long-term survival.
- Legal and ethical issues: addressing challenges relating to intellectual property rights, data ownership and ethical use remain critical issues that have yet to be fully resolved.
- Interoperability: Ensuring compatibility between datasets and platforms is a persistent technical hurdle in almost any data sharing initiative, and the data commons were to be no exception.
The way forward
To unlock their full potential, the data commons require collective action and a determined commitment to innovation. Key actions include:
- Develop standardised governance models that strike a balance between ethical considerations and technical requirements.
- Apply the principle of reciprocity in the use of data, requiring those who benefit from it to share their results back with the community.
- Protection of sensitive data through anonymisation, preventing data from being used for mass surveillance or discrimination.
- Encourage investment in infrastructure to support scalable and sustainable data exchange.
- Promote awareness of the social benefits of data commons to encourage participation and collaboration.
Policy makers, researchers and civil society organisations should work together to create an ecosystem in which the data commons can thrive, fostering more equitable growth in the digital economy and ensuring that the data commons can benefit all.
Conclusion
The data commons can be a powerful tool for democratising access to data and fostering innovation. In this era defined by AI and digital transformation, they offer us an alternative path to equitable, sustainable and inclusive progress. Addressing its challenges and adopting a collaborative governance approach through cooperation between communities, researchers and regulators will ensure fair and responsible use of data.
This will ensure that data commons become a fundamental pillar of the digital future, including new applications of Artificial Intelligence, and could also serve as a key enabling tool for some of the key actions that are part of the recently announced European competitiveness compass, such as the new Data Union strategy and the AI Gigafactories initiative.
Content prepared by Carlos Iglesias, Open data Researcher and consultant, World Wide Web Foundation. The contents and views expressed in this publication are the sole responsibility of the author.
Entrevista
In this episode we will discuss artificial intelligence and its challenges, based on the European Regulation on Artificial Intelligence that entered into force this year. Come and find out about the challenges, opportunities and new developments in the sector from two experts in the field:
- Ricard Martínez, professor of constitutional law at the Universitat de València where he directs the Chair of Privacy and Digital Transformation Microsoft University of Valencia.
- Carmen Torrijos, computational linguist, expert in AI applied to language and professor of text mining at the Carlos III University.
Listen to the full podcast (only available in Spanish)
Summary / Transcript of the interview
1. It is a fact that artificial intelligence is constantly evolving. To get into the subject, I would like to hear about the latest developments in AI?
Carmen Torrijos: Many new applications are emerging. For example, this past weekend there has been a lot of buzz about an AI for image generation in X (Twitter), I don't know if you've been following it, called Grok. It has had quite an impact, not because it brings anything new, as image generation is something we have been doing since December 2023. But this is an AI that has less censorship, that is, until now we had a lot of difficulties with the generalist systems to make images that had faces of celebrities or had certain situations and it was very monitored from any tool. What Grok does is to lift all that up so that anyone can make any kind of image with any famous person or any well-known face. It is probably a passing fad. We will make images for a while and then it will pass.
And then there are also automatic podcast creation systems, such as Notebook LM. We've been watching them for a couple of months now and it's really been one of the things that has really surprised me in the last few months. Because it already seems that they are all incremental innovations: on top of what we already have, they give us something better. But this is something really new and surprising. You upload a PDF and it can generate a podcast of two people talking in a totally natural, totally realistic way about that PDF. This is something that Notebook LM, which is owned by Google, can do.
2. The European Regulation on Artificial Intelligence is the world's first legal regulation on AI, with what objectives is this document, which is already a reference framework at international level, being published?
Ricard Martínez: The regulation arises from something that is implicit in what Carmen has told us. All this that Carmen tells is because we have opened ourselves up to the same unbridled race that we experienced with the emergence of social media. Because when this happens, it's not innocent, it's not that companies are being generous, it's that companies are competing for our data. They gamify us, they encourage us to play, they encourage us to provide them with information, so they open up. They do not open up because they are generous, they do not open up because they want to work for the common good or for humanity. They open up because we are doing their work for them. What does the EU want to stop? What we learned from social media. The European Union has two main approaches, which I will try to explain very succinctly. The first approach is a systemic risk approach. The European Union has said: "I will not tolerate artificial intelligence tools that may endanger the democratic system, i.e. the rule of law and the way I operate, or that may seriously infringe fundamental rights". That is a red line.
The second approach is a product-oriented approach. An AI is a product. When you make a car, you follow rules that manage how you produce that car, and that car comes to market when it is safe, when it has all the specifications. This is the second major focus of the Regulation. The regulation says that you can be developing a technology because you are doing research and I almost let you do whatever you want. Now, if this technology is to come to market, you will catalogue the risk. If the risk is low or slight, you are going to be able to do a lot of things and, practically speaking, with transparency and codes of conduct, I will give you a pass. But if it's a high risk, you're going to have to follow a standardised design process, and you're going to need a notified body to verify that technology, make sure that in your documentation you've met what you have to meet, and then they'll give you a CE mark. And that's not the end of it, because there will be post-trade surveillance. So, throughout the life cycle of the product, you need to ensure that this works well and that it conforms to the standard.
On the other hand, a tight control is established with regard to big data models, not only LLM, but also image or other types of information, where it is believed that they may pose systemic risks.
In that case, there is a very direct control by the Commission. So, in essence, what they are saying is: "respect rights, guarantee democracy, produce technology in an orderly manner according to certain specifications".
Carmen Torrijos: Yes, in terms of objectives it is clear. I have taken up Ricard's last point about producing technology in accordance with this Regulation. We have this mantra that the US does things, Europe regulates things and China copies things. I don't like to generalise like that. But it is true that Europe is a pioneer in terms of legislation and we would be much stronger if we could produce technology in line with the regulatory standards we are setting. Today we still can't, maybe it's a question of giving ourselves time, but I think that is the key to technological sovereignty in Europe.
3. In order to produce such technology, AI systems need data to train their models. What criteria should the data meet in order to train an AI system correctly? Could open data sets be a source? In what way?
Carmen Torrijos: The data we feed AI with is the point of greatest conflict. Can we train with any dataset even if it is available? We are not talking about open data, but about available data.
Open data is, for example, the basis of all language models, and everyone knows this, which is Wikipedia. Wikipedia is an ideal example for training, because it is open, it is optimised for computational use, it is downloadable, it is very easy to use, there is a lot of language, for example, for training language models, and there is a lot of knowledge of the world. This makes it the ideal dataset for training an AI model. And Wikipedia is in the open, it is available, it belongs to everyone and it is for everyone, you can use it.
But can all the datasets available on the Internet be used to train AI systems? That is a bit of a doubt. Because the fact that something is published on the Internet does not mean that it is public, for public use, although you can take it and train a system and start generating profit from that system. It had a copyright, authorship and intellectual property. That I think is the most serious conflict we have right now in generative AI because it uses content to inspire and create. And there, little by little, Europe is taking small steps. For example, the Ministry of Culture has launched an initiative to start looking at how we can create content, licensed datasets, to train AI in a way that is legal, ethical and respectful of authors' intellectual property rights.
All this is generating a lot of friction. Because if we go on like this, we will turn against many illustrators, translators, writers, etc. (all creators who work with content), because they will not want this technology to be developed at the expense of their content. Somehow you have to find a balance in regulation and innovation to make both happen. From the large technological systems that are being developed, especially in the United States, there is a repeated idea that only with licensed content, with legal datasets that are free of intellectual property, or that the necessary returns have been paid for their intellectual property, it is not possible to reach the level of quality of AIs that we have now. That is, only with legal datasets alone we would not have ChatGPT at the level ChatGPT is at now.
This is not set in stone and does not have to be the case. We have to continue researching, that is, we have to continue to see how we can achieve a technology of that level, but one that complies with the regulation. Because what they have done in the United States, what GPT-4 has done, the great models of language, the great models of image generation, is to show us the way. This is as far as we can go. But you have done so by taking content that is not yours, that it was not permissible to take. We have to get back to that level of quality, back to that level of performance of the models, respecting the intellectual property of the content. And that is a role that I believe is primarily Europe's responsibility.
4. Another issue of public concern with regard to the rapid development of AI is the processing of personal data. How should they be protected and what conditions does the European regulation set for this?
Ricard Martínez: There is a set of conducts that have been prohibited essentially to guarantee the fundamental rights of individuals. But it is not the only measure. I attach a great deal of importance to an article in the regulation that we are probably not going to give much thought to, but for me it is key. There is an article, the fourth one, entitled AI Literacy, which says that any subject that is intervening in the value chain must have been adequately trained. You have to know what this is about, you have to know what the state of the art is, you have to know what the implications are of the technology you are going to develop or deploy. I attach great value to it because it means incorporating throughout the value chain (developer, marketer, importer, company deploying a model for use, etc.) a set of values that entail what is called accountability, proactive responsibility, by default. This can be translated into a very simple element, which has been talked about for two thousand years in the world of law, which is 'do no harm', the principle of non-maleficence.
With something as simple as that, "do no harm to others, act in good faith and guarantee your rights", there should be no perverse effects or harmful effects, which does not mean that it cannot happen. And this is precisely what the Regulation says in particular when it refers to high-risk systems, but it is applicable to all systems. The Regulation tells you that you have to ensure compliance processes and safeguards throughout the life cycle of the system. That is why it is so important to have robustness, resilience and contingency plans that allow you to revert, shut down, switch to human control, change the usage model when an incident occurs.
Therefore, the whole ecosystem is geared towards this objective of no harm, no rights, no harm. And there is an element that no longer depends on us, it depends on public policy. AI will not only infringe on rights, it will change the way we understand the world. If there are no public policies in the education sector that ensure that our children develop computational thinking skills and are able to have a relationship with a machine-interface, their access to the labour market will be significantly affected. Similarly, if we do not ensure the continuous training of active workers and also the public policies of those sectors that are doomed to disappear.
Carmen Torrijos: I find Ricard's approach of to train is to protect very interesting. Train people, inform people, get people trained in AI, not only people in the value chain, but everybody. The more you train and empower, the more you are protecting people.
When the law came out, there was some disappointment in AI environments and especially in creative environments. Because we were in the midst of the generative AI boom and generative AI was hardly being regulated, but other things were being regulated that we took for granted would not happen in Europe, but that have to be regulated so that they cannot happen. For example, biometric surveillance: Amazon can't read your face to decide whether you are sadder that day and sell you more stuff or get more advertising or a particular advertisement. I say Amazon, but it can be any platform. This, for example, will not be possible in Europe because it is forbidden by law, it is an unacceptable use: biometric surveillance.
Another example is social scoring, the social scoring that we see happening in China, where citizens are given points and access to public services based on these points. That is not going to be possible either. And this part of the law must also be considered, because we take it for granted that this is not going to happen to us, but when you don't regulate it, that's when it happens. China has installed 600 million TRF cameras, facial recognition technology, which recognise you with your ID card. That is not going to happen in Europe because it cannot, because it is also biometric surveillance. So you have to understand that the law perhaps seems to be slowing down on what we are now enraptured by, which is generative AI, but it has been dedicated to addressing very important points that needed to be covered in order to protect people. In order not to lose fundamental rights that we have already won.
Finally, ethics has a very uncomfortable component, which nobody wants to look at, which is that sometimes it has to be revoked. Sometimes it is necessary to remove something that is in operation, even that is providing a benefit, because it is incurring some kind of discrimination, or because it is bringing some kind of negative consequence that violates the rights of a collective, of a minority or of someone vulnerable. And that is very complicated. When we have become accustomed to having an AI operating in a certain context, which may even be a public context, to stop and say that this is discriminating against people, then this system cannot continue in production and has to be removed. This point is very complicated, it is very uncomfortable and when we talk about ethics, which we talk very easily about ethics, we must also think about how many systems we are going to have to stop and review before we can put them back into operation, however easy they make our lives or however innovative they may seem.
5. In this sense, taking into account all that the Regulation contains, some Spanish companies, for example, will have to adapt to this new framework. What should organisations already be doing to prepare? What should Spanish companies review in the light of the European regulation?
Ricard Martínez: This is very important, because there is a corporate business level of high capabilities that I am not worried about because these companies understand that we are talking about an investment. And just as they invested in a process-based model that integrated the compliance from the design for data protection. The next leap, which is to do exactly the same thing with artificial intelligence, I won't say that it is unimportant, because it is of relevant importance, but let's say that it is going down a path that has already been tried. These companies already have compliance units, they already have advisors, and they already have routines into which the artificial intelligence regulatory framework can be integrated as part of the process. In the end, what it will do is to increase risk analysis in one sense. It will surely force the design processes and also the design phases themselves to be modular, i.e., while in software design we are practically talking about going from a non-functional model to chopping up code, here there are a series of tasks of enrichment, annotation, validation of the data sets, prototyping that surely require more effort, but they are routines that can be standardised.
My experience in European projects where we have worked with clients, i.e. SMEs, who expect AI to be plug and play, what we have seen is a huge lack of capacity building. The first question you should ask yourself is not whether your company needs AI, but whether your company is ready for AI. This is an earlier and rather more relevant question. Hey, you think you can make a leap into AI, that you can contract a certain type of services, and we are realising that you don't even comply with the data protection regulation.
There is something, an entity called the Spanish Agency for Artificial Intelligence, AESIA, and there is a Ministry of Digital Transformation, and if there are no accompanying public policies, we may incur risky situations. Why? Because I have the great pleasure of training future entrepreneurs in artificial intelligence in undergraduate and postgraduate courses. When confronted with the ethical and legal framework, I won't say they want to die, but the world comes crashing down on them. Because there is no support, there is no accompaniment, there are no resources, or they cannot see them, that do not involve a round of investment that they cannot bear, or there are no guided models that help them in a way that is, I won't say easy, but at least usable.
Therefore, I believe that there is a substantial challenge in public policies, because if this combination does not happen, the only companies that will be able to compete are those that already have a critical mass, an investment capacity and an accumulated capital that allows them to comply with the standard. This situation could lead to a counterproductive outcome.
We want to regain European digital sovereignty, but if there are no public investment policies, the only ones who will be able to comply with the European standard are companies from other countries.
Carmen Torrijos: Not because they are from other countries but because they are bigger.
Ricard Martínez: Yes, not to mention countries.
6. We have talked about challenges, but it is also important to highlight opportunities. What positive aspects could you highlight as a result of this recent regulation?
Ricard Martínez: I am working on the construction, with European funding, of Cancer Image EU , which is intended to be a digital infrastructure for cancer imaging. At the moment, we are talking about a partnership involving 14 countries, 76 organisations, on the way to 93, to generate a medical imaging database of 25 million cancer images with associated clinical information for the development of artificial intelligence. The infrastructure is being built, it does not yet exist, and even so, at the Hospital La Fe in Valencia, research is already underway with mammograms of women who have undergone biennial screening and then developed cancer, to see if it is capable of training an image analysis model that is capable of preventively recognising that little spot that the oncologist or radiologist did not see and that later turned out to be a cancer. Does it mean you're getting chemotherapy five minutes later? No. It means they are going to monitor you, they are going to have an early reaction capability. And that the health system will save 200,000 euros. To mention just one opportunity.
On the other hand, opportunities must also be sought in other rules. Not only in the Artificial Intelligence Regulation. You have to go to Data Governance Act. It wants to counter the data monopoly held by US companies with a sharing of data from the public, private sectorand from the citizenry itself. With Data Act, which aims to empower citizens to retrieve their data and share it by consent. And finally with the European Health Data Space which aims to create ahealth data ecosystem to promote innovation, research and entrepreneurship. It is this ecosystem of data spaces that should be a huge generator of opportunity spaces.
And furthermore, I don't know whether they will succeed or not, but it aims to be coherent with our business ecosystem. That is to say, an ecosystem of small and medium-sized enterprises that does not have high data generation capabilities and what we are going to do is to build the field for them. We are going to create the data spaces for them, we are going to create the intermediaries, the intermediation services, and we hope that this ecosystem as a whole will allow European talent to emerge from small and medium-sized enterprises. Will it be achieved or not? I don't know, but the opportunity scenario looks very interesting.
Carmen Torrijos: If you ask for opportunities, all opportunities. Not only artificial intelligence, but all technological progress, is such a huge field that it can bring opportunities of all kinds. What needs to be done is to lower the barriers, which is the problem we have. And we also have barriers of many kinds, because we have technical barriers, talent barriers, salary barriers, disciplinary barriers, gender barriers, generational barriers, and so on.
We need to focus energies on lowering those barriers, and then I also think we still come from the analogue world and have little global awareness that both digital and everything that affects AI and data is a global phenomenon. There is no point in keeping it all local, or national, or even European, but it is a global phenomenon. The big problems we have come because we have technology companies that are developed in the United States working in Europe with European citizens' data. A lot of friction is generated there. Anything that can lead to something more global will always be in favour of innovation and will always be in favour of technology. The first thing is to lift the barriers within Europe. That is a very positive part of the law.
7. At this point, we would like to take a look at the state we are in and the prospects for the future. How do you see the future of artificial intelligence in Europe?
Ricard Martínez: I have two visions: one positive and one negative. And both come from my experience in data protection. If now that we have a regulatory framework, the regulatory authorities, I am referring to artificial intelligence and data protection, are not capable of finding functional and grounded solutions, and they generate public policies from the top down and from an excellence that does not correspond to the capacities and possibilities of research - I am referring not only to business research, but also to university research - I see a very dark future. If, on the other hand, we understand regulation in a dynamic way with supportive and accompanying public policies that generate the capacities for this excellence, I see a promising future because in principle what we will do is compete in the market with the same solutions as others, but responsive: safe, responsible and reliable.
Carmen: Yes, I very much agree. I introduce the time variable into that, don't I? Because I think we have to be very careful not to create more inequality than we already have. More inequality among companies, more inequality among citizens. If we are careful with this, which is easy to say but difficult to do, I believe that the future can be bright, but it will not be bright immediately. In other words, we are going to have to go through a darker period of adapting to change. Just as many issues of digitalisation are no longer alien to us, have already been worked on, we have already gone through them and have already regulated them, artificial intelligence also needs its time.
We have had very few years of AI, very few years of generative AI. In fact, two years is nothing in a worldwide technological change. And we have to give time to laws and we also have to give time for things to happen. For example, I give a very obvious example, the New York Times' complaint against Microsoft and OpenAI has not yet been resolved. It's been a year, it was filed in December 2023, the New York Times complains that they have trained AI systems with their content and in a year nothing has been achieved in that process. Court proceedings are very slow. We need more to happen. And that more processes of this type are resolved in order to have precedents and to have maturity as a society in what is happening, and we still have a long way to go. It's like almost nothing has happened. So, the time variable I think is important and I think that, although at the beginning we have a darker future, as Ricard says, I think that in the long term, if we keep clear limits, we can reach something brilliant.
Interview clips
1. What criteria should the data have to train an AI system?
2. What should Spanish companies review in light of the IA Regulation?
Blog
As we do every year, the datos.gob.es team wishes you happy holidays. If this Christmas you feel like giving or giving yourself a gift of knowledge, we bring you our traditional Christmas letter with ideas to ask Father Christmas or the Three Wise Men.
We have a selection of books on a variety of topics such as data protection, new developments in AI or the great scientific discoveries of the 20th century. All these recommendations, ranging from essays to novels, will be a sure hit to put under the tree.
Maniac by Benjamin Labatut.
- What is it about? Guided by the figure of John von Neumann, one of the great geniuses of the 20th century, the book covers topics such as the creation of atomic bombs, the Cold War, the birth of the digital universe and the rise of artificial intelligence. The story begins with the tragic suicide of Paul Ehrenfest and progresses through the life of von Neumann, who foreshadowed the arrival of a technological singularity. The book culminates in a confrontation between man and machine in an epic showdown in the game of Go, which serves as a warning about the future of humanity and its creations.
- Who is it aimed at? This science fiction novel is aimed at anyone interested in the history of science, technology and its philosophical and social implications. Es ideal para quienes disfrutan de narrativas que combinan el thriller con profundas reflexiones sobre el futuro de la humanidad y el avance tecnológico. It is also suitable for those looking for a literary work that delves into the limits of thought, reason and artificial intelligence.
Take control of your data, by Alicia Asin.
- What is it about? This book compiles resources to better understand the digital environment in which we live, using practical examples and clear definitions that make it easier for anyone to understand how technologies affect our personal and social lives. It also invites us to be more aware of the consequences of the indiscriminate use of our data, from the digital trail we leave behind or the management of our privacy on social networks, to trading on the dark web. It also warns about the legitimate but sometimes invasive use of our online behaviour by many companies.
- Who is it aimed at? The author of this book is CEO of the data reuse company Libelium who participated in one of our Encuentros Aporta and is a leading expert on privacy, appropriate use of data and data spaces, among others. In this book, the author offers a business perspective through a work aimed at the general public.
Governance, management and quality of artificial intelligence by Mario Geraldo Piattini.
- What is it about? Artificial intelligence is increasingly present in our daily lives and in the digital transformation of companies and public bodies, offering both benefits and potential risks. In order to benefit properly from the advantages of AI and avoid problems it is very important to have ethical, legal and responsible systems in place. This book provides an overview of the main standards and tools for managing and assuring the quality of intelligent systems. To this end, it provides clear examples of best available practices.
- Who is it aimed at? Although anyone can read it, the book provides tools to help companies meet the challenges of AI by creating systems that respect ethical principles and align with engineering best practices.
Nexus, by Yuval Noah.
- What is it about? In this new installment, one of the most fashionable writers analyzes how information networks have shaped human history, from the Stone Age to the present era. This essay explores the relationship between information, truth, bureaucracy, mythology, wisdom and power, and how different societies have used information to impose order, with both positive and negative consequences. In this context, the author discusses the urgent decisions we must make in the face of current threats, such as the impact of non-human intelligence on our existence.
- Who is it aimed at? It is a mainstream work, i.e. anyone can read it and will most likely enjoy reading it. It is a particularly attractive option for readers seeking to reflect on the role of information in modern society and its implications for the future of humanity, in a context where emerging technologies such as artificial intelligence are challenging our way of life.
Generative Deep Learning: Teaching Machines to Paint, Write, Compose, and Play by David Foster (second edition 2024)
- What is it about? This practical book dives into the fascinating world of generative deep learning, exploring how machines can create art, music and text. Throughout, Foster guides us through the most innovative architectures such as VAEs, GANs and broadcasting models, explaining how these technologies can transform photographs, generate music and even write text. The book starts with the basics of deep learning and progresses to cutting-edge applications, including image creation with Stable Diffusion, text generation with GPT and music composition with MuSEGAN. It is a work that combines technical rigour with artistic creativity.
- Who is it aimed at? This technical manual is intended for machine learning engineers, data scientists and developers who want to enter the field of generative deep learning. It is ideal for those who already have a background in programming and machine learning, and wish to explore how machines can create original content. It will also be valuable for creative professionals interested in understanding how AI can amplify their artistic capabilities. The book strikes the perfect balance between mathematical theory and practical implementation, making complex concepts accessible through concrete examples and working code.
Information is beautiful, by David McCandless.
- What is it about? Esta guía visual en inglés nos ayuda a entender cómo funciona el mundo a través de impactantes infografías y visualizaciones de datos. This new edition has been completely revised, with more than 20 updates and 20 new visualisations. It presents information in a way that is easy to skim, but also invites further exploration.
- Who is it aimed at? This book is aimed at anyone interested in seeing and understanding information in a different way. It is perfect for those looking for an innovative and visually appealing way to understand the world around us. It is also ideal for those who enjoy exploring data, facts and their interrelationships in an entertaining and accessible way.
Collecting Field Data with QGIS and Mergin Maps, de Kurt Menke y Alexandra Bucha Rasova.
- What is it about? This book teaches you how to master the Mergin Maps platform for collecting, sharing and managing field data using QGIS. The book covers everything from the basics, such as setting up projects in QGIS and conducting field surveys, to advanced workflows for customising projects and managing collaborations. In addition, details on how to create maps, set up survey layers and work with smart forms for data collection are included.
- Who is it aimed at? Although it is a somewhat more technical option than the previous proposals, the book is aimed at new users of Mergin Maps and QGIS. It is also useful for those who are already familiar with these tools and are looking for more advanced workflows.
A terrible greenery by Benjamin Labatut.
- What is it about? This book is a fascinating blend of science and literature, narrating scientific discoveries and their implications, both positive and negative. Through powerful stories, such as the creation of Prussian blue and its connection to chemical warfare, the mathematical explorations of Grothendieck and the struggle between scientists like Schrödinger and Heisenberg, the author, Benjamin Labatut, leads us to explore the limits of science, the follies of knowledge and the unintended consequences of scientific breakthroughs. The work turns science into literature, presenting scientists as complex and human characters.
- Who is it aimed at? The book is aimed at a general audience interested in science, the history of discoveries and the human stories behind them, with a focus on those seeking a literary and in-depth approach to scientific topics. It is ideal for those who enjoy works that explore the complexity of knowledge and its effects on the world.
Designing Better Maps: A Guide for GIS Users, de Cynthia A. Brewer.
- What is it about? It is a guide in English written by the expert cartographer that teaches how to create successful maps using any GIS or illustration tool. Through its 400 full-colour illustrations, the book covers the best cartographic design practices applied to both reference and statistical maps. Topics include map planning, using base maps, managing scale and time, explaining maps, publishing and sharing, using typography and labels, understanding and using colour, and customising symbols.
- Who is it aimed at? This book is intended for all geographic information systems (GIS) users, from beginners to advanced cartographers, who wish to improve their map design skills.
Although in the post we link many purchase links. If you are interested in any of these options, we encourage you to ask your local bookshop to support small businesses during the festive season. Do you know of any other interesting titles? Write it in comments or send it to dinamizacion@datos.gob.es. We read you!
Blog
2023 was a year full of new developments in artificial intelligence, algorithms and data-related technologies. Therefore, these Christmas holidays are a good time to take advantage of the arrival of the Three Wise Men and ask them for a book to enjoy reading during the holidays, the well-deserved rest and the return to routine after the holiday period.
Whether you are looking for a reading that will improve your professional profile, learn about new technological developments and applications linked to the world of data and artificial intelligence, or if you want to offer your loved ones a didactic and interesting gift, from datos.gob.es we want to offer you some examples. For the elaboration of the list we have counted on the opinion of experts in the field.
Take paper and pencil because you still have time to include them in your letter to the Three Wise Men!
1. Inteligencia Artificial: Ficción, Realidad y... sueños, Nuria Oliver, Real Academia de Ingeniería GTT (2023)
What it’s about: The book has its origin in the author's acceptance speech to the Royal Academy of Engineering. In it, she explores the history of AI, its implications and development, describes its current impact and raises several perspectives.
Who should read it: It is designed for people interested in entering the world of Artificial Intelligence, its history and practical applications. It is also aimed at those who want to enter the world of ethical AI and learn how to use it for social good.
2. A Data-Driven Company. 21 Claves para crear valor a través de los datos y de la Inteligencia Artificial, Richard Benjamins, Lid Editorial (2022)
What it's about: A Data-Driven Company looks at 21 key decisions companies need to face in order to become a data-driven, AI-driven enterprise. It addresses the typical organizational, technological, business, personnel, business, and ethical decisions that organizations must face to start making data-driven decisions, including how to fund their data strategy, organize teams, measure results, and scale.
Who should read it: It is suitable for professionals who are just starting to work with data, as well as for those who already have experience, but need to adapt to work with big data, analytics or artificial intelligence.
3. Digital Empires: The Global Battle to Regulate Technology, Anu Bradford, OUP USA (2023)
What it's about: In the face of technological advances around the world and the arrival of corporate giants spread across international powers, Bradford examines three competing regulatory approaches: the market-driven U.S. model, the state-driven Chinese model, and the rights-based European regulatory model. It examines how governments and technology companies navigate the inevitable conflicts that arise when these regulatory approaches clash internationally.
Who should read it: This is a book for those who want to learn more about the regulatory approach to technologies around the world and how it affects business. It is written in a clear and understandable way, despite the complexity of the subject. However, the reader will need to know English, because it has not yet been translated into Spanish.
4. El mito del algoritmo, Richard Benjamins e Idoia Salazar, Anaya Multimedia (2020)
What it's about: Artificial intelligence and its exponential use in multiple disciplines is causing an unprecedented social change. With it, philosophical thoughts as deep as the existence of the soul or debates related to the possibility of machines having feelings are beginning to emerge. This is a book to learn about the challenges, challenges and opportunities of this technology.
Who should read it: It is aimed at people with an interest in the philosophy of technology and the development of technological advances. By using simple and enlightening language, it is a book within the reach of a general public.
5. ¿Cómo sobrevivir a la incertidumbre?, de Anabel Forte Deltell, Next Door Publishers
What it is about: It explains in a simple way and with examples how statistics and probability are more present in daily life. The book starts from the present day, in which data, numbers, percentages and graphs have taken over our daily lives and have become indispensable for making decisions or for understanding the world around us.
Who should read it: A general public that wants to understand how the analysis of data, statistics and probability are shaping a large part of political, social, economic and social decisions?
6. Análisis espacial con R: Usa R como un Sistema de Información Geográfica, Jean François Mas, European Scientific Institute
What it is about: This is a more technical book, which provides a brief introduction to the main concepts for handling the R programming language and environment (types of objects and basic operations) and then introduces the reader to the use of the sf library or package for spatial data in vector format through its main functions for reading, writing and analysis. The book approaches, from a practical and applicative perspective with an easy-to-understand language, the first steps to get started with the use of R in spatial analysis applications; for this, it is necessary that users have basic knowledge of Geographic Information Systems.
Who should read it: A public with some knowledge of R and basic knowledge of GIS who wish to enter the world of spatial analysis applications.
This is just a small sample of the great variety of existing literature related to the world of data. We are sure that we have left some interesting book without including it, so if you have any extra recommendation you would like to make, do not hesitate to leave us your favorite title in the comments. Those of us on the datos.gob.es team would be delighted to read your recommendations.